Nearest Embedded and Embedding Self-Nested Trees


Laboratoire Reproduction et Développement des Plantes, Univ Lyon, ENS de Lyon, UCB Lyon 1, CNRS, INRA, Inria, F-69342 Lyon, France
Algorithms 2019, 12(9), 180; https://0-doi-org.brum.beds.ac.uk/10.3390/a12090180
Submission received: 25 June 2019
/
Revised: 23 August 2019
/
Accepted: 27 August 2019
/
Published: 29 August 2019
(This article belongs to the Special Issue Data Compression Algorithms and their Applications)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Self-nested trees present a systematic form of redundancy in their subtrees and thus achieve optimal compression rates by directed acrylic graph (DAG) compression. A method for quantifying the degree of self-similarity of plants through self-nested trees was introduced by Godin and Ferraro in 2010. The procedure consists of computing a self-nested approximation, called the nearest embedding self-nested tree, that both embeds the plant and is the closest to it. In this paper, we propose a new algorithm that computes the nearest embedding self-nested tree with a smaller overall complexity, but also the nearest embedded self-nested tree. We show from simulations that the latter is mostly the closest to the initial data, which suggests that this better approximation should be used as a privileged measure of the degree of self-similarity of plants.
1. Introduction
Trees form a wide family of combinatorial objects that offers many application fields, e.g., plant modeling and XML files analysis. Modern databases are huge and thus stored in compressed form. Compression methods take advantage of repeated substructures appearing in the tree. As explained in [1], one often considers the following two types of repeated substructures: subtree repeat (used in DAG compression [2,3,4,5]) and tree pattern repeat (exploited in tree grammars [6,7] and top tree compression [1]). We restrict ourselves to DAG compression of unordered rooted trees, which consists of building a Directed Acyclic Graph (DAG) that represents a tree without the redundancy of its identical subtrees (see Figure 1). Two different algorithms exist for computing the DAG reduction of a tree [5] (2.2 Computing Tree Reduction), which share the same time-complexity in where denotes the set of vertices of and its outdegree.
Trees that are the most compressed by DAG compression present the highest level of redundancy in their subtrees: all the subtrees of a given height are isomorphic. In this case, the DAG related to a tree is linear, i.e., there exists a path going through all vertices, with exactly vertices, denoting the height of , which is the minimal number of vertices among trees of this height (see in Figure 1). This family of trees has been introduced in [8] as the first interesting class of trees for which the subtree isomorphism problem is in NC. It has been known under the name of nested trees [8] and next self-nested trees [5] to insist on their recursive structure and their proximity to the notion of structural self-similarity.
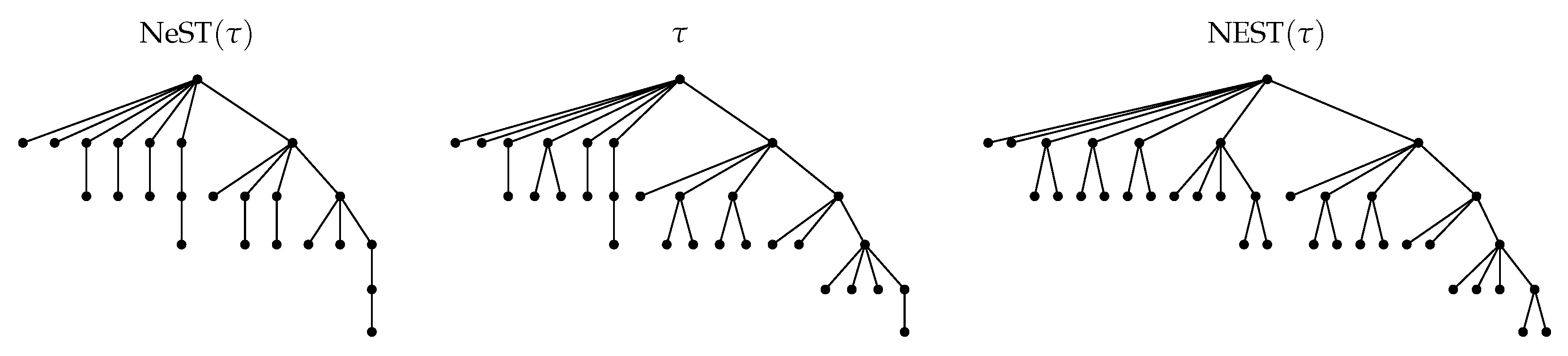
The authors of [5] are interested in capturing the self-similarity of plants through self-nested trees. They propose to construct a self-nested tree that minimizes the distance of the original tree to the set of self-nested trees that embed the initial tree. The distance to this Nearest Embedding Self-nested Tree (NEST) is then used to quantify the self-nestedness of the tree and thus its structural self-similarity (see and in Figure 2). The main result of [5] (Theorem 1 and E. NEST Algorithm) is an algorithm that computes the NEST of a tree from its DAG reduction in .
The goal of the present article is three-fold. We aim at proposing a new and more explicit algorithm that computes the NEST of a tree with the same time-complexity as in [5] but that takes as input the height profile of and not its DAG reduction. We establish that the height profile of a tree can be computed in reducing the overall complexity of a linear factor. Based on this work, we also provide an algorithm in that computes the Nearest embedded Self-nested Tree (NeST) of a tree (see and in Figure 2). Finally, we show from numerical simulations that the distance of a tree to its NeST is much lower than the distance to its NEST. The NeST is most of the time a better approximation of a tree than the NEST and thus should be privileged to quantify the degree of self-nestedness of plants.
The paper is organized as follows. The structures of interest in this paper, namely unordered trees, DAG compression and self-nested trees, are defined in Section 2. Section 3 is dedicated to the definition and the study of the height profile of a tree. The approximation algorithms are presented in Section 4. We give a new insight on the definitions of the NEST and of the NeST in Section 4.1. Our NEST algorithm is presented in Section 4.2, while the NeST algorithm is given in Section 4.3. Section 5 is devoted to simulations. We state that the NeST is mostly a better approximation of a tree than the NEST in Section 5.1. An application to a real rice panicle is presented in Section 5.2. A summary of the paper and concluding remarks can be found in Section 6. All the figures and numerical experiments presented in the article have been made with the Python library treex [9].
