
Analysis of the Forecast Price as a Factor of Sustainable Development of Agriculture

 ,
,  , , , and
, , , and
Abstract
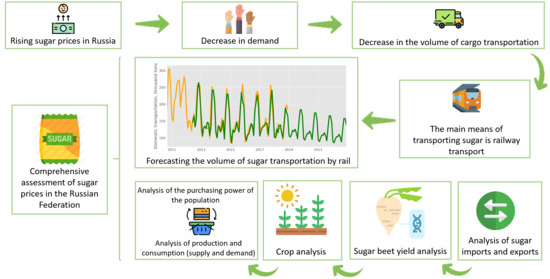
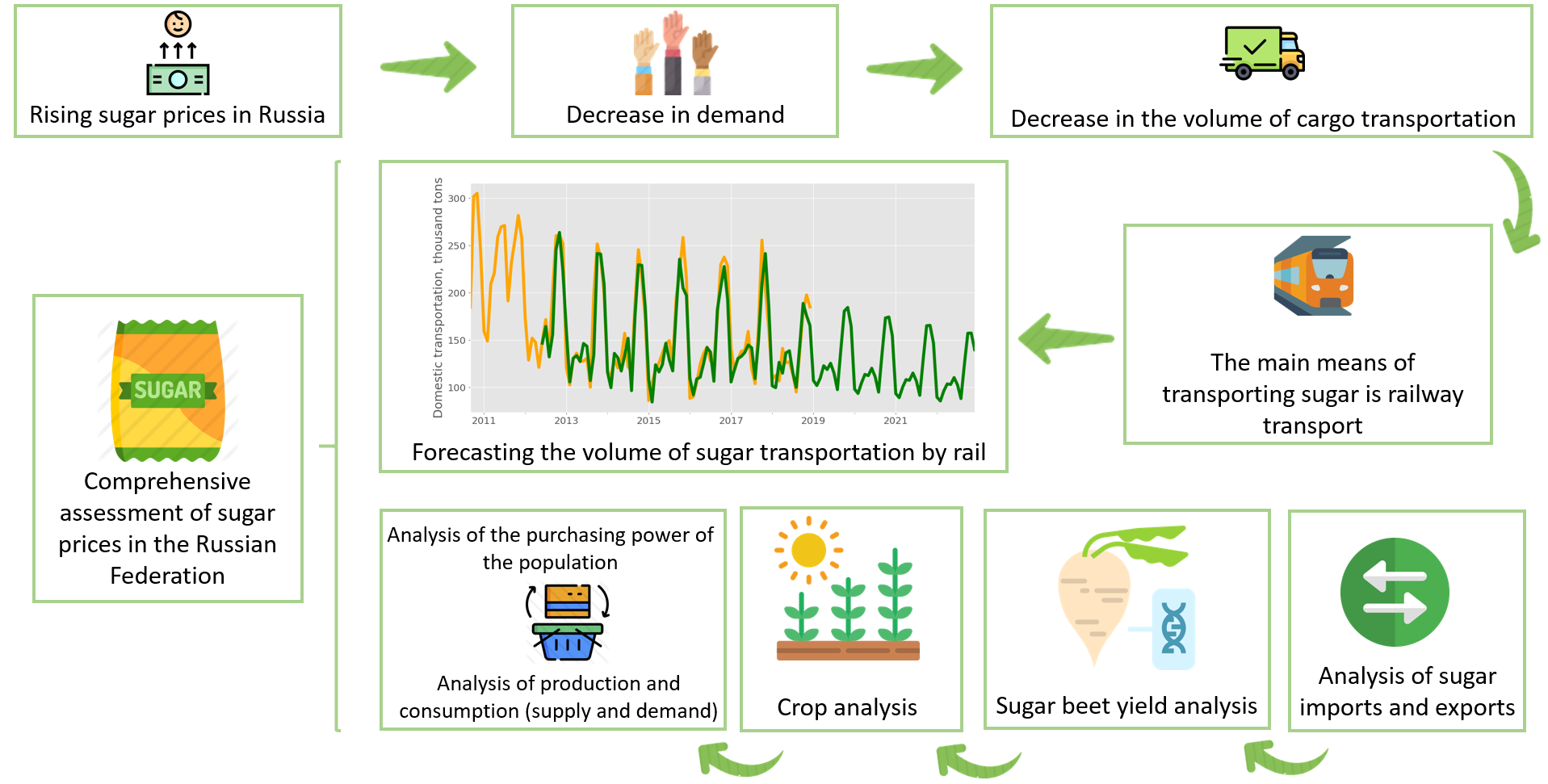
:
{kind=link}
{kind=link}
{kind=link}
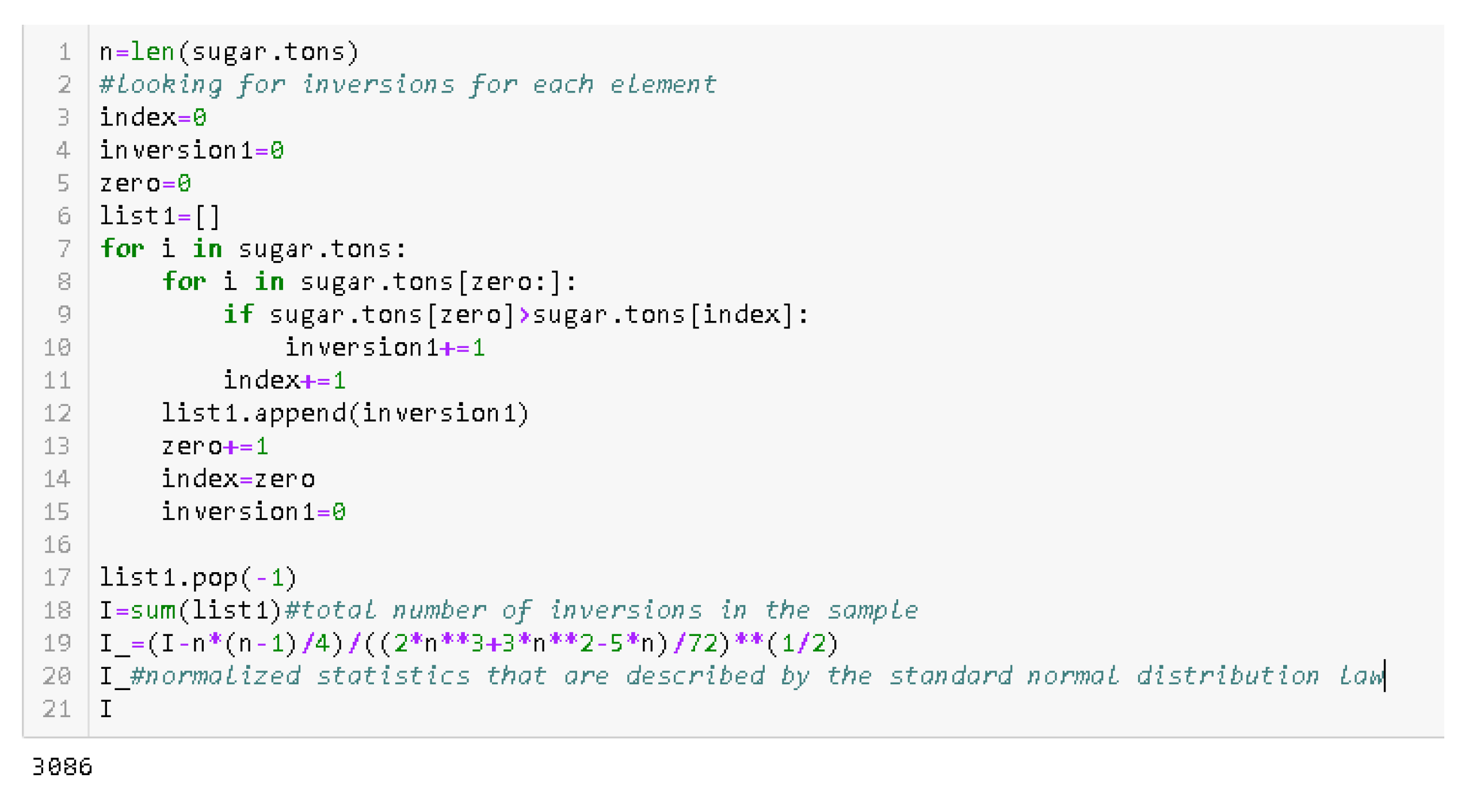{kind=link}
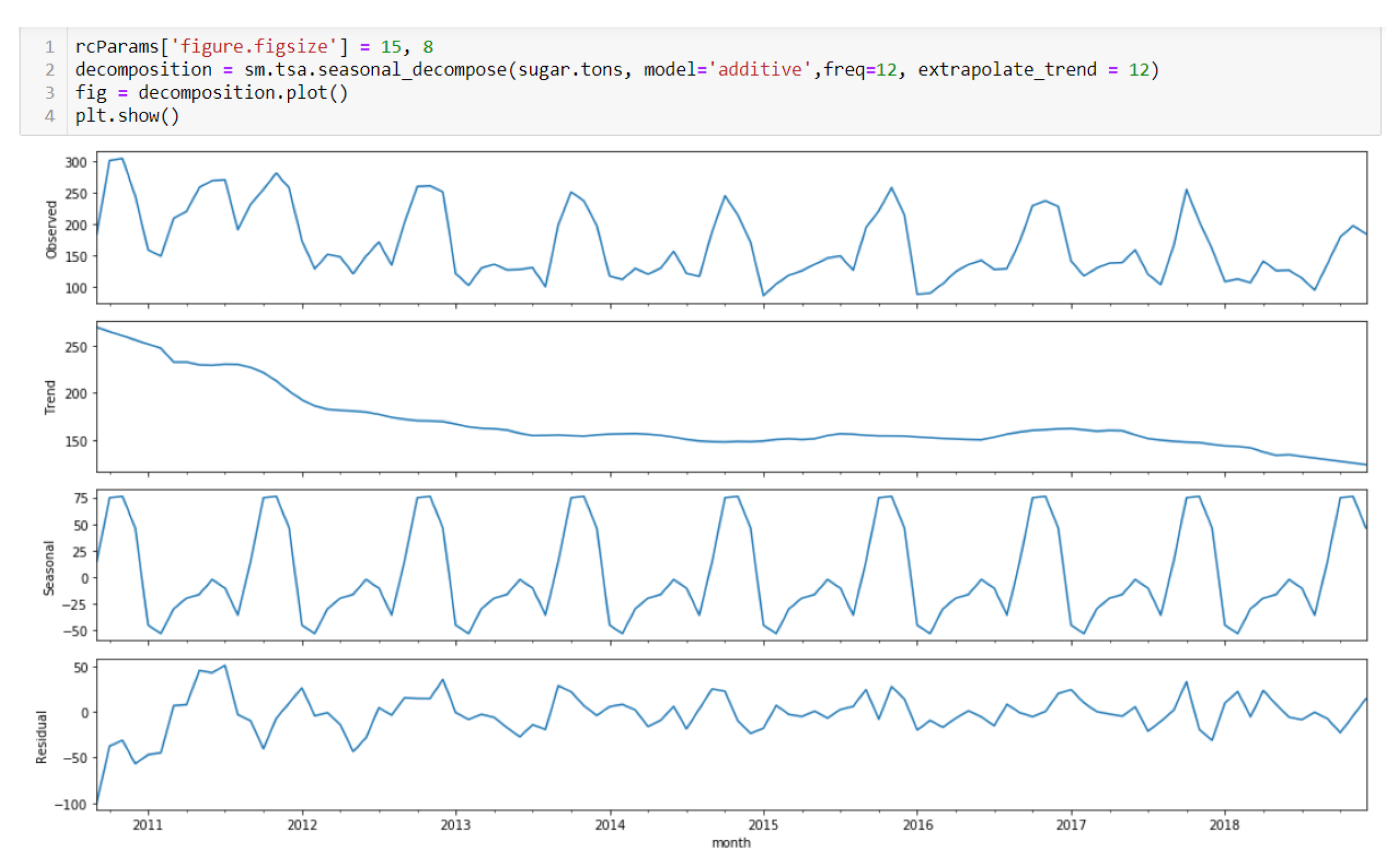{kind=link}
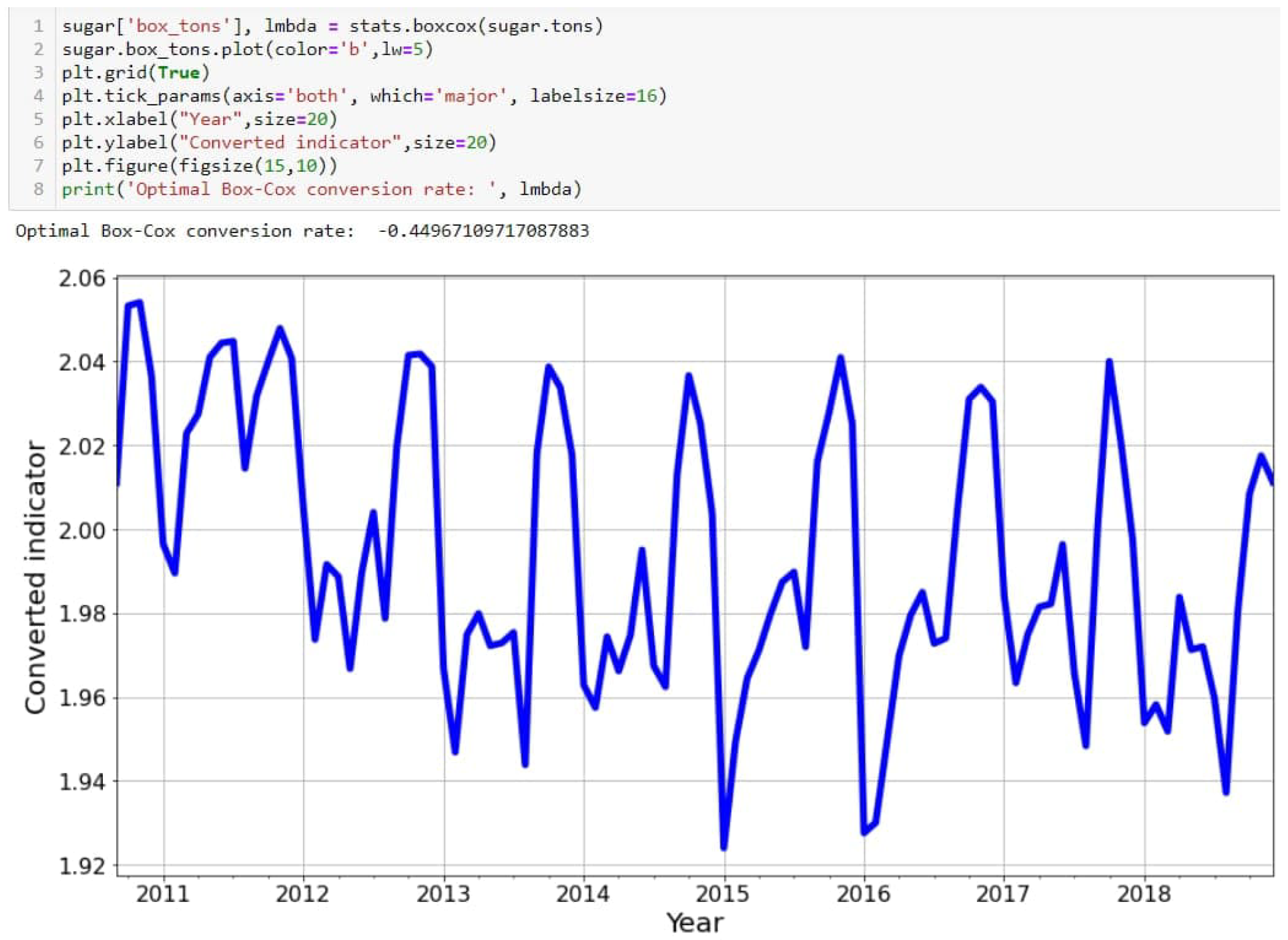{kind=link}
{kind=link}
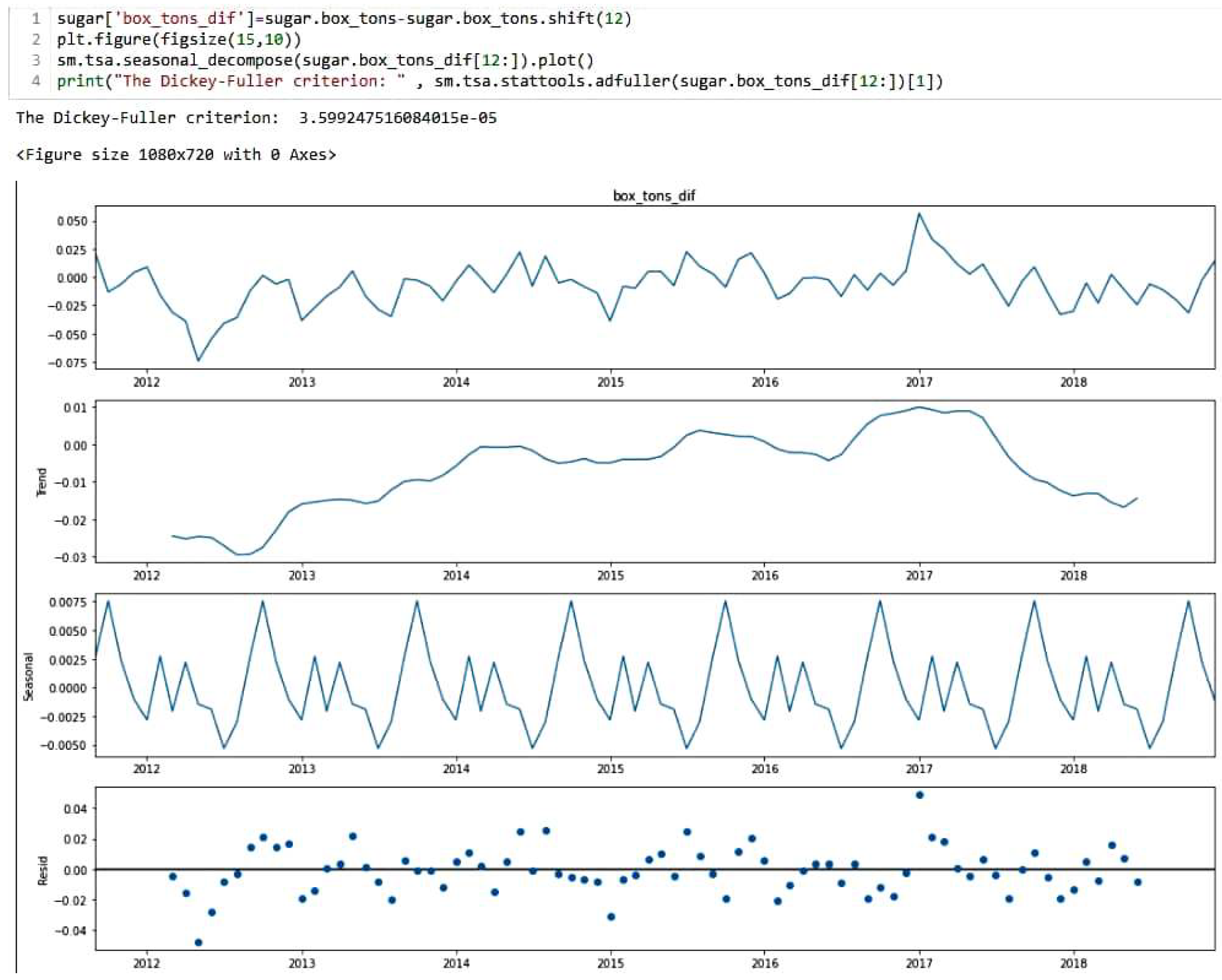{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
1.1. Problem Statement
1.2. Justification of the Choice of Methods for Solving the Problem
2. Data Preparation and Transformation
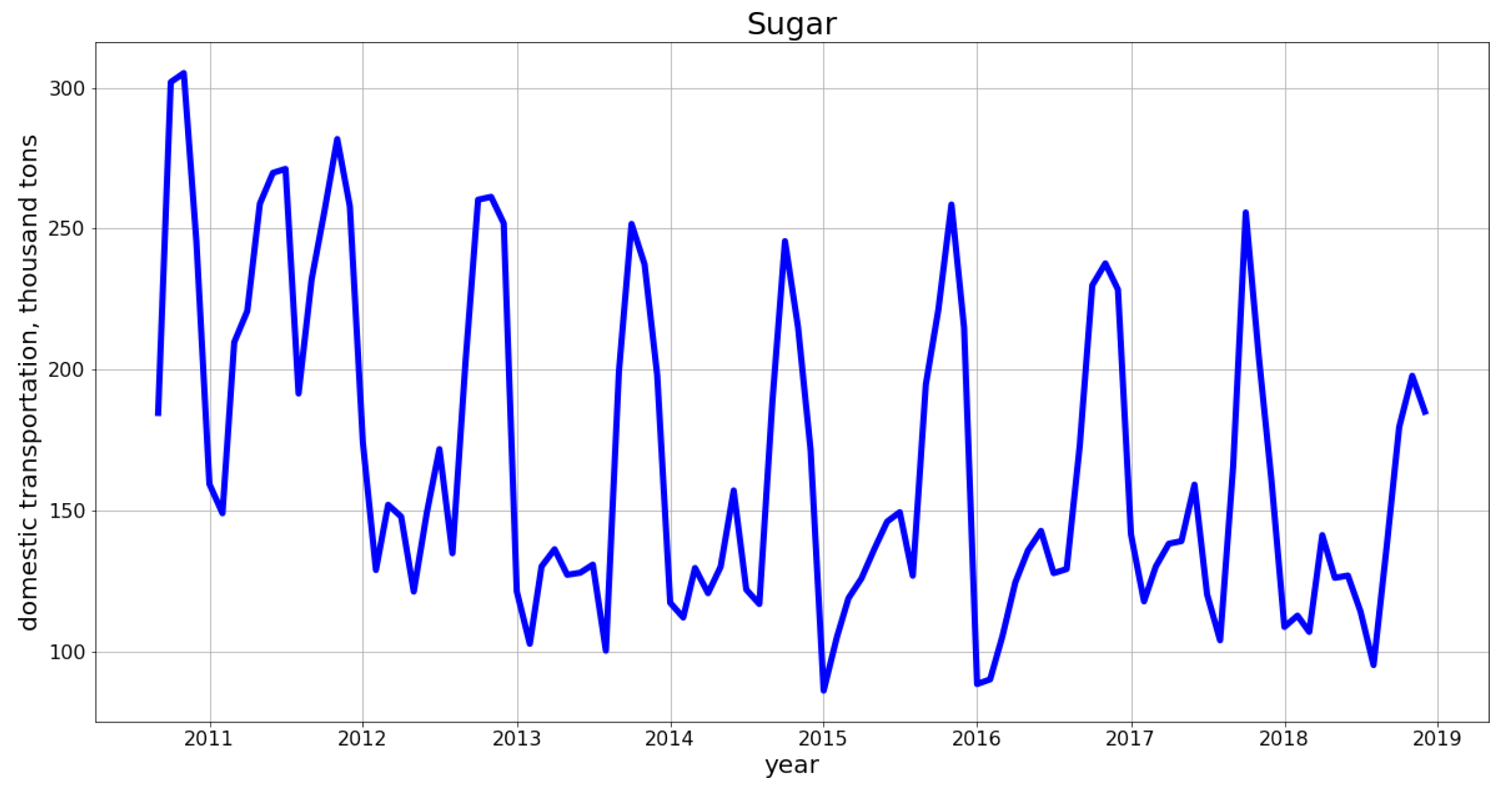
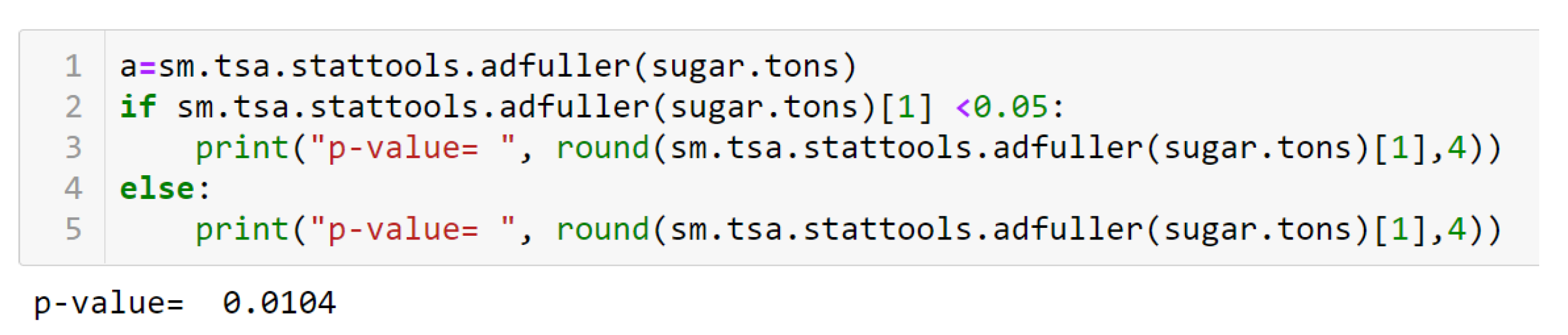
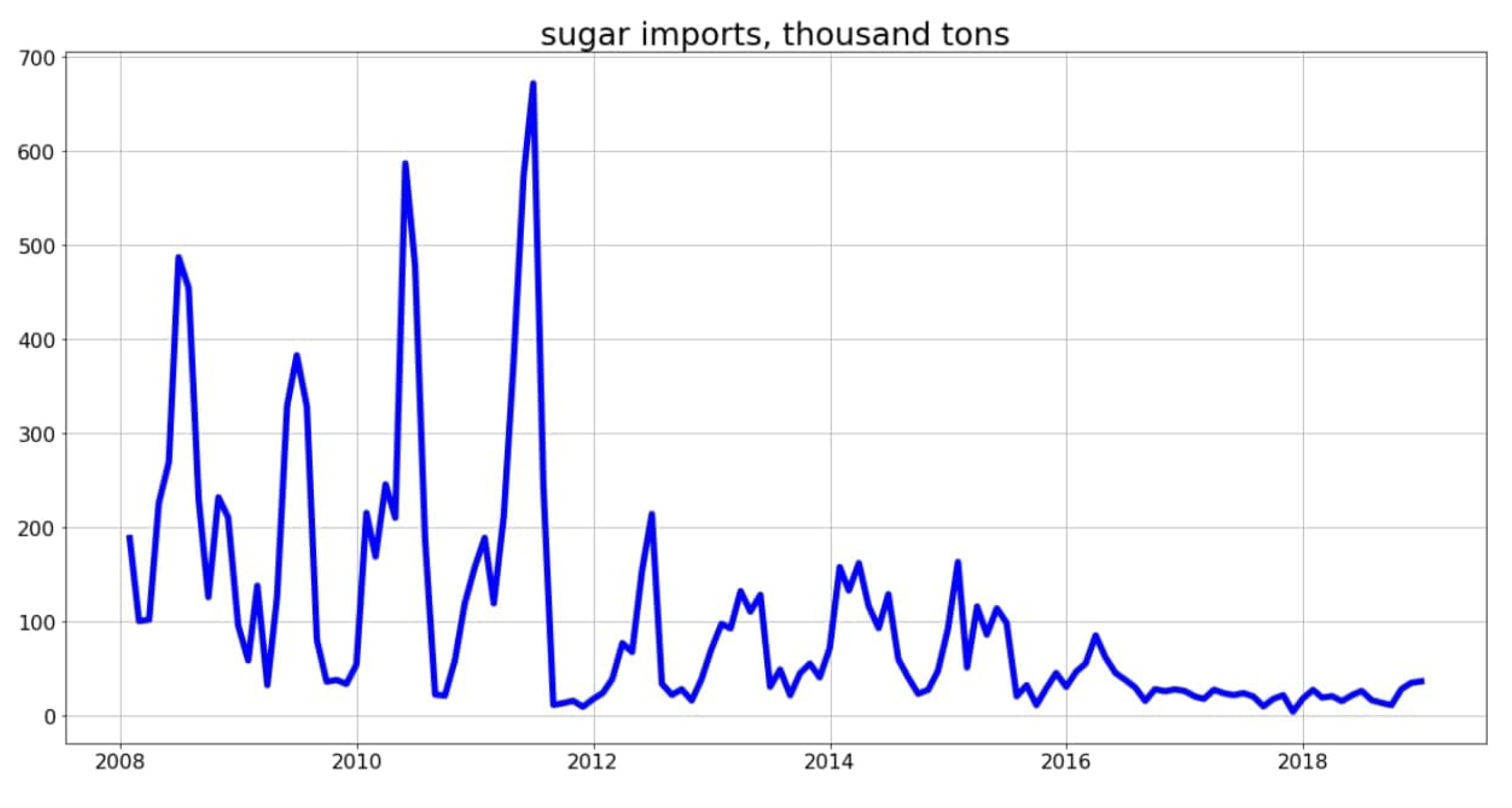
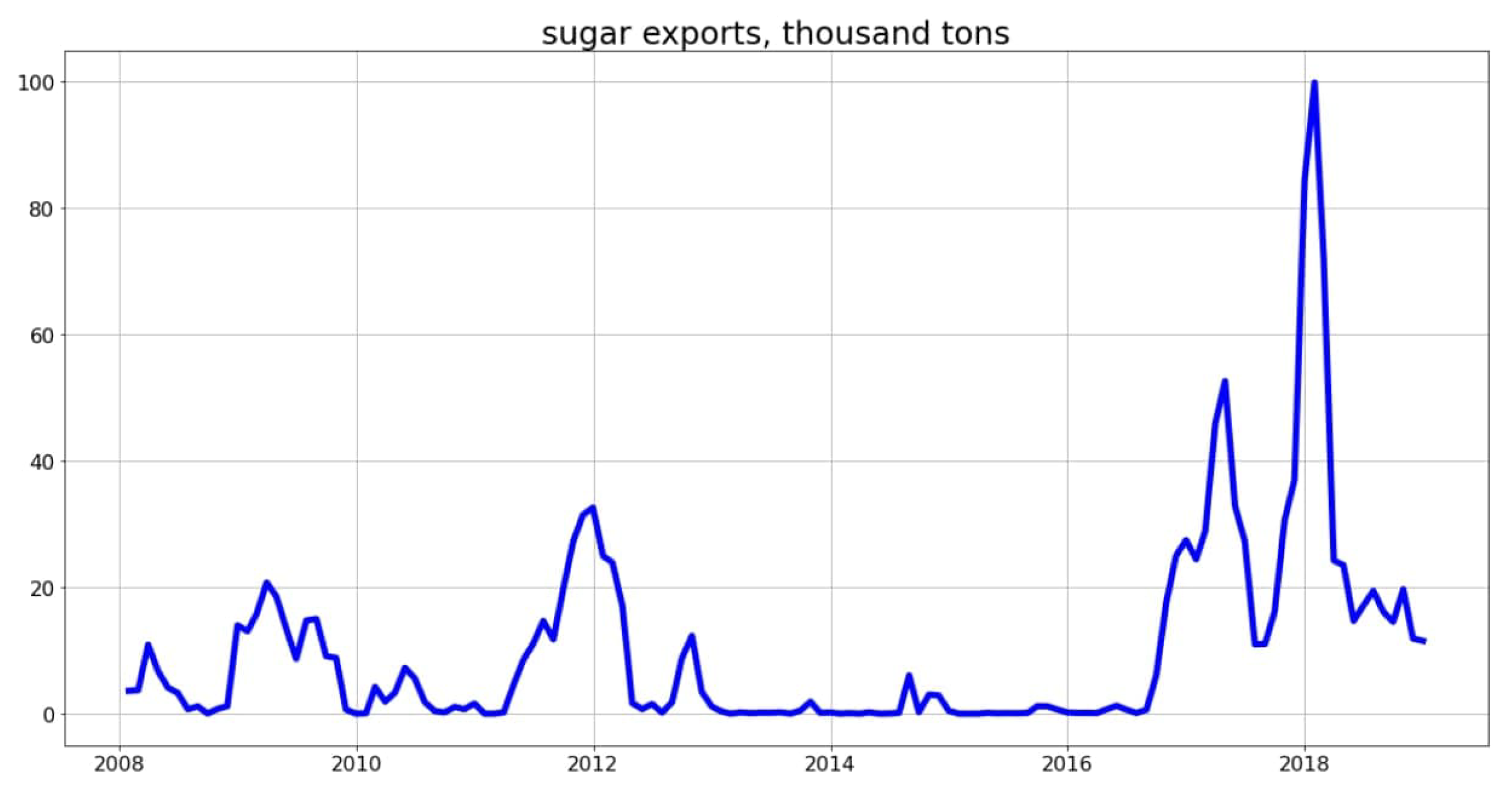
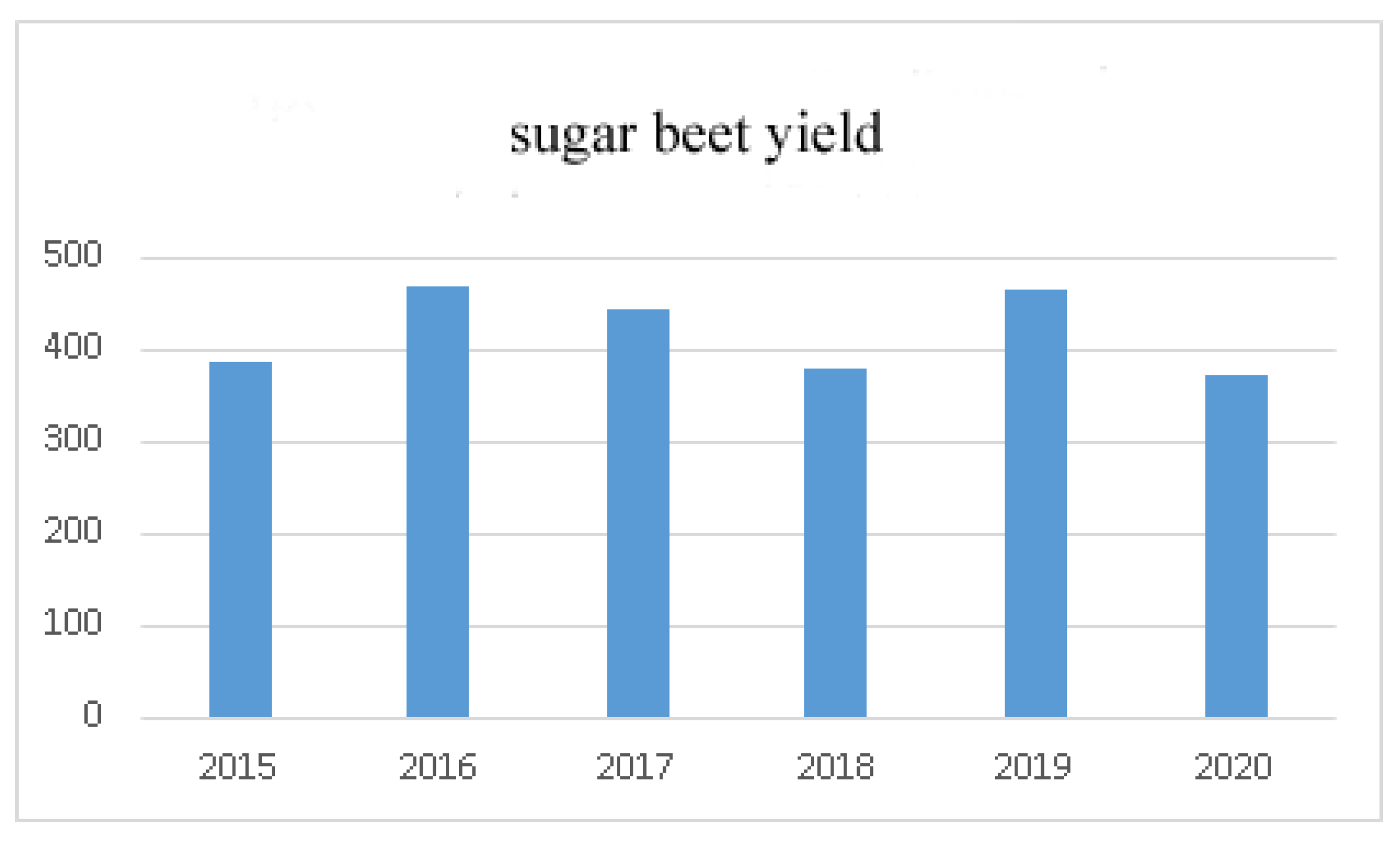
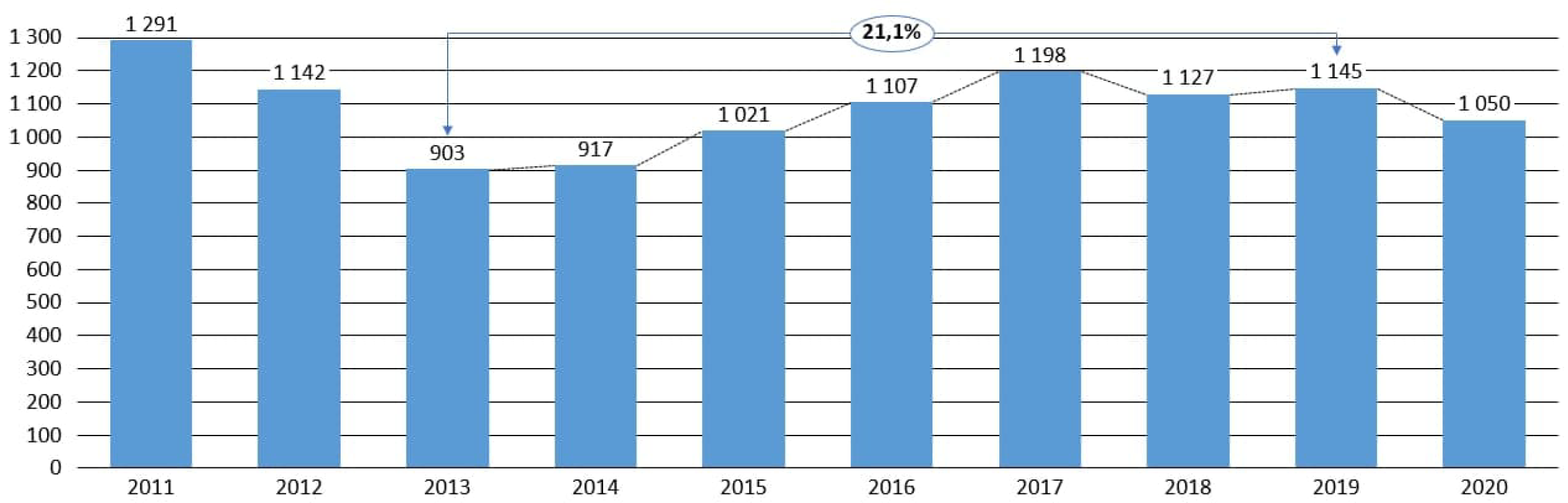
2.1. Time Series: Visualization and Checking for Stationarity
2.2. Box–Cox Transform and Data Stabilization
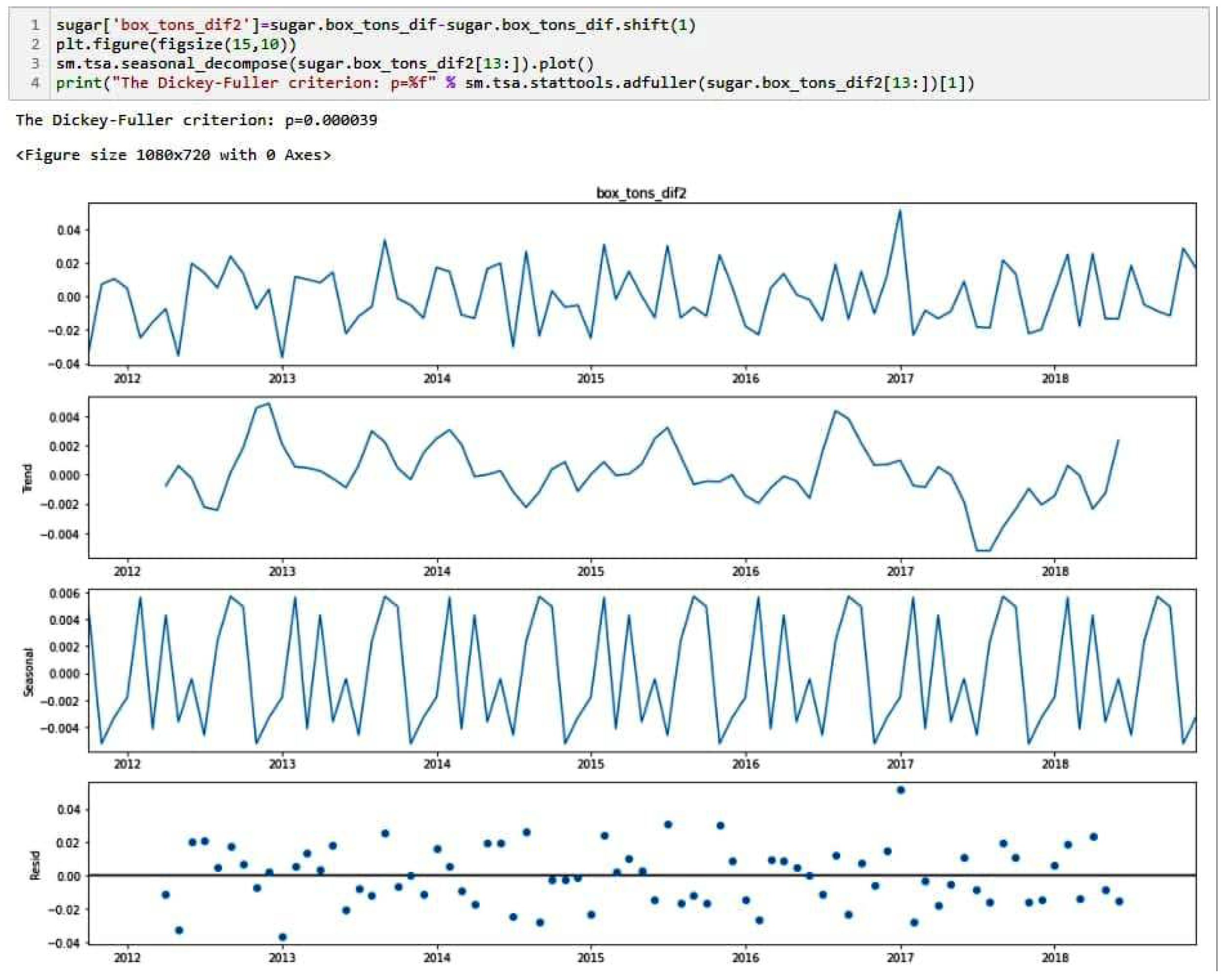
2.3. Time Series Differentiation
3. Making a Forecast of the Volume of Domestic Sugar Shipments by Rail
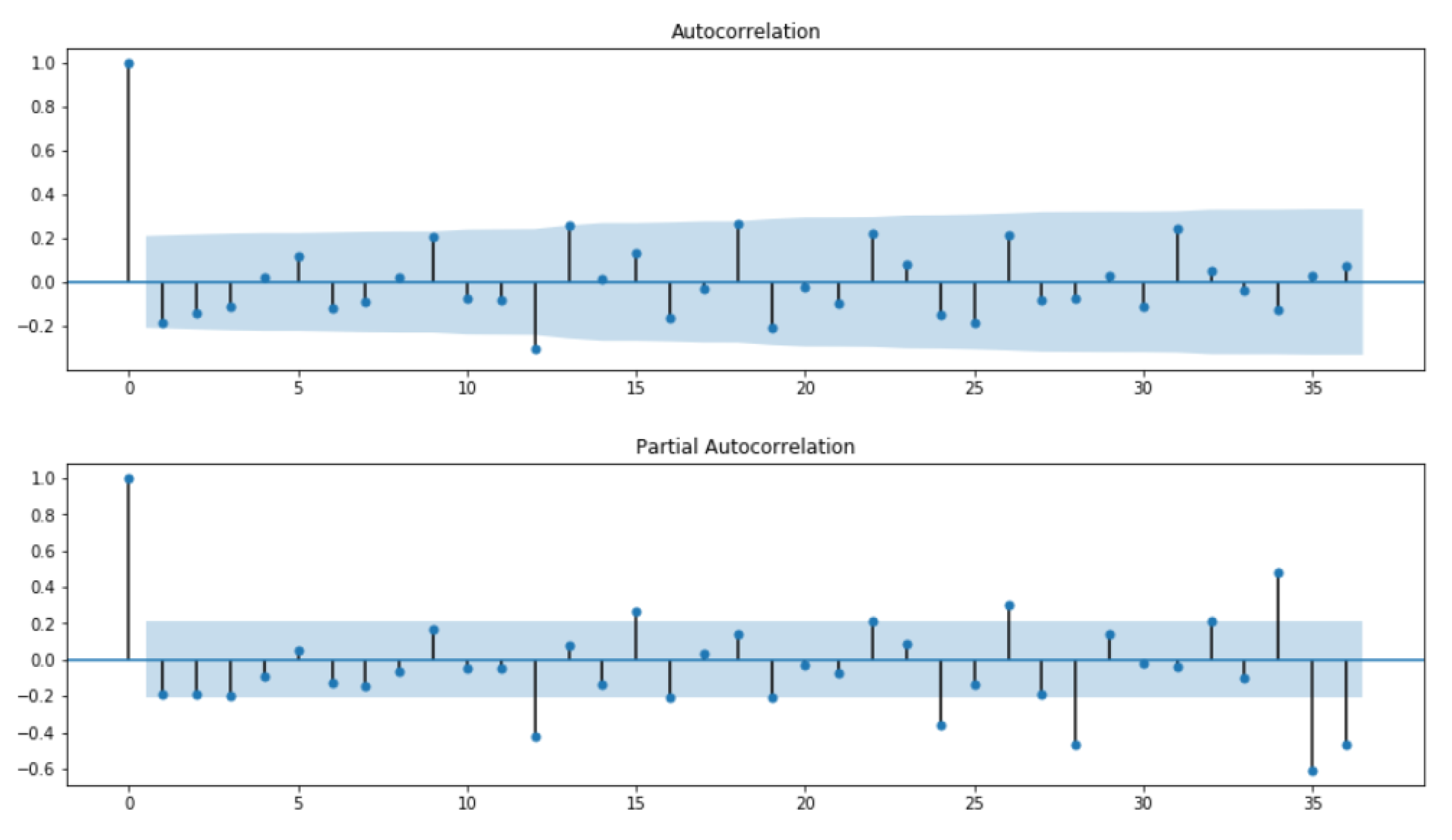
3.1. Finding Initial Approximations for the Predictive Model
3.2. Finding the Optimal Parameters for the Predictive Model
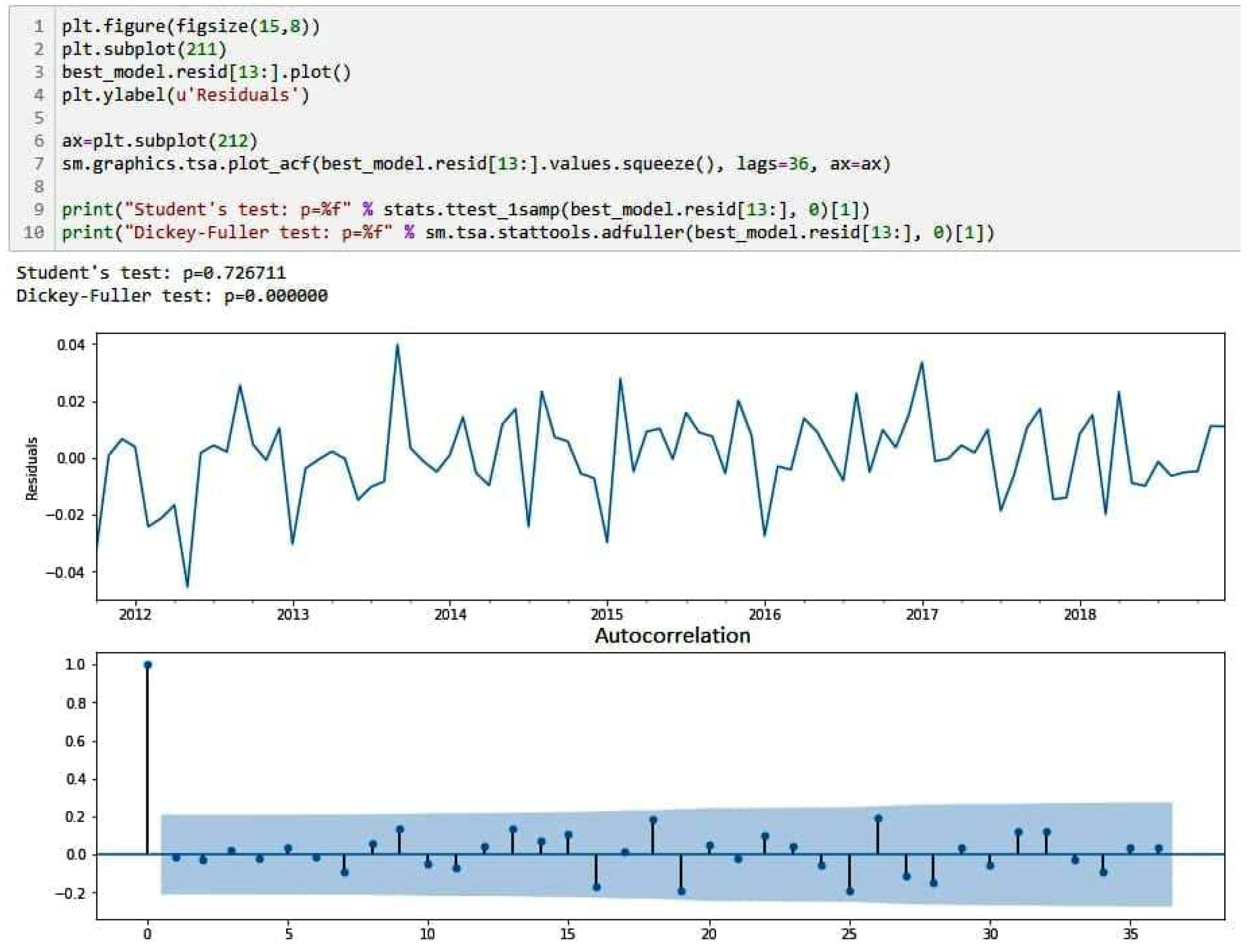
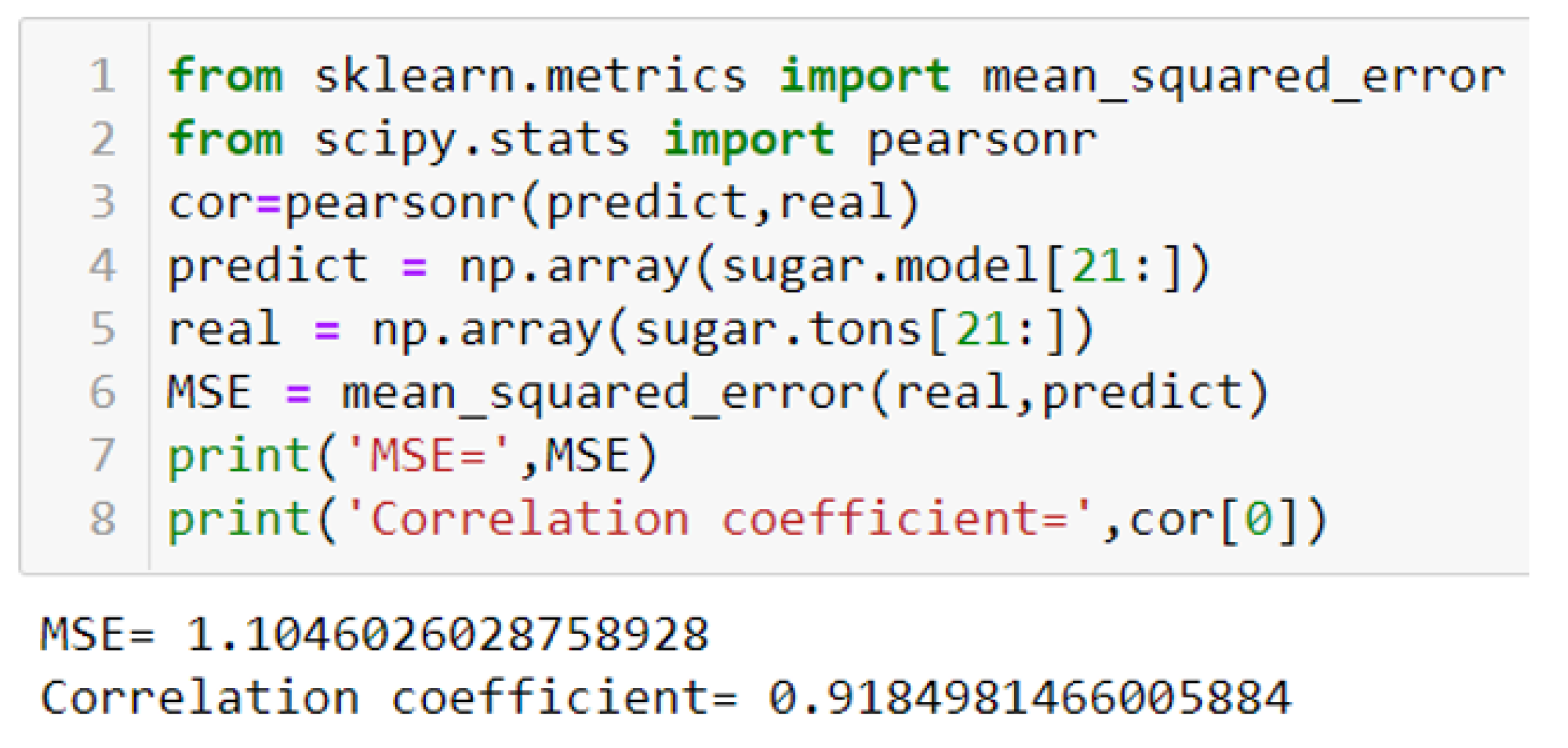
3.3. Analysis of the quality of the constructed model
