
Interaction Research on the Antiviral Molecule Dufulin Targeting on Southern Rice Black Streaked Dwarf Virus P9-1 Nonstructural Protein


Abstract
:1. Introduction
2. Materials and Methods
2.1. Samples and RNA Isolation
2.2. Cloning of the Complete SRBSDV-P9 Gene

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Primer Name | Sequence(5'→3') a |
|---|---|
| P9-N1 | AAGTTTTTTAAGCCTGGAACTGAC |
| P9-C1 | GACATCAGCTGTAAGCCGG |
| WT-His-P9-1-N2 | GGAATTCCATATGGCAGACCTAGAGCGTAGAA |
| WT-His-P9-1-C2 | CCGCTCGAGTCAAACGTCCAATTTAAGTGAAGAA |
| TR-ΔC23-His-P9-1-N3 | GGAATTCCATATGGCAGACCTAGAGCGTAGA |
| TR-ΔC23-His-P9-1-C3 | CCGCTCGAGTCAAAAACGACGATATCTTTT |
| TR-ΔN6-His-P9-1-N4 | GGAATTCCATATGACGTTTGGATCATATA |
| TR-ΔN6-His-P9-1-C4 | CCGCTCGAGTCAAACGTCCAATTTAAGTGAA |
| Mu-138-His-P9-1-N5 | CTTTTTGGTCTTTAGTTGTGGATTCGCTTTCAACGAC |
| Mu-138-His-P9-1-C5 | GTCGTTGAAAGCGAATCCACAACTAAAGACCAAAAAG |
2.3. Bioinformatic Analysis of the SRBSDV-P9-1 Sequence
2.4. Construction of WT-His-P9-1 and Mutant Plasmids
2.5. Purification of the SRBSDV-P9-1 Proteins
2.6. Fluorescence Spectra Studies
2.7. MST Studies
3. Results
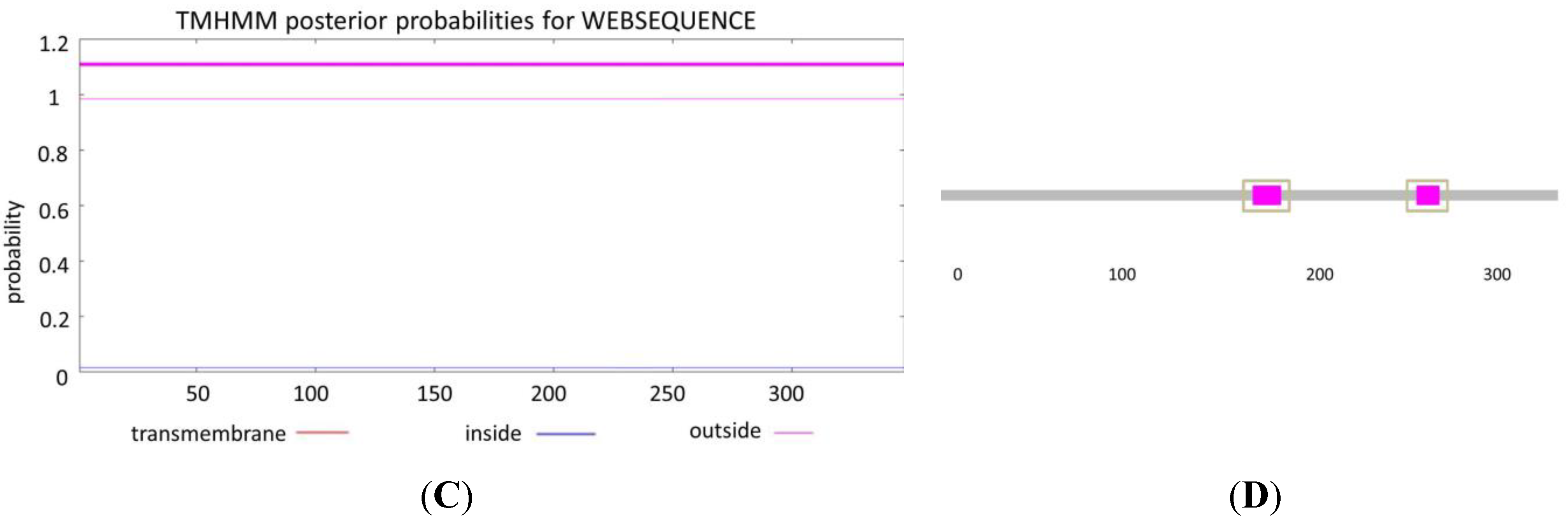
3.1. Bioinformatic Analysis of SRBSDV-P9-1 Sequence


3.2. Recombination and Multiple-Sequence Alignment Analysis of the SRBSDV-P9-1 Sequence

3.3. SNP Analysis of the SRBSDV-P9-1 Sequence
| NO. | Amino Acids | CDS Position | Codon |
|---|---|---|---|
| 1 | 951 | AAT → AAC | |
| 2 | P → T | 898 | CCA → ACA |
| 3 | 540 | TCT → TCC | |
| 4 | S → T | 415 | TCT → ACT |
| 5 | 384 | GTC → GTT | |
| 6 | 141 | CTC → CTA |
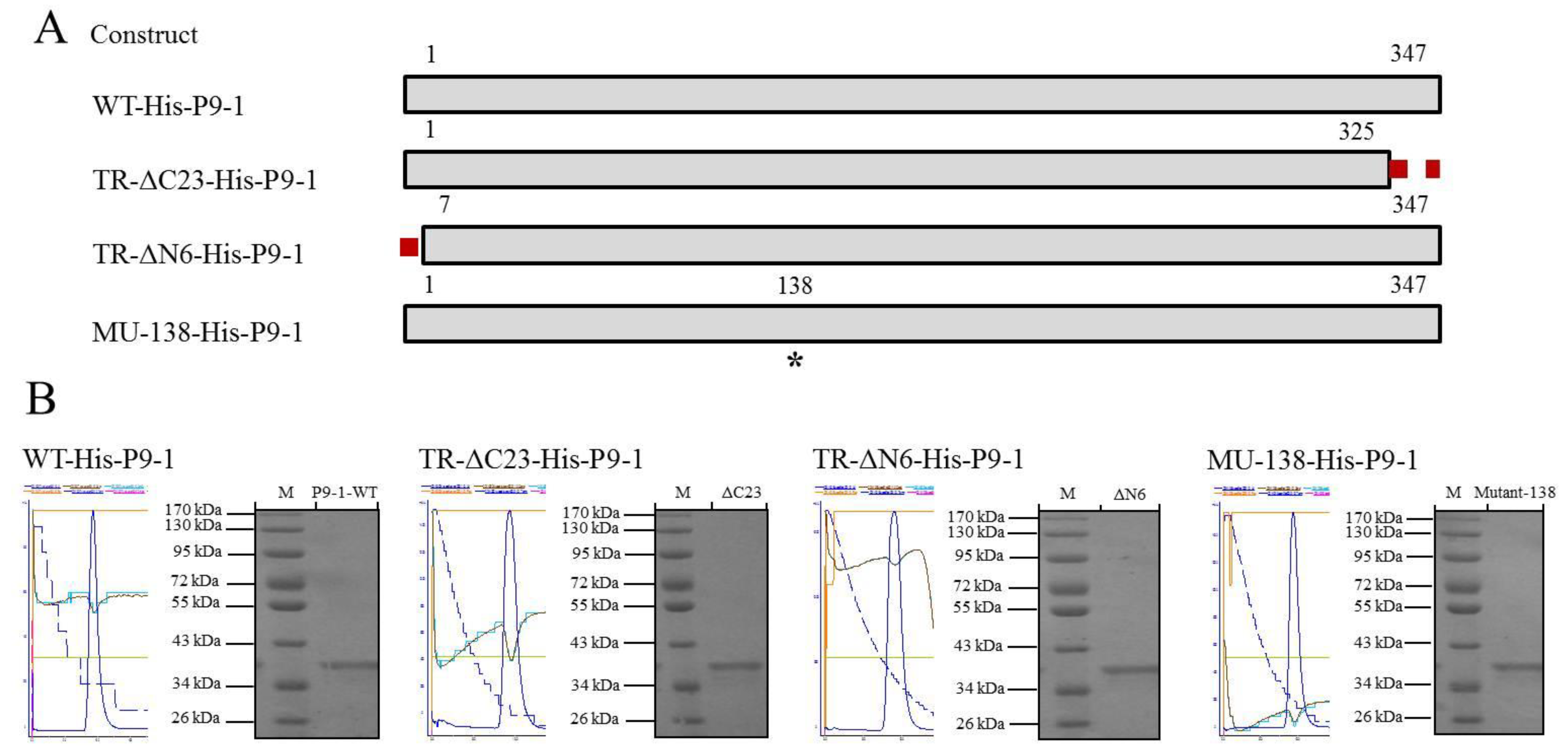
3.4. Expression and Purification of the SRBSDV-P9-1 Nonstructural Proteins

