A Jacobi–Davidson Method for Large Scale Canonical Correlation Analysis


College of Computer and Information Science, Fujian Agriculture and Forestry University, Fuzhou 350002, China
*
Author to whom correspondence should be addressed.
Algorithms 2020, 13(9), 229; https://0-doi-org.brum.beds.ac.uk/10.3390/a13090229
Submission received: 14 August 2020
/
Revised: 3 September 2020
/
Accepted: 9 September 2020
/
Published: 12 September 2020
Abstract
:In the large scale canonical correlation analysis arising from multi-view learning applications, one needs to compute canonical weight vectors corresponding to a few of largest canonical correlations. For such a task, we propose a Jacobi–Davidson type algorithm to calculate canonical weight vectors by transforming it into the so-called canonical correlation generalized eigenvalue problem. Convergence results are established and reveal the accuracy of the approximate canonical weight vectors. Numerical examples are presented to support the effectiveness of the proposed method.
1. Introduction
Canonical correlation analysis (CCA) is one of the most representative two-view multivariate statistical techniques and has been applied to a wide range of machine learning problems including classification, retrieval, regression and clustering [1,2,3]. It seeks a pair of linear transformations for two view high-dimensional features such that the associated low-dimensional projections are maximally correlated. Denote the data matrices and from two data sets with m and n features, respectively, where d is the number of samples. Without loss of generality, we assume and are centered, i.e., and where is the vector of all ones, otherwise, we can preprocess and as and , respectively. CCA aims to find a pair of canonical weight vectors and that maximize the canonical correlation
where
and then projects the high-dimensional data and onto low-dimensional subspaces spanned by x and y, respectively, to achieve the purpose of dimensionality reduction. In most cases [1,4,5], only one pair of canonical weight vectors is not enough since it means the dimension of low-dimensional subspaces is just one. When a set of canonical weight vectors are required, the single-vector CCA (1) has been extended to obtain the pair of canonical weight matrices and by solving the optimization problem
Usually, both A and B are symmetric positive definite. However, there are cases, such as the under-sampled problem [6], that A and B may be semi-definite. In such a case, some regular techniques [7,8,9,10] by adding a multiple of the identity matrix to them are applied to find the optimal solution of
where and are called regularization parameters and they usually are chosen to maximize the cross-validation score [11]. In other words, A and B are replaced by and to keep the invertible of A and B, respectively. Hence, in this paper, by default we assume A and B are both positive definite and unless explicitly stated otherwise.
As shown in [4], the optimization problem (3) can be equivalently transformed into solving the following generalized eigenvalue problem
where the positive definiteness of the matrices A and B implies M being positive definite. The generalized eigenvalue problem (4) is referred as the Canonical Correlation Generalized Eigenvalue Problem (CCGEP) in this paper. Define where
are their Cholesky decomposition. It is easy to verify that
gives rise to
where
and it implies
It means that the eigenpairs of (4) can be obtained by computing the singular values and the associated left and right singular vectors of . This method works well when the sample size d and feature dimension m and n are of moderate size but it will be very slow and numerically unstable for large-scale datasets which are ubiquitous in the age of “Big Data” [12]. For large-scale datasets, the equivalence between (4) and (6) makes it possible for us to simply adapt the subspace type algorithms for calculating the partial singular values decomposition, such as Lanczos type algorithms [13,14] and Davidson type algorithms [15,16], and then translate them for CCGEP (4). However, in practice, the decompositions of the sample covariance matrices A and B are usually unavailable in large scale matrix cases. The reason is that the decomposition is too expensive to compute explicitly for large scale problems, and may destroy the sparsity and some structural information. Furthermore, sometime sample covariance matrices A and B should never be explicitly formed, such as in online learning systems.
Meanwhile, in [17], it is suggested to solve CCGEP (4) by considering the large scale symmetric positive definite pencil . Some subspace type numerical algorithms also have been generalized to computing partial eigenpairs of , see [18,19]. However, these generic algorithms do not make use of the special structure in (4), and they usually are less efficient than custom-made algorithms. Therefore, existing algorithms either can not avoid the covariance matrices decomposition, or do not consider the structure of CCGEP.
In this paper, we will focus on the Jacobi–Davidson type subspace method for canonical correlation analysis. The idea of Jacobi–Davidson algorithm proposed in [20] is Jacobi’s approach combined with Davidson type subspace method. Its essence is to construct a correction for a given eigenvector approximation in a subspace orthogonal to the given approximation. The correction in a given subspace is extracted in a Davidson manner, and then the expansion of the subspace is done by solving its correction equation. Due to the significant improvement in convergence, the Jacobi–Davidson has been one of the most powerful algorithms in the matrix eigenvalue problem, and is almost generalized to all fields of matrix computation. For example, in [15,21], Hochstenbach presented Jacobi–Davidson methods for singular value problems and generalized singular value problems, respectively. In [22,23], Jacobi–Davidson methods are developed to solve the nonlinear and two-parameter eigenvalue problems, respectively. Some other recent work on Jacobi–Davidson methods can be found in [24,25,26,27,28,29]. Motivated by these facts, we will continue the effort by extending the Jacobi–Davidson variant to canonical correlation analysis. The main contribution is that the algorithm directly tackles CCGEP (4) without involving the large matrix decomposition, and does take advantage of the special structure of K and M, while the significance of transforming (4) into (6) lies only in our theoretical developments.