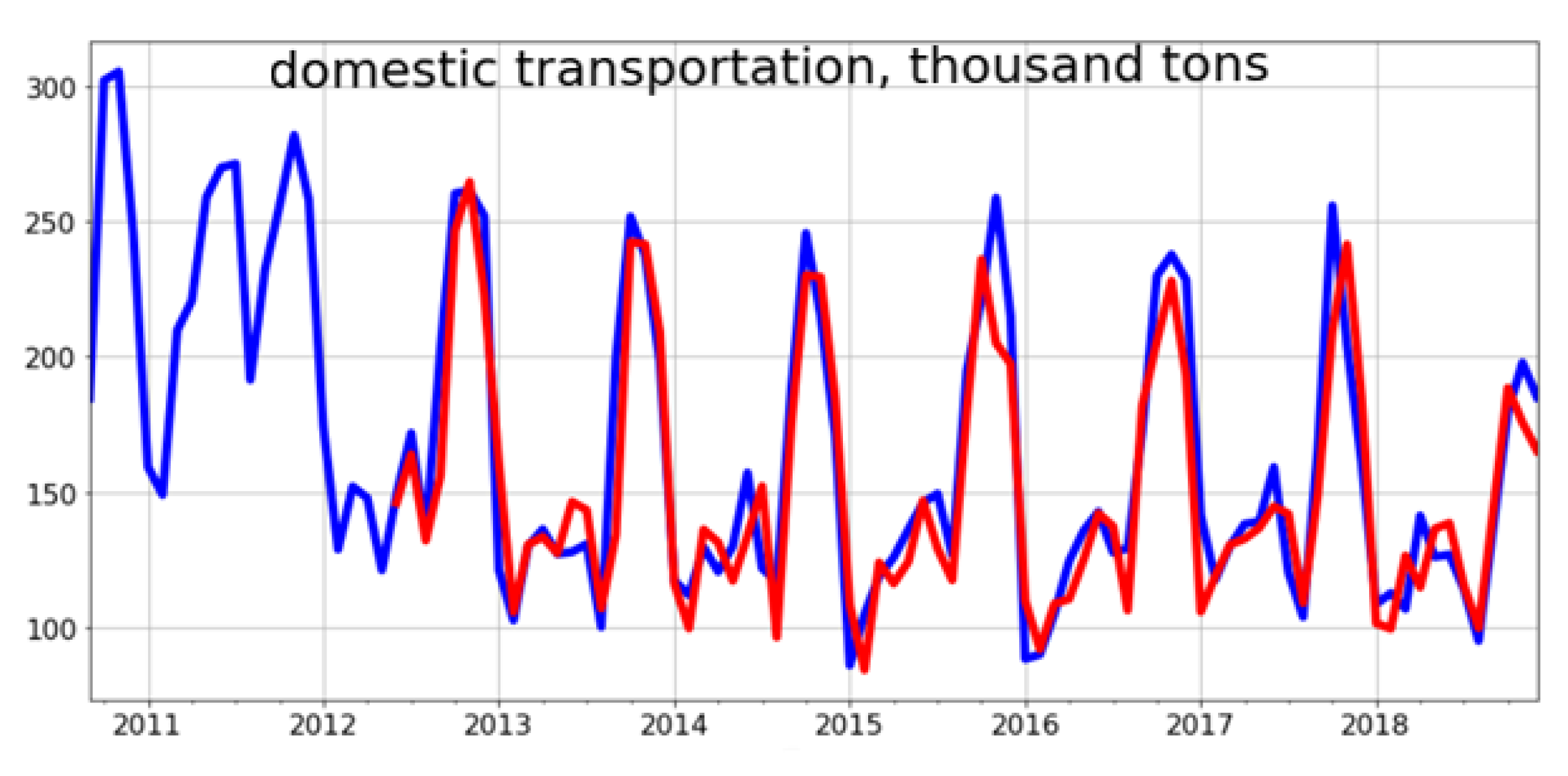
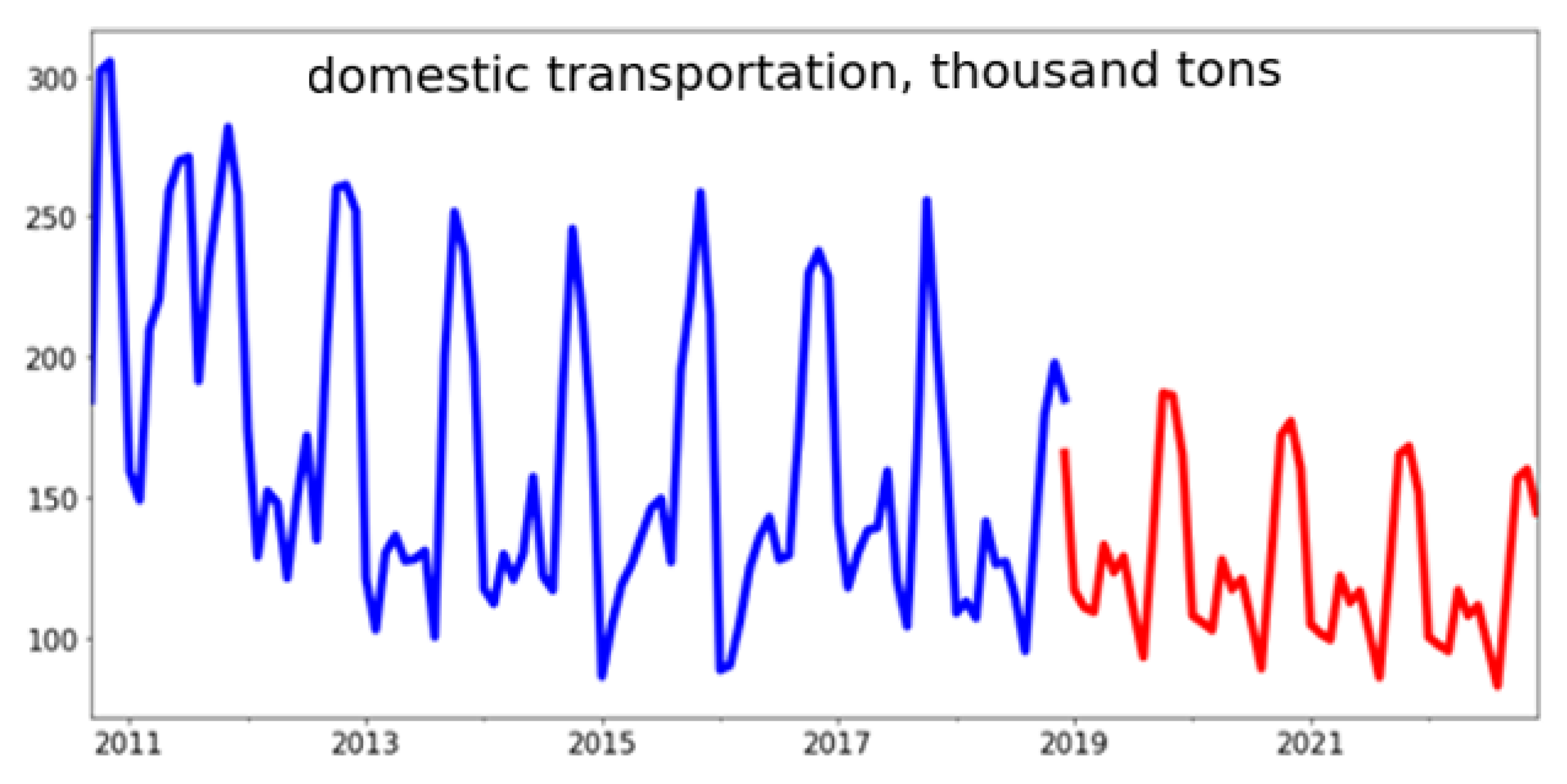
3.4. Building a Predictive Model
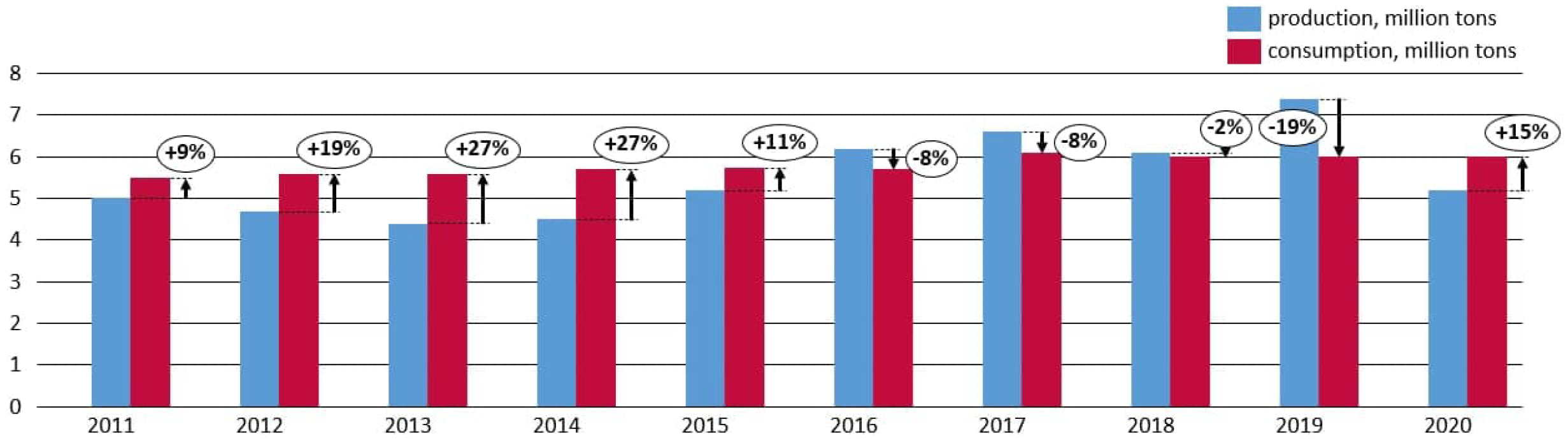
4. Economic Interpretation of Rising Sugar Prices
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Mohammadi-Ahmadmahmoudi, E.; Deihimfard, R.; Noori, O. Yield gap analysis simulated for sugar beet-growing areas in water-limited environments. Eur. J. Agron. 2020, 113, 125988. [Google Scholar] [CrossRef]
- Khozaei, M.; Kamgar Haghighi, A.A.; Zand Parsa, S.; Sepaskhah, A.R.; Razzaghi, F.; Yousefabadi, V.; Emam, Y. Evaluation of direct seeding and transplanting in sugar beet for water productivity, yield and quality under different irrigation regimes and planting densities. Agric. Water Manag. 2020, 238, 106230. [Google Scholar] [CrossRef]
- Rajaeifar, M.A.; Sadeghzadeh Hemayati, S.; Tabatabaei, M.; Aghbashlo, M.; Mahmoudi, S.B. A review on beet sugar industry with a focus on implementation of waste-to-energy strategy for power supply. Renew. Sustain. Energy Rev. 2019, 103, 423–442. [Google Scholar] [CrossRef]
- Hu, Y.; Xia, X.; Fang, J.; Ding, Y.; Jiang, W.; Zhang, N. A Multivariate Regression Load Forecasting Algorithm Based on Variable Accuracy Feedback. Energy Procedia 2018, 152, 1152–1157. [Google Scholar] [CrossRef]
- Hu, J.; Heng, J.; Wen, J.; Zhao, W. Deterministic and probabilistic wind speed forecasting with de-noising-reconstruction strategy and quantile regression based algorithm. Renew. Energy 2020, 162, 1208–1226. [Google Scholar] [CrossRef]
