
Building Tree Allometry Relationships Based on TLS Point Clouds and Machine Learning Regression




Abstract
:1. Introduction
2. Materials and Methods
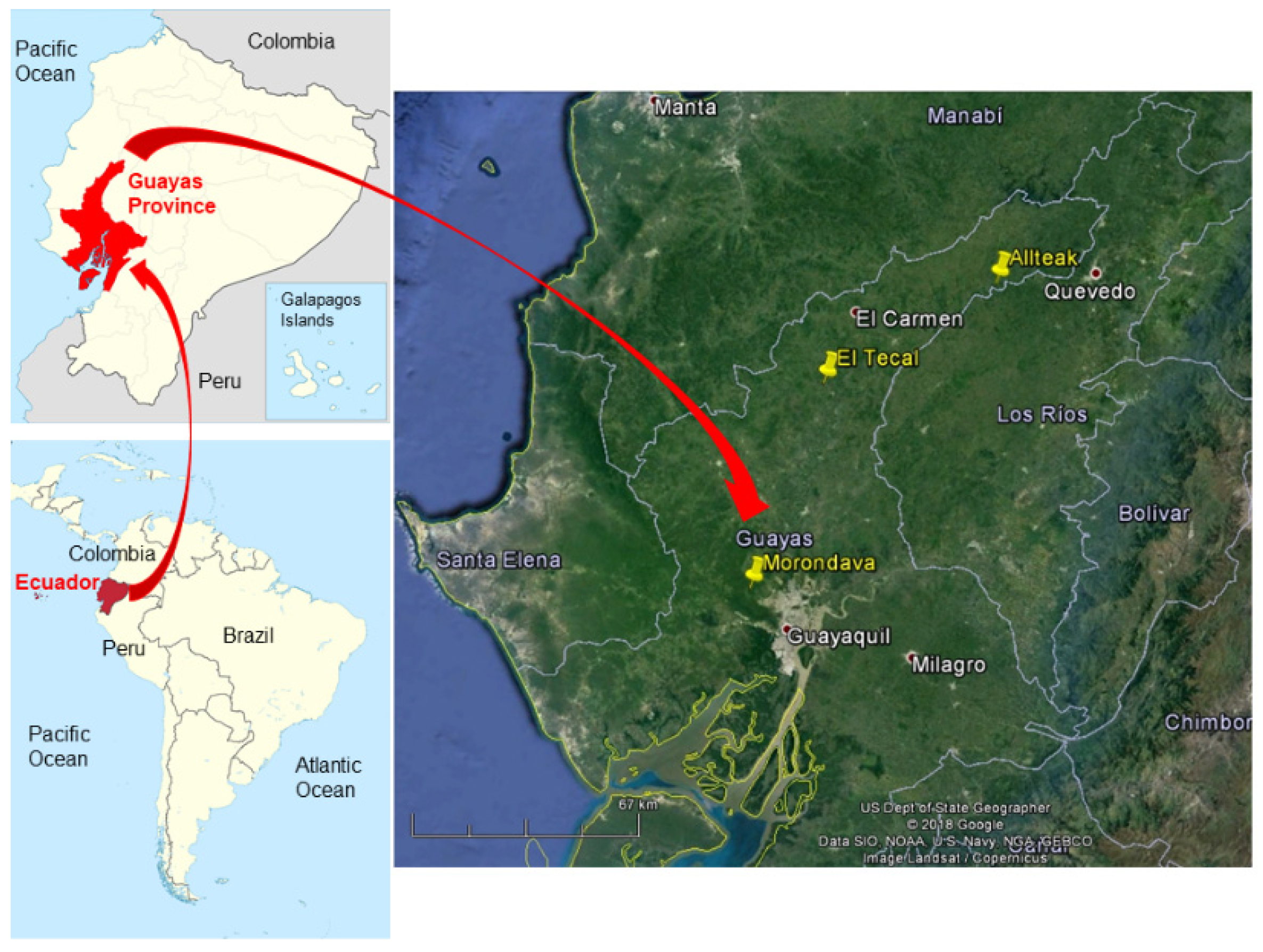
2.1. Study Area
- Morondava. With an area of 78.28 ha and teak trees between 2 and 3 years old at the time of the inventory. Geographic coordinates: latitude 2°6′11.72″ S and longitude 80°2′59.43″ W.