The rest of this paper is organized as follows. Section 2 collects some notations and a basic result for CCGEP that are essential to our later development. Our main algorithm is given and analyzed in detail in Section 3. We present some numerical examples in Section 4 to show the behaviors of our proposed algorithm and to support our analysis. Finally, conclusions are made in Section 5.
2. Preliminaries
Throughout this paper, is the set of all real matrices, , and . is the identity matrix. The superscript “” takes transpose only, and denotes the -norm of a vector or matrix. For any matrix with , for is used to denote the singular values of N in descending order.
For vectors , the usual inner product and its induced norm are conveniently defined by
With them, the usual acute angle between x and y can then be defined by
Similarly, given any symmetric positive definite , the W-inner product and its induced W-norm are defined by
If , then we say or . The W-acute angle between x and y can then be defined by
Let the singular value decomposition of be where and are orthonormal, i.e., and , and with is a leading diagonal matrix. The singular value decomposition of closely relates to the eigendecomposition of the following symmetric matrix [30] (p. 32):
whose eigenvalues are for plus zeros, i.e.,
with associated eigenvectors are
respectively. The equivalence between (4) and (6) leads that the eigenvalues of CCGEP (4) are for plus zeros, and the corresponding eigenvectors are
respectively, where
Let and . Then, the A- and B-orthonormal constraints of X and Y, respectively, i.e.,
are followed by and . Here, the first few and for with are wanted canonical correlation weight vectors. Furthermore, their corresponding eigenvalues satisfy the following maximization principle which is critical to our later developments. For the proof see Appendix A.1.
3. The Main Algorithm
The idea of the Jacobi–Davidson method [20] is to construct iteratively approximations of certain eigenpairs. It uses solving a correction equation to expand the search subspace, and finds approximate eigenpairs as best approximations in such search subspace.
3.1. Subspace Extraction
Let and with and , respectively. As stated in [31], we call a pair of defalting subspaces of CCGEP (4) if
Let and be A- and B-orthonormal basis matrices of the subspaces and , respectively, i.e.,
They imply . So (14) is equivalent to
Now if is a singular triplet of , then gives an eigenpair of (4), where , and . This is because
and similarly . That means
Hence, we have shown that a pair of deflating subspaces can be used to recover those eigenpairs associated with the pair of deflating subspaces of CCGEP (4). In practice, pairs of exact deflating subspaces are usually not available, and one usually use Lanczos type methods [14] or Davidson type methods [15] to generate approximate ones, such as Krylov subspaces in Lanczos method [33]. Next, we will discuss how to extract best approximate eigenpairs from a given pair of approximate deflating subspaces.
In what follows, we consider the simple case: . Suppose is an approximation of a pair of deflating subspaces with . Let and be the A- and B-orthonormal basis matrices of the subspaces and , respectively. Denote , the singular values of in descending order with associated left and right singular vectors and , respectively, i.e.,
Even though U and V as A- and B-orthonormal basis matrices are not unique, these are. Motivated by the maximization principle in Theorem 1, we would seek the best approximations associated with the pair of approximate deflating subspaces to the eigenpairs () in the sense of
for any and satisfying , and . We claim that the quantity in (15) is given by . To see this, we notice that any and in (15) can be written as
for some and with , and vice versa. Therefore the quantity in (15) is equal to
which is by the proposition of the singular value decomposition of [30]. The maximum is attended at and . Therefore naturally, the best approximations to () in the sense of (15) are given by
Define the residual
where K and M defined in (4), and . It is noted that
and similarly = 0. We summarize what we do in this subsection in the following theorem.
Theorem 2.
Suppose is a pair of approximate deflating subspaces with . Let and be the A- and B-orthonormal basis matrices of the subspaces and , respectively. Denote , the singular values of in descending order. Then, for any ,
the best approximations to the eigenpairs () in the sense of (15) are () given by (16), and the associated residuals defined in (17) admit and .
3.2. Correction Equation
In this subsection, we turn to construct a correction equation for a given eigenpair approximation. Suppose with is an approximation of the eigenpair of CCGEP (4), and is the associated residual. We seek A- and B-orthogonal modifications of and , respectively, such that
where and . Then, by (18), we have
Notice that and by Theorem 2, which gives rise to
and
Because and , Equation (20) is rewritten as
However, we do not know here. It is natural that we use to replace in (21) to get the final correction equation, i.e.,
We summarize what we have so far into Algorithm 1, and make a few comments on Algorithm 1.
- (1)
- At step 2, A- and B-orthogonality procedures are applied to make sure and .
- (2)
- At step 7, in most cases, the correct equation is not necessity to solve exactly. Some steps of iterative methods for symmetric linear systems, such as linear conjugate gradient method (CG) [34] or the minimum residual method (MINRES) [35], are sufficient. Usually, more steps in solving the correction equation lead to fewer outer iterations. This will be shown in numerical examples.