2. Preliminaries
2.1. Unordered Rooted Trees
A rooted tree is a connected graph containing no cycle, i.e., without chain from any vertex v to itself, and such that there exists a unique vertex , called the root, which has no parent, and any vertex different from the root has exactly one parent. The leaves of are all the vertices without children. The set of vertices of is denoted by . The height of a vertex v may be recursively defined as if v is a leaf of and
otherwise, denoting the set of children of v in . The height of the tree is defined as the height of its root, . The outdegree of is the maximal branching factor that can be found in , i.e.,
A subtree rooted in v is a particular connected subgraph of . Precisely, where is the set of the descendants of v in and is defined as
with the set of edges of .
In all the sequel, we consider unordered rooted trees for which the order among the sibling vertices of any vertex is not significant. A precise characterization is obtained from the additional definition of isomorphic trees. Let and two rooted trees. A one-to-one correspondence is called a tree isomorphism if, for any edge , . Structures and are called isomorphic trees whenever there exists a tree isomorphism between them. One can determine if two n-vertex trees are isomorphic in [10] (Example 3.2 and Theorem 3.3). The existence of a tree isomorphism defines an equivalence relation on the set of rooted trees. The class of unordered rooted trees is the set of equivalence classes for this relation, i.e., the quotient set of rooted trees by the existence of a tree isomorphism.
2.2. DAG Compression
Now we consider the equivalence relation “existence of a tree isomorphism” on the set of the subtrees of a tree . We consider the quotient graph obtained from using this equivalence relation. V is the set of equivalence classes on the subtrees of , while E is a set of pairs of equivalence classes such that up to an isomorphism. The graph is a DAG [5] (Proposition 1) that is a connected directed graph without path from any vertex v to itself.
Let be an edge of the DAG . We define as the number of occurrences of a tree of just below the root of any tree of . The tree reduction is defined as the quotient graph augmented with labels on its edges [5] (Definition 3 (Reduction of a tree)). Intuitively, the graph represents the original tree without its structural redundancies (see Figure 1).
2.3. Self-Nested Trees
A tree is called self-nested [5] (III. Self-nested trees) if for any pair of vertices v and w, either the subtrees and are isomorphic, or one is (isomorphic to) a subtree of the other. This characterization of self-nested trees is equivalent to the following statement: for any pair of vertices v and w such that , , i.e., all the subtrees of the same height are isomorphic.
Linear DAGs are DAGs containing at least one path that goes through all their vertices. They are closely connected with self-nested trees by virtue of the following result.
Proposition 1
(Godin and Ferraro [5]). A tree τ is self-nested if and only if its reduction is a linear DAG.
This result proves that self-nested trees achieve optimal compression rates among trees of the same height whatever their number of nodes (compare with and in Figure 1). Indeed, has at least nodes and the inequality is saturated if and only if is self-nested.
3. Height Profile of the Tree Structure
3.1. Definition and Complexity
This section is devoted to the definition of the height profile of a tree and to the presentation of an algorithm to calculate it. In the sequel, we assume that the tree is always traversed in the same order, depth-first search to set the ideas down. In particular, when vectors are indexed by nodes of sharing the same property, the order of the vector is important and should be always the same.
Given a vertex ,
is the number of subtrees of height h directly under v. Now, we consider the vector
made of the concatenation of the integers over subtrees of height ordered in depth-first search. Consequently, is an array made of vectors with varying lengths.
Let and be two arrays for which each entry is a vector. We say that and are equivalent if, for any line i, there exists a permutation such that for any column j,
In particular, i being fixed, all the vectors and must have the same length. This condition defines an equivalence relation. The height profile of is the array as an element of the quotient space of arrays of vectors under this equivalence relation. In other words, the vectors , and fixed, must be ordered in the same way but the choice of the order is not significant. Finally, it should be already remarked that when or . Consequently, the height profile can be reduced to the triangular array
