
Assessing Field Spectroscopy Metadata Quality



Abstract
:
1. Introduction
1.1. The Importance of Field Spectroscopy Metadata
1.2. Defining Metadata Quality
1.3. Quality and Completeness within Existing Metadata Standards
“is applicable to data producers providing quality information to describe and assess how well a dataset meets its mapping of the universe of discourse as specified in the product specification, formal or implied, and to data users attempting to determine whether or not specific geographic data is of sufficient quality for their particular application”.[11]
- ▪
- an ordinal scale “good/moderate/poor/unusable” describing the overall quality of the metadataset [23]
- ▪
- quantification of the problems themselves (ambiguity, inaccuracy, inconsistency, redundancy) as percentage of occurrence within a recordset [20]
- ▪
- accuracy as a measure of semantic distance between a metadata instance and the textual information it references [21]
- ▪
- reputation of a metadataset as a linear combination of weighted sub-parameters including number of unique editors, edits, connectivity, reverts, registered user edits, anonymous user edits [20]
1.4. A Quality and Completeness Definition for Field Spectroscopy Metadata
2. Methods
2.1. Datasets

{kind=link}
{kind=link}
{kind=link}
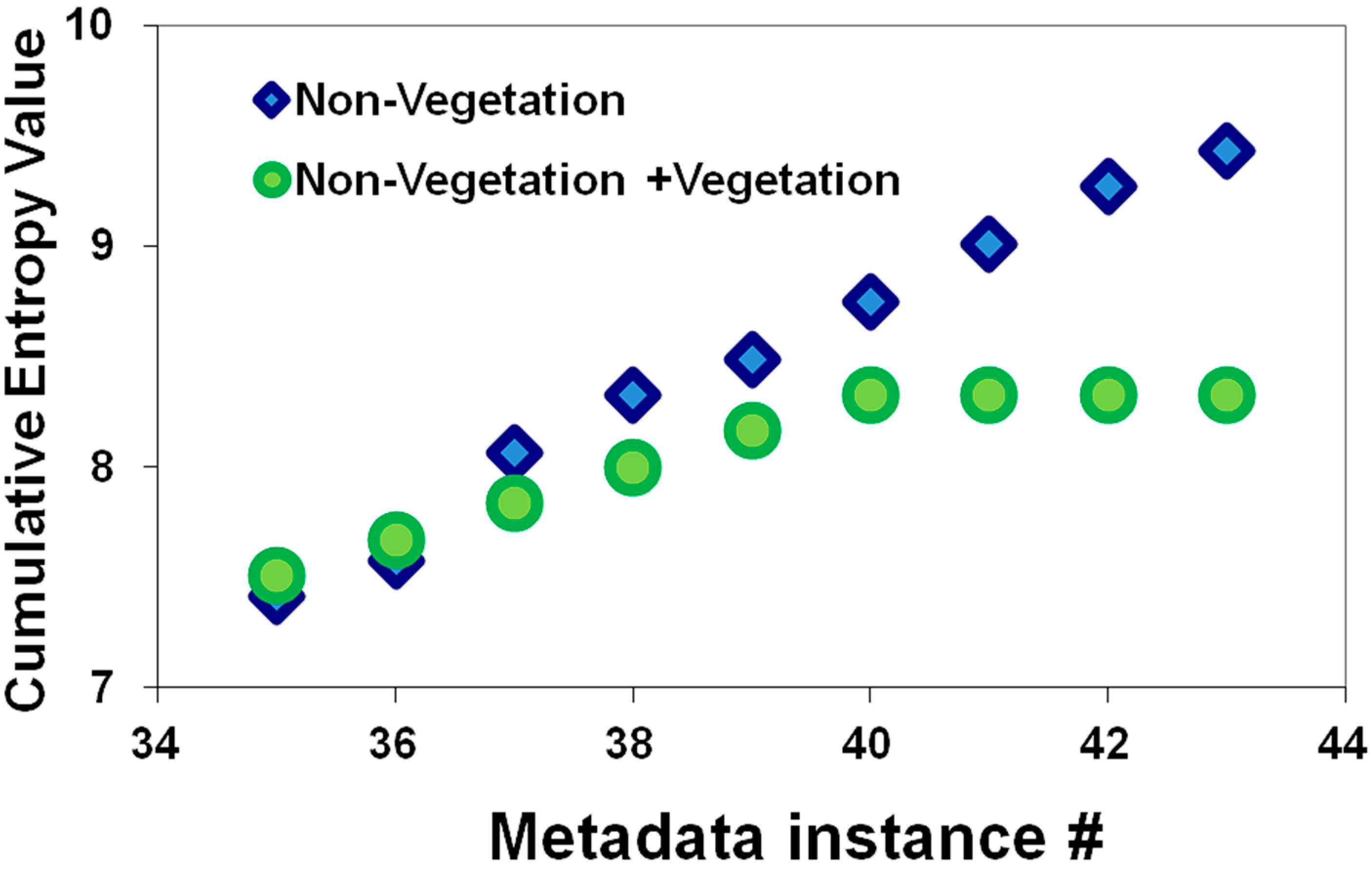{kind=link}
| Spectral Library | Agency | Purpose | Year Created | Format | # of Campaigns | # of Spectra | Explicit Quality Assurance | Mandatory Metadataset |
|---|---|---|---|---|---|---|---|---|
| USGS | USGS |
| 2003 | Static archive (online) | Data not defined at campaign level | 820 | No | Yes; pre-formatted templates |
| SPECCHIO | RSL |
| 2007 | Open access database (online and as a single or multi-user instance) | 71 | 111,023 | No | Yes; at campaign and spectrum level |
2.2. Data Analysis
2.2.1. Metadata Completeness Analysis Methods
2.2.2. Metadata Quality Analysis Methods
3. Results and Discussion
3.1. Mappings for Metadata Elements between the Core Metadataset and SPECCHIO and USGS Spectral Library
