Remote Sensing Scene Classification Based on Convolutional Neural Networks Pre-Trained Using Attention-Guided Sparse Filters


Abstract
:
1. Introduction
1.1. Background
1.2. Related Work
1.3. Motivation
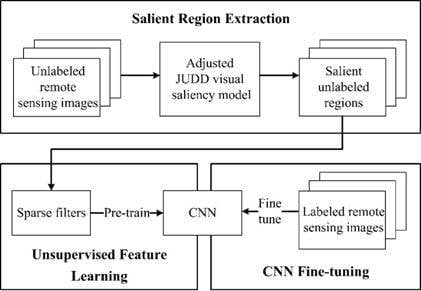
2. Methodology
2.1. Salient Region Extraction
- The local energy of the steerable pyramid filters;
- The saliency based on sub-band pyramids described by Torralba and Rosenholtz;
- Center-surrounded features in intensity, orientation, and color contrast calculated by Itti and Koch’s saliency method;
- The values and probabilities of each color channel;
- The probability of each color channel as computed from three-dimensional (3D) color histograms of the image filtered with a median filter at six different scales.
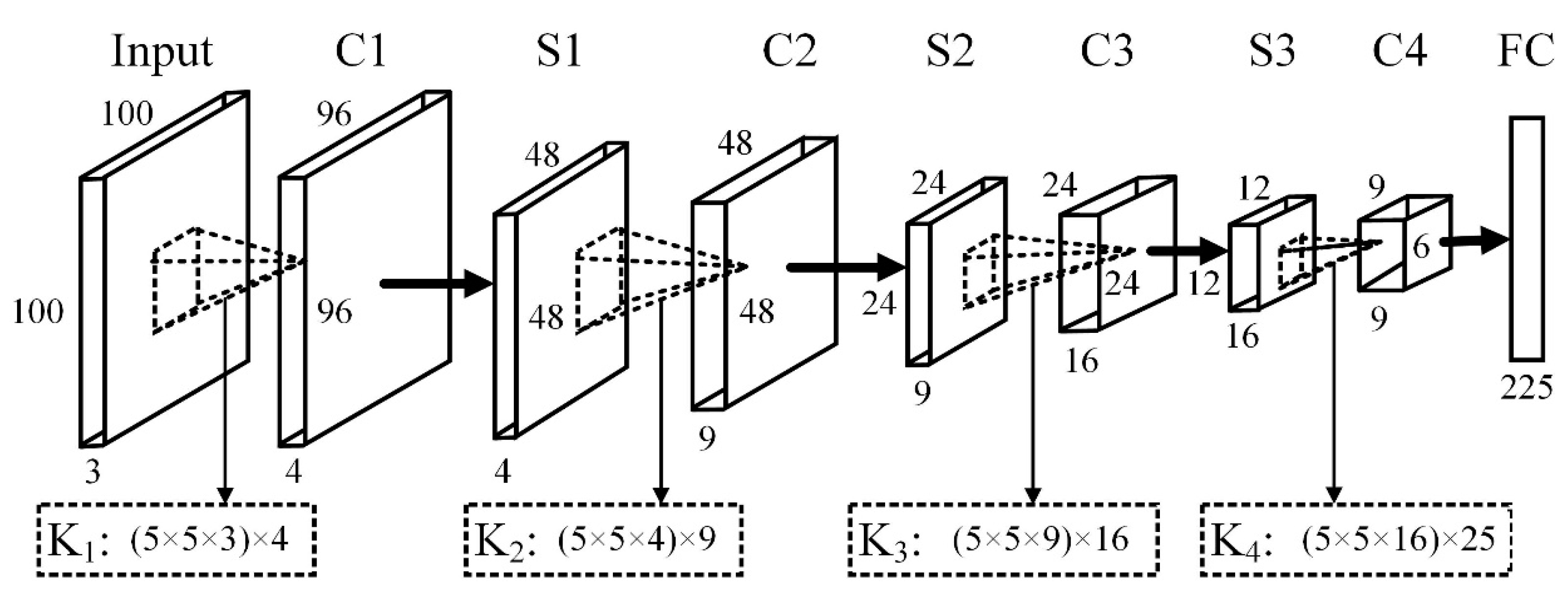
2.2. Unsupervised Feature Learning
2.3. CNN Fine-Tuning
3. Experiment and Discussion
3.1. Datasets
3.1.1. Unlabeled Dataset
3.1.2. Labeled Datasets
3.2. Experimental Setup
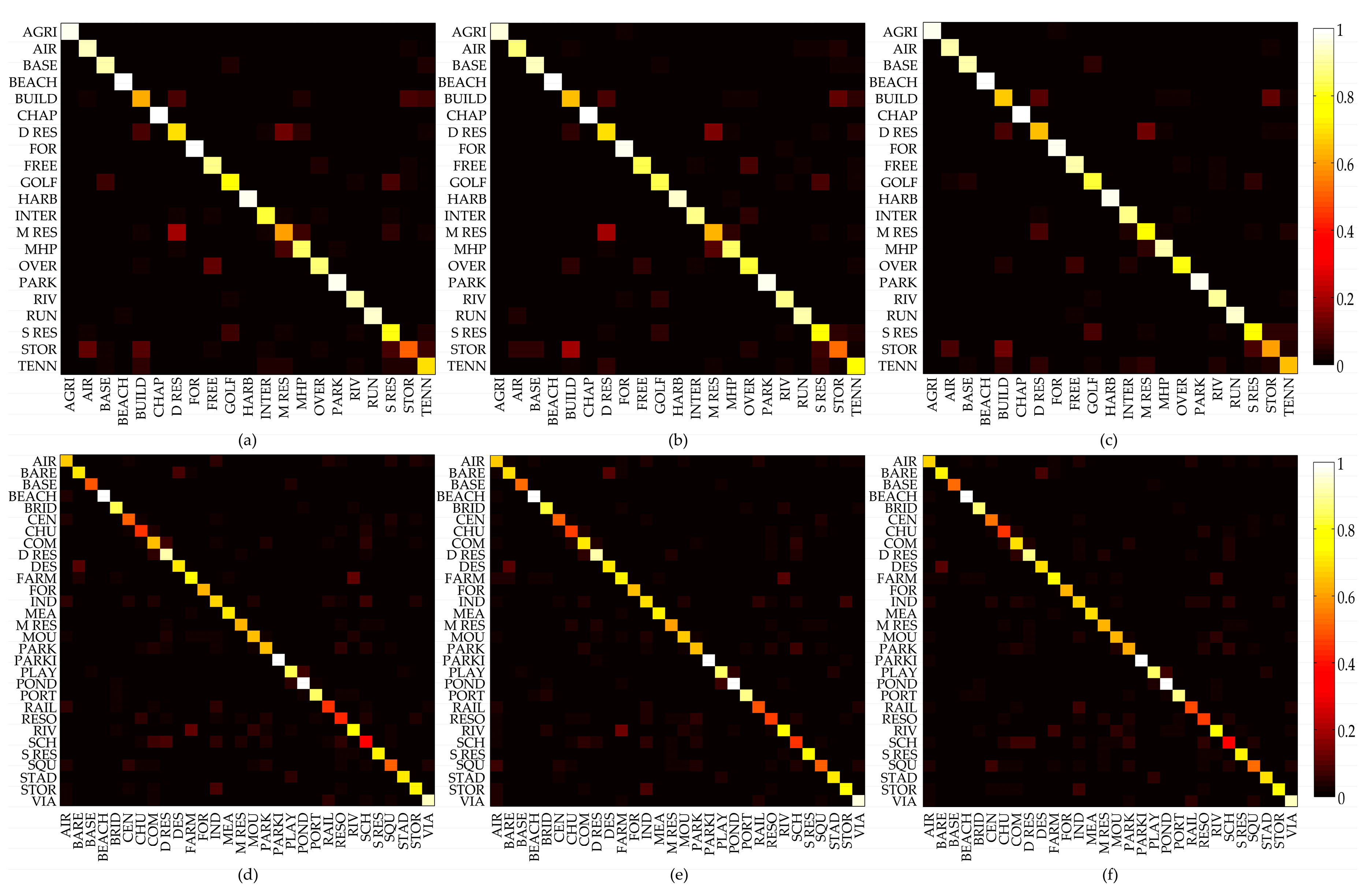
3.3. Validation of the Proposed Method
3.4. Comparison with AlexNet Pre-Trained on ImageNet
3.5. Comparison with State-of-the-Art Research on the UCMerced Dataset
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th ACM SIGSPATIAL International Symposium on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Yang, Y.; Newsam, S. Spatial pyramid co-occurrence for image classification. In Proceedings of the 2011 IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1465–1472. [Google Scholar]
- Cheng, G.; Han, J.; Guo, L.; Liu, Z.; Bu, S.; Ren, J. Effective and efficient midlevel visual elements-oriented land-use classification using VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4238–4249. [Google Scholar] [CrossRef]
- Risojevic, V.; Babic, Z. Fusion of global and local descriptors for remote sensing image classification. IEEE Geosci. Remote Sens. Lett. 2013, 10, 836–840. [Google Scholar] [CrossRef]
- Zou, J.; Li, W.; Chen, C.; Du, Q. Scene classification using local and global features with collaborative representation fusion. Inf. Sci. 2016, 348, 209–226. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Cheriyadat, A.M. Unsupervised feature learning for aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 439–451. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.S.; Wang, Z.; Huang, X.; Zhang, L.; Sun, H. Unsupervised feature learning via spectral clustering of multidimensional patches for remotely sensed scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2015–2030. [Google Scholar] [CrossRef]
