Active Safety System for Urban Environments with Detecting Harmful Pedestrian Movement Patterns Using Computational Intelligence †





Abstract
:1. Introduction
2. Methodology: Image Processing and Pattern Detection
2.1. Image Processing
- Capture consists in acquiring raw images from a source (e.g., surveillance cameras). In this step, noise and other types of degradation such as blurring, high contrast of the scene, and others, are always added to the image, depending on the specific device used [7].
- Preprocessing applies techniques to remove or reduce the information in those images that are not of interest for solving the problem. The main goal of the preprocessing step is to improve those characteristics of the image that are important for solving the problem (e.g., contour and shine), by using mathematical tools.
- Segmentation consists of splitting each image into regions that represent different objects or background, based on contour, connectivity, or in pixel based characteristics (e.g., shades of gray, textures, gradient magnitude). Some authors state that segmentation algorithms focus on two relevant properties of images: discontinuity and similarity [8], while others add a third property: connectivity [9]. The output of this step is a binary representation of the original image.
- Features extraction consists in finding, selecting, and extracting relevant features of an image, which allow identifying objects of interest for the problem. The features identified in the image must satisfy three properties: robustness, discrimination, and invariance [6].
- Object identification is responsible for categorizing the set of features extracted in the previous step. In this step, different decision models are applied, such as supervised classifiers.
2.2. Pattern Detection
- Segmentation in pattern detection systems is similar to the segmentation applied in image processing systems. The goal of the segmentation stage is to simplify the input, resulting in a set of information that is easier to process.
- Feature extraction takes as input the result of the segmentation stage. The input is processed to extract relevant information about specific objects, remove redundant/irrelevant information, to reduce the dimension of the problem. Quantitative (e.g., speed, distance) and qualitative (e.g., occupation, sex) features are extracted and used to build a vector of features. The goal is to select a subset of features (from the original set) in order to optimize a predefined target function. Feature selection can be done by applying statistical techniques. This procedure usually requires a deep knowledge of the problem. Selection feature methods consist of three components: at least one evaluation criterion, a procedure or search algorithm and a stop criterion [11].
- Classification processes features a vector to assign features to specific classes, according to predefined metrics. Classification methods (i.e., classifiers) depend on the nature of the problem and, in general, their performance also depends on the quality and number of extracted features. There are two main groups of classifiers: supervised, and unsupervised [12]. Supervised classifiers are based on a set of elements, known as training data, for which the class they belong is previously known by the classifier [13]. Some typical supervised methods are Bayesian, Support Vector Machine (SVM), k-nearest neighbors (k-NN) and neural networks, among others [14]. Unsupervised classifiers tries to discover the classes of a given problem from a set of elements of which the classes are unknown [13]. The number of classes to be discovered by an unsupervised classifier can be known in advance or not, depending exclusively on the datasets handled. Some typical unsupervised methods are Simple Link, ISODATA and k-means, among others [14].
