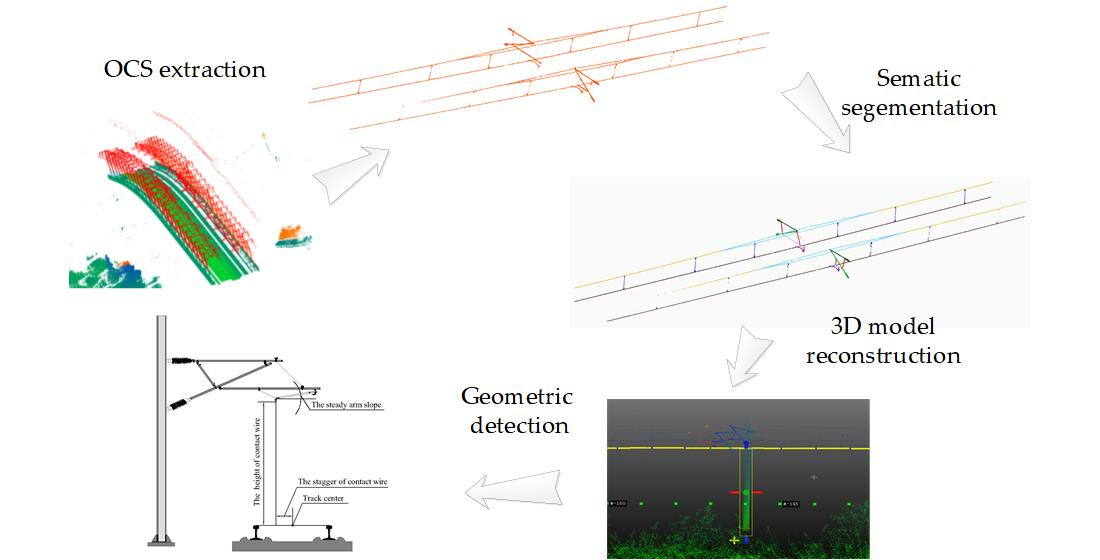
Considering the advantage of deep learning in OCS segmentation, this paper tried to improve the current DL network by addressing the shortcomings summarized in
Section 2.2. The proposed framework in this work mainly consists of four steps (
Figure 2). First, the method can effectively deal with the automatic extraction of OCS facility samples in 3D scenes and can remove background interference points. An automatic fast search and extraction based on the original point cloud scenario can be realized. Second, the extraction of the catenary facilities sample classification can be achieved through the means of a manual label. Third, the semantic segmentation of catenary facilities based on deep learning is implemented. Finally, the 3D model of catenary facilities is reconstructed, and the application of catenary geometric parameters detection is carried out.
3.1. Study Area and VMMS Data Generation
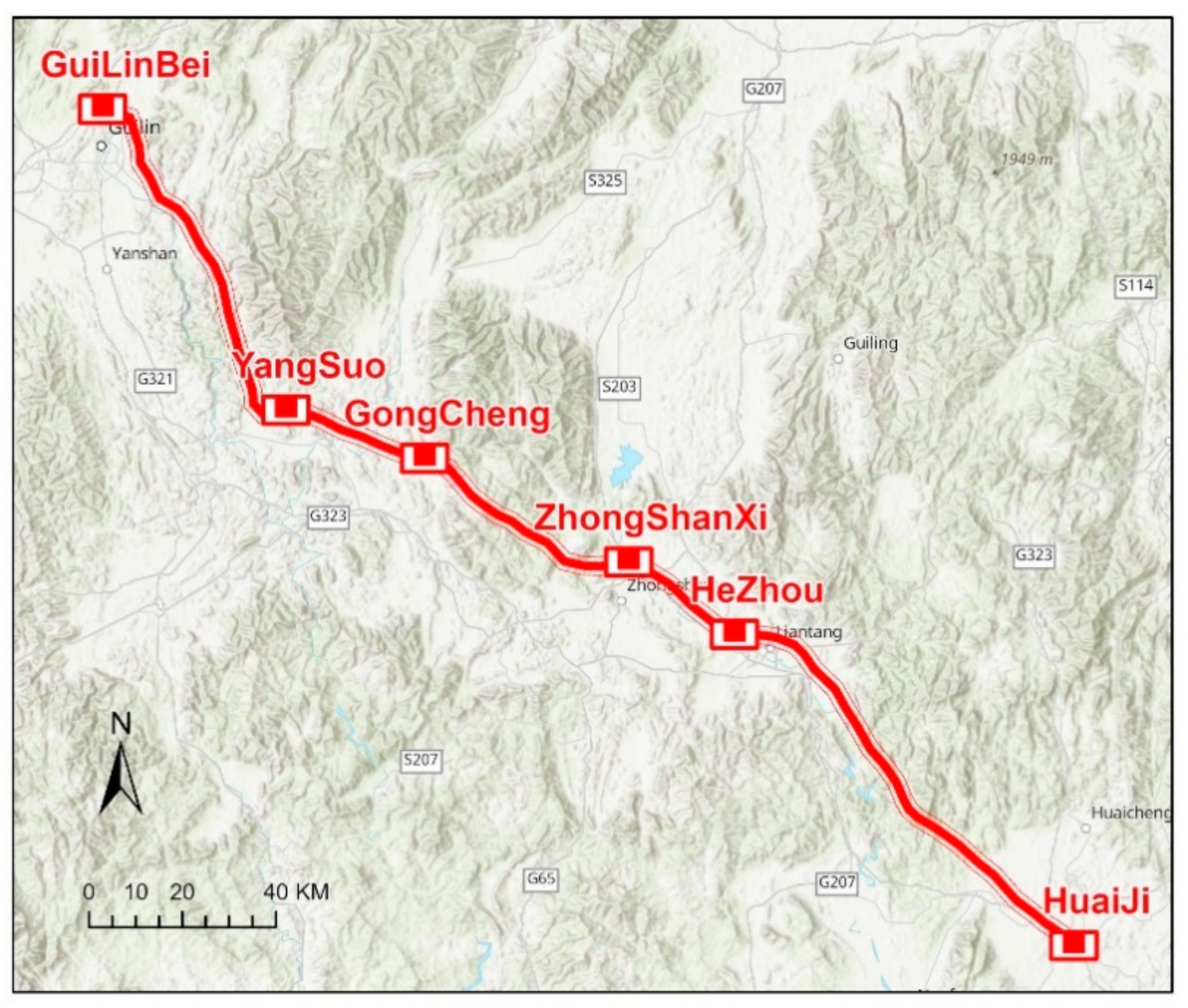
In this study, part of the Guiyang–Guangzhou railway was selected to conduct experiments to verify the method effectiveness. This line is an interregional high-speed railway that connects Guiyang and Guangzhou in China, with a total of 857.00 km. A sub-line of 100.66 km from HeZhou station to HuaiJi Station was selected for VMMS LiDAR survey and scanning. The survey was conducted on the left and right lines of the railway, as shown in
Figure 3.
A VMMS was applied and improved in this study to collect data along the railway quickly and effectively.
