
A Roadmap towards Breast Cancer Therapies Supported by Explainable Artificial Intelligence

 ,
,  , , , , , , ,
, , , , , , ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Enrolled Patients and Clinical Features
- Luminal A (ER ≥ 1% or PgR ≥ 1%, Ki67 ≤ 20%, HER2 = 0);
- Luminal B HER2 negative (ER ≥ 1% or PgR ≥ 1%, Ki67 > 20%, HER2 = 0);
- Luminal B HER2 positive (ER ≥ 1% or PgR ≥ 1%, HER2 = 1);
- HER2 positive (ER = 0% and PgR = 0%, HER2 = 1);
- Triple negative (ER = 0% and PgR = 0%, HER2 = 0).
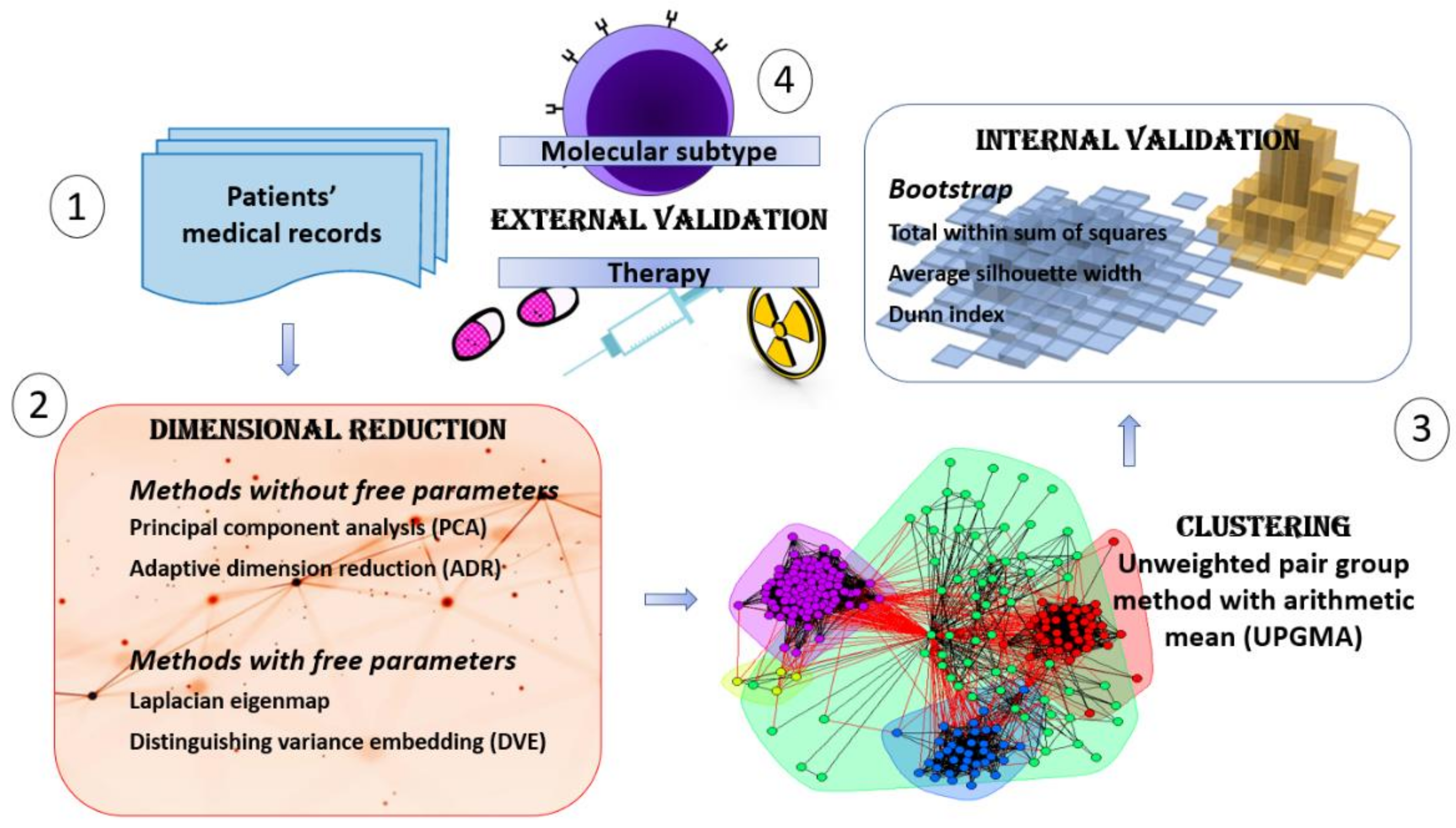
2.2. An XAI Framework for Patients’ Profiling
- Collection of patients’ records, subject to a features processing which excludes those endowed with missing data.
