
A Set-Theoretic Approach to Modeling Network Structure


Department of Computer Science, University of Virginia, Charlottesville, VA 22911, USA
Algorithms 2021, 14(5), 153; https://0-doi-org.brum.beds.ac.uk/10.3390/a14050153
Submission received: 27 March 2021
/
Revised: 27 April 2021
/
Accepted: 28 April 2021
/
Published: 11 May 2021
(This article belongs to the Special Issue Network Science: Algorithms and Applications)
Abstract
:Three computer algorithms are presented. One reduces a network to its interior, . Another counts all the triangles in a network, and the last randomly generates networks similar to given just its interior . However, these algorithms are not the usual numeric programs that manipulate a matrix representation of the network; they are set-based. Union and meet are essential binary operators; contained_in is the basic relational comparator. The interior is shown to have desirable formal properties and to provide an effective way of revealing “communities” in social networks. A series of networks randomly generated from is compared with the original network, .
1. Introduction
The textbook way of describing network structure is to represent a network, , as two sets where N is a set of nodes and L is a set of unordered pairs , called links (In graph theory, these unordered pairs are called “edges”. This seems to be derived from the edges of the solid “dodecahedron puzzle” of Sir William Hamilton (1857) and retained through inertia. However, since in social networks they connect individuals, it seems more appropriate to call them “links”) [1,2]. However, although textbook network theory is almost always set based, virtually all computer network algorithms are algebraic [3,4]. Any network can be represented by its adjacency matrix, , where if is a link and 0 otherwise. There is an abundance of matrix algorithms one can use, such as eigenvector evaluation [3]. In this paper, we supplement these matrix-based algorithms. The common goal is to describe the nature of a network in terms of fundamental properties. A matrix based approach yields numeric properties; the set based approach of this paper yields set-theoretic properties.
Unfortunately, there is a dearth of practical set manipulation software. To overcome this problem, we created our own set management system [5]. In this system, sets are strongly typed; for example, there are “sets of nodes” and “sets of links” which are completely distinct. Invoking the subroutines that execute set operations can be awkward and takes time to master; however, one can faithfully duplicate all of the pseudocode presented in this paper. (The source code for all procedures of this paper can be obtained from the author.)
Section 2 is long and somewhat heavy for an algorithm paper. The pseudocode for the set based procedure that reduces any network to its “interior” is presented as Pseudocode I. However, first, we must formally develop the notions of neighborhood closure and irreducibility on which this algorithm, , is based. Then, it must be shown (Proposition 2) that really is a well-defined function mapping into itself, that is that the output of is unique, regardless of the order in which the elements of are encountered. Finally, it must be shown (Proposition 4) that can be characterized as a network of “chordless” cycles.
We believe it is worth it. First, the reduction algorithm separates into distinct “communities”, a process which is always of interest. Second, appears to be an excellent, compressed descriptor of the network . Much of the remaining paper is a justification of this observation.
To support the claim that is a rather good descriptor of any network , the paper follows an unusual course. It is shown in Section 4 that from one can generate a series of networks , each of which has the same interior and similar network properties as . Section 3 develops those properties, most of which come from the network literature. A short procedure (Pseudocode II) is presented, primarily to illustrate the flexibility of a set based approach since such algorithms already exist in the literature.
Section 3.3 is devoted to showing that preserves important centrality features, including both the “center” and “betweeness centers” of a network. This requires three lemmas and two propositions, which might be skipped on a first reading.
Finally, in Section 4, the interior of a small network (Figure 3) is used to generate by expansion (Pseudocode III) three networks together with Table 2 comparing their properties including their principal eigenvector, with those of . We leave it to the reader to decide if these generated networks are similar to .
2. The Interior
Let S be a set. An operator is an injective function which maps subsets of S into subsets of S. We denote operators by Greek letters and use postfix notation, as in , where . An operator is said to be a closure operator if, for all , (C1) (expansive), (C2) implies (monotone) and (C3) (idempotent). Closure operators are a staple of topological mathematics.
If we replace axiom C1 with an contractive axiom I1, so that for all : (I1) (contractive); (I2) implies (monotone); and (I3) (idempotent), then is said to be an interior operator. We use to denote interior operators and to denote closure operators; they are similar, except that one is contractive while the other is expansive.
If one visualizes S as a polytope, then its closure might be the smallest sphere containing (often called its convex hull), while its interior could be the largest inscribed sphere, or ball. Alternatively, if one thinks of S as being a bit of irregular surface terrain with ridges and valleys, then a closure operator fills in the valleys until the terrain is uniformly smooth. An interior operator, in contrast, levels the peaks and ridges until a smooth terrain is obtained.
Let be a network. For any , we say the neighborhood of Y is . (In graph theory, is sometimes called the “closed neighborhood” of Y, and denoted , while is called the “open neighborhood” [1,2]). Finally, since all operators map sets into sets, even when we are talking about the neighborhood of a single node, for example z in (1) below, we express it as . A neighborhood closure operator, , on can be defined by
, so is expansive. It is not hard to see that is monotone. Finally, since , must be idempotent, implying is a closure operator. (C3, or idempotency, is normally the most difficult property to prove when establishing a closure, or interior, operator.) The neighborhood closure operator, , is fundamental to the development of following sections.
2.1. The Network Interior
Consider any node , and suppose there exists implying . Such a node, z whose “horizon” is contained in that of y, contributes very little to the information content of the network so that its removal from will result in little information loss. This node can be reduced. The node y is irreducible if . A sub-network, , of irreducible nodes is called the network’s interior. In the remainder of this section we define an operator, , which reduces any network to its irreducible core, and prove that it is almost an interior operator.
If is not closed, only elements z in could possibly be in so only those need be considered. If so that , we say z is subsumed by y, or z belongs to y. We can remove z from N, together with all its connections, and add z to , the set of all nodes belonging to . This set is called its -set. Of course, . The cardinality is called its -count.
