1. Introduction
The space pursuit-evasion (PE) game is a typical zero-sum game [
1,
2], where the goals of both confrontation sides are completely opposite and irreconcilable. With the development of space technology, it is one of the focuses of space security and has been investigated extensively by many scholars. Differential game theory was firstly proposed by Isaacs [
3] in 1965 and is an effective approach to address the zero-sum game problem [
4,
5]. In differential game, the PE game is transformed into a two-point boundary value problem (TPBVP) using Hamilton–Jacobi–Bellman equation [
6]. However, for the space PE game, it is a challenge to solve the transformed TPBVP due to its high dimensionality and strong nonlinearity.
Some approaches were proposed to address these two challenges and improve the performance of differential theory on space PE game problems. Anderson et al. [
7] linearized the equations of the spacecraft motion and approximated the thrust angle control using polynomial to obtain a simplified spacecraft planar PE analytical expression. Li et al. [
8] modeled the relative states of two spacecraft in near-circular orbits with the circular-orbit variational equations to reduce the dimensionality. Jagat and Sinclair [
9] applied the state-dependent Riccati equation method to obtain nonlinear control law for two spacecraft PE game in the Hill coordinate system. Blasch et al. [
10] degenerated the three-dimensional (3D) PE game into a two-dimensional coplanar PE game by firstly assuming that the pursuer matches the orbital plane of the escaper, which is easy to address. However, both the linear simplified approaches and the planarity assumptions are inconsistent with the actual situation as the space PE game is a typical 3D nonlinear PE game. Furthermore, the perturbations in realistic dynamics of the actual space PE game missions make it more challenging to solve the game. The major perturbation is from the J2 spherical harmonic term of the Earth gravity field.
Li et al. [
11] developed the combined shooting and collocation method to address the accurate saddle point of the 3D PE game using the J2-perturbed dynamics. Based on the state-dependent Riccati equation method, Jagat et al. [
12] used a state-dependent coefficient matrix to derive a nonlinear control law from the linear quadratic differential game theory. Pontani and Conway [
13] proposed a semi-direct collocation with nonlinear programming (SDCNLP) method, which obtains the solution for one side with the analytical necessary conditions of another side, and the initial guesses of the nonlinear programming method are generated using the genetic algorithm (GA). Carr et al. [
14] developed a fast method to obtain initial guesses of the co-states needed in the SDCNLP method and a penalty-functions technique to deal with state inequality constraints in the indirect player’s objective. Because SDCNLP only uses the analytic optimal necessary condition for the evader, the obtained saddle point is not accurate. Therefore, Sun et al. [
15] proposed a hybrid method combining the new SDCNLP that introduces two optimal control problems corresponding to the differential game and the multiple shooting method to improve the convergence and accuracy of solving the TPBVP of the space PE game. Hafer et al. [
16] employed the sensitivity method to address space PE game problems and utilized a homotopy strategy to improve the efficiency of the algorithms. Shen et al. [
17] applied an indirect optimization method to the 3D space PE game and found the local optimal solutions, which satisfy the analytical necessary conditions for optimality. Further, the constraints of the minimum altitude and mass variation were considered for making the saddle-point solution more accurate.
For the above studies, the information of both players is completely disclosed and both two players in space PE game are assumed to be sane enough. Actually, due to the communication delay and the non-cooperation of the players, there are large uncertainties during the PE game. Cavalieri et al. [
18] applied a two-step dynamic inversion to allow behavior learning methods to estimate the opponent behavior for incomplete-information PE games with uncertain relative dynamics. Shen et al. [
19] considered the uncertainty of the J2-perturbed dynamical model and used quantitative indicators of uncertainty as the game payoff function to solve the incomplete-information space PE problem. Li et al. [
20] developed a currently optimal evasive control method using a modified strong tracking unscented Kalman filter to modify the guess and to update the strategy during the game.
The closed-loop control method, which can update the trajectory based on the real-time feedback, is a valid approach to deal with uncertainties and emergencies and is widely used in space missions, especially for the realistic space PE game that is a dynamical process [
20]. However, the approaches based on the differential game theory are mainly used for continuous-thrust cases and inapplicable for impulse cases. In addition, the computational time cost of solving the saddle point is expensive. Therefore, it is challenging to develop a feedback closed-loop control method with high efficiency for the impulsive space PE game missions considering the perturbations of the dynamics. The development of artificial intelligence provides alternative ways to address this challenge. Reinforcement learning (RL) as the representative of intelligent algorithms can interact with the environment in real time and obtains the optimal control of the maximum reward through data training [
21,
22]. RL has been widely employed to solve PE problems in the field of unmanned aerial vehicle (UAV) [
23,
24,
25]. Different from the UAV PE game, the space PE game has a long mission duration and complex dynamics. In the field of space PE game, Liu [
26] and Wang [
27] developed the improved branching deep Q networks and the fuzzy actor-critic learning algorithm, respectively. These previous researches usually restricted the initial distance between the two spacecraft to reduce the PE game duration and used a simplified dynamical model to improve the computational efficiency. To remove this limitation and consider realistic space PE game problems, in this paper, a novel two-stage pursuit strategy is developed to find a robust solution for incomplete-information impulsive space pursuit-evasion missions considering J2 perturbation. For the far-distance rendezvous stage (FRS), a new game capability index of the pursuer is proposed as the objective function of multi-impulses transfer trajectory optimization with the J2-perturbed dynamical model. For the close-distance game stage (CGS), a novel closed-loop approach using the deep deterministic policy gradient (DDPG) algorithm is developed to solve the impulsive maneuver strategy according to the incomplete feedback information. The proposed method is applied to the scenarios of spacecraft games in the sun-synchronous orbit, which demonstrates outstanding advantages in robustness to various initial states of the pursuer and the evader and to the different evasion strategies.
3. Two-Stage Pursuit Strategy Using Reinforcement Learning
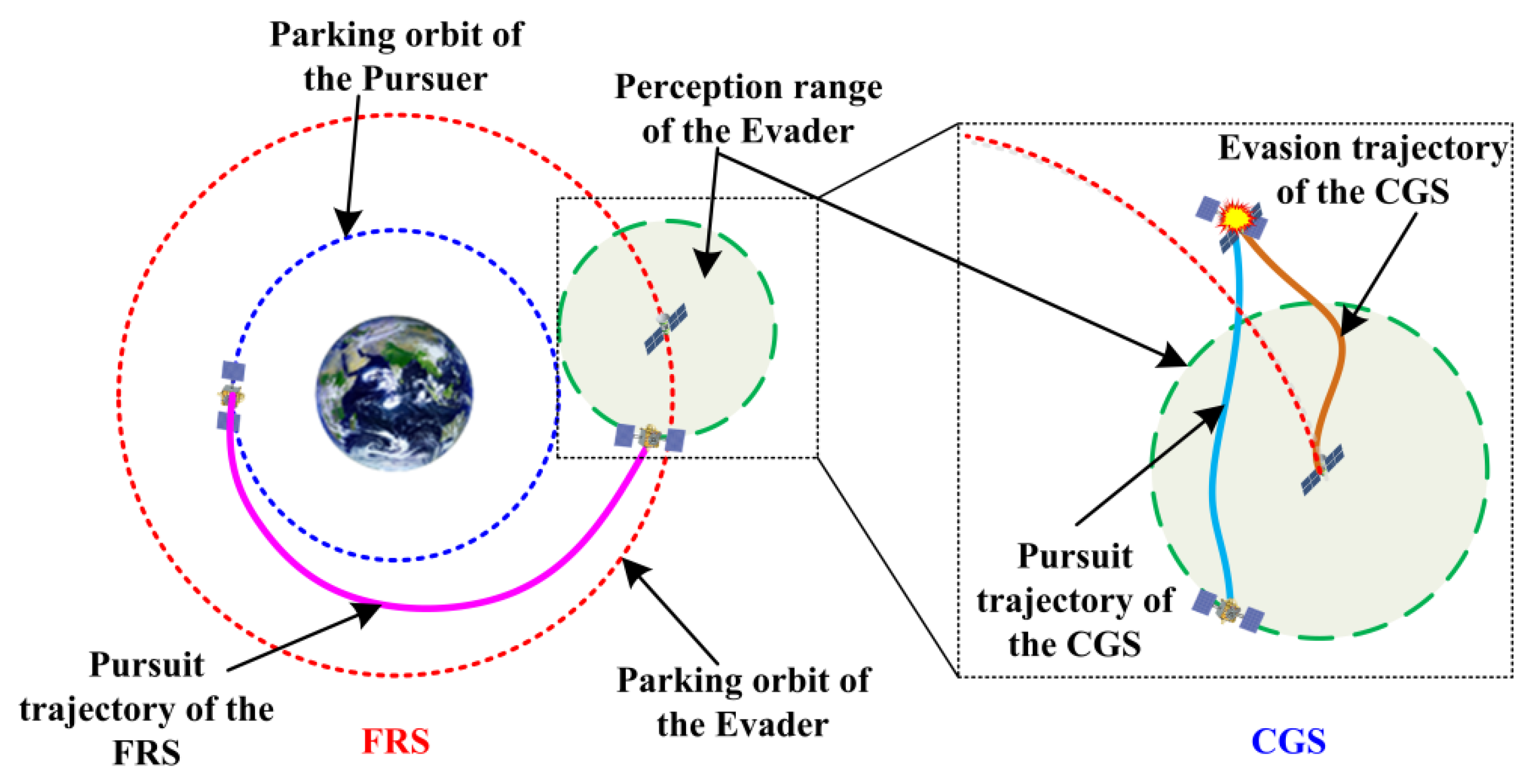
A two-stage pursuit strategy that consists of an FRS and a CGS is proposed in this section for incomplete-information impulse pursuit-evasion missions. Firstly, a GA is employed to solve the multi-impulse rendezvous trajectory with the optimal terminal game capability. Then, a closed-loop pursuit method using the DDPG algorithm is developed to address a robust impulsive pursuit trajectory for the incomplete-information PE game.
