1. Introduction
Pea (
Pisum sativum L.) is considered to be the second most important protein crop after soybean, with a total production area of 2,436,344 ha in Europe in 2020 [
1]. Despite the fact that the production area under peas has increased by 3.6% in the past five years [
1], the demand for new sources of protein continues to grow [
2], as total protein consumption in Europe, including plant-derived proteins, is about 70% higher than recommended [
3]. To meet growing demand for quality protein while reducing reliance on imported plant protein from outside of Europe, improvement of the yield of protein crops produced in the region is desirable [
4,
5]. Protein content in pea as quoted in literature ranges from 16% to 30.9% [
6,
7]. In organic production systems in the European Union, peas are considered an important plant species because they are a source of biologically-fixed nitrogen and provide high-quality animal feed that is rich in crude protein and minerals [
8]. Although soybean is one of the primary sources of plant-based protein, the advantages of growing peas over soybeans are its wider geographical area of cultivation and its ability to thrive in colder climates. Soybean, unlike pea, is one of the significant food allergens [
9]; moreover, the fact that pea grain, unlike soybeans, can be used directly in the diet without prior heat treatment is essential, as this simplifies use and reduces processing costs. Combined sowing of peas with cereals is increasingly used in practice to improve the efficiency of land and water resources, nutrients, and solar radiation [
8]. Furthermore, peas can also be grown as green manure [
10] and as a forage crop, especially in regions where climatic conditions are not favorable for a good seed yield [
11]. Their adaptability to a broad range of environmental conditions makes them an excellent cover crop due to the short vegetation season [
12] and can improve productivity in successor crops. Therefore, there are great needs and benefits for increasing the production area under peas.
The fundamental goal of pea breeders is to increase seed yield to maximize plant productivity and allow for more widespread use of pea in various agricultural production systems. Seed yield is a complex trait that is quantitatively inherited, and its expression depends on genetic factors, environment, and interaction (GxE) [
13]. Many studies have shown a significant influence of environment and genotype-by-environment (GxE) interaction on seed yield and the yield components of their phenotypic performance [
14,
15,
16]. Genetic variability is a prerequisite in increasing the seed yield, since it helps peas adapt to changing environmental conditions and is the source of variation and raw material for yield improvement. In this type of study, seed availability can be a limiting factor, as variability testing requires a large number of genotypes (lines or populations). In many of those, there is generally little seed material. Furthermore, the logistics of fully replicated trials can be prohibitive in terms of space. This can be solved by using an augmented trial design [
17], which requires a significantly smaller number of seeds, giving access to a broader choice for populations in germplasm collections than when using traditional experiment designs. Assessment of genetic variability is essential for efficient parent selection in breeding programs and long-term selection gain [
18]. The broad cultivation range of pea and reliable pea yield stability [
19] is associated with a broad genetic variation observed at the phenotypic and molecular levels [
13]. Before initiating any effective selection program, it is necessary to know the association of various traits with yield and with each other, as a negative association between the desired attributes under selection may result in genetic slippage. Consequently, this could limit the genetic advance of the yield, which represents the end product of many correlated characters. An understanding of the influence of individual contributors on seed yield informs the breeder on how effective selection can take place. It is considered that yield selection can be more effective when it is based on component traits that are highly heritable and positively correlated [
20].
The objectives of this study were to examine the phenotypic and genotypic variability in a set of diverse pea genotypes using morphological and agronomic traits, assess heritability, discover the relationships among seed yield components of pea genotypes, identify germplasm structure using correlation analysis, and determine sensitivity to environmental conditions and possible GxE interaction for yield and yield components. This research aimed to assess the phenotypic diversity of studied pea germplasm in order to enrich the breeding collection of the pea used in Western and Central Europe.
2. Results
2.1. Phenotypic Evaluation
Descriptive statistics and Pearson’s Correlation were conducted on morphological traits of analyzed pea genotypes. The studied features were number of grains per pod (GPP), number of pods per plant (PPP), number of seeds per plant (SPP), flowering duration (FD), plant height (PH), plot lodging (PL), pod length (PoL), thousand seed weight (TSW), seed weight per plant (SWPP), seed yield (SY), and protein content (PC).
According to the results of experiments at IFVCNS, Serbia, extensive phenotypic variation was observed in the analyzed pea panel. Means for PPP, SPP, SWPP, and PH were significantly lower in 2020 than in 2019, which is likely to be the consequence of drought in the flowering period in May 2020 (
Table S1). In contrast, GPP, PoL, TSW, and SY were higher in 2020 than 2019. For all characteristics, statistically significant differences were observed for mean values between two seasons, except for PL and FD. The highest coefficients of variation (CV) were observed for SY and TSW in both years (42 and 36%, and 31 and 30%, respectively). High variation was also evident in SWPP and FD in both years (21–23%), while for PH and PL, higher values were recorded in the 2020 season (
Table 1). The lowest CV was observed for PC (5%) in both years. The broad-sense heritability estimates were moderate for GPP, PPP, SPP, and SWPP and high for FD, PH, PoL, TSW, SY, and PC, which indicates that genetic constituents are the primary source of these traits. An exception was PL, whose heritability was significantly higher in 2020. The highest heritability of 96.6% and 97.7% were estimated for TSW in 2019 and 2020, respectively. Heritability was consistent between years for SPP, PH, PoL, TSW, SY, and PC and inconsistent for GPP, PPP, and PL (
Table 1). Inconsistency between years for given traits could indicate their higher sensitivity to environmental conditions.
Results recorded at Agro Seed, Belgium, had mean SPP, PH and SY significantly lower in 2019 than in 2020. In contrast, TSW was higher in 2019 than in 2020, which is possibly explicable by higher temperatures observed during the pod filling period (
Table S2). For all characteristics, statistically, significant differences were observed for mean values between two seasons for all traits, except for GPP. The highest coefficients of variation (CV) were observed for PL and SY in 2019 (37 and 31%) and for SY and GPP (31 and 28%) in 2020 (
Table 2). High variation was also evident in PH and TSW in both years (16–31%). The coefficient of variability for all traits was generally higher in 2019. The lowest CV in 2019 was observed for PC (5%) and in 2020 for PC (6%).
