1. Introduction
Diesel engine is the power core of the ship. In the manufacturing process of the diesel engine, the assembly quality affects the performance indexes of the diesel engine, which is an important factor to measure the quality of the whole engine. Previous studies on the relationship between assembly clearance and machine quality have mainly focused on the mechanical principle, while the data mining method is still less used to mine the relationship between assembly clearance and machine quality. With the development of data mining technology and the accumulation of a large number of raw data, it is possible to apply data mining methods to solve this problem.
With the development of computers and the internet, the amount of data is increasing. Data always contain noise; therefore, it is necessary to handle noisy data to obtain accurate results. Some researchers have put forward methods to address this issue. Among these methods, the two classic methods are fuzzy set [
1] and evidence theory [
2]. However, these methods sometimes require additional information or prior knowledge, such as fuzzy membership functions, basic probability assignment functions and statistical probability distributions, which are not always easy to obtain.
Rough set theory provides a new way to address vagueness and uncertainty [
3]. The core concept of rough set theory is to deduce imprecise data, or to find the correlation between different data by representing the given finite set as an upper approximation set or a lower approximation set.
Despite the advantages of rough set theory, some challenges need to be overcome in practical applications. These problems can be classified into two categories: (1) There are certain limitations of a rough set in practical applications. Many extension and correction theories to the classical rough set have been developed. For example, a model integrating distance and partition distance with a rough set on the basis of a rough set based on a similarity relation was proposed [
4]. This model also provided a new understanding of the classification criteria of rough set equivalence classes. Φ-Rough set, another extension of the rough set theory based on the similarity relation, was proposed [
5]. Φ-Rough set replaces the indiscernibility relation of the crisp rough set theory by the notion of the Φ-approximate equivalence relation. Use of dynamic probabilistic rough sets with incomplete data addressed the challenge of processing such dynamic and incomplete data [
6]. Based on a three-way classification of attributes into the pair-wise disjoint sets of core, marginal, and non-useful attributes, the relationships between the corresponding classes of classification-based and class-specific attributes were examined [
7]. (2) A rough set is sensitive to noisy data. The accuracy of a decision-making model based on a rough set is low when applied to the analysis of datasets containing noisy data [
8]. To strengthen its ability to resist noisy data, the variable precision rough set (in short, VPRS) was proposed [
9]. VPRS has been applied in several fields, such as data mining [
10], decision systems [
11], and expert systems [
12], and provides satisfactory results. Similarly, knowledge reduction is an important research direction of VPRS. However, the related methods and theories are not mature. The most popular study based on VPRS is attribute reduction. In addition, variable precision threshold beta is usually determined by experts. Hence, some researchers have proposed the selection method of beta, which can reduce the difficulty of beta determination due to a lack of prior knowledge [
13,
14]. Zavareh M. and Maggioni V. proposes an approach to analyze water quality data that is based on rough set theory [
15]. Bo C. studies multigranulation neutrosophic rough sets (MNRSs) and their applications in multi-attribute group decision-making [
16]. Akram M., Ali G. and Alsheh N. O. introduce notions of soft rough m-polar fuzzy sets and m-polar fuzzy soft rough sets as novel hybrid models for soft computing, and investigate some of their fundamental properties [
17]. Jia X. et al. propose an optimization representation of decision-theoretic rough set model. An optimization problem is proposed by considering the minimization of the decision cost [
18]. Cao T. et al. discusses the use of parallel computation to obtain rough set approximations from large-scale information systems where missing data exist in both condition and decision attributes [
19].
The linear programming method is a classical mathematical method, and its principle is to solve a series of linear constraint equations or inequalities on the premise of satisfying the method of solving linear functions of extreme objectives. Though its mathematical model is simple, it is widely used in various fields, such as location problems, route planning problems, manufacturing problems, marketing problems, and resource allocation problems. Application of the linear programming method can provide an effective and feasible decision-making basis for the aforementioned problems.
The linear programming problem (LP) is a problem of solving the maximum or minimum value of a linear function under a set of linear equality and inequality constraints [
20]. The general linear programming model is composed of the following elements parameters and variables, objective functions, and constraint conditions.
There has been much research on optimization problems based on linear programming theory, such as the theory of linear programming and establishment of a mathematical model [
21], as well as the combination of practical production, and enterprise and establishment of a linear programming model to solve the problem of allocating enterprise production resources [
22]. Linear programming methods have also been used to optimize input–output models, and to establish a multi-objective linear programming model to maximize economic benefits and to minimize resource utilization [
23]. One of the most important application fields of linear programming are location problems. A mixed integer linear programming model has been built to select the location of renewable energy facilities [
24], and to study a multi-stage facility location problem [
25]. To solve the vehicle routing problem of a distribution center, a two-stage solution was proposed.
