
Monte Carlo Simulation of the Moments of a Copula-Dependent Risk Process with Weibull Interwaiting Time


Abstract
:1. Introduction
2. Materials and Methods
2.1. Aggregate Risk Model
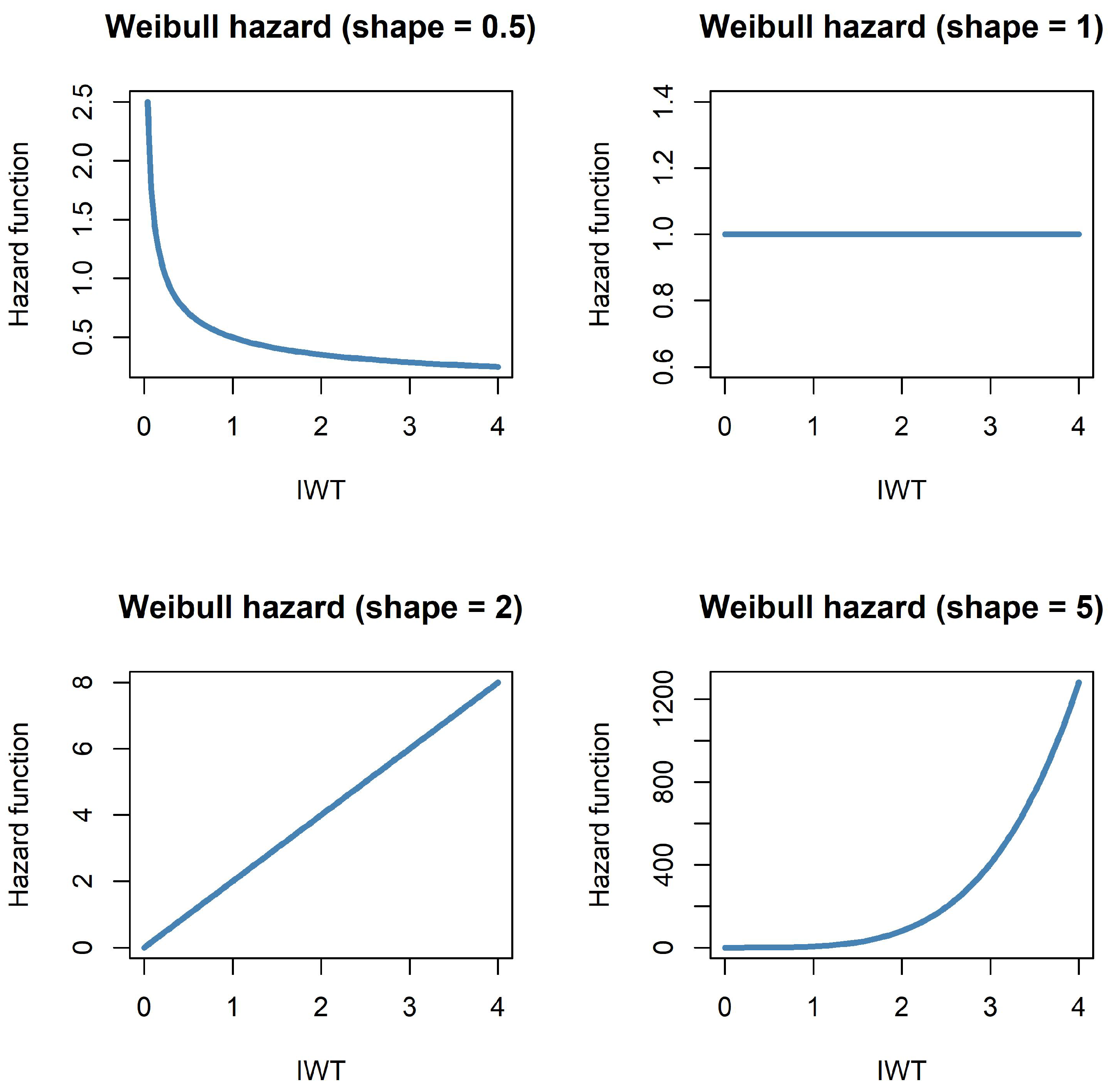
2.1.1. Weibull Counting Process
2.1.2. Copula
2.2. Recursive Moment Expressions
2.3. Monte Carlo Simulation
- Generate pairs of dependent random variates from multivariate distributions constructed from the chosen copula. The multivariate distributions are based on the best-fit distribution obtained from the insurance dataset.
- Compute the random time , from the accumulated as in Equation (2).
- Compute the aggregate discounted claims , by assuming deterministic .
- Stop running the iterations once the is above a pre-determined term of a policy contract.
- Repeat the process from step 1 to 4 for n simulations.
- Determine the moments, premium and VaR from the simulated risk process .
3. Results and Discussion
3.1. Results Verification
3.2. Fitting Distribution and Parameter Estimation of Insurance Datasets
3.2.1. The Claim Sizes Distribution
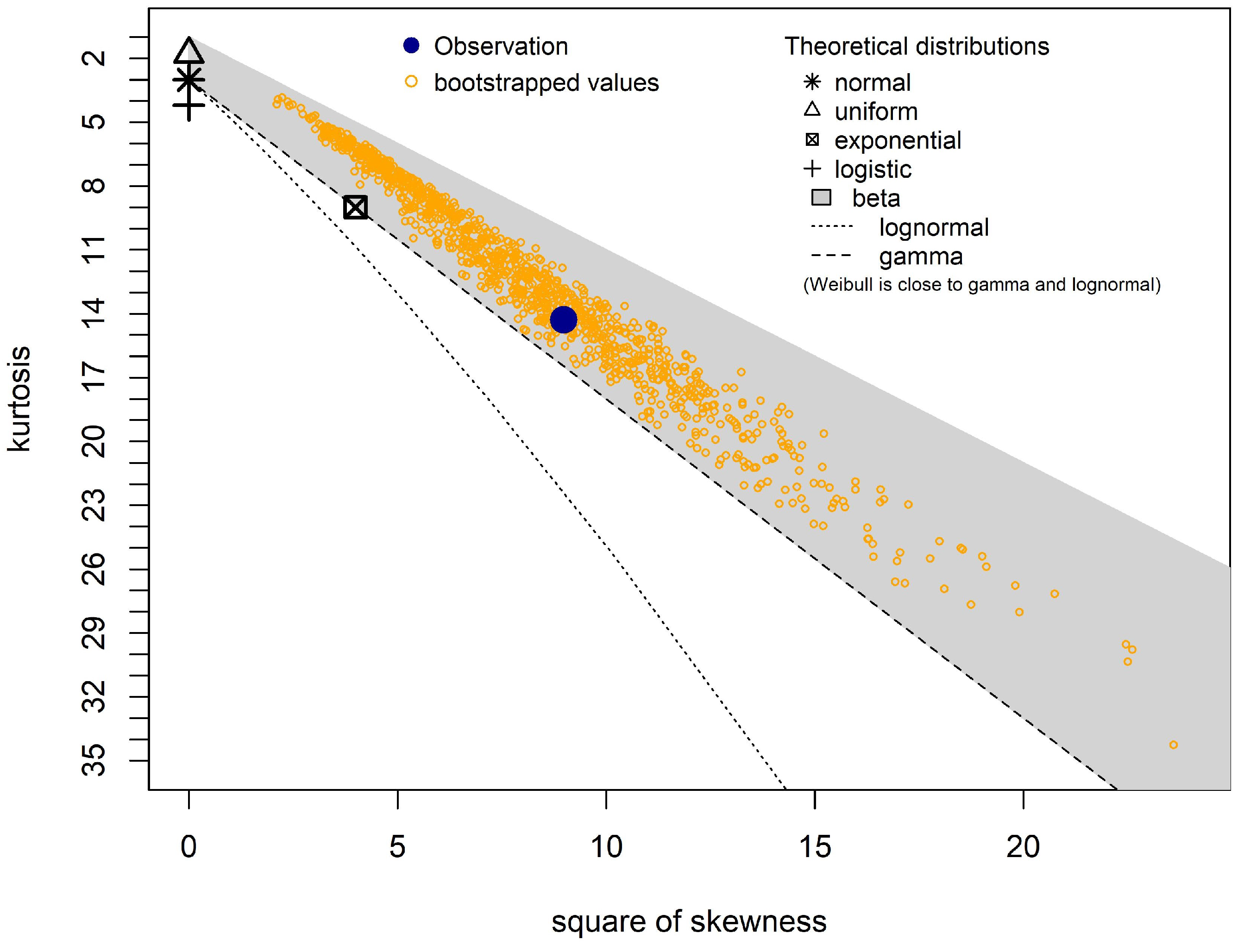
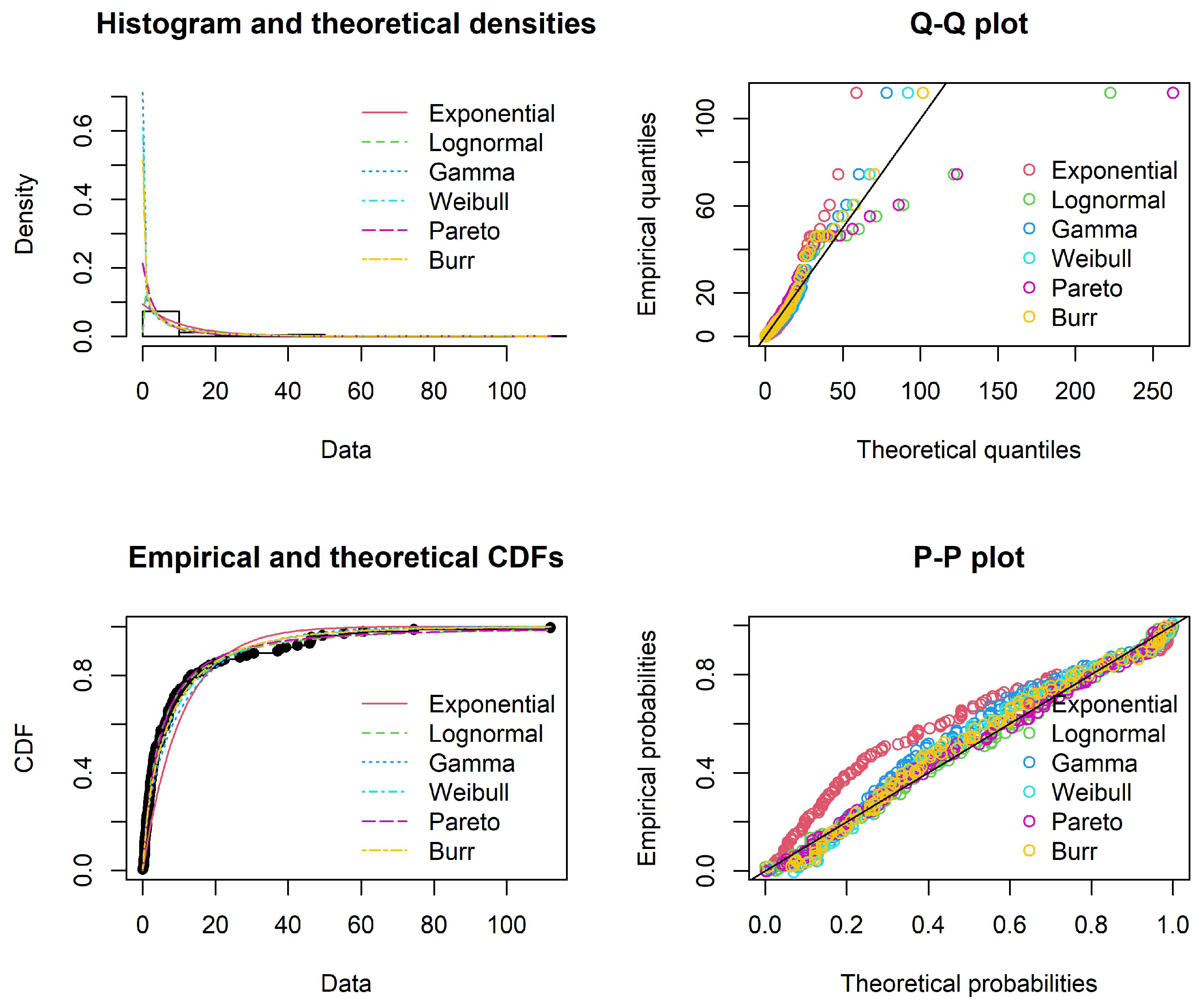
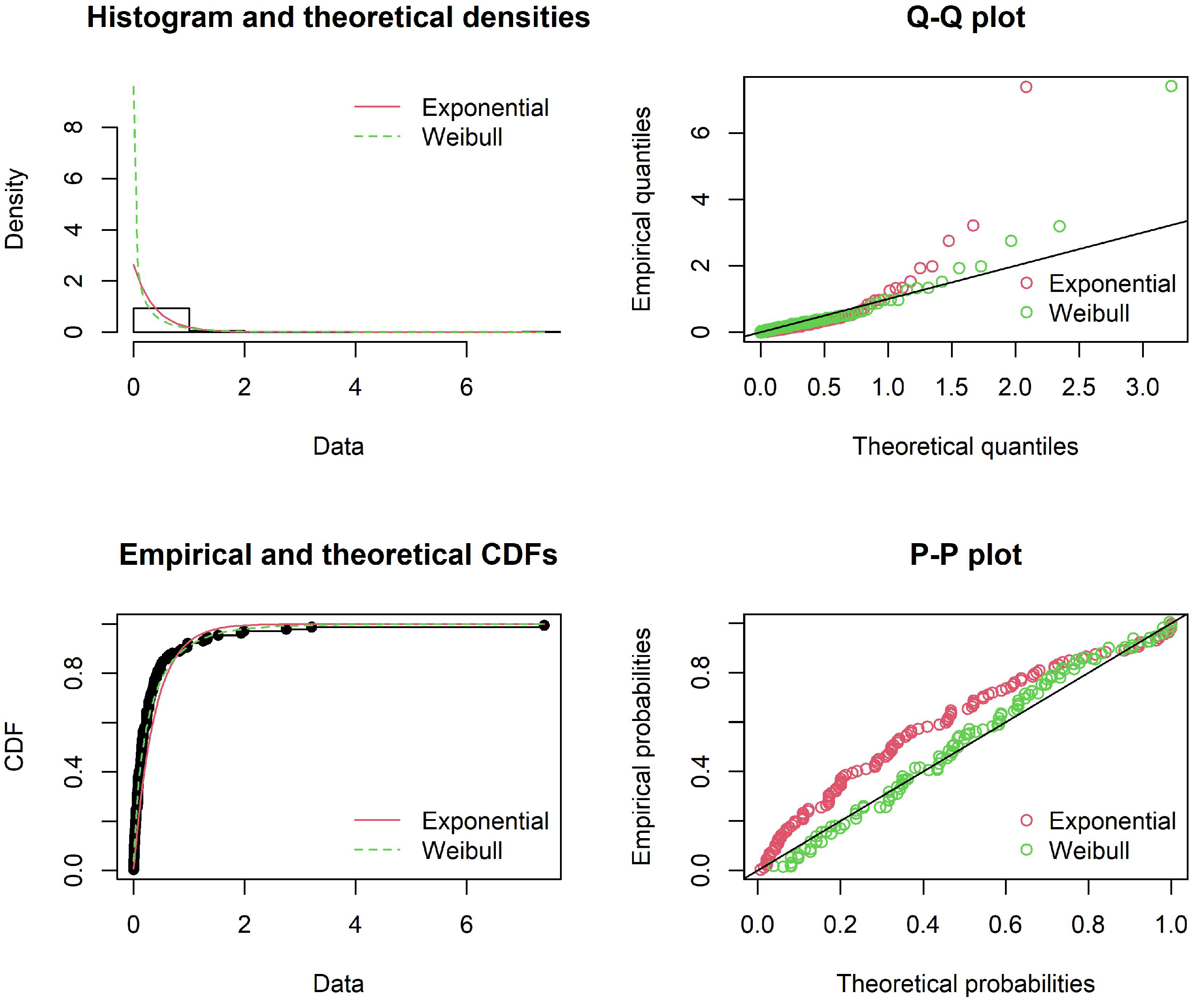
3.2.2. The Interwaiting Time Distribution
3.2.3. The Dependency between the Claim Sizes and the IWT