For LiDAR scanning, an Optech Lynx HS 600 VMMS (
Figure 4) with a minimum measurement distance of 1.5 m is used. The inclined installation of two laser scanning heads of Lynx HS 600 can effectively reduce the scanning blind area along the railway. The actual practice shows that it is a better and more convenient way of installing the onboard radar system to the rear of the flat car utilizing a customized rigid elevated frame. The heightening frame can increase the distance from the scanner center to the bottom rail, and the top of the support is equipped with a fast fixing device for convenient installation. The lifting bracket and vehicle can be fixed by a binding belt. This enhanced system can be quickly installed in two hours. The actual acquisition scanner parameter settings are from many preliminary field tests: the laser scanner frequency is 600 kHz and the scanning frequency of a single laser head is 400 lines/s. This setting can maintain a balance between the density and accuracy of the collected point cloud.
For accurate position information, Applanix POSLV620 GNSS and the integrated high-precision fiber optic gyroscope were used. The roll and pitch accuracy of this device is 0.005 degrees and the heading accuracy is 0.015 degrees when the satellite signal is good. The gyroscope can maintain its nominal accuracy within 60 s when the satellite signal loses lock. During scanning, a total of 7 GNSS reference stations were set up at an interval of approximately 15 km along the line. The sampling frequency of the reference station was uniformly set to 1 Hz, and GNSS signals were received continuously throughout the entire process. When VMMS enters the railway tunnel, the position and orientation system (POS) could not accept satellite signals. After driving in the tunnel for more than 60 s, it was necessary to stop and stand at the entrance and exit of the tunnel, respectively, in order to improve the position and orientation accuracy of the POS. Due to the fact that POS will always drift when parking and standing, an odometer (DMI)-assisted POS needs to be installed on the train wheels for zero speed correction. A metal protective cover of DMI on the axle was installed to protect it from the outside train transmission shaft and to achieve accurate synchronisation between the DMI and the train wheel rotation (
Figure 5).
Finally, considering the normal operation of the railway, the maintenance time from 23:00 to 03:00 on two days (no other trains running on the railway line) is selected for scanning, with a total duration of eight hours. During the scanning, the average vehicle moving speed is approximately 60 km/h. As a result of the large number of long tunnels or tunnel groups in this section, it is necessary to stop before entering the tunnel for the positioning and attitude measurement system to stand for 5–10 min each time. During the parking waiting period, the scanner stops data acquisition, the positioning and attitude measurement system still works normally and the original generated point cloud data are approximately 180 GB (as shown in
