1. Introduction
Bacillus thuringiensis (
Bt) is an entomopathogenic bacterium that produces several types of insecticidal proteins, such as Cry, Cyt, Vip, Sip, Mtx-like, and Bin-like proteins, along with other virulence factors contributing to its pathogenicity [
1,
2]. The Vip proteins are a family of proteins that are secreted during the vegetative growth phase and that have been classified into four groups according to their sequence homology: Vip1, Vip2, Vip3, and Vip4 [
2]. Because of repeated applications of
Bt sprays and the widespread adoption of
Bt-crops (transgenic crops protected from insects by the expression of
cry and/or
vip3 genes), some insect populations have developed resistance to
Bt toxins [
3,
4,
5,
6]. Therefore, in this arms race against insects, it is necessary to explore the potential of new insecticidal proteins for pest control. A series of approaches have been used for isolating novel insecticidal protein genes from
Bt, such as PCR, which has further evolved into specific applications to mining new insecticidal genes, such as PCR hybridization, PCR-RFLP, E-PCR and PCRSSCP [
7,
8,
9,
10,
11]. In addition, the construction of
Bt DNA libraries, followed by screening by Western Blotting or a hybridization-based method, has also been used to detect novel insecticidal protein genes [
12,
13,
14]. The PCR approaches being used to detect
vip genes are based on the presence of conserved blocks in the DNA sequence of these genes [
11,
15] and most of the studies have focused on genes from the
vip3 family. Therefore, the PCR approach is limited to finding
vip genes with enough homology to the primers used. An additional problem with the PCR approach is that it does not provide the full length of the new
vip genes. On the other hand, the library-based methods are time-consuming and laborious. The next generation sequencing (NGS) allows rapid sequencing of entire genomes at a low cost-effective ratio [
16,
17]. The number of
Bt whole genomes that have been sequenced has increased quickly in the past decade. To date, 459
Bt strains have been sequenced, with a mean genome size ranging from 5.3 MB to 6.7 MB and a mean guanine-cytosine content (GC content) between 34% and 35% (
https://0-www-ncbi-nlm-nih-gov.brum.beds.ac.uk/genome/?term=Bacillus+thuringiensis). The combination of the low cost NGS with the development of many freeware tools has enabled the rapid detection of insecticidal protein genes at the genome level. On the other hand, the development of the mass spectrometry (MS)-based proteomics has enabled the detection of proteins from complex mixtures from different stages of a microorganism [
18]. The combination of the genomic and proteomic approaches is a very successful approach for validation and correction of predicted genomic coding information in a wide variety of organisms [
18,
19,
20,
21,
22].
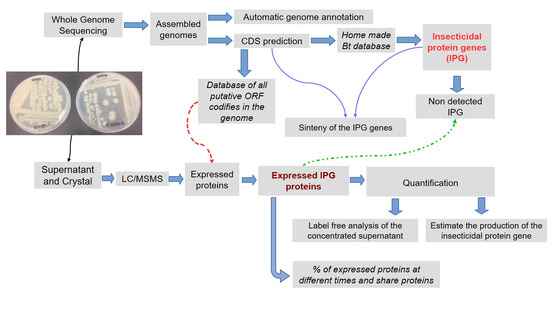
In this study, the identity of vip genes has been determined in nine Bt isolates which were candidates to harboring new vip1 and vip2 genes (Vip1 and Vip2 constitute a binary toxin and their genes are normally located in an operon). Two of these isolates, which were found to carry vip-type genes with a similarity lower than 45% to already reported genes, were subjected to whole genome sequencing and to different kinds of proteomic analysis to determine and estimate the relative abundance of the expressed insecticidal protein genes.
