1. Introduction
Cross validation (CV) methods were proposed for model selection and performance evaluation without generating additional testing points and have been widely used in various engineering fields. Stone [
1] applied the cross-validatory choice and assessment to prediction of a multinomial indicator. Stone [
2] emphasized the pragmatic character of cross-validatory statistical methods and concluded some standards approaches to the assessment of choice of statistical procedures. Cudeck et al. [
3] proposed a cross validation procedure and explored its properties. Picard and Cook [
4] used the CV method to assess the predictive ability of regression models. Dai [
5] developed a competitive ensemble pruning approach based on CV in ensemble system. Arlot et al. [
6] applied the CV method and model selection in noise detection and they proposed a new change-point detection procedures for the heteroscedastic signal.
The CV methods are mainly divided into two types [
7], i.e., leave-one-out CV (LOO-CV) and bootstrap, in which LOO-CV is the same as k-fold CV (K-CV) and bootstrap is similar to Monte Carlo CV (MCCV) sometimes. Xu and Liang [
8] proposed a Monte Carlo CV (MCCV) method which is an asymptotically consistent method to select the dimension of calibration model in chemistry. A few years later, Xu et al. [
9] developed the MCCV method, named as a corrected MCCV (CMCCV) which can assess accurately the prediction performance of the selected model. Although k-fold CV method has been widely used, k distinct samples have inherent correlations among them. Roberts et al. [
10] indicated that dependence structures in data persist as dependence structures in model residuals, violating the assumption of independence. This is one of the reasons for poor performance of CV. They recommended that block CV (BCV) be used wherever dependence structures exist in a dataset. Airola et al. [
11] considered that it is difficult to estimate the reliability of the classification performance of inferred predictive models with small data sets, and then they proposed a Leave-pair-out CV (LPO-CV) to assess the performance in this case. Kale et al. [
12] defined a new measure of algorithm stability to analyze the reduction in variance of the gap between the CV estimate and the true error rate. For the K-CV method it is unreasonable to choose the number of subsets by empirical methods. Anguita et al. [
13] developed an approach for adjusting the number of subsets in a data-dependent way, and then they can estimate misclassification probability of the chosen model reliably and rigorously. Yu and Feng [
14] modified the CV method to select the penalty parameter of Lasso penalized linear regression models in high-dimensional settings. Jung and Hu [
15] proposed a new K-CV approach; the key point of this method is to select a candidate ‘optimal’ model from each hold-out fold and average the K candidate ‘optimal’ models to obtain the ultimate model. Finally, it is worth noting that the computational cost of LOO-CV is very high due to multiple times of learner training. For the calculation efficiency of LOO-CV, Liu et al. [
16] developed a fast CV based on the Bouligand influence function (BIF) for kernel-based algorithms.
The CV method has also been widely used in surrogate techniques for fitting multiple surrogates and choosing one, based on errors evaluated by LOO-CV method (LOO-CVerror). Song et al. [
17] used the LOO-CV to pick the best surrogate and eliminate worse ones when constructs a hybrid surrogate model by combining several typical single surrogate models. Xu et al. [
18] proposed an adaptive sampling strategy, named CV-Voronoi method, in which the Voronoi diagram is used to partition the design space and CV is employed to estimate the error behavior of each partition. Viana et al. [
19] investigated systematically whether and how errors generated by CV helped to obtain the best predictor among multiple surrogates. They concluded that CV method can filter out inaccurate surrogates well and may identify the best surrogate if sample points which are used to build surrogate models are enough. Later Zhang and Yang [
20] concluded how CV is applied to consistently choose the best method and addressed several seemingly common misconceptions on CV, such as better estimation of prediction error by CV does not mean better model selection.