3.3. Risk Characteristic of the Risk Process with Overdispersed Claim Arrival
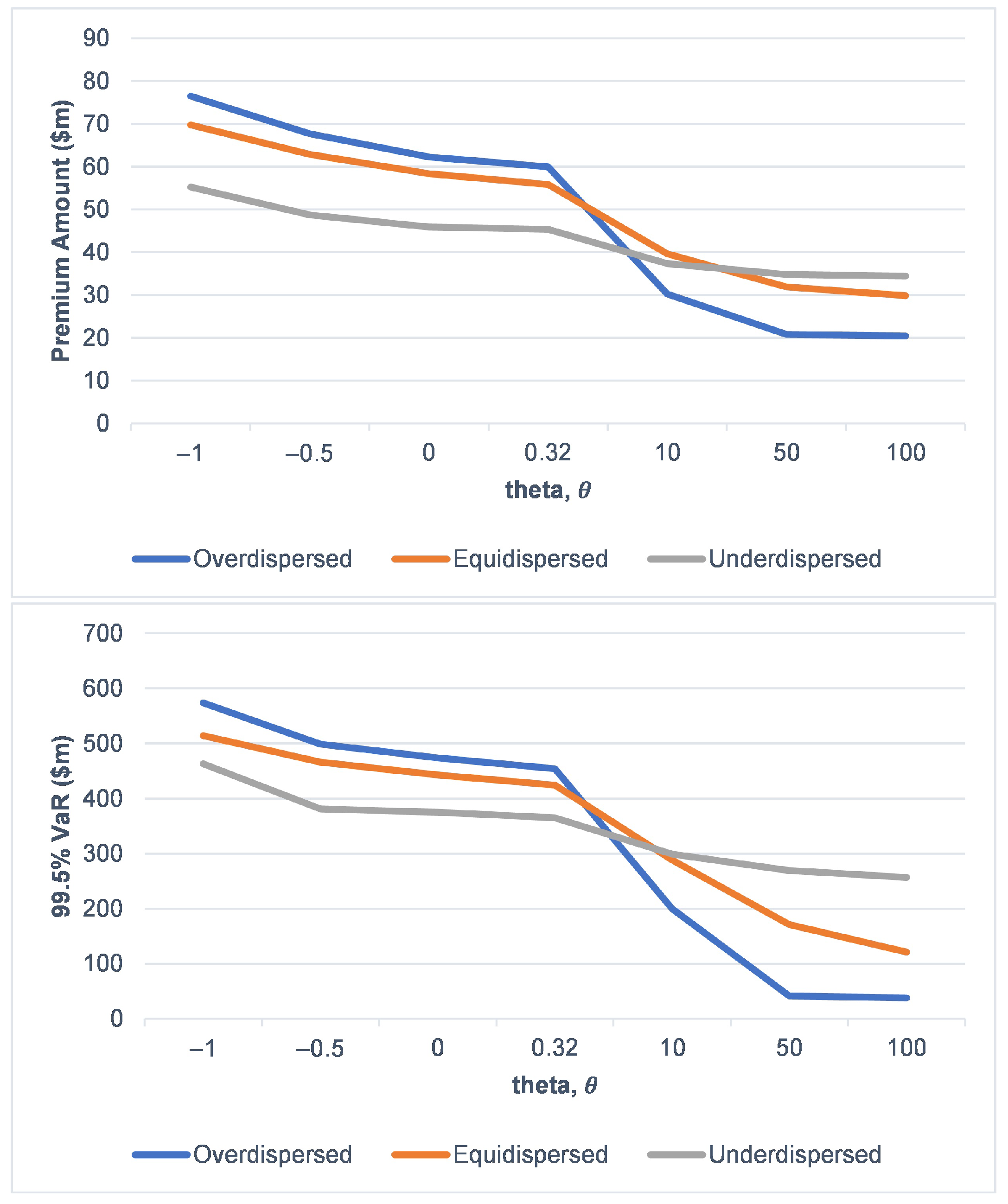
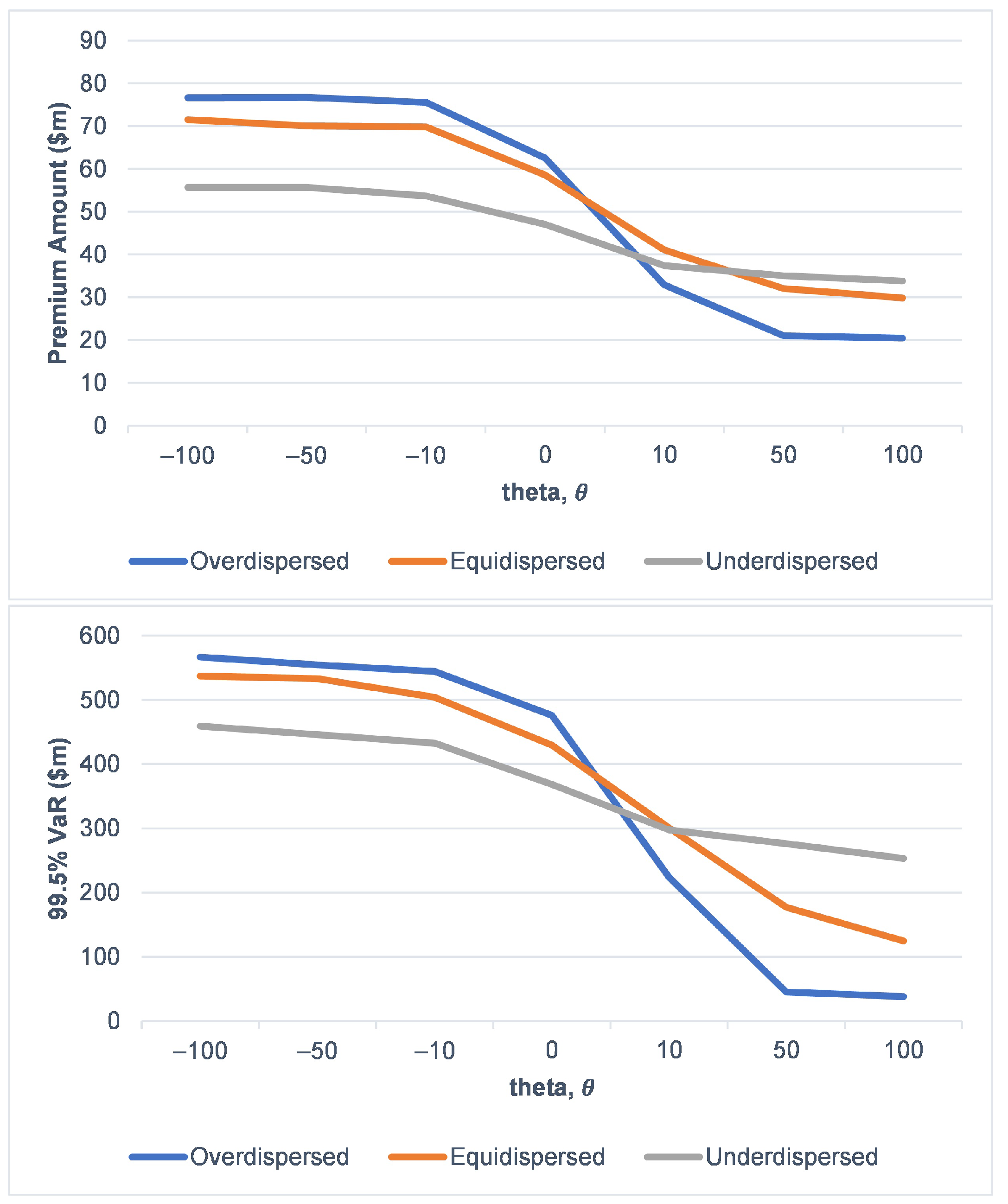
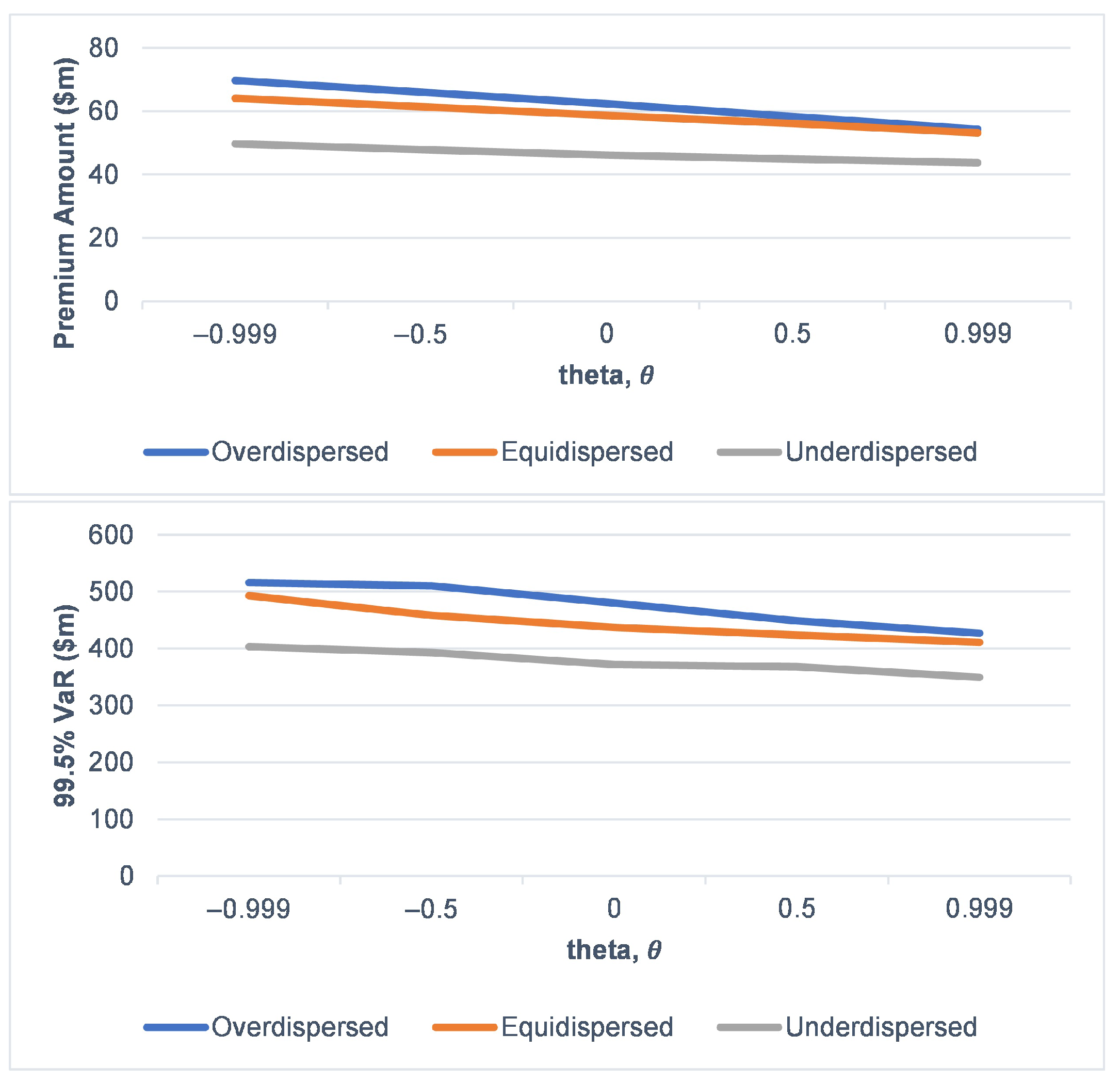
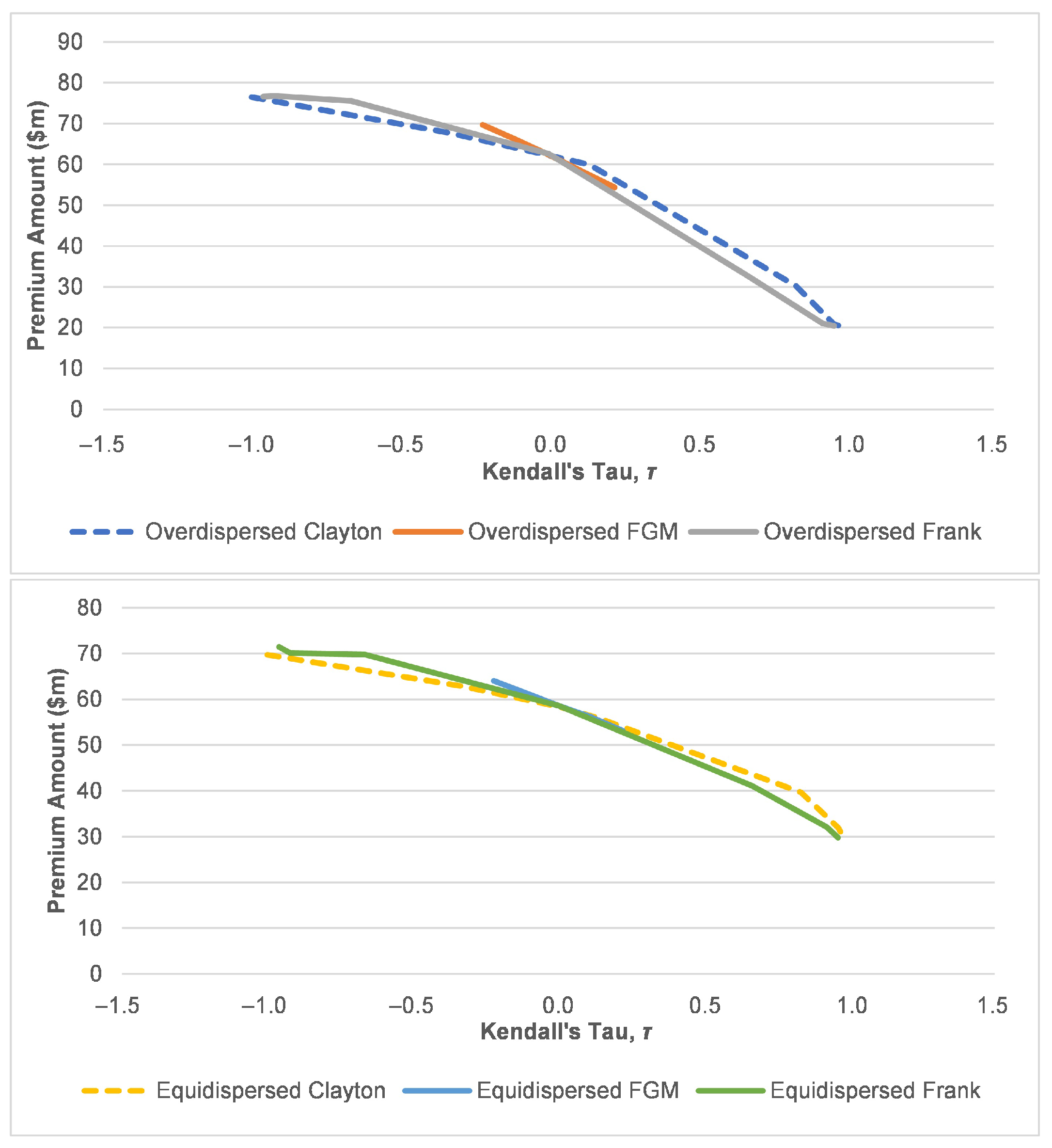
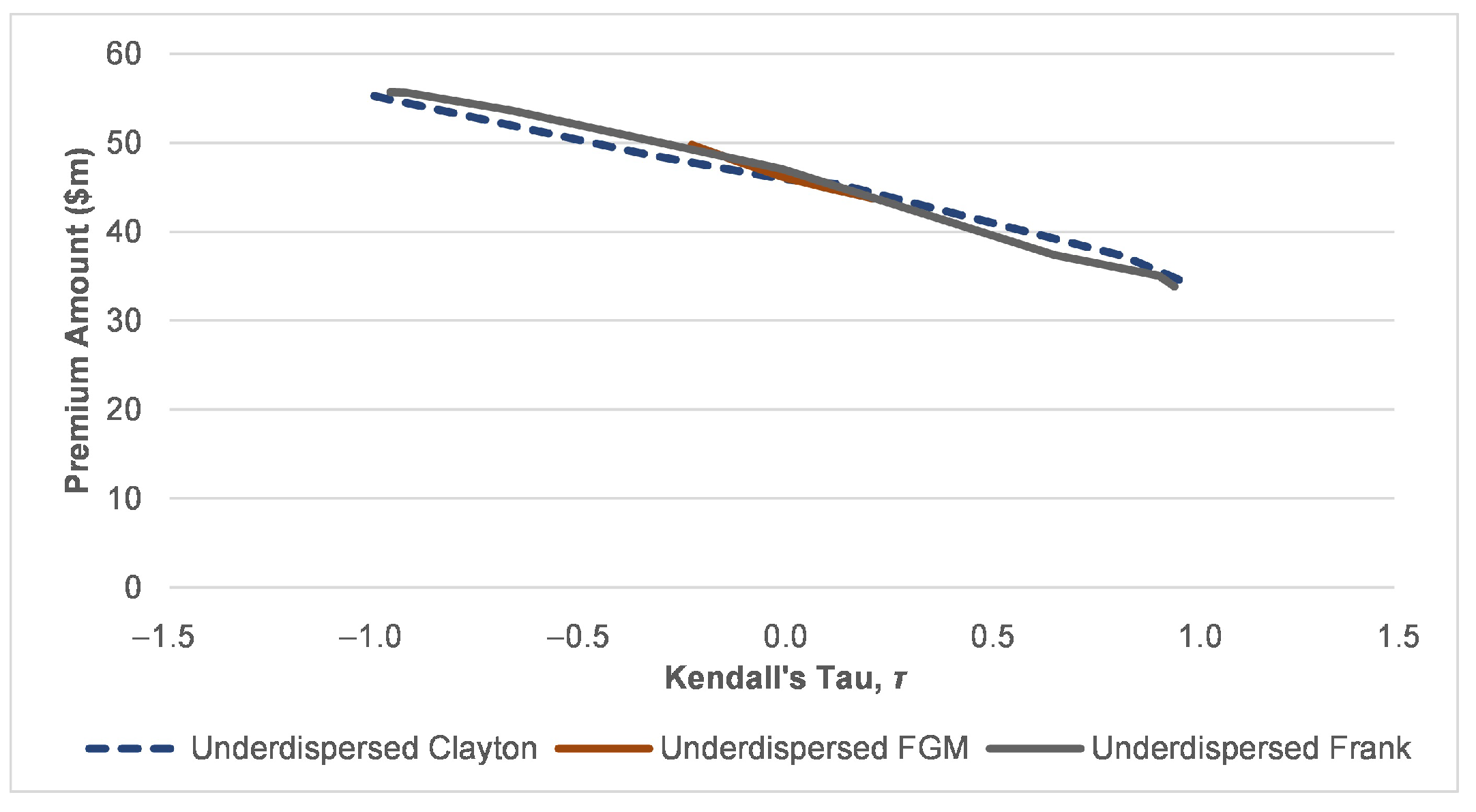
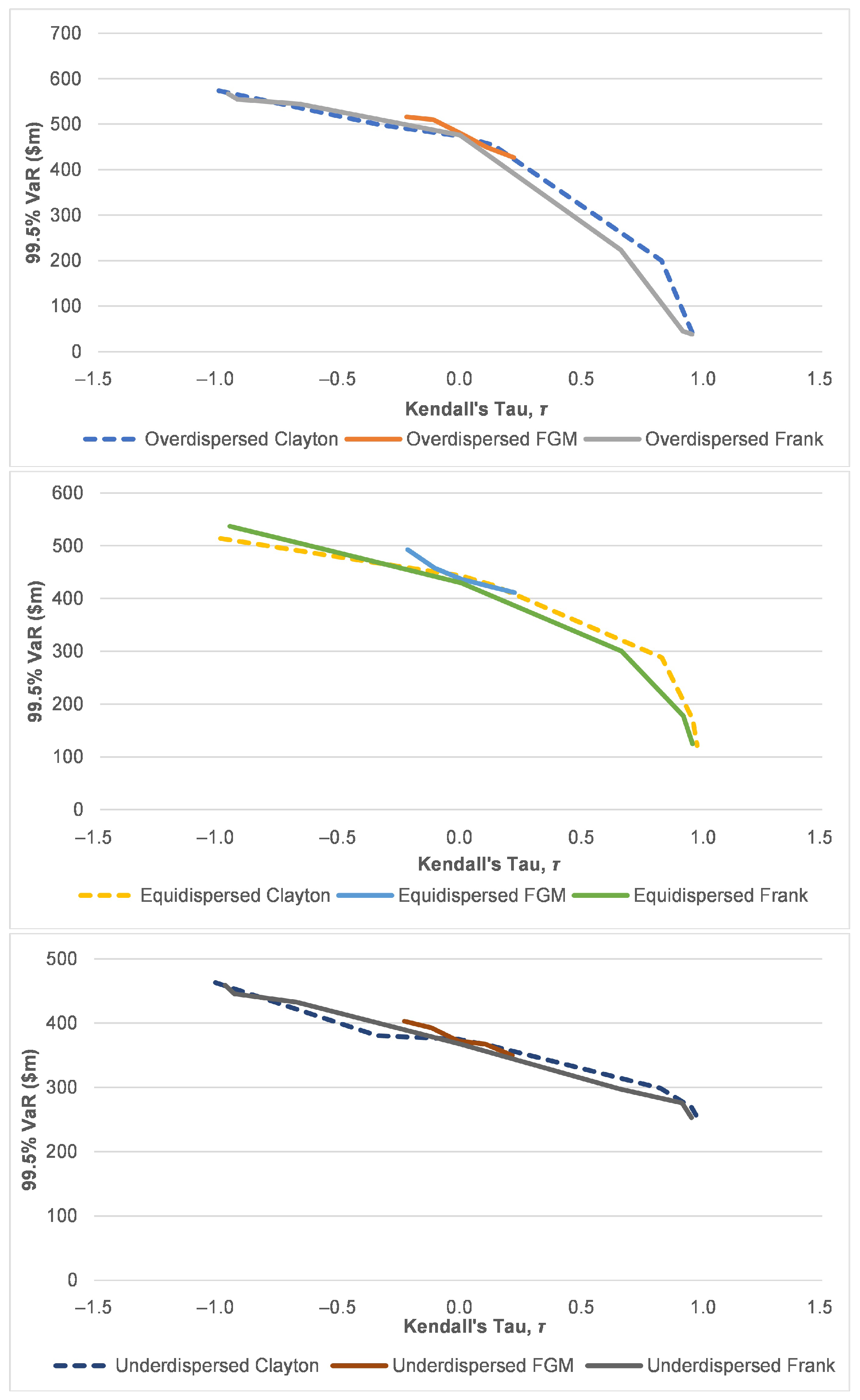
3.4. Scenario Analysis on Risk Characteristic of the Risk Process under Various Dispersion Effect on Claims Arrival
Premium Computation and VaR of the Risk Portfolio
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AD | Anderson-Darling |
| AIC | Akaike information criterion |
| BIC | Bayesian information criterion |
| CDF | Cumulative distribution function |
| FGM | Farlie-Gumbel-Mogenstern |
| GOF | Goodness-of-fit |
| IWT | Interwaiting time |
| KS | Kolmogorov–Smirnov |
| MDPI | Multidisciplinary Digital Publishing Institute |
| SCR | Solvency capital requirement |
| Std Dev | Standard deviation |
| VaR | Value-at-Risk |
References
- Albrecher, Hansjörg, Corina Constantinescu, and Stéphane Loisel. 2011. Explicit ruin formulas for models with dependence among risks. Insurance: Mathematics and Economics 48: 265–70. [Google Scholar] [CrossRef] [Green Version]
- Bar-Lev, Shaul, and Ad Ridder. 2019. Monte Carlo methods for insurance risk computation. International Journal of Statistics and Probability 8: 54–74. [Google Scholar] [CrossRef]