| Core Metadataset Category | Core Metadataset Parameter | SPECCHIO Metadata Parameter |
|---|---|---|
| Instrument | Make and model | description |
| Dark signal correction | time since last dc | |
| Integration time | integration time | |
| Mode (cos-conical, bi–conical) | Bidirectional/Directional-conical/Directional-hemispherical/Conical-directional/Biconical/Conical-hemispherical/Hemispherical-directional/Hemispherical-conical/Bihemispherical | |
| Manufacturer | manufacturer_name | |
| Serial number | serial_number | |
| Gain settings (Automatic/Manual) | instr_setting_type_id | |
| Signal averaging (instrumental) | InternalAverageCount | |
| Reference Standard | No reference standard used | IsReference |
| Reference material | name | |
| Serial number | serial_number | |
| Hyperspectral Signal Properties | Data type (Reflectance, Radiance…) | Reflectance/Radiance/Absorbance/Transmittance/DN/Wavelength/Mueller10/Mueller20/Irrance |
| Wavelength interval | avg_wavelength | |
| Wavelength data | avg_wavelength | |
| Illumination Information | Source of illumination (e.g., sun, lamp) | IlluminationSourceID |
| Viewing Geometry | Distance from target | sensor_distance |
| Illumination zenith angle | illumination_zenith | |
| Illumination azimuth angle | illumination_azimuth | |
| Sensor zenith angle | sensor_zenith | |
| Sensor azimuth angle | sensor_azimuth | |
| Atmospheric Conditions | Cloud cover (%) | cover_in_octas |
| Humidity | relative_humidity | |
| Wind speed | wind_speed | |
| General Project Information | Relevant websites | Specchio_User WWW, InstituteWWW |
| Project participants | Specchio FirstName, SpecchioUser_LastName, Institute_Name | |
| Name of experiment/Project | Campaign Name | |
| Location Information | Location Description | location_name; landcover cover_desc |
| Longitude | longitude | |
| Latitude | latititude | |
| Altitude | altitude |
| Core Metadataset Category | Core Metadataset Parameter | USGS Metadata Template Profile | |||||