- Dimensional reduction analysis, reducing the data dimensionality in a suitable two-dimensional space (for XAI transparency) and evaluating which are the clinical features driving the embedding (prodromal for XAI justification).
- Clustering analysis, exploring and assessing the patients’ similarities according to clinical features unveiled by embedding and bootstrap for robustness evaluation (for XAI justification and uncertainty estimation).
- Clinical and Therapy interpretation, evaluating how and to what extent the features and the clusterization previously outlined have a direct interpretation in terms of therapy differences (for XAI justification).
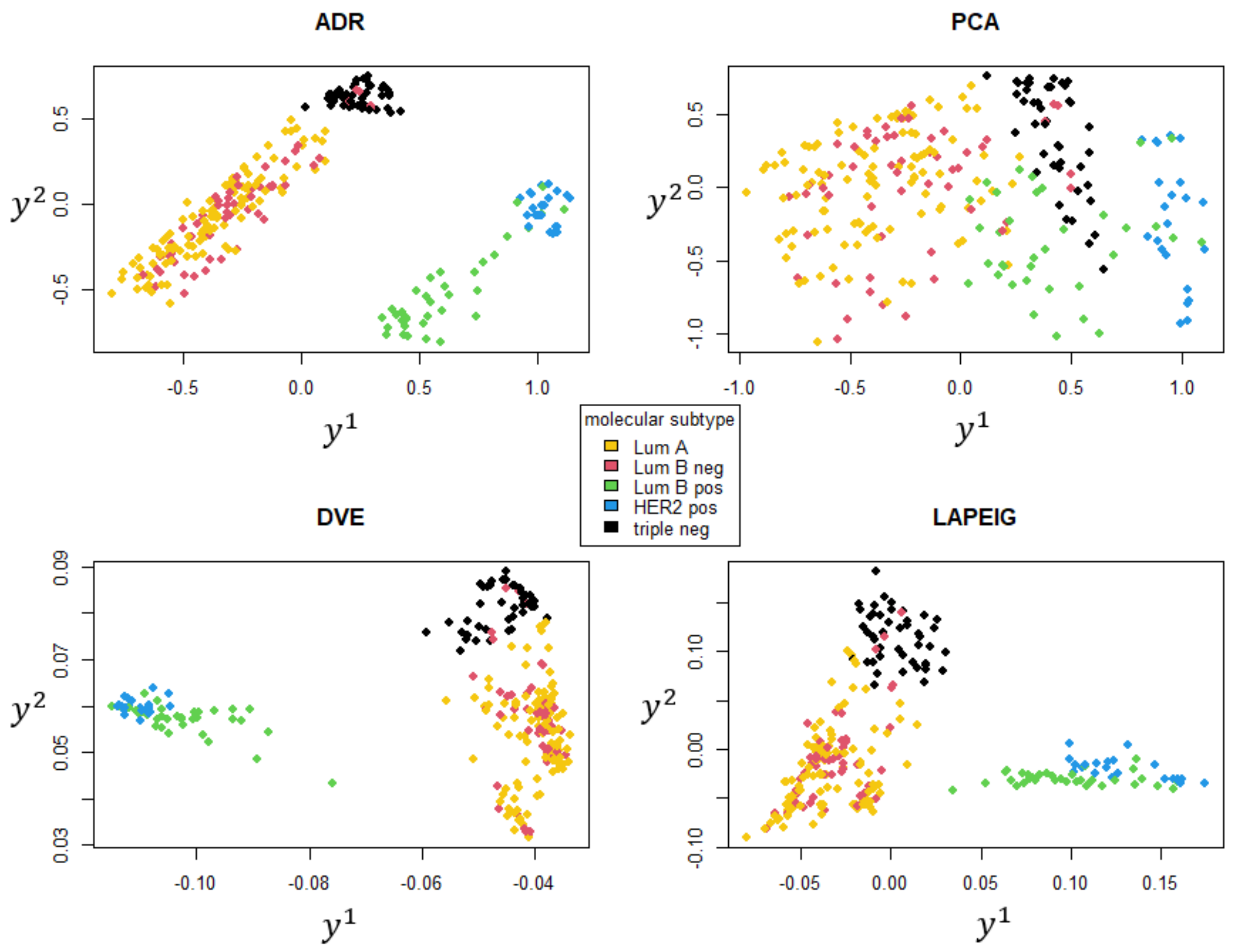
2.3. Dimensional Reduction Techniques
- on the one hand, the application of a principal component analysis (PCA) takes into account the information contained in the whole data set;
- on the other hand, the definition of clusters during each iteration rules further projections in the subspace spanned by principal components of the covariance matrix of cluster centers coordinates, weighted by the cardinality of each cluster, whose separation is improved.