- Barges, Mathieu, Hélene Cossette, Stéphane Loisel, and Etienne Marceau. 2011. On the moments of aggregate discounted claims with dependence introduced by a FGM copula. ASTIN Bulletin: The Journal of the IAA 41: 215–38. [Google Scholar]
- Boshnakov, Georgi, Tarak Kharrat, and Ian G. McHale. 2017. A bivariate Weibull count model for forecasting association football scores. International Journal of Forecasting 33: 458–66. [Google Scholar] [CrossRef] [Green Version]
- Casarano, Giuseppe, Gilberto Castellani, Luca Passalacqua, Francesca Perla, and Paolo Zanetti. 2017. Relevant applications of Monte Carlo simulation in Solvency II. Soft Computing 21: 1181–92. [Google Scholar] [CrossRef]
- Christiansen, Marcus C., and Andreas Niemeyer. 2014. Fundamental definition of the solvency capital requirement in Solvency II. Astin Bulletin 44: 501–33. [Google Scholar] [CrossRef] [Green Version]
- Cullen, Alison C., H. Christopher Frey, and Christopher H. Frey. 1999. Probabilistic Techniques in Exposure Assessment: A Handbook for Dealing with Variability and Uncertainty in Models and Inputs. Berlin: Springer Science & Business Media. [Google Scholar]
- Driels, Morris R., and Young S. Shin. 2004. Determining the Number of Iterations for Monte Carlo Simulations of Weapon Effectiveness. Technical Report. Monterey: Naval Postgraduate School Monterey. [Google Scholar]
