In this section, first a dynamic model is identified, with the model output being measured variables. In the next subsection, a dynamic model is identified that uses a combination of measured and calculated variables to directly estimate metabolite consumption rates.
3.1. Dynamic Model Identification and Validation Using Measured Outputs
The first model examines the daily metabolite concentrations and their impact on cell titer. In this process, the following measurements are available: glucose concentration (mg/L), temperature setpoint (deg C), pH setpoint, titer (mg/L), viable cell density (VCD) (10 × 10−5 cells/mL), cell viability (%), glutamine concentration (mg/L), lactate concentration (mg/L), glutamate concentration (mg/L) and ammonia concentration (mg/L). One of the first decisions in developing subspace identification based models is determining the input and output variables that allows for model identification, and it is also in line with process implementation. Thus, pH and the temperature setpoints are selected as two of the input variables. The controller on the process works reasonably well, thus the pH and temperature values pretty closely follow the setpoints. The objective in this work is to determine the effect of these variables on the metabolites and cell titer, not the effect of the pH and temperature setpoints on the pH and temperature. In essence, the temperature and pH directly influence cell growth dynamics and the shifts in the setpoints represents changes in the growth profiles. The other measured variables inside the bioreactor, however, do not cause significant changes in the temperature or pH values and so the measured output values have more noise than useful information and are consequently omitted. Thus only the titer, viable cell density (VCD), cell viability, glutamine concentration, lactate concentration, glutamate concentration and ammonia concentration are chosen as the seven outputs.