Figure 6).
3.2. Double Selection Stereo Frame of OCS
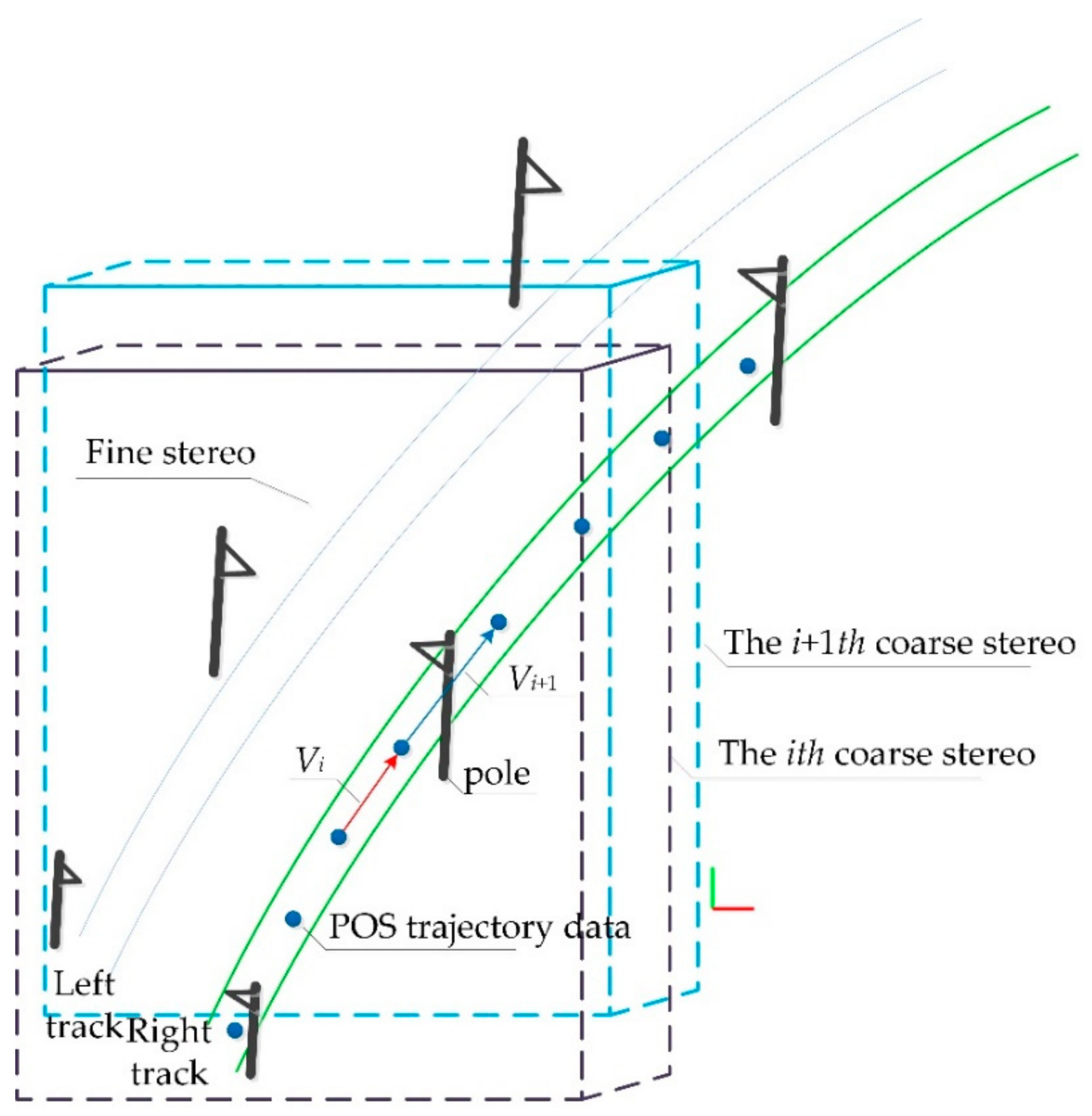
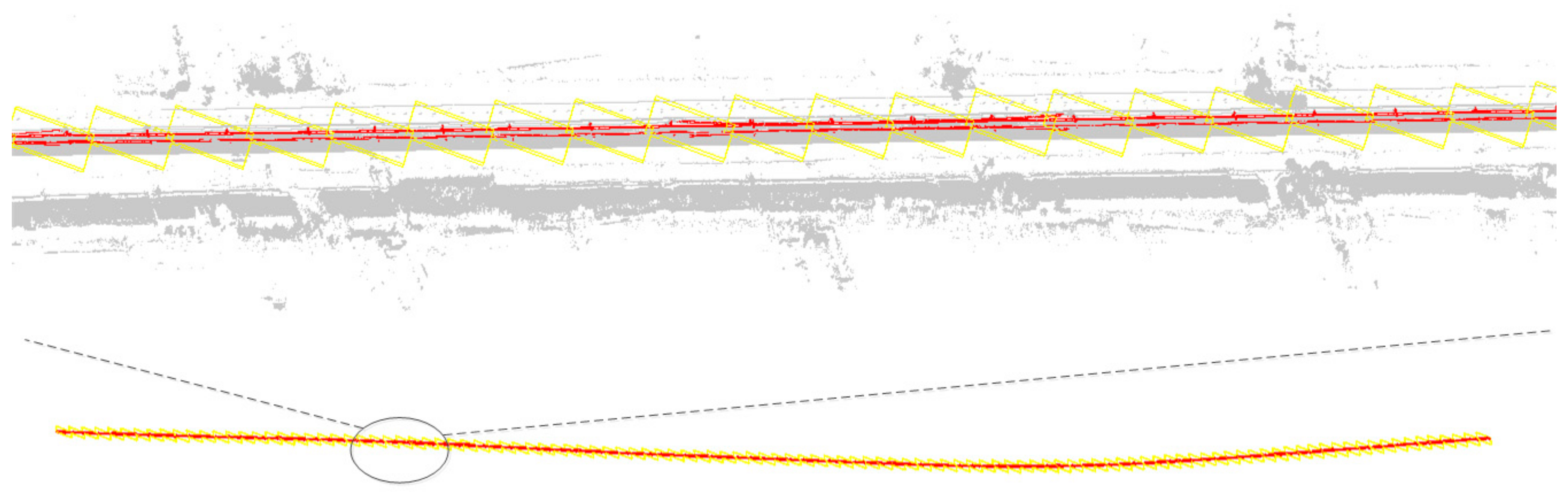
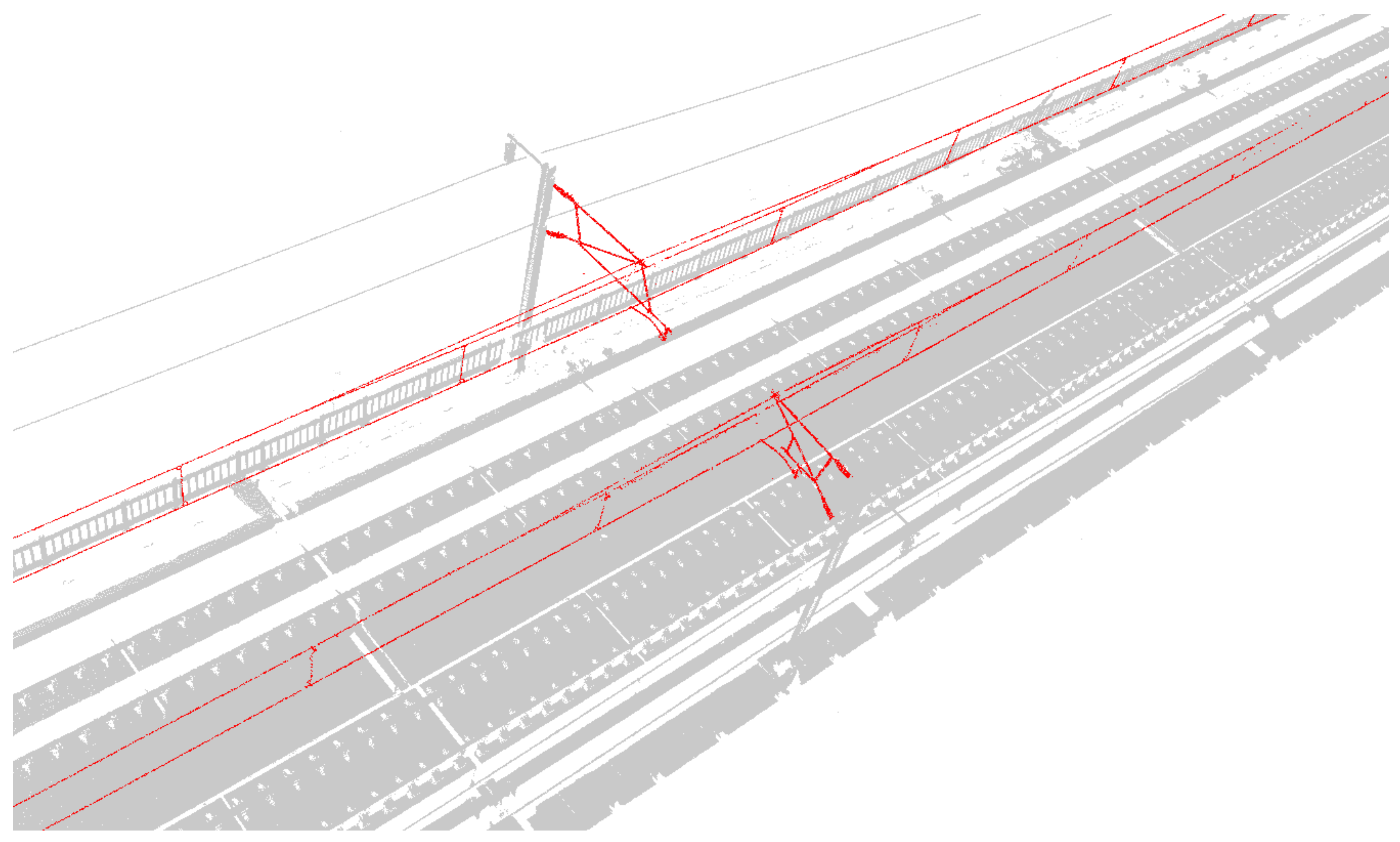
In the obtained point cloud data, the subgrade section accounts for 21.03%, the tunnel section accounts for 38.30%, the bridge section accounts for 40.67% and the point cloud of OCS facilities accounts for no more than 1% of the entire point cloud scene. If the deep learning network is used directly for semantic segmentation of the original point cloud data when the category samples are extremely unbalanced, it may lead to the poor generalization ability of the network and easy overfitting, finally leading to the misclassification and omission of OCS components. Therefore, the OCS facilities need to be extracted from the original scene in advance to eliminate the interference of other types of point cloud objects on the identification of OCS facilities. This paper presents an automatic search and extraction method of scene double selection stereo frame catenary based on POS data (
Figure 7) to reduce the computation of point cloud in translation and rotation and to assist in clipping POS trajectory points in a certain range. First, the search range is determined by roughly selecting the 3D box, and the track lines and points within the range are obtained according to this box. Then, the stereo frame is selected to track, cut and extract along the track direction. The method includes four steps (Algorithm 1): double selection stereo frame attitude and positioning, determination of double selection stereo frame offset vector, automatic adjustment of selected frame attitude assisted by POS trajectory data and clipping and extraction of OCS facilities.
| Algorithm 1. Automatic extraction algorithm of OCS facilities |
Input: Rail region point cloud: C = {Ck}, k = 1, 2, 3, …, M POS Trajectory lines L = {li}, I = 1, 2, 3, …, N An initial coarse selection of stereo frame - (1)
Traverse the points in the POS track line, obtain three adjacent track points and calculate the direction vector Vdif between the two points; - (2)
Calculate an initial fine selection of stereo frame - (3)
Cut and extract the point cloud in the selected stereo frame area and extract the track point cloud CD1; - (4)
Obtain the next track point and recalculate the new coarse selection stereo box and selected stereo box; - (5)
Calculate , which is the distance between adjacent columns, as the cutting interval distance; - (6)
Recalculate the rotation matrix and translation at the next track point, and realize the advance along the track of rough selection solid frame and selected solid frame according to this information; - (7)
When the forward distance of the selected stereo frame is equal to the distance between adjacent columns, carry out the cutting and extraction operations; - (8)
Repeat steps 2 to 7 until the point cloud C in the track area is empty.