- He, F.; Zhou, J.; Mo, L.; Feng, K.; Liu, G.; He, Z. Day-ahead short-term load probability density forecasting method with a decomposition-based quantile regression forest. Appl. Energy 2020, 262, 114396. [Google Scholar] [CrossRef]
- Yu, Z.; Qin, L.; Chen, Y.; Parmar, M.D. Stock price forecasting based on LLE-BP neural network model. Phys. A Stat. Mech. Appl. 2020, 124197. [Google Scholar] [CrossRef]
- Begam, K.M.; Deepa, S.N. Optimized nonlinear neural network architectural models for multistep wind speed forecasting. Comput. Electr. Eng. 2019, 78, 32–49. [Google Scholar] [CrossRef]
- Du, Z.; Hu, Y.; Buttar, N.A. Analysis of mechanical properties for tea stem using grey relational analysis coupled with multiple linear regression. Sci. Hortic. 2020, 260, 108886. [Google Scholar] [CrossRef]
- Yilmazer, S.; Kocaman, S. A mass appraisal assessment study using machine learning based on multiple regression and random forest. Land Use Policy 2020, 99, 104889. [Google Scholar] [CrossRef]
- Rastgou, M.; Bayat, H.; Mansoorizadeh, M.; Gregory, A.S. Estimating the soil water retention curve: Comparison of multiple nonlinear regression approach and random forest data mining technique. Comput. Electron. Agric. 2020, 174, 105502. [Google Scholar] [CrossRef]