- (3)
- For the convergence test, we use the relative residual normsto determine if the approximate eigenparis has converged to a desired accuracy. In addition, in the practical implementation, once one or several of approximate eigenpairs converge to a preset accuracy, they should be deflated so that they will not be re-computed in the following iterations. Suppose for , and have been computed where . We can consider the generalized eigenvalue problemwhereBy (11), it is clear that the eigenvalues of (24) consist of two groups. Those eigenvalues associated with the eigenvectors are shifted to zero and the others remain unchanged. Furthermore, for the correction equation, we find s and t subject to additional A- and B-orthogonality constrains for s and t against and , respectively. By a similar derivation of (22), the correction equation after deflation becomeswhere . Notice that and mean and in Algorithm 1, respectively. It follows that .
- (4)
- At step 5, LAPACK’s routine xGESVD can be used to solve the singular value problem of because of its small size, where takes the following form:This form is preserved in the algorithm during refining the basis U and V at step 8. The new basis matrices and are reassigned to U and V, respectively. Although a few extra costs are incurred, this refinement is necessary in order to have faster convergence for eigenvectors as stated in [36,37]. Furthermore, the restart is easily executed by keeping the first columns of U and V when the dimension of the subspaces and exceeds . The restart technique appears at step 8 to keep the size of U, V and small. There are many ways to specify and . In our numerical examples, we just simply take and .
![Algorithms 13 00229 i001]()

| Algorithm 1 Jacobi–Davidson method for canonical correlation analysis (JDCCA) |
| Input: Initial vectors , , , and . Output: Converged canonical weight vectors and for .
|
3.3. Convergence
The convergence theories on the Jacobi–Davidson method for the eigenvalue and singular value problem are given in [15,38], respectively. Here we prove a similar convergence result for the Jacobi–Davidson method of CCGEP based on the following lemma. Specifically, if we solve the correction Equation (22) exactly, and then and are close enough to x and y, respectively, it can be hoped that the approximate eigenvectors converge cubically. For the proof see Appendix A.2 and Appendix A.3.
Lemma 1.
Let λ be a simple eigenvalue of CCGEP (4) with the corresponding eigenvector . Then the matrix
is a bijection from onto itself, where and are A- and B-orthogonal complementary spaces of and , respectively.
Theorem 3.
Assume the condition of Lemma 1, and . Let be the exact solution of the correction Equation (22). Then,
4. Numerical Examples
In this section, we present some numerical examples to illustrate the effectiveness of Algorithm 1. Our goal is to compute the first few canonical weight vectors. A computed approximate eigenpair is considered converged when its relative residual norm
All the experiments in this paper are executed on a Ubuntu 12.04 (64 bit) Desktop-Intel(R) Core(TM) i7-6700 [email protected] GHz, 32 GB of RAM using MATLAB 2010a with machine epsilon in double-precision floating point arithmetic.
Example 1.
We first examine Theorem 3 by using two pairs of data matrices and which come from a publicly available handwritten numerals dataset (https://archive.ics.uci.edu/ml/datasets/Multiple+Features). It consists of features handwritten numerals (‘0’–‘9’) and each digit has 200 patterns. Each pattern is represented by six different feature sets, i.e., Fou, Fac, Kar, Pix, Zer and Mor. Two pairs of feature sets Fou-Zer and Pix-Fou are chosen for and , respectively, such that and in Fou-Zer, and and in Pix-Fou with . To make the numerical example repeatable, the initial vectors are set to be
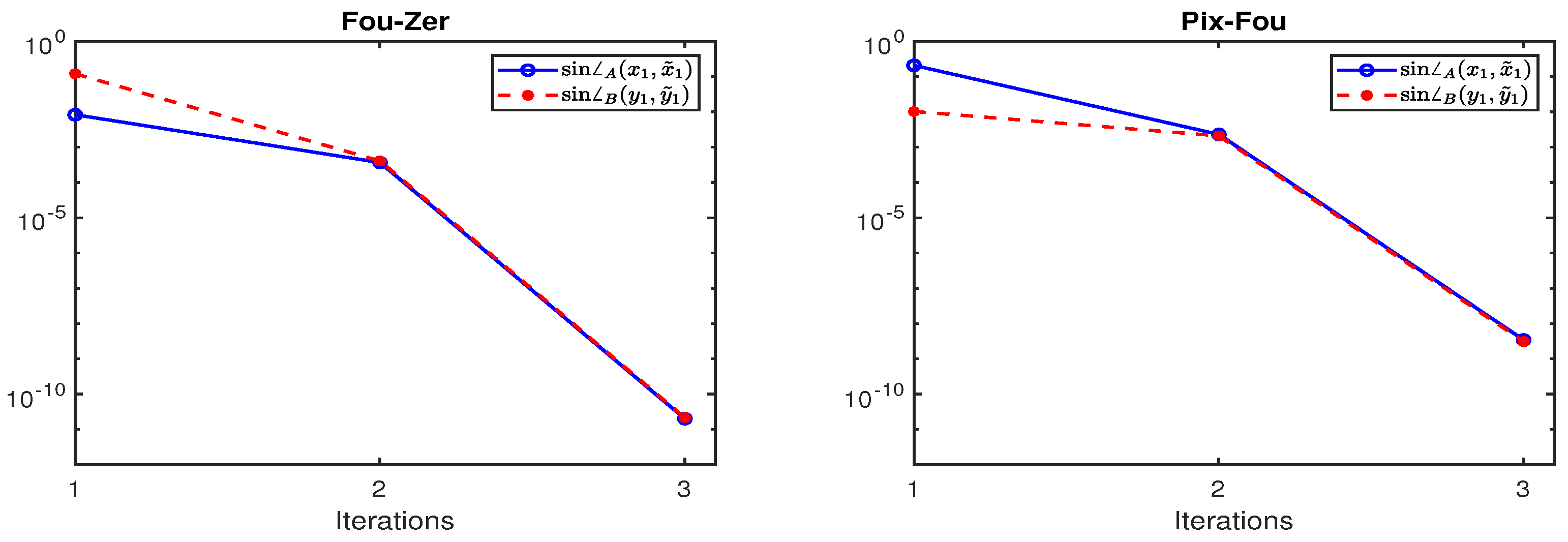
where m and n are the dimension of and , respectively, is MATLAB built-in function, and is computed by MATLAB’s function eig on (4) and considered to be the “exact” eigenvector for testing purposes. The corrected Equation (22) in Algorithm 1 is solved by direct methods, such as Gaussian elimination, and the solution by such methods is regarded as “exactly” in this example. Figure 1 plots and in the first three iterations of Algorithm 1 for computing first canonical weight vector of Fou-Zer and Pix-Fou. It is clearly shown by Figure 1 that the convergence of Algorithm 1 is very fast when the initial vectors are enough close to the exact vectors, and the cubical convergence of Algorithm 1 appears in the third iteration.
