
Effect of Data Scaling Methods on Machine Learning Algorithms and Model Performance
 ,
,  ,
,  and
and
Abstract
:1. Introduction
2. Literature Review
- Applied eleven different ML algorithms with data scaling methods on UCI heart disease dataset;
- Investigated the algorithms’ performance without data scaling methods;
- Identified the best algorithm and scaling method by analyzing the study outcome.
3. Methods
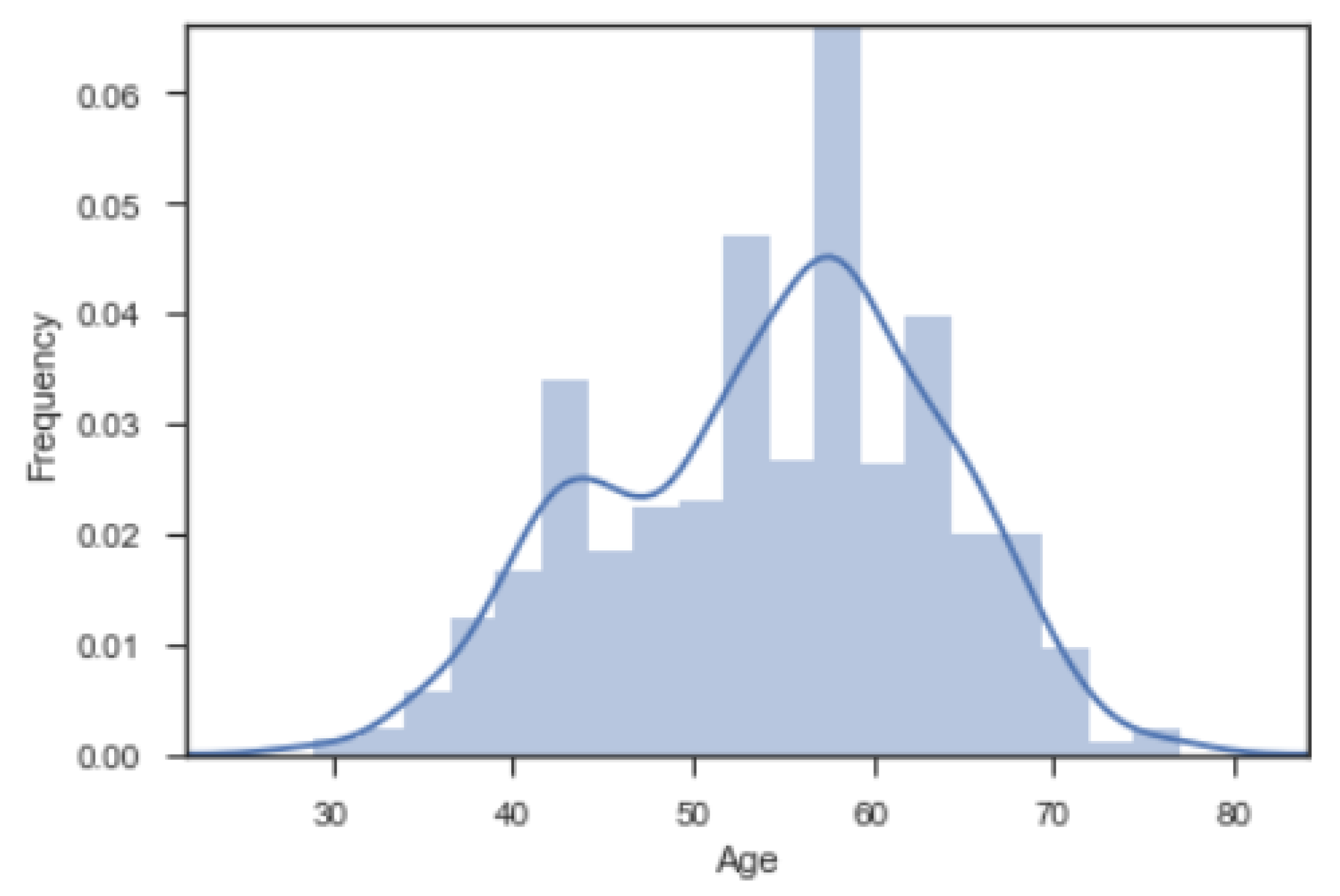
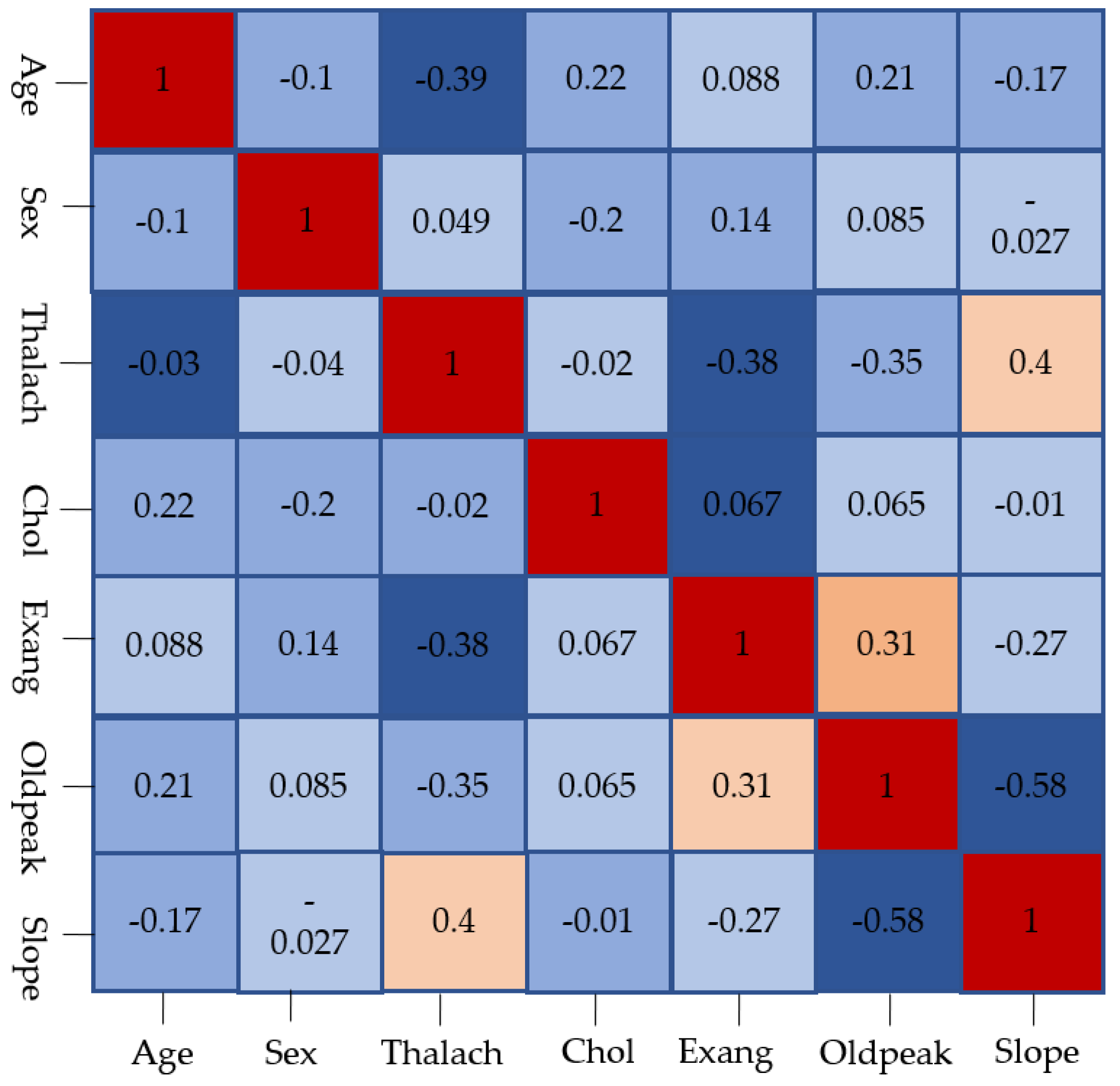
3.1. Data Visualization
3.2. Experimental Setup
- True Positive ( ) = Heart patient classified as patient;
- False Positive ( ) = Healthy people classified as patient;
- True Negative ( ) = Healthy people classified as healthy;
- False Negative ( ) = Heart patient classified as Healthy.