- Risojevic, V.; Babic, Z. Unsupervised quaternion feature learning for remote sensing image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 1521–1531. [Google Scholar] [CrossRef]
- Li, Y.; Tao, C.; Tan, Y.; Shang, K.; Tian, J. Unsupervised multilayer feature learning for satellite image scene classification. IEEE Geosci. Remote Sens. Lett. 2016, 13, 157–161. [Google Scholar] [CrossRef]
- Fan, J.; Chen, T.; Lu, S. Unsupervised feature learning for land-use scene recognition. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2250–2261. [Google Scholar] [CrossRef]
- Lu, X.; Zheng, X.; Yuan, Y. Remote sensing scene classification by unsupervised representation learning. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5148–5157. [Google Scholar] [CrossRef]
- Zhang, F.; Du, B.; Zhang, L. Saliency-guided unsupervised feature learning for scene classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2175–2184. [Google Scholar] [CrossRef]
- Hu, J.; Xia, G.S.; Hu, F.; Zhang, L. A comparative study of sampling analysis in scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14988–15013. [Google Scholar] [CrossRef]
- Ngiam, J.; Pang, W.K.; Chen, Z.; Bhaskar, S.; Ng, A.Y. Sparse filtering. In Proceedings of the International Conference on Neural Information Processing Systems, Granada, Spain, 12–15 December 2011. [Google Scholar]
- Li, N.; Zhao, X.; Yang, Y.; Zou, X. Objects classification by learning-based visual saliency model and convolutional neural network. Comput. Intell. Neurosci. 2016, 2016. [Google Scholar] [CrossRef] [PubMed]
- Judd, T.; Ehinger, K.; Durand, F.; Torralba, A. Learning to predict where humans look. In Proceedings of the 2009 IEEE International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2106–2113. [Google Scholar]
- Bengio, Y.; Courville, A.C.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Q.; Koch, C. Learning saliency-based visual attention: A review. Signal Process. 2013, 93, 1401–1407. [Google Scholar] [CrossRef]
- Itti, L.; Koch, C. A saliency-based search mechanism for overt and covert shifts of visual attention. Vis. Res. 2000, 40, 1489–1506. [Google Scholar] [CrossRef]
