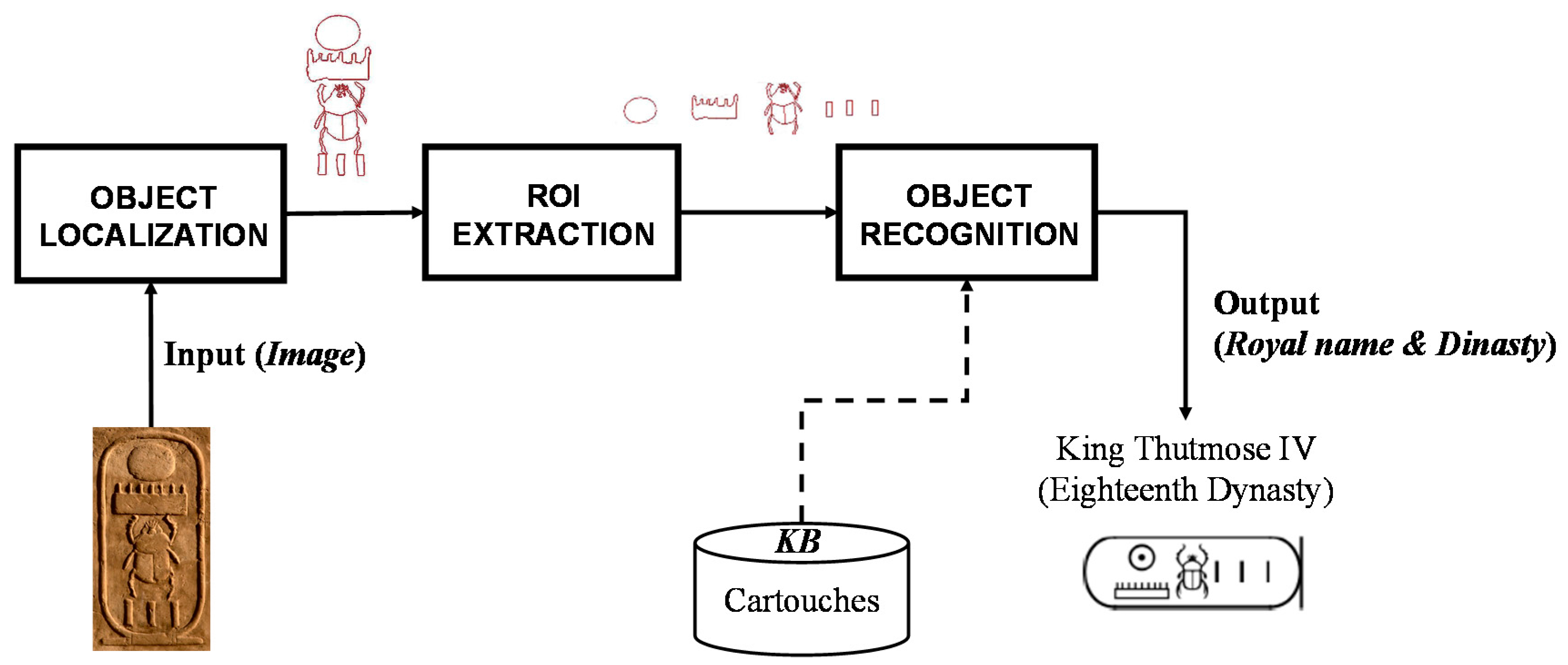
1. Introduction
Egyptian writing is complex and is based on more than 800 characters, named hieroglyphs. They were initially considered pictograms representing words, but Champollion deciphered the writing system and discovered that in fact, they are characters. Although most of hieroglyphs are sounds composed of one, two or three phonemes, some of them are pictograms [
1]. The name of the monarchs, named pharaohs, was composed of a box with usually rounded corners, called cartouche, and a word inside. This word usually can be translated as a phrase, e.g., Tutankhamen would be “Living image of god Amen”.
During the last decades, the advancements in the field of computer vision have facilitated the study of ancient writing systems, especially regarding the automatic recognition of characters. For instance, several methods have been developed to detect edges and recognize objects [
2,
3,
4]. With respect to the Egyptian writing system, several authors have studied the hieroglyph detection problem. The difference between the intensity values of the hieroglyphs and the rest of the surface is used in [
5] to extract hieroglyphs. Shape descriptors are used for hieroglyph retrieval purposes in [
6,
7]. The shape context descriptor proposed by [
8] takes as input a finite set of
n points, which represent the contours of a given shape, and describes it as a set of
n histograms. With these histograms, the difference between a pixel in one contour and the rest of the pixels in the other contour is evaluated. Locating the minor difference between the pixels of the first contour and the second, the global difference between the two contours is evaluated. This descriptor is used to obtain Mayan hieroglyphs in [
6]. The main limitation of this method is to consider that hieroglyphs are complete. It would be more effective if edges could be entirely extracted. However, in some cases, ancient texts are not well preserved and these defects are reflected as noise in the images. An evaluation of the performance of three shape-based contextual descriptors (Shape Context—SC, Generalized Shape Context—GSC, and Histogram of Orientation Shape-Context—HOOSC) using two datasets of syllabic Maya hieroglyphs is presented in [
7]. SC and GSC proved to generate reliable descriptions of Maya hieroglyphs whereas HOOSC proved to be more robust. According to these studies, hieroglyphs may be extracted and a shape descriptor applied to obtain each character. Other recent works are focused on the identification of handwritten hieroglyphic transcriptions drawn in plain (i.e., black or white) backgrounds and are based on text mining and natural language processing techniques [
9,
10]. Nevertheless, hieroglyphic texts encoding has been reported to be time-consuming.
In order to solve the above-mentioned problems, other strategies have been proposed. It was initially considered extracting the hieroglyphs using a conversion to grey scale and applying a threshold and the Hu moments [
11,
12,
13]. It could be a right method if the color of the hieroglyphs was different. However, the hieroglyphs have the same color than other parts of the cartouche and the extraction process becomes difficult. Secondly, it was tried to use a strategy of regions by frontier based on the gradient, the Laplacian and the Hu moments [
2]. To use this proposal the edges were detected using Sobel, Canny and Susan methods [
2,
14,
15]. The problem with this another method is that sometimes there is noise or edges that are not well defined.