The pseudocode reduce Pseudocode I was used to implement a process that reduces any network to its irreducible core, .
| while there exist reduceable nodes { |
| reducible = 0 |
| for_each {y} in N { |
| for_each {z} in {y}.nbhd - {y} { |
| if ({z}.nbhd contained_in {y}.nbhd { |
| // z is subsumed by y |
| remove z from network; |
| {y}.beta = {y}.beta union {z}.beta |
| reducible = 1 } } } } |
| Pseudocode I, , reduce_network |
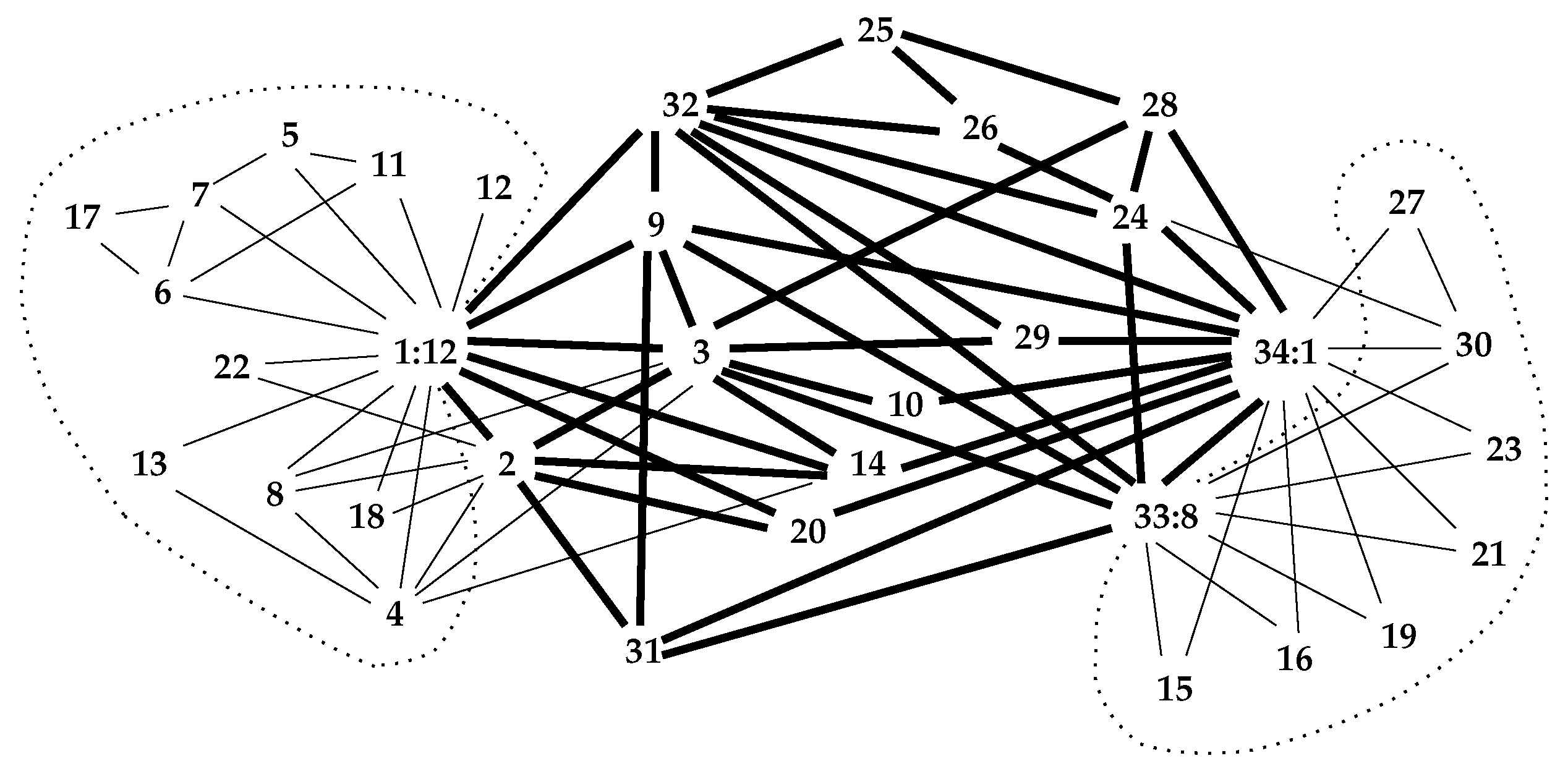
Applied to , the well-known “Karate” network [6], this reduction code yields the interior depicted by bolder links in Figure 1.
In this figure, two nodes of the interior have been suffixed by “:n” to denote their -count. Only nodes 1 and 33 have non-trivial -sets of 12 and 8 elements, respectively, which have been delimited by dotted lines. (The -set of node 33 might equally well have been the -set of node 34; however, 33 precedes 34 in the reduction process).
Proposition 1.
The process ω described above is (I1) contractive and (I3) idempotent.
Proof.
Readily, is contractive and it is idempotent because, when is irreducible, the loop is not executed, so . □
One can show that need not imply that , so is not an interior operator, even though we call the “interior”.
Proposition 2.
Let and be irreducible subsets of a finite network , then .
Proof.
Let , . Then, belongs to some point in and else because implies so would not be irreducible.
Similarly, since and , there exists such that belongs to . Now, we have two possible cases; either , or not.
Suppose (which is often the case), then and or . Hence, is part of the desired isometry, i.
Now, suppose . There exists such that , and so forth. Since is finite, this construction must halt with some . The points constitute a complete graph with , for . In any reduction, all reduce to a single point. All possibilities lead to mutually isomorphic maps. □
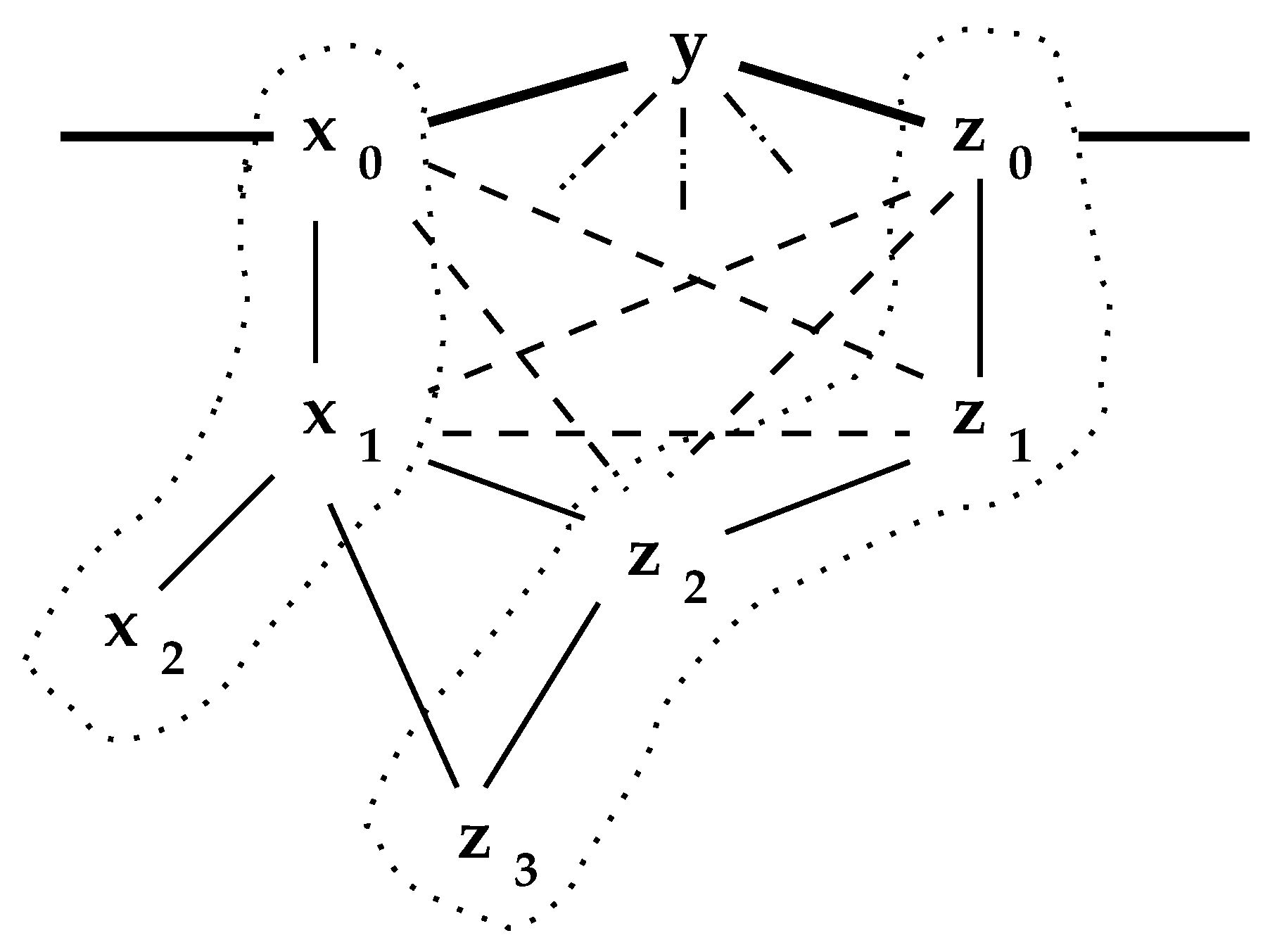
Proposition 2 assures us that, even though which nodes are preserved in is completely dependent on the order in that they are visited, the output must be effectively identical. For example, in Figure 2, assume the nodes x and z are irreducible elements of .