|---|---|---|---|---|---|---|---|
| Man Made | Volatile | Minerals | Micro-Organisms | Mixtures | Plants | ||
| Metadata Parameter | Metadata Parameter | Metadata Parameter | Metadata Parameter | Metadata Parameter | Metadata Parameter | ||
| General Project Information | Project participants | original donor | |||||
| Location Information | Location Description | collection locality | |||||
| Referencing Datum | datum | ||||||
| Longitude | collection longitude | ||||||
| Latitude | collection latitude | ||||||
| General Target Sampling Information | Description of target/sample | title, material, formula, sample description | title, mineral, formula, sample description | title, micro-organism, latin name, sample description | title, mixture, mixture formula , sample description | title, plant, plant latin name, sample description | |
| Target type (vegetation, mineral, aquatic, etc.) | material type | mineral type | micro-organism type | mixture type | plant type | ||
| Target ID | sample id | ||||||
| Target photograph | image of sample | ||||||
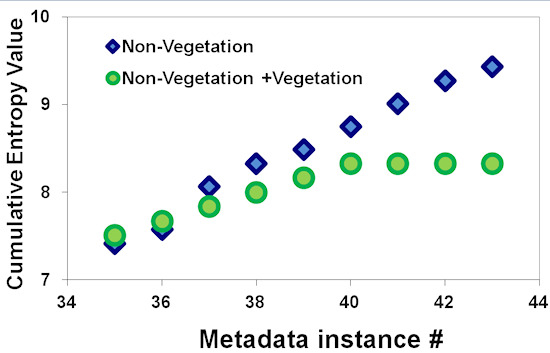
3.2. Metadata Completeness Analysis Results
| Spectral Library/Database | Completeness Statistics | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| SPECCHIO | Campaign Completeness (Internal Metadata Policy) | Core Metadataset Compliance (Campaign + Spectrum) | |||||||||
| # of campaigns examined | # of parameters | min | max | avg % | stdev | min | max | avg % | stdev | ||
| 55 | 15 | 6 | 15 | 59.3% | 12.7% | 11 | 21 | 18.4% | 1.3% | ||
| Spectrum Completeness (Internal Metadata Policy) | |||||||||||
| # of spectra examined | # of parameters | min | max | avg % | stdev | ||||||
| 111 023 | 35 | 10 | 20 | 51.7% | 4.0% | ||||||
| USGS | Spectrum Completeness (Internal Metadata Policy) | Core Metadataset Compliance (Spectrum) | |||||||||
| # of spectra examined | # of parameters | min | max | avg % | stdev | min | max | avg % | stdev | ||
| Man-made * | 11 | 24 | 15 | 18 | 68.8% | 5.4% | 7 | 8 | 7.2% | 0.5% | |
