2. Perception—Space Relation
In contrast to existing domestic engineering or ubiquitous computing systems, social robots are mobile and partly autonomously operating technologies. We are currently living in spaces permeated by technology, and the influence of technology is constantly increasing. In modern buildings, basic utility and domestic engineering systems are already in effect for electricity, wireless networks, and ventilation/lighting systems. In this paper we refer to robots which resemble humans in form and which are built and used for that very reason, namely to humanoid robots. We understand humanoid robots as artificial agents resembling human bodies, perceiving input from their environment, possessing action capabilities and having some aspects of autonomy.
The innovative functions of humanoid robots range from having access to physical objects and digital objects from other technical systems, to their movement in a room and social interaction with humans. Mobile robots introduce new possibilities where fixed technologies reach their limits. They do not only move in physical space but also operate in virtual space through their digital capabilities. They represent an interface in a network between different types of spaces—a mobile and autonomous interface.
In the development of contemporary technology, two approaches complement each other. So-called ubiquitous computing, conceptualized by Mark Weiser in the early nineties [
3], and the development of robots [
4] are two related strands of 21st century technological achievements. Weiser’s approach assumes that technology is woven into everyday life and eventually becomes indistinguishable. While some technologies discreetly infiltrate our living environment, we perceive social robots as material entities. Since they simulate human skills and human appearance, we see humanoids as the most expressive form of robots, about to operate in our intimate spaces.
A perception system allows for the active reception and coordination of information received through one or several sensory systems. The purpose of a perception system is to let us behave effectively within a certain environment. In this case, technical perception is understood as the transformation of sensor information into data models to be processed algorithmically by software. A data model is understood as an abstract formalization of objects and relations that occur in a specific set of environments, in our case, in living spaces. In both developments, technical performance is achieved through a network of automated operating sensors and the algorithmic processing of data in models by means of software. The collaboration of these components leads to technical perception systems. It is state of the art that technical perception systems express objects and users in numbers, register spaces geometrically and present them visually. For instance, the tasks of this technology can range from the trivial regulation of room temperature to enabling the autonomous behaviour of hyper-complex machines such as humanoid robots. These examples show the expediency of different technical perception systems, whose different objectives produce different forms of spatial perception. While in the first example, air temperature is simply connected with heating, the second example constitutes “the world” of an artificial intelligence system. The complexity and unpredictability of the everyday world in which we humans move effortlessly presents a major challenge for hyper-complex technical systems. All technical perception systems are fundamentally different from human perception systems. Their quantitatively formal and abstract parameters contrast with our personal parameters that are embedded in a cultural context. Humans and humanoid assistants act according to very different perceptions of living space.
Technological developments are currently faced with a paradox: some robots are developed for intimate areas of human existence, yet they cannot participate in the space we humans perceive. Artificial intelligence is limited by its technical perception systems and data models. Data are only recorded according to their perception systems and processed according to the model. This defines the performance characteristics of technical systems. Thus, technical systems exist in different spaces of perception than humans. Technical perception systems are fundamentally different from the human system since they conceive space through geometries, numbers and images. For humans, space is only marginally defined by formal-abstract factors and mostly through personal experience, association and habits, all rooted in cultural meaning that is not absolutely defined. Instead, there is permanent negotiation between inter-subjective meaning and individual meaning—negotiation among individuals and between individuals, objects and processes. Even though robots are equipped with very advanced, sophisticated technical perception systems, they are unable to grasp human meaning or to cope with human perception of space. That is where the problems culminate that motivate our research.
For instance, the state of research in this field is defined by concepts such as “object recognition” [
5], “semantic scene labeling” [
6] and “intention recognition” [
7]. Object detection allows for a technical system to recognize material objects which consequently are labeled by means of object recognition or scene labeling, however this is only possible for objects which do not deviate too much from the form that is typical for this class of objects. Furthermore, intention recognition considers a functional connection between recognized objects and their related actions. These existing concepts share the fact that they solve the given problem according to technical possibilities. Thereby the cultural meaning of objects is marginalized, individual meanings cannot be introduced and tend to disappear within the formal representation of data.
2.1. Theory of Relationships between Human and Humanoids
The term language game [
8], coined by Ludwig Wittgenstein, implies that every verbal expression is rooted in human life, not only because the various human language games make sense there, but also because language is woven into human action. Every word, every term and every sentence has a meaning which depends on the context of the action and situation in which it is uttered. Language games also involve mathematics and formal logic. Referring to the philosophical language- game, we conceive a space game that also makes use of relations between verbal expressions and human practices. The concept is extended by the fact that human action is woven into space (see details on space in
Section 2.2). In contrast to the language game, the space game aims to negotiate cultural meaning between humans and humanoids to constitute a shared cultural meaning of space. Through natural language communication between humans and machines, a mutual construction of space and meaning becomes possible with dialogue. Thanks to its humanoid shape, the social robot can imitate human gestures and postures to enrich interaction with non-verbal communication. Using this interaction, humanoids can perceive space which was formed interactively from meanings, hence exceeding mere technical parameters.