4. Result
Accuracy
NR: CART>RF/ET/GB>XGB>AB>LDA>NB>KNN>LR>SVM
SS: CART>RF/ET>GB>XGB>SVM>AB>KNN>LR>LDA>NB
MM: CART/RF/ET>GB/XGB>AB>KNN>LR>SVM>LDA>NB
MA: CART/RF/ET>GB/XGB>AB>KNN>LR/SVM>LDA/NB
RS: CART/RF/ET>GB/XGB>AB>SVM>KNN/LR>LDA/NB
QT: CART/RF/ET>GB>XGB>AB>KNN>SVM/LDA>LR>NB
LDA: QT>NR>WS/SC/MM/MA/RS
KNN: MA/QT>SC>MM>RS>NR>WS
CART: RS/QT>WS/NR/SC/MM/MA
NB: QT>WS/NR/SC/MM/MA/RS
SVM: WS>SC>RS>QT>MA>MM>NR
XGB: WS/NR>SC/MM/MA/RS/QT
RF: Same performance for all scaling
GB: NR>/WSQT>SC/MM/MA/RS
AB: NR>WS/SC/MM/MA/RS>QT
ET: Same performance for all scaling
NR: CART/RF/GB/ET>XGB>AB>KNN/NB>LDA>LR>SVM
SS: CART/RF/ET>GB>XGB>KNN>AB>LR>NB>SVM>LDA
MM: CART>RF/ET>GB>XGB>KNN>AB>LR>NB>SVM>LDA
MA: CART/RF>ET>GB>XGB>KNN>AB>LR>NB/SVM>LDA
RS: CART>RF/ET>GB>XGB>AB>KNN>SVM>LR>NB>LDA
QT: CART>RF/ET/GB>XGB>KNN>AB>NB>SVM>LR/LDA
LDA: QT>MA>WS/NR/SS/MM/RS
KNN: MA>MM/QT>SS>RS>NR>WS
CART: WS/SS/MM/MA/RS/QT>NR
NB: QT>WS/NR/SS/MM/MA/RS
SVM: WS>SS>RS/QT>MA>MM>NR
XGB: NR>WS/SS/MM/MA/RS/QT
RF: MA>WS/NR/SS/MM/RS/QT
GB: NR>QT>WS/SS/MM/MA/RS
NR: CART/RF>ET/XGB>GB>AB>LDA>SVM>NB>KNN>LR
SS: CART>RF/ET>XGB/GB>SVM>AB/LDA>LR>NB>KNN
MM: CART/ET>RF>XGB/GB>SVM>AB/LDA>LR>NB>KNN
MA: CART/ET/RF>XGB/GB>SVM>AB/LDA>LR>NB>KNN
RS: CART>ET/RF>XGB/GB>SVM>AB>LDA>LR>NB>KNN
QT: CART/ET>RF>XGB/GB>SVM/AB/LDA>LR>NB>KNN
LDA: NR>WS/SC/MM/MA/RS/QT
KNN: SS/MA>QT>RS>MM>NR>WS
CART: WS/MM>NR/SC/MA/RS/QT
NB: WS/NR/SC/MM/MA/RS>QT
SVM: WS>SC/RS>MM/MA>QT>NR
XGB: NR>WS/SC/MM/MA/RS/QT
RF: NR>WS/MA>SC/MM/RS/QT
GB: NR>WS/SC/MM/MA/RS/QT
AB: NR>WS/SC/MM/MA/RS/QT
ET: WS/NR/MM/MA/QT>SC/RS
NR: CART>RT/RF/ET/XGB/GB>AB>LDA>NB>KNN>SVM/LR
SS: CART>RF/ET>XGB/GB>SVM>AB>KNN>LR>LDA>NB
MM: CART/RF/ET>XGB/GB>AB>KNN/LR>SVM/LDA>NB
MA: CART>RF/ET>XGB/GB>AB>KNN>LR/SVM>LDA/NB
RS: CART>RF>ET>XGB/GB>AB/SVM>LR>KNN/LDA>NB
QT: CART>ET>RF>GB>XGB>AB>SVM/KNN/LDA>LR>NB
LDA: QT>WS/NR/SS/MM/MA/RS
KNN: MA>SS/QT>MM>RS>NR>WS
CART: RS/QT>WS/NR/SS/MM/MA
NB: QT>WS/SS/MM/MA/RS>NR
SVM: WS>SS>RS>QT>MA>MM>NR
XGB: NR>WS/SS/MM/MA/RS/QT
RF: MM/RS>WS/NR/SS/MA/QT
GB: NR>QT>WS/SS/MM/MA/RS
AB: NR>WS/SS/MM/MA/RS>QT
ET: MM/QT>WS/NR/SS/MA/RS
5. Discussion
- Since the experiment was conducted using only one dataset, it could be difficult to conclude that the algorithm performance will remain the same if experimented with a different heart disease dataset.
- During this study, we did not emphasize the feature selection process. Instead, we decided to choose a similar number of features as chosen and used by previous literatures for direct comparison. However, experimenting with different features, ML algorithms, and scaling approaches may produce different results.
