1. Introduction
Rapid damage assessment after a disaster event such as an earthquake is critical for efficient response and recovery actions. Direct manual field inspection is labor intensive, time consuming, and cannot assess the damages in inaccessible areas. Remote sensing technology is the most predominant and early source to provide data for performing such assessments, either manually or using automated image analysis procedures [
1,
2]. Various kinds of remote sensing data such as optical, synthetic aperture radar (SAR), and LiDAR are being used for the damage assessment process [
1]. However, optical data are often preferred as they are relatively easy to interpret [
1]. Moreover, optical remote sensing provides very high resolution images ranging from the decimeter to the centimeter scale through various platforms such as satellites, manned aircrafts, and unmanned aerial vehicles (UAVs) [
3,
4,
5]. This allows for performing comprehensive damage assessment through identifying different levels of damage evidence, ranging from complete collapse to cracks on the building roof or façades, by choosing images at appropriate scales. Particularly oblique airborne images are recognized as the most suitable source, as they facilitate the damage assessment on both roofs and lateral elements [
6,
7]. For example, even extensive building damage such as inter-story collapse or pancake collapse can be identified reliably only with oblique view images, while conventional nadir views at best provide damage proxies such as external debris [
1,
7,
8]. Although current remote sensing yields images at a vast range of views and scales, automatic recognition of even heavy damages to buildings is still challenging [
1]. This is due to various reasons such as the complexity of the scene, uncertain characteristics of damage patterns, and the varying scale problem in oblique view images.
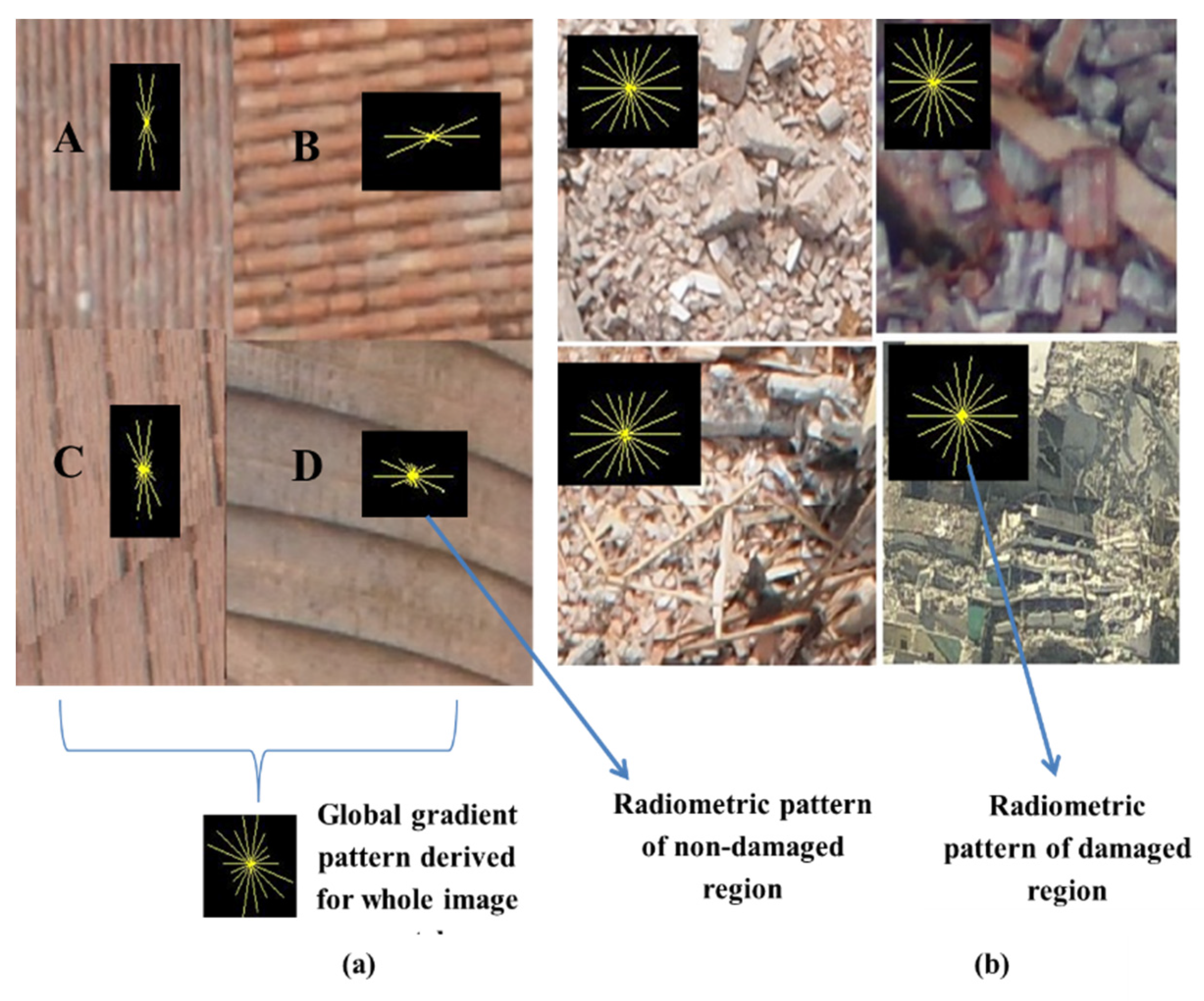
Generally, the regions corresponding to heavy damage are determined through the identification of damage patterns corresponding to rubbles piles, debris, and spalling in an image region (refer to
Figure 1) [
8]. Those damage evidences have a specific meaning and play a major role in damage classification. For example, the presence of significant amounts of debris/rubble piles around the building is the strong indication of (partial) building collapse. Spalling is an indicator of minor damage or partially broken structural elements. The recognition process of those damage patterns can be performed by analyzing features extracted either at the pixel or the region level [
