
A Time-Series Data Generation Method to Predict Remaining Useful Life


1
Data Analytic Team 1, Hyundai Motors Company, Seoul 06797, Korea
2
Department of Industrial and Management Engineering, Hanyang University, Ansan 15588, Korea
3
Korean Research Institute for Human Settlements, Sejong 30147, Korea
*
Author to whom correspondence should be addressed.
Processes 2021, 9(7), 1115; https://0-doi-org.brum.beds.ac.uk/10.3390/pr9071115
Submission received: 25 May 2021
/
Revised: 18 June 2021
/
Accepted: 25 June 2021
/
Published: 26 June 2021
(This article belongs to the Section Sustainable Processes)
Abstract
:Accurate predictions of remaining useful life (RUL) of equipment using machine learning (ML) or deep learning (DL) models that collect data until the equipment fails are crucial for maintenance scheduling. Because the data are unavailable until the equipment fails, collecting sufficient data to train a model without overfitting can be challenging. Here, we propose a method of generating time-series data for RUL models to resolve the problems posed by insufficient data. The proposed method converts every training time series into a sequence of alphabetical strings by symbolic aggregate approximation and identifies occurrence patterns in the converted sequences. The method then generates a new sequence and inversely transforms it to a new time series. Experiments with various RUL prediction datasets and ML/DL models verified that the proposed data-generation model can help avoid overfitting in RUL prediction model.
1. Introduction
Prognostics and health management (PHM) is an important contributor to maintaining manufacturing productivity and has rapidly evolved from corrective maintenance to condition-based maintenance (CBM). Also known as predictive or data-driven maintenance, CBM decisions are based on analysis of data gathered from equipment and sensors [1].
The established applications of CBM are monitoring, fault diagnosis, maintenance scheduling, and remaining useful life (RUL) prediction [2]. Among them, RUL prediction is the subject of growing interest because of its effectiveness in maintenance scheduling. The RUL can be defined as the difference between the current time and the time failure occurs, and RUL prediction is to predict RUL (or failure time) at the current time based on collected signals, condition, and so forth [3]. The RUL prediction techniques can be categorized into physical model-driven and data-driven techniques [4].
Zhu and Yang [5] computed the themo-elasto-plastic stress and strain fields of turbine blade using finite element methods. They predicted the fatigue life through Basquin and Manson–Coffin formulae. They performed the thermal stress field analysis by using of Ansys software and then diagnosed thermal–mechanical stress for some nodes. Then, they predicted the fatigue life by maximum stress and mean stress. The remaining lifetime was predicted by extracting the parameter of the formula from controlled stress test data. While they introduced the influence of limited external factors such as thermal and mechanical stress on the remaining life, we consider the state as a time series and predicted the remaining life in a continuous situation probabilistically. Taheri and Taheri [6] studied the feasibility and technical design for implementing a combined heat and power system for the Mahshad Power plant. They figured out the remaining life for gas turbines on the basis of available data by approximated approach, whose prediction is derived by using predetermined elements or formulae. In addition, they used the operation data reflecting the current status for prediction, while our method in this paper adopts a probabilistic approach and uses obtainable data rather than deriving the close-formed formula.
Even though the physical model is easy to understand and very accurate, it is almost impossible to formulate modern industrial system. In contrast, the data-driven technique using machine learning (ML) and deep learning (DL) can formulate a very complex system with data collected from the system. For this reason, this paper focuses on data-driven RUL prediction.
Recently, ML and DL models have been frequently applied to predict RUL after training them with run-to-failure data [7]. These models learn the degradation patterns and relationships between the pattern and the RUL from the data collected until the end of the life of the components and predict the RUL of target components. In many recent studies, ML and DL models have shown superior performance for RUL problems [8,9,10,11,12,13,14,15].
Data insufficiency is a major challenge when training ML- or DL-based RUL models. Because a time-series sample is collected only after a component fails, collecting training data tends to be time-consuming and expensive. A model trained with insufficient data can be overfitted [16] and fail to accurately predict the RUL of a new component. Collecting more data can mitigate overfitting but may not be an option because of the required time and cost.
In this paper, we propose a time-series data-generation method that avoids overfitting when training an RUL model. The proposed method generates a sample on the basis of two existing samples called parents in a probabilistic manner and contributes to avoiding overfitting and increasing prediction performance. The generated samples will be added to training data for an RUL prediction model and contribute to avoid overfitting. In other words, an RUL prediction model is trained with union of original samples and generated samples. This approach is similar to SMOTE (Synthetic Minority Over-sampling Technique [17]), one of the most widely used oversampling methods that generates a minority class samples between two selected samples at random, and accordingly, the generated one may not be similar to the original samples in terms of relationship among features while contributing to the increase of classification performance such as recall and F1-score.
As far as our literature survey is concerned, ours is the first attempt to address the data insufficiency problem when training an RUL prediction model. In this paper, we propose a method to transform a time series into an alphabetical sequence and inversely transform the sequence that can be applied in time-series classification and clustering. The proposed data-generation method is not only efficient (i.e., it is inexpensive in terms of computational time) but also effective (i.e., the generated time series cab help avoid overfitting).
The remainder of this paper is organized as follows. Section 2 introduces background theory and related works of RUL prediction and symbolic aggregate approximation. Section 3 proposes a time-series data-generation method for RUL prediction in detail, and Section 4 illustrates the process of the proposed method using a small example. Section 5 experimentally verifies the performance of the proposed method, and Section 6 draws conclusions and suggests future research directions.
2. Background Theory and Related Works
2.1. Remaining Useful Life Prediction
Training and usage process of the RUL prediction model proceeds as follows. First, a set of training time series samples is transformed by extracting features and the RUL such that:
where is a set of transformed time series in , and is a set of pairs (feature, RUL) extracted from :
where is a vector of feature functions, is a part of the time series collected from time 1 to of sample , is the RUL of sample measured at , and is the length of . Second, a model is trained using , and finally, the RUL of the new sample at is predicted as .
Many researchers have developed RUL prediction models based on ML or DL. For example, Ali et al. [18] introduced a root mean square entropy estimator (RMSEE), which is the entropy of the root mean square (RMS) of the windows, to capture bearing degradation and used it as a feature. They also converted an RUL prediction model into a classification problem with seven classes according to the degradation rate (that is, class 1: under 10%, class 2: 10%–25%, class 3: 25%–40%, class 4: 40%–55%, class 5: 55%–70%, class 6: 70%–85%, and class 7: 85%–100%). Finally, they used a multi-layered perceptron (MLP) combined with a simplified fuzzy adaptive resonance theory map as a prediction model. Zheng et al. [19] pointed out that a traditional regression model using features from a window is not appropriate for RUL prediction because it does not fully consider sequence information, and other sequence learning models have also flaws (e.g., hidden Markov model and recurrent neural networks do not consider long-term dependency among nodes). They proposed a deep long short-term memory (LSTM) consisting of four layers: an input layer, a multi-layer LSTM, a multi-layer perceptron (MLP), and an output layer. In their experiment, MLP, support vector regression (SVR), relevance vector regression, and a convolutional neural network were compared in terms of root mean squared error (RMSE), with the deep LSTM exhibiting the smallest RMSE for four datasets.
Table 1 summarizes previous research that developed RUL prediction models using ML and DL including convolution neural network (CNN), in terms of domain, feature, and base model. As seen Table 1, statistics such as RMS, kurtosis, and skewness are frequently used as features, and MLP, LSTM, and SVR are used primarily for models.