- Some of the recent trending ML approaches such as deep learning, CNN, and RNN were ignored, as the dataset was quite straightforward and easy to handle with standard ML algorithms.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| LR | Logistic Regression |
| LDA | Linear Discriminant Analysis |
| KNN | K-Nearest Neighbors |
| CART | Classification and Regression Trees |
| NB | Naive Bayes |
| SVM | Support Vector Machine |
| XGB | XGBoost |
| RF | Random Forest Classifier |
| GB | Gradient Boost |
| AB | AdaBoost |
| ET | Extra Tree Classifier |
| DT | Decision Tree |
| NR | Normalization |
| SS | Standscale |
| MM | MinMax |
| MA | MaxAbs |
| RS | Robust Scaler |
| QT | Quantile Transformer |
| ML | Machine Learning |
| MLP | Multilayer Perceptron |
| AI | Artificial Intelligence |
References
- Tripoliti, E.E.; Papadopoulos, T.G.; Karanasiou, G.S.; Naka, K.K.; Fotiadis, D.I. Heart failure: Diagnosis, severity estimation and prediction of adverse events through machine learning techniques. Comput. Struct. Biotechnol. J. 2017, 15, 26–47. [Google Scholar] [CrossRef] [Green Version]
- Pawlovsky, A.P. An ensemble based on distances for a kNN method for heart disease diagnosis. In Proceedings of the 2018 International Conference on Electronics, Information, and Communication (ICEIC), Honolulu, HI, USA, 24–27 January 2018; pp. 1–4. [Google Scholar]
- Soni, J.; Ansari, U.; Sharma, D.; Soni, S. Predictive data mining for medical diagnosis: An overview of heart disease prediction. Int. J. Comput. Appl. 2011, 17, 43–48. [Google Scholar] [CrossRef]
- Lord, W.P.; Wiggins, D.C. Medical decision support systems. In Advances in Health care Technology Care Shaping the Future of Medical; Springer: Berlin/Heidelberg, Germany, 2006; pp. 403–419. [Google Scholar]
- Bashir, S.; Khan, Z.S.; Khan, F.H.; Anjum, A.; Bashir, K. Improving Heart Disease Prediction Using Feature Selection Approaches. In Proceedings of the 2019 16th International Bhurban Conference on Applied Sciences and Technology (IBCAST), Islamabad, Pakistan, 8–12 January 2019; pp. 619–623. [Google Scholar]
- Bhatia, S.; Prakash, P.; Pillai, G. SVM based decision support system for heart disease classification with integer-coded genetic algorithm to select critical features. In Proceedings of the World Congress on Engineering and Computer Science, San Francisco, CA, USA, 22–24 October 2008; pp. 34–38. [Google Scholar]
- Gudadhe, M.; Wankhade, K.; Dongre, S. Decision support system for heart disease based on support vector machine and artificial neural network. In Proceedings of the 2010 International Conference on Computer and Communication Technology (ICCCT), Allahabad, India, 17–19 September 2010; pp. 741–745. [Google Scholar]
- Ghumbre, S.; Patil, C.; Ghatol, A. Heart disease diagnosis using support vector machine. In Proceedings of the International Conference on Computer Science and Information Technology (ICCSIT’), Pattaya, Thailand, 17–18 December 2011. [Google Scholar]
- Takci, H. Improvement of heart attack prediction by the feature selection methods. Turk. J. Electr. Eng. Comput. Sci. 2018, 26, 1–10. [Google Scholar] [CrossRef]
- Zhao, H.; Zhang, C. An online-learning-based evolutionary many-objective algorithm. Inf. Sci. 2020, 509, 1–21. [Google Scholar] [CrossRef]
- Dulebenets, M.A. A novel memetic algorithm with a deterministic parameter control for efficient berth scheduling at marine container terminals. Marit. Bus. Rev. 2017, 2, 303–330. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.Z.; Wang, Y.; Huang, P.Q. AnD: A many-objective evolutionary algorithm with angle-based selection and shift-based density estimation. Inf. Sci. 2020, 509, 400–419. [Google Scholar] [CrossRef] [Green Version]