Glucose on the other hand poses its own challenge. There are two potential ways to include glucose in the model. The first is to include the glucose addition as an input, and model glucose as an output. In such a scenario, the model would be trying to decipher the effect of glucose addition on the glucose concentration—which is a fairly straightforward mole balance. The other is the effect of the rate of consumption of glucose in its role as a metabolite. While this is possible in principle, every discrete addition of glucose would cause a jump in the glucose measurement, and would in turn cause the states to ‘jump’. Such a discrete addition piece could be modeled using the subspace identification approach in [
18], but it would lead to having to split the batch into multiple batches—with each batch comprising the time period between discrete additions. While this would be possible in principle (and reasonable for the process considered in [
18]), in the present instance, this would lead to each of the batches having very sparse measurements- thereby comprising mostly missing data. In this case, the recently developed missing data approach [
24] would not be directly applicable.
Glucose is therefore considered an input in the present manuscript. From a practical standpoint, it is reasonable because the glucose concentration can be readily measured and modified and thus be an input in a controller implementation. The dataset however poses an interesting challenge in this regard because the measurements of glucose are taken before the glucose addition, but not measured right after the glucose addition. The first measure to handle that includes the computation of the glucose concentration right after the glucose addition. This is the more intuitive part and can be computed readily as follows: , where V is the volume in L, is the concentration of glucose in mg/L and the + and − represent after and before feed addition, respectively
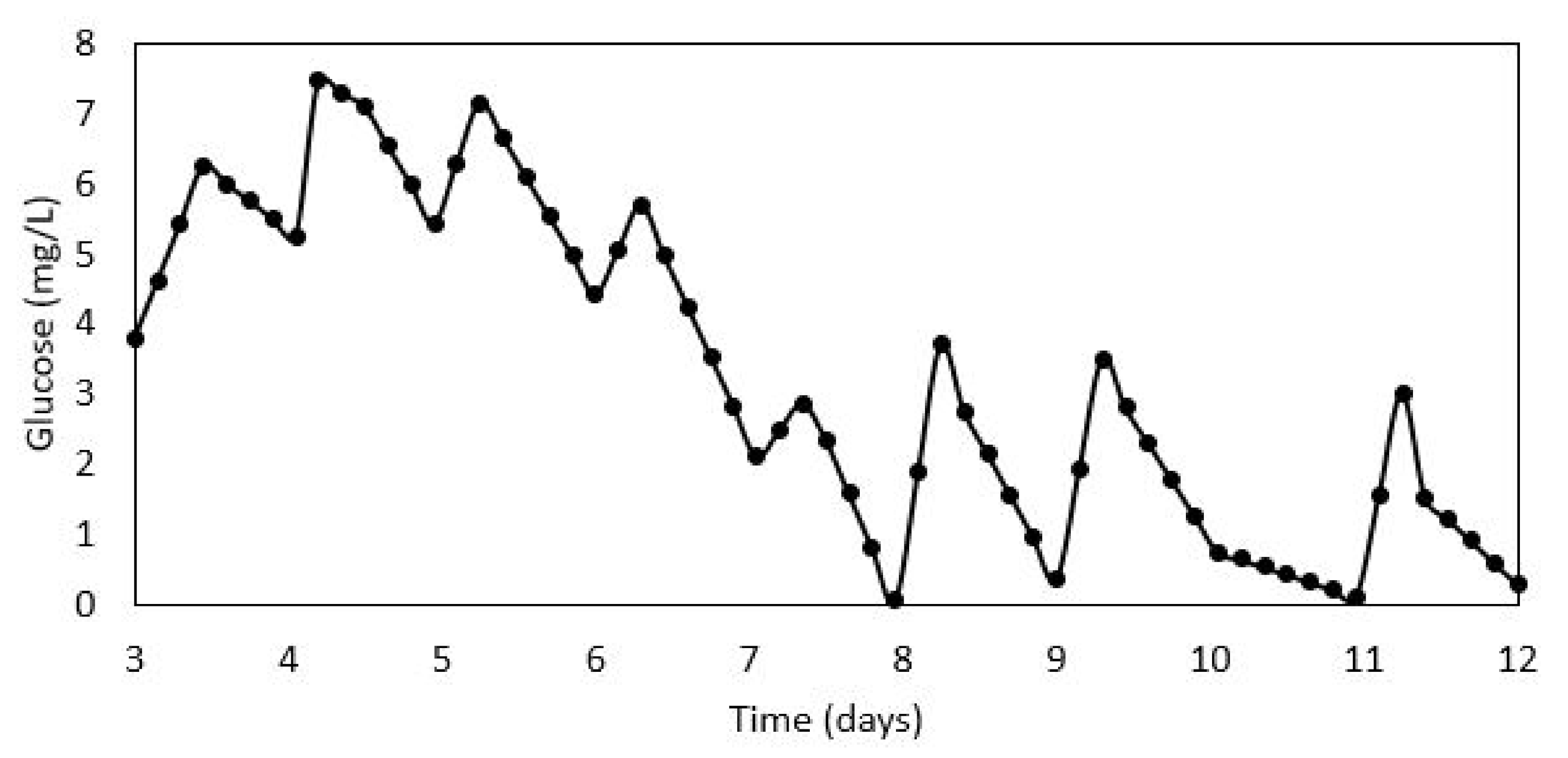
The other more important question is how to utilize the newly computed glucose concentration. Again, there are two alternatives and here one approach is clearly incorrect. The first alternative is to add an additional data point in the batch. Thus, right after the data point before the addition, a new point is added where the value of the glucose measurement is changed, but the value of the other variables is kept the same. While this sounds intuitively right, such a choice would provide the model with false information. In particular, it would suggest to the model that the value of the glucose changed in one sampling time while the others stayed the same. This is counter to what happens in the process in that the value of the glucose jumps instantaneously. The implementation of this approach is shown in
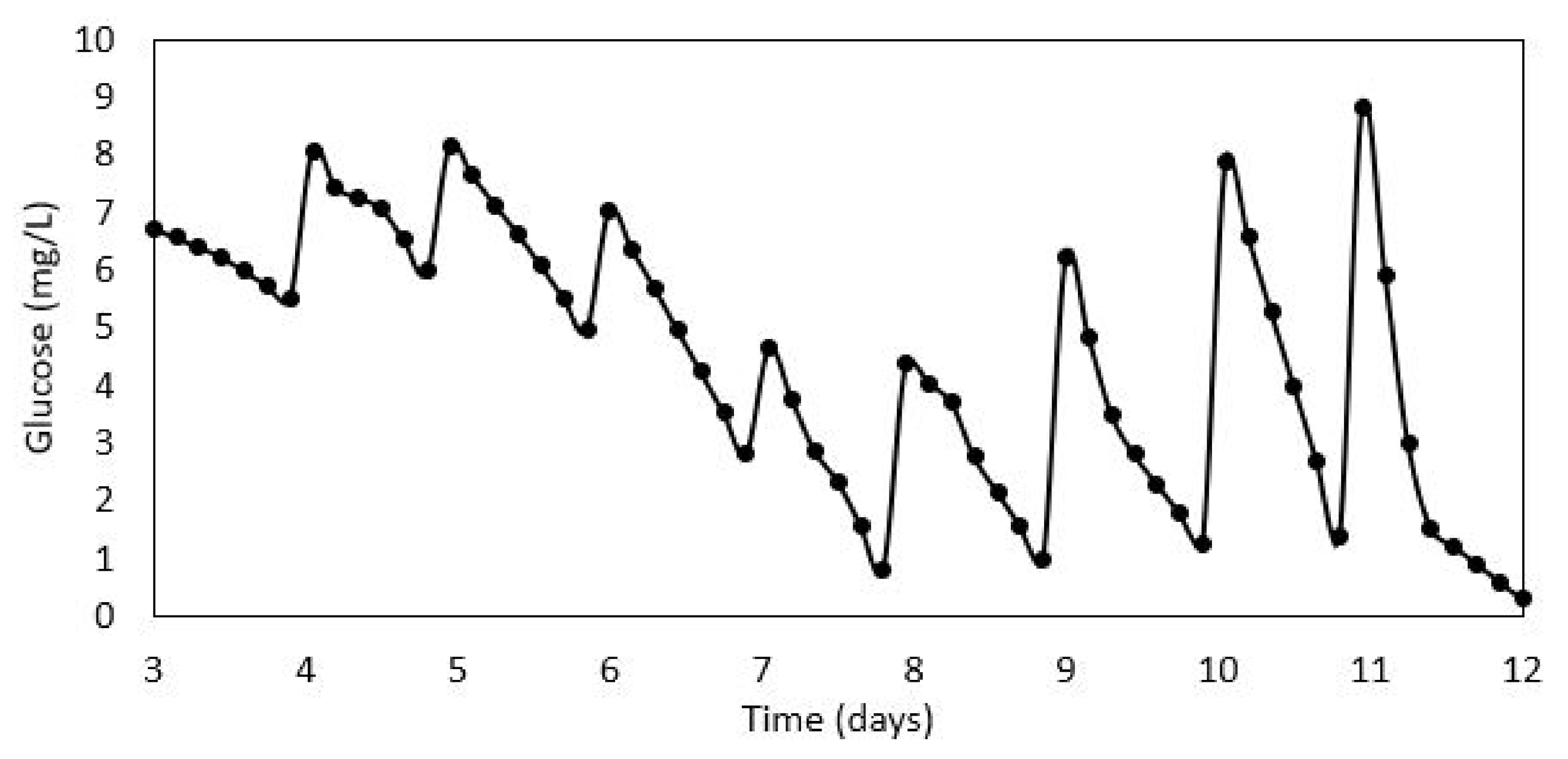
Figure 1 and it clearly shows how the concentration in the reactor ‘increases’ between sampling intervals. For example, after Days 3, 6, 7, 8, 9 and 11, the glucose concentration seems to increase slowly over time, which is contrary to what we know happens (i.e., glucose gets consumed). The second and correct adaptation then is to replace the value of the glucose measurement by the newly calculated measurement. As shown in
Figure 2, the concentration increases instantly upon glucose addition and the next measured sample shows that the glucose concentration decreases between sampling instances.