- Dutang, Christophe, and Arthur Charpentier. 2020. CASdatasets: Insurance Datasets. R Package Version 1.0-11. Vienna: R Core Team. [Google Scholar]
- Hasumi, Tomohiro, Takuma Akimoto, and Yoji Aizawa. 2009. The Weibull–log Weibull distribution for inter-occurrence times of earthquakes. Physica A: Statistical Mechanics and Its Applications 388: 491–98. [Google Scholar] [CrossRef] [Green Version]
- Jang, Jiwook. 2004. Martingale approach for moments of discounted aggregate claims. Journal of Risk and Insurance 71: 201–11. [Google Scholar] [CrossRef]
- Jose, Kanichukattu K., and Bindu Abraham. 2011. A count model based on Mittag-Leffler interarrival times. Statistica 71: 501–14. [Google Scholar]
- Kelly, Dana L. 2007. Using copulas to model dependence in simulation risk assessment. Paper presented at the ASME 2007 International Mechanical Engineering Congress and Exposition, Seattle, WA, USA, November 11–15; vol. 43084, pp. 81–89. [Google Scholar]
- Klugman, Stuart A., and Rahul Parsa. 1999. Fitting bivariate loss distributions with copulas. Insurance: Mathematics and Economics 24: 139–48. [Google Scholar] [CrossRef]
