1. Introduction
Drug resistance testing (DRT) methods for HIV-1 are continually evolving as exemplified by NGS technology, which is gradually replacing Sanger chemistry in clinical diagnostics [
1,
2]. NGS has the capability to generate high-quality genotypic data at a low cost when a large volume of samples is available, with a relatively shorter turn-around time and higher sensitivity compared to traditional Sanger methods. NGS technology is versatile and can deal with different specimen types and HIV-1 subtypes, producing an unprecedented high volume of data. It is able to detect low abundance viral variants, such as minority resistant variants (MRV), that are not readily detectable by Sanger methods, with potential added value for clinical management [
3,
4,
5,
6]. However, the analysis of the large volumes of raw NGS data generated in such tests requires complex and reproducible bioinformatic tools to provide robust and clinically actionable results. Therefore, the capacity of a laboratory in the effective management of NGS data constitutes an essential component in external quality assessment (EQA) of the laboratory’s competence in performing NGS-based HIV-DRT.
Reference materials or proficiency test (PT) panels have long been used in the validation of experimental procedures and EQA applications for laboratories performing Sanger-based HIV-DRT [
7,
8,
9]. While validated experimental methods are essential to EQA, every execution of a wet lab protocol may result in variations in the derived output dataset, which may lead to discrepancies in the downstream analysis. Because of the high sensitivity and quantitative nature of NGS-based HIV-DRT, such differences are of more significance than in Sanger-based technologies. Converting large volume raw NGS data, of different quality, into end-user interpretable HIV-DRT reports is, thus, a challenging task. Various noise and errors resulting from the laboratory procedures may significantly hamper the design, optimization, and performance of software tools, and eventually, the competence of a laboratory in conducting NGS DRT. Due to the limited capacity of a wet panel in assessing the particular lab ability for effective NGS HIV-DRT data management, well-characterized reference in silico NGS datasets with known ground truth on the genotype composition at all examined loci and the exact frequencies of HIV variations they may harbor, so-called dry panels, are urgently required but yet to be developed.
Software pipelines that support NGS HIVDR assays are required to perform a series of data analytical steps to covert raw NGS data into an HIV drug resistance report. While some variations exist, these pipelines share many essential procedures, including filtering of short and poor quality reads, reference alignment, variant calling, drug resistance mutation (DRM) identification, query against selected clinically validated algorithm(s), and a final data reporting step [
10,
11,
12]. Many bioinformatic pipelines are currently available with different degrees of complexity in their use [
13,
14,
15,
16,
17]. While a simple-to-use interface is preferred, especially for diagnostic use, methods for the specific validation of the different algorithmic approaches and the corresponding implementation and execution by the final user are needed. That is, the accuracy of the algorithm needs to be verified so that the final output can be guaranteed to an end-user, as high-quality results. The validation of the existing algorithms largely relies on the analysis of plasmid derived NGS, which is not representative of the complexity of data from real clinical specimens. Besides its foreseeable EQA application, well-characterized dry panels consisting of data from different samples, of different quality, and representative of the major NGS platforms, would certainly benefit the development and refinement of software tools and serve the technical training needs for conducting such analysis properly.
2. Goals of NGS Dry Panels for HIV-DRT
The primary applications of a dry panel in genotypic assays include: (1) facilitating the development, refinement, and validation of effective data processing software or bioinformatics tools; (2) enabling technical training and troubleshooting on issues that arise from non-lab procedures; and lastly but most importantly; (3) allowing EQA assessment of the lab competence in relevant data management while involving no real sample processing. Therefore, well-designed dry panels for a genotypic assay should include reference sequences representing raw sequencing outputs containing all major variations, possible artificial biases, and uncommon sequencing errors one may encounter while processing genuine NGS HIV-DRT data.
The ground truth or reference values for the subjects of interest (i.e., genotypes, mutations, and their expected frequencies) should be pre-determined, against which downstream comparative analyses could be conducted. The ground truth represents the reference values against which the specificity, sensitivity, and additional accuracy and precision quantitative measures could be determined. These can include a reference resistance genotype, a genetic sequence, the presence/absence of specific mutations, or additional information regarding the quality grade of the data.
In addition to standard PT specimen panels, capacity building and EQA programs for Sanger-based HIV-DRT have previously benefited from the use of data dry panels [
18,
19,
20,
21,
22,
23], by sharing specific electropherogram and sequence data with linked ground truth. For that, dry panels for SS HIV-DRT include not only regular SS files containing specific HIV DRMs, but also datasets of low quality or erroneous data that approximate typical quality problems one may encounter in the use of this technology. Within the contexts of EQA programs, these panels help to specifically assess data analysis capabilities of testing laboratories to reliably detect DRMs by interpreting the same sequencing data, since raw SS data files are provided instead of biological specimens and, thus, comparisons are not affected by the intrinsic variability of wet lab techniques and protocols.