It was a relatively simple and everyday situation from which the French philosopher Jacques Derrida developed his complex thoughts and profound reflections. One day when Derrida stepped out of the shower, he realized that he was standing naked in front of his cat which had sneaked into the bathroom. What fascinated him about the situation was the simple observation that he had felt ashamed to be exposed to his cat’s glance. Although the cat certainly did not have any idea what nudity meant and was most likely not interested in his nudity, Derrida still felt observed by the gaze of his cat. “How can an animal look you in the face?” Derrida asked in the lecture, “The Animal That Therefore I Am”, in which he describes this very situation [
9]. Humanoid robots for domestic needs are built to look us in the face. It almost seems as if this skill were their main purpose, even one of the reasons why they were invented. These robots have a face we can look at, a face that can look back at us and is able to return our gaze [
10,
11,
12]. With cameras as their eyes, humanoid robots do not only have the ability to “see”, but they can also film. Additionally, they possess a number of other sensors which constantly monitor and evaluate their environment. Furthermore, they are connected with numerous other helping and assistive technical artifacts. All this generates a completely different perception of space, time and actions than that of humans who are socioculturally conditioned and influenced by architecture. Now that humanoid robots are advancing more and more into our private and intimate spaces and are thereby able to look at us—should we feel ashamed? Or are these robots simply an accumulation of technically based offers in a system they represent, merely robotic servants whose glances are not touching us? Or are they companions, hybrid creatures who share our intimate spaces while potentially being able to share what they see worldwide via the internet?
Which principles make sense for creating a relationship between unique, human individuals and some kind of serial, distorted, robotic “mirror image of a human”, namely a humanoid? All too often the relationship between humans and robots is understood as one of many different variations of master and servant, different yet always hierarchical relationships. However, we have developed a very different concept for the relationship by integrating its spatial context.
In her book “When Species Meet” [
13], the American philosopher and theorist Donna Haraway criticizes Derrida’s approach because he did not take the possibilities of the cat’s gaze seriously and overlooked the various opportunities and meanings of the cat’s glance. This gaze of the cat is—according to Haraway—an invitation to a “becoming with”, what she calls “companion species”, because each glance is always a reciprocal process, each instance of living with such a creature is a becoming with. According to Haraway this becoming with requires a different approach to ethics, an ethics of shared responsibility. Just as a guide dog is responsible for its owner, the owner is likewise responsible for the dog. A life together is based on a shared responsibility. This is a principle which is not only valid for relationships between humans and dogs: “Responsibility is a relationship crafted in intra-action through which entities, subjects and objects, come into being” [
13].
Based on Haraway’s approach, we understand the humanoid robot as some kind of “companion (species)” to the humans who live closely with these technical devices. What can a shared responsibility between humans and robots look like? Based on a similar understanding of shared responsibility, we want to reflect upon ethical, political and spatial consequences and develop a technical system in which humans take care of their robots which likewise support humans in everyday life. Furthermore, it always has to be considered in which power structure these humanoids are developed, explored and applied. As Langdon Winner asked in his essay, “Do Artifacts have Politics?” [
14], we also want to question which cultural, ethical and political conceptions should be installed in such robots, especially related to architectural spaces for living that constitute our residential environment.
Technical perception systems express objects and humans by means of abstract representations. However, they are not capable of associating, varying and contextualizing meaning. Hence, they are not capable of placing those objects in a meaningful relation to each other. In contrast to this we have developed an approach in which the creation of a spatial model of cultural meaning is based on interaction between human and robot. The machine is thereby considered a “companion”.
2.2. Theory of Cultural Space Production
The human lifeworld is essentially spatial. Thus, space is mainly a holistic substrate of meanings and their positioning from which all relations discussed in social and cultural space theories emerge [
15,
16]. Architecture devotes itself especially to aspects of the space in which we live. Changes lie ahead of the domain that will transform behaviour concerning the creation and use of space that has been culturally conserved for a long time. Increasingly, buildings as we know them will be altered by mobile parts and sophisticated control systems. We are standing on the cusp of a new development. In the near future, interaction between technical artefacts such as houses and robots will become part of the common understanding of space.