- Kreer, Markus, Ayşe Kızılersü, Anthony W. Thomas, and Alfredo D Egídio dos Reis. 2015. Goodness-of-fit tests and applications for left-truncated Weibull distributions to non-life insurance. European Actuarial Journal 5: 139–63. [Google Scholar] [CrossRef]
- Léveillé, Ghislain, and Jose Garrido. 2001a. Moments of compound renewal sums with discounted claims. Insurance: Mathematics and Economics 28: 217–31. [Google Scholar]
- Léveillé, Ghislain, and José Garrido. 2001b. Recursive moments of compound renewal sums with discounted claims. Scandinavian Actuarial Journal 2001: 98–110. [Google Scholar] [CrossRef]
- Li, Shuanming, and Yi Lu. 2018. On the moments and the distribution of aggregate discounted claims in a Markovian environment. Risks 6: 59. [Google Scholar] [CrossRef] [Green Version]
- Liu, Hanlin. 2019. Reliability and maintenance modeling for competing risk processes with Weibull inter-arrival shocks. Applied Mathematical Modelling 71: 194–207. [Google Scholar] [CrossRef]
- Lora, Mayra Ivanoff, and Julio M. Singer. 2011. Beta-binomial/gamma-Poisson regression models for repeated counts with random parameters. Brazilian Journal of Probability and Statistics 25: 218–35. [Google Scholar] [CrossRef]
- Ly, Sel, Kim-Hung Pho, Sal Ly, and Wing-Keung Wong. 2019. Determining distribution for the product of random variables by using copulas. Risks 7: 23. [Google Scholar] [CrossRef] [Green Version]