| Microorganism * | 2 | 19 | 11 | 14 | 65.8% | 11.1% | 7 | 10 | 8.2% | 2.0% | |
| Minerals * | 44 | 25 | 16 | 20 | 74.8% | 4.8% | 7 | 8 | 8.2% | 0.5% | |
| Mixture * | 13 | 25 | 16 | 23 | 82.0% | 12.0% | 6 | 11 | 8.0% | 0.3% | |
| Plant * | 18 | 19 | 11 | 16 | 62.6% | 7.4% | 7 | 10 | 7.1% | 0.8% | |
| Volatile * | 2 | 25 | 17 | 22 | 78.0% | 14.0% | 8 | 8 | 7.7% | 0.0% | |
| Average | 72.0% | 9.1% | 7.7% | 0.7% | |||||||
| Metadata Element | Dimension | ||||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
| AirPressure | 0.034 | 0.797 | −0.555 | −0.228 | −0.010 | −0.047 | −0.003 |
| Altitude | −0.299 | −0.415 | 0.034 | −0.670 | −0.111 | −0.338 | 0.207 |
| AmbientTemperature | 0.034 | 0.797 | −0.555 | −0.228 | −0.010 | −0.047 | −0.003 |
| CloudCoverInOctas | 0.066 | −0.015 | −0.011 | −0.114 | −0.090 | 0.600 | −0.001 |
| IlluminationAzimuth | 0.553 | −0.304 | −0.107 | −0.516 | −0.432 | 0.090 | −0.199 |
| IlluminationDistance | −0.073 | 0.003 | 0.037 | −0.125 | 0.439 | −0.219 | −0.420 |
| IlluminationZenith | 0.872 | −0.219 | −0.133 | −0.177 | 0.036 | −0.099 | 0.188 |
| InstrumentName | 0.457 | 0.052 | −0.075 | 0.618 | −0.463 | −0.199 | −0.027 |
| InstrumentSerialNumber | 0.457 | 0.052 | −0.075 | 0.618 | −0.463 | −0.199 | −0.027 |
| InternalAverageCount | −0.892 | −0.060 | 0.158 | −0.201 | 0.053 | −0.065 | −0.126 |
| LandcoverDescription | −0.257 | −0.042 | 0.065 | −0.485 | 0.116 | 0.441 | 0.271 |
| Latitude | 0.543 | −0.311 | −0.101 | −0.570 | −0.422 | 0.121 | −0.167 |
| LocationName | 0.903 | −0.197 | −0.127 | −0.085 | 0.157 | −0.191 | 0.042 |
| Longitude | 0.543 | −0.311 | −0.101 | −0.570 | −0.422 | 0.121 | −0.167 |
| ManufacturerName | 0.226 | 0.511 | 0.810 | −0.126 | −0.104 | −0.042 | 0.011 |
| ManufacturerShortName | 0.226 | 0.511 | 0.810 | −0.126 | −0.104 | −0.042 | 0.011 |
| ManufacturerWWW | 0.227 | 0.274 | 0.383 | 0.087 | 0.452 | 0.315 | −0.211 |
| MeasurementType | 0.918 | 0.086 | −0.128 | 0.243 | 0.118 | 0.177 | 0.054 |
| MeasurementUnit | 0.125 | −0.003 | 0.037 | −0.076 | 0.038 | −0.052 | 0.720 |
