Landslide Susceptibility Mapping Using the Stacking Ensemble Machine Learning Method in Lushui, Southwest China


Abstract
:1. Introduction
2. Study Area
3. Data and Methodology
3.1. Spatial Database
3.2. Preparation of Training and Validation Datasets
3.3. Importance Analysis of Landslide Conditioning Factors
3.4. Modeling Methods
3.4.1. Support Vector Machine
3.4.2. Artificial Neural Network
3.4.3. Logistic Regression
3.4.4. Naïve Bayes
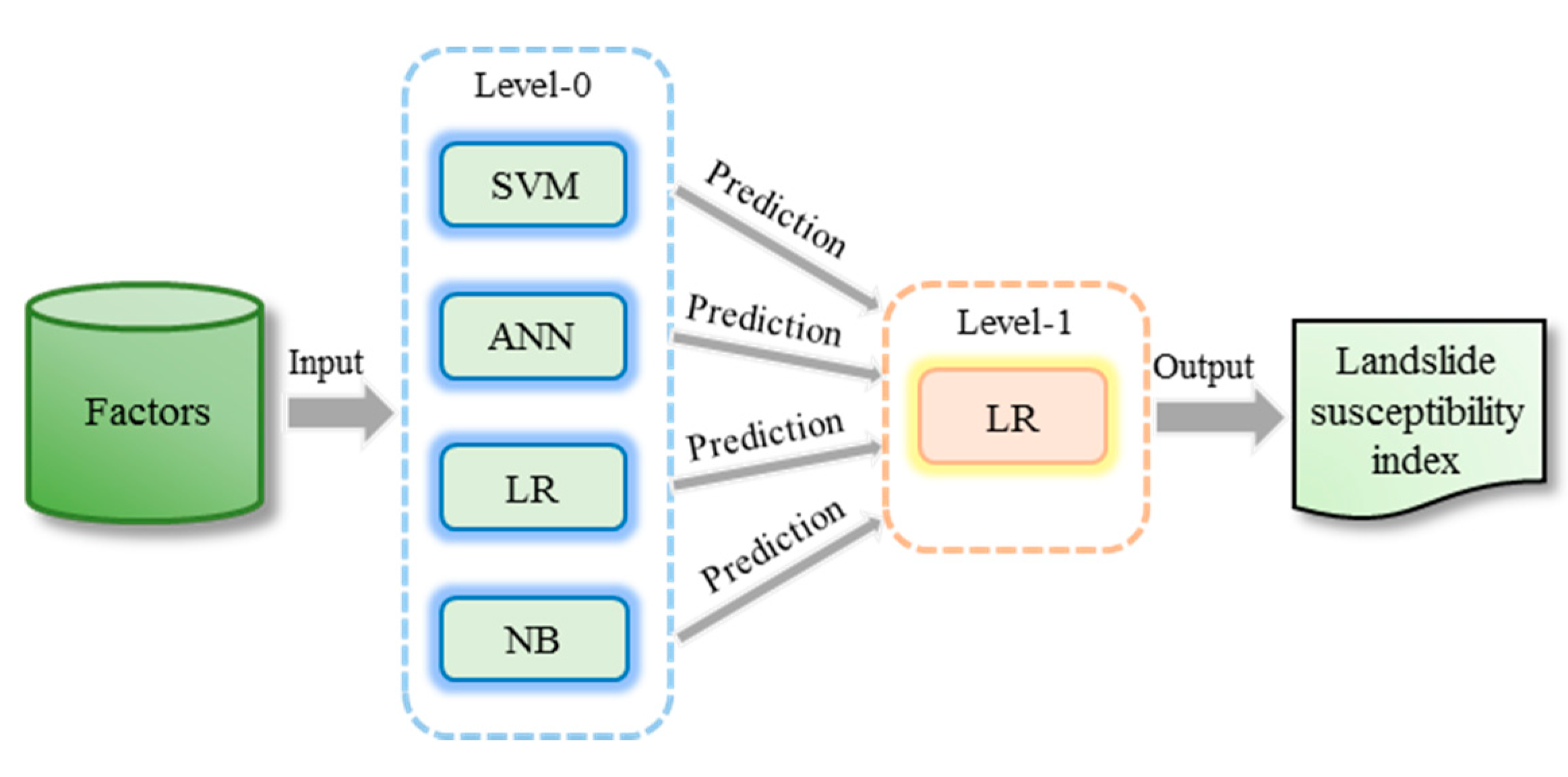
3.4.5. Ensemble Modeling
3.5. Resampling Strategy and Correlation Analysis
4. Results
4.1. Selection of Conditioning Factors
4.2. Appropriateness Evaluation for Base Learners
4.3. Landslide Susceptibility Assessment Using Ensemble Modeling
4.4. Performance Evaluation of Landslide Models
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Gutiérrez, F.; Linares, R.; Roqué, C.; Zarroca, M.; Carbonel, D.; Rosell, J.; Gutiérrez, M. Large landslides associated with a diapiric fold in Canelles Reservoir (Spanish Pyrenees): Detailed geological–geomorphological mapping, trenching and electrical resistivity imaging. Geomorphology 2015, 241, 224–242. [Google Scholar] [CrossRef]
- Pham, B.T.; Pradhan, B.; Tien Bui, D.; Prakash, I.; Dholakia, M.B. A comparative study of different machine learning methods for landslide susceptibility assessment: A case study of Uttarakhand area (India). Environ. Model. Softw. 2016, 84, 240–250. [Google Scholar] [CrossRef]
- Song, Y.; Gong, J.; Gao, S.; Wang, D.; Cui, T.; Li, Y.; Wei, B. Susceptibility assessment of earthquake-induced landslides using Bayesian network: A case study in Beichuan, China. Comput. Geosci. 2012, 42, 189–199. [Google Scholar] [CrossRef]
- Jiao, Y.; Zhao, D.; Ding, Y.; Liu, Y.; Xu, Q.; Qiu, Y.; Liu, C.; Liu, Z.; Zha, Z.; Li, R. Performance evaluation for four GIS-based models purposed to predict and map landslide susceptibility: A case study at a World Heritage site in Southwest China. Catena 2019, 183, 104–221. [Google Scholar] [CrossRef]
- Dou, J.; Yunus, A.P.; Bui, D.T.; Merghadi, A.; Sahana, M.; Zhu, Z.; Chen, C.W.; Han, Z.; Pham, B.T. Improved landslide assessment using support vector machine with bagging, boosting, and stacking ensemble machine learning framework in a mountainous watershed, Japan. Landslides 2019. [Google Scholar] [CrossRef]
- Dahal, R.K.; Hasegawa, S.; Nonomura, A.; Yamanaka, M.; Dhakal, S.; Paudyal, P. Predictive modelling of rainfall-induced landslide hazard in the Lesser Himalaya of Nepal based on weights-of-evidence. Geomorphology 2008, 102, 496–510. [Google Scholar] [CrossRef]
- Guzzetti, F.; Carrara, A.; Cardinali, M.; Reichenbach, P. Landslide hazard evaluation: A review of current techniques and their application in a multi-scale study, Central Italy. Geomorphology 1999, 31, 181–216. [Google Scholar] [CrossRef]
- Korup, O.; Stolle, A. Landslide prediction from machine learning. Geol. Today 2014, 30, 26–33. [Google Scholar] [CrossRef]