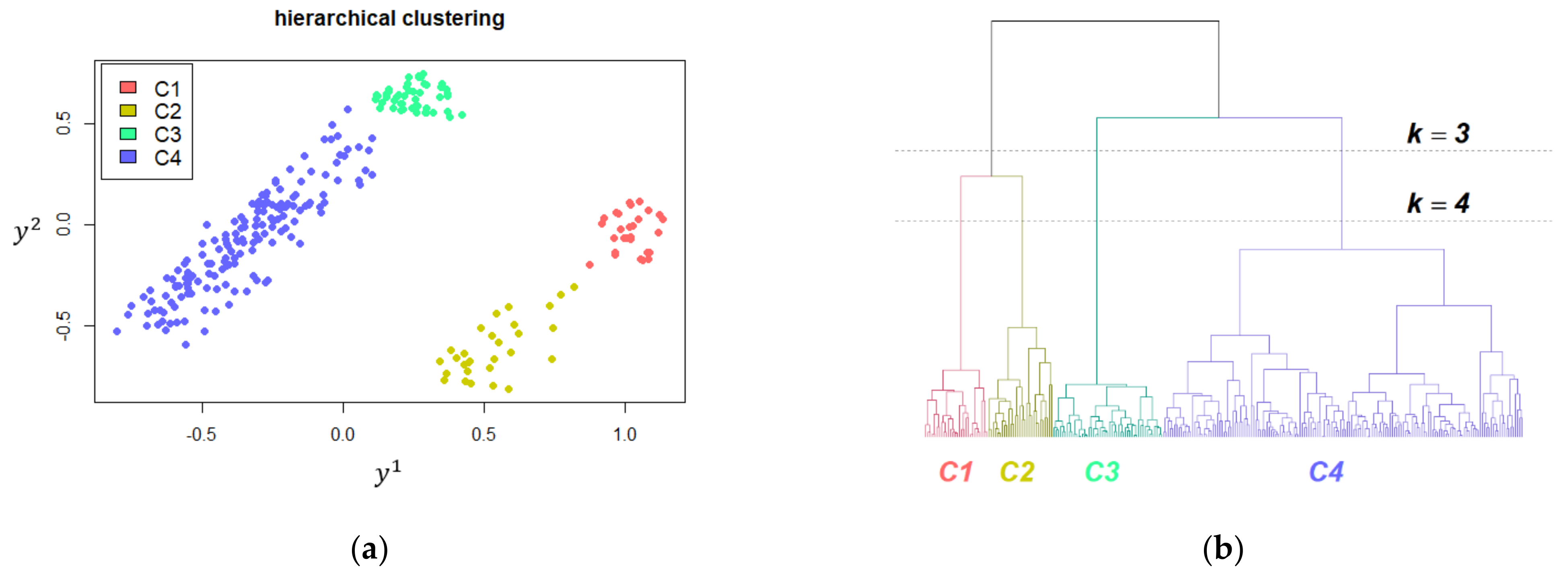
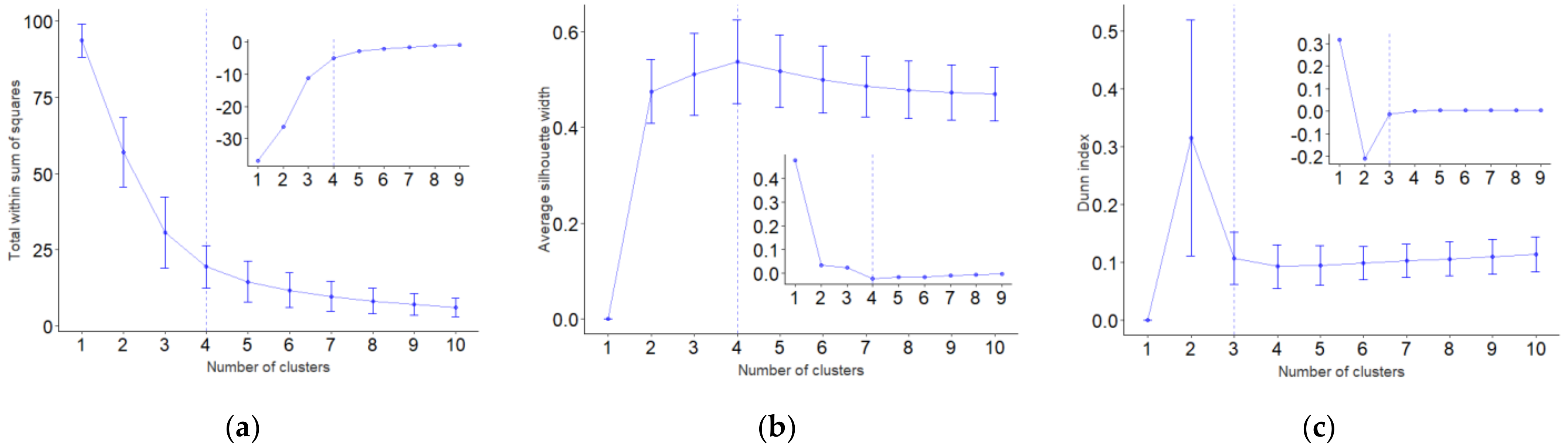
2.4. Unsupervised Clustering and Validation
3. Results
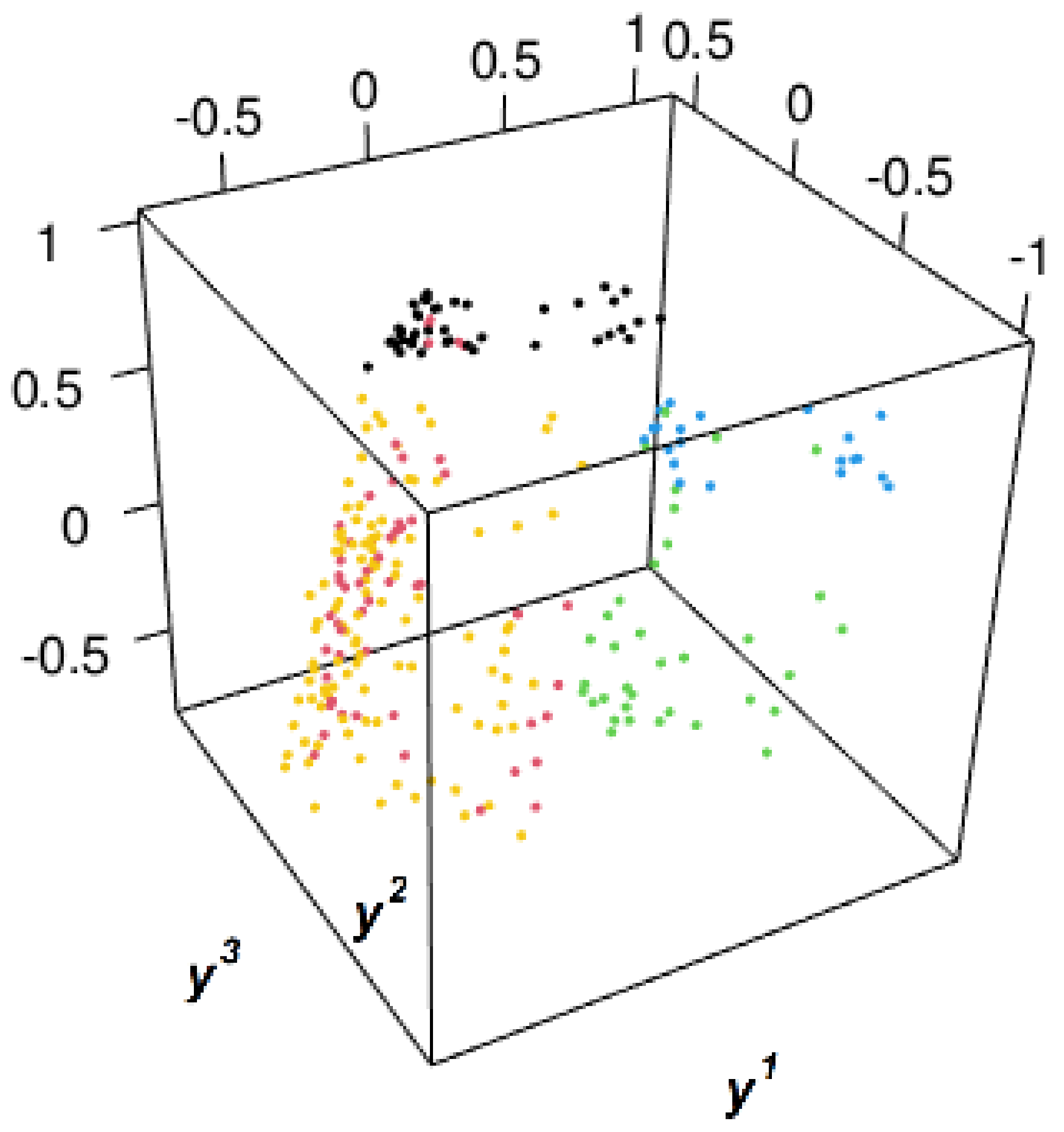
3.1. Comparing the Embedding Techniques
3.2. Clustering Oncological Patients
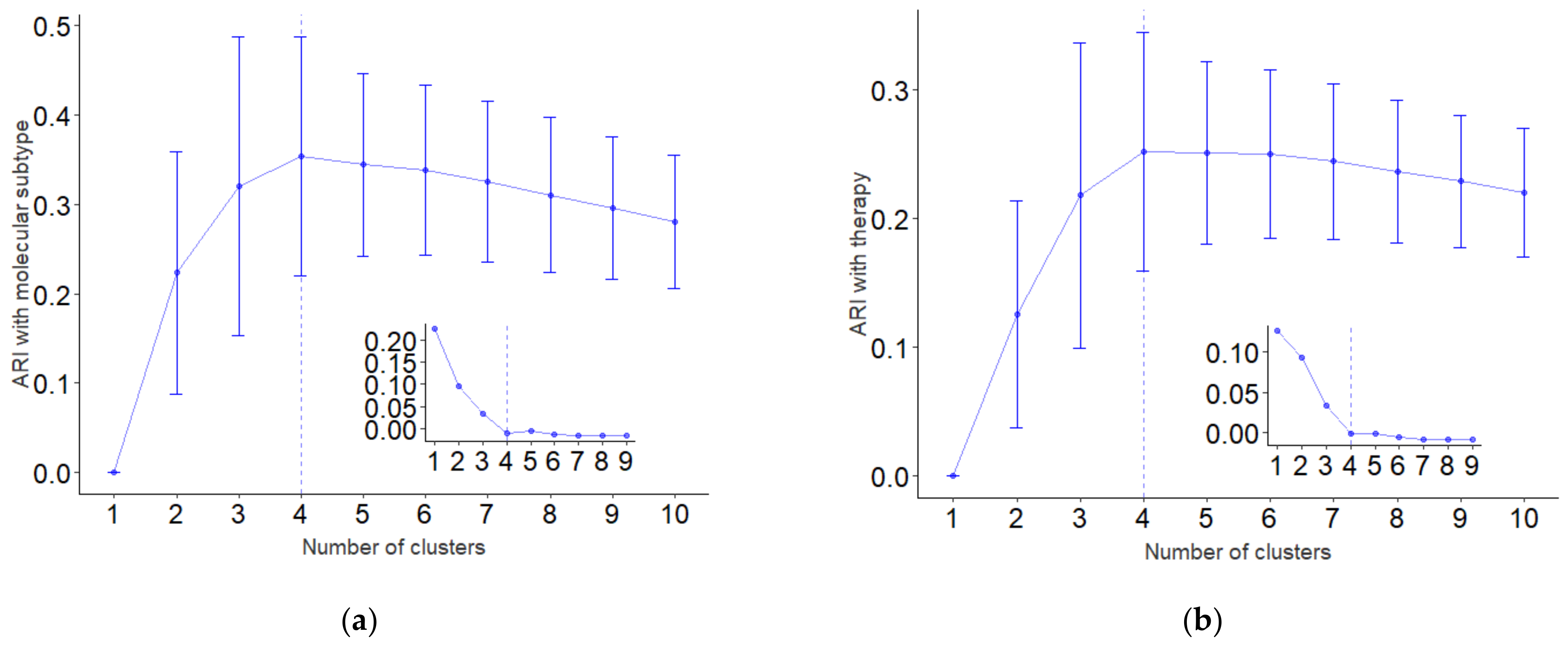
3.2.1. Internal Validation
3.2.2. External Validation
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Adaptive Dimension Reduction

Appendix B. Embedding Techniques Adopting Local Patches
Appendix C. Internal and External Validation
References
- Hulsen, T.; Jamuar, S.S.; Moody, A.R.; Karnes, J.H.; Varga, O.; Hedensted, S.; Spreafico, R.; Hafler, D.A.; McKinney, E.F. From Big Data to Precision Medicine. Front. Med. 2019, 6, 34. [Google Scholar] [CrossRef] [Green Version]
- Avanzo, M.; Trianni, A.; Botta, F.; Talamonti, C.; Stasi, M.; Iori, M. Artificial Intelligence and the Medical Physicist: Welcome to the Machine. Appl. Sci. 2021, 11, 1691. [Google Scholar] [CrossRef]
- Syeda-Mahmood, T. Role of Big Data and Machine Learning in Diagnostic Decision Support in Radiology. J. Am. Coll. Radiol. 2018, 15, 569–576. [Google Scholar] [CrossRef] [PubMed]
- Arabi, H.; Zaidi, H. Applications of artificial intelligence and deep learning in molecular imaging and radiotherapy. Eur. J. Hybrid Imaging 2020, 4, 17. [Google Scholar] [CrossRef]
- Avanzo, M.; Porzio, M.; Lorenzon, L.; Milan, L.; Sghedoni, R.; Russo, G.; Massafra, R.; Fanizzi, A.; Barucci, A.; Ardu, V.; et al. Artificial intelligence applications in medical imaging: A review of the medical physics research in Italy. Phys. Med. 2021, 83, 221–241. [Google Scholar] [CrossRef]
