Semantic-Based Building Extraction from LiDAR Point Clouds Using Contexts and Optimization in Complex Environment

 ,
,
Abstract
:1. Introduction
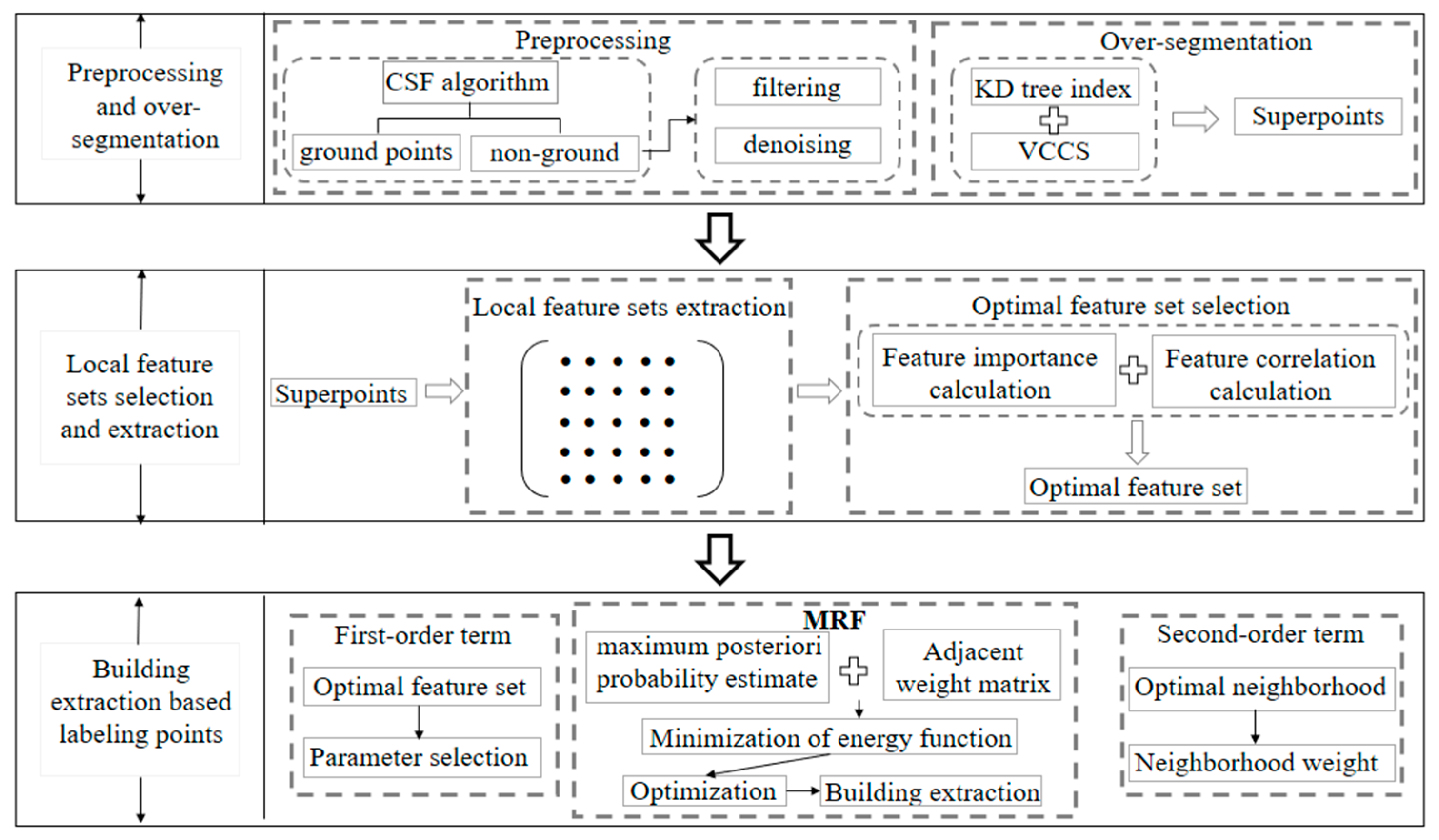
2. Materials and Methods
- Non-ground points are over-segmented to generate super-points;
- Local feature sets selection and extraction;
- Building extraction based on point cloud classification using context information.
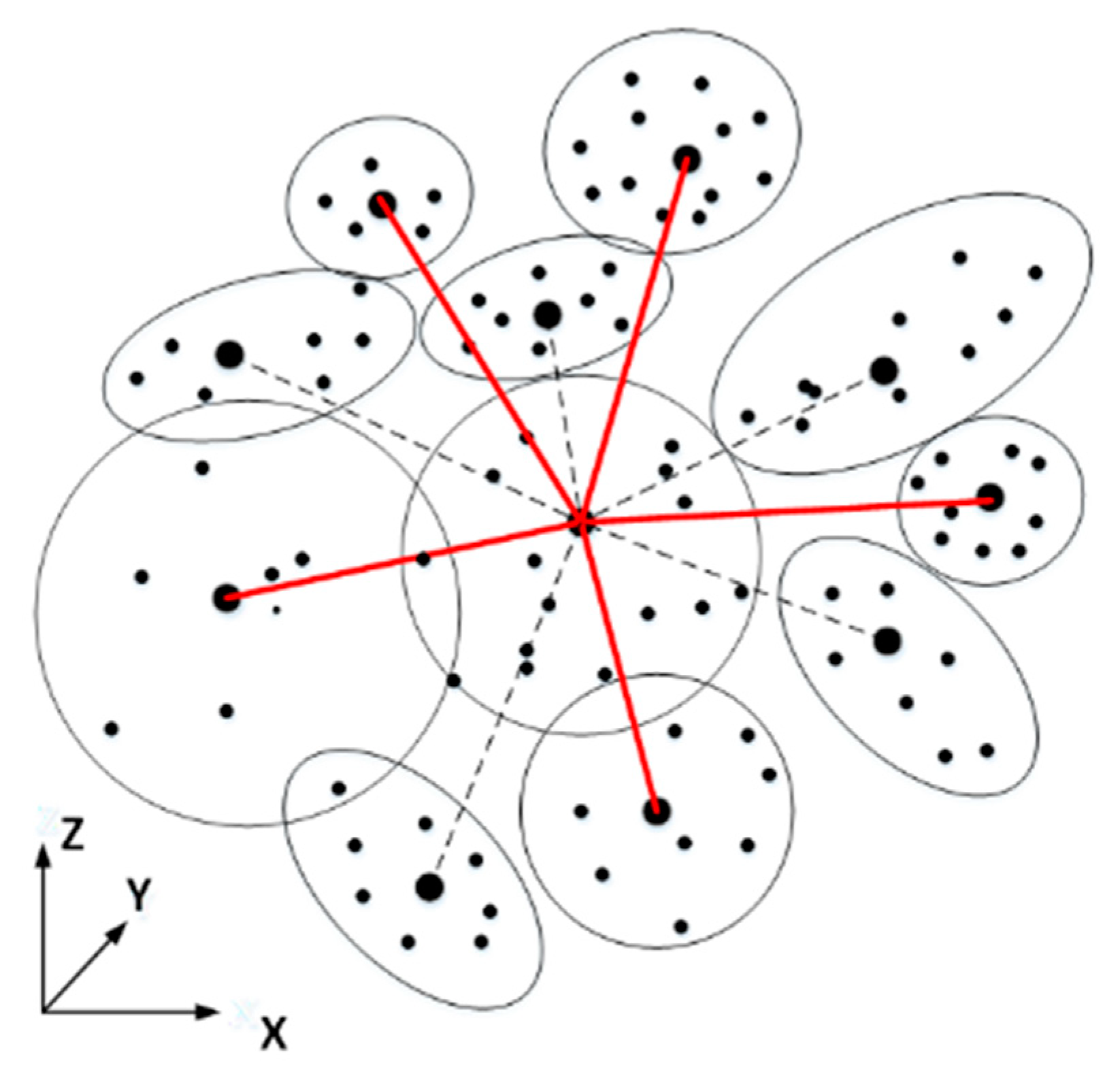
2.1. Super-Points Generation of Non-Ground Points
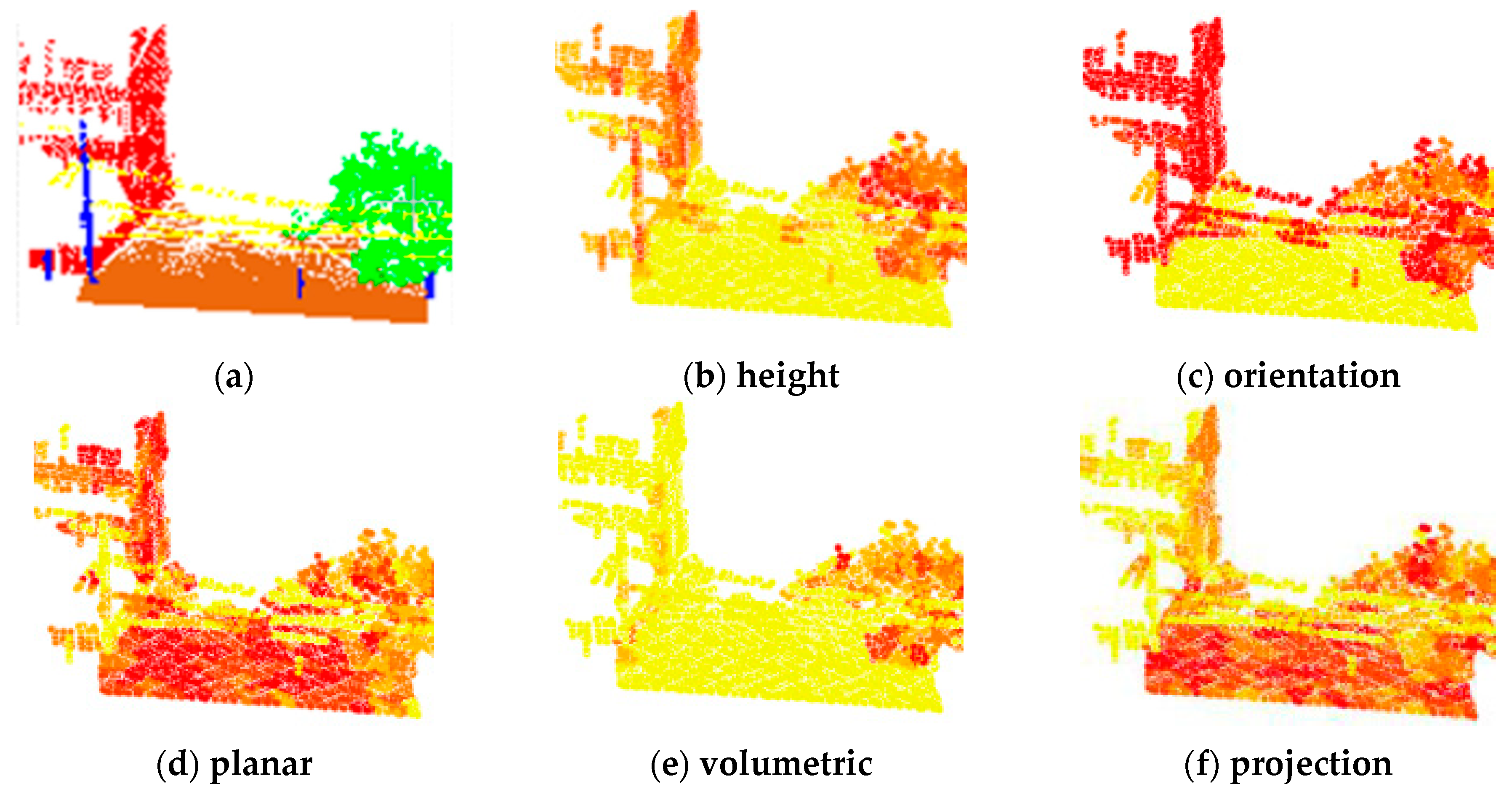
2.2. Local Feature Sets Selection and Extraction
2.3. Label Refinement by Higher Order MRF
2.4. Building Extraction Based on Semantic Labels
3. Results
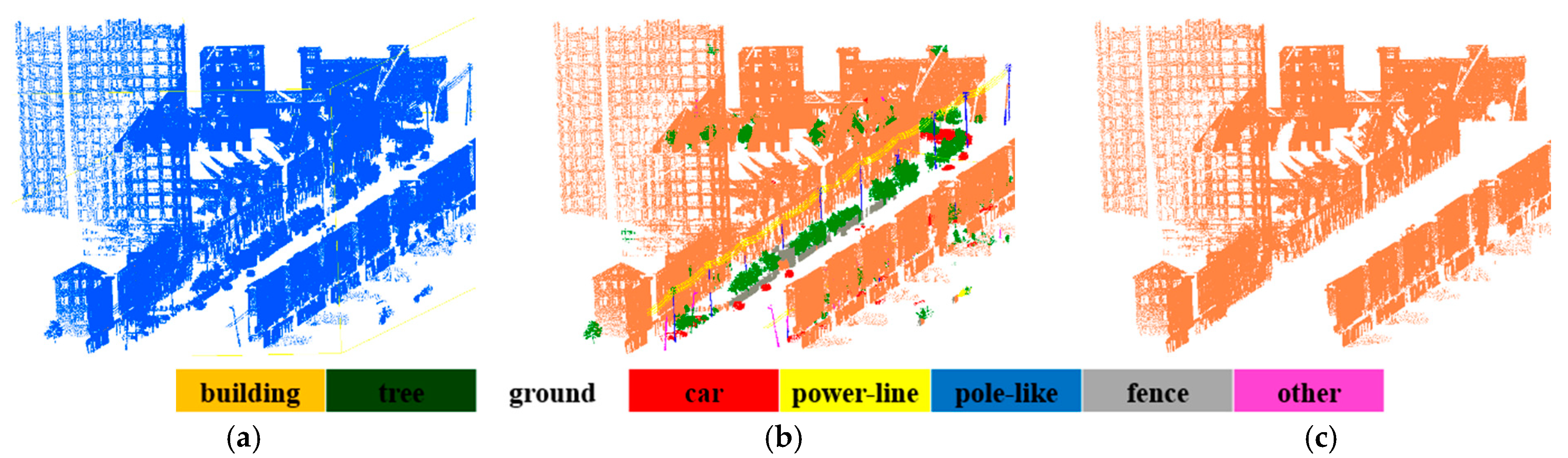
3.1. Experimental Data Description
3.2. Experimental Results
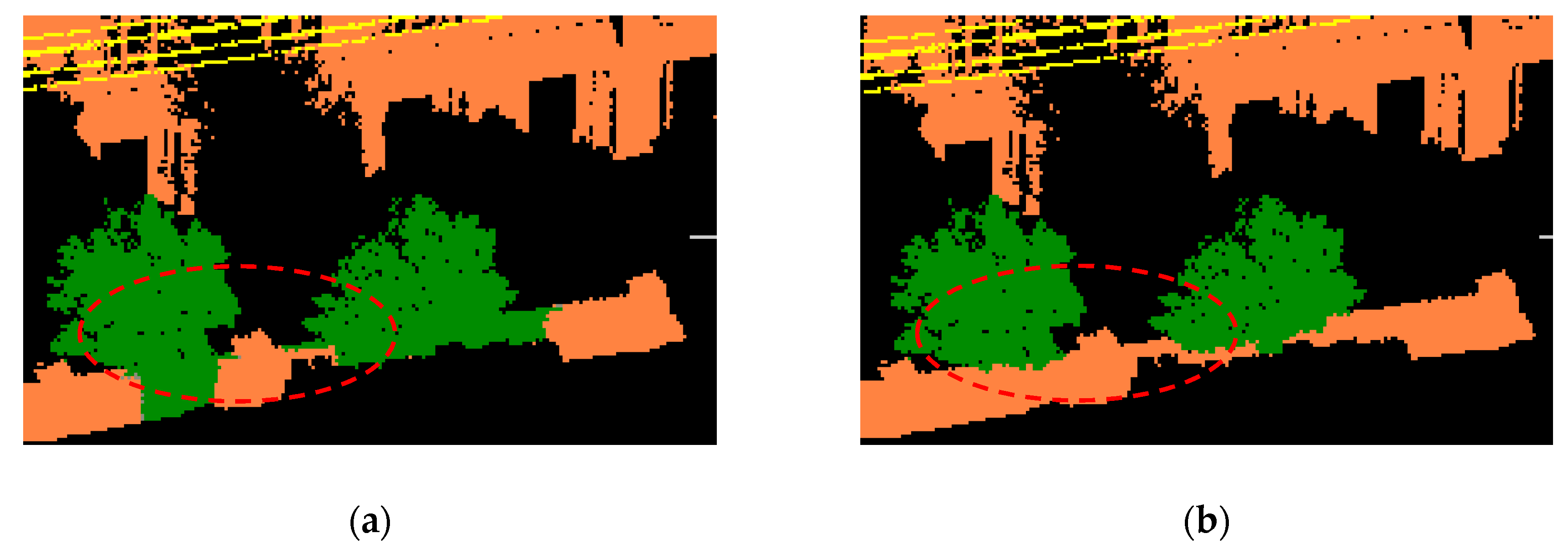
3.2.1. Preliminary Results of Semantic Labeling Using Contexts and MRF-Based Optimization
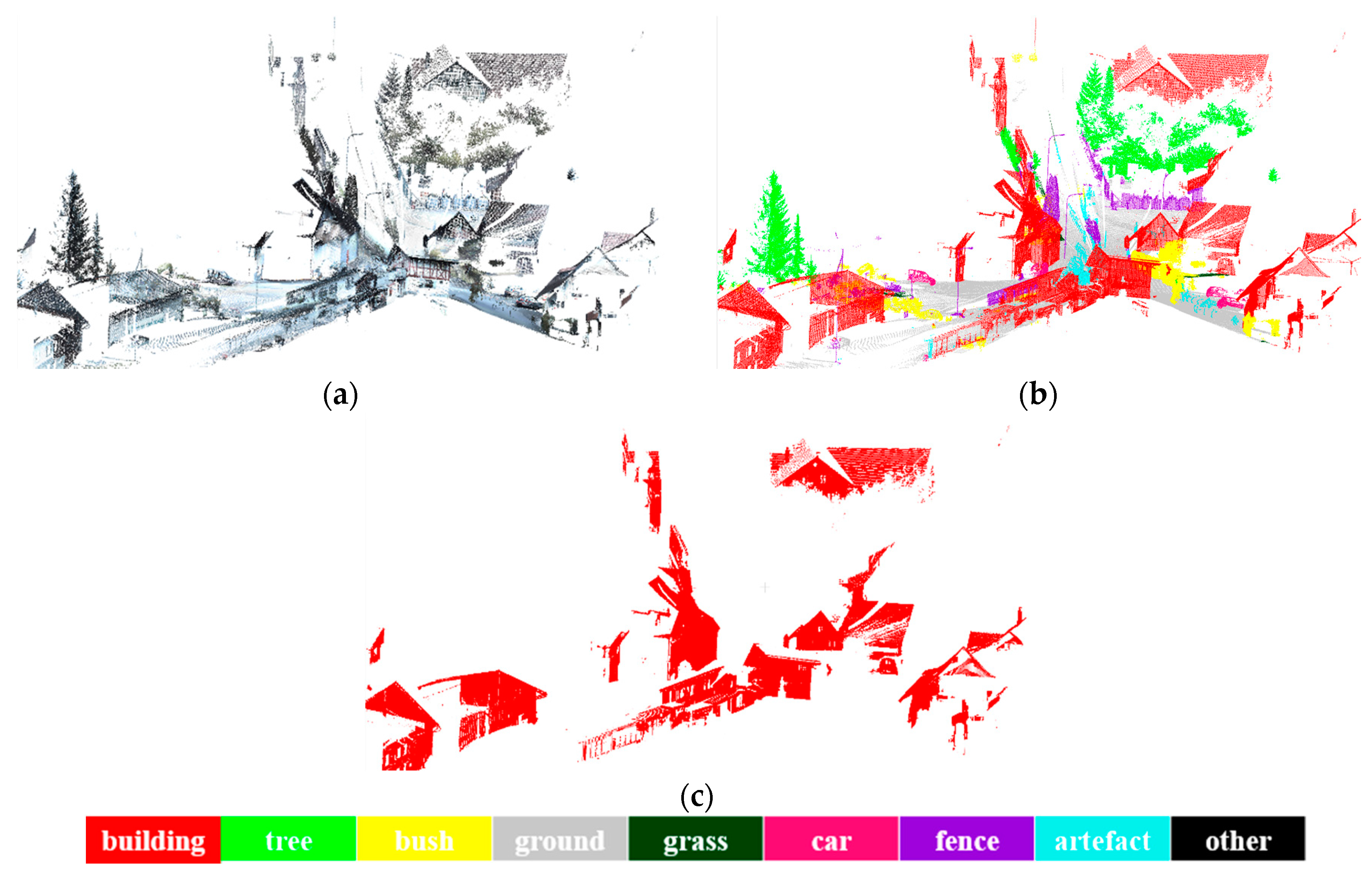
3.2.2. Classification-Based Extraction of Buildings
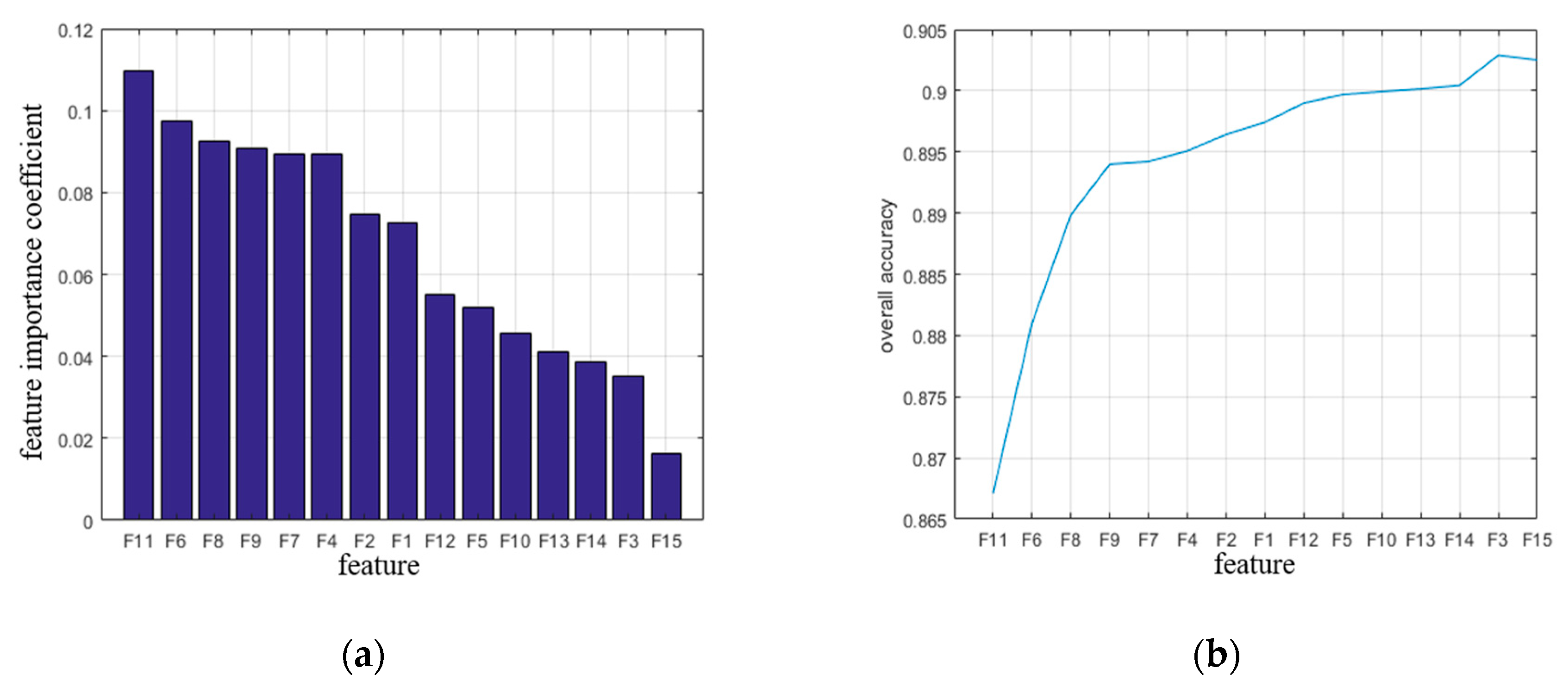
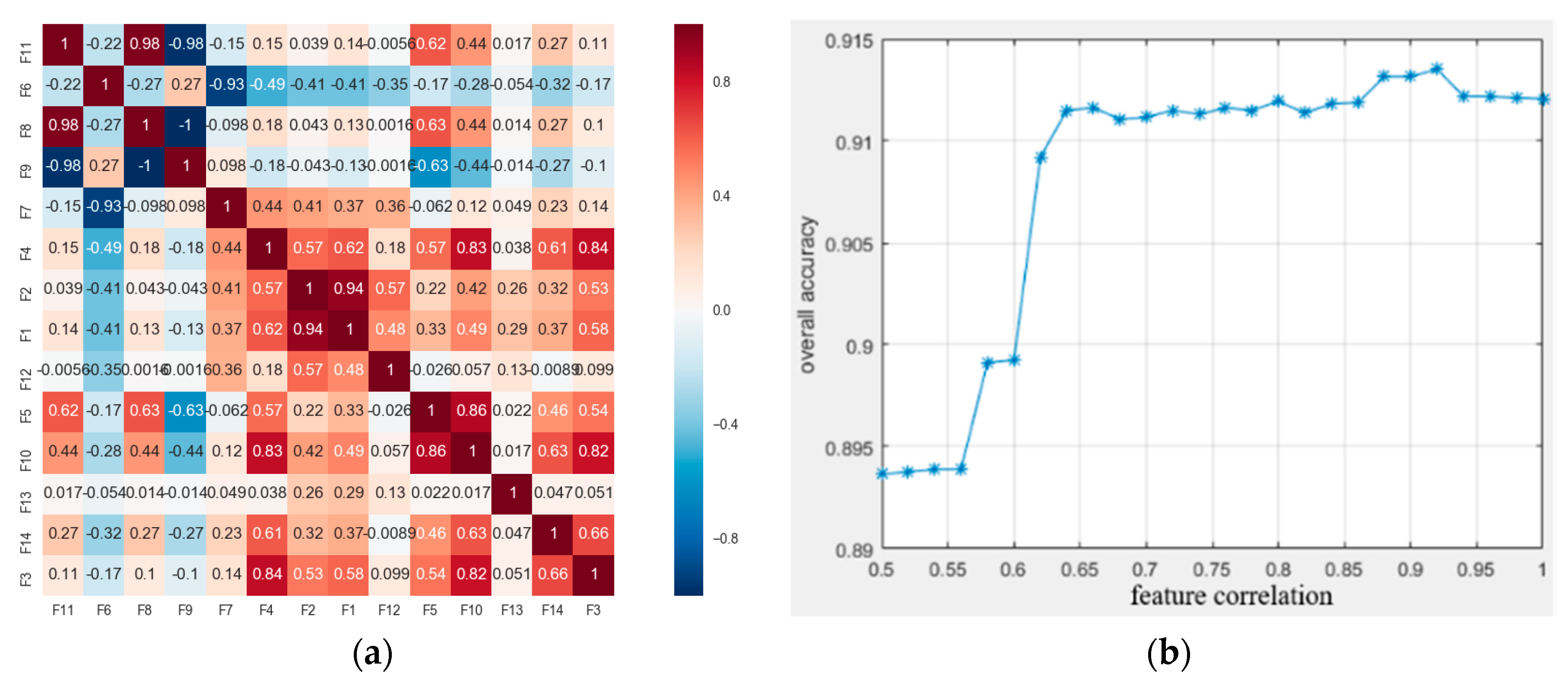
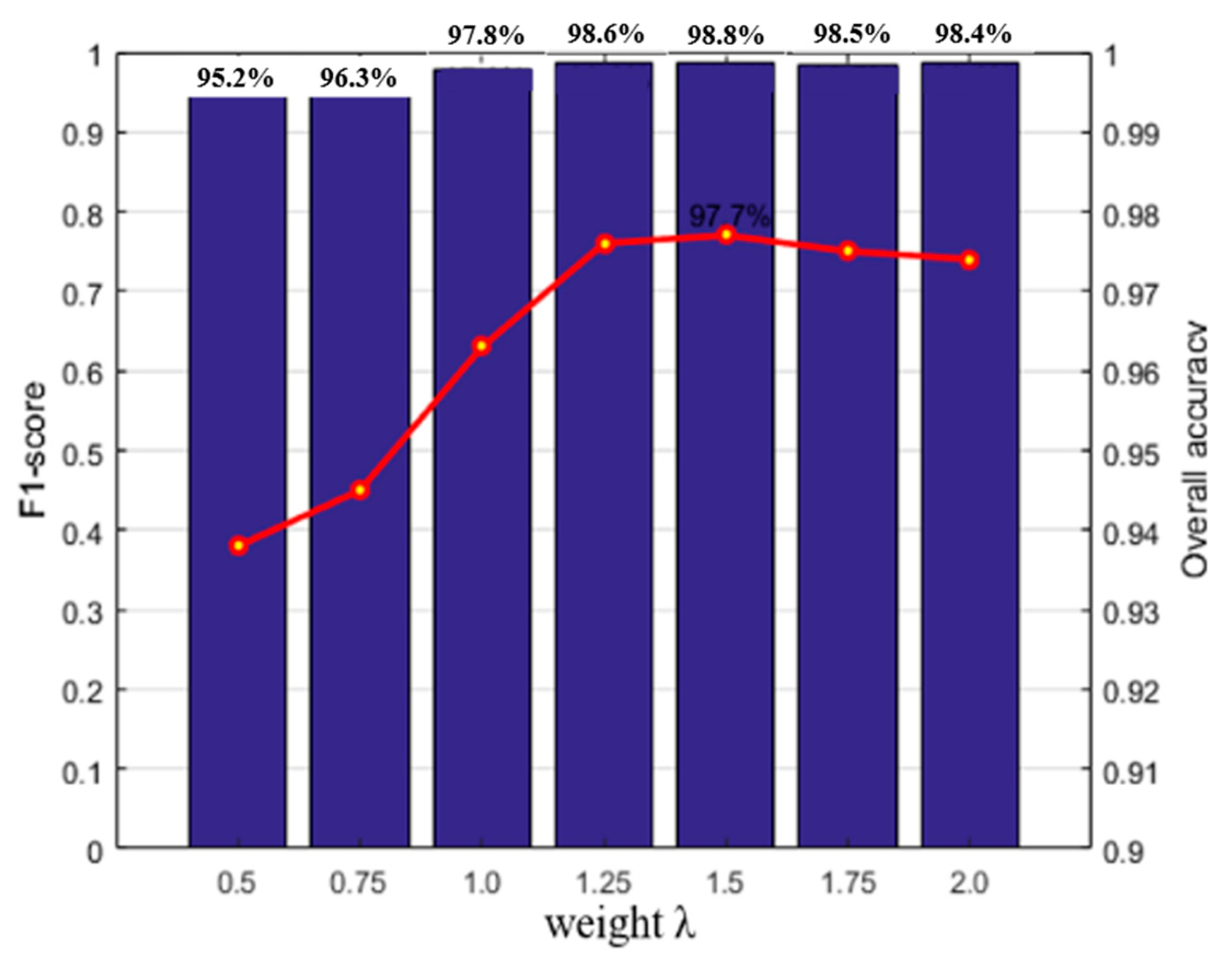
3.3. Experimental Analysis
3.4. Comparative Studies
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Yang, B.; Xu, W.; Dong, Z. Automated extraction of building outlines from airborne laser scanning point clouds. IEEE Geosci. Remote Sens. Lett. 2013, 10, 1399–1403. [Google Scholar] [CrossRef]
- Albers, B.; Kada, M.; Wichmann, A. Automatic extraction and regularization of building outlines from airborne LiDAR point clouds. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41, 555–560. [Google Scholar] [CrossRef]
- Du, S.; Zhang, Y.; Zou, Z.; Xu, S.; He, X.; Chen, S. Automatic building extraction from LiDAR data fusion of point and grid-based features. ISPRS J. Photogramm. Remote Sens. 2017, 130, 294–307. [Google Scholar] [CrossRef]