- Amoozad-Khalili, M.; Rostamian, R.; Esmaeilpour-Troujeni, M.; Kosari-Moghaddam, A. Economic modeling of mechanized and semi-mechanized rainfed wheat production systems using multiple linear regression model. Inf. Process. Agric. 2019, 7, 30–40. [Google Scholar] [CrossRef]
- Fan, J.; Yue, W.; Wu, L.; Zhang, F.; Cai, H.; Wang, X.; Xiang, Y. Evaluation of SVM, ELM and four tree-based ensemble models for predicting daily reference evapotranspiration using limited meteorological data in different climates of China. Agric. For. Meteorol. 2018, 263, 225–241. [Google Scholar] [CrossRef]
- Koklu, M.; Ozkan, I.A. Multiclass classification of dry beans using computer vision and machine learning techniques. Comput. Electron. Agric. 2020, 174, 105507. [Google Scholar] [CrossRef]
- García Nieto, P.J.; García–Gonzalo, E.; Arbat, G.; Duran–Ros, M.; Ramírez de Cartagena, F.; Puig-Bargués, J. Pressure drop modelling in sand filters in micro-irrigation using gradient boosted regression trees. Biosyst. Eng. 2018, 171, 41–51. [Google Scholar] [CrossRef]
- Li, S.; Wang, K.; Ren, Y. Robust estimation and empirical likelihood inference with exponential squared loss for panel data models. Econ. Lett. 2018, 164, 19–23. [Google Scholar] [CrossRef]
- Mikkelsen, J.G.; Hillebrand, E.; Urga, G. Consistent estimation of time-varying loadings in high-dimensional factor models. J. Econom. 2018, 208, 535–562. [Google Scholar] [CrossRef]