1,
9,
10]. However, the pixel level analysis is not meaningful for very high spatial resolution images, particularly in the context of damage assessment, as the evidences are identified based on the characteristics of their radiometric distribution pattern, which can be captured more precisely at a region level. However, in region-level classification the critical step is to define the region that is appropriate to identify the specific damage patterns. Generally, image regions are obtained either through a gridding approach or though image segmentation [
11]. The most simple, efficient, and straightforward strategy is the gridding approach, where the image is split into uniform rectangular cells. However, the regions derived from gridding are often cluttered, as they may comprise different kinds of objects. For example, a single cell may contain trees, building elements, cars, road sections, debris,
etc. Moreover, oblique images are more complex compared to nadir images, since they also capture façades that frequently comprise various elements, such as windows, balconies, staircases,
etc. They generally also look more cluttered than nadir images containing largely roofs, and reveal façade information only at the image border, depending on the lens opening angle. It is quite challenging to identify the damage patterns in such a cluttered region. This can be alleviated by using a segmentation approach, which segments the damaged portions and other objects in the scene as separate regions. However, the selection of appropriate features and a segmentation algorithm that is suitable for a given damaged and cluttered environment is a challenging problem, one that requires substantial semantic analysis. Apart from clutter, the regions obtained from oblique images vary in scale. Nevertheless, the identification of damage patterns regardless of image scale is an important prerequisite in damage assessment. For example, damage at a building level such as inter-story collapse can be captured better at coarser scales (e.g., 100 × 100 pixel region in an image of the decimeter scale), while minor damages such as spalling at a building element level require finer scales (e.g., 100 × 100 pixel region in an image of the centimeter scale). Therefore, a robust method is required to recognize the damage pattern in a defined region irrespective of the scale and clutter. This is an analogue of the human visual pattern recognition system, which is extremely proficient at identifying the damage patterns regardless of the scale and complexity of the scene.