3.1. Multi-Impulse Pursuit Trajectory Optimization for FRS
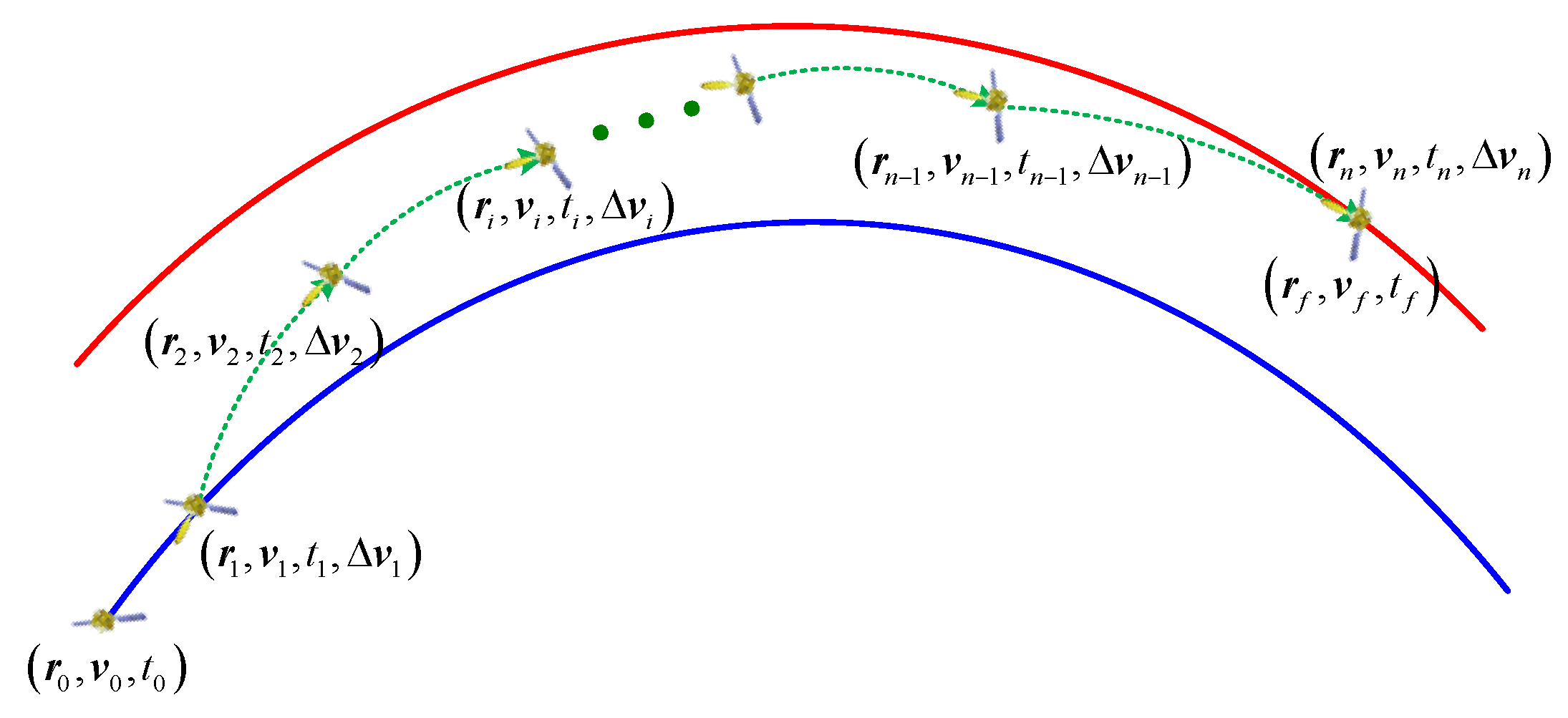
During the FRS, the pursuit trajectory solving is a typical transfer trajectory optimization problem because the evader cannot perceive the pursuer. The process of multi-impulse rendezvous is shown in
Figure 2. In order to ensure successful rendezvous with the evader at the terminal time epoch, the last two impulse maneuvers are obtained by solving the Lambert problem. Therefore, the independent variables to be optimized are the maneuver time
ti and the first
n−2 velocity increments Δ
vi, i.e.,
X = {
t1,
t2, …,
tn, Δ
v1, Δ
v2, …, Δ
vn−2,}.
Different from the traditional rendezvous mission trajectory, the pursuit trajectory of the FRS terminates when it reaches the perception range of the evader. Therefore, the maneuvers planned in the perception range of the evader are not actually implemented. The pursuit trajectory aims to achieve the optimal terminal game capability for the FRS. Firstly, the pursuer has a stronger pursuit potential when the terminal residual velocity increment is large. Secondly, when the pursuer’s terminal state is closer to that of the evader, it is easier for the subsequent operations in the CGS. The required velocity increment for the close-distance PE game is the minimum if the evader does not perform any evasive maneuvers, which is equal to the sum of the Δ
v that were planned in FRS but not executed because they are within the perception range. Therefore, the terminal game capability of the pursuer is defined as the ratio of the minimum velocity increments required for the close-distance PE game to the terminal residual velocity increments of the pursuer in the FRS. The corresponding formula is defined as follows,
where
n is the number of the planned impulse maneuvers, and
k is the number of impulse maneuvers actually performed in the FRS. Δ
vj denotes the
j-th velocity increment vector. Δ
vtol is the total velocity increment of the pursuit spacecraft.
The equations of motion of the spacecraft with the J2-perturbed dynamics are given as Equation (1), and it is assumed that the impulsive maneuver is performed instantaneously. Therefore, the constraints on the states before and after impulsive maneuver are listed as follows.
where the superscripts “+” and “−” indicate before and after the
i-th impulse maneuver, respectively.
Finally, the GA is used to search the optimal pursuit trajectory for the FRS. The velocity increment vector is described by the spherical coordinate to improve the optimization performance of algorithm, i.e., Δvj = [Δv, α, β]T, where Δv, α, and β are the magnitude, azimuthal angle, and polar angle of the velocity increment vector.
3.2. DDPG-Based Pursuit Method for CGS
After completing the FRS, the pursuer moves within the evader’s perception range and is discovered by the evader. Then, the evader will perform evasive maneuvers in response to the threat of the pursuer during the CGS. As mentioned in
Section 2.2, the close-distance PE game is actually an incomplete-information game, where the pursuer does not know the game strategy of the evader. Therefore, the pursuer must have the capability to continuously update its pursuit strategy based on the feedback information, to improve the robustness of the pursuit during the CGS. Reinforcement learning, as an important methodology of machine learning, is mainly used to describe and solve the problem of maximizing returns or achieving specific goals through learning strategies in the process of interaction between the agent and the environment. Therefore, a closed-loop pursuit method using a deep deterministic policy gradient algorithm, which is one of the earliest deep RL algorithms, is proposed in this section to solve the robust pursuit strategy for the incomplete-information PE game.