- Kasahara, H.; Shimotsu, K. Asymptotic properties of the maximum likelihood estimator in regime switching econometric models. J. Econom. 2018, 208, 442–467. [Google Scholar] [CrossRef] [Green Version]
- Balti, H.; Abbes, A.B.; Mellouli, N.; Farah, I.R.; Sang, Y.; Lamolle, M. A review of drought monitoring with big data: Issues, methods, challenges and research directions. Ecol. Inform. 2020, 101136. [Google Scholar] [CrossRef]
- Shittu, O.I.; Asemota, M.J. Comparison of Criteria for Estimating the Order of Autoregressive Process: A Monte Carlo Approach. Eur. J. Sci. Res. 2009, 30, 409–416. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Maleva, T.; Soloviev, V. Using YOLOv3 algorithm with pre-and post-processing for apple detection in fruit-harvesting robot. Agronomy 2020, 10, 1016. [Google Scholar] [CrossRef]
- Du, H.; Zhao, Z.; Xue, H. ARIMA-M: A New Model for Daily Water Consumption Prediction Based on the Autoregressive Integrated Moving Average Model and the Markov Chain Error Correction. Water 2020, 12, 760. [Google Scholar] [CrossRef] [Green Version]
- Sentas, A.; Psilovikos, A.; Karamoutsou, L.; Charizopoulos, N. Monitoring, modeling, and assessment of water quality and quantity in River Pinios, using ARIMA models. Desalin. Water Treat. 2018, 133, 336–347. [Google Scholar] [CrossRef]
- Sentas, A.; Psilovikos, A.; Psilovikos, T. Statistical analysis and assessment of water quality parameters in Pagoneri, river Nestos. Eur. Water 2016, 55, 115–124. [Google Scholar]