- Suzen, M.L.; Kaya, B.Ş. Evaluation of environmental parameters in logistic regression models for landslide susceptibility mapping. Int. J. Digit. Earth 2012, 5, 338–355. [Google Scholar] [CrossRef]
- Wang, L.J.; Sawada, K.; Moriguchi, S. Landslide susceptibility analysis with logistic regression model based on FCM sampling strategy. Comput. Geosci. 2013, 57, 81–92. [Google Scholar] [CrossRef]
- Dimri, S.; Lakhera, R.C.; Sati, S. Fuzzy-based method for landslide hazard assessment in active seismic zone of Himalaya. Landslides 2007, 4, 101–110. [Google Scholar] [CrossRef]
- Feizizadeh, B.; Blaschke, T.; Roodposhti, M.S. Integrating GIS Based Fuzzy Set Theory in Multicriteria Evaluation Methods for Landslide Susceptibility Mapping. Int. J. Geoinformatics 2013, 9, 49–57. [Google Scholar]
- Park, N.W. Using maximum entropy modeling for landslide susceptibility mapping with multiple geoenvironmental data sets. Environ. Earth Sci. 2015, 73, 937–949. [Google Scholar] [CrossRef]
- Zare, M.; Pourghasemi, H.R.; Vafakhah, M.; Pradhan, B. Landslide susceptibility mapping at Vaz Watershed (Iran) using an artificial neural network model: A comparison between multilayer perceptron (MLP) and radial basic function (RBF) algorithms. Arab. J. Geosci. 2013, 6, 2873–2888. [Google Scholar] [CrossRef]
- Conforti, M.; Pascale, S.; Robustelli, G.; Sdao, F. Evaluation of prediction capability of the artificial neural networks for mapping landslide susceptibility in the Turbolo River catchment (northern Calabria, Italy). Catena 2014, 113, 236–250. [Google Scholar] [CrossRef]
- Oh, H.-J.; Lee, S. Shallow Landslide Susceptibility Modeling Using the Data Mining Models Artificial Neural Network and Boosted Tree. Appl. Sci. 2017, 7, 1000. [Google Scholar] [CrossRef] [Green Version]
- Tien Bui, D.; Pradhan, B.; Lofman, O.; Revhaug, I. Landslide Susceptibility Assessment in Vietnam Using Support Vector Machines, Decision Tree, and Naïve Bayes Models. Math. Probl. Eng. 2012, 2012, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Xu, C.; Dai, F.; Xu, X.; Lee, Y.H. GIS-based support vector machine modeling of earthquake-triggered landslide susceptibility in the Jianjiang River watershed, China. Geomorphology 2012, 145, 70–80. [Google Scholar] [CrossRef]
- Hong, H.; Pradhan, B.; Xu, C.; Bui, D.T. Spatial prediction of landslide hazard at the Yihuang area (China) using two-class kernel logistic regression, alternating decision tree and support vector machines. Catena 2015, 133, 266–281. [Google Scholar] [CrossRef]
- Yao, X.; Than, L.G.; Dai, F.C. Landslide susceptibility mapping based on Support Vector Machine: A case study on natural slopes of Hong Kong, China. Geomorphology 2008, 101, 572–582. [Google Scholar] [CrossRef]
