
Kernel-Based Phase Transfer Entropy with Enhanced Feature Relevance Analysis for Brain Computer Interfaces

 , , , ,
, , , ,
Abstract
:1. Introduction
2. Methods
2.1. Phase Transfer Entropy
2.2. Kernel-Based Renyi’s Phase Transfer Entropy
2.3. Phase-Based Effective Connectivity Estimation Approaches Considered in This Study
2.3.1. Phase Transfer Entropy
2.3.2. Phase Slope Index
2.3.3. Granger Causality
2.4. Kernel-Based Relevance Analysis
3. Experiments
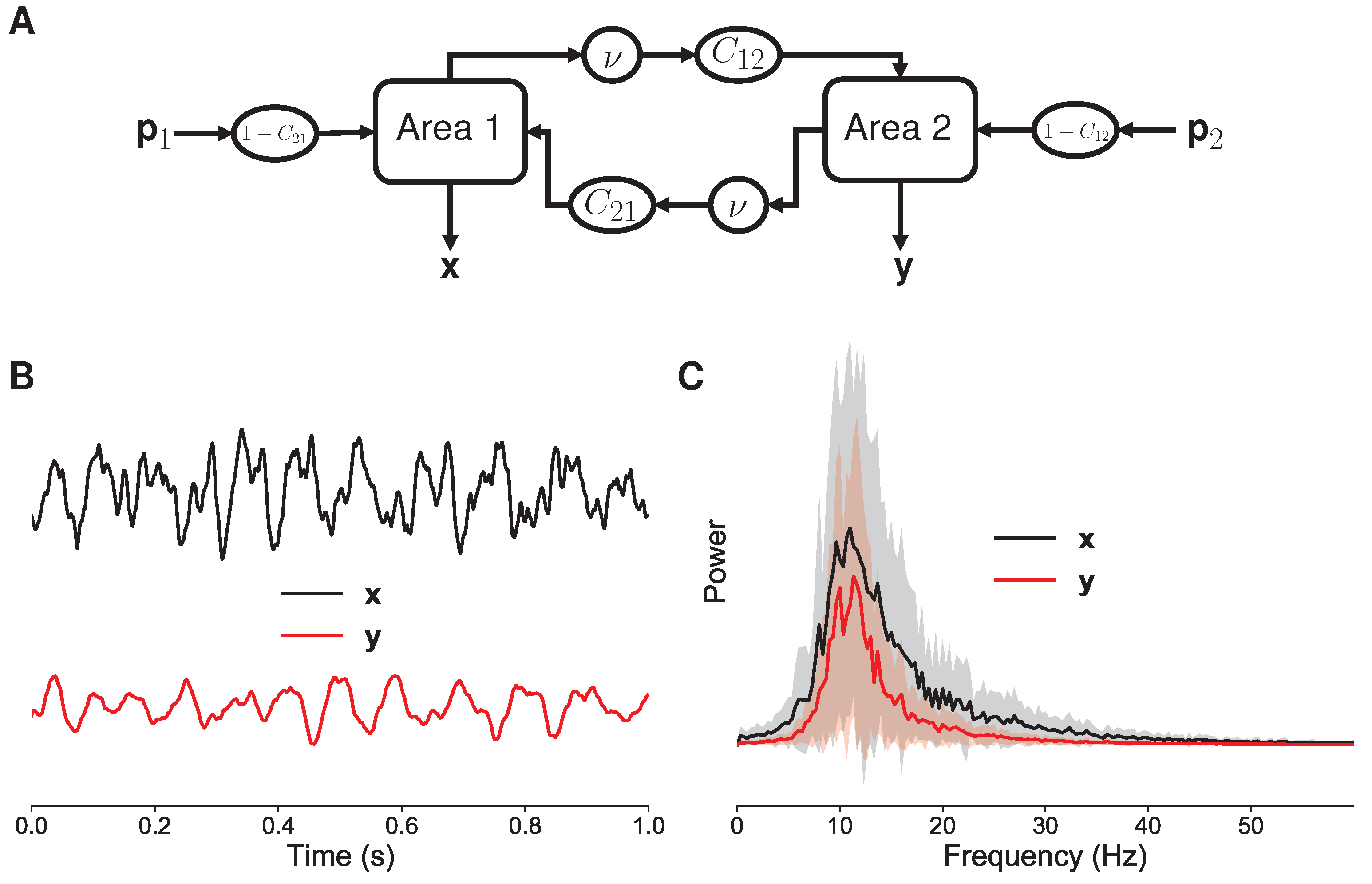
3.1. Neural Mass Models
3.1.1. Coupling Strength
3.1.2. Noise and Signal Mixing
3.1.3. Narrowband Bidirectional Interactions
3.2. EEG Data
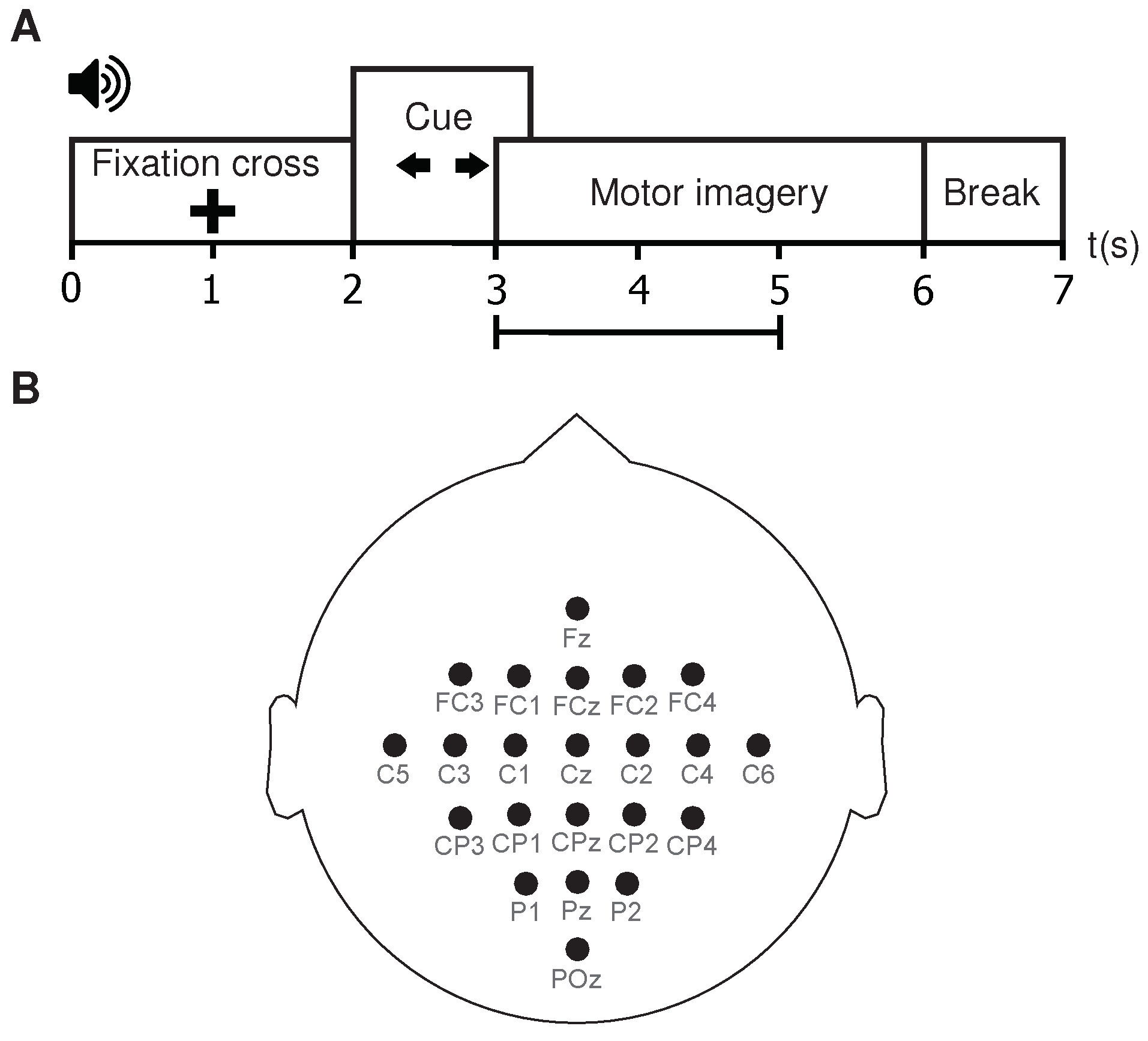
3.2.1. Motor Imagery
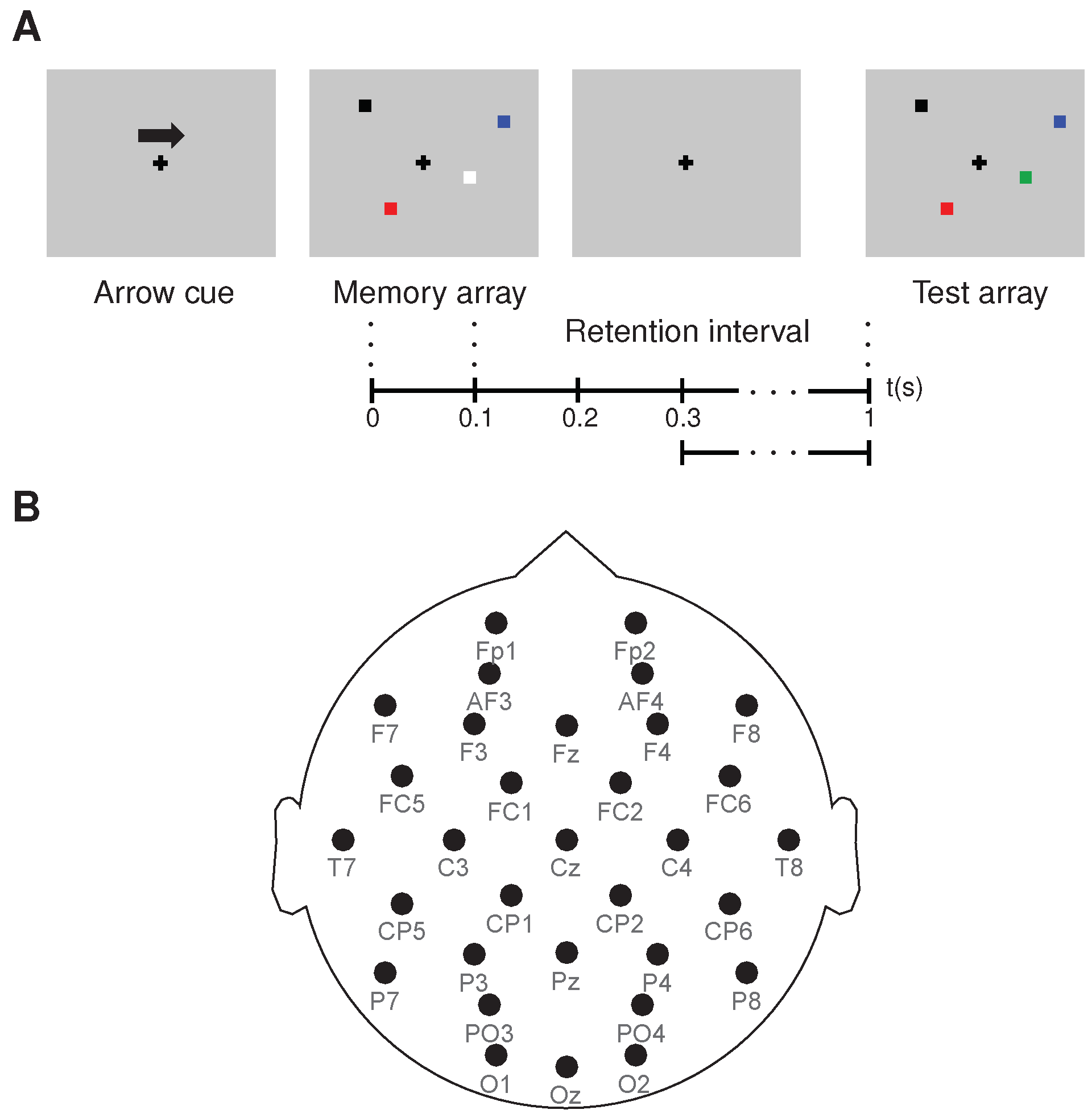
3.2.2. Working Memory
3.2.3. Classification Setup
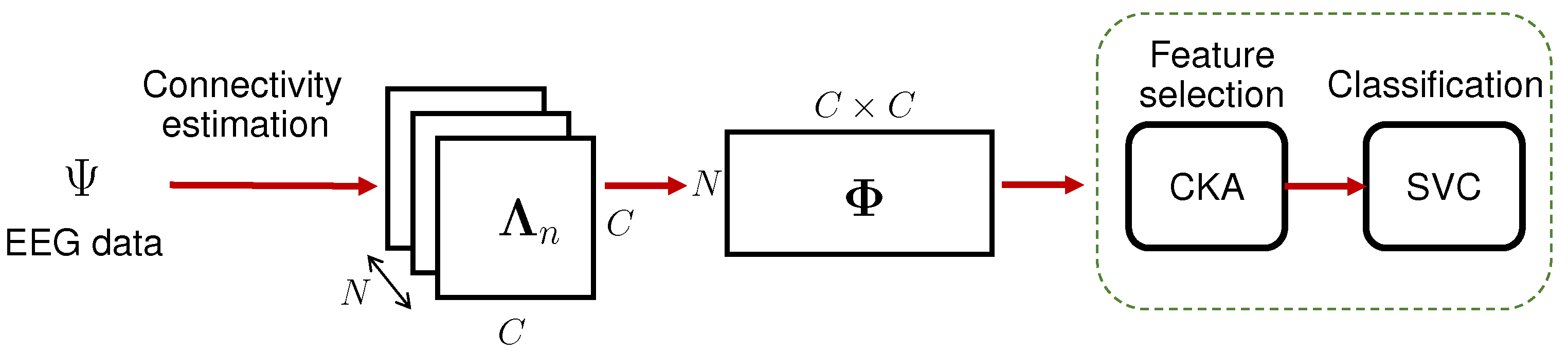
Feature Extraction
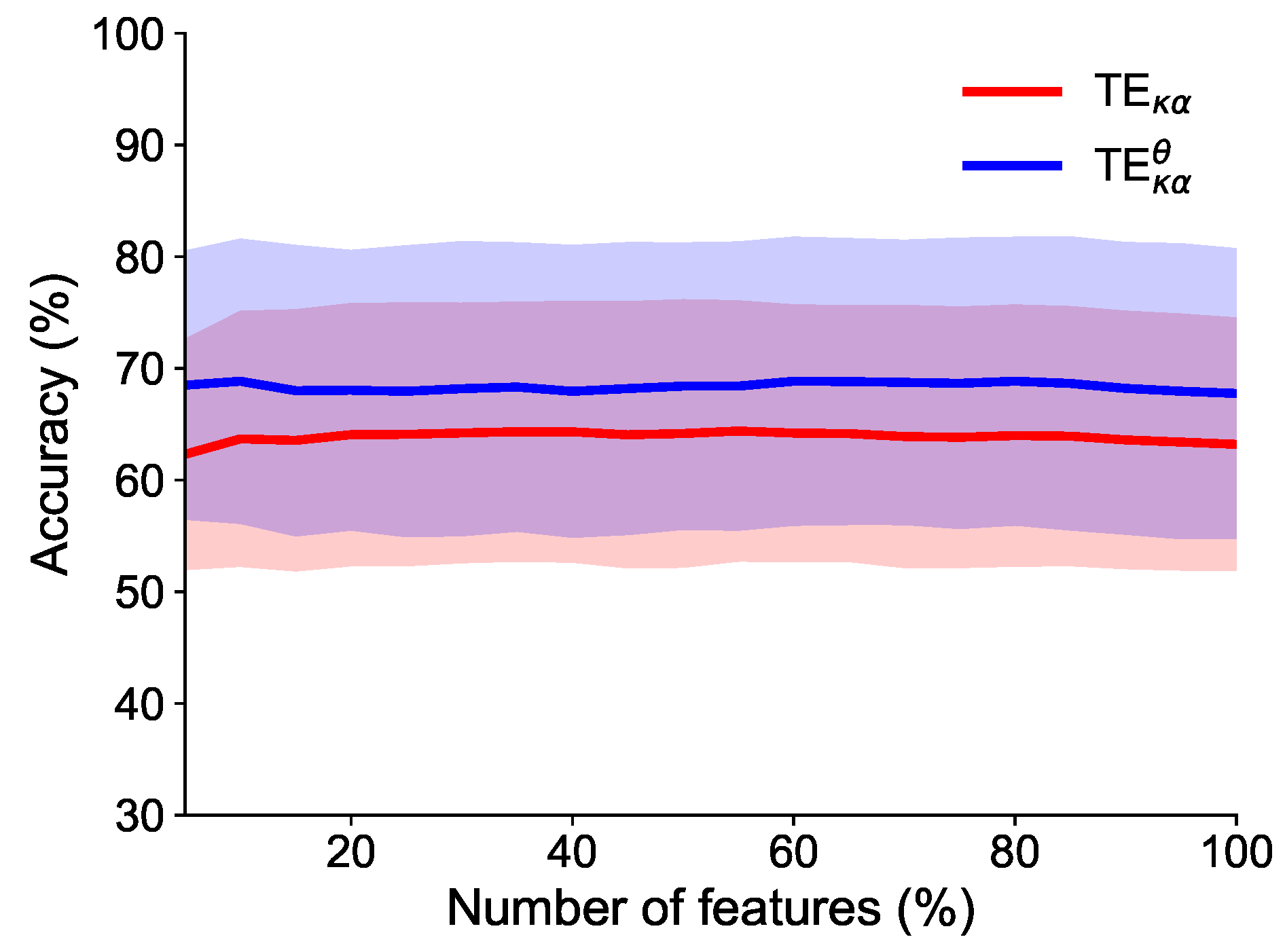
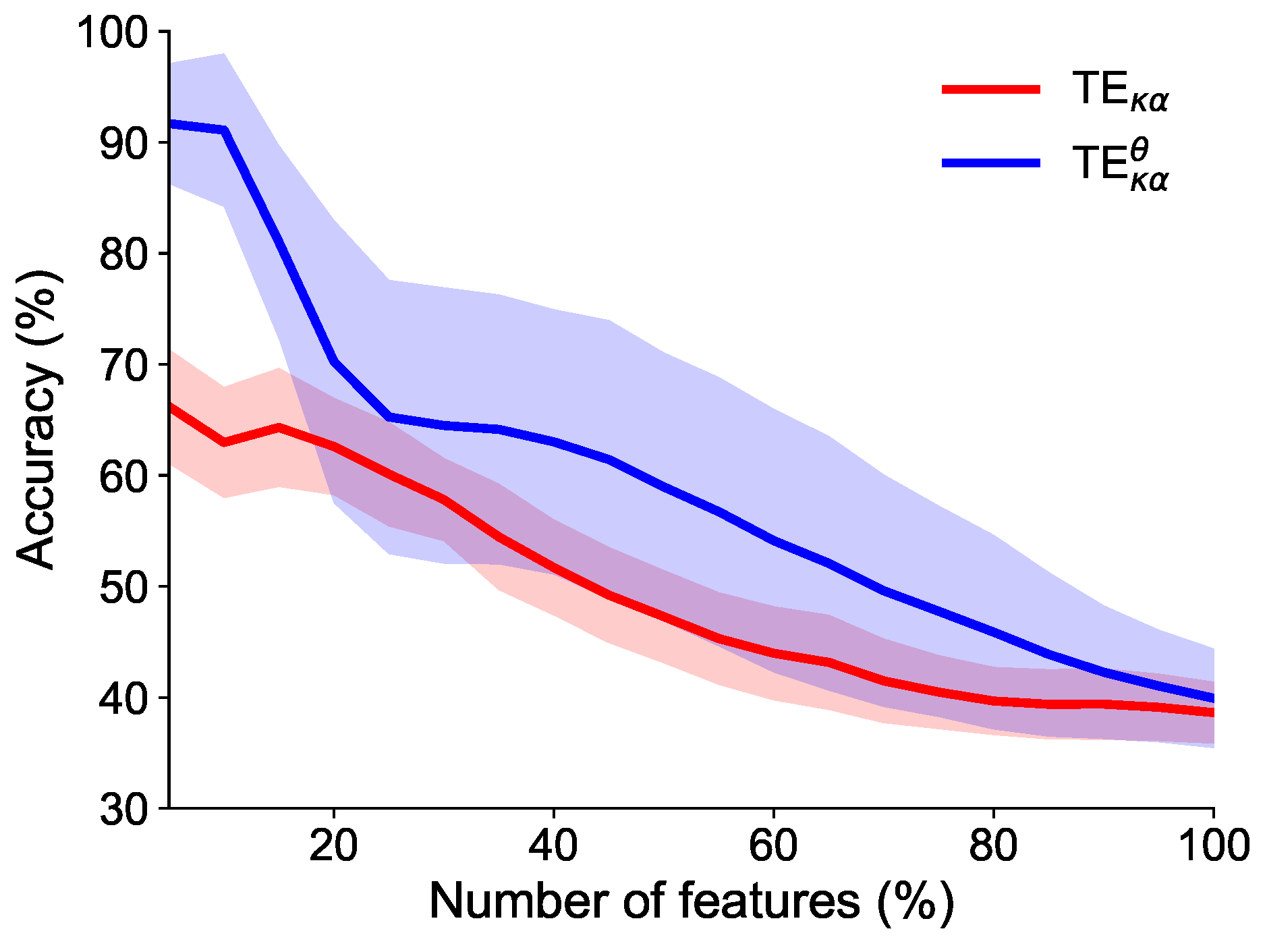
Feature Selection and Classification
3.3. Parameter Selection
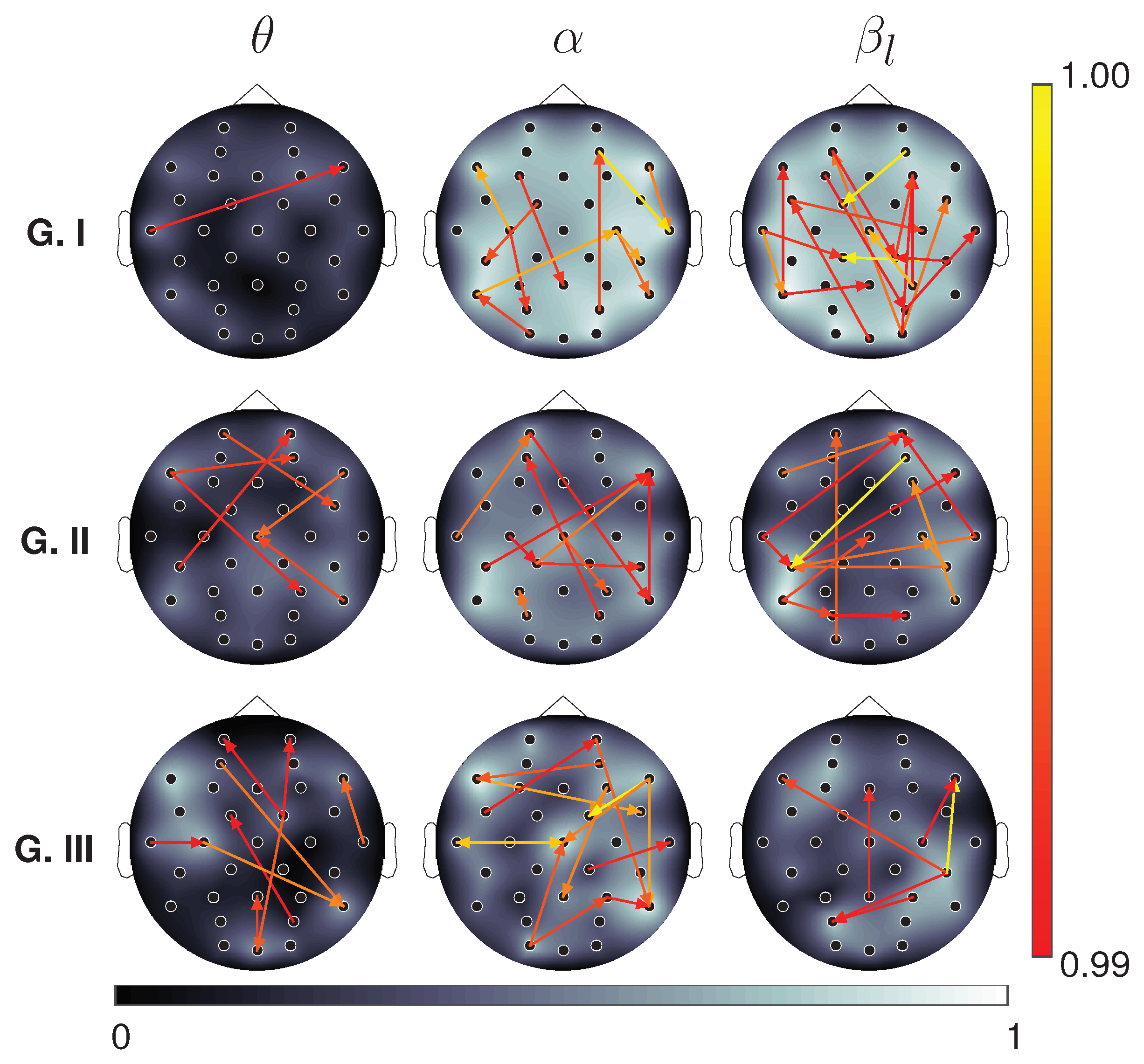
4. Results and Discussion
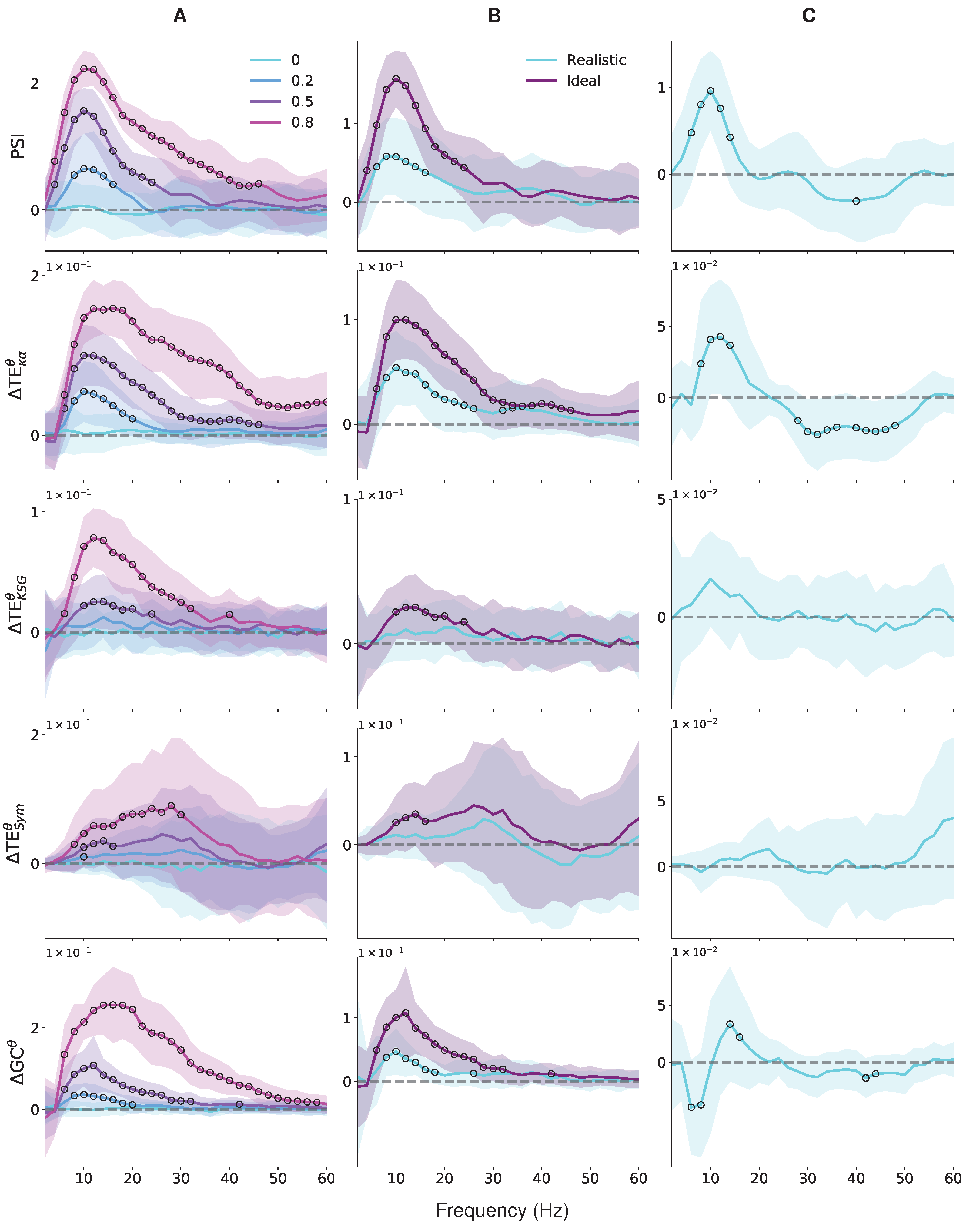
4.1. Neural Mass Models Results
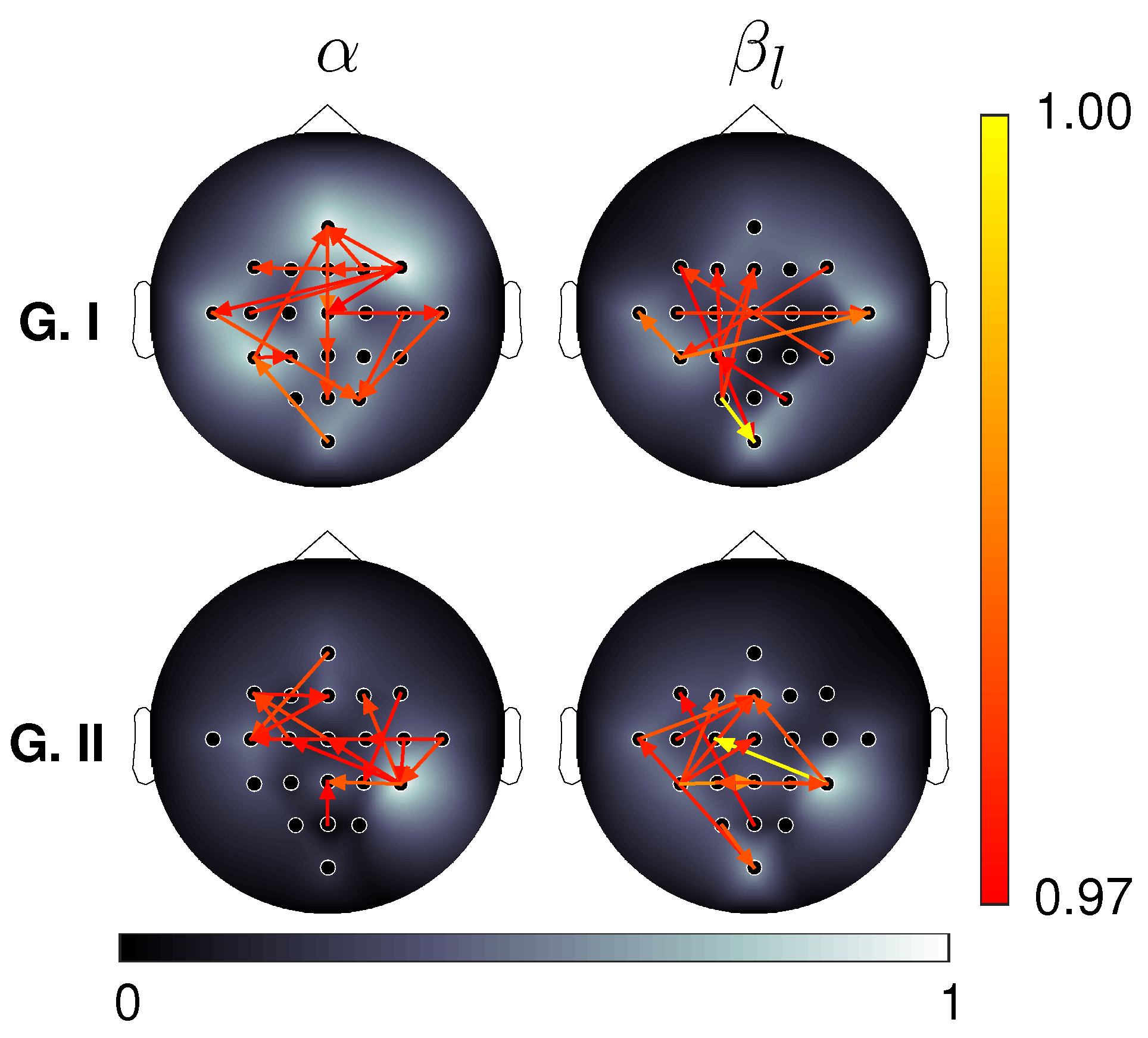
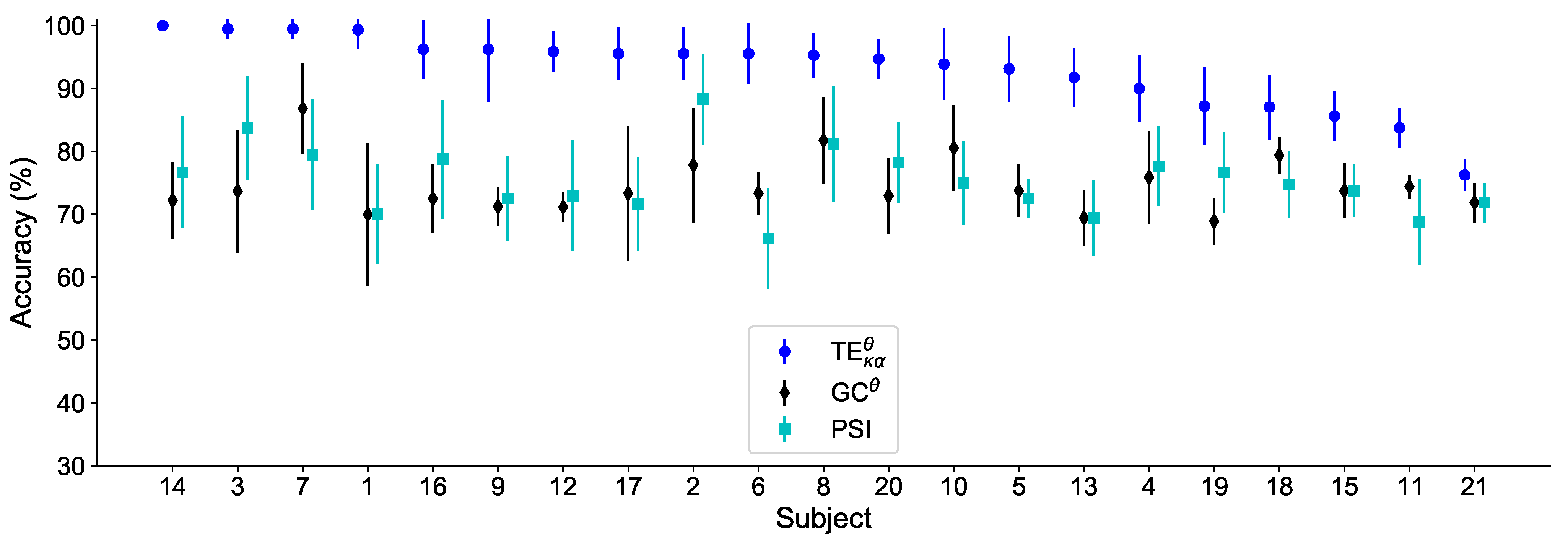
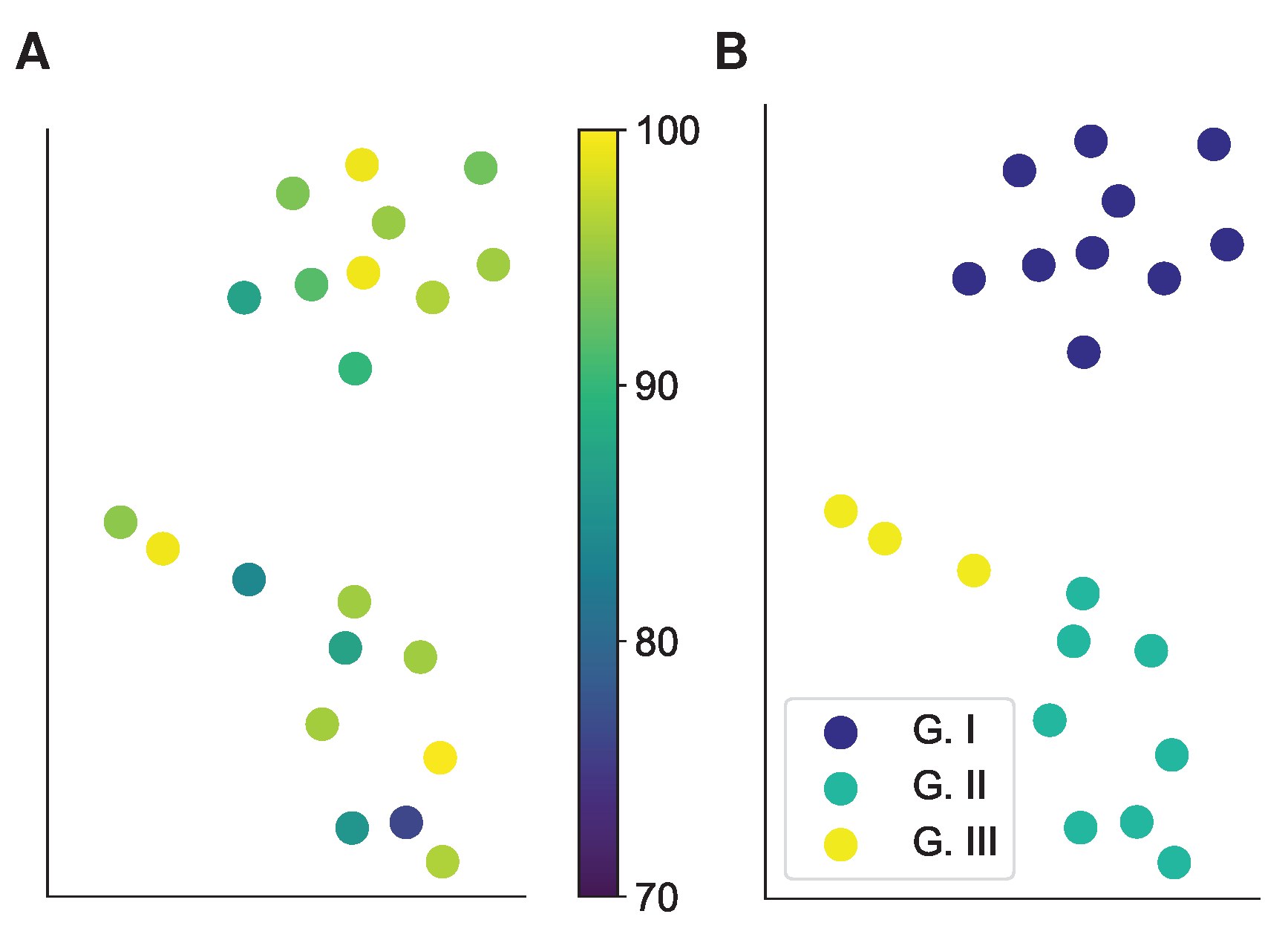
4.2. EEG Data Results
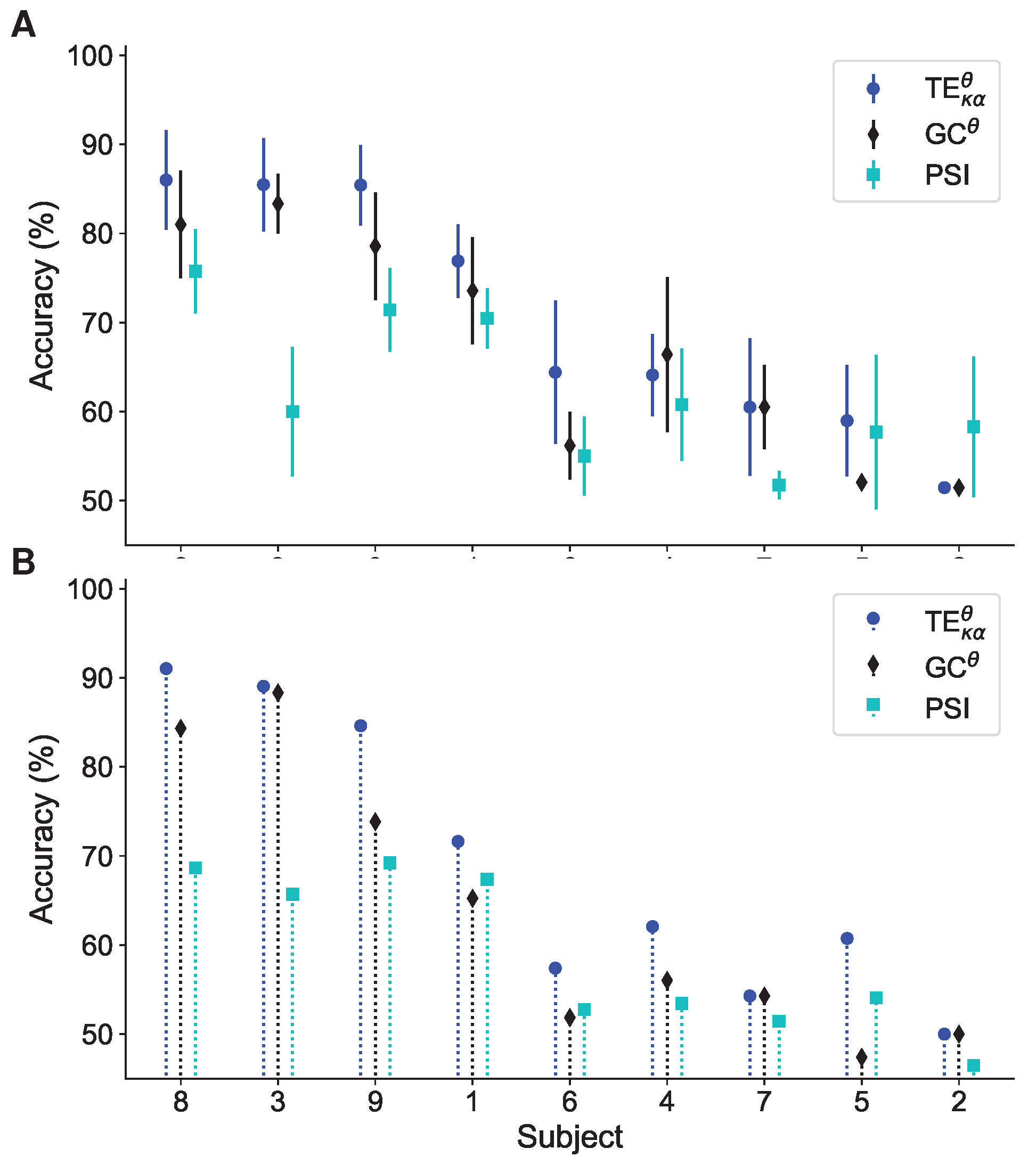
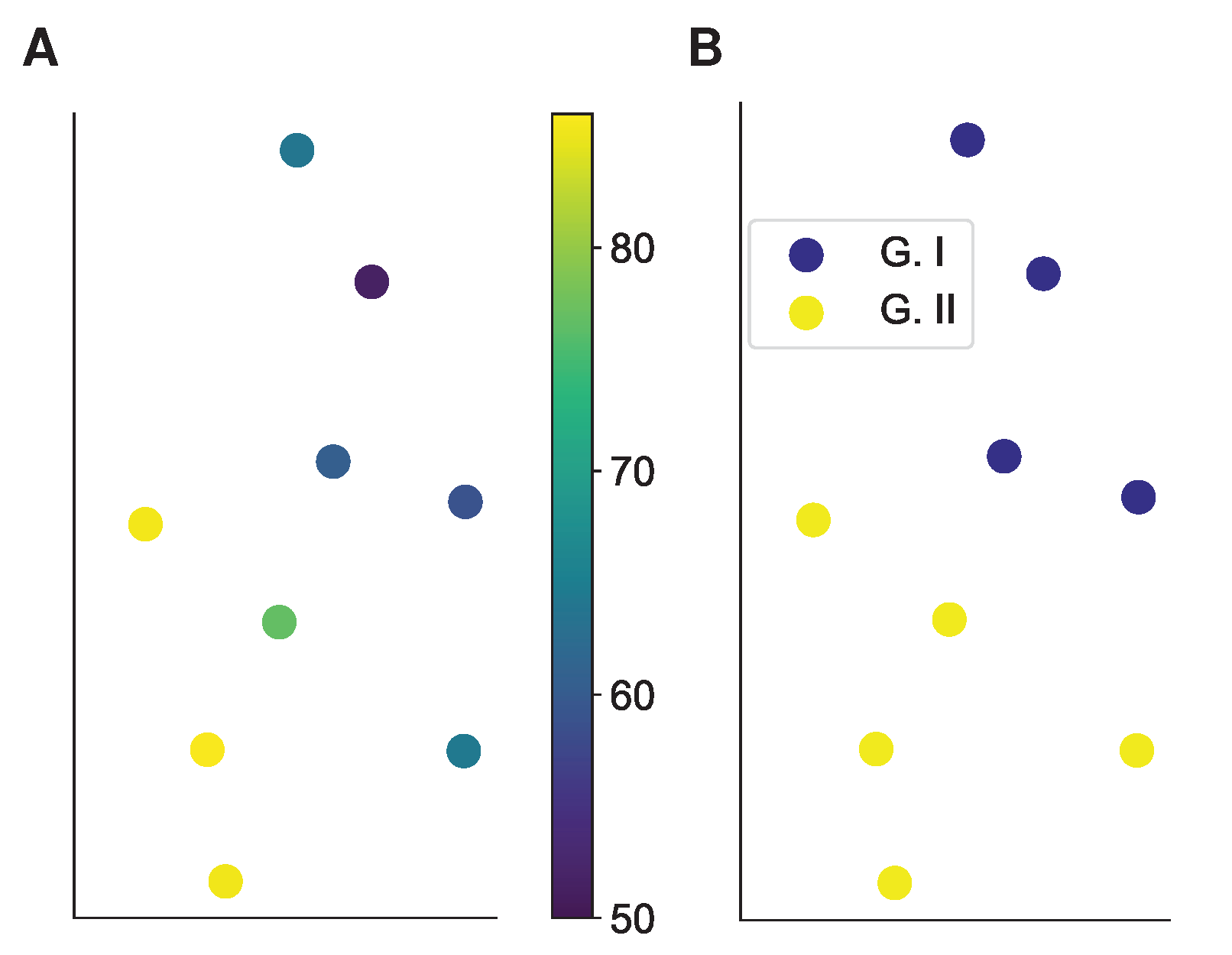
4.2.1. Motor Imagery Results
4.2.2. Working Memory Results
4.3. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- La Tour, T.D.; Tallot, L.; Grabot, L.; Doyère, V.; Van Wassenhove, V.; Grenier, Y.; Gramfort, A. Non-linear auto-regressive models for cross-frequency coupling in neural time series. PLoS Comput. Biol. 2017, 13, e1005893. [Google Scholar]
- Da Silva, F.L. EEG: Origin and measurement. In EEg-fMRI; Springer: Berlin/Heidelberg, Germany, 2009; pp. 19–38. [Google Scholar]
