Road Extraction from Remote Sensing Images Using the Inner Convolution Integrated Encoder-Decoder Network and Directional Conditional Random Fields


Abstract
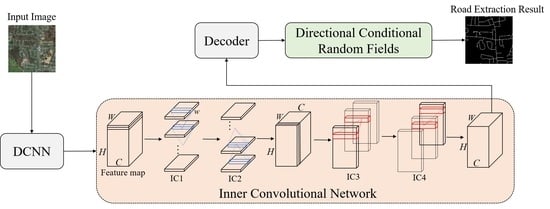
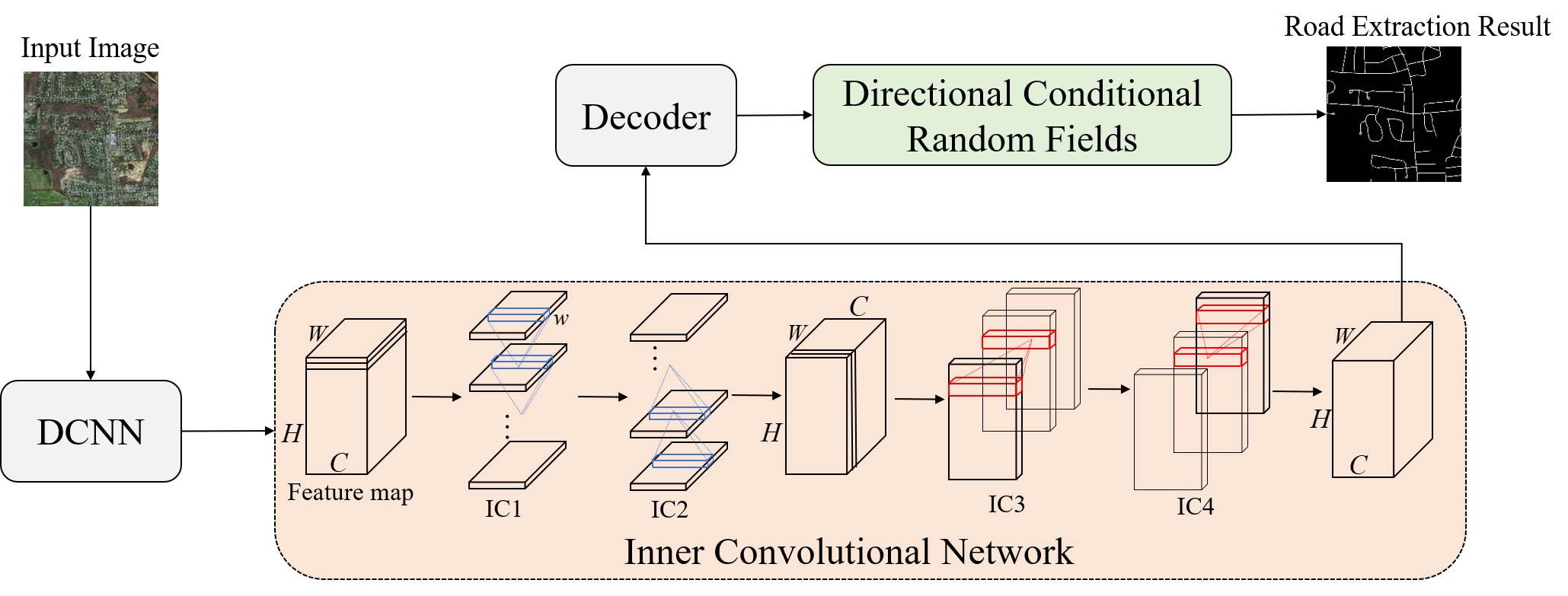
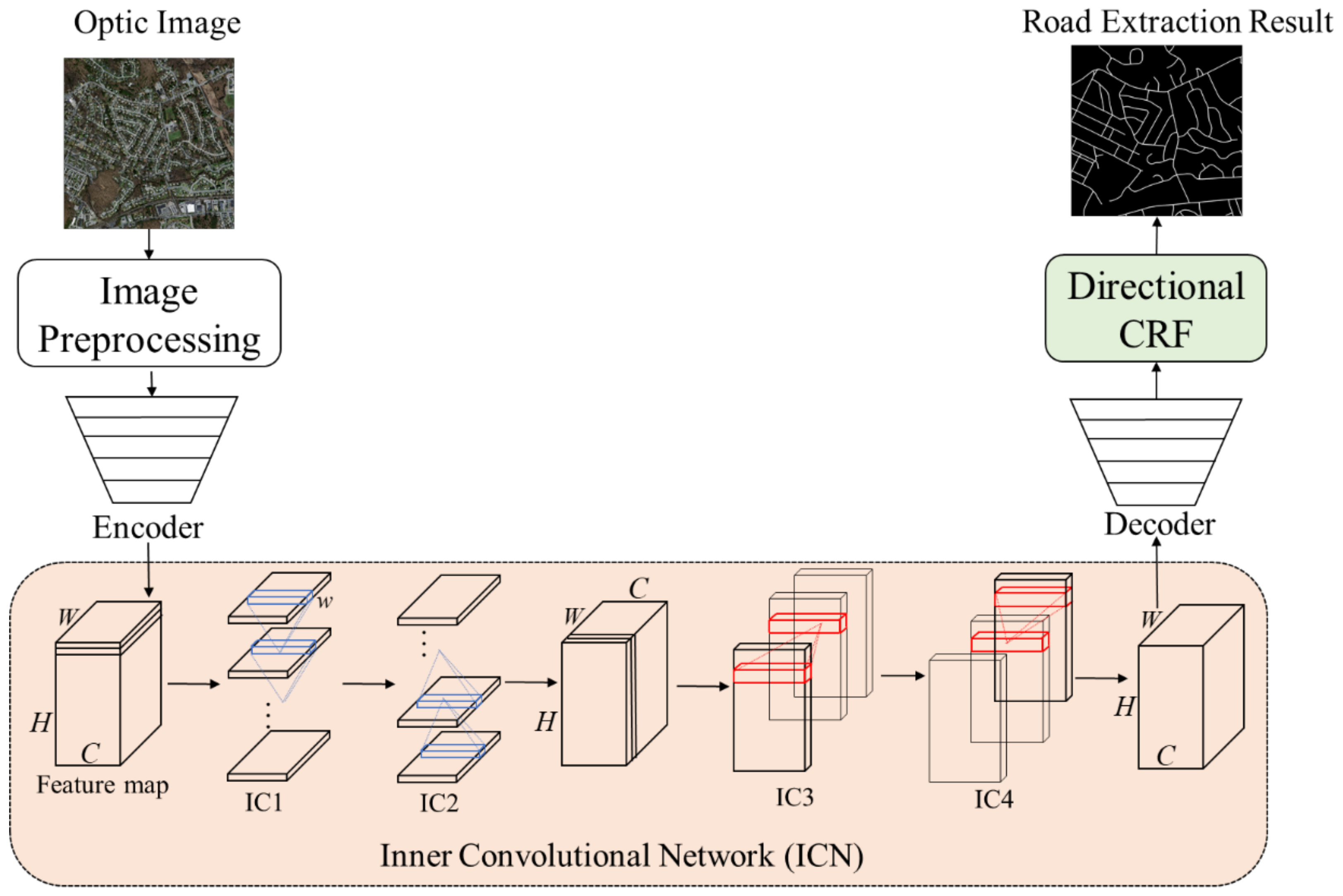
:
1. Introduction
- We designed a novel inner convolutional network (ICN) integrated encoder-decoder network for road extraction. ICN splits the feature map into slices along a row or column and views these slices of feature maps as layers of traditional CNN, and then applies convolution, activation, etc. to these slice maps sequentially. Therefore, the spatial information can be transmitted in the same layer, which is helpful for enhancing the ability of CNN to extract a road covered by other objects;
- We proposed the directional conditional random fields (DCRF) as a post-processing method to further improve the quality of road extraction. The DCRF adds the direction of the road as an energy term of CRF, which will favor the assignment of the same label to pixels with similar directions, so it can help to connect roads and remove noise;
- Ablation studies on the Massachusetts dataset verify the effectiveness of the proposed ICN and DCRF. Experimental results show that the proposed method can improve the accuracy of the extracted road and solve the road connectivity problem produced by occlusions to some extent.