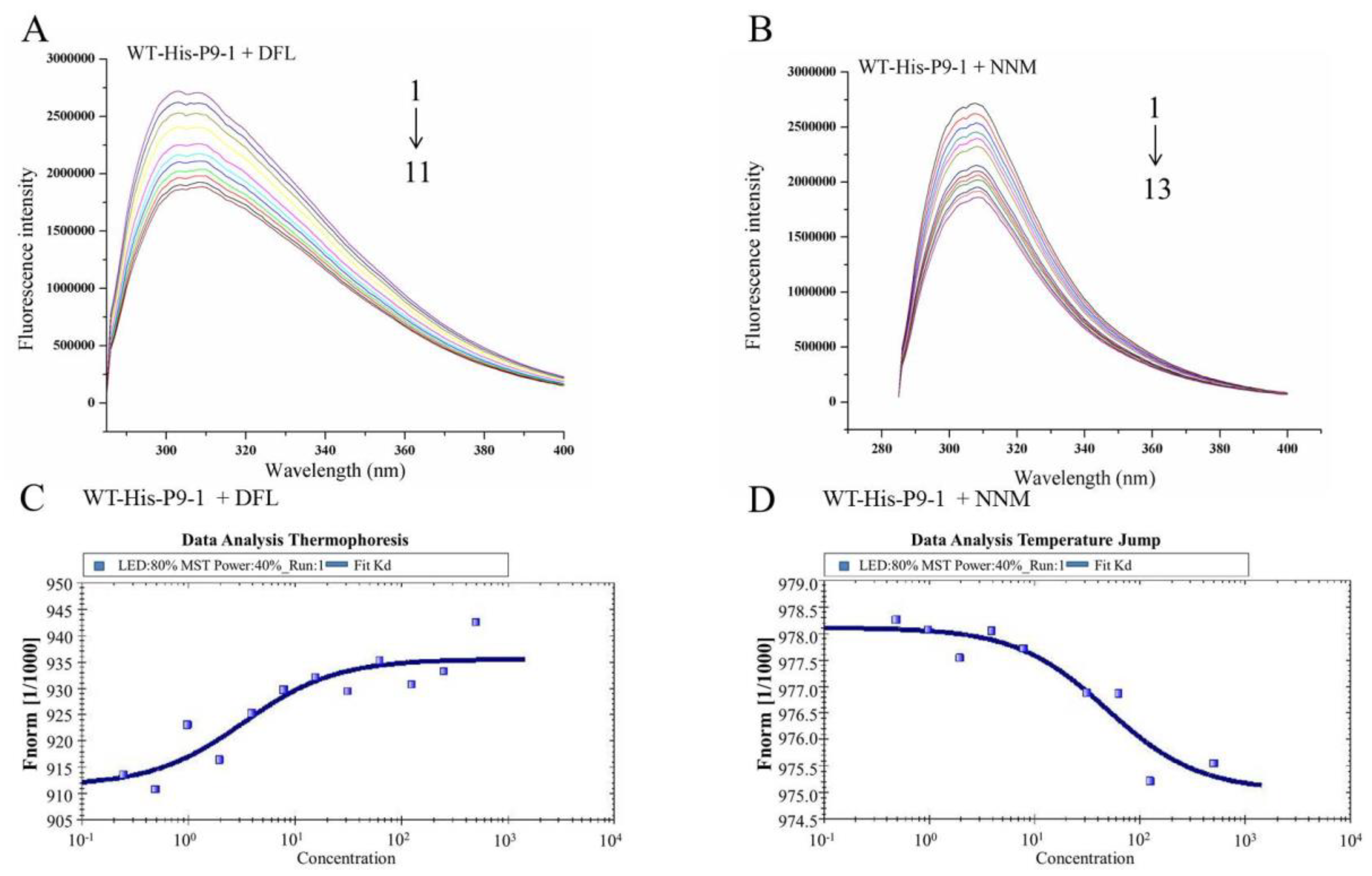
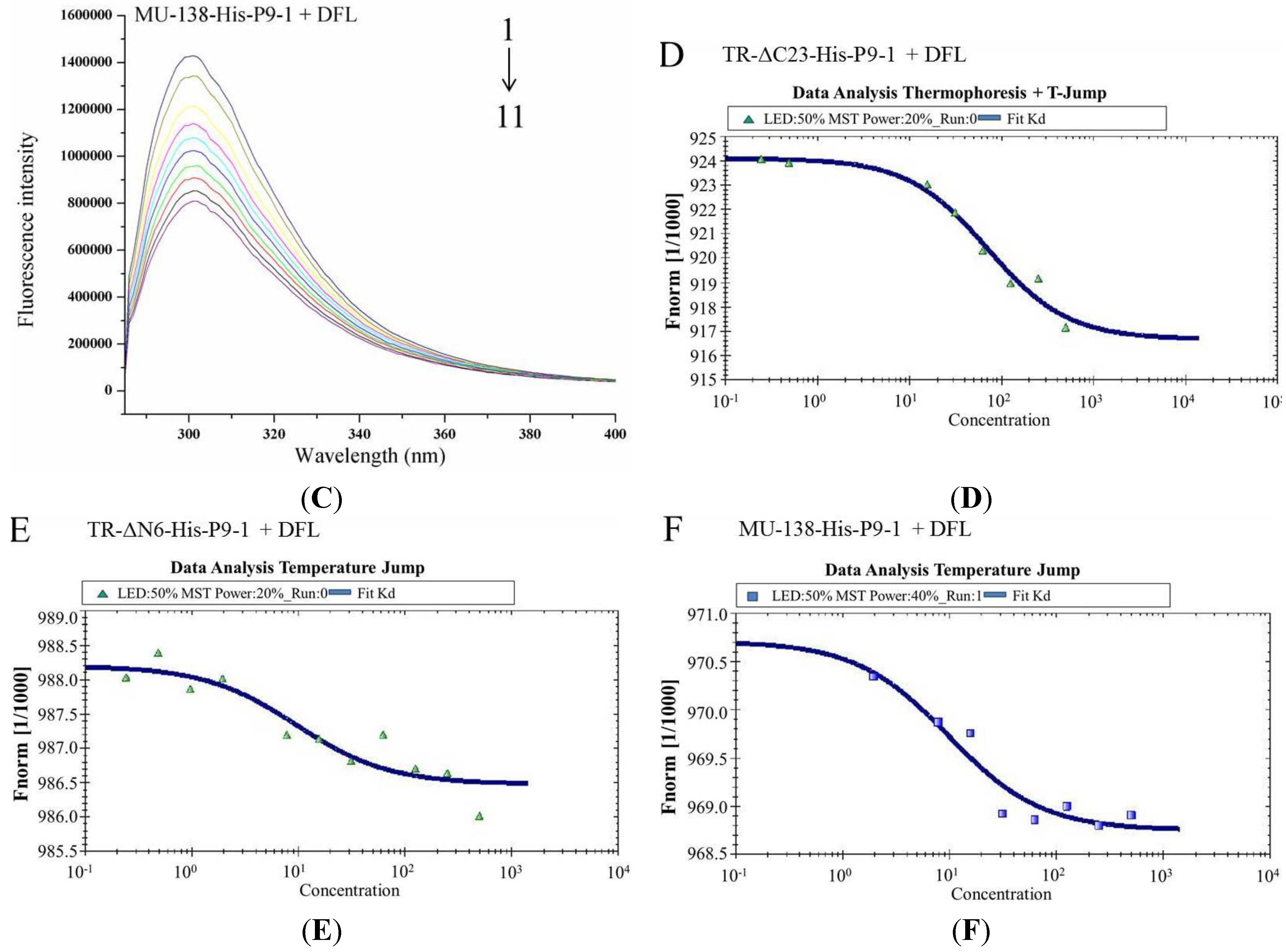
3.5. Binding Properties of DFL and NNM to Wild-Type SRBSDV-P9-1 Nonstructural Protein
| Stern–Volmer quenching constants | Binding parameters | |||||
|---|---|---|---|---|---|---|
| No. | Kq (M−1·S−1) | KSV (M−1) | R | KA (M−1) | n | R |
| WT-His-P9-1+DFL | 7.817 × 1010 | 7.817 × 102 | 0.991 | 1 × 105.061 | 1.139 | 0.991 |
| WT-His-P9-1+NNM | 1.040 × 1012 | 1.040 × 104 | 0.986 | 1 × 104.244 | 1.053 | 0.991 |

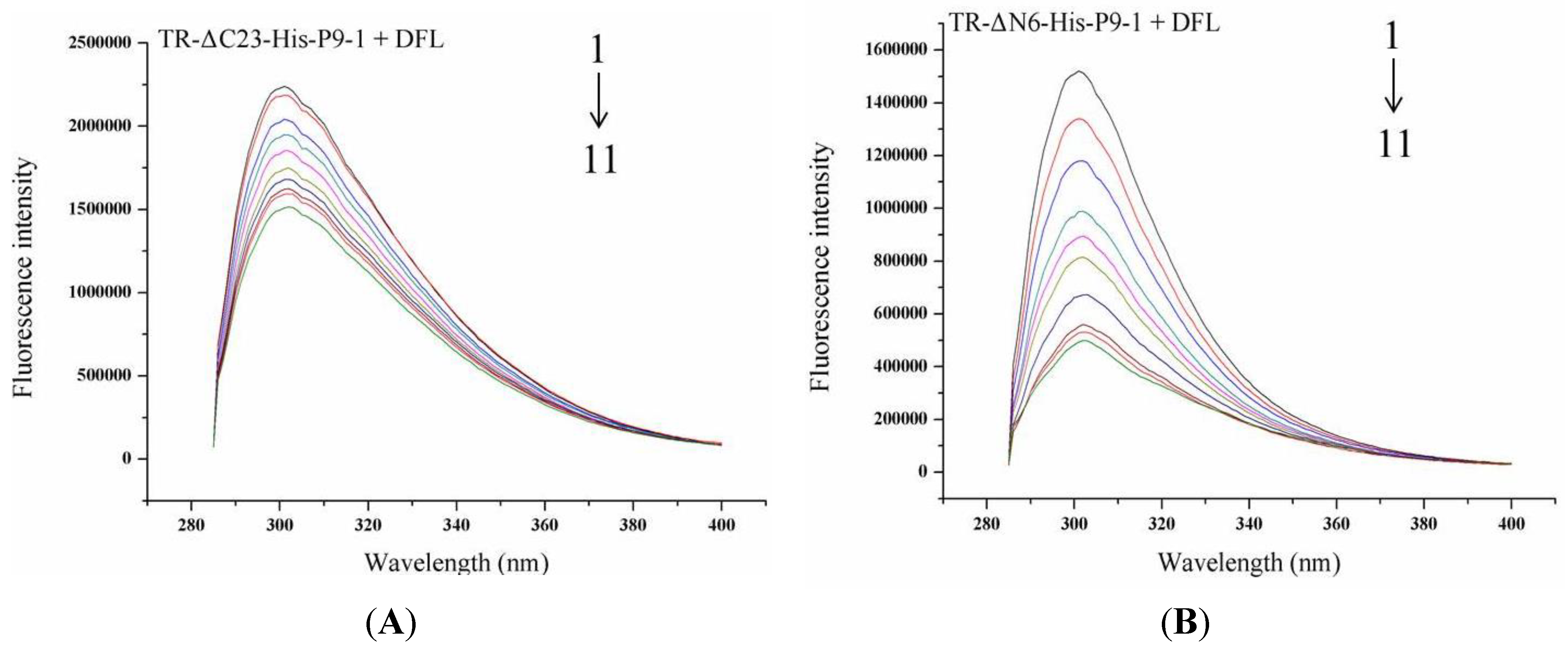
3.6. Binding Sites of DFL to SRBSDV-P9-1 Mutant Protein
| Stern–Volmer quenching constants | Binding parameters | |||||
|---|---|---|---|---|---|---|
| No. | Kq (M−1·S−1) | KSV (M−1) | R | KA (M−1) | n | R |
| TR-ΔC23-His-P9-1+DFL | 4.715 × 1010 | 4.715 × 102 | 0.991 | 1 × 104.470 | 1.074 | 0.992 |
| TR-ΔN6-His-P9-1+DFL | 5.751 × 1011 | 5.751 × 103 | 0.986 | 1 × 106.421 | 1.286 | 0.992 |
| MU-138-His-P9-1+DFL | 8.750 × 1010 | 8.750 × 102 | 0.997 | 1 × 105.026 | 1.082 | 0.990 |


4. Discussion
5. Conclusions
Supplementary Files
Supplementary File 1Acknowledgments
Author Contributions
Conflicts of Interest
References
- Lot, H.; Delecolle, B.; Boccardo, G.; Marzachi, C.; Milne, R.G. Partial characterization of reovirus-like particles associated with garlic dwarf disease. Plant Pathol. 1994, 43, 537–546. [Google Scholar] [CrossRef]
- Marzachì, C.; Boccardo, G.; Milne, R.; Isogai, M.; Uyeda, I. Genome structure and variability of Fijiviruses. Semin. Virol. 1995, 6, 103–108. [Google Scholar] [CrossRef]
- Zhou, G.H.; Wen, J.J.; Cai, D.J.; Li, P.; Xu, D.L.; Zhang, S.G. Southern rice black-streaked dwarf virus: A new proposed Fijivirus species in the family Reoviridae. Chin. Sci. Bull. 2008, 53, 3677–3685. [Google Scholar] [CrossRef]