Space, the basis of the relational lifeworld of humans, is fed into the managing algorithms of specific technical systems by technical perception systems through numbers, geometries and images. However, they are neither able to detect the meanings, nor to put these parameters of our surroundings into culturally meaningful mutual relationships. Thus, technical systems exist in other spaces of perception than humans. The powers of each space of perception compete for the interpretational sovereignty concerning the actual everyday world. This structural otherness of human and technical realties contains potential conflicts and risks. Often users feel intimidated or pressured by assistive systems and therefore alienated and denaturalized in a lifeworld that is no longer theirs and thus are therefore rejected.
The social and cultural spaces of humans are diverse. We understand culture in this context as the values and knowledge that inform society as the realm of communication, activities and organizations of humans. Humanoid robots can be employed in private households, on semipublic premises or in public malls. Social space is not a permanently fixed space, but is in fact constantly “produced” [
17] and is therefore in a permanent state of change. The production of space is therefore never a neutral process, but always determined by power structures, economic interests and cultural hegemonies. We call such an understanding of space a cultural concept of space. Just as space technologies should not be considered neutral because even those power structures are interwoven, our project tries to address those questions of power and also wants to support the empowerment of users in relation to artificial intelligence. “Technical objects” [
18] are regarded as active protagonists. Humanoid robots are not only simple objects or neutral actors, but must be regarded and examined as active designers of such spaces.
How spaces are designed, modified and produced and how we move and interact with each other in these spaces is mainly influenced by perception. What we see, hear and feel is co-determined by our environment. However, the way in which objects, spaces and humans are seen, felt and heard is significantly influenced by cultural factors. It is also constantly re-negotiated and transformed what cultural meanings the spaces and objects have. Hence, we see humanoids as co-producers of social spaces and feel that they interact equally with the space and the humans in it. For these machines to perform tasks such as caregiving, selling products or other assistive services, and also to interact appropriately with humans, they must learn to cope with these cultural meanings, i.e., with this cultural concept of space. Cultural meaning cannot simply be programmed. Not only because meanings change, but also because they constantly must be re-negotiated and can differ greatly from one individual to the next. Thus, humanoid robots must not only learn to recognize these cultural meanings, but also to co-create them. They will occupy a new position between existing technologies and humans.
With this approach, technical systems must be enabled to develop a concept of space through the interactive requisition of cultural meanings; humanoid robots and artificial intelligence are being domesticated. The intended spatial model of cultural meaning is understood as an adaptive system. Through interaction it adapts to its environment and to different individual and spatial conditions.
3. Hypothesis and Questions
Summarizing
Section 2, the overall context of our research questions is how to develop a spatial model of cultural meaning in a machine learning system as the operational basis for human as well as humanoid perception systems. As a hybrid spatial model, it is conceived to mediate between humans and humanoids by integrating cultural meanings into human-robot interaction (HRI) on the inter-subjective and the individual level. Hence, a kind of medium will be created that is informed by the different perception systems. Thus, the humanoid robot and its artificial intelligence can be involved in a shared context of meaning with humans. For this, we use the skills of a humanoid robot for human-like interaction as an approach for data acquisition and for model generation. In the spatial model discussed here, the meanings of objects and their relations are determined through verbal interaction and interconnected use of the algorithms of machine learning. Through the gathering and connecting of located meanings a spatial model is developed, which is no longer reducible to technical parameters or to human perception. Instead, a hybrid spatial model based on interaction is created.
Our approach follows the hypothesis that in natural language communication between humans and robots and with the help of the particular features of a humanoid robot (body language, autonomous movement, having a very intuitively designed conversation), a spatial model of cultural meaning can be developed. We decided to use and combine existing robust technical solutions to set up the system, to create a proof of concept. This model is neither reducible to technical quantifiability nor to human spatial perceptions, but it introduces a third hybrid interpretation of space based on the cultural meaning of objects and spatial features.
The most important research questions for this first stage of development of our prototype are:
Can the interactive creation of a spatial model of cultural meaning be technically robust, even in a bustling environment, and can it be successful in real-time?
Will users accept the generated model as representative? (narrative interviews)
Will users consider this representation as a relevant abstraction of individual and inter-subjective meaning of space and objects? (narrative interviews)
How do users react to the humanoid as a dialogue partner? (Kind of acceptance, e.g., terms used, usage and modulation of speech such as adult versus child, dominance versus subordination by observation and filming).
4. Research Methodology Based on the Arts
These questions will be asked using trans-disciplinary methods known from artistic research and will be reflected philosophically; thus, new trans-disciplinary approaches and methods ought to be developed and interpolated in the current debates and discussions concerning robot ethics [
19].