2.3. Methodology Applied in the Proposed System
3. Related Works
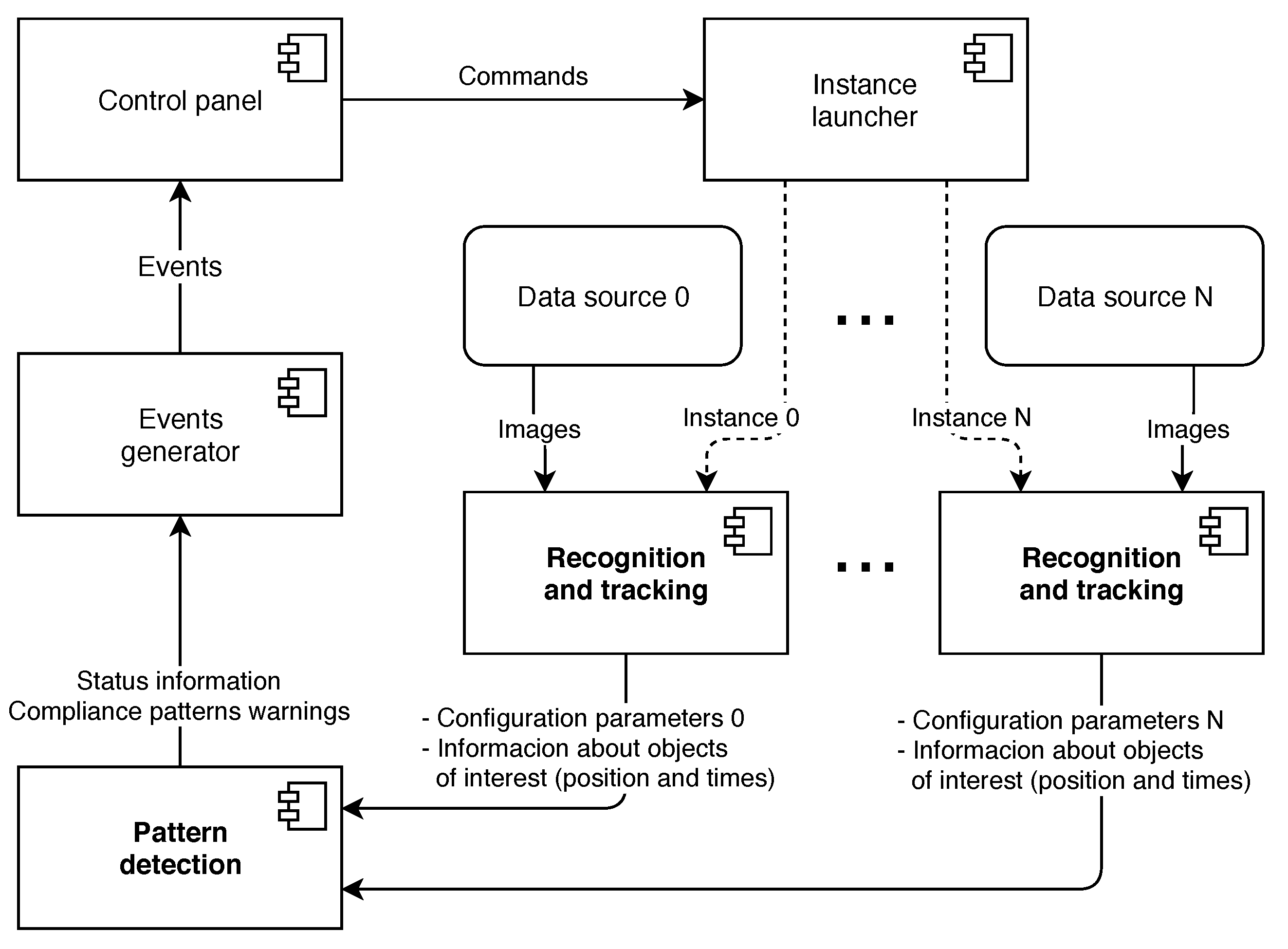
4. The Proposed Detection System
4.1. Architecture and Design
4.2. Recognition and Tracking Module
4.3. Pattern Detection Module
4.4. Auxiliary Modules
5. Implementation
5.1. Technology Selection
5.2. Communication between Modules
5.3. Recognition and Tracking Module
5.3.1. Background Subtraction
| Algorithm 1 Background subtraction steps |
| 1: frame ← raw image |
| 2: grey image ← BGRToGrey(frame) |
| 3: blurred image ← GaussianBlur(grey image) |
| 4: binary image ← BackgroundSubtractor(blurred image) |
| 5: binary image without noise ← MorphologicalOperations(binary image) |
| 6: output ← binary image without noise |
5.3.2. Blobs Detection
5.3.3. Blobs Classification
- Aspect ratio (AR) classifies blobs based on the relation (ratio) between their width and height. If the ratio is close to the average value of the objects of interest, AR indicates that the blob contains at least one object of interest. The major benefit of AR is its low computational cost. However, it tends to be inaccurate because the reference aspect ratio often varies significantly for different data sources. AR is not useful for discarding blobs (i.e., the fact that a blob fulfills the relation does not mean that it contains an object of interest) and wrongly discards blobs that do not comply with the established aspect ratio criterion due to the fact that they contain multiple objects of interest (e.g., objects close enough one of each other that conforms a unique blob).