- Zhang, H.M.; Yang, J.; Chen, J.P. A black-streaked dwarf disease on rice in China is caused by a novel fijivirus. Arch. Virol. 2008, 153, 1893–1989. [Google Scholar] [CrossRef] [PubMed]
- Cuong, H.V.; Hai, N.V.; Man, V.T.; Matsumoto, M. Rice dwarf disease in North Vietnam in 2009 is caused by southern rice black-streaked dwarf virus (SRBSDV). Bull. Inst. Trop. Agric. Kyushu Univ. 2009, 32, 85–92. [Google Scholar]
- Jiang, Y.Y.; Guo, R.; Liu, Y.; Feng, X.D. The occurrence and prevention profile of rice virus disease in Vietnam. Chin. Plant Prot. 2010, 30, 54–57. [Google Scholar]
- Wang, Z.C.; Yu, D.D.; Li, X.Y.; Zeng, M.J.; Chen, Z.; Bi, L.; Liu, J.J.; Jin, L.H.; Hu, D.Y.; Yang, S.; et al. The development and application of a Dot-ELISA assay for diagnosis of southern rice black-streaked dwarf disease in the field. Viruses 2012, 4, 167–183. [Google Scholar] [CrossRef] [PubMed]
- Yin, X.; Xu, F.F.; Zheng, F.Q.; Li, X.D.; Liu, B.S.; Zhang, C.Q. Molecular characterization of segments S7 to S10 of a southern rice black-streaked dwarf virus isolate from maize in northern China. Virol. Sin. 2011, 26, 47–53. [Google Scholar] [CrossRef] [PubMed]
- Jia, D.S.; Chen, H.Y.; Mao, Q.Z.; Liu, Q.F.; Wei, T.Y. Restriction of viral dissemination from the midgut determines incompetence of small brown planthopper as a vector of Southern rice black-streaked dwarf virus. Virus Res. 2012, 167, 404–408. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Yang, J.; Zhou, G.H.; Zhang, H.M.; Chen, J.P.; Adams, M.J. The complete genome sequence of two isolates of southern rice black-streaked dwarf virus, a new member of the genus fijivirus. J. Phytopathol. 2010, 158, 733–737. [Google Scholar] [CrossRef]