The broad-sense heritability estimates were moderate to high for all traits, indicating that genetic constituents are the primary source of these traits. The highest heritability of 89.5% was estimated for TSW in 2019 and 88.5% for PC in 2020, respectively. Heritability was consistent between years for GPP, SPP, PoL and TSW, SY, and PC, and inconsistent for PPP, FL, PH, PL, and SWPP.
2.2. Correlation Analysis between Traits
The correlation coefficients for the IFVCNS trial between different traits are shown in
Table 3. SWPP had positive and significant correlation with a great number of traits (GPP, PPP, SPP, PoL, TSW, and SY), but was highly negatively correlated with PC (−0.46); PC was also negatively correlated with SY and TSW. Furthermore, TSW was negatively correlated with GPP, PPP, and SPP, and positively with SY and PoL. Correlation between the remaining pairs of traits was mainly low and non-significant in both years.
The correlation coefficients for the Agro Seed trial are shown in
Table 4. Trait SWPP had positive correlation with all the traits (insignificant for GPP, FD, and PC). Trait SPP had significant positive correlation with FD and PH. Traits SY and PC were positively correlated (0,14). PC was also highly positively correlated with SPP.
The differences between the two locations, regarding correlations between traits, were no significant correlation of GPP with FD, PH, PL, PoL, and SWPP in the Agro Seed trial, while the IFVCNS trial showed high correlations