In the field of computer vision, various methods have been reported for pattern recognition tasks in various applications, such as object categorization, face recognition, and natural scene classification [
12,
13,
14]. These methods are mostly based on supervised learning approaches, which work well for conventional image classification applications. However, the overall performance of the learning approach completely depends on the discriminative power of the image descriptors (features) considered for the classification [
15]. Generally, images are described through either global (e.g., textures) or local features, like point descriptors such as Scale Invariant Feature Transform (SIFT) [
13,
16]. However, most global features are very sensitive to scale and clutter [
17]. In contrast, the local descriptors are robust to clutter but cannot capture the global characteristics of the image [
18,
19]. An alternate feature representation strategy, such as Visual-Bag-of-Words (BoW), captures the global characteristics of the image through encoding a set of local features, which makes them robust to scale and clutter [
20,
21]. For example, in texture-based classification, the global texture pattern of the image is captured by the frequencies of the co-occurrence of the local texture patterns. This kind of feature representation outperforms the conventional global feature representation approaches in image classification [
22]. Apart from general image classification, the Bag-of-Words framework has been demonstrated as a potential approach in many image-based domain specific applications including image retrieval [
23], human action and facial expression recognition [
24,
25], image quality assessment [
26], and medical image annotation [
27]. Conceptually, thus, the BoW approach seems to be appropriate for identifying the damaged regions in airborne oblique images, which generally look cluttered and vary in scale.
Pattern recognition methods including BoW are based on a supervised learning approach that attempts to learn the underlying relationship between the image-derived features and the pattern of a specific category, in this case the damage pattern. Therefore, apart from a feature representation strategy, the choice of features that best discriminate the damaged and non-damaged regions is also a key element. Numerous studies reported that textures are the most influential feature for damage pattern recognition, as the damaged regions tend to show uneven and peculiar texture patterns, in contrast to non-damaged regions [
28,
29,
30]. Many damage classification studies used statistical textures such as grey level co-occurrence matrix (GLCM)-based features for the damage pattern recognition [
10,
31,
32]. However, other texture measures such as wavelets have been recognized as superior to GLCM in many pattern recognition problems, including land cover classification [
33]. Particularly for region-level pattern classification problems, descriptors such as Histogram of Gradient Orientation (HoG), Gabor wavelets, SIFT and Speeded-Up Robust Features (SURF) have led to good results [
34,
35,
36]. All these features describe the pattern of the given region in a unique way, based on the magnitude of gradient along various orientations and scales. Vetrivel
et al. [
37] demonstrated the potential of HoG and Gabor features to classify the damaged regions in very high resolution UAV images. However, they found limitations with the conventional global representation of HoG and Gabor features, especially with respect to generalization. So far, however, to our knowledge no work exists that combines the named features in a BoW fashion for damage mapping.
The objective of this paper is thus to develop a robust method based on the BoW approach that is suitable especially (but not only) for oblique images to identify the damage patterns related to rubble piles, debris, and spalling, regardless of the scale and the clutter of the defined region in an image. Following the above argumentation, a grid-based region definition is pursued. The robustness of the developed method based on this BoW approach is analyzed by comparing the performance of various learning algorithms and image descriptors (Gabor and HoG) under both the conventional and the BoW approach. Also, the generalization capability of the developed method is analyzed, by testing it on a variety of images corresponding to various scales, camera views, capturing platforms, and levels of scene complexity.
2. Methods
For the identification of damaged regions in an image, as a preparation step we provide reference data. That is, the given image is split into M × N regions, which are termed image patches. The image patches are manually labeled as damaged if any kind of damage pattern related to debris, spalling, and rubble piles is observed in them. The automatic detection of those damage patterns within the patches is carried out using two different feature representation approaches: global and BoW representation. The feature descriptors and learning algorithms considered for both the global and BoW-based damage classification process are described in the respective sub-sections.
2.1. Damage Classification Based on Global Representation of Features
This process includes two steps: (1) extraction of image descriptors that provide the global description of the given image patch; and (2) classification of the given image patch as damaged or non-damaged, based on the extracted feature descriptors using a supervised learning algorithm.
2.1.1. Extraction of Feature Descriptors
The HoG and Gabor wavelets-based feature descriptors are considered for the global feature representation-based damage classification process.
- (a)
Histogram of Gradient Orientation (HoG)
The standard approach is used to extract the HoG features (e.g., Dalal Triggs [
38]), where the given image patch is split into a number of overlapping blocks, and histograms of gradient orientation derived for each block are concatenated to form a feature vector. This gives the global representation of the image patch.
Procedure:
- (1)
Derive gradient magnitude and its orientation for each pixel in the image patch.
- (2)
Split the gradient image into A × B cells.
- (3)
Again split the gradient image into a number of overlapping blocks, where each block contains C × D cells with 50% of overlapping cells between the blocks.