In previous work, we have proposed a hybrid surrogate model, named the extended hybrid surrogate model (E-AHF) [
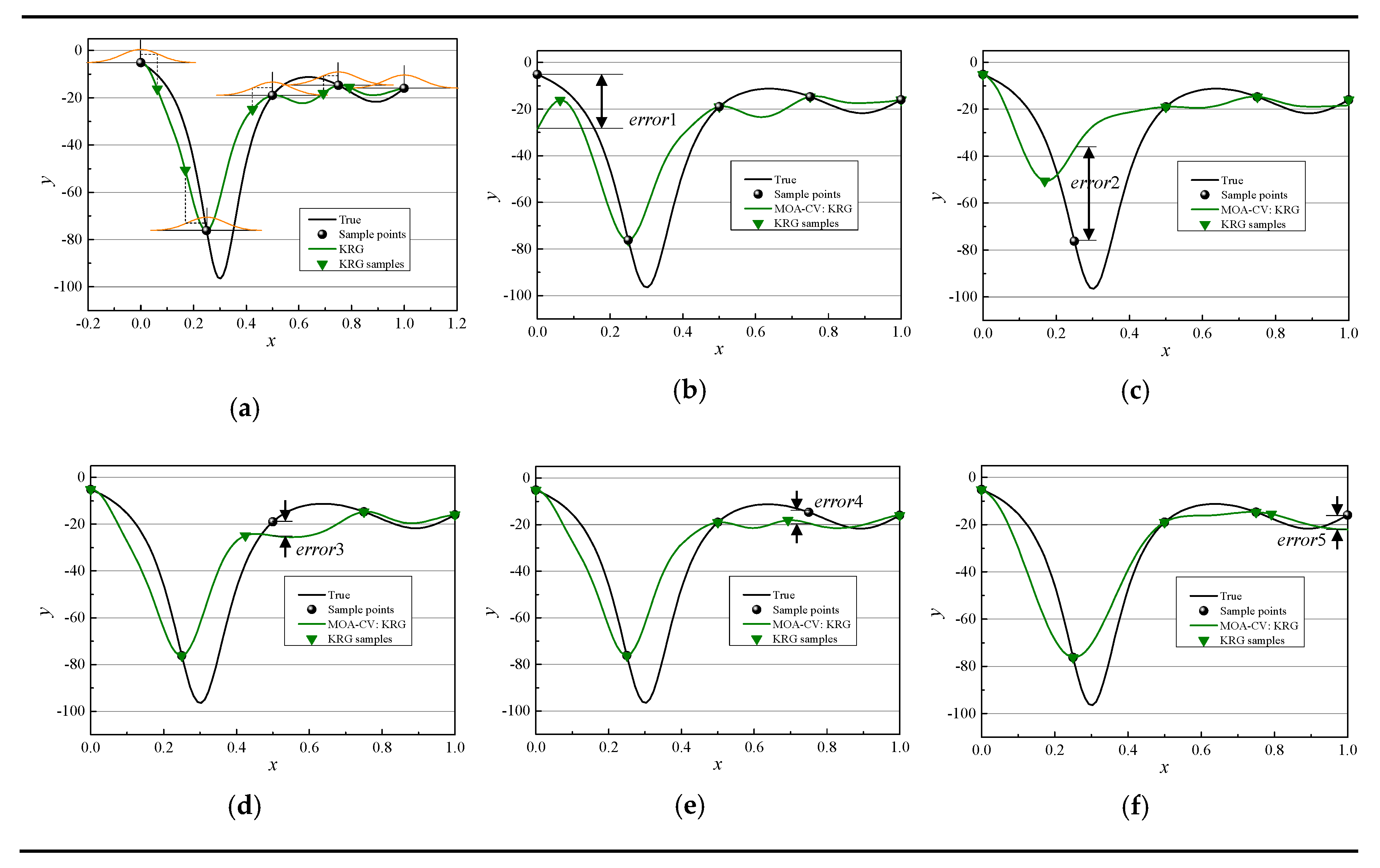
17]. In the process of constructing the E-AHF model, the LOO-CV was used to select the best surrogate model and filter out worse ones. The best surrogate model is considered as the benchmark model for others; worse ones are removed, finally the rest surrogate models are saved to build the final surrogate library. In the E-AHF model, the key step is to construct the library of surrogate models and determine the best surrogate. Therefore, the criterion for modeling rank, i.e., the LOO-CV, is significant to E-AHF. However, there still exists a problem: the LOO-CV method cannot always filter out inaccurate models exactly and select accurately the best one without enough sample points. In the LOO-CV method, the sample points are divided into two parts, i.e., training points and one validation point. We modified the LOO-CV by moving a validation point around random normal distributions rather than leaving it out, named move-one-away cross validation (MOA-CV).
In this paper, four surrogate techniques are used to construct models; errors generated by MOA-CV and LOO-CV methods, i.e., MOA-CVerror and LOO-CVerror, respectively, were used to select the best model from those four surrogate models through four standard mathematical functions and one engineering problems. A higher MOA-CVerror/LOO-CVerror indicates worse performance of surrogate models. However, how can we know exactly which best model is the true best model? Hence, we used the coefficient of determination (R-square, R2) which is reliable to evaluate the accuracy of a model to be a calibration of MOA-CV and LOO-CV. Additionally, extra testing points need to be generated randomly for R2. The accurate rate of selecting the best surrogate model is used to assess and compare the performance of MOA-CV and LOO-CV. To explain the MOA-CV method clearly, a 1-dimensional (1D) function was used to demonstrate the operation process first.
The remaining of this paper is organized as follows. The LOO-CV method is briefly introduced in
Section 2, followed by the introduction of the MOA-CV method in
Section 3. Results and discussions through four standard mathematical functions and one engineering problem are conducted in
Section 4. Conclusions are presented in
Section 5.