Similar to SS, to-be-developed dry panels for NGS DRT are expected to satisfy all alike needs with additional capacity in the quantitative assessment of NGS output for HIV DRM detection. In addition, NGS dry panels should also represent NGS data variability, with a broad scope of potential errors and artifacts that may arise from the manipulation of samples in NGS experimental protocols. The main goals of an HIV-DRT NGS dry panel are to: 1) test the ability of a bioinformatic tool/pipeline to reliably predict a resistance profile; 2) accurately detect HIV DRMs in both qualitative and quantitative manners; and 3) comply with a standard of quality while being representative of the different NGS technologies and the application context, including error profiles of sequencing platforms, HIV diversity and variability, and experimental design.
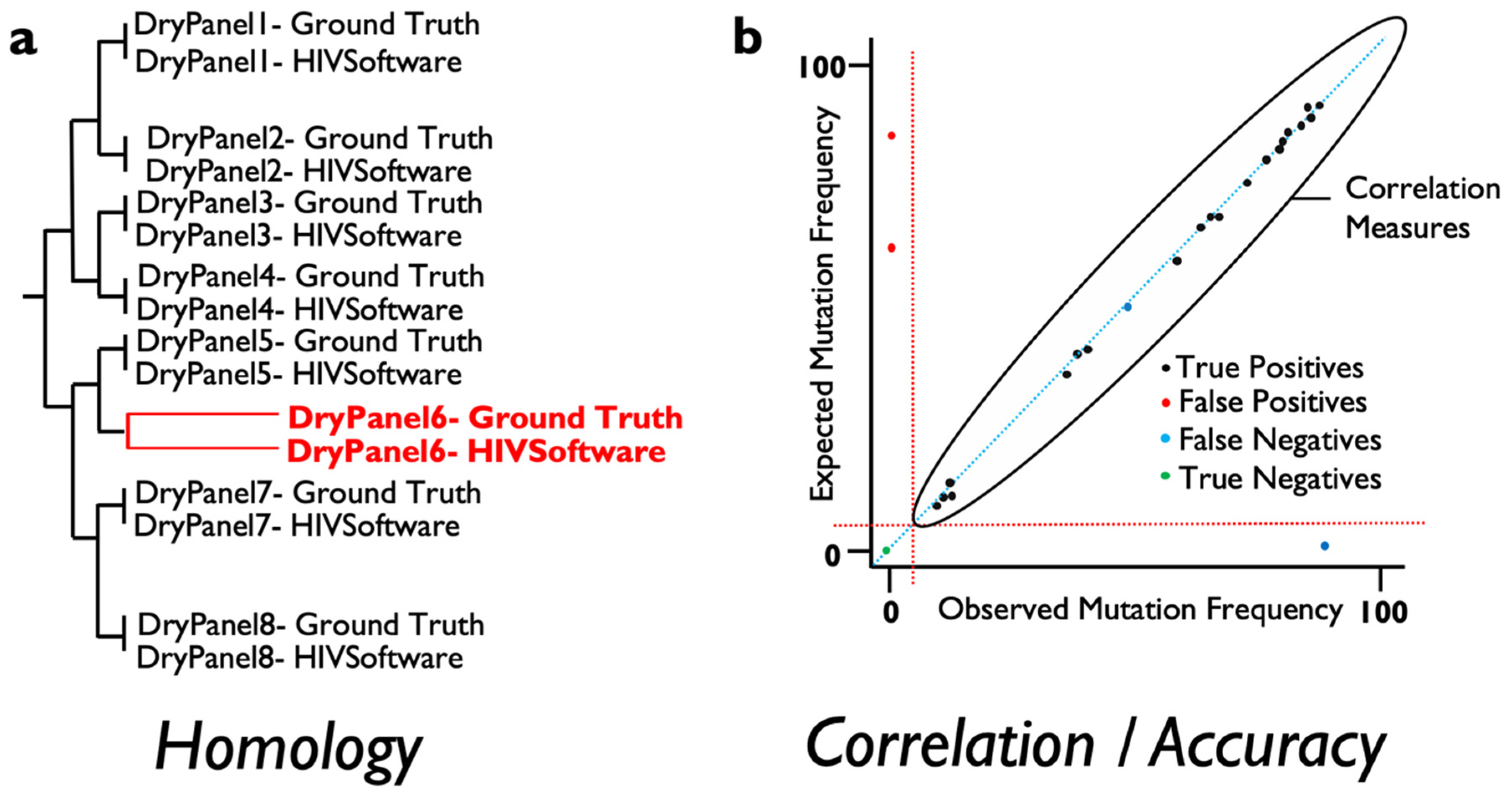
For this, several measures of agreement between ground truth and the results derived from varied software can be obtained and automatically implemented to score the validity of results when NGS data are analyzed. At the consensus (Sanger-like sequence) level, a single sequence representing the whole NGS-based viral population, the number of discrepancies or nucleotide mismatches between the ground truth sequence, and the obtained sequence should ideally be 0 in terms of similarity across the genome region examined. In addition, a measure of similarity can be measured for every pair of ground truth result data to detect those sequence datasets where the analysis has failed to provide an equal representation of the consensus sequence for the viral population. These measures include phylogenetic distances and tree building that include within-codon mixtures or the calculation of the proportion of differences (
Figure 1a). On the other hand, in order to assess whether the frequency of the mutations detected by a specific software is accurate, standard correlation, specificity and sensitivity analysis can be performed to ensure that results are above a pre-defined threshold analysis (
Figure 1b). Linking failures to particular features in the dry panel dataset can help determine which steps need revision in the evaluated software or testing laboratory.