2.2. Symbolic Aggregate Approximation
Pattern extraction is very important for time series analysis such as classification and clustering, but it is hard to extract patterns directly from time series due to huge search space [25]. Thus, representation methods such as symbolic aggregate approximation (SAX), discrete cosine transform (DCT), and discrete wavelet transform (DWT) are usually used to represent time series as sequence before pattern extraction. In this paper, each time series is discretized as alphabet sequence using SAX, patterns are extracted from the sequences, and a new sequence is generated considering the extracted pattern.
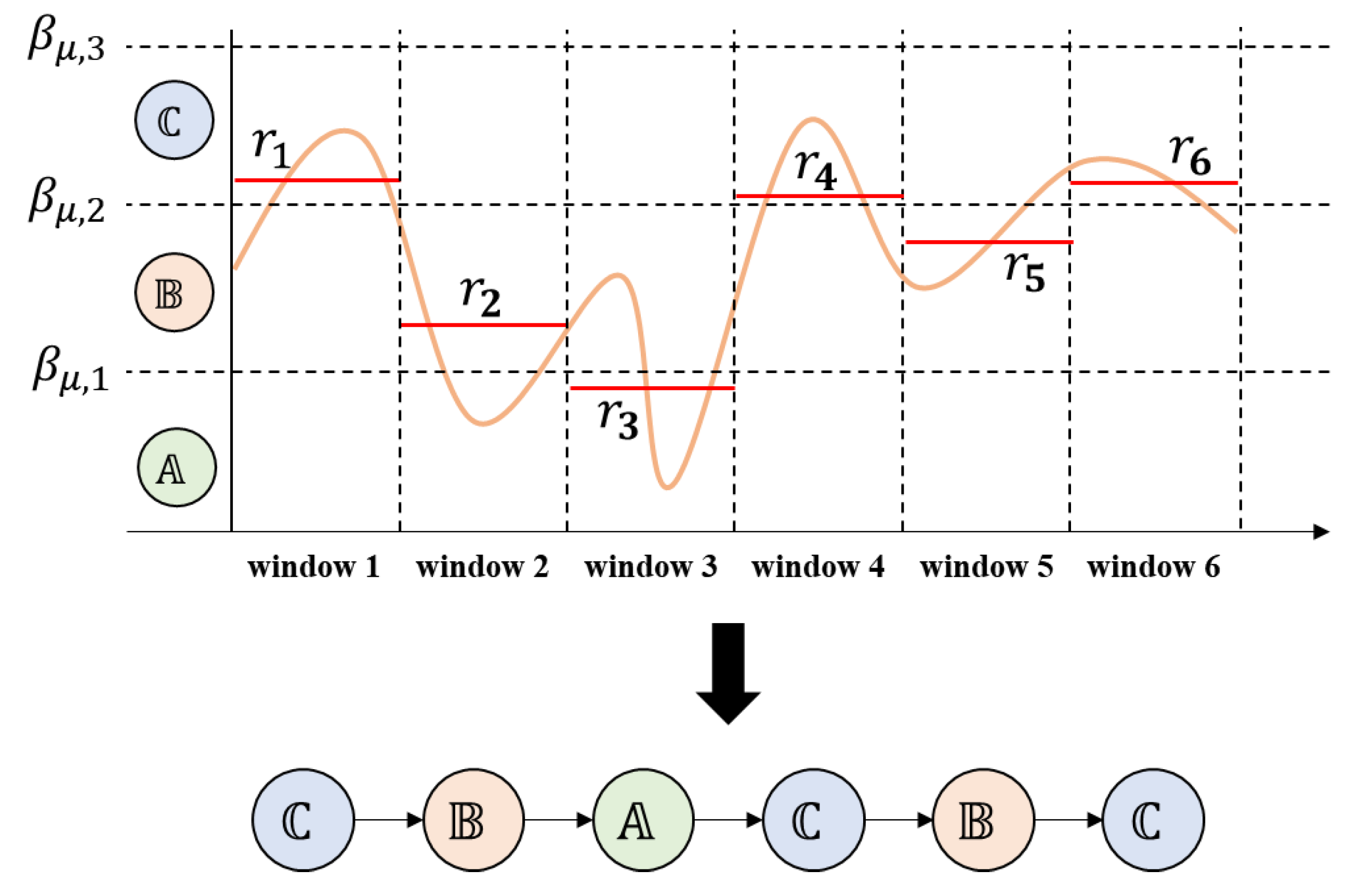
SAX can convert a time series into an alphabetical sequence for efficient time-series data mining in the following manner [26]. First, the element of is normalized as , where and denote the mean and standard deviation of , respectively. Second, is split into windows and, where is a representative value such as the mean of the values in the window, is calculated. One can introduce the standard deviation as the alternative representative value. Third, break points for are computed, where is the number of alphabetical strings defined by the user, satisfying . Finally, an alphabet is assigned to each window on the basis of the break points. That is, if , then the alphabet string is assigned to the window.
Figure 1 illustrates a SAX application process when the time series is assumed to be normalized. Time series is split into windows, and mean values in each window are calculated. Three () alphabetical strings , , and are introduced, and then three break points , , for means are obtained. Then, the alphabet is assigned to those means less than , to those bigger than , and to those between and . Then, we obtain a sequence S = − − − − − of alphabetical strings that is converted from the time series.
SAX has been used to extract features from time series for various tasks such as classification and clustering. For example, Georgoulas et al. [27] extracted alphabetical features to represent the vibration of bearings and used them to detect bearing faults with various classifiers. Park and Jung [28] proposed a method to reveal rules from multivariate time series. It transforms a time series to an alphabetical sequence through SAX and identifies frequent patterns from the sequences using association rule mining. Notaristefano et al. [29] made groups of electrical load pattern by reducing data size using SAX.
3. Proposed Data Generation Method
This section explains the proposed three-phase data-generation method: preprocessing, generating an alphabetical sequence, and generating time-series values. In the first phase, every time-series sample is transformed into a pair of vectors, one of window means and another of window standard deviations, and then each vector is transformed into an alphabetical sequence. In the second phase, two arbitrarily selected pairs of alphabetical sequences form a new sequence pair, with a pattern similar to those of the originally selected sequences. In the third phase, time-series values for each window are generated from the generated pair. Table 2 presents the mathematical notations used in this paper.