Example 2.
As stated in Algorithm 1, the implementation of JDCCA involves solving the correction Equation (22) in every step. Direct solvers mentioned in Example 1 referring to operations are prohibitively expensive in solving large-scale sparse linear systems. In such a case, iterative methods, such as MINRES method which is simply GMRES [39] applied to symmetric linear systems, are usually preferred. In this example, we report the effect of the number of steps in the solution of the correction equation, denoted by , on the total number of matrix-vector products (denoted by “#mvp”), outer iteration number (denoted by “#iter”), and CPU time in seconds for Algorithm 1 to compute the first 10 canonical weight vectors of the test problems appeared in Table 1. Table 1 presents three face datasets, i.e., ORL (https://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html,) FERET (http://www.nist.gov/itl/iad/ig/colorferet.cfm) and Yale (https://computervisiononline.com/dataset/1105138686) datasets. The ORL database contains 400 face images of 40 distinct persons. For each individual, there are 10 different gray scale images with pixels. These images are collected by volunteers at different times, different lighting and different facial expressions (blinking or closed eyes, smiling or no-smiling, wearing glasses or no-glasses). In order to apply CCA, as numerical experiments in [40], the ORL dataset is partitioned into two groups. We select the first five images per individual as the first view to generate the data matrix , while the remaining for . Similarly, we get data matrices and for the FERET and Yale datasets. The numbers of row and column of and are detailed in Table 1.