2. Introduction of LOO-CV
It has been proven that no single surrogate model always performs the best for all engineering practice [
21]. In the model building process of E-AHF, we first construct several single surrogate models without any prior information about the true model and then use the LOO-CV method to select the best model and filter out worse ones. For hybrid surrogate model, instead of randomly determining library of surrogate models, a filtering process, e.g., the LOO-CV method, which is a common modeling selection approach, could be performed first to eliminate poorly-performing individual surrogates and select the best one. The basic idea of the LOO-CV method is to take one sample point from the data set containing
n sample points as the validation set, and then use the remaining
n − 1 sample points as the training set to build a model. Obtain the prediction error at the validation point and repeat this process
n times sequentially until all
n sample points have been validated once. Finally,
n prediction errors are obtained, and the average value of
n prediction errors is taken as the LOO-CVerror of the model constructed from
n sample points. The LOO-CVerror is shown in Equation (1).
where LOO-CVerror means the error generated by LOO-CV,
n is the number of training points,
is the true response at
and
stands for the prediction at
, which is calculated using the
n − 1 training points except the
jth training point (validation point). In general, the model with the smallest LOO-CVerror is the most accurate, and vice versa.
However, it may occur some problems when using the LOO-CV method. LOO-CV cannot always filter out inaccurate models well and select accurately the best one without enough samples in some cases. We use four common surrogate models, i.e., polynomial regression surface (PRS) [
22], radial basis function with multiquadric kernel function (RBF-MQ) [
23], radial basis function with thin plate spline basis function (RBF-TPS) [
23] and kriging (KRG) [
24], to fit the true function. Details about those four surrogate techniques see References [
22,
23,
24]. In this work, we use MOA-CVerror and LOO-CVerror to select the most accurate of those four surrogate models.
R2 is considered as the calibration criterion of MOA-CVerror and LOO-CVerror. That is, we assume that the results of
R2 is reliable, then compare the results of MOA-CVerror and LOO-CVerror with
R2 to get the accurate rate of MOA-CV and LOO-CV. A higher
R2 means an accurate model. On the contrary, a lower MOA-CVerror or LOO-CVerror indicates a better model.
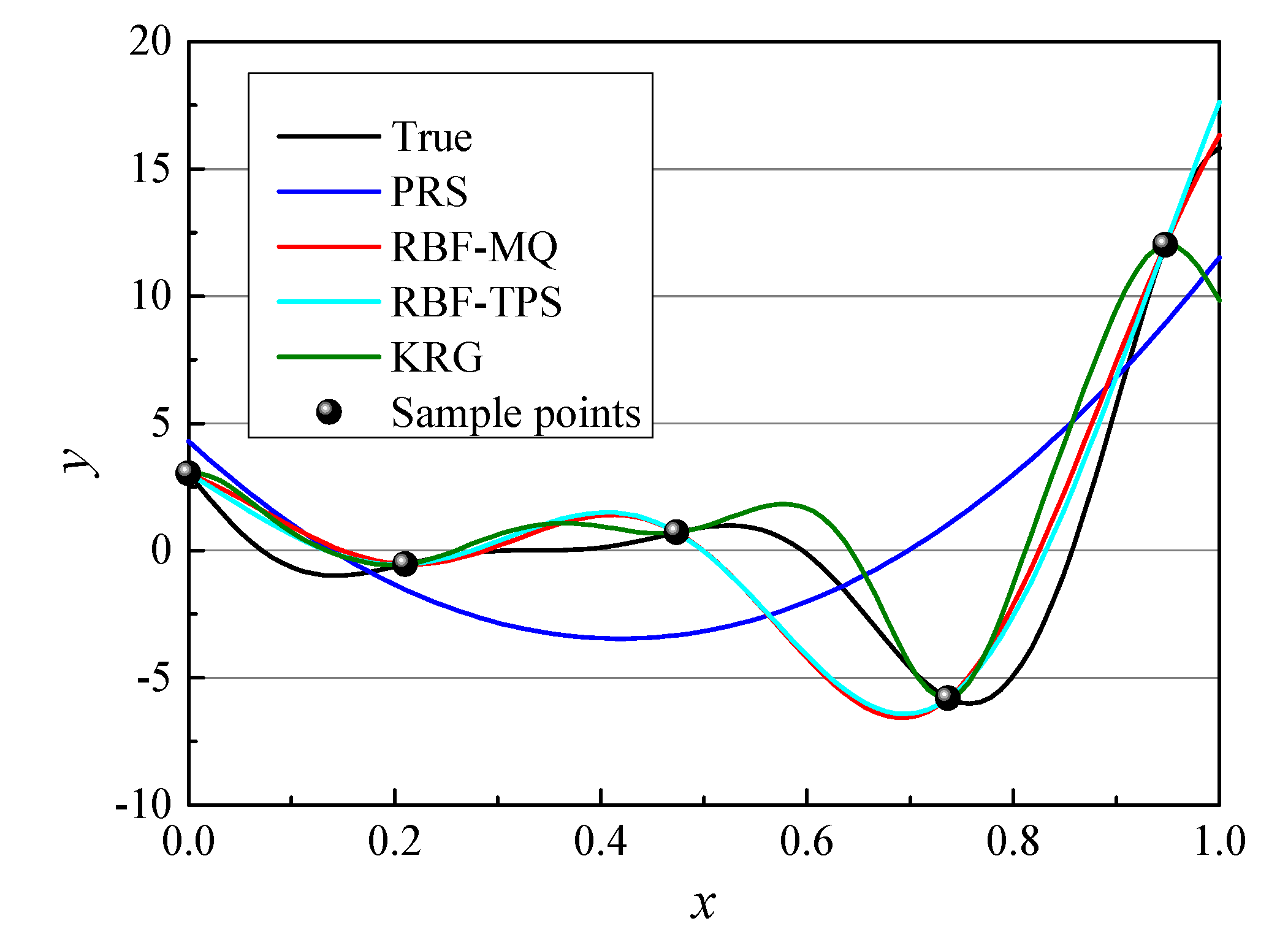
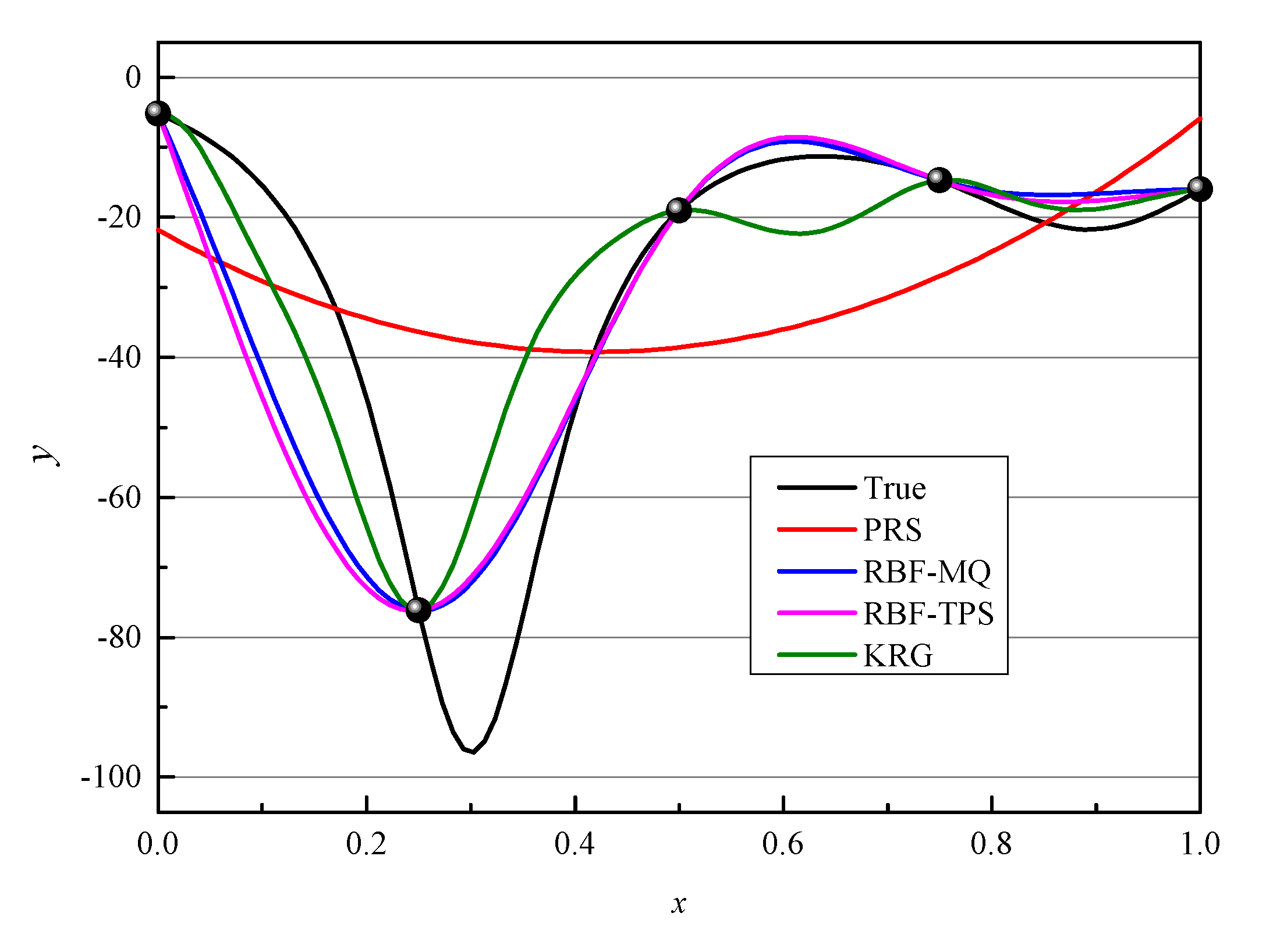
Take a 1-dimensional (1D) function as an example to explain the problem occur for LOO-CV as shown in
Figure 1. Five sample points are generated (as black ball shows), and four surrogate models are built based on five sample points. The true function is shown as the black line.