Research on humanoid robots as a possible future “companion species” also means to integrate the above questions concerning new kinds of perception. Attributing meanings to objects, rooms, components, people and machines is a network-type reference system consisting of geometric, figurative, social and cultural relations. Thus, the meanings of single parts and their relationships constitute each other mutually and are constantly transformed dynamically in negotiations. Integrating/using sensors, which technically produce completely different images of the environment than the human perception system, trans-disciplinary artistic research can especially help to make these types of perception visible and can also show how interaction between humanoids and the human perception system can be interwoven to generate a cultural model of lifeworld from individual and inter-subjective meanings: A spatial model which is neither reducible to the human nor to the humanoid perspective.
Research on problems of the lifeworld requires a methodical course of action which integrates approaches from different disciplines. The transdisciplinary approach to this project requires merging expertise from architecture, automation technology and philosophy. Synergies develop through the overlapping and sharpening of questions such as ours in search of a spatial model of cultural meaning. In addition, we use methods of artistic research to widen our approach. Artistic research is already being used in HRI studies as in the case of the Theatrical Robot [
2]. There, the artistic implementation of human-robot interaction is applied in a performance for the benefit of studies in social science. In contrast, the artistic research we use in our project is not an artistic tool for social science, but a contribution to research methodology.
Our complex lifeworld actually consists of a surprisingly large number of individual objects and processes. With teleological methods we can only grasp some of these objects and processes in our everyday discourse. Artistic research methods do not follow explicit targets but are developed on an open-ended and yet goal-oriented scale. They do not necessarily need to be developed along cause-effect relations and can apply non-causal effects. They explicitly apply vagueness, intentional misreading and superpositions of established concepts. Artistic research can integrate references and sources from different academic disciplines, but also from non-scientific bodies of human knowledge. Original phantasies and deductive argumentation are both considered: “[…] where logical thinking is naturally intertwined with associative and intuitive conceptualization” [
20]. For the present project, it is necessary to work with artistic research methodology since it does not focus on efficiency, but on the aesthetics of interaction, not on reproducibility, but on the variability of interaction, not on precision, but on cultural depth of interaction. Artistic research in conjunction with social scientific methods enables us to develop, evaluate and reflect upon questions concerning the cultural meaning of space, the different kinds of spatial perception, and spatial relationships between robots and non-robots. These specific kinds of interactive and reflective processes [
21,
22,
23] are applied to the actualization of a spatial model of cultural meaning. The findings and insights will not be rated with social, technical and technological targets in a cause-effect relation, but will be evaluated in the form of open results in context of the lifeworld.
5. Prototype, Verbal and Non-Verbal Communication between Humanoid Robots and Humans to Learn Meanings, Using a Machine Learning System
5.1. Experimental Settings
As a first attempt of implementation, we developed a prototype, to be tested in two different experimental settings. A first experiment was held at “The Long Night of the Robots”, an event open to the public at the Technical University of Vienna, which we used to involve different people of all ages. We had a variety of participants reaching from those unfamiliar with machine learning and robots, to interested experts from various different domains, including but not limited to philosophy, linguistics and electrical engineering. The second experiment was held with a sample of voluntary participants of architecture students in a controlled laboratory setting. The results of the experiments are expected to produce considerations on how the prototype of a spatial model of cultural meaning can be further developed, and which problems and questions still have to be solved.
5.1.1. Setting 1: “Long Night of the Robots”
We were invited to contribute to the “Long Night of the Robots”, which took place in Vienna on 25 November 2016 as part of the “European Robotics Week”. We took the opportunity for a first experiment with our first prototype of verbal and non-verbal communication between the humanoid and the visitors to generate cultural meaning in the machine learning system. We expected the visitors to have different degrees of prior knowledge, different social and cultural backgrounds and interests, and that they would be mostly interested in robotics as lay persons. Our contribution was to offer visitors a “conversation” with a humanoid robot: a natural-verbal interaction supported by gestures about the space and the meanings of some surrounding objects.
The principle elements of the setting to generate a spatial model of cultural meaning consist of the following: (a) humanoid robot, (b) machine learning system, (c) test persons, (d) objects and areas in the room.