3. Discussion
A screening of Spanish collections of
Bt isolates was undertaken to search for novel members of the Vip family. As a result, nine
Bt isolates were selected for harboring new binary insecticidal protein genes of the
vip1/vip2 family [
11]. As a first step, the PCR-Sanger Sequencing approach revealed new alleles of already described
vip1 and
vip2 genes (
vip2Ac2-vip1Ca2 and
vip2Bb4-vip1Bb3) and two sequences with low similarity to the
vip1Bb1 (from the
Bt isolate E-SE10.2) and
vip4Aa1 (from the
Bt isolate O-V84.2) genes. In a second step, the
Bt isolates E-SE10.2 and O-V84.2 were subjected to whole genome sequencing with the Illumina HiSeq-PE150 sequencing platform. Then, the genomes of E-SE10.2 and O-V84.2 were assembled in 222 and 249 scaffolds codifying for 6156 CDS and 6457 CDS, respectively. The CDS predicted for both genomes represented close to the 99% of the total number of genes predicted in the genomes. In addition, from this 99% of the predicted CDS, 28% belonged to hypothetical genes and 72% to annotated genes by the Rast server. Moreover, the results obtained from the automated annotation indicated that both
Bt genomes had a similar subsystems category distribution (
Figure S1).
The supernatants at 24 h (growth Phase T1) and 48 h (growth Phase T2) and the crystal proteins (growth Phase T3) of both
Bt isolates were also analyzed and annotated with GO terms (
Figure S2). The quantity of the proteins expressed at the three different growth phases for the
Bt isolates E-SE10.2 and O-V84.2 were 10.2–3.5% and 10.4–8.2%, 8.3–2.8%, respectively, of their genome encoded sequences. This low percentage of expressed proteins detected indicates that, in our experimental conditions, we only detect a small part of the predicted proteins by the genome data prediction, a phenomenon that has also been found in other studies [
21,
22]. The low percentage of detected expressed proteins should not be interpreted as that the rest of the proteins cannot be expressed, since they could do it under different growth conditions. Considering both isolates together, the number of annotated proteins in each growth phase, T1, T2 and T3, was 42.3%, 49.8% and 56.9%, respectively. The distribution of the GO terms over the different growth phases is similar in the
Bt isolates E-SE10.2 and O-V84.2 (
Figure S2). The most common and abundant GO terms in all the phases (cellular biosynthetic process, organic substance biosynthetic process, cellular nitrogen compound metabolic process, and organonitrogen compound metabolic process) indicate that both
Bt isolates metabolize the carbon and nitrogen in the media to produce all the organic and organonitrogen compounds that they need (
Figure S2). The specific GO term macromolecule metabolic process of the T3 growth phase indicates that both
Bt isolates express proteins of a relatively high molecular mass, such as the Cry-like proteins detected (
Figure S2).
Regarding the predicted insecticidal protein genes in both
Bt genomes, we were able to find some of the predicted gene products: one new couple of binary Vip-like proteins (Vip2Ac-like_1-Vip4Aa-like_1), two new Vip-like proteins (Vip2Ac-like_1 and Vip4Aa-like_2), one Sip1A-like protein (Sip1A-like_1), and eight Crystal-like proteins (Cry23A-like, Cry45Aa-like_1, Cry45Aa-like_2, Cry45Aa-like_3, Cry32Ea-like, Cry32eDa-like, Cry32Eb-like and Cry73Aa-like) (
Table 4). The discrepancies of the protein identification between the replicates can be attributed to metabolic flow changes in cells during development, resulting from enzyme-related changes or that some proteins exist with extremely low abundances such that they cannot be detected by MS. To determine if the detected
Bt-like proteins are being secreted or that they form inclusion bodies, we performed an LC/MSMS analysis with the supernatant (24 h and 48 h) and solubilized crystal proteins. In the supernatant of both
Bt isolates at 24 h, the Vip4Aa-like_1, Vip4Aa-like_2, Vip2Ac-like_1, Vip2Ac-like_2, and Sip1Aa-like_1 proteins were detected, while at 48 h only Vip4Aa-like_1, Vip2Ac-like_1, Vip2Ac-like_2, and Sip1Aa-like_1 were detected. Again, the extremely low abundance of these proteins might be responsible for the differences found at 24 h and 48 h. Regarding the Vip4Aa-like proteins, this is the first time that there has been demonstrated that they are expressed and secreted to the medium in the log phase. Regarding the crystal proteins, they were found in the crystal of both
Bt isolates, except for the Cry23Aa-like, which was also found in the supernatant at 24 h and 48 h. The detection of the Cry23Aa-like protein and sporulation factors (Stage V sporulation protein, spore coat protein B, spore coat polysaccharide biosynthesis protein spsB and spore coat polysaccharide synthesis) in the supernatant at 24 h (and also at 48 h) of the
Bt isolate E-SE10.2 indicates that the cells already started the sporulation process.