The application provides the distribution of subtrees of height just below the root of subtrees of height for all couples , which typically represents the height profile of . For clarity’s sake, we give the values of for the trees of Figure 1, coefficient of the matrix being ,
It should be noticed that the height profile does not contain all the topology of the tree since trees and of Figure 1 are different but share the same height profile (1). However, the height of a tree can be recovered from its height profile through the relation , the dimension of being defined by
Proposition 2.
can be computed in -time.
Proof.
First, attribute to each node the height of the subtree with complexity . Next, traverse the tree in depth-first search in and calculate for each vertex v the vector in operations. Finally, append this vector to component by component. □
3.2. Relation with Self-Nested Trees
Self-nested trees are characterized by their height profile considering the following result.
Proposition 3.
Proof.
If is self-nested, the subtrees of height appearing in are isomorphic and thus have the same number of subtrees of height just below their root. Consequently,
The reciprocal result may be established considering the following lemma which proof presents no difficulty. □
Lemma 1.
If all the subtrees of height appearing in a tree τ are isomorphic, and if all the subtrees of height H have the same number of subtrees of height just below their root, then all the subtrees of height H appearing in τ are isomorphic.
All the subtrees of height 1 in are isomorphic because all the components of are the same. The expected result is shown by induction on the height thanks to the previous lemma which assumptions are satisfied since always contains vectors for which all the entries are equal. The previous reasoning also provides a way (presented in Algorithm 1) to build a unique (self-nested) tree from the height profile . In addition, this is easy to see that and are isomorphic.
To present the algorithm of reconstruction of a self-nested tree from its height profile, we need to define the restriction of a height profile to some height. Let p be a height profile. The restriction of p to height is the array defined by
Consequently, . A peculiar case is for which each entry is the empty set and thus . It should be also remarked that there may exist no tree such that is the height profile of .
| Algorithm 1: Construction of a self-nested tree from its height profile. |
 |
As we can see in the proof of Proposition 3 or in Algorithm 1, the lengths of the vectors are not significant to reconstruct a self-nested tree . Consequently, since all the components of are the same, we can identify the height profile of a self-nested tree with the integer-valued array .
Proposition 4.
The number of nodes of a self-nested tree τ can be computed from in .
Proof.
By induction on the height, one has , where the sequence is defined by (number of nodes of a tree reduced to a root) and,
The number of operations required to compute is of order . □
The authors of [5] (Proposition 6) calculate the number of nodes of a tree (self-nested or not) from its DAG reduction by a formula very similar to (2), and which achieve the same complexity on self-nested trees. As mentioned before, a tree cannot be recovered from its height profile in general, thus we cannot expect such a result from the height profile of any tree.
4. Approximation Algorithms
4.1. Definitions
4.1.1. Editing Operations
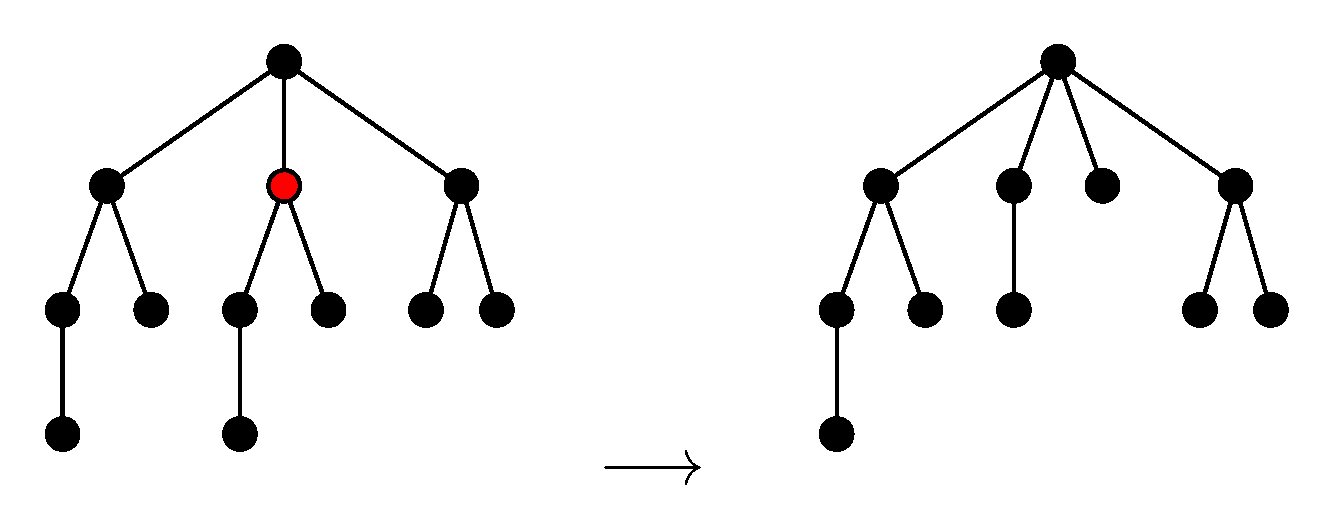
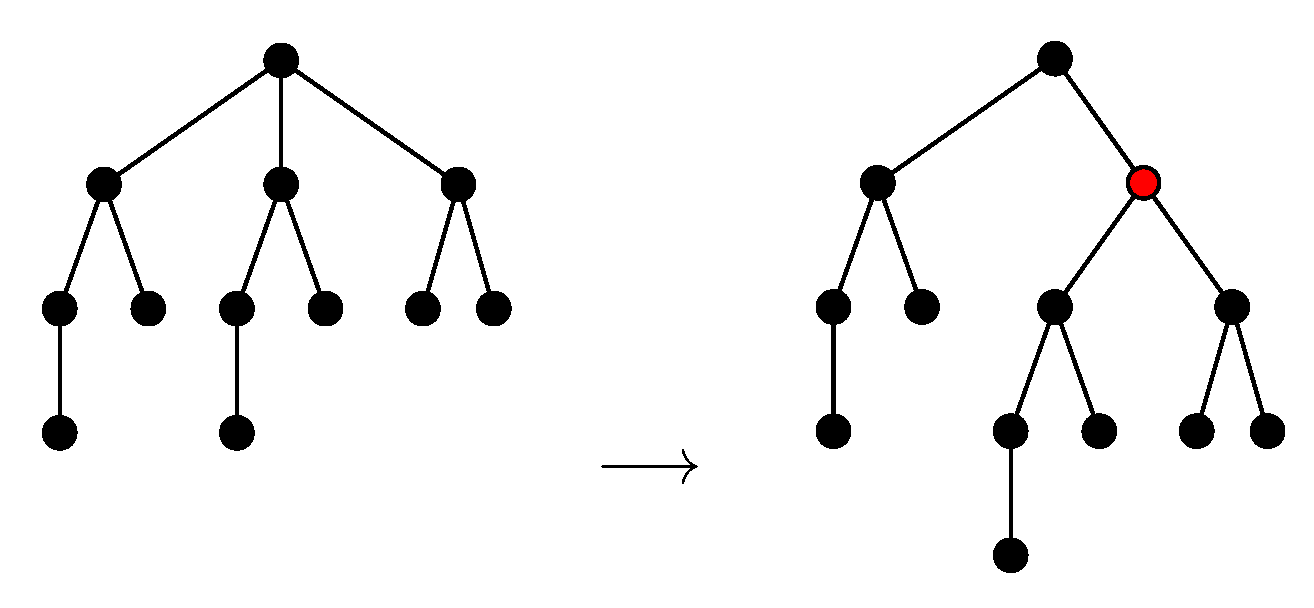
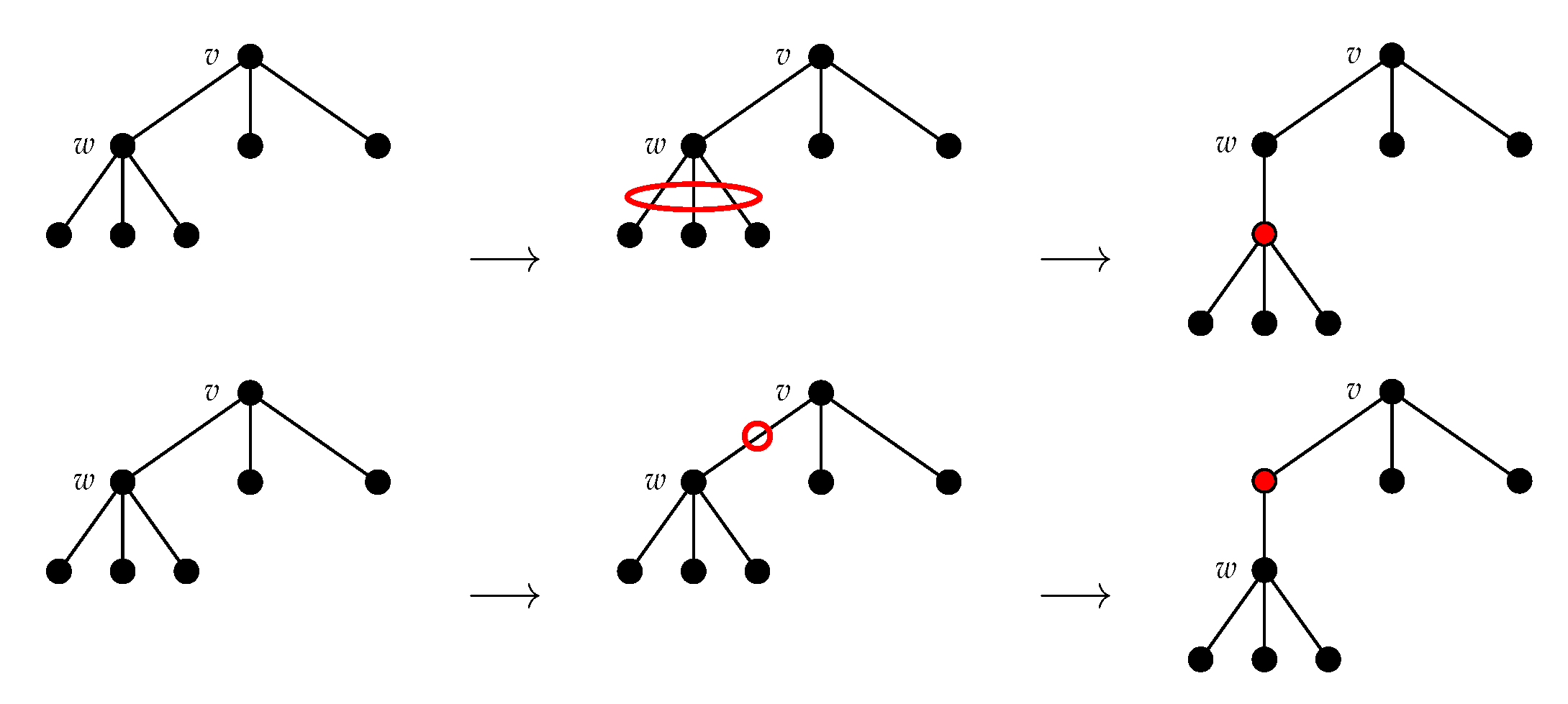
We shall define the NEST and the NeST of a tree . As in [5] (Equation (5)), we ask these approximations to be consistent with Zhang’s edit distance between unordered trees [11] denoted in this paper. Thus, as in [11] (2.2 Editing Operations), we consider the following two types of editing operations: adding a node and deleting a node. Deleting a node w means making the children of w become the children of the parent v of w and then removing w (see Figure 3). Adding w as a child of v will make w the parent of a subset of the current children of v (see Figure 4).
4.1.2. Constrained Editing Operations
Zhang’s edit distance is defined from the above editing operations and from constrained mappings between trees [11] (3.1 Constrained Edit Distance Mappings). A constrained mapping between two trees and is a mapping [11] (2.3.2 Editing Distance Mappings), i.e., a one-to-one correspondence from a subset of into a subset of preserving the ancestor order, with an additional condition on the Least Common Ancestors (LCAs) [11] (condition (2) p. 208): if, for , and , then is a proper ancestor of if and only if is a proper ancestor of .
Let be a tree that approximates obtained by inserting nodes in only and consider the induced mapping that associates nodes of with themselves in . We want the approximation process to be consistent with Zhang’s edit distance , i.e., we want the mapping to be a constrained mapping in the sense of Zhang, which in particular implies . We shall prove that this requirement excludes some inserting operations in our context.
