
Machine-Learning-Assisted Prediction of Maximum Metal Recovery from Spent Zinc–Manganese Batteries



Abstract
:1. Introduction
2. Methods
2.1. Linear Regression
2.2. Random Forest Regression
2.3. AdaBoost Regression
2.4. Gradient Boosting Regression
2.5. XG Boost Regression
3. Problem Description
4. Results and Discussion
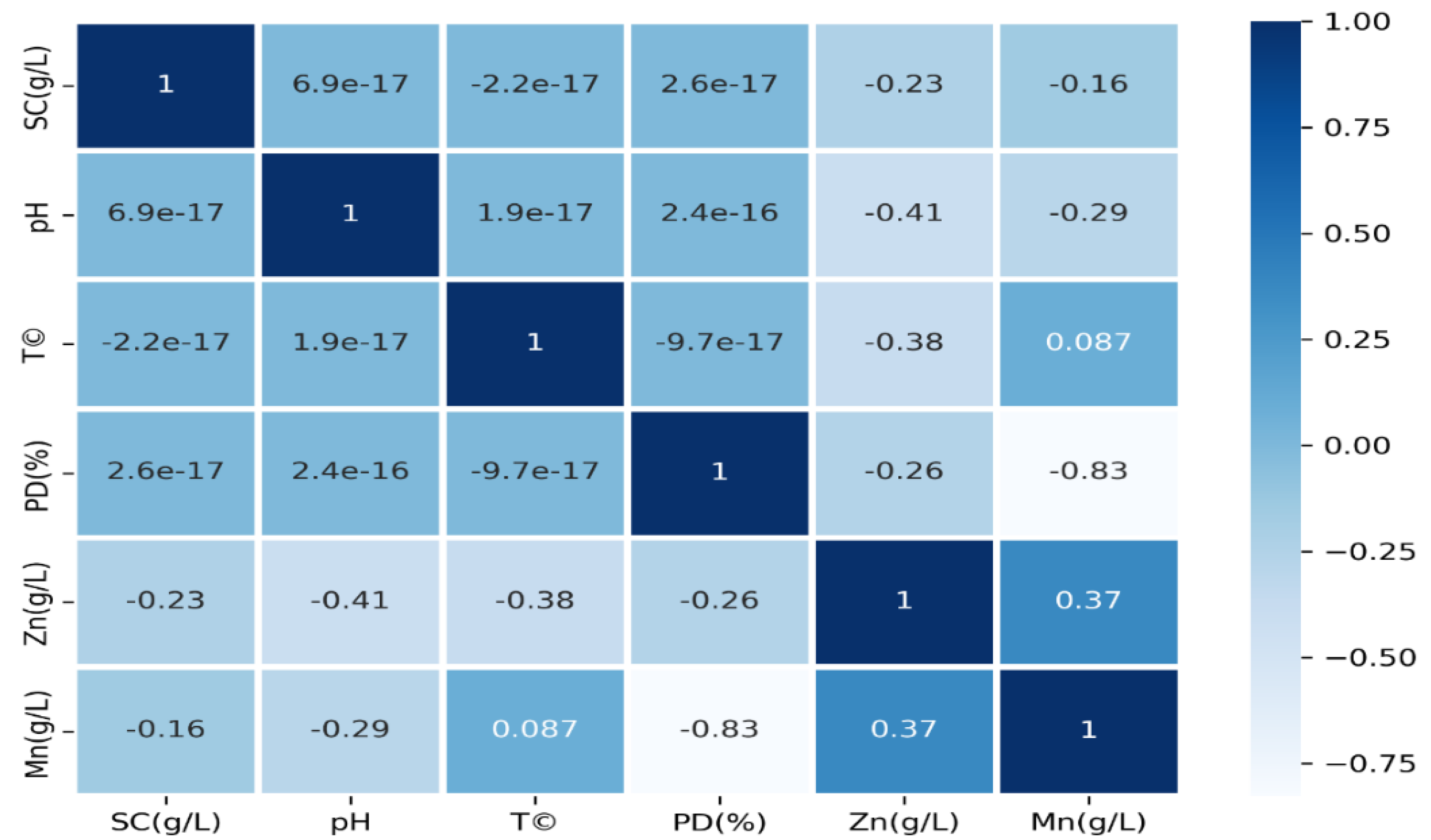
4.1. Data Characteristics
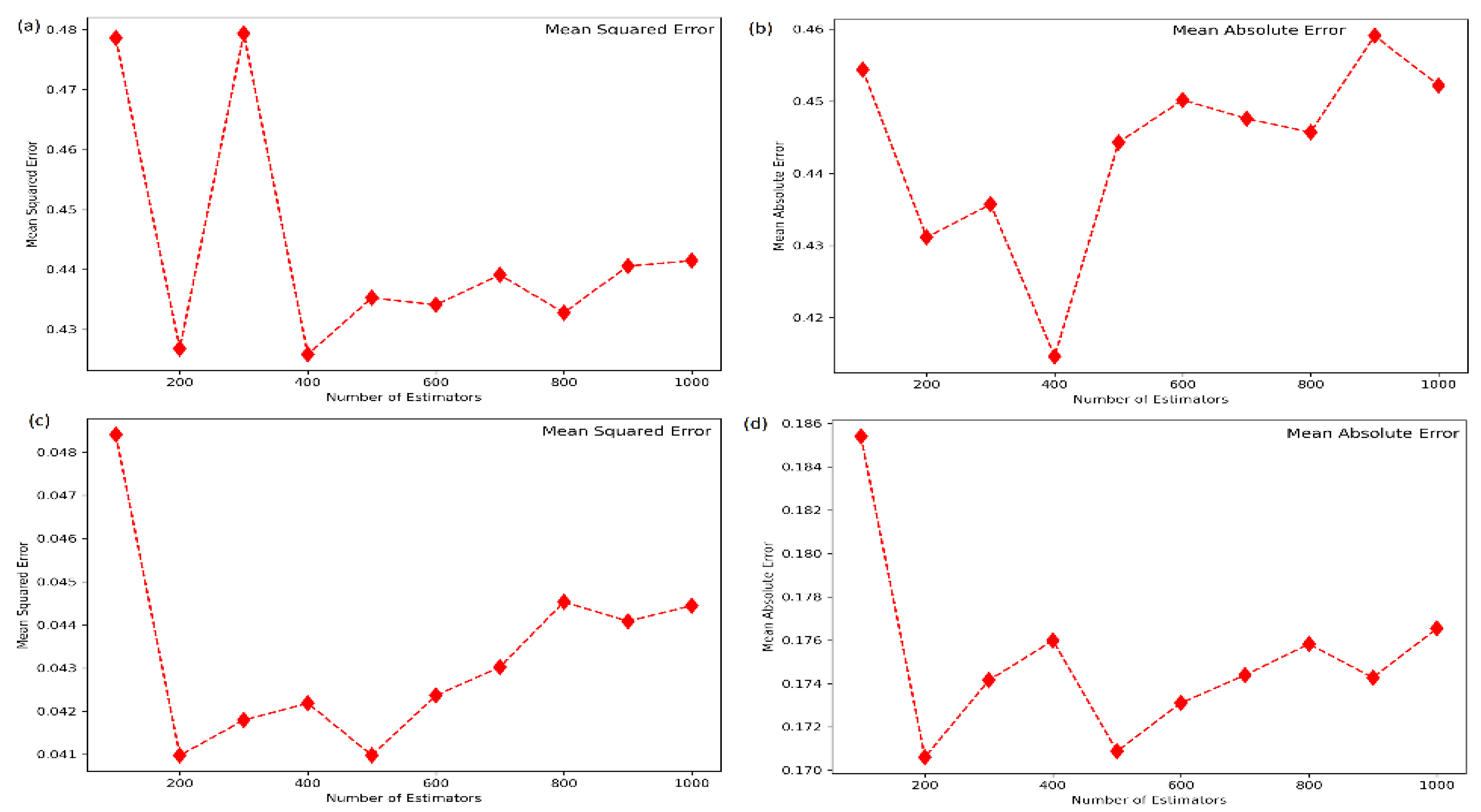
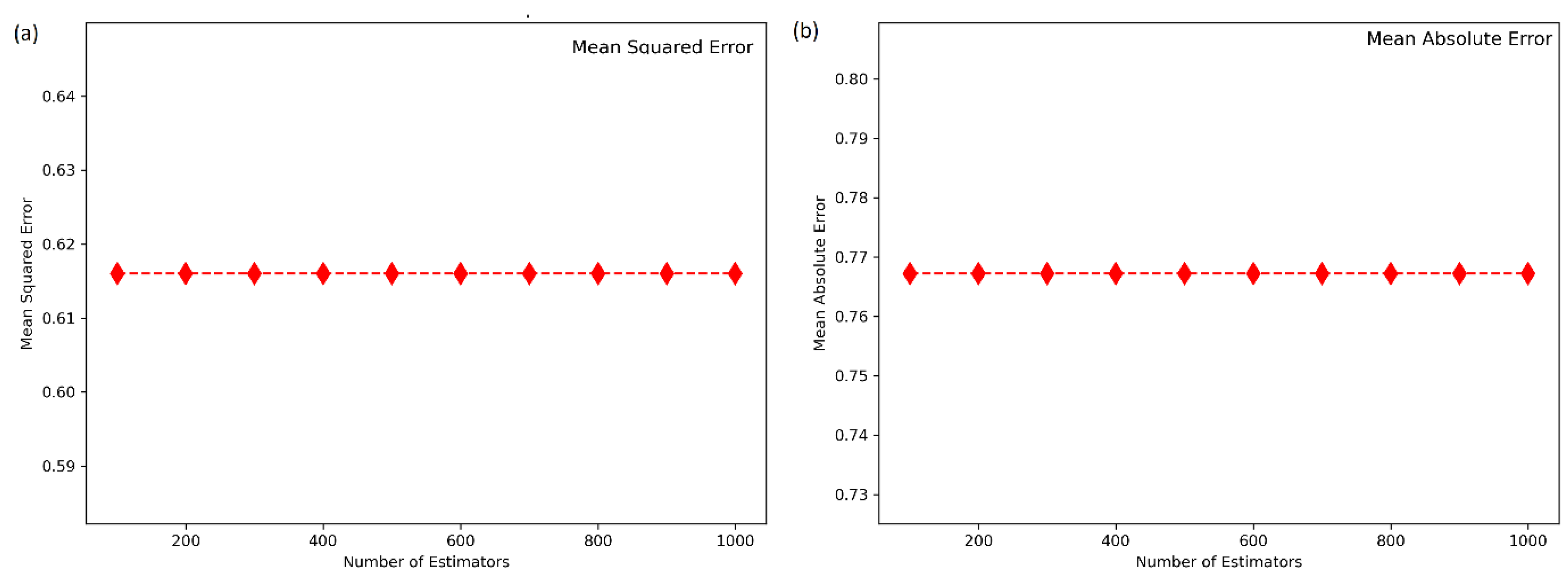
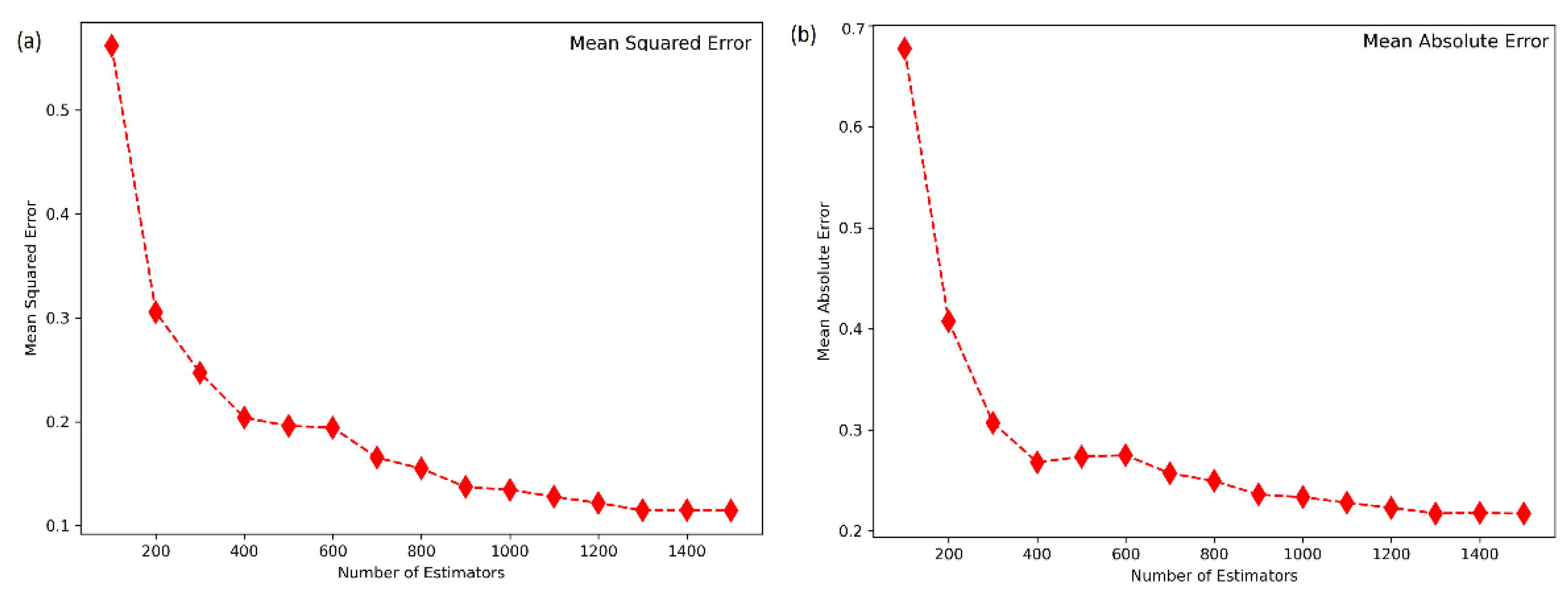
4.2. Hyperparameter Tuning of the Machine Learning Models
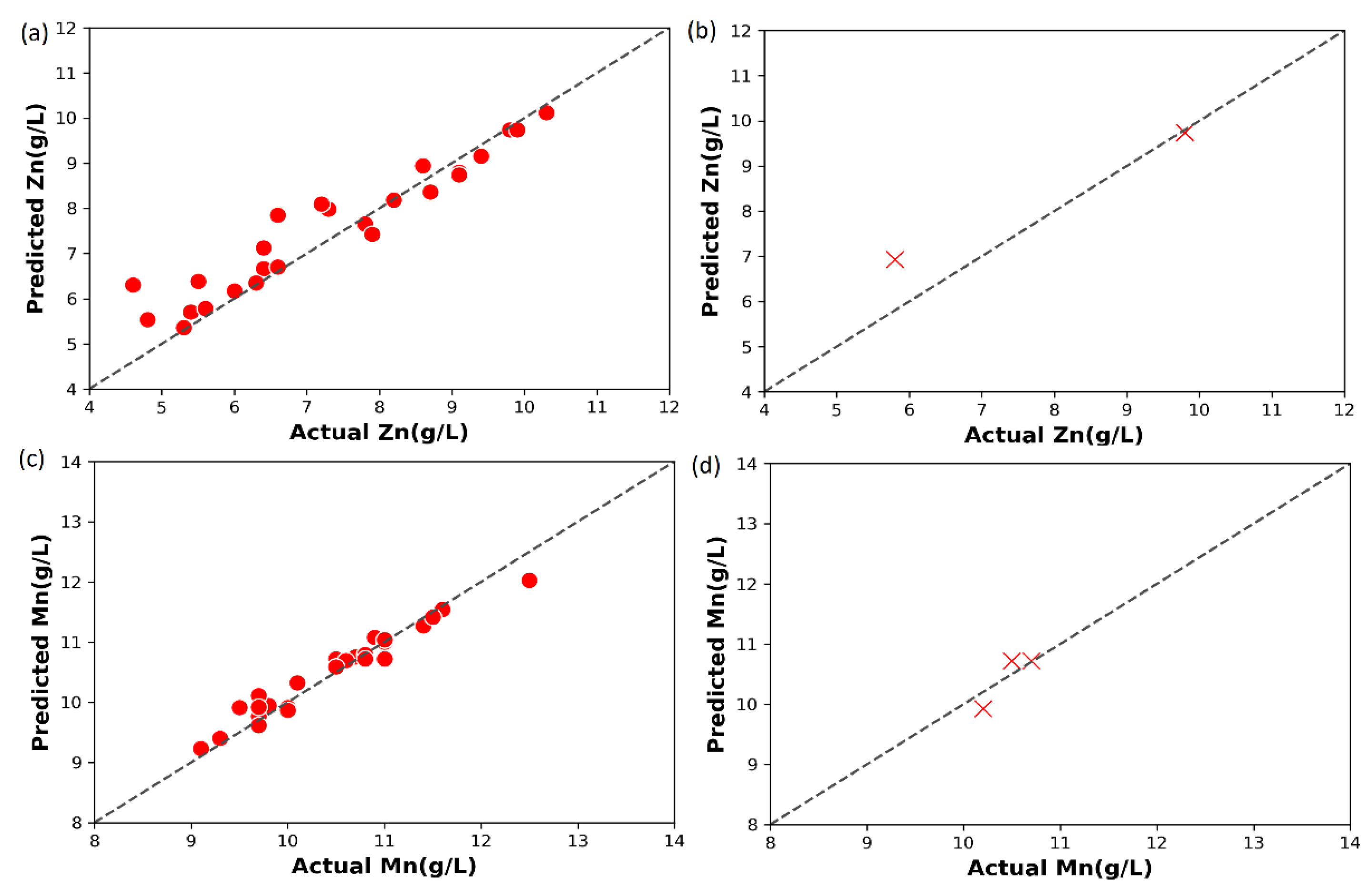
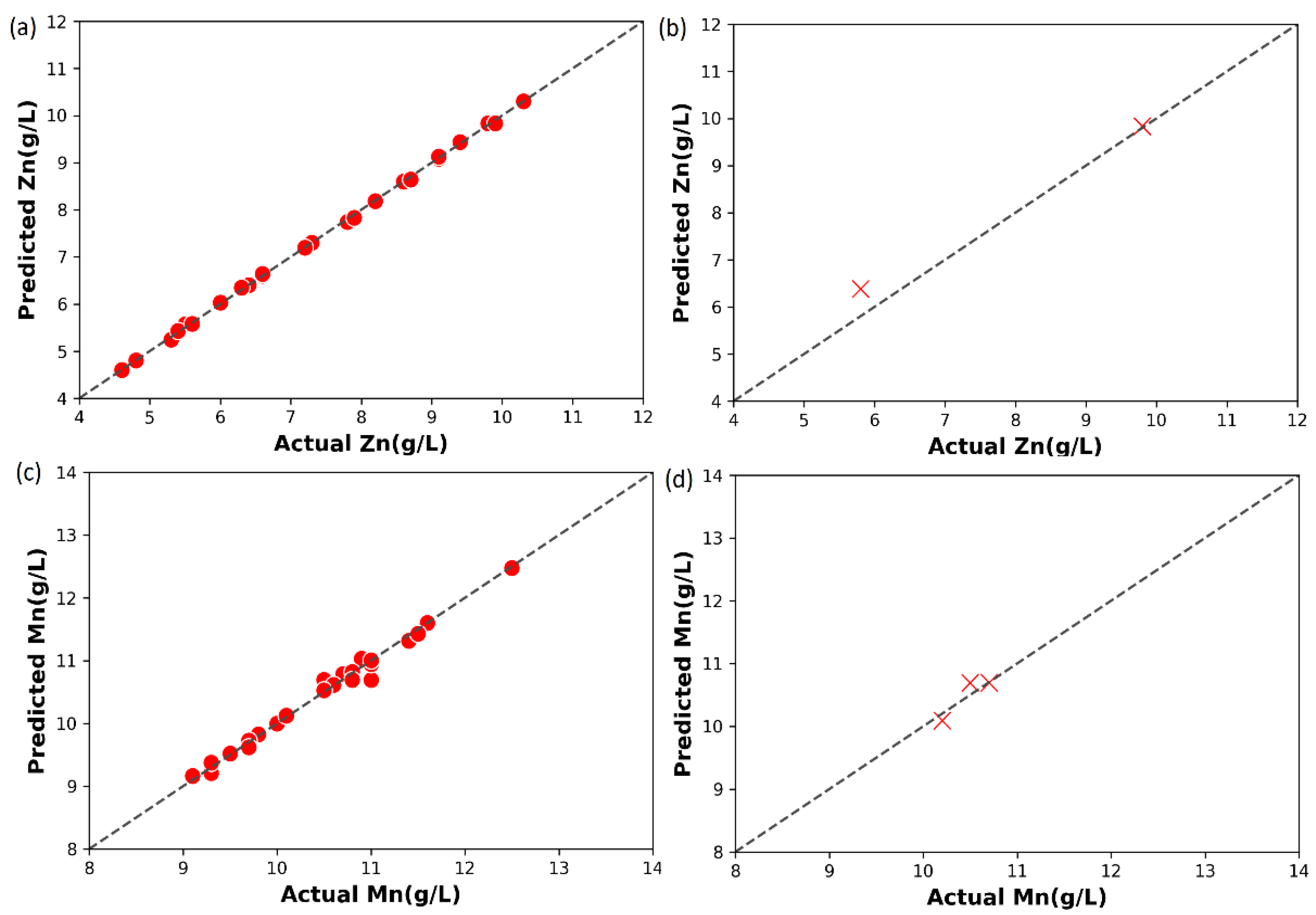
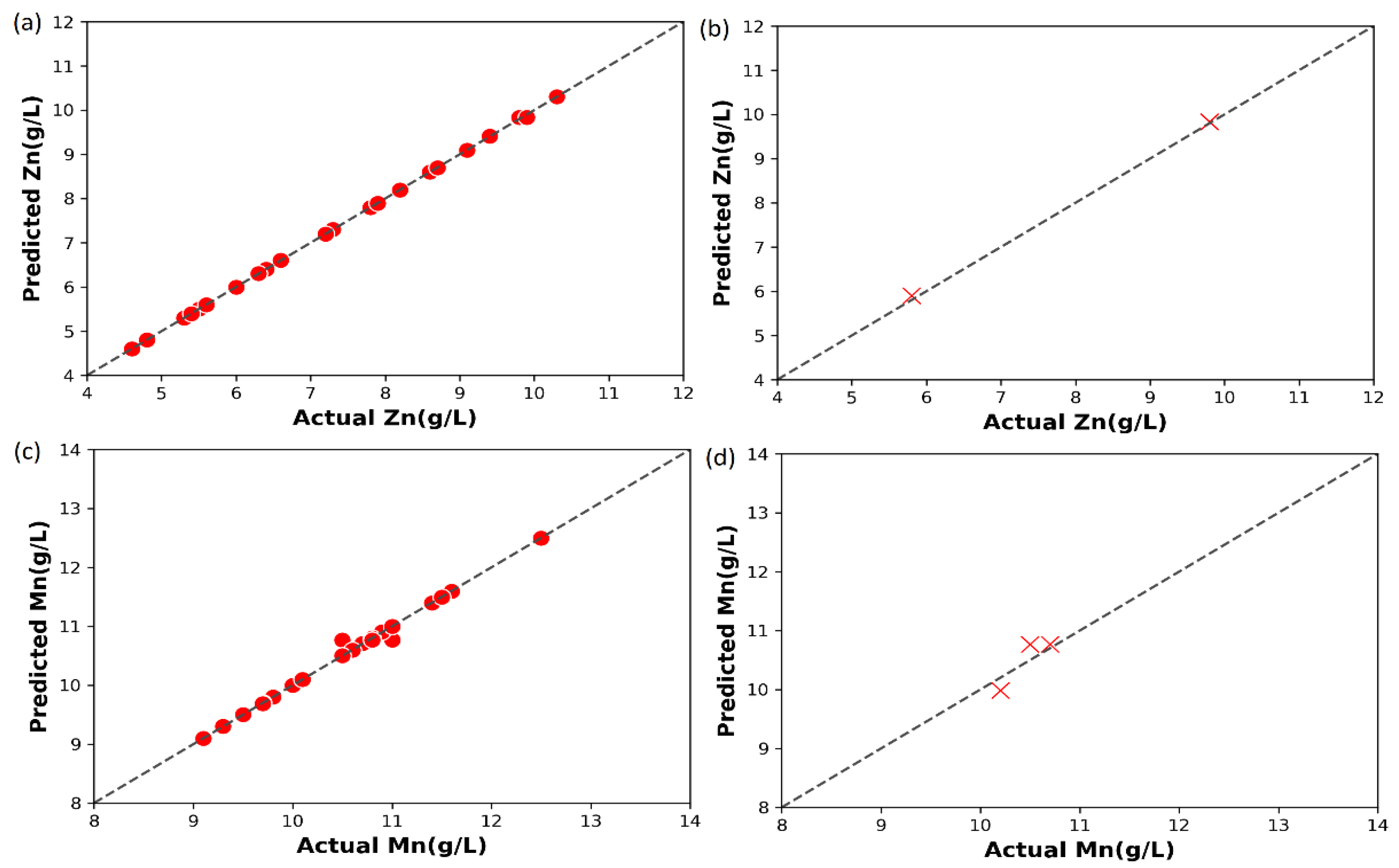
4.3. Performance of the Machine Learning Models
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Millette Environmental. Research Study on Reuse and Recycling of Batteries Employed in Electric Vehicles: The Technical, Environmental, Economic, Energy and Cost Implications of Reusing and Recycling EV Batteries. Energy API. 2019. Available online: https://www.api.org/~/media/Files/Oil-and-Natural-Gas/Fuels/Kelleher%20Final%20EV%20Battery%20Reuse%20and%20Recycling%20Report%20to%20API%2018Sept2019%20edits%2018Dec2019.pdf (accessed on 5 April 2022).