- El Tecal. With an area of 21.12 ha and a homogeneous age of 17 years at the time of the inventory. Geographic coordinates: latitude 1°31′53.07″ S and longitude 80°20′30.51″ W.
- Allteak. With an area of 57.22 ha and variable ages of 4, 10, and 12 years at the time of the inventory. Geographic coordinates: latitude 1°8′7.23″ S and longitude 79°41′58.08″ W.
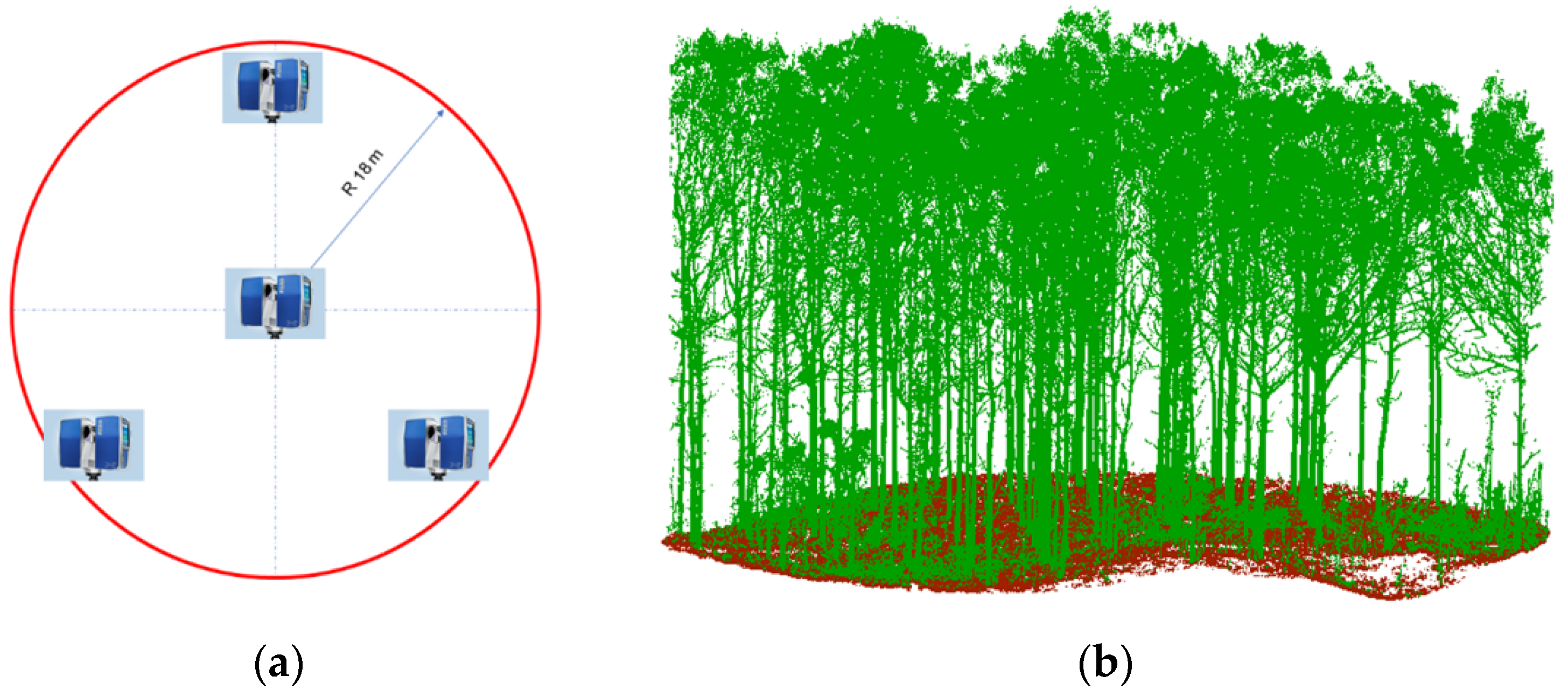
2.2. Field Data
2.3. Allometric Models
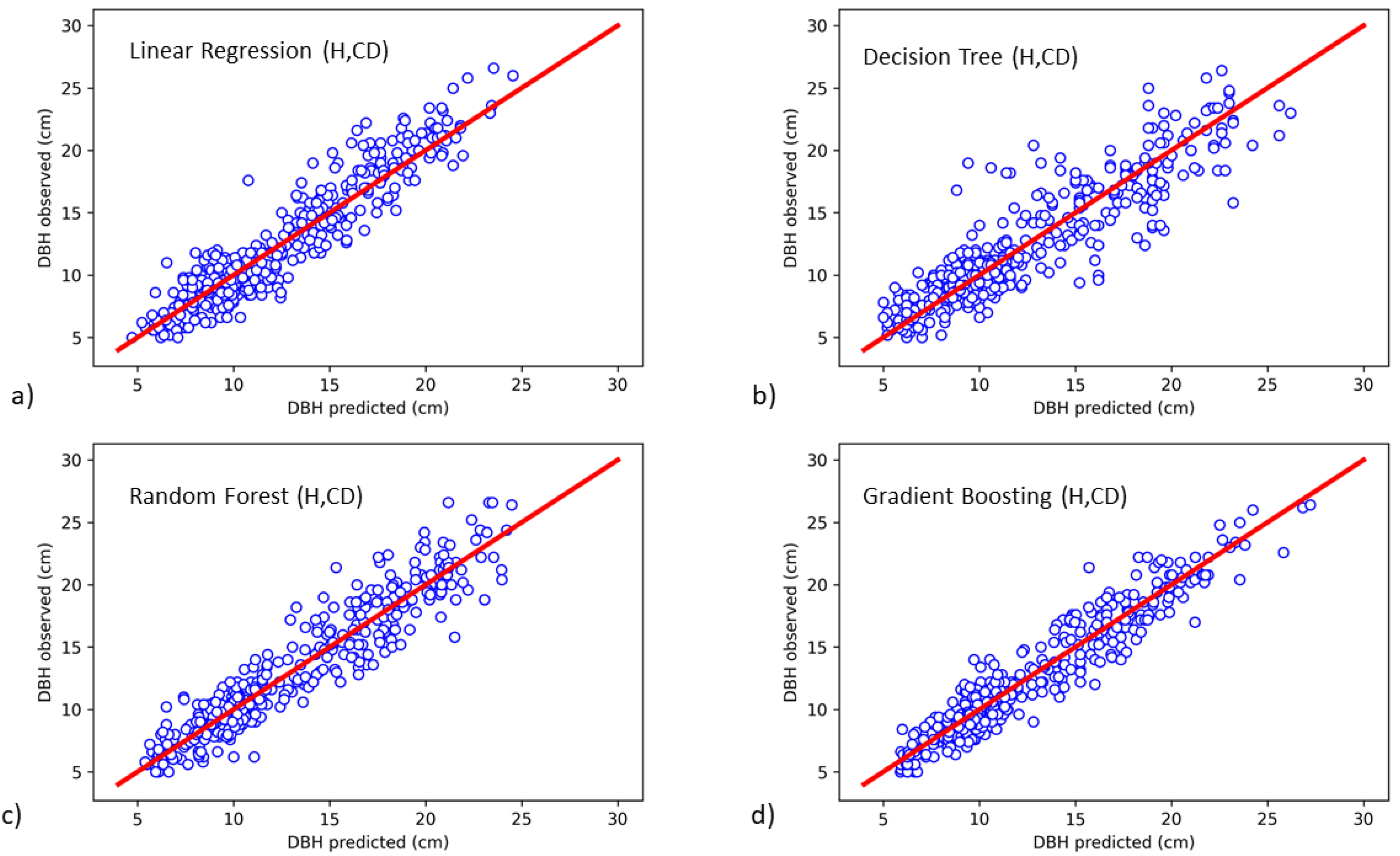
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Pan, Y.; Birdsey, R.A.; Phillips, O.L.; Jackson, R.B. The structure, distribution, and biomass of the world’s forests. Annu. Rev. Ecol. Evol. Syst. 2013, 44, 593–622. [Google Scholar] [CrossRef] [Green Version]
- Beer, C.; Reichstein, M.; Tomelleri, E.; Ciais, P.; Jung, M.; Carvalhais, N.; Rödenbeck, C.; Arain, M.A.; Baldocchi, D.; Bonan, G.B.; et al. Terrestrial Gross Carbon Dioxide Uptake: Global Distribution and Covariation with Climate. Science 2010, 329, 834–838. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pan, Y.; Birdsey, R.A.; Fang, J.; Houghton, R.; Kauppi, P.E.; Kurz, W.A.; Phillips, O.L.; Shvidenko, A.; Lewis, S.L.; Canadell, J.G.; et al. A large and persistent carbon sink in the world’s forests. Science 2011, 333, 988–993. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lindberg, E.; Holmgren, J. Individual Tree Crown Methods for 3D Data from Remote Sensing. Curr. For. Rep. 2017, 3, 19–31. [Google Scholar] [CrossRef] [Green Version]
- Houghton, R.A.; Nassikas, A.A. Negative emissions from stopping deforestation and forest degradation, globally. Glob. Chang. Biol. 2018, 24, 350–359. [Google Scholar] [CrossRef]
- Li, W.; Guo, Q.; Jakubowski, M.K.; Kelly, M. A New Method for Segmenting Individual Trees from the Lidar Point Cloud. Photogramm. Eng. Remote Sens. 2012, 78, 75–84. [Google Scholar] [CrossRef] [Green Version]
- Wallace, L.; Lucieer, A.; Malenovskỳ, Z.; Turner, D.; Vopěnka, P. Assessment of forest structure using two UAV techniques: A comparison of airborne laser scanning and structure from motion (SfM) point clouds. Forests 2016, 7, 62. [Google Scholar] [CrossRef] [Green Version]