2. Materials and Methods
2.1. Overview of the Proposed Method
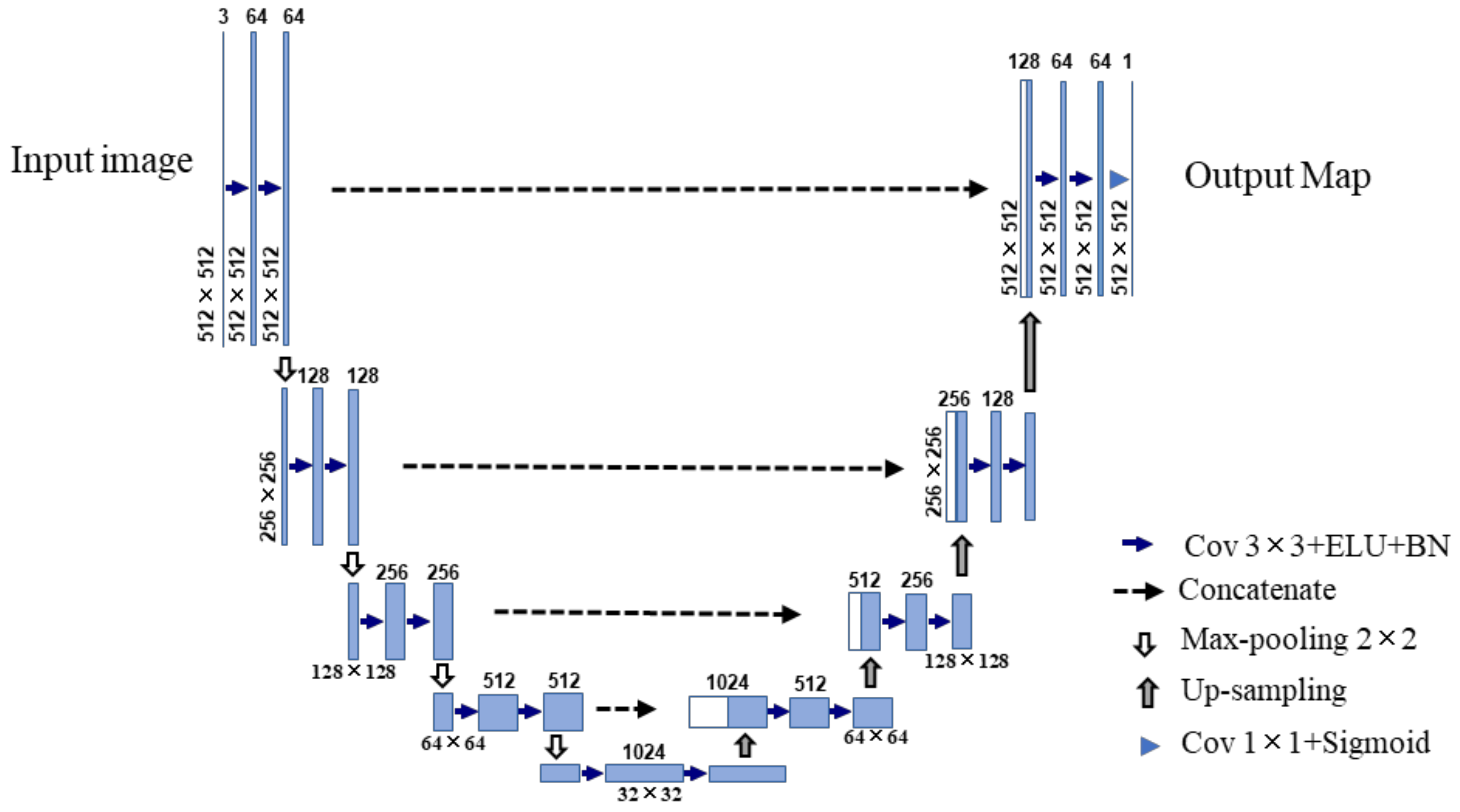
2.2. Inner Convolutional Network
2.3. Directional Conditional Random Fields
| Algorithm 1 Algorithm for Generating the Direction Map |
| Input: Binary map of road segmentation result Parameters: angle step , detecting radius ; Output: road direction map 1. for in 2. if () 3. for to step 4. 5. end for 6. find 7. 8. 9. else 10. 11. end if 12. end for 13. return |
3. Experimental Results and Discussion
3.1. The Dataset and Preprocessing
3.2. Evaluation Method
3.3. Experimental Results and Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BN | Batch Normalization |
| CNN | Convolutional Neural Network |
| CRF | Conditional Random Fields |
| DCRF | Directional Conditional Random Fields |
| DCNN | Deep Convolutional Neural Network |
| ELU | Exponential Linear Unit |
| FCN | Fully Convolutional Network |
| FP | False Positive |
| FSM | Finite State Machine |
| GIS | Geographic Information System |
| GSD | Ground Sampling Distance |
| ICN | Inner Convolutional Network |
| MRF | Markov Random Field |
| ReLU | Rectified Linear Unit |
| SVM | Support Vector Machines |
| TN | True Negative |
| TP | True Positive |
References
- Wang, W.; Yang, N.; Zhang, Y.; Wang, F.; Cao, T. A review of road extraction from remote sensing images. J. Traffic Transp. Eng. 2016, 3, 271–282. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Hou, Y.; Ren, M. A shape-aware road detection method for aerial images. Int. J. Pattern Recognit. Artif. Intell. 2017, 31, 1–21. [Google Scholar] [CrossRef]
- Shao, Y.; Guo, B.; Hu, X.; Di, L. Application of a Fast Linear Feature Detector to Road Extraction From Remotely Sensed Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2011, 4, 626–631. [Google Scholar] [CrossRef]
- Hu, J.; Razdan, A.; Femiani, J.; Cui, M.; Wonka, P. Road Network Extraction and Intersection Detection from Aerial Images by Tracking Road Footprints. IEEE Trans. Geosci. Remote Sens. 2007, 45, 4144–4157. [Google Scholar] [CrossRef]
- Ronggui, M.; Weixing, W.; Sheng, L. Extracting roads based on Retinex and improved Canny operator with shape criteria in vague and unevenly illuminated aerial images. J. Appl. Remote Sens. 2012, 6, 3610. [Google Scholar] [CrossRef] [Green Version]
- Marikhu, R.; Dailey, M.N.; Makhanov, S.; Honda, K. A Family of Quadratic Snakes for Road Extraction. In Proceedings of the 8th Asia Conference on Computer Vision, Tokyo, Japan, 18–22 November 2007; pp. 85–94. [Google Scholar]
- Sawano, H.; Okada, M. A Road Extraction Method by an Active Contour Model with Inertia and Differential Features; Oxford University Press: Oxford, UK, 2006. [Google Scholar]
