
A General-Purpose Spatial Survey Design for Collaborative Science and Monitoring of Global Environmental Change: The Global Grid

Abstract
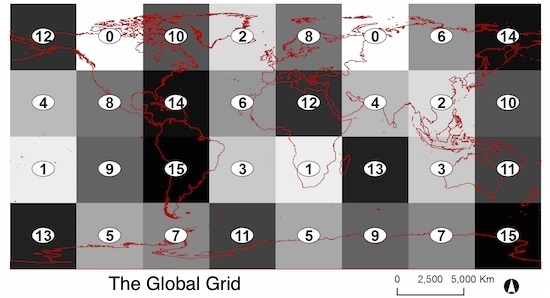
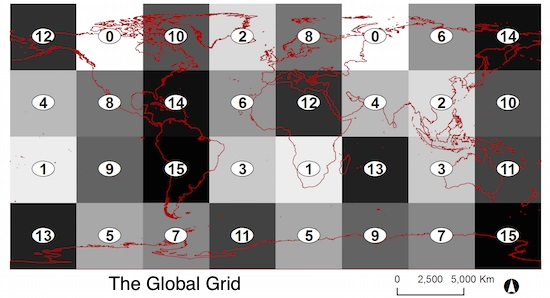
:
1. Introduction
2. Materials and Methods
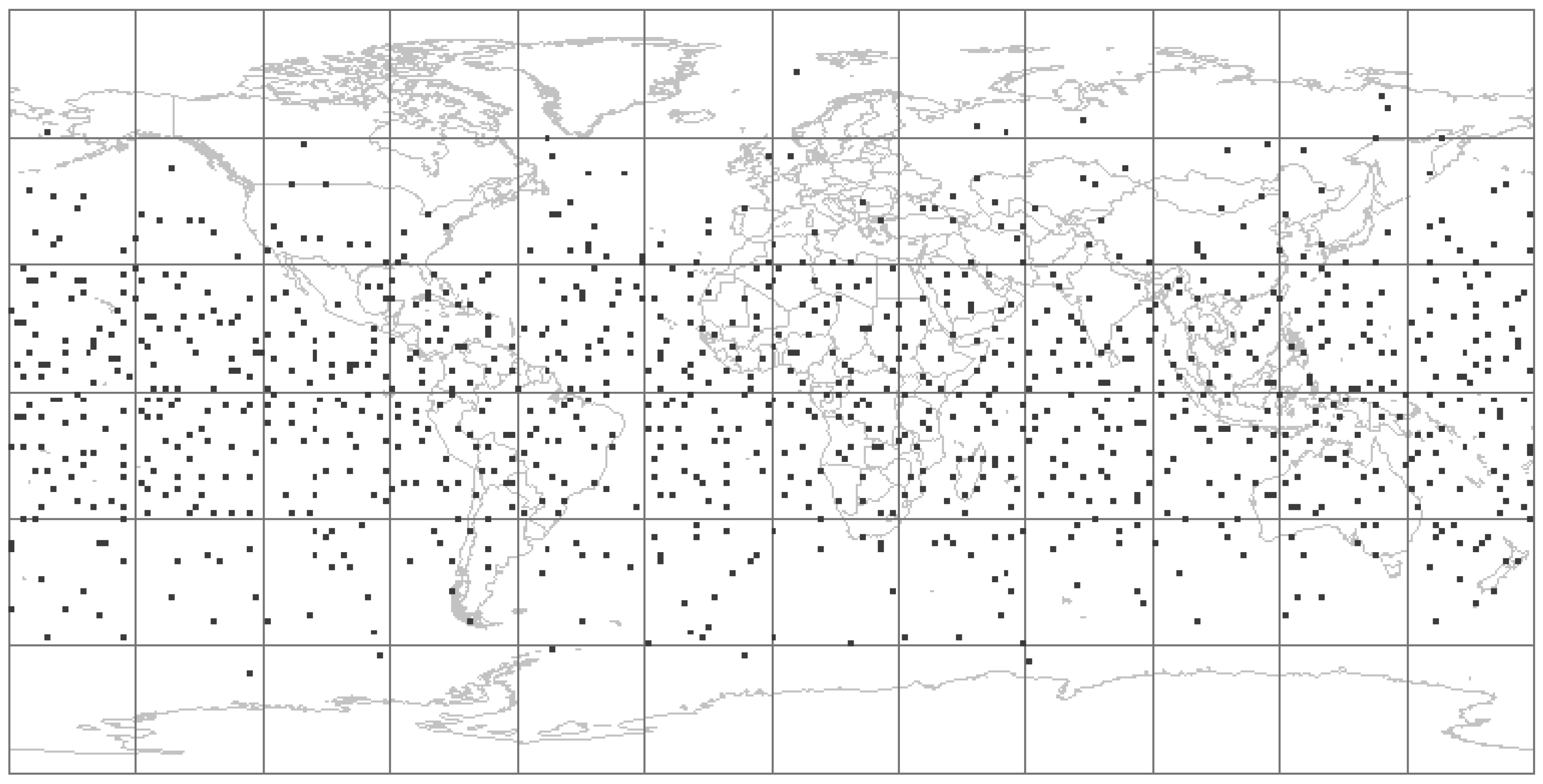
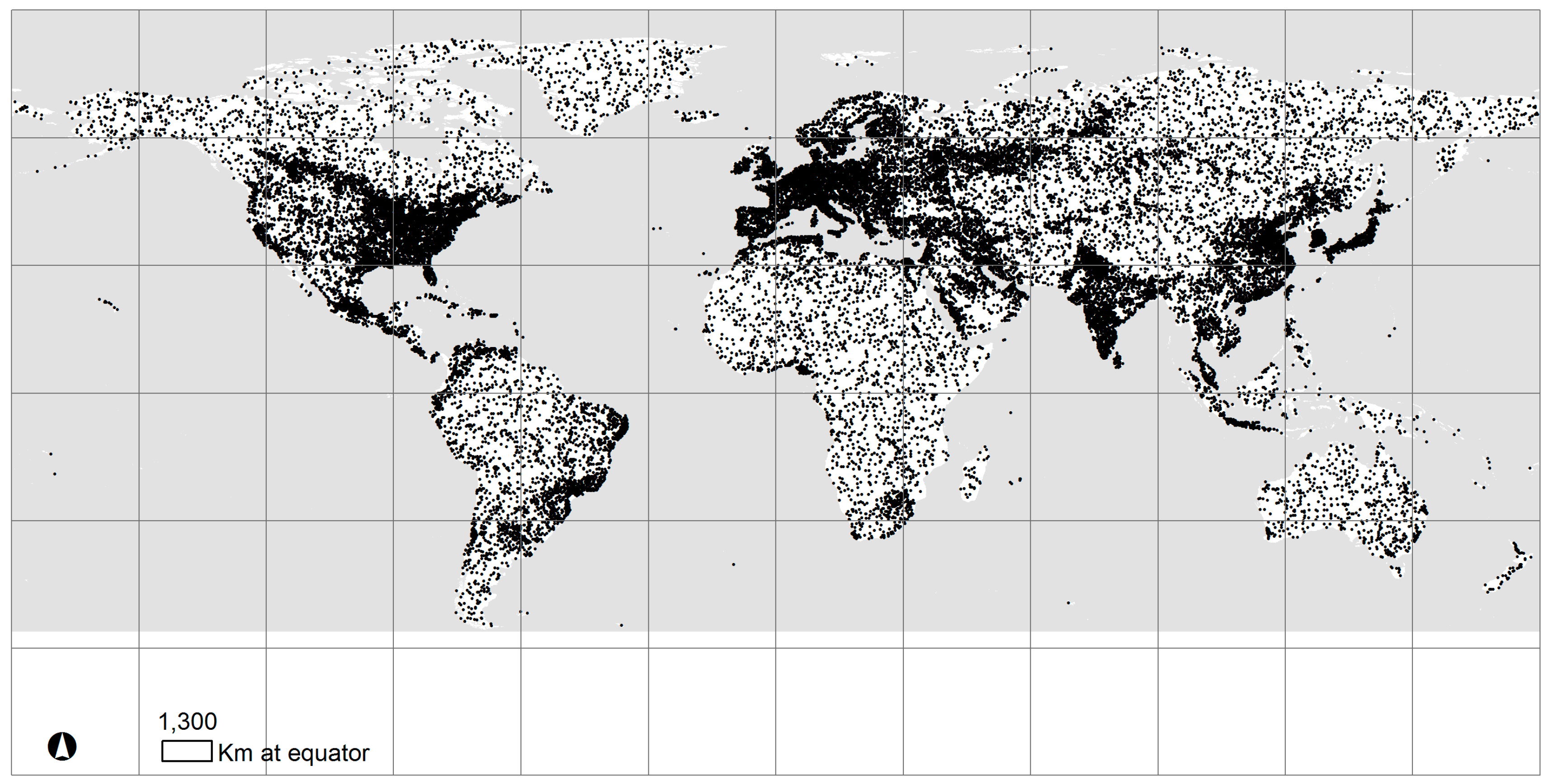
2.1. RRQRR Sample Design
2.2. The Global Grid
3. Results
4. Discussion
- Level: determine the appropriate level (L) for the GGL sampling “chips” (see Table 1). Typically, GG14 is used for land use/cover validation (~1 km2). Note that GG sequence values are nested among scales, but each sequence value is particular to a given level.