- Massafra, R.; Latorre, A.; Fanizzi, A.; Bellotti, R.; Didonna, V.; Giotta, F.; La Forgia, D.; Nardone, A.; Pastena, M.; Ressa, C.M.; et al. A Clinical Decision Support System for Predicting Invasive Breast Cancer Recurrence: Preliminary Results. Front. Oncol. 2021, 11, 1–13. [Google Scholar] [CrossRef]
- Fanizzi, A.; Pomarico, D.; Paradiso, A.; Bove, S.; Diotaiuti, S.; Didonna, V.; Giotta, F.; La Forgia, D.; Latorre, A.; Pastena, M.I.; et al. Predicting of Sentinel Lymph Node Status in Breast Cancer Patients with Clinically Negative Nodes: A Validation Study. Cancers 2021, 13, 352. [Google Scholar] [CrossRef]
- Pomarico, D.; Fanizzi, A.; Amoroso, N.; Bellotti, R.; Biafora, A.; Bove, S.; Didonna, V.; La Forgia, D.; Pastena, M.I.; Tamborra, P.; et al. A proposal of quantum-inspired machine learning for medical purposes: An application case. Mathematics 2021, 9, 410. [Google Scholar] [CrossRef]
- Jiménez-Luna, J.; Grisoni, F.; Schneider, G. Drug discovery with explainable artificial intelligence. Nat. Mach. Intell. 2020, 2, 573–584. [Google Scholar] [CrossRef]
- Gunning, D. Explainable Artificial Intelligence (XAI); Defense Advanced Research Projects Agency (DARPA): Arlington, VA, USA, 2017; Web 2.2. [Google Scholar]
- Došilović, F.K.; Brčić, M.; Hlupić, N. Explainable artificial intelligence: A survey. In Proceedings of the 2018 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 21–25 May 2018. [Google Scholar]
- Coates, A.S.; Winer, E.P.; Goldhirsch, A.; Gelber, R.D.; Gnant, M.; Piccart-Gebhart, M.; Thürlilmann, B.; Senn, H.-J.; André, F.; Baselga, J.; et al. Tailoring therapies—Improving the management of early breast cancer: St Gallen International Expert Consensus on the Primary Therapy of Early Breast Cancer. Ann. Oncol. 2015, 26, 1533–1546. [Google Scholar] [CrossRef] [PubMed]