for these traits. Furthermore, in the Agro Seed trial there was no correlation between SY and traits FD and PL, while in the IFVCNS trial, there was no correlation between PC and SPP. The main difference between locations was in the correlation between PC and SY; IFVCNS trial showed negative correlation, while Agro Seed trial showed positive correlation.
2.3. Correlation of Traits between Two Years
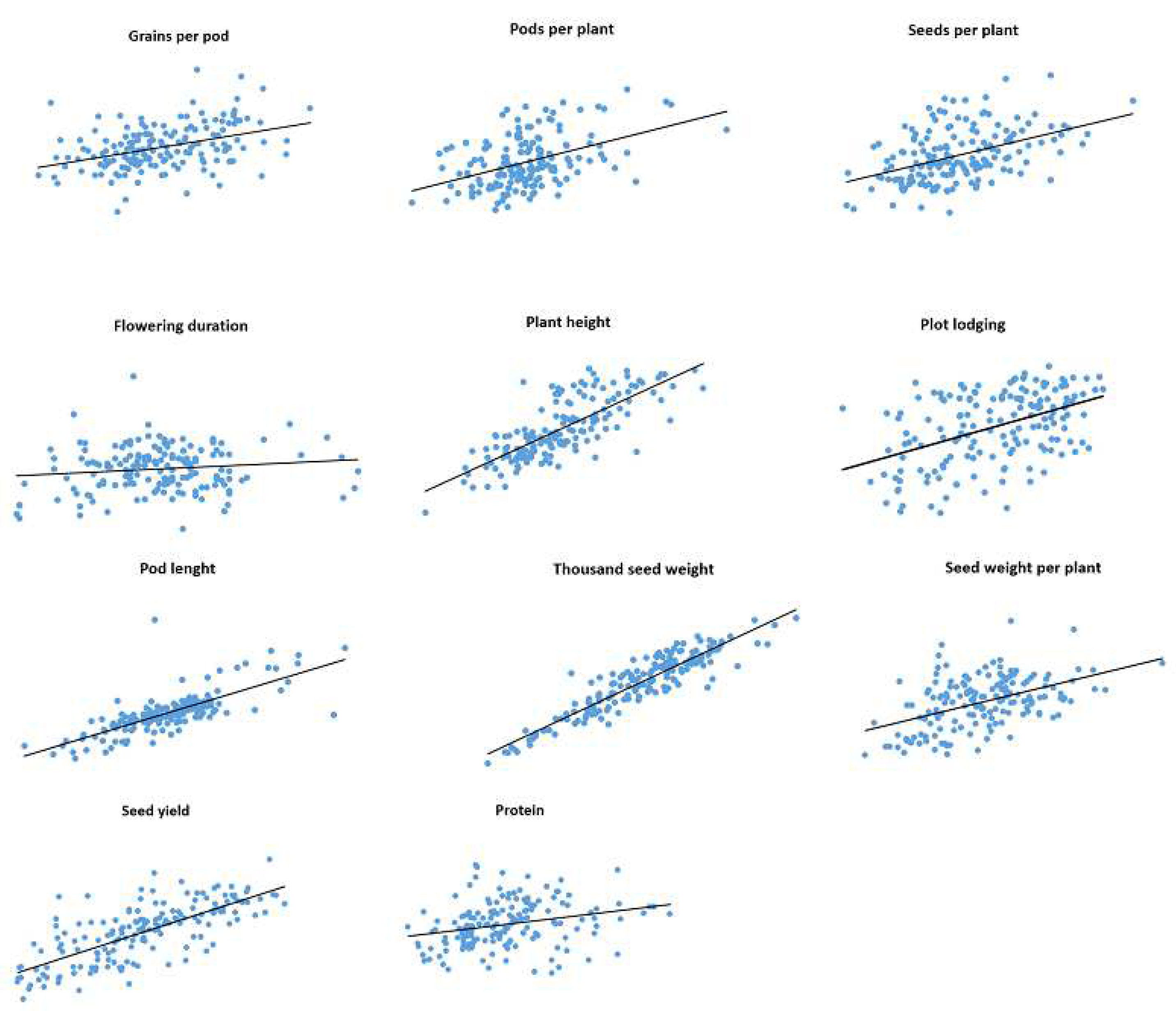
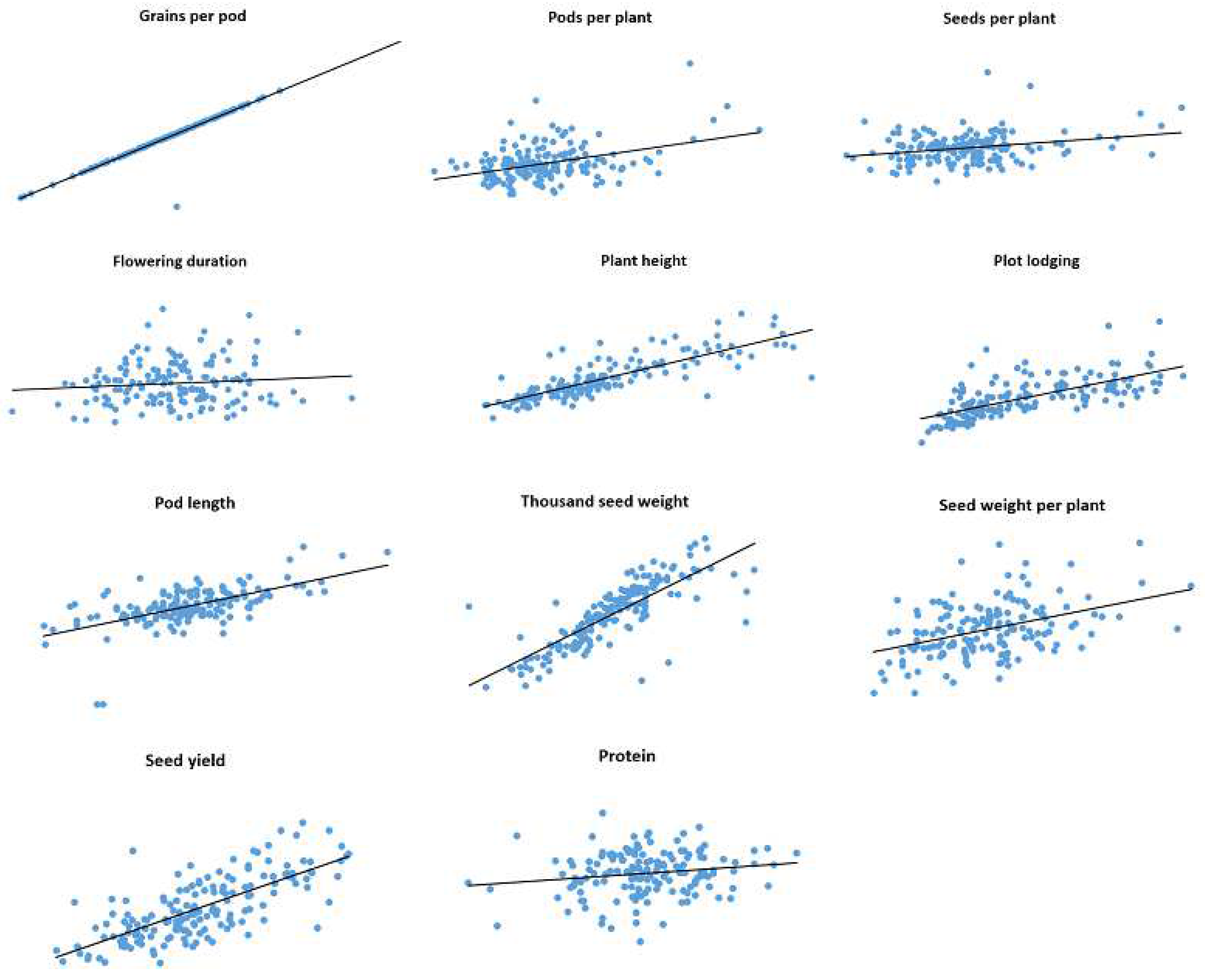
Correlations between trait values observed in 2019 and 2020 for IFVCNS and Agro Seed were graphically represented using scatter diagrams (
Figure 1 and
Figure 2). For all examined traits, linear regressions in pairwise comparisons between years revealed positive correlations (
Table S3).
For the IFVCNS trial, correlations between seasons were mostly highly significant, except for flowering duration (FD). The strongest correlation was noticed for TSW (0.92), PH (0.77), and PoL (0.75), followed by GPP (0.60), SWPP (0.48), PL (0.46), SPP (0.45), and PPP (0.44), which had lower Pearson’s correlation coefficients (r). FD and PC had the lowest correlation between years (0.13 and 0.07, respectively).
For the Agro Seed trial, the strongest correlation was noticed for GPP (0.96), PH (0.67), TSW (0.64), and the lowest correlation was for SPP (0.07) due to the high virus presence in 2020 (data not shown), FD (0.01), and PC (0.03). PC had a low correlation between localities (0.27 at IFVCNS and 0.17 at Agro Seed).