- Area: account for area differences in the amount of resource within each sample (quadrangle).
- 2.1.
- Global: if a global sample is desired, then samples need to be removed relative to their area, which changes with the cosine of latitude. Query the GGL file to find samples where cos(Lat) > R, where R is a random value drawn from a uniform probability distribution.
- 2.2.
- Regional: although less flexible and extendable, for some purposes a regional sample may be desired. In this case, the area of each sample polygon (quadrangle) can be calculated, and an area-based inclusion probability A can be calculated where A = Ai/Ax, where Ai is the area of sample i and Ax is the largest area within the regional sample (typically at the latitude closest to the equator). Query the GGL file to find samples where R < A.
- 2.3.
- Variable area: frequently, the areal extent of a resource of interest to be sampled (e.g., a river or animal habitat) may vary within a given sample unit. To account for this, an exogenous raster layer can be provided by the user that calculates ai, the proportion of the resource found within cell i. Query the GGL file to find samples where (cos(Lat) × ai) > R.
- Filtering: often additional filtering of samples is desired to adjust the sampling intensity to account for relatively rare features (e.g., using various strata) or to account for practical challenges in collecting response data at a given location (e.g., declining with further access from a road). If non-uniform inclusion probabilities are desired, then a separate spatial raster layer (I) of the same resolution as GGL, can be generated with values ranging from 0.0 to 1.0. Query the GGL file to find samples where (cos(Lat) × ai) > R and I > R.
- Sequence: as standard practice, sequence values are sorted in ascending order (on the RRQRRL field). Capturing information typically proceeds in the order of the sequence values.
5. Conclusions
Supplementary Materials
Acknowledgments
Conflicts of Interest
References
- Keller, M.; Schimel, D.S.; Hargrove, W.W.; Hoffman, F. A continental strategy for the National Ecological Observatory Network. Front. Ecol. Environ. 2008, 6, 282–284. [Google Scholar] [CrossRef]
- Stehman, S.V. Basic probability sampling designs for thematic map accuracy assessments. Int. J. Remote Sens. 1999, 20, 2423–2441. [Google Scholar] [CrossRef]
- Dobbie, M.J.; Henderson, B.L.; Stevens, D.L., Jr. Sparse sampling: Spatial design for monitoring stream networks. Stat. Surv. 2008, 2, 113–153. [Google Scholar] [CrossRef]
- Theobald, D.M.; Stevens, D.L., Jr.; White, D.; Urquhart, N.S.; Olsen, A.R.; Norman, J.B. Using GIS to generate spatially-balanced random survey designs for natural resource applications. Environ. Manag. 2007, 40, 134–146. [Google Scholar] [CrossRef] [PubMed]
- Olofsson, P.; Stehman, S.V.; Woodcock, C.E.; Sulla-Menashe, D.; Sibley, A.M.; Newell, J.D.; Friedl, M.A.; Herold, M. A global land-cover validation data set, part I: Fundamental design principles. Int. J. Remote Sens. 2012, 33, 5768–5788. [Google Scholar] [CrossRef]
- Tsendbazar, N.E.; de Bruin, S.; Herold, M. Assessing global land cover reference datasets for different user communities. ISPRS J. Photogramm. Remote Sens. 2015, 103, 93–114. [Google Scholar] [CrossRef]
- Oakley, K.L.; Thomas, L.P.; Fancy, S.G. Guidelines for long-term monitoring protocols. Wildl. Soc. Bull. 2003, 31, 1000–1003. [Google Scholar]
- Fancy, S.G.; Gross, J.E.; Carter, S.L. Monitoring the condition of natural resources in US National Parks. Environ. Monit. Assess. 2009, 151, 161–174. [Google Scholar] [CrossRef] [PubMed]
- Schreuder, H.T.; Czaplewski, R.L. Long-term strategy for the statistical design of a forest health monitoring system. Environ. Monit. Assess. 1992, 27, 81–94. [Google Scholar] [CrossRef] [PubMed]