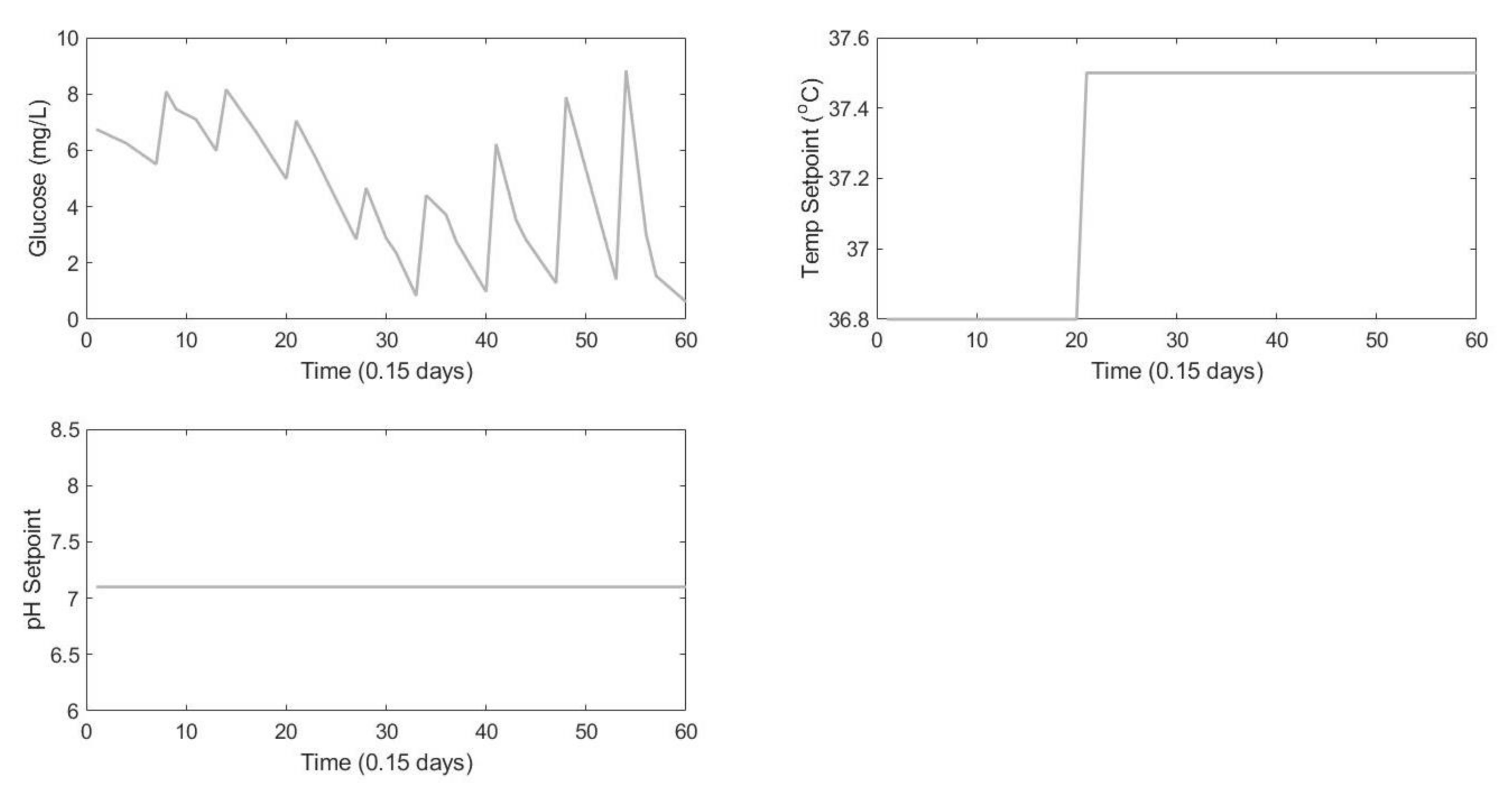
Having determined the right set of inputs and outputs, the training input sequence from one batch is shown below in
Figure 3. Note that the temperature and pH setpoints are only moved from the center line values to induce variations in the dataset, reflective of the true process, and as such not all batches have these shifts. To identify the model, data from 11 different batch runs were used for training batches. The training batches were chosen to establish the daily operating conditions of the Sartorius Bioreactor with sufficient variation provided by different temperature and pH setpoint changes providing a reasonably rich dataset.