The First Winnipeg Consensus proposed prototypic guidelines specific to NGS data analysis for HIV-DRT, which may serve as a scaffold when designing dry panels for such assays [
10]. It specified the essential steps and criteria for relevant data management, including: (1) quality controls, incorporating low quality and contamination detection; (2) sequence read alignment strategies for HIV-1 protease, reverse transcriptase, and integrase proteins; (3) variant calling and quality control based on these alignments; (4) variant interpretation and reporting; and (5) general data management. Accordingly, dry panel datasets need to be designed to challenge the analysis process in detecting both specific features within the sequence data and how these data are analyzed that can result in artifactual results when real data are used for diagnostics. A dry panel should satisfy the needs for assessing and validating all steps in an analysis pipeline including identifying and filtering out low quality data and ruling out false drug resistance mutations caused by signature hypermutation, erroneous base-calling, or improper alignments (
Table 1).
3. Challenges for NGS Dry Panel Development
3.1. NGS Accuracy Assessment
The sensitivity and specificity assessment of NGS HIV-DRT pose different challenges, compared to SS HIV-DRT, because of the quantitative nature and higher sensitivity of such assays [
24]. NGS HIV-DRT is privileged to have the capacity to detect MRVs in the viral population. SS can arguably detect viral variants down to the ~15% of abundance and the dry panels used for SS HIV-DRT are qualitative or semi-quantitative by nature. They are able to detect the presence/absence of a mutation but not quantify its frequency in the viral population. Conversely, NGS HIV-DRT detects DRMs at a much lower prevalence and quantifies their frequency within a viral population. The technical threshold for DRM detection depends on the experimental procedures used to obtain the NGS dataset and is usually defined based on positive DNA controls. This threshold often lies well below reporting thresholds for clinical use [
4,
25]. Thus, EQA for NGS is quantitative and needs to specifically assess the ability of software tools to determine the frequency of a particular mutant, without the variability of the experimental protocol that is inherently linked to the generation of such data. For that, the definition of what is the ground truth for a specific dataset needs to be established based on the accuracy and precision of a particular data analysis tool or the performance of an EQA-evaluated laboratory.
3.2. Sequencing Technologies and Experimental Approaches
Currently, Illumina and Ion Torrent are the dominant NGS technologies used for HIV-DRT [
26,
27]. Each of them has its specific error profile and characteristics that need to be considered during analysis. In other words, a bioinformatic tool that provides robust results on a dataset from one specific NGS technology may fail to provide reliable output for other technologies. Therefore, all main NGS platforms need to be represented in NGS dry panels if they are to be used in a multi-platform context to ensure the adequate dataset option of choice for specific laboratories in the context of EQA programs.
In addition, several experimental strategies exist for NGS sequencing of the HIV genome. For instance, genome sequencing- or amplicon sequencing-based experimental designs may show different features in the data that result in different biases in terms of sequence duplication, recombination, or template sampling. It is also common to aim for different depths of coverage or use diverse sequencing lengths in order to balance laboratory costs. All such factors should be taken into consideration while constructing the perspective dry panels for NGS HIV-DRT. Unique Molecular Identifiers have also been proposed as a way to overcome the bias introduced at the DNA amplification steps and correct for sequencing error, provided that specific data analysis steps are used [
28,
29]. Thus, the ability to test any software to adapt to and address challenges specific to particular experimental designs is also needed, the assessment of which requires exemplar reference datasets that approximate those from different experimental approaches.
3.3. Data Availability and Exchange Formats
The data format of dry panel files needs to be readily usable by all different software platforms. FASTQ and SAM/BAM are used by most common sequencing platforms and are suitable for data exchange. On the other hand, to be able to exchange and evaluate results in a timely and reproducible manner, the amino acid variant format (AAVF) was defined by the First Winnipeg Consensus [
30]. This format was designed to keep the codon-level results and all associated metadata. Parsers and format compliance checking tools were also provided as open-source software. The Winnipeg Consensus advised that newly developed software tools aimed for HIV NGS-based genotyping validation should produce results in this format to facilitate quality assessment processes. Finally, FASTQ files will need to be provided as downloadable files shared through public data servers or specific repositories such as HIVdb. This would be accompanied by the creation of evaluation methods using the tools as mentioned above on AAVF outputs from the client labs. Notably, steady access to internet is required for both the participating labs, for reference datasets downloading and analysis data submission, and the EQA administrator, who require web-based servers for handling large data files during the program operation.