Output: Segmented and extracted rail region point cloud data CD = {CDj}, j = 1, 2, 3, …, H |
Coarse selection of stereo frame is performed by a bounding box
BBox in a 3D scene, and a subset of 3D point cloud meeting the conditions is selected from the scene with this frame as the constraint range, which satisfies the following equation:
where min_point and max_point denote the minimum and maximum points of coordinate values within the range of the rough-selected stereo frame, respectively.
In general, determining min_point and max_point should consider that the area of the rough-selected stereo frame can contain the area of the track line points and all of the facilities of the catenary. The frame center point should be placed in the middle of the pair of adjacent poles in the XOY projection plane to reduce the selection error caused by translation on the track line. The initial center point will be set artificially from the point cloud. In the process of cutting and extraction, the rough-selected stereo frame moves along the direction of the track line, and the height of BBox is constant. Moving distance is determined according to the distance between the adjacent poles.
The fine stereo frame is cut along the track direction, and the catenary facility point cloud is extracted by clipping box
from the track data with the frame along the track, which satisfies the following equation:
where
minBox is the minimum stereo frame for cutting a pair of OCS facilities,
RMatrix is the rotation matrix and
T is the offset vector. The frame is transformed along the track by rotating and translating the
minBox. The fine stereo frame should be of an appropriate length, width and height, and the minimum cutting stereo frame should be contained completely in the coarse selection box
BBox. The long side of the finely selected stereo frame should be parallel to the track, and the width should be vertical to the track.
The offset vector of the center point of the double selection stereo frame along the rail line should consider terrain fluctuation and obstacle blocking. The offset vector T in Equation (2) of the adjacent stereo frame includes the offset direction and offset distance.
The offset distance along the railway line in the scene needs to be adjusted according to the distance between adjacent poles, which can be achieved as follows: the center position of each column from the scene {
1, ...,
i, ...,
n} is extracted and then projected onto the XOY plane, and then the distance from the center of the adjacent column
is calculated to obtain the offset distance information of the dual selection stereo frame:
where
Dis(·) is a function of finding the Euclidean distance of the XOY plane between two points.
[
i] refers to the coordinate information of the center point of the column
i.
When the coarse selection stereo frame (
Figure 7) is moving from the
ith frame (red box) to the
i+1th frame (blue box), the offset direction
can be determined by calculating the vector difference formed by the POS data:
where
is the direction vector of the POS track in the
ith frame and