Remark 1. We recognize that the use of 11 training batches does limit the ability to accurately validate the model. In future work, as more data become available, the identification can be redone to include more batches. What is perhaps more important to recognize is that the model is good for the data range it is used for in the training. Thus, in conjunction with existing model monitoring techniques [28], one can readily monitor if the model continues to be valid for the batch under consideration. If the monitoring technique reveals that the model predictions are diverging from the observations, the model can be retrained using the new on-line measurements in order to improve model accuracy. Having handled the discrete nature of the input addition, the data driven modeling approach [
24] was subsequently implemented to identify a system model. A state space model of order 3 was identified by ensuring the best model fit during the training stages. The subspace identification approach removes any dependent relationships between the inputs and the outputs; therefore, it is possible to model all of the outputs with only three states using the relationships defined in Equation (
1). Note that, while there are several inputs and outputs, the choice in the number of states is determined by the ability of the model to explain the correlations between the past inputs and outputs and the future outputs, and, if some of the outputs observed in the data are co-linear, it might be possible to capture the observed process dynamics using fewer states.
Remark 2. With regards to the number of states, while it is understood that the process dynamics are nonlinear, what the identified model captures is the process dynamics observed in the training data. In fact, one of the strengths of the subspace identification approach is the ability to determine the number of states in the system (as observed in the data) by utilizing linear algebra based techniques. The first principle model of Karra et al. [2] is an alternate approach to process modeling, one that uses first principles techniques to set up the model structure. In future work, there is the possibility of using the first principles model as a part of a hybrid model structure [29] to better predict the process behavior—such a hybrid model design remains outside the scope of the present work. The modeling identification procedure [
24] used is a combination of subspace identification with PCA and PLS techniques to handle variable batch length missing data problems. The identification approach used in this paper identifies an LTI model as follows: Given
s measurements (where
s represents the length of the data) of the input
and the output
variables from each batch, a model with order
n can be identified using the following equations:
where the objective is to determine the order
n, from cross validation, and the system matrices
,
,
,
.
The system matrices are identified in two stages where first a state sequence is identified and then subsequently the system matrices. The subspace identification approach is carried out using a series of PCA and PLS regressions with non-iterative partial least squares algorithms (NIPALS). The first part of subspace identification is to identify a state trajectory. This is done using PCA by projecting the past inputs and outputs perpendicular to the future inputs. We recognize that the future inputs should be completely independent of any past data, however this step insures we remove any potential correlations as a result of insufficient excitation. Additionally, the future outputs are projected perpendicular to the future inputs. Recognizing that the future outputs are a result of the states and future inputs by removing the correlation between the future inputs the remaining correlation depends on the states. In the next step, PLS is carried out between the newly deflated past inputs and outputs and future outputs. This is done to explain how the past data results in the current states for the future data and to expose the underlying state relationship. Finally, to explicitly identify the state trajectory, where traditional methods [
14] utilize singular value decomposition, this approach uses PCA. The end result is a state trajectory that can be used to identify the system matrices using regression techniques. The key use of NIPALS algorithms in these steps gives this approach the ability to handle missing data. For a more detailed explanation of the approach used in this paper, see the work of Patel et al. [
24].
Remark 3. Sartorius has developed a good first principles model of the bioreactor; however, the parameter estimation problem continues to be a focus of future work. That said, the proposed data driven approach could readily be utilized with the first principles model. Thus, a data driven approach which leverages the process data can be utilized to develop a hybrid model for improved prediction power [29]. Remark 4. One of the considerations when modeling a dynamic process such as cell growth is that there are different phases in cell growth that occur over the course of one batch. The metabolic response of cells to their environment is complex and therefore strongly nonlinear. This response is also widely believed by biologists to be non-Markov (i.e., cells have memory of historical conditions). In these different phases, the process may behave differently making a linear time invariant model an unsuitable choice. To handle this situation, it is possible to treat each different growth phase as a separate smaller batch. This differs from the traditional batch problem since the beginning of each smaller batch represents the end of the previous smaller batch. These smaller batches would then be used as part of the model identification allowing the identified subspace model to appropriately capture the behavior in each phase. As can be seen in the Application Section, the present data driven modeling approach works reasonably well. In future work, as more batches need to be modeled (and the model will likely be utilized for feedback control purposes), such phase-based identification approaches will be pursued. Finally, another direction of generalization would be to determine good initial conditions for the states based on the measured observations. Presently, the states are initialized at a value which is the average of the value for the batches used in training. In future work, an approach can be followed where the subspace model is better initialized for quick convergence of the state observer and the resultant ability to predict starting from early on in the batch.