One of the preprocessing methods of noisy data is regression. Hence, it is obvious that the linear programming model has a strong ability to resist noisy data, and designing a decision-making model based on rough set achieves the ideal accuracy. The integration of the rough set with the linear programming model will not only improve the inadequacies of the rough set, but will also make the decision-making model reach optimal accuracy, theoretically. There are a few studies on the integration of the rough set and linear programming model so far. Zhang et al. proposed a multi-objective linear programming method based on the rough set, to develop a classification for data mining. Based on their model, an improved model to predict hot spots of protein interactions was proposed [
26]. However, among all of the above studies, the rough set was only used to reduce the attribute set. Because nonlinear models are considered to be the only way to describe the rough set, there are no studies on the application of linear programming methods to optimize decision-making models based on the rough set.
The biggest weakness of the decision model based on the rough set is its sensitivity to noisy data. VPRS only broadens the requirement of the upper and lower approximations in the definition, and the selection of precision often has strong subjectivity and lacks scientific evidence. VPRS can only be used as an auxiliary method to improve the resistance of the rough set model to noisy data, rather than the main method. Therefore, in this study, we extend the rough set theory via mixed-integer linear programming and we propose a model called the mixed-integer linear programming model for rough set-based classification with flexible attribute selection (in short, MILP-FRST). This model includes the advantages of MILP in resisting noisy data, and it has the ability to select attributes flexibly and automatically. MILP-FRST is able to divide the universe by attribute sets, calculate the lower approximation set under the condition of the presupposed variable precision and the minimum support number, and calculate the decision accuracy and screen out attributes. We set the maximum number of elements in the determination area as the objective function of the model. The processing of attribute selection, and partitioning of the attribute set for the universe are maximized by the objective function. During implementation, attributes that have a significant influence on the accuracy of the decision system will be selected, and the attribute set partition scheme is calculated to achieve the highest accuracy of the decision-making system. In addition, rough set models are often considered to be nonlinear. This paper first describes the related concepts and theories using linear models, which are an extension of rough set theory.
Next, we use the model to mine the correlation between the assembly clearance of diesel engine and the quality of the whole engine based on the dataset, which contains 28 attributes of the assembly clearance parameters and the whole machine quality of 29 diesel engines. Before applying the model, we carry out data pretreatment, and we screen out 15 principal components. These components cover the vast majority of information on the assembly clearance parameters of all diesel engines. Then, we input these data into the model. The experimental results verified the effectiveness and advantages of MILP-FRST.
The rest of the paper is organized as follows. In
Section 2, we introduce the concept of the rough set and functional dependence. In
Section 3, we build a mixed-integer linear programming model for rough set-based classification with flexible attribute selection. In
Section 4, we use the clearance parameter data of 29 diesel engines and the quality data of the whole engine to verify the validity and accuracy of the model. Finally, in
Section 5, conclusions are presented.
2. Rough Set Theory
2.1. Concepts and Definitions of Rough Sets
Consider a rough set based on an information system [
27]:
, where
I is the universe;
A is the attribute set. Both
I and
A are nonempty finite sets.
If the information system meets the conditions that , this information system can be called a decision-making system , where C is the conditional attribute set, and D is the decisive attribute set.
Definition 1. Indiscernibility relations [27]: In an information system , set B is a subset of the attribute set A, binary relation is the indiscernibility relation of IS, recorded as , where x and y are elements of the universe; a is an attribute of the attribute set; and is the value of the element x in attribute a.
Definition 2. Equivalence class [27]: In an information system , set B is a subset of the attribute set A. The indiscernibility relation divides the universe I into several equivalence classes, where is the set of all equivalence classes, and is the equivalence class containing element x.
Definition 3. Upper and lower approximation [27]: In an information system , set B is a subset of the attribute set A, and set X is a subset of the universe I:
where is the lower approximation; is the upper approximation.
Definition 4. The accuracy and membership grade [27] are:where is the accuracy of rough set X, and is the membership grade of rough set X.
Definition 5. The membership function [27] is: The membership function indicates the membership degree of element to the rough set X.
Definition 6. The accuracy of the decision-making system [27] is: Given that the strict definitions of the upper and lower approximations make the rough set sensitive to noisy data, the rough set cannot adapt well to all situations in practical applications. VPRS decreases the influence of missing data, incorrect data, and noisy data. In VPRS, an approximation variable precision , which ranges from 0.5 to 1, represents the tolerance degree of the rough set to noisy data and incorrect data. can be defined as follows:
Definition 7. where set B is a subset of the attribute set A; set X is a subset of the universe I; is the variable precision, which ranges from 0.5 to 1; is the lower approximation; and is the upper approximation.
Compared with the rough set, VPRS extends the range of the upper and lower approximation, thus restricting the sensitivity of the rough set model to noisy data.
The rough set uses the indiscernibility relation to classify equivalence classes, but it is unsuitable for numerical data, especially in the case of the application of big data and high accuracy. One way to overcome this difficulty is to use the similarity relation, so we can extend the rough set based on the similarity relation.