- Hua, Y.; Zhou, S.; Huang, Y.; Liu, X.; Ling, H.; Zhou, X.; Zhang, C.; Yang, S. Sustainable value chain of retired lithium-ion batteries for electric vehicles. J. Power Sources 2020, 478, 228753. [Google Scholar] [CrossRef]
- Eftekhari, A. Lithium Batteries for Electric Vehicles: From Economy to Research Strategy. ACS Sustain. Chem. Eng. 2019, 7, 5602–5613. [Google Scholar] [CrossRef]
- Chung, D.; Elgqvist, E.; Santhanagopalan, S. Automotive Lithium-ion Cell Manufacturing: Regional Cost Structures and Supply Chain Considerations; National Renewable Energy Lab. (NREL): Golden, CO, USA, 2016. [Google Scholar] [CrossRef] [Green Version]
- Sayilgan, E.; Kukrer, T.; Civelekoglu, G.; Ferella, F.; Akcil, A.; Veglio, F.; Kitis, M. A review of technologies for the recovery of metals from spent alkaline and zinc–carbon batteries. Hydrometallurgy 2009, 97, 158–166. [Google Scholar] [CrossRef]
- Reuter, M.; Hudson, C.; Van Schaik, A.; Heiskanen, K.; Meskers, C.; Hagelüken, C. Metal recycling: Opportunities, limits, infrastructure. In A Report of the Working Group on the Global Metal Flows to the International Resource Panel; UNEP: Nairobi, Kenya, 2013. [Google Scholar]
- Bonhomme, R.; Gasper, P.; Hines, J.; Miralda, J.P. Economic Feasibility of a Novel Alkaline Battery Recycling Process; Worcester Polytechnic Institute: Worcester, MA, USA, 2013. [Google Scholar]
- Chen, L.; Tang, X.; Zhang, Y.; Li, L.; Zeng, Z.; Zhang, Y. Process for the recovery of cobalt oxalate from spent lithium-ion batteries. Hydrometallurgy 2011, 108, 80–86. [Google Scholar] [CrossRef]