- Aguilar, F.J.; Rivas, J.R.; Nemmaoui, A.; Peñalver, A.; Aguilar, M.A. UAV-Based Digital Terrain Model Generation under Leaf-Off Conditions to Support Teak Plantations Inventories in Tropical Dry Forests. A Case of the Coastal Region of Ecuador. Sensors 2019, 19, 1934. [Google Scholar] [CrossRef] [Green Version]
- Gómez, C.; Alejandro, P.; Hermosilla, T.; Montes, F.; Pascual, C.; Ruiz, L.Á.; Álvarez-Taboada, F.; Tanase, M.A.; Valbuena, R. Remote sensing for the Spanish forests in the 21stcentury: A review of advances, needs, and opportunities. For. Syst. 2019, 28, 2171–9292. [Google Scholar] [CrossRef]
- White, J.C.; Coops, N.C.; Wulder, M.A.; Vastaranta, M.; Hilker, T.; Tompalski, P. Remote Sensing Technologies for Enhancing Forest Inventories: A Review. Can. J. Remote Sens. 2016, 42, 619–641. [Google Scholar] [CrossRef] [Green Version]
- Kankare, V.; Holopainen, M.; Vastaranta, M.; Puttonen, E.; Yu, X.; Hyyppä, J.; Vaaja, M.; Hyyppä, H.; Alho, P. Individual tree biomass estimation using terrestrial laser scanning. ISPRS J. Photogramm. Remote Sens. 2013, 75, 64–75. [Google Scholar] [CrossRef]
- Liang, X.; Kankare, V.; Hyyppä, J.; Wang, Y.; Kukko, A.; Haggrén, H.; Yu, X.; Kaartinen, H.; Jaakkola, A.; Guan, F.; et al. Terrestrial laser scanning in forest inventories. ISPRS J. Photogramm. Remote Sens. 2016, 115, 63–77. [Google Scholar] [CrossRef]
- Cabo, C.; Ordóñez, C.; López-Sánchez, C.A.; Armesto, J. Automatic dendrometry: Tree detection, tree height and diameter estimation using terrestrial laser scanning. Int. J. Appl. Earth Obs. Geoinf. 2018, 69, 164–174. [Google Scholar] [CrossRef]
- Aguilar, F.J.; Nemmaoui, A.; Peñalver, A.; Rivas, J.R.; Aguilar, M.A. Developing allometric equations for teak plantations located in the coastal region of ecuador from terrestrial laser scanning data. Forests 2019, 10, 1050. [Google Scholar] [CrossRef] [Green Version]
- Gleason, C.J.; Im, J. Forest biomass estimation from airborne LiDAR data using machine learning approaches. Remote Sens. Environ. 2012, 125, 80–91. [Google Scholar] [CrossRef]