This extension essentially involves modifications of the two concepts of the rough set, the indiscernibility relation and equivalence class. The classical indiscernibility relation is more suitable for those descriptive attributes, while elements of an attribute set that satisfy the indiscernibility relation are divided into an equivalence class. However, when dealing with numeric data, the effect of this method will be considerably reduced. The rough set, based on the similarity relation extends the indiscernibility relation into a similarity relation, and the equivalence class classified by the indiscernibility relation is replaced by a similarity relation.
2.2. Rough Set and Functional Dependence
With the establishment of the rough set model with variable precision based on the similarity relation, the decision rules between approximately equivalence classes divided by the conditional attribute set and the approximate equivalence classes divided by decisive attribute set can be worked out. However, this is not enough to explain the correlation between the conditional attribute set and the decisive attribute set, and so, functional dependence is introduced. Although the rough set and functional dependence are two different fields, many concepts of functional dependence can be explained from the perspective of the rough set.
Definition 8. Functional dependence, the complete dependence between universe I and attribute A, can be expressed as , where , .
Definition 9. Partial dependence, the partial dependence between universe I and attribute A, can be expressed as , where , .
Inference 1. Complete dependence of attribute set, any attribute , , works. Accordingly, there is functional dependence between and , and this relationship can be expressed as , where D is an attribute set.
Inference 2. Partial dependence of attribute set, any attribute , , works. Accordingly, there is partial functional dependence between and , and this relationship can be expressed as , where D is an attribute set.
We now explain complete dependence and partial dependence from the perspective of the rough set. For a decision-making system based on the rough set, means that the decisive attribute set completely depends on the conditional attribute set, that is, there is complete dependence between the decisive attribute set and conditional attribute set. means that there are some factors that affect the decisive attribute set in addition to the conditional attribute set, that is, the decisive attribute set partially depends on the conditional attribute set, so the following inferences are introduced.
Inference 3. Complete dependence in the rough set, in a decision-making system , only occurs when p , and the complete dependence comes into effect.
Inference 4. Partial dependence in the rough set, in a decision-making system , indicates that there is partial dependence between C and D, and the degree of partial dependence equals .
After calculating the accuracy of the model, according to inference 3 and inference 4, if , the decisive attribute set completely depends on the conditional attribute set. If , the decisive attribute set partially depends on the conditional attribute set. In other words, there is a certain correlation between the conditional attribute set and the decisive attribute set, and can be used as a parameter to measure the degree of correlation.
This section proposes the rough set model with variable precision, based on the similarity relation and some inferences related to functional dependence. This method will not only dig out the correlation between the conditional attribute set and the decisive attribute set, but also use accuracy to measure the degree of correlation.
3. A Mixed-Integer Linear Programming Model for Rough Set-Based Classification with Flexible Attribute Selection
There is no doubt that the decision-making model based on the rough set has the congenital defect of the rough set; thus, adding variable precision to extend the rough set into the rough set with variable precision is necessary while building the model. Nevertheless, adding variable precision only broadens the range of the upper and lower approximations. The choice of precision is often subjective and lacks scientific basis. Above all, variable precision can only be used as an auxiliary method to improve the ability of the rough set model to reduce noisy data’s bad influence on accuracy.
In this study, we build a mixed-integer linear programming model for a rough set-based classification with flexible attribute selection, which has a strong ability to overcome the noise sensitivity of the rough set model. Meanwhile, this study explains the rough set model, which is often considered to be nonlinear, by using a linear model for the first time. It is also an extension of the rough set.
3.1. Rough Set Model Based on Mixed Integer Linear Programming
Applying mixed integer linear programming to optimize the rough set model is essentially explaining the definition that is related to the rough set by linear programming. The rough set in a linear model enables the maximum accuracy of dividing the equivalence class, so that the decision-making system based on the rough set can correctly determine the correlation between the conditional attribute set and the decisive attribute set.
This model focuses on the rough set based on the similarity relation, and compares the similarity of each attribute in the attribute set. Next, the elements that satisfy the similarity threshold on each attribute are selected as the elements to be divided into an approximate equivalence class.
This model can also screen out attributes in the attribute set and take the attribute makes a considerable impact in dividing the universe into the final attribute set to reduce the dimension of the attributes.
We use the following notations:
I: Universe of elements.
: A set of approximate equivalence classes obtained by partitioning the conditional attribute set in the universe.
: A set of approximate equivalence classes obtained by partitioning the decisive attribute set in the universe.
C: Conditional attribute set.
D: Decisive attribute set.
N: Minimum support number of the conditional attribute set.
: Variable precision.
: Similarity threshold of the conditional attribute set.
: Similarity threshold of the decisive attribute set.
M: A large number.
: Value of each element in each conditional attribute.
: Value of each element in each decisive attribute.
: For any two elements i and j in universe I, if and are in the same approximate equivalence class divided by the conditional attribute set; otherwise, .
: if attribute c will be selected as a new attribute set to divide universe; otherwise, .