- Zhang, H.M.; Chen, J.P.; Adams, M.J. Molecular characterization of segments 1 to 6 of rice black-streaked dwarf virus from China provides the complete genome. Arch. Virol. 2001, 146, 2331–2339. [Google Scholar] [CrossRef] [PubMed]
- Isogai, M.; Uyeda, I.; Lee, B.C. Detection and assignment of proteins encoded by rice black streaked dwarf fijivirus S7, S8, S9 and S10. J. Gen. Virol. 1998, 79, 1487–1494. [Google Scholar] [PubMed]
- Zhang, H.M.; Chen, J.P.; Lei, J.L.; Adams, M.J. Sequence analysis shows that a dwarfing disease on rice, wheat and maize in China is caused by rice black-streaked dwarf virus. Eur. J. Plant Pathol. 2001, 107, 563–567. [Google Scholar] [CrossRef]
- Lu, Y.H.; Zhang, J.F.; Xiong, R.Y.; Xu, Q.F.; Zhou, Y.J. Identification of an RNA silencing suppressor encoded by southern rice black-streaked dwarf virus S6. Sci. Agric. Sin. 2011, 44, 2909–2917. [Google Scholar]
- Liu, Y.; Jiao, D.S.; Chen, H.Y.; Chen, Q.; Xie, L.H.; Wu, Z.J.; Wei, T.Y. The P7-1 protein of southern rice black-streaked dwarf virus, a fijivirus, induces the formation of tubular structures in insect cells. Arch. Virol. 2011, 156, 1729–1736. [Google Scholar] [CrossRef] [PubMed]
- Takumi, S.; Eiko, N.N.; Fusamichi, A.; Tamaki, U.I.; Toshihiro, O.; Takahide, S. Immunity to rice black streaked dwarf virus, a plant reovirus, can be achieved in rice plants by RNA silencing against the gene for the viroplasm component protein. Virus Res. 2011, 160, 400–403. [Google Scholar] [CrossRef] [PubMed]