- Mao, Tiantian, and Fan Yang. 2015. Risk concentration based on expectiles for extreme risks under FGM copula. Insurance: Mathematics and Economics 64: 429–39. [Google Scholar] [CrossRef]
- McShane, Blake, Moshe Adrian, Eric T. Bradlow, and Peter S. Fader. 2008. Count models based on Weibull interarrival times. Journal of Business & Economic Statistics 26: 369–78. [Google Scholar]
- Mohd Ramli, Siti Norafidah, and Jiwook Jang. 2014. Neumann series on the recursive moments of copula-dependent aggregate discounted claims. Risks 2: 195–210. [Google Scholar] [CrossRef] [Green Version]
- Mohd Ramli, Siti Norafidah, Nur Atikah Mohamed Rozali, Sharifah Farah Syed Yusoff Alhabshi, and Ishak Hashim. 2018. Laplace transform on the recursive moments of copula-dependent aggregate discounted claims. In AIP Conference Proceedings. Melville: AIP Publishing LLC, vol. 1974, p. 020110. [Google Scholar]
- Mohd Ramli, Siti Norafidah, Nur Atikah Mohamed Rozali, Sharifah Farah Syed Yusoff Alhabshi, and Ishak Hashim. 2019. Laplace transform on the recursive moments of aggregate discounted claims with Weibull interwaiting time. In AIP Conference Proceedings. Melville: AIP Publishing LLC, vol. 2184, p. 050017. [Google Scholar]
- MunichRE. 2018. NatCatSERVICE. Available online: http://natcatservice.munichre.com (accessed on 14 February 2018).