: For any element i in universe I and any approximate equivalence class k in the set of approximate equivalence classes divided by the conditional attribute set, if i belongs to k; otherwise, .
: Any two elements i and j in universe I and any attribute c in the conditional attribute set. on attribute c satisfies the corresponding similarity threshold otherwise, .
: Number of elements in the approximate equivalent class k, which is obtained from the partition of the conditional attribute set to the universe.
: if any two elements i and j belong to the same approximate equivalence class divided by the decisive attribute set; otherwise, .
: if an attribute d in decisive attribute set will be selected as a new conditional attribute set to divide the universe; otherwise, , and d will be eliminated.
: if any element i in universe belongs to the approximate equivalent class ; otherwise, .
: if value of any two points i and j on attribute d satisfies the corresponding similarity threshold ; .
: Number of elements in the approximate equivalent class , which is obtained from the partition of decisive attribute set to the universe.
: if point i not only belongs to the approximate equivalent class k of the conditional attribute set but also belongs to the approximate class of decisive attribute set; otherwise, .
: The number of elements is not only the approximate equivalence class k of the conditional attribute set, but also the approximate equivalence class of the decisive attribute set.
if the number of elements in the approximate equivalence class k of the conditional attribute set satisfies the minimum support threshold, so that the approximate equivalence class k can be a lower approximation set; otherwise, .
: if the approximate equivalence class in is the lower approximation set of the approximate equivalence class in ; otherwise, .
: If the approximate equivalence class in is the lower approximation set, is the number of elements of lower approximation set .
The objective function and constraints of the model are as follows:
Objective function: Maximize ()
Subject to:
- 1)
;
- 2)
;
- 3)
;
- 4)
;
- 5)
;
- 6)
;
- 7)
;
- 8)
;
- 9)
;
- 10)
;
- 11)
;
- 12)
;
- 13)
;
- 14)
;
- 15)
;
- 16)
;
- 17)
;
- 18)
;
- 19)
;
- 20)
;
- 21)
;
- 22)
;
- 23)
;
- 24)
;
- 25)
.
In MILP-FRST, the objective function and constraints are critical parts. These parts introduce the concept of the rough set and the way to complete related theories.
The objective function in the model is the number of elements that belong to the conditional attribute set and the decisive attribute set. For MILP-FRST, it is obvious that the maximum accuracy is essentially the number of elements in the maximum region by integrating the objective function with the definition of precision in the rough set. The goal of constructing this objective function is to determine the method of division to find a more accurate correlation between the conditional attribute set and decisive attribute set.
The description of concepts related to the rough set and the complement of related theories are both completed in the process of setting constraints. These descriptions and complements consist of filtering out attributes from the conditional attribute set and the decisive attribute set, dividing the universe by the decisive attribute set, dividing the universe by the conditional attribute set, calculating the lower approximation set, calculating the number of elements, and limiting the coverage of the lower approximation set. Each constraint will be explained as follows.
The process of choosing the attributes and dividing the universe will be completed in the model.
if the distance between two elements of the attribute
c is closer than the corresponding similarity threshold
; otherwise,
. The constraints are established as follows:
where
i and
j are two elements of the same condition attribute
c, and both
i and
j are natural numbers.
If attribute
c is selected to divide the universe,
, we can establish constraint (11). Otherwise,
as shown in constraint (12), and attribute
c has no influence on dividing the universe, that is, the two elements have an indiscernibility relation on attribute
c. Constraint (11) is defined as the necessary condition that indicates that when classifying two elements into an approximate equivalence class, it is not enough to make
. The condition of
means that all of the attributes of the attribute set meet the corresponding similarity threshold, so that constraint (13) is established. Elements
i and
j have an indiscernibility relation under the condition that all
in attribute set
C are 1:
Constraints (9)–(13) initially divide the universe by the conditional attribute set, and select attributes from the conditional attribute set. Attribute sets divide the universe in accordance with the similarity between the elements of the attribute.
The processes of dividing the universe and filtering out attributes are almost the same for the conditional attribute set and decisive attribute set. Therefore, we establish constraints (14)–(18) to divide the universe by the decisive attribute set and filter out attributes from the decisive attribute set:
We can obtain and through constraints (9)–(18), but there is much to be done to fulfil the process of dividing the universe. Each element in the universe should be allocated into or .
To complete model building, we need to specify the initial element and the initial equivalence class, and set the initial element belong to the initial equivalence class. As the initial element and the initial equivalence class are only numbers, there is no specific meaning, and so this set will not affect the results of the model calculation. According to the definition of
,
is the number of elements,
is the number of the approximation equivalence class, and
means dividing this element into this approximation equivalence class. We can establish constraint (19):
Each element belongs to only one approximate equivalence class. However, not every predetermined approximate equivalence class has its own elements. When the number of approximate equivalence classes is unknown, the number of approximate equivalence classes in the set of approximate equivalence classes may be redundant. If the number of the provided approximate equivalence classes is less than the number of actual approximate equivalence classes, the model will not be solvable, so we establish constraint (20):
Only when it is confirmed that the two elements
i and
j can be classified into the same approximate equivalence class can elements
i and
j be classified into an approximate equivalence class. The value of
and
can be 1 at the same time only when
We establish constraint (21):
Variable
counts the number of elements allotted into each approximate equivalence class divided by the conditional attribute set. We establish constraint (22):
Similarly, constraints (23)–(18) implement the process of allotting the element of the decisive attribute set:
The above constraints complete the process of selecting attributes and dividing the universe.