3.2.1. Deep Deterministic Policy Gradient Algorithm
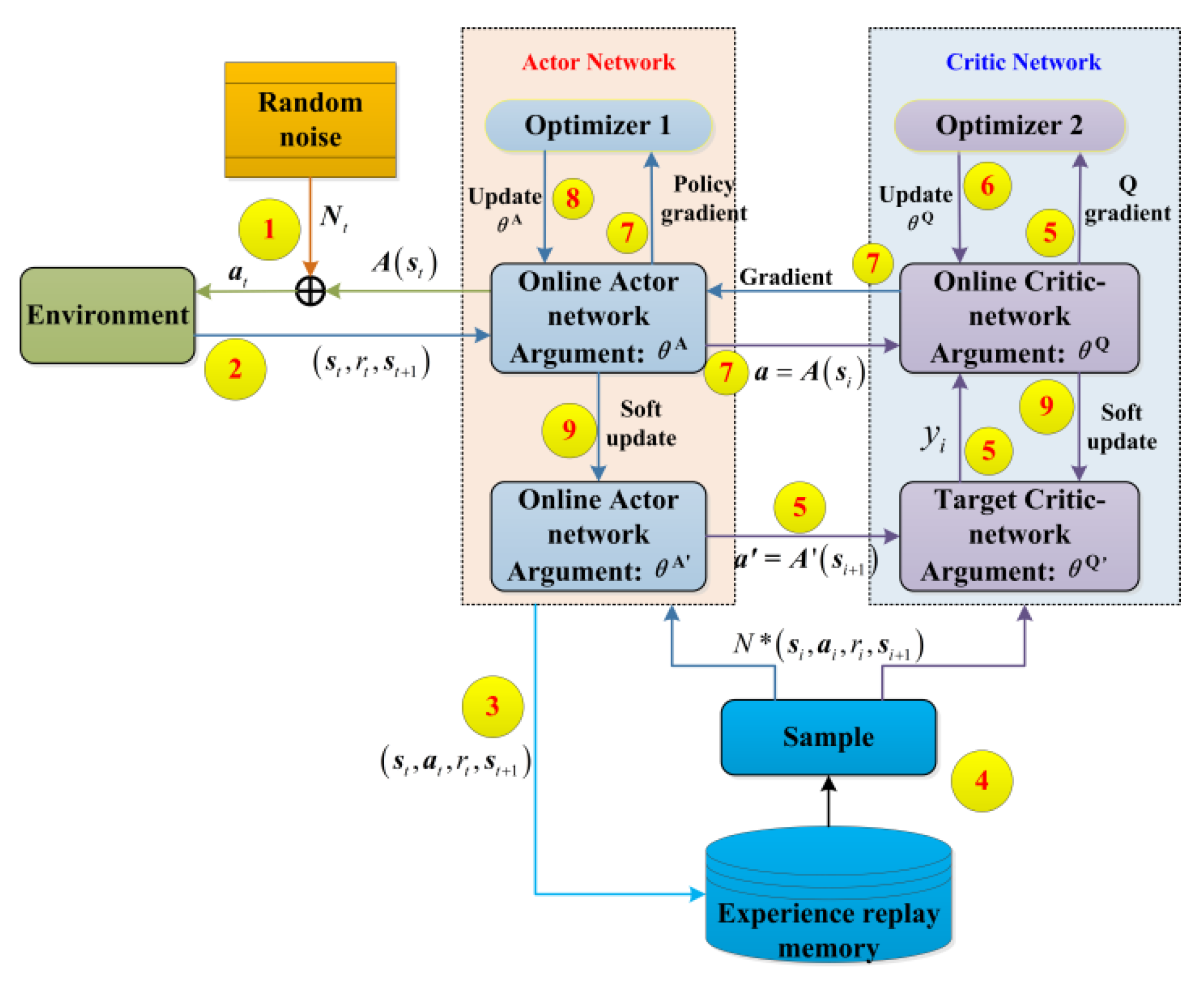
The DDPG algorithm is designed to operate on the large potential state and action spaces with a deterministic policy, which combines both Q-learning and Policy gradients and uses the deep neural networks to approximate the action and the Q-value [
25]. DDPG adopts the actor and critic (AC) architecture, as shown in
Figure 3. The actor is a policy network that takes the state as the input and outputs the exact action, rather than a probability distribution over actions. The critic is a Q-value network to evaluate the value of the action, which takes state and action as the inputs and outputs the Q-value. Both actor and critic have two networks: the online network and the target network. The roles of these four networks in DDPG are briefly introduced as follows.
Online actor network a = A(s, θA): it takes state s and returns the corresponding action a that maximizes the long-term reward R.
Target actor network a′ = A′(s′, θA′): it outputs the next action a′ using the next state s′ sampled in the experience replay memory. Its parameters θA′ are regularly updated according to the parameters of the online actor network θA.
Online critic network q = Q(s, a, θQ): it takes state s and action a as inputs and returns the corresponding expectation of Q-value q.
Target critic network q′ = Q′(s′, a′, θQ′): it outputs the next expectation of Q-value q′ using the next action a′ and the next state s′ sampled in the empirical playback pool. Its parameters θQ′ are regularly updated according to the parameters of the online critic network θQ.
θQ and θQ′ are the weights of the online critic network and the target critic network, respectively. θA and θA′ denote the weights of the online actor network and the target actor network, respectively.
The soft update technique and the target network are applied to improve the convergence and robustness of the training. The parameters of the online networks are firstly updated through the optimizers (e.g., stochastic gradient descent algorithm), and then the parameters of the target networks are updated through the soft update algorithm, where only a fraction of the weight parameters is transferred in the following manner.
where
τ∈[0, 1] is the parameter of soft update algorithm.
The loss function of the online critic network is formatted as follows
where
N is the number of samples from the replay memory buffer.
Ri is the reward of the
i-th action.
γ is the discount factor of the future reward.
The policy gradient of the online actor network was formulated according to the deterministic policy gradient method as,
According to the deterministic policy gradient method, the actor-network only outputs the action with the highest probability. This effectively improves the computational efficiency of the algorithm, while its exploration capability was significantly insufficient. Therefore, the off-policy method, which chooses the action
at based on the current policy and the exploration noise
Nt, was employed to improve the exploratory capability of the algorithm.
3.2.2. Closed-Loop Pursuit Method Using DDPG
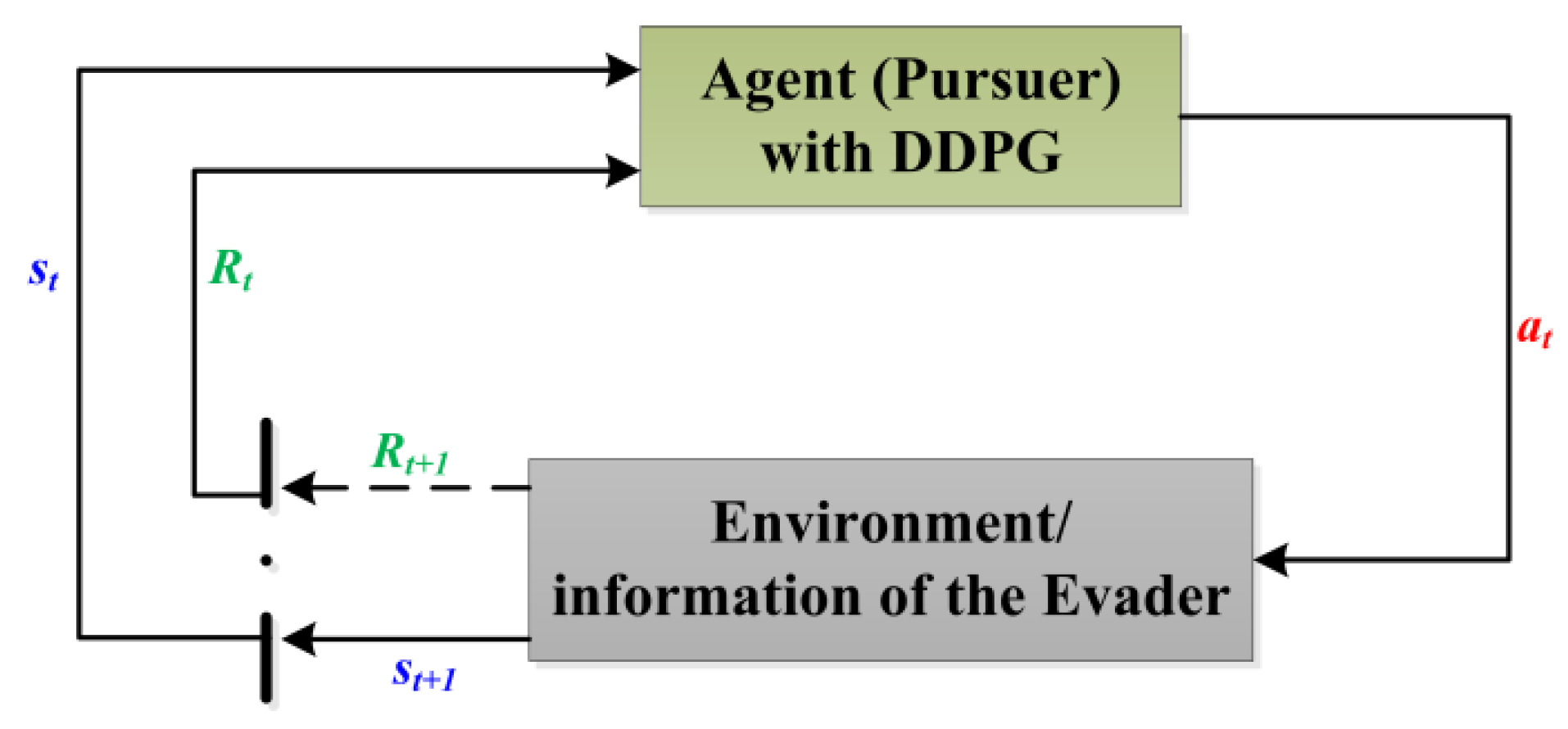
This section presents a closed-loop pursuit method using DDPG, which enables the pursuer to interact with the environment, to address the incomplete-information PE game problem, as shown in
Figure 4. Markov Decision Process (MDP) [
28], which is a common model for RL, was used to model the space PE game problem. According to the MDP theory, the agent (here, it is the pursuit spacecraft) takes action after interacting with the environment to change its state for obtaining a reward.