| RelativeHumidity | 0.034 | 0.797 | −0.555 | −0.228 | −0.010 | −0.047 | −0.003 |
| SamplingEnvironmentName | 0.904 | −0.124 | 0.000 | −0.150 | 0.309 | −0.049 | 0.026 |
| SensorAzimuth | 0.919 | −0.089 | −0.028 | −0.034 | 0.251 | −0.045 | −0.025 |
| SensorDistance | 0.921 | −0.005 | −0.071 | 0.084 | 0.239 | 0.052 | −0.001 |
| SensorZenith | 0.929 | −0.083 | −0.027 | −0.020 | 0.271 | −0.049 | −0.010 |
| SensorDescription | 0.226 | 0.511 | 0.810 | −0.126 | −0.104 | −0.042 | 0.011 |
| SensorName | 0.226 | 0.511 | 0.810 | −0.126 | −0.104 | −0.042 | 0.011 |
| SensorNoOfChannels | 0.226 | 0.511 | 0.810 | −0.126 | −0.104 | −0.042 | 0.011 |
| TargetHomogeneity | −0.186 | −0.337 | 0.219 | −0.644 | 0.273 | −0.379 | −0.054 |
| WindDirection | 0.034 | 0.797 | −0.555 | −0.228 | −0.010 | −0.047 | −0.003 |
| WindSpeed | 0.034 | 0.797 | −0.555 | −0.228 | −0.010 | −0.047 | −0.003 |
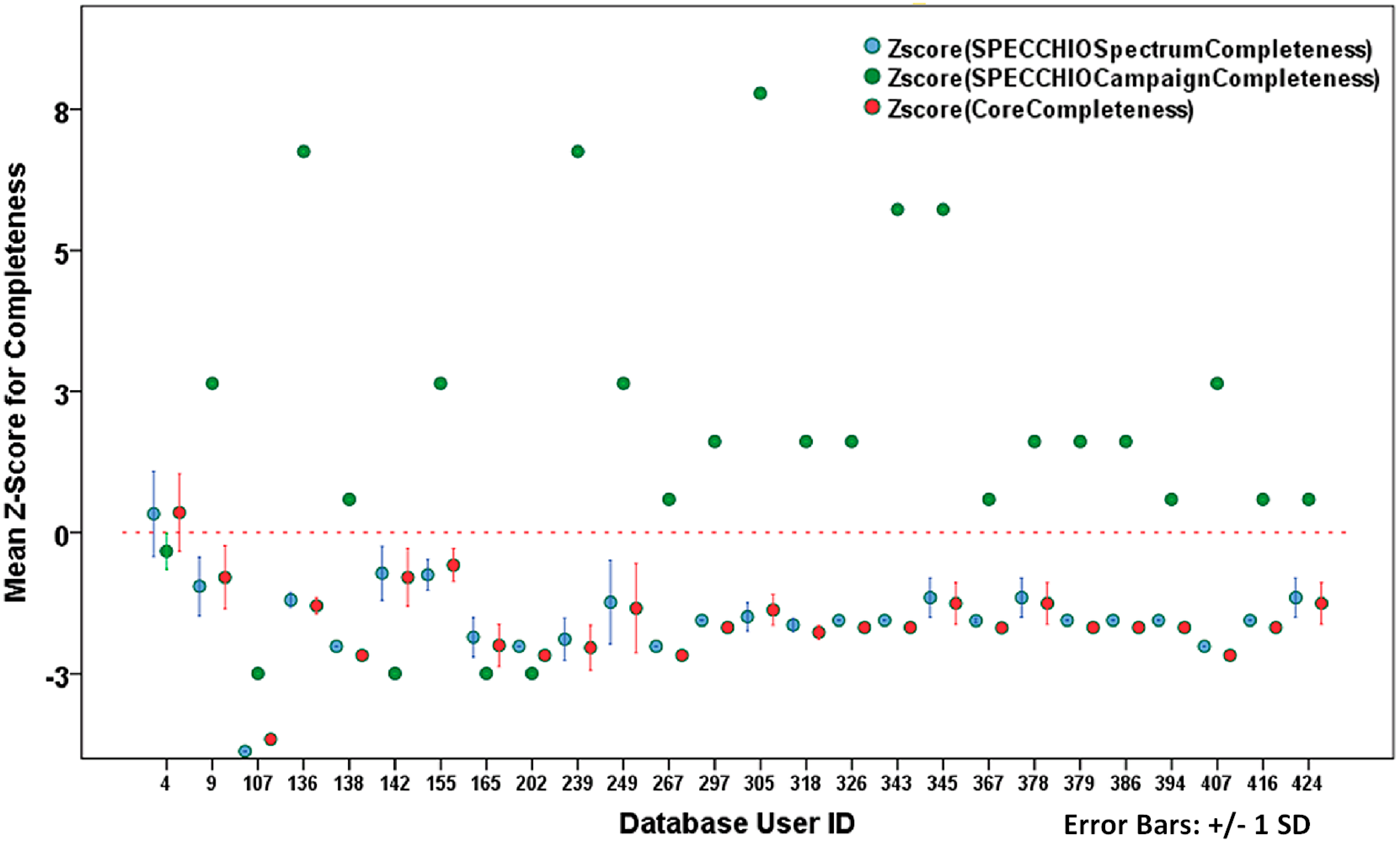
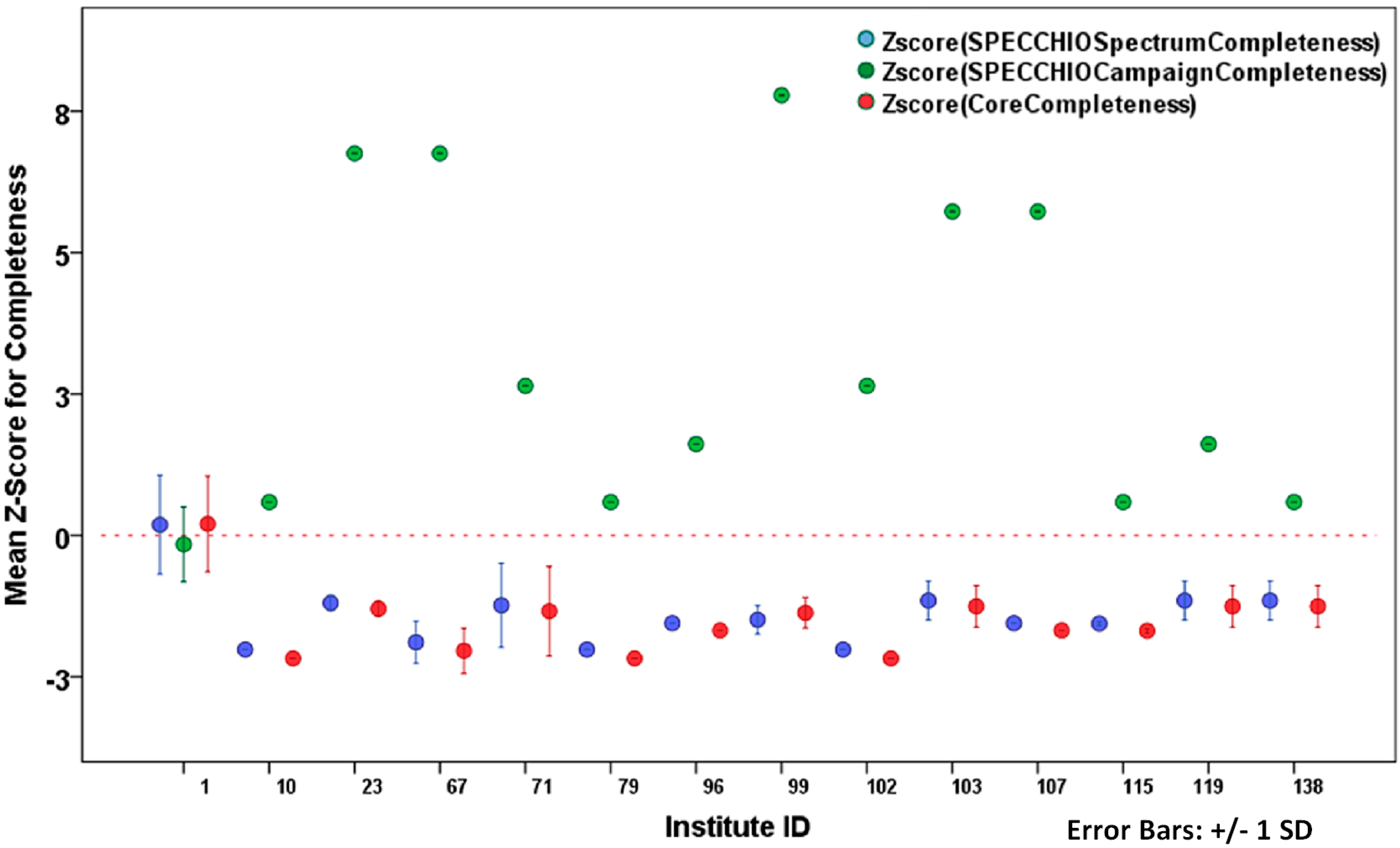
3.3. Metadata Quality Analysis Results
3.3.1. Quality Assurance
3.3.2. Lineage
3.3.3. Reputational Authority


3.3.4. Error Rates
3.3.5. Logical Consistency

4. Conclusions
Acknowledgments
Author Contributions
Appendix
Appendix A
SPECCHIO Metadata Parameters not Mapped to the Core Metadataset
Appendix B
USGS Library Metadata Parameters not Mapped to the Core Metadataset
- COMPOSITION (New Total)
- COMPOSITION Al2O3 (Oxide ASCII, Amount, wt%, Oxide html)
- COMPOSITION BaO (Oxide ASCII, Amount, wt%, Oxide html)
- COMPOSITION CaO (Oxide ASCII, Amount, wt%, Oxide html)
- COMPOSITION Cellulose
- COMPOSITION Chlorophyll_A
- COMPOSITION Chlorophyll_B
- COMPOSITION Cl (Oxide ASCII, Amount, wt%, Oxide html)
- COMPOSITION CO2 (Oxide ASCII, Amount, wt%, Oxide html)
- COMPOSITION Cr2O3 (Oxide ASCII, Amount, wt%, Oxide html)
- COMPOSITION F (Oxide ASCII, Amount, wt%, Oxide html)
- COMPOSITION Fe2O3 (Oxide ASCII, Amount, wt%, Oxide html)
- COMPOSITION FeO (Oxide ASCII, Amount, wt%, Oxide html)
- COMPOSITION H2O (Oxide ASCII, Amount, wt%, Oxide html)
- COMPOSITION H2O- (Oxide ASCII, Amount, wt%, Oxide html)