- Phan, T.-T.-H.; Nguyen, X.H. Combining Statistical Machine Learning Models with ARIMA for water level forecasting: The case of the Red River. Adv. Water Resour. 2020, 142, 103656. [Google Scholar] [CrossRef]
- Paschke, R.; Prokopczuk, M. Commodity derivatives valuation with autoregressive and moving average components in the price dynamics. J. Bank. Financ. 2010, 34, 2742–2752. [Google Scholar] [CrossRef]
- Yang, L.; Lee, C.; Su, J.-J. Behavior of the standard Dickey–Fuller test when there is a Fourier-form break under the null hypothesis. Econ. Lett. 2017, 159, 128–133. [Google Scholar] [CrossRef]
- Guisande, C.; Rueda-Quecho, A.J.; Rangel-Silva, F.A.; Ríos-Vasquez, J.M. EIA: An algorithm for the statistical evaluation of an environmental impact assessment. Ecol. Indic. 2018, 93, 1081–1088. [Google Scholar] [CrossRef]
- Xiong, T.; Li, C.; Bao, Y. Seasonal forecasting of agricultural commodity price using a hybrid STL and ELM method: Evidence from the vegetable market in China. Neurocomputing 2018, 275, 2831–2844. [Google Scholar] [CrossRef]
- Nguyen, L.; Novák, V. Forecasting seasonal time series based on fuzzy techniques. Fuzzy Sets Syst. 2018, 361. [Google Scholar] [CrossRef]
- Voyant, C.; Notton, G.; Duchaud, J.-L.; Almorox, J.; Yaseen, Z.M. Solar irradiation prediction intervals based on Box–Cox transformation and univariate representation of periodic autoregressive model. Renew. Energy Focus 2020, 33, 43–53. [Google Scholar] [CrossRef]