4. Dry Panel Data Types
4.1. Real Data Dry Panels
Real data are the primary real-world source of data for HIV-DRT bioinformatic tools. Importantly, real data harbors actual errors and artifacts derived from experimental protocols. Real data can be obtained from HIV RNA extracted from patient samples, HIV culture supernatants, or HIV DNA using commercially available HIV plasmids, commonly used in most diagnostic labs as positive controls. Each of these genetic material sources shows specific features in terms of quality control. For instance, plasmid-derived NGS data do not show errors linked to the reverse transcription step needed to process RNA samples.
The use of plasmids or RNA from culture genetic material provides a way to create artificial viral mixtures with controlled MRV abundance of interests. Still, the quantification of such mixtures shows intrinsic error and variability. Thus, its link to the readouts from different data analysis tools on the same NGS dataset and its usability as ground truth can’t be derived solely from those measured concentrations.
Similarly, one of the main disadvantages of using real datasets for dry panel design is that the ground truth of the exact frequencies of the DRMs they harbor cannot be reliably determined. As an approximation to ground truth, the majority vote consensus of results obtained from several well-established tools could be used to establish the ground truth which could then be used to measure the accuracy of additional tools as they become available [
31]. This is especially important when trying to assess the presence of MRV (those between 1% and 15%) where most discrepancies among the available software are found.
Once a methodology has been established to define ground truth for real data by using statistical agreement, datasets obtained from clinical specimens, viral culture, or plasmid samples can be obtained and analyzed through generic or HIV-DRT specific repositories such as NCBI/SRA and EMBL/ENA or HIVdb-NGS [
12], respectively, to contribute to dry panel construction. These data are suitable to test bulk batches of sample datasets with evident errors or quality problems and to test new tools for accuracy in describing highly prevalent viral mutations.
4.2. Synthetic and in Silico Dry Panels
Aside from real-world data, the generation of synthetic data has been widely used to test software in all biomedical fields using NGS technologies [
32,
33,
34]. A myriad of software tools is available that are capable of mimicking the sequence-specific error (SSE) profiles of the different NGS platforms. These tools can also model different experimental designs or organism-linked mutation generation models to represent mixtures. In addition, they are able to include mutation and recombination events, based on statistical models alone or a combination of statistical models with parametrization obtained from real data. Therefore, quality, mutation frequencies, mixtures and contamination can be modelled to create input files for synthetic dry panels. Nevertheless, these data are still a result of a model and may fail to account for the artificial errors or amplification biases introduced during the wet lab procedures, especially the PCR steps, which are drastically different from SSEs and should be properly managed by the data analytics tools. This represents one of the main weaknesses of such a strategy for dry panels since a software tool that performs well on model-derived data may show a decreased performance on real data.
A forged dry panel can be described as a carefully crafted combination of real data sequence reads in order to create real datasets with a known ground truth supporting them. The main idea behind a forged dry panel is the careful annotation of NGS sequence data at the read level, by linking each read to the presence/absence of mutations, technology, experimental design, quality score, HIV-1 genome region, and other artifacts that reads harbor. By adding up all these read-level annotations, a composite read data library can be built with thousands or millions of reads that can be combined into forged sample datasets by selecting the reads with the properties expected to be tested in the dry panel. In this way, the real error profile is kept and the specific features to be tested can be combined in a controlled manner.
5. Design of Dry Panels
To date, most of the available software tools for NGS-based HIV-DRT have been validated through internally generated datasets. Few studies have reported validation using different data analysis methods and often comparing different sequencing platforms [
35,
36]. While studies regarding the comparison of data analysis procedures for NGS HIV-DRT are scarce, recent reports on the cross-validation of various data analysis pipelines on the same real datasets show an excellent agreement between different pipelines when a modest sensitivity threshold (>2%) is required [
31,
37]. Lee et al. used datasets obtained from several different laboratories on the same set of PT specimens and cross-analyzed them using five available analysis platforms. Ground truth for these samples was defined on a majority vote basis, defining a mutation present if 4 out of 5 analysis platforms detected it. Similarly, Jair et al. validated publicly available pipelines with similar results on real HIV NGS data. In addition, abundant and diverse HIV NGS real data are available at public repositories such as NCBI/SRA or EMBL-EBI/ENA, shared by HIV studies involving software development or epidemiological characterization [
38]. These include most of the available NGS platforms and datasets representative of HIV diversity and can be easily accessed and used through appropriate mechanisms for dry panel design purposes. However, the diversity of experimental protocols may be linked to specific features data analysis pipelines that are suited to protocol-derived features but not to others. Thus, the testing of these may require additional datasets to correctly validate these pipelines.