- Pasha, J.; Dulebenets, M.A.; Kavoosi, M.; Abioye, O.F.; Wang, H.; Guo, W. An optimization model and solution algorithms for the vehicle routing problem with a “factory-in-a-box”. IEEE Access 2020, 8, 134743–134763. [Google Scholar] [CrossRef]
- Ahsan, M.M.; Gupta, K.D.; Islam, M.M.; Sen, S.; Rahman, M.; Shakhawat Hossain, M. Covid-19 symptoms detection based on nasnetmobile with explainable ai using various imaging modalities. Mach. Learn. Knowl. Extr. 2020, 2, 27. [Google Scholar] [CrossRef]
- Ahsan, M.M.; E Alam, T.; Trafalis, T.; Huebner, P. Deep MLP-CNN model using mixed-data to distinguish between COVID-19 and Non-COVID-19 patients. Symmetry 2020, 12, 1526. [Google Scholar] [CrossRef]
- Ahsan, M.M.; Ahad, M.T.; Soma, F.A.; Paul, S.; Chowdhury, A.; Luna, S.A.; Yazdan, M.M.S.; Rahman, A.; Siddique, Z.; Huebner, P. Detecting SARS-CoV-2 From Chest X-Ray Using Artificial Intelligence. IEEE Access 2021, 9, 35501–35513. [Google Scholar] [CrossRef]
- Sen, S.; Gupta, K.D.; Poudyal, S.; Ahsan, M.M. A genetic algorithm approach to optimize dispatching for a microgrid energy system with renewable energy sources. In Proceedings of the CS & IT Conference Proceedings, Dubai, United Arab Emirates, 30 November–1 December 2019; Volume 9. [Google Scholar]
- Ahsan, M.M.; Gupta, K.D.; Nag, A.K.; Pouydal, S.; Kouzani, A.Z.; Mahmud, M.P. Applications and evaluations of bio-inspired approaches in cloud security: A review. IEEE Access 2020, 8, 180799–180814. [Google Scholar] [CrossRef]
- D’Angelo, G.; Pilla, R.; Tascini, C.; Rampone, S. A proposal for distinguishing between bacterial and viral meningitis using genetic programming and decision trees. Soft Comput. 2019, 23, 11775–11791. [Google Scholar] [CrossRef]
- Ahsan, M.M.; Li, Y.; Zhang, J.; Ahad, M.T.; Gupta, K.D. Evaluating the Performance of Eigenface, Fisherface, and Local Binary Pattern Histogram-Based Facial Recognition Methods under Various Weather Conditions. Technologies 2021, 9, 31. [Google Scholar] [CrossRef]
- Amin, M.S.; Chiam, Y.K.; Varathan, K.D. Identification of significant features and data mining techniques in predicting heart disease. Telemat. Inform. 2019, 36, 82–93. [Google Scholar] [CrossRef]
- Tu, M.C.; Shin, D.; Shin, D. Effective diagnosis of heart disease through bagging approach. In Proceedings of the 2009 2nd International Conference on Biomedical Engineering and Informatics, Tianjin, China, 17–19 October 2009; pp. 1–4. [Google Scholar]
- Srinivas, K.; Rani, B.K.; Govrdhan, A. Applications of data mining techniques in healthcare and prediction of heart attacks. Int. J. Comput. Sci. Eng. (IJCSE) 2010, 2, 250–255. [Google Scholar]
- Shouman, M.; Turner, T.; Stocker, R. Integrating decision tree and k-means clustering with different initial centroid selection methods in the diagnosis of heart disease patients. In Proceedings of the International Conference on Data Science (ICDATA); The Steering Committee of The World Congress in Computer Science, Computer Engineering and Applied Computing (WorldComp): Northcott Drive, Canberra, 2012; p. 1. [Google Scholar]
- Chaurasia, V.; Pal, S. Early prediction of heart diseases using data mining techniques. Caribb. J. Sci. Technol. 2013, 1, 208–217. [Google Scholar]
- Hari Ganesh, S.; Gajenthiran, M. Comparative study of data mining approaches for prediction heart diseases. IOSR J. Eng. 2014, 4, 36–39. [Google Scholar] [CrossRef]