Constraints (27)–(31) implement the process of defining the lower approximation set and setting the minimum support threshold.
If one element belongs to the approximate equivalence class
k and the approximate equivalence class
on the basis of the definition of the lower approximate set, this element will be selected, so we establish constraint (27):
The number of elements obtained by constraint (19) should be counted, so we establish constraint (28):
The minimum support threshold requires that the lower approximation set should meet the requirement of the minimum support number. Constraints (29) and (31) complete the limitation of the minimum support number for the lower approximate set. In constraints (29) and (31),
shows whether the number of elements in the corresponding approximate equivalence class satisfies the minimum support number; if
, then
must be 0. MILP-FRST introduces variable precision as an auxiliary method of improving the ability of resisting noisy data. Constraint (30) realizes the process of defining the lower approximate set:
Finally, the number of elements in the lower approximate set is counted. If the approximate equivalence class obtained by conditional attribute set does not belong to any approximate equivalence class obtained by the decisive attribute set, this approximate equivalence class will be deemed to be an uncertain region, so the number of elements in the certain region is 0. Otherwise, this approximate equivalence class is a certain region, so the number of elements in the region equals the number of element points in this approximate equivalence class. Above all, we establish constraints (32) and (33):
3.2. Characteristics of the Model
Aiming at solving the problem that the rough set model has weak resistance to noisy information in a dataset, this study proposes the mixed-integer linear programming model for rough set-based classification with flexible attribute selection (MILP-FRST). This model integrates the mixed integer linear programming method with the rough set model to define the related concepts and to describe the related theories. It is not only an optimization of the original mining model, but also an extension of the rough set theory. This model has the following characteristics:
(1) The model can realize the process of filtering out attributes from the attribute set. In a practical application, the first step of analyzing a high-dimension dataset is the descending dimension. After the dimensionality reduction, the dataset can only contain partial information of the raw dataset; specifically, implementation of the dimensionality reduction process is at the expense of sacrificing the information contained in some raw datasets. MILP-FRST is able to eliminate the attributes that have little influence on the decisive accuracy, and to automatically complete the process of attribute selection. Therefore, only a simple preprocessing process based on data quality analysis needs to be performed, and the maximum extent of all of the information contained in the raw dataset is preserved.
(2) The model implements the partition of the attribute set to the universe, defines the lower approximation set and the lower approximation set, sets the variable precision, restricts the support of the lower approximation set, and calculates the determined region, and so on. All of the above are implemented in the linear model. The attribute set partitioning scheme that allows the decisive accuracy to reach the optimal value can be obtained.
(3) The model has strong extensibility. According to the specific object of this study, we can select the attribute set, and specific division of the universe and method to adapt to the dataset composed of various data types.
4. Application Study on Data from Diesel Engines
In this section, we report the results of computational experiments on an assembly clearance parameter dataset from a diesel engine to test the models and compare them. The MIP solver AMPL/CPLEX (version 12.6.0.1) was used to solve problem instances. All computational experiments were performed on a MacBook with a 2.90 GHz Intel Core i7 Processor and 8 GB memory.
This paper takes a certain type of marine diesel engine as the verification object. At present, this type of diesel engine has been put into the market for many years, and the production enterprises have accumulated a lot of valuable data.
Table 1 lists the main technical parameters of this type of diesel engine.
Figure 1 the side view and main view of this diesel engine.
4.1. Data Set Introduction.
The object of study is 29 16-cylinder diesel engines of the same type. The data set includes assembly clearance parameter data and quality grade data of the diesel engine. The assembly clearance parameter data of the diesel engine is numerical data, and the quality grade data of the diesel engine is classified data.
The marine diesel engine has a complex structure and many components, so there are many assembly clearance parameters. Chybowski L. and Gawdzixuska K. put forward the latest technology of component importance analysis for complex technical systems [
28,
29,
30]. Choosing important components in complex systems is a key step. This type of diesel engine mainly includes four parts assembly clearance parameters: 2K, 5K, 10K and 11K. Among them, 2K refers to the mating clearance parameters of the crankshaft and the seat hole of the main bearing, 5K refers to the mating clearance parameters of the camshaft and the seat hole, 10K refers to the meshing clearance parameters of the gears, and 11K refers to the mating clearance parameters of the gear hole and the bearing.
Table 2 lists the components involved in four types of assembly clearance parameters and the number of parameters.