- Huang, R.; Yang, B.; Liang, F.; Dai, W.; Li, J.; Tian, M.; Xu, W. A top-down strategy for buildings extraction from complex urban scenes using airborne LiDAR point clouds. Infrared Phys. Technol. 2018, 92, 203–218. [Google Scholar] [CrossRef]
- Gao, J.; Yang, R. Online building segmentation from ground-based LiDAR data in urban scenes. In Proceedings of the IEEE International Conference on 3D Vision (3DV), Seattle, WA, USA, 29 June–1 July 2013. [Google Scholar]
- Fan, H.; Yao, W.; Tang, L. Identifying man-made objects along urban road corridors from mobile LiDAR data. IEEE Geosci. Remote Sens. Lett. 2014, 11, 950–954. [Google Scholar] [CrossRef]
- Wang, Y.; Ma, Y.; Zhu, A.X.; Zhao, H.; Liao, L. Accurate facade feature extraction method for buildings from three-dimensional point cloud data considering structural information. ISPRS J. Photogramm. Remote Sens. 2018, 139, 146–153. [Google Scholar] [CrossRef]
- Pu, S.; Vosselman, G. Knowledge based reconstruction of building models from terrestrial laser scanning data. ISPRS J. Photogramm. Remote Sens. 2009, 64, 575–584. [Google Scholar] [CrossRef]
- Börcs, A.; Nagy, B.; Benedek, C. Fast 3D urban object detection on streaming point clouds. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Xia, S.; Wang, R. Extraction of residential building instances in suburban areas from mobile LiDAR data. ISPRS J. Photogramm. Remote Sens. 2018, 144, 453–468. [Google Scholar] [CrossRef]
- Aijazi, A.; Checchin, P.; Trassoudaine, L. Segmentation based classification of 3d urban point clouds: A super-voxel based approach with evaluation. Remote Sens. 2013, 5, 1624–1650. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Cheng, L.; Chen, Y.; Wu, Y.; Li, M. Building point detection from vehicle-borne LiDAR data based on voxel group and horizontal hollow analysis. Remote Sens. 2016, 8, 419. [Google Scholar] [CrossRef] [Green Version]