3.1. Preprocessing
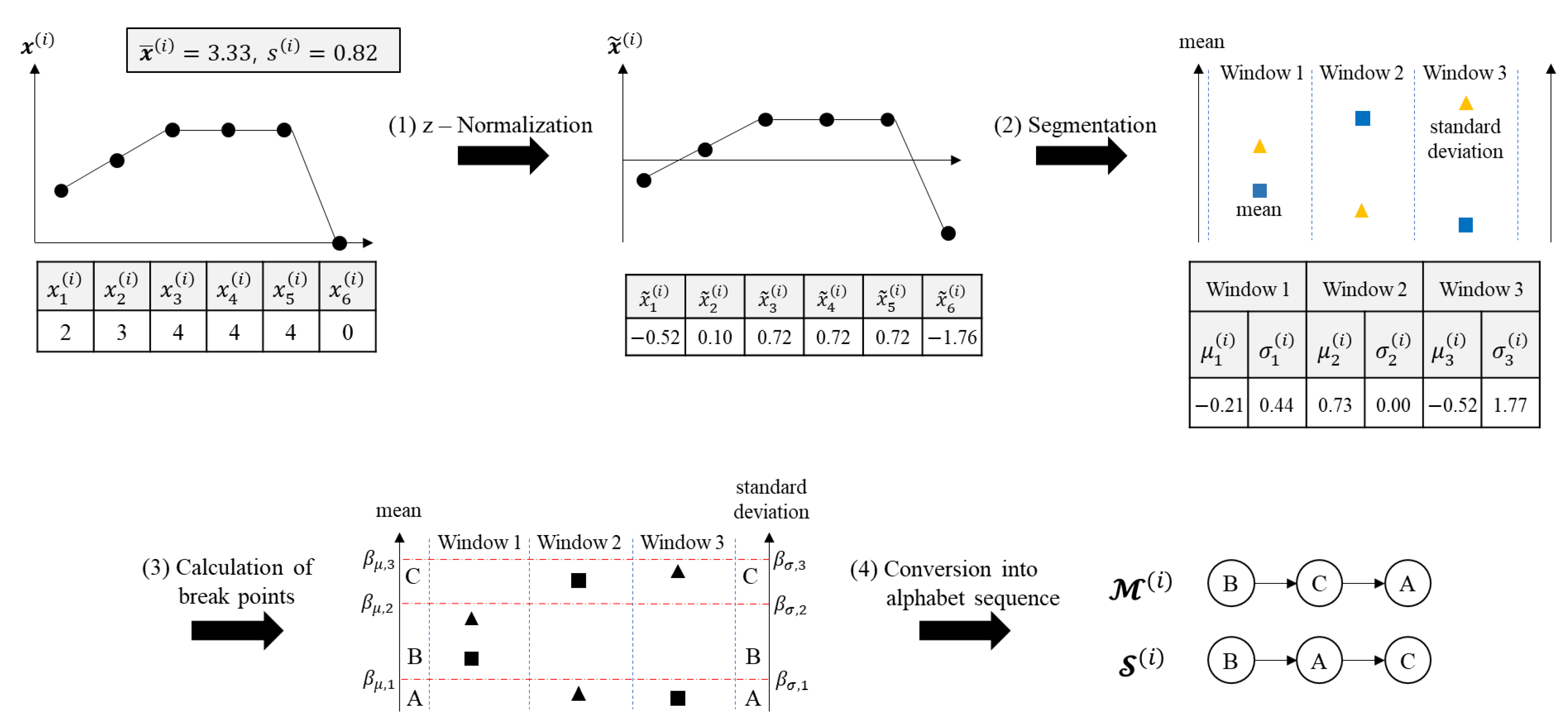
The objective of the preprocessing phase is to express as a tuple , where and are window mean vector and window standard deviation vector , respectively. The preprocessing phase consists of four steps: z-normalization, segmentation, calculation of break points, and conversion into an alphabetical sequence, as illustrated in Figure 2.
In the first step, for is normalized to with its mean and standard deviation as:
In the second step, for is split into windows, where is the number of windows set by the user, and the mean and standard deviation of each window are calculated by:
where is the number of elements in the window of , which equals when , and is expressed as a pair of vectors, one of window mean vector , and another of window standard deviation vector .
In the third step, break points and for and (, ), respectively, are obtained according to the size of the set of the alphabetical strings, , which is also the user parameter. As explained in Section 2.2, the break points and are used as criterion to convert mean and standard deviation of each window into alphabets. and are calculated and used not for individual samples but for all samples to consider the sample’s scale when generating new sample. The break point is obtained from , which implies that each interval , , contains the same number of values, and is therefore .
In the fourth step, and are expressed as alphabetical sequences and , respectively, as follows:
where and are negative infinity, and and indicate the predefined alphabet (e.g., , ) for the window mean and standard deviation, respectively.
The first phase is summarized in Algorithm A1 in the Appendix A.
3.2. Generating Alphabetical Sequences
The second phase is to generate artificial sequences of alphabets for and on the basis of two randomly selected parental samples and . Figure 3 illustrates an example of the generating process of alphabetical sequence based on and . Note that generating process of is the same as the process of .
In this figure, an edge from alphabet A to B denotes that alphabet A impacts on generating alphabet B.
Sequence for the window mean is generated by sequentially selecting an element from either and on the basis of the probabilities and , where is a partial sequence of . Sequence for the window standard deviation is similarly generated on the basis of and . and are assumed to be independent of each other for simplicity.
Probabilities and , which are used to select the first element , can be calculated by:
where is an indicator function, which returns 1 if is satisfied, and 0, otherwise, and is a Laplace smoothing parameter to prevent and from becoming either zero or one. That is, and are calculated as smoothed ratio of and among the first alphabets of mean sequences, respectively.
Because and are selected with probabilities in (8) and (9), respectively, these probabilities should be normalized by dividing each by their sum as presented in Equations (10) and (11):
Probabilities, and , used to select the element , can be calculated using the Markovian assumption:
where and are calculated by:
In Equations (14) and (15), is a parameter to restrict the search space to determine the number of alphabets that match , , in for all values of . The parent sample is randomly selected, and to produce the next sample, we adopt the Markov process for randomness and variability. In the Markov assumption, we can add more variability by properly setting the value of representing the size of the search space (Equations (14) and (15)). These probabilities should be normalized as follows:
An algorithm to generate alphabetical sequences of an artificial sample’s mean and standard deviation is presented as Algorithm A2. It is based on sampling from categorical distribution to select either or . For example, the first element of follows the categorical distribution , implying that is selected from and with probabilities and .
3.3. Generating Time-Series Values
In this phase, time-series values in window are generated from and for . Let be implying that , and be , implying that . We assume that follows a normal distribution, with the mean and standard deviation , and and uniformly distributed in and , respectively, when and are not 1. When is 1, we set , and when is 1. We also assume that the length of follows a uniform distribution in , where and are indices of the parents of , and and denote the number of elements in each window of and , respectively.
After a for every value of is generated, it should be inversely transformed to using its mean and standard deviation . We set them as a weighted average of and , and and , respectively, as presented Equations (18) and (19):
where is randomly chosen. That is, Equation (18) means is randomly selected between and , and Equation (19) means is randomly selected between and .
4. Numerical Example
This section describes an example of how a new time series is generated using the proposed method. Table 3 shows example dataset , which consists of five samples. Each sample is a time series collected from start to failure of a part by a sensor. In each sample, there are 18 numeric data, implying that life of each corresponding part is 18. Please note that the proposed method can be applied to the data that includes samples with different lengths.
Phase 1. Preprocessing
- (1)
- z-normalization
Each sample in Table 3 is normalized according to its mean and standard deviation as follows.
(−1.79, −1.79, −1.22, −1.22, −0.66, −0.09, −0.09, 0.47, −0.09, −0.09, −0.09, 0.47, 1.03, 0.47, 0.47, 1.03, 1.6, 1.6),
(1.15, 0.16, 0.16, 0.16, 1.15, 0.16, 1.15, 1.15, 1.15, 0.16, 0.16, −0.82, 0.16, 0.16, −0.82, −1.81, −1.81, −1.81),
(0.33, 0.33, 1.08, 1.82, 1.08, 1.08, 1.08, 0.33, 0.33, 0.33, −0.41, −1.16, −1.9, −1.16, −1.16, −0.41, −1.16, −0.41),
(−0.41, −1.46, −0.41, −0.41, −0.41, −1.46, −0.41, −0.41, −0.41, 0.64, 1.69, 1.69, 1.69, 0.64, 0.64, 0.64, −0.41, −1.46),
(−1.07, −1.07, −1.07, −0.27, −0.27, −0.27, −0.27, 0.53, −0.27, −1.07, −1.07, −0.27, −0.27, 0.53, 0.53, 1.34, 2.14, 2.14).
- (2)
- Segmentation
Each normalized sample is split into windows, and the mean and standard deviation of each window are calculated. For example, the first window of is (1.15, 0.16, 0.16) and its mean and standard deviation and are 0.49 and 0.47, respectively. Values for and for all and are calculated as follows.