- (a)
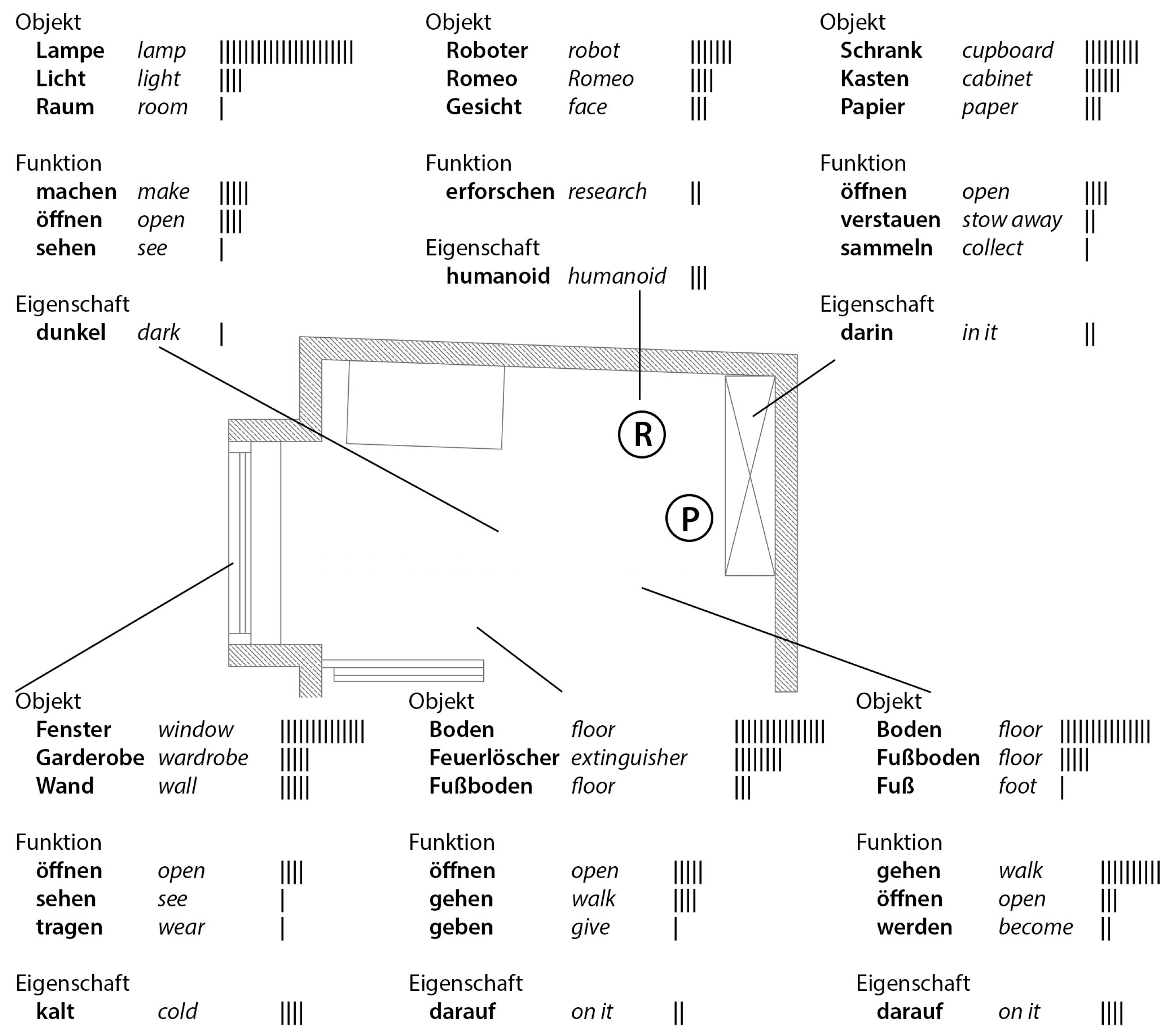
Humanoid robot: A stationary humanoid robot, the model called “Romeo” by the firm of Softbank Robotics, is equipped with our machine learning system. Besides speech input and output, a crucial ability of the robot is to extend verbal communication by using various gestures. We consider it of crucial importance to create a communication experience, similar to a conversation among humans. The robot was trained to use various non-verbal gestures and common-sense phrases of small talk, to enrich the interaction. In order to clearly communicate the gestures of the robot in the turbulent and completely crowded room, the robot pointed at the objects with a flashlight to ask for their name, function and meaning (
Figure 1).
- (b)
Machine learning system: Through the cloud-based speech recognition of Google, the voice input is converted into text. The access to Wordnet through LibLeipzig enables the definition of a particular grammatical element and thus a first categorization of each term by its word class. The specific categorization of the entire input is made by the library of machine learning by Orange in Python. The machine learning system contextualizes the meanings generated through interaction with certain areas of the room in relation to the position of the robot. Terms were categorized and reduced to their basic form. The answers by the visitors were itemized for each of the six objects in the categories of name, function and features (
Figure 2). Our machine learning system generates a hierarchy of meanings, but without letting the individual meanings vanish. On the contrary, the individual meanings are especially used as part of the further exchange by an individual user with the machine. An important aim is to correspond also to the individual range of meanings of the users of the assistive technology. With this prototype, individual meanings are captured and counted, but they are not yet set in relation, in order to accurately develop the accumulation of inter-subjective meanings.