- Wegner, J.D.; Montoya-Zegarra, J.A.; Schindler, K. A higher-order CRF model for road network extraction. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1698–1705. [Google Scholar]
- Guo, C.; Mita, S.; McAllester, D.A. Adaptive non-planar road detection and tracking in challenging environments using segmentation-based Markov Random Field. In Proceedings of the IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1172–1179. [Google Scholar]
- Zhou, S.; Gong, J.; Xiong, G.; Chen, H.; Iagnemma, K. Road detection using support vector machine based on online learning and evaluation. In Proceedings of the IEEE Intelligent Vehicles Symposium, La Jolla, CA, USA, 21–24 June 2010; pp. 256–261. [Google Scholar]
- Yager, N.; Sowmya, A. Support Vector Machines for Road Extraction from Remotely Sensed Images. In Proceedings of the 10th International Conference on Computer Analysis of Images and Patterns, Groningen, The Netherlands, 25–27 August 2003; pp. 285–292. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Los Alamitos, CA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Mnih, V.; Hinton, G.E. Learning to detect roads in high-resolution aerial images. In Proceedings of the European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; pp. 210–223. [Google Scholar]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Wang, J.; Song, J.; Chen, M.; Yang, Z. Road network extraction: A neural-dynamic framework based on deep learning and a finite state machine. Int. J. Remote Sens. 2015, 36, 3144–3169. [Google Scholar] [CrossRef]
- Alshehhi, R.; Marpu, P.R.; Woon, W.L.; Mura, M.D. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2017, 130, 139–149. [Google Scholar] [CrossRef]
- Rezaee, M.; Zhang, Y. Road detection using Deep Neural Network in high spatial resolution images. In Proceedings of the Joint Urban Remote Sensing Event (JURSE 2017), Dubai, United Arab Emirates, 6–8 March 2017; pp. 1–4. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with atrous separable convolution for semantic image segmentation. arXiv 2018, arXiv:1802.02611. [Google Scholar]
- Abdollahi, A.; Pradhan, B.; Shukla, N.; Chakraborty, S.; Alamri, A.M. Deep Learning Approaches Applied to Remote Sensing Datasets for Road Extraction: A State-Of-The-Art Review. Remote Sens. 2020, 12, 1444. [Google Scholar] [CrossRef]
- Wei, Y.; Wang, Z.; Xu, M. Road Structure Refined CNN for Road Extraction in Aerial Image. IEEE Geosci. Remote Sens. Lett. 2017, 14, 709–713. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Cui, W.; Jiang, H. Fully convolutional networks for building and road extraction: Preliminary results. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 1591–1594. [Google Scholar]