A total of 28 assembly clearance parameters of the diesel engine were selected, that is, the experimental data set is 28-dimensional. The quality grade data comes from the test run of the diesel engine by the manufacturer before the diesel engine is delivered, including tests on flammability, diesel viscosity, and reliability. Through various test runs, the manufacturer determines the quality grade of the diesel engine. The quality grades are divided into three grades, Qualified, First grade, and High grade.
Table 3 shows the part of data of the 28 assembly clearance parameters and the corresponding quality grades of the diesel engine.
4.2. Data Pre-Treatment
After the correlation analysis of the dataset, it is obvious that there is a strong correlation between the assembly clearance parameters of the same part of the diesel engine, and this strong correlation will affect the effectiveness and efficiency of the model. Therefore, according to the correlation analysis of the assembly clearance parameters of the diesel engine, the principal component analysis method is used to reduce the dimension of the dataset. Taking all diesel engine assembly clearance parameters as the input, principal component analysis is carried out, and the cumulative variance contribution rate of each principal component is obtained.
As listed in
Table 4, the cumulative variance contribution rate of the first 15 principal components is up to 89%; that is, these 15 principal components can cover most of the information of the assembly clearance parameters. A new dataset made up of these 15 principal components is presented in
Table 5.
The new dataset simplifies the original dataset and retains most of the information contained in the original dataset. Consequently, we can avoid a series of problems that the high-dimensional datasets creates in data mining. Simultaneously, the simplification of the original dataset can improve the efficiency of the model.
Finally, we need to integrate the assembly clearance parameters and whole-quality grades after dimension reduction, and obtain the final dataset that is directly applied to the subsequent computation (see
Table 6).
4.3. Demonstration of the Process of the Model
Considering the specific object and dataset, the whole quality grades of diesel engine are known in this case, so that the result of partitioning the decisive attribute set to the universe is known in this instance. Therefore, we can simplify the model. We first remove the selected attributes in the decisive attribute set, and relative variables and constraints in the dividing universe. Then, we transfer the variable into a parameter matrix, which is known to be a parameter that describes the result of universe partitioning by the decisive attribute set.
The model will be implemented in the MIP solver AMPL/CPLEX (version 12.6.0.1). In the operation of the model, the following parameters need to be set in advance:
- 1)
Minimum support number of the lower approximation set N = 3,
- 2)
Variable precision ,
- 3)
A large number M = 999,
- 4)
The initial condition of the conditional attribute set partitioning universe ,
- 5)
List of the threshold of the similarity of the conditional attribute set , where c = 15 is the number of assembly clearance parameters in the instance,
- 6)
The initial number of the approximate equivalence class of the partition of the conditional attribute set to the universe is 10.
The model input consists of the principal component data of the assembly clearance parameters obtained by dimensionality reduction processing, quality grades of the diesel engine, and preset parameters described above. The output of the model includes the selection results of the principal components of the input, division results of the universe according to the conditional attribute set, calculation results of the lower approximation set, and calculation results of the number of elements in the determined region.
Fifteen principal component attributes are included in the conditional attribute set, which is composed of the assembly clearance parameters of a diesel engine. The model can filter the attributes from the attribute set to eliminate the attributes that have little impact on the accuracy of the decision system, and its filtering result are expressed by the variable
. The result is:
If the value of attribute c is 1, this attribute will be selected; otherwise, this attribute will be eliminated. Therefore, the result shows that all 15 principal component attributes will be selected.
The conditional attribute set partitioning the universe is an important step in the calculation process of the model. Meanwhile, it is also the prerequisite for the subsequent calculation;
represents the 10 approximate equivalence classes. If a diesel engine belongs to an approximate equivalence class, the value of the element in the matrix is 1; otherwise, it is 0. The result is:
This result indicates the number of diesel engines in each approximate equivalence class obtained by the partitioning of conditional attribute set to the universe. Among the 10 approximate equivalence classes, one has not been allocated any element; this approximate equivalence class will be deleted. One has been allocated only one element, and its number is less than the minimum support number; therefore, it will also be deleted. Only eight approximate equivalence classes can be regarded as the lower approximation set.
The
E matrix is the most important part of the model output. The
E matrix represents the number of elements that not only belong to approximate equivalence class
c, but also belong to one quality grade.
E matrix is an important basis for solving the lower approximation set. In the
E matrix for this case, the 10 lines indicates that the number of approximate equivalence classes determined by conditional attribute set partitioning of the universe is 10. Similarly, the number of approximate equivalence classes determined by decisive attribute set partitioning of the universe is 3.
is the number of elements in each lower approximation set. It can be concluded that eight approximate equivalence classes meet the condition of being members of the lower approximate set by analyzing the minimum support number and variable precision. Hence, the number of elements in the determined area is:
The area of the model is:
On the basis of the inferences of the rough set and the function dependence,
. Thus, there is partial dependence between the conditional attribute set and the decisive attribute set of the decision system:
4.4. Performance Comparison of Models
To validate the effectiveness and advantages of the model, experiments are performed to compare the accuracy of the models. The model that our model is compared to is the Φ-rough set.