The state and action spaces of the PE game are defined as follows
The states of the pursuer and the evader are propagated using Equation (1). The return and reward functions are defined as follows
where the variables in Equation (15) have the same definition as those in Equation (3).
WP-E is equal to
06 × 6 because the strategy of the evader was unknown.
Nf denotes the number of steps when the successful pursuit condition in Equation (6) or terminal constraints in Equation (7) are met.
κ is the scale coefficient, whose default value is 0.0001.
εf is the reward of the mission completion and is defined as
If the pursuer has a successful rendezvous with the evader, it receives a positive constant reward. Otherwise, it was punished with a negative constant reward.
It is assumed that the evader will perform an impulse maneuver to evade the pursuer when the evasive condition was activated. The evasive condition is defined as
where
rtP and
rtE are the position vectors of the pursuer and evader at time
t.
tc and
tf are the current and terminal time of the mission.
rec denotes the warning distance of the evader.
The maneuver time
tm and delta-v
Δv are optimized using the sequential quadratic programming (SQP) with the following objective function
where the variables in Equation (19) have the same definition as those in Equation (4). Therefore, the evader’s strategy was adjusted by changing the weight matrix
QE,
WE-E and
QfE during the training.
In order to improve the robustness and generalization capability of the training agent, the initial states of the pursuer and evader and the evasive strategy of the evader are randomly initialized before each episode. The initial states of the pursuer and evader for the CGS are their terminal states of the FRS that are solved using the multi-impulse pursuit trajectory optimization for FRS in
Section 3.2.1.
4. Simulations and Analysis
A series of PE games in the sun-synchronous orbit (SSO), whose right ascension of ascending node drifts with a fixed precession rate under the effect of J2 perturbation, are studied to verify the feasibility and performance of the proposed two-stage pursuit strategy. The pursuit and evasion spacecraft park on a sun-synchronous circular orbit and a sun-synchronous elliptical orbit, respectively. Both the pursuer and the evader use the impulse to implement orbital maneuver. According to the realistic space PE mission requirements, the mission constraints are listed in
Table 1. The mission duration was limited to 4 h for the consideration of the timeliness of the space PE mission. In addition, considering the difference between the initial orbital planes of the pursuer and evader, the total delta-V of the pursuer was set to be 3 times of that of the evader.
The initial orbital ranges of the pursuit and evasion spacecraft are given in
Table 2. We always generate the initial conditions starting from an initial set of orbital elements. Values of the orbital elements for each sample are randomly generated with the
rand function in MATLAB using the intervals defined in
Table 2.
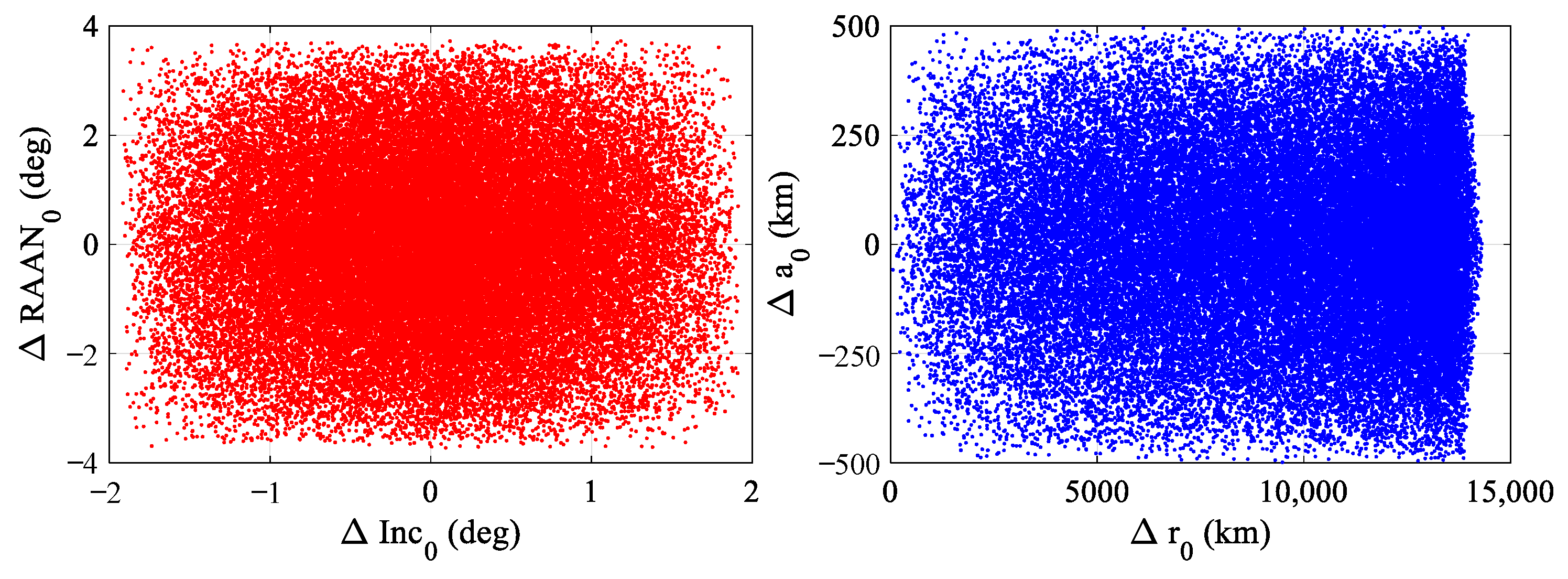
A pair of pursuer and evader forms one PE game sample scenario and 50,000 game sample scenarios are randomly generated. The disparity of the initial parking orbits of the pursuer and evader of all sample scenarios are given in
Figure 5. It is seen that the difference of the semi-major axis and the orbital plane are limited to 500 km and 5 deg respectively. In addition, the initial relative distances between the pursuers and evaders are all over 200 km, making sure that the pursuer was out of the perceived range of the evader. Therefore, the proposed two-stage pursuit strategy in
Section 3 can be applied to generate the pursuit trajectory.
4.1. Far-Distance Rendezvous
The number of the impulse maneuvers was set to three for the FRS because the mission duration was limited to 4 h. GA was used as the optimizer to find the optimal transfer trajectory, and the fitness function is defined as Equation (8). For the training, the population was 200 and the maximal generation was 300. The rates of reproduction, crossover and mutation are 0.9, 0.75 and 0.05, respectively.