- Wianda, E.; Ross, B. The roles of alpha oscillation in working memory retention. Brain Behav. 2019, 9, e01263. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hyafil, A.; Giraud, A.L.; Fontolan, L.; Gutkin, B. Neural cross-frequency coupling: Connecting architectures, mechanisms, and functions. Trends Neurosci. 2015, 38, 725–740. [Google Scholar] [CrossRef] [PubMed]
- Xie, P.; Pang, X.; Cheng, S.; Zhang, Y.; Yang, Y.; Li, X.; Chen, X. Cross-frequency and iso-frequency estimation of functional corticomuscular coupling after stroke. Cogn. Neurodyn. 2021, 15, 439–451. [Google Scholar] [CrossRef] [PubMed]
- Ahmadi, A.; Davoudi, S.; Behroozi, M.; Daliri, M.R. Decoding covert visual attention based on phase transfer entropy. Physiol. Behav. 2020, 222, 112932. [Google Scholar] [CrossRef]
- Kang, H.; Zhang, X.; Zhang, G. Phase permutation entropy: A complexity measure for nonlinear time series incorporating phase information. Phys. A Stat. Mech. Appl. 2021, 568, 125686. [Google Scholar] [CrossRef]
- Lobier, M.; Siebenhühner, F.; Palva, S.; Palva, J.M. Phase transfer entropy: A novel phase-based measure for directed connectivity in networks coupled by oscillatory interactions. Neuroimage 2014, 85, 853–872. [Google Scholar] [CrossRef]
- Sakkalis, V. Review of advanced techniques for the estimation of brain connectivity measured with EEG/MEG. Comput. Biol. Med. 2011, 41, 1110–1117. [Google Scholar] [CrossRef]
- De La Pava Panche, I.; Alvarez-Meza, A.M.; Orozco-Gutierrez, A. A data-driven measure of effective connectivity based on Renyi’s α-entropy. Front. Neurosci. 2019, 13, 1277. [Google Scholar] [CrossRef] [PubMed]
- Cekic, S.; Grandjean, D.; Renaud, O. Time, frequency, and time-varying Granger-causality measures in neuroscience. Stat. Med. 2018, 37, 1910–1931. [Google Scholar] [CrossRef]
- Nolte, G.; Ziehe, A.; Nikulin, V.V.; Schlögl, A.; Krämer, N.; Brismar, T.; Müller, K.R. Robustly estimating the flow direction of information in complex physical systems. Phys. Rev. Lett. 2008, 100, 234101. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jiang, H.; Bahramisharif, A.; van Gerven, M.A.; Jensen, O. Measuring directionality between neuronal oscillations of different frequencies. Neuroimage 2015, 118, 359–367. [Google Scholar] [CrossRef]