- Computational intelligence uses the default people detector, a pre-trained learning algorithm included in OpenCV. Dalal and Triggs [37] demonstrated that a combination of Histograms of Oriented Gradients (HOG) for feature extraction, and Support Vector Machine (SVM) for the classification of the feature vectors, allows obtaining accurate detection results. The method is based on moving a gridded window all over the image, extracting the vectors of features (using HOG) and classifying them (using SVM) to decide if the image contains a person. Considering that the proposed system studies the movement of persons, the blob classification technique processes just those areas where movement was detected. Thus, the default people detector algorithm is applied just over each detected blob, reducing the computational cost of the processing. This method returns a set of rectangles that contains persons, some of them overlapped. To reduce and unify the number of rectangles, the Non-Maximum Suppression algorithm [38] is used.
- Aspect ratio frequency filters blobs depending on the frequency that similar blobs were filtered by computational intelligence algorithms. In this way it is possible to simulate a behavior close to the computational intelligence algorithms without having to execute them in each iteration. Aspect ratio frequency can be applied in two different ways: (i) directly filtering those blobs in which the frequency is greater than a threshold, or (ii) categorizing the blobs frequencies into three different levels and depending on that level, discarding the blob, requesting a computational intelligence method to process the blob, or keeping the blob.
5.3.4. Tracking
- The group has no assigned blobs. If the tracklet was recently updated with a blob position, then it will be updated in the current frame with the prediction values (line 17), otherwise, the tracklet is removed from the system, assuming that the objects that were tracked disappeared from the scene (line 19).
- The group has a single assigned blob. If the group has just one tracklet (the ideal case), the tracklet is updated with the blob data (line 24). Otherwise, if the group has more than one tracklet, it is the case where many objects are occluded in one blob. In this case, the system first deletes the tracklets with ghost blobs and then deletes all tracklets, except the most reliable, updating it with the blob data (line 26).
- The group has more than one assigned blob. This is the case where objects that were occluded are splitting up. To avoid any loss of information between iterations, each blob is assigned to a new group and the Hungarian algorithm is executed (up to two times, using different weights) between the tracklets of the current group and the blobs associated to it (line 30). After applying the Hungarian algorithm, if there are still many tracklets assigned to a single blob in a group, it is a situation where occlusions and/or ghost blobs happen. In this case, the method in line 26 is applied again.
| Algorithm 2 Tracking steps |
| 1: calculate assignations between tracklets and blobs using Hungarian algorithm |
| 2: for each blob in the system do |
| 3: if assigned to a tracklet then |
| 4: add blob to the group of the tracklet |
| 5: else |
| 6: create tracklet containing blob |
| 7: create group containing the just created tracklet |
| 8: end if |
| 9: end for |
| 10: for each group without assigned blobs do |
| 11: move tracklets to the group of the closest blob, or the group of the blob that contains it |
| 12: end for |
| 13: for each group in the system do |
| 14: if has no blobs assigned then |
| 15: for each tracklet in the group do |
| 16: if object disappears for a moment then |
| 17: update position with prediction |
| 18: else |
| 19: remove the tracklet |
| 20: end if |
| 21: end for |
| 22: else if has one blob then |
| 23: if has one tracklet then |
| 24: update it with the blob information |
| 25: else if has many tracklets then |
| 26: resolves with one-blob-to–many algorithm |
| 27: end if |
| 28: else |
| 29: if has more tracklets than blobs then |
| 30: resolves with many–to–many algorithm |
| 31: end if |
| 32: end if |
| 33: if the group has no tracklets then |
| 34: remove the group from the system |
| 35: end if |
| 36: end for |
5.4. Pattern Detection Module
- The first stage receives messages from multiple instances of the Recognition and Tracking module and routes them depending on the source identifier. Two types of messages exist. The first type of message is the least common (but always necessary) and correspond to the ones used when processing requests by new instances of recognition and tracking. When a request arrives, the Pattern Detection module creates the structures to handle data from the new data source identified in the message, and configuration values in the message are applied to process data from the respective data source. The second type of message is used for communicating data of detected objects. When these data messages arrive, they are routed to the structures previously created to handle the data source.