- Shilaskar, S.; Ghatol, A. Feature selection for medical diagnosis: Evaluation for cardiovascular diseases. Expert Syst. Appl. 2013, 40, 4146–4153. [Google Scholar] [CrossRef]
- Kausar, N.; Palaniappan, S.; Samir, B.B.; Abdullah, A.; Dey, N. Systematic analysis of applied data mining based optimization algorithms in clinical attribute extraction and classification for diagnosis of cardiac patients. In Applications of Intelligent Optimization in Biology and Medicine; Springer: Berlin/Heidelberg, Germany, 2016; pp. 217–231. [Google Scholar]
- Khourdifi, Y.; Bahaj, M. K-Nearest Neighbour Model Optimized by Particle Swarm Optimization and Ant Colony Optimization for Heart Disease Classification. In International Conference on Big Data and Smart Digital Environment; Springer: Berlin/Heidelberg, Germany, 2018; pp. 215–224. [Google Scholar]
- Mishra, S. Handling imbalanced data: SMOTE vs. random undersampling. Int. Res. J. Eng. Technol. (IRJET) 2017, 4, 317–320. [Google Scholar]
- Ambarwari, A.; Adrian, Q.J.; Herdiyeni, Y. Analysis of the Effect of Data Scaling on the Performance of the Machine Learning Algorithm for Plant Identification. J. Resti (Rekayasa Sist. Dan Teknol. Inf.) 2020, 4, 117–122. [Google Scholar] [CrossRef]
- Shahriyari, L. Effect of normalization methods on the performance of supervised learning algorithms applied to HTSeq-FPKM-UQ data sets: 7SK RNA expression as a predictor of survival in patients with colon adenocarcinoma. Briefings Bioinform. 2019, 20, 985–994. [Google Scholar] [CrossRef] [PubMed]
- Balabaeva, K.; Kovalchuk, S. Comparison of Temporal and Non-Temporal Features Effect on Machine Learning Models Quality and Interpretability for Chronic Heart Failure Patients. Procedia Comput. Sci. 2019, 156, 87–96. [Google Scholar] [CrossRef]
- Khan, M.A. An IoT Framework for Heart Disease Prediction Based on MDCNN Classifier. IEEE Access 2020, 8, 34717–34727. [Google Scholar] [CrossRef]
- Masih, N.; Naz, H.; Ahuja, S. Multilayer perceptron based deep neural network for early detection of coronary heart disease. Health Technol. 2021, 11, 127–138. [Google Scholar] [CrossRef]
- Jalali, S.M.J.; Karimi, M.; Khosravi, A.; Nahavandi, S. An efficient neuroevolution approach for heart disease detection. In Proceedings of the 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), Bari, Italy, 6–9 October 2019; pp. 3771–3776. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Methods | |||||
|---|---|---|---|---|---|---|
| LR | KNN | NB | SVM | DT | RF | |
| Bhatia et al. (2008) | * | |||||
| Gudadhe et al. (2010) [7] | ||||||
| Ghumbre et al. (2011) [8] | * | |||||
| Shilaskar and Ghatol (2013) [27] | * | |||||
| Kausar et al. (2016) [28] | * | |||||
| Amin et al. (2019) [21] | * | * | * | * | * | * |
| Bashir et al. (2019) [5] | * | * | * | * | ||
| Pawlovsky (2018) [2] | * | |||||
| Takci (2018) [9] | * | * | * | |||
| Khourdifi and Bahaj (2018) [29] | * | |||||
| Age | Sex | cp | Trestbps | Chol | fbs | Restecg | Thalach | Exang | Oldpeak |
|---|---|---|---|---|---|---|---|---|---|
| 52 | 1 | 0 | 125 | 212 | 0 | 1 | 168 | 0 | 1.0 |
| 53 | 1 | 0 | 140 | 203 | 1 | 0 | 155 | 1 | 3.1 |
| 70 | 1 | 0 | 145 | 174 | 0 | 1 | 125 | 1 | 2.6 |
| 61 | 1 | 0 | 148 | 203 | 0 | 1 | 161 | 0 | 0.0 |
| 62 | 0 | 0 | 138 | 294 | 1 | 1 | 106 | 0 | 1.9 |
| Attribute | Description | Values |
|---|---|---|
| age | Age in years | Continuous |
| sex | Male/female | 1 = male, 0 = female |
| cp | Chest pain type | 1 = typical type 1, 2 = typical type agina, 3 = nonagina pain, 4 = asymptomatic |