- Li, Y.; Li, C.; Li, M.; Liu, Z. Influence of Variable Selection and Forest Type on Forest Aboveground Biomass Estimation Using Machine Learning Algorithms. Forests 2019, 10, 1073. [Google Scholar] [CrossRef] [Green Version]
- Chave, J.; Réjou-Méchain, M.; Búrquez, A.; Chidumayo, E.; Colgan, M.S.; Delitti, W.B.C.; Duque, A.; Eid, T.; Fearnside, P.M.; Goodman, R.C.; et al. Improved allometric models to estimate the aboveground biomass of tropical trees. Glob. Chang. Biol. 2014, 20, 3177–3190. [Google Scholar] [CrossRef]
- Jucker, T.; Caspersen, J.; Chave, J.; Antin, C.; Barbier, N.; Bongers, F.; Dalponte, M.; van Ewijk, K.Y.; Forrester, D.I.; Haeni, M.; et al. Allometric equations for integrating remote sensing imagery into forest monitoring programmes. Glob. Chang. Biol. 2017, 23, 177–190. [Google Scholar] [CrossRef]
- Dalponte, M.; Coomes, D.A. Tree-centric mapping of forest carbon density from airborne laser scanning and hyperspectral data. Methods Ecol. Evol. 2016, 7, 1236–1245. [Google Scholar] [CrossRef] [Green Version]
- McRoberts, R.E.; Westfall, J.A. Propagating uncertainty through individual tree volume model predictions to large-area volume estimates. Ann. For. Sci. 2016, 73, 625–633. [Google Scholar] [CrossRef] [Green Version]
- Holdridge, L.R. Ecología Basada en Zonas de Vida; IICA. Serie de Libros y Materiales Educativos; Instituto Interamericano de Cooperacion para la Agricultura: San José, Costa Rica, 1982; ISBN 9789290390398. [Google Scholar]
- Pueschel, P.; Newnham, G.; Rock, G.; Udelhoven, T.; Werner, W.; Hill, J. The influence of scan mode and circle fitting on tree stem detection, stem diameter and volume extraction from terrestrial laser scans. ISPRS J. Photogramm. Remote Sens. 2013, 77, 44–56. [Google Scholar] [CrossRef]
- Trochta, J.; Krůček, M.; Vrška, T.; Král, K. 3D Forest: An application for descriptions of three-dimensional forest structures using terrestrial LiDAR. PLoS ONE 2017, 12, e0176871. [Google Scholar] [CrossRef] [Green Version]
- FUSION/LDV LIDAR Analysis and Visualization Software. Available online: http://forsys.cfr.washington.edu/fusion/fusion_overview.html (accessed on 22 April 2021).