- Ding, C.; He, X.; Zha, H.; Simon, H.D. Adaptive dimension reduction for clustering high dimensional data. In Proceedings of the 2002 IEEE International Conference on Data Mining, Maebashi City, Japan, 9–12 December 2002. [Google Scholar]
- Hotelling, H. Analysis of a complex of statistical variables into principal components. J. Educ. Psychol. 1933, 24, 417–441, 498–520. [Google Scholar] [CrossRef]
- Kutz, J.N. Data-Driven Modeling & Scientific Computation: Methods for Complex Systems & Big Data; Oxford University Press: Oxford, UK, 2013. [Google Scholar]
- Belkin, M.; Niyogi, P. Laplacian eigenmap for dimensionality reduction and data representation. Neural Comput. 2003, 15, 1373–1396. [Google Scholar] [CrossRef] [Green Version]
- Qinggang, W.; Jianwei, L. Combining local and global information for nonlinear dimensionality reduction. Neurocomputing 2009, 72, 2235–2241. [Google Scholar]
- Qinggang, W.; Jianwei, L.; Xuchu, W. Distinguishing variance embedding. Image Vis. Comput. 2010, 28, 872–880. [Google Scholar] [CrossRef]
- Duffy, M.J.; Crown, J. A personalized approach to cancer treatment: How biomarkers can help. Clin. Chem. 2008, 54, 1770–1779. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rivenbark, A.G.; O’Connor, S.M.; Coleman, W.B. Molecular and cellular heterogeneity in breast cancer: Challenges for personalized medicine. Am. J. Pathol. 2013, 183, 1113–1124. [Google Scholar] [CrossRef] [Green Version]
- Tannock, I.F.; Hickman, J.A. Limits to personalized cancer medicine. N. Engl. J. Med. 2016, 375, 1289–1294. [Google Scholar] [CrossRef] [Green Version]