2.4. Multivariate Analysis
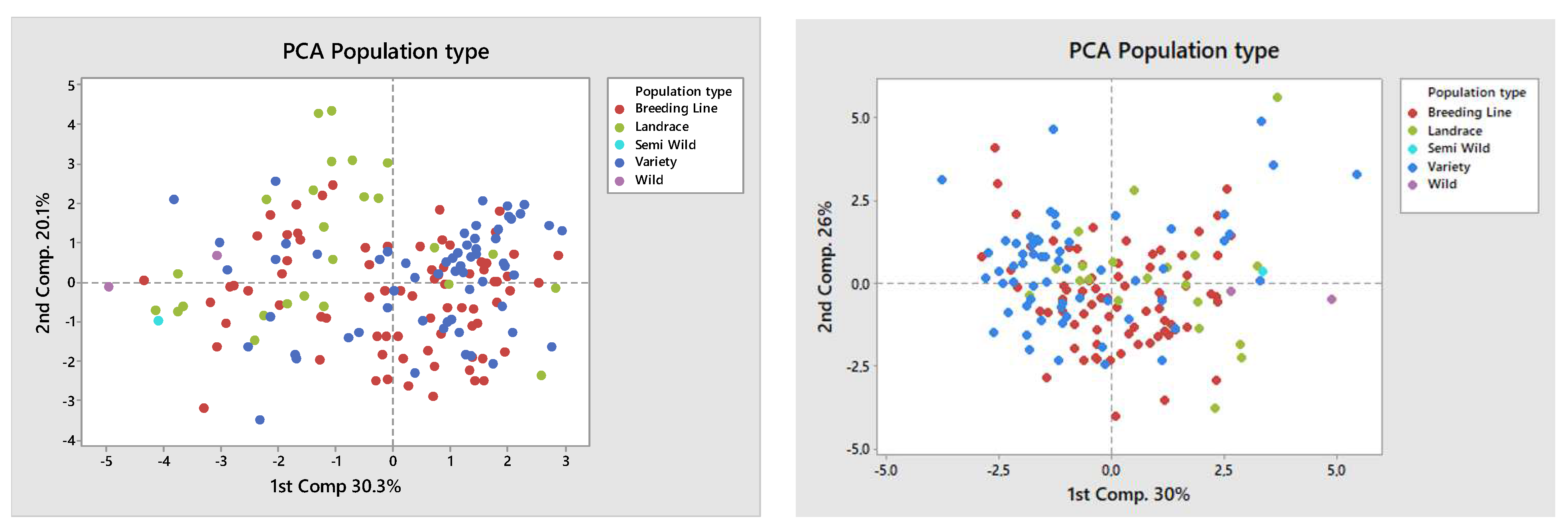
Multivariate analysis was performed based on all examined traits for both trial sites using mean values of both years to explore the population structure of the pea genotypes of different plant types (
Figure 3), as well as of the variety type by use (
Figure 4). The PCA gave a graphical representation of the broad phenotypic diversity of the investigated pea panel. Based on the results from IFVCNS, the first principal component accounted for 30.3% of the variance and showed no apparent clustering of the genotypes based on population type. The second principal component accounted for 20.1% of the variance and showed clustering of landrace types and overlapping of varieties and most breeding lines. Based on the results from Agro Seed, the first principal component accounted for 30% of the variance and showed some clustering of the breeding lines. In comparison, the second principal component accounted for 26% of the variance and showed a less clear subdivision of varieties. A large number of the breeding lines and varieties originated from North America and Serbia, while most of the landraces originated from Sweden (
Table S4).
Morpho-phenological data in both trial sites did not allow completely clear subdivision between or within gene pools.
PCA analysis based on the variety type on both locations showed a higher prevalence of dry pea type and showed that accessions of dry pea type were generally clustered according to their use. However, it did not provide a clearer subdivision of pea genotypes by use.
Although PCA analysis did not show a clear grouping of genotypes based on plant type, an analysis of variance was conducted to determine possible differences within the germplasm. Analysis of variance for results at IFVCNS indicated a statistically significant difference among pea genotypes for the following traits: GPP, PH, PoL, and TSW in both years (
Table 5). Furthermore, differences were observed for SPP and SWPP only in 2019. Analysis of variance for results at Agro Seed indicated a statistically significant difference among pea genotypes for the following traits: PH and TSW in both years, and PC, PoL, and PC in 2020.
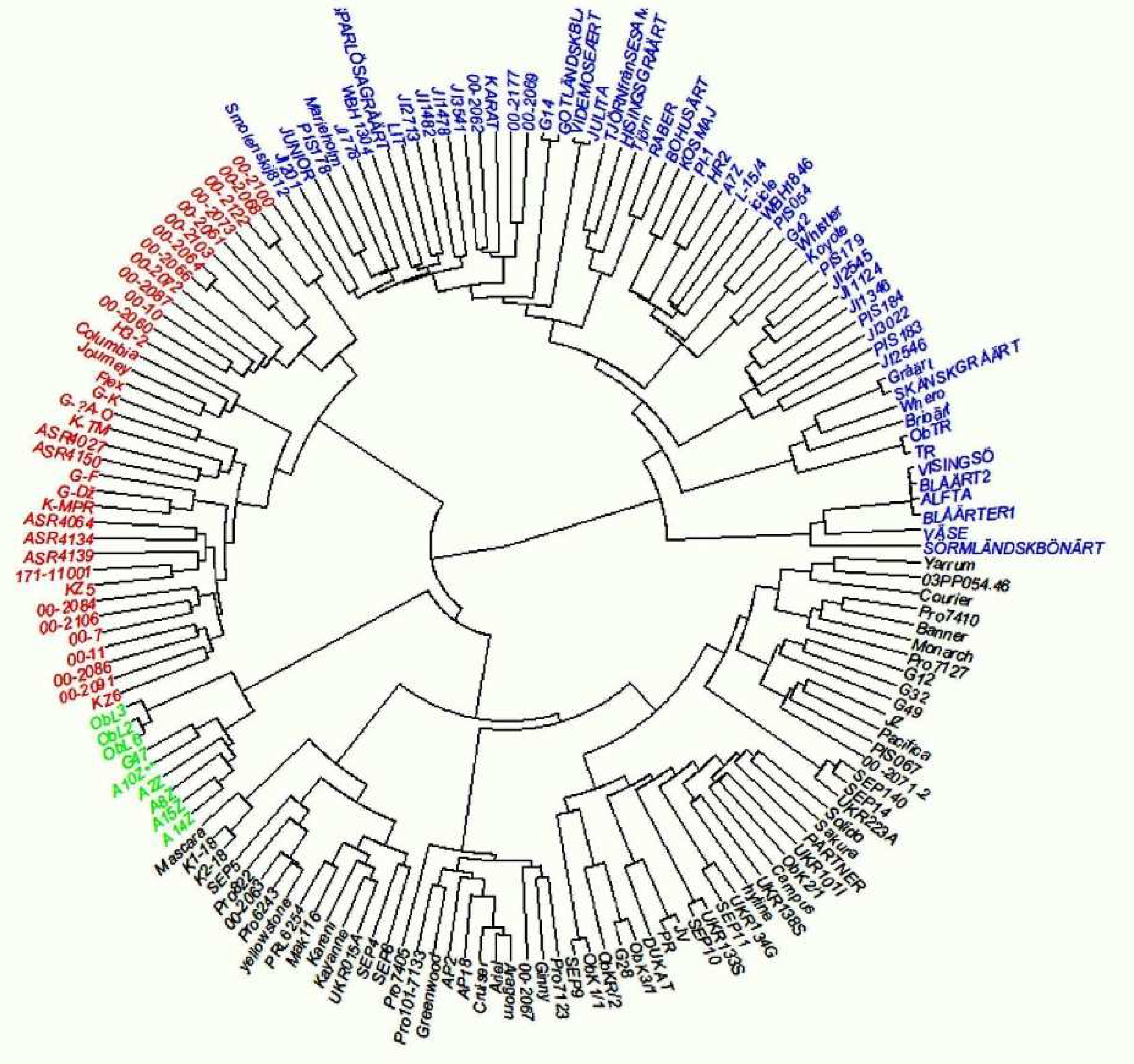
2.5. Genetic Distance and Hierarchical Clustering