A specific scenario (denoted as case A) with initial states given in
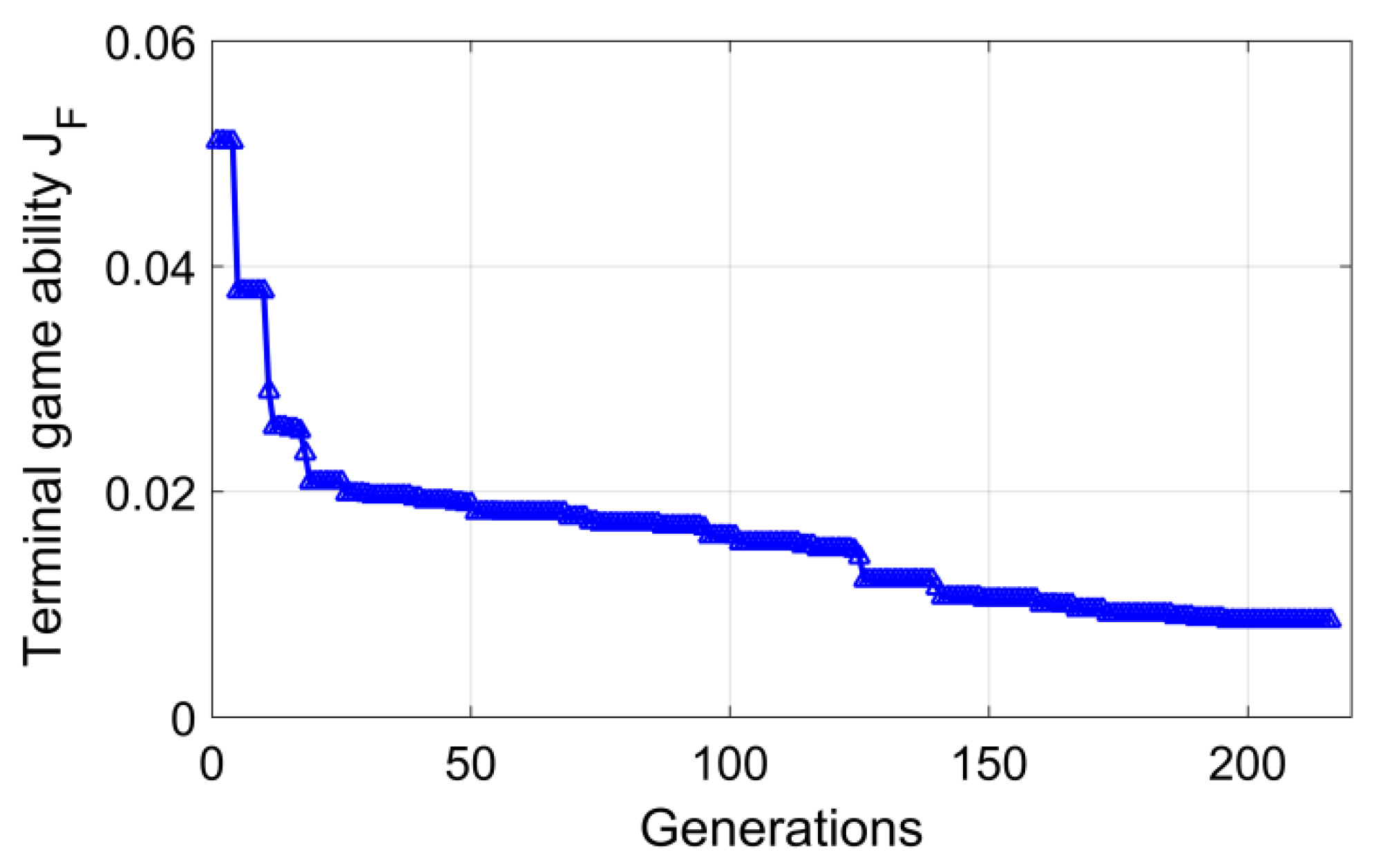
Table 3 was implemented to verify the performance of the proposed method. The variation of the pursuer’s terminal game capability
JF with the generations is given in
Figure 6. After 216 generations, the
JF finally converges to 0.00789, which indicates that the pursuer retains a strong pursuit potential when reaching the evader’s perception boundary.
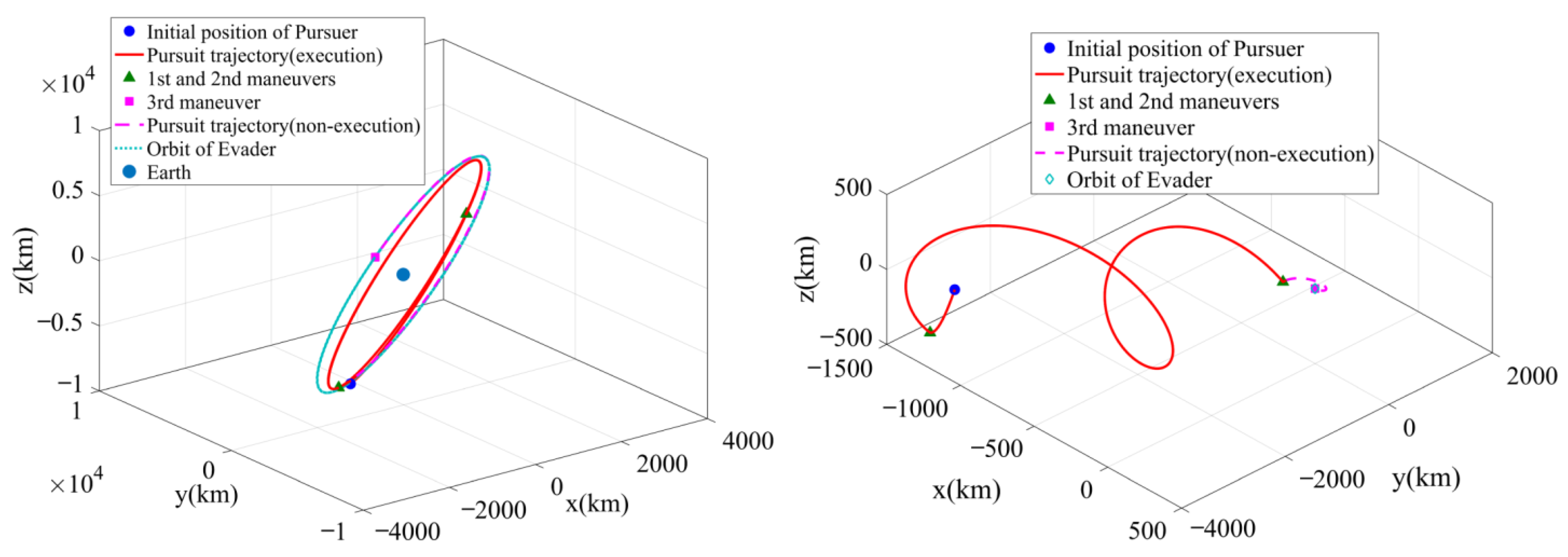
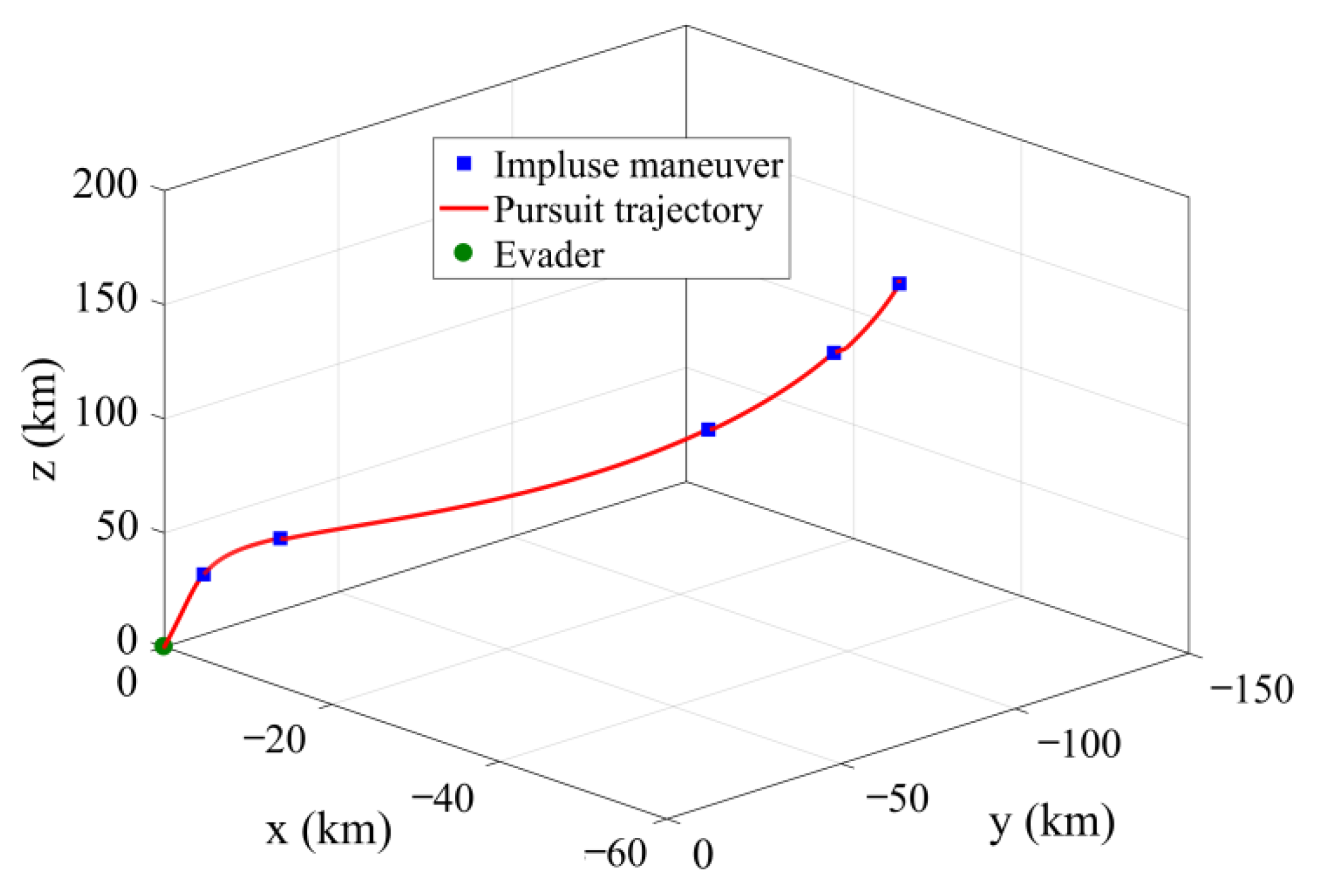
The pursuit trajectory of the FRS for case A is shown in
Figure 7. The pursuer performed the first impulse maneuver at 25.11 min to be injected into the pursuit trajectory. Then, the second impulse maneuver was performed at 2 h 51 min to rendezvous with the evader. With these two maneuvers, the trajectory of the pursuer until it reached the evader’s perception boundary is given as the red solid line in
Figure 7. The trajectory represented by the pink dotted line is the planned pursuit trajectory but not executed because it is within the evader’s perception range. The third maneuver was planned at the rendezvous position with the evader, which was also not executed. The obtained pursuit trajectory in the FRS allowed the pursuer to retain the pursuit potential and obtain more advantage in the subsequent close-distance PE game.