- Yang, B.; Dong, Z.; Zhao, G.; Dai, W. Hierarchical extraction of urban objects from mobile laser scanning data. ISPRS J. Photogramm. Remote Sens. 2015, 99, 45–57. [Google Scholar] [CrossRef]
- Niemeyer, J.; Rottensteiner, F.; Soergel, U.; Heipke, C. Contextual Classification of Point Clouds Using a Two-Stage CRF. Comput. Inf. Technol. 2015, 2, 141–148. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Q.; Li, Y.; Hu, H.; Wu, B. Robust point cloud classification based on multi-level semantic relationships for urban scenes. ISPRS J. Photogramm. Remote Sens. 2017, 129, 86–102. [Google Scholar] [CrossRef]
- Landrieu, L.; Simonovsky, M. Large-scale Point Cloud Semantic Segmentation with Superpoint Graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, Utah, UT, USA, 18–22 June 2018. [Google Scholar]
- Boulch, A.; Saux, B.; Audebert, N. Unstructured Point Cloud Semantic Labeling Using Deep Segmentation Networks. In Proceedings of the 10th Eurographics Workshop on 3D Object Retrieval, Lyon, France, 23–24 April 2017. [Google Scholar]
- Boulch, A. ConvPoint: Continuous convolutions for cloud processing. In Proceedings of the 12th Eurographics Workshop on 3D Object Retrieval, Genova, Italy, 5–6 May 2019. [Google Scholar]
- Tchapmi, L.; Choy, C.; Armeni, I.; Gwak, J.; Savarese, S. SEGCloud: Semantic Segmentation of 3D Point Clouds. In Proceedings of the IEEE International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L. KPConv: Flexible and Deformable Convolution for Point Clouds. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Hackel, T.; Savinov, N.; Ladicky, L.; Wegner, J.; Schindler, K.; Pollefeys, M. Semantic3D.net: A new Large-scale Point Cloud Classification Benchmark. ISPRS-Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 4, 91–98. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Qi, J.; Wan, P.; Xie, D.; Wang, X.; Yan, G. An easy-to-use airborne LiDAR data filtering method based on cloth simulation. Remote Sens. 2016, 8, 501. [Google Scholar] [CrossRef]
- Papon, J.; Abramov, A.; Schoeler, M.; Worgotter, F. Voxel Cloud Connectivity Segmentation-Supervoxels for Point Clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 2027–2034. [Google Scholar]
- Ramiya, A.M.; Nidamanuri, R.R.; Ramakrishnan, K. A supervoxel-based spectro-spatial approach for 3D urban point cloud labelling. Int. J. Remote Sens. 2016, 37, 4172–4200. [Google Scholar] [CrossRef]
- Babahajiani, P.; Fan, L.; Kamarainen, J.; Gabbouj, M. Automated super-voxel based features classification of urban environments by integrating 3D point cloud and image content. In Proceedings of the IEEE International Conference on Signal & Image Processing Applications (ICSIPA), Kuala Lumpur, Malaysia, 19–20 October 2015. [Google Scholar]
- Song, S.; Jo, S.; Lee, H. Boundary-enhanced supervoxel segmentation for sparse outdoor LiDAR data. Electron. Lett. 2014, 50, 1917–1919. [Google Scholar] [CrossRef] [Green Version]
- Luo, H.; Wang, C.; Wen, C.; Chen, Z.; Zai, D.; Yu, Y.; Li, j. Semantic Labeling of Mobile LiDAR Point Clouds via Active Learning and Higher Order MRF. IEEE Trans. Geosci. Remote Sens. 2018, 56, 1–14. [Google Scholar] [CrossRef]
- Lin, Y.; Wang, C.; Zai, D.; Li, W.; Li, J. Toward better boundary preserved supervoxel segmentation for 3D point clouds. ISPRS J. Photogramm. Remote Sens. 2018, 143, 39–47. [Google Scholar] [CrossRef]