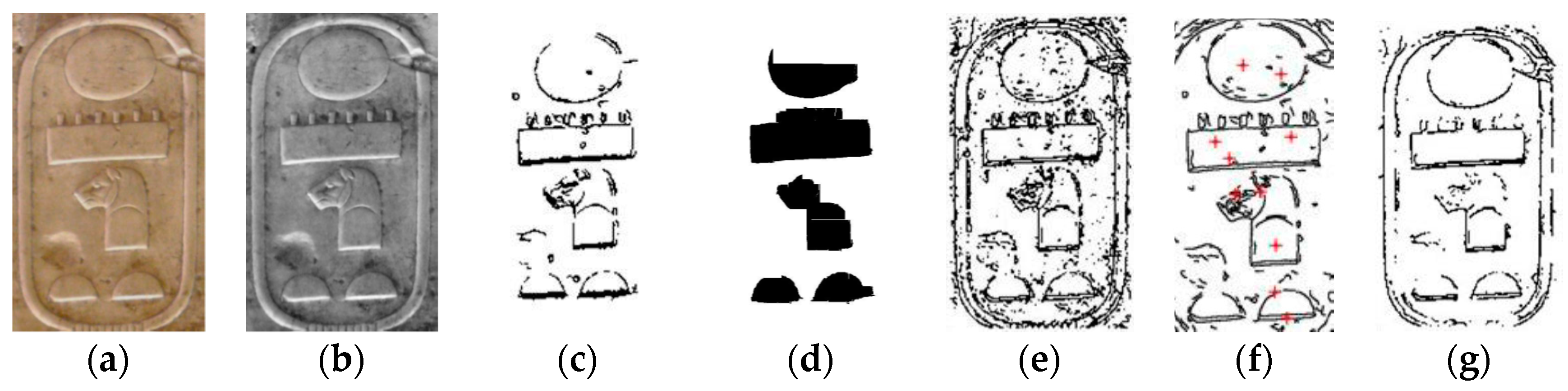
Figure 1 shows examples of application of the methods evaluated on the images used in this work. The Generic Hough Transform (GHT) is a well-known method that can be used to obtain a concrete object using its edge [
16]. However, the main drawback is that it only considers the points that exactly match with the model. If there is a big difference between the points of the edge and the edge of the image, it returns non-valid results as one can see in
Figure 1f. The hieroglyph represented in
Figure 1a was not properly detected because there are no perfect circles in the image. The curvature and structural salience method tries to extract the regions with special interest [
17]. This method was tested on edges of cartouches for extracting the hieroglyphs, but the results were similar to apply a threshold to the edges as can be seen in
Figure 1g.
Other methods as Statistical Shape Models (SSM), Active Shape Models (ASM), and Active Appearance Models (AAM) are used to find objects with a similar shape using key points or landmarks and the textures between these landmarks [
18,
19]. These methods work better when there is a clear difference between the object and the rest of the image. In this work, the hieroglyphs have the same color than the rest of the cartouche, and the edges are very soft.
Figure 2a,b shows an example of AAM method. Other approach implements a skeleton search using a Skeletal Shape Model for object segmentation and recognition that works directly on real images [
20]. A fragment-based generative model for shape that is capable of generating a wide variation of shapes as instances of a given object category is proposed. It develops a progressive selection mechanism to search among the generated shapes for the category instances that are present in the image. This method seems to be robust against spurious edges, missing edges, and accidental alignment between the image edges and the shape boundary contour. The segmentation of the object using global holistic properties of object shape is proposed in [
21]. Concretely, it proposes a figure/ground segmentation method for extraction of image regions that resemble the global properties of a model boundary structure and are perceptually salient. Its shape representation, called the chordiogram, is based on geometric relationships of object boundary edges, but this work takes into account the perceptual saliency in favor of coherent regions distinct from the background. A new weighting function, which helps constructing words representations for detection of Maya hieroglyphs is introduced in [
22]. This weighting function depends on the ratio of intersection of the local descriptors, and their respective distances to the center of the bounding box that is under evaluation. The Active Contours Algorithm was also tested in order to detect the edges of the Egyptian cartouches used in this work [
23,
24].
Figure 2c–e shows an example. Its performance was not suitable in terms of time.
Aiming to deal with the above-mentioned limitations, this work presents a new method to recognize Egyptian cartouches based on several computer vision techniques. This paper is organized as follows:
Section 2 describes the approach developed for hieroglyphs interpretation: firstly, the localization of the cartouche in the initial picture is carried out; next, the hieroglyphs are extracted and identified; and lastly, the symbols are interpreted.
Section 3 analyses the performance of the proposed method. Finally,
Section 4 presents the conclusions and future work.