- Schreiber, T. Measuring information transfer. Phys. Rev. Lett. 2000, 85, 461. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhu, J.; Bellanger, J.J.; Shu, H.; Le Bouquin Jeannès, R. Contribution to transfer entropy estimation via the k-nearest-neighbors approach. Entropy 2015, 17, 4173–4201. [Google Scholar] [CrossRef] [Green Version]
- Wilmer, A.; de Lussanet, M.; Lappe, M. Time-delayed mutual information of the phase as a measure of functional connectivity. PLoS ONE 2012, 7, e44633. [Google Scholar] [CrossRef]
- Numan, T.; Slooter, A.J.; van der Kooi, A.W.; Hoekman, A.M.; Suyker, W.J.; Stam, C.J.; van Dellen, E. Functional connectivity and network analysis during hypoactive delirium and recovery from anesthesia. Clin. Neurophysiol. 2017, 128, 914–924. [Google Scholar] [CrossRef]
- Hillebrand, A.; Tewarie, P.; Van Dellen, E.; Yu, M.; Carbo, E.W.; Douw, L.; Gouw, A.A.; Van Straaten, E.C.; Stam, C.J. Direction of information flow in large-scale resting-state networks is frequency-dependent. Proc. Natl. Acad. Sci. USA 2016, 113, 3867–3872. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, S.; Zhang, D.; Fang, B.; Liu, X.; Yan, G.; Sui, G.; Huang, Q.; Sun, L.; Wang, S. A Study on Resting EEG Effective Connectivity Difference before and after Neurofeedback for Children with ADHD. Neuroscience 2021, 457, 103–113. [Google Scholar] [CrossRef]
- Yang, P.; Shang, P.; Lin, A. Financial time series analysis based on effective phase transfer entropy. Phys. A Stat. Mech. Appl. 2017, 468, 398–408. [Google Scholar] [CrossRef]
- Rathee, D.; Cecotti, H.; Prasad, G. Single-trial effective brain connectivity patterns enhance discriminability of mental imagery tasks. J. Neural Eng. 2017, 14, 056005. [Google Scholar] [CrossRef]