- Hou, X.; Zhang, L. Saliency detection: A spectral residual approach. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007. [Google Scholar]
- Rosenholtz, R. A simple saliency model predicts a number of motion popout phenomena. Vis. Res. 1999, 39, 3157–3163. [Google Scholar] [CrossRef]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2016, 55, 3965–3981. [Google Scholar] [CrossRef]
- Vedeldi, A.; Lenc, K. MatConvNet: Convolutional neural networks for MATLAB. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Labeled Dataset | Method | Overall Accuracy (%) |
|---|---|---|
| UCMerced | Plain-CNN | 86.67 ± 1.50 |
| SF-CNN | 87.52 ± 0.82 | |
| SSF-CNN | 88.91 ± 0.57 | |
| AID | Plain-CNN | 78.95 ± 1.17 |
| SF-CNN | 79.32 ± 1.04 | |
| SSF-CNN | 79.57 ± 0.91 |
| Stage | Time (h) |
|---|---|
| Salient regions extraction | 0.3 |
| Unsupervised feature learning | 55.2 |
| CNN fine-tuning | 12.1 |
| Total | 67.6 |
| Labeled Dataset | Method | Overall Accuracy (%) |
|---|---|---|
| UCMerced | ImageNet-AlexNet | 94.29 ± 1.43 |
| SSF-AlexNet | 92.43 ± 0.46 | |
| AID | ImageNet-AlexNet | 91.66 ± 0.38 |
| SSF-AlexNet | 88.71 ± 0.86 |
| Method | Overall Accuracy (%) |
|---|---|
| SPCK++ [2] | 77.38 |
| OMP-k [7] | 81.70 |
| Saliency + SC [13] | 82.72 |
| Multilayer learning [10] | 89.10 |
| UFL-SC [8] | 90.26 |
| Partlets [3] | 91.33 |
| Multipath SC [11] | 91.95 |
| Quaternion + Q-OMP [9] | 92.29 |
| LGF [5] | 95.48 |
| Deconvolution + SPM [12] | 95.71 |
| SSF-CNN | 88.91 |
| SSF-AlexNet | 92.43 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Wang, C.; Ma, Z.; Chen, J.; He, D.; Ackland, S. Remote Sensing Scene Classification Based on Convolutional Neural Networks Pre-Trained Using Attention-Guided Sparse Filters. Remote Sens. 2018, 10, 290. https://0-doi-org.brum.beds.ac.uk/10.3390/rs10020290
Chen J, Wang C, Ma Z, Chen J, He D, Ackland S. Remote Sensing Scene Classification Based on Convolutional Neural Networks Pre-Trained Using Attention-Guided Sparse Filters. Remote Sensing. 2018; 10(2):290. https://0-doi-org.brum.beds.ac.uk/10.3390/rs10020290
Chicago/Turabian StyleChen, Jingbo, Chengyi Wang, Zhong Ma, Jiansheng Chen, Dongxu He, and Stephen Ackland. 2018. "Remote Sensing Scene Classification Based on Convolutional Neural Networks Pre-Trained Using Attention-Guided Sparse Filters" Remote Sensing 10, no. 2: 290. https://0-doi-org.brum.beds.ac.uk/10.3390/rs10020290