Through the different conversations the machine learning system culminates in a variety of terms for each item requested by the robot, and also for all the other items which might have been used. These terms are evaluated by the artificial intelligence, depending on frequency.
- (c)
Test persons: To make the technical system transparent to the visitors, the inclusion of human statements and the placing of meanings are presented to the visitors on a screen. Since both happen in real time, the visitors can follow how their stated meanings are included in the system. Since a German-speaking public in Vienna had been invited to this public event, the robot communicated in German. Modifying the speech recognition from German to English and changing the LibLeipzig library to TextBlob would make the experiment reproducible in English.
- (d)
The setting of the interaction was a 60 m2 room in the robotics laboratory, divided into an experiment area and a visitor area that included several objects and parts of the room: a cabinet, an overhead light, a fire extinguisher, the floor, a window and the robot Romeo itself. The objects were spread out through the room.
5.1.2. Experimental Process 1
The robot points at objects and parts of the room and asks the visitors about personal meaning (
Figure 1). Four types of questions in different variations were asked about six predefined objects in the room. Types of questions were: name, property, function and meaning of an object. Questions were asked in natural language with common-sense phrasing and accompanied by distinct non-verbal gestures. The responses of the visitors were registered by the machine-learning system. Parallel to communication with the robot, visitors could also observe on a screen how their spoken answers were allocated to a specific location within a floor plan of the room and weighted by previous answers (
Figure 2).
5.1.3. Setting 2: “Young Architects”
The principal elements for the setting to generate a spatial model of cultural meaning were as mentioned above (
Section 5.1.1).
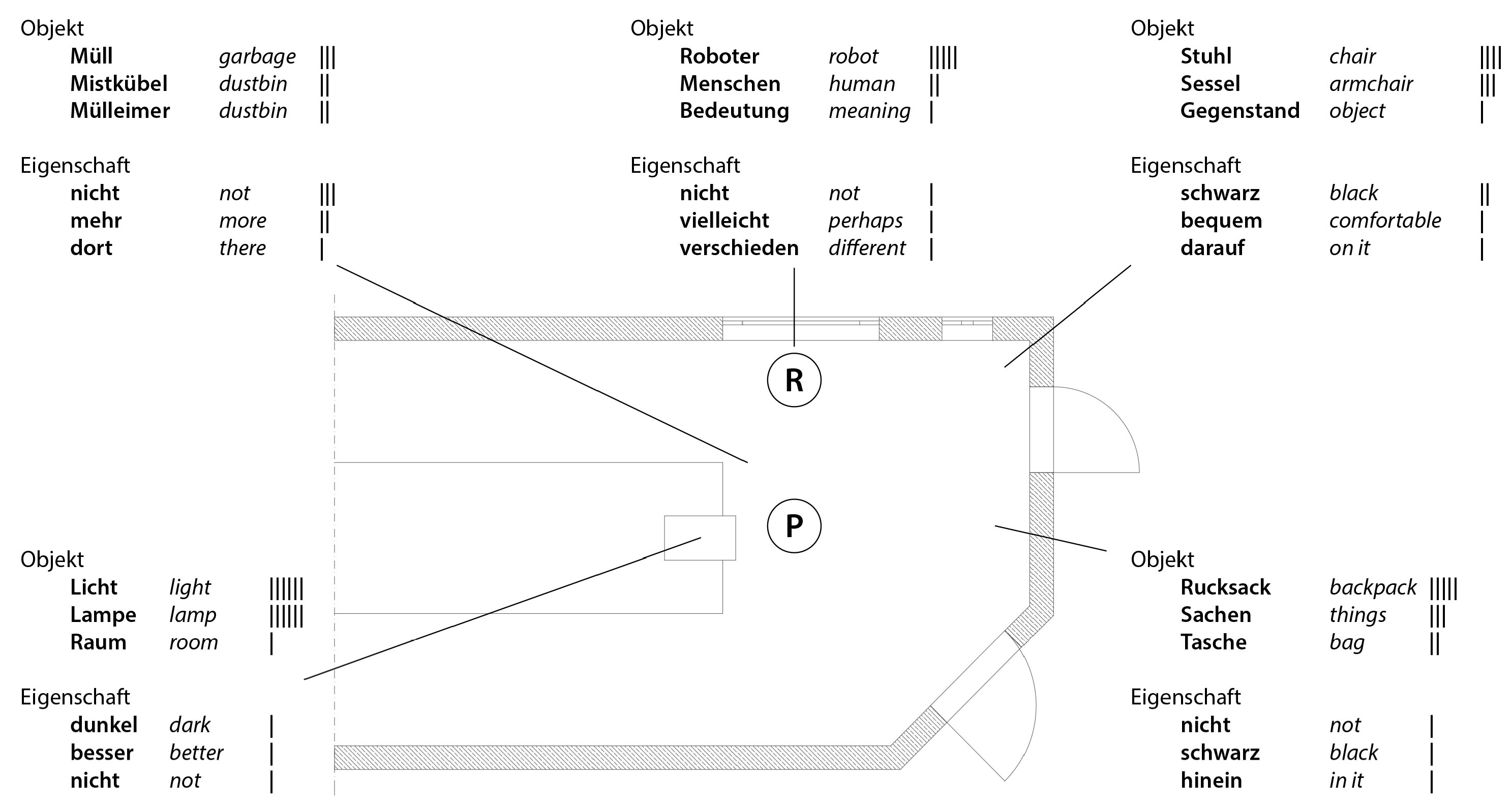
In the second setting (
Figure 3 and
Figure 4), we expanded the system to another robot developed especially for social interaction, the Pepper model by Softbank Robotics. Based on our experience from the first experiment, we adapted the following points:
Less ambiguity in the non-verbal gestures for separate single objects in the room.
Questioning an individual person rather than individuals from among a group.
To evaluate the accuracy of speech recognition, we also transcribed the user input manually, parallel to autonomous speech recognition.
Larger number of persons and more intensive questioning.
After interacting with the robot, the participants completed a brief quantitative questionnaire. It asked for general assessments of the robot, the setting and the experiment, and also about experience with robotics. In addition, some of the participants were asked for a narrative individual interview. The 17 interviews were recorded with a video camera and generally lasted 15 to 25 min. They were guideline-supported narrative interviews. The participants had an opportunity to speak freely about the experiment itself, about their general opinion regarding robots in the private and the public sphere, and their relevant expectations and emotions. Another goal of the narrative interviews was to find out how the participants perceived the experiment, what the participants thought was being researched with the experiment, and whether they feel that generating a spatial model of cultural meaning is possible and useful. Another goal was to improve interaction with the robot as indicated by the feedback in the first experiment.