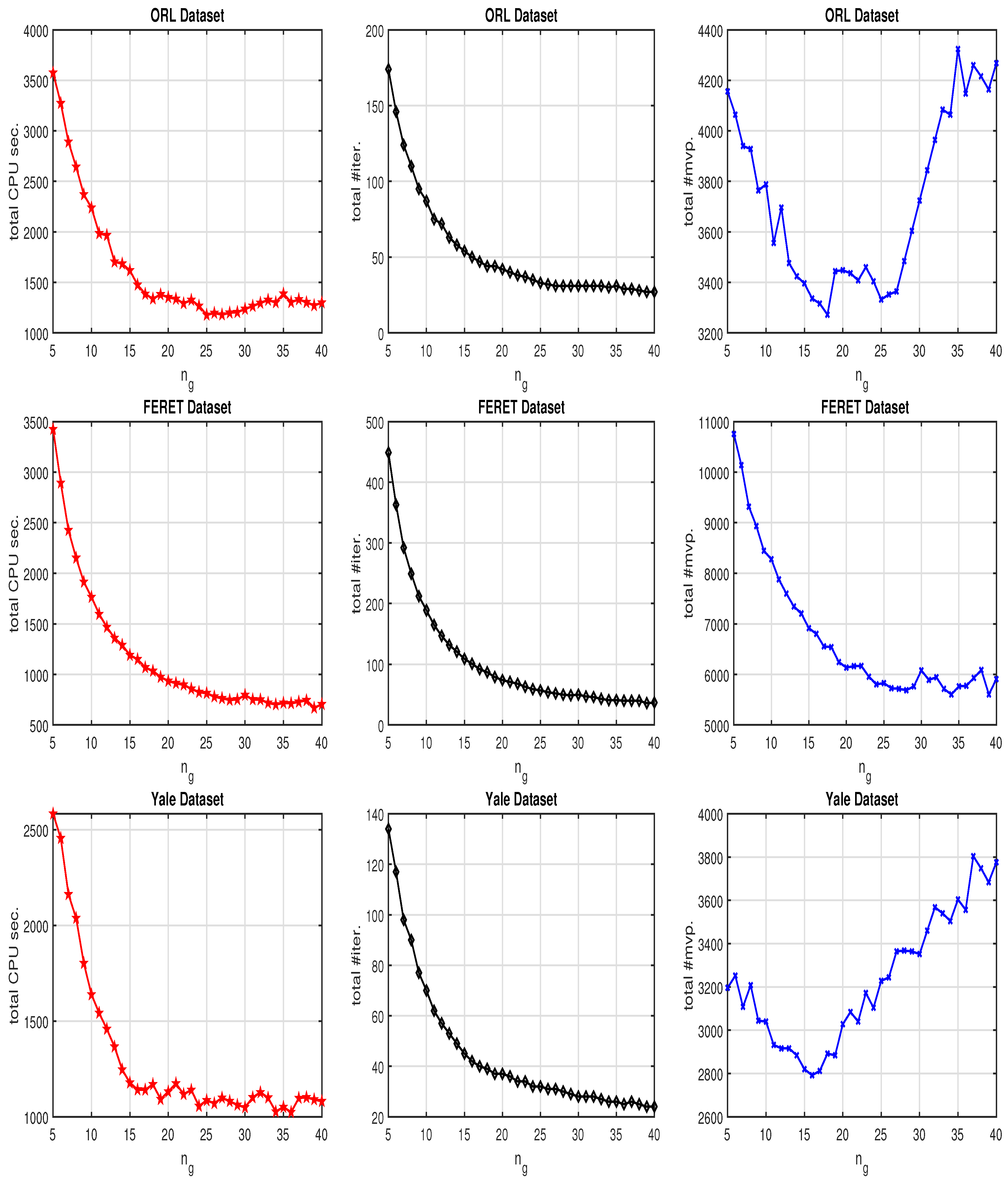
In this example, we set the initial vectors and with and for restarting and simply take regularization parameter . We let MINRES steps vary from to 5 to 40, and collect the numerical results in Figure 2. As expected, the number of total outer iterations decreases as increases, while the total number of matrix-vector products does not change monotonically with . It depends on the degree of reduction of outer iterations by the increasing of . In addition, it is shown by Figure 2 that the total #mvp is not a unique deciding factor on the total CPU time. When is larger, the significantly reduced #iter leads to smaller total CPU time. For these three test examples, the MINRES steps around 15 to 25 appear to be cost-effective, further increasing over 40 usually does not have significant effect. The least efficient case is when is too small.
Example 3.
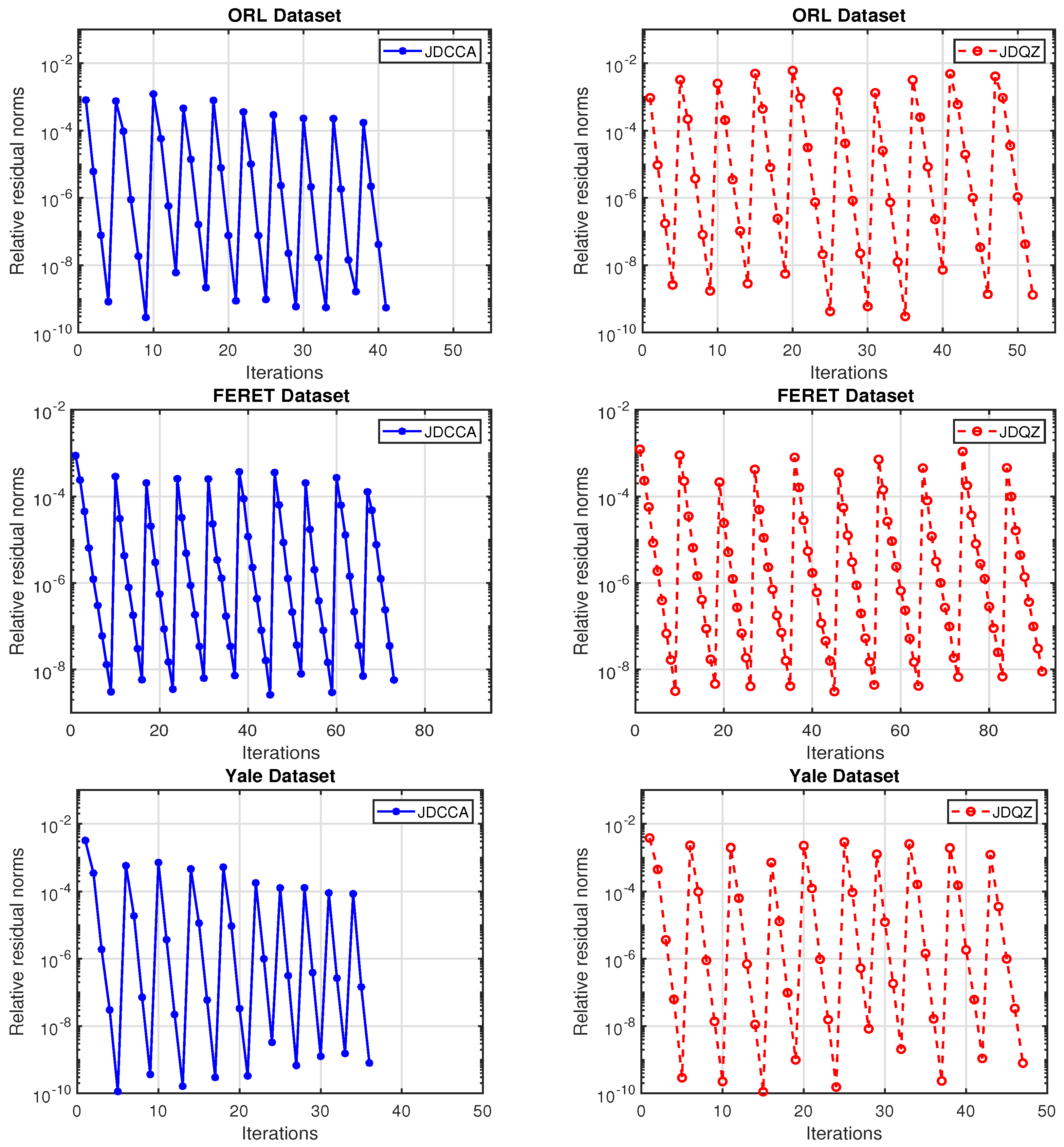
In this example, we compare Algorithm 1, i.e., JDCCA, with Jacobi–Davidson QZ type method [41] (JDQZ) for the large scale symmetric positive definite pencil defined in (4) to compute the first 10 canonical weight vectors of the test problems appeared in Table 1 with MINRES steps . We take and in Algorithm 1 and the initial vector for the JDQZ algorithm, and compute the same relative residual norms . The corresponding numerical results are plotted in Figure 3. For these three test problems, it is suggested by Figure 3 that Algorithm 1 always outperforms the JDQZ algorithm. Other experiments that we tested with different test problems and MINRES steps not reported here also illustrate our points.