- Nusser, S.M.; Breidt, F.J.; Fuller, W.A. Design and estimation for investigating the dynamics of natural resources. Ecol. Appl. 1998, 8, 234–245. [Google Scholar] [CrossRef]
- Stehman, S.V.; Sohl, T.L.; Loveland, T.R. Statistical sampling to characterize recent United States land-cover change. Remote Sens. Environ. 2003, 86, 517–529. [Google Scholar] [CrossRef]
- Overton, W.S. Probability sampling and population inference in monitoring programs. In Environmental Modeling with GIS; Goodchild, M.F., Parks, B.O., Stayert, L.T., Eds.; Oxford University Press: New York, NY, USA, 1993; pp. 470–480. [Google Scholar]
- White, D.; Kimerling, A.J.; Overton, W.S. Cartographic and geometric components of a global sampling design for environmental monitoring. Cartogr. Geogr. Inf. Syst. 1992, 19, 5–22. [Google Scholar] [CrossRef]
- Stevens, D.L., Jr.; Olsen, A.R. Spatially balanced sampling of natural resources. J. Am. Stat. Assoc. 2004, 99, 262–278. [Google Scholar] [CrossRef]
- Olsen, A.R. Software for R: Psurvey Analysis (3.3). 2016. Available online: https://cran.r-project.org/web/packages/spsurvey/index.html (accessed on 28 September 2016).
- Robertson, B.L.; Brown, J.A.; McDonald, T.; Jaksons, P. BAS: Balanced acceptance sampling of natural resources. Biometrics 2013, 69, 776–784. [Google Scholar] [CrossRef] [PubMed]
- Lister, T.W.; Lister, A.J.; Alexander, E. Land use change monitoring in Maryland using a probabilistic sample and rapid photointerpretation. Appl. Geogr. 2014, 51, 1–7. [Google Scholar] [CrossRef]
- Rindfuss, R.R.; Walsh, S.J.; Turner, B.L., II; Fox, J.; Mishra, V. Developing a science of land change: Challenges and methodological issues. Proc. Natl. Acad. Sci. USA 2004, 101, 13976–13981. [Google Scholar] [CrossRef] [PubMed]
- Overton, W.S.; White, D.; Stevens, D.L., Jr. Environmental Monitoring and Assessment Program: Design Report; EPA/600/3-91/053; US Environmental Protection Agency: Washington, DC, USA, 1990; p. 52.
- Wickman, F.E.; Elvers, E.; Edvarson, K. A system of domains for global sampling problems. Geogr. Ann. Ser. A 1974, 56, 201–212. [Google Scholar] [CrossRef]
- Dutton, G. Planetary modelling via hierarchical tessellation. In Proceedings of the Eleventh International Conference on Computer-Assisted Cartography (Auto-Carto 9); Anderson, E., Ed.; American Congress on Surveying and Mapping: Baltimore, MD, USA, 1989; pp. 462–471. [Google Scholar]
- Goodchild, M.F.; Shiren, Y. A hierarchical spatial data structure for global geographic information systems. Comput. Vis. Graph. Image Process. 1992, 54, 31–44. [Google Scholar] [CrossRef]
- Sahr, K.; White, D.; Kimerling, A.J. Geodesic discrete global grid systems. Cartogr. Geogr. Inf. Sci. 2003, 30, 121–134. [Google Scholar] [CrossRef]
- Mayaux, P.; Eva, H.; Gallego, J.; Strahler, A.H.; Herold, M.; Agrawal, S.; Naumov, S.; De Mirando, E.E.; Di Bella, C.M.; Ordoyne, C.; et al. Validation of the Global Land Cover 2000 map. IEEE Trans. Geosci. Remote Sens. 2006, 44, 1728–1739. [Google Scholar] [CrossRef]
- Stevens, D.L., Jr. Variable density grid-based sampling designs for continuous spatial populations. Environmetrics 1997, 8, 167–195. [Google Scholar] [CrossRef]
- Holmes, C. Problems in location sampling. Ann. Assoc. Am. Geogr. 1967, 57, 757–780. [Google Scholar] [CrossRef]
- Stohlgren, T.J.; Chong, G.W.; Kalkhan, M.A.; Schell, L.D. Multiscale sampling of plant diversity: Effects of minimum mapping unit size. Ecol. Appl. 1997, 7, 1064–1074. [Google Scholar] [CrossRef]
- US Environmental Protection Agency. Wadeable Streams Assessment; EPA 841-B-06-002; Office of Research and Development: Washington, DC, USA, 2006.