- Youssef, A.M.; Pourghasemi, H.R.; Pourtaghi, Z.S.; Al-Katheeri, M.M. Landslide susceptibility mapping using random forest, boosted regression tree, classification and regression tree, and general linear models and comparison of their performance at Wadi Tayyah Basin, Asir Region, Saudi Arabia. Landslides 2016, 13, 839–856. [Google Scholar] [CrossRef]
- Felicísimo, Á.M.; Cuartero, A.; Remondo, J.; Quirós, E. Mapping landslide susceptibility with logistic regression, multiple adaptive regression splines, classification and regression trees, and maximum entropy methods: A comparative study. Landslides 2013, 10, 175–189. [Google Scholar] [CrossRef]
- Chen, W.; Xie, X.; Wang, J.; Pradhan, B.; Hong, H.; Bui, D.T.; Duan, Z.; Ma, J. A comparative study of logistic model tree, random forest, and classification and regression tree models for spatial prediction of landslide susceptibility. Catena 2017, 151, 147–160. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Pourghasemi, H.R.; Kornejady, A.; Zhang, N. Landslide spatial modeling: Introducing new ensembles of ANN, MaxEnt, and SVM machine learning techniques. Geoderma 2017, 305, 314–327. [Google Scholar] [CrossRef]
- Tien Bui, D.; Shirzadi, A.; Shahabi, H.; Geertsema, M.; Omidvar, E.; Clague, J.; Thai Pham, B.; Dou, J.; Talebpour Asl, D.; Bin Ahmad, B.; et al. New Ensemble Models for Shallow Landslide Susceptibility Modeling in a Semi-Arid Watershed. Forests 2019, 10, 743. [Google Scholar] [CrossRef] [Green Version]
- Merghadi, A.; Abderrahmane, B.; Tien Bui, D. Landslide Susceptibility Assessment at Mila Basin (Algeria): A Comparative Assessment of Prediction Capability of Advanced Machine Learning Methods. ISPRS Int. J. Geo-Inf. 2018, 7, 268. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.H.; Sameen, M.I.; Pradhan, B.; Park, H.J. Modeling landslide susceptibility in data-scarce environments using optimized data mining and statistical methods. Geomorphology 2018, 303, 284–298. [Google Scholar] [CrossRef]
- Hong, H.; Liu, J.; Bui, D.T.; Pradhan, B.; Acharya, T.D.; Pham, B.T.; Zhu, A.X.; Chen, W.; Ahmad, B.B. Landslide susceptibility mapping using J48 Decision Tree with AdaBoost, Bagging and Rotation Forest ensembles in the Guangchang area (China). Catena 2018, 163, 399–413. [Google Scholar] [CrossRef]
- Rokach, L. Taxonomy for characterizing ensemble methods in classification tasks: A review and annotated bibliography. Comput. Stat. Data Anal. 2009, 53, 4046–4072. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z. Ensemble learning. Encycl. Biom. 2009, 1, 411–416. [Google Scholar]
- Tien Bui, D.; Ho, T.-C.; Pradhan, B.; Pham, B.-T.; Nhu, V.-H.; Revhaug, I. GIS-based modeling of rainfall-induced landslides using data mining-based functional trees classifier with AdaBoost, Bagging, and MultiBoost ensemble frameworks. Environ. Earth Sci. 2016, 75. [Google Scholar] [CrossRef]