- Zhang, Y.; Ma, J.; Liang, S.; Li, X.; Li, M. An Evaluation of Eight Machine Learning Regression Algorithms for Forest Aboveground Biomass Estimation from Multiple Satellite Data Products. Remote Sens. 2020, 12, 4015. [Google Scholar] [CrossRef]
- Luo, M.; Wang, Y.; Xie, Y.; Zhou, L.; Qiao, J.; Qiu, S.; Sun, Y. Combination of Feature Selection and CatBoost for Prediction: The First Application to the Estimation of Aboveground Biomass. Forests 2021, 12, 216. [Google Scholar] [CrossRef]
- Hancock, J.T.; Khoshgoftaar, T.M. CatBoost for big data: An interdisciplinary review. J. Big Data 2020, 7. [Google Scholar] [CrossRef] [PubMed]
- Maack, J.; Kattenborn, T.; Fassnacht, F.E.; Enßle, F.; Hernández, J.; Corvalán, P.; Koch, B. Modeling forest biomass using Very-High-Resolution data—Combining textural, spectral and photogrammetric predictors derived from spaceborne stereo images. Eur. J. Remote Sens. 2015, 48, 245–261. [Google Scholar] [CrossRef] [Green Version]
- Agrawal, A.; Nepstad, D.; Chhatre, A. Reducing Emissions from Deforestation and Forest Degradation. Annu. Rev. Environ. Resour. 2011, 36, 373–396. [Google Scholar] [CrossRef] [Green Version]
- Ogana, F.N.; Ercanli, I. Modelling height-diameter relationships in complex tropical rain forest ecosystems using deep learning algorithm. J. For. Res. 2021 2021, 1, 1–16. [Google Scholar] [CrossRef]
- Lara, C.E. Aplicación de ecuaciones de conicidad para teca (Tectona grandis L.F.) en la zona costera ecuatoriana. Cienc. Tecnol. 2012, 4, 19–27. [Google Scholar] [CrossRef]
- Pérez, L.D.; Kanninen, M. Aboveground biomass of Tectona grandis plantations in Costa Rica. J. Trop. For. Sci. 2003, 15, 199–213. [Google Scholar] [CrossRef]
- White, J.; Wulder, M.; Vastaranta, M.; Coops, N.; Pitt, D.; Woods, M. The Utility of Image-Based Point Clouds for Forest Inventory: A Comparison with Airborne Laser Scanning. Forests 2013, 4, 518–536. [Google Scholar] [CrossRef] [Green Version]
- Mohan, M.; Silva, C.; Klauberg, C.; Jat, P.; Catts, G.; Cardil, A.; Hudak, A.; Dia, M. Individual Tree Detection from Unmanned Aerial Vehicle (UAV) Derived Canopy Height Model in an Open Canopy Mixed Conifer Forest. Forests 2017, 8, 340. [Google Scholar] [CrossRef] [Green Version]