- King, A.J. The master sample of agriculture. J. Am. Stat. Assoc. 1945, 40, 38–45. [Google Scholar] [CrossRef]
- Larsen, D.P.; Olsen, A.R.; Stevens, D.L., Jr. Using a master sample to integrate stream monitoring programs. J. Agric. Biol. Environ. Stat. 2008, 13, 243–254. [Google Scholar] [CrossRef]
- National Research Council (NRC). Review of EPA’s Environmental Monitoring and Assessment Program: Overall Evaluation; National Academies Press: Washington, DC, USA, 1995. [Google Scholar]
- Schmeller, D.S.; Julliard, R.; Bellingham, P.J.; Böhm, M.; Brummitt, N.; Chiarucci, A.; Couvet, D.; Elmendorf, S.; Forsyth, D.M.; Moreno, J.G.; et al. Towards a global terrestrial species monitoring program. J. Nat. Conserv. 2015. [Google Scholar] [CrossRef]
- Becker, M.L.; Congalton, R.G.; Budd, R.; Fried, A. A GLOBE collaboration to develop land cover data collection and analysis protocols. J. Sci. Educ. Technol. 1998, 7, 85–96. [Google Scholar] [CrossRef]
- Goodchild, M.F. Citizens as sensors: The world of volunteered geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef]
- Lesiv, M.; Moltchanova, E.; Schepaschenko, D.; See, L.; Shvidenko, A.; Comber, A.; Fritz, S. Comparison of data fusion methods using crowdsourced data in creating a hybrid forest cover map. Remote Sens. 2016, 8, 261. [Google Scholar] [CrossRef]
- Fritz, S.; McCallum, I.; Schill, C.; Perger, C.; Grillmayer, R.; Achard, F.; Kraxner, F.; Obersteiner, M. Geo-Wiki.org: The use of crowdsourcing to improve global land cover. Remote Sens. 2009, 1, 345–354. [Google Scholar] [CrossRef]
- Dodge, M.; McDerby, M.; Turner, M. (Eds.) Geographic Visualization: Concepts, Tools and Applications; Wiley-Blackwell: Hoboken, NJ, USA, 2008; p. 348.
- The Degree Confluence Project. Available online: www.confluence.org (accessed on 27 September 2016).
- Tipton, H.C.; Dreitz, V.J.; Doherty, P.F. Occupancy of mountain plover and burrowing owl in Colorado. J. Wildl. Manag. 2008, 72, 1001–1006. [Google Scholar] [CrossRef]
- Pettebone, D.; Newman, P.; Theobald, D.M. A comparison of sampling designs for monitoring recreational trail impacts in Rocky Mountain National park. Environ. Manag. 2009, 43, 523–532. [Google Scholar] [CrossRef] [PubMed]
- Galway, L.P.; Bell, N.; Al Shatari, S.A.E.; Hagopian, A.; Burnham, G.; Flaxman, A.; Weiss, W.M.; Rajaratnam, J.; Takaro, T.K. A two-stage cluster sampling method using gridded population data, a GIS, and Google Earth imagery in a population-based mortality survey in Iraq. Int. J. Health Geogr. 2012, 11. [Google Scholar] [CrossRef] [PubMed]
- Marshall, K.N.; Cooper, D.J.; Hobbs, N.T. Interactions among herbivory, climate, topography and plant age shape riparian willow dynamic sin northern Yellowstone National Park, USA. J. Ecol. 2014. [Google Scholar] [CrossRef]
- Meunier, J.; Brown, P.M.; Romme, W.H. Tree recruitment in relation to climate and fire in northern Mexico. Ecology 2014, 95, 197–209. [Google Scholar] [CrossRef] [PubMed]
- ArcGIS Software, version 10.0; Esri: Redlands, CA, USA, 2015.