Remark 5. Note that one of the advantages of a first principles modeling approach is that it can be more easily extrapolated. Thus if a first principles modeling approach is used, the resultant rate expressions can be utilized to model the operation of the process in a continuous fashion. On the other hand, a data driven model identified using data from batch operation cannot be directly applied to continuous operation. It can serve as a ‘starting point’ and adapted using the monitoring based re-identification approach, and, even more quickly retrained if it is utilized as part of a hybrid modeling strategy via leveraging the extrapolation capability of the underlying first principles model.
3.2. Dynamic Model Validation
This section illustrates the validation procedure for a new batch. Recall that validation is the key step in model identification, by providing a means to evaluate the successes of a developed model. Note that one of the inherent features of any state space based model is the requirement of the knowledge of initial states. If it is a first principles model, where not all the state variables are measured (as is often the case) using the first principles model would require an initial state estimation process step. In the present instance, the model is a linear state space mode, with the states being a realization of the input output dynamics, and thus, by construction, unmeasured. By the same construction, however, the states are observable from the measured outputs, and thus enable the design of a state observer/estimator. Therefore, for a new dataset, an initial state estimate is first computed before prediction is possible. In the present work, a Luenberger observer design is used at the beginning of the batch until the predicted outputs converge with the process outputs. The observer has the following form:
where
is the observer gain and is chosen to ensure that
is stable.
The missing data problem has specific implication in this regard and needs to be adequately accounted for. Thus, the above observer cannot be ‘implemented’ directly when parts of the output are missing. Specifically, when the output measurement is missing, the term used to update the prediction, , yields an undefined value. To operate the state observer with missing data, this work uses the linearly interpolated value as the process measurement at time k in order to update the states.
Remark 6. The use of linear interpolation for state estimation is only one of the possible approaches. In addition to multirate state estimation, which is a well documented problem, it possible to build a smaller model without missing data for state estimation. This approach involves building a separate subspace model using the continuous output observations. This model can then be used to estimate the states of the system until they converge and the full model can be used for validation. This approach is not considered in the present manuscript, primarily because of the observed success of the modeling approach, but, with increased data availability and modeling challenges, it could very well be included in future work.
After the states have converged, this is where the identified model’s predictive capabilities are tested with the missing outputs. The remainder of the batch is predicted using the model; however, as the process measurement comes in, the model uses that estimate with the observer in order to update the state estimate at that specific sampling time.
Remark 7. While the present illustration utilizes linear interpolation for the state estimator, it does not assume any knowledge of the process instead taking measurements as they become available. Linear interpolation is only used to allow for a good state estimate to be obtained which is not a part of validating the identified model’s predictive capabilities. The model is still identified from a dataset with missing values and can be used to predict when process measurements are not available. Note that the model’s predictive capability is not limited to a ‘next step prediction’; the model predicts to the end of the batch and updates the trajectory with each available measurement to predict the final quality more accurately.
To show the effectiveness of the missing data approach on the Sartorius Bioreactor case study, this section identifies a dynamic model used to predict the quality variables and a dynamic model to identify the metabolite rates. These models are built on training data from the Sartorius Bioreactor and then validated on a separate batch. The error is calculated as the normalized prediction error between the predicted model and the true process outputs. Note that the error is only calculated at the points where process measurements are available. The error is calculated as follows:
where
represents the process outputs,
represents the predicted outputs and predictions represent the number of available measurements. The identified dynamic model is presented below to show how the output profiles are generated.