- Razak, Nor Iza Anuar, Zamira Hasanah Zamzuri, and Nur Riza Mohd Suradi. 2019. The Implementation Of Double Bootstrap Method In Structural Equation Modeling. Asm Science Journal 12: 8–14. [Google Scholar]
- Sun, Weiwei, Xiang Hu, and Lianzeng Zhang. 2020. Moments of discounted aggregate claims with dependence based on Spearman copula. Journal of Computational and Applied Mathematics 377: 112889. [Google Scholar] [CrossRef]
- Waters, Howard R. 1983. Probability of ruin for a risk process with claims cost inflation. Scandinavian Actuarial Journal 1983: 148–64. [Google Scholar] [CrossRef]
- Winkelmann, Rainer. 1995. Duration dependence and dispersion in count-data models. Journal of Business & Economic Statistics 13: 467–74. [Google Scholar]
- Woo, Jae-Kyung, and Eric C. K. Cheung. 2013. A note on discounted compound renewal sums under dependency. Insurance: Mathematics and Economics 52: 170–79. [Google Scholar] [CrossRef]
- Yang, Hailiang, and Lihong Zhang. 2001. On the distribution of surplus immediately after ruin under interest force. Insurance: Mathematics and Economics 29: 247–55. [Google Scholar] [CrossRef]
- Zamzuri, Zamira Hasanah, and Gwee Jia Hui. 2020. Comparing and forecasting using stochastic mortality models: A Monte Carlo simulation. Sains Malaysiana 49: 2013–22. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Moments | Monte Carlo | Laplace Transform | Relative Deviation | |
|---|---|---|---|---|
| −0.999 | 479.23 | 477.66 | 0.330% | |
| −0.9 | 474.83 | 475.23 | 0.084% | |
| −0.5 | 469.16 | 465.43 | 0.803% | |
| Mean | 0 | 452.79 | 453.17 | 0.084% |
| 0.5 | 440.59 | 440.92 | 0.074% | |
| 0.9 | 433.43 | 431.12 | 0.537% | |
| 0.999 | 430.23 | 428.69 | 0.359% | |
| −0.999 | 106,554.00 | 106,351.84 | 0.190% | |
| −0.9 | 105,554.20 | 103,929.50 | 1.563% | |
| −0.5 | 94,099.89 | 94,253.78 | 0.163% | |
| Variance | 0 | 80,630.85 | 82,420.23 | 2.171% |
| 0.5 | 69,601.11 | 70,874.44 | 1.797% | |
| 0.9 | 61,217.14 | 61,845.86 | 1.017% | |
| 0.999 | 59.182.13 | 59,638.74 | 0.766% |
| Min | Max | Median | Mean | Estimated Std Dev | Estimated Skewness | Estimated Kurtosis |
|---|---|---|---|---|---|---|
| 0.01 | 112 | 3.6 | 10.67252 | 17.14509 | 2.997792 | 14.29496 |
| GOF Criterion | GOF Test | ||||
|---|---|---|---|---|---|
| Distribution | −2 Log Likelihood | AIC | BIC | KS Test (p-Value) | AD Test (p-Value) |
| Exponential | 828.447 | 830.447 | 833.260 | 0.0000 | 0.0000 |
| Lognormal | 787.928 | 791.928 | 797.552 | 0.9980 | 0.9775 |
| Gamma | 804.195 | 808.195 | 813.820 | 0.0912 | 0.0389 |
| Weibull | 796.037 | 800.037 | 805.662 | 0.4291 | 0.1797 |
| Pareto | 788.541 | 792.541 | 798.165 | 0.9096 | 0.8201 |
| Burr | 788.420 | 794.421 | 802.857 | 0.9339 | 0.8521 |
| Min | Max | Median | Mean | Estimated Std Dev | Estimated Skewness | Estimated Kurtosis |
|---|---|---|---|---|---|---|
| 0.0027 | 7.3922 | 0.1478 | 0.3786 | 0.8125 | 6.0819 | 49.9694 |
| GOF Criterion | GOF Test | ||||
|---|---|---|---|---|---|
| Distribution | Estimated Parameters | AIC | BIC | KS Test (p-Value) | AD Test (p-Value) |
| Weibull | = 0.700152 = 0.282022 | −27.4824 | −21.8580 | 0.5383 | 0.2877 |
| Exponential | = 2.641138 | 9.08241 | 11.8946 | 0.0001 | 0.0000 |
| Copula | Estimated Parameter, | Log Likelihood | AIC | BIC |
|---|---|---|---|---|
| Independence | 0 | 0 | 0 | 0 |
| Gaussian | 0.19 | 2.02 | −2.04 | 0.77 |
| T | 0.19 | 2.12 | −0.25 | 5.38 |
| Clayton | 0.32 | 3.57 | −5.13 | −2.32 |
| Gumbel | 1.09 | 0.92 | 0.17 | 2.98 |
| Frank | 1.1 | 1.91 | −1.81 | 1 |
| Joe | 1.06 | 0.17 | 1.65 | 4.47 |
| IWT Distribution | Mean | Variance | Skewness | Kurtosis |
|---|---|---|---|---|
| Weibull | 169.343 | 21313.540 | 6.296 | 145.444 |
| Exponential | 154.034 | 18239.790 | 7.242 | 150.931 |
| IWT | VaR ($m) | Premium Amount ($m) | ||
|---|---|---|---|---|
| Distribution | 95% | 99.50% | Mean Principle | Std Dev Principle |
| Weibull | 406.757 | 846.901 | 186.278 | 183.942 |
| Exponential | 363.706 | 809.141 | 169.438 | 167.540 |
| Overdispersed | Equidispersed | Underdispersed | |
|---|---|---|---|
() | () | () | |
| Mean | 4.243 | 4.243 | 4.243 |
| Variance | 9.903 | 4.243 | 1.375 |
| Overdispersed | ||||
|---|---|---|---|---|
| Mean | Variance | Skewness | Kurtosis | |
| −1 | 66.359 | 10202.750 | 9.423 | 276.883 |
| −0.5 | 58.933 | 7595.139 | 7.010 | 128.587 |
| 0 | 53.764 | 7168.824 | 10.130 | 294.856 |
| 0.32 | 51.266 | 7538.556 | 22.392 | 1599.203 |
| 10 | 26.722 | 1205.303 | 16.188 | 714.862 |
| 50 | 19.757 | 109.521 | 2.620 | 105.380 |
| 100 | 19.454 | 90.367 | −0.336 | −0.839 |
| Equidispersed | ||||
| Mean | Variance | Skewness | Kurtosis | |
| −1 | 60.663 | 8240.178 | 7.779 | 162.108 |
| −0.5 | 54.657 | 6749.611 | 8.895 | 190.364 |
| 0 | 50.751 | 5835.950 | 10.186 | 315.298 |
| 0.32 | 48.389 | 5557.512 | 13.696 | 576.241 |
| 10 | 34.768 | 2378.918 | 13. | 372.840 |
| 50 | 28.978 | 855.983 | 21.968 | 1236.261 |
| 100 | 27.540 | 533.322 | 25.754 | 1589.694 |