The relative abundance of the Bt-like proteins was estimated in the supernatant and the parasporal crystal in both Bt isolates. In the supernatant (24 h and 48 h) of both Bt isolates, the Vip-like, Sip1-like and Cry23Aa-like were marginally expressed. Regarding the crystal proteins in the Bt isolate O-V84.2, the Cry-like proteins represent around the half of the total crystal weight, while for the Bt isolate E-SE10.2, the Cry23Aa-like protein represents between 2.5% and 30% of the crystal weight. The high variability observed in the amount of Cry23Aa-like could be due to the different replicates are not in the same time point of the sporulation process. The crystal composition of the Bt isolate O-V84.2 was also determined for those proteins with a percentage of similarity lower than 45%. The crystal was composed by four kinds of proteins: 7.0–9.8% Cry45-like proteins (Cry45Aa-like_1, Cry45Aa-like_2 and Cry45Aa-like_3), 30.4–30.5% Cry32-like proteins (Cry32Ea-like and Cry32Da-like), 5.0–6.2% Cry32Eb-like, and 2.8–4.25% Cry73Aa-like, while the Bt isolate E-SE10.2 only produced the Cry23Aa-like protein.
The expression levels of the Vip-like, Sip1-like and Cry23Aa-like proteins were compared between 24 h and 48 h. The amount of Vip4Aa-like_1 protein was increased two-fold at 24 h vs. 48 h, while the Vip4Aa-like_2 was only detected at 24 h. As regard to the rest of the proteins (Vip2Ac-like, Sip1A-like, and Cry23A-like proteins), no differences in expression were observed. These results suggest that the Vip4Aa-like_2, Vip2A-like and Sip1A-like proteins were expressed at the 24 h while the Vip4Aa-like_1 was expressed later at the end of the 24 h and the beginning of the 48 h periods.
5. Materials and Methods
5.1. Bacterial Strains and Growth Conditions for DNA Analysis
Nine
Bt isolates from a Spanish collection, known to carry
vip1 and
vip2 genes, were selected for this study [
11]. For further gene identification of the
vip1 and
vip2 genes, the
Bt isolates were grown in 4 mL LB medium overnight (ON) at 29 °C and 200 rpm. For the whole genome sequencing, only those
Bt isolates with
vip1 and
vip2 genes with less than 60% similarity to already described
vip1 and
vip2 genes were chosen. The isolates were grown in 10 mL LB medium until OD of 0.6 at 29 °C and 200 rpm.
5.2. Genomic DNA Preparation
Total genomic DNA used for gene identification (GI) was isolated from a single colony of the Bt isolates. Cells were collected at 9000× g for 10 min at 4 °C and the pellet was washed in 2 mL of TE buffer (1 M Tris-HCl, 10 mM EDTA, pH 8.0). The pellet was dissolved in 200 μL of TEL buffer (TE buffer + 4 mg/mL lysozyme) and further incubated at 37 °C for 30 min. Then, 400 μL of lysis solution (0.2 M NaOH, 1% SDS) was added. After gentle mixing, 300 μL of the neutralization buffer (3 M KAc, pH 5.5) was added and the mixture incubated for 5 min on ice. The mixture was centrifuged at 14,000× g for 15 min at 4 °C and the supernatant was transferred to a new tube. One volume of cold 100% ethanol was added and the samples kept at −20 °C for 16 h. The samples were centrifuged at 14,000× g for 15 min at 4 °C and the supernatant was transferred to a new tube and the pellet washed with 1 mL of cold 70% ethanol. The pellet was dried with the Eppendorf concentrator 5301 for 5 min at 42 °C and solubilized in 50 μL of TE buffer. Total genomic DNA, used for whole genome sequencing (WGS), was purified as described in the manufacturer instructions of the DNeasy Blood & Tissue Kit Qiagen. The DNA for GI was quantified using Nanodrop 2000 (Thermo Scientific, Waltham, MA, USA), while for WGS, the DNA was measured with a Qubit Fluorimetrer. In addition, the integrity of the DNA for GI and WGS was evaluated by agarose gel electrophoresis (1% agarose).