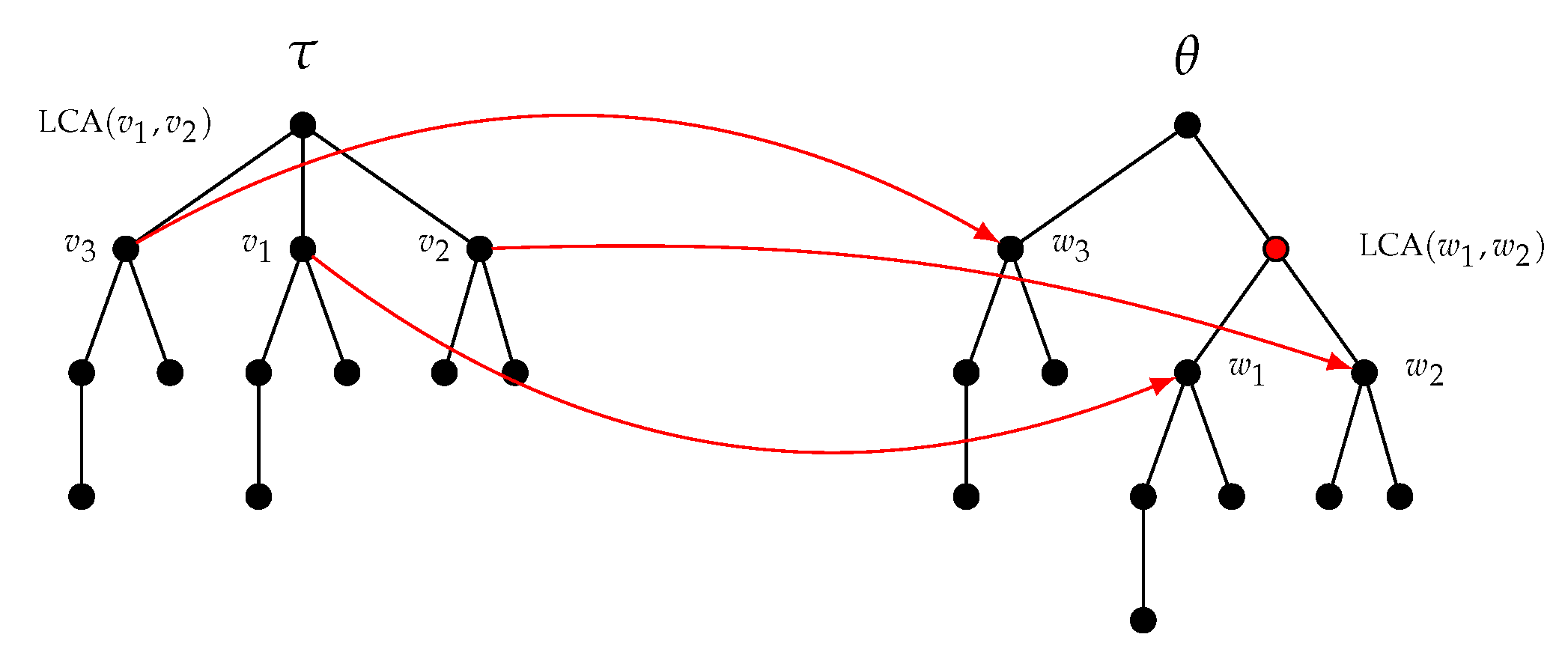
Indeed, the mapping involved in the inserting operation of Figure 4 is partially displayed in Figure 5, nodes of being associated with nodes of . The LCA of and in is a proper ancestor of . However, the LCA of and in is not a proper ancestor of . Consequently, this mapping is not a constrained mapping as defined by Zhang. A necessary and sufficient condition for to be a constrained mapping is given in Lemma 2.
Lemma 2.
Let τ be a tree and . Let θ be the tree obtained from τ by adding a node w as a child of v making the nodes of the subset children of w. The mapping induced by these inserting operations is a constrained mapping in the sense of Zhang if and only if , or .
Proof.
The proof is obvious if v has one or two children. Thus, we assume that v has at least three children , and . In , the LCA of and is v and v is an ancestor of . Adding w as the parent of and makes it the LCA of these two nodes, but not an ancestor of in . The additional condition on the LCAs is then not satisfied. This problem appears only when making w the parent of at least two children and of not all the children of v. □
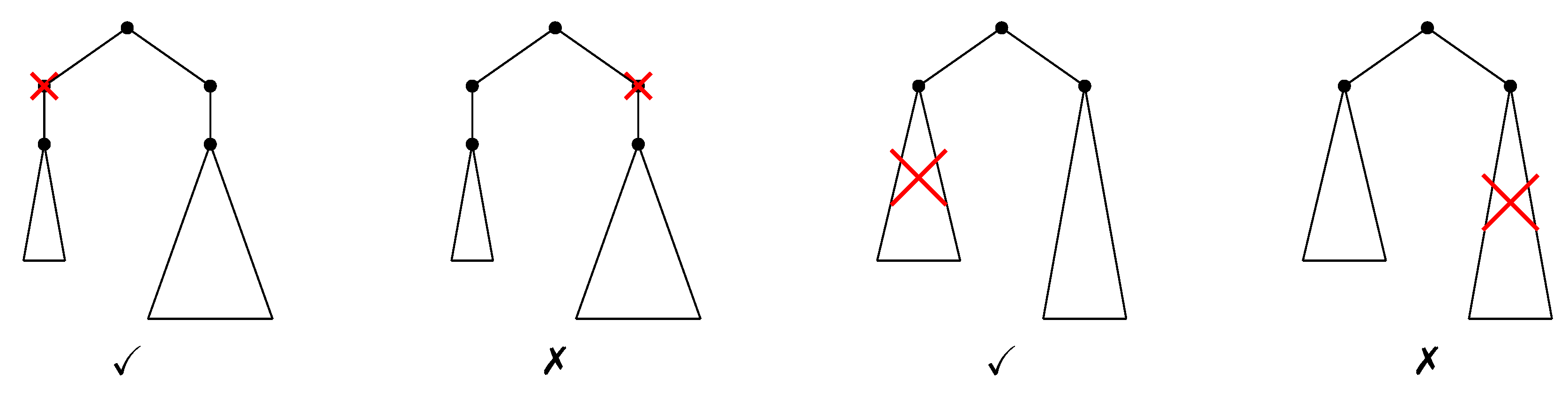
Consequently, we restrict ourselves to the following inserting operations which are the only ones that ensure that the associated mapping satisfies Zhang’s condition: adding w as a child of v will make w (i) a leaf, (ii) the parent of one current child of v, or (iii) the parent of all the current children of v. However, it should be noticed that (iii) can always be expressed as (ii) (see Figure 6). Finally, we only consider the inserting operations that make the new child of v the parent of zero or one current child of v. For obvious reasons of symmetry, the allowed deleting operations are the complement of inserting operations, i.e., one can delete an internal node if and only if it has a unique child, which also ensures that the induced mapping is constrained in the sense of Zhang.
4.1.3. Preserving the Height of the Pre-Existing Nodes
In [5] (Definition 9 and Figure 6), the NEST of a tree is obtained by successive partial linearizations of the (non-linear) DAG of which consist of merging all the nodes at the same height of the DAG. A consequence is that the height of any pre-existing node of is not changed by the inserting operations. For the sake of consistency with [5], we only consider inserting and deleting operations that preserve the height of all the pre-existing nodes of .
The next two results deal with inserting operations that preserve the height of the pre-existing nodes.
Lemma 3.
Let τ be a tree, and . Let θ be the tree obtained from τ by adding the internal node w as a child of v making w the parent of c. Then,
Proof.
Adding w may only increase the height of v and the one of its ancestors in . If the height of v is not changed by adding w, the height of its ancestors will not be modified. The height of v remains unchanged if and only if the height of w in , i.e., , is strictly less than the height of . □
Lemma 4.
Let τ be a tree and . Let θ be the tree obtained from τ by adding a tree t as a child of v. Then,
Proof.
Adding a subtree t under v may only increase the height of v and the one of its ancestors in . If the height of v is not changed by adding t, the height of its ancestors will not be modified. Adding t will make the height of v increase if is strictly greater than the height of the higher child of v. □
A particular case of Lemma 4 is the insertion of leaves in a tree. Considering the above result, a leaf can be added under v if and only if , i.e., v is not a leaf. The below results concern deleting operations that preserve the height of the remaining nodes of .
Lemma 5.
Let τ be a tree, , and . Let θ be the tree obtained from τ by deleting the internal node w making its unique child c a child of v. Then,
Proof.
Deleting w may only decrease the height of v and the one of its ancestors in . If the height of v is not changed by deleting w, the height of its ancestors will not be modified. The height of v remains unchanged if and only if it has a child different of w of height . □
Lemma 6.
Let τ be a tree, , . Let θ be the tree obtained from τ by deleting the subtree . Then,
Proof.
The proof follows the same reasoning as in the previous result. □
4.1.4. NEST and NeST
In view of the foregoing, we consider the set of inserting and deleting operations that fulfill the below requirements.
Adding operations (see Figure 7)
- Internal nodes (AI): adding w as a child of v making w the parent of the child c of v can be done only if .
- Subtrees (AS): adding t as a child of v can be done only if .
Deleting operations (see Figure 8)
- Internal nodes (DI): deleting (making the unique child w of v a child of u) can be done only if there exists , , such that .
- Subtrees (DS): deleting the subtree , , of can be done if there exists , , such that .