In each case, if , then or could be as well. They are the equivalent nodes defining the isometry. Each set of equivalent nodes must be a “complete” subgraph of . (A graph, or network, K is said to be complete if for all , there is a link . A complete graph on n nodes is denoted by .)
A sequence, of nodes, where , or a set of n links is called a path of length n. It is often easier to describe a path in terms of its nodes, rather than , which is more precise. By , we mean the length of the path independent of whether we are counting nodes or links.
A cycle , where , of length is said to have a bridge if there exists a path where [2]. If the path consists of a single link, it is called a chord. If C has no such chords, it is said to be a chordless cycle. Graphs, in which every cycle of length must have a chord, are called “chordal graphs” [7].)
Proposition 3.
The nodes of a chordless cycle are irreducible.
Proof.
Let . Suppose implying or contradicting chordless assumption. □
Proposition 4.
Let be a finite network with being an irreducible subset. If is not an isolated point, then either:
(1) there exists a chordless k-cycle , such that ; or
(2) there exist chordless k-cycles each of length with and y lies on a path from x to z.
Proof.
Let . Since is not isolated, let , so . . Since is not subsumed by , , and since is not subsumed by , , . Since , .
Suppose , then constitutes a k-cycle , and we are done.
Suppose . We repeat the same path extension. implies , . If or , we have the desired cycle. If not and so forth. Because is finite, this path extension must terminate with , where , .
The preceding establishes that any link sequence in terminates in a cycle of length ≥4. Since is symmetric, the link sequence could be extended in the opposite direction yielding (2).
Thus, if (1) is not the case, (2) must be. □
The condition that y not be an isolated point is significant. Any tree structured network reduces to a single point, as do many networks consisting of triangles.
Corollary 1.
is connected if and only if is connected.
A collection of chordless cycles constitutes a cycle system which is itself a matroid [8] with a well defined rank [9]. If the network is projected onto a planar representation, then counting those cycles without a bridge yields the rank.
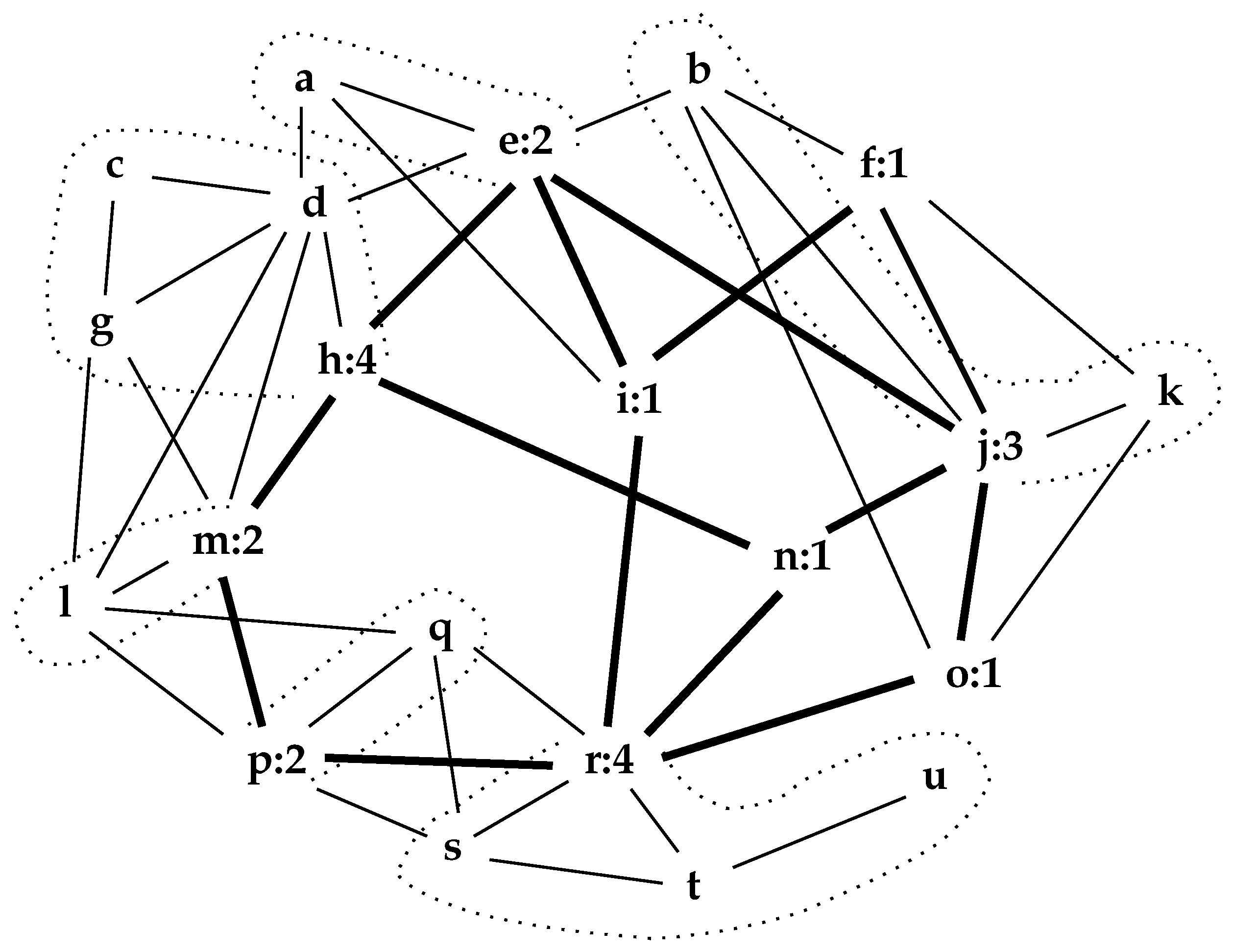
Figure 3 illustrates the interior of a small network on 21 nodes. It is a cycle system of rank 5. Here, the links of the interior have been made bolder and again its nodes have their -counts appended.