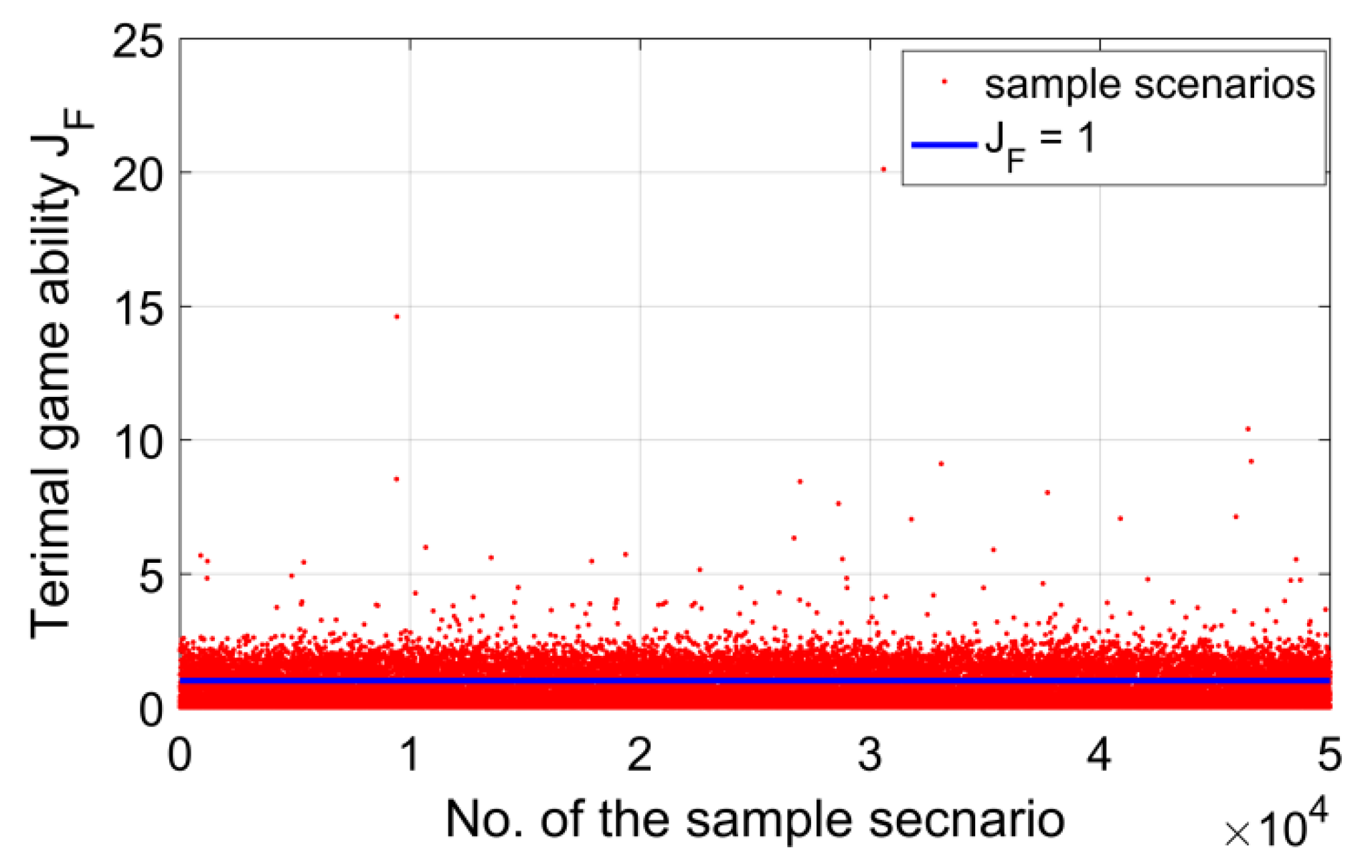
Similarly, the pursuit trajectory of the FRS is optimized using GA for all 50,000 sample scenarios to obtain the initial state of the close-distance game, which generates the initial state database for the DDPG training. The optimization results of 50,000 sample scenarios are given in
Figure 8.
The terminal game ability of the pursuer
JF represents the pursuit potential of the pursuer. If
JF is greater than 1, it means the pursuer does not have enough delta-v to reach the evader. A smaller
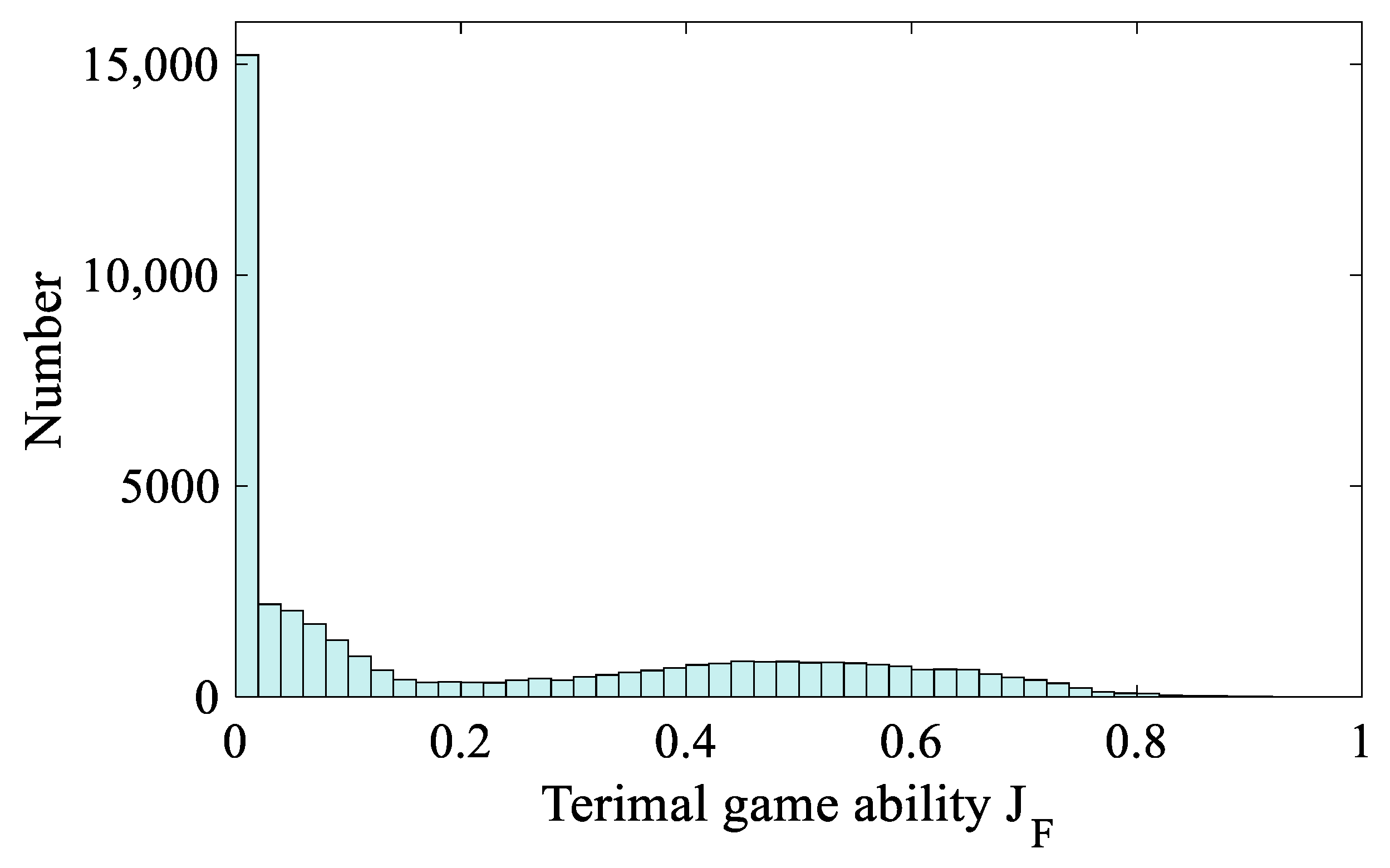
JF indicates the greater pursuit potential of the pursuer. There are 41,926 sample scenarios, whose
JF are all less than 1, have enough delta-v to continue the subsequent close-distance game. The
JF distribution of these 41,926 sample scenarios is given in
Figure 9.