A comprehensive dry panel should be able to test all of the required quality criteria in a minimal dataset. The First Winnipeg Consensus outlined the essential data analysis steps for NGS HIV-DRT [
10]. Accordingly, the prospective dry panel may be constructed to address the need for testing the capacity of the bioinformatics tools in performing these designated tasks (
Table 1).
For sequence quality control, short or low-quality sequence reads can be included that harbor a specific signal mutation that should not pass acceptable quality filters. Similarly, highly contaminated or cross-contaminated samples can be included in the dry panel dataset to ascertain if the analysis software can correctly detect and/or describe sample contamination and its source.
The sequence alignment strategy is a central point in NGS-based HIV-DRT and also needs to be considered for dry panel design. Many alignment algorithms and derived software tools exist that can be used for HIV-1-DRT. The performance of these alignment tools may vary depending on the error profiles of varied NGS platforms and on the genetic diversity of the examined genomic regions [
39]. Aside from the strategy of choice, alignment should be performed using the HXB2 HIV-1 reference [
40] or a sample specific consensus
pol gene sequence, albeit this may not be a requirement for some analysis strategies. HXB2 is suggested as an aligner reference based on considerations including: (1) HIV-1
pol gene is highly conservative among all HIV subtypes, for which the choice of reference has minimal impact on subsequent alignment; (2) HXB2 is a common coordinate system for HIV-1 DRM calling and reporting; (3) the use of a “unified” aligner reference facilitates inter-lab or inter-pipeline comparisons during EQA. Insertions and deletions with respect to a reference are especially challenging to detect and manage, which can benefit from codon-aware alignment strategies and improved alignment quality control [
41,
42]. Both in-frame and out-of-frame insertions and deletions should be included in the dry panel datasets for assessing the pipeline capacity in properly managing such challenging sequence variations.
For the variant calling quality control step, the Winnipeg Consensus recommended using codon-level variant calls and reporting, advising against the use of consensus sequence to represent NGS-based drug resistance data. This is because mixed bases present at two or more loci within a codon may result in artifactual or assumptive mutations if only data at consensus level are interpreted. Inclusion of such within-codon mixes is therefore advised to check whether the analysis software is treating variants at the codon-level or nucleotide-level. Additional controls for variant calling include minimum count number of specific mutations and minimum coverage to call variations at a specified threshold since sensitivity is dependent on the depth of coverage.
In order to perform an accuracy/precision assessment of the results, the most important measure is the agreement between the obtained drug resistance profile and pre-determined ground truth, which may serve as the ultimate standard. To assess accuracy, specifically for MRV, the presence or absence of amino acid mutations above these different reporting thresholds can be detected and true/false positive/negative measures calculated as the matching or mismatching with the ground truth that is linked to the sample data. This will allow accuracy measures calculation and validation of specific software when reporting drug resistant variants at different thresholds. In addition, a linear correlation between the obtained frequencies of amino acid mutations and the ground truth mutations can also be calculated to obtain generic linear correlation measures and assess the precision of the tool being evaluated.
Finally, HIVDR reporting of the obtained results in a standardized format is critical for the ability to exchange and validate results obtained from a dry panel or real data. Systematic EQA programs will benefit from the standardized format. The First Winnipeg Consensus recommended AAVF format specification as an additional report that would be useful for automatic result validation. This format includes codon coverage, mutation frequencies, reference, and the analysis features that are needed for traceable result validation. Therefore, reference AAVF outcomes from the prospective dry panels should be provided as part of the ground truth for pipeline validation or EQA assessment purposes, along with automatic parsing and comparison tools.
6. Conclusions
EQA capacity building programs, as well as software development for NGS-based HIV-DRT, will benefit from strategically designed and well-characterized dry panels that remain to be established. Many challenging but essential requirements need to be taken into account while constructing such dry panels. With the increasing adoption of NGS HIV-DRT worldwide, more research and development efforts are desired for the construction, validation and appropriate application of these panels, especially to serve the needs for effective EQA for such assays.
Author Contributions
All co-authors (E.R.L., R.W.S. and R.K.) are the members of the organizing committee for the symposium series and the leaders of themed discussion sessions during the meeting. M.N.-J. and H.J. drafted the manuscript, and all co-authors contributed significantly to the revisions of this manuscript and gave consent to this submission. All authors have read and agreed to the published version of the manuscript.
Funding
H.J. acknowledges funding from the Canadian Federal Initiative to Address HIV and AIDS and the Public Health Agency of Canada (H.J., E.R.L.).