Proposition 5.
The editing operations AI and AS (DI and DS, respectively) are the only inserting (deleting, respectively) operations that ensure that (i) the induced mapping is a constrained mapping and that (ii) the height of all the pre-existing nodes is unchanged.
Proof.
This result is a direct corollary of Lemmas 2–6. □
The NEST (the NeST, respectively) of a tree is the self-nested tree obtained by the set of inserting operations AI and AS (of deleting operations DI and DS, respectively) of minimal cost, the cost of inserting a subtree being its number of nodes. Existence and uniqueness of the NEST are not obvious at this stage. The NeST exists because the (self-nested) tree composed of a unique root can be easily obtained by deleting operations from any tree, but its uniqueness is not evident.
4.2. NEST Algorithm
To present our NEST algorithm in a concise form in Algorithm 2, we need to define the following operations involving two vectors u and v of the same size n and a real number ,
In other words, these operations must be understood component by component. In addition, in a condition, (, respectively) means that for all , (, respectively). Finally, for , denotes the vector of length . This notation will also be used in Algorithm 3 for calculating the NeST. It should be noticed that an illustrative example that can help the reader to follow the progress of the algorithm is provided in Section 6.
| Algorithm 2: Construction of the nearest embedding self-nested tree. |
 |
The relation between the above algorithm and the NEST of a tree is provided in the following result, which states in particular the existence of the NEST.
Proposition 6.
For any tree τ, Algorithm 2 returns the unique NEST of τ in .
Proof.
By definition of the NEST, the height of all the pre-existing nodes of cannot be modified. Thus, the number of nodes of height under a node of height h can only increase by inserting subtrees in the structure. Then we have
Let v be a vertex of height h in . We recall that denotes the number of subtrees of height i under v. Our objective is to understand the consequences for of inserting operations to obtain subtrees of height under v. To this aim, we shall define a sequence starting from that corresponds to the modified versions of . The first exponent means that this sequence concerns editing operations used to get the good number of subtrees of height under v. □
Let be the number of subtrees of height that must be added under v to obtain the height profile of the NEST under v, i.e.,
Implicitly, it means that for . The subtrees of height that we must add are isomorphic, self-nested and embed all the subtrees of height appearing in by definition of the NEST. In particular, they can be obtained by the allowed inserting operations from the subtrees of height under v, by first adding an internal node to increase their height to . In addition, it is less costly in terms of editing operations to construct the subtrees of height from the subtrees of height available under v than to directly add these subtrees under v. If all the subtrees of height under v must be reconstructed later, it will be possible to insert them and the total cost will be same as by directly adding the subtrees of height under v. Consequently, all the available subtrees of height are used to construct subtrees of height under v and it remains
subtrees of height to be built under v. Furthermore, in the new version of , we have
The subtrees of height can be constructed from subtrees of height (with a larger cost than from subtrees of height ), and so on. To this aim, we define the sequence of the modified versions of by, for ,
At the final step , the subtrees of height have been constructed from all the available subtrees appearing under v, starting from subtrees of height , then , etc., and then have been added if necessary.
From now on, the number of subtrees of height under v will not decrease. Indeed, it would mean that an internal node has been added between v and the root of a subtree of height . This would have the consequence to increase of one unit the number of subtrees of height in subtrees of height h, which cost is (strictly) larger than adding a subtree of height in all the subtrees of height h. Consequently, we obtain
We can reproduce the above reasoning to construct under v subtrees of height , i from 2 to , from subtrees with a smaller height, which defines a sequence of modified versions of , which size is , and we get the following inequality,
The tree returned by Algorithm 2 is self-nested and its height profile saturates the inequalities (3) and (4) for all the possible values of h and i by construction. In addition, we have shown that this tree can be obtained from by the allowed inserting operations. Since increasing of one unit the height profile at has a (strictly) positive cost, this tree is thus the (unique) NEST of . As seen previously, the number of iterations of the while loop at line 7 is the number of subtrees of height available to construct a tree of height , i.e., the degree of in the worst case, which states the complexity.