- Lin, Y.; Wang, C.; Chen, B.; Zai, D.; Li, J. Facet Segmentation-Based Line Segment Extraction for Large-Scale Point Clouds. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4839–4854. [Google Scholar] [CrossRef]
- Li, Q.; Cheng, X. Comparison of Different Feature Sets for TLS Point Cloud Classification. Sensors 2018, 18, 4206. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Saeys, Y.; Inza, I.; Larrañaga, P. A review of feature selection techniques in bioinformatics. Bioinformatics 2007, 23, 2507–2517. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Weinmann, M.; Jutzi, B.; Hinz, S.; Mallet, C. Semantic point cloud interpretation based on optimal neighborhoods, relevant features and efficient classifiers. ISPRS J. Photogramm. Remote Sens. 2015, 105, 286–304. [Google Scholar] [CrossRef]
- Weinmann, M.; Jutzi, B.; Mallet, C. Feature relevance assessment for the semantic interpretation of 3d point cloud data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, 2, 313–318. [Google Scholar] [CrossRef] [Green Version]
- Quinlan, J.R. Induction of decision trees. Mach. Learn 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Pearson, K. Mathematical contributions to the theory of evolution. III. Regression, heredity and panmixia. Philos. Trans. Roy. Soc. Lond. A 1896, 187, 253–318. [Google Scholar]
- Edelsbrunner, H.; Kirkpatrick, D.; Seidel, R. On the shape of a set of points in the plane. IEEE Trans. Inf. Theory 1983, 29, 551–559. [Google Scholar] [CrossRef] [Green Version]
- Boykov, Y.; Jolly, M. Interactive graph cuts for optimal boundary & region segmentation of objects in N-D images. IEEE Int. Conf. Comput. Vis. 2001, 1, 105–112. [Google Scholar]
