1. Introduction
Due to the availability of new data sources, there is a need to rethink existing architectures that enable big data analytics, especially in healthcare. Some sources include mobile phones (sensors), genomics, sensor networks, social media, internet of things, and medical imaging modalities that determine medical diagnostic and medical records. All these sources produce data at a rapid pace, which needs to be stored and processed somewhere in an efficient way [
1]. Storing and analyzing such a huge amount of data is a challenge, especially when it does not conform to the traditional notion of data structures. Big data characteristics include huge volume, wide variety, high velocity, veracity, and value. The processing of these data requires new architecture, new tools, and new analytical methods [
2]. Distributed and parallel computing architectures are preferred approaches to process such large scale unstructured and semi-structured data. Using technologies, such as Hadoop and Spark, to perform natural language processing on these data can significantly improve performance and create valuable information.
The image data processing is an important aspect of clinical diagnosis; for example, the correct analysis and interpretation of images are vital for the early detection of diseases [
3]. The use of state-of-the-art devices for medical imaging, such as X-ray, magnetic resonance imaging (MRI), computerized tomography (CT), and positron emission tomography (PET), has greatly improved data acquisition process. These imaging modalities are being used for spatial representation of different biological tissues for different diagnosis. CT combines multiple x-ray scans to reconstruct the image representing a slice/volume of the imaged object. The advantages of CT imaging include its excellent resolution and contrast, along with being relatively faster than MRI. However, it requires larger dose of ionizing radiation, as well as being slower and more complex, compared to planar X-ray. X-ray and CT expose patients to ionizing radiation that increases the risk of cell mutation. Moreover, the equipment is costly and therefore not available at all hospitals [
4]. Conversely, ultrasound is a low-cost solution, due to its cost-effectiveness and portable ability. The disadvantages of ultrasound is that it requires a good physical contact with the imaged tissue for a high wave impedance contrast to reconstruct high resolution image [
5]. Photoacoustic imaging (PAI) is an emerging modality for imaging human tissues based on thermoelastic effect. This imaging modality used short laser pulse to reconstruct the optical absorption map of the human tissue. The main advantages of PAI is combining the high spatial resolution of ultrasound and high contrast of optical imaging. PAI is a multiscale imaging modality used in different preclinical and clinical applications, such as tumor detection [
6] and functional imaging [
7]. The downside of PAI are inherent artifacts in the reconstructed images caused by imperfect reconstruction algorithms [
8].
The most common and one of the newest imaging modality is MRI. It is a tomographic technique based on the phenomenon of nuclear magnetic resonance. It produces high-quality images having excellent spatial resolution in the order of millimeters and is more suited for imaging soft tissues (e.g., distinguishing white and grey matter in the human brain) due to higher concentration of the hydrogen molecules. The disadvantages of MRI are its high cost of equipment and maintenance, system complexity and time needed for data acquisition [
9]. A single scan of MRI takes about 5 min. Furthermore, MRI is not suitable in different situations, such as for patients with a heart pacemaker, as magnetic fields can upset the operations of pacemakers. In addition, heating can occur in some metallic implants [
10].
Microwave imaging is an alternative imaging modality being investigated for different biomedical applications, such as breast cancer and brain imaging [
11]. It is non-ionizing with emission power less than cellular devices radiation and less system complexity similar to ultrasound technology. Furthermore, it offers safe, low-cost, and portable method for medical imaging applications [
12]. The downside of microwave imaging is it does not create images of high resolutions as compared to CT and MRI. However, due to its advantages, many research groups are exploiting improved antenna design, imaging setup optimization, tissue scattering modeling, development and optimization of image reconstruction algorithms, and in vitro and in vivo validation of these imaging systems. They have successfully designed and developed prototypes, as well as conducted trials on volunteers and/or patients, mainly targeting breast [
13,
14] and brain imaging [
15,
16,
17].
Large-scale image processing applications, especially those involving multistage analysis, often indicate substantial inconsistency in processing times ranging from a few seconds to several hours [
18]. Microwave techniques in medical imaging and remote sensing applications reconstruct the image of dielectric regions to retrieve the location, shape, and size of the targeted object. For many years, new optimization algorithms have been studied to address the compute-intensive inverse scattering problem associated with these techniques [
19].
Field programmable gates arrays (FPGAs) and graphics processing unit (GPU)-based parallel approaches are commonly used to solve problems of image processing, especially in multi-modality image diagnoses, that require huge processing time [
20,
21]. Although, these approaches improve processing speed significantly, they are limited by non-scalability and higher cost. The use of parallel or cloud computing technology for image-guided diagnostics is a recent trend and has caught the attention of many researchers in the field [
22]. Some of the potential reasons to use cloud computing for medical image analysis are huge data storage, remote availability, faster processing demands, and scalability. In order to enhance the efficacy and accuracy of imaging modalities, medical imaging societies need to consider and embrace parallel approaches using high-performance computing (HPC) or cloud computing technologies as accelerators and use them as powerful tools for multi-modality imaging data analysis. Big data frameworks, such as Hadoop and Spark, are getting attention as it makes possible the scalable utilization of these parallel systems [
23]. However, parallel implementation of algorithms on these frameworks faces several technical challenges depending on the level of their complexity. An inexpensive solution is to place the required data on the computational nodes to avoid network saturation. Hadoop and Map-reduce provide tools to address this issue; however, they are still not widely being integrated into medical image processing, despite having shown great success in online commerce, social media, and video streaming [
24].
Data acquisition from sensors and its image reconstruction process using different algorithms and machine learning (ML) techniques is a recent trend and is gaining a lot of interest [
25]. Consequently, to make it more efficient and scalable, healthcare entities are adopting big data frameworks, for instance, Apache Hadoop and Spark [
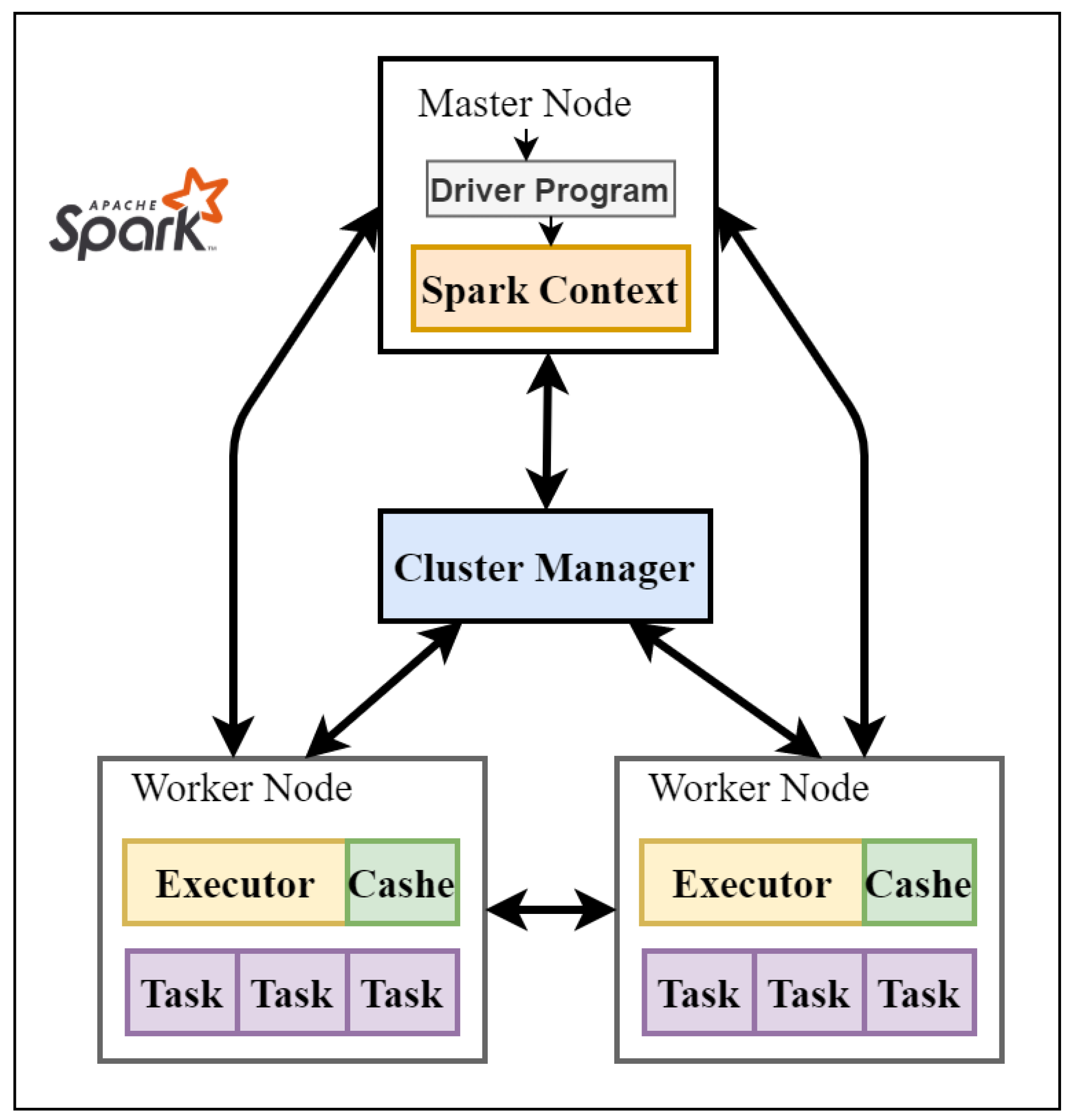
26]. These are the most common big data processing frameworks being used for the implementation of the algorithm over distributed systems. The main goal is to process a huge amount of data on a cluster of hundreds or thousands of machines in parallel, which helps in the real-time decision-making process.
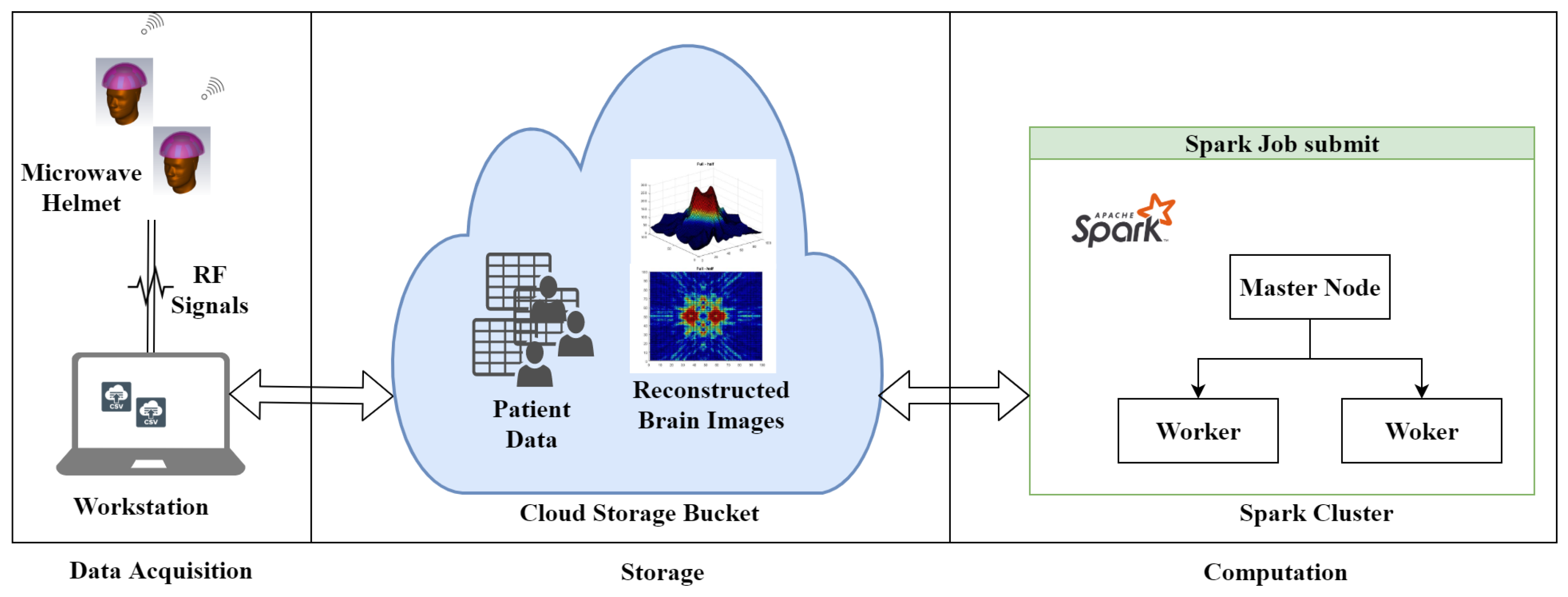
This paper aimed to contribute to this growing area of research by exploring the use of Apache Spark on HPC and Google Cloud Platform (GCP) for microwave imaging of head diagnostics. This work has made use of Eddie [
27] provided by Edinburgh Compute and Data Facility. Eddie is the third generation HPC cluster running a Linux operating system. It consists of some 7000 Intel
® Xeon
® cores, with up to 3 TB of memory available per compute node. The cluster can be used to run jobs in parallel, taking advantage of its multiple compute core. It uses Open Multi-Processing (OpenMP) to run memory-intensive jobs and shared memory programs. The work provides two different implementations of the microwave-based image reconstruction algorithm. The sequential implementation is based on the general Python using NumPy array, while the parallel implementation is based on PySpark. The goal is to assess the effectiveness of using big data technologies for medical image reconstruction that involves multiple iterations on a massive amount of data points. The main contributions of this paper are as follows:
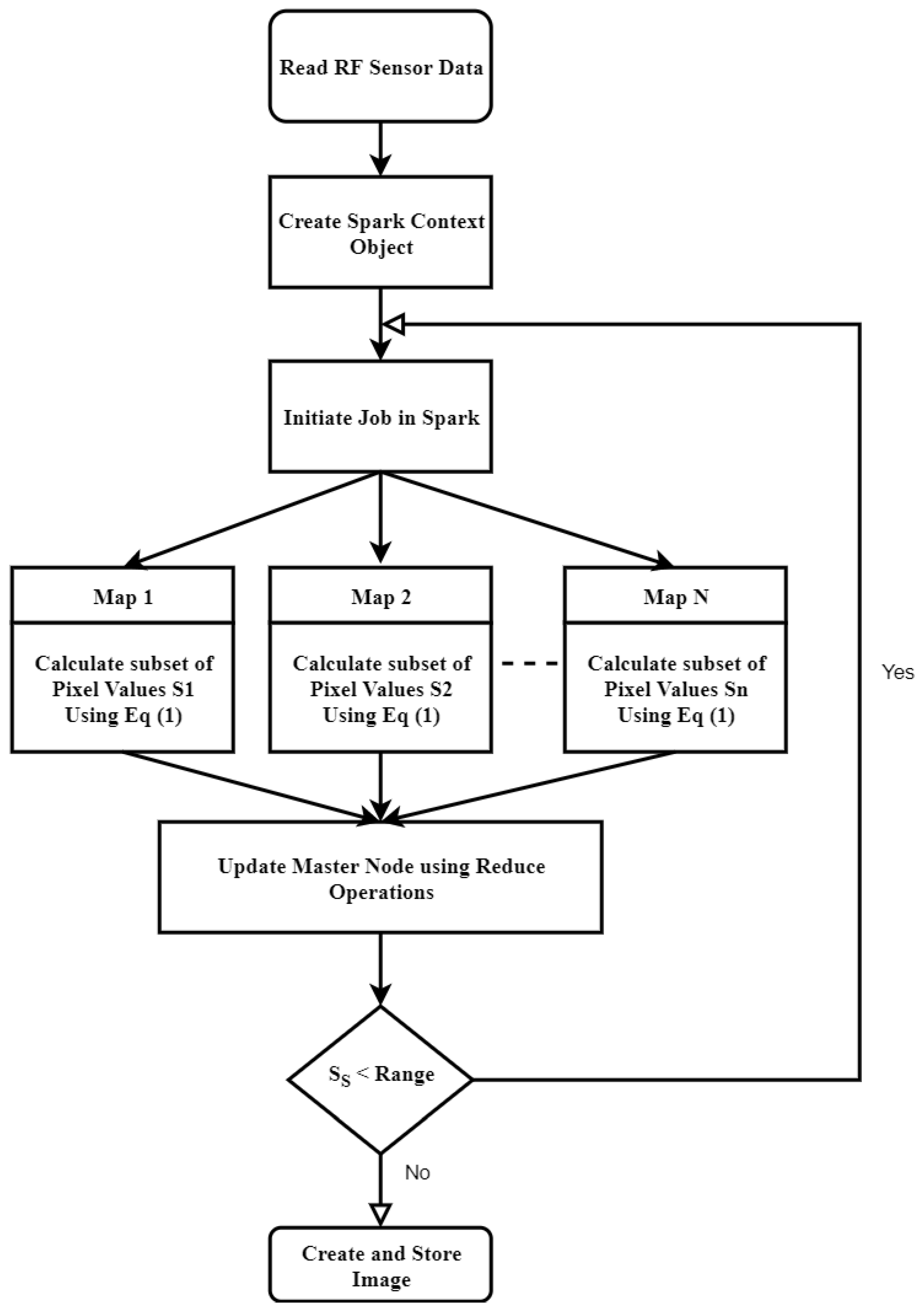
The parallelism of the microwave image reconstruction (MIR) algorithm is first identified. Then, the computational model of Apache Spark is studied, and the parallel version of the algorithm is presented.
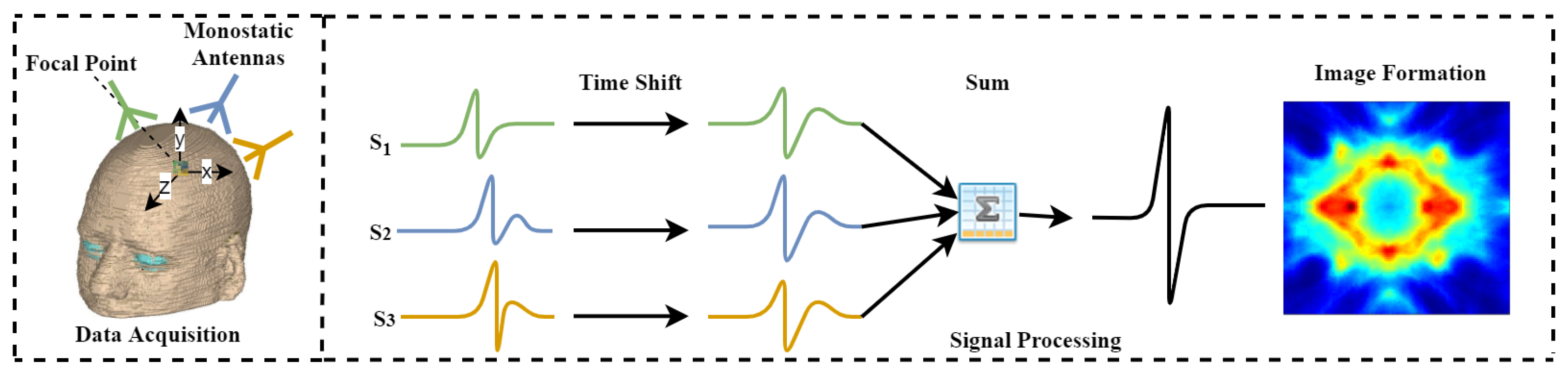
A novel distributed approach, which adopts both data and algorithm in parallel, for efficient image reconstruction of head imaging is proposed. The imaging algorithm is optimized using PySpark on HPC clusters to improve the processing speed and make it real-time. The imaging system retrieves input data generated through radio frequency (RF) sensors and store in Eddie. An integrated imaging algorithm optimized through PySpark creates and saves images back to Eddie Storage.
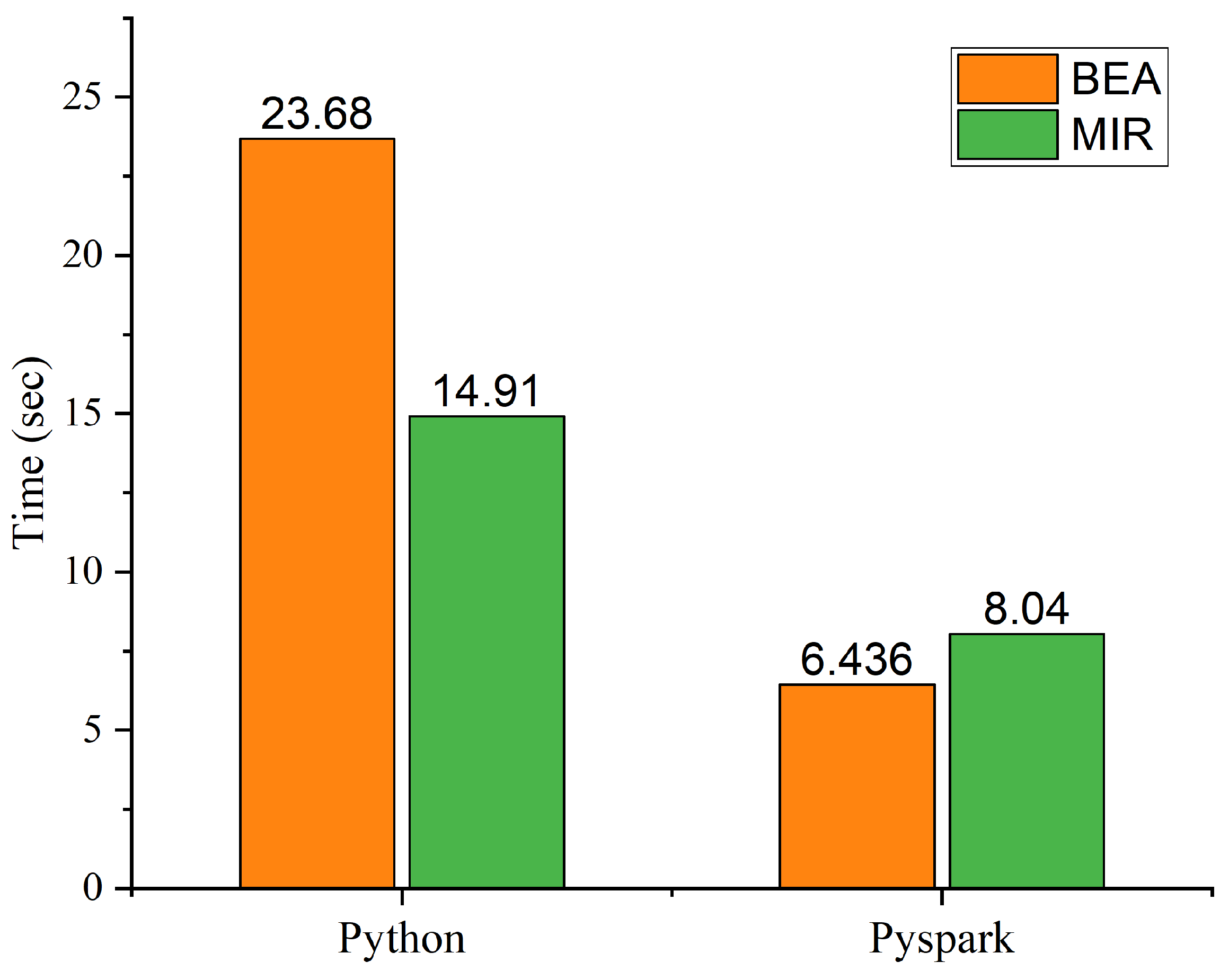
The proposed parallel microwave image reconstruction (PMIR) algorithm is implemented on the PySpark version of Apache Spark. Experimental results indicate that the proposed PMIR algorithm fully inherits the parallelism of the MIR algorithm, resulting in the fast reconstruction of images from RF sensor’s data. The proposed parallel algorithm performs an average of 28.56 times faster than sequential Python implementation.
The remaining part of the paper proceeds as follows: In
Section 2, related literature on image processing on cloud and/or HPC is presented.
Section 3 briefly describes image reconstruction, the microwave imaging reconstruction algorithm, Hadoop, and Spark, along with the Map-reduce programming model. In
Section 4, data acquisition through RF sensors and the implementation of the PMIR algorithm are presented in detail.
Section 5 describes the experimental results. Finally, conclusions and future work are presented in
Section 6.
2. Related Work
A considerable amount of work had been published on the use of HPC or cloud computing for healthcare big data processing in health. Most of the research focuses on images/data analysis acquired through traditional imaging modalities. This section highlights the most recent work on the use of HPC, cloud computing, and big data frameworks for medical image/data processing. An overview of the recent tools and techniques proposed for large scale image data processing using cloud and big data frameworks can be found in
Table 1.
A cloud-based system to process and analyze MRI Scans was proposed in Reference [
28]. The tool was integrated with a threshold-based brain segmentation method to analyze regions of interest. It enabled users to upload their data on a simplified web page. The proposed tool has several benefits, such as better speed due to scalability and automatic up-gradation of the system without bothering the end-users. Experimental data was used to test the performances and functionality of the system. However, no parallel computing techniques were taken into consideration. A smart cloud system is proposed to address the problems related to big data storage by providing infrastructure support to small hospitals with limited resources [
29]. The confidence connected segmentation method was used to detect the tumor object. It allowed users to upload MRI or CT scan images for detecting the tumor in real-time.
A special issue on the use of cloud and parallel computing have been published in the Journal of X-Ray Science and Technology to highlight the state-of-the-art advances in image-guided diagnosis and therapy [
22]. For instance, the use of parallel computing is investigated for modeling blood flow using computational fluid dynamics and smooth particle hydrodynamics in Reference [
34]. An imaging application for neurological diseases and neuroimaging is presented in Reference [
35]. An approach called “cloud-based medical image processing- as-a-service”, utilizing the Apache Hadoop framework and HBase is proposed for efficient processing and retrieval of medical images [
36]. Similarly, a cloud-based medical imaging system was designed and developed to reconstruct images for cancer patients using Proton Computing Tomography [
37]. The proposed service uses Amazon Web Service (AWS) to process multi-client requests simultaneously.
A generalized flow for medical image classification was proposed based on Azure cloud by Roychowdhury et al. [
38]. Similarly, Serrano et al. [
39] stated that big data paradigms fit very well for the workflow needed for image reconstruction. The paper focuses on improving the image quality of CT scan through the iterative reconstruction algorithm. The work also evaluated the costs associated with different execution policies on a single node and distributed configurations. A processing pipeline for processing functional magnetic resonance imaging (fMRI) based upon PySpark was proposed in [
30]. The proposed pipeline was evaluated on a single node, and the results revealed an improvement of fourfold. However, the efficiency was not evaluated on a computing cluster.
An ultra-fast, scalable, and reliable reconstruction method for four-dimensional cone-beam CT was developed using Map-reduce [
40]. The work revealed the potential use of Map-reduce to solve large-scale imaging problems using cloud computing. A tool called “Java Image Science Toolkit (JIST)” was developed and integrated with AWS [
41]. Similarly, a Spark-based image segmentation algorithm was proposed to accelerate the processing of agriculture image big data [
31].The input images are converted into pixel data and then distributed to the computing platform. In order to improve the efficiency of iterative computing, membership degrees of a pixel are calculated and updated in parallel. The experimental results indicated that the proposed Spark-based fuzzy C-means algorithm can perform 12.54 times faster on ten computing nodes.
A distributed computing approach was implemented for the segmentation of skeletal muscle cell images using Apache Spark [
32]. The authors aim to balance the load on available Spark cluster resources. A parallelized region selection algorithm based on the hierarchical tree was proposed, for the efficient segmentation of muscle cells. In the same vein, an architecture for medical image analysis based upon Hadoop and Spark was proposed in Reference [
42]. Image classification was performed as a case study. The proposed architecture contains two parts of medical image big data processing relies on traditional imaging modalities, such as CT, MRI, and X-ray. Moreover, they reviewed existing algorithms used for image classification, compression, and prediction and proposed a theoretical framework based on traditional computing. A parallel computing approach to accelerate single-molecule localization microscopy data processing using ThunderSTORM on the HPC cluster was proposed in Reference [
33]. The performance was compared to a desktop workstation, which indicated that data processing speed can be improved by accessing more HPC resources.
The aforementioned cloud or parallel computing-based services mainly focus on hosting the application on the cloud for experiencing the benefit of large storage or to ease image retrieval of X-ray, CT scan, or PET scan images. Moreover, the use of big data frameworks were also considered for image segmentation, including agriculture and medical images. However, they do not aim to deal with novel modalities for image reconstruction, such as microwave imaging for breast and head diagnostics. Moreover, none of them consider the performance improvement of image reconstructions using Apache Spark for head imaging, using radio frequency data.
5. Experimental Evaluation
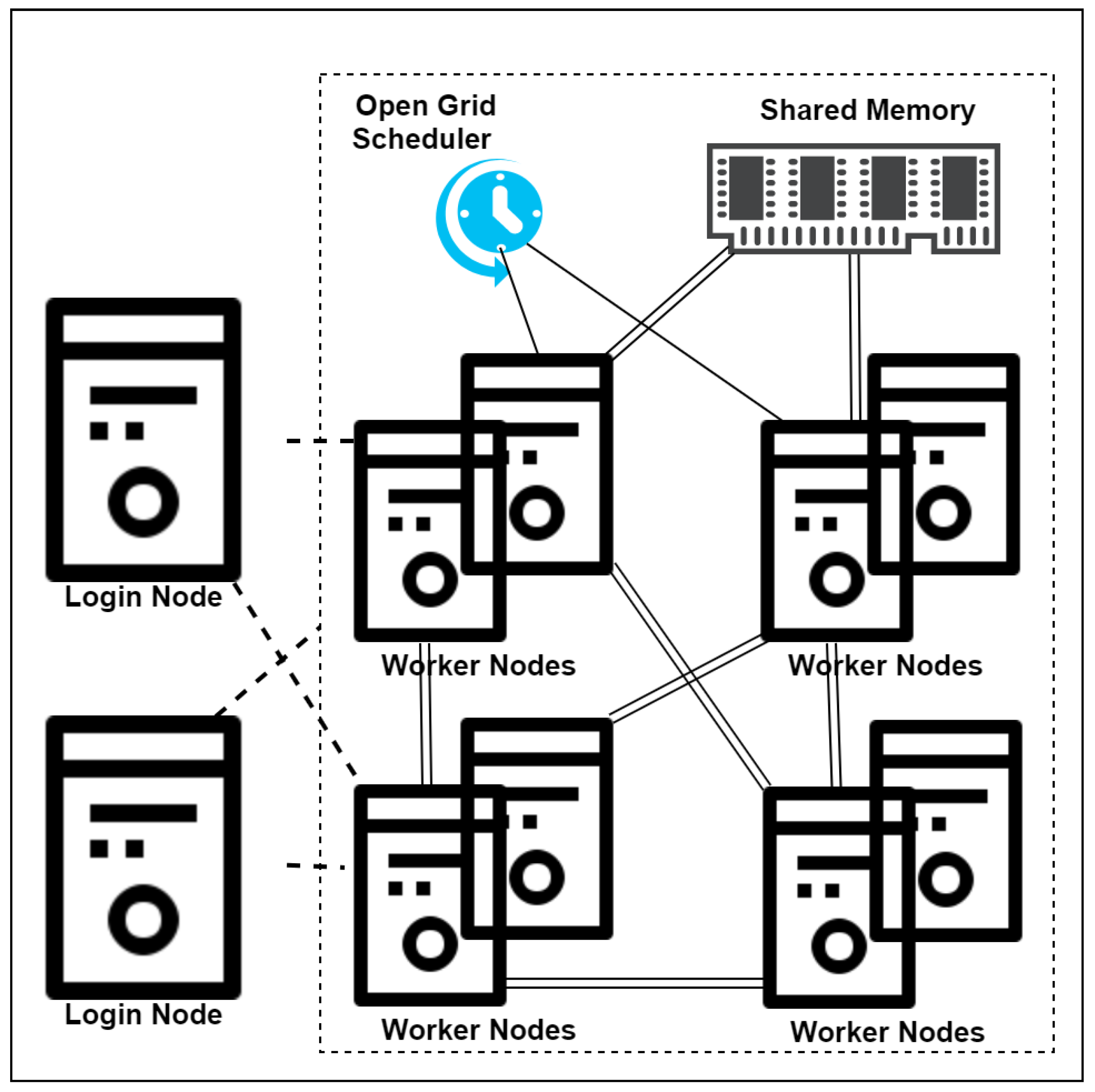
Using the PySpark based Map-reduce programming model, the parallel MIR algorithm for head imaging big data is implemented on Eddie. Eddie (see
www.ecdf.ed.ac.uk) is the University of Edinburgh’s research computing cluster. It has 7000 CPU cores. Each server (compute node) has up to 3 TB of RAM. It runs Open Grid schedule and Scientific Linux 7.x. An overview of Eddie architecture is shown in
Figure 4.
The login node has limited memory and lets users submit job scripts or start an interactive session. All these nodes are connected with a 10 Gbps Ethernet network. The Open Grid Scheduler is responsible for scheduling the jobs. All nodes have access to shared memory called Eddie distribute file system. The user either submits batch jobs from login nodes to the cluster or starts an interactive session by specifying the number of cores required and memory per core.
After setting up the environment for PySpark and Python, PySpark was launched with a configuration of having one master and three workers node. Each node has the same configuration as shown in
Table 2.
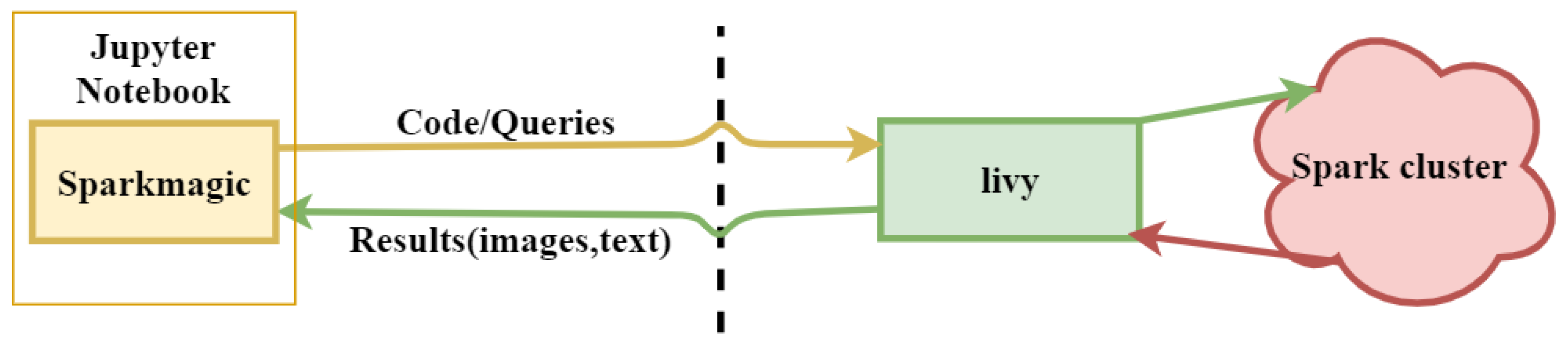
In order to run the job on the localhost, Spark magic is used. Spark magic is a set of tools used to connect to remote Spark clusters through Livy, a Spark REST server, in Jupyter notebooks, as shown in
Figure 5.
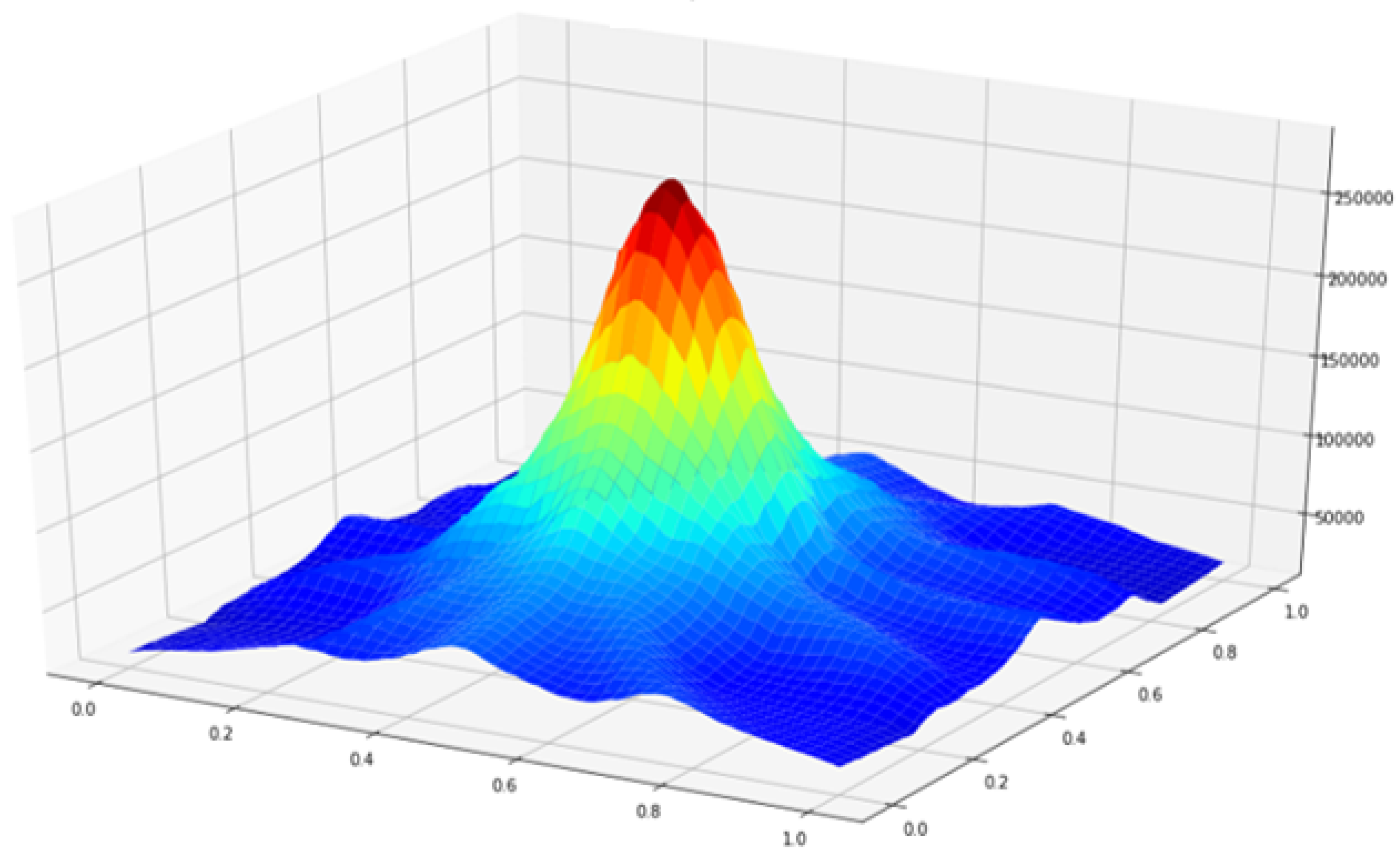
The input data contains 06 antenna and 201 points each making 1206 input points in total for a single output image. The efficiency of the MIR and PMIR algorithm is evaluated based on single-image reconstruction in a homogeneous environment.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
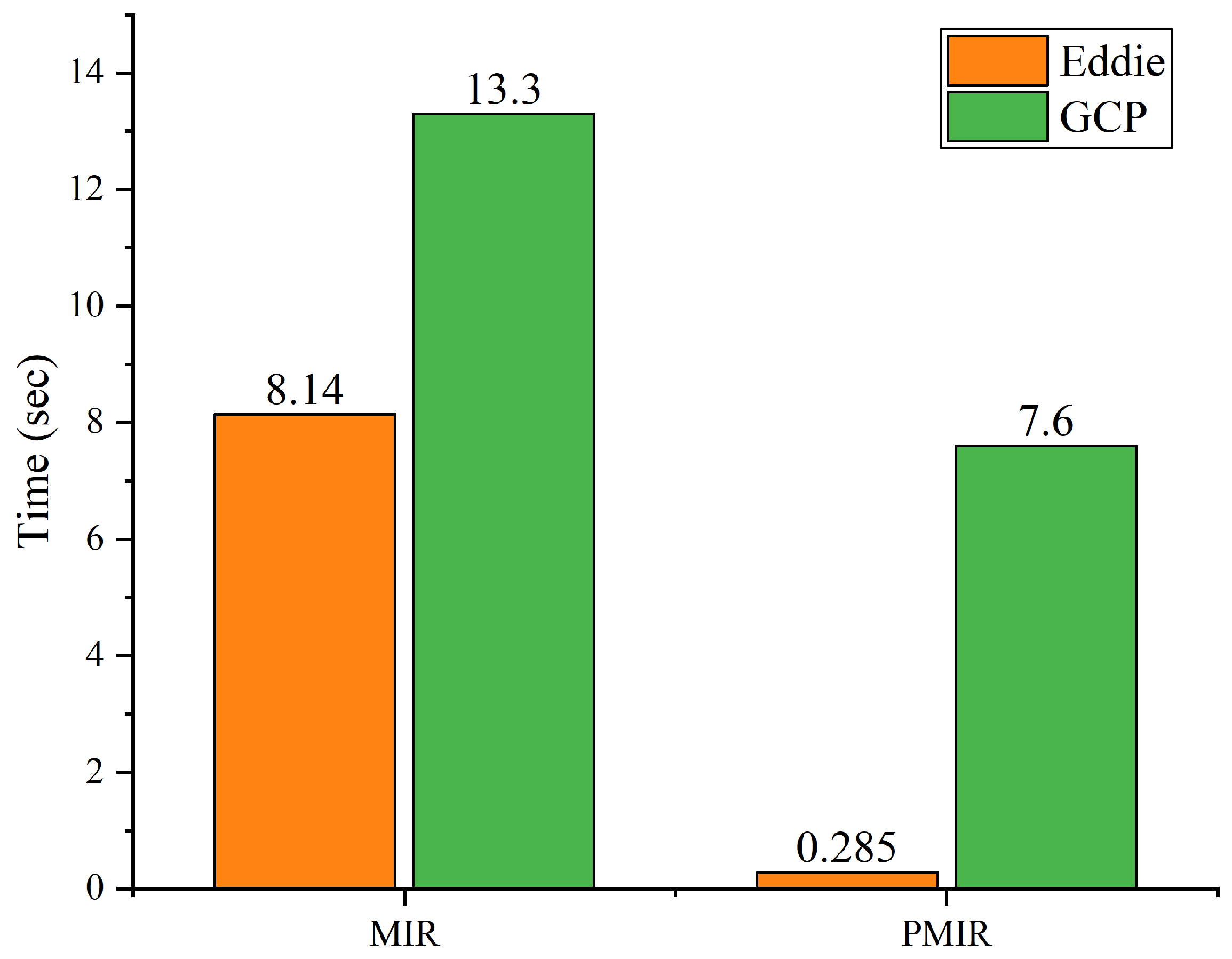{kind=link}
{kind=link}
{kind=link}