- The second stage receives data of the detected objects and has the patterns definition, the recent history of primitives fulfilled by each detected object, and all the logic needed to check patterns compliance. Patterns are defined as a sequence of primitives, defined by a ‘primitive type’, an ‘event type’ for each type of primitive, and a ‘quantifier’ that defines how the values of the met primitives are compared with that required by the pattern. For example, the primitives defined in the implemented system are SPEED, DIRECTION, and AGGLOMERATION. Each primitive type has events, for example, for the SPEED primitive, three events are possible: WALKING, RUNNING and STOPPED. The quantifiers defined in the proposed system are LE–lesser or equal, GE–greater or equal, AX–approximate, EQ–equal and NM–irrelevant value.
6. Validation and Results
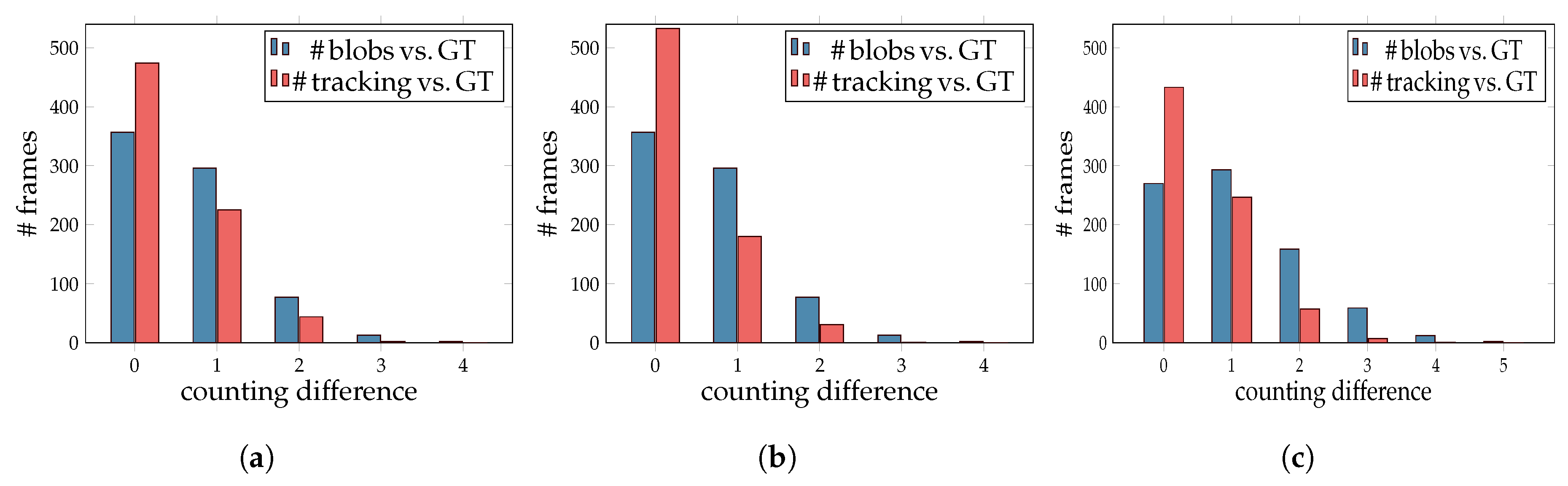
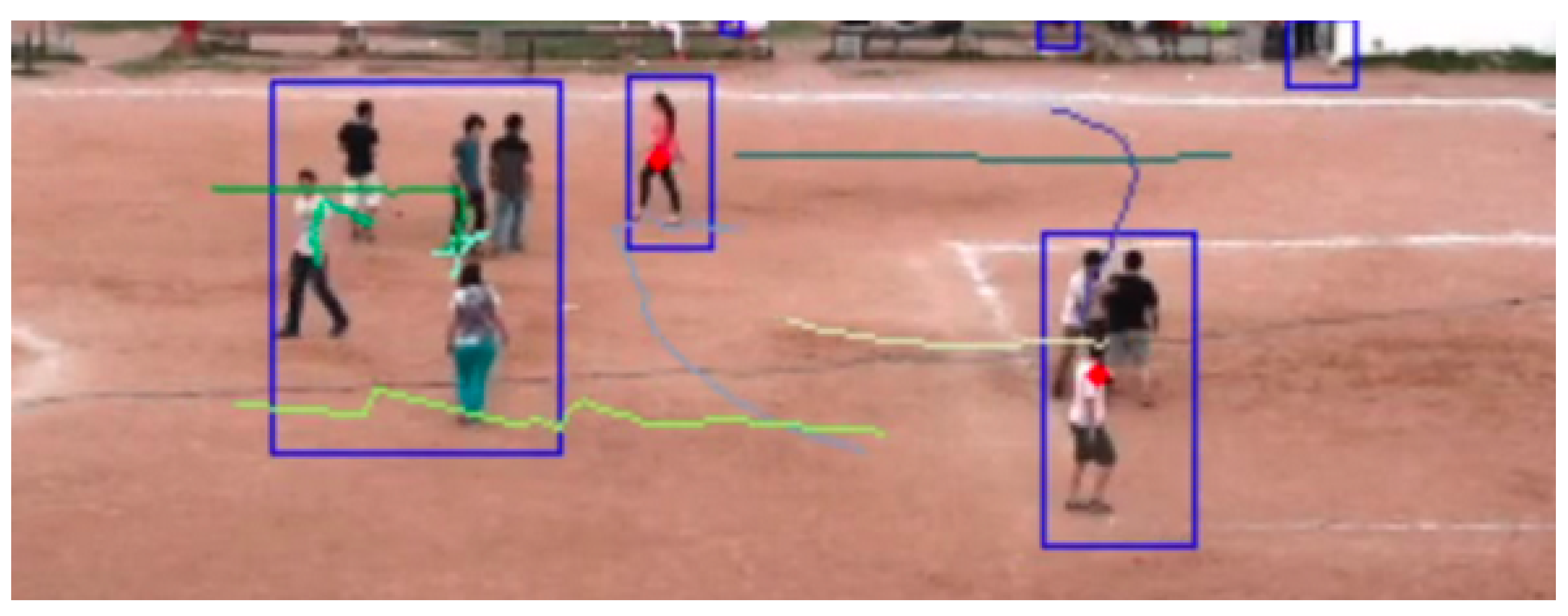
6.1. Recognition and Tracking Module
6.2. Pattern Detection Module
7. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- La Vigne, N.; Lowry, S.; Markman, J.; Dwyer, A. Evaluating the Use of Public Surveillance Cameras for Crime Control and Prevention. Technical Report. Urban Institute, Justice Policy Center, 2011. Available online: https://www.urban.org/research (accessed on 1 October 2018).