- (4)
Define the bin size for the histogram of gradient orientation, where each bin corresponds to a specific orientation (the bin size remains fixed for all experiments later).
- (5)
For each cell, compute the histogram of gradient orientation by adding the magnitude of the gradient to its corresponding orientation bin. Therefore, the size of the feature description of each cell is equal to the number of bins.
- (6)
Concatenate the histograms of gradient orientation of all cells within each block to get the block level description. Normalize the histograms’ magnitude within the block to compensate for the local illumination variations [
39].
- (7)
Concatenate all block level descriptors to form the global descriptor of the patch.
- (b)
Gabor wavelets descriptors
The Gabor wavelets descriptors are obtained by convolving the image with a set of Gabor wavelet filters. These filters are derived by appropriate rotation and scaling of the mother Gabor wavelet function, where each filter is tuned to capture the pixel information at a specific orientation and frequency. The detailed procedure for Gabor wavelets filter generation can be found in Arivazhagan
et al. [
40]. After obtaining the Gabor filter responses for each pixel in the image patch, the region-level Gabor wavelet descriptor is represented by the histogram of magnitude of filter responses for all combinations of orientations and frequencies (
cf. Jun Fei [
41]). This histogram is computed for three consecutive pyramid levels of image patches, in order to capture the variation across scales, in addition to the variation across frequencies and orientations. The procedure used for extracting the global Gabor feature descriptors for an image patch is described below.
Procedure:
- (1)
Generate I × J number of 2D Gabor wavelet filters, where I and J are the number of frequencies and number of orientations used to generate the Gabor wavelet filters, respectively.
- (2)
Convolve the image patch with the generated filter banks, which results in I × J number of feature images.
- (3)
Normalize each feature image using l2 normalization.
- (4)
Compute the histogram of Gabor filter responses, where each histogram bin corresponds to a specific frequency and orientation. Therefore, the number of histogram bins is equal to I × J, which is the size of the final feature vector.
- (5)
Also, extract the Gabor wavelet features for the other two pyramid levels of the image patch, by subsampling it to ½ and ¼ of the image patch size.
- (6)
Feature vectors derived at different scales are concatenated to form the final feature vector. Therefore, this final feature vector will comprise features extracted at multiple scales, multiple frequencies, and multiple orientations.
2.1.2. Damage Classification Using the Derived Global Feature Descriptors
Supervised learning approaches are adopted to classify the given image patch as damaged or non-damaged, based on the global feature descriptors. Three state-of-the-art and widely used supervised learning algorithms, Support Vector Machines (SVM) [
42], Random Forests (RF) [
43], and Adaboost [
44], are considered for the damage classification process. These learning algorithms belong to the families of different learning paradigms, which learn the underlying relationship between the input features and the output label in a unique way. Three different learning paradigms are considered in order to analyze whether the considered feature descriptors are independent of the supervised algorithm,
i.e., how the classification task is solved independently of the applied learning strategy. Also, each learning algorithm has a number of tunable parameters, referred to as hyper-parameters, which have a significant impact on the performance of the learning model [
45]. Therefore, the hyper-parameters are tuned for the best model by searching the parameter space using the grid space search approach [
46]. This approach constructs a number of learning models for different settings of the hyper-parameters, using the training set. The performance of each model is assessed using a cross-validation procedure. The best performing model is selected as the final model with tuned hyper-parameters, and then evaluated using the testing set.