Acknowledgments
This symposium was sponsored primarily by the Public Health Agency of Canada and the Federal Initiative to Address HIV/AIDS in Canada. We appreciate the generous in-kind support from all participating parties and institutes for the symposium series and the related research and development efforts. The funders played no role in the study design, data collection and analyses, manuscript preparation, and the decision-making for the publication of this work. We thank Paul Sandstrom from the National HIV and Retrovirology Laboratories, Public Health Agency of Canada, for his consistent support for this project.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Raymond, S.; Nicot, F.; Abravanel, F.; Minier, L.; Carcenac, R.; Lefebvre, C.; Harter, A.; Martin-Blondel, G.; Delobel, P.; Izopet, J. Performance evaluation of the Vela Dx Sentosa next-generation sequencing system for HIV-1 DNA genotypic resistance. J. Clin. Virol. 2020, 122, 104229. [Google Scholar] [CrossRef]
- Ávila-Ríos, S.; Parkin, N.; Swanstrom, R.; Paredes, R.; Shafer, R.W.; Kantor, R. NGS for HIVDR testing; laboratory, clinical and implementation considerations. Viruses 2020, 12, 617. [Google Scholar] [CrossRef] [PubMed]
- Stella-Ascariz, N.; Arribas, J.R.; Paredes, R.; Li, J.Z. The Role of HIV-1 Drug-Resistant Minority Variants in Treatment Failure. J. Infect. Dis. 2017, 216, S847–S850. [Google Scholar] [CrossRef] [PubMed]
- Inzaule, S.C.; Hamers, R.L.; Noguera-Julian, M.; Casadellà, M.; Parera, M.; Kityo, C.; Steegen, K.; Naniche, D.; Clotet, B.; Rinke de Wit, T.F.; et al. Clinically relevant thresholds for ultrasensitive HIV drug resistance testing: A multi-country nested case-control study. Lancet HIV 2018, 5, e638–e646. [Google Scholar] [CrossRef]
- Casadellà, M.; Paredes, R. Deep sequencing for HIV-1 clinical management. Virus Res. 2017, 239, 69–81. [Google Scholar] [CrossRef] [PubMed]
- Fisher, R.G.; Smith, D.M.; Murrell, B.; Slabbert, R.; Kirby, B.M.; Edson, C.; Cotton, M.F.; Haubrich, R.H.; Kosakovsky Pond, S.L.; Van Zyl, G.U. Next generation sequencing improves detection of drug resistance mutations in infants after PMTCT failure. J. Clin. Virol. 2015, 62, 48–53. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Parkin, N.; de Mendoza, C.; Schuurman, R.; Jennings, C.; Bremer, J.; Jordan, M.R.; Bertagnolio, S. WHO DBS Genotyping Working Group Evaluation of In-house Genotyping Assay Performance Using Dried Blood Spot Specimens in the Global World Health Organization Laboratory Network. Clin. Infect. Dis. 2012, 54, S273–S279. [Google Scholar] [CrossRef] [Green Version]
- Parkin, N.; Bremer, J.; Bertagnolio, S. Genotyping External Quality Assurance in the World Health Organization HIV Drug Resistance Laboratory Network During 2007–2010. Clin. Infect. Dis. 2012, 54, S266–S272. [Google Scholar] [CrossRef] [Green Version]
- Lee, E.R.; Gao, F.; Sandstrom, P.; Ji, H. External quality assessment for next-generation sequencing-based HIV drug resistance testing: Unique requirements and challenges. Viruses 2020, 12, 550. [Google Scholar] [CrossRef]
- Ji, H.; Enns, E.; Brumme, C.J.; Parkin, N.; Howison, M.; Lee, E.R.; Capina, R.; Marinier, E.; Avila-Rios, S.; Sandstrom, P.; et al. Bioinformatic data processing pipelines in support of next-generation sequencing-based HIV drug resistance testing: The Winnipeg Consensus. J. Int. AIDS Soc. 2018, 21, e25193. [Google Scholar] [CrossRef] [Green Version]
- Döring, M.; Büch, J.; Friedrich, G.; Pironti, A.; Kalaghatgi, P.; Knops, E.; Heger, E.; Obermeier, M.; Däumer, M.; Thielen, A.; et al. Geno2pheno[ngs-freq]: A genotypic interpretation system for identifying viral drug resistance using next-generation sequencing data. Nucleic Acids Res. 2018, 46, W271–W277. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tzou, P.L.; Kosakovsky Pond, S.L.; Avila-Rios, S.; Holmes, S.P.; Kantor, R.; Shafer, R.W. Analysis of unusual and signature APOBEC-mutations in HIV-1 pol next-generation sequences. PLoS ONE 2020, 15, e0225352. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Taylor, T.; Lee, E.R.; Nykoluk, M.; Enns, E.; Liang, B.; Capina, R.; Gauthier, M.-K.; Van Domselaar, G.; Sandstrom, P.; Brooks, J.; et al. A MiSeq-HyDRA platform for enhanced HIV drug resistance genotyping and surveillance. Sci. Rep. 2019, 9, 8970. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Garcia-Diaz, A.; McCormick, A.; Booth, C.; Gonzalez, D.; Sayada, C.; Haque, T.; Johnson, M.; Webster, D. Analysis of transmitted HIV-1 drug resistance using 454 ultra-deep-sequencing and the DeepChek(®)-HIV system. J. Int. AIDS Soc. 2014, 17, 19752. [Google Scholar] [CrossRef]
- Poon, A.F.Y.; Kirkby, D.; Martin, E.; Liang, R.H. MiCall Pipeline for processing FASTQ data from an Illumina MiSeq to genotype human RNA viruses like HIV and hepatitis C. Available online: https://github.com/cfe-lab/MiCall (accessed on 15 June 2020).