- Amoroso, N.; Cilli, R.; Bellantuono, L.; Massimi, V.; Monaco, A.; Nitti, D.O.; Nutricato, R.; Samarelli, S.; Taggio, N.; Tangaro, S.; et al. PSI Clustering for the Assessment of Underground Infrastructure Deterioration. Remote Sens. 2020, 12, 3681. [Google Scholar] [CrossRef]
- Sokal, R.B.; Michener, C.D. A statistical method for evaluating systematic relationships. Univ. Kans. Sci. Bull. 1958, 38, 1409–1438. [Google Scholar]
- Hubert, L.; Arabie, P. Comparing partitions. J. Classif. 1985, 2, 193–218. [Google Scholar] [CrossRef]
- Pérez, L.A.; García Vico, A.M.; González, P.; Carmona, C.J. Techniques for Evaluating Clustering Data in R. The Clustering package 2020. [Google Scholar]
- Efron, B.; Tibshirani, R. An Introduction to the Bootstrap; Chapman & Hall/CRC: Boca Raton, FL, USA, 1993. [Google Scholar]
- Kim, Y.Y.; Oh, S.J.; Chun, Y.S.; Lee, W.K.; Park, H.K. Gene expression assay and Watson for Oncology for optimization of treatment in ER-positive, HER2-negative breast cancer. PLoS ONE 2018, 13, e0200100. [Google Scholar] [CrossRef] [PubMed]
- Tjoa, E.; Guan, C. A Survey on Explainable Artificial Intelligence (XAI): Toward Medical XAI. IEEE Trans. Neural Netw. Learn. Syst. 2020. [Google Scholar] [CrossRef]
- Lamy, J.-B.; Sekar, B.; Guezennec, G.; Bouaud, J.; Séroussi, B. Explainable artificial intelligence for breast cancer: A visual case-based reasoning approach. Artif. Intell. Med. 2019, 94, 42–53. [Google Scholar] [CrossRef] [PubMed]
- Walsh, D.; Rybicki, L. Symptom clustering in advanced cancer. Support Care Cancer 2006, 14, 831–836. [Google Scholar] [CrossRef]