- COMPOSITION H2O+ (Oxide ASCII, Amount, wt%, Oxide html)
- COMPOSITION K2O (Oxide ASCII, Amount, wt%, Oxide html)
- COMPOSITION Li2O (Oxide ASCII, Amount, wt%, Oxide html)
- COMPOSITION Lignin
- COMPOSITION LOI (Oxide ASCII, Amount, wt%, Oxide html)
- COMPOSITION MgO (Oxide ASCII, Amount, wt%, Oxide html)
- COMPOSITION MnO (Oxide ASCII, Amount, wt%, Oxide html)
- COMPOSITION Na2O (Oxide ASCII, Amount, wt%, Oxide html)
- COMPOSITION NiO (Oxide ASCII, Amount, wt%, Oxide html)
- COMPOSITION Nitrogen
- COMPOSITION NNO2
- COMPOSITION O=Cl,F,S (Oxide ASCII, Amount, wt%, #correction for Cl, F)
- COMPOSITION P2O5 (Oxide ASCII, Amount, wt%, Oxide html)
- COMPOSITION S (Oxide ASCII, Amount, wt%, Oxide html)
- COMPOSITION SiO2 (Oxide ASCII, Amount, wt%, Oxide html)
- COMPOSITION SO3 (Oxide ASCII, Amount, wt%, Oxide html)
- COMPOSITION SrO (Oxide ASCII, Amount, wt%, Oxide html)
- COMPOSITION TiO2 (Oxide ASCII, Amount, wt%, Oxide html)
- COMPOSITION Total
- COMPOSITION Total_Chlorophyll
- COMPOSITION V2O3 (Oxide ASCII, Amount, wt%, Oxide html)
- COMPOSITION volatile
- COMPOSITION Water
- COMPOSITION YYO2
- COMPOSITION ZnO (Oxide ASCII, Amount, wt%, Oxide html)
- COMPOSITION_DISCUSSION
- COMPOSITION_TRACE
- COMPOSITIONAL_ANALYSIS_TYPE
- CURRENT_SAMPLE_LOCATION
- FORMULA_HTML
- LIB_SPECTRA
- LIB_SPECTRA_HED
- MICROSCOPIC_EXAMINATION
- SPECTRAL_PURITY (1_2_3_4_ # 1= 0.2–3, 2= 1.5–6, 3= 6–25, 4= 20–150)
- SPECTROSCOPIC_DISCUSSION
- TRACE_ELEMENT_ANALYSIS
- TRACE_ELEMENT_DISCUSSION
- ULTIMATE_SAMPLE_LOCATION
- XRD_ANALYSIS
Conflicts of Interest
References
- Rasaiah, B.A.; Jones, S.D.; Bellman, C.; Malthus, T.J. Critical metadata for spectroscopy field campaign. Remote Sens. 2014, 6, 3662–3680. [Google Scholar] [CrossRef]
- Rasaiah, B.; Malthus, T.; Jones, S.D.; Bellman, C. Building better hyperspectral datasets: The fundamental role of metadata protocols in hyperspectral field campaigns. In Proceedings of the Surveying & Spatial Sciences Conference, Wellington, New Zealand, 21–25 November 2011.