- Zhang, R.; Li, X.; Wang, Y.; Liu, B.; Shi, L.; Chen, M.; Zhang, L.; Hu, Y. Using brain network features to increase the classification accuracy of MI-BCI inefficiency subject. IEEE Access 2019, 7, 74490–74499. [Google Scholar] [CrossRef]
- García-Murillo, D.G.; Alvarez-Meza, A.; Castellanos-Dominguez, G. Single-Trial Kernel-Based Functional Connectivity for Enhanced Feature Extraction in Motor-Related Tasks. Sensors 2021, 21, 2750. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Zhang, Y.; Cheng, S.; Xie, P. Transfer spectral entropy and application to functional corticomuscular coupling. IEEE Trans. Neural Syst. Rehabil. Eng. 2019, 27, 1092–1102. [Google Scholar] [CrossRef] [PubMed]
- Pinzuti, E.; Wollstadt, P.; Gutknecht, A.; Tüscher, O.; Wibral, M. Measuring spectrally-resolved information transfer. PLoS Comput. Biol. 2020, 16, e1008526. [Google Scholar] [CrossRef] [PubMed]
- Rényi, A. On measures of entropy and information. In Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistics; The Regents of the University of California: California, CA, USA, 1961. [Google Scholar]
- Principe, J.C. Information Theoretic Learning: Renyi’s Entropy and Kernel Perspectives; Springer Science & Business Media: New York, NY, USA, 2010. [Google Scholar]
- Giraldo, L.G.S.; Rao, M.; Principe, J.C. Measures of entropy from data using infinitely divisible kernels. IEEE Trans. Inf. Theory 2015, 61, 535–548. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Mohri, M.; Rostamizadeh, A. Algorithms for learning kernels based on centered alignment. J. Mach. Learn. Res. 2012, 13, 795–828. [Google Scholar]
- Wibral, M.; Pampu, N.; Priesemann, V.; Siebenhühner, F.; Seiwert, H.; Lindner, M.; Lizier, J.T.; Vicente, R. Measuring information-transfer delays. PLoS ONE 2013, 8, e55809. [Google Scholar] [CrossRef] [PubMed]