2.2. Reduction Performance
Technically, the process of Pseudocode I is since it can achieve a worst case performance on the unbalanced network of Figure 4 provided the outer loop of the code of Pseudocode I encounters the nodes in order of their subscripts.
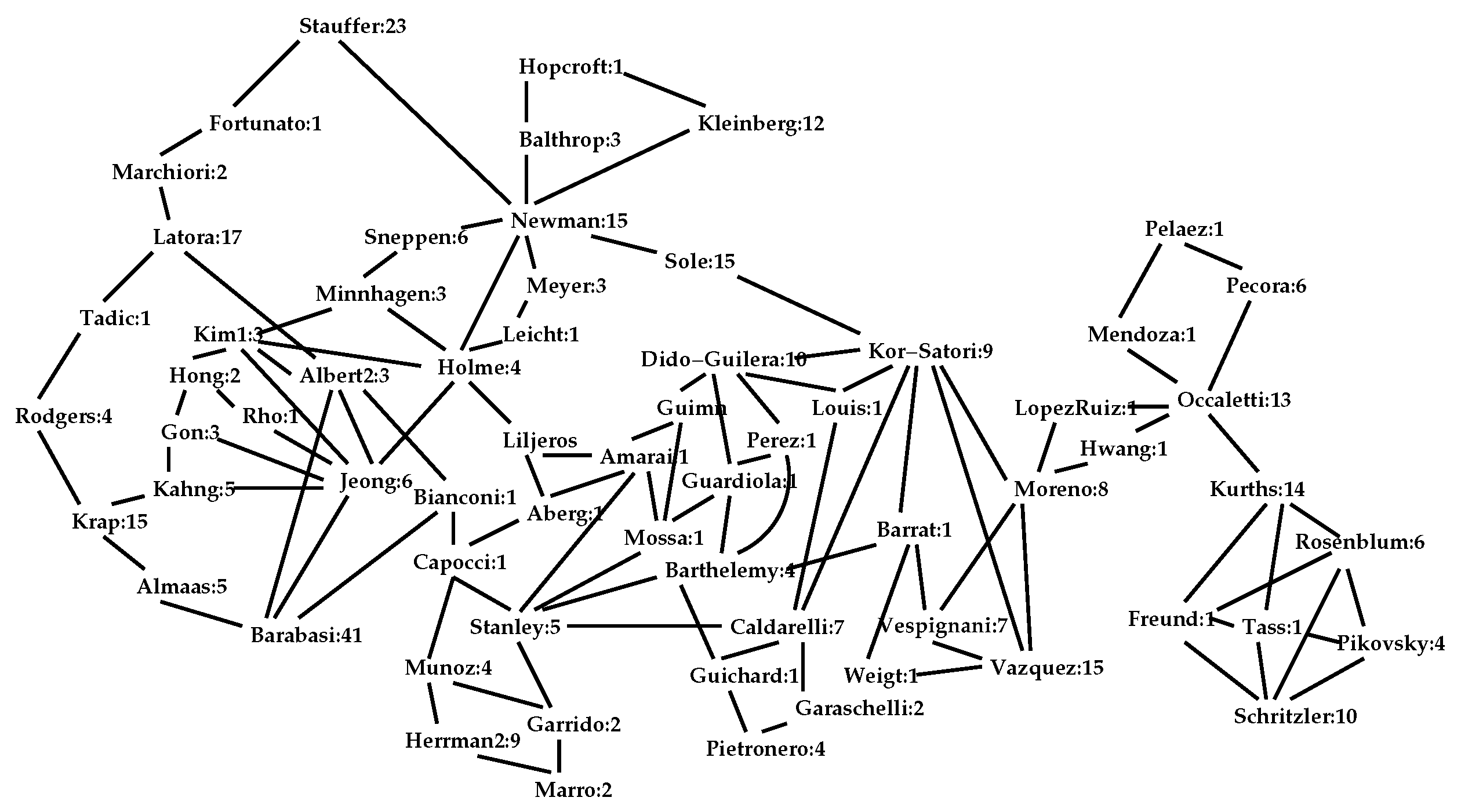
Then, it will remove only one node on each iteration. However, in practice, appears to actually offer sub-linear performance. With networks of several thousand nodes, has never required more than seven iterations. For example, given the well-known Newman co-authorship network [12] of 363 persons with 823 connecting links, three iterations of the outer loop of the code of Pseudocode I reduces the network to 65 individuals with 111 links constituting its interior shown in Figure 5. (A fourth iteration is required to verify that there are no more reducible nodes.) The node Stauffer, in the upper left, has a -set of 23 elements for which it may be regarded as a surrogate, and the lower left node Barabasi has a -set of 41 elements. In the case of the Newman co-authorship network, the interior represents a significant reduction in the complexity of the network,
3. Network Properties
There are several scalar properties associated with every network , including , and . The average node degree over all nodes is , since every link has two end nodes [1,2]. These are trivial to calculate given N and L.
The number of triangles [13] embedded in can be calculated by the count_triangles whose code is given in Pseudocode II.
| k_total = 0 |
| for_each link {x, z} in L { |
| MEET = {x}.nbhd meet {z}.nbhd |
| {x, z}.k_count = cardinality_of(MEET) |
| k_total = k_total + {x, z}.k_count } |
| n_triangles = k_total/3 |
| Pseudocode II, count_triangles |
Here, the of a link denotes the number of triangles for which the link is one “side”. Since that triangle has three links, . The computational cost of is essentially constant, so the cost of count_triangles is linear, or .
Other scalar properties are dependent on the concept of shortest paths. Let be two nodes in a connected network . Because is connected, there exists a path of length n. This may, or may not, be the shortest path (of minimal length) between them. We let denote the (or all) shortest path(s) between x and z. The path length is also known as the distance, , between x and y [1,2]. The of the network is the maximal distance, for all . The of a node x is for all . The , , of the network is minimum eccentricity of any node y [2].