This work was part of a more extensive study on genetic diversity and phenotypic variation in yield and protein content of pea accessions in Europe. After filtering, markers with a Gentrain score (Illumina quality measure) below 0.7 and a minimum allele frequency of 0.05–a total of 11,693 polymorphic markers—were left in the panel of 165 accessions used here. The genetic distance matrix was based on all the 16,693 markers and the phenotypic distance matrices were based on all the phenotypic traits measured in this study. The hierarchical grouping chart showed four groups (
Figure 5). The first group (green) consists of nine genotypes, exclusively of the breeding line population type and dry type of use, originating from Serbia. The second group (red) consists of 36 genotypes, mainly of the breeding line population type and dry type of use, with some exceptions of the vegetable type. In this group, vegetable pea lines, as expected, are clustered very closely together (mainly the 00 lines,
Table S4); however, a set of 00 lines shows introgressions from other types of peas. A number of forage peas are also part of this genetic group (Flex, H3) The third group (blue) consists of 57 genotypes, mainly landraces, forage, wild/semi-wild population, and dry types of use. Clustering showed that some of the landraces are very closely related. The fourth group (black) consists of 63 genotypes, mostly varieties and dry types of use. This group consists of modern dry varieties, which are related and grouped together.
A Mantel test was performed to test the correlations between the genetic distance matrix and the phenotypic distance matrices at the two sites and years (
Table 6). There were significant correlations at both sites and in both years. However, the correlations were highest for the two seasons at IFVCNS, Serbia.
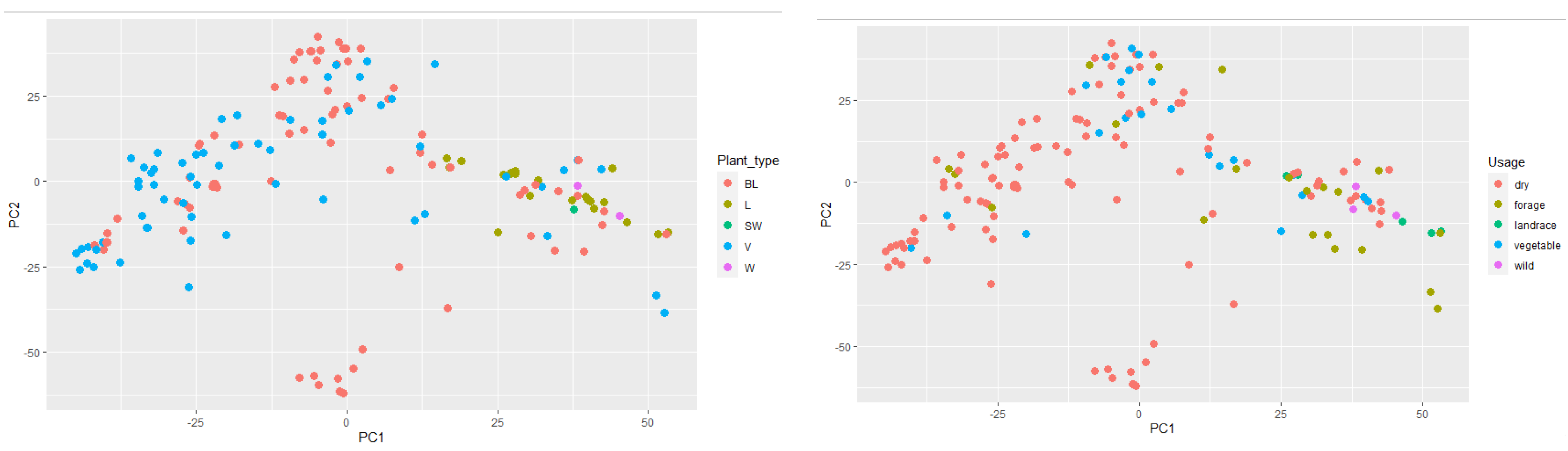
A Principal Component Analysis (PCA) was also performed on the genotype data and the data for the first two components were related to population type (
Figure 6, left) and plant type (
Figure 6, right). In the PCA graph grouped by plant type, it is noticeable that landraces and semi-wild and wild materials were concentrated on the cluster’s right side, while breeding lines and varieties were mainly concentrated on the left. This shows a clear morphological group formed from landraces (longer internodes), semi-wild and wild, and the modern bred dry pea varieties.
PCA analysis in relation to plant usage shows and reinforces the structure in the PCA graph by plant type, successfully grouping modern bred varieties (dry and vegetable) whose accessions dominate on the left, while the landrace, forage, and wild types, being clearly distinct phenotypically, are on the right-hand side.