- Vicente, R.; Wibral, M.; Lindner, M.; Pipa, G. Transfer entropy—A model-free measure of effective connectivity for the neurosciences. J. Comput. Neurosci. 2011, 30, 45–67. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Takens, F. Detecting strange attractors in turbulence. In Dynamical Systems and Turbulence, Warwick 1980; Springer: Berlin/Heidelberg, Germany, 1981; pp. 366–381. [Google Scholar]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E 2004, 69, 066138. [Google Scholar] [CrossRef] [Green Version]
- Lindner, M.; Vicente, R.; Priesemann, V.; Wibral, M. TRENTOOL: A Matlab open source toolbox to analyse information flow in time series data with transfer entropy. BMC Neurosci. 2011, 12, 119. [Google Scholar] [CrossRef] [Green Version]
- Dimitriadis, S.; Sun, Y.; Laskaris, N.; Thakor, N.; Bezerianos, A. Revealing cross-frequency causal interactions during a mental arithmetic task through symbolic transfer entropy: A novel vector-quantization approach. IEEE Trans. Neural Syst. Rehabil. Eng. 2016, 24, 1017–1028. [Google Scholar] [CrossRef]
- Barnett, L.; Barrett, A.B.; Seth, A.K. Granger causality and transfer entropy are equivalent for Gaussian variables. Phys. Rev. Lett. 2009, 103, 238701. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Principe, J.C.; Haykin, S. Kernel Adaptive Filtering: A Comprehensive Introduction; John Wiley & Sons: Hoboken, NJ, USA, 2011; Volume 57. [Google Scholar]
- Fernández-Ramírez, J.; Álvarez-Meza, A.; Pereira, E.; Orozco-Gutiérrez, A.; Castellanos-Dominguez, G. Video-based social behavior recognition based on kernel relevance analysis. Vis. Comput. 2020, 36, 1535–1547. [Google Scholar] [CrossRef]
- David, O.; Friston, K.J. A neural mass model for MEG/EEG:: Coupling and neuronal dynamics. NeuroImage 2003, 20, 1743–1755. [Google Scholar] [CrossRef]
- David, O.; Cosmelli, D.; Friston, K.J. Evaluation of different measures of functional connectivity using a neural mass model. Neuroimage 2004, 21, 659–673. [Google Scholar] [CrossRef] [PubMed]
- Ursino, M.; Ricci, G.; Magosso, E. Transfer Entropy as a Measure of Brain Connectivity: A Critical Analysis With the Help of Neural Mass Models. Front. Comput. Neurosci. 2020, 14, 45. [Google Scholar] [CrossRef]