3.1. Communities
Many networks, especially those that represent social connections, are spotted with “clusters” of more densely connected nodes. These clusters of triangular links, which are often called communities, arise from the social phenomenon called triadic closure [14]. It is known that, in many social contexts, if x is connected to y and y is connected to z, then x is likely to be connected to z. Even though triadic closure is not really a closure operator, its principle has been identified on many repeated occasions [11,15]. (As normally encountered, triadic closure is not idempotent. Applied literally, the triadic closure of any network would be the complete graph/network on its n nodes).
However, we know of no formal definition as to what really constitutes a “community”.
There have been numerous efforts to identify communities in a network [16]. Several work on the principle of “bisection” in which removal of certain links separates the network into n distinct communities [10]. A common problem is that usually n must be designated in advance. Others iteratively partition the network, often using the Fiedler eigenvector [17]. Here, the question is when to stop the iteration.
A portion of the network that is dense with triangles may be regarded as a community. A connected sub-network of triangles is called a k-truss [18]. A connected subset of triangles could be tree-structured, so it is common to specify that a k-truss is a connected collection of links with a , where the of a link is as in Pseudocode II. If , the Karate network of Figure 1 has just one 2-truss, consisting of links connecting the nodes {1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 14, 30, 31, 33, 34} or just less than half the network. It has two 3-trusses connecting the nodes {1, 2, 3, 4, 8, 14} and {9, 24, 33, 34}. The small network of Figure 3 has two 2-trusses of links connecting the nodes {a, e, d, g, h, l, m, p, q, r, s} and {b, f, j, k, o} and four small 3-trusses, which are {b, j}, {d, g, l, m}, {p, q} and {r, s}. There are 23 2-trusses in the Newman network and each is large; however, there are only three 8-trusses. They are {Arenas, Dido-Guilera}, {Mano, Occaletti} and {Barabasi, Jeong, Oltavi, Raven, Schubert}; however, Arenas, Mano, Oltavi, Raven, and Schubert are not elements of the interior and thus not shown in Figure 5.
The larger values of the principal eigenvector of (the adjacency matrix of the network) can indicate well-connected nodes, and often communities [3]. Nodes 1, 3, 33 and 34 of , the Karate network of Figure 1, dominate its principal eigenvector. The principal eigenvector of , the small network of Figure 3, are given in Table 2. Here, nodes stand out. Higher values in this eigenvector appear to correlate with higher node degree. The nodes , and (in ) are most prominent in the eigenvector of the Newman network.
All of these methods have been proposed to denote “communities”. We would suggest that the -sets attached to also denote “communities”.
3.2. Important Nodes
A fundamental quest in the analysis of many networks is the identification of its “important” nodes. They may be a node of high degree in a community, but need not be. In social networks, “importance” may also be defined with respect to the path structure [19,20]. Those nodes, for which the eccentricity, , or , is , have traditionally been called the center of [1,2]; they are “closest” to all other nodes. It is well known that this subset of nodes must be edge connected. One may assume that these nodes in the “center” of a network are “important” nodes.
Alternatively, one may consider those nodes which “connect” many other nodes, or clusters of nodes, to be the “important” ones. Let denote the number of shortest paths containing y; then, those nodes y for which is are involved in the most connections. Let , for which is locally maximal. This is sometime called “betweenness centrality” [19,20,21]. (In [20], Newman proposed the notion of “random walk betweenness” as an alternative to shortest path betweenness).
3.3. Network Properties Preserved by the Interior
The next three lemmas, culminating in Proposition 5, help clarify the interaction of -sets with the nodes of . In these lemmas, we assume that and .
Lemma 1.
Let . There exists a node sequence such that , .
Proof.
In the reduction process of Pseudocode I, if is subsumed by , then yielding the chain of nested sets . □
Note that, even if belongs to , there may be other nodes such that .
Lemma 2.
Let and let where . Then, for all , .
Proof.
By the reduction process , when is subsumed by , . Thus, if , then or . □
Lemma 3.
Let where . If , then there exists such that .
Proof.
By Lemma 2, we know . If we are done. Thus, let us suppose not. By Proposition 4, we can assume (or a sequence ) such that . We claim , since otherwise is a chordless cycle of length , and hence by Proposition 3 is irreducible. Similarly, . □
Two -sets, are said to be -connected if there exists where , and . The preceding lemmas describe links that must exist if -sets are connected. These are illustrated in Figure 6.
In this figure, solid lines denote links that are “known” to exist for one reason or another. The dotted (⋯) lines that enclose -sets were established by the reduction process. Each conforms to Lemma 1. Observe that the entire set of nodes, could constitute either or depending solely on the order of node reduction. This is illustrated in , Figure 1, where could have been . Proposition 2 establishes that the structure of the interior, , is independent of the order in which nodes are encountered in the process; however, the structure of -sets produced by the code reduce can be very dependent on this order.
The dashed links ( - - - ) denote links that can be inferred from Lemma 2. For instance, cannot subsume unless because . The ( - - ) links connecting y to the nodes can be inferred from Proposition 3.
While in many networks the -sets will be separated (as in Figure 3), they may be links between them. It is not hard to imagine a link between and . The lemmas establish that either such a link must introduce a new chordless cycle into , or else there must be an abundance of “triangles” surrounding the network interior.
Proposition 5.
Let be a path where () and and . Then, there exists a path where and .
Proof.
We may assume that , else there is nothing to prove. Thus, we may also assume that lies entirely within connected -sets. By Lemma 3, such that , so . □
3.4. Network Centrality
Proposition 6.
If is not unbalanced, then the center (in terms of distance) is an element of (or intersects with) the interior of .
Proof.
If x and z are in separated -sets, then where , and . Since is not unbalanced, we may assume , so the center of is one of the .
If x and z are in connected -sets and , then Proposition 5 establishes the existence of a shortest path through as well.
If , then no shortest path involves ; however, since is not unbalanced, these constitute a small number of cases and can be ignored. □
In Figure 2b, if is in the center C, then so are and , implying .
Proposition 6 requires that not be too unbalanced. Figure 4 illustrates why. It is not hard to show that is the center with maximum distance over all x being . Our rule of thumb is that a network is reasonably well-balanced if, given any , then the probability that a randomly chosen y is also in is small, that is where .
Proposition 7.
If is not unbalanced, then any center of (in terms of betweenness) is an element of .
Proof.
This proof follows the line of Proposition 6, in which, unless x and z are in the same -set, all shortest paths either involve or have a path of the same length through . Hence, a node y for which is maximal will be an element of . □
That contains the betweenness center is evident in the Karate network of Figure 1 and the small network of Figure 3.