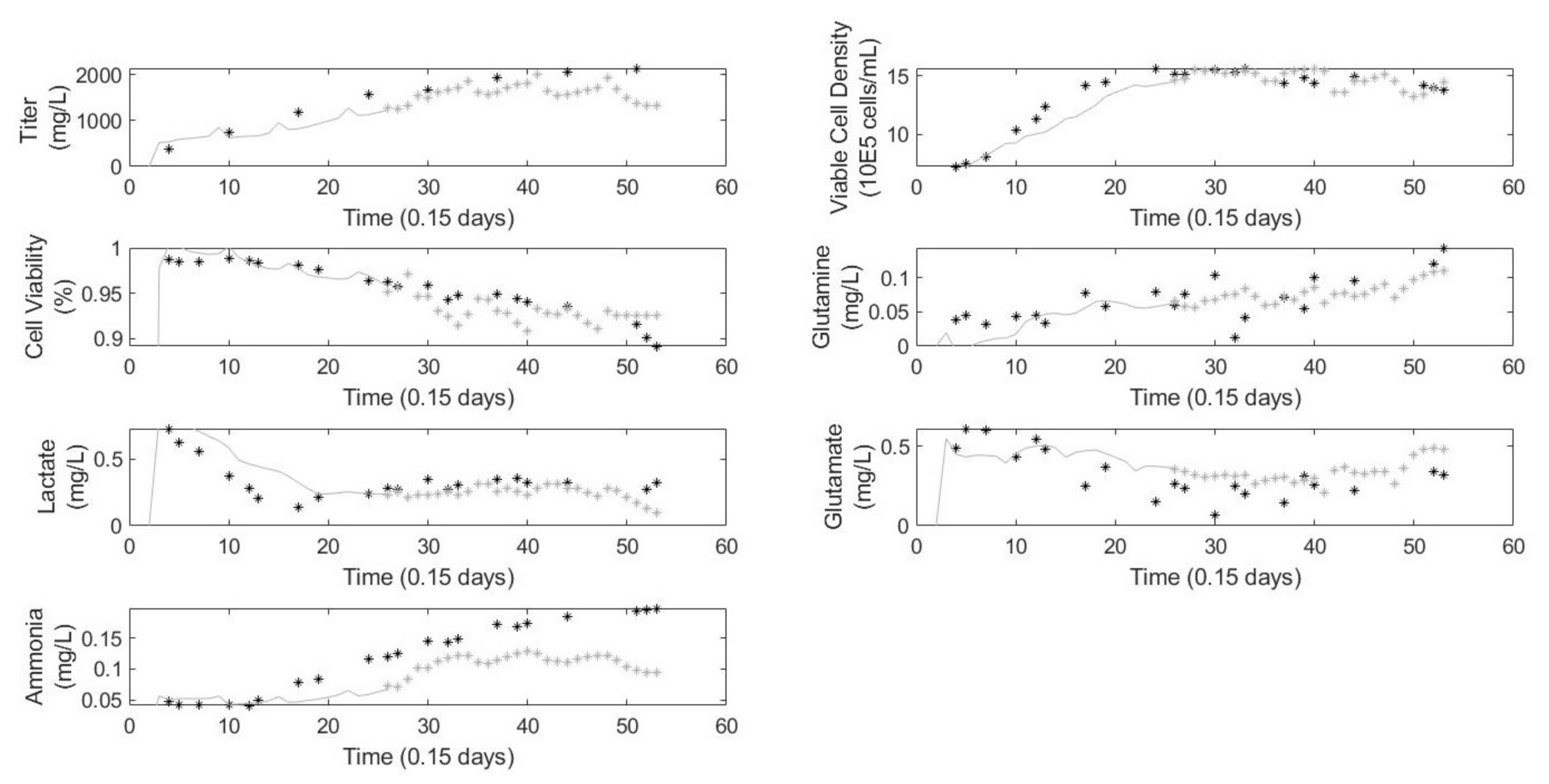
The prediction errors from both the training data and the validation batch are shown in
Table 1. As expected, the validation error is slightly larger than the training error since the validation batch was not used in model identification.