- Weber, I.; Florin, E.; Von Papen, M.; Timmermann, L. The influence of filtering and downsampling on the estimation of transfer entropy. PLoS ONE 2017, 12, e0188210. [Google Scholar] [CrossRef] [Green Version]
- Collazos-Huertas, D.; Álvarez-Meza, A.; Acosta-Medina, C.; Castaño-Duque, G.; Castellanos-Dominguez, G. CNN-based framework using spatial dropping for enhanced interpretation of neural activity in motor imagery classification. Brain Inform. 2020, 7, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Tangermann, M.; Müller, K.R.; Aertsen, A.; Birbaumer, N.; Braun, C.; Brunner, C.; Leeb, R.; Mehring, C.; Miller, K.J.; Mueller-Putz, G.; et al. Review of the BCI competition IV. Front. Neurosci. 2012, 6, 55. [Google Scholar]
- Perrin, F.; Pernier, J.; Bertrand, O.; Echallier, J. Spherical splines for scalp potential and current density mapping. Electroencephalogr. Clin. Neurophysiol. 1989, 72, 184–187. [Google Scholar] [CrossRef]
- Cohen, M.X. Comparison of different spatial transformations applied to EEG data: A case study of error processing. Int. J. Psychophysiol. 2015, 97, 245–257. [Google Scholar] [CrossRef] [PubMed]
- Zhang, D.; Zhao, H.; Bai, W.; Tian, X. Functional connectivity among multi-channel EEGs when working memory load reaches the capacity. Brain Res. 2016, 1631, 101–112. [Google Scholar] [CrossRef] [PubMed]
- Villena-González, M.; Rubio-Venegas, I.; López, V. Data from brain activity during visual working memory replicates the correlation between contralateral delay activity and memory capacity. Data Brief 2020, 28, 105042. [Google Scholar] [CrossRef] [PubMed]
- Vogel, E.K.; Machizawa, M.G. Neural activity predicts individual differences in visual working memory capacity. Nature 2004, 428, 748–751. [Google Scholar] [CrossRef] [PubMed]
- Johnson, E.L.; Adams, J.N.; Solbakk, A.K.; Endestad, T.; Larsson, P.G.; Ivanovic, J.; Meling, T.R.; Lin, J.J.; Knight, R.T. Dynamic frontotemporal systems process space and time in working memory. PLoS Biol. 2018, 16, e2004274. [Google Scholar] [CrossRef] [Green Version]