4.3. NeST Algorithm
This section is devoted to the presentation of the calculation of the NeST in Algorithm 3. An illustrative example that can help the reader to follow the progress of the algorithm is provided in Section 6.
| Algorithm 3: Construction of the nearest embedded self-nested tree. |
 |
Proposition 7.
For any tree τ, Algorithm 3 returns the unique NeST of τ in .
Proof.
The proof follows the same reasoning as the proof of Proposition 6. First, one may remark that
because the number of subtrees of height under a node v of height h can only decrease by the allowed deleting operations. Let v be a node of height h in and the number of subtrees of height i under v. If a subtree of height under v that must be deleted is not self-nested, one can first modify it to get a self-nested tree and then remove it with the same overall cost. Thus, we can assume without loss of generality that all the subtrees under v are self-nested. denotes the number of subtrees of height that have to be removed from v. Let the sequence of the modifications to obtain subtrees of height under v, with . Instead of deleting a subtree of height , it is always less costly to decrease its height of one unit by deleting its root. However it is possible only if this internal node has only one child, i.e., if and for . If this new tree of height must be deleted in the sequel, it will be done with the same global cost as by directly deleting the subtree of height . Consequently,
From now on, the number of subtrees of height under v will thus not increase and we obtain
There are subtrees of height to be deleted under v. We can repeat the previous reasoning and delete the root of subtrees of height if possible rather than delete the whole structure, and so on for any height. Thus, the sequence is defined from
and we have
The tree returned by Algorithm 3 saturates the inequalities (5) and (6) for all the possible values of h and i. Decreasing of one unit the height profile at has a (strictly) positive cost. Thus, this tree is the (unique) NeST of . The time-complexity is given by the size of the height profile array. □
5. Numerical Illustration
5.1. Random Trees
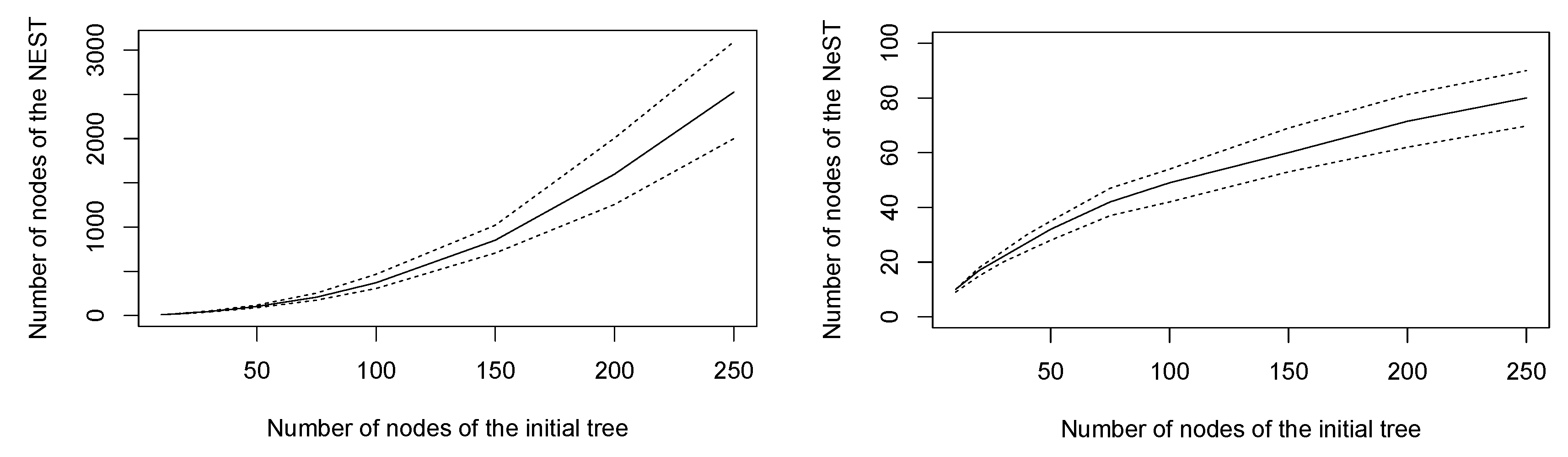
The aim of this section is to illustrate the behavior of the NEST and of the NeST on a set of simulated random trees regarding both the quality of the approximation and the computation time. We have simulated 3000 random trees of size 10, 20, 30, 40, 50, 75, 100, 150, 200, and 250. For each tree, we have calculated the NEST and the NeST. The number of nodes of these approximations is displayed in Figure 9. We can observe that the number of nodes of the NEST is very large in regards with the size of the initial tree: approximately one thousand nodes on average for a tree of 150 nodes, which is to say an approximation error of 750 vertices. Remarkably, the NEST has never been a better approximation than the NeST on the set of simulated trees.
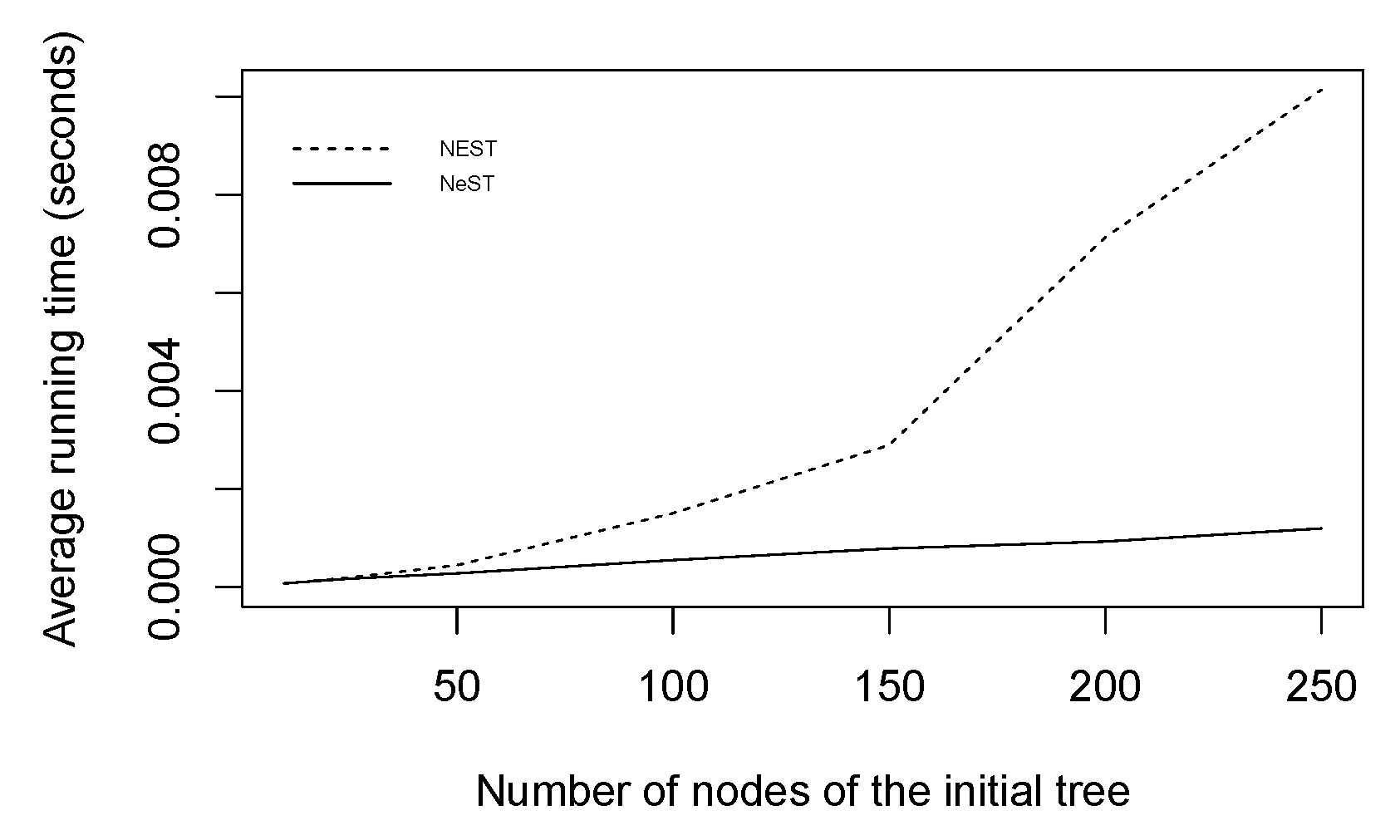
The computation time required to compute the NEST or the NeST of one tree on a 2.8 GHz Intel Core i7 has also been estimated on the set of simulated trees and is presented in Figure 10. As predicted by the theoretical complexities given in Propositions 6 and 7, the NeST algorithm requires less computation time than the NEST. Consequently, the NeST provides a much better and faster approximation of the initial data than the NEST.
5.2. Structural Analysis of a Rice Panicle
Considering [5], we propose to quantify the degree of self-nestedness of a tree by the following indicator based on the calculation of ,
where stands for Zhang’s edit distance [11]. In [5] (Equation (6)), the degree of self-nestedness of a plant is defined as in (7) but normalizing by the number of nodes of the NEST and not the size of the initial data, which avoids the indicator to be negative. In the present paper, we prefer normalizing by the number of nodes of to obtain the following comparable self-nestedness measure based on the calculation of ,
The main advantage of this normalization is that if the NEST and the NeST offer equally good approximations, i.e., , then the degree of self-nestedness does not depend on the chosen approximation scheme, .
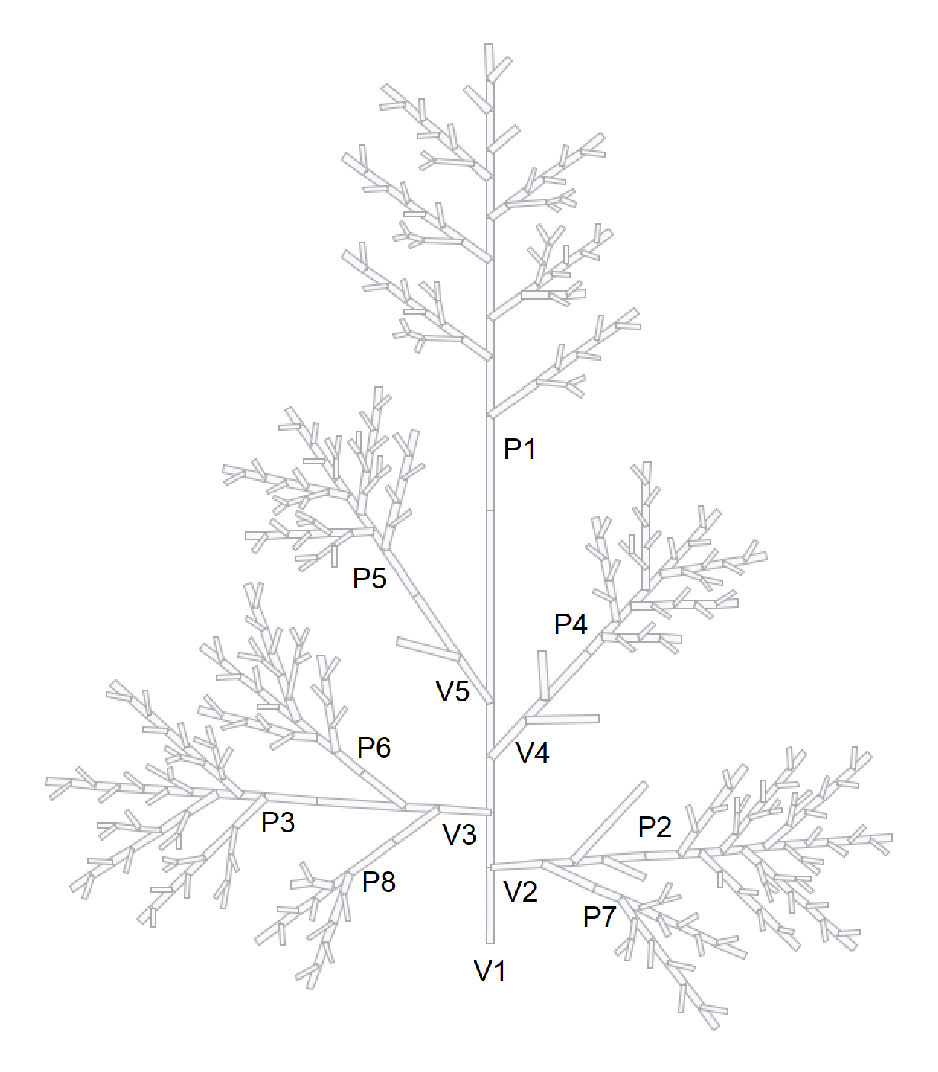
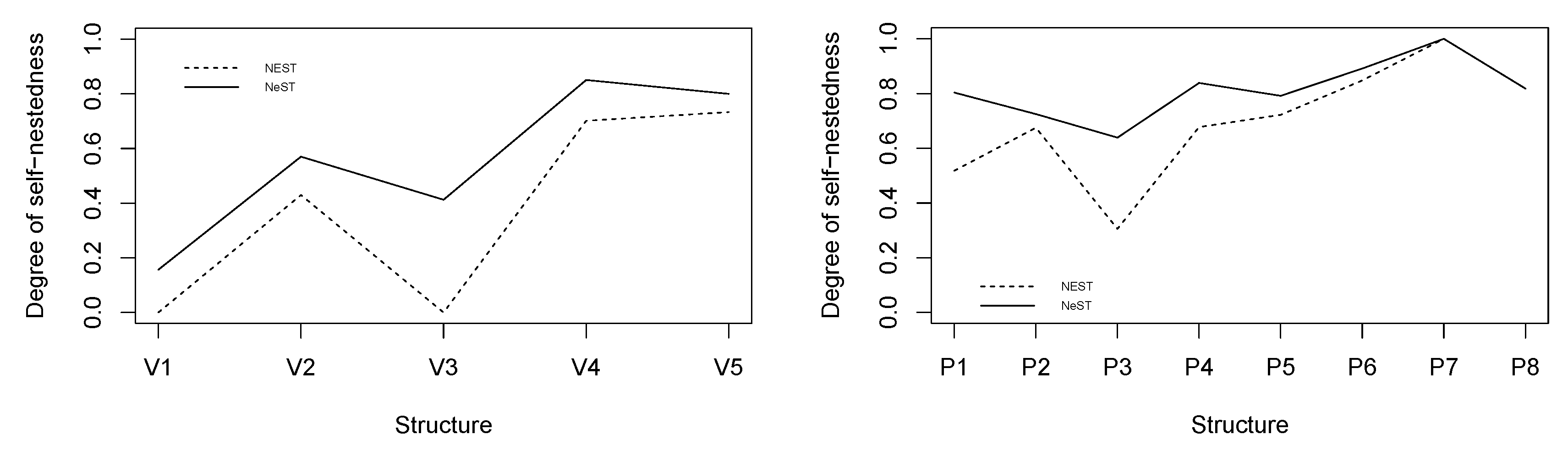
We propose to investigate the degree of structural self-similarity of the topological structure of the rice panicle studied in [5] (4.2 Analysis of a Real Plant) through these self-nested approximations. The rice panicle is made of a main axis bearing a main inflorescence and lateral systems , , each composed of inflorescences , (see Figure 11). We have computed the indicators of self-nestedness and for each substructure composing the whole panicle (see Figure 12). The numerical values and the shape of these indicators are similar. However, is always greater than , in particular for the largest structures . Based on a better approximation procedure as highlighted in the previous section, the NeST better captures the self-nestedness of the rice panicle.