(−1.60, −0.66, 0.10, 0.10, 0.66, 1.41), (0.27, 0.46, 0.26, 0.26, 0.26, 0.27),
(0.49, 0.49, 1.15, −0.17, −0.17, −1.81), (0.47, 0.47, 0.00, 0.46, 0.46, 0.00),
(0.58, 1.33, 0.58, −0.41, −1.41, −0.66), (0.35, 0.35, 0.35, 0.61, 0.35, 0.35),
(−0.76, −0.76, −0.41, 1.34, 0.99, −0.41), (0.49, 0.49, 0.00, 0.49, 0.49, 0.86),
(−1.07, −0.27, −0.00, −0.80, 0.26, 1.87), (0.00, 0.00, 0.38, 0.38, 0.38, 0.38).
- (3)
- Calculation of break points
We set , and break points and are those that divide the values of all values of and , respectively, into three equal parts. For example, is 1/3 quantile of {−1.60, −0.66, 0.10, 0.10, 0.66, 1.41, 0.49, 0.49, 1.15, −0.17, −0.17, −1.81, 0.58, 1.33, 0.58, −0.41, −1.41, −0.66, −0.76, −0.76, −0.41, 1.34, 0.99, −0.41, −1.07, −0.27, −0.00, −0.80, 0.26, 1.87}. In this manner, all break points can be calculated by:
(−0.41, 0.49, 1.87),
(0.32, 0.46, 0.86).
- (4)
- Conversion into an alphabetical sequence
On the basis of and , and are converted to an alphabetical sequence and for all , respectively. For example, is converted as alphabet because , and is converted as alphabet because . Thus, (−1.60, −0.66, 0.10, 0.10, 0.66, 1.41) is converted as . and for all are obtained as follows.
= , ,
= , ,
= , ,
= , ,
= , .
Phase 2. Generating an alphabetical sequence
Suppose sample 1 and 3 are randomly selected as parents. The first mean alphabetical strings of sample 1 and 3 are and , and the first standard deviation alphabetical strings are and . Thus, , , , and should be calculated and normalized using Equations (6)–(9).
is sampling from , and is sampling from , and as a result, and are selected.
The second mean alphabets of sample 1 and 3 are and , and the second standard deviation alphabets are and . Therefore, , , , and should be calculated and normalized using Equations (10)–(15). For convenience, we set to 1, and accordingly, and for all were used for the calculation.
is sampling from , and is sampling from , and as a result, and are selected. This process repeats until becomes .
From this phase, we obtain and .
Phase 3. Generating time-series values
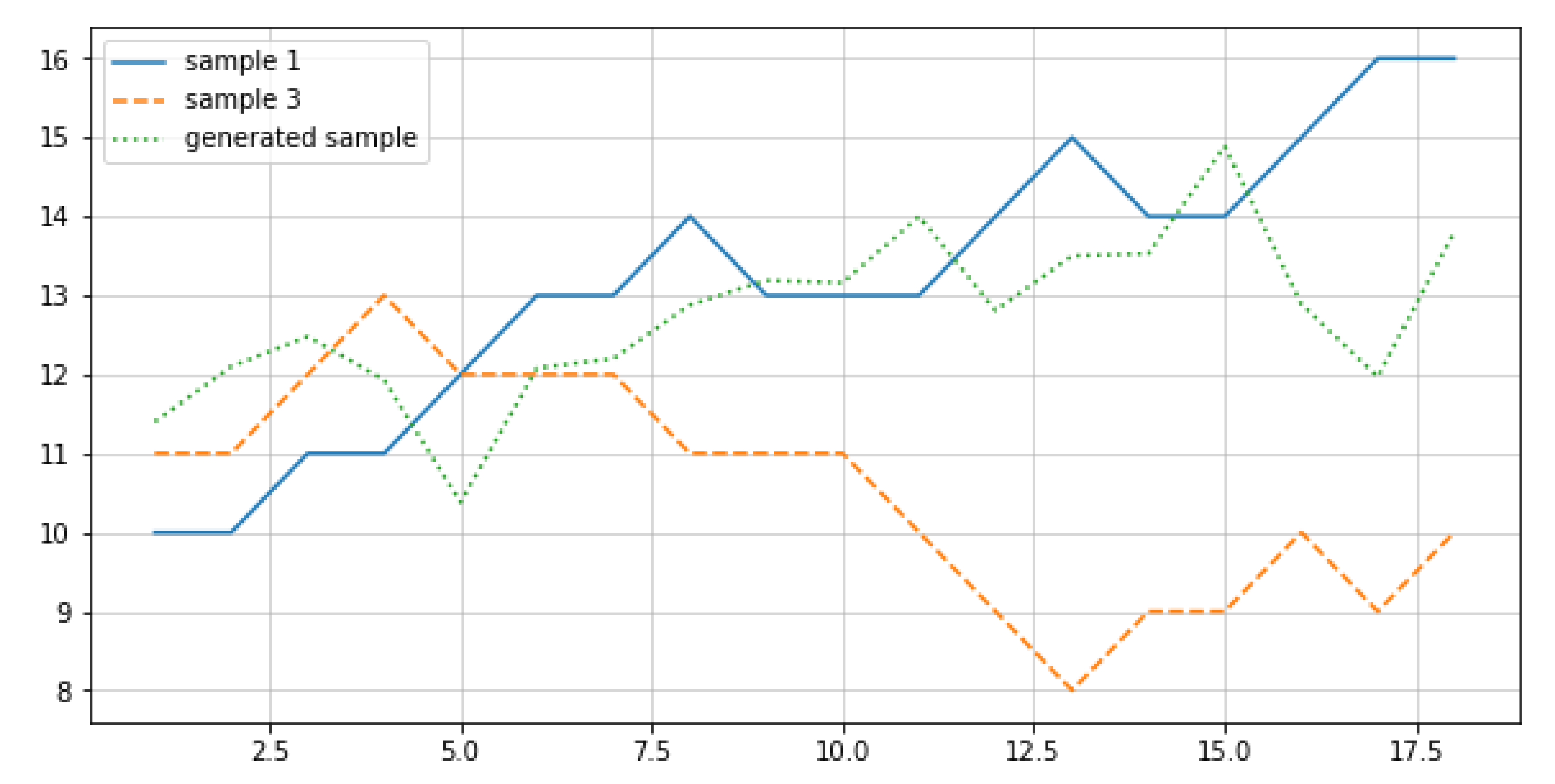
In this phase, are generated from and for , and we obtain (−0.6, −0.11, 0.16, −0.23, −1.32, −0.12, −0.04, 0.44, 0.66, 0.64, 1.23, 0.39, 0.88, 0.9, 1.86, 0.45, −0.2, 1.09).
The generation process for the first window is as follows. Since and , samples are generated, where each sample follows a normal distribution with a mean and standard deviation , because and are the first alphabets, and we use the constant mean and standard deviation. As a result, we obtain . As an another example, for the fourth window (), and , and three samples are generated if each sample follows a normal distribution with a mean in ] and standard deviation in 0.32, 0.46]. As a result, we obtain .
Finally, is obtained by inversely transforming with and , where and 0.18 are randomly chosen weights.
(11.4, 12.1, 12.48, 11.93, 10.38, 12.08, 12.2, 12.88, 13.19, 13.16, 14.00, 12.81, 13.5, 13.53, 14.89, 12.89, 11.97, 13.80).
Figure 4 shows the generated sample and its parents (sample 1 and 3) of the example. Dashed and dotted lines denote samples 1 and 3 in Table 3, respectively, and solid line denotes the generated sample when the parents are the sample 1 and 3. Y-axis denotes the sensor value and X-axis denotes time, and thus the horizontal length of a line indicates the whole life. As explained before, the length (i.e., whole life) of every sample in X is 18, and thus the length of the generated sample is also 18. To be more accurate, the length of the generated sample follows uniform distribution with [minimum length of parents, maximum length of parents].