2.2. Damage Detection Using Visual-Bag-of-Words
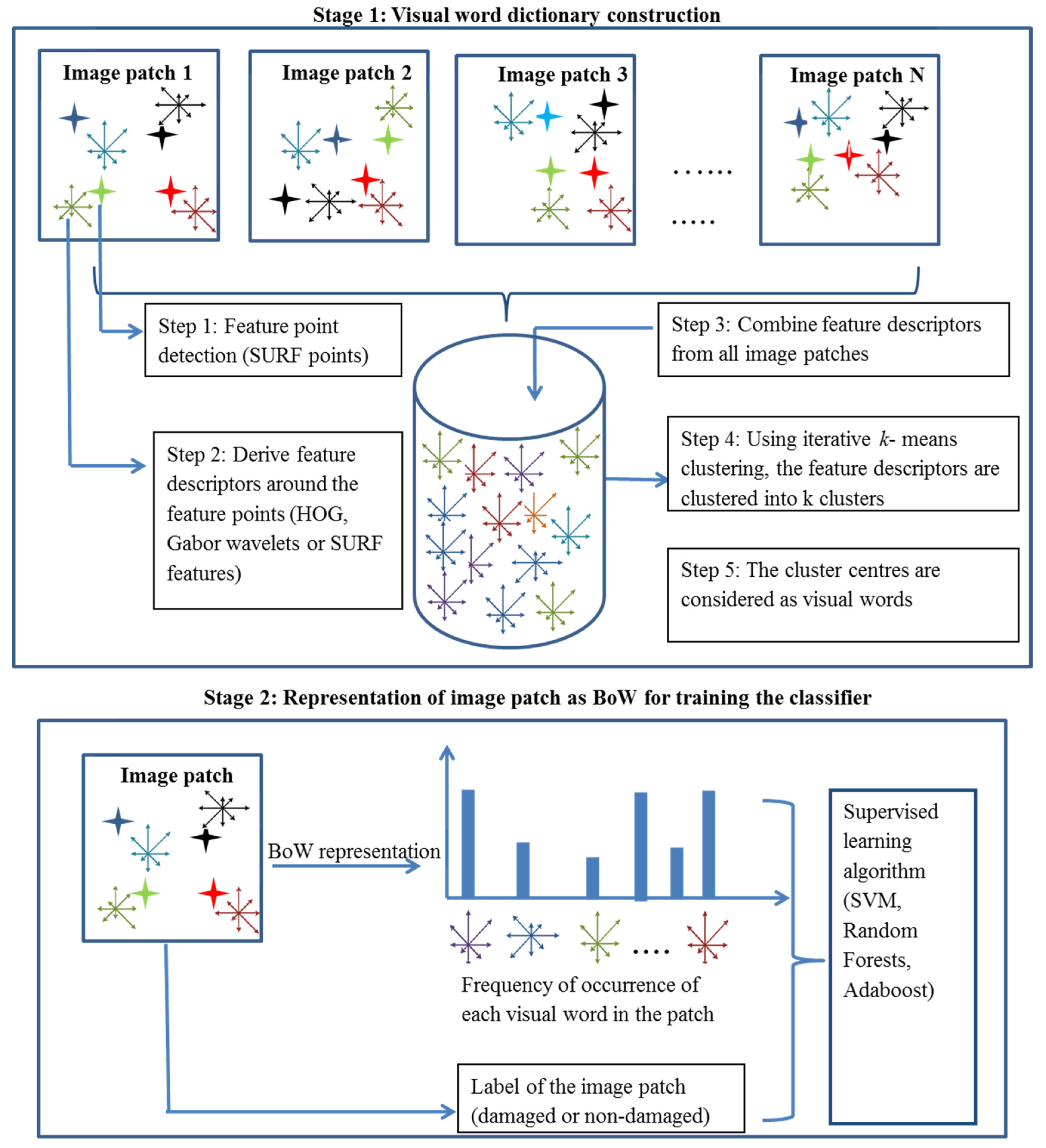
The standard BoW framework is adopted for the damage classification process. The BoW framework comprises different components, such as feature point detection, feature descriptors, visual word dictionary, and a classifier. The algorithms used for each component and the overall procedure are described below.
Overall, the BoW-based damage classification process is carried out in two stages: (1) construction of visual word dictionary; and (2) representation of the image in terms of BoW (histogram of visual words), and training the classifier based on them.
Stage 1:
(a) Feature point detection
The basic idea behind this step is that an image can be described by a small number of significant pixels (salient points). For example, pixels corresponding to edges and corners contain the most significant information compared to pixels of homogenous regions. Salient point descriptors that are invariant to scale and orientation are most appropriate to build an image classification model that is robust to scale and rotation. Numerous such salient point detection methods are available, with SIFT and SURF commonly being used in the BoW context [
19]. In this study, SURF was used since it is faster than SIFT and its descriptor is suitable to be used as the feature in the BoW framework, as discussed in the following sub-section. A description of the SURF points detection process can be found in Bay
et al. [
47].