- De Lima e Silva, P.C.; Severiano, C.A.; Alves, M.A.; Silva, R.; Cohen, M.W.; Guimarães, F.G. Forecasting in non-stationary environments with fuzzy time series. Appl. Soft Comput. 2020, 106825. [Google Scholar] [CrossRef]
- García, C.A.; Otero, A.; Félix, P.; Presedo, J.; Márquez, D.G. Simultaneous estimation of deterministic and fractal stochastic components in non-stationary time series. Phys. D Nonlinear Phenom. 2018, 374–375, 45–57. [Google Scholar] [CrossRef]
- Aich, U.; Banerjee, S. Characterizing topography of EDM generated surface by time series and autocorrelation function. Tribol. Int. 2017, 111, 73–90. [Google Scholar] [CrossRef]
- Bakar, N.A.; Rosbi, S. Autoregressive integrated moving average (ARIMA) model for forecasting cryptocurrency exchange rate in high volatility environment: A new insight of bitcoin transaction. Int. J. Adv. Eng. Res. Sci. 2017, 4, 237–311. [Google Scholar] [CrossRef]
- Afyouni, S.; Smith, S.M.; Nichols, T.E. Effective degrees of freedom of the Pearson’s correlation coefficient under autocorrelation. NeuroImage 2019, 199, 609–625. [Google Scholar] [CrossRef]
- Şahinli, M.A. Potato price forecasting with Holt-Winters and ARIMA methods: A case. Am. J. Potato Res. 2020, 97, 336–346. [Google Scholar] [CrossRef]