R2 of the four models are listed in
Table 1. We can see that from
R2 the most accurate model is RBF-TPS, RBF-MQ performs the second, KRG performs the third and PRS performs the worst. However, from LOO-CVerror, the best model is KRG, the second one is PRS, the third one is RBF-MQ and the last one is RBF-TPS. That is, RBF-TPS is actually the most accurate model, however, in the construction of E-AHF, the step of using LOO-CV method to filter worse surrogate models means will remove the RBF-TPS model from the library of surrogate models and remain the PRS model which is the worst one.
4. Results and Discussions
4.1. Test Problems
In order to test and compare the model selection performance of the MOA-CV method and the LOO-CV method, two 2-dimensional (2D) and two 10-dimensional (10D) numerical functions are used in this work [
24,
25] as shown in
Table 5. In addition, one engineering problem is also employed in this section.
4.2. Design of Experiments
The first process of constructing models is generating sample points, also called design of experiments (DoEs) which is the computational strategy to produce sample points for computer simulations and surrogate modeling. In this section, Latin hypercube sampling (LHS) with better space-filling and projective properties are used to generate sample points. In this work, we use the built-in Matlab function lhsdesign. Three samples sizes, i.e., 5n, 8n and 10n (where n is the dimension of a function), respectively, are chosen to investigate the effect of different sample sizes on the performance of MOA-CV and LOO-CV. For each function and each sample size, ten random sets of DoEs are generated. The abovementioned surrogate models are used to build models; MOA-CVerror and LOO-CVerror are used to rank models based on the calibrated criterion R2.
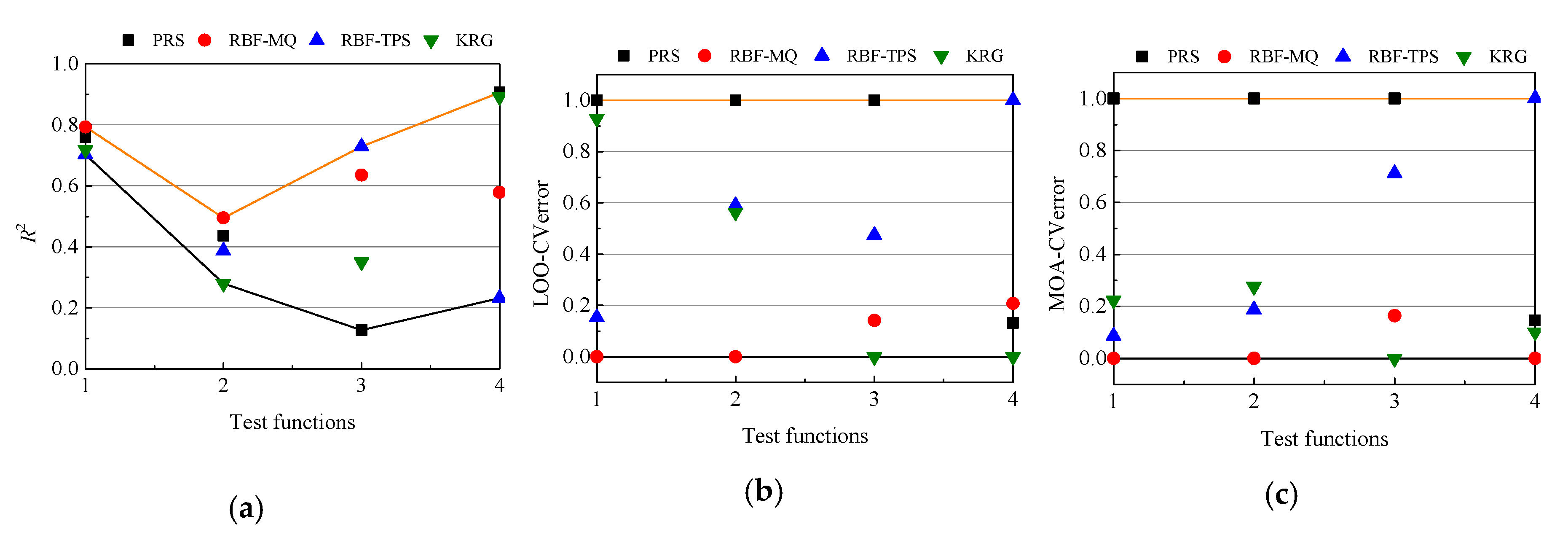
Table 6 lists the percentages of choosing the best surrogate models for the four functions, with a higher value in italic bold. Almost for any function, the accurate rates of best model selection of MOA-CV and LOO-CV rise with the increase in samples sizes from 5
n to 10
n. MOA-CV performs much better than LOO-CV in selecting best models, especially when the sample size is larger. In terms of HD functions, when the sample size is 5
n, MOA-CV and LOO-CV perform quite poor. That is, with small samples neither the MOA-CV nor the LOO-CV method can find the best model. When the sample size increases to 10
n, MOA-CV is more likely than LOO-CV to find the best model. The average result over four functions also shows that it is a little easier for the MOA-CV method to discover the best model than the LOO-CV method.
Table 7 lists the accurate rate of finding the worst surrogate models for the four functions, also with a higher value in italic bold. MOA-CV has the best accurate rate when the sample size is 8
n. When the sample sizes are 5
n and 10
n, LOO-CV performs better than MOA-CV in terms of removing worst models. Similar to selecting the best models, MOA-CV and LOO-CV also perform quite poor with 5
n sample points in cases of HD functions. From the average result over four functions, it is seen that the MOA-CV method performs slightly worse than the LOO-CV method in finding worst models.
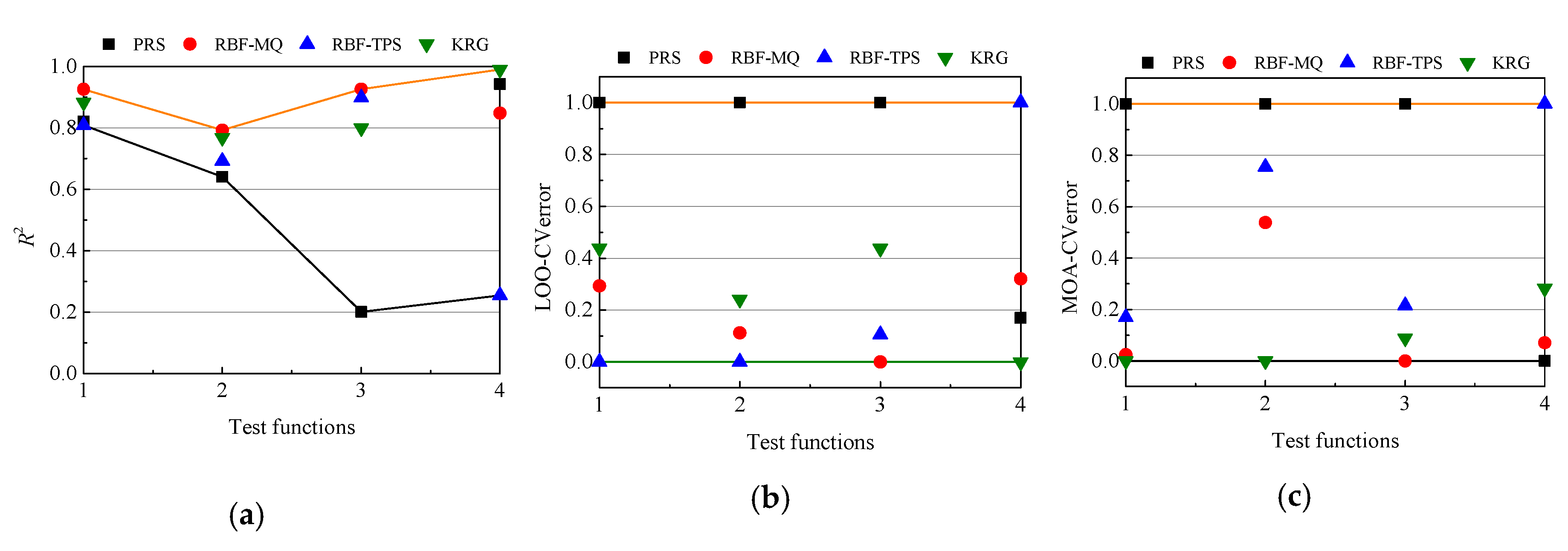
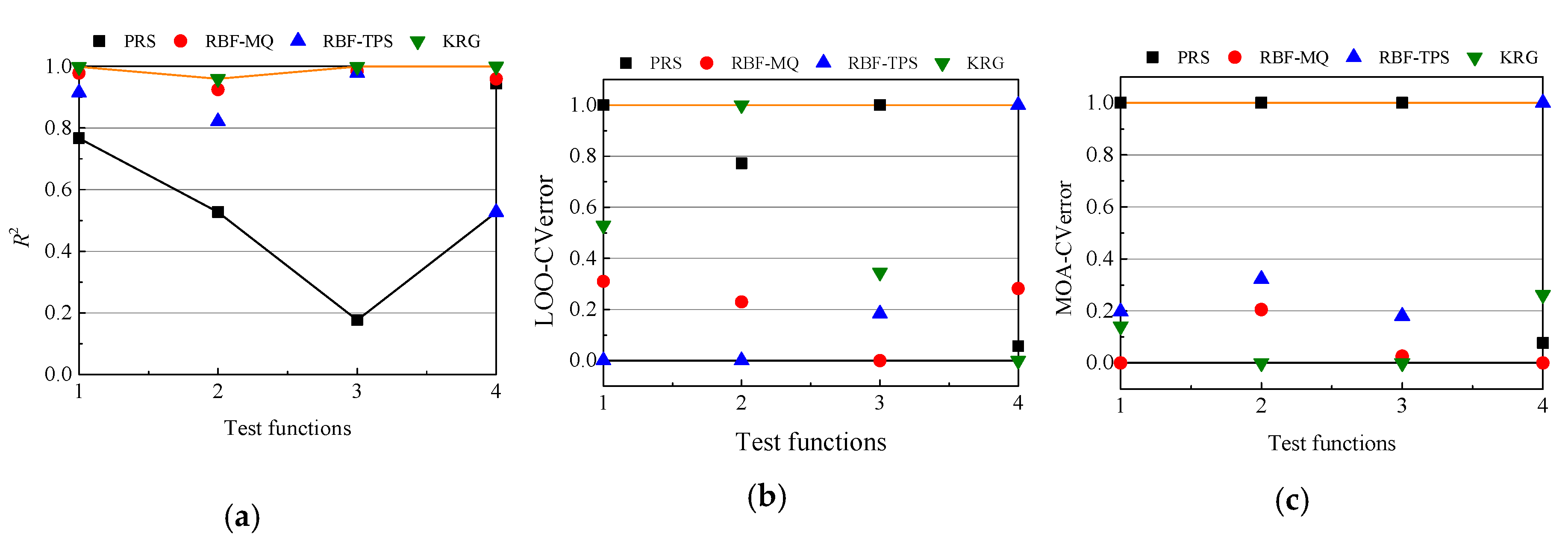
As described above, for each function and each sample size, 10 sets of DoEs are generated randomly. Here, we compare the averaged results of selecting best and worst models over these 10 sampling plans.
Figure 4,
Figure 5 and
Figure 6 show the model ranks by using
R2, LOO-CVerror and MOA-CVerror under 5
n, 8
n and 10
n sample points.
Table 8 and
Table 9 summarize the average accurate rates of selecting best and worst models for four tests functions over 10 groups of DoEs, and the higher values are in italic bold. In order to intuitively describe accurate rates of MOA-CV and LOO-CV, the MOA-CVerror and LOO-CVerror are regularized between 0 to 1. Hence, the worst model has the largest MOA-CVerror/LOO-CVerror of 1, while the best model has the smallest MOA-CVerror/LOO-CVerror of 0. It is concluded that both the MOA-CV and LOO-CV methods have a 50% probability of selecting the best model. With increase in sample sizes, the MOA-CV model may become better in selecting best and worst models.
4.3. Engineering Problems
In addition to numerical problems, one engineering problem, i.e., the prediction of the thrust (TH) on the whole rotor of a small aerial vehicle (UAV), is also employed to investigate and compare the model selection performance of MOA-CV and LOO-CV methods.
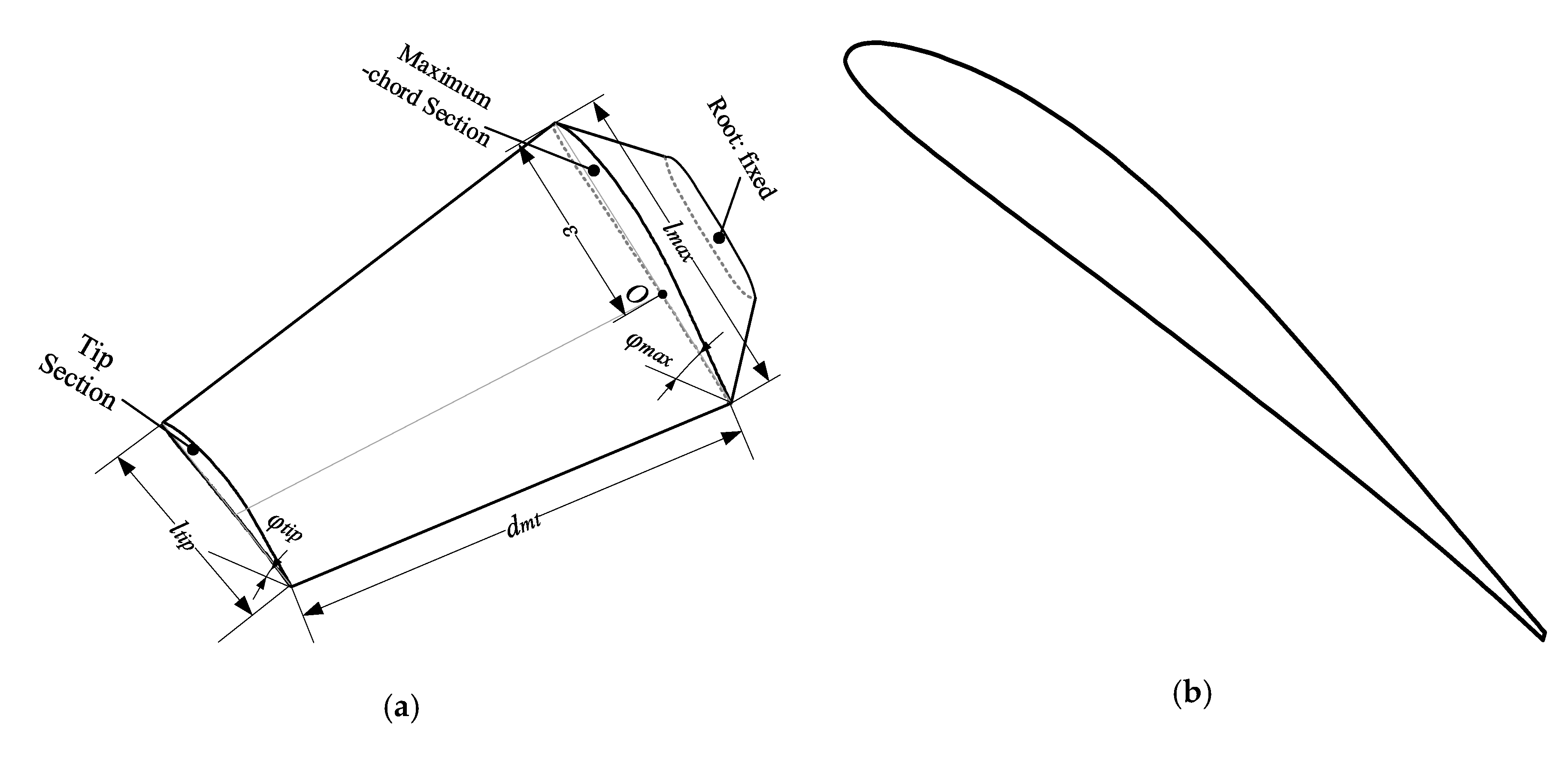
The rotor blade and airfoil of a small (UAV) are shown in
Figure 7. The whole rotor consists of three blades. In this problem, we focus on the thrust (TH) on the whole rotor. The airfoil (as shown in
Figure 7b) is generated by using the class shape function transformation (CST) [
26] which is a parametric modeling method. The airfoil has 16 parametric modeling variables. Six structural variables are presented in
Figure 7a. Hence, the rotor blade of the UAV totally has 22 variables listed in
Table 10. For the 16 parametric modeling variables, please see Reference [
26]. Two sections are shown in
Figure 7, i.e., blade tip and maximum-chord sections.
and
are chord length and mounting angle of the blade tip section, respectively.
and
are chord length and mounting angle of the maximum-chord section, respectively. The position of maximum-chord section is represented by
.
is the forward sweep.
We use the LHS approach built-in MATLAB to randomly generate 220 samples and get the corresponding TH. Then we choose 110, 176 and 220 (i.e., 5n, 8n and 10n, where n is the number of variables) samples to construct PRS, RBF-MQ, RBF-TPS and KRG, respectively. The MOA-CV and LOO-CV methods are employed to select the most accurate and the worst accurate models. Then other 50 samples are generated for the calibrated criterion, i.e., R2.
The results of
R2, MOA-CVerror and LOO-CVerror are shown in
Table 11,
Table 12 and
Table 13, respectively. The best model presented by each criterion are in bold; the worst model are shown in italic. From the result of
R2 we can see that RBF-MQ has the best accuracy and PRS has the worst accuracy. Results of MOA-CVerror indicate RBF-MQ is the most accurate when the sample sizes are 5
n and 10
n, which is consistent with those of
R2, while results of LOO-CVerror show KRG is the most accurate, which is different from the results of
R2. However, when the sample size is 8
n, MOA-CV cannot select the best model, while LOO-CV can choose the best one. Both the MOA-CVerror and the LOO-CVerror indicate that the PRS is the worst model regardless of sample size. Overall, in this case, both the MOA-CV and the LOO-CV can choose the worst models, and in most cases, MOA-CV is likely to find the best model than LOO-CV.
5. Conclusions
In order to improve the E-AHF model which has been proposed in previous work, we modified the LOO-CV method, which is used to build the surrogate library in E-AHF. By moving a validation point around random normal distributions rather than leaving it out, the move-one-away cross validation (MOA-CV) is proposed. Four surrogate techniques are used to construct models; errors generated by MOA-CV and LOO-CV methods, i.e., MOA-CVerror and LOO-CVerror, respectively, were used to select the best model from those four surrogate models through 20 standard mathematical functions and one engineering problem. We used the R2 which is reliable to evaluate the accuracy of a model to be a calibration of MOA-CV and LOO-CV. The accurate rate of selecting the best and worst surrogate was used to assess and compare the performance of MOA-CV and LOO-CV.
Results show that with the increase in sample sizes, MOA-CV and LOO-CV are more likely to select the best models. MOA-CV performs much better than LOO-CV in selecting best models, especially when the sample size is larger. For HD functions, with small samples, neither the MOA-CV nor the LOO-CV method can find the best model. Similar to selecting the best models, MOA-CV and LOO-CV also perform quite poor with smaller samples for HD functions.
From the average accurate rates over ten sets of DoEs, it is concluded that with increase in sample sizes, the MOA-CV model may become better in selecting best and worst models. In the engineering problem, both the MOA-CV and LOO-CV can choose the worst models, and in most cases, MOA-CV has a higher probability to select the best model than LOO-CV.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}