- Rasaiah, B.; Malthus, T.; Jones, S.D.; Bellman, C. Designing a robust hyperspectral dataset: The fundamental role of metadata protocols in hyperspectral field campaigns. In Proceedings of the GSR 1, Melbourne, Australia, 28–30 November 2011.
- Rasaiah, B.; Malthus, T.; Jones, S.D.; Bellman, C. Critical metadata protocols in hyperspectral field campaigns for building robust hyperspectral datasets. In Proceedings of the XXII ISPRS Congress, Melbourne, Australia, 26 August–1 September 2012.
- Rasaiah, B.; Jones, S.D.; Chisholm, L.; Hueni, A.; Bellman, C.; Malthus, T.J.; Chisholm, L.; Gamon, J.; Huete, A.; Ong, C.; et al. Approaches to establishing a metadata standard for field spectroscopy datasets. In Proceedings of IGARSS 2013, Melbourne, Australia, 21–26 July 2013.
- Gamon, J.A.; Rahman, A.F.; Dungan, J.L.; Schildhauer, M.; Huemmrich, K.F. Spectral Network (SpecNet)—What is it and why do we need it? Remote Sens. Environ. 2006, 103, 227–235. [Google Scholar] [CrossRef]
- Jung, A.; Götze, C.; Glässer, C. Overview of experimental setups in spectroscopic laboratory measurements–the SpecTour Project. Photogramm.-Fernerkund.-Geoinf. 2012, 4, 433–442. [Google Scholar] [CrossRef]
- Dor, E.B.; Ong, C.; Lau, I.C. Reflectance measurements of soils in the laboratory: Standards and protocols. Geoderma 2015, 245, 112–124. [Google Scholar]
- FGDC. Content Standard for Digital Geospatial Metadata: Extensions for Remote Sensing Metadata. Available online: http://www.fgdc.gov/standards/projects/FGDC-standards-projects/csdgm_rs_ex/MetadataRemoteSensingExtens.pdf (accessed on 24 August 2013).
- ISO. Project Information--Fact Sheet 19113: 19113 Geographic Information—Quality Principle. Available online: http://www.isotc211.org/Outreach/Overview/Factsheet_19113.pdf (accessed on 13 October 2013).
- ISO. ISO 19113:2002: Geographic Information--Quality Principles. Available online: http://www.iso.org/iso/catalogue_detail.htm?csnumber=26018 (accessed on 13 October 2013).
- ISO. ISO/WD 19159 Geographic Information–Calibration and validation of remote sensing imagery sensors and data. 2011. Lysaker: ISO/TC 211 Secreteriat. Available online: http://www.iso.org/iso/iso_catalogue/catalogue_tc/catalogue_tc_browse.htm?commid=54904 (accessed on 13 October 2013).
- ANZLIC. ANZLIC Metadata Profile Version 1.1. Available online: http://spatial.gov.au/sites/default/files/legacy/osdm.gov.au/Metadata/ANZLIC%2BMetadata%2BProfile/default.html (accessed on 27 August 2013).
- INSPIRE. INSPIRE Metadata Implementing Rules: Technical Guidelines Based on ENISO 19915 and ENISO 19119. Available online: http://inspire.jrc.ec.europa.eu/documents/Metadata/INSPIRE_MD_IR_and_ISO_v1_2_20100616.pdf (accessed on 17 May 2010).
- Margaritopoulos, T.; Margaritopoulos, M.; Mavridis, I.; Manitsaris, A. A conceptual framework for metadata quality assessment. In Proceedings of the International Conference on Dublin Core and Metadata Applications, Berlin, Germany, 22–26 September 2008.
- Stvilia, B.; Gasser, L.; Twidale, M.B.; Shreeves, S.L.; Cole, T.W. Metadata quality for federated collections. In Proceedings of the Ninth International Conference on Information Quality, Cambridge, MA, USA, 5–7 November 2004.
- Park, J.R. Metadata quality in digital repositories: A survey of the current state of the art. Cat. Classif. Quart. 2009, 47, 213–228. [Google Scholar]
- NISO. A Framework of Guidance for Building Good Digital Collections. Available online: http://www.niso.org/publications/rp/framework3.pdf (accessed on 7 January 2014).