- Huang, B.; Pan, Z.; Su, X.; An, L. Recycling of lithium-ion batteries: Recent advances and perspectives. J. Power Sources 2018, 399, 274–286. [Google Scholar] [CrossRef]
- Huang, K.; Li, J.; Xu, Z. Characterization and recycling of cadmium from waste nickel–cadmium batteries. Waste Manag. 2010, 30, 2292–2298. [Google Scholar] [CrossRef]
- Reuter, M.A.; Kojo, I.V. Challenges of metal recycling. Materia 2012, 2, 50–57. [Google Scholar]
- Mayyas, A.; Steward, D.; Mann, M. The case for recycling: Overview and challenges in the material supply chain for automotive li-ion batteries. Sustain. Mater.Technol. 2019, 19, e00087. [Google Scholar] [CrossRef]
- Ruhatiya, C.; Tibrewala, H.; Gao, L.; Sleesongsom, S.; Chin, C.M.M. Intelligent optimization of process conditions for maximum metal recovery from spent zinc-manganese batteries. IOP Conf. Series Earth Environ. Sci. 2020, 463, 012160. [Google Scholar] [CrossRef]
- Niu, Z.; Huang, Q.; Xin, B.; Qi, C.; Hu, J.; Chen, S.; Li, Y. Optimization of bioleaching conditions for metal removal from spent zinc-manganese batteries using response surface methodology. J. Chem. Technol. Biotechnol. 2014, 91, 608–617. [Google Scholar] [CrossRef]