| thestbps | Resting blood pressure | Continuous value in mm hg |
| chol | Serum Cholesterol | Continuous value in mm/dl |
| Restecg | Resting electrographic results | 0 = normal, 1 = having_ST_T wave abnormal, 2 = left ventricular hypertrophy |
| fbs | Fasting blood sugar | mg/dl, mg/dl |
| thalach | Maximum heart rate achieved | Continuous value |
| exang | Exercise induced agina | 0 = no, 1 = yes |
| oldpeak | ST depression induced by exercise relative to rest | Continuous value |
| solpe | Slope of the peak exercise ST segment | 1 = unsloping, 2 = flat, 3 = downsloping |
| ca | Number of major vessels colored by floursopy | 0-3 value |
| thal | Defect type | 3 = normal, 6 = fixed, 7 = reversible defect |
| Test Result | Truth | Performance Measure | |
|---|---|---|---|
| Heart Disease | Non-Heart-Disease | ||
| Accuracy | |||||||
|---|---|---|---|---|---|---|---|
| Algorithm | WS | NR | SS | MM | MA | RS | QT |
| LR | 0.84 | 0.68 | 0.84 | 0.84 | 0.84 | 0.84 | 0.84 |
| LDA | 0.82 | 0.83 | 0.82 | 0.82 | 0.82 | 0.82 | 0.85 |
| KNN | 0.75 | 0.79 | 0.86 | 0.85 | 0.87 | 0.84 | 0.87 |
| CART | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 1.0 | 1.0 |
| NB | 0.82 | 0.82 | 0.82 | 0.82 | 0.82 | 0.82 | 0.83 |
| SVM | 0.99 | 0.63 | 0.92 | 0.83 | 0.84 | 0.88 | 0.85 |
| XGB | 0.97 | 0.97 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 |
| RF | 0.98 | 0.98 | 0.98 | 0.98 | 0.98 | 0.98 | 0.98 |
| GB | 0.97 | 0.98 | 0.96 | 0.96 | 0.96 | 0.96 | 0.97 |
| AB | 0.89 | 0.93 | 0.89 | 0.89 | 0.89 | 0.89 | 0.88 |
| ET | 0.98 | 0.98 | 0.98 | 0.98 | 0.98 | 0.98 | 0.98 |
| Precision | |||||||
|---|---|---|---|---|---|---|---|
| Algorithm | WS | NR | SS | MM | MA | RS | QT |
| LR | 0.81 | 0.67 | 0.81 | 0.82 | 0.82 | 0.81 | 0.82 |
| LDA | 0.789 | 0.78 | 0.78 | 0.78 | 0.79 | 0.78 | 0.82 |
| KNN | 0.78 | 0.8 | 0.88 | 0.9 | 0.91 | 0.87 | 0.9 |
| CART | 1.0 | 0.99 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| NB | 0.8 | 0.8 | 0.8 | 0.8 | 0.8 | 0.8 | 0.84 |
| SVM | 0.99 | 0.6 | 0.91 | 0.79 | 0.8 | 0.86 | 0.83 |
| XGB | 0.96 | 0.98 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 |
| RF | 0.99 | 00.99 | 0.99 | 0.99 | 1 | 0.99 | 0.99 |
| GB | 0.97 | 0.99 | 0.97 | 0.97 | 0.97 | 0.97 | 0.98 |
| AB | 0.88 | 0.92 | 0.88 | 0.88 | 0.88 | 0.88 | 0.87 |
| ET | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 |
| Recall | |||||||
|---|---|---|---|---|---|---|---|
| Algorithm | WS | NR | SS | MM | MA | RS | QT |
| LR | 0.89 | 0.74 | 0.89 | 0.89 | 0.89 | 0.89 | 0.88 |
| LDA | 0.90 | 0.92 | 0.90 | 0.90 | 0.90 | 0.90 | 0.90 |
| KNN | 0.72 | 0.77 | 0.84 | 0.81 | 0.84 | 0.82 | 0.83 |
| CART | 1.0 | 0.99 | 0.99 | 1.0 | 0.99 | 0.99 | 0.99 |
| NB | 0.85 | 0.85 | 0.85 | 0.85 | 0.85 | 0.85 | 0.84 |
| SVM | 0.99 | 0.86 | 0.93 | 0.91 | 0.91 | 0.93 | 0.90 |
| XGB | 0.96 | 0.98 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 |
| RF | 0.98 | 0.99 | 0.97 | 0.97 | 0.98 | 0.97 | 0.97 |
| GB | 0.96 | 0.97 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 |
| AB | 0.90 | 0.94 | 0.90 | 0.90 | 0.90 | 0.90 | 0.90 |
| ET | 0.98 | 0.98 | 0.97 | 0.98 | 0.98 | 0.97 | 0.98 |
| F1 Score | |||||||
|---|---|---|---|---|---|---|---|
| Algorithm | WS | NR | SS | MM | MA | RS | QT |
| LR | 0.85 | 0.70 | 0.85 | 0.85 | 0.85 | 0.85 | 0.85 |
| LDA | 0.84 | 0.84 | 0.84 | 0.84 | 0.84 | 0.84 | 0.86 |
| KNN | 0.75 | 0.79 | 0.86 | 0.85 | 0.87 | 0.84 | 0.86 |
| CART | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 1 | 1 |
| NB | 0.83 | 0.82 | 0.83 | 0.83 | 0.83 | 0.83 | 0.84 |