is the direction vector of the POS track in the
i + 1th frame.
When the double-selected stereo offset vector is determined, the selected stereo box needs to be shifted to the next area to be clipped. First, the double-selected stereo box is shifted according to the offset vector. Then, the current double-selected stereo box is updated. The center of the currently selected stereo box is re-calculated to become the new center of rotation.
The carefully selected stereo frame posture should change with the fluctuation of the railway track and the change in the curve in order to be more helpful in clipping and extracting the contact network facilities that could meet the accuracy requirements. The complete transformation information, including the center of rotation, translation and rotation at i + 1 of the selected stereo frame, can be obtained.
The selected stereo box of the OCS facility can be generated by clipping the original point cloud using the clipping box (CBox). The clipped data will be stored separately for training and prediction based on the deep learning network model.
3.3. Deep Learning Based Semantic Segmentation
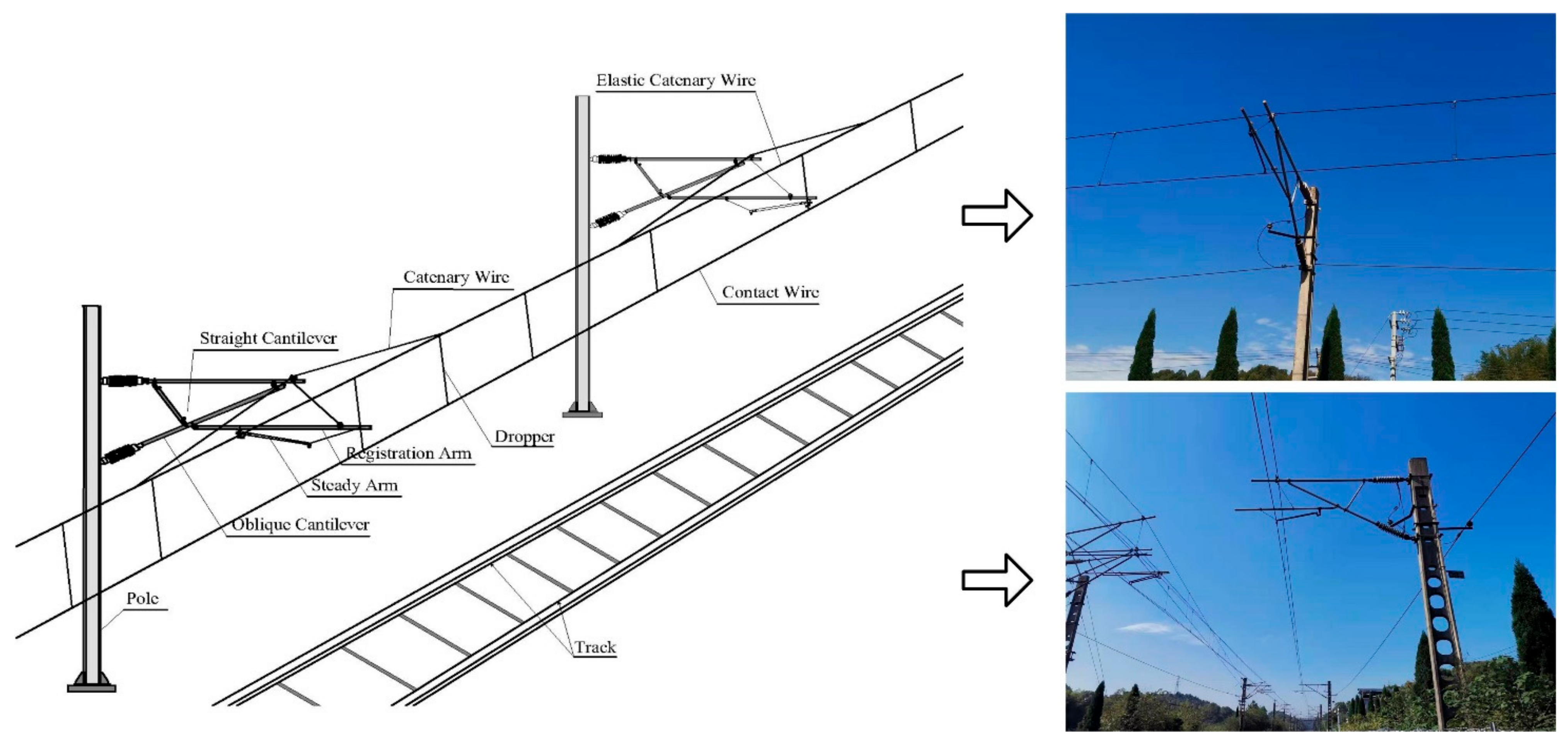
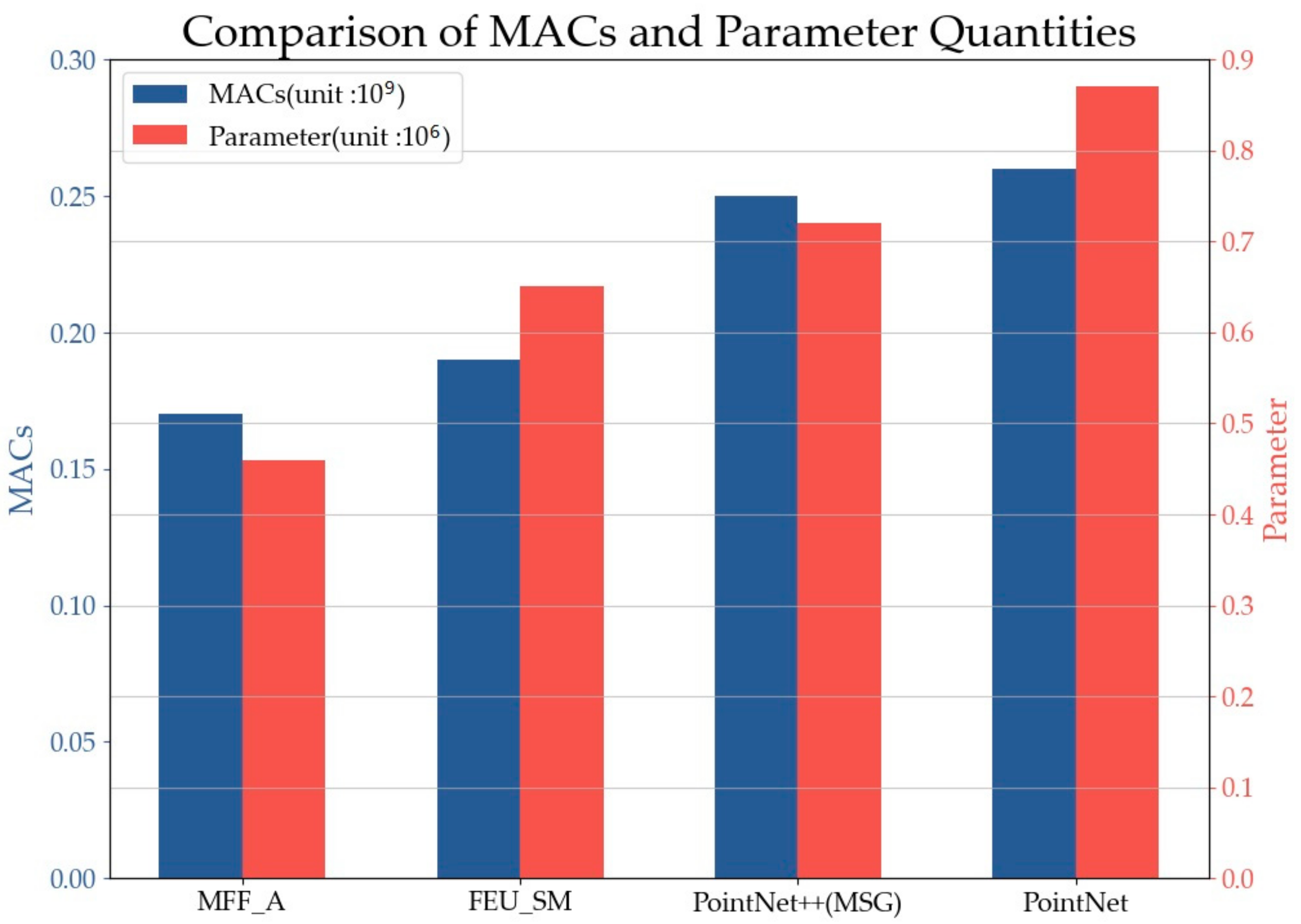
After the automatic search and extraction of OCS facilities, they are segmented into eight categories through deep learning, including oblique cantilever, straight cantilever, elastic catenary wire, catenary wire, dropper, contact wire, steady arm, registration arm, etc. Manual labels of the point cloud data are generated to train the model. Deep learning network architecture needs to be redesigned considering the relative imbalance of point cloud density and percentage among different categorizations. Spatial and channel attention mechanisms are introduced in the construction of a deep learning network. A semantic segmentation model based on multi-scale feature fusion and attention mechanism (MFF_A) is proposed to classify contact network facilities. First, a feature extraction method based on efficient channel attention (ECA) and convolutional block attention module (CBAM) is proposed to enhance the important features in point clouds from channels and spatial domains. Then, a residual refinement structure based on OCS preliminary results is introduced, which refines OCS results through feature extraction and fusion of multi-scale sensing fields. The architecture of the re-designed network is shown in
Figure 8.
The proposed MFF_A in this paper takes PointNet as the backborn structure, while removing the T-shaped input feature transformation from the original structure. Instead, the network adopts a multilayer perception (MLP) module (two or more convolution layers form weight sharing) to extract point cloud features, and adopts the ECA channel attention mechanism to realize the channel enhancement of extracted features. The shallow features processed in ECA are enhanced by CBAM, and the multi-layer shallow features and deep features are fused. The preliminary results are then entered into the refine structure to generate the final refined results.