- Johnson, E.L.; King-Stephens, D.; Weber, P.B.; Laxer, K.D.; Lin, J.J.; Knight, R.T. Spectral imprints of working memory for everyday associations in the frontoparietal network. Front. Syst. Neurosci. 2019, 12, 65. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Cao, L. Practical method for determining the minimum embedding dimension of a scalar time series. Phys. D Nonlinear Phenom. 1997, 110, 43–50. [Google Scholar] [CrossRef]
- Schölkopf, B.; Smola, A.J.; Bach, F. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Gong, A.; Liu, J.; Chen, S.; Fu, Y. Time–Frequency Cross Mutual Information Analysis of the Brain Functional Networks Underlying Multiclass Motor Imagery. J. Mot. Behav. 2018, 50, 254–267. [Google Scholar] [CrossRef]
- Debener, S.; Minow, F.; Emkes, R.; Gandras, K.; De Vos, M. How about taking a low-cost, small, and wireless EEG for a walk? Psychophysiology 2012, 49, 1617–1621. [Google Scholar] [CrossRef]
- Mennes, M.; Wouters, H.; Vanrumste, B.; Lagae, L.; Stiers, P. Validation of ICA as a tool to remove eye movement artifacts from EEG/ERP. Psychophysiology 2010, 47, 1142–1150. [Google Scholar] [CrossRef]
- Li, D.; Zhang, H.; Khan, M.S.; Mi, F. A self-adaptive frequency selection common spatial pattern and least squares twin support vector machine for motor imagery electroencephalography recognition. Biomed. Signal Process. Control 2018, 41, 222–232. [Google Scholar] [CrossRef]
- Gómez, V.; Álvarez, A.; Herrera, P.; Castellanos, G.; Orozco, A. Short Time EEG Connectivity Features to Support Interpretability of MI Discrimination. In Iberoamerican Congress on Pattern Recognition; Springer: Cham, Switzerland, 2018; pp. 699–706. [Google Scholar]
- Elasuty, B.; Eldawlatly, S. Dynamic Bayesian Networks for EEG motor imagery feature extraction. In Proceedings of the 2015 7th International IEEE/EMBS Conference on Neural Engineering (NER), Montpellier, France, 22–24 April 2015; pp. 170–173. [Google Scholar]