- Pham, B.T.; Tien Bui, D.; Prakash, I.; Dholakia, M.B. Hybrid integration of Multilayer Perceptron Neural Networks and machine learning ensembles for landslide susceptibility assessment at Himalayan area (India) using GIS. Catena 2017, 149, 52–63. [Google Scholar] [CrossRef]
- Truong, X.; Mitamura, M.; Kono, Y.; Raghavan, V.; Yonezawa, G.; Truong, X.; Do, T.; Tien Bui, D.; Lee, S. Enhancing Prediction Performance of Landslide Susceptibility Model Using Hybrid Machine Learning Approach of Bagging Ensemble and Logistic Model Tree. Appl. Sci. 2018, 8, 1046. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Shahabi, H.; Zhang, S.; Khosravi, K.; Shirzadi, A.; Chapi, K.; Pham, B.; Zhang, T.; Zhang, L.; Chai, H.; et al. Landslide Susceptibility Modeling Based on GIS and Novel Bagging-Based Kernel Logistic Regression. Appl. Sci. 2018, 8, 2540. [Google Scholar] [CrossRef] [Green Version]
- Park, S.; Kim, J. Landslide Susceptibility Mapping Based on Random Forest and Boosted Regression Tree Models, and a Comparison of Their Performance. Appl. Sci. 2019, 9, 942. [Google Scholar] [CrossRef] [Green Version]
- Pham, B.T.; Prakash, I.; Singh, S.K.; Shirzadi, A.; Shahabi, H.; Tran, T.-T.-T.; Bui, D.T. Landslide susceptibility modeling using Reduced Error Pruning Trees and different ensemble techniques: Hybrid machine learning approaches. Catena 2019, 175, 203–218. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Schapire, R.E. The strength of weak learnability. Mach. Learn. 1990, 5, 197–227. [Google Scholar] [CrossRef] [Green Version]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forest. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Rodriguez, J.J.; Kuncheva, L.I.; Alonso, C.J. Rotation forest: A new classifier ensemble method. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1619–1630. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.; Ryu, J.H.; Won, J.S.; Park, H.J. Determination and application of the weights for landslide susceptibility mapping using an artificial neural network. Eng. Geol. 2004, 71, 289–302. [Google Scholar] [CrossRef]
- Kanungo, D.P.; Arora, M.K.; Sarkar, S.; Gupta, R.P. A comparative study of conventional, ANN black box, fuzzy and combined neural and fuzzy weighting procedures for landslide susceptibility zonation in Darjeeling Himalayas. Eng. Geol. 2006, 85, 347–366. [Google Scholar] [CrossRef]
- Rossi, M.; Guzzetti, F.; Reichenbach, P.; Mondini, A.C.; Peruccacci, S. Optimal landslide susceptibility zonation based on multiple forecasts. Geomorphology 2010, 114, 129–142. [Google Scholar] [CrossRef]
- Aghdam, I.N.; Varzandeh, M.H.M.; Pradhan, B. Landslide susceptibility mapping using an ensemble statistical index (Wi) and adaptive neuro-fuzzy inference system (ANFIS) model at Alborz Mountains (Iran). Environ. Earth Sci. 2016, 75, 1–20. [Google Scholar] [CrossRef]
- Wang, G.; Hao, J.; Ma, J.; Jiang, H. A comparative assessment of ensemble learning for credit scoring. Expert Syst. Appl. 2011, 38, 223–230. [Google Scholar] [CrossRef]
- Shu, C.; Burn, D.H. Artificial neural network ensembles and their application in pooled flood frequency analysis. Water Resour. Res. 2004, 40. [Google Scholar] [CrossRef] [Green Version]
- Rahali, H. Improving the reliability of landslide susceptibility mapping through spatial uncertainty analysis: A case study of Al Hoceima, Northern Morocco. Geocarto Int. 2017, 34, 43–77. [Google Scholar] [CrossRef]
- Nsengiyumva, J.B.; Luo, G.; Amanambu, A.C.; Mind’je, R.; Habiyaremye, G.; Karamage, F.; Ochege, F.U.; Mupenzi, C. Comparing probabilistic and statistical methods in landslide susceptibility modeling in Rwanda/Centre-Eastern Africa. Sci. Total Environ. 2019, 659, 1457–1472. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pourghasemi, H.R.; Kerle, N. Random forests and evidential belief function-based landslide susceptibility assessment in Western Mazandaran Province, Iran. Environ. Earth Sci. 2016, 75, 185. [Google Scholar] [CrossRef]
- Juliev, M.; Mergili, M.; Mondal, I.; Nurtaev, B.; Pulatov, A.; Hubl, J. Comparative analysis of statistical methods for landslide susceptibility mapping in the Bostanlik District, Uzbekistan. Sci. Total Environ. 2019, 653, 801–814. [Google Scholar] [CrossRef] [PubMed]
- Grelle, G.; Soriano, M.; Revellino, P.; Guerriero, L.; Anderson, M.G.; Diambra, A.; Fiorillo, F.; Esposito, L.; Diodato, N.; Guadagno, F.M. Space–time prediction of rainfall-induced shallow landslides through a combined probabilistic/deterministic approach, optimized for initial water table conditions. Bull. Eng. Geol. Environ. 2013, 73, 877–890. [Google Scholar] [CrossRef]
- Bennett, G.L.; Miller, S.R.; Roering, J.J.; Schmidt, D.A. Landslides, threshold slopes, and the survival of relict terrain in the wake of the Mendocino Triple Junction. Geology 2016, 44, 363–366. [Google Scholar] [CrossRef] [Green Version]
- Kornejady, A.; Ownegh, M.; Bahremand, A. Landslide susceptibility assessment using maximum entropy model with two different data sampling methods. Catena 2017, 152, 144–162. [Google Scholar] [CrossRef]
- MacQueen, J. Some Methods for classification and Analysis of Multivariate Observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 19 June 1967; Volume 1, pp. 281–297. [Google Scholar]
- Ghailan, O.; Mokhtar, H.M.; Hegazy, O. Improving Credit Scorecard Modeling Through Applying Text Analysis. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 512–517. [Google Scholar] [CrossRef] [Green Version]
- Refaat, M. Credit Risk Scorecard: Development and Implementation Using SAS; Lulu: San Francisco, CA, USA, 2011. [Google Scholar]
- Jopia, H.R. Package ‘Smbinning’ Optimal Binning for Scoring Modeling. Available online: https://www.blog.revolutionanalytics.com201503r-package-smbinning-optimal-binning-for-scoring-modeling.html (accessed on 1 April 2019).
- Hothorn, T.; Hornik, K.; Zeileis, A. Ctree: Conditional inference trees. Compr. R Arch. Netw. 2015, 1–34. [Google Scholar]
- Wolpert, D.H. Stacked Generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Zhou, Z. Ensemble Methods: Foundations and Algorithms; Chapman and Hall/CRC: Cambridge, UK, 2012; pp. 1–219. [Google Scholar] [CrossRef]
- Lee, S.; Ryu, J.H.; Kim, I.S. Landslide susceptibility analysis and its verification using likelihood ratio, logistic regression, and artificial neural network models: Case study of Youngin, Korea. Landslides 2007, 4, 327–338. [Google Scholar] [CrossRef]
- Tsangaratos, P.; Ilia, I. Comparison of a logistic regression and Naïve Bayes classifier in landslide susceptibility assessments: The influence of models complexity and training dataset size. Catena 2016, 145, 164–179. [Google Scholar] [CrossRef]
- Ting, K.M.; Witten, L.H. Issues in Stacked Generalization. J. Artif. Intell. Res. 1999, 10, 271–289. [Google Scholar] [CrossRef] [Green Version]
- Witten, I.H.; Frank, E. Data Mining: Practical Machine Learning Tools and Techniques; Todd Green: Cambridge, MA, USA, 2005; pp. 1–622. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar] [CrossRef]
- Dixon, B.; Candade, N. Multispectral landuse classification using neural networks and support vector machines: One or the other, or both? Int. J. Remote Sens. 2008, 29, 1185–1206. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Jebur, M.N. Flood susceptibility mapping using a novel ensemble weights-of-evidence and support vector machine models in GIS. J. Hydrol. 2014, 512, 332–343. [Google Scholar] [CrossRef]
- Kawabata, D.; Bandibas, J. Landslide susceptibility mapping using geological data, a DEM from ASTER images and an Artificial Neural Network (ANN). Geomorphology 2009, 113, 97–109. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Cogn. Model. 1988, 5, 1. [Google Scholar] [CrossRef]
- Pradhan, B.; Lee, S. Delineation of landslide hazard areas on Penang Island, Malaysia, by using frequency ratio, logistic regression, and artificial neural network models. Environ. Earth Sci. 2010, 60, 1037–1054. [Google Scholar] [CrossRef]
- Kavzoglu, T.; Sahin, E.K.; Colkesen, I. Landslide susceptibility mapping using GIS-based multi-criteria decision analysis, support vector machines, and logistic regression. Landslides 2014, 11, 425–439. [Google Scholar] [CrossRef]
- Soria, D.; Garibaldi, J.M.; Ambrogi, F.; Biganzoli, E.M.; Ellis, I.O. A ‘Non-Parametric’ Version of the Naive Bayes Classifier. Knowl.-Based Syst. 2011, 24, 775–784. [Google Scholar] [CrossRef] [Green Version]
- Domingos, P.; Pazzani, M. Beyond independence: Conditions for the optimality of the simple Bayesian classifier. In Proceedings of the 13th Intl. Conf. Machine Learning, Miami, FL, USA, 4–7 December 2013; pp. 105–112. [Google Scholar]
- Hothorn, T.; Leisch, F.; Zeileis, A.; Hornik, K. The design and analysis of benchmark experiments. J. Comput. Graph. Stat. 2005, 14, 675–699. [Google Scholar] [CrossRef] [Green Version]
- Rodriguez-Lujan, I.; Huerta, R.; Elkan, C.; Cruz, C.S. Quadratic programming feature selection. J. Mach. Learn. Res. 2010, 11, 1491–1516. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Sun, Z.; Han, J. Landslide Susceptibility Modeling Using Integrated Ensemble Weights of Evidence with Logistic Regression and Random Forest Models. Appl. Sci. 2019, 9, 171–197. [Google Scholar] [CrossRef] [Green Version]