| Underdispersed | ||||
| Mean | Variance | Skewness | Kurtosis | |
| −1 | 47.414 | 6147.893 | 8.180 | 148.807 |
| −0.5 | 42.014 | 4487.100 | 11.205 | 347.476 |
| 0 | 39.587 | 3991.358 | 9.331 | 190.339 |
| 0.32 | 38.672 | 4477.052 | 13.927 | 431.441 |
| 10 | 32.096 | 2714.674 | 14.606 | 497.202 |
| 50 | 30.036 | 2288.304 | 22.567 | 1324.124 |
| 100 | 29.623 | 2289.057 | 25.280 | 1591.957 |
| Overdispersed | ||||
|---|---|---|---|---|
| VaR ($m) | Premium Amount ($m) | |||
| 95% | 99.50% | Mean Principle | Std Dev Principle | |
| −1 | 225.744 | 573.577 | 72.994 | 76.459 |
| −0.5 | 197.729 | 498.658 | 64.827 | 67.649 |
| 0 | 180.155 | 473.747 | 59.140 | 62.231 |
| 0.32 | 167.568 | 454.264 | 56.392 | 59.948 |
| 10 | 63.731 | 199.876 | 29.394 | 30.194 |
| 50 | 34.147 | 41.335 | 21.733 | 20.804 |
| 100 | 32.855 | 37.793 | 21.399 | 20.405 |
| Equidispersed | ||||
| VaR ($m) | Premium Amount ($m) | |||
| 95% | 99.50% | Mean Principle | Std Dev Principle | |
| −1 | 202.152 | 514.118 | 66.729 | 69.741 |
| −0.5 | 176.053 | 466.067 | 60.122 | 62.872 |
| 0 | 161.369 | 443.094 | 55.827 | 58.391 |
| 0.32 | 151.449 | 424.326 | 53.228 | 55.844 |
| 10 | 88.749 | 288.379 | 38.245 | 39.646 |
| 50 | 58.319 | 170.823 | 31.876 | 31.904 |
| 100 | 52.508 | 120.991 | 30.293 | 29.849 |
| Equidispersed | ||||
| VaR ($m) | Premium Amount ($m) | |||
| 95% | 99.50% | Mean Principle | Std Dev Principle | |
| −1 | 163.186 | 463.176 | 52.155 | 55.254 |
| −0.5 | 138.329 | 380.708 | 46.215 | 48.712 |
| 0 | 128.152 | 374.841 | 43.546 | 45.905 |
| 0.32 | 121.294 | 364.802 | 42.540 | 45.363 |
| 10 | 91.612 | 298.824 | 35.306 | 37.307 |
| 50 | 80.044 | 269.078 | 33.039 | 34.819 |
| 100 | 77.195 | 256.812 | 32.585 | 34.407 |
| Overdispersed | ||||
|---|---|---|---|---|
| VaR ($m) | Premium Amount ($m) | |||
| 95% | 99.50% | Mean Principle | Std Dev Principle | |
| −100 | 225.816 | 566.751 | 73.363 | 76.605 |
| −50 | 227.023 | 554.466 | 73.356 | 76.737 |
| −10 | 222.041 | 544.253 | 72.451 | 75.522 |
| 0 | 179.770 | 475.843 | 59.577 | 62.559 |
| 10 | 74.381 | 223.736 | 31.722 | 32.858 |
| 50 | 34.979 | 45.038 | 21.940 | 21.018 |
| 100 | 33.045 | 38.072 | 21.427 | 20.435 |
| Equidispersed | ||||
| VaR ($m) | Premium Amount ($m) | |||
| 95% | 99.50% | Mean Principle | Std Dev Principle | |
| −100 | 203.215 | 536.925 | 67.420 | 71.469 |
| −50 | 204.435 | 532.854 | 67.100 | 70.079 |
| −10 | 200.478 | 504.214 | 66.215 | 69.807 |
| 0 | 161.197 | 429.608 | 55.876 | 58.620 |
| 10 | 94.393 | 300.319 | 39.512 | 41.085 |
| 50 | 58.900 | 177.422 | 31.990 | 32.082 |
| 100 | 52.942 | 124.696 | 30.383 | 29.798 |
| Underdispersed | ||||
| VaR ($m) | Premium Amount ($m) | |||
| 95% | 99.50% | Mean Principle | Std Dev Principle | |
| −100 | 162.916 | 459.141 | 52.387 | 55.664 |
| −50 | 161.985 | 445.691 | 52.355 | 55.655 |
| −10 | 153.385 | 432.808 | 50.560 | 53.662 |
| 0 | 128.944 | 368.501 | 44.232 | 47.049 |
| 10 | 92.540 | 297.590 | 35.405 | 37.388 |
| 50 | 81.145 | 275.849 | 33.254 | 35.059 |
| 100 | 77.572 | 252.967 | 32.445 | 33.838 |
| Overdispersed | ||||
|---|---|---|---|---|
| VaR ($m) | Premium Amount ($m) | |||
| 95% | 99.50% | Mean Principle | Std Dev Principle | |
| −0.999 | 204.390 | 515.814 | 66.564 | 69.693 |
| −0.5 | 190.822 | 509.914 | 62.891 | 66.048 |
| 0 | 178.699 | 480.092 | 59.106 | 62.356 |
| 0.5 | 165.488 | 448.837 | 55.451 | 58.282 |
| 0.999 | 154.182 | 426.935 | 51.789 | 54.361 |
| Equidispersed | ||||
| VaR ($m) | Premium Amount ($m) | |||
| 95% | 99.50% | Mean Principle | Std Dev Principle | |
| −0.999 | 178.922 | 492.664 | 60.988 | 64.017 |
| −0.5 | 172.109 | 458.163 | 58.608 | 61.381 |
| 0 | 161.823 | 436.838 | 56.028 | 58.640 |
| 0.5 | 151.357 | 423.809 | 53.247 | 56.144 |
| 0.999 | 140.298 | 411.168 | 50.556 | 53.115 |
| Underdispersed | ||||
| VaR ($m) | Premium Amount ($m) | |||
| 95% | 99.50% | Mean Principle | Std Dev Principle | |
| −0.999 | 140.496 | 403.169 | 46.940 | 49.749 |
| −0.5 | 133.912 | 392.826 | 45.231 | 47.897 |
| 0 | 126.499 | 372.115 | 43.538 | 46.174 |
| 0.5 | 120.662 | 367.651 | 42.261 | 44.904 |
| 0.999 | 115.166 | 349.602 | 40.982 | 43.725 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Syed Yusoff Alhabshi, S.F.; Zamzuri, Z.H.; Mohd Ramli, S.N. Monte Carlo Simulation of the Moments of a Copula-Dependent Risk Process with Weibull Interwaiting Time. Risks 2021, 9, 109. https://0-doi-org.brum.beds.ac.uk/10.3390/risks9060109
Syed Yusoff Alhabshi SF, Zamzuri ZH, Mohd Ramli SN. Monte Carlo Simulation of the Moments of a Copula-Dependent Risk Process with Weibull Interwaiting Time. Risks. 2021; 9(6):109. https://0-doi-org.brum.beds.ac.uk/10.3390/risks9060109
Chicago/Turabian StyleSyed Yusoff Alhabshi, Sharifah Farah, Zamira Hasanah Zamzuri, and Siti Norafidah Mohd Ramli. 2021. "Monte Carlo Simulation of the Moments of a Copula-Dependent Risk Process with Weibull Interwaiting Time" Risks 9, no. 6: 109. https://0-doi-org.brum.beds.ac.uk/10.3390/risks9060109