- Cheng, G.; Wang, Y.; Xu, S.; Wang, H.; Xiang, S.; Pan, C. Automatic Road Detection and Centerline Extraction via Cascaded End-to-End Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3322–3337. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, Y. JointNet: A Common Neural Network for Road and Building Extraction. Remote Sens. 2019, 11, 696. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual U-net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef] [Green Version]
- Xin, J.; Zhang, X.; Zhang, Z.; Fang, W. Road Extraction of High-Resolution Remote Sensing Images Derived from DenseUNet. Remote Sens. 2019, 11, 2499. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Peng, B.; He, L.; Fan, K.; Li, Z.; Tong, L. Road extraction from unmanned aerial vehicle remote sensing images based on improved neural networks. Sensors 2019, 19, 4115. [Google Scholar] [CrossRef] [Green Version]
- Mosinska, A.; Márquez-Neila, P.; Kozinski, M.; Fua, P. Beyond the pixel-wise loss for topology-aware delineation. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Munich, Germany, 8–14 September 2018; pp. 3136–3145. [Google Scholar]
- Abdollahi, A.; Pradhan, B.; Alamri, A.M. VNet: An End-to-End Fully Convolutional Neural Network for Road Extraction from High-Resolution Remote Sensing Data. IEEE Access 2020, 8, 179424–179436. [Google Scholar] [CrossRef]
- He, H.; Yang, D.; Wang, S.; Wang, S.; Li, Y. Road Extraction by Using Atrous Spatial Pyramid Pooling Integrated Encoder-Decoder Network and Structural Similarity Loss. Remote Sens. 2019, 11, 1015. [Google Scholar] [CrossRef] [Green Version]
- Sun, T.; Chen, Z.; Yang, W.; Wang, Y. Stacked U-nets with multi-output for road extraction. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Work, Salt Lake City, UT, USA, 18–22 June 2018; pp. 187–191. [Google Scholar]
- Liangchieh, C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. Computence 2014, 40, 357–361. [Google Scholar]
- Panboonyuen, T.; Jitkajornwanich, K.; Lawawirojwong, S.; Srestasathiern, P.; Vateekul, P. Road segmentation of remotely-sensed images using deep convolutional neural networks with landscape metrics and conditional random fields. Remote Sens. 2017, 9, 680. [Google Scholar] [CrossRef] [Green Version]
- Clevert, D.A.; Unterthiner, T.; Hochreiter, S. Fast and accurate deep network learning by exponential linear units (ELUs). arXiv 2015, arXiv:1511.07289. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Lafferty, J.D.; McCallum, A.; Pereira, F.C.N. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. In Proceedings of the Eighteenth International Conference on Machine Learning, Williamstown, MA, USA, 28 June–1 July 2001; pp. 282–289. [Google Scholar]
- Krähenbühl, P.; Koltun, V. Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials. In Proceedings of the Advances in Neural Information Processing Systems, Granada, Spain, 12–14 December 2011; pp. 109–117. [Google Scholar]