As seen in this graph, the generated sample follows a similar pattern to the ones of sample 1 and 3, which implies it contains the characteristics of exiting samples. However, at the same time, the generated sample should not be too close to the exiting samples in order to ensure the variability. The proposed method selects two parent samples at random, and all alphabet sequences are created on the basis of the Equations (12)–(17), which ensure enough randomness and variability of the generated samples when, e.g., selecting time series size for each alphabet, selecting the first alphabet, and so forth.
5. Experiment and Results
In this section, we describe an experiment to verify that the samples generated by the proposed method contribute to training an RUL model without overfitting. Two RUL prediction models were compared in terms of mean absolute percent error (MAPE), one with an original dataset and the other with a dataset , where is an artificially generated dataset. Section 5.1 explains the procedure of the experiment, Section 5.2 introduces the datasets and hyperparameters used in the experiment, and Section 5.3 shows the results.
5.1. Procedure
First, an original sample , is reserved for the test, and the others (i.e., ) are used for training. Second, an RUL prediction model is trained with , to which the transformation for RUL prediction is applied, . Third, the MAPE of the model for , is calculated. Fourth, we repeat times to generate using the proposed algorithm for under hyperparameters , , , and ; train with ; and then calculate . Finally, and the mean of 〖 are compared. This procedure is repeated for all possible values of , , , , , and the models.
The specific procedure is described in Algorithm A3 and the flowchart to illustrate to calculate , and is presented in Figure 5.
In Step 6 and Step 7 of this algorithm, MAPE is calculated by:
This figure illustrates an example of the procedure to calculate and . The specific process illustrated in this figure is as follows:
- (1)
- ,,, and are transformed into , , , and by applying feature functions, respectively.