2. Overview of the Proposed Method to Interpret Hieroglyphs
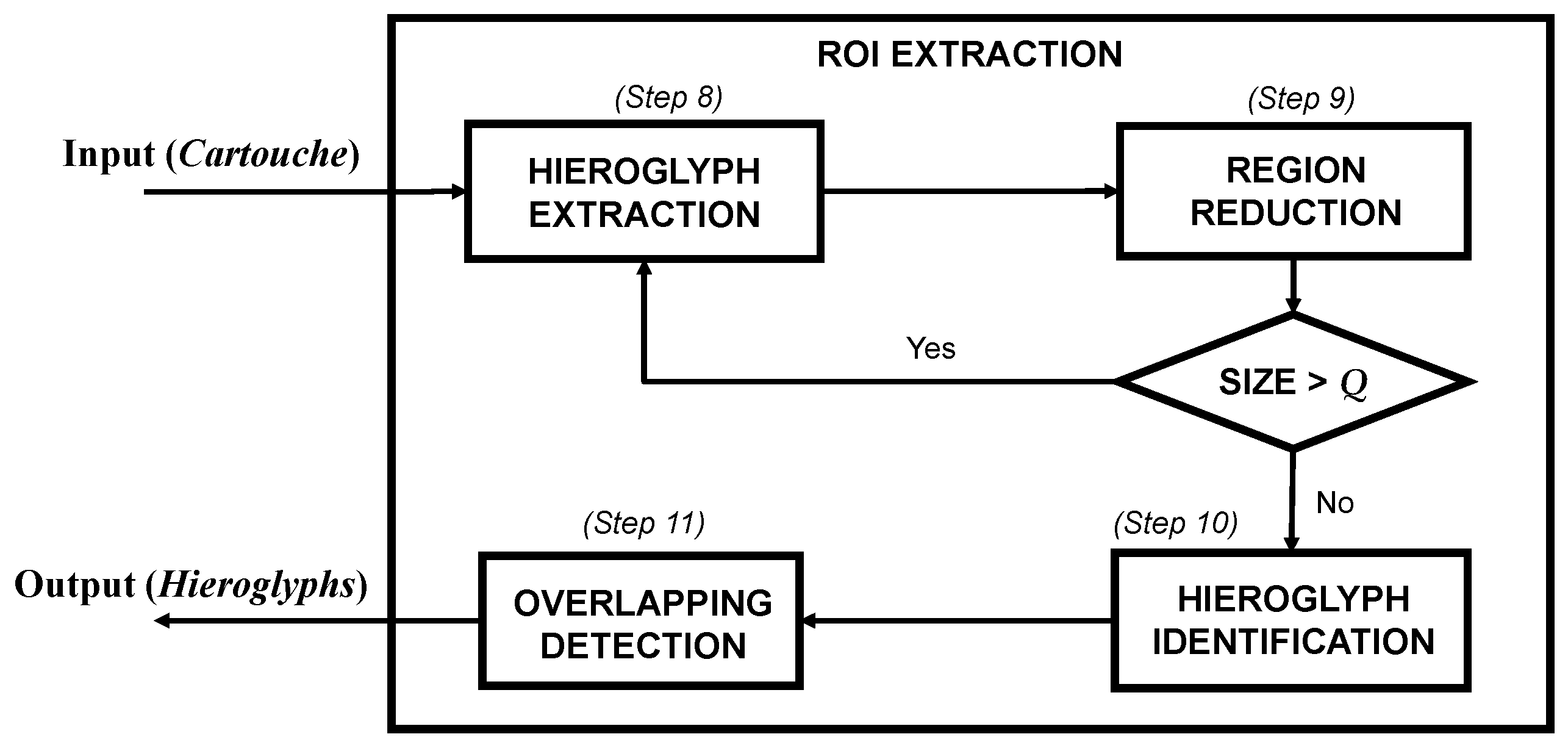
This section illustrates the strategy developed to localize and recognize the objects of interest in the image (i.e., hieroglyphs). As previously mentioned, this approach is based on different techniques used in computer vision and consists in the following three stages: (1) localization of the object (i.e., the cartouche) in the image and deletion of object’s contour; (2) extraction of regions of interest (ROIs), which are the hieroglyphs; (3) recognition of cartouches considering the identification of each hieroglyph.
Figure 3 shows the described process. First of all, it is worth mentioning some factors that should be considered for an automatic visual analysis and interpretation of the Egyptian writing:
Texts were written to be read from the left to the right or from the right to the left.
Egyptian scribes were able to write in different materials: stone, wood, faience, papyrus, gold, bronze, etc. Hieroglyphs were even painted.
Differences between hieroglyphs in different texts or materials are not remarkable, as a similar model was used.
Texts were written in both low-relief and high-relief art. In low-relief, hieroglyphs were incised in the stone. In high-relief, the rest of the cartouche was incised.
Most texts preserved until the present day have suffered the effects of time, exposure and even vandalism.
Although the presented approach has been designed to be applied to cartouches written in stone, it can be also employed for painted hieroglyphs. Besides, it can be used for low-relief or high-relief writing. The state of preservation of the material (usually stone) as well as missing parts have an important effect in the final result. Thus, images can be noisy or intermediate results, like extracted contours, can correspond to incomplete hieroglyphs, making the recognition process more complicated.
Figure 4 shows a set of images used in this work.
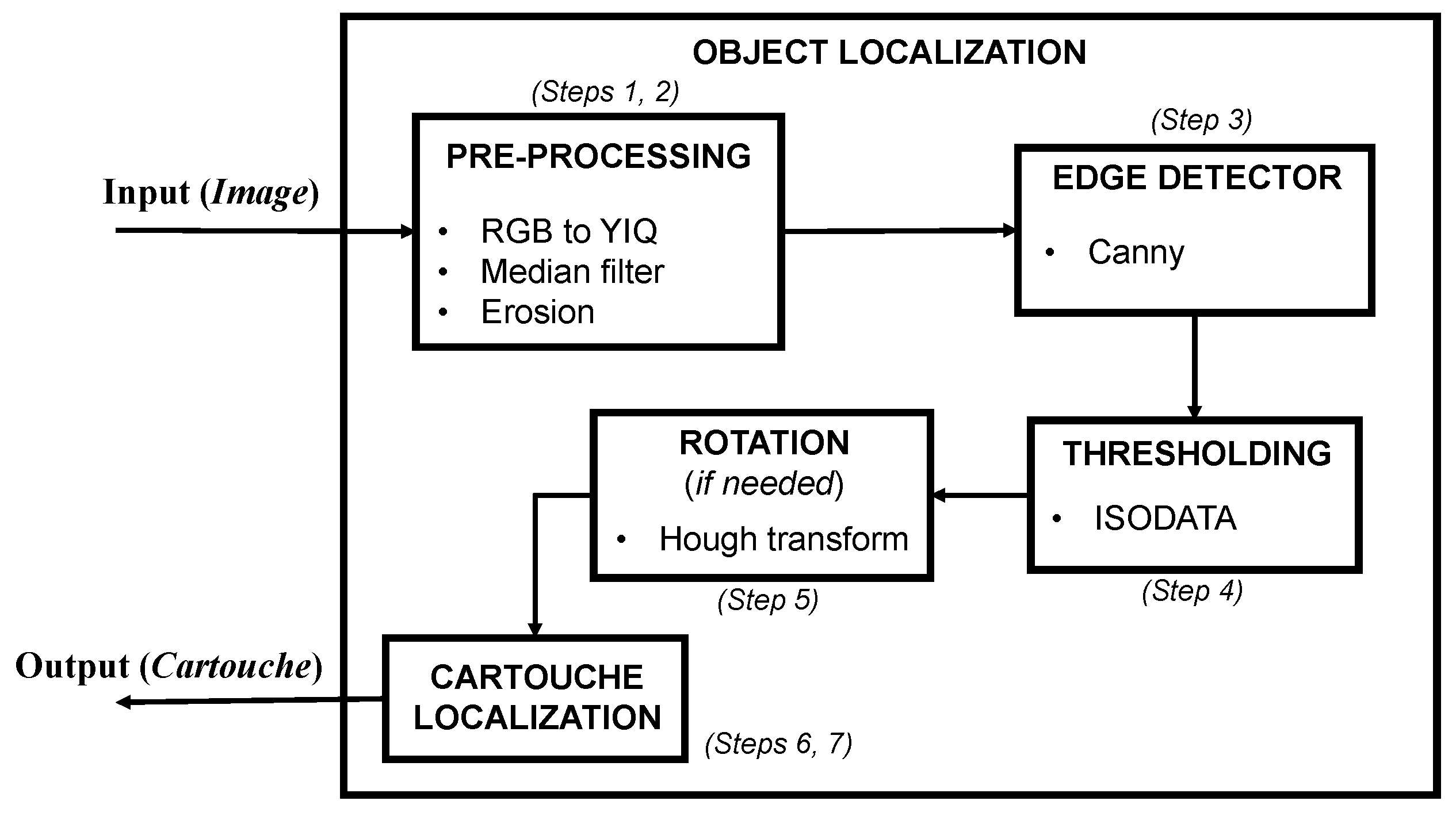