- Batra, A.; Singh, S.; Pang, G.; Basu, S.; Jawahar, C.V.; Paluri, M. Improved Road Connectivity by Joint Learning of Orientation and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10385–10393. [Google Scholar]
- Ding, L.; Bruzzone, L. DiResNet: Direction-aware Residual Network for Road Extraction in VHR Remote Sensing Images. arXiv 2020, arXiv:2005.07232. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wegner, J.D.; Montoya-Zegarra, J.A.; Schindler, K. Road networks as collections of minimum cost paths. ISPRS J. Photogramm. Remote Sens. 2015, 108, 128–137. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| Road direction map | |
| An image | |
| Segmentation map of | |
| A graph on | |
| Gibbs distribution | |
| Gibbs energy | |
| Unary potential function | |
| Pairwise potential function | |
| Compatibility function | |
| Linear combination weights | |
| Gaussian kernels | |
| Feature vector for pixels i in an arbitrary feature space | |
| Positive-definite precision matrix |
| Method | Precision | Recall | F1-Score |
|---|---|---|---|
| Wegner et al. [8] | 40.5% | 33.2% | 35.9% |
| Wegner et al. [47] | 47.1% | 67.9% | 55.6% |
| RSRCNN [27] | 60.6% | 72.9% | 66.2% |
| FCN-4s [28] | 71.0% | 66.0% | 68.4% |
| DeepLab v3+ [25] | 74.9% | 73.3% | 74.0% |
| JointNet [30] | 85.4% | 71.9% | 78.1% |
| Pixel-wiseNet [34] | 77.4% | 80.5% | 78.9% |
| CasNet [29] | 77.7% | 80.9% | 79.3% |
| ResUNet [31] | 77.8% | 81.1% | 79.5% |
| DiResNet [45] | 80.4% | 79.4% | 79.7% |
| Our method | 87.1% | 82.2% | 84.6% |
| Method | Precision | Recall | F1-Score |
|---|---|---|---|
| Baseline | 80.4% | 78.6% | 79.4% |
| Baseline-ICN | 84.9% | 81.7% | 83.3% |
| Baseline-CRF | 81.8% | 77.6% | 79.6% |
| Baseline-DCRF | 82.2% | 80.3% | 81.3% |
| Baseline-ICN-DCRF | 87.1% | 82.2% | 84.6% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Mu, X.; Yang, D.; He, H.; Zhao, P. Road Extraction from Remote Sensing Images Using the Inner Convolution Integrated Encoder-Decoder Network and Directional Conditional Random Fields. Remote Sens. 2021, 13, 465. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13030465
Wang S, Mu X, Yang D, He H, Zhao P. Road Extraction from Remote Sensing Images Using the Inner Convolution Integrated Encoder-Decoder Network and Directional Conditional Random Fields. Remote Sensing. 2021; 13(3):465. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13030465
Chicago/Turabian StyleWang, Shuyang, Xiaodong Mu, Dongfang Yang, Hao He, and Peng Zhao. 2021. "Road Extraction from Remote Sensing Images Using the Inner Convolution Integrated Encoder-Decoder Network and Directional Conditional Random Fields" Remote Sensing 13, no. 3: 465. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13030465