5.1.4. Experimental Process 2
Showing and questioning was conducted as described in
Section 5.1.2. In the first experiment, many people found it necessary to formulate extensive descriptions for the objects, and these were partly imprecise due to their length. It was shown in the first experiment that the answers pertaining to name and characteristic sometimes led to shorter answers to questions about the name and the meaning of the objects, which were of greater importance for the project. Therefore, in the second experiment, the type of questions was limited to those about the name and the meaning of an object. To make the dialogue more diversified, there were five versions for each of these questions (
Figure 5,
Figure 6 and
Figure 7). To make the questioning process more accessible to visitors, we asked questions in two parts. In the first part, the robot asked for the name, in the second part for the meaning of objects (
Supplementary Material Code S1).
In total, 60 persons in four groups were questioned about five objects each. This means that there was a total of 600 interactions. The average duration per session was between 3 and 5 min.
5.2. Results of the Experiment
Evaluation of research question 1: As part of the “European Robotics Week”, we invited the public, and there were other appeals in the form of press releases inviting people to the “Long Night of the Robots” at Vienna University of Technology. The organizers were overwhelmed by the response (more than 1000 visitors). This large number of visitors exceeded our expectations and greatly strained our resources. We had an opportunity to do narrative interviews with mainly lay people, but also with a philosopher specializing in Philosophy of Technology, a psychoanalyst, and several researchers in the field of robotics. However, a total of 258 interactions between visitors and the robot Romeo could be recorded.
In the “Young Architects” experiment, the environmental conditions were exactly controlled. The result was that 603 interactions between robots and participants were recorded. We did 60 interviews using questionnaires and 17 narrative video interviews.
Evaluation of research question 2: In the narrative interviews that we conducted with some of the visitors, nearly everyone instantly accepted the representation of the model. The reason was familiarity with a floor plan and the fact that the text was shown on the screen. This made up for the strangeness of the humanoid and the abstractness of the invisible machine learning system. Hence it was mostly understood as relevant.
We did not show the floor plan of the room to the architecture students, only the script for the machine learning system. The script was an unfamiliar abstraction for the students, but they understood it for the most part.
Evaluation of research question 3: The level of abstraction was understood and considered relevant for matters of the everyday lifeworld.