- Yang, B.; Dong, Z.; Liu, Y.; Liang, F.; Wang, Y. Computing multiple aggregation levels and contextual features for road facilities recognition using mobile laser scanning data. ISPRS J. Photogramm. Remote Sens. 2017, 126, 180–194. [Google Scholar] [CrossRef]
- Dong, Z.; Yang, B.; Hu, P.; Sebastian, S. An efficient global energy optimization approach for robust 3D plane segmentation of point clouds. ISPRS J. Photogramm. Remote Sens. 2018, 137, 112–133. [Google Scholar] [CrossRef]
- Wang, L.; Huang, Y.; Shan, J.; Liu, H. MSNet: Multi-Scale Convolutional Network for Point Cloud Classification. Remote Sens. 2018, 10, 612. [Google Scholar] [CrossRef] [Green Version]
- Kang, Z.; Yang, J. A probabilistic graphical model for the classification of mobile LiDAR point clouds. ISPRS J. Photogramm. Remote Sens. 2018, 143, 108–123. [Google Scholar] [CrossRef]
- Rusu, R.; Cousins, S. 3D is here: Point cloud library (PCL). In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011. [Google Scholar]
- Culjak, I.; Abram, D.; Pribanic, T.; Dzapo, H. A brief introduction to OpenCV. In Proceedings of the 35th IEEE International Convention MIPRO, Opatija, Croatia, 21–25 May 2012. [Google Scholar]
- Swami, A.; Jain, R. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2012, 12, 2825–2830. [Google Scholar]
- Zhang, Z.; Hua, B.; Yeung, S. ShellNet: Efficient Point Cloud Convolutional Neural Networks using Concentric Shells Statistics. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Local Features | Descriptors | Dimension | Identifiable Objects | |
|---|---|---|---|---|
| 1 | Height feature | 2 | power line | |
| 2 | ||||
| 3 | Covariance matrix feature | 9 | building, power line | |
| 4 | building | |||
| 5 | tree | |||
| 6 | building, power line | |||
| 7 | building | |||
| 8 | tree | |||
| 9 | tree | |||
| 10 | tree | |||
| 11 | building | |||
| 12 | Angle feature | 1 | building façade, tree | |