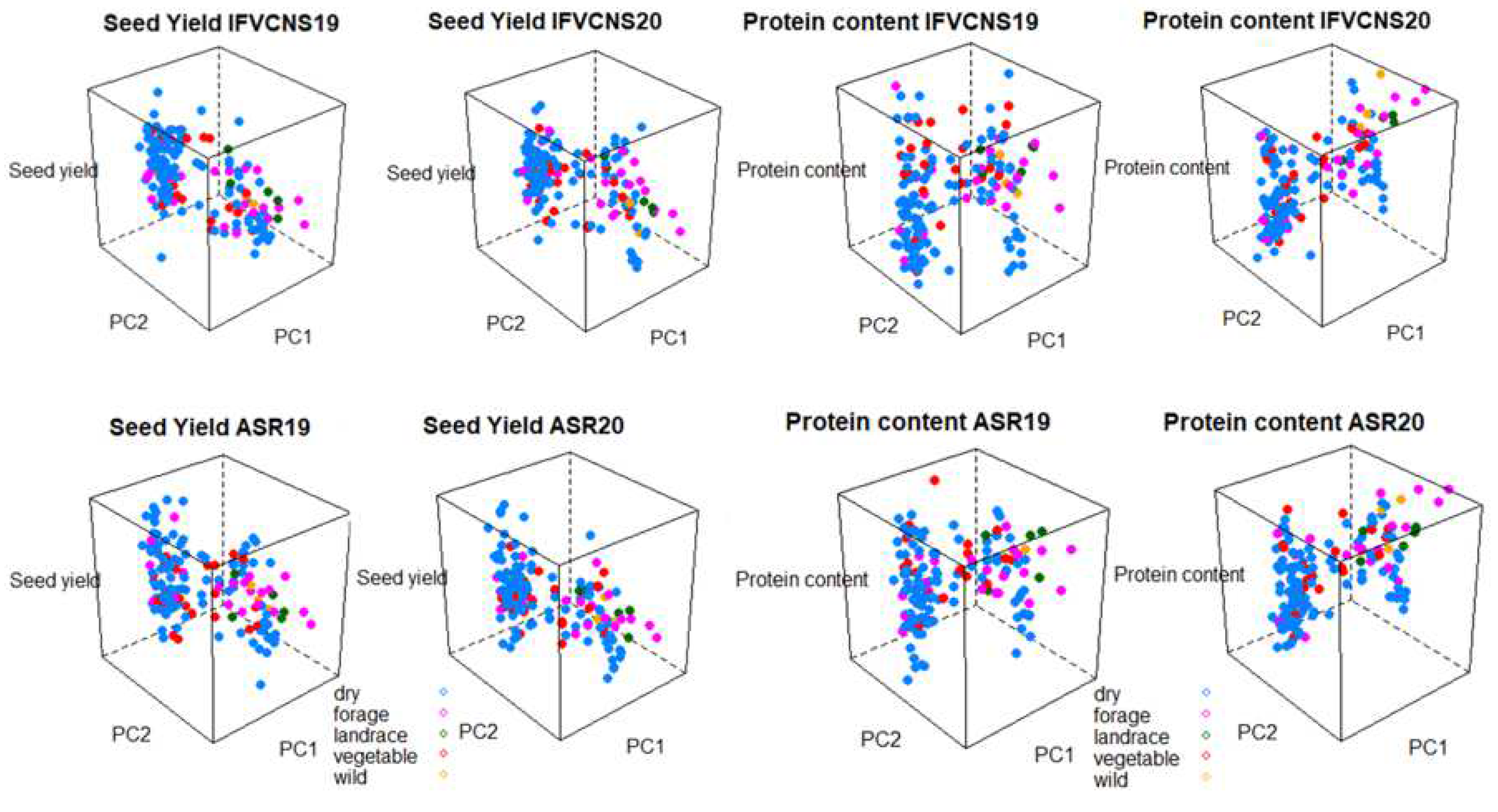
The seed yield and protein content was projected on the first two principal components from the PCA of the genotype data to further analyze the phenotypic variance and G*E interaction using 3D graphs (
Figure 7 and
Figure 8). The interactions between the genotypes of the accessions, the two sites, years, and usage or plant type showed that for seed yield, the dry and vegetable types tended to have the widest range of yields irrespective of year and site, while the forage, landraces, and wild types tended to be intermediary (
Figure 7). For protein content, the forage, landraces and wild types were highest, particularly in 2020, at both sites.
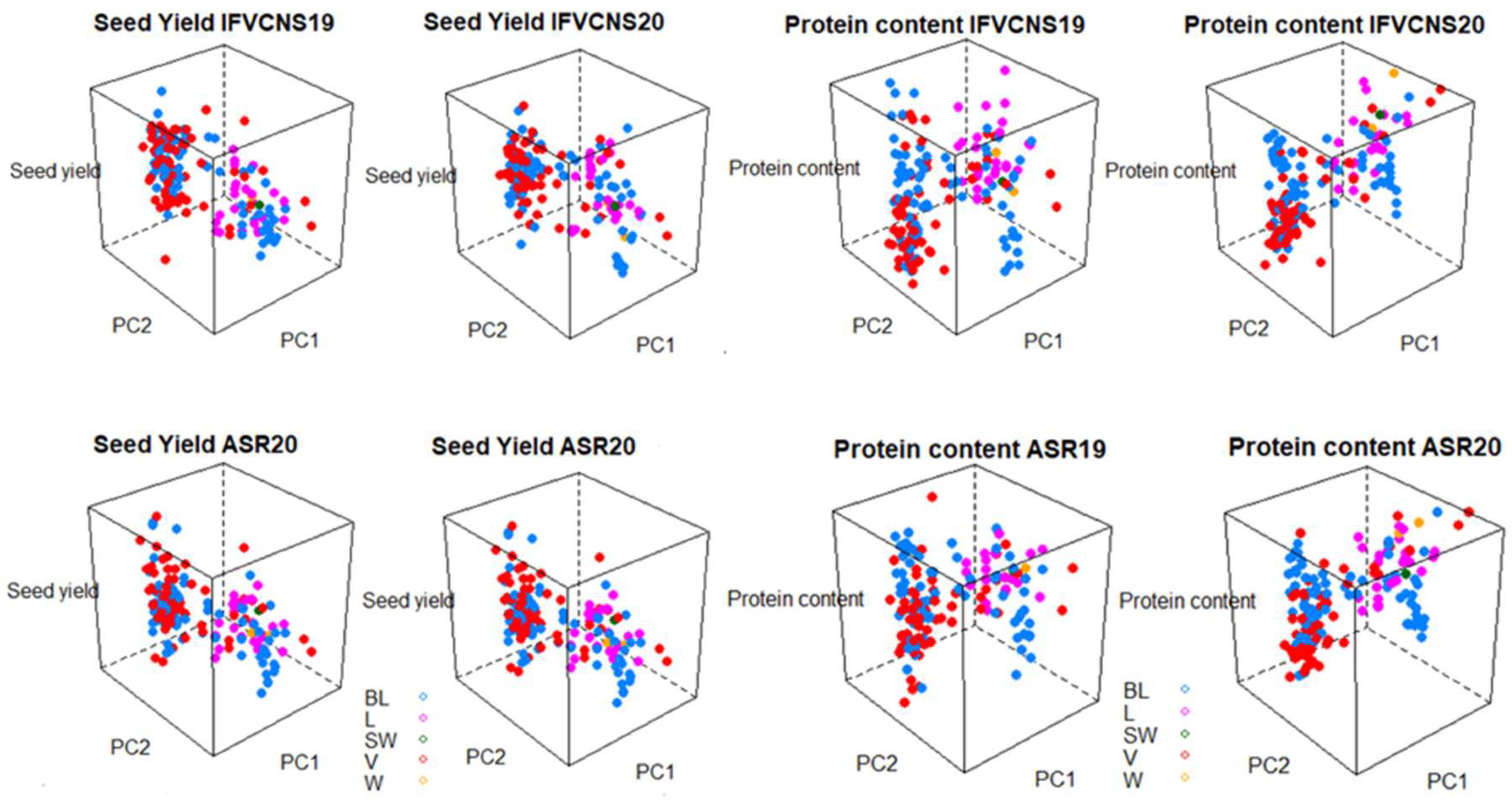
In terms of plant type, the varieties and breeding lines had the accessions with the highest seed yield, but also the widest range of yield. Again, the patterns were similar within the same year at the two sites (
Figure 8). For protein content, landraces and wild and semi-wild accessions were in the high category, together with a few varieties, particularly in 2020.
3. Discussion
High variability in germplasm collection is desirable when it comes to introducing new sources of variation in breeding programs. Evaluation and characterization of inherited agronomic traits can improve the identification of the phenotypic clusters within broad geographic groups [
21]. In order to assess the phenotypic variability of a pea germplasm collection, the partially-replicated experimental design used in this work allowed successful estimation of broad-sense heritability (He
2B) using limited seed quantities, significantly reducing the cost of phenotyping [
22] a diversity panel containing a large number of lines. Extensive phenotypic variation was present in the diversity panel at both trial sites, illustrated particularly by high coefficients of variation for SY (at IFVCNS and Agro Seed), for TSW (at IFVCNS), and for GPP (at Agro Seed), as well as for SWPP and PL (at IFVCNS) in 2020 and for PH in 2019 and TSW in 2020 (at Agro Seed), while for PH, higher values were recorded in the 2020 season for both trial sites. High heritability of TSW was observed at both IFVCNS and Agro Seed, similar to previous findings [
15,
19,
23,
24], showing that this trait is highly genetically controlled. The lowest heritability was recorded for PPP in 2019 and SPP in 2020 for IFVCNS, and for PPP in 2019 and PL in 2020 for Agro Seed, similar to the findings of [
19]. Lower heritability for these traits could be due to the significant error variance caused by high environmental influence (particularly with regards to rainfall) and not the narrow genetic variance. Means for PPP, SPP, SWPP, and PH were significantly lower in 2020 than in 2019, which might be the consequence of drought during the flowering period in May 2020 in Serbia (
Table S1). The mean for SY was higher in 2020; similar findings were given by [
6], where a high amount of precipitation, especially at the flowering stage, positively affected the grain yield of field pea. Means for PPP, SPP, PH, and SY were lower in 2019 in Belgium. In contrast, TSW was higher in 2019 compared to 2020, which is similar to the findings of [