3.3.1. ECA
Previous studies have shown that embedding the attention module into CNN can result in significant performance improvement (e.g., SENet [
30], CBAM [
31], ECANet [
32], EPSANet [
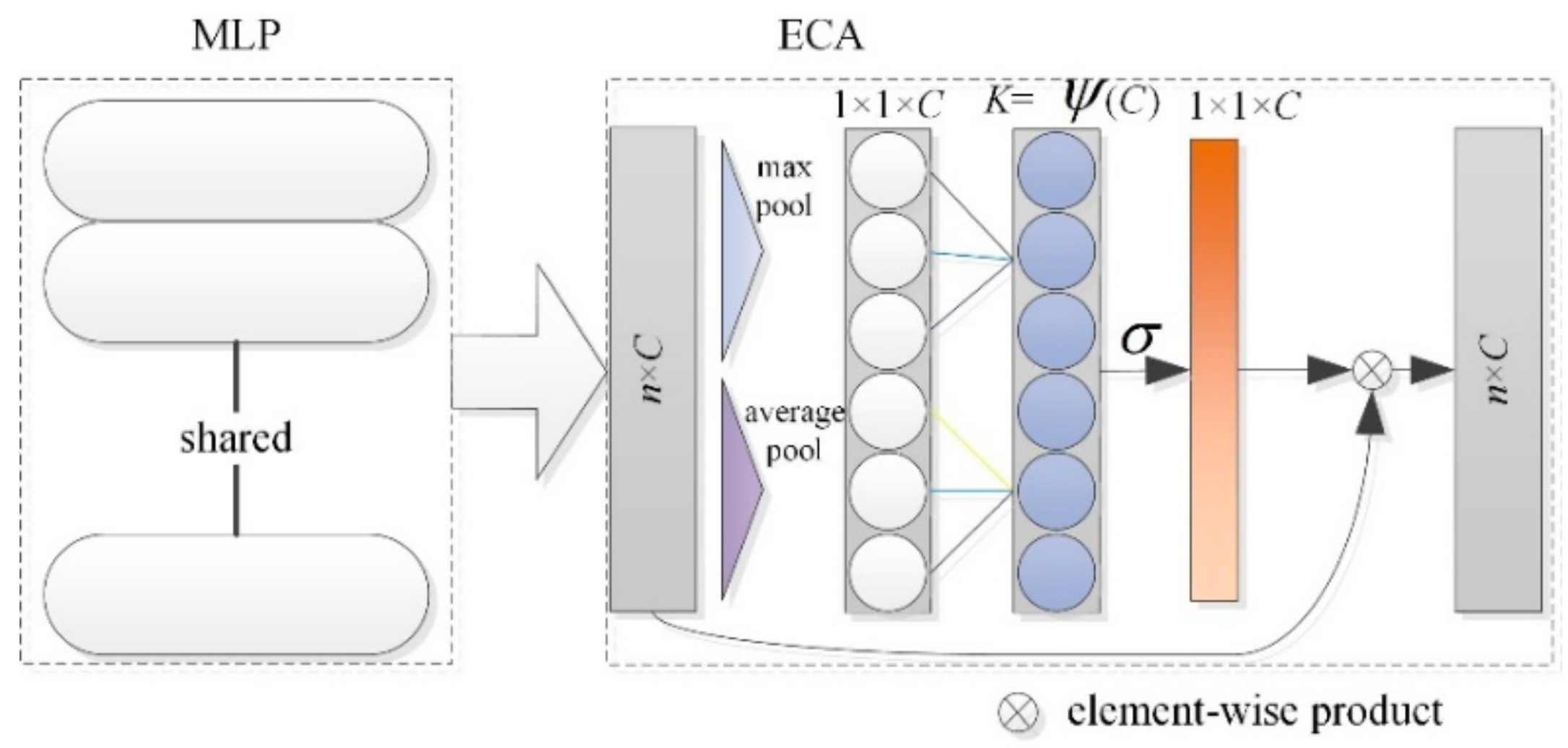
33]). In the traditional PointNet network structure, shared weight MLP is used to extract the point cloud features, and different numbers of convolution kernels are combined to achieve dimensionality enhancement or reduction in the extracted features. The convolution kernel size is (1,1). The introduction of ECA improves the ability of important feature extraction in global feature extraction (
Figure 9). The original ECA module is improved to combine global average pooling (GAP) and global max pooling (GMP).
where |
t|
odd take the nearest odd number to
t. In this paper, γ and
b are set to 2 and 1, respectively. The
ψ function causes the larger channel to have long-distance interaction, and vice versa.
The multi-dimensional feature map obtained after the MLP feature extraction of shared weight is taken as the input of the ECA module, and the consistency between the input and output feature dimensions can effectively prevent the reduction in the feature dimensions. In addition, a grouping convolution strategy is applied to capture cross-channel interactions. Given a fully connected layer, grouping convolution divides it into multiple groups and performs linear transformation independently for each group. Therefore, the weight calculation is as follows:
where
represents the activation function and
represents a set of adjacent channels. In Equation (6), cross-channel local interactions are captured. Such local scale constraints effectively avoid cross-channel interactions, thereby improving the efficiency of the network model. In this way, each channel attention module affects the
K*
C parameters. All channels share the same learning parameters to reduce the model complexity further and to improve efficiency. The final structure of the ECA module is as depicted in
Figure 9.
3.3.2. CBAM
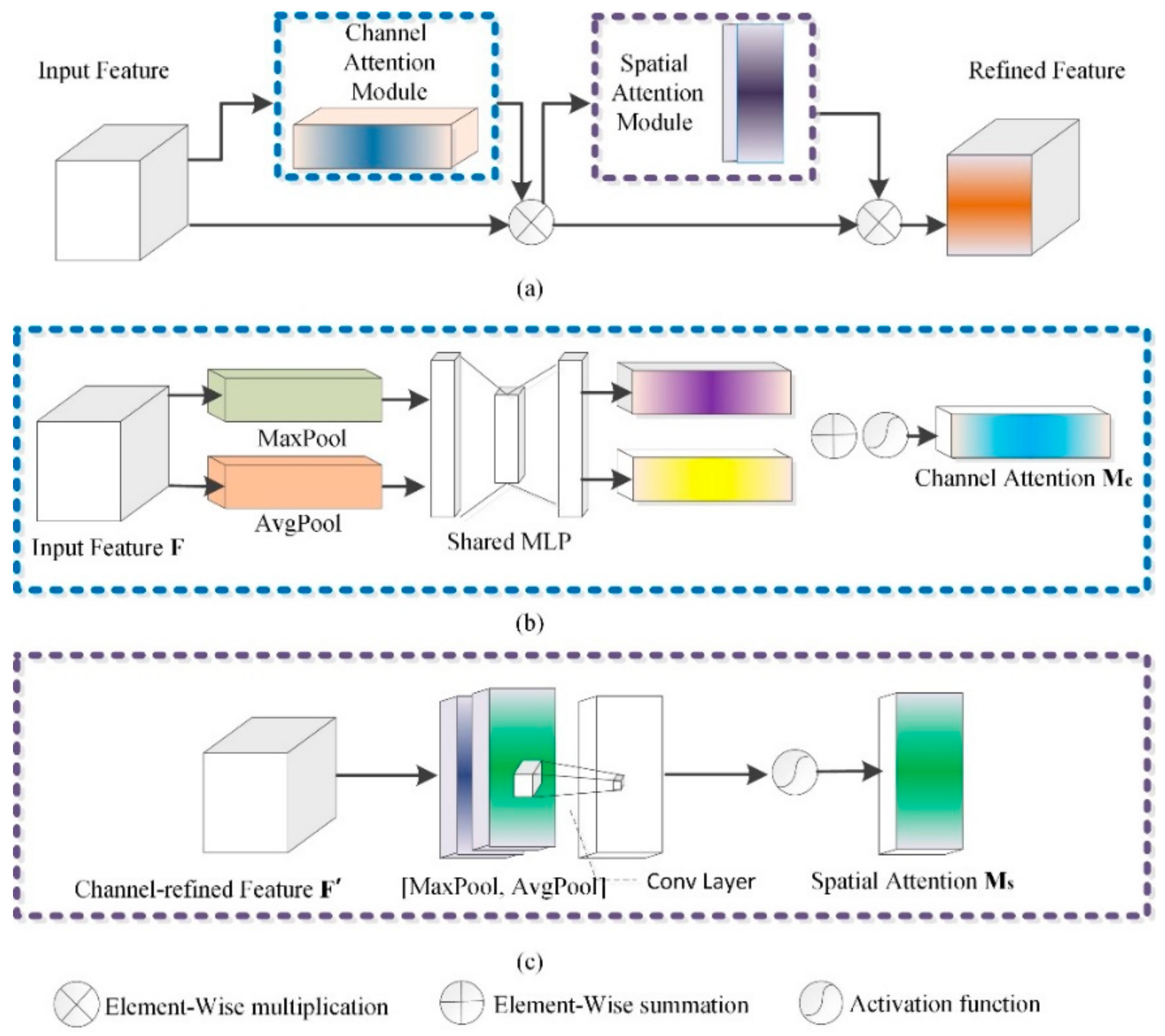
In encoder–decoder network architecture, although a normal network jumping connection can improve the fusion of shallow features and deep features, it cannot effectively reduce the degradation of neural networks. CBAM could solve the problem [
31]. Due to the fact that the MLP operation in this study extracts features by mixing cross-channel and spatial information, a CBAM-based jump connection can be adopted to strengthen important features.