| SVM | 0.99 | 0.70 | 0.92 | 0.84 | 0.85 | 0.89 | 0.86 |
| XGB | 0.96 | 0.98 | 0.96 | 0.96 | 0.96 | 0.96 | 0.96 |
| DT | 0.98 | 0.98 | 0.98 | 0.98 | 0.98 | 0.98 | 0.98 |
| RF | 0.98 | 0.98 | 0.98 | 0.99 | 0.98 | 0.99 | 0.98 |
| GB | 0.96 | 0.98 | 0.96 | 0.96 | 0.96 | 0.96 | 0.97 |
| AB | 0.89 | 0.93 | 0.89 | 0.89 | 0.89 | 0.89 | 0.88 |
| ET | 0.98 | 0.98 | 0.98 | 0.99 | 0.98 | 0.98 | 0.99 |
| Our Study | ||||
|---|---|---|---|---|
| Authors | Accuracy | Without Scaling | With Scaling | |
| Maximum | Minimum | |||
| Amin et al. (2019) [21] | 85.86% | |||
| 84% | 84% (SC, MM, MA, ES, QT) | 68% (NR) | ||
| Bashir et al. (2019) [5] | 82.56% | |||
| Our Study | ||||
|---|---|---|---|---|
| Authors | Accuracy | Without Scaling | With Scaling | |
| Maximum | Minimum | |||
| Amin et al. (2019) [21] | 82.49% | |||
| 75% | 87% (MA, QT) | 79% (NR) | ||
| Pawlovsky (2018) [2] | 85% | |||
| Our Study | ||||
|---|---|---|---|---|
| Authors | Accuracy | Without Scaling | With Scaling | |
| Maximum | Minimum | |||
| Srinivas et al. (2010) [23] | 84.14 | |||
| Hari Ganesh et al. (2014) [26] | 83.40% | |||
| 82% | 83% (QT) | 82% (NR, SC, MM, MA, RS) | ||
| Amin et al. (2019) [21] | 85.86% | |||
| Bashir et al. (2019) [5] | 84.24% | |||
| Our Study | ||||
|---|---|---|---|---|
| Authors | Accuracy | Without Scaling | With Scaling | |
| Maximum | Minimum | |||
| Bhatia et al. (2008) [6] | 90.57% | |||
| Gudadhe et al. (2010) [7] | 80.41% | |||
| Ghumbre et al. (2011) [8] | 85.05% | |||
| 99% | 92%(SC) | 63%(NR) | ||
| Kausar et al. (2016) [28] | 81% | |||
| Amin et al. (2019) [21] | 86.87% | |||
| Bashir et al. (2019) [5] | 84.85% | |||
| Takci (2018) [9] | 84.88% | |||
| Our Study | ||||
|---|---|---|---|---|
| Authors | Accuracy | Without Scaling | With Scaling | |
| Maximum | Minimum | |||
| Bashir et al. (2019) [5] | 84.17% | 98% | 98% (for all scaling methods) | No minimum |
| Algorithm | Previous Study | WS | NR | SS | MM | MA | RS | QT |
|---|---|---|---|---|---|---|---|---|
| SVM | 0.88 | 0.99 | 0.70 | 0.92 | 0.84 | 0.85 | 0.89 | 0.86 |
| NB | 0.87 | 0.83 | 0.82 | 0.83 | 0.83 | 0.83 | 0.83 | 0.84 |
| LR | 0.87 | 0.85 | 0.70 | 0.85 | 0.85 | 0.85 | 0.85 | 0.85 |
| KNN | 0.84 | 0.75 | 0.79 | 0.86 | 0.85 | 0.87 | 0.84 | 0.86 |
| DT | 0.84 | 0.98 | 0.98 | 0.98 | 0.98 | 0.98 | 0.98 | 0.98 |
| Algorithm | Previous Study | WS | NR | SS | MM | MA | RS | QT |
|---|---|---|---|---|---|---|---|---|
| SVM | 0.86 | 0.99 | 0.6 | 0.91 | 0.79 | 0.8 | 0.86 | 0.83 |
| NB | 0.87 | 0.8 | 0.8 | 0.8 | 0.8 | 0.8 | 0.8 | 0.84 |
| LR | 0.86 | 0.81 | 0.67 | 0.81 | 0.82 | 0.82 | 0.81 | 0.82 |
| KNN | 0.95 | 0.78 | 0.8 | 0.88 | 0.9 | 0.91 | 0.87 | 0.9 |
| DT | 0.95 | 0.99 | 0.98 | 0.98 | 0.99 | 0 0.99 | 0.98 | 0.98 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahsan, M.M.; Mahmud, M.A.P.; Saha, P.K.; Gupta, K.D.; Siddique, Z. Effect of Data Scaling Methods on Machine Learning Algorithms and Model Performance. Technologies 2021, 9, 52. https://0-doi-org.brum.beds.ac.uk/10.3390/technologies9030052
Ahsan MM, Mahmud MAP, Saha PK, Gupta KD, Siddique Z. Effect of Data Scaling Methods on Machine Learning Algorithms and Model Performance. Technologies. 2021; 9(3):52. https://0-doi-org.brum.beds.ac.uk/10.3390/technologies9030052
Chicago/Turabian StyleAhsan, Md Manjurul, M. A. Parvez Mahmud, Pritom Kumar Saha, Kishor Datta Gupta, and Zahed Siddique. 2021. "Effect of Data Scaling Methods on Machine Learning Algorithms and Model Performance" Technologies 9, no. 3: 52. https://0-doi-org.brum.beds.ac.uk/10.3390/technologies9030052