- Liang, S.; Choi, K.S.; Qin, J.; Wang, Q.; Pang, W.M.; Heng, P.A. Discrimination of motor imagery tasks via information flow pattern of brain connectivity. Technol. Health Care 2016, 24, S795–S801. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Linderman, G.C.; Steinerberger, S. Clustering with t-SNE, provably. SIAM J. Math. Data Sci. 2019, 1, 313–332. [Google Scholar] [CrossRef] [Green Version]
- Hétu, S.; Grégoire, M.; Saimpont, A.; Coll, M.P.; Eugène, F.; Michon, P.E.; Jackson, P.L. The neural network of motor imagery: An ALE meta-analysis. Neurosci. Biobehav. Rev. 2013, 37, 930–949. [Google Scholar] [CrossRef] [PubMed]
- Martínez-Cancino, R.; Delorme, A.; Wagner, J.; Kreutz-Delgado, K.; Sotero, R.C.; Makeig, S. What can local transfer entropy tell us about phase-amplitude coupling in electrophysiological signals? Entropy 2020, 22, 1262. [Google Scholar] [CrossRef] [PubMed]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
De La Pava Panche, I.; Álvarez-Meza, A.; Herrera Gómez, P.M.; Cárdenas-Peña, D.; Ríos Patiño, J.I.; Orozco-Gutiérrez, Á. Kernel-Based Phase Transfer Entropy with Enhanced Feature Relevance Analysis for Brain Computer Interfaces. Appl. Sci. 2021, 11, 6689. https://0-doi-org.brum.beds.ac.uk/10.3390/app11156689
De La Pava Panche I, Álvarez-Meza A, Herrera Gómez PM, Cárdenas-Peña D, Ríos Patiño JI, Orozco-Gutiérrez Á. Kernel-Based Phase Transfer Entropy with Enhanced Feature Relevance Analysis for Brain Computer Interfaces. Applied Sciences. 2021; 11(15):6689. https://0-doi-org.brum.beds.ac.uk/10.3390/app11156689
Chicago/Turabian StyleDe La Pava Panche, Iván, Andrés Álvarez-Meza, Paula Marcela Herrera Gómez, David Cárdenas-Peña, Jorge Iván Ríos Patiño, and Álvaro Orozco-Gutiérrez. 2021. "Kernel-Based Phase Transfer Entropy with Enhanced Feature Relevance Analysis for Brain Computer Interfaces" Applied Sciences 11, no. 15: 6689. https://0-doi-org.brum.beds.ac.uk/10.3390/app11156689