6. Summary and Concluding Remarks
Self-nested trees are unordered rooted trees that are the most compressed by DAG compression. Since DAG compression takes advantage of subtree repetitions, they present the highest level of redundancy in their subtrees. In this paper, we have developed a new algorithm for computing the Nearest Embedding Self-nested Tree (NEST) of a tree in , as well as the first algorithm for determining its Nearest embedded Self-nested Tree (NeST) with time-complexity .
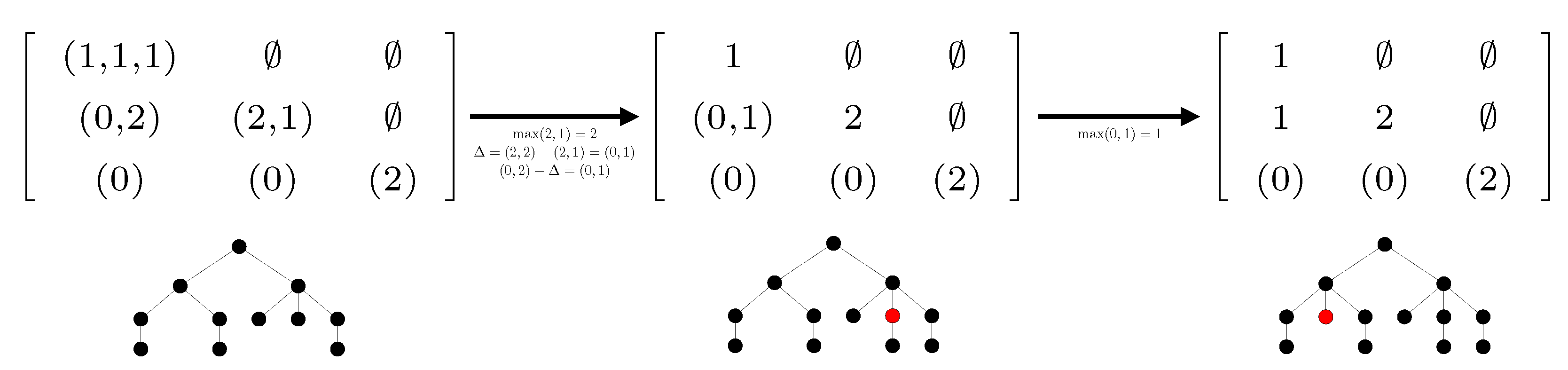
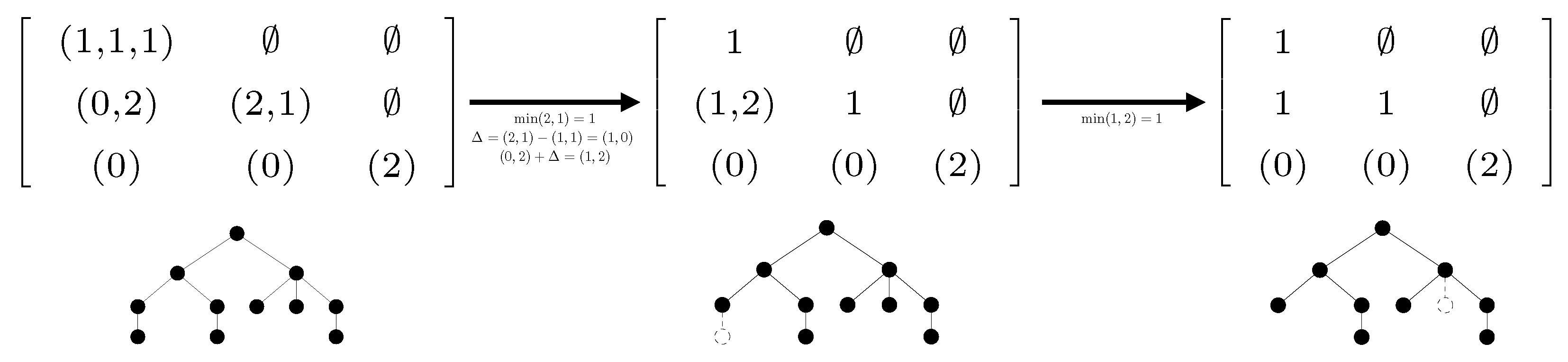
To this end, we have introduced the notion of height profile of a tree. Roughly speaking, the height profile is a triangular array which component , with , is the list of the numbers of direct subtrees of height in subtrees of height , where a subtree is said direct if it is attached to the root. We have shown in Proposition 3 that self-nested trees are characterized by their height profile. While the first NEST algorithm [5] was based on edition of the DAG related to the tree to be compressed, the two approximation algorithms developed in the present paper take as input the height profile of any tree , which can be computed in -time (see Proposition 2), and modify it from top to bottom and from right to left, to return the self-nested height profile of the expected estimate (see Algorithms 2 and 3). Figure 13 and Figure 14 illustrate the progress of the algorithms on a simple example. They should be examined in relation to the corresponding algorithms. We would like to emphasize that our paper also states the uniqueness of the NEST and of the NeST, and studies the link with edit operations admitted in Zhang’s distance.
Remarkably, estimations performed on a dataset of random trees establish that the NeST is a more accurate approximation of the initial tree than the NEST. This observation could be investigated from a theoretical perspective. In addition, we have shown that the NeST better captures the degree of structural self-similarity of a rice panicle than the NEST.
The algorithms developed in this paper are available in the last version of the Python library treex [9].
Funding
This research received no external funding.
Acknowledgments
The author would like to show his gratitude to two anonymous reviewers for their relevant comments on a first version of the manuscript.
Conflicts of Interest
The author declares no conflicts of interest.
References
- Bille, P.; Gørtz, I.L.; Landau, G.M.; Weimann, O. Tree compression with top trees. Inf. Comput. 2015, 243, 166–177. [Google Scholar] [CrossRef] [Green Version]
- Bousquet-Mélou, M.; Lohrey, M.; Maneth, S.; Noeth, E. XML Compression via Directed Acyclic Graphs. Theory Comput. Syst. 2014, 57, 1322–1371. [Google Scholar] [CrossRef] [Green Version]
- Buneman, P.; Grohe, M.; Koch, C. Path Queries on Compressed XML. In Proceedings of the 29th International Conference on Very Large Data Bases, VLDB’03, Berlin, Germany, 9–12 September 2003; Volume 29, pp. 141–152. [Google Scholar]
- Frick, M.; Grohe, M.; Koch, C. Query evaluation on compressed trees. In Proceedings of the 18th Annual IEEE Symposium of Logic in Computer Science, Ottawa, ON, Canada, 22–25 June 2003; pp. 188–197. [Google Scholar]
- Godin, C.; Ferraro, P. Quantifying the degree of self-nestedness of trees. Application to the structural analysis of plants. IEEE Trans. Comput. Biol. Bioinform. 2010, 7, 688–703. [Google Scholar] [CrossRef] [PubMed]
- Busatto, G.; Lohrey, M.; Maneth, S. Efficient Memory Representation of XML Document Trees. Inf. Syst. 2008, 33, 456–474. [Google Scholar] [CrossRef]
- Lohrey, M.; Maneth, S. The Complexity of Tree Automata and XPath on Grammar-compressed Trees. Theor. Comput. Sci. 2006, 363, 196–210. [Google Scholar] [CrossRef]
- Greenlaw, R. Subtree Isomorphism is in DLOG for Nested Trees. Int. J. Found. Comput. Sci. 1996, 7, 161–167. [Google Scholar] [CrossRef]
- Azaïs, R.; Cerutti, G.; Gemmerlé, D.; Ingels, F. treex: A Python package for manipulating rooted trees. J. Open Source Softw. 2019, 4, 1351. [Google Scholar] [CrossRef]
- Aho, A.V.; Hopcroft, J.E.; Ullman, J.D. The Design and Analysis of Computer Algorithms, 1st ed.; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 1974. [Google Scholar]
- Zhang, K. A constrained edit distance between unordered labeled trees. Algorithmica 1996, 15, 205–222. [Google Scholar] [CrossRef]
Figure 1.
Trees and their DAG (Directed Acyclic Graph) reduction. In the tree, roots of isomorphic subtrees are colored identically. In the DAG, vertices are equivalence classes colored according to the class of isomorphic subtrees that they represent.
Figure 1.
Trees and their DAG (Directed Acyclic Graph) reduction. In the tree, roots of isomorphic subtrees are colored identically. In the DAG, vertices are equivalence classes colored according to the class of isomorphic subtrees that they represent.