5.3. Identification of Vip1- and Vip2-Type Genes
Identification of
vip1 and
vip2 genes was performed with primer pairs designed from conserved regions within the
vip1 and
vip2 gene families, respectively. A first PCR with “screening primers” [
11] was performed to confirm the presence of
vip genes. With the positive samples, a second PCR was performed with the “typing primers” [
11,
23] for the identification of the
vip1 and
vip2 genes. PCR reactions contained, in a final volume of 25 μL, 100 ng of the DNA template, 0.25 U of Biotools polymerase (Biotools), 2.5 μL of 10-fold reaction buffer, 10 mM of each dNTPs, and 0.3 µM of the corresponding primers (
vip1sc,
vip2sc,
vip2 typing [
11] or
vip1 typing [
23]). PCR amplifications were carried out in an Eppendorf Mastercycler thermal cycler as follows: 5 min denaturation at 95 °C, 35 cycles of amplification (1 min denaturation at 94 °C, 1 min of annealing at 45 °C, and 2 min of extension at 72 °C), and an extra extension step of 10 min at 72 °C. To determine the similarity of the amplified sequences to already described
vip1 and
vip2 genes, the PCR products obtained with the “typing primers” (or with the “screening primers” for those samples that did not give amplification with the “typing primers”) were ligated into the pGEM
®-T Easy plasmid (Promega), cloned in
Escherichia coli DH10β, and sequenced. DNA sequence analysis and contig assembly was performed using DNAstar v5 and NCBI BLAST tools (Blastx) [
24].
5.4. Genome Sequencing, Assembly and Annotation Analysis
Genome Sequencing for the
Bt isolates E-SE10.2 and O-V84.2 was performed with the Illumina HiSeq-PE150 sequencing platform (Novogene S.L Hong Kong, China). From the clean reads (without adapters, low quality, N and duplication) provided by Novogene S.L., first we evaluated the quality of the data with FastQC software (0.11.5, Babraham Bioinformatics Institute, Cambridge, Cambridgeshire, United Kingdom, 2016). Then, the reads were assembled with SoapdeNovo2 (kmer size 35 and genome size 5,600,000 bp) and the gaps were closed with GapCloser (maximum read length 150, overlap 25 bp and thread number 1) [
25]. The assembled reads were annotated with Rast server (
Figure S1) and the coding sequence (CDS) prediction was performed with the Glimmer v2 [
26]. First, the predicted genes were filtered against a customized
Bt protein database (
https://sourceforge.net/projects/bt-proteindatabase/files/Btdatabase/) with Blastx (genetic code bacteria and archaea, e-value 0.001 and word size 6) to select those CDS with homology to the
Bt toxins [
24]. Next, the putative insecticidal protein genes were compared against the Non-Redundant database and only the concordant results along the customized
Bt protein database and Non-Redundant database were selected as true positive. Moreover, for the selected putative insecticidal genes, prediction of conserved domains was carried out with CD-search [
27] and the gene sinteny was determined in the assembled sequences.
5.5. Sample Preparation for in Gel Digestion LC/MSMS Analysis and Insecticidal Activity of Bt Isolates
A single colony of
Bt was grown in 100 mL of LB at 29 °C for 24 h and 48 h for detection of the secretable proteins, while for the detection of proteins in the parasporal crystal the culture was grown in 100 mL of CCY at 29 °C until culture sporulation (72 h). The supernatant of
Bt was concentrated by trichloroacetic acid (TCA) precipitation. Briefly, the cells were collected at 6000×
g for 15 min at 4 °C and filtered through sterile 0.45 μm cellulose acetate filters (GE Healthcare Life Sciences). The sample was incubated with 10% TCA (final concentration) and kept at 4 °C for 24 h. Then, the sample was centrifuged at 16,000×
g for 20 min at 4 °C. The pellet was washed with 100 mL of cold acetone (−18 °C), centrifuged at 16,000×
g for 20 min at 4 °C, and let dry at room temperature for 5 min. The precipitated proteins were solubilized in 50 mM carbonate buffer containing 10 mM dithiothreitol (pH 11.3) for 48 h, with two buffer changes (
Figure S3). Crystals (together with spores) were separated by centrifugation at 6000×
g for 12 min at 4 °C. The pellet containing the parasporal crystals was washed three times with ice cold solution A (1 M NaCl, 5 mM EDTA, 10 mM PMSF, 1% Triton X-100) and centrifuged at 17,000×
g for 12 min at 4 °C between washes. The pellet was then washed three times with ice cold solution B (10 mM KCl) and centrifuged at 24,000×
g for 15 min at 4 °C. The crystals in the final pellet were solubilized in 20 mL of 50 mM carbonate buffer containing 10 mM dithiothreitol (pH 11.3) by incubation at room temperature for 2 h with continuous shaking (
Figure S3). Concentration of the proteins in the supernatant and in the solubilized crystals was estimated with the Bradford method [
28]. The purity of the expressed proteins in the supernatant and the crystal was analyzed by SDS-PAGE and stained with Coomassie brilliant blue R-250 (Sigma-Aldrich, St. Louis, MO, USA) (
Figure S3).