5. Conclusions
To analyze the correlations between two data sets, several numerical algorithms have been available to find the canonical correlations and the associated canonical weight vectors; however, there is very little discussion of the large scale sparse and structured matrix cases in the literature. In this paper, a Jacobi–Davidson type method, i.e., Algorithm 1, is presented for large scale canonical correlation analysis by computing a small portion of eigenpairs of the canonical correlation generalized eigenvalue problem (4). The theoretical result is established in Theorem 3 to demonstrate that the cubic convergence of the approximate eigenvector if the correction equation is solved exactly and the approximate eigenvector of the previous step is close enough to the exact one. The corresponding numerical results are presented to confirm the effectiveness of asymptotic convergence rate provided by Theorem 3, and to demonstrate that Algorithm 1 performs far superior to the JDQZ method for the large scale symmetric positive definite pencil .
Notice that the main computational tasks in every iteration of Algorithm 1 consist of solving the correction Equation (22). In our numerical example, we only focus on the plain version of MINRES, i.e., without considering any preconditioner. However, it is not hard to notice that incorporating a preconditioner presents no difficulty and can promote the numerical performance if the preconditioner is available. In addition, from the point of view that multi-set canonical correlation analysis (MCCA) [42] proposed to analyze linear relationships among more than two data sets can be equivalently transformed to the following generalized eigenvalue problem
where and is the data matrix, the development of efficient Jacobi–Davidson methods for treating such large scale MCCA will be a subject of our future study.
Author Contributions
Writing—original draft, Z.T.; Writing—review and editing, X.Z. and Z.T. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported in part by National Natural Science Foundation of China NSFC-11601081 and the research fund for distinguished young scholars of Fujian Agriculture and Forestry University No. xjq201727.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Appendix A.1
Proof of Theorem 1.
To prove (12), for any and satisfying and , respectively, we first consider the augmented matrices of and , i.e.,
whose eigenvalues for plus zeros and for plus , respectively. Notice that
where and are defined in (5), and and satisfy and , respectively. Hence, apply Cauchy’s interlacing inequalities [30] (Corollary 4.4) for the symmetric eigenvalue problem to the matrices and , to get for and consequently
for any and such that and .
Appendix A.2
Proof of Lemma 1.
Let and it satisfies . We will prove . Since
then we have
where and , which leads to
Let and . Then the equality (A3) can be rewritten as
where , p and q are defined in (7). Multiply the first and second equations of (A4) by and from left, respectively, to get
Therefore, both and p belong to the kernel of , and both and q belong to the kernel of . The simplicity of implies and are multiples of p and q, respectively. Since and , we have and , which means . Therefore, . The bijectivity follow from comparing dimensions. □
Appendix A.3
Proof of Theorem 3.