2.1. Localization of Cartouches in Images
The localization process consists of seven steps where various image processing techniques are used. The main challenge of this stage is to localize the contour of each cartouche in the image. Once the cartouche is localized, the process deletes the contour. In the following, the mentioned localization steps are detailed:
Step 1. The input image, shown in
Figure 5a, is transformed from RGB to grayscale (
Figure 5b), using the luma, in-phase, quadrature (YIQ) color space as illustrated in Equation (1). Note that this system is usually employed in color image processing transformations [
2].
Step 2. A median filter and a morphological erosion are applied. These filters are used to remove the noise without reducing the edges.
Figure 5c presents the result of these operations.
Step 3. A Canny edge detector is applied to obtain the edges of the image [
25] (see
Figure 5d), being this one of the most powerful edge-detection methods.
Step 4. The Iterative Self-Organizing Data Analysis Technique (ISODATA) threshold is used to detect the most important edges, as illustrated in
Figure 5e [
26]. The objective is to split non-homogeneous regions into two sub-regions (objects and background) as follows:
- (a)
A threshold T is set to a random value
- (b)
The image is binarized using T
- (c)
The mean values , of the two sub-regions (objects and background) generated with T are obtained. is the mean value of all values under or equal to T. is the mean value of all values above T
- (d)
A new threshold is calculated as
- (e)
Repeat steps (b) to (d) until T stops changing its value.
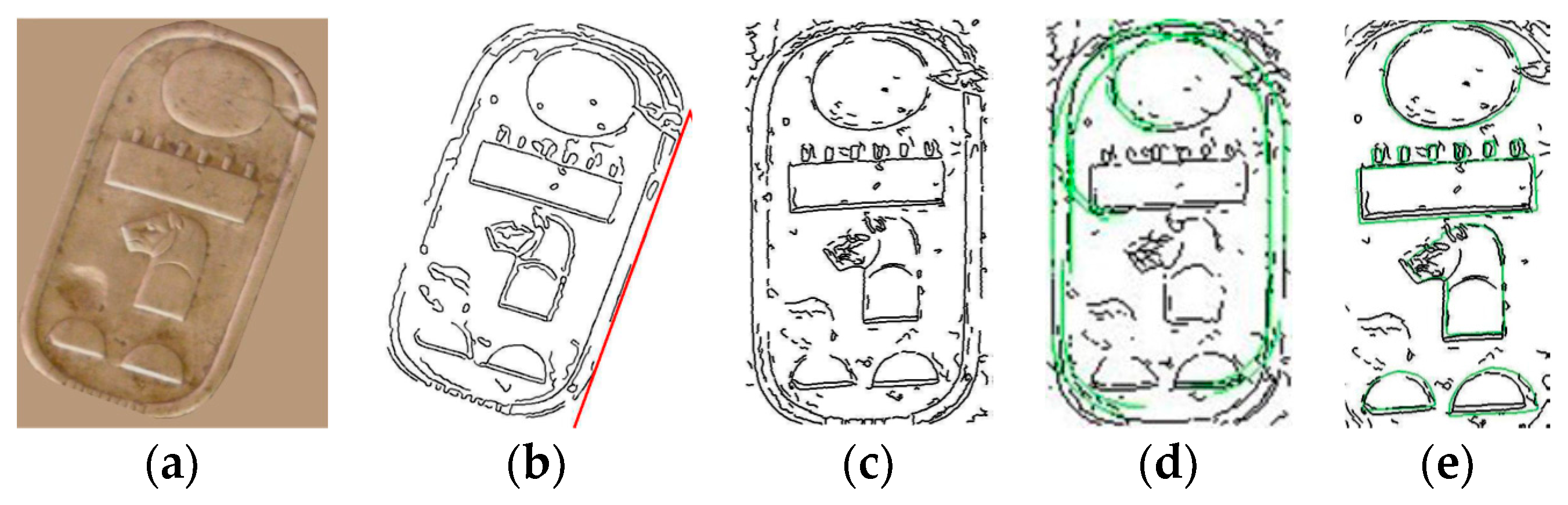
Step 5. If an image contains a rotated cartouche, as exemplified in
Figure 6a, an alignment process is optionally performed to place their main directions parallel to the vertical and horizontal axes (
Figure 6b). Following the procedure to detect lines in picture presented by [
27], the longest line of the cartouche’s edge is obtained, as well as its orientation.