- Cavanaugh, J.E.; Neath, A.A. The Akaike information criterion: Background, derivation, properties, application, interpretation, and refinements. Wiley Interdiscip. Rev. Comput. Stat. 2019, 11, e1460. [Google Scholar] [CrossRef]
- Bullock, E.L.; Woodcock, C.E.; Olofsson, P. Monitoring tropical forest degradation using spectral unmixing and Landsat time series analysis. Remote Sens. Environ. 2020, 238, 110968. [Google Scholar] [CrossRef]
- Huang, H. More on the t-interval method and mean-unbiased estimator for measurement uncertainty estimation. Cal Lab Int. J. Metrol. 2018, 25, 24–33. [Google Scholar]




















Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tatarintsev, M.; Korchagin, S.; Nikitin, P.; Gorokhova, R.; Bystrenina, I.; Serdechnyy, D. Analysis of the Forecast Price as a Factor of Sustainable Development of Agriculture. Agronomy 2021, 11, 1235. https://0-doi-org.brum.beds.ac.uk/10.3390/agronomy11061235
Tatarintsev M, Korchagin S, Nikitin P, Gorokhova R, Bystrenina I, Serdechnyy D. Analysis of the Forecast Price as a Factor of Sustainable Development of Agriculture. Agronomy. 2021; 11(6):1235. https://0-doi-org.brum.beds.ac.uk/10.3390/agronomy11061235
Chicago/Turabian StyleTatarintsev, Maxim, Sergey Korchagin, Petr Nikitin, Rimma Gorokhova, Irina Bystrenina, and Denis Serdechnyy. 2021. "Analysis of the Forecast Price as a Factor of Sustainable Development of Agriculture" Agronomy 11, no. 6: 1235. https://0-doi-org.brum.beds.ac.uk/10.3390/agronomy11061235