As listed in
Table 7, obviously, the accuracy of model MILP-FRST is higher than that of the model Φ-Rough set. The accuracy is close to one, which shows that our proposed model can establish an accurate decision-making rule between the diesel engine assembly clearance parameters and whole machine quality grades, and excavate a higher correlation between them.
MILP-FRST is an extension of the rough set. An obvious characteristic of a linear model is its ability to find the optimum solution. This characteristic enables the model to find the best way to classify attributes, even if the dataset can also obtain ideal results merely through simple data preprocessing, and it considerably increases the ability to resist noisy data.
4.5. Extension of the Model
As mentioned above, the minimum support number of the lower approximation set
N and variable precision
are set in advance. The classification quality reflects the degree of dependence of decisive attribute D on the conditional attribute C and the uncertainty of decision system. The classification quality is inversely proportional to the uncertainty. In the model, the classification quality largely depends on the value of
[
31]. Practically, the user does not always know how to set the value of
to obtain the maximum accuracy model. The minimum support number of the lower approximation set
N also influences the accuracy of the model. Similarly, the user always sets the value of
N in accordance with their experience. To determine the best value of
and
N, we propose an algorithm. We set up a loop traverses all the values between 0.5–1, adding 0.01 each time. The results of the different
N values are shown in
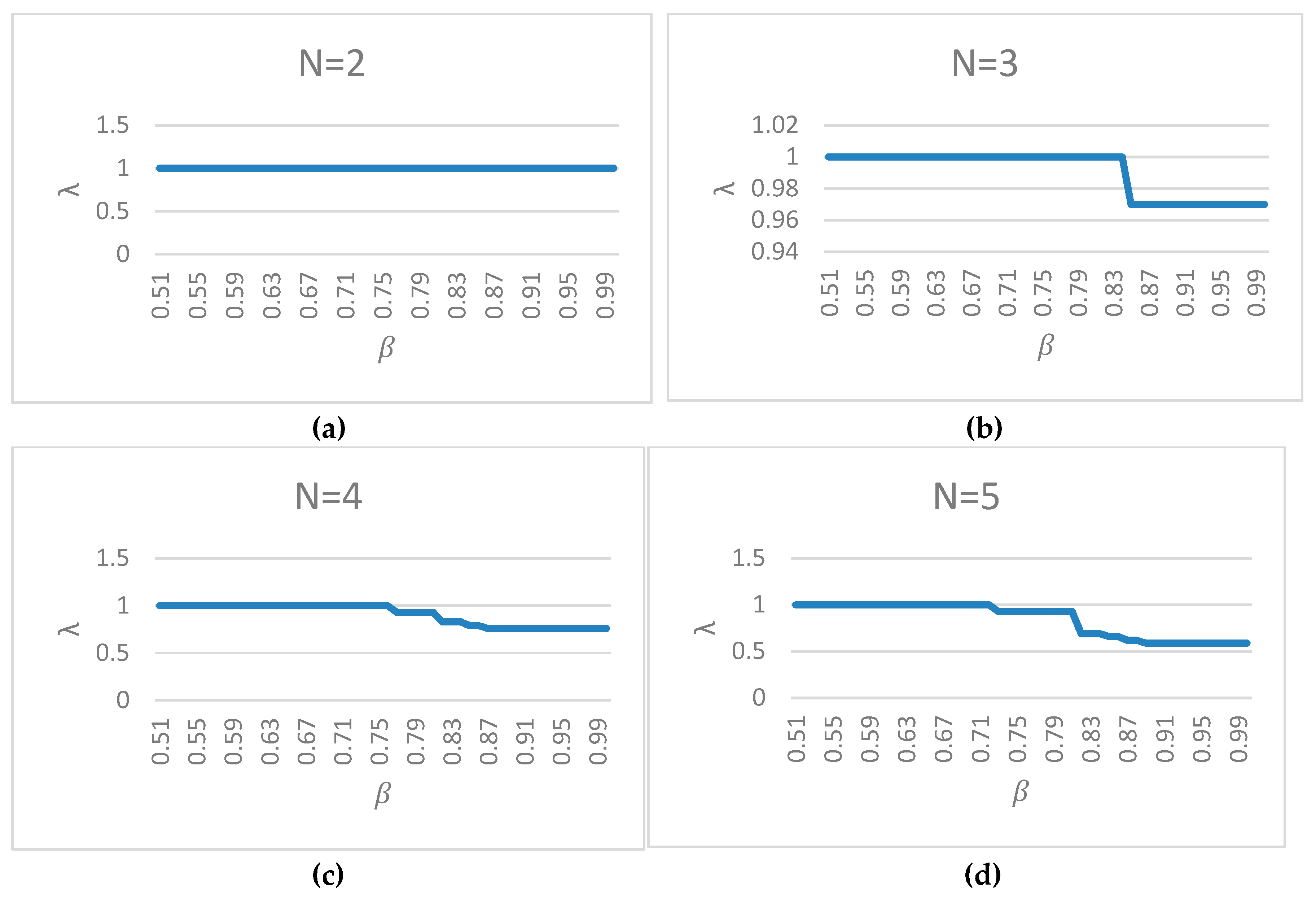
Figure 2.