Step 6. In order to extract the hieroglyphs of the image, a search of the four corners of the cartouche is accomplished. A further explanation of this technique can be found in Step 8, as this is also applied to identify hieroglyphs. The image is reduced to a maximum width, keeping the aspect rate.
Step 7. Once the limits of the cartouche are calculated, each Region of Interest (ROI) will be extracted. In this work, each ROI corresponds to a hieroglyph and is always located within a cartouche in the image.
Figure 6d,e shows the recognition of the cartouche borders and the ROI extraction process, respectively. Differences between hieroglyphs and cartouches are not remarkable because a similar model was used by Egyptian scribes. The ROI extraction process is described in
Section 2.2. As a summary,
Figure 7 shows a scheme of the object localization process described in this section.
2.2. Extraction and Identification of Hieroglyphs
At this point, the cartouche has been localized and the hieroglyphs will be individually extracted and identified. During the identification process, Chamfer [
28] and Hausdorff [
29] distances have been calculated between pairs of objects (one extracted by our algorithm from an image and the other coming from a database).
On one hand, Chamfer distance is calculated by means of the sum of the minimum distance for each point of the edge of an object
A and a point of the another edge of object
B. Chamfer distance considers all the points of the first object for obtaining the total sum:
On the other hand, Hausdorff distance is different because it only considers the greatest of all the distances from each point in the contour of object
A to the closest point in the contour of object
B. It is obtained as in Equation (3); firstly, calculating the minimal distance for each point of one edge to another edge and finally, selecting the maximum of them:
Table 1 shows the results of Chamfer and Hausdorff distances once compared the hieroglyph in
Figure 8a to the three hieroglyphs in
Figure 8b–d. One can observe that lower distances, and therefore a better matching, are achieved for the hieroglyph in
Figure 8d. Following the technique previously mentioned, an approximation to the Euclidean distance using Chamfer method is used. The extraction and identification of each hieroglyph is carried out by means of the following steps.
Step 8. First, the width of the hieroglyph is considered to be 8/10 of the width of the image, keeping the aspect rate. A hieroglyph is extracted when at least
T% of the points of the hieroglyph’s contour satisfy that:
- (a)
The Chamfer distance between each point of the hieroglyph’s contour (
ph) and each point of the cartouche’s contour (
pc) is lower than
d.
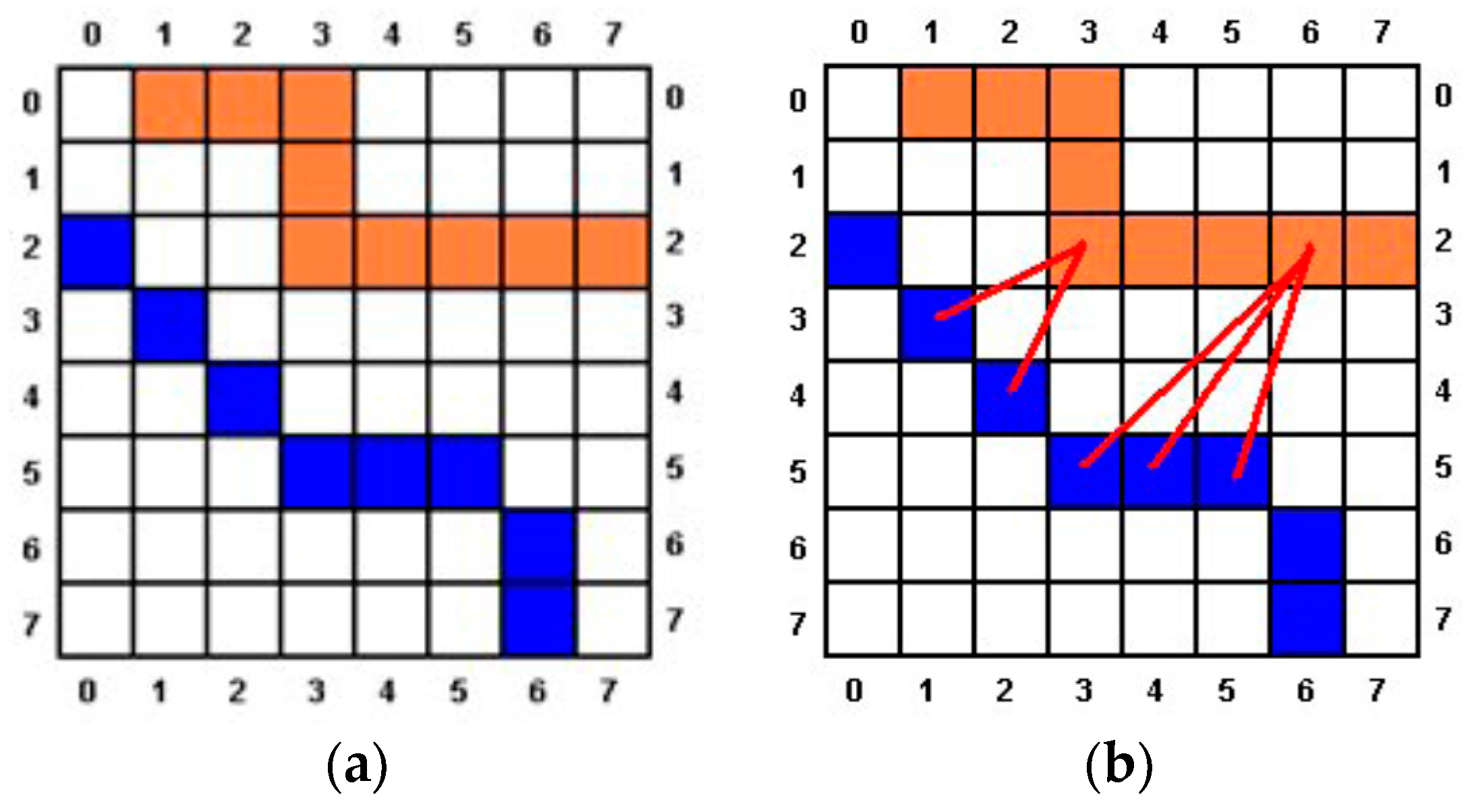
d is set to 3 pixels for a cartouche of 100 pixels width.