4.2. Close-Distance Pursuit-Evasion Game
DDPG includes four deep neural networks that are fully connected, and the specific parameters of these neural networks are given in
Table 4. All critic neural networks have five hidden layers and actor neural networks have three hidden layers. Based on the experience from the multiple tests and the test results, the number of neurons per hidden layer was 100 for all neural networks. The activation functions of all deep neural networks used a combination of the linear function “relu” and the hyperbolic tangent function “tanh”.
The maximum time duration of the CGS was set to 3600 s, and the time-step of the training was set to 10 s. Therefore, the maximal steps of each game were 360. The learning rates of online actor network and online critic network are 0.001 and 0.0001, respectively. The discount factor of future reward was 0.95. In order to increase the agent’s exploration ability, the action interference factor was introduced with the initial value of 0.1, and it decayed at a rate of 0.8 per episode. The capacity of the experience library was set to 30,000. When the experience library was full, the network training was carried out. In the follow-up training, the experience library was gradually updated. In order to obtain independent samples as many as possible, each episode extracted a small batch of samples from the experience library for training. The number of the batch samples set was 256.
For each episode, the sample scenario was randomly selected from the initial state database that is obtained in
Section 4.1, and the evasion strategy of the evader was updated as well. According to Equations (5) and (19), the weight matrices
QE,
WE-E and
QfE in Equation (19) are updated by the random parameters
qE,
wE-E, and
qfE, whose value ranges are listed in
Table 5. Similarly, the weight matrices in Equation (15), which are defined in Equation (5), and the values of weight parameters are also given in
Table 5.
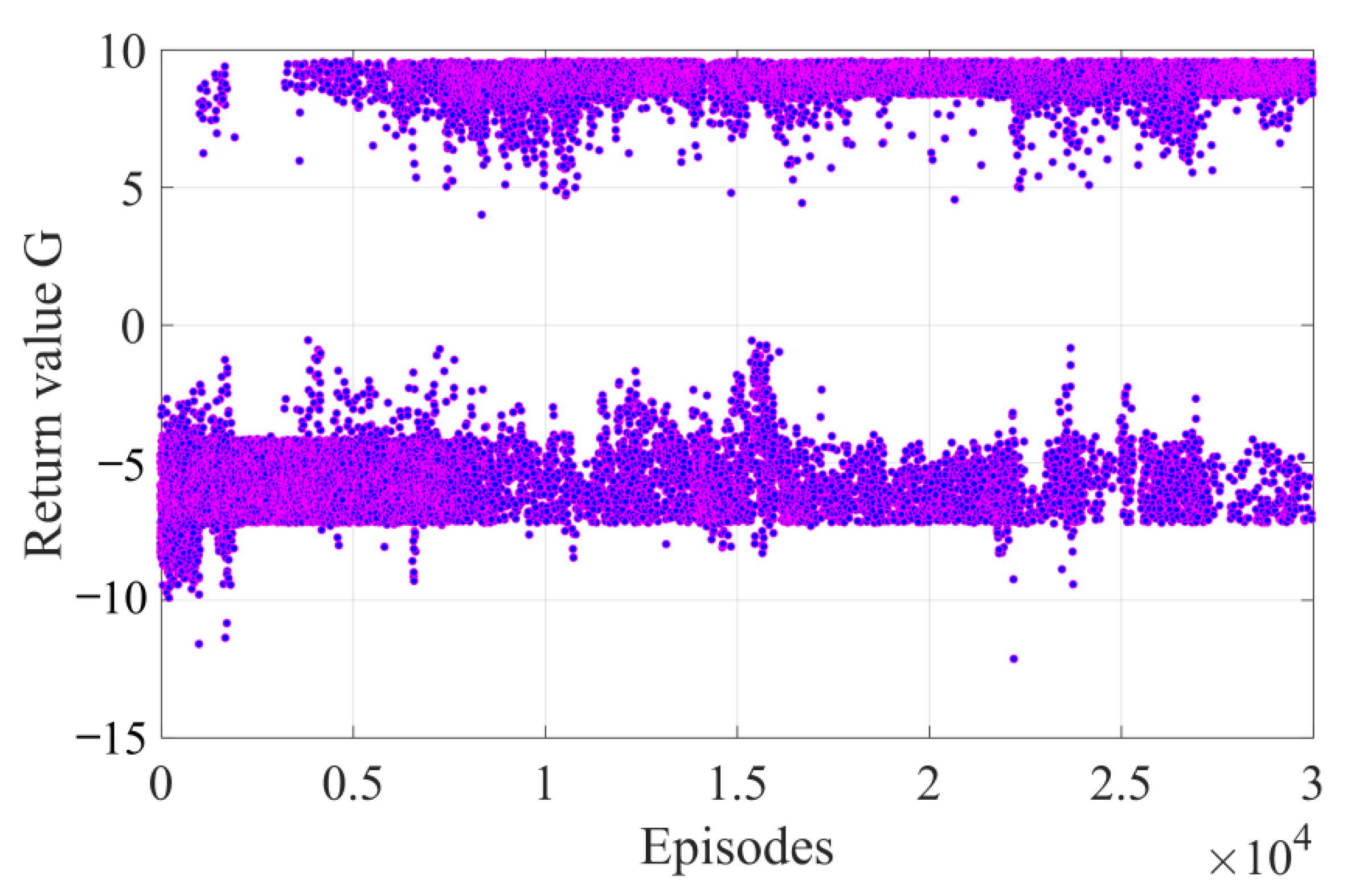
The return value in the DDPG training process is obtained and given in
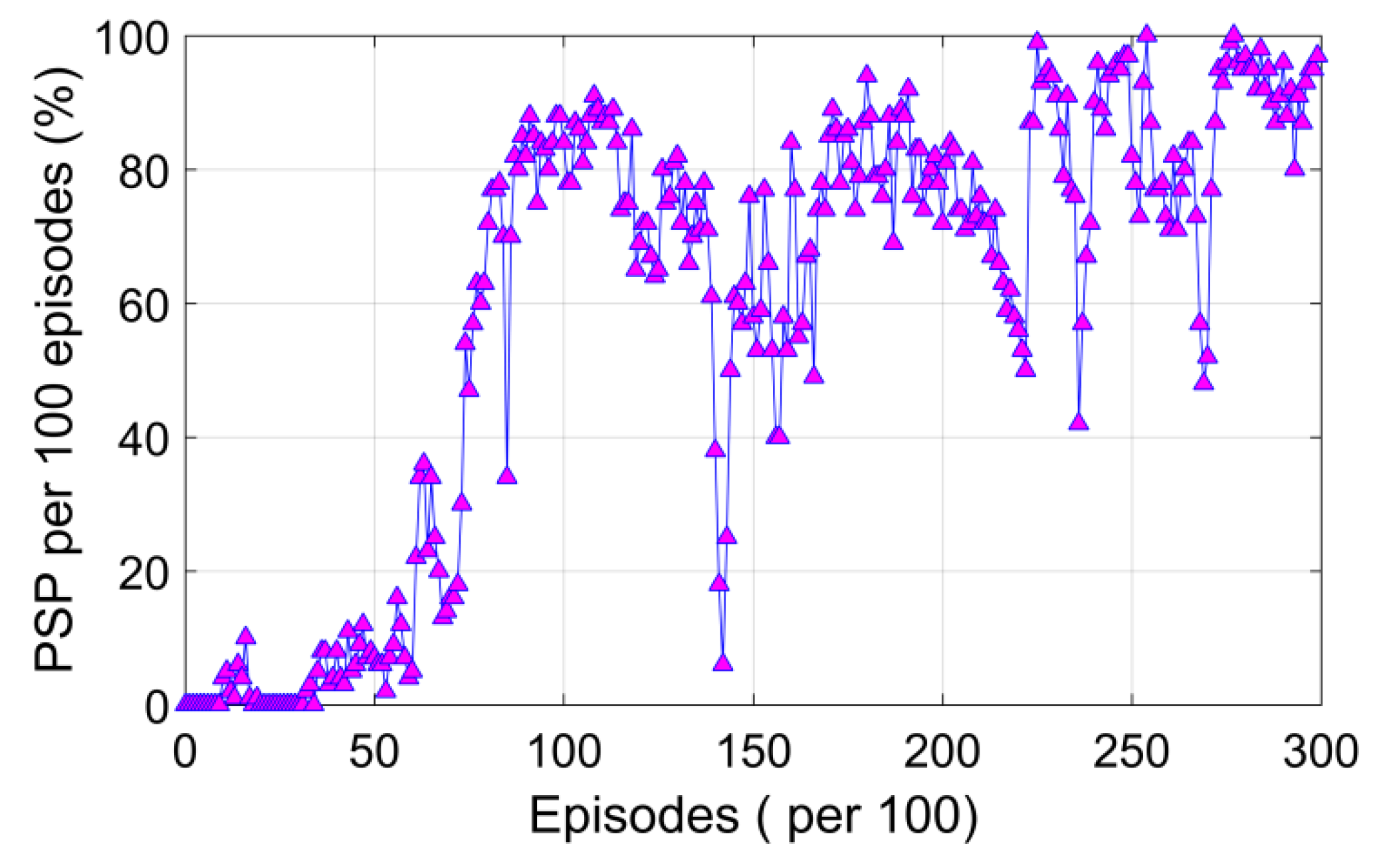
Figure 10. After more than 5000 episodes of random exploration, the return value of the agent and the probability of successful rendezvous gradually increased. Finally, after 30,000 episodes, the pursuit success percentage (PSP) per 100 episodes reached above 95%, as shown in
Figure 11.