- Feizizadeh, B.; Roodposhti, M.S.; Jankowski, P.; Blaschke, T. A GIS-based extended fuzzy multi-criteria evaluation for landslide susceptibility mapping. Comput. Geosci. 2014, 73, 208–221. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Razavi Termeh, S.V.; Kornejady, A.; Pourghasemi, H.R.; Keesstra, S. Flood susceptibility mapping using novel ensembles of adaptive neuro fuzzy inference system and metaheuristic algorithms. Sci. Total Environ. 2018, 615, 438–451. [Google Scholar] [CrossRef] [PubMed]
- Menahem, E.; Rokach, L.; Elovici, Y. Troika—An improved stacking schema for classification tasks. Inf. Sci. 2009, 179, 4097–4122. [Google Scholar] [CrossRef] [Green Version]
- Džeroski, S.; Ženko, B. Is combining classifiers with stacking better than selecting the best one? Mach. Learn. 2004, 54, 255–273. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.; Wu, J.; Wei, T. Ensembling neural networks: Many could be better than all. J. Artif. Intell. 2002, 137, 239–263. [Google Scholar] [CrossRef] [Green Version]
- Zeng, X.D.; Chao, S.; Wong, F. Optimization of bagging classifiers based on SBCB algorithm. In Proceedings of the 2010 International Conference on Machine Learning and Cybernetics, Qingdao, China, 11–14 July 2010; pp. 262–267. [Google Scholar]
- Pourghasemi, H.R.; Yousefi, S.; Kornejady, A.; Cerda, A. Performance assessment of individual and ensemble data-mining techniques for gully erosion modeling. Sci. Total Environ. 2017, 609, 764–775. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krogh, A.; Vedelsby, J. Neural network ensembles, cross validation, and active learning. In Proceedings of the 7th International Conference on Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, January 1994; pp. 231–238. [Google Scholar]
- Kuncheva, L.I.; Whitaker, C.J. Measures of diversity in classifier ensembles. Mach. Learn. 2003, 51, 181–207. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ERG | Code | Lithology |
|---|---|---|
| 1. Layered, massive hard metamorphic rock | Ptgl1, Ptgl2, Ptch1, Ptch2, Ptch3 | Migmatite, granulite, gneiss, and mylonite intercalated with mica schist, quartzite |
| 2. Layered, flaky soft mudstone, shale, and sandstone | O3p, S1r, P1b | Mudstone, shale, and sandstone |
| 3. Layered karst medium hard carbonate rock | ϵ3s, S2r, D2hy, D3d, C1x, C1p, P1d, T2h1, T2h2, T3nn | Chert limestone, argillaceous limestone, oolitic limestone, argillaceous strip limestone, biological limestone, limestone, dolomite, lime dolomite, and dolomitic limestone |
| 4. Layered hard sandy mudstone | D1w, C3d, J2m, | Glutenite, sandstone, siltstone, and mudstone intercalated with marlite |
| 5. Massive, hard extrusive rock with veins | β | Amygdaloidal basalt intercalated with lens |
| 6. Massive hard intrusive rock | γ, ν, βμ | Granite, gabbro, and diabase |
| 7. Loose and semi-cemented rock dominated by gravel and sand | Q | Fine sand, gravel, clay, and silt |
| Conditioning Factors | Classes | Numbers of Landslide Pixel | Numbers of Non- Landslide Pixel | IV of Classes | IV of Factors |
|---|---|---|---|---|---|
| Distance to roads (m) | 0–67.26 | 144 | 27,281 | 0.408 | 3.329 |
| 67.26–179.97 | 115 | 35,161 | 0.180 | ||
| 179.97–430.47 | 75 | 51,765 | 0.003 | ||
| 430.47–803.09 | 32 | 45,260 | 0.036 | ||
| 803.09–2048.00 | 19 | 70,570 | 0.261 | ||
| 2048.00–2556.69 | 3 | 16,078 | 0.108 | ||
| >2556.69 | 0 | 64,101 | 2.333 | ||
| Elevation (m) | 740.00–1043.67 | 88 | 12,262 | 0.334 | 2.694 |
| 1043.67–2138.90 | 271 | 105,623 | 0.254 | ||
| 2138.90–2389.03 | 25 | 35,515 | 0.025 | ||
| 2389.03–4160.00 | 4 | 156,816 | 2.081 | ||