- Kim, T.-H.; Senanayake, G.; Kang, J.-P.; Sohn, J.-S.; Rhee, K.-I.; Lee, S.-W.; Shin, S.-M. Reductive acid leaching of spent zinc–carbon batteries and oxidative precipitation of Mn–Zn ferrite nanoparticles. Hydrometallurgy 2009, 96, 154–158. [Google Scholar] [CrossRef]
- Flores, V.; Leiva, C. A Comparative Study on Supervised Machine Learning Algorithms for Copper Recovery Quality Prediction in a Leaching Process. Sensors 2021, 21, 2119. [Google Scholar] [CrossRef] [PubMed]
- Ebrahimzade, H.; Khayati, G.R.; Schaffie, M. A novel predictive model for estimation of cobalt leaching from waste Li-ion batteries: Application of genetic programming for design. J. Environ. Chem. Eng. 2018, 6, 3999–4007. [Google Scholar] [CrossRef]
- Garg, A.; Yun, L.; Gao, L.; Putungan, D.B. Development of recycling strategy for large stacked systems: Experimental and machine learning approach to form reuse battery packs for secondary applications. J. Clean. Prod. 2020, 275, 124152. [Google Scholar] [CrossRef]
- Ng, M.F.; Zhao, J.; Yan, Q.; Conduit, G.J.; Seh, Z.W. Predicting the state of charge and health of batteries using data-driven machine learning. Nat. Mach. Intell. 2020, 2, 161–170. [Google Scholar] [CrossRef] [Green Version]
- Lu, Y.; Maftouni, M.; Yang, T.; Zheng, P.; Young, D.; Kong, Z.J.; Li, Z. A novel disassembly process of end-of-life lithium-ion batteries enhanced by online sensing and machine learning techniques. J. Intell. Manuf. 2022, 1–13. [Google Scholar] [CrossRef]