- Bruce, T.R.; Hillmann, D.I. The continuum of metadata quality: Defining, expressing, exploiting. In Metadata in Practice; Hillmann, D., Westbrooks, E., Eds.; American Libray Association Editions: Chicago, IL, USA, 2004; pp. 238–256. [Google Scholar]
- Stvilia, B.; Gasser, L.; Twidale, M.B.; Smith, L.C. A framework for information quality assessment. J. Am. Soc. Inf. Sci. Technol. 2007, 58, 1720–1733. [Google Scholar] [CrossRef]
- Ochoa, X.; Duval, E. Automatic evaluation of metadata quality in digital repositories. Int. J. Digit. Libr. 2009, 10, 67–91. [Google Scholar] [CrossRef] [Green Version]
- Liolios, K.; Schriml, L.; Hirschman, L.; Pagani, I.; Nosrat, B.; Sterk, P.; Field, D. The Metadata Coverage Index (MCI): A standardized metric for quantifying database metadata richness. Stand. Genomic Sci. 2012, 6, 438–447. [Google Scholar] [CrossRef] [PubMed]
- Currier, S.; Barton, J.; O’Beirne, R.; Ryan, B. Quality assurance for digital learning object repositories: Issues for the metadata creation process. Res. Learn. Technol. 2004, 12, 5–20. [Google Scholar] [CrossRef] [Green Version]
- Goovaerts, M.; Leinders, D. Metadata quality evaluation of a repository based on a sample technique. In Metadata and Semantics Research; Springer: Berlin/Heidelberg, Germany, 2012; pp. 181–189. [Google Scholar]
- ANDS. Metadata. Available online: http://ands.org.au/guides/metadata-awareness.html (accessed on 7 January 2014).
- USGS. USGS Digital Spectral Library splib06a. Available online: http://speclab.cr.usgs.gov/spectral.lib06/ds231/index.html (accessed on 26 October 2013).
- Hueni, A.; Nieke, J.; Schopfer, J.; Kneubuehler, J.; Itten, K.I. The spectral database SPECCHIO for improved long-term usability and data sharing. Comput. Geosci. 2009, 35, 557–565. [Google Scholar] [CrossRef] [Green Version]
- SAS Institute. Data Mining and the Case for Sampling. Available online: http://www.inst-informatica.pt/servicos/informacao-e-documentacao/dossiers-tematicos/dossier-tematico-no-8-business-intelligence-abril-2010/estudos-de-caso/data-mining-and-the-case-for-sampling (accessed on 15 October 2013).
- Khandar, P.V.; Dani, S.V. Knowledge discovery and sampling techniques with data mining for identifying trends in data sets. Int. J. Comput. Sci. Eng. 2011, 2011, 7–11. [Google Scholar]
- Linting, M.; Meulman, J.J.; Groenen, P.J.; van der Koojj, A.J. Nonlinear principal component analysis: Introduction and application. Psychol. Methods 2007, 12, 36–58. [Google Scholar]
- Meulman, J.J.L.; Heiser, W.J. IBM SPSS Categories 21. Available online: ftp://public.dhe.ibm.com/software/analytics/spss/documentation/statistics/21.0/en/client/Manuals/IBM_SPSS_Categories.pdf (accessed on 14 January 2014).
- Starkweather, J. RSS SPSS Short Course Module 9 Categorical PCA. Available online: http://www.unt.edu/rss/class/Jon/SPSS_SC/Module9/M9_CATPCA/SPSS_M9_CATPCA.htm (accessed on 30 August 2013).
- Kaiser, H.F. The application of electronic computers to factor analysis. Educ. Psychol. Meas. 1960, 20, 141–151. [Google Scholar] [CrossRef]
- Simon, S.P. Mean: Checks for Data Quality Using Metadata. Available online: http://www.pmean.com/08/CheckMetadata.html (accessed on 26 October 2013).
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley: Hoboken, NJ, USA, 1991; pp. 112–113. [Google Scholar]
- Hueni, A. SPECCHIO User Guide V. 2.1.2. Available online: http://specchio.ch/user_guides.php (accessed on 23 March 2012).
- Goodchild, M.F. Beyond metadata: Towards user-centric description of data quality. In Proceedings of the 2007 International Symposium on Spatial Data Quality, Enschede, The Netherlands, 13–15 June 2007.
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rasaiah, B.A.; Jones, S.D.; Bellman, C.; Malthus, T.J.; Hueni, A. Assessing Field Spectroscopy Metadata Quality. Remote Sens. 2015, 7, 4499-4526. https://0-doi-org.brum.beds.ac.uk/10.3390/rs70404499
Rasaiah BA, Jones SD, Bellman C, Malthus TJ, Hueni A. Assessing Field Spectroscopy Metadata Quality. Remote Sensing. 2015; 7(4):4499-4526. https://0-doi-org.brum.beds.ac.uk/10.3390/rs70404499
Chicago/Turabian StyleRasaiah, Barbara A., Simon. D. Jones, Chris Bellman, Tim J. Malthus, and Andreas Hueni. 2015. "Assessing Field Spectroscopy Metadata Quality" Remote Sensing 7, no. 4: 4499-4526. https://0-doi-org.brum.beds.ac.uk/10.3390/rs70404499