5.6. In Gel Digestion LC/MSMS Analysis
The detection of the expression of the putative insecticidal proteins was done by LC/MSMS at the proteomics facility of the SCSIE (Servei Central de Suport a la Investigació Experimental), at the University of Valencia, Spain. First, a 1D SDS-PAGE (without resolving gel) was performed with 30 µg of total protein in three replicates of the concentrated supernatant (24 h and 48 h) and solubilized crystal proteins. The bands were cut out and in gel digested with 500 ng sequencing grade trypsin (Promega). The digestion was stopped with trifluoroacetic acid (TFA, 1% final concentration). After subjecting the samples to a double extraction with acetonitrile (ACN), all the peptide solutions were dried in a rotatory evaporator. Samples were solubilized with 50 μL of 2% ACN, 0.1% TFA. A sample aliquot of 5 μL was loaded onto a trap column (NanoLC Column, 3 µ C18-CL, 350 µm × 0.5 mm, Eksigent) and desalted with 0.1% TFA at 3 μL/min for 5 min. The peptides were then loaded onto an analytical column (LC Column, 3 µ C18-CL, 75 µm × 12 cm, Nikkyo) equilibrated in 5% ACN 0.1% formic acid (FA). The elution was carried out with a linear gradient of 5–35% B in A for 30 min (A: 0.1% FA; B: ACN, 0.1% FA) at a flow rate of 0.3 μL/min. Peptides were analyzed in a nanoESI qQTOF (5600 TripleTOF, ABSCIEX) mass spectrometer. Eluted peptides were ionized applying 2.8 kV to the spray emitter. Analysis was carried out in a data-dependent mode (DDA). Survey MS1 scans were acquired from 350 to 1250 m/z for 250 ms. The quadrupole resolution was set to “UNIT” for MS2 experiments, which were acquired 100–1500 m/z for 50 ms in “high sensitivity” mode. The following switch criteria were used: charge: 2+ to 5+; minimum intensity; 70 counts per second (cps). Up to 25 ions were selected for fragmentation after each survey scan and the collision energy was automatically selected by the instrument according to the following equation: |CE| = (slope) × (m/z) + (intercept); Charge (Unknown, 1, 2, 3, 4, 5), Slope (0.0575, 0.0575, 0.0625, 0.0625, 0.0625, 0.0625), Intercept (9, 9, −3, −3, −6, −6)
5.7. Protein Identification of the in Gel Digestion LC/MSMS Analysis with Paragon Algorithm and Mascot
The MS/MS information of three replicates of the concentrated supernatant (24 h and 48 h) and solubilized crystal proteins were sent to Paragon algorithm [
29] via the Protein Pilot v 4.5 (ABSciex). Protein Pilot v 4.5 default parameters were used to generate peak list directly from the 5600 TripleTof Sciex. The Paragon algorithm of Protein Pilot v 4.5 was used to search in a homemade database that was created combining all the coding sequences predicted by Glimmer v2 software for the
Bt isolates E-SE10.2 and O-V84.2; the new database was named
Bt_combined (
https://sourceforge.net/projects/bt-combined/files/Bt_combined/). The search in the respective protein database was done with the following parameters: trypsin specificity, cys-alkylation, and the search effort set to through. To avoid using the same spectral evidence in more than one protein, the identified proteins were grouped based on MS/MS spectra (proteins sharing MS/MS spectra are grouped, regardless of the peptide sequence assigned) by the Protein-Pilot Progroup algorithm. A protein group in a Progroup Report is a set of proteins that share some physical evidence, the formation of protein groups in Pro Group was guided entirely by observed peptides only and the unobserved regions of protein sequence play no role in explaining the data (
Tables S1 and S2). The protein within each group which can explain more spectral data is that protein shown as the primary protein of the group. Only the proteins of the group for which there is individual evidence (unique peptides with enough confidence) are also listed (