(b) Feature extraction
The purpose of this step is to extract the local feature descriptor for each salient point in the given image patch. The feature descriptors HoG and Gabor wavelets, which are used in the global representation-based damage classification, are also considered here for the local description of salient points in the BoW-based damage classification. This allows us to compare the potential of BoW and global feature representation irrespective of the features. In the BoW approach the SURF descriptor is additionally used to describe the salient points. This is because SURF is a well-proven point descriptor (local descriptor), widely used in BoW-based image classification processes [
48]. Furthermore, SURF descriptors are based on wavelet responses, which also describe the image region in terms of textures, similar to HOG and Gabor feature descriptors. Therefore, the three feature descriptors
HoG,
Gabor wavelets, and
SURF are used independently to describe each salient point in the given image patch for the BoW-based damage classification. The local pattern description for each salient point is derived by considering a local neighborhood of P × Q pixels around the salient point. The same procedure as described in
Section 2.1.1 is followed to extract the Gabor and HoG features. The standard procedure is used to extract the SURF feature descriptor (
cf. Bay
et al. [
47]).
(c) Visual words dictionary construction
The feature descriptors of salient points from all image patches (regardless of their class) are concatenated into a single feature vector. Numerous feature encoding methods have been reported for visual word dictionary construction [
49]. We adopted the most commonly used iterative
k-means clustering algorithm [
48]. The obtained feature vector is clustered into
k clusters using the iterative
k-means clustering [
50]. Each cluster center is considered as the visual word, and the cluster centers are collectively referred to as a visual word dictionary.
Stage 2:
(a) Image description based on visual words
To represent the given image patch in terms of BoW (histogram of visual words), the salient points in the image patch are detected and feature descriptors are obtained for each point. The detected points in the image are assigned to their closest visual word in the dictionary. Subsequently, the frequency of occurrence of the visual words in the image is represented as a single histogram, which is referred to as the BoW representation of the image, which will be fed into the classifier in the next step.
(b) Classification of visual words using machine learning algorithms
Again, the three learning algorithms SVM, RF, and Adaboost are used as classifiers for classifying the damage and non-damaged image patches based on BoW. The procedure described in
Section 2.1.2 is followed to develop the supervised learning models based on the BoW features.