| 13 | Planarity feature | D | 1 | building façade, tree |
| 14 | Projection feature | 2 | building façade, pole | |
| 15 | pole-like |
| Dataset A | Dataset B | Dataset C | |||||||
|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | |
| Buildings | 96.9% | 97.6% | 97.2% | 94.3% | 98.6% | 96.4% | 93.2% | 92.1% | 92.5% |
| Trees | 88.1% | 94.1% | 91.0% | 84.7% | 98.6% | 91.1% | 85.8% | 94.2% | 89.1% |
| Bush | / | / | / | 94.1% | 46.0% | 61.8% | / | / | / |
| Pole-like | 84.4% | 79.4% | 81.8% | / | / | / | 27.9% | 32.4% | 30.1% |
| Ground | 98.9% | 99.1% | 99.0% | 98.8% | 98.5% | 98.6% | 99.1% | 97.2% | 98.1% |
| Grass | / | / | / | 94.1% | 96.5% | 95.3% | / | / | / |
| Powerline | 84.6% | 85.4% | 85.0% | / | / | / | / | / | / |
| Cars | 81.5% | 86.8% | 84.1% | 83.4% | 83.4% | 83.4% | 57.6% | 95.2% | 60.9% |
| Fence | 93.2% | 96.5% | 95.4% | 10.4% | 4.4%% | 6.2% | 99.8% | 60.9% | 87.1% |
| Artefacts | / | / | / | 52.9% | 74.7% | 61.9% | / | / | / |
| Others | 90.9% | 91.5% | 91.2% | 88.6% | 89.3% | 88.9% | 15.9% | 1.9% | 2.8% |
| OA | 93.2% | 93.2% | 83.3% | ||||||
| Dataset A | Dataset B | Dataset C | |||||||
|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | |
| Buildings | 97.7% | 97.5% | 97.5% | 95.4% | 98.5% | 96.9% | 94.6% | 93.5% | 92.9% |
| Trees | 94.8% | 93.7% | 93.8% | 84.9% | 98.5% | 91.2% | 89.1% | 95.0% | 93.4% |
| Bush | / | / | / | 94.2% | 50.3% | 65.6% | / | / | / |
| Pole-like | 84.9% | 88.1% | 86.5% | / | / | / | 85.6% | 40.6% | 79.0% |
| Ground | 99.5% | 99.1% | 99.3% | 98.9% | 98.6% | 98.7% | 98.4% | 98.8% | 98.6% |
| Grass | / | / | / | 94.4% | 96.7% | 95.5% | / | / | / |
| Powerline | 91.2% | 92.2% | 93.3% | / | / | / | / | / | / |
| Cars | 94.5% | 92.2% | 93.3% | 85.6% | 86.2% | 85.9% | 56.7% | 90.3% | 70.1% |