- Howison, M.; Coetzer, M.; Kantor, R. Measurement error and variant-calling in deep Illumina sequencing of HIV. Bioinformatics 2019, 35, 2029–2035. [Google Scholar] [CrossRef]
- Wymant, C.; Blanquart, F.; Golubchik, T.; Gall, A.; Bakker, M.; Bezemer, D.; Croucher, N.J.; Hall, M.; Hillebregt, M.; Ong, S.H.; et al. Easy and accurate reconstruction of whole HIV genomes from short-read sequence data with shiver. Virus Evol. 2018, 4. [Google Scholar] [CrossRef] [Green Version]
- WHO/HIVResNet HIV Drug Resistance Laboratory Operational Framework. Geneva: World Health Organization. 2017. Licence: CC BY-NC-SA 3.0 IGO. Available online: https://www.who.int/hiv/pub/drugresistance/hivdr-laboratory-framework-2017/en/ (accessed on 1 May 2020).
- Land, S.; Zhou, J.; Cunningham, P.; Sohn, A.H.; Singtoroj, T.; Katzenstein, D.; Mann, M.; Sayer, D.; Kantor, R. Capacity building and predictors of success for HIV-1 drug resistance testing in the Asia-Pacific region and Africa. J. Int. AIDS Soc. 2013, 16. [Google Scholar] [CrossRef]
- Land, S.; Cunningham, P.; Zhou, J.; Frost, K.; Katzenstein, D.; Kantor, R.; Chen, Y.M.A.; Oka, S.; DeLong, A.; Sayer, D.; et al. TREAT Asia Quality Assessment Scheme (TAQAS) to standardize the outcome of HIV genotypic resistance testing in a group of Asian laboratories. J. Virol. Methods 2009, 159, 185–193. [Google Scholar] [CrossRef] [Green Version]
- Hamers, R.L.; Straatsma, E.; Kityo, C.; Wallis, C.L.; Stevens, W.S.; Sigaloff, K.C.E.; Siwale, M.; Conradie, F.; Botes, M.E.; Mandaliya, K.; et al. Building capacity for the assessment of HIV drug resistance: Experiences from the pharmaccess African studies to evaluate resistance network. Clin. Infect. Dis. 2012, 54, S261–S265. [Google Scholar] [CrossRef]
- Pandit, A.; Mackay, W.G.; Steel, C.; van Loon, A.M.; Schuurman, R. HIV-1 drug resistance genotyping quality assessment: Results of the ENVA7 Genotyping Proficiency Programme. J. Clin. Virol. 2008, 43, 401–406. [Google Scholar] [CrossRef]
- Huang, D.D.; Eshleman, S.H.; Brambilla, D.J.; Palumbo, P.E.; Bremer, J.W. Evaluation of the Editing Process in Human Immunodeficiency Virus Type 1 Genotyping. J. Clin. Microbiol. 2003, 41, 3265–3272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Becker, M.; Liang, D.; Cooper, B.; Le, Y.; Taylor, T.; Lee, E.R.; Wu, S.; Sandstrom, P.; Ji, H. Development and Application of Performance Assessment Criteria for Next Generation Sequencing-Based HIV Drug Resistance Assays. Viruses 2020, 12, 627. [Google Scholar] [CrossRef] [PubMed]
- Ávila-Ríos, S.; García-Morales, C.; Matías-Florentino, M.; Romero-Mora, K.A.; Tapia-Trejo, D.; Quiroz-Morales, V.S.; Reyes-Gopar, H.; Ji, H.; Sandstrom, P.; Casillas-Rodríguez, J.; et al. Pretreatment HIV-drug resistance in Mexico and its impact on the effectiveness of first-line antiretroviral therapy: A nationally representative 2015 WHO survey. Lancet HIV 2016, 3, e579–e591. [Google Scholar] [CrossRef]
- Maljkovic Berry, I.; Melendrez, M.C.; Bishop-Lilly, K.A.; Rutvisuttinunt, W.; Pollett, S.; Talundzic, E.; Morton, L.; Jarman, R.G. Next Generation Sequencing and Bioinformatics Methodologies for Infectious Disease Research and Public Health: Approaches, Applications, and Considerations for Development of Laboratory Capacity. J. Infect. Dis. 2019. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Parikh, U.M.; McCormick, K.; Van Zyl, G.; Mellors, J.W. Future technologies for monitoring HIV drug resistance and cure. Curr. Opin. HIV AIDS 2017, 12, 182–189. [Google Scholar] [CrossRef] [PubMed]
- Zhou, S.; Jones, C.; Mieczkowski, P.; Swanstrom, R. Primer ID Validates Template Sampling Depth and Greatly Reduces the Error Rate of Next-Generation Sequencing of HIV-1 Genomic RNA Populations. J. Virol. 2015, 89, 8540–8555. [Google Scholar] [CrossRef] [Green Version]
- Keys, J.R.; Zhou, S.; Anderson, J.A.; Eron, J.J.; Rackoff, L.A.; Jabara, C.; Swanstrom, R. Primer ID informs next-generation sequencing platforms and reveals preexisting drug resistance mutations in the HIV-1 reverse transcriptase coding domain. AIDS Res. Hum. Retroviruses 2015, 31, 658–668. [Google Scholar] [CrossRef] [Green Version]
- Enns, E.; Noguera-Julian, M.; Howison, M. Winnipeg AAV Format Specification.