Let
Then the correction equation is
Since , there exists such that where . It follows that where and . Similarly, there are and a scalar such that where . It is noted that
where and . Since and , the equality (A6) leads to
It is noted that , , and . Then, we have by (A7)
In addition, since and , multiplying (A7) on the left by leads to
By Lemma 1, when and are close enough to x and y, respectively, we see that is invertible. It follows by (A9) that
The last equality holds because of , and (A10), which means and . Therefore,
where . Similarly, we have . □
References
- Hardoon, D.R.; Szedmak, S.; Shawe-Taylor, J. Canonical correlation analysis: An overview with application to learning methods. Neural Comput. 2004, 16, 2639–2664. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Harold, H. Relations between two sets of variates. Biometrika 1936, 28, 321–377. [Google Scholar]
- Wang, L.; Zhang, L.H.; Bai, Z.; Li, R.C. Orthogonal canonical correlation analysis and applications. Opt. Methods Softw. 2020, 35, 787–807. [Google Scholar] [CrossRef]
- Uurtio, V.; Monteiro, J.M.; Kandola, J.; Shawe-Taylor, J.; Fernandez-Reyes, D.; Rousu, J. A tutorial on canonical correlation methods. ACM Comput. Surv. 2017, 50, 1–33. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.H.; Wang, L.; Bai, Z.; Li, R.C. A self-consistent-field iteration for orthogonal CCA. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 1–15. [Google Scholar] [CrossRef]
- Fukunaga, K. Introduction to Statistical Pattern Recognition; Elsevier: Amsterdam, The Netherlands, 2013. [Google Scholar]
- González, I.; Déjean, S.; Martin, P.G.P.; Gonçalves, O.; Besse, P.; Baccini, A. Highlighting relationships between heterogeneous biological data through graphical displays based on regularized canonical correlation analysis. J. Biol. Syst. 2009, 17, 173–199. [Google Scholar] [CrossRef]
- Leurgans, S.E.; Moyeed, R.A.; Silverman, B.W. Canonical correlation analysis when the data are curves. J. R. Stat. Soc. B. Stat. Methodol. 1993, 55, 725–740. [Google Scholar] [CrossRef]
- Raul, C.C.; Lee, M.L.T. Fast regularized canonical correlation analysis. Comput. Stat. Data Anal. 2014, 70, 88–100. [Google Scholar]
- Vinod, H.D. Canonical ridge and econometrics of joint production. J. Econ. 1976, 4, 147–166. [Google Scholar] [CrossRef]
- González, I.; Déjean, S.; Martin, P.G.P.; Baccini, A. CCA: An R package to extend canonical correlation analysis. J. Stat. Softw. 2008, 23, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Ma, Z. Canonical Correlation Analysis and Network Data Modeling: Statistical and Computational Properties. Ph.D. Thesis, University of Pennsylvania, Philadelphia, PA, USA, 2017. [Google Scholar]
- Golub, G.; Kahan, W. Calculating the singular values and pseudo-inverse of a matrix. SIAM J. Numer. Anal. 1965, 2, 205–224. [Google Scholar] [CrossRef]
- Jia, Z.; Niu, D. An implicitly restarted refined bidiagonalization Lanczos method for computing a partial singular value decomposition. SIAM J. Matrix Anal. Appl. 2003, 25, 246–265. [Google Scholar] [CrossRef]
- Hochstenbach, M.E. A Jacobi—Davidson type SVD method. SIAM J. Sci. Comput. 2001, 23, 606–628. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Y.; Wang, Z.; Zhou, A. Accelerating large partial EVD/SVD calculations by filtered block Davidson methods. Sci. China Math. 2016, 59, 1635–1662. [Google Scholar] [CrossRef]
- Allen-Zhu, Z.; Li, Y. Doubly accelerated methods for faster CCA and generalized eigendecomposition. In Proceedings of the International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; pp. 98–106. [Google Scholar]
- Saad, Y. Numerical Methods for Large Eigenvalue Problems: Revised Edition; SIAM: Philadelphia, PA, USA, 2011. [Google Scholar]
- Stewart, G.W. Matrix Algorithms Volume II: Eigensystems; SIAM: Philadelphia, PA, USA, 2001; Volume 2. [Google Scholar]
- Sleijpen, G.L.G.; Van der Vorst, H.A. A Jacobi—Davidson iteration method for linear eigenvalue problems. SIAM Rev. 2000, 42, 267–293. [Google Scholar] [CrossRef]
- Hochstenbach, M.E. A Jacobi—Davidson type method for the generalized singular value problem. Linear Algebra Appl. 2009, 431, 471–487. [Google Scholar] [CrossRef] [Green Version]
- Betcke, T.; Voss, H. A Jacobi–Davidson-type projection method for nonlinear eigenvalue problems. Future Gen. Comput. Syst. 2004, 20, 363–372. [Google Scholar] [CrossRef] [Green Version]
- Hochstenbach, M.E.; Plestenjak, B. A Jacobi—Davidson type method for a right definite two-parameter eigenvalue problem. SIAM J. Matrix Anal. Appl. 2002, 24, 392–410. [Google Scholar] [CrossRef] [Green Version]
- Arbenz, P.; Hochstenbach, M.E. A Jacobi—Davidson method for solving complex symmetric eigenvalue problems. SIAM J. Sci. Comput. 2004, 25, 1655–1673. [Google Scholar] [CrossRef] [Green Version]