Figure 10 shows the structure of the CBAM. The input features pass through the channel and spatial attention mechanism so that each branch can learn “what” and “where” on the channel and spatial axis, respectively, which strengthens effective transmission.
- (1)
Channel attention submodule in CBAM
The implementation of the channel attention structure in CBAM is as follows. First, the average and maximum pooling operations are used to aggregate the spatial information of feature mapping for input feature
F, and two spatial context descriptors, average pool feature
and maximum pool feature
, are generated. The two descriptors were then fed into a shared MLP structure to generate a channel attention feature map
. The hidden activation size is set to
, where
r is the reduction ratio, to reduce the number of parameters. After the shared network is applied to each descriptor, the output feature vectors are combined by element accumulation. The calculation of channel attention is shown in Equation (7):
where
represents the activation function and
and
refer to the weight of MLP, which satisfies the condition
and
.
and
, the input feature and subsequent ReLU activation function, share the weight.
- (2)
Spatial attention submodule in CBAM
The GAP and GMP are adopted to pool channel reinforcement feature
F′, and the two are connected to generate an effective feature descriptor for spatial information. On the connected feature descriptors, convolution layer is used to generate spatial attention feature maps
and encode them to emphasize or suppress features. Two types of feature graphs are generated by aggregating the channel information of feature graphs through two pooling operations:
and
. The channel attention mechanism is adopted for each average and maximum pooling feature, which are then connected and convolved through a standard convolution layer to generate 2D spatial attention feature maps.
where
σ represents the activation function and
represents a 7 × 7 convolution.
3.3.3. Refine Structure
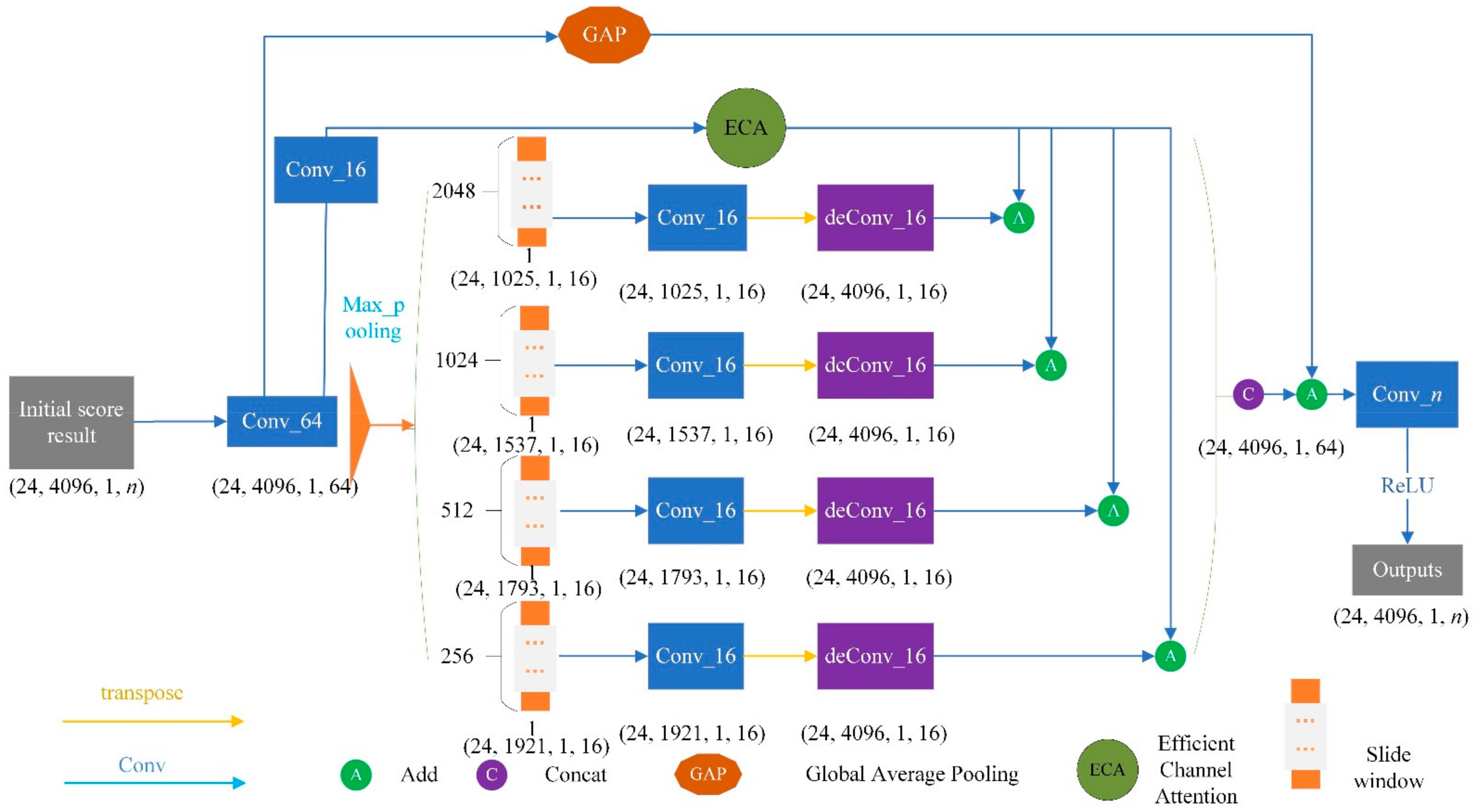
Context is very important in complex scene analysis. Many prediction networks may ignore small and medium-scale targets in complex scenes if the contexts are not considered. Meanwhile, large-scale targets may exceed the receptive field of network feature extraction, which results in discontinuous segmentation. The pyramid pooling module (PPM) structure can effectively obtain the cloud feature information of contact points with different scales, which is conducive to the identification of small target objects [
34,
35]. Thus, PPM is introduced into this study.