- Chen, D.; Xing, K.; Henson, D.; Sheng, L.; Schwartz, A.M.; Cheng, X. Developing Prognostic Systems of Cancer Patients by Ensemble Clustering. J. Biomed. Biotech. 2009. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Counts (%) | Features | Counts (%) |
|---|---|---|---|
| Overall | 267 (100) | HER2 | |
| Lymph Node Stage | negative | 210 (78.7) | |
| N0 | 124 (46.4) | positive | 57 (21.3) |
| N1 | 102 (38.2) | Type of Surgery | |
| N2 | 27 (10.1) | quadrantectomy | 162 (60.7) |
| N3 | 14 (5.2) | mastectomy | 105 (39.3) |
| Diameter | In Situ | ||
| T1a | 3 (1.1) | absent | 186 (69.7) |
| T1b | 18 (6.7) | G1 | 9 (3.4) |
| T1c | 117 (43.8) | G2 | 11 (4.1) |
| T2 | 107 (40.1) | G3 | 10 (3.7) |
| T3 | 7 (2.6) | present, not typed | 51 (19.1) |
| T4 | 14 (5.2) | Vascular Invasion | |
| Histologic Type | absent | 141 (52.8) | |
| ductal | 234 (87.6) | focal | 69 (25.8) |
| lobular | 21 (7.9) | extensive | 22 (8.2) |
| other | 12 (4.5) | present, not typed | 35 (13.1) |
| Grading | Therapy | ||
| G1 | 11 (4.1) | chemotherapy | 190 (71.2) |
| G2 | 128 (47.9) | hormone therapy | 191 (71.5) |
| G3 | 128 (47.9) | trastuzumab | 43 (16.1) |
| Median [] | Median [] | ||
| ER | 45 [0, 0, 80, 95] | Age | 53 [25, 45, 61, 80] |
| PgR | 20 [0, 0, 70, 95] | Metastatic lymph nodes | 1 [0, 0, 2, 24] |
| Ki67 | 20 [0, 10, 35, 90] |
| Molecular Subtype | HT (%) | CT (%) | CT + HT (%) | CT + Trast. (%) | CT + HT + Trast. (%) | Others (%) |
|---|---|---|---|---|---|---|
| Luminal A | 47.3 | 1.8 | 48.2 | 0 | 1.8 | 0.9 |
| Luminal B HER2 neg | 30.9 | 12.7 | 54.6 | 0 | 1.8 | 0 |
| Luminal B HER2 pos | 5.7 | 2.9 | 25.7 | 0 | 65.7 | 0 |
| HER2 pos | 0 | 31.8 | 0 | 59.1 | 4.6 | 4.6 |