- Campos, C.; Roman, J.E. A polynomial Jacobi—Davidson solver with support for non-monomial bases and deflation. BIT Numer. Math. 2019, 60, 295–318. [Google Scholar] [CrossRef]
- Hochstenbach, M.E. A Jacobi—Davidson type method for the product eigenvalue problem. J. Comput. Appl. Math. 2008, 212, 46–62. [Google Scholar] [CrossRef]
- Hochstenbach, M.E.; Muhič, A.; Plestenjak, B. Jacobi—Davidson methods for polynomial two-parameter eigenvalue problems. J. Comput. Appl. Math. 2015, 288, 251–263. [Google Scholar] [CrossRef]
- Meerbergen, K.; Schröder, C.; Voss, H. A Jacobi–Davidson method for two-real-parameter nonlinear eigenvalue problems arising from delay-differential equations. Numer. Linear Algebra Appl. 2013, 20, 852–868. [Google Scholar] [CrossRef]
- Rakhuba, M.V.; Oseledets, I.V. Jacobi–Davidson method on low-rank matrix manifolds. SIAM J. Sci. Comput. 2018, 40, A1149–A1170. [Google Scholar] [CrossRef]
- Stewart, G.W.; Sun, J.G. Matrix Perturbation Theory; Academic Press: Boston, FL, USA, 1990. [Google Scholar]
- Teng, Z.; Wang, X. Majorization bounds for SVD. Jpn. J. Ind. Appl. Math. 2018, 35, 1163–1172. [Google Scholar] [CrossRef]
- Bai, Z.; Li, R.C. Minimization principles and computation for the generalized linear response eigenvalue problem. BIT Numer. Math. 2014, 54, 31–54. [Google Scholar] [CrossRef]
- Teng, Z.; Li, R.C. Convergence analysis of Lanczos-type methods for the linear response eigenvalue problem. J. Comput. Appl. Math. 2013, 247, 17–33. [Google Scholar] [CrossRef]
- Demmel, J.W. Applied Numerical Linear Algebra; SIAM: Philadelphia, PA, USA, 1997. [Google Scholar]
- Saad, Y. Iterative Methods for Sparse Linear Systems; SIAM: Philadelphia, PA, USA, 2003. [Google Scholar]
- Teng, Z.; Zhou, Y.; Li, R.C. A block Chebyshev-Davidson method for linear response eigenvalue problems. Adv. Comput. Math. 2016, 42, 1103–1128. [Google Scholar] [CrossRef]
- Zhou, Y.; Saad, Y. A Chebyshev–Davidson algorithm for large symmetric eigenproblems. SIAM J. Matrix Anal. Appl. 2007, 29, 954–971. [Google Scholar] [CrossRef] [Green Version]
- Sleijpen, G.L.G.; Van der Vorst, H.A. The Jacobi–Davidson method for eigenvalue problems as an accelerated inexact Newton scheme. In Proceedings of the IMACS Conference, Blagoevgrad, Bulgaria, 17–20 June 1995. [Google Scholar]
- Saad, Y.; Schultz, M.H. GMRES: A generalized minimal residual algorithm for solving nonsymmetric linear systems. SIAM J. Sci. Statist. Comput. 1986, 7, 856–869. [Google Scholar] [CrossRef] [Green Version]
- Lee, S.H.; Choi, S. Two-dimensional canonical correlation analysis. IEEE Signal Process. Lett. 2007, 14, 735–738. [Google Scholar] [CrossRef]
- Fokkema, D.R.; Sleijpen, G.L.G.; Van der Vorst, H.A. Jacobi–Davidson style QR and QZ algorithms for the reduction of matrix pencils. SIAM J. Sci. Comput. 1998, 20, 94–125. [Google Scholar] [CrossRef] [Green Version]
- Desai, N.; Seghouane, A.K.; Palaniswami, M. Algorithms for two dimensional multi set canonical correlation analysis. Pattern Recognit. Lett. 2018, 111, 101–108. [Google Scholar] [CrossRef]
Figure 1.
Convergence behavior of Algorithm 1 for computing the first canonical weight vector of Fou-Zer and Pix-Fou.
Figure 1.
Convergence behavior of Algorithm 1 for computing the first canonical weight vector of Fou-Zer and Pix-Fou.

Figure 2.
Cost in computing the first 10 canonical weight vectors of ORL (top), FERET (middle) and Yale (bottom) datasets with MINRES steps for the correction equation varying from 5 to 40.
Figure 2.
Cost in computing the first 10 canonical weight vectors of ORL (top), FERET (middle) and Yale (bottom) datasets with MINRES steps for the correction equation varying from 5 to 40.

Figure 3.
Convergence behavior of JDCCA and JDQZ for computation of the first 10 canonical weight vectors of ORL (top), FERET (middle) and Yale (bottom) datasets with MINRES step .
Figure 3.
Convergence behavior of JDCCA and JDQZ for computation of the first 10 canonical weight vectors of ORL (top), FERET (middle) and Yale (bottom) datasets with MINRES step .


{kind=link}
{kind=link}
{kind=link}
Table 1.
Test problems.
| Problems | ORL | FERET | Yale |
|---|---|---|---|
| m | 10,304 | 6400 | 10,000 |
| n | 10,304 | 6400 | 10,000 |
| d | 200 | 600 | 75 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Teng, Z.; Zhang, X. A Jacobi–Davidson Method for Large Scale Canonical Correlation Analysis. Algorithms 2020, 13, 229. https://0-doi-org.brum.beds.ac.uk/10.3390/a13090229
AMA Style
Teng Z, Zhang X. A Jacobi–Davidson Method for Large Scale Canonical Correlation Analysis. Algorithms. 2020; 13(9):229. https://0-doi-org.brum.beds.ac.uk/10.3390/a13090229
Chicago/Turabian StyleTeng, Zhongming, and Xiaowei Zhang. 2020. "A Jacobi–Davidson Method for Large Scale Canonical Correlation Analysis" Algorithms 13, no. 9: 229. https://0-doi-org.brum.beds.ac.uk/10.3390/a13090229
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.