- Kruegle, H. CCTV Surveillance, Second Edition: Video Practices and Technology; Butterworth-Heinemann: Newton, MA, USA, 2006. [Google Scholar]
- World Health Organization. Pedestrian Safety: A Road Safety Manual for Decision-Makers and Practitioners; World Health Organization: Geneva, Switzerland; Foundation for the Automobile and Society: London, UK; Global Road Safety Partnership: Geneva, Switzerland; World Bank: Geneva, Switzerland, 2013. [Google Scholar]
- Chavat, J.; Nesmachnow, S. Computational Intelligence for Detecting Pedestrian Movement Patterns. In Smart Cities; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 148–163. [Google Scholar]
- University of Reading. Performance Evaluation of Tracking and Surveillance. Available online: www.cvg.reading.ac.uk/PETS2009 (accessed on 26 October 2019).
- Gonzalez, R.; Woods, R. Digital Image Processing; Pearson Education: London, UK, 2008. [Google Scholar]
- Ramírez, B. Procesamiento Digital de Imágenes: Fundamentos de la Imagen Digital; Universidad Nacional Autónoma de México: Mexico City, Mexico, 2006. [Google Scholar]
- Martín, M. Técnicas Clásicas de Segmentación de Imagen; Universidad de Valladolid: Valladolid, Spain, 2002. [Google Scholar]
- Muñoz, J. Segmentación de Imágenes. 2009. Available online: www.lcc.uma.es/~munozp/documentos/procesamiento_de_imagenes/temas/pi_cap6.pdf (accessed on 26 October 2019).
- Jain, A.; Duin, R.; Mao, J. Statistical pattern recognition: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 4–37. [Google Scholar] [CrossRef] [Green Version]
- Ramírez, D. Desarrollo de un méTodo de Procesamiento de Imágenes para la Discriminación de Maleza en Cultivos de Maíz. Master’s Thesis, Universidad Autónoma de Querétaro, Santiago de Querétaro, Mexico, 2012. [Google Scholar]
- Webb, A. Statistical Pattern Recognition; John Wiley & Sons: Hoboken, NJ, USA, 2003. [Google Scholar]
- Corso, C. Aplicación de Algoritmos de Clasificación Supervisada usando Weka; Facultad Regional Córdoba, Universidad Tecnológica Nacional: Buenos Aires, Argentina, 2009. [Google Scholar]
- Carrasco, J.; Martínez, J. Reconocimiento de patrones. Komput. Sapiens 2011, 2, 5–9. [Google Scholar]
- Valera, M.; Velastin, S. Intelligent distributed surveillance systems: A review. IEE Proc. Image Signal Process. 2005, 152, 192–204. [Google Scholar] [CrossRef]
- Piccardi, M. Background subtraction techniques: A review. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, The Hague, The Netherlands, 10–13 October 2004; pp. 3099–3104. [Google Scholar]
- López, H. Detección y Seguimiento de Objetos con Cámaras en Movimiento. Bachelor’s Thesis, Universidad Autónoma de Madrid, Madrid, Spain, 2011. [Google Scholar]
- Stauffer, C.; Grimson, E. Adaptive background mixture models for real-time tracking. In Proceedings of the 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Fort Collins, CO, USA, 23–25 June 1999; Volume 2. [Google Scholar]
- Kalman, R. A new approach to linear filtering and prediction problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef] [Green Version]
- Lefloch, D. Real-Time People Counting System Using Video Camera. Master’s Thesis, Université de Bourgogne, Dijon, France, 2007. [Google Scholar]
- Rodriguez, M.; Laptev, I.; Sivic, J.; Audibert, J. Density-aware person detection and tracking in crowds. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 7–13 November 2011; pp. 2423–2430. [Google Scholar]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian Detection: An Evaluation of the State of the Art. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 743–761. [Google Scholar] [CrossRef] [PubMed]