In the second experiment the level of abstraction was not understood but considered relevant for matters of the everyday lifeworld.
Evaluation of research question 4: In the first experiment, the robot was set up to ask questions and store the answers in a machine learning system. The participants reacted with different modes of speech to the robot and his questions: some spoke slowly and noticeably more articulated, almost as if they were speaking to a toddler. Others used only single words. Another group of visitors spoke as if they were answering the question of another human.
For the most part, the architecture students spoke slowly and in very articulated form.
Both groups were aware that the robot could not reply in context, nevertheless many still tried to turn the question and answer dialogue into a complex conversation. Counter-questions were often asked, and the robot was asked whether it had understood what was said. Many people tried different modes of speech in their conversation with the robot, and therefore changed their modes of speech as the conversation developed (
Supplementary Material Table S1).
5.3. Experimental Results, Evaluation of Prototype
Our system achieved reliable terms for most of the objects and areas of the room. In Experiment 1, however, the objects “fire extinguisher” and “floor” where mentioned more often as a result of equivocal pointing and its interpretations. In this case the attribution of “fire extinguisher” was succeeded by “floor”.
Additionally, some unexpected connections occurred. As an example, “wardrobe” was associated with the feature “cold”. “Light” was associated with “darkness” in both experiments. This was not obvious at the beginning, exemplifying therefore the before mentioned constant negotiation process. The same occurred with terms like “cold” to express the season. The object “cabinet” was connected to the feature that something is “in it”, just like the floor is a part of the room “on which” something is situated. The examples “wardrobe” and “floor” show that inherent features and concepts from the verbal analysis were filtered out correctly. In the machine learning system, our space game maps cognitive connections between objects. For example, the term wardrobe is directly associated with the terms “wear” and “cold”. Furthermore “trash can” is connected to topics like environment and the waste of things. The development of these connections was confirmed in the second experiment. An interesting detail was found in relation to the term “robot”. The machine learning system showed relations to the term “help”, indicating at a general acceptance of a humanoid robot as an assistive system.
We learned that our system has to solve the challenge to separate the context and to bring terms into context (future work 2), furthermore we have to strengthen the filter of the system, as for example the often-used word “not”, in sentences as “I’m not sure” or “I don’t know exactly” was categorized as a function in the second experiment.
With both experiments we found that names of objects were resolved with a high likelihood, followed by function and property (
Figure 2 and
Figure 4). Meanings on the other hand where found to vary greatly, but at the same time we found that core descriptions started to emerge. Here, experiments with bigger samples of participants need to be conducted. A combination with the field of Scene Labeling might be promising. Speech recognition was not satisfying even in the controlled environment of the second experiment. We used a special voice-optimized microphone in both experiments and transcribed the input of participants by-hand to learn about error sources. This is a technical problem to be solved in both hardware and software.
Most importantly, our expectation was that inter-subjective and individual meanings could be mapped and related with a non-verbal and natural-language dialogue. In this respect, the prototype worked. Indeed, a spatial model of cultural meaning started to develop.
6. Conclusions
The two experiments are only the first for building and constantly improving our first prototype of a cultural spatial model. These experiments and the generated first prototype are still very basic and therefore in no way able to compete with state of the art technical perception systems. As space is constantly produced (and by no means is this production a neutral process), we could already see in this basic stage of the cultural spatial model, that even basic questions on everyday objects and room elements in humanoid-human-interaction opened up moments of reflection and irritation. Speaking with a humanoid about space forced some of the participants, especially the architecture students, to rethink how to explain objects and their functions. This basic act of reflecting on everyday objects is already part of the process we described in the first part of the paper. Therefore, playing the architecture space game is not only for producing data for the machine learning system, but also to start processes of reflection and to add new viewpoints regarding the question of space in human participants. As we have also argued in the theoretical part, it is essential for our space game to talk about artifacts with a humanoid robot in order to produce space, to follow the robot’s gaze, to follow his arm movements in natural language and in non-verbal interaction.
Although most of the conversation between the robot and the participants was about concrete objects, questions about their function concerned their spatiality, i.e., their position in the room, their relation to other objects, their function in the room, their collective and individual meanings, etc. In future experiments, we hope not only to constantly expand the number of objects to be talked about, but also to introduce more elements of the room as a container, such as the floor, the windows, the doors, and so on. The aim of the cultural spatial model is to produce a hybrid spatial model, combining technical and formal perceptions of space with the cultural and subjective viewpoints of the participants. In the long run, we expect the emergence of a dense, hybrid and shared model of space that does not depend on the actual object in a certain room but on what these objects mean in both contexts—in the technical as well as the human perception system.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