- Ferraz, A.; Bretar, F.; Jacquemoud, S.; Gonçalves, G.; Pereira, L.; Tomé, M.; Soares, P. 3-D mapping of a multi-layered Mediterranean forest using ALS data. Remote Sens. Environ. 2012, 121, 210–223. [Google Scholar] [CrossRef]
- Calders, K.; Jonckheere, I.; Nightingale, J.; Vastaranta, M. Remote Sensing Technology Applications in Forestry and REDD+. Forests 2020, 11, 188. [Google Scholar] [CrossRef] [Green Version]
- Vafaei, S.; Soosani, J.; Adeli, K.; Fadaei, H.; Naghavi, H.; Pham, T.D.; Bui, D.T. Improving Accuracy Estimation of Forest Aboveground Biomass Based on Incorporation of ALOS-2 PALSAR-2 and Sentinel-2A Imagery and Machine Learning: A Case Study of the Hyrcanian Forest Area (Iran). Remote Sens. 2018, 10, 172. [Google Scholar] [CrossRef] [Green Version]
- Vieira, G.; de Mendonça, A.; da Silva, G.; Zanetti, S.; da Silva, M.; Dos Santos, A. Prognoses of diameter and height of trees of eucalyptus using artificial intelligence. Sci. Total Environ. 2018, 619–620, 1473–1481. [Google Scholar] [CrossRef]
- Bayat, M.; Bettinger, P.; Heidari, S.; Khalyani, A.H.; Jourgholami, M.; Hamidi, S.K. Estimation of Tree Heights in an Uneven-Aged, Mixed Forest in Northern Iran Using Artificial Intelligence and Empirical Models. Forests 2020, 11, 324. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Yang, H.; Man, R.; Wang, W.; Sharma, M.; Peng, C.; Parton, J.; Zhu, H.; Deng, Z. Using machine learning to synthesize spatiotemporal data for modelling DBH-height and DBH-height-age relationships in boreal forests. For. Ecol. Manage. 2020, 466, 118104. [Google Scholar] [CrossRef]
- Ercanlı, İ. Innovative deep learning artificial intelligence applications for predicting relationships between individual tree height and diameter at breast height. For. Ecosyst. 2020, 7, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Filho, S.V.S.D.C.; Arce, J.E.; Montaño, R.A.N.R.; Pelissari, A.L. Configuração de algoritmos de aprendizado de máquina na modelagem florestal: Um estudo de caso na modelagem da relação hipsométrica. Ciência Florest. 2019, 29, 1501–1515. [Google Scholar] [CrossRef] [Green Version]
- Tavares Júnior, I.D.S.; Torres, C.M.M.E.; Leