A Compendium of Parameterized Problems at Higher Levels of the Polynomial Hierarchy


1
Institute for Logic, Language and Computation (ILLC), University of Amsterdam, 1000–1183 Amsterdam, The Netherlands
2
Algorithms and Complexity Group, Institute for Logic and Computation, Faculty of Informatics, Technische Universität Wien, 1040 Vienna, Austria
*
Author to whom correspondence should be addressed.
Algorithms 2019, 12(9), 188; https://0-doi-org.brum.beds.ac.uk/10.3390/a12090188
Submission received: 19 July 2019
/
Revised: 30 August 2019
/
Accepted: 3 September 2019
/
Published: 9 September 2019
(This article belongs to the Special Issue New Frontiers in Parameterized Complexity and Algorithms)
{kind=link}
Abstract
:We present a list of parameterized problems together with a complexity classification of whether they allow a fixed-parameter tractable reduction to SAT or not. These problems are parameterized versions of problems whose complexity lies at the second level of the Polynomial Hierarchy or higher.
1. Introduction
The remarkable performance of today’s SAT solvers (see, e.g., [1]) offers a practically successful strategy for solving NP-complete combinatorial search problems by reducing them in polynomial time to the propositional satisfiability problem—also known as SAT. In order to apply this strategy to problems that are harder than NP, one needs to employ reductions that are more powerful than polynomial-time reductions. A compelling option for this strategy is to use fixed-parameter tractable reductions (or fpt-reductions)—i.e., reductions that are computable in time for some computable function f and some constant c—as they can exploit some structural aspects of the problem instances in terms of a problem parameter k.
To illustrate this approach, let us consider as an example the problem of deciding the truth of quantified Boolean formulas (QBFs) of the form , where is a DNF formula over the variables in . (We define and consider this example problem—as well as the parameterized variants of this problem that we consider in this section—in more detail in Section 3.3.) This problem is -complete [2,3], so there is no polynomial-time reduction from this problem to SAT, unless the Polynomial Hierarchy collapses. In other words, the strategy of first reducing the problem to SAT, and then using a SAT solver to solve the problem seems not viable.
Another strategy would be to consider the problem from a parameterized point of view—i.e., investigating in which cases structural properties of the input allow the problem to be solved efficiently (in fpt-time). For example, if the incidence treewidth of the DNF formula is bounded, we can solve the problem in fpt-time [4,5]. However, this is the case only in very restricted settings, and so this strategy is also only viable to a limited extent.
The approach of using fpt-reductions to SAT combines the merits of the above two strategies. It uses the remarkable performance of today’s SAT solvers, and it can exploit structural properties of the problem inputs. As a result, this approach has the potential of being useful in a much wider range of settings than either of the two separate strategies. It can work for problems that lie at higher levels of the Polynomial Hierarchy. Moreover, it can work for choices of problem parameters that are much less restrictive than those needed to get traditional fixed-parameter tractability results.
As a demonstration of this, let us consider two other parameterized variants of our example problem of deciding the truth of formulas of the form . In the first variant, the parameter is the treewidth of the incidence graph of where we delete all nodes corresponding to variables in X—in other words, the incidence graph of with respect to the universally quantified variables. This variant is para-NP-complete [6,7], which means that it allows an fpt-reduction to SAT. Thus, for this variant, we can exploit the problem parameter to efficiently reduce the problem to SAT, and subsequently use a SAT solver to solve the problem. In the second variant that we consider, the parameter is the treewidth of the incidence graph of where we delete all nodes corresponding to variables in Y—in other words, the incidence graph of with respect to the existentially quantified variables. This variant is para--complete [6,7], indicating that fpt-reductions to SAT are not possible (unless the Polynomial Hierarchy collapses).
For both of these variants of our example problem, both the approach of polynomial-time reducing the problem to SAT and the approach of finding (traditional) fixed-parameter tractable algorithms do not work. However, for only one of them, an fpt-reduction to SAT is possible (under common complexity-theoretic assumptions). This indicates that, to establish whether an fpt-reduction to SAT is possible, a suitable parameterized complexity analysis at higher levels of the Polynomial Hierarchy is needed. Various parameterized complexity classes have been developed for this purpose [7,8] that, together with previously studied classes, enable such analyses. This includes both classes that correspond to various types of fpt-reductions to SAT—e.g., para-NP, para-co-NP, and —and classes that indicate that no fpt-reductions to SAT are possible, under suitable complexity-theoretic assumptions—e.g., , , , , , , para-, para-, PH, and para-PSPACE. (We define all of these parameterized complexity classes in Section 2.2 and Section 2.3.)
Outline
In this compendium, we give a list of parameterized problems that are based on problems at higher levels of the Polynomial Hierarchy, together with a complexity classification indicating whether they allow a (many-to-one or Turing) fpt-reduction to SAT or not.
The compendium that we provide is similar in concept to the compendia by Schaefer and Umans [9] and Cesati [10] that also list problems along with their computational complexity. We group the list by the type of problems. A list of problems grouped by their complexity can be found at the end of this paper.
The remainder of the paper is structured as follows. In Section 2, we give an overview of the parameterized complexity classes involved in the classification of whether problems allow an fpt-reduction to SAT, as well as some other notions and definitions that are used throughout the paper. Then, in Section 3, Section 4, Section 5 and Section 6, we present (i) problems related to (quantified variants of) propositional logic, (ii) problems from the area of Knowledge Representation and Reasoning, (iii) graph problems, and (iv) other problems, respectively. Finally, we conclude in Section 7.
2. Preliminaries
2.1. Computational Complexity
We assume that the reader is familiar with basic notions from the theory of computational complexity, such as the complexity classes P and NP. For more details, we refer to textbooks on the topic (see, e.g., [11,12]).
There are many natural decision problems that are not contained in the classical complexity classes P and NP (under some common complexity-theoretic assumptions). The Polynomial Hierarchy [2,3,12,13] contains a hierarchy of increasing complexity classes , for all . We give a characterization of these classes based on the satisfiability problem of various classes of quantified Boolean formulas. A quantified Boolean formula is a formula of the form , where each is either ∀ or ∃, the are disjoint sets of propositional variables, and is a Boolean formula over the variables in . The quantifier-free part of such formulas is called the matrix of the formula. Truth of such formulas is defined in the usual way. Let be a function that maps some variables of a formula to other variables or to truth values. We let denote the application of such a substitution to the formula . We also write to denote . For each , the decision problem QSat is defined as follows.
|
Input formulas to the problem QSat are called -formulas. For each nonnegative integer , the complexity class can be characterized as the closure of the problem QSat under polynomial-time reductions [2,3]—that is, all decision problems that are polynomial-time reducible to QSat. The -hardness of QSat holds already when the matrix of the input formula is restricted to for odd i, and restricted to for even i. Note that the class coincides with P, and the class coincides with NP. For each , the class is defined as co-—that is, .
The classes and can also be defined by means of nondeterministic Turing machines with an oracle. Intuitively, oracles are black-box machines that can solve a problem in a single time step—for more details, see, e.g., Chapter 3 of [11]. For any complexity class C, we let be the set of decision problems that are decided in polynomial time by a nondeterministic Turing machine with an oracle for a problem that is in the class C. Then, the classes and , for , can be equivalently defined by letting , and for each letting and .
The Polynomial Hierarchy also includes complexity classes between and —such as the classes and . The class consists of all decision problems that are decided in polynomial time by a deterministic Turing machine with an oracle for a problem that is in the class . Similarly, the class consists of all decision problems that are decided in polynomial time by a deterministic Turing machine with an oracle for a problem that is in the class , with the restriction that the Turing machine is only allowed to make oracle queries, where n denotes the input size [14,15]. It holds that .
There are also natural decision problems that are located between NP and . The Boolean Hierarchy (BH) [16,17,18] consists of a hierarchy of complexity classes , for each , that can be used to classify the complexity of decision problems between NP and . Each class can be characterized as the class of problems that can be reduced to the problem -Sat, which is defined inductively as follows. The problem -Sat consists of all sequences of length 1, where is a satisfiable propositional formula. For even , the problem -Sat consists of all sequences of propositional formulas such that both -Sat and is unsatisfiable. For odd , the problem -Sat consists of all sequences of propositional formulas such that -Sat or is satisfiable. The class is also denoted by DP, and the problem -Sat is also denoted by . The class BH is defined as the union of all , for . It holds that .
2.2. Parameterized Complexity
We introduce some core notions from parameterized complexity theory. For an in-depth treatment, we refer to other sources [19,20,21,22,23]. A parameterized problem L is a subset of for some finite alphabet . For an instance , we call x the main part and k the parameter. The following generalization of polynomial-time computability is commonly regarded as the main tractability notion of parameterized complexity theory. A parameterized problem L is fixed-parameter tractable if there exists a computable function f and a constant c such that there exists an algorithm that decides whether in time , where denotes the size of x. Such an algorithm is called an fpt-algorithm, and this amount of time is called fpt-time. FPT is the class of all parameterized problems that are fixed-parameter tractable. If the parameter is constant, then fpt-algorithms run in polynomial time where the order of the polynomial is independent of the parameter. This provides a good scalability in the parameter in contrast to running times of the form , which are also polynomial for fixed k, but are already impractical for, say, .
Parameterized complexity also generalizes the notion of polynomial-time reductions. Let and be two parameterized problems. A (many-one) fpt-reduction from L to is a mapping from instances of L to instances of for which there exist some computable function such that for all : (i) is a yes-instance of L if and only if is a yes-instance of , (ii) , and (iii) R is computable in fpt-time. Let K be a parameterized complexity class. A parameterized problem L is K-hard if for every there is an fpt-reduction from to L. A problem L is K-complete if it is both in K and K-hard. Reductions that satisfy properties (i) and (ii) but that are computable in time , for some fixed computable function f, we call xp-reductions.
The parameterized complexity classes , for , , and can be used to give evidence that a given parameterized problem is not fixed-parameter tractable. These classes are based on the satisfiability problems of Boolean circuits and formulas. We consider Boolean circuits with a single output gate. We call input nodes variables. We distinguish between small gates, with fan-in , and large gates, with fan-in . The depth of a circuit is the length of a longest path from any variable to the output gate. The weft of a circuit is the largest number of large gates on any path from a variable to the output gate. We say that a circuit C is in negation normal form if all negation nodes in C have variables as inputs. A Boolean formula can be considered as a Boolean circuit where all gates have fan-out . We adopt the usual notions of truth assignments and satisfiability of a Boolean circuit. We say that a truth assignment for a Boolean circuit has weight k if it sets exactly k of the variables of the circuit to true. We denote the class of Boolean circuits with depth u and weft t by . We denote the class of all Boolean circuits by CIRC, and the class of all Boolean formulas by FORM. For any class of Boolean circuits, we define the following parameterized problem:
|
We denote closure under fpt-reductions by —that is, for any set of parameterized problems, is the set of all parameterized problems that are fpt-reducible to some problem . The classes are defined by letting p-WSat for all . The classes and are defined by letting p-WSat and p-WSat .
Let K be a classical complexity class, e.g., NP. The parameterized complexity class para-K is defined as the class of all parameterized problems , for some finite alphabet , for which there exist a computable function , and a problem such that and for all instances of L we have that if and only if . (Here, we implicitly use a representation of pairs of strings in as strings in .) Intuitively, the class para-K consists of all problems that are in K after a precomputation that only involves the parameter. The class para-NP can also be defined via nondeterministic fpt-algorithms [24]. The class para-K can be seen as a direct analogue of the class K in parameterized complexity. In particular, for the case of , we have .
We consider the following (trivial) parameterization of SAT, the satisfiability problem for propositional logic. We let . In other words, is the parameterized variant of SAT where the parameter is the constant value 1. Similarly, we let . The problem is para-NP-complete, and the problem is para--complete. In other words, the class para-NP consists of all parameterized problems that can be fpt-reduced to , and para- consists of all parameterized problems that can be fpt-reduced to .
Another analogue to the classical complexity class K is the parameterized complexity class , that is defined as the class of those parameterized problems Q whose slices are in K, i.e., for each positive integer k the classical problem is in K [20]. For instance, the class consists of those parameterized problems whose slices are decidable in polynomial time. Note that this definition is non-uniform, that is, for each positive integer k, there might be a completely different polynomial-time algorithm that witnesses that is polynomial-time solvable. There are also uniform variants of these classes . We define XP to be the class of parameterized problems Q for which there exists a computable function f and an algorithm A that decides whether in time [20,22,24]. Similarly, we define XNP to be the class of parameterized problems that are decidable in nondeterministic time . Its dual class we denote by Xco−NP. Alternatively, we can view XNP as the class of parameterized problems for which there exists an xp-reduction to and Xco−NP as the class of parameterized problems for which there exists an xp-reduction to . (For any , we know that L can be xp-reduced to by following a suitable variant of the proof of the Cook-Levin Theorem [25,26]. Conversely, any parameterized problem L that can be xp-reduced to we can solve in nondeterministic time by first carrying out the xp-reduction, and then solving the resulting instance of . The case for Xco−NP and is entirely analogous.)
2.3. Fpt-Reductions to SAT and Parameterized Complexity Classes at Higher Levels of the PH
Problems in NP and co-NP can be encoded into SAT in such a way that the time required to produce the encoding and consequently also the size of the resulting SAT instance are polynomial in the input (the encoding is a polynomial-time many-one reduction). Typically, the SAT encodings of problems proposed for practical use are of this kind (see, e.g., [27]). For problems that are “beyond NP”, say for problems on the second level of the PH, such polynomial SAT encodings do not exist, unless the PH collapses. However, for such problems, there still could exist SAT encodings which can be produced in fpt-time with respect to some parameter associated with the problem. In fact, such fpt-time SAT encodings have been obtained for various problems on the second level of the PH [28,29,30,31]. The classes para-NP and para-co-NP contain exactly those parameterized problems that admit such a many-one fpt-reduction to and , respectively. Thus, with fpt-time encodings, one can go significantly beyond what is possible by conventional polynomial-time SAT encodings.
Fpt-time encodings to SAT also have their limits. Clearly, para--hard and para--hard parameterized problems do not admit fpt-time encodings to SAT, even when the parameter is a fixed constant, unless the PH collapses. There are problems that apparently do not admit fpt-time encodings to SAT, but seem not to be para--hard nor para--hard either. Recently, several complexity classes have been introduced to classify such intermediate problems [7,8,30]. These parameterized complexity classes are dubbed the class and the hierarchy, inspired by their definition, which is based on the following weighted variants of the quantified Boolean satisfiability problem that is canonical for the second level of the PH. The problem -WSat() provides the foundation for the class.
|
Similarly, the problem -WSat() provides the foundation for the hierarchy—where is a class of Boolean circuits. (The parameterized problems -WSat() seem not to be fpt-reducible to each other for various classes of Boolean circuits—similarly to the problems p-WSat that are used to define the classes , , and . This is in contrast to the case of -WSat, where we can use a Tseitin transformation [32] to reduce arbitrary Boolean circuits to equisatisfiable 3CNF formulas.)
|
The parameterized complexity class (also called the class) is then defined as follows:
Similarly, the classes of the hierarchy are defined as follows:
= -WSat,
= -WSat(FORM) , and
= -WSat(CIRC) .
Note that these definitions are entirely analogous to those of the parameterized complexity classes of the W-hierarchy [20]. The following inclusion relations hold between the classes of the hierarchy:
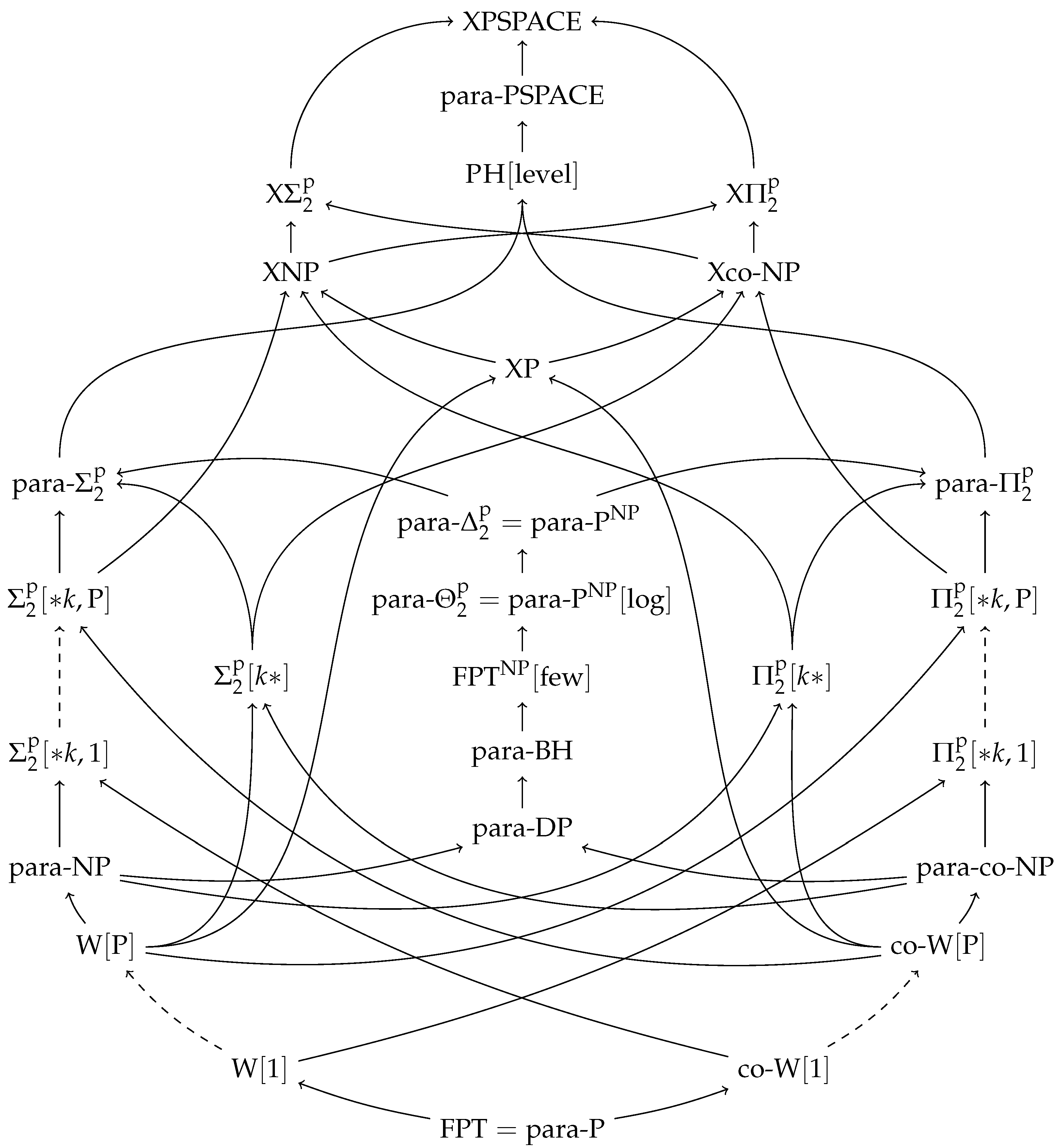
(See also Figure 1 for a visual overview of these inclusion relations.)
Dual to the classical complexity class is its co-class , whose canonical complete problem is complementary to the problem QSat. Similarly, we can define dual classes for the class and for each of the parameterized complexity classes in the hierarchy. These co-classes are based on problems complementary to the problems -WSat and -WSat—i.e., these problems have as yes-instances exactly the no-instances of -WSat and -WSat, respectively. Equivalently, these complementary problems can be considered as variants of -WSat and -WSat where the existential and universal quantifiers are swapped, and are therefore denoted with -WSat and -WSat. We use a similar notation for the dual complexity classes, e.g., we denote co- by .
The class includes the class para- as a subset, and is contained in the class Xco−NP as a subset. Similarly, each of the classes include the the class para-NP as a subset, and is contained in the class XNP. Under some common complexity-theoretic assumptions, the class can be separated from para-NP on the one hand, and para- on the other hand. In particular, assuming that , it holds that , that and that [7,8]. Similarly, the classes can be separated from para- and para-. Assuming that , it holds that , that and thus in particular that , and that [7,8].
One can also enhance the power of polynomial-time SAT encodings by considering polynomial- time algorithms that can query a SAT solver multiple times—that is, polynomial-time Turing reductions. Such an approach has been shown to be quite effective in practice (see, e.g., [33,34,35]) and extends the scope of SAT solvers to problems in the class , but not to problems that are -hard or -hard. In addition, here, switching from polynomial-time to fpt-time provides a significant increase in power. The class para- contains all parameterized problems that can be decided by an fpt-algorithm that can query a SAT oracle multiple times—i.e., by an fpt-time Turing reduction to SAT. (One can prove this by following the proof of Theorem 4 in [24] that , with the modification that the algorithms are given access to a SAT oracle.) In addition, one could restrict the number of queries that the algorithm is allowed to make. The class para- consists of all parameterized problems that can be decided by an fpt-algorithm that can query a SAT oracle at most many times, where k is the parameter value, n is the input size, and f is some computable function. (This statement one can prove by following the proof of Theorem 4 in [24] that , with the modification that the algorithms can query a SAT oracle an amount of times that depends logarithmically on the input size.) Restricting the number of queries even further, we define the parameterized complexity class as the class of all parameterized problems that can be decided by an fpt-algorithm that can query a SAT oracle at most times, where k is the parameter value and f is some computable function [7,8].
We get the parameterized analogue para-PSPACE of the class PSPACE by using the definition of para-K for . Similarly, we can define the parameterized complexity class XPSPACE, consisting of all parameterized problems Q for which there exists a computable function f and an algorithm A that decides whether in space . We also consider another parameterized variant of PSPACE, which is based on parameterizing the number of quantifier alternations in QSat. An unbounded number of quantifier alternations in this problem results in the class PSPACE, and bounding the number of quantifier alternations by a constant leads to some fixed level of the PH. The parameterized complexity class PH is based on bounding the number of quantifier alternations by the problem parameter [7,36]. Formally, we consider the following parameterized problem QSat(level).
|
The parameterized complexity class PH is defined to be the class of all parameterized problems that can be fpt-reduced to QSat(level). We have that .
An overview of the parameterized complexity classes relevant for this paper can be found in Figure 1.
2.4. Treewidth and Tree Decompositions
We conclude this section with explaining the notions of tree decompositions and treewidth that we use in various places through the paper. For more details on these notions, we refer to textbooks—e.g., [19,20,21,22,23,42].
A tree decomposition of a graph is a pair where is a rooted tree and is a family of subsets of V such that:
- for every , the set is nonempty and connected in ; and
- for every edge , there is a such that .
The width of the decomposition is the number . The treewidth of G is the minimum of the widths of all tree decompositions of G. Let G be a graph and k a nonnegative integer. There is an fpt-algorithm that computes a tree decomposition of G of width k if it exists, and fails otherwise [43]. We call a tree decomposition nice if every node is of one of the following four types:
- leaf node: t has no children and ;
- introduce node: t has one child and for some vertex ;
- forget node: t has one child and for some vertex ; or
- join node: t has two children and .
Given any graph G and a tree decomposition of G of width k, a nice tree decomposition of G of width k can be computed in polynomial time [42].
3. Propositional Logic Problems
We start with the quantified circuit satisfiability problems on which the and hierarchies are based. We present two canonical forms of the problems in the hierarchy. For problems in the hierarchy, we let range over classes of Boolean circuits.
|
| Complexity:-complete [7,8]. |
|
| Complexity:-complete [7,8]. |
|
| Complexity: -complete when restricted to circuits of weft t, for any (by definition); -complete if (by definition); -complete if (by definition). |
3.1. Weighted Quantified Boolean Satisfiability for the Classes
Consider the following variants of -WSat, most of which are -complete.
|
| Complexity:-complete [7,8]. |
|
| Complexity:-complete [7,8]. |
|
| Complexity: para--complete [7]. |
|
| Complexity:-complete [7]. |
3.2. Weighted Quantified Boolean Satisfiability in the Hierarchy
Let be an arbitrary constant. Then, the following problem is also -complete.
|
| Complexity:-complete for any [7,8]. |
The problem -WSat(2-DNF) is -hard, even when we restrict the input formula to be anti-monotone in the universal variables, i.e., the universal variables occur only in negative literals [7,8].
Let C be a Boolean circuit with input nodes Z that is in negation normal form, and let be a subset of the input nodes. We say that C is monotone in Y if the only negation nodes that occur in the circuit C act on input nodes in , i.e., input nodes in Y can appear only positively in the circuit. Similarly, we say that C is anti-monotone in Y if the only nodes that have nodes in Y as input are negation nodes, i.e., all input nodes in Y appear only negatively in the circuit. The following problems are -complete.
|
| Complexity:-complete [7,8]. |
|
| Complexity:-complete [7]. |
It remains open what the exact parameterized complexity is of ∃-monotone and ∃-anti-monotone variants of -WSat—i.e., variants of -WSat that are based on circuits over two disjoint sets X and Y of variables that are in negation normal form and that are (anti-)monotone in X. The proofs used to show -completeness of the ∀-monotone and ∀-anti-monotone variants [7,8] do not immediately carry over to this case.
3.3. Quantified Boolean Satisfiability with Bounded Treewidth
Let be a DNF formula. For any subset of variables, we define the incidence graph of ψ with respect to Z to be the graph , where and . If is a DNF formula, is a subset of variables, and is a tree decomposition of , we let denote , for any .
The following parameterized decision problems are variants of QSat, where the treewidth of the incidence graph graph for certain subsets of variables is bounded.
|
| Complexity: fixed-parameter tractable [4,5]. |
|
| Complexity: para--complete [6,7]. |
|
| Complexity: para-NP-complete [6,7]. |
The above problems are parameterized by the treewidth of the incidence graph of the formula (with respect to different subsets of variables). Since computing the treewidth of a given graph is NP-hard, it is unlikely that the parameter value can be computed in polynomial time for these problems. Alternatively, one could consider a variant of the problem where a tree decomposition of width k is given as part of the input.
3.4. Other Quantified Boolean Satisfiability
The following parameterized quantified Boolean satisfiability problem is para-NP-complete.
|
| Complexity: para-NP-complete [6,44,45]. |
3.5. Minimization for DNF Formulas
Let be a propositional formula in DNF. We say that a set C of literals is an implicant of if all assignments that satisfy also satisfy . Moreover, we say that a DNF formula is a term-wise subformula of if for all terms there exists a term such that . The following parameterized problems are natural parameterizations of problems shown to be -complete by Umans [46].
|
| Complexity:-complete [6,7]. |
|
| Complexity:-complete [6,7]. |
|
| Complexity:-complete [6,7]. |
|
| Complexity: para--hard, in , and in [6,7]. |
3.6. Sequences of Propositional Formulas
The following problem is related to a Boolean combination of satisfiability checks on a sequence of propositional formulas. This is a parameterized version of the problem -Sat, which is canonical for the different levels of the Boolean Hierarchy (see Section 1). The problem is complete for the class .
|
| Complexity:-complete [7,28,37]. |
The above problem is used to show the following lower bound result for -complete problems. No -hard problem can be decided by an fpt-algorithm that uses only many queries to an NP oracle, unless the Polynomial Hierarchy collapses to the third level [18,37].
The next -complete problem is based on the problem .
|
| Complexity:-complete [7,28,37]. |
3.7. Maximal Models
The following -complete problems are based on various notions of (local) maximality for models of propositional formulas. Let be a (satisfiable) propositional formula, and let be a subset of variables. Then, a truth assignment is an X-maximal model of if (i) satisfies and (ii) there is no truth assignment that satisfies and that sets more variables among X to true than . Moreover, take an arbitrary ordering over the variables —for the sake of presentation, let and let the ordering < specify . We say that a truth assignment is the lexicographically X-maximal model of (with respect to the given ordering) if (i) satisfies and (ii) each truth assignment that satisfies (with ) has the property that there is some such that and and for all it holds that .
|
| Complexity:-complete [7,47]. |
|
| Complexity:-complete [7]. (The problem Local-Lex-Max-Model isn’t considered explicitly in the literature. -completeness for this problem follows immediately from proofs in the literature—i.e., Propositions 73 and 74 in [7]). |
|
| Complexity:-complete [7]. |
|
| Complexity:-complete [7]. |
4. Knowledge Representation and Reasoning Problems
4.1. Disjunctive Answer Set Programming
The following problems from the setting of disjunctive answer set programming (ASP) are based on the notions of disjunctive logic programs and answer sets for such programs (cf. [48,49]). A disjunctive logic program P is a finite set of rules of the form , for , where all , and are atoms. For each such rule, is called the head of the rule, and is called the body of the rule. A rule is called disjunctive if , and it is called normal if (note that we only call rules with strictly more than one disjunct in the head disjunctive). A rule is called dual-normal if . A program is called normal if all its rules are normal, it is called negation-free if all its rules are negation-free, and it is called dual-normal if all its rules are dual-normal. We let denote the set of all atoms occurring in P. By literals, we mean atoms a or their negations . The (Gelfond–Lifschitz) reduct of a program P with respect to a set M of atoms, denoted , is the program obtained from P by: (i) removing rules with in the body, for each , and (ii) removing literals from all other rules [50]. An answer set A of a program P is a subset-minimal model of the reduct . One important decision problem is to decide, given a disjunctive logic program P, whether P has an answer set.
We consider various parameterizations of this problem. Two of these are related to atoms that must be part of any answer set of a program P. We identify a subset of compulsory atoms, that any answer set must include. Given a program P, we let be the smallest set such that: (i) if is a rule of P, then ; and (ii) if is a rule of P, and , then . We then let the set of contingent atoms be those atoms that occur in P but are not in . We call a rule contingent if all the atoms that appear in the head are contingent. Another of the parameterizations that we consider is based on the notion of backdoors to normality for disjunctive logic programs. A set B of atoms is a normality-backdoor for a program P if deleting the atoms from the rules of P results in a normal program. Deciding if a program P has a normality-backdoor of size at most k can be decided in fixed-parameter tractable time [29].
|
| Complexity: para--complete [7,30]. |
|
| Complexity:-complete [7,30]. |
|
| Complexity:-complete [7,30]. |
|
| Complexity:-complete [7]. |
|
| Complexity: para-NP-complete [29]. |
|
| Complexity: para--complete [7,30]. |
4.2. Robust Constraint Satisfaction
The following problem is based on the class of robust constraint satisfaction problems introduced by Gottlob [51] and Abramsky, Gottlob and Kolaitis [52]. These problems are concerned with the question of whether every partial assignment of a particular size can be extended to a full solution, in the setting of constraint satisfaction problems.
A CSP instance N is a triple , where X is a finite set of variables, the domain D is a finite set of values, and C is a finite set of constraints. Each constraint is a pair , where , the constraint scope, is a finite sequence of distinct variables from X, and R, the constraint relation, is a relation over D whose arity matches the length of S, i.e., , where r is the length of S.
Let be a CSP instance. A partial instantiation of N is a mapping defined on some subset . We say that satisfies a constraint if and . If satisfies all constraints of N then it is a solution of N. We say that violates a constraint if there is no extension of defined on such that .
Let k be a positive integer. We say that a CSP instance is k-robustly satisfiable if for each instantiation defined on some subset of k many variables (i.e., ) that does not violate any constraint in C, it holds that can be extended to a solution for the CSP instance .
|
| Complexity:-complete [7,30]. |
4.3. Abductive Reasoning
The setting of (propositional) abductive reasoning can be formalized as follows. An abduction instance consists of a tuple , where V is the set of variables, is the set of hypotheses, is the set of manifestations, and T is the theory, a formula in CNF over V. It is required that . A set is a solution (or explanation) of if (i) is consistent and (ii) . One central problem is to decide, given an abduction instance and an integer m, whether there exists a solution S of of size at most m. This problem is -complete in general [53].
|
| Complexity: para-NP-complete [31]. |
|
| Complexity:-complete [7]. |
|
| Complexity: para-NP-complete [31]. |
|
| Complexity:-complete [7]. |
5. Graph Problems
5.1. Clique Extensions
Let be a graph. A clique of G is a subset of vertices that induces a complete subgraph of G, i.e., for all such that . The -complete problem of determining whether a graph has a clique of size k is an important problem in the W-hierarchy, and is used in many -hardness proofs. We consider a related problem that is complete for .
|
| Complexity:-complete [7]. |
5.2. Graph Coloring Extensions
The following problem related to extending colorings to the leaves of a graph to a coloring on the entire graph, is -complete in the most general setting [54].
Let be a graph. We will denote those vertices v that have degree 1 by leaves. We call a (partial) function a 3-coloring (of G). Moreover, we say that a 3-coloring c is proper if c assigns a color to every vertex , and if for each edge it holds that . The problem of deciding, given a graph with n many leaves and an integer m, whether any 3-coloring that assigns a color to exactly m leaves of G (and to no other vertices) can be extended to a proper 3-coloring of G, is -complete [54]. We consider several parameterizations.
|
| Complexity: para--complete [7,41]. |
|
| Complexity: para-NP-complete [7,41]. |
|
| Complexity:-complete [7,41]. |
|
| Complexity: para--complete [7,41]. |
6. Other Problems
6.1. First-Order Logic Model Checking
First-order logic model checking is at the basis of a well-known hardness theory in parameterized complexity theory [22]. The following problem, also based on first-order logic model checking, offers another characterization of the parameterized complexity class . We introduce a few notions that we need for defining the model checking perspective on . A (relational) vocabulary is a finite set of relation symbols. Each relation symbol R has an arity . A structure of vocabulary , or τ-structure (or simply structure), consists of a set A called the domain and an interpretation for each relation symbol . We use the usual definition of truth of a first-order logic sentence over the vocubulary in a -structure . We let denote that the sentence is true in structure .
|
| Complexity:-complete [41]. |
6.2. Quantified Fagin Definability
The W-hierarchy can also be defined by means of Fagin-definable parameterized problems [22], which are based on Fagin’s characterization of NP. We provide an additional characterization of the class by means of some parameterized problems that are quantified analogues of Fagin-defined problems.
Let be an arbitrary vocabulary, and let be a subvocabulary of . We say that a -structure extends a -structure if (i) and have the same domain, and (ii) and coincide on the interpretation of all relational symbols in , i.e., for all . We say that extends with weight k if . Let be a first-order formula over with a free relation variable X of arity s.
We let denote the class of all first-order logic formulas of the form , where is quantifier-free. Let be a first-order logic formula over , with a free relation variable X with arity s. Consider the following parameterized problem.
|
| Complexity: in for each , and ; -hard for some , and [7]. |
Note that this means the following. We let T denote the set of all relational vocabularies, and for any we let denote the set of all first-order logic formulas over the vocabulary with a free relation variable X. We then get the following characterization of [7]:
Additionally, the following parameterized problem is hard for .
|
| Complexity:-hard for some [7]. |
6.3. Symbolic Model Checking for Temporal Logics
The following problems are concerned with the task of verifying whether a temporal logic formula is true in a Kripke structure. This task is of importance in the area of software and hardware verification (see, e.g., [55,56]). We consider three different temporal logics: linear-time temporal logic (LTL), computation tree logic (CTL), and CTL, which is a superset of both LTL and CTL.
Truth of formulas in these logics is defined over Kripke structures —we write if is true in . We consider Kripke structures that are represented symbolically using propositional formulas. Moreover, for each of the logics , we consider various restricted fragments X, U and U,X, where certain operators are disallowed. For a full description of the syntax and semantics of these logics, how Kripke structures can be represented symbolically and the restricted fragments that we consider, we refer to Appendix A.
In general, the problem of deciding whether a given temporal logic formula is true in a given symbolically represented Kripke structure is PSPACE-hard, even when restricted to formulas of constant size [7,36]. We consider a variant of this problem where the Kripke structures have limited recurrence diameter. The recurrence diameter of a Kripke structure is the length of the longest simple (non-repeating) path in .
|
| Complexity: |
6.4. Judgment Aggregation
The following problems are related to judgment aggregation, in the domain of computational social choice. Judgment aggregation studies procedures that combine individuals’ opinions into a collective group opinion.
An agenda is a finite nonempty set of formulas that is closed under complementation. A judgment set J for an agenda is a subset . We call a judgment set J complete if or for all formulas , and we call it consistent if there exists an assignment that makes all formulas in J true. Let denote the set of all complete and consistent subsets of . We call a sequence of complete and consistent subsets a profile. A (resolute) judgment aggregation procedure for the agenda and n individuals is a function that returns for each profile a non-empty set of non-empty judgment sets. An example is the majority rule , where and where if and only if occurs in the majority of judgment sets in , for each . We call F complete and consistent, if each is complete and consistent, respectively, for every . For instance, the majority rule is complete, whenever the number n of individuals is odd. An agenda is safe with respect to an aggregation procedure F, if F is consistent when applied to profiles of judgment sets over . We say that an agenda satisfies the median property (MP) if every inconsistent subset of has itself an inconsistent subset of size at most 2. Safety for the majority rule can be characterized in terms of the median property as follows: an agenda is safe for the majority rule if and only if satisfies the MP [57,58]. The problem of deciding whether an agenda satisfies the MP is -complete [57].
|
| Complexity: para--complete [7,37]. |
|
| Complexity: para--complete [7,37]. |
|
| Complexity: para--complete [7,37]. |
The above three parameterized problems remain para--hard even when restricted to agendas based on formulas that are Horn formulas containing only clauses of size at most 2 [7,37].
|
| Complexity:-complete [7,37]. |
Moreover, the following upper and lower bounds on the number of oracle queries are known for the above problem. Maj-Agenda-Safety can be decided in fpt-time using queries to an NP oracle, where [7,37]. In addition, there is no fpt-algorithm that decides Maj-Agenda-Safety using queries to an NP oracle, unless the Polynomial Hierarchy collapses [7,37].
|
| Complexity:-hard [7,37]. |
Let be an agenda, where each is a CNF formula. We define the following graphs that are intended to capture the interaction between formulas in . The formula primal graph of has as vertices the variables occurring in the agenda, and two variables are connected by an edge if there exists a formula in which they both occur. The formula incidence graph of is a bipartite graph whose vertices consist of (1) the variables occurring in the agenda and (2) the formulas . A variable is connected by an edge with a formula if x occurs in , i.e., . The clausal primal graph of has as vertices the variables occurring in the agenda, and two variables are connected by an edge if there exists a formula and a clause in which they both occur. The clausal incidence graph of is a bipartite graph whose vertices consist of (1) the variables occurring in the agenda and (2) the clauses c occurring in formulas . A variable is connected by an edge with a clause c of the formula if x occurs in c, i.e., . Consider the following parameterizations of the problem Maj-Agenda-Safety.
|
| Complexity: fixed-parameter tractable [7,37]. |
|
| Complexity: para--complete [7,37]. |
|
| Complexity: para--complete [7,37]. |
|
| Complexity: para--complete [7,37]. |
6.5. Planning
The following parameterized problems are related to planning in the face of uncertainty. We begin by describing the framework of SAS planning (see, e.g., [59]). Let be a finite set of variables over a finite domain D. Furthermore, let , where is a special undefined value not present in D. Then is the set of total states and is the set of partial states over V and D. Intuitively, a state corresponds to an assignment that assigns to each variable the value , and a partial state corresponds to a partial assignment that assigns a value to some variables . Clearly, —that is, each total state is also a partial state. Let be a state. Then, the value of a variable in state s is denoted by .
An SAS instance is a tuple , where V is a set of variables, D is a domain, A is a set of actions, is the initial state and is the (partial) goal state. Each action has a precondition and an effect .
We will frequently use the convention that a variable has the value in a precondition/effect unless a value is explicitly specified. Furthermore, by a slight abuse of notation, we denote actions and partial states such as preconditions, effects, and goals as follows. Let be an action, and let be the set of variables that are not assigned by to the value —that is, . Moreover, suppose that . Then, we denote the precondition by . In particular, if is the partial state such that for each , we denote by ∅. We use a similar notation for effects. Let a be the action with and . We then use the notation to describe the action a.
Let be an action and be a state. Then, a is valid in s if for all , either or . The result of a in s is the state defined as follows. For all , if and otherwise. Let and let be a sequence of actions (of length ℓ). We say that is a plan from to if either (i) is the empty sequence (and , and thus ), or (ii) there are states such that for each , is valid in and is the result of in . A state is a goal state if for all , either or . An action sequence is a plan for if is a plan from I to a goal state.
We also allow actions to have conditional effects (see, e.g., [60]). A conditional effect is of the form , where are partial states. Intuitively, such a conditional effect ensures that the variable assignment t is only applied if the condition s is satisfied. When allowing conditional effects, the effect of an action is not a partial state , but a set of conditional effects. (For the sake of simplicity, we assume that the partial states are non-conflicting—that is, there exist no and no with such that .) The result of an action a with in a state s (in which a is valid) is the state that is defined as follows. For all , if there exists some such that is satisfied in s and , and otherwise.
For the parameterized planning problems that we consider, in addition to the variables V, we consider a set of variables—constituting an uncertain planning instance . Intuitively, the value of the variables in in the initial state is unknown. The question is whether there exists an action sequence such that, for each state that extends I—that is, for each —it holds that is a plan for the SAS instance . If there exists such an action sequence , we say that is a plan that works for each complete initial state that extends I.
|
| Complexity:-complete [7,39]. |
|
| Complexity:-complete [7,39]. |
6.6. Turing Machine Halting
The following problems are related to alternating Turing machines (ATMs), possibly with multiple tapes. ATMs are nondeterministic Turing machines where the states are divided into existential and universal states, and where each configuration of the machine is called existential or universal according to the state that the machine is in. A run of the ATM on an input x is a tree whose nodes correspond to configurations of in such a way that (1) for each non-root node v of the tree with parent node , the machine can transition from the configuration corresponding to to the configuration corresponding to v, (2) the root node corresponds to the initial configuration of , and (3) each leaf node corresponds to a halting configuration. A computation path in a run of is a root-to-leaf path in the run. Moreover, the nodes of a run are labelled accepting or rejecting, according to the following definition. A leaf of is labelled accepting if the configuration corresponding to it is an accepting configuration, and the leaf is labelled rejecting if it is a rejecting configuration. A non-leaf node of that corresponds to an existential configuration is labelled accepting if at least one of its children is labelled accepting. A non-leaf node of that corresponds to a universal configuration is labelled accepting if all of its children are labelled accepting. An ATM is 2-alternating if for each input x, each computation path in the run of on input x switches at most once from an existential configuration to a universal configuration, or vice versa. For more details on the terminology, we refer to the work of De Haan and Szeider [8,41] and to the work of Flum and Grohe—Appendix A.1 in [22].
We consider the following restrictions on ATMs. An -Turing machine (or simply -machine) is a 2-alternating ATM, where the initial state is an existential state. Let be positive integers. We say that an -machine halts (on the empty string) with existential cost ℓ and universal cost t if: (1) there is an accepting run of with the empty input , and (2) each computation path of contains at most ℓ existential configurations and at most t universal configurations. The following problem, where the number of Turing machine tapes is given as part of the input, is -complete.
|
| Complexity:-complete [7,8]. |
Let be a constant integer. Then, the following parameterized decision problem, where the number of Turing machine tapes is fixed, is also -complete.
|
| Complexity:-complete [7,8]. |
In addition, the parameterized complexity class can also be characterized by means of alternating Turing machines in the following way. Let P be a parameterized problem. An -machine for P is a -machine such that there exists a computable function f and a polynomial p such that: (1) decides P in time ; and (2) for all instances of P and each computation path R of with input , at most of the existential configurations of R are nondeterministic. We say that a parameterized problem P is decided by some -machine if there exists a -machine for P. Then, is exactly the class of parameterized decision problems that are decided by some -machine [7,8].
7. Conclusions
In this paper, we provided a list of parameterized problems that are based on problems at higher levels of the Polynomial Hierarchy, together with a complexity classification indicating whether they allow a (many-to-one or Turing) fpt-reduction to SAT or not. These complexity classifications are based in part on recently developed parameterized complexity classes—e.g., and [7,8], [6,7] and PH [7,36]. The problems that we considered are related to propositional logic, quantified Boolean satisfiability, disjunctive answer set programming, constraint satisfaction, (propositional) abductive reasoning, cliques, graph coloring, first-order logic model checking, temporal logic model checking, judgment aggregation, planning, and (alternating) Turing machines.
Author Contributions
Conceptualization, Methodology, Formal analysis, Investigation, Project administration, R.d.H. and S.S; Resources, Funding acquisition, S.S.; Writing—original draft preparation, R.d.H., Writing—review and editing, R.d.H. and S.S.; Supervision, S.S.
Funding
This research was funded by the European Research Council (ERC), project 239962 (COMPLEX REASON), and the Austrian Science Fund (FWF), project P26200 (Parameterized Compilation).
Acknowledgments
Open Access Funding by the Austrian Science Fund (FWF).
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
Appendix A
We begin by defining the syntax of the logic LTL. LTL formulas are formed according to the following grammar (here p ranges over a fixed set P of propositional variables), given by:
(Further temporal operators that are considered in the literature can be defined in terms of the operators X and U.)
The semantics of LTL is defined along paths of Kripke structures. A Kripke structure is a tuple , where S is a finite set of states, where is a binary relation on the set of states called the transition relation, where is a valuation function that assigns each state to a set of propositions, and where is the initial state. We say that a finite sequence of states is a finite path in if for each . Similarly, we say that an infinite sequence of states is an infinite path in if for each .
Let be a Kripke structure, and be a path in . Moreover, let for each . Truth of LTL formulas on paths (denoted ) is defined inductively as follows:
| if | , | |
| , | if | and , |
| , | if | , |
| , | if | , |
| , | if | for some , , |
| if | there is some such that and for each . |
Then, we say that an LTL formula is true in the Kripke structure (denoted ) if for all infinite paths starting in it holds that .
Next, we define the syntax of the logic CTL, which consists of two different types of formulas: state formulas and path formulas. When we refer to CTL formulas without specifying the type, we refer to state formulas. Given the set P of atomic propositions, the syntax of CTL formulas is defined by the following grammar (here denotes CTL state formulas, denotes CTL path formulas, and p ranges over P), given by:
Path formulas have the same intended meaning as LTL formulas. State formulas, in addition, allow explicit quantification over paths, which is not possible in LTL.
Formally, the semantics of CTL formulas are defined inductively as follows. Let be a Kripke structure, be a state in and be a path in . Again, let for each . The truth of CTL state formulas on states (denoted ) is defined as follows:
| if | , | |
| , | if | and , |
| , | if | , |
| , | if | there is some path in starting in s such that . |
The truth of CTL path formulas on paths (denoted ) is defined as follows:
| if | , | |
| , | if | and , |
| , | if | , |
| , | if | , |
| , | if | for some , , |
| , | if | there is some such that and for each . |
Then, we say that a CTL formula is true in the Kripke structure (denoted ) if .
The syntax of the logic CTL is defined similarly to the syntax of CTL. Only the grammar for path formulas differs, namely:
In particular, this means that every CTL state formula, (CTL formula for short) is also a CTL formula. The semantics for CTL formulas is defined as for their CTL counterparts. Moreover, we say that a CTL formula is true in the Kripke structure (denoted ) if .
For each of the logics , we consider the fragments X, U and U,X. In the fragment X, the X-operator is disallowed. Similarly, in the fragment U, the -operator is disallowed. In the fragment U,X, neither the X-operator nor the -operator is allowed.
Next, we define how Kripke structures can be represented symbolically using propositional formulas. Let be a finite set of propositional variables. A symbolically represented Kripke structure over P is a tuple , where is a propositional formula over the variables , and where is a truth assignment to the variables in P. The Kripke structure associated with is , where consists of all truth assignments to P, where if and only if is true, and where .
References
- Vardi, M.Y. Boolean satisfiability: Theory and engineering. Commun. ACM 2014, 57, 5. [Google Scholar] [CrossRef]
- Stockmeyer, L.J. The polynomial-time hierarchy. Theor. Comput. Sci. 1976, 3, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Wrathall, C. Complete Sets and the Polynomial-Time Hierarchy. Theor. Comput. Sci. 1976, 3, 23–33. [Google Scholar] [CrossRef]
- Chen, H. Quantified Constraint Satisfaction and Bounded Treewidth. In Proceedings of the 16th European Conference on Artificial Intelligence (ECAI 2004), Valencia, Spain, 22–27 August 2004; pp. 161–165. [Google Scholar]
- Feder, T.; Kolaitis, P.G. Closures and dichotomies for quantified constraints. In Electronic Colloquium on Computational Complexity (ECCC); Technical Report TR06-160; Weizmann Institute of Science: Rehovot, Israel, 2006. [Google Scholar]
- De Haan, R.; Szeider, S. Fixed-parameter tractable reductions to SAT. In Proceedings of the 17th International Symposium on the Theory and Applications of Satisfiability Testing (SAT 2014), Vienna, Austria, 14–17 July 2014; Egly, U., Sinz, C., Eds.; Springer: Berlin, Germany, 2014; Volume 8561, pp. 85–102. [Google Scholar]
- De Haan, R. Parameterized Complexity in the Polynomial Hierarchy. Ph.D. Thesis, Technische Universität Wien, Vienna, Austria, 2016. [Google Scholar]
- De Haan, R.; Szeider, S. Parameterized complexity classes beyond para-NP. J. Comput. Syst. Sci. 2017, 87, 16–57. [Google Scholar] [CrossRef]
- Schaefer, M.; Umans, C. Completeness in the Polynomial-Time hierarchy: A Compendium. SIGACT News 2002, 33, 32–49. [Google Scholar]
- Cesati, M. Compendium of Parameterized Problems. Available online: http://cesati.sprg.uniroma2.it/research/compendium/ (accessed on 4 September 2019).
- Arora, S.; Barak, B. Computational Complexity—A Modern Approach; Cambridge University Press: Cambridge, UK, 2009; pp. I–XXIV, 1–579. [Google Scholar]
- Papadimitriou, C.H. Computational Complexity; Addison-Wesley: Boston, MA, USA, 1994. [Google Scholar]
- Meyer, A.R.; Stockmeyer, L.J. The Equivalence Problem for Regular Expressions with Squaring Requires Exponential Space. In Proceedings of the 13th Annual Symposium on Switching & Automata Theory (SWAT), College Park, MD, USA, 25–27 October 1972; pp. 125–129. [Google Scholar]
- Hemachandra, L.A. The strong exponential hierarchy collapses. J. Comput. Syst. Sci. 1989, 39, 299–322. [Google Scholar] [CrossRef] [Green Version]
- Buss, S.R.; Hay, L. On truth-table reducibility to SAT. Inf. Comput. 1991, 91, 86–102. [Google Scholar] [CrossRef] [Green Version]
- Cai, J.; Gundermann, T.; Hartmanis, J.; Hemachandra, L.A.; Sewelson, V.; Wagner, K.W.; Wechsung, G. The Boolean Hierarchy I: Structural Properties. SIAM J. Comput. 1988, 17, 1232–1252. [Google Scholar] [CrossRef]
- Chang, R.; Kadin, J. The Boolean Hierarchy and the Polynomial Hierarchy: A Closer Connection. SIAM J. Comput. 1993, 25, 169–178. [Google Scholar]
- Kadin, J. The Polynomial Time Hierarchy Collapses if the Boolean Hierarchy Collapses. SIAM J. Comput. 1988, 17, 1263–1282. [Google Scholar] [CrossRef]
- Cygan, M.; Fomin, F.V.; Kowalik, L.; Lokshtanov, D.; Marx, D.; Pilipczuk, M.; Pilipczuk, M.; Saurabh, S. Parameterized Algorithms; Springer: Berlin, Germany, 2015. [Google Scholar]
- Downey, R.G.; Fellows, M.R. Parameterized Complexity. In Monographs in Computer Science; Springer: New York, NY, USA, 1999. [Google Scholar]
- Downey, R.G.; Fellows, M.R. Texts in Computer Science. Fundamentals of Parameterized Complexity; Springer: Berlin, Germany, 2013. [Google Scholar]
- Flum, J.; Grohe, M. Parameterized Complexity Theory. In Texts in Theoretical Computer Science. An EATCS Series; Springer: Berlin, Germany, 2006; Volume XIV. [Google Scholar]
- Niedermeier, R. Invitation to Fixed-Parameter Algorithms. In Oxford Lecture Series in Mathematics and Its Applications; Oxford University Press: Oxford, UK, 2006. [Google Scholar] [Green Version]
- Flum, J.; Grohe, M. Describing parameterized complexity classes. Inf. Comput. 2003, 187, 291–319. [Google Scholar] [CrossRef] [Green Version]
- Cook, S.A. The Complexity of Theorem-Proving Procedures. In Proceedings of the Third Annual ACM Symposium on Theory of Computing, Shaker Heights, OH, USA, 3–5 May 1971; pp. 151–158. [Google Scholar]
- Levin, L. Universal sequential search problems. Probl. Inf. Transm. 1973, 9, 265–266. [Google Scholar]
- Prestwich, S.D. CNF Encodings. In Handbook of Satisfiability; Biere, A., Heule, M., van Maaren, H., Walsh, T., Eds.; IOS Press: Amsterdam, The Netherlands, 2009; pp. 75–97. [Google Scholar]
- Endriss, U.; De Haan, R.; Szeider, S. Parameterized Complexity Results for Agenda Safety in Judgment Aggregation. In Proceedings of the 14th International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2015), Istanbul, Turkey, 4–8 May 2015. [Google Scholar]
- Fichte, J.K.; Szeider, S. Backdoors to Normality for Disjunctive Logic Programs. ACM Trans. Comput. Log. 2015, 17, 7:1–7:23. [Google Scholar] [CrossRef]
- De Haan, R.; Szeider, S. The Parameterized Complexity of Reasoning Problems Beyond NP. In Proceedings of the Fourteenth International Conference on the Principles of Knowledge Representation and Reasoning (KR 2014), Vienna, Austria, 20–24 July 2014; Baral, C., De Giacomo, G., Eiter, T., Eds.; AAAI Press: Palo Alto, CA, USA, 2014. [Google Scholar]
- Pfandler, A.; Rümmele, S.; Szeider, S. Backdoors to Abduction. In Proceedings of the 23rd International Joint Conference on Artificial Intelligence (IJCAI 2013), Beijing, China, 3–9 August 2013; Rossi, F., Ed.; AAAI Press: Palo Alto, CA, USA, 2013. [Google Scholar]
- Tseitin, G.S. Complexity of a Derivation in the Propositional Calculus. Zap. Nauchn. Sem. Leningrad Otd. Mat. Inst. Akad. Nauk SSSR 1968, 8, 23–41. [Google Scholar]
- Belov, A.; Lynce, I.; Marques-Silva, J. Towards efficient MUS extraction. AI Commun. 2012, 25, 97–116. [Google Scholar] [Green Version]
- Dvořák, W.; Järvisalo, M.; Wallner, J.P.; Woltran, S. Complexity-sensitive decision procedures for abstract argumentation. Artif. Intell. 2014, 206, 53–78. [Google Scholar] [CrossRef]
- Marques-Silva, J.; Janota, M.; Belov, A. Minimal Sets over Monotone Predicates in Boolean Formulae. In Proceedings of the 25th International Conference Computer Aided Verification (CAV 2013), Saint Petersburg, Russia, 13–19 July 2013; Sharygina, N., Veith, H., Eds.; Springer: Berlin, Germany, 2013; Volume 8044, pp. 592–607. [Google Scholar]
- De Haan, R.; Szeider, S. Parameterized Complexity Results for Symbolic Model Checking of Temporal Logics. In Proceedings of the Fifteenth International Conference on the Principles of Knowledge Representation and Reasoning (KR 2016), Cape Town, South Africa, 25–29 April 2016; pp. 453–462. [Google Scholar]
- Endriss, U.; De Haan, R.; Szeider, S. Parameterized Complexity Results for Agenda Safety in Judgment Aggregation. In Proceedings of the 5th International Workshop on Computational Social Choice (COMSOC-2014), Istanbul, Turkey, 4–8 May 2014. [Google Scholar]
- De Haan, R. An Overview of Non-Uniform Parameterized Complexity. In Electronic Colloquium on Computational Complexity (ECCC); Technical Report TR15-130; Weizmann Institute of Science: Rehovot, Israel, 2015. [Google Scholar]
- De Haan, R.; Kronegger, M.; Pfandler, A. Fixed-parameter Tractable Reductions to SAT for Planning. In Proceedings of the 24th International Joint Conference on Artificial Intelligence (IJCAI 2015), Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- De Haan, R.; Szeider, S. Compendium of Parameterized Problems at Higher Levels of the Polynomial Hierarchy. In Electronic Colloquium on Computational Complexity (ECCC); Technical Report TR14–143; Weizmann Institute of Science: Rehovot, Israel, 2014. [Google Scholar]
- De Haan, R.; Szeider, S. Machine Characterizations for Parameterized Complexity Classes beyond para-NP. In Proceedings of the 41st Conference on Current Trends in Theory and Practice of Computer Science (SOFSEM 2015), Pec pod Sněžkou, Czech Republic, 24–29 January 2015; Springer: Berlin, Germany, 2015; Volume 8939. [Google Scholar]
- Kloks, T. Treewidth: Computations and Approximations; Springer: Berlin, Germany, 1994. [Google Scholar]
- Bodlaender, H.L. A linear-time algorithm for finding tree-decompositions of small treewidth. SIAM J. Comput. 1996, 25, 1305–1317. [Google Scholar] [CrossRef]
- Ayari, A.; Basin, D.A. QUBOS: Deciding Quantified Boolean Logic Using Propositional Satisfiability Solvers. In Proceedings of the 4th International Conference on Formal Methods in Computer-Aided Design (FMCAD 2002), Portland, OR, USA, 6–8 November 2002; Aagaard, M., O’Leary, J.W., Eds.; Springer: Berlin, Germany, 2002; Volume 2517, pp. 187–201. [Google Scholar]
- Biere, A. Resolve and Expand. In Proceedings of the Seventh International Conference on Theory and Applications of Satisfiability Testing (SAT 2004), Vancouver, BC, Canada, 10–13 May 2004; pp. 59–70. [Google Scholar]
- Umans, C. Approximability and Completeness in the Polynomial Hierarchy. Ph.D. Thesis, University of California, Berkeley, CA, USA, 2000. [Google Scholar]
- De Haan, R. Parameterized Complexity Results for the Kemeny Rule in Judgment Aggregation. In Proceedings of the 22nd European Conference on Artificial Intelligence (ECAI 2016), The Hague, The Netherlands, 29 August–2 September 2016; Kaminka, G.A., Fox, M., Bouquet, P., Hüllermeier, E., Dignum, V., Dignum, F., van Harmelen, F., Eds.; IOS Press: Amsterdam, The Netherlands, 2016; Volume 285, pp. 1502–1510. [Google Scholar]
- Brewka, G.; Eiter, T.; Truszczynski, M. Answer set programming at a glance. Commun. ACM 2011, 54, 92–103. [Google Scholar] [CrossRef]
- Marek, V.W.; Truszczynski, M. Stable models and an alternative logic programming paradigm. In The Logic Programming Paradigm: A 25-Year Perspective; Springer: Berlin, Germany, 1999; pp. 169–181. [Google Scholar]
- Gelfond, M.; Lifschitz, V. Classical Negation in Logic Programs and Disjunctive Databases. New Gener. Comput. 1991, 9, 365–386. [Google Scholar] [CrossRef]
- Gottlob, G. On minimal constraint networks. Artif. Intell. 2012, 191–192, 42–60. [Google Scholar] [CrossRef]
- Abramsky, S.; Gottlob, G.; Kolaitis, P.G. Robust Constraint Satisfaction and Local Hidden Variables in Quantum Mechanics. In Proceedings of the 23rd International Joint Conference on Artificial Intelligence (IJCAI 2013), Beijing, China, 3–9 August 2013; Rossi, F., Ed.; AAAI Press: Palo Alto, CA, USA, 2013. [Google Scholar]
- Eiter, T.; Gottlob, G. The complexity of logic-based abduction. J. ACM 1995, 42, 3–42. [Google Scholar] [CrossRef]
- Ajtai, M.; Fagin, R.; Stockmeyer, L.J. The Closure of Monadic NP. J. Comput. Syst. Sci. 2000, 60, 660–716. [Google Scholar] [CrossRef]
- Baier, C.; Katoen, J.P. Principles of Model Checking; MIT Press: Cambridge, MA, USA, 2008. [Google Scholar]
- Clarke, E.M.; Grumberg, O.; Peled, D.A. Model Checking; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Endriss, U.; Grandi, U.; Porello, D. Complexity of Judgment Aggregation. J. Artif. Intell. Res. 2012, 45, 481–514. [Google Scholar] [CrossRef]
- Nehring, K.; Puppe, C. The structure of strategy-proof social choice—Part I: General characterization and possibility results on median spaces. J. Econ. Theory 2007, 135, 269–305. [Google Scholar] [CrossRef]
- Bäckström, C.; Nebel, B. Complexity Results for SAS+ Planning. Comput. Intell. 1995, 11, 625–656. [Google Scholar] [CrossRef]
- Pednault, E.P.D. ADL: Exploring the Middle Ground Between STRIPS and the Situation Calculus. In Proceedings of the 1st International Conference on Principles of Knowledge Representation and Reasoning (KR 1989), Toronto, ON, Canada, 15–18 May 1989; pp. 324–332. [Google Scholar]
Figure 1.
An overview of parameterized complexity classes up to the second level of the Polynomial Hierarchy, and higher. Dashed lines indicate a hierarchy of classes—e.g., between and lies the hierarchy .
Figure 1.
An overview of parameterized complexity classes up to the second level of the Polynomial Hierarchy, and higher. Dashed lines indicate a hierarchy of classes—e.g., between and lies the hierarchy .

© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
de Haan, R.; Szeider, S. A Compendium of Parameterized Problems at Higher Levels of the Polynomial Hierarchy. Algorithms 2019, 12, 188. https://0-doi-org.brum.beds.ac.uk/10.3390/a12090188
AMA Style
de Haan R, Szeider S. A Compendium of Parameterized Problems at Higher Levels of the Polynomial Hierarchy. Algorithms. 2019; 12(9):188. https://0-doi-org.brum.beds.ac.uk/10.3390/a12090188
Chicago/Turabian Stylede Haan, Ronald, and Stefan Szeider. 2019. "A Compendium of Parameterized Problems at Higher Levels of the Polynomial Hierarchy" Algorithms 12, no. 9: 188. https://0-doi-org.brum.beds.ac.uk/10.3390/a12090188
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.