- Liu, K.; Li, Y.; Hu, X.; Lucu, M.; Widanage, W.D. Gaussian Process Regression With Automatic Relevance Determination Kernel for Calendar Aging Prediction of Lithium-Ion Batteries. IEEE Trans. Ind. Inform. 2019, 16, 3767–3777. [Google Scholar] [CrossRef] [Green Version]
- Ruhatiya, C.; Shaosen, S.; Wang, C.; Jishnu, A.K.; Bhalerao, Y. Optimization of process conditions for maximum metal recovery from spent zinc-manganese batteries: Illustration of statistical based automated neural network approach. Energy Storage 2019, 2, e111. [Google Scholar] [CrossRef]
- Bhattacharya, S.; Kalita, K.; Čep, R.; Chakraborty, S. A Comparative Analysis on Prediction Performance of Regression Models during Machining of Composite Materials. Materials 2021, 14, 6689. [Google Scholar] [CrossRef]
- Shanmugasundar, G.; Vanitha, M.; Čep, R.; Kumar, V.; Kalita, K.; Ramachandran, M. A Comparative Study of Linear, Random Forest and AdaBoost Regressions for Modeling Non-Traditional Machining. Processes 2021, 9, 2015. [Google Scholar] [CrossRef]
- Jain, P.; Choudhury, A.; Dutta, P.; Kalita, K.; Barsocchi, P. Random Forest Regression-Based Machine Learning Model for Accurate Estimation of Fluid Flow in Curved Pipes. Processes 2021, 9, 2095. [Google Scholar] [CrossRef]