- Jia, D.S.; Chen, H.Y.; Zheng, A.L.; Chen, J.; Liu, Q.F.; Xie, L.H.; Wu, Z.J.; Wei, T.Y. Development of an insect vector cell culture and RNA interference system to investigate the functional role of fijivirus replication protein. J. Virol. 2012, 86, 5800–5807. [Google Scholar] [CrossRef] [PubMed]
- Mao, Q.Z.; Zheng, S.L.; Han, Q.M.; Chen, H.Y.; Ma, Y.Y.; Jiao, D.S.; Chen, Q.; Wei, T.Y. New model for the genesis and maturation of viroplasms induced by Fijiviruses in Insect Vector Cells. J. Virol. 2013, 87, 6819–6828. [Google Scholar] [CrossRef] [PubMed]
- Yu, D.D.; Liu, J.; Lv, M.M.; Liu, J.J.; Wang, Z.C.; Li, X.Y.; Chen, Z.; Jin, L.H.; Yang, S.; Song, B.A. Screening anti-southern rice black-streaked dwarf virus drugs based on S7-1 gene expression in rice suspension cells. J. Agric. Food Chem., 2013, 61, 8049–8055. [Google Scholar] [CrossRef]
- Hu, X.D.; Zhu, J.; Wu, W.D.; Ren, G.M.; Li, F. Bioinformatic analysis for the functions of S9 encoded proteins of southern rice black streaked dwarf virus. Chin. Agri. Sci. Bull. 2013, 29, 12–19. [Google Scholar]
- ExPASy. ProtParam. Available online: http://www.expasy.ch/tools/protparam.html (accessed on 1 January 2015).
- ExPASy. ProtScale. Available online: http://us.expasy.org/cgi-bin/protscale.pl (accessed on 1 January 2015).
- SignalP 4.1 Server. Available online: http://www.cbs.dtu.dk/services/SignalP/ (accessed on 1 January 2015).
- WoLF PSORT. Protein Subcellular Localization Prediction. Available online: http://www.genscript.com/psort/wolf_psort.html (accessed on 1 January 2015).
- TMHMM Server v. 2.0. Available online: http://www.cbs.dtu.dk/services/TMHMM/ (accessed on 1 January 2015).
- SMART. Available online: http://smart.embl-heidelberg.de/smart/set_mode.cgi?NORMAL=1# (accessed on 1 January 2015).