Figure 7 illustrates a somewhat different “unbalanced” network in which x and are betweenness centers.
One can calculate that which are locally maximal.
Calculating betweenness centers is computationally expensive, even with improved algorithms (e.g., [21]). Knowing that they must exist in the interior and restricting the calculation to just those nodes can greatly improve performance, especially when betweenness is employed in other procedures (e.g., [10]). Consequently, dwelling too much on unbalanced networks can be self defeating since the majority, and possibly almost all, networks are well-balanced.
4. Network Generation by Expansion
The interior, , of a network represents its global structure. If the -count is appended to each node of , how well does represent as a whole? In effect, what is the information content of , so augmented?
One measure of the information content of any collection of network properties is the ability to construct, or generate, similar networks based on those properties. For example, given a network one can construct many different networks such that and . However, they need not be at all similar to . Here, we are using “similar” in its colloquial sense. A formal notion of “similarity” would require it to be an equivalence relation. One way of determining the nature of networks with a given interior, , and known -counts is to randomly generate some. Let be given. Suppose the -count of a node y is greater than one. New nodes can be attached to replace those of the original -set. Let y:n be the node to be expanded () and let z denote the new node. Our code generates artificial node names of the form ‘A0, B0, …, Z0, A1, …’. The last generated node in the expansion of Figure 5 is . Besides the link , we require . A random number determines how many of the other nodes in will be linked to z, and which, if any, of those are also randomly chosen.
In the reduction process, , nodes with considerable -sets may be subsequently reduced themselves. In the re-expansion, a portion of the -count of y may be transferred to the -count of z. Pseudocode for a procedure expand to implement an operator that generates new nodes relative to the interior is given in Pseudocode III. (, as shown here, is a round-robin procedure expanding one node in a -set at a time. An alternative, and slightly faster, process can be found in [22]).
| while still_expanding { |
| still_expanding = 0 |
| for_each y in NODES { |
| if (y.beta_count > 1) { |
| z = new_node() |
| add new_node to NODES |
| chosen = choose_subset (y.nbhd) |
| // distribute some of y.beta_count to z |
| increment = y.beta_count/(n_chosen+1) |
| y.beta_count = y.beta_count - increment |
| z.beta_count = 1 + increment |
| add (y, z) to LINKS |
| // link z to chosen nodes in y.nbhd |
| for_each x in chosen { |
| add (x, z) to LINKS } |
| still_expanding = 1 } } } |
| Pseudocode III, , expand_network |
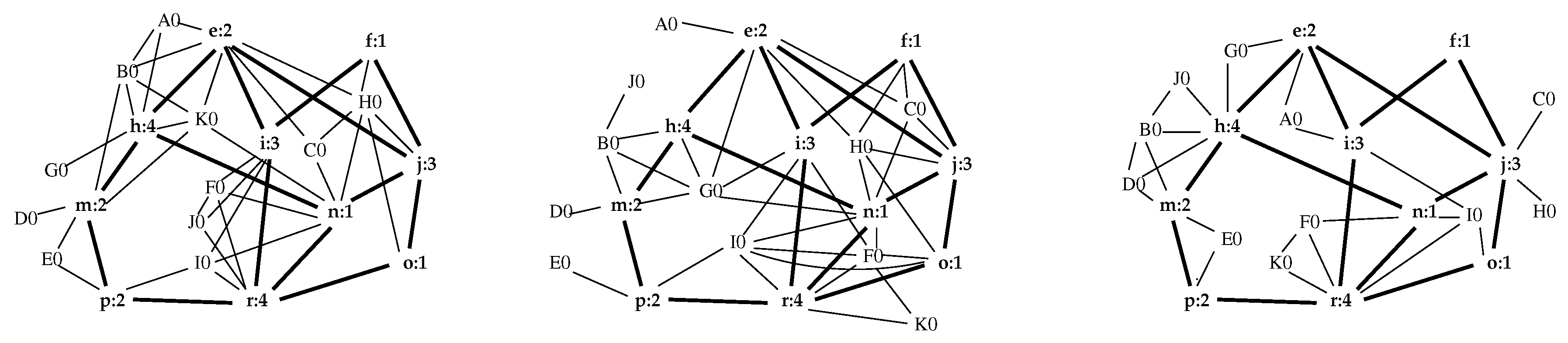
As a test, the interior of , Figure 3, was expanded three times (using different random number seeds) to yield , and of Figure 8.
Proposition 8.
Let be the interior of a network , that is , then .
Proof.
The expansion procedure of Pseudocode III was written to make this true. Consider , the last node appended by . By construction, for some ; thus, can be subsumed into . A finite induction completes the proof. □
Considered as operators, is a left-inverse of since , where 1 denotes the identity operator. However, , as shown by Figure 8.
To what extent are the network features of enumerated in the preceding section preserved in the randomly generated networks, ? Readily, the generation process was constrained so that and , thus the path-based centers of Section 3.4 are preserved. Some other network properties are illustrated in Table 1.
Table 2 presents the principal eigenvector associated with the nodes of in Figure 3 and for the three expansions shown in Figure 8. Note that, except for the ten nodes of , node values for generated expansions are not comparable with node values of the original .
This section began with the question “how well does represent as a whole?” Figure 8 and Table 1 and Table 2 provide abundant evidence that, given just , with each node augmented with its -count, a random process can generate new networks whose properties are very similar to those of . It would seem to be a very good description of .
5. Observations
This paper might have been titled “An Operator Approach to …” since the operators , , and play such an important role. This aspect is briefly suggested by Proposition 8, but not enlarged. However, surely, interesting networks are dynamic; they change over time which demands an operator approach. Thus, one might ask: “Is a transformation continuous?” [23] The operators and are, in fact, “continuous” with respect to . Moreover, it appears that is a violator space in the sense of [24]. This could be expanded in the future.
However, computability is such a dominant theme in current network analysis and understanding that we thought focusing on the use of set-theoretic computer procedures such as reduce, count_triangles and expand was more important. Programming with set operators is not widespread. However, these set-theoretic procedures appear to be fast and quite scalable. The reduction, , of the Newman co-authorship network to Figure 5 took 0.008 s; reduction of the smaller networks (Figure 1 and Figure 3) were each less than 0.001 s. Calculation of the eigenvectors of Figure 5 exceeded 5 s. Such anecdotal evidence is suggestive, but far from definitive.
Only standard set-theoretic reasoning was used to develop the reduction process, , which leads to the concept of the “interior”, , of a network, , and its -set. It is a powerful concept that effectively captures the essence of many networks, as shown by Section 4, in which very similar networks can be generated from alone. Moreover, by reducing a network to its interior, one effectively partitions the network into it constituent -set communities.