- (2)
- RUL prediction model, , is trained with .
- (3)
- is used to validate . That is, for all is obtained and the prediction results are used to calculate .
- (4)
- Three new samples, , , and , are generated by means of the proposed method.
- (5)
- ,, and are also transformed into , , and .
- (6)
- RUL prediction model, is trained with .
- (7)
- is used to validate . That is, for all is obtained, and the prediction results are used to calculate .
5.2. Experiment Setting
Datasets were obtained from the prognostic data repository of the U.S. National Aeronautics and Space Administration. Table 4 shows information of the datasets.
All three datasets are well known and have been widely used in the literature for the purpose of verifying the performance of the developed machine learning methods. Each sample in the first and second dataset is a time series of the capacity of lithium-ion battery until it is dead. Discharge was carried out at 24 °C, and each battery was regarded as dead when its capacity was at 30%. Each sample of the third dataset was a signal from vibration sensor attached to bearing. The operating condition of the bearing was 1800 rpm and 4000N, and sampling frequency of the sensor was 25.6 kHz.
Hyperparameters for each experiment are given in the following Table 5.
Battery: Battery #1 and #6; bearing: FEMTO Bearing Set #1; MLP(, ): multi-layered perceptron with two hidden layers with and nodes, respectively; LSTM(, , , ): long short-term memory with neurons, timestamps, batch size, and epochs; SVR(, , ): support vector regression with regularization parameter , epsilon , and kernel function .
5.3. Results
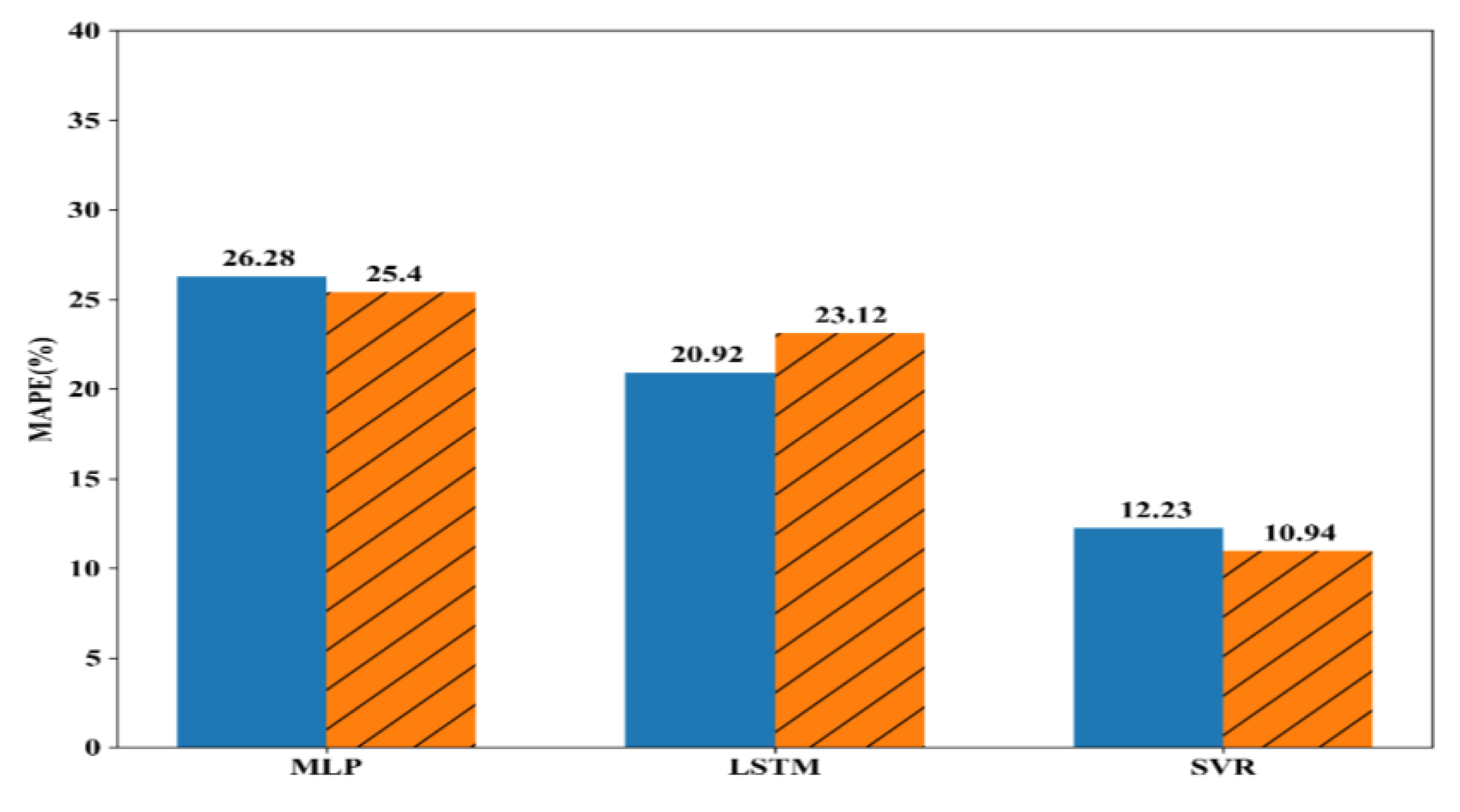
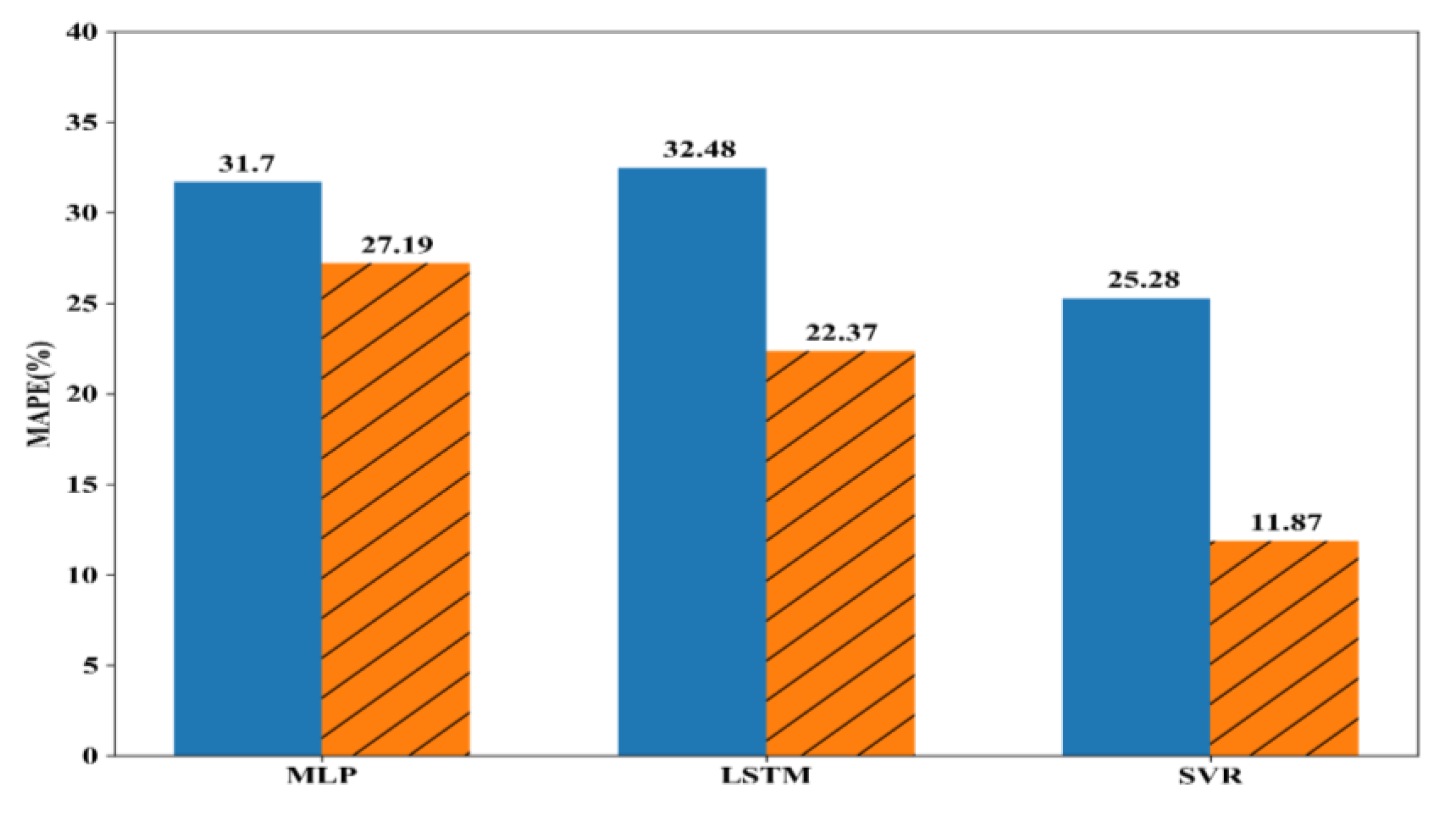
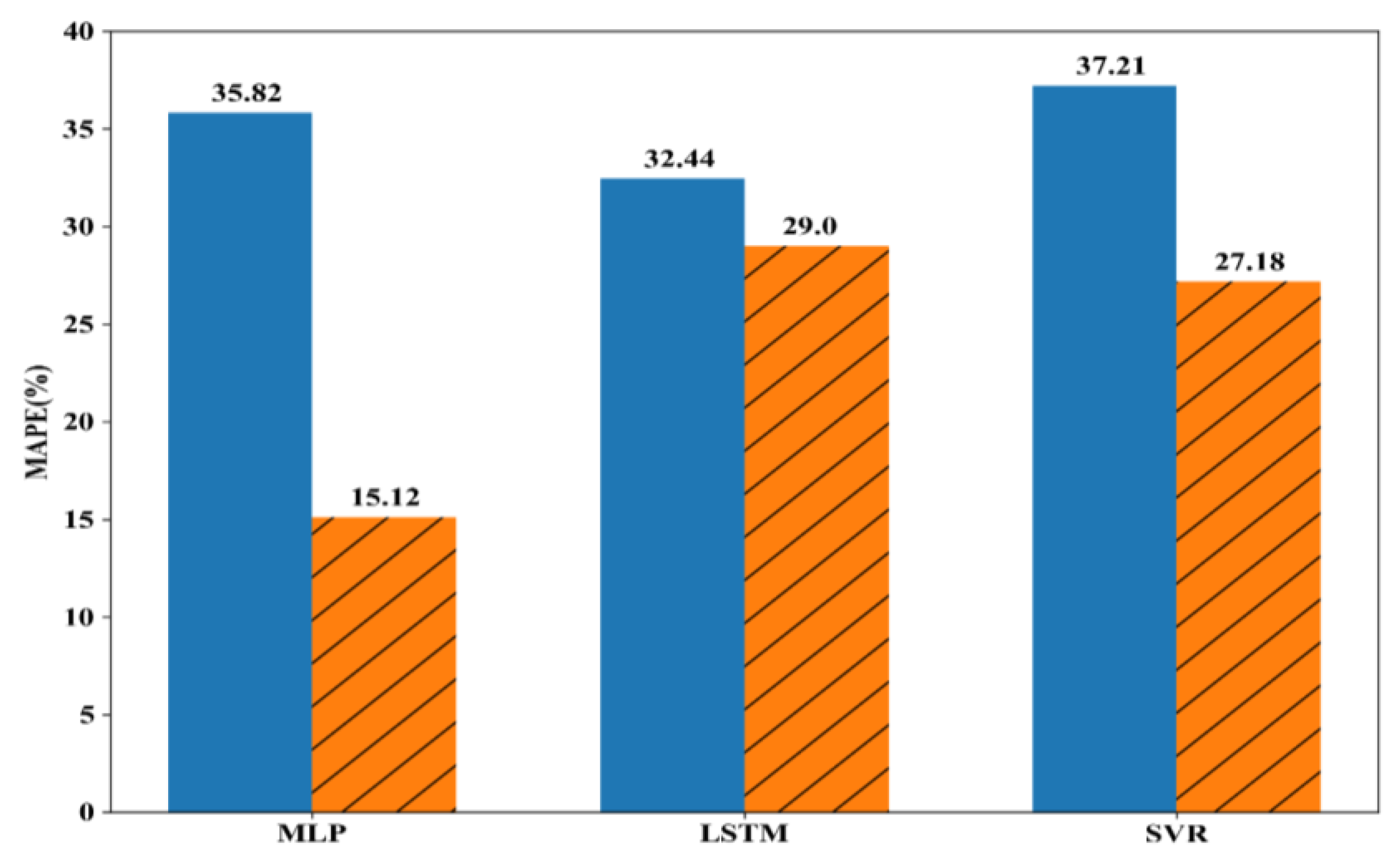
Figure 6, Figure 7 and Figure 8 show the experiment results with battery #1, battery #6, and bearing datasets. In the figures, blue bars denote the MAPEs of the model trained with original samples except for the test sample, and the orange bars denote the MAPEs of a model trained with original samples and generated samples.