Tables S1 and S2). In addition, to support the identification of the Protein Pilot v 4.5 (ABSciex) and estimate the relative production of the insecticidal proteins in the three replicates of the concentrated supernatant and solubilized crystal proteins, a series of Mascot MS/MS ion searches with the output of the 5600 TripleTof Sciex were done with the
Bt_combined protein database. The following parameters were used: MS/MS “ion search”, enzyme “trypsin”, fixed modifications “carbamidomethyl (C)”, variable modifications “deamidated (NQ) and oxidation (M)”, mass values “monoisotopic”, protein mass “unrestricted”, peptide mass tolerance “50 ppm”, fragment mass tolerance “0.6 Da”, max miss cleavages “1”, instrument type “ESI-QUAD-TOF”, number of queries for E-SE10.2 “(Supernatant 24 h: R1 7468, R2 8755, R3 7682; Supernatant 48 h: R1 9, 243, R2 8602, R38,286; Crystal: R1 6779, R2 7173 R3 7790)” and for O-V84.2 “(Supernatant 24 h: R1 3708, R2 4459, R3 3536 Supernatant 48 h: R1 6016, R2 6654, R3 6123; Crystal: R1 5206 R2 5206 R3 4476)”, significance threshold “
p-value < 0,05”, max number of families “auto”, ions score or expect cut-off “20”, and preferred taxonomy “all entries”. The Exponentially Modified Protein Abundance Index (emPAI) was expressed as molar and weight percentage [
30] (
Table 5 and
Table S3).
We defined as a true positive all those proteins with homology to the
Bt toxins higher than 100 aa that had been identified with Protein Pilot v4.5 and Mascot in at least two of the replicates. In addition, for the identified proteins, the functional annotation was performed with the SwissProt Database using the Blast2GO v5.0 software (
Figure S2) [
31].
5.8. Label Free Analysis of the Concentrated Supernatant 24 h vs. 48 h in Both Bt Isolates
The data obtained from the 5600 TripleTof Sciex of the concentrated supernatant and solubilized proteins from the crystal were analyzed by Peak View 1.1 following the parameters: Unused ≥ 1.3, confidence > 95% and with maximum 50 peptides for protein. For the protein library construction of the global analysis, a joint search with the
Bt_combined protein database was performed with the three replicates of the concentrated supernatant (24 h and 48 h) and solubilized crystal proteins (
Table S5). In the case of the specific conditions analysis (Supernatant: E-SE10.2 24 h vs. 48 h, and O-V84.2 24 h vs. 48 h), a joint search with the
Bt_combined protein database was performed with the three replicates of the concentrated supernatant (
Table S4). The search in the respective analysis was done with the following parameters: trypsin specificity, cys-alkylation, and the search effort set to through. First, a global analysis was done to study grouped data analysis and samples distribution. A joined search with all the samples was performed with the Peak View 1.1 that identified 1816 proteins and the quantitative data obtained was analyzed with Marker View 1.3. Briefly, for the grouped data analysis, a PCA analysis was done with the non-normalized area of the peaks and with the area peaks corrected by the total areas sum. In the case of the samples distribution, a PCA analysis was done with the area of the peaks corrected by the total areas sum (
Table S5). For the specific conditions analysis, a specific search with Peak View 1.1 was done with the respective samples to study the statistical significant differences. The quantitative data was analyzed with Marker View 1.3. Prior to data analysis of the E-SE10.2 24 h vs. 48 h, and O-V84.2 24 h vs. 48 h, we applied a normalization by total areas sum, and then a grouped data analysis with PCA analysis was done. A student’s
t-test statistical analysis with the concentrated supernatant (E-SE10.2 24 h vs. 48 h, and O-V84.2 24 h vs. 48 h) was performed to determine the differentially expressed proteins between two experimental conditions with the Marker View 3.1 software (
Table S4).






{kind=link}
{kind=link}
{kind=link}
{kind=link}