The overall workflow of BoW-based damage classification process is depicted in
Figure 2.
5. Discussion
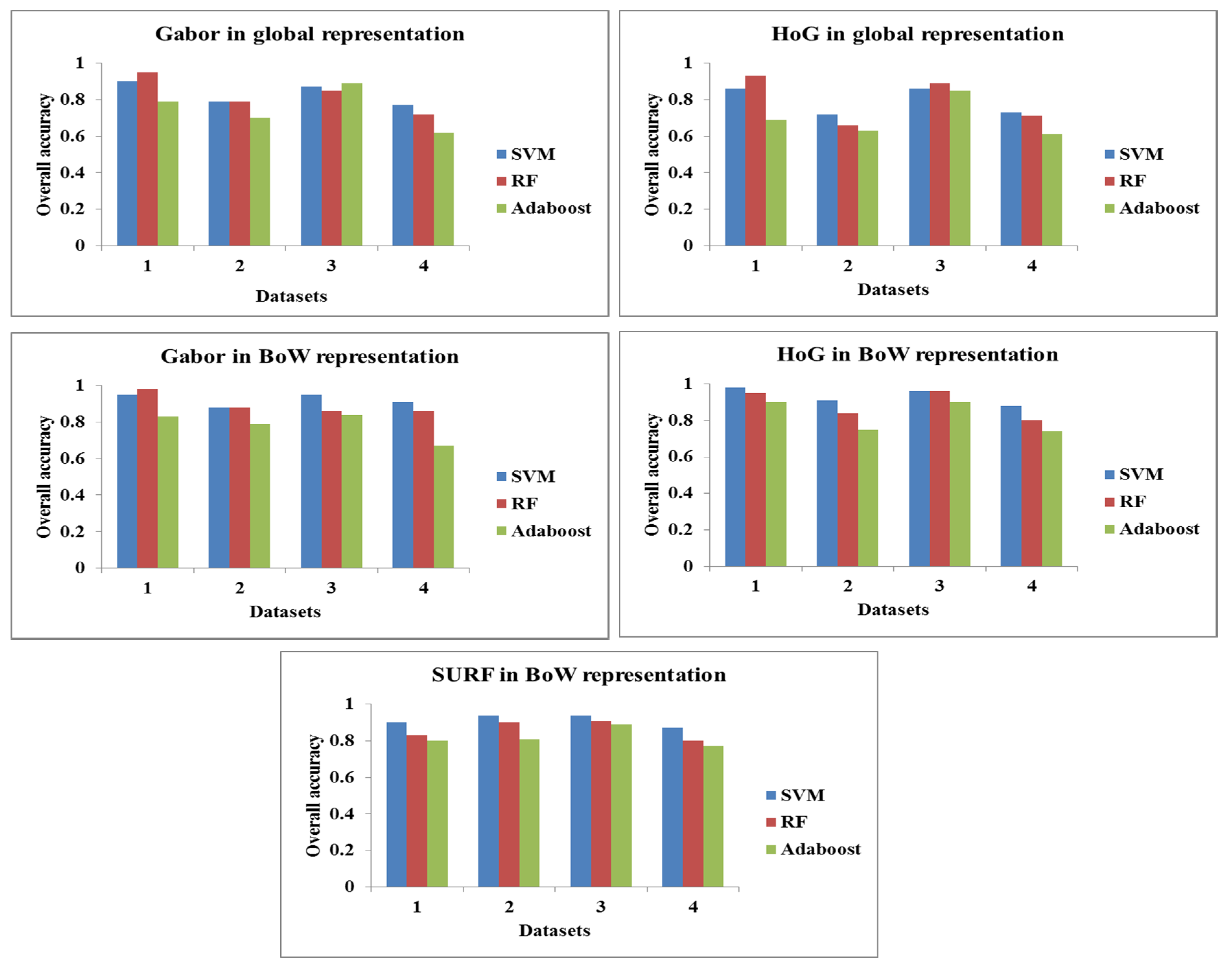
The primary objective of this paper was to develop a damage classification method that classifies a given image patch as damaged or non-damaged, irrespective of scale, image characteristics, and scene complexity. The damage classification method was developed by considering various feature descriptors (HoG, Gabor, and SURF), different feature descriptor representations (Global and BoW), different learning algorithms (SVM, RF, and Adaboost) and image datasets with different levels of scale and scene complexity. It was shown that the feature representation has a significant impact on the performance of the damage classification compared to other components such as features descriptors and learning algorithms. For all datasets, the BoW-based damage classification models performed well for all combinations of feature descriptors and learning algorithms, compared to the models developed based on global representation. Particularly, concerning COM
3109 (the comprehensive dataset), the accuracy obtained with the best-performing feature descriptor (Gabor) and learning algorithm (SVM) with the global representation improved by 14% (from 77% to 91%), when tested with the BoW representation (
cf.
Table 6). The choice of learning algorithm was found to be the second significant factor in the performance of the damage classification model: the SVM produced significantly better results than RF and Adaboost for all feature descriptors in the BoW representation (
cf.
Table 6). The considered feature descriptors performed equally well and, hence, the choice of feature descriptor was found to have least impact on the performance of the model. The Gabor features led to a 3% and 4% improvement in accuracy compared to HoG and SURF, respectively, when the image patches were classified with SVM in the BoW framework. This small improvement also may be due to the additional information that Gabor features possess compared to HoG. For example, in Gabor, the gradient orientations information is extracted based on five different frequency scales, whereas in HoG the gradient orientation information is extracted at only one frequency scale (
cf.
Section 2.1.1). However, these improvements are significantly more modest when compared to the 14% improvement in accuracy between BoW and global representation (
cf.
Table 6). This highlights the importance of feature representation, regardless of the potential of features. Overall, SVM associated with Gabor feature descriptors in the BoW framework was found to produce the most robust and generalized damage classification model. Even visually, the damage classification was found to be more accurate when the images of different scales, camera views, and capturing platforms, and different levels of scene complexity, were classified by the best performing model (
cf.