- Kalita, K.; Chakraborty, S.; Madhu, S.; Ramachandran, M.; Gao, X.-Z. Performance Analysis of Radial Basis Function Metamodels for Predictive Modelling of Laminated Composites. Materials 2021, 14, 3306. [Google Scholar] [CrossRef]
- Montgomery, D.C.; Peck, E.A.; Vining, G.G. Introduction to Linear Regression Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2021. [Google Scholar]
- Seber, G.A.; Lee, A. Linear Regression Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Li, X. Using “random forest” for classification and regression. Chin. J. Appl. Entomol. 2013, 50, 1190–1197. [Google Scholar]
- Collins, M.; Schapire, R.E.; Singer, Y. Logistic Regression, AdaBoost and Bregman Distances. Mach. Learn. 2002, 48, 253–285. [Google Scholar] [CrossRef]
- Kalita, K.; Haldar, S.; Chakraborty, S. A Comprehensive Review on High-Fidelity and Metamodel-Based Optimization of Composite Laminates. Arch. Comput. Methods Eng. 2022, 1–36. [Google Scholar] [CrossRef]
- Kalita, K.; Dey, P.; Haldar, S. Search for accurate RSM metamodels for structural engineering. J. Reinf. Plast. Compos. 2019, 38, 995–1013. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistical Feature | SC (g/L) | pH | T (°C) | PD (%) | Zn (g/L) | Mn (g/L) |
|---|---|---|---|---|---|---|
| Count | 29 | 29 | 29 | 29 | 29 | 29 |
| Mean | 32 | 2 | 35 | 10 | 7.517 | 10.417 |
| Standard deviation | 3.703 | 0.185 | 2.314 | 0.925 | 1.794 | 0.793 |