| Fence | 93.5% | 95.6% | 94.7% | 13.8% | 7.9%% | 10.0% | 94.1% | 61.8% | 88.2% |
| Artefacts | / | / | / | 62.8% | 73.5% | 67.7% | / | / | / |
| Others | 89.5% | 90.8% | 90.5% | 87.9% | 89.8% | 88.8% | 8.9% | 0.5% | 1.4% |
| OA | 95.9% | 94.1% | 84.7% | ||||||
| Dataset | Super-Points Generation | Features Computation | Initial Classification | Optimized Results | Buildings Extraction | Total Time Cost |
|---|---|---|---|---|---|---|
| A | 859.543 | 106.425 | 2.343 | 3.194 | 20.161 | 1188.909 |
| B | Total: 513.35 min | |||||
| C | 305.532 | 46.317 | 0.520 | 1.672 | 8.413 | 375.145 |
| Dataset | Yang et al. [13] | Zhang et al. [45] | Wang et al. [40] | Proposed Method | ||||
|---|---|---|---|---|---|---|---|---|
| Overall | Building | Overall | Building | Overall | Building | Overall | Building | |
| A | 92.3% | 97.5% | 90.6% | 91.4% | / | / | 95.9% | 97.7% |
| B | 85.3% | 94.5% | 93.2% | 94.2% | / | / | 94.1% | 95.4% |
| C | 82.9% | 86.4% | / | / | 83.2% | 93.1% | 84.7% | 94.6% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Jiang, T.; Yu, M.; Tao, S.; Sun, J.; Liu, S. Semantic-Based Building Extraction from LiDAR Point Clouds Using Contexts and Optimization in Complex Environment. Sensors 2020, 20, 3386. https://0-doi-org.brum.beds.ac.uk/10.3390/s20123386
Wang Y, Jiang T, Yu M, Tao S, Sun J, Liu S. Semantic-Based Building Extraction from LiDAR Point Clouds Using Contexts and Optimization in Complex Environment. Sensors. 2020; 20(12):3386. https://0-doi-org.brum.beds.ac.uk/10.3390/s20123386
Chicago/Turabian StyleWang, Yongjun, Tengping Jiang, Min Yu, Shuaibing Tao, Jian Sun, and Shan Liu. 2020. "Semantic-Based Building Extraction from LiDAR Point Clouds Using Contexts and Optimization in Complex Environment" Sensors 20, no. 12: 3386. https://0-doi-org.brum.beds.ac.uk/10.3390/s20123386