A well-trained agent was applied to solve the pursuit trajectory in the CGS for case A. Without loss of generality, the evasion strategy parameters
qE,
wE-E, and
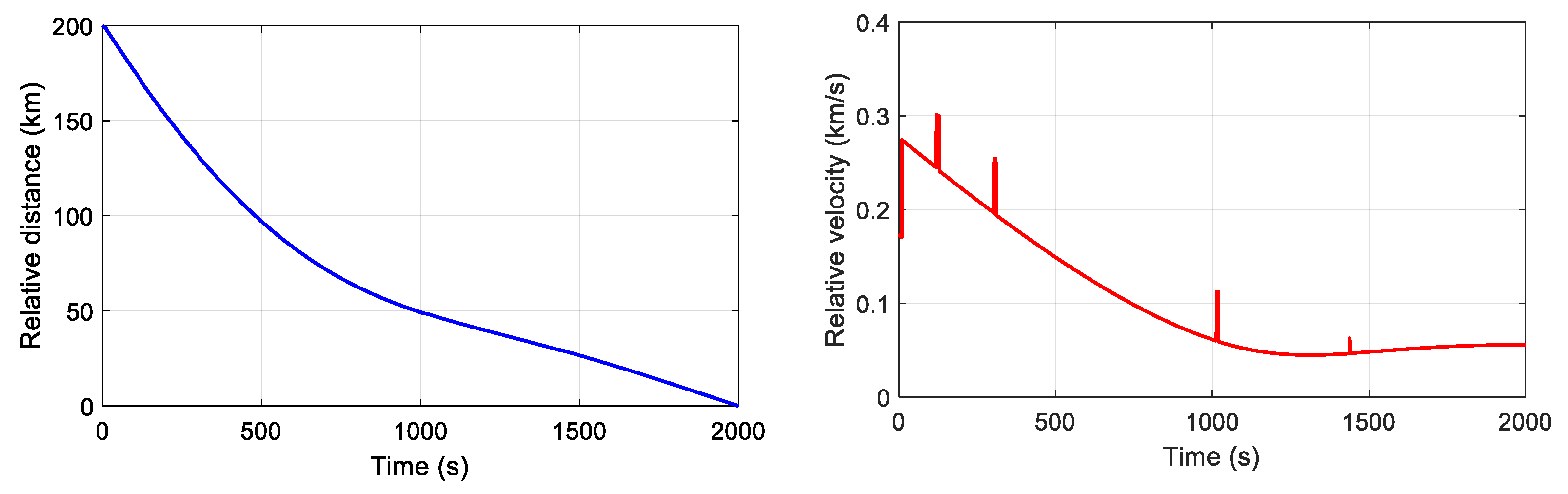
qfE are 1, 2 and 1, respectively. The relative distance and velocity between the pursuer and evader during the CGS are given in
Figure 12. The evader performed five impulse maneuvers to evade the pursuer. However, the pursuer with DDPG always updated the pursuit strategy and implemented corresponding maneuvers in time to maintain the tendency of approaching the evader. The trajectory of the pursuer in the orbital coordinate system of the evader is given in
Figure 13.
4.3. Monte Carlo Analysis
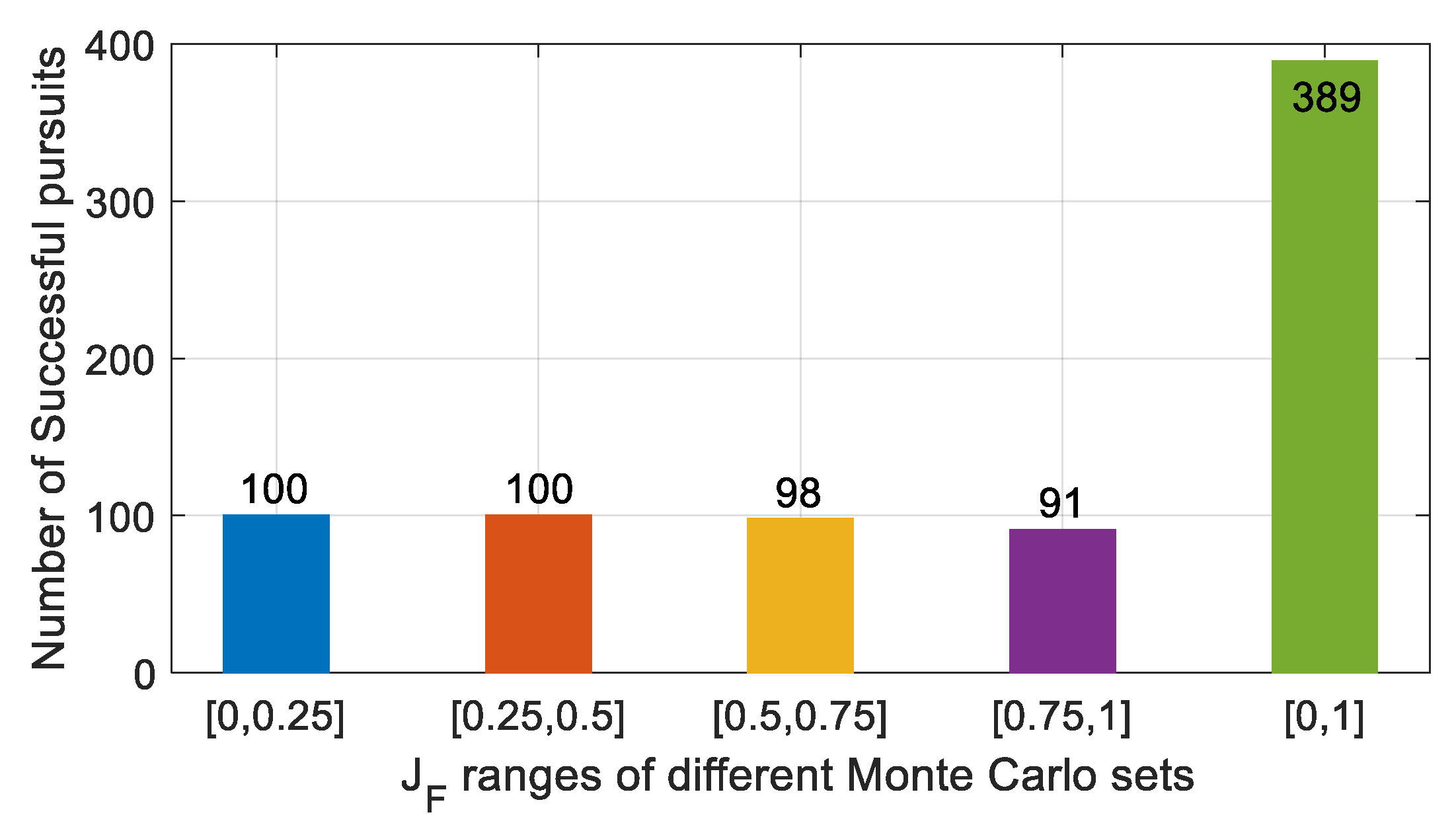
In order to verify the robustness of the DDPG-based pursuit approach to the initial states of the pursuer and the evader and to the evasion strategies for the CGS, four sets of Monte Carlo simulations were performed. The
JF value ranges of the four sets are [0, 0.25], [0.25, 0.5], [0.5, 0.75] and [0.75, 1], respectively. Each set contained 100 samples and the evasion strategy of the evader for each sample was obtained by randomly generating parameters
qE,
wE-E, and
qfE. The number of successful pursuits for each set is given in
Figure 14. When
JF is less than 0.5, all pursuers successfully rendezvous with the corresponding evaders. The successful pursuit rate decreased with the increase of
JF, because a large
JF indicates poor pursuit capability. The total successful pursuit rate was 99.5% and the successful pursuit rate also achieved 91% even for the worst set with JF of [0.75, 1]. This indicates that the proposed method has good robust performance for incomplete-information impulsive pursuit-evasion missions.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}