However, the reduction process has its limitations. Some networks are nearly irreducible to start with. The sparse network of Norwegian corporate directors [25] is an example. Hierarchical networks reduce to a single node, that is a single node interior with a very large -set. Other networks can be too dense. The complete network also reduces to a single node. However, we believe that the easily computed interior is a most effective network descriptor and possibly should be an automatic first step in network description and understanding.
Funding
This research received no external funding.
Data Availability Statement
Source code and test networks are available from the author.
Acknowledgments
The author would thank Christopher Taylor for coding the set manipulating code and John Burkardt who made his eigenvector code available on the Internet.
Conflicts of Interest
The author declares no conflict of interest.
References
- Agnarsson, G.; Greenlaw, R. Graph Theory: Modeling, Applications and Algorithms; Prentice Hall: Upper Saddle River, NJ, USA, 2007. [Google Scholar]
- Harary, F. Graph Theory; Addison-Wesley: Reading, MA, USA, 1969. [Google Scholar]
- Newman, M.E.J. Finding community structure in networks using the eigenvectors of matrices. Phys. Rev. E 2006, 74, 1–22. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Newman, M. Networks; Oxford University Press: Oxford, UK, 2018. [Google Scholar]
- Orlandic, R.; Pfaltz, J.L.; Taylor, C. A Functional Database Representation of Large Sets of Objects. In Proceedings of the 25th Australasian Database Conference (ADC 2014), Brisbane, Australia, 14–16 July 2014; Wang, H., Saraf, M.A., Eds.; Springer: Cham, Switzerland, 2014; pp. 189–196. [Google Scholar]
- Zachary, W.W. An Information Flow Model for Conflict and Fission in Small groups. J. Anthropol. Res. 1977, 33, 452–473. [Google Scholar] [CrossRef] [Green Version]
- McKee, T.A. How Chordal Graphs Work. Bull. ICA 1993, 9, 27–39. [Google Scholar]
- White, N. Theory of Matroids; Cambridge University Press: Cambridge, UK, 1986. [Google Scholar]
- Pfaltz, J.L. Cycle Systems. Math. Appl. 2020, 9, 55–66. [Google Scholar] [CrossRef]
- Girvan, M.; Newman, M.E.J. Community structure in social and biological networks. Proc. Natl. Acad. Sci. USA 2002, 99, 7821–7826. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E.J. Detecting community structure in networks. Eur. Phys. J. B 2004, 38, 321–330. [Google Scholar] [CrossRef]
- Newman, M.E.J. The structure and function of complex networks. SIAM Rev. 2003, 45, 167–256. [Google Scholar] [CrossRef] [Green Version]
- Tsourakakis, C.E.; Drineas, P.; Michelakis, E.; Koutis, I.; Faloutos, C. Spectral counting of triangles via element-wise sparsification and triangle-based link recommendation. Soc. Netw. Anal. Min. 2011, 1, 75–81. [Google Scholar] [CrossRef] [Green Version]
- Mollenhorst, G.; Völker, B.; Flap, H. Shared contexts and triadic closure in core discussion networks. Soc. Netw. 2012, 34, 292–302. [Google Scholar] [CrossRef]
- Granovetter, M.S. The Strength of Weak Ties. Am. J. Sociol. 1973, 78, 1360–1380. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E.J. Modularity and community structure in networks. Proc. Natl. Acad. Sci. USA 2006, 103, 8577–8582. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fiedler, M. Algebraic Connectivity of Graphs. Czechoslovak Math. J. 1973, 23, 298–305. [Google Scholar] [CrossRef]
- McCulloh, I.; Savas, O. k-Truss Network Community Detection. In Proceedings of the 2020 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), The Hague, The Netherlands, 7–10 December 2020. [Google Scholar]
- Freeman, L.C. Centrality in Social Networks, Conceptual Clarification. Soc. Netw. 1978, 1, 215–239. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E.J. A measure of betweenness centrality based on random walks. Soc. Netw. 2005, 27, 39–45. [Google Scholar] [CrossRef] [Green Version]
- Brandes, U. A Faster Algorithm for Betweeness Centrality. J. Math. Sociol. 2001, 25, 163–177. [Google Scholar] [CrossRef]
- Pfaltz, J.L. Computational Processes that Appear to Model Human Memory. In Proceedings of the 4th International Conference, Algorithms for Computational Biology (AlCoB 2017), Aveiro, Portugal, 5–6 June 2017; pp. 85–99. [Google Scholar]
- Pfaltz, J.; Šlapal, J. Transformations of discrete closure systems. Acta Math. Hung. 2013, 138, 386–405. [Google Scholar] [CrossRef]
- Kempner, Y.; Levit, V.E. Violator spaces vs closure spaces. Eur. J. Comb. 2019, 80, 203–213. [Google Scholar] [CrossRef] [Green Version]
- Seierstad, C.; Opsahl, T. For the few not the many? The effects of affirmative action on presence, prominence, and social capital of female directors in Norway. Scand. J. Manag. 2011, 27, 44–54. [Google Scholar] [CrossRef]
Figure 1.
The interior of , the Karate network, is shown with bolder links.

Figure 2.
Equivalent nodes in an interior .

Figure 3.
A small network, , of 21 nodes. Interior links are bolder. -sets are dotted.

Figure 4.
An unbalanced network.

Figure 5.
The interior of , the 363 node co-authorship network of Newman [12].
Figure 5.
The interior of , the 363 node co-authorship network of Newman [12].

Figure 6.
Links that can be inferred between connected -sets.

Figure 7.
Another unbalanced network.

Figure 8.
Three different expansions of , Figure 3.
Figure 8.
Three different expansions of , Figure 3.