Figure 9, if the hieroglyph’s contour is marked in orange and the cartouche’s contour one is colored in blue, the distance between
ph(2,3) and the image is 2 because
pc(3,1) and
pc(4,2) are the closest points of the cartouche, and the distance to them is 2. The minimum distance from
ph(2,6) to the cartouche is higher than 3 because the closest points are
pc(5,3),
pc(5,4) and
pc(5,5). To calculate the distance it can be used a convolution mask over the central point, and it will be increased each iteration
- (b)
The angle of the contour line in
pc minus the angle of the contour line in
ph is less than
Max_Angle. The contours have been obtained by using the Canny algorithm, which produces non-maximum suppression (the width of the contour is 1 pixel), so the contours that include
pc and
ph have 1 pixel width.
Max_Angle is calculated as in (4):
The angle
of a point respect to their neighboring points is obtained as in (5) where
A is the number of pixels in the region,
xi are the
x positions with pixels, and
yi are the
y positions with pixels. The gradient of a point is not used in this proposal because the gradient gives the angle change of a point in a segment:
If a point pc satisfied (a) and (b), Pc is assigned to ph, and ph is assigned to pc. If a cartouche’s point (pck) has been assigned to a hieroglyph’s point (phk) then pck is not used again in the process.
The processed region is identified as a hieroglyph if it is satisfied the T percentage of the points assigned to the image and the number of continue lines that compose the contour assigned to the image (i.e., pc points that have been linked to ph) is lower than L (L = 20 in this work). This restriction prevents from some detected cases where noise provoke errors in detection.
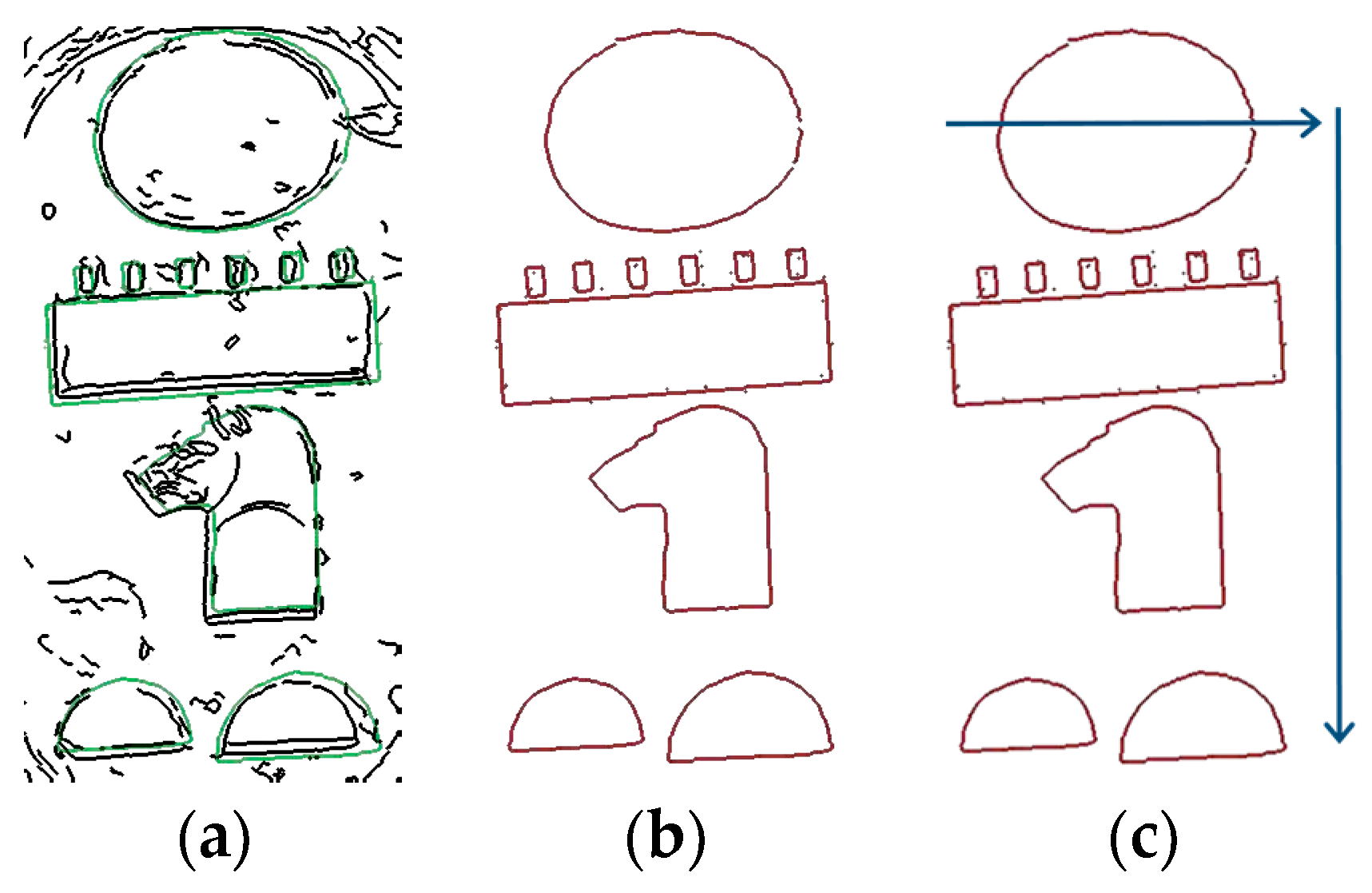
Step 9. The size of the region is reduced in
R pixels (
R = 2 pixels in this work) and the step 8 is repeated in order to find the same region in the image. See the two bread bun shape hieroglyphs at the bottom of
Figure 6e. The region’s size is reduced until its size is less than a percentage
Q of the cartouche’s width (concretely
Q = 33).
