Using Graph Partitioning for Scalable Distributed Quantum Molecular Dynamics
by
 , , ,
, , ,
Hristo N. Djidjev
1 ,
,
Georg Hahn
2,*,†,
Susan M. Mniszewski
1,
Christian F. A. Negre
1 and
Anders M. N. Niklasson
1 1
Los Alamos National Laboratory, Los Alamos, NM 87544, USA
2
Department of Mathematics and Statistics, Lancaster University, Bailrigg, Lancaster LA1 4YW, UK
*
Author to whom correspondence should be addressed.
†
Part of the work was done when the author was visiting Los Alamos National Laboratory.
Algorithms 2019, 12(9), 187; https://0-doi-org.brum.beds.ac.uk/10.3390/a12090187
Submission received: 26 June 2019
/
Revised: 5 September 2019
/
Accepted: 5 September 2019
/
Published: 7 September 2019
(This article belongs to the Special Issue Graph Partitioning: Theory, Engineering, and Applications)
Abstract
:The simulation of the physical movement of multi-body systems at an atomistic level, with forces calculated from a quantum mechanical description of the electrons, motivates a graph partitioning problem studied in this article. Several advanced algorithms relying on evaluations of matrix polynomials have been published in the literature for such simulations. We aim to use a special type of graph partitioning to efficiently parallelize these computations. For this, we create a graph representing the zero–nonzero structure of a thresholded density matrix, and partition that graph into several components. Each separate submatrix (corresponding to each subgraph) is then substituted into the matrix polynomial, and the result for the full matrix polynomial is reassembled at the end from the individual polynomials. This paper starts by introducing a rigorous definition as well as a mathematical justification of this partitioning problem. We assess the performance of several methods to compute graph partitions with respect to both the quality of the partitioning and their runtime.
1. Introduction
The physical movements of multi-body systems on an atomistic level is at the core of molecular dynamics (MD) simulations. Those dynamics take place at the femtosecond ( s) time scale and they are incorporated in a larger simulation which typically is of the order of pico- to nanoseconds ( to s). A simple way to conduct MD simulations is to derive all forces from the potential energy surface for all interacting particles, and to compute molecular trajectories for the multi-particle system by solving Newton’s equations numerically. In quantum-based molecular dynamics (QMD) simulations, the electronic structure is based on an underlying quantum mechanical description, from which interatomic forces are calculated.
Several QMD methods are published in the literature for a variety of materials systems. So-called first principle methods can simulate a few hundred atoms over a picosecond range. Important approaches of this type include Hartree–Fock or density functional theory. Semiempirical methods such as self-consistent tight-binding techniques increase the applicability to systems of several thousand atoms. In contrast to regular first principle methods, approximate methods are often two to three orders of magnitude faster while still capturing the quantum mechanical behavior (for example, charge transfer, bond formation, excitations, and quantum size effects) of the system.
One of the most efficient and widely used methods is density functional-based self-consistent tight-binding theory [1,2,3]. In this approach, the main computational effort stems from the diagonalization of a matrix, the so-called Hamiltonian matrix, which encodes the electronic energy of the system. The Hamiltonian matrix is needed to construct the density matrix describing the electronic structure of the system. Before evaluating the forces at each time step of a QMD simulation, the self-consistent construction of the density matrix is carried out. Computing the density matrix requires matrix diagonalization with a computational cost of , where N is the dimension of the Hamiltonian matrix. This makes diagonalization only viable for small system sizes. For this reason, the last two decades have seen the development of several linear runtime (i.e., ) algorithms.
One such linear runtime approach is based on a recursive polynomial expansion of the density matrix [4]. A linear scaling with the system size for non-metallic systems is achieved by the sparse-matrix second-order spectral projection (SM-SP2) algorithm. On dense or sparse matrices, SM-SP2 competes with or outperforms regular diagonalization schemes with respect to both speed and accuracy [5]. SM-SP2 uses the expression
to compute the density matrix D from the Hamiltonian H, where is a quadratic function (either or , depending on or ), and the initial matrix is a linearly modified version of H. Usually, 20–30 iterations suffice to obtain a close approximation of D. Additionally, thresholding is applied to further reduce the computational complexity, where small nonzero elements of the matrix (typically between to ) are set to zero. Thresholding the matrix elements of the Hamiltonian is essential to arrive at a fast way to calculate the density matrix: without thresholding, the resulting matrix would quickly become dense due to fill-in.
The cost of computing a matrix polynomial P (which is mainly due to the squaring of a matrix) dominates the computational cost of the SM-SP2 algorithm. Since we are interested in performing a large number of time steps (of the order of –) in a typical QMD simulation, we need to parallelize the evaluation of the matrix polynomials in order to keep the wall-clock time low. However, the significant communication overhead for every iteration causes SM-SP2 to not parallelize well. Linear scaling complexity has been achieved with thresholded blocked sparse-matrix algebra [5,6,7,8]. In our paper, we present an alternative formulation that reduces communication overhead via graph partitioning and enables scalable parallelism. Our basic approach was introduced in [9], but with the main focus being on the physics aspects.
This paper addresses the aforementioned parallel version of SP2 together with an inbuilt partitioning scheme applied to the graph representation of the density matrix, denoted as G-SP2 in the remainder of the article. In particular, the computational aspects of evaluating the matrix polynomial in G-SP2 are investigated. We represent the Hamiltonian (or density) matrix as a graph where atomic orbitals are given as vertices and nonzero interactions become edges, and then partition that graph into blocks (parts) with the aim to minimize a suitable cost function. The submatrices of the Hamiltonian or density matrix correspond to the divisions of the molecule, and are derived from the graph partitioning. We rigorously prove that applying the matrix polynomial to the entire Hamiltonian is equivalent to applying it to the partitioned Hamiltonian matrix and re-assembling the partial solutions, thus justifying our approach to parallelize the computational workload via graph partitioning. Although demonstrated numerically [9], no such proof exists in the literature to the best of our knowledge.
Our algorithm is related to the general framework of [10] (specifically the case of overlapped subdomains), who present a general methodology to partition workloads among several processors. Their work is similar in that standard graph partitionings are considered, which are then locally modified to further optimize them (we attempt the same with a simulated annealing approach in Section 3.2). However, there are crucial differences to the work presented in this article: Since their framework is very general, it does not consider our specific objective function presented later in Section 2, their general algorithm works with a distance cutoff for modifying partitions which we do not recommend, and most importantly, we prove that for our problem, the partitioned matrix polynomial indeed allows lossless parallelization.
We show that partitions with overlapping blocks (or halos) need to be computed to obtain accurate results with our graph approach. Naturally, the computational overhead increases with the overlap. The aim of this work is to minimize the computational cost of the matrix polynomial evaluation through appropriate partitioning schemes. Those schemes will directly minimize the cost of the corresponding polynomial evaluation as opposed to traditional edge cut minimization. In our article, we will experimentally study several algorithms for the aforementioned graph partitioning problem, which we formally introduce first. In [11], the authors consider a similar set-up in which the graph encoding the molecular structure is partitioned (using various techniques) for faster heuristic computation; however, their article crucially differs from ours in that there are no generally applicable results pertaining to lossless partitioning of the matrix polynomial using overlapping blocks.
Our approach allows us to avoid communication between processors after each iteration of (1) until the entire polynomial is evaluated. To this end, each processor independently evaluates its assigned polynomial after partitioning and distributing the initial matrix, and the final output is assembled from the computed submatrices. In this article, different algorithmic approaches for computing graph partitions are assessed with respect to the aforementioned objective function and their computational effort. Importantly, we analyze the tradeoff between the additional computational costs for computing graph partitions before running the SP2 algorithm in parallel, and carrying out regular molecular dynamics. We also investigate the tuning of the number of blocks as a function of the graph size to minimize computational effort.
The structure of this paper is as follows. Section 2 introduces the mathematical foundations for partitioning the evaluation of matrix polynomials, states our algorithm including a proof of correctness, and defines the graph partitioning problem we consider. Algorithms for constructing such partitions and their implementations are discussed in Section 3. Experimental results for several physical test systems are given in Section 4. Section 5 discusses our results. Proofs for Section 2 can be found in Appendix A and Appendix B presents further experimental results.
A preliminary version of this article has been published as a conference paper in the SIAM Workshop on Combinatorial Scientific Computing (CSC16), see [12]. This article is an extension of the work of [12], and includes proofs of all theoretical results of Section 2 in Appendix A, pseudo-code of our simulated annealing approach in Section 3.2, a visualization of the relationship between the graph structure of a molecule and its partitioned graph representation in Section 4.3, and more detailed performance data used for all experiments in Appendix B.
2. Evaluating Matrix Polynomials on Partitions
We define a thresholded matrix polynomial, justify its parallelized evaluation, present an algorithm to evaluate a matrix polynomial in a parallelized fashion, and conclude by defining the cost function for an implied graph partitioning problem.
We encode the zero–nonzero structure of a symmetric matrix as a graph , called the sparsity graph of X. contains a vertex for each row (or column) in X, and contains an edge between vertices i and j if and only if . We now generalize the matrix polynomial defined in (1) for any symmetric matrix A. Denote the superposition of operators of the type
as a thresholded matrix polynomial of degree , where is a thresholding operation and is a polynomial of degree 2. For any graph I, we formally define as the graph operator (with associated edge set ) such that is a graph with a vertex set and an edge set .
The application of a superpositioned operator P of the type (2) to a matrix A of appropriate dimension is denoted as . In (2), P is composed of polynomials and thresholding operations . For our SM-SP2 application, the Hamiltonian is A and the density matrix is .
For any matrix A, we define all matrices B which have the same zero–nonzero structure as A (that is, ) to be in the structure class . We observe that the nonzero structure of and can be different.
Let for a matrix A and let P be a thresholded matrix polynomial. We denote by the minimal graph with the same vertices as G such that if for any matrix and any , then there is an edge . We interpret as the worst-case zero–nonzero structure of that excludes cancellations resulting from the addition of opposite-sign numbers, thus resulting in coincidental zeros. All diagonal elements of A are assumed to be nonzero, and is assumed to not contain a loop edge.
Assume we are given a set , where each , called a block of , is a union of a core vertex set and a halo vertex set . Given the two following conditions hold true, we call a CH-partition (or core-halo partition):
- for all ;
- neighbors of vertices in that are themselves not in are contained in .
Let be the subgraph of induced by all neighbors of in H. We combine all rows and columns of A that correspond to vertices of in a submatrix of A. The following lemma shows that can be computed on submatrices of the Hamiltonian.
Lemma 1.
For any and any neighbor w of v in , the element of corresponding to the edge of is equal to the element of corresponding to the edge of .
The proof is given in Appendix A. Lemma 1 justifies the parallelized evaluation of a matrix polynomial.
Let us apply the aforementioned results to a Hamiltonian matrix A in a QMD simulation. (See the example in Figure 1). In this case, we can assume that the sparsity structure of the density matrix D from the previous QMD simulation step is being passed on to . We can thus approximate with since the graph H is unknown until is computed. This is a reasonable approximation since the connectivity will only change marginally from step to step in the QMD simulation. Since by construction, the graph H is totally contained in the graph of its density matrix (which is the object we want to compute and thus unknown), it is sensible to approximate its connectivity from the density matrix of the previous time step of the QMD simulation. The halos can also be taken from H in practice.
We propose the following algorithm for computing from :
- Divide into q disjoint sets and define a CH-partition , where has core and halo ;
- Construct submatrices for all ;
- Compute for all i independently using dense matrix algebra;
- Given a vertex i, let k be the index such that the set contains i. Let j be the row in that corresponds to the i-th row in A. Then, define as a matrix whose i-th row equals the j-th row of .
This algorithm computes as demonstrated in Lemma 1.
The computational bottleneck of the algorithm for is caused by the dense matrix-matrix multiplication required to compute for all i in step (3).
To be precise, according to (2), computing takes operations, where and are the size of the core and the halo of and s is the number of superpositioned operators (see (2)). In this calculation, the computational effort for thresholding some matrix elements is excluded, since this effort is quadratic in the worst case and linear in in average cases. We observe that a CH-partitioning which minimizes the effort to compute also minimizes due to the fact that s is independent of .
This observation motivates our CH-partitioning problem, defined as follows: For an undirected graph G and an integer , split G into q blocks such that
is minimized, where has a core of size and a halo of size .
As an example, the optimal CH-partitioning for a star graph of n vertices has a single non-empty block containing all vertices: this block is composed of the central vertex, whose halo contains all other vertices. In contrast, a standard (edge cut) partitioning will have n parts, thus demonstrating that a CH-partitioning minimizing (3) can be quite different from a standard balanced partitioning.
3. Algorithms for Graph Partitioning Considered in Our Study
In this section, we investigate the ability of existing graph partitioning packages, as well as our own heuristic algorithm, for computing CH-partitions that minimize the objective function (3). Those algorithms are: METIS (version 5.1.0) and hMETIS (version 1.5) due to their widespread use, and KaHIP (version 0.7) based on its convincing performance at the 10th DIMACS Implementation Challenge [13].
3.1. Edge Cut Graph Partitioning
We observe that we obtain when leaving out the cubes in the objective function (3), thus making it necessary to minimize the sum of the halo nodes over all blocks.
Regular graph partitions and CH-partitions are related. Suppose we are given a regular partition P. For any part in P, we can define a core corresponding to that part, and a halo consisting of all adjacent vertices of the core vertices (excluding the core vertices themselves). We define the CH-partition to consist of precisely those blocks for any element of P. It must then be true that either v or w is a halo vertex for any cut edge of P. Conversely, there exists a core vertex w such that is a cut edge for any halo vertex v belonging to some part in .
This shows that the cut edges of P and the set of halo nodes in are related but not equal. We observe that another measure, the total communication volume, exactly corresponds to the sum of halo nodes. Certain tools such as METIS allow us to optimize with respect to the total communication volume. By ignoring the cubes in (3), we aim to study how well CH-partitions can be produced by regular graph partitioning tools. Additionally, we improve the solutions obtained by standard graph partitioning tools with our own heuristic in Section 3.2. The three following algorithms will be used:
3.1.1. METIS
METIS [14] uses a three-phase multilevel approach to perform graph partitioning:
- Starting from the original graph (where ), METIS generates a sequence of graphs for some to coarsen the input graph. The coarsening ends with a suitably small graph (typically with vertices).
- An algorithm of choice is used to partition .
- Using the sequence , the partitions are expanded back from to the full graph .
Additionally, METIS employs a refinement algorithm such as the one of Fiduccia–Mattheyses [15] to improve the partitioning after each projection. This is necessary since the finer the partition, the more degrees of freedom it has during the uncoarsening phase. Several tuning parameters can be set in METIS, including the size of , the coarsening algorithm, and the algorithm used for partitioning .
3.1.2. KaHIP
Several multilevel graph partitioning algorithms are combined in KaHIP [16]. KaHIP works similarly to METIS. A given input graph is first contracted, partitions are computed on the coarsest contraction level, and the partitions obtained in this way are projected back to coarser levels, where refinement algorithms are used to enhance the solutions. KaHIP offers max-flow/min-cut [17,18] and Fiduccia–Mattheyses refinement [15] for local improvement of the solution. Additionally, F-cycles [17] can be employed as a global search technique.
3.1.3. Hypergraph Partitioning
A hypergraph formulation is an alternative approach to the classical interpretation of the density matrix as an adjacency matrix (where each nonzero interaction in the density matrix is an undirected and unweighted edge).
The set of all neighbors of a vertex form a single hyperedge in the hypergraph formulation. The main advantage of using hyperedges consists of the fact that minimizing the edge cut with respect to hyperedges results in either all or zero vertices being included in a block: if a hyperedge is not a cut edge, then this automatically implies that all the neighbors of that core vertex (i.e., its halo) are included in the same block.
We use hMETIS of [19] to compute hypergraph partitionings. hMETIS is the hypergraph analog of METIS.
3.2. Refinement with Simulated Annealing
The objective function (3) we aim to minimize differs from the size of the edge or hyperedge cut minimized by standard graph and hypergraph partitioning algorithms. With the help of the algorithm derived in this section we explicitly minimize (3).
A standard tool in optimization is the probabilistic algorithm of [20], called simulated annealing (SA). SA iteratively proposes random modifications to an existing solution to improve it, and thus optimizes without gradients. If a proposed modification (or move) does not immediately lower the objective function, it might still be accepted with a certain acceptance probability. The acceptance probability is proportional to the magnitude of the (unfavorable) increase in the objective function, and antiproportional to the runtime. The latter makes it more likely for SA to accept unfavorable moves in the exploration phase at the start of each run, and it is implemented using a strictly decreasing temperature function. Modifications to the existing solution which further minimize the objective function are always accepted.
A fixed number of iterations, a vanishingly small temperature, or the lack of further improvements in the solution over a certain number of iterations can be employed as stopping criteria for SA.
We test the following proposal functions that return modifications to subgraphs induced by an existing block of the partition, where P and are simply sets of nodes:
- Select a random block , select one of its halo nodes v at random and move v into block P.
- Select a random block , select one of its nodes v at random and move v into P.
- Select the block with most halo nodes and (a) move a random node v into P, (b) make a random halo node of P a core node, or (c) move any node of P to another block.
- Like (3.) using the block with the largest sum of core and halo nodes.
Many more sensible proposal functions could be devised. However, in our experiments we observed that the above proposals result in a similar behavior of SA, with the best tradeoff between speed and performance being achieved by scheme (1.).
Algorithm 1 states the SA implementation we use in our experiments. Any regular (edge cut) partitioning (e.g., obtained with METIS), and even a random partitioning, serves as input (the set of blocks) to Algorithm 1. The SA algorithm runs over a fixed number of N iterations. In each iteration, we randomly select a block as well as a random edge joining a core vertex v with a halo vertex w in . Afterwards, is updated with w being a core vertex. After storing the new partitioning in a set , both and are assessed. For this we compute the change in the objective function (3) between and , which is used to update the acceptance probability p. We accept (thus overwriting ) with probability p. Note that if , thus leading to a guaranteed acceptance of a proposal that directly improves (3). Afterwards, the iteration is repeated.
| Algorithm 1: Simulated Annealing. |
 |
SA is run with a maximal number of iterations as stopping criterion, and the temperature function is chosen as . In practice, we first threshold a density matrix (see Section 2), convert it to a graph, compute regular edge cut partitionings for the converted graph with a standard software, and post-process the partition with SA.
4. Experiments
Using three measures the quality of the CH-partitions returned by the algorithms of Section 3 is evaluated. Those measures are the objective function (3), the algorithmic runtime, and the number of MPI ranks and threads in an assessment of the scaling behavior of the G-SP2 algorithm (for one fixed system). We employ graphs derived from representations of actual molecules as opposed to simulated random graphs.
Unless noted otherwise, all experiments were performed on the Darwin cluster of Los Alamos National Laboratory, which hosts 20-core 2.60 GHz Intel Xeon E5-2660 processors with v3 architecture.
4.1. Parameter Choices for METIS and hMETIS
Using a grid search over sensible values, we tune the parameters of METIS and hMETIS, and will keep the set of parameters yielding the best average performance for all systems considered in this section fixed throughout the remainder of the simulations.
The default multilevel k-way partitioning as well as the default sorted heavy-edge matching for coarsening the graph were employed to run METIS. Importantly, the user can choose to minimize either the edge cut or the total communication volume of the partitioning within the k-way partitioning routine of METIS. As our definition of the sum of halo nodes in Section 2 is equivalent to the definition of the total communication volume of METIS, we choose this option.
We employ hMETIS with the followed parameters: we use recursive bisectioning (instead of k-way partitioning) with vertex grouping scheme Ctype (meaning the hybrid first-choice scheme HFC), Fiduccia–Mattheyses refinement (refinement heuristic parameter set to 1), and V-cycle refinement on each intermediate solution (V-cycle refinement parameter set to 3). These parameters are explained in the hMetis manual [21].
4.2. A Collection of Test Graphs Derived from Molecular Systems
This section uses a selection of physical test systems to evaluate all algorithms of Section 3, which were chosen to represent a variety of realistic scenarios where graph partitioning can be applied to MD simulations. Those test systems are available from the authors upon request. We demonstrate how the graph structure influences the results (Section 4.3) and additionally provide insights into the physics of each test system.
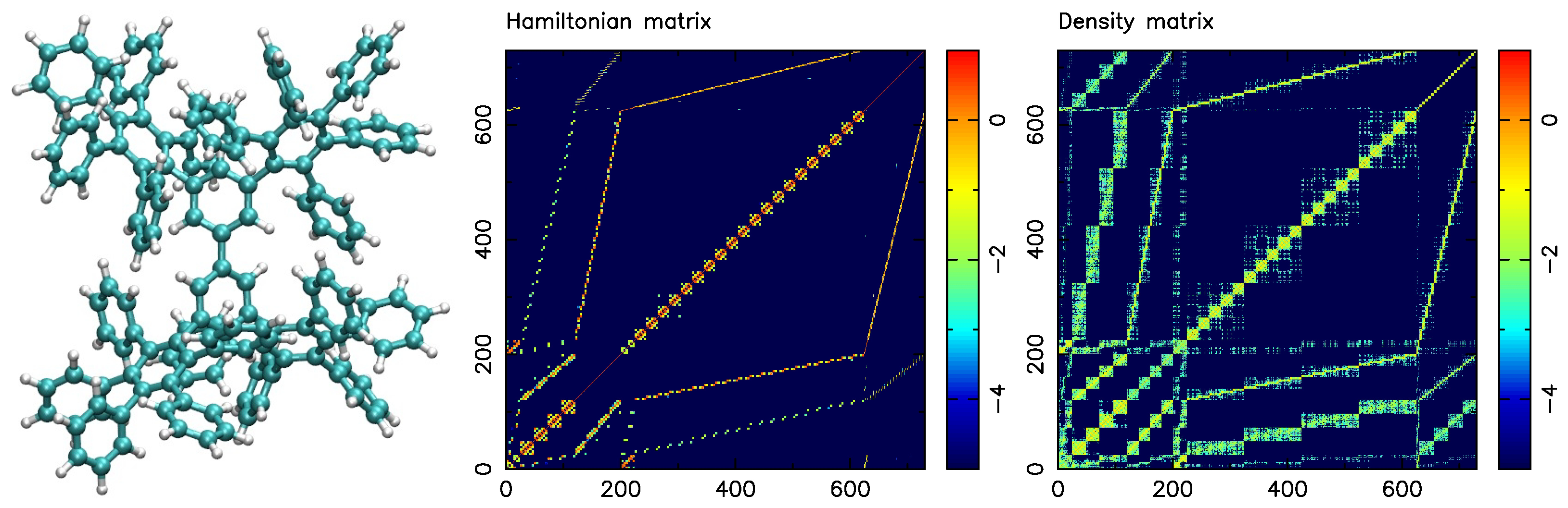
A dendrimer molecule with 22 covalently bonded phenyl groups of solely C and H atoms is schematically shown in Figure 2 (left). The graph of the dendrimer molecule has 730 vertices, composed of 262 atoms and 730 orbitals.
Figure 2 (middle) displays the absolute values of the Hamiltonian matrix for the dendrimer system. Figure 2 (right) displays the density matrix encoding the physical properties of the system, which is obtained by applying the SM-SP2 algorithm to the Hamiltonian.
We threshold the density matrix at to convert it into a graph needed to find meaningful physical components via graph partitioning. This is done with all systems of Table 1 to arrive at their adjacency matrices.
Table 1 displays the molecule name (first column), the number of vertices n and edges m (second and third column) of its graph representation, and its average vertex degree (fourth column). A short description of the molecule can be found in the last column.
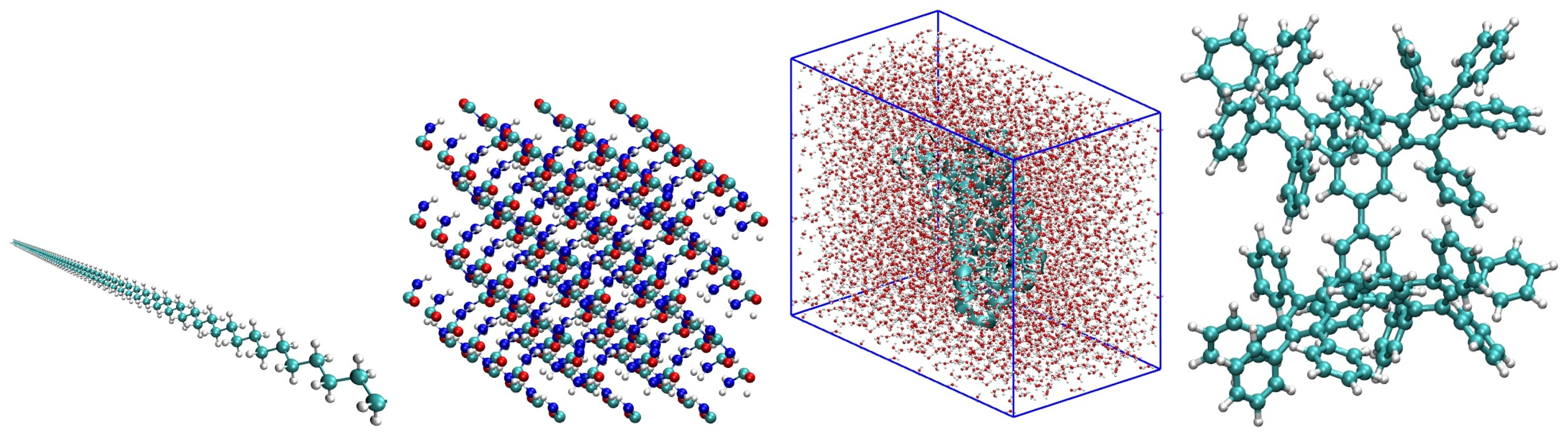
We consider four topologically different types of molecular systems (see Figure 3) as test beds for the partitioning algorithms. This is to provide a wider range of test systems for our algorithms. Figure 3 displays a one-dimensional system in the first panel (polyethyene linear chain with repeated CH units), an anisotropic pristine 3D urea crystal (second panel), a polyalanine molecule solvated in water (third panel) with a typical -helix secondary structure, and a dendrimeric system with a fractal arrangement of phenyl rings (fourth panel) to challenge our partitioning algorithms.
4.3. Comparison of the Partitioning Algorithms
Six methods are tested to partition each graph of Table 1 into 16 blocks:
- METIS with parameters of Section 4.1;
- METIS with subsequent simulated annealing (SA);
- hMETIS;
- hMETIS with subsequent SA;
- KaHIP;
- KaHIP with subsequent SA.
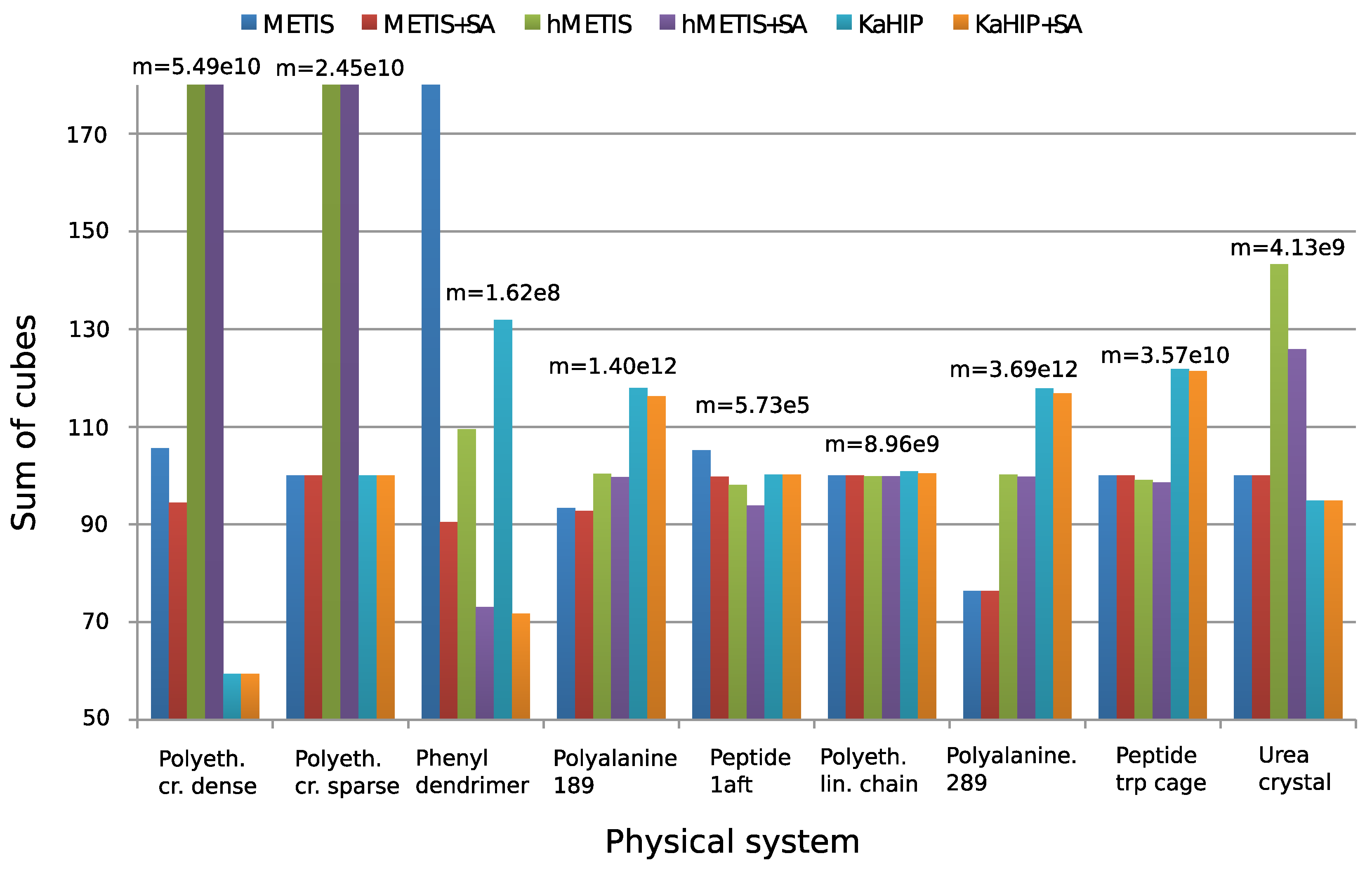
As before, the sum of cubes (3) criterion is used to assess the effectiveness of each method.
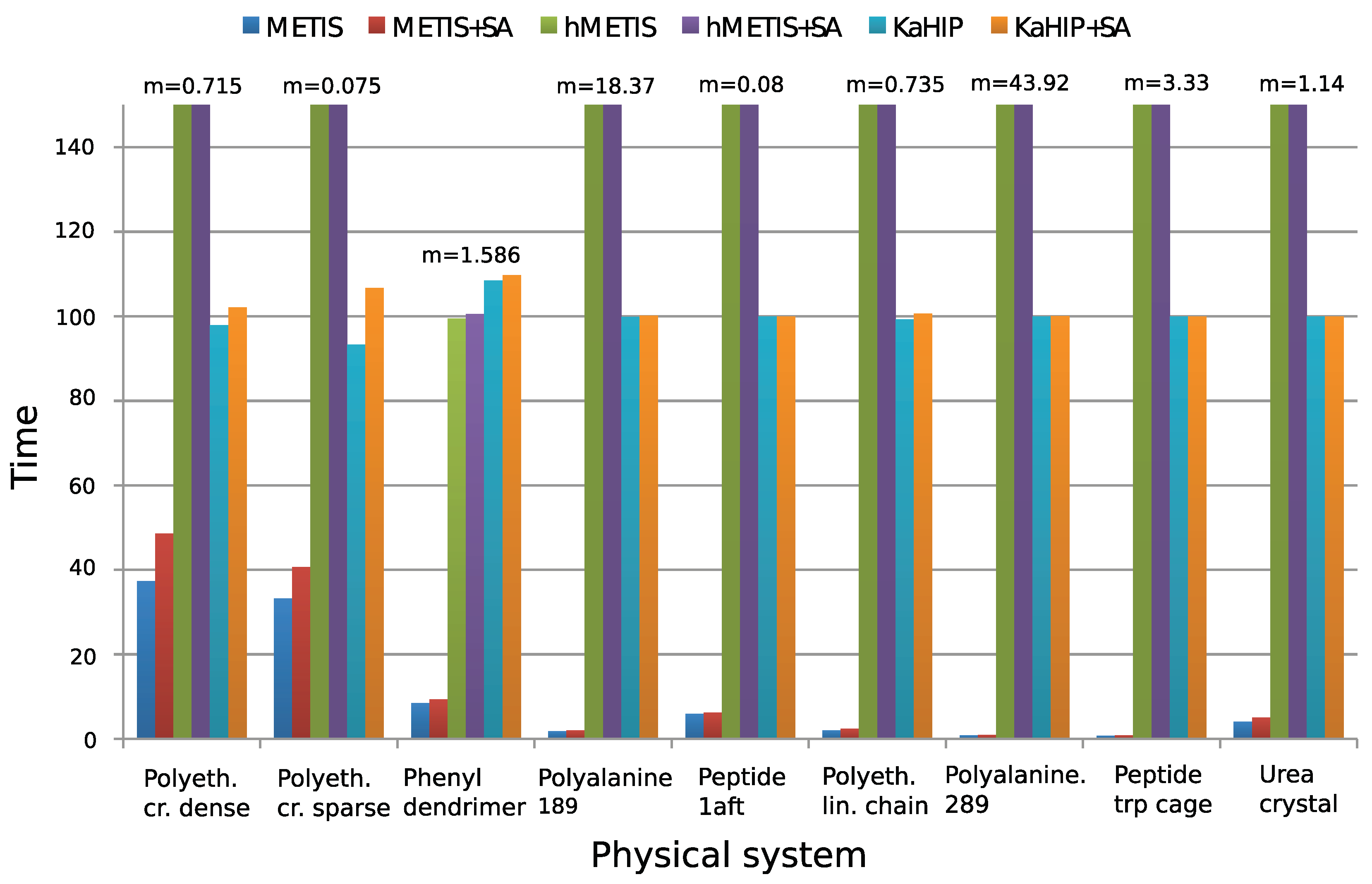
Figure 4 and Figure 5 show experimental results. We observe that all algorithms perform well (except for the first two systems), and that METIS and KaHIP are significantly faster than hMETIS. Importantly, post-processing with SA seems to improve solutions in almost all cases at negligible additional runtime, and is thus recommended.
Surprisingly, CH-partitions seem to pose a challenge for hMETIS as its solutions are usually worse than those of the other two methods, and its runtime significantly exceeds the one of the other methods (an explanation of this remains for further research). We conclude that for these two reasons, hMETIS seems unsuited for QMD simulations over longer time intervals, which is the aim of this work.
Although solutions returned by KaHIP are of very good quality (measured with the sum of cubes criterion), the combination of METIS and SA still outperforms KaHIP while also having a shorter combined runtime.
The behavior of our algorithms seems to be dependent on the sparsity of the graph of a physical system. First, METIS can outperform hMETIS for denser graphs, but not for sparser ones. Second, the post-improvement of partitions with SA seems to be especially effective for dense graphs, which can be explained with the fact that dense graphs offer more possibilities to reassign and optimize edges than sparse graphs. This can be seen when applying the combination of METIS+SA to the dense dendrimer system, see ([12], Table 2) for details.
Figure 6 visualizes the relationship between the graph structure of a molecule (for the phenyl dendrimer molecule of Table 1) and its graph partitioning obtained through METIS and SA. After partitioning the molecular graph structure, the fractal-like structure of the phenyl dendrimer molecule and its dense components become clearly visible, as well as its sparse connections to other dense components. This structure is what our algorithm exploits to reduce the computations of the density matrix. Interestingly, SA sometimes dissolves entire blocks (meaning it produces blocks with no vertices), since such imbalanced partitionings still yield a further decrease of the objective function (3).
4.4. Parallelized Implementation of G-SP2
We also assess the quality of the CH-partitions by measuring the speed-up when parallelizing the G-SP2 algorithm and applying it to real physical systems. To do this, the implementation of the G-SP2 algorithm of [9] was modified to incorporate the graph partitioning step.
In particular, to measure the speed-up, we run METIS and METIS+SA on the polyalanine 259 protein system of Table 1 and record the obtained CH-partitions. Computations were carried out with the Wolf IC cluster of Los Alamos National Laboratory, whose computing nodes have 2 sockets each containing an 8-core Intel Xeon SandyBridge E5-2670, amounting to a total of 16 cores per computing node. A total of 32 GB of RAM is shared between the 16 cores on each node, which are connected using a Qlogic Infiniband (IB) Quad Data Rate (QDR) network in a fat tree topology using a 7300 Series switch. Parallelization across nodes was done with OpenMPI (version 1.8.5), and parallelization across cores within a node was done with OpenMP 4.
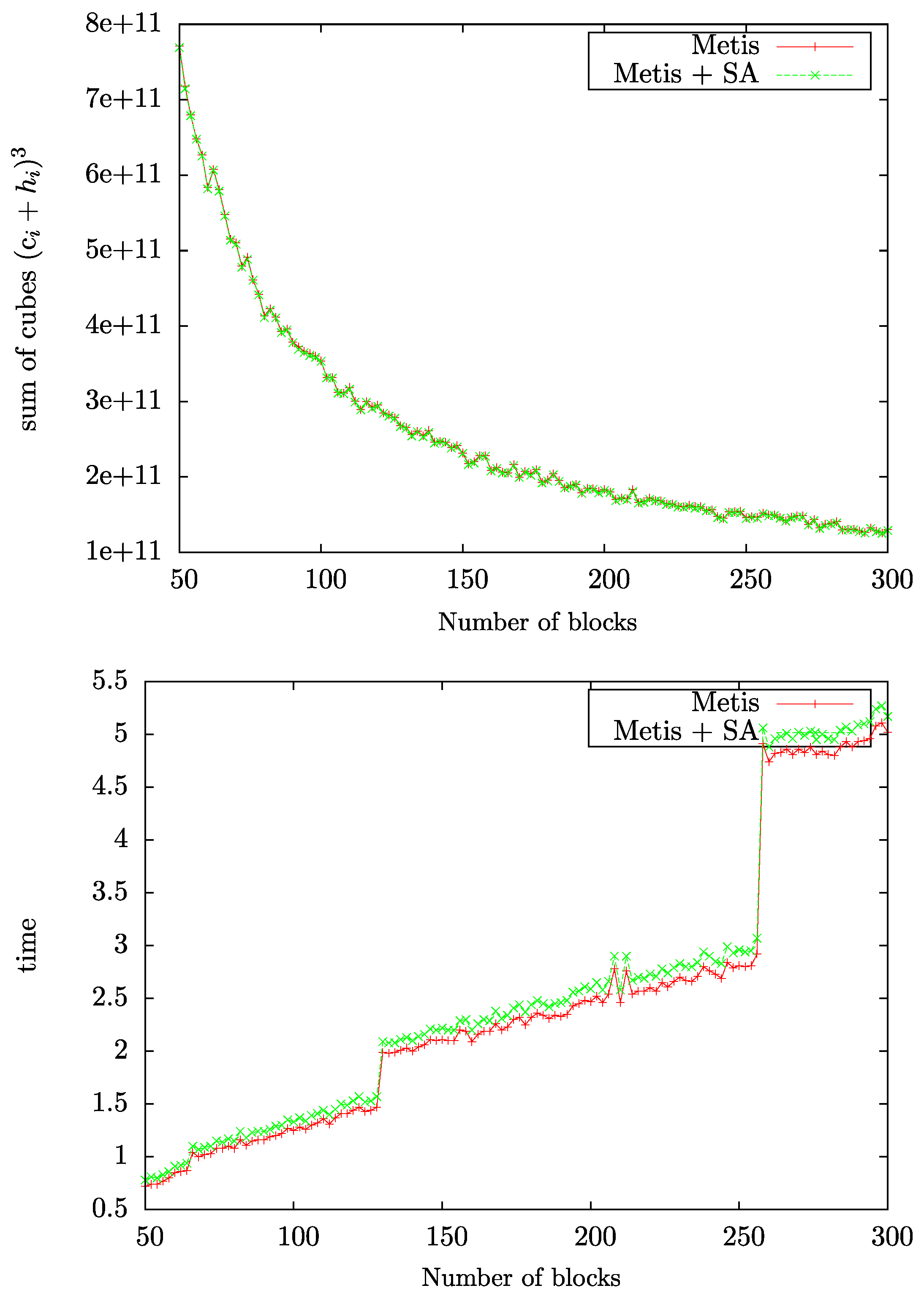
The sum of cubes measure and the computing time are displayed in Figure 7 as a function of the number of CH-partitions for the polyalanine 259 protein system. We observe in Figure 7 (top) that the total effort of G-SP2, measured with the sum of cubes criterion, decreases monotonically as a function of the number of blocks and parallelized subproblems.
Figure 7 (bottom) displays the computing time for the graph partitioning step alone. We observe that the partitioning effort increases with the number of blocks. The steps occurring at 65, 129, 257 etc. partitions in the plot can easily be explained: Every time the number of blocks surpasses a power of two, the multilevel algorithm which METIS is based on bisects the partitioning problem into one more (recursive) layer. Figure 7 (bottom) also displays that employing the SA post-processing step only adds a minimal additional effort to the overall computation (when compared to the graph partitioning step alone). The usage of SA thus seems very sensible in light of the improvements it achieves when applied to the edge cut optimized partitions computed by a conventional algorithm. To summarize, Figure 7 demonstrates that the total effort of the G-SP2 algorithm decreases when applied in parallel despite the increasing effort to compute a partitioning.
4.5. Single-Node SM-SP2 versus Parallelized Implementation of G-SP2
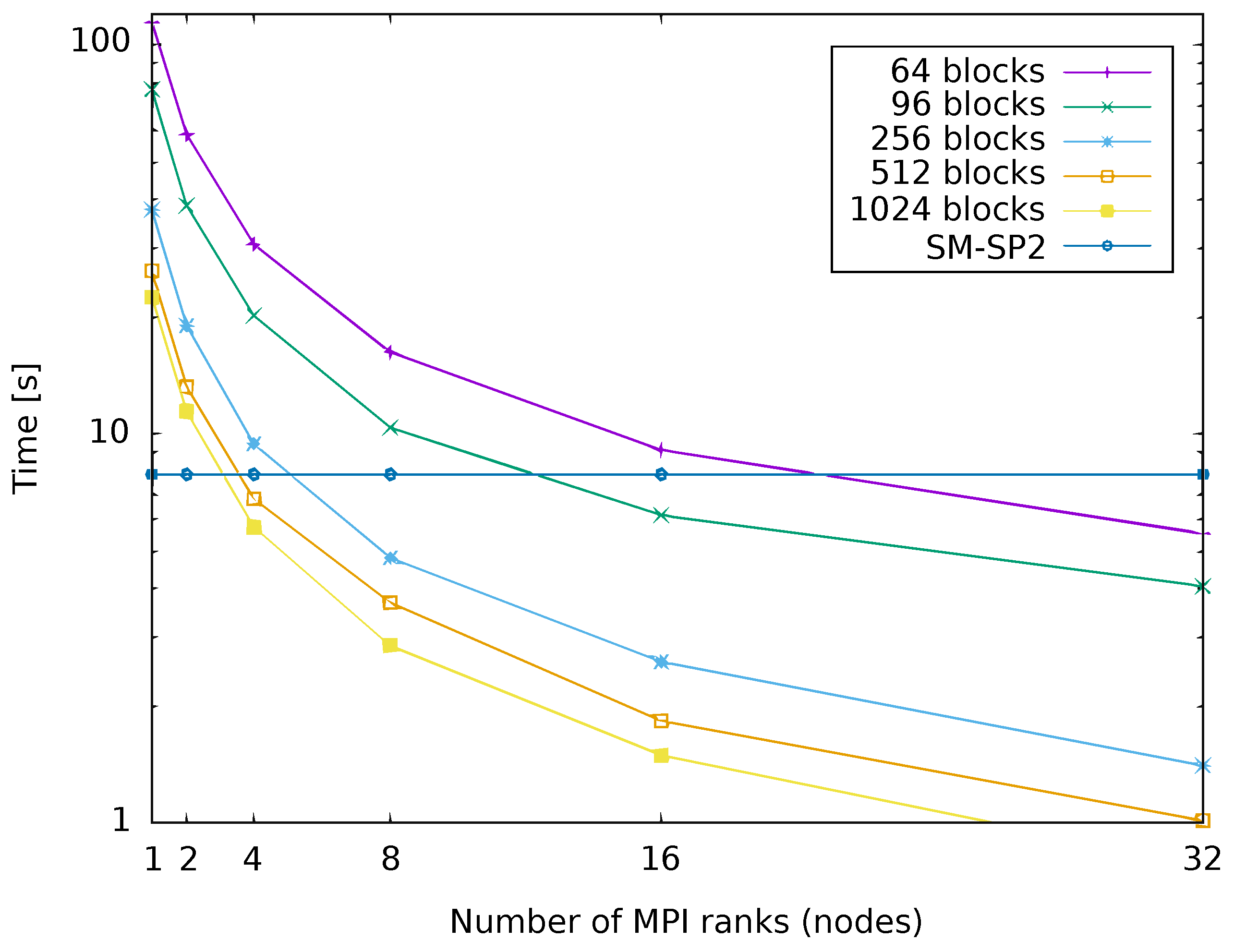
Figure 8 aims to quantify the computational savings over single-node G-SP2 when running our proposed parallel SP2 algorithm. For this, Figure 8 compares the runtime for our parallel G-SP2 on 1-32 nodes against a threaded single-node implementation of SM-SP2. We use G-SP2 here since the communication overhead exceeds the gain obtained by the extra computing power in a multi-node implementation, the main motivation for developing G-SP2 in the first place. As before, we employed METIS with parameters specified in Section 4.1 together with SA for post-processing. The test system is again the polyalanine 259 molecule.
Figure 8 shows that as expected, both an increasing number of nodes and an increasing number of blocks decreases the G-SP2 runtime. When only a few nodes are used for parallelization, the decrease in runtime is most pronounced since then, increasing the number of parallel nodes causes the runtime to drop sharply. For a higher number of nodes the curves somewhat flatten out.
Due to the overhead from the parallel G-SP2 computation, the parallelized run of SP2 is actually slower than the SM-SP2 computation on a single node for low numbers of nodes (between 4 and 16 nodes depending on the number of blocks). The runtime decreases with an increase in the number of nodes. Eventually, the effort falls below the one of a single node implementation. For the particular physical system of the polyalanine 259 molecule, a computational speed-up is only observed for at least 4 nodes.
4.6. Relationship between Molecular System and Partitions
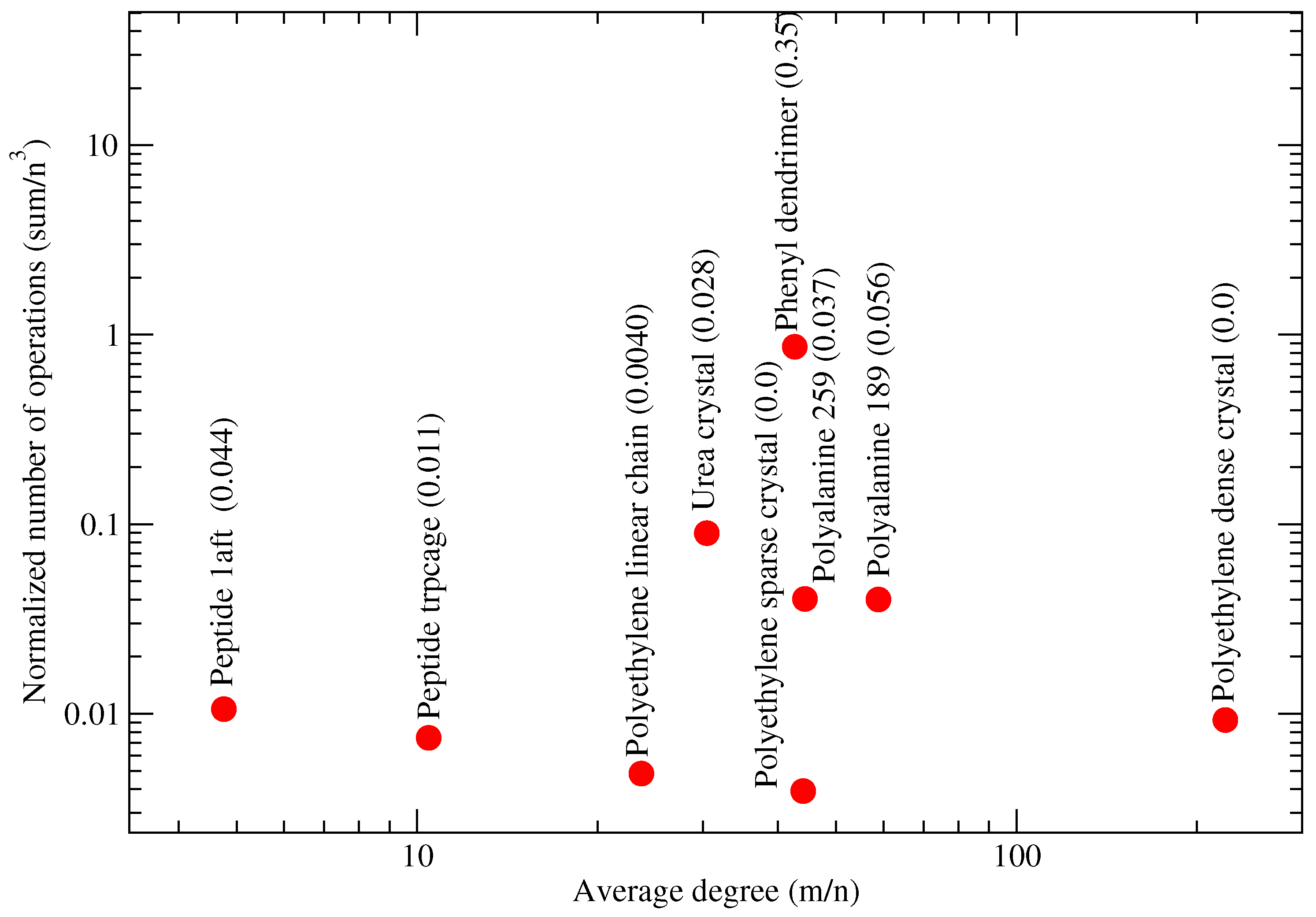
Figure 9 does not seem to exhibit a correlation between the molecular connectivity (measured with the average graph degree) and the normalized number of operations (NNO), defined as the sum of cubes criterion (3) normalized by the complexity of the dense matrix-matrix multiplication. The observation also applies to the polyethylene dense crystal, whose normalized number of operations remains low although its average degree is high. Similar observations can be made for other molecules with a smaller average degree.
Our G-SP2 algorithm with METIS being used in the graph partitioning step is capable of finding the lowest NNO for 1-dimensional systems such as the polyethylene linear chain and the polyethylene sparse crystal (compare the MMPN values in the brackets in Figure 9 to the measured normalized number of operations on the y-axis). According to [22], regular agglomerates of polyethylene chains align along a particular direction with a large chain-to-chain distance.
We do not observe any advantage of our approach (measured via NNO) for regular systems (polyethylene linear chain, polyethylene sparse crystal, polyethylene dense crystal, and urea crystal).
A difficult case for our graph partitioning task is the phenyl dendrimer (expressed through its high NNO values). This is due to the fractal-like structure of the graph associated with the molecule.
Another class with a large NNO is proteins (solvated polyalanines). We conjecture that the large average node degree (in comparison to peptides, i.e., small proteins) is responsible for the large NNO measurements. Based on Figure 9, we further conjecture that the difference of maximum and minimum partition norms (MMPN) is correlated with the NNO. Here, the number of vertices is denoted as n, and the maximal and minimal sizes of the obtained blocks are denoted as max and min, respectively. The conjectured correlation is clearly visible in Figure 9: the dendrimer tends to both large MMPN and NNO values, proteins exhibit intermediate values of both MMPN and NNO and finally, we observe low values of both MMPN and NNO for sparse ordered systems such as polyethyene chains.
5. Discussion
This paper speeds up the computation of the density matrix in MD simulations through parallelization, informed by graph partitioning applied to the structure graph underlying a molecule. Our experimental results are based on graphs derived from density matrices of physical systems.
In our article we focus on a certain flavor of the classical graph partitioning problem arising from molecular dynamics simulations. In contrast to classical edge cut partitioning, we minimize blocks with respect to both the number of their core vertices and the number of their neighbors in adjacent blocks (halos). To the best of our knowledge, this type of graph partitioning (which we coin CH-(core-halo)-partitioning) has not been studied previously.
This work makes two contributions. First, the CH-partitioning problem under consideration is mathematically described and justified. We prove that the partitioned evaluation of a matrix polynomial is equivalent to the evaluation of the original (unpartitioned) matrix given a sufficient condition is satisfied. Second, we evaluate several approaches for computing CH-partitions using three performance measures: the total computational effort, the maximal effort per processor, and the overall computational runtime. Special focus is given to the post-processing of partitions obtained with conventional graph partitioning algorithms for which we use our own modified SA approach.
We find that our flavor of the partitioning problem can be solved using standard graph partitioning packages. Moreover, post-optimization of the partitions obtained through classical graph partitioning packages can be performed well with our SA scheme. As expected, the time to evaluate matrix polynomials for different system (graph) sizes decreases with both the number of processors and blocks in our simulations. Our main result is that the increased effort for graph partitioning and post-optimization with SA is beneficial overall when applying our parallelized version of the G-SP2 algorithm to meaningful physical systems. Based on our observation that METIS with a SA post-processing step is significantly faster than competing methods while giving the best results on average, we recommend this combination for practical use. Of course, the research in this article can be always updated by including newer partitioning algorithms as time progresses, such as KaHyPar [23]. Additionally, a consideration of the statistical significance of our results could be of interest as future work.
Author Contributions
H.N.D. provided the mathematical theory on graph partitioning and all proofs. G.H. was responsible for writing the manuscript, as well as for conducting simulations. S.M.M. helped with all details related to the chemistry aspects of QMD in the paper, as well as with proof reading the manuscript. C.F.A.N. conducted some of the simulations, helped with the details related to the chemistry aspects of the paper, as well as with the preparation of the manuscript. A.M.N.N. helped with details related to the chemistry aspects of the paper, with writing the introduction, and with proof reading the manuscript.
Funding
We acknowledge support from the Office of Basic Energy Sciences (LANL2014E8AN) and the Laboratory Directed Research and Development program of Los Alamos National Laboratory. This research used resources provided by the Los Alamos National Laboratory Institutional Computing Program, which is supported by the U.S. Department of Energy National Nuclear Security Administration. This research has been supported at Los Alamos National Laboratory under the Department of Energy contract DE-AC52-06NA25396.
Acknowledgments
The authors would like to thank Vivek B. Sardeshmukh for his help with various aspects related to graph partitioning, Purnima Ghale and Matthew Kroonblawd for their help with selecting meaningful physical datasets of real-world molecules, and Ben Bergen, Nick Bock, Marc Cawkwell, Christoph Junghans, Robert Pavel, Sergio Pino, Jerry Shi, and Ping Yang for their feedback. This work was supported by the U.S. Department of Energy through Los Alamos National Laboratory. Los Alamos National Laboratory is operated by Triad National Security, LLC, for the National Nuclear Security Administration of the U.S. Department of Energy (Contract No. 89233218CNA000001) and by the Laboratory Directed Research and Development program of Los Alamos National Laboratory under project numbers 20140074DR and 20180267ER.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proofs for Section 2
For any graph I and vertex , the neighborhood of v in I is the set . Let , v be a vertex of G, and denote the subgraph of H induced by . For the following lemmas we assume that for all i, i.e., none of the edges in are thresholded. (With thresholding, the partitioned matrix algorithm is not exact, but approximate.) We have the following properties.
Lemma A1.
Let v be a vertex of G. Then .
Proof.
First we prove that . Let . Then and hence . Since by assumption , for all i. From , the last relation, and the fact that all vertices of H have loops, . Hence, .
Now we prove that . Let . Since and have the same vertex sets, we have . Furthermore, since is a subgraph of H, . □
The lemma shows that v has the same neighbors in and , i.e., their corresponding matrices have nonzero entries in the same positions in the row (or column) corresponding to v. We will next strengthen that claim by showing that the corresponding nonzero entries contain equal values.
Let be the submatrix of A defined by all rows and columns that correspond to vertices of . We will call vertex v the core and the remaining vertices the halo of . We define the set to be the CH-partition of G. Please note that unlike other definitions of a partition used elsewhere, the vertex sets of CH-partitions (and, specifically, the halos) can be, and typically are, overlapping.
Lemma A2.
For any and any , the element of corresponding to the edge of is equal to the element of corresponding to the edge of .
Proof.
Let be the degree of P. We will prove the lemma by induction on s. Clearly, the claim is true for since the elements of both and are original elements of the matrix A. Assume the claim is true for . Define . By the inductive assumption, the corresponding elements in the matrices and have equal values. We need to prove the same for the elements of and .
Let . By Lemma A1, . For each vertex u of let denote the corresponding row/column of X. We want to show that .
By definition of matrix product, , where the summation is over all u such that . Similarly, , where the summation is over the values of corresponding to the values of u from the previous formula, by Lemma A1. By the inductive assumption, and , thus . Since by assumption , we have , and hence . □
Clearly, in many cases it will be advantageous to consider CH-partitions whose cores contain multiple vertices. We will next show that the above approach for CH-partitions with single-node cores can be generalized to the multi-node core case.
We will generalize the definitions of and for the case where the vertex v is replaced by a set U of vertices of G. For any graph I, we define . Furthermore, we define by the subgraph of H induced by .
Suppose the sets are such that and . In this case, we can define a CH-partition of consisting of q sets, where for each i, is the core and is the halo of .
The following generalizations of Lemmas A1 and A2 follow in a straightforward manner.
Lemma A3.
Denote by the subgraph of G. Let v be a vertex of . Then .
Denote by the submatrix of A consisting of all rows and columns that correspond to vertices of . The following main result of this section shows that can be computed on submatrices of the Hamiltonian: this insight justifies the parallelized evaluation of a matrix polynomial.
Lemma A4.
For any and any , the element of corresponding to the edge of is equal to the element of corresponding to the edge of .
In case of a QMD simulation, as outlined in Section 2, we assume that the sparsity structure of can be approximated by the one of the density matrix D from the previous QMD simulation step. For the halos we approximate with as before, and use the current H as a substitute for the halos. This leads to the generalization of the algorithm for computing in case of multi-vertex cores given at the end of Section 2.
Appendix B. Further Details on Experimental Results
Raw data for the experiments described in Section 4.3 can be found in Table A1. The six partitioning schemes we use are listed in column “methods”. The performance of those methods is measured in four different ways: As a measure of the total matrix multiplication cost of a step of the SP2 algorithm, we report the sum of cubes criterion (3) in column 3 (“sum”). The sum of cubes criterion is also a measure of the computational effort of SP2 since matrix multiplications consume most of the computation time in SP2. As a measure of the variability of block sizes created by our algorithm, we report the smallest and largest block size of any CH-partition (columns 4 (“min”) and 5 (“max”)). In the best-case scenario, the sizes of all blocks should be roughly equal since otherwise, the nodes or processors will have very unequal computational loads in our parallel implementation of the SP2 algorithm. This is undesirable in practice. The average computation time (in seconds) for each partitioning algorithm is shown in the last column (“time”). As pointed out by a referee, it would be interesting to investigate closer how the discrepancy of the block sizes from the mean influences the performance of SP2: this is left as future research.

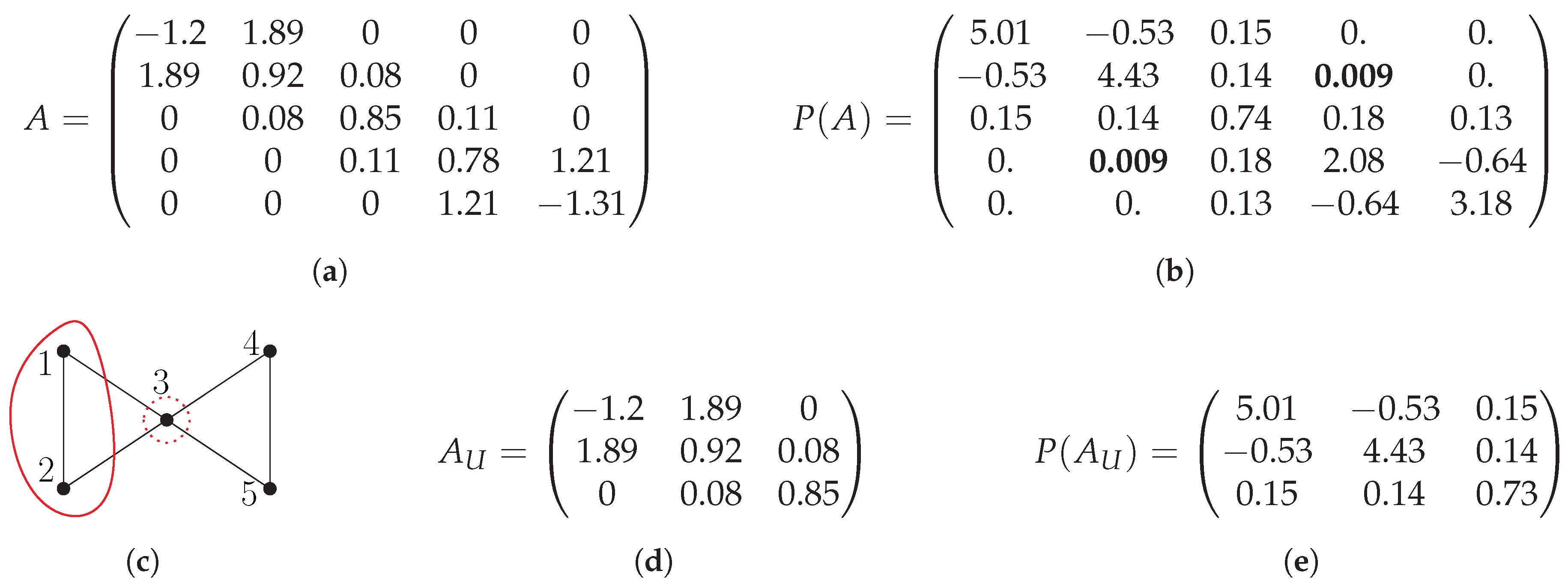{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table A1.
Various test systems (first column) evaluated by different partition schemes (second column; number of vertices n, edges m, and blocks p are given). Results measured with the sum of cubes (3) criterion (sum), the sum of size and halo for the smallest CH-partition (min) as well as the biggest CH-partition (max), and the overall runtime (in seconds) are given in columns 3–6.
Table A1.
Various test systems (first column) evaluated by different partition schemes (second column; number of vertices n, edges m, and blocks p are given). Results measured with the sum of cubes (3) criterion (sum), the sum of size and halo for the smallest CH-partition (min) as well as the biggest CH-partition (max), and the overall runtime (in seconds) are given in columns 3–6.
| Test System | Method | Sum | Min | Max | Time [s] |
|---|---|---|---|---|---|
| polyethylene dense crystal | METIS | 57,982,058,496 | 1536 | 1536 | 0.267175 |
| n = 18,432 | METIS + SA | 51,856,752,364 | 976 | 1536 | 0.347209 |
| m = 4,112,189 | HMETIS | 7,126,357,377,024 | 3840 | 9984 | 141.426 |
| p = 16 | HMETIS + SA | 1,362,943,612,944 | 2520 | 5814 | 141.79 |
| KaHIP | 32,614,907,904 | 768 | 1536 | 0.7 | |
| KaHIP + SA | 32,614,907,904 | 768 | 1536 | 0.73 | |
| polyethylene sparse crystal | METIS | 24,461,180,928 | 1152 | 1152 | 0.024942 |
| n = 18,432 | METIS + SA | 24,461,180,928 | 1152 | 1152 | 0.030508 |
| m = 812,343 | HMETIS | 195,689,447,424 | 2304 | 2304 | 55.9726 |
| p = 16 | HMETIS + SA | 170,056,587,295 | 2013 | 2299 | 55.9943 |
| KaHIP | 24,461,180,928 | 1152 | 1152 | 0.07 | |
| KaHIP + SA | 24,461,180,928 | 1152 | 1152 | 0.08 | |
| phenyl dendrimer | METIS | 336,049,081 | 150 | 409 | 0.13482 |
| n = 730 | METIS + SA | 146,550,740 | 0 | 382 | 0.14877 |
| m = 31,147 | HMETIS | 177,436,462 | 135 | 358 | 1.578 |
| p = 16 | HMETIS + SA | 118,409,940 | 0 | 358 | 1.59436 |
| KaHIP | 231,550,645 | 55 | 381 | 1.72 | |
| KaHIP + SA | 116,248,715 | 0 | 324 | 1.74 | |
| polyethylene dense crystal | METIS | 57,982,058,496 | 1536 | 1536 | 0.267175 |
| n = 18,432 | METIS + SA | 51,856,752,364 | 976 | 1536 | 0.347209 |
| m = 4,112,189 | HMETIS | 7,126,357,377,024 | 3840 | 9984 | 141.426 |
| p = 16 | HMETIS + SA | 1,362,943,612,944 | 2520 | 5814 | 141.79 |
| KaHIP | 32,614,907,904 | 768 | 1536 | 0.7 | |
| KaHIP + SA | 32,614,907,904 | 768 | 1536 | 0.73 | |
| peptide 1aft | METIS | 603,251 | 24 | 41 | 0.004755 |
| n = 384 | METIS + SA | 572,281 | 24 | 41 | 0.005007 |
| m = 1833 | HMETIS | 562,601 | 24 | 40 | 0.820561 |
| p = 16 | HMETIS + SA | 538,345 | 24 | 42 | 0.820771 |
| KaHIP | 575,978 | 11 | 44 | 0.08 | |
| KaHIP + SA | 575,978 | 11 | 44 | 0.08 | |
| polyethylene chain 1024 | METIS | 8,961,763,376 | 800 | 848 | 0.01513 |
| n = 12,288 | METIS + SA | 8,961,763,376 | 800 | 848 | 0.017951 |
| m = 290,816 | HMETIS | 8,951,619,584 | 824 | 824 | 27.3297 |
| p = 16 | HMETIS + SA | 8,951,619,584 | 824 | 824 | 27.3332 |
| KaHIP | 9,037,266,968 | 782 | 875 | 0.73 | |
| KaHIP + SA | 9,000,224,048 | 782 | 872 | 0.74 | |
| polyalanine 289 | METIS | 2,816,765,783,803 | 4591 | 6102 | 0.366308 |
| n = 41,185 | METIS + SA | 2,816,141,689,603 | 4591 | 6093 | 0.399265 |
| m = 1,827,256 | HMETIS | 3,694,884,690,563 | 5733 | 6828 | 710.084 |
| p = 16 | HMETIS + SA | 3,681,874,557,307 | 5733 | 6830 | 710.128 |
| KaHIP | 4,347,865,055,912 | 52 | 8955 | 43.9 | |
| KaHIP + SA | 4,309,969,305,955 | 52 | 8907 | 43.94 | |
| peptide trp cage | METIS | 35,742,302,607 | 1228 | 1414 | 0.025795 |
| n = 16,863 | METIS + SA | 35,740,265,780 | 1228 | 1414 | 0.029837 |
| m = 176,300 | HMETIS | 35,428,817,730 | 1214 | 1472 | 31.0506 |
| p = 16 | HMETIS + SA | 35,237,003,004 | 1214 | 1472 | 31.0545 |
| KaHIP | 43,551,196,287 | 515 | 1898 | 2.81 | |
| KaHIP + SA | 43,388,946,192 | 536 | 1896 | 2.81 | |
| urea crystal | METIS | 4,126,744,977 | 608 | 708 | 0.047032 |
| n = 3584 | METIS + SA | 4,126,744,977 | 608 | 708 | 0.057645 |
| m = 109,067 | HMETIS | 5,913,680,136 | 643 | 811 | 15.2321 |
| p = 16 | HMETIS + SA | 5,194,749,106 | 604 | 785 | 15.2443 |
| KaHIP | 3,907,671,473 | 622 | 630 | 1.05 | |
| KaHIP + SA | 3,907,671,473 | 622 | 630 | 1.05 |
References
- Elstner, M.; Porezag, D.; Jungnickel, G.; Elsner, J.; Haugk, M.; Frauenheim, T.; Suhai, S.; Seifert, G. Self-consistent-charge density-functional tight-binding method for simulations of complex materials properties. Phys. Rev. B 1998, 58, 7260–7268. [Google Scholar] [CrossRef]
- Finnis, M.W.; Paxton, A.T.; Methfessel, M.; van Schilfgarde, M. Crystal structures of zirconia from first principles and self-consistent tight binding. Phys. Rev. Lett. 1998, 81, 5149. [Google Scholar] [CrossRef]
- Frauenheim, T.; Seifert, G.; Elsterner, M.; Hajnal, Z.; Jungnickel, G.; Poresag, D.; Suhai, S.; Scholz, R. A self-consistent charge density-functional based tight-binding method for predictive materials simulations in physics, chemistry and biology. Phys. Stat. Sol. 2000, 217, 41–62. [Google Scholar] [CrossRef]
- Niklasson, A.M. Expansion algorithm for the density matrix. Phys. Rev. B 2002, 66, 155115–155121. [Google Scholar] [CrossRef]
- Mniszewski, S.M.; Cawkwell, M.J.; Wall, M.; Moyd-Yusof, J.; Bock, N.; Germann, T.; Niklasson, A.M. Efficient parallel linear scaling construction of the density matrix for Born-Oppenheimer molecular dynamics. J. Chem. Theory Comput. 2015, 11, 4644–4654. [Google Scholar] [CrossRef] [PubMed]
- Bock, N.; Challacombe, M. An Optimized Sparse Approximate Matrix Multiply for Matrices with Decay. SIAM J. Sci. Comput. 2013, 35, C72–C98. [Google Scholar] [CrossRef] [Green Version]
- Borstnik, U.; VandeVondele, J.; Weber, V.; Hutter, J. Sparse matrix multiplication: The distributed block-compressed sparse row library. Parallel Comput. 2014, 40, 47–58. [Google Scholar] [CrossRef] [Green Version]
- VandeVondele, J.; Borštnik, U.; Hutter, J. Linear Scaling Self-Consistent Field Calculations with Millions of Atoms in the Condensed Phase. J. Chem. Theory Comput. 2012, 8, 3565–3573. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Niklasson, A.M.; Mniszewski, S.M.; Negre, C.F.; Cawkwell, M.J.; Swart, P.J.; Mohd-Yusof, J.; Germann, T.C.; Wall, M.E.; Bock, N.; Rubensson, E.H.; et al. Graph-based linear scaling electronic structure theory. J. Chem. Phys. 2016, 144, 234101. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pınar, A.; Hendrickson, B. Partitioning for Complex Objectives. In Proceedings of the 15th International Parallel and Distributed Processing Symposium (CDROM), San Francisco, CA, USA, 23–27 April 2001; IEEE Computer Society: Washington, DC, USA, 2001; pp. 1–6. [Google Scholar]
- Von Looz, M.; Wolter, M.; Jacob, C.R.; Meyerhenke, H. Better partitions of protein graphs for subsystem quantum chemistry. arXiv 2016, arXiv:1606.03427, 1–20. [Google Scholar]
- Djidjev, H.N.; Hahn, G.; Mniszewski, S.M.; Negre, C.F.; Niklasson, A.M.; Sardeshmukh, V. Graph Partitioning Methods for Fast Parallel Quantum Molecular Dynamics (full text with appendix). In Proceedings of the SIAM Workshop on Combinatorial Scientific Computing (CSC16), Albuquerque, NM, USA, 10–12 October 2016; pp. 1–17. [Google Scholar]
- Bader, D.A.; Meyerhenke, H.; Sanders, P.; Wagner, D. (Eds.) Graph Partitioning and Graph Clustering—10th DIMACS Implementation Challenge Workshop. Contemp. Math. 2013, 588. [Google Scholar] [CrossRef]
- Karypis, G.; Kumar, V. A Fast and High Quality Multilevel Scheme for Partitioning Irregular Graphs. SIAM J. Sci. Comput. 1999, 20, 359–392. [Google Scholar] [CrossRef]
- Fiduccia, C.; Mattheyses, R. A linear time heuristic for improving network partitions. In Proceedings of the 19th IEEE Design Automation Conference, Las Vegas, NV, USA, 14–16 June 1982; pp. 175–181. [Google Scholar]
- Sanders, P.; Schulz, C. Think Locally, Act Globally: Highly Balanced Graph Partitioning. In Proceedings of the International Symposium on Experimental Algorithms (SEA), Rome, Italy, 5–7 June 2013; Springer: Berlin/Heidelberg, Germany, 2013; Volume 7933, pp. 164–175. [Google Scholar]
- Sanders, P.; Schulz, C. Engineering multilevel graph partitioning algorithms. LNCS 2011, 6942, 469–480. [Google Scholar] [CrossRef]
- Ford, L., Jr.; Fulkerson, D. Maximal flow through a network. Canad. J. Math. 1956, 8, 399–404. [Google Scholar] [CrossRef]
- Karypis, G.; Kumar, V. Multilevel k-way Hypergraph Partitioning. VLSI Des. 2000, 11, 285–300. [Google Scholar] [CrossRef]
- Kirkpatrick, S.; Gelatt, C., Jr.; Vecchi, M. Optimization by Simulated Annealing. Science 1983, 200, 671–680. [Google Scholar] [CrossRef] [PubMed]
- Karypis, G.; Kumar, V. A Hypergraph Partitioning Package. Available online: http://glaros.dtc.umn.edu/gkhome/fetch/sw/hmetis/manual.pdf (accessed on 7 September 2019).
- Bunn, C. The crystal structure of long-chain normal paraffin hydrocarbons. The “shape” of the CH2 group. Trans. Faraday Soc. 1939, 35, 482–491. [Google Scholar] [CrossRef]
- Schlag, S.; Henne, V.; Heuer, T.; Meyerhenke, H.; Sanders, P.; Schulz, C. k-way Hypergraph Partitioning via n-Level Recursive Bisection. arXiv 2015, arXiv:1511.03137, 1–21. [Google Scholar]
Figure 1.
Example of using CH-partitioning for distributed evaluation of matrix polynomial , with a thresholding operator that removes all edges/matrix entries with values below . (a) Input symmetric matrix A. (b) . (c) After the thresholding operator removes elements and (in bold) from , the sparsity graph of the resulting matrix is shown. We are considering a block of a CH-partitioning with core set (encircled with a solid line) and halo the set (encircled with a dashed line). (d) Submatrix consisting of the first three (by ) rows and columns of A. (e) Matrix . According to Lemma 1, the elements of the first two (by ) columns/rows of are equal to the corresponding nonzero elements of the first two columns/rows of thresholded .
Figure 1.
Example of using CH-partitioning for distributed evaluation of matrix polynomial , with a thresholding operator that removes all edges/matrix entries with values below . (a) Input symmetric matrix A. (b) . (c) After the thresholding operator removes elements and (in bold) from , the sparsity graph of the resulting matrix is shown. We are considering a block of a CH-partitioning with core set (encircled with a solid line) and halo the set (encircled with a dashed line). (d) Submatrix consisting of the first three (by ) rows and columns of A. (e) Matrix . According to Lemma 1, the elements of the first two (by ) columns/rows of are equal to the corresponding nonzero elements of the first two columns/rows of thresholded .

Figure 2.
Molecular representation of phenyl dendrimer (left) using cyan and white spheres for carbon and hydrogen atoms, respectively. Hamiltonian matrix as 2D representation (middle) and thresholded density matrix (right). All plots show log of the absolute values of all matrix elements. The SM-SP2 algorithm was used to compute the density matrix. Figure taken from [12]. Copyright ©2016 Society for Industrial and Applied Mathematics. Reprinted with permission. All rights reserved.
Figure 2.
Molecular representation of phenyl dendrimer (left) using cyan and white spheres for carbon and hydrogen atoms, respectively. Hamiltonian matrix as 2D representation (middle) and thresholded density matrix (right). All plots show log of the absolute values of all matrix elements. The SM-SP2 algorithm was used to compute the density matrix. Figure taken from [12]. Copyright ©2016 Society for Industrial and Applied Mathematics. Reprinted with permission. All rights reserved.

Figure 3.
Molecular systems of this study: polyethyene linear chain (first plot), urea crystal (second plot), 189 residue polyalanine solvated in a water box (third plot), and phenyl dendrimer molecule (fourth plot). Cyan, blue, red, and white spheres represent carbon, nitrogen, oxygen, and hydrogen atoms, respectively. Figure taken from [12]. Copyright ©2016 Society for Industrial and Applied Mathematics. Reprinted with permission. All rights reserved.
Figure 3.
Molecular systems of this study: polyethyene linear chain (first plot), urea crystal (second plot), 189 residue polyalanine solvated in a water box (third plot), and phenyl dendrimer molecule (fourth plot). Cyan, blue, red, and white spheres represent carbon, nitrogen, oxygen, and hydrogen atoms, respectively. Figure taken from [12]. Copyright ©2016 Society for Industrial and Applied Mathematics. Reprinted with permission. All rights reserved.

Figure 4.
Sum of cubes performance measure to evaluate partitions. Values are normalized to have a median of 100. To make the chart more informative, very large values are truncated, though all exact values can be found in ([12], Table 2). Figure taken from [12]. Copyright ©2016 Society for Industrial and Applied Mathematics. Reprinted with permission. All rights reserved.
Figure 4.
Sum of cubes performance measure to evaluate partitions. Values are normalized to have a median of 100. To make the chart more informative, very large values are truncated, though all exact values can be found in ([12], Table 2). Figure taken from [12]. Copyright ©2016 Society for Industrial and Applied Mathematics. Reprinted with permission. All rights reserved.

Figure 5.
Computing time for partitioning. Test systems of Table 1. We use the formatting of Figure 4 to handle the big discrepancy between values for different graphs. Figure taken from [12]. Copyright ©2016 Society for Industrial and Applied Mathematics. Reprinted with permission. All rights reserved.
Figure 5.
Computing time for partitioning. Test systems of Table 1. We use the formatting of Figure 4 to handle the big discrepancy between values for different graphs. Figure taken from [12]. Copyright ©2016 Society for Industrial and Applied Mathematics. Reprinted with permission. All rights reserved.

Figure 6.
(Left): Original graph extracted from the density matrix for the phenyl dendrimer molecular structure. Note the fractal-like structure of the graph. (Right): Rearranged graph by the partitions resulting from the METIS + SA algorithms. Only edges with weights larger than 0.01 were kept to ease visualization.
Figure 6.
(Left): Original graph extracted from the density matrix for the phenyl dendrimer molecular structure. Note the fractal-like structure of the graph. (Right): Rearranged graph by the partitions resulting from the METIS + SA algorithms. Only edges with weights larger than 0.01 were kept to ease visualization.

Figure 7.
Sum of cubes measure (top) and runtime to find the partitions (bottom) as a function of the number of blocks. Figure taken from [12]. Copyright ©2016 Society for Industrial and Applied Mathematics. Reprinted with permission. All rights reserved.
Figure 7.
Sum of cubes measure (top) and runtime to find the partitions (bottom) as a function of the number of blocks. Figure taken from [12]. Copyright ©2016 Society for Industrial and Applied Mathematics. Reprinted with permission. All rights reserved.

Figure 8.
Runtime of parallelized G-SP2 as a function of the number of nodes. Different numbers of blocks. G-SP2 applied to the polyalanine 259 molecule. Figure taken from [12]. Copyright ©2016 Society for Industrial and Applied Mathematics. Reprinted with permission. All rights reserved.
Figure 8.
Runtime of parallelized G-SP2 as a function of the number of nodes. Different numbers of blocks. G-SP2 applied to the polyalanine 259 molecule. Figure taken from [12]. Copyright ©2016 Society for Industrial and Applied Mathematics. Reprinted with permission. All rights reserved.

Figure 9.
Sum of cubes criterion (3) normalized by the complexity of the dense matrix-matrix multiplication for G-SP2 with METIS. Number of vertices n, number of edges m, and average degree . Test systems of Table 1. Brackets show fractions of (MMPN). Figure taken from [12]. Copyright ©2016 Society for Industrial and Applied Mathematics. Reprinted with permission. All rights reserved.
Figure 9.
Sum of cubes criterion (3) normalized by the complexity of the dense matrix-matrix multiplication for G-SP2 with METIS. Number of vertices n, number of edges m, and average degree . Test systems of Table 1. Brackets show fractions of (MMPN). Figure taken from [12]. Copyright ©2016 Society for Industrial and Applied Mathematics. Reprinted with permission. All rights reserved.

Table 1.
Physical systems of our study: Number of vertices n in the graph and number of edges m. Table taken from [12]. Copyright ©2016 Society for Industrial and Applied Mathematics. Reprinted with permission. All rights reserved.
Table 1.
Physical systems of our study: Number of vertices n in the graph and number of edges m. Table taken from [12]. Copyright ©2016 Society for Industrial and Applied Mathematics. Reprinted with permission. All rights reserved.
| Name | n | m | Description | |
|---|---|---|---|---|
| polyethylene dense crystal | 18,432 | 4,112,189 | 223.1 | crystal molecule in water solvent (low threshold) |
| polyethylene sparse crystal | 18,432 | 812,343 | 44.1 | crystal molecule in water solvent (high threshold) |
| phenyl dendrimer | 730 | 31,147 | 42.7 | polyphenylene branched molecule |
| polyalanine 189 | 31,941 | 1,879,751 | 58.9 | polyalanine protein solvated in water |
| peptide 1aft | 385 | 1833 | 4.76 | ribonucleoside-diphosphate reductase protein |
| polyethylene chain 1024 | 12,288 | 290,816 | 23.7 | chain of polymer molecule, almost 1-dimensional |
| polyalanine 289 | 41,185 | 1,827,256 | 44.4 | large protein in water solvent |
| peptide trp cage | 16,863 | 176,300 | 10.5 | smallest protein with ability to fold (in water) |
| urea crystal | 3584 | 109,067 | 30.4 | organic compound in living organisms |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Djidjev, H.N.; Hahn, G.; Mniszewski, S.M.; Negre, C.F.A.; Niklasson, A.M.N. Using Graph Partitioning for Scalable Distributed Quantum Molecular Dynamics. Algorithms 2019, 12, 187. https://0-doi-org.brum.beds.ac.uk/10.3390/a12090187
AMA Style
Djidjev HN, Hahn G, Mniszewski SM, Negre CFA, Niklasson AMN. Using Graph Partitioning for Scalable Distributed Quantum Molecular Dynamics. Algorithms. 2019; 12(9):187. https://0-doi-org.brum.beds.ac.uk/10.3390/a12090187
Chicago/Turabian StyleDjidjev, Hristo N., Georg Hahn, Susan M. Mniszewski, Christian F. A. Negre, and Anders M. N. Niklasson. 2019. "Using Graph Partitioning for Scalable Distributed Quantum Molecular Dynamics" Algorithms 12, no. 9: 187. https://0-doi-org.brum.beds.ac.uk/10.3390/a12090187
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.