Figure 11 shows the detailed PPM structure in proposed MFF_A network, which consists of four pooling processes with different kernel sizes of (256, 1), (512, 1), (1024, 1) and (2048, 1). This makes the PPM able to generate multi-scale features of OCS. First, the PPM obtains the feature map through the convolution operation and obtains the feature map of different scales through the global maximum pooling operation. Then, the characteristic tensors of the different scales are convoluted to reduce the channel. Finally, the transposed convolution operation is carried out to facilitate the superposition and fusion of these feature tensors in the later stage. In addition, refinement process is also used, which puts the initial segmentation result back into the PPM. This PPM refinement can obtain the feature information of OCS facilities based on context with the spatial relationship, and can achieve a fine classification of OCS segments.
3.3.4. Channel Feature Enhancement
The feature enhancement strategy adopted in the proposed MFF_A starts from two aspects. On the one hand, the feature channel is transformed from the original 64 to 16 through the convolution layer, and the ECA module is introduced to strengthen the learning of channel features and to improve the expression ability of the feature channel in important features. Then, the feature enhancement results are superimposed with the feature extraction results of each scale in PPM. Finally, the features of these four scales are superimposed and fused through and connected to realize the enhancement and fusion of multi-scale features. On the other hand, the average pooled feature tensor of the feature tensor (24, 4096, 1, 64) is obtained through the GAP module, which is then superimposed with the multi-scale feature fusion tensor obtained in the previous step to achieve the goal of feature enhancement. This channel feature enhancement module adds only a small number of parameters to obtain obvious performance gain.
3.4. 3D Model Reconstruction and Parameter Detection of OCS
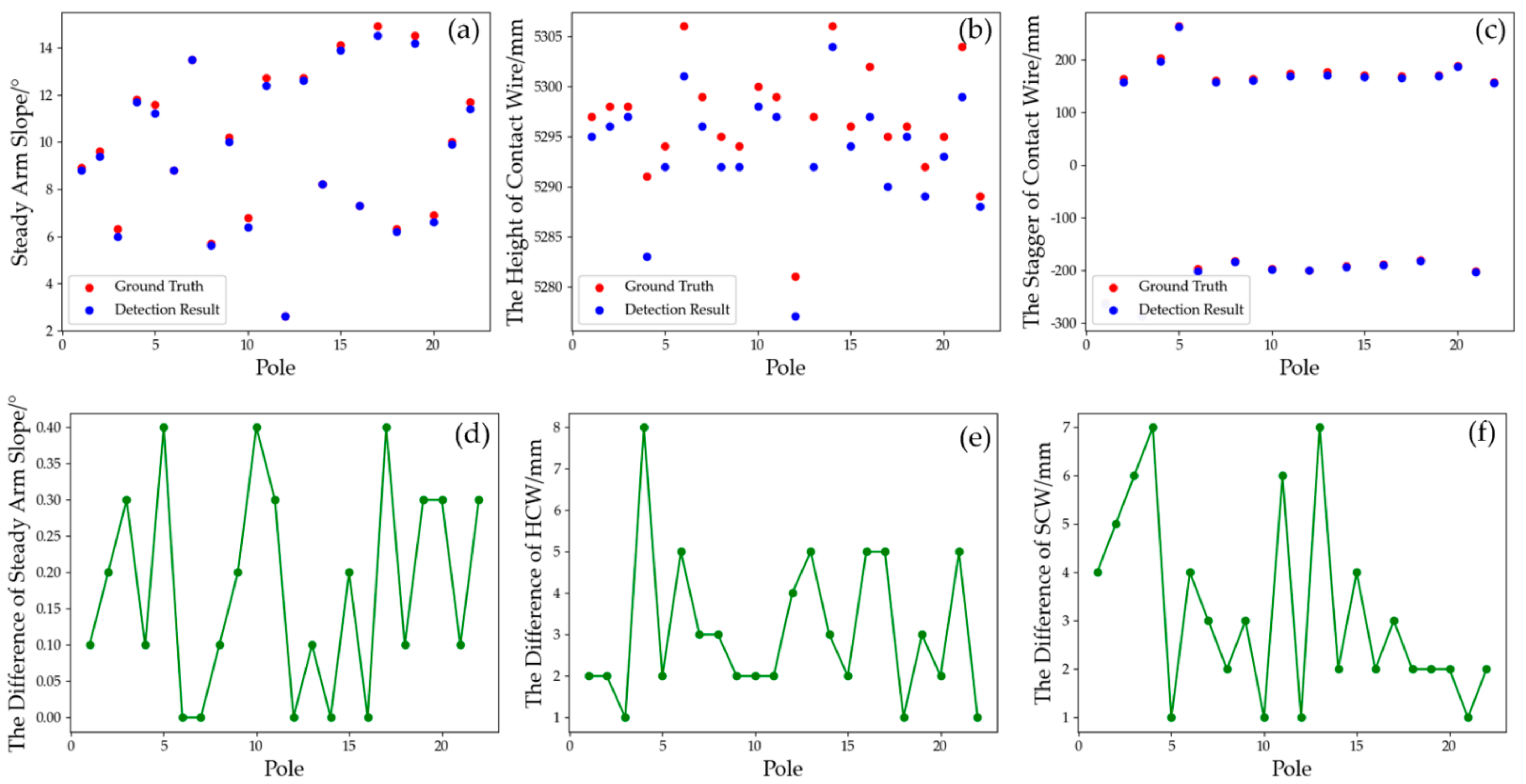
The 3D model of various components of OCS is reconstructed after the deep-learning-based semantic segmentation from the point cloud. We use piecewise straight line fitting for contact wire and dropper; cylindrical fitting for the oblique cantilever, straight cantilever and registration arm; and cube fitting for the steady arm.
As an important component of the catenary structure, the steady arm and the contact wire interact directly with the pantograph to complete the current collection of the train. The slope of the steady arm is essential to the pantograph contact performance and operation safety [
36]. In the process of rapid train operation, the vibration-induced effects caused by pantograph coupling will usually loosen the bolt and nut structure of the positioner, resulting in an abnormal slope value of the steady arm. The abnormal slope value will accelerate the wear of the pantograph and hit the steady arm, which will affect the current collection quality of the pantograph. Therefore, the normalized detection of steady arm slope has significance in ensuring the safe operation of the train.
Catenary geometric parameters, such as contact wire height, stagger value and steady arm slope angle, are measured based on the 3D modelling results. The contact wire height measurement uses the elevation difference between the reconstructed suspension point and the track centerline. Stagger value in a straight-line section is measured as the distance from the vertical projection of the contact wire to the centerline of the track line, and the reconstructed contact line model parameters are defined by Equation (9).
where
a denotes the stagger value of the catenary,
m denotes the horizontal distance between the contact wire of locating point and line center,
h denotes the superelevation of the outer rail,
H denotes the height of the contact line and
L denotes gauge.
The steady arm slope can be calculated through iterative closest point (ICP) registration between the steady arm model and steady arm point cloud by Equation (10).
where
is the spatial coordinate values of the beginning point,
is the endpoint and
is the
projected onto the XOY plane.

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}