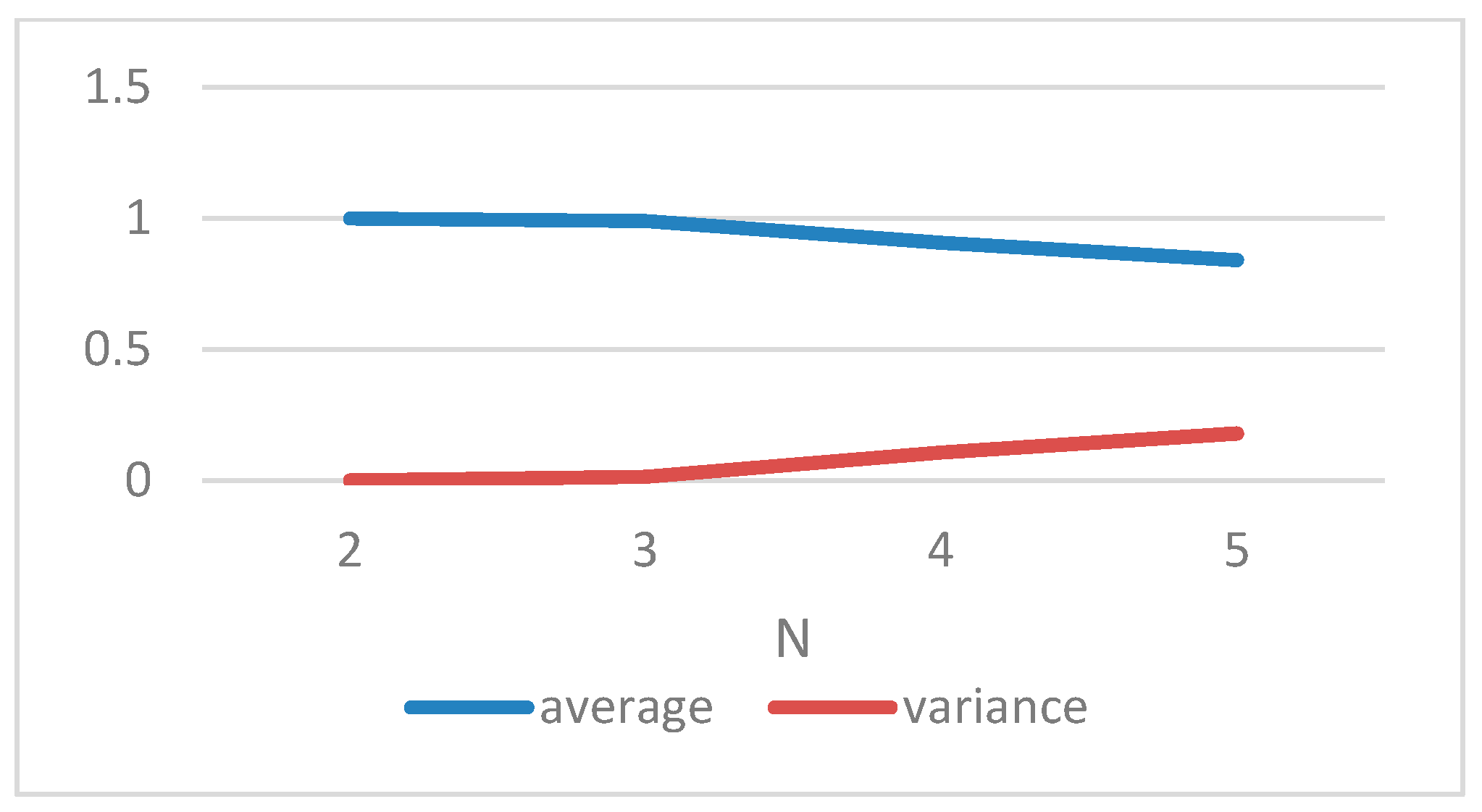
As shown in
Figure 3, it is obvious that with the increase in
N, the average of λ decreases and the variance of λ increases.
Although the model’s accuracy increases when decreases, for this model, the smaller does not make the model better. represents the tolerance degree of the rough set to noisy and incorrect information in the dataset, while a smaller tolerates more noisy data, but this violates our purpose in building MILP-FRST. Therefore, how to balance against λ requires further research. As for the minimum support number N, our results indicate that the smaller the N, the better the λ. This rule is useful in practical applications, but when using this rule, the characteristics of the object should be considered to determine the appropriate N.

 ,
, 



{kind=link}
{kind=link}
{kind=link}