| Triple neg | 0 | 82.2 | 2.2 | 6.7 | 0 | 8.9 |
| Cluster | Luminal A (%) | Luminal B HER2 Neg (%) | Luminal B HER2 Pos (%) | HER2 Pos (%) | Triple Neg (%) |
| C1 | 0 | 0 | 21.4 | 78.6 | 0 |
| C2 | 0 | 0 | 100.0 | 0 | 0 |
| C3 | 0 | 10.2 | 0 | 0 | 89.8 |
| C4 | 68.3 | 31.1 | 0 | 0 | 0.6 |
| Cluster | HT (%) | CT (%) | CT + HT (%) | CT + Trast. (%) | CT + HT + Trast. (%) | Others (%) |
|---|---|---|---|---|---|---|
| C1 | 0 | 25.0 | 3.6 | 46.4 | 21.4 | 3.6 |
| C2 | 6.9 | 3.4 | 27.6 | 0 | 62.1 | 0 |
| C3 | 0 | 85.7 | 2.0 | 6.1 | 0 | 6.1 |
| C4 | 42.9 | 2.4 | 51.6 | 0 | 1.9 | 1.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amoroso, N.; Pomarico, D.; Fanizzi, A.; Didonna, V.; Giotta, F.; La Forgia, D.; Latorre, A.; Monaco, A.; Pantaleo, E.; Petruzzellis, N.; et al. A Roadmap towards Breast Cancer Therapies Supported by Explainable Artificial Intelligence. Appl. Sci. 2021, 11, 4881. https://0-doi-org.brum.beds.ac.uk/10.3390/app11114881
Amoroso N, Pomarico D, Fanizzi A, Didonna V, Giotta F, La Forgia D, Latorre A, Monaco A, Pantaleo E, Petruzzellis N, et al. A Roadmap towards Breast Cancer Therapies Supported by Explainable Artificial Intelligence. Applied Sciences. 2021; 11(11):4881. https://0-doi-org.brum.beds.ac.uk/10.3390/app11114881
Chicago/Turabian StyleAmoroso, Nicola, Domenico Pomarico, Annarita Fanizzi, Vittorio Didonna, Francesco Giotta, Daniele La Forgia, Agnese Latorre, Alfonso Monaco, Ester Pantaleo, Nicole Petruzzellis, and et al. 2021. "A Roadmap towards Breast Cancer Therapies Supported by Explainable Artificial Intelligence" Applied Sciences 11, no. 11: 4881. https://0-doi-org.brum.beds.ac.uk/10.3390/app11114881