25], where lack of moisture in the pod-filling period led to lower number of pods and seeds per plant. This causes the plants to concentrate their nutrients and energy in the weight of the seeds, giving a higher mass of 1000 seeds, but generally lower yields. The coefficient of variation for all traits in the Serbia trial was generally higher in 2020, which is most likely due to uneven rain distribution during the pea growing season (
Table S1), which can affect all the elements of the yielding structure, the length of flowering, and the height and lodging of plants.
The phenotypic correlation is conditioned by the relationship among individual traits and the influence of environmental factors [
26]. If there is a correlation between two traits, direct selection of one will cause a change in the other. Before initiating any effective selection program, it is necessary to know the association of various traits with each other [
27]. The relationship between various traits of peas has been studied previously, but the results were found to vary significantly according to varietal differences and environmental conditions [
28,
29,
30,
31]. This study used a very diverse group of pea genotypes and many varieties have a low number of seeds per pod or small grains, therefore diluting the correlation. However, in both trial sites, a positive and significant correlation was found between the traits that represent plant yield (SWPP) with PoL, PPP, SPP, and TSW, similar to previous findings [
32,
33], as well as a high positive correlation of SY with TSW and SWPP. The high positive correlation between PPP and SPP is similar to the results of [
34]. These results indicate that number of pods per plant has a significant influence on yield. The positive correlation of PPP with PH and the negative correlation of GPP with PH, both observed at IFVCNS, is similar to [
35], suggesting that the height of the plant could affect the number and size of seeds. Furthermore, the negative correlation between PH and PoL and the positive correlation between PoL and GPP observed at IFVCNS may indicate an indirect negative correlation between height and grains per pod. A significant negative correlation was expressed between TSW with GPP, PPP, and SPP for both trial sites, and GPP with PL (in the IFVCNS trial). SPP and FL were positively correlated only in the Agro Seed trial. PC was significantly negatively correlated with TSW only in the IFVCNS trial, unlike the results of [
36], who noted positive correlations between these two traits. Our results for the IFVCNS trial, similar to [
37], showed that in pea, the relationship between seed yield and seed weight per plant is always positive, regardless of the environment and the genetic background, which implies that the relationship between seed protein content and seed yield is almost always negative. Correlations between remaining pairs of traits mainly were low and non-significant in both years, which might indicate the presence of nonlinear interaction between traits [
38].