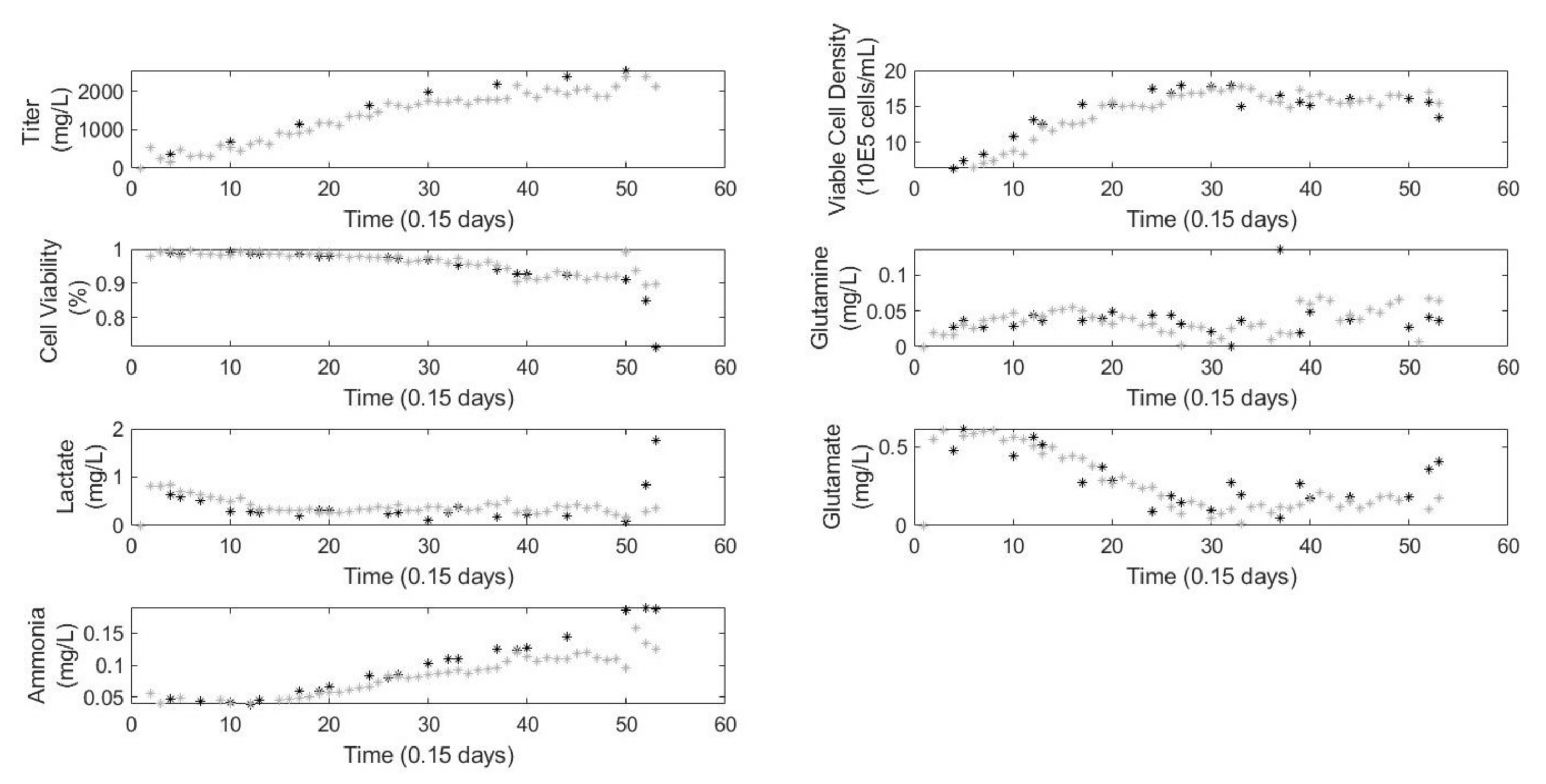
Figure 4 shows the training results and
Figure 5 shows the validation results from the quality model. In
Figure 4, there are model predictions despite the lack of a process measurement because the model keeps track of the states internally allowing it to make predictions at every time step. As shown in both sets of figures, the model is able to accurately predict the trends in the metabolites and more importantly the viable cell density which shows the cell concentration at the end of the batch. This is the key parameter Sartorius uses in downstream processes, and, despite the large amounts of missing data, the trend was accurately predicted.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}