| Min | 24 | 1.6 | 30 | 8 | 4.6 | 9.1 |
| 25% | 28 | 1.8 | 32.5 | 9 | 6 | 9.7 |
| 50% | 32 | 2 | 35 | 10 | 7.3 | 10.5 |
| 75% | 36 | 2.2 | 37.5 | 11 | 9.1 | 10.9 |
| Max | 40 | 2.4 | 40 | 12 | 10.3 | 12.5 |
| Range | 16 | 0.8 | 10 | 4 | 5.7 | 3.4 |
| Data | Model | MSE | MAE | Maximum Error | MedAE | |
|---|---|---|---|---|---|---|
| Train | Linear Regression | 51.88% | 1.4157 | 0.9088 | 2.4791 | 0.6072 |
| Random Forest Regression | 88.67% | 0.3333 | 0.4115 | 1.7072 | 0.2829 | |
| AdaBoost Regression | 85.44% | 0.4285 | 0.5206 | 1.3500 | 0.4100 | |
| Gradient Boosting Regression | 99.95% | 0.0014 | 0.0279 | 0.0725 | 0.0306 | |
| XG Boost Regression | 99.99% | 0.0003 | 0.0078 | 0.0677 | 0.0019 | |
| Test | Linear Regression | −42.33% | 5.0605 | 2.2411 | 2.3791 | 2.3791 |
| Random Forest Regression | 88.02% | 0.4258 | 0.4146 | 1.1273 | 0.0583 | |
| AdaBoost Regression | 82.67% | 0.6160 | 0.7673 | 0.8842 | 0.8842 | |
| Gradient Boosting Regression | 96.76% | 0.1150 | 0.2177 | 0.5855 | 0.0339 | |
| XG Boost Regression | 99.88% | 0.0041 | 0.0554 | 0.1017 | 0.0323 |
| Data | Model | MSE | MAE | Maximum Error | MedAE | |
|---|---|---|---|---|---|---|
| Train | Linear Regression | 80.33% | 0.1324 | 0.2646 | 0.8467 | 0.1960 |
| Random Forest Regression | 94.40% | 0.0377 | 0.1513 | 0.4747 | 0.1113 | |
| AdaBoost Regression | 94.92% | 0.0342 | 0.1476 | 0.4500 | 0.1388 | |