Figure 7). Shadowed areas continue to pose a major problem in damage classification. Since the damaged regions covered by shadows show low contrast, they were not detected by our BoW-based approach (no SURF points in those areas). However, it is important to identify the damages in low-contrast regions as well; therefore, further tuning of the methods or identifying the optimal strategy that can make our approach work even in low contrast regions is required to increase the robustness of the model.
The BoW framework consists of various components such as feature descriptors, learning algorithms, and the visual word dictionary construction. The algorithms used for each component are associated with a number of parameters (
cf.
Table 1). The performance of the BoW-based damage classification model might be further improved by tuning the parameters of the algorithm or modifying/replacing the algorithm of the specific component. For example, the iterative
k-means clustering was used to construct the visual word dictionary, whereas other feature encoding methods such as auto-encoders (e.g., Vincent
et al. [
51]), which encode the features differently compared to
k-means, may produce a better visual word dictionary and thereby can potentially improve the performance of the model as well. Concerning the feature descriptors, all three-feature descriptors were used independently to construct the damage classification models, whereas the combined use of feature descriptors may also improve the performance of our model. Similarly, concerning the learning algorithm we used a single kernel-based SVM for constructing the damage classification model, whereas the multiple-kernel (e.g., Bucak
et al. [
52]) based learning may improve the performance of the model as well. We did not attempt to fine-tune the model by exploring all those possible approaches, because the principal focus of this paper was to analyze the potential of the BoW framework in damage classification.
The developed method can identify the damages related to debris/rubble piles that are strong indicators of building collapse or severe structural damage, which would be very useful for first responders involved in disaster response, but also other stakeholders such as governmental agencies assessing post-disaster construction needs, or insurance companies. However, for detailed building level damage assessment, this evidence alone is not sufficient to infer the complete damage state of the building, nor the total damage cost, as the latter also depends on internal (invisible) damage, and on building functions being affected, which is not always visible. However, along with other damage evidences such as cracks, inclined elements,
etc., this evidence is also important in the damage classification process. From a practical point of view, especially, the observations we made using the combined dataset 4 (COM
3109) are very interesting. Although the used patches vary significantly in terms of scale and complexity, an overall accuracy of around 90% was reached (
cf.
Table 6). Transferred to an actual disaster scenario, where quick interpretation of image data is needed, this would mean that an already existing database can be used to train a model and new images can be readily classified, and a similar overall accuracy might be expected. Hence, at least for a first damage assessment, the tedious manual referencing might not be necessary.
6. Conclusions and Outlook
A damage classification based on BoW was developed to classify a given image patch as damaged or non-damaged, irrespective of scale, image characteristics, and scene complexity. Various combinations of image features (Gabor wavelets, HoG, and SURF) and supervised classifiers (SVM, RF, and Adaboost) are tested in both the BoW framework and conventional global feature representation approach using four different datasets. The BoW framework outperformed conventional global feature representation approaches in all scenarios (i.e., for all combinations of feature descriptors, classifiers, and datasets) and produced an average accuracy of approximately 90%. Although the developed model can identify the damaged regions in the images well, it cannot classify the detected damaged regions into specific types, such as debris, rubble piles, spalling, and inter-story collapse. We need contextual information and 3D geometric features such as shape, location, characteristics of the neighboring elements, and local height variation of the damaged region to identify the actual category of damage. For example, the damage patterns on large intact planar elements could be classified as spalling, whereas the damage pattern on the ground with large local height variations and no large 3D segments could be classified as debris. Therefore, the potential extension of this work will be the development of methods for classification of the detected damaged regions into actual damage categories.
As stated earlier, the feature descriptor component in the BoW framework has a significant impact on the performance of the model. Here, the texture features are chosen to examine our BoW framework as their potential in damage detection has been demonstrated well by previous studies, as highlighted in the Introduction. However, recent studies report that supervised feature learning methods such as convolutional neural networks (CNN) could learn the feature and its representation directly from the image pixel values chosen for a specific application [
53]. Hence, these features are referred to as data-adaptive features and are found to be superior to well-proven handcrafted features such as Gabor and HoG for many computer vison applications including image classification [
54,
55]. Therefore, we intend to explore the potential of CNNs for damage classification in the future.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}