- Leach, M.; Sparks, E.; Robertson, N. Contextual anomaly detection in crowded surveillance scenes. Pattern Recognit. Lett. 2014, 44, 71–79. [Google Scholar] [CrossRef] [Green Version]
- Felzenszwalb, P.; Girshick, R.; McAllester, D.; Ramanan, D. Object Detection with Discriminatively Trained Part-Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kalal, Z.; Matas, J.; Mikolajczyk, K. Online learning of robust object detectors during unstable tracking. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, Kyoto, Japan, 27 September–4 October 2009; pp. 1417–1424. [Google Scholar]
- Cho, S.; Kang, H. Abnormal behavior detection using hybrid agents in crowded scenes. Pattern Recognit. Lett. 2014, 44, 64–70. [Google Scholar] [CrossRef]
- Zhu, X.; Jin, X.; Zhang, X.; Li, C.; He, F.; Wang, L. Context-aware local abnormality detection in crowded scene. Sci. China Inf. Sci. 2015, 58, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Garlan, D.; Shaw, M. An Introduction to Software Architecture. In Advances in Software Engineering and Knowledge Engineering; Ambriola, V., Tortora, G., Eds.; World Scientific Publishing: Singapore, 1993. [Google Scholar]
- Van Huis, J.; Bouma, H.; Baan, J.; Burghouts, G.; Eendebak, P.; den Hollander, R.; Dijk, J.; van Rest, J. Track-based event recognition in a realistic crowded environment. In Proceedings of the SPIE–The International Society for Optical Engineering, Amsterdam, The Netherlands, 22–25 September 2014; Volume 9253, p. 92530E. [Google Scholar]
- Mallick, S. Learn OpenCV (C++/Python). 2016. Available online: www.learnopencv.com/ (accessed on 26 October 2019).
- Coelho, L. Why Python is Better than Matlab for Scientific Software. 2013. Available online: metarabbit.wordpress.com/2013/10/18/ (accessed on 26 October 2019).
- Pivotal Software Inc. RabbitMQ–Messaging that just Works. Available online: www.rabbitmq.com/ (accessed on 26 October 2019).
- Nixon, M.; Aguado, A. Feature Extraction and Image Processing; Academic Press: Amsterdam, The Netherlands, 2008. [Google Scholar]
- Zivkovic, Z. Improved adaptive Gaussian mixture model for background subtraction. In Proceedings of the 17th International Conference on Pattern Recognition, 2004, ICPR 2004, Cambridge, UK, 23 August 2004; Volume 2, pp. 28–31. [Google Scholar]
- Zivkovic, Z.; Van Der Heijden, F. Efficient adaptive density estimation per image pixel for the task of background subtraction. Pattern Recognit. Lett. 2006, 27, 773–780. [Google Scholar] [CrossRef]
- OpenCV Developers Team. OpenCV Simple Blob Detector. Available online: https://docs.opencv.org/3.4/d0/d7a/classcv_1_1SimpleBlobDetector.html (accessed on 26 October 2019).
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; pp. 886–893. [Google Scholar]
- Rosebrock, A. Non-Maximum Suppression for Object Detection in Python. 2014. Available online: www.pyimagesearch.com/2014/11/17 (accessed on 26 October 2019).
- Kuhn, H. The Hungarian method for the assignment problem. Nav. Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef] [Green Version]
- Leal-Taixé, L.; Milan, A.; Reid, I.; Roth, S.; Schindler, K. MOTChallenge: Multiple Object Tracking Benchmark. Available online: motchallenge.net/ (accessed on 26 October 2019).
- Nesmachnow, S.; Iturriaga, S. Cluster-UY: Collaborative Scientific High Performance Computing in Uruguay. In Proceedings of the 10th International Conference on Supercomputing in Mexico, Monterrey, Mexico, 25–29 March 2019; Volume 1151, pp. 188–202. [Google Scholar]
- Leal-Taixé, L.; Milan, A.; Reid, I.; Roth, S.; Schindler, K. MOTChallenge Results 2D. Available online: motchallenge.net/results/2D_MOT_2015/ (accessed on 26 October 2019).