Step 10. If there are candidates to be labeled as hieroglyphs, the object with more coincidences is the accepted, i.e., the object with highest number of assigned points.
Step 11. Once all the candidates have been identified, a new searching process is launched to detect possible small hieroglyphs contained by bigger ones. To do this, it is checked if there are two objects sharing an area of at least 33%. In this case, the smaller object is rejected. This overlapping is calculated by considering each object as a box that contains the object itself, being this limited by the detected edges. As a summary,
Figure 10 shows a scheme of the hieroglyphs extraction process described in this section.
2.3. Interpretation of Cartouches
After analyzing the contents of the evaluated cartouche, a list of hieroglyphs with their positions is delivered. According to the procedures about Egyptian writing interpretation presented at the beginning of this section (i.e., studying the image from top to bottom and from left to right), the sequence of the hieroglyphs is read (see
Figure 11).
Note that ancient Egyptian texts can be also written from right to left, so this option is also considered. The list of labeled hieroglyphs obtained in the previous steps are analyzed to figure out the name of the represented monarch. As these symbols can be read from left to right or vice versa, several combinations should be considered. Aiming to arrange the symbols in a proper manner and obtain a coherent result (i.e., name and dynasty), Levenshtein distance is calculated for each group of symbols. Levenshtein distance is a string metric used to measure the difference between two text sequences
and
, e.g., the distance between two words is the minimum number of single-character edits (i.e., additions, subtractions or substitutions) required to change one word into the other [
30]. In this work, each hieroglyph corresponds to a character in the string, e.g., the distance between RA-MN-PHTY-T-T (Ramesses I), and RA-MN-HPR (Thutmose III) is 3 (one substitution and two additions). The Levenshtein distance for each name is calculated as in Equation (6), and the name with minor value is returned:
where
is the distance between the first hieroglyph
i of the text sequence
s and the first hieroglyph
j of the string
t; and
is the indicator function (equal to 0 when
and equal to 1 otherwise). The first expression in the bracket after
min corresponds to subtraction, the second one to addition and the third one to matching (if the respective hieroglyphs are similar).
Figure 12 shows a set of hieroglyphs and their equivalent phonetic transliteration, as generated by [
1]. Bearing this table in mind and considering the symbols obtained by our algorithm, from
Figure 11 the following sequence is obtained: RA (Circle), MN (Senet board), PHTY (Leopard head), T (Bread bun), T (Bread bun). The name of the king is RA-MN-PHTY-T-T (Ramesses I).
3. Results
This section presents the results obtained by the method presented in the previous section. Aiming to test our system, 261 images of cartouches were used: 76 images obtained from the Abydos King List, 109 images selected from the dataset in [
5], and 76 images from other Egyptian monuments and archaeological excavations. The Abydos King List, also known as the Abydos Table, is a list of the names of seventy-six kings of Ancient Egypt.
Although it was found on a wall in the Temple of Seti I at Abydos (Egypt), the table is currently exhibited at the British Museum in London (UK). The dataset of [
5] was built from ten pictures of the hieroglyphs found in texts covering the walls of the burial chambers of the Pyramid of Unas at Saqqara (Egypt).The proposed approach has been tested using 1785 hieroglyphs corresponding to the processed cartouches. For the validation of the hieroglyph recognition process, 743 hieroglyphs from the Gardiner’s sign list [
1] were used.
Table 2 shows information related to some of the evaluated cartouches, containing: inventory number, cartouche drawing, phonetic transliteration, and royal name and dynasty of the king. Intermediate and final visual results, corresponding to these cartouches, are shown in
Table 3.
Table 4 displays the averaged percentage of errors and standard deviations for the processed images. Because of the differences during the acquisition process and for comparative purposes, results obtained with images from the Abydos King List and the Egyptian Hieroglyph Dataset in [
5] are presented separately. Also for comparative purposes, results obtained after each of the three stages of the process are displayed. Images from the Abydos King List and Egyptian Hieroglyph Dataset [
5] presented the cartouche conveniently orientated. This makes easier the localization process as one can see from the obtained results. The rest of images used in this experiment do not present the cartouche individually. For this reason, the localization process of the cartouche in the image becomes more difficult than the previous one. Nevertheless, the average rate of success is 89.5. For the whole set of images used in this work, the average rate of success of the localization process is 95.4. Furthermore, the proposed localization process is also valid to recognize some other elements, such as stonemason’s marks as can be seen in
Figure 13.
The average rate of success obtained with the second stage (extraction and identification process) is 87.1. It outperforms the hieroglyphs recognition approach described in [
5].
Bad preservation of hieroglyphs is the most probably cause of error increase. In fact, the majority of the hieroglyphics that have survived until the present day have suffered the effects of time, weather exposure and even vandalism (
Figure 14 shows a set of cartouches).
The last stage of the method and the most important one is the recognition process. In this case, the average rate of success reached with the proposed method is 92.3. Although some hieroglyphs were not properly identified at second stage, it did not affect the recognition process because it took into account the whole hieroglyphs of the cartouche (see the results of Sekhemkhet and Amenhotep III cartouches in
Table 3). Thus, properly identified hieroglyphs favor the recognition of the cartouche to the detriment of not acceptably identified hieroglyphs.
The proposed method is able to increase the quantity of hieroglyphs without having the necessity of a training process. Low quality images produce errors in the recognition because of noise. In that case, the same hieroglyph with different changes may be introduced to reduce the error. Common methods to recognize Latin texts were revised but do not work well when there is noise in the image. Therefore, it is difficult to extract the regions, calculate descriptors or moments and use decision-making methods as proposed in previous works [
12,
13].
One advantage of the proposed method is that the color of hieroglyphs and background can be homogeneous. Besides this proposal avoids the problem of hieroglyphs that cannot be detected with threshold. Previous works revised at
Section 1 have considered threshold as the base to extract regions of interest.