- De Smith, M.J.; Goodchild, M.F.; Longley, P.A. Geospatial Analysis: A Comprehensive Guide to Principles, Techniques and Software Tools, 2nd ed.; Troubador: Leicester, UK, 2008. [Google Scholar]
- Hall, R.K.; Olsen, A.; Stevens, D.L., Jr.; Rosenbaum, B.; Husby, P.; Wolinsky, G.A.; Heggem, D.T. EMAP design and river reach file 3 (RF3) as a sample frame in the Central Valley, California. Environ. Monit. Assess. 2000, 64, 69–80. [Google Scholar] [CrossRef]
- QGIS. Available online: www.qgis.org (accessed on 27 September 2016).
- Theobald, D.M. A general model to quantify ecological integrity for landscape assessments and US application. Landsc. Ecol. 2013. [Google Scholar] [CrossRef]
- Elvidge, C.D.; Baugh, K.E.; Dietz, J.B.; Bland, T.; Sutton, P.C.; Kroehl, H.W. Radiance calibration of DMSP-OLS low-light imaging data of human settlements. Remote Sens. Environ. 1999, 68, 77–88. [Google Scholar] [CrossRef]
- Global Land Use Emergent Database Group. Available online: https://groups.google.com/forum/?fromgroups#!forum/global-land-use-emergent-database (accessed on 27 September 2016).
- Theobald, D.M. Data from: A General-Purpose Spatial Survey Design for Collaborative Science and Monitoring of Global Environmental Change: The Global Grid. Dryad Digital Repository. Available online: datadryad.com (accessed on 27 September 2016).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level | Degrees | km (at Equator) | No. of Cells |
|---|---|---|---|
| 0 | 180.00000 | 2 | |
| 1 | 90.00000 | 9990.000 | 8 |
| 2 | 45.00000 | 4995.000 | 32 |
| 3 | 22.50000 | 2497.500 | 128 |
| 4 | 11.25000 | 1248.750 | 512 |
| 5 | 5.62500 | 624.375 | 2048 |
| 6 | 2.81250 | 312.188 | 8192 |
| 7 | 1.40625 | 156.094 | 32,768 |
| 8 | 0.70313 | 78.047 | 131,072 |
| 9 | 0.35156 | 39.023 | 5.24 × 105 |
| 10 | 0.17578 | 19.512 | 2.10 × 106 |
| 11 | 0.08789 | 9.756 | 8.39 × 106 |
| 12 | 0.04395 | 4.878 | 3.36 × 107 |
| 13 | 0.02197 | 2.439 | 1.34 × 108 |
| 14 | 0.01099 | 1.219 | 5.37 × 108 |
| 15 | 0.00549 | 0.610 | 2.15 × 109 |
| 16 | 0.00275 | 0.305 | 8.59 × 109 |
| 17 | 0.00137 | 0.152 | 3.44 × 1011 |
| 18 | 0.00069 | 0.076 | 1.37 × 1011 |
| 19 | 0.00034 | 0.038 | 5.50 × 1011 |
| 20 | 0.00017 | 0.019 | 2.20 × 1011 |
| 21 | 0.00009 | 0.010 | 8.80 × 1011 |
| 22 | 0.00004 | 0.005 | 3.52 × 1011 |
| 23 | 0.00002 | 0.002 | 1.41 × 1014 |
© 2016 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Theobald, D.M. A General-Purpose Spatial Survey Design for Collaborative Science and Monitoring of Global Environmental Change: The Global Grid. Remote Sens. 2016, 8, 813. https://0-doi-org.brum.beds.ac.uk/10.3390/rs8100813
Theobald DM. A General-Purpose Spatial Survey Design for Collaborative Science and Monitoring of Global Environmental Change: The Global Grid. Remote Sensing. 2016; 8(10):813. https://0-doi-org.brum.beds.ac.uk/10.3390/rs8100813
Chicago/Turabian StyleTheobald, David M. 2016. "A General-Purpose Spatial Survey Design for Collaborative Science and Monitoring of Global Environmental Change: The Global Grid" Remote Sensing 8, no. 10: 813. https://0-doi-org.brum.beds.ac.uk/10.3390/rs8100813