Correlation of a single trait between years was analyzed. A low correlation between years might suggest a higher genotype by environment (GxE) interaction [
15]. Thus, it can be concluded that traits with lower correlation between 2019 and 2020, such as PPP, SPP, PL, and SWPP, were influenced by environmental factors, while TSW, PoL, GPP, and PH were less affected. Similar findings were observed by [
15] and [
19], which also detected lower GxE interactions for TSW and higher interactions for SPP. The lowest correlation was observed for FL, which might indicate genotype reaction to agro-ecological conditions (high GxE). This might be influenced by the fact that the varieties, wild accessions, and landraces included in the assessed germplasm collection originated from different climatic conditions. Since the correlations of all examined traits in two years were positive, it can be concluded that the studied set of genotypes did not have strong reactions to different agro-ecological factors.
Despite the absence of clearly separate groups among pea genotypes based on plant type, comparison among groups by different subtypes (forage, dry, and vegetable) indicated their differences in phenotypic traits based on PCA, so deviations in morphological characteristics between groups comparing trial sites can still be visible. Based on the IFVCNS trials, where the grouping of most landraces is visible on the PCA diagram (
Figure 5, left), grouping could result from landrace characteristics to have a higher plant height and smaller grains. Clustering can also be seen for some of the varieties and breeding lines. However, both these groups consist of genotypes from different climates and origins and different uses. Further studies, similar to [
15] and [
39], performed at the molecular level, could show a more detailed grouping of these genotypes. Comparing type by use, in the IFVCNS trial, clustering can be seen mostly for the dry pea subtype, followed by the forage subtype (
Figure 6, left). Dry pea varieties are characterized by small number of seeds per pod, large grains, and about 20–25% protein content [
40,
41], while forage peas are mainly characterized by small grains, indeterminate type, and 17–24% protein content [
41,
42]. Similar clustering can be seen in the Agro Seed trial, with a less visible structure. Wild and landrace types are clustered together (on the right).
There were marked phenotypic differences between the wild peas (climbing, low lodging resistance, indeterminate growth) and commercial pea varieties (dry pea, forage). However, there was significant variation in the traits themselves, which was confirmed by analysis of variance. In contrast, when the genotypes were analyzed by the population type, no apparent structure of phenotypic data was present because, within groups (such as breeding lines, varieties, landraces), there were variations resulting from different subtype representations (such as dry pea, vegetable pea, forage pea) within each of them.
Based on the hierarchical clustering, there was evidently a difference between genotypes. This can be explained by the fact that both pea varieties and pea breeding lines can be classified into vegetable peas, dry peas for feed and food, and forage peas (grown primarily for forage) [
42]. Landraces have distinctive characteristics arising from development and adaptation over time to conditions of a localized geographic region, and typically display greater genetic diversity than types subjected to formal breeding practices [
43].
Higher correlations for the IFVCNS trials, compared to the Agro Seed trials, as calculated by the Mantel test, may partially be because the analyzed pea panel consisted of 64 accessions with a Serbian provenance. If they were adapted to conditions in Serbia more than other accessions, this may be reflected in the overall genetic makeup, meaning that these accessions would likely be genetically more similar due to adaptation to conditions in this specific region. In contrast, accessions from a broader range of geographic and ecologically distinct regions will be more genetically diverse.
The fact that landraces and semi-wild, and wild material were separated from most breeding lines and varieties (
Figure 6, Left), and that forage types were separated from garden and dry peas (
Figure 6, Right) confirms that there is a decrease in similarity between the genotypes, which can be explained by their different purposes.
The 3D graphs (
Figure 7 and
Figure 8) show that the patterns of variation in seed yield and protein content were remarkably similar at the two sites and relatively consistent between years. This was the case regardless of whether the accessories were grouped according to use or plant type; this confirms the adaptability of peas to different agroclimatic factors.
5. Conclusions
Examination of phenotypic diversity of pea genotypes of different origins indicated considerable variation for a range of traits. The broad-sense heritability estimates were moderate to high for all examined traits, indicating the major influence of genetic factors. Inconsistent heritability between years and between sites for certain traits indicated their higher sensitivity to environmental conditions. Based on this work, it could be concluded that selection of traits with high and consistent heritability would be most valuable to breeders, including stable traits that effect seed weight per plant such as pod length and thousand seed weight. Moderate, consistent heritability with a long-lasting effect on seed weight per plant was observed for the number of seeds per plant, so direct selection of this trait could also be effective. Breeding for increased seed protein content is hampered by the negative correlation between protein content and yield. Therefore, increasing protein production can be done by increasing the area under protein crops or by improving protein quality over protein content, given that difference in protein content can be the result of many different environmental factors. The seed yield is a less challenging breeding target than protein content; therefore, high yields have been achieved among some of the cultivated accessions. Given the lack of the strong influence of GxE, confirmed by positive correlations between two years, this gene pool provides numerous possibilities as a starting point for future pea varieties adaptable to different agroclimatic conditions. Traits such as the number of grains per pod, plant height, pod length, thousand seed weight, seed yield, and protein content showed highly significant variations among the tested groups of genotypes. Knowledge of these variations could be used in further plant selection programs.
Given the proven and evident differences between the analyzed genotypes based on type and use, and their great adaptability to tested conditions, it can be concluded that pea is a very adaptable plant species with untapped production potential.
The results of this study should contribute to a better knowledge of variability and seed yield stability of pea genotypes used in Europe for future production and breeding. Obtained phenotypic results could improve pea breeding by developing new cultivars carrying favorable traits to attain more sustainable production and higher yields. In conclusion, this work should promote the broader use of pea as a grain legume within diverse agricultural systems to provide multiple beneficial advantages, in line with the principles of sustainability.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}