| Gradient Boosting Regression | 98.78% | 0.0082 | 0.0624 | 0.3072 | 0.0285 | |
| XG Boost Regression | 99.28% | 0.0049 | 0.0225 | 0.2651 | 0.0012 | |
| Test | Linear Regression | 19.36% | 0.0340 | 0.1517 | 0.2985 | 0.0985 |
| Random Forest Regression | 22.96% | 0.0410 | 0.1706 | 0.2726 | 0.2196 | |
| AdaBoost Regression | 12.32% | 0.0559 | 0.1933 | 0.3800 | 0.1400 | |
| Gradient Boosting Regression | 61.24% | 0.0164 | 0.1030 | 0.1928 | 0.1090 | |
| XG Boost Regression | 95.97% | 0.0397 | 0.1805 | 0.2651 | 0.2111 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Priyadarshini, J.; Elangovan, M.; Mahdal, M.; Jayasudha, M. Machine-Learning-Assisted Prediction of Maximum Metal Recovery from Spent Zinc–Manganese Batteries. Processes 2022, 10, 1034. https://0-doi-org.brum.beds.ac.uk/10.3390/pr10051034
Priyadarshini J, Elangovan M, Mahdal M, Jayasudha M. Machine-Learning-Assisted Prediction of Maximum Metal Recovery from Spent Zinc–Manganese Batteries. Processes. 2022; 10(5):1034. https://0-doi-org.brum.beds.ac.uk/10.3390/pr10051034
Chicago/Turabian StylePriyadarshini, Jayaraju, Muniyandy Elangovan, Miroslav Mahdal, and Murugan Jayasudha. 2022. "Machine-Learning-Assisted Prediction of Maximum Metal Recovery from Spent Zinc–Manganese Batteries" Processes 10, no. 5: 1034. https://0-doi-org.brum.beds.ac.uk/10.3390/pr10051034