An initial drawback of this method was processing time. Nevertheless, to solve this issue some modifications could be considered. To calculate the orientation, a table containing all of them was created. This increases the speed of processing. Several threads can be used to look for each hieroglyph.
4. Conclusions
This work presents an automatic method for hieroglyph deciphering that has been conceived to segment and identify the Egyptian characters contained in a cartouche. The proposed three-stage method takes into account several parameters, like the distance between points, and the orientation and the continuity of the edges. Although other techniques have been examined and applied to similar problems, this method has proven to be insensitive to the intensity and the completeness of the objects as well as variable lighting conditions. Promising results have been obtained from this study, delivering good results in terms of image analysis and Egyptian characters’ identification.
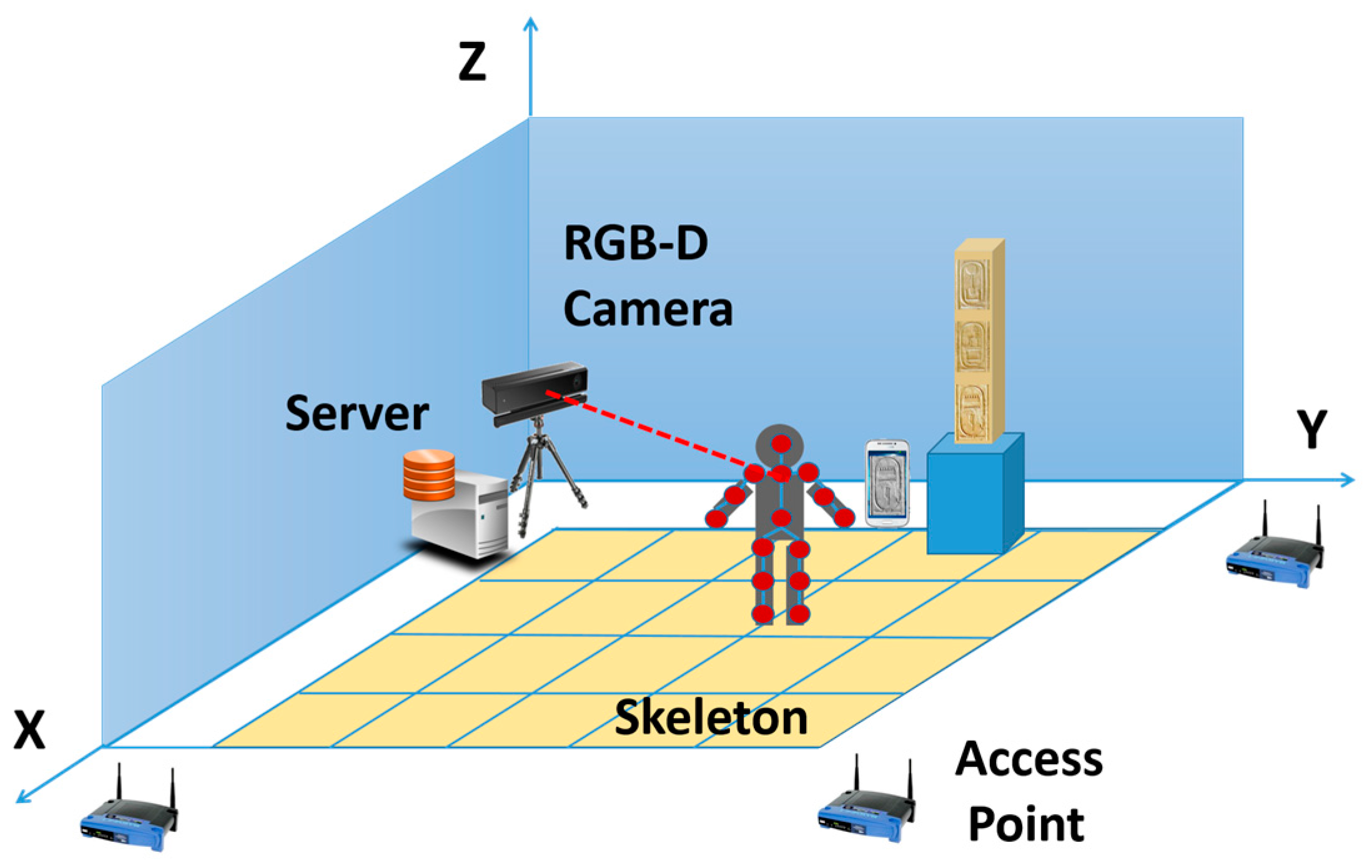
Aiming to deliver a new strategy for enriching the experience of users visiting a museum, this method can be combined with a positioning system. According to the approach presented in [
31], a combination of sensors of different nature, such as RGD-B cameras and WiFi positioning systems (as shown in
Figure 15), are employed to accurately locate users in an interior environment. Every access points (i.e., routers) spread in the facilities sends wireless signals that are received by the portable devices—usually smartphones—carried out by users. The Received Signal Strength Indication (RSSI) in each point is used to estimate the position of people in the museum. The identification of 3D skeletons by means of RGB-D cameras is combined with WPS data, making more precise this positioning.
RGB-D sensor used is based on a time-of-flight technology (ToF), Kinect v2. This device delivers up to 2 MPx images (1920 × 1080) at 30 Hz and 0.2 MPx depth maps with a resolution of 512 × 424 pixels. This Kinect camera is connected to a web server where data is saved and processed. The horizontal field of view of the RGB-D sensor is 70 degrees so it is only able to detect people in a section of the room. This section has a size of 3.71 × 3.71 m.
On the other hand, the cellphones employed for localization are also used to take pictures of the objects where the hieroglyphs are written. The processing of these pictures is detailed in this paper.
Although some trials have been already carried out in a controlled environment, the test of the whole infrastructure under more complex and variable circumstances will be performed in the near future, mounting the positioning system in a real gallery with several people visiting the room.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



