| Land use | Residential area | 36 | 1951 | 0.233 | 1.136 |
| Forest | 146 | 247,017 | 0.315 | ||
| Grassland | 20 | 26,894 | 0.018 | ||
| Farmland | 33 | 3918 | 0.138 | ||
| Bare land | 131 | 28,544 | 0.319 | ||
| Engineering land | 2 | 169 | 0.010 | ||
| Other | 20 | 1723 | 0.103 | ||
| NDVI | −1–0.12 | 10 | 28,751 | 0.087 | 1.089 |
| 0.12–0.35 | 97 | 19,308 | 0.282 | ||
| 0.35–0.58 | 144 | 50,805 | 0.168 | ||
| 0.58–0.75 | 62 | 38,833 | 0.006 | ||
| 0.75–0.89 | 38 | 39,805 | 0.008 | ||
| 0.89–1 | 37 | 132,714 | 0.539 | ||
| Distance to faults(m) | 0–583.52 | 226 | 101,844 | 0.148 | 0.733 |
| 583.52–1782.99 | 125 | 83,965 | 0.009 | ||
| 1782.99–2317.76 | 18 | 18,050 | 0.004 | ||
| >2317.76 | 19 | 106,357 | 0.572 | ||
| ERG | 1 | 131 | 110,304 | 0.001 | 0.396 |
| 2 | 0 | 335 | 0.007 | ||
| 3 | 104 | 63,313 | 0.017 | ||
| 4 | 36 | 26,766 | 0.001 | ||
| 5 | 52 | 21,698 | 0.042 | ||
| 6 | 30 | 81,418 | 0.226 | ||
| 7 | 35 | 6382 | 0.103 | ||
| Slope angle (°) | 0–6.22 | 18 | 5105 | 0.035 | 0.176 |
| 6.22–21.27 | 126 | 63,154 | 0.054 | ||
| 21.27–32.86 | 156 | 121,863 | 0.000 | ||
| >32.86 | 88 | 120,094 | 0.086 | ||
| Profile curvature | −16.00–0.04 | 106 | 130,893 | 0.068 | 0.105 |
| −0.04–26.53 | 282 | 179,323 | 0.037 | ||
| Slope aspect (°) | 0–302.33 | 358 | 262,403 | 0.007 | 0.065 |
| >302.33 | 30 | 47,813 | 0.057 | ||
| Annual rainfall (mm) | 773.87–1210.57 | 292 | 202,052 | 0.015 | 0.052 |
| 1210.57–1419.27 | 96 | 108,164 | 0.037 | ||
| Distance to rivers (m) | 0–272.17 | 199 | 124,775 | 0.027 | 0.050 |
| 272.17–2566.56 | 189 | 185,441 | 0.023 | ||
| Plan curvature | −28.56–20.05 | 388 | 310,216 | 0.000 | 0.000 |
| Class | SANL | SAN | ANL | SAL | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PC (%) | PL (%) | LD | PC (%) | PL (%) | LD | PC (%) | PL (%) | LD | PC (%) | PL (%) | LD | |
| Very low | 35.60 | 0.00 | 0.00 | 36.16 | 0.00 | 0.00 | 36.79 | 0.00 | 0.00 | 27.81 | 0.26 | 0.01 |
| Low | 13.32 | 0.77 | 0.06 | 13.24 | 0.52 | 0.04 | 12.47 | 0.52 | 0.04 | 20.84 | 0.52 | 0.02 |
| Moderate | 8.13 | 2.06 | 0.25 | 7.89 | 2.06 | 0.26 | 7.88 | 2.32 | 0.29 | 7.20 | 1.55 | 0.21 |
| High | 26.14 | 27.32 | 1.05 | 19.82 | 13.66 | 0.69 | 21.04 | 17.78 | 0.85 | 32.35 | 39.95 | 1.23 |
| Very high | 16.80 | 69.85 | 4.16 | 22.90 | 83.76 | 3.66 | 21.82 | 79.38 | 3.64 | 11.80 | 57.73 | 4.89 |
| Models | On the Training Stage | On the Validation Stage | ||||
|---|---|---|---|---|---|---|
| ACC (%) | K | AUC | ACC (%) | K | AUC | |
| SANL | 86.40 | 0.728 | 0.945 | 85.34 | 0.707 | 0.931 |
| SAN | 86.95 | 0.739 | 0.951 | 85.34 | 0.707 | 0.940 |
| ANL | 86.58 | 0.732 | 0.944 | 85.34 | 0.707 | 0.932 |
| SAL | 84.93 | 0.699 | 0.927 | 82.33 | 0.647 | 0.886 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, X.; Zhang, H.; Mei, H.; Xiao, D.; Li, Y.; Li, M. Landslide Susceptibility Mapping Using the Stacking Ensemble Machine Learning Method in Lushui, Southwest China. Appl. Sci. 2020, 10, 4016. https://0-doi-org.brum.beds.ac.uk/10.3390/app10114016
Hu X, Zhang H, Mei H, Xiao D, Li Y, Li M. Landslide Susceptibility Mapping Using the Stacking Ensemble Machine Learning Method in Lushui, Southwest China. Applied Sciences. 2020; 10(11):4016. https://0-doi-org.brum.beds.ac.uk/10.3390/app10114016
Chicago/Turabian StyleHu, Xudong, Han Zhang, Hongbo Mei, Dunhui Xiao, Yuanyuan Li, and Mengdi Li. 2020. "Landslide Susceptibility Mapping Using the Stacking Ensemble Machine Learning Method in Lushui, Southwest China" Applied Sciences 10, no. 11: 4016. https://0-doi-org.brum.beds.ac.uk/10.3390/app10114016