- Lee, E.R.; Parkin, N.; Jennings, C.; Brumme, C.J.; Enns, E.; Casadellà, M.; Howison, M.; Coetzer, M.; Avila-Rios, S.; Capina, R.; et al. Performance comparison of next generation sequencing analysis pipelines for HIV-1 drug resistance testing. Sci. Rep. 2020, 10, 1634. [Google Scholar] [CrossRef] [Green Version]
- Escalona, M.; Rocha, S.; Posada, D. A comparison of tools for the simulation of genomic next-generation sequencing data. Nat. Rev. Genet. 2016, 17, 459–469. [Google Scholar] [CrossRef]
- Stephens, Z.D.; Hudson, M.E.; Mainzer, L.S.; Taschuk, M.; Weber, M.R.; Iyer, R.K. Simulating next-generation sequencing datasets from empirical mutation and sequencing models. PLoS ONE 2016, 11, 1–18. [Google Scholar] [CrossRef]
- Zhao, M.; Liu, D.; Qu, H. Systematic review of next-generation sequencing simulators: Computational tools, features and perspectives. Brief. Funct. Genomics 2016, 16, elw012. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Perrier, M.; Désiré, N.; Storto, A.; Todesco, E.; Rodriguez, C.; Bertine, M.; Le Hingrat, Q.; Visseaux, B.; Calvez, V.; Descamps, D.; et al. Evaluation of different analysis pipelines for the detection of HIV-1 minority resistant variants. PLoS ONE 2018, 13, 1–13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jair, K.; McCann, C.D.; Reed, H.; Castel, A.D.; Pérez-Losada, M.; Wilbourn, B.; Greenberg, A.E.; Jordan, J.A. Validation of publicly-available software used in analyzing NGS data for HIV-1 drug resistance mutations and transmission networks in a Washington, DC, Cohort. PLoS ONE 2019, 14, e0214820. [Google Scholar] [CrossRef] [PubMed]
- Noguera-Julian, M.; Edgil, D.; Harrigan, P.R.; Sandstrom, P.; Godfrey, C.; Paredes, R. Next-Generation Human Immunodeficiency Virus Sequencing for Patient Management and Drug Resistance Surveillance. J. Infect. Dis. 2017, 216, S829–S833. [Google Scholar] [CrossRef] [PubMed]
- Posada-Cespedes, S.; Seifert, D. Recent advances in inferring viral diversity from high-throughput sequencing data. Virus Res. 2017, 239, 17–32. [Google Scholar] [CrossRef] [Green Version]
- Borozan, I.; Watt, S.N.; Ferretti, V. Evaluation of alignment algorithms for discovery and identification of pathogens using RNA-Seq. PLoS ONE 2013, 8, e76935. [Google Scholar] [CrossRef] [Green Version]
- Korber, B.; Kuiken, C.; Foley, B.; Hahn, B.; McCutchan, F.; Mellors, J.; Sodroski, J. Human retroviruses and AIDS. Los Alamos Natl. Lab. Los Alamos NM 1998. [Google Scholar]
- Wright, I.A.; Travers, S.A. RAMICS: Trainable, high-speed and biologically relevant alignment of high-throughput sequencing reads to coding DNA. Nucleic Acids Res. 2014, 42, e106. [Google Scholar] [CrossRef] [Green Version]
- Weese, D.; Holtgrewe, M.; Reinert, K. RazerS 3: Faster, fully sensitive read mapping. Bioinformatics 2012, 28, 2592–2599. [Google Scholar] [CrossRef] [Green Version]
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).




{kind=link}