- Honovich, J. Frame Rate Guide for Video Surveillance. 2014. Available online: ipvm.com/reports/frame-rate-surveillance-guide (accessed on 26 October 2019).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Speed | Memory | Accuracy |
|---|---|---|---|
| Running Gaussian Average | O (1) | O (1) | L/M |
| Temporal Median Filter | O () | O () | L/M |
| Mixture of Gaussians | O (m) | O (m) | H |
| Kernel Density Estimation | O (n) | O (n) | H |
| Sequential Kernel Density Approximation | O () | O (m) | M/H |
| Concurrence of Image Variations | O () | O () | M |
| Eigen-backgrounds | O (M) | O (n) | M |
| Configuration | Background Subtraction | Blobs Detection | Blobs Classification | Tracking | Total |
|---|---|---|---|---|---|
| M-MOTA | 0.00357 | 0.00051 | 0.03894 | 0.00294 | 0.04595 |
| M-Count | 0.00355 | 0.00053 | 0.03902 | 0.00296 | 0.04606 |
| M-MOTA-TC | 0.00356 | 0.00049 | 0.01712 | 0.00265 | 0.02381 |
| Configuration | Background Subtraction | Blobs Detection | Blobs Classification | Tracking | Tracking |
|---|---|---|---|---|---|
| M-MOTA | 0.00552 | 0.00094 | 0.09065 | 0.00657 | 0.10369 |
| M-Count | 0.00559 | 0.00080 | 0.08779 | 0.00562 | 0.09980 |
| M-MOTA-TC | 0.00578 | 0.00091 | 0.04628 | 0.00556 | 0.05853 |
| Best Three Configurations | # Blobs vs. GT | # Trackings vs. GT | ||||
|---|---|---|---|---|---|---|
| Mean | Min. | Max. | Mean | Min. | Max. | |
| M-MOTA | 0.67 | 0 | 4 | 0.43 | 0 | 3 |
| M-Conteo | 0.67 | 0 | 4 | 0.33 | 0 | 3 |
| M-MOTA-TC | 1.14 | 0 | 5 | 0.52 | 0 | 4 |
| Best Three Configurations | ||||
|---|---|---|---|---|
| M-MOTA | M-Count | M-MOTA-TC | ||
| Metrics on MOT Challenge | Recall | 78.6 | 78.9 | 75.3 |
| Precisión | 76.3 | 74.5 | 76.5 | |
| FAF | 1.31 | 1.44 | 1.24 | |
| MT | 10 | 10 | 8 | |
| PT | 9 | 9 | 11 | |
| ML | 0 | 0 | 0 | |
| FP | 1040 | 1148 | 986 | |
| FN | 910 | 898 | 1053 | |
| IDs | 63 | 55 | 58 | |
| FRA | 253 | 235 | 234 | |
| MOTA | 52.7 | 50.7 | 50.8 | |
| MOTP | 64.2 | 64.1 | 64.3 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chavat, J.; Nesmachnow, S.; Tchernykh, A.; Shepelev, V. Active Safety System for Urban Environments with Detecting Harmful Pedestrian Movement Patterns Using Computational Intelligence. Appl. Sci. 2020, 10, 9021. https://0-doi-org.brum.beds.ac.uk/10.3390/app10249021
Chavat J, Nesmachnow S, Tchernykh A, Shepelev V. Active Safety System for Urban Environments with Detecting Harmful Pedestrian Movement Patterns Using Computational Intelligence. Applied Sciences. 2020; 10(24):9021. https://0-doi-org.brum.beds.ac.uk/10.3390/app10249021
Chicago/Turabian StyleChavat, Juan, Sergio Nesmachnow, Andrei Tchernykh, and Vladimir Shepelev. 2020. "Active Safety System for Urban Environments with Detecting Harmful Pedestrian Movement Patterns Using Computational Intelligence" Applied Sciences 10, no. 24: 9021. https://0-doi-org.brum.beds.ac.uk/10.3390/app10249021