- ExPASy Proteomics Server. SOPMA SECONDARY STRUCTURE PREDICTION METHOD. Available online: https://npsa-prabi.ibcp.fr/cgi-bin/npsa_automat.pl?page=npsa_sopam.html (accessed on 1 January 2015).
- Yin, Q.Y.; Teng, Y.G.; Ding, M.; Zhao, F.K. Site-directed mutagenesis of aromatic residues in the carbohydrate-binding module of Bacillusendoglucanase EGA decreases enzyme thermostability. Biotechnol. Lett. 2011, 33, 2209–2216. [Google Scholar] [CrossRef] [PubMed]
- Shen, H.; Gu, Z.Q.; Jian, K.; Qi, J. In vitro study on the binding of gemcitabine to bovine serum albumin. J. Pharmaceut. Biomed. 2013, 75, 86–93. [Google Scholar] [CrossRef]
- Charbonneau, D.M.; Tajmir-Riahi, H.A. Study on the interaction of cationic lipids with bovine serum albumin. J. Phys. Chem. B 2010, 114, 1148–1155. [Google Scholar] [CrossRef] [PubMed]
- Abdollahpour, N.; Asoodeh, A.; Saberi, M.R.; Chamani, J. Separate and simultaneous binding effects of aspirin and amlodipine to human serum albumin based on fluorescence spectroscopic and molecular modeling characterizations: A mechanistic insight for determining usage drugs doses. J. Lumin. 2011, 131, 1885–1899. [Google Scholar] [CrossRef]
- Chamani, J.; Vahedian-Movahed, H.; Saberi, M.R. Lomefloxacin promotes the interaction between human serum albumin and transferrin: A mechanistic insight into the emergence of antibiotic’s side effects. J. Pharm. Biomed. Anal. 2011, 55, 114–124. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Q.; Xiang, J.; Tang, Y.; Liao, J.; Yu, C.; Zhang, H.; Li, L.; Yang, Y.; Xu, G. Investigation on the interaction between a heterocyclic aminal derivative, SBDC, and human serum albumin. Colloids Surf. B Biointerfaces 2008, 61, 75–80. [Google Scholar] [CrossRef] [PubMed]
- Taillon-Moller, P.; Gu, Z.J.; Li, Q.; Hillier, L.D.; Kwork, P.Y. Overlapping genomic sequences: A treasure trove of single-nucleotide polymorphisms. Genome Res. 1998, 8, 748–754. [Google Scholar] [PubMed]
- Mullikin, J.C.; Hunt, S.E.; Cole, C.G.; Mortimore, B.J.; Rice, C.M.; Button, J.; Matthews, L.H.; Pavitt, R.; Plumb, R.W.; Sims, S.K.; et al. An SNP map of human chromosome 22. Nature 2000, 407, 516–520. [Google Scholar] [CrossRef] [PubMed]
- Anand, U.; Jash, C.; Boddepalli, R.K.; Shrivastava, A.; Mukherjee, S. Exploring the mechanism of fluorescence quenching in proteins induced by tetracycline. J. Phys. Chem. B. 2011, 115, 6312–6320. [Google Scholar] [CrossRef] [PubMed]
- Wienken, C.J.; Baaske, P.; Rothbauer, U.; Braun, D.; Duhr, S. Protein-binding assays in biological liquids using microscale thermophoresis. Nat. Commun. 2010. [Google Scholar] [CrossRef]
- Chen, Z.; Zeng, M.J.; Hou, C.R.; Hu, D.Y.; Li, X.Y.; Wang, Z.C.; Fan, H.T.; Bi, L.; Liu, J.J.; Yu, D.D.; et al. Dufulin Activates HrBP1 to Produce Antiviral Responses in Tobacco. PLoS One 2012, 7, e37944. [Google Scholar] [CrossRef] [PubMed]
- Park, C.J.; Kim, K.J.; Shin, R.; Park, J.M.; Shin, Y.C.; Paek, K.H. Pathogenesis-related protein 10 isolated from hot pepper functions as a ribonuclease in an antiviral pathway. Plant J. 2004, 37, 186–198. [Google Scholar] [CrossRef] [PubMed]
- Kulye, M.; Liu, H.; Zhang, Y.L.; Zeng, H.M.; Yang, X.F.; Qiu, D.W. Hrip1, a novel protein elicitor from necrotrophic fungus, Alternaria tenuissima, elicits cell death, expression of defence-related genes and systemic acquired resistance in tobacco. Plant Cell Environ. 2012, 35, 2104–2120. [Google Scholar] [CrossRef] [PubMed]
- Wang, B.N.; Yang, X.F.; Zeng, H.M.; Liu, H.; Zhou, T.T.; Tan, B.B.; Yuan, J.J.; Guo, L.H.; Qiu, D.W. The purification and characterization of a novel hypersensitive-like response-inducing elicitor from Verticillium dahliae that induces resistance responses in tobacco. Appl. Microbiol. Biotechnol. 2012, 93, 191–201. [Google Scholar] [CrossRef] [PubMed]
- Atita, F.; Higashiura, A.; Shimizu, T.; Pu, Y.Y.; Suzuki, M.; Uehara-Ichiki, T.; Sasaya, T.; Kanamaru, S.; Arisaka, F.; Tsukihara, T.; et al. Crystallographic analysis reveals octamerization of viroplasm matrix protein P9-1 of rice black streaked dwarf virus. J. Virol. 2012, 86, 746–756. [Google Scholar] [CrossRef] [PubMed]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Li, X.; Wang, W.; Zhang, W.; Yu, L.; Hu, D.; Song, B. Interaction Research on the Antiviral Molecule Dufulin Targeting on Southern Rice Black Streaked Dwarf Virus P9-1 Nonstructural Protein. Viruses 2015, 7, 1454-1473. https://0-doi-org.brum.beds.ac.uk/10.3390/v7031454
Wang Z, Li X, Wang W, Zhang W, Yu L, Hu D, Song B. Interaction Research on the Antiviral Molecule Dufulin Targeting on Southern Rice Black Streaked Dwarf Virus P9-1 Nonstructural Protein. Viruses. 2015; 7(3):1454-1473. https://0-doi-org.brum.beds.ac.uk/10.3390/v7031454
Chicago/Turabian StyleWang, Zhenchao, Xiangyang Li, Wenli Wang, Weiying Zhang, Lu Yu, Deyu Hu, and Baoan Song. 2015. "Interaction Research on the Antiviral Molecule Dufulin Targeting on Southern Rice Black Streaked Dwarf Virus P9-1 Nonstructural Protein" Viruses 7, no. 3: 1454-1473. https://0-doi-org.brum.beds.ac.uk/10.3390/v7031454