Figure 2.
A tree (middle) with 30 nodes and its approximations (left) with 24 nodes and (right) with 37 nodes.
Figure 2.
A tree (middle) with 30 nodes and its approximations (left) with 24 nodes and (right) with 37 nodes.

Figure 3.
Deleting a node.

Figure 4.
Inserting a node.

Figure 5.
The tree is obtained from by inserting an internal node. The associated mapping does not satisfy the conditions imposed by Zhang [11] because the LCA (Least Common Ancestor) of and is a proper ancestor of whereas the LCA of and is not a proper ancestor of .
Figure 5.
The tree is obtained from by inserting an internal node. The associated mapping does not satisfy the conditions imposed by Zhang [11] because the LCA (Least Common Ancestor) of and is a proper ancestor of whereas the LCA of and is not a proper ancestor of .

Figure 6.
Adding a node as new child of w making all the current children of w children of this new node (top) provides the same topology as adding a new node between v and its child w (bottom).
Figure 6.
Adding a node as new child of w making all the current children of w children of this new node (top) provides the same topology as adding a new node between v and its child w (bottom).

Figure 7.
Allowed (✓) and forbidden (✗) inserting operations to construct the NEST of a tree.

Figure 8.
Allowed (✓) and forbidden (✗) deleting operations to construct the NeST of a tree.

Figure 9.
Number of nodes of the NEST (left) and of the NeST (right) estimated from 3000 random trees: average (full lines) and first and third quartiles (dashed lines).
Figure 9.
Number of nodes of the NEST (left) and of the NeST (right) estimated from 3000 random trees: average (full lines) and first and third quartiles (dashed lines).

Figure 10.
Average running time required to compute the NEST (dashed line) or the NeST (full line) estimated from 3000 simulated trees.
Figure 10.
Average running time required to compute the NEST (dashed line) or the NeST (full line) estimated from 3000 simulated trees.

Figure 11.
The rice panicle is composed of a main axis and lateral systems , each made of one or several inflorescences .
Figure 11.
The rice panicle is composed of a main axis and lateral systems , each made of one or several inflorescences .

Figure 12.
Degree of self-nestedness measured by (dashed lines) and (full lines) of the different substructures appearing in the rice panicle.
Figure 12.
Degree of self-nestedness measured by (dashed lines) and (full lines) of the different substructures appearing in the rice panicle.

Figure 13.
Progress of Algorithm 2 to compute the NEST of the left tree from its height profile. Only the second line must be edited to get the correct output. Editions of the height profile are associated with addition of vertices in red. The output tree is self-nested and has been constructed by adding a minimal number of nodes to the initial tree.
Figure 13.
Progress of Algorithm 2 to compute the NEST of the left tree from its height profile. Only the second line must be edited to get the correct output. Editions of the height profile are associated with addition of vertices in red. The output tree is self-nested and has been constructed by adding a minimal number of nodes to the initial tree.

Figure 14.
Progress of Algorithm 3 to compute the NeST of the left tree from its height profile. Only the second line must be edited to get the correct output. Editions of the height profile are associated with deletion of vertices in dashed lines. The output tree is self-nested and has been constructed by removing a minimal number of nodes from the initial tree.
Figure 14.
Progress of Algorithm 3 to compute the NeST of the left tree from its height profile. Only the second line must be edited to get the correct output. Editions of the height profile are associated with deletion of vertices in dashed lines. The output tree is self-nested and has been constructed by removing a minimal number of nodes from the initial tree.

© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Azaïs, R. Nearest Embedded and Embedding Self-Nested Trees. Algorithms 2019, 12, 180. https://0-doi-org.brum.beds.ac.uk/10.3390/a12090180
AMA Style
Azaïs R. Nearest Embedded and Embedding Self-Nested Trees. Algorithms. 2019; 12(9):180. https://0-doi-org.brum.beds.ac.uk/10.3390/a12090180
Chicago/Turabian StyleAzaïs, Romain. 2019. "Nearest Embedded and Embedding Self-Nested Trees" Algorithms 12, no. 9: 180. https://0-doi-org.brum.beds.ac.uk/10.3390/a12090180
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.