{kind=link}
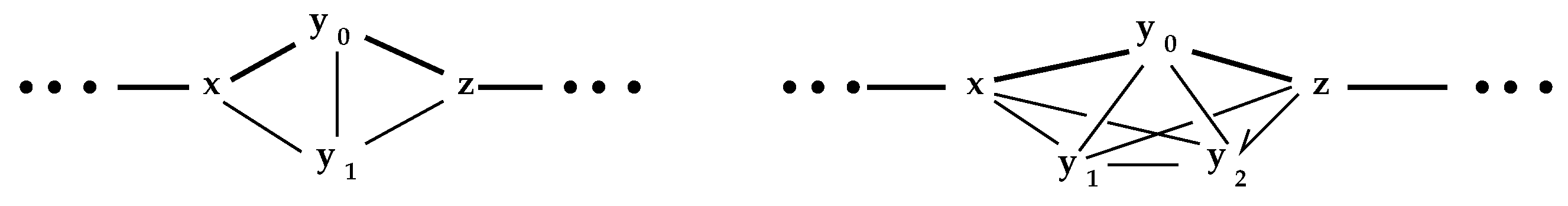{kind=link}
{kind=link}
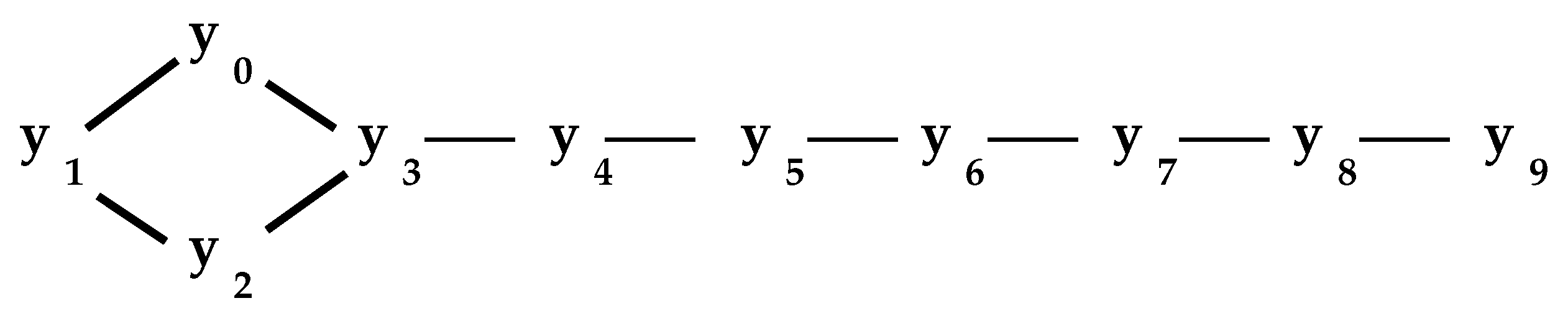{kind=link}
{kind=link}
{kind=link}
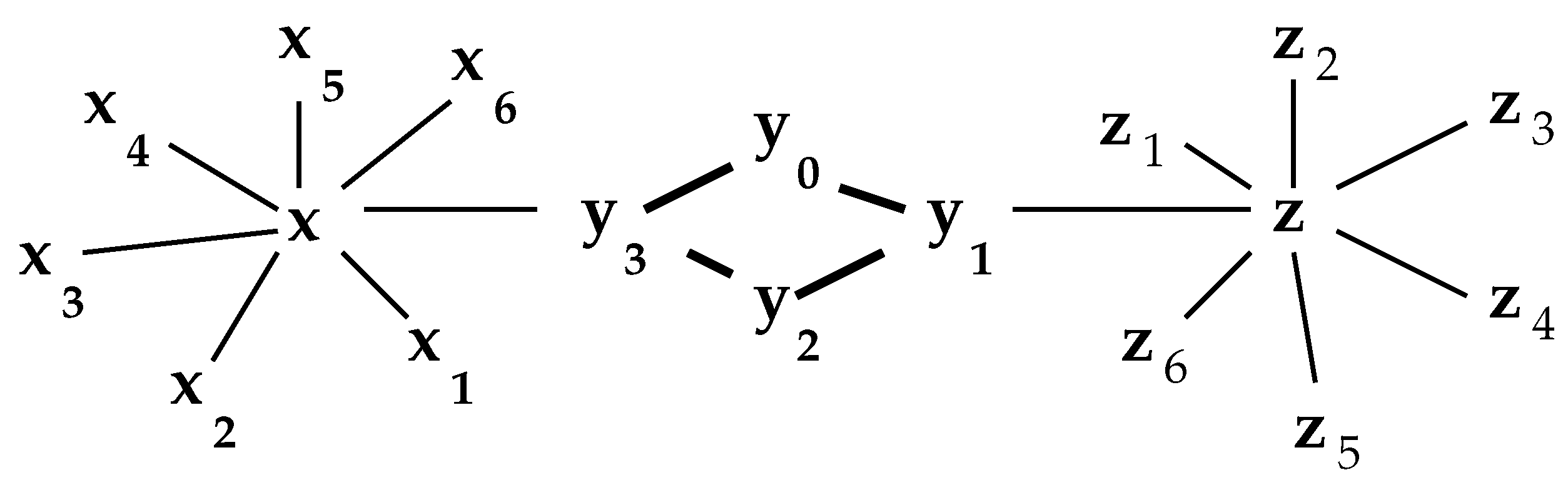{kind=link}
{kind=link}
| 21 | 44 | 2.095 | 21 | 2 | 4 | |
| exp.1 | 21 | 49 | 2.333 | 31 | 1 | 3 |
| exp.2 | 21 | 46 | 2.190 | 25 | 2 | 3 |
| exp.3 | 21 | 37 | 1.762 | 13 | 2 | 2 |
| a | b | c | d | e | f | g | h | i | j | k | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.179 | 0.182 | 0.123 | 0.350 | 0.293 | 0.155 | 0.226 | 0.234 | 0.194 | 0.231 | 0.120 | |
| A0 | B0 | C0 | D0 | e | f | E0 | h | i | j | F0 | |
| exp.1 | 0.170 | 0.295 | 0.225 | 0.033 | 0.355 | 0.129 | 0.053 | 0.306 | 0.202 | 0.265 | 0.162 |
| exp.2 | 0.048 | 0.095 | 0.203 | 0.021 | 0.262 | 0.183 | 0.026 | 0.192 | 0.254 | 0.285 | 0.303 |
| exp.3 | 0.125 | 0.212 | 0.056 | 0.187 | 0.265 | 0.120 | 0.093 | 0.353 | 0.270 | 0.243 | 0.195 |
| l | m | n | o | p | q | r | s | t | u | ||
| 0.291 | 0.293 | 0.159 | 0.174 | 0.271 | 0.220 | 0.280 | 0.187 | 0.104 | 0.022 | ||
| G0 | m | n | o | p | H0 | r | I0 | J0 | K0 | ||
| exp.1 | 0.054 | 0.190 | 0.387 | 0.133 | 0.112 | 0.265 | 0.224 | 0.164 | 0.104 | 0.272 | |
| exp.2 | 0.192 | 0.118 | 0.379 | 0.271 | 0.142 | 0.253 | 0.325 | 0.307 | 0.017 | 0.115 | |
| exp.3 | 0.144 | 0.236 | 0.336 | 0.208 | 0.163 | 0.056 | 0.369 | 0.276 | 0.132 | 0.132 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Pfaltz, J.L. A Set-Theoretic Approach to Modeling Network Structure. Algorithms 2021, 14, 153. https://0-doi-org.brum.beds.ac.uk/10.3390/a14050153
AMA Style
Pfaltz JL. A Set-Theoretic Approach to Modeling Network Structure. Algorithms. 2021; 14(5):153. https://0-doi-org.brum.beds.ac.uk/10.3390/a14050153
Chicago/Turabian StylePfaltz, John L. 2021. "A Set-Theoretic Approach to Modeling Network Structure" Algorithms 14, no. 5: 153. https://0-doi-org.brum.beds.ac.uk/10.3390/a14050153
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.