From the results presented in Figure 6, Figure 7 and Figure 8, we found the following. First, when we included the generated samples for training, except for the LSTM with battery #1 as shown in Figure 6, the MAPEs were smaller than those of cases with only original samples. In the case of MLP with bearing, shown in Figure 8, 20.6% of MAPE was decreased, which was the largest improvement. This shows the proposed method to artificially generate the training samples is effective and could be used to improve the performance of models. Second, MAPE of the model trained using original samples without test sample could be very high. For example, MAPEs of MLP and SVR for the bearing dataset were 35.82% and 37.21%, respectively. This may have been because the features of some test samples (i.e., cumulative root mean square and kurtosis) are quite different from those of the other samples. In other words, the relationships between feature vectors and label (i.e., RUL) are markedly different from each other. In this case, the proposed method effectively decreased the MAPE, as in the case of the MLP for the bearing dataset. Third, the proposed method showed bigger MAPE when using LSTM for battery #1 (Figure 6), contrary to the other results. In essence, LSTM considered previous feature values (i.e., cumulative RMS and kurtosis at time ) to predict the current label (i.e., RUL at t), but the proposed method did not consider the relationship between two consecutive values. Instead, it took the relationship between two consecutive windows into the consideration, and the values within a window were aggregated to single value, either mean or standard deviation. We think this sometimes may worsen the performance of the model when using more samples for training, which, in turn, results in the larger value of MAPE. However, we obtained smaller MAPEs in battery #6 and bearing, as shown in Figure 7 and Figure 8.
From the experiment, we verified that the proposed method can solve the data insufficiency problem that is common for RUL prediction and often leads to overfitting. In other words, the RUL prediction model trained with original samples and generated samples is more generalized than the one trained with original samples only.
6. Conclusions
Due to time and cost, it is often difficult to collect sufficient run-to-failure data to train ML- and DL-based RUL models. The data insufficiency problem can result in overfitting and undermining of a model’s performance. In this paper, we proposed a time-series data-generation method that identifies patterns from alphabetical sequences converted from original time-series samples using SAX and generates new sequence on the basis of these patterns. Finally, it generates time-series values from each alphabet in the generated sequence. In an experiment using three benchmark datasets, we found that the samples generated by the proposed method effectively increased the performance of the RUL prediction model.
Future efforts to improve the proposed method should take into the account the relationship between consecutive values when generating time-series values. In addition, the proposed method was designed for a univariate time series and may be not appropriate for multivariate time series, which are common in datasets used for RUL predictions. The proposed method should therefore be expanded to consider multivariate time series. Finally, the proposed method has many parameters such as the number of windows, alphabets, and generated samples, which would impact the prediction performance of RUL prediction model. Thus, in the future research, sensitivity analysis of the parameters should be conducted and the method to choose the proper parameter values should be developed.
Author Contributions
Conceptualization, G.A., S.H. and S.L.; methodology, G.A.; software, G.A. and H.Y.; data curation, H.Y.; original draft preparation, G.A. and H.Y.; review and editing, G.A., S.H. and S.L.; funding acquisition, S.H. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korean government ((MSIT)2019R1A2C1088255).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
| Algorithm A1. Preprocessing phase. | |
| Input | for , , , . |
| Notation |
|
| Output | . |
| Algorithm A2. Alphabetical sequence generation. | |
| Input | , . |
| Procedure |
|
| Output | . |
| Algorithm A3. Procedure of the experiment. | |
| Input | , , , , , , , . |
| Procedure |
|
| Output | for . |
References
- Xia, T.; Dong, Y.; Xiao, L.; Du, S.; Pan, E.; Xi, L. Recent advances in prognostics and health management for advanced manufacturing paradigms. Reliab. Eng. Syst. Saf. 2018, 178, 255–268. [Google Scholar] [CrossRef]
- Ahmad, R.; Kamaruddin, S. An overview of time-based and condition-based maintenance in industrial application. Comput. Ind. Eng. 2012, 63, 135–149. [Google Scholar] [CrossRef]
- Si, X.S.; Wang, W.; Hu, C.H.; Zhou, D.H. Remaining useful life estimation–a review on the statistical data driven approaches. Eur. J. Oper. Res. 2011, 213, 1–14. [Google Scholar] [CrossRef]
- Okoh, C.; Roy, R.; Mehnen, J.; Redding, L. Overview of remaining useful life prediction techniques in through-life engineering services. Procedia Cirp 2014, 16, 158–163. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.; Yang, Z. Themo-elasto-plastic stress and strain analysis and life prediction of gas turbine. Proc. Int. Conf. Meas. Technol. Mechatron. Autom. 2010, 1019–1022. [Google Scholar]
- Taheri, M.J.; Taheri, P. Feasibility study of congeneration for a gas power plant. In Proceedings of the 2017 IEEE Electrical Power and Energy Conference, Saskatoon, SK, Canada, 22–25 October 2017. [Google Scholar]
- Liao, L.; Köttig, F. Review of hybrid prognostics approaches for remaining useful life prediction of engineered systems, and an application to battery life prediction. IEEE Trans. Reliab. 2014, 63, 191–207. [Google Scholar] [CrossRef]
- Lyu, Y.; Gao, J.; Chen, C.; Jiang, Y.; Li, H.; Chen, K.; Zhang, Y. Joint model for residual life estimation based on Long-Short Term Memory network. Neurocomputing 2020, 410, 284–294. [Google Scholar] [CrossRef]
- Ruiz-Tagle Palazuelos, A.; Droguett, E.L.; Pascual, R. A novel deep capsule neural network for remaining useful life estimation. Proceedings of the Institution of Mechanical Engineers. Part O J. Risk Reliab. 2020, 234, 151–167. [Google Scholar]
- Sun, H.; Zhang, J.; Mo, R.; Zhang, X. In-process tool condition forecasting based on a deep learning method. Robot. Comput. Integr. Manuf. 2020, 64, 101924. [Google Scholar] [CrossRef]
- Mo, Y.; Wu, Q.; Li, X.; Huang, B. Remaining useful life estimation via transformer encoder enhanced by a gated convolutional unit. J. Intell. Manuf. 2021, 1–10. [Google Scholar] [CrossRef]
- An, D.; Choi, J.H.; Kim, N.H. Prediction of remaining useful life under different conditions using accelerated life testing data. J. Mech. Sci. Technol. 2018, 32, 2497–2507. [Google Scholar] [CrossRef]
- Borst, N.G. Adaptations for CNN-LSTM Network for Remaining Useful Life Prediction: Adaptable Time Window and Sub-Network Training. Master’s Thesis, Delft University of Technology, Delft, The Netherlands, August 2020. [Google Scholar]
- Xie, Z.; Du, S.; Lv, J.; Deng, Y.; Jia, S. A Hybrid Prognostics Deep Learning Model for Remaining Useful Life Prediction. Electronics 2021, 10, 39. [Google Scholar] [CrossRef]
- Ramasso, E.; Gouriveau, R. Remaining useful life estimation by classification of predictions based on a neuro-fuzzy system and theory of belief functions. IEEE Trans. Reliab. 2014, 63, 555–566. [Google Scholar] [CrossRef]
- Huang, S.; Guo, Y.; Liu, D.; Zha, S.; Fang, W. A two-stage transfer learning-based deep learning approach for production progress prediction in iot-enabled manufacturing. IEEE Internet Things J. 2019, 6, 10627–10638. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmever, W.P. SMOTE: Synthetic Minority Over-Sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Ali, J.B.; Chebel-Morello, B.; Saidi, L.; Malinowski, S.; Fnaiech, F. Accurate bearing remaining useful life prediction based on Weibull distribution and artificial neural network. Mech. Syst. Signal Process. 2015, 56, 150–172. [Google Scholar]
- Zheng, S.; Ristovski, K.; Farahat, A.; Gupta, C. Long short-term memory network for remaining useful life estimation. In Proceedings of the 2017 IEEE International Conference on Prognostics and Health Management, Dallas, TX, USA, 19–21 June 2017. [Google Scholar]
- Zhu, J.; Chen, N.; Peng, W. Estimation of bearing remaining useful life based on multiscale convolutional neural network. IEEE Trans. Ind. Electron. 2018, 66, 3208–3216. [Google Scholar] [CrossRef]
- Deutsch, J.; He, D. Using deep learning-based approach to predict remaining useful life of rotating components. IEEE Trans. Syst. Man Cybern. Syst. 2017, 48, 11–20. [Google Scholar] [CrossRef]
- Saidi, L.; Ali, J.B.; Bechhoefer, E.; Benbouzid, M. Wind turbine high-speed shaft bearings health prognosis through a spectral Kurtosis-derived indices and SVR. Appl. Acoust. 2017, 120, 1–8. [Google Scholar] [CrossRef]
- Sutrisno, E.; Oh, H.; Vasan, A.S.S.; Pecht, M. Estimation of remaining useful life of ball bearings using data driven methodologies. In Proceedings of the 2012 IEEE Conference on Prognostics and Health Management, Denver, CO, USA, 18–21 June 2012. [Google Scholar]
- Zhang, B.; Zhang, S.; Li, W. Bearing performance degradation assessment using long short-term memory recurrent network. Comput. Ind. 2019, 106, 14–29. [Google Scholar] [CrossRef]
- Sun, Y.; Li, J.; Liu, J.; Sun, B.; Chow, C. An improvement of symbolic aggregate approximation distance measure for time series. Neurocomputing 2014, 138, 189–198. [Google Scholar] [CrossRef]
- Lin, J.; Keogh, E.; Lonardi, S.; Chiu, B. A symbolic representation of time series, with implications for streaming algorithms. In Proceedings of the 8th ACM SIGMOD Workshop on Research Issues in Data Mining and Knowledge Discovery, New York, NY, USA, 13 June 2003. [Google Scholar]
- Georgoulas, G.; Karvelis, P.; Loutas, T.; Stylios, C.D. Rolling element bearings diagnostics using the Symbolic Aggregate approXimation. Mech. Syst. Signal Process. 2015, 60, 229–242. [Google Scholar] [CrossRef]
- Park, H.; Jung, J.Y. SAX-ARM: Deviant event pattern discovery from multivariate time series using symbolic aggregate approximation and association rule mining. Expert Syst. Appl. 2020, 141, 112950. [Google Scholar] [CrossRef]
- Notaristefano, A.; Chicco, G.; Piglione, F. Data size reduction with symbolic aggregate approximation for electrical load pattern grouping. IET Gener. Transm. Distrib. 2013, 7, 108–117. [Google Scholar] [CrossRef]
- Saha, B.; Goebel, K.; Battery Data Set. NASA Ames Prognostics Data Repository. Available online: http://ti.arc.nasa.gov/project/prognostic-data-repository (accessed on 16 May 2020).
- Nectoux, P.; Gouriveau, R.; Medjaher, K.; Ramasso, E.; Chebel-Morello, B.; Zerhouni, N.; Varnier, C. PRONOSTIA: An experimental platform for bearings accelerated degradation tests. In Proceedings of the IEEE International Conference on Prognostics and Health Management, Denver, CO, USA, 18–21 June 2012. [Google Scholar]
Figure 1.
Symbolic aggregate approximation.

Figure 2.
Steps of the preprocessing phase.

Figure 3.
Generating process of alphabetical sequences.

Figure 4.
Generated sample example.

Figure 5.
Example flowchart of the experimental procedure.

Figure 6.
Experiment result for battery #1.

Figure 7.
Experiment result for battery #6.

Figure 8.
Experiment result for bearing.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Previous studies on RUL prediction.
| Research | Domain | Feature | Base Model |
|---|---|---|---|
| [18] | Bearing | RMSEE | MLP |
| [19] | General | Original | LSTM |
| [20] | Bearing | Original | CNN |
| [21] | Rotating machine | RMS, kurtosis, etc. | MLP |
| [22] | Bearing | Spectral kurtosis | SVR |
| [23] | Data | RMS, peak, kurtosis, crest factor, etc. | SVR |
| [24] | Bearing | RMS and kurtosis | LSTM |
General: not considering specific industry domain; original: not using specific feature functions but using raw values.
Table 2.
Mathematical notations used in this paper.
| Notation | Meaning |
|---|---|
| Time series sample , , where denotes value measured at , and denotes length of (i.e., whole life of . | |
| RUL of at , where . | |
| Vector of feature functions to extract features from to train an RUL prediction model. | |
| Dataset generated by transforming for RUL prediction, where the bottom 30% and top 30% are trimmed for stability, that is, . | |
| Supervised model for RUL prediction. | |
| Generated time-series , where denotes length of (i.e., whole life of ). | |
| , | Mean and standard deviation of . |
| Normalized with mean and standard deviation . | |
| Number of windows. | |
| Window mean vector , , where denotes mean of in the window. | |
| Window standard deviation vector , , where denotes standard deviation of in the window. | |
| Alphabetical set for , . | |
| Alphabetical set for , . | |
| The break point for . | |
| The break point for . | |
| Alphabetical sequence of window mean vector , , where denotes alphabet for . | |
| Alphabetical sequence of window standard deviation vector , , where denotes alphabet for . |
Table 3.
Example original dataset.
| Index | Data | Mean | Standard Deviation |
|---|---|---|---|
| 1 | (10, 10, 11, 11, 12, 13, 13, 14, 13, 13, 13, 14, 15, 14, 14, 15, 16, 16) | 13.17 | 1.77 |
| 2 | (10, 9, 9, 9, 10, 9, 10, 10, 10, 9, 9, 8, 9, 9, 8, 7, 7, 7) | 8.83 | 1.01 |
| 3 | (11, 11, 12, 13, 12, 12, 12, 11, 11, 11, 10, 9, 8, 9, 9, 10, 9, 10) | 10.56 | 1.34 |
| 4 | (9, 8, 9, 9, 9, 8, 9, 9, 9, 10, 11, 11, 11, 10, 10, 10, 9, 8) | 9.39 | 0.95 |
| 5 | (11, 11, 11, 12, 12, 12, 12, 13, 12, 11, 11, 12, 12, 13, 13, 14, 15, 15) | 12.33 | 1.25 |
Table 4.
Used datasets.
| Dataset | Feature | Number of Samples | Mean Length | Reference |
|---|---|---|---|---|
| Battery #1 | Capacity | 4 | 159.00 | [30] |
| Battery #6 | Capacity | 4 | 90.75 | |
| FEMTO Bearing Set #1 | Vibration signal | 4 | 44,154,880.00 | [31] |
Table 5.
Hyper parameters for each experiment.
| Dataset | Model | |||||
|---|---|---|---|---|---|---|
| Battery | MLP (5, 5) LSTM (10, 5, 32, 50) SVR (1, 0.1, rbf) | 50 | 3 | 3 | 3 | Cumulative RMS and kurtosis |
| Bearing | MLP (10, 10) LSTM (20, 10, 32, 50) SVR (1, 0.1, rbf) | 10000 | 6 | 4 | 4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Ahn, G.; Yun, H.; Hur, S.; Lim, S. A Time-Series Data Generation Method to Predict Remaining Useful Life. Processes 2021, 9, 1115. https://0-doi-org.brum.beds.ac.uk/10.3390/pr9071115
AMA Style
Ahn G, Yun H, Hur S, Lim S. A Time-Series Data Generation Method to Predict Remaining Useful Life. Processes. 2021; 9(7):1115. https://0-doi-org.brum.beds.ac.uk/10.3390/pr9071115
Chicago/Turabian StyleAhn, Gilseung, Hyungseok Yun, Sun Hur, and Siyeong Lim. 2021. "A Time-Series Data Generation Method to Predict Remaining Useful Life" Processes 9, no. 7: 1115. https://0-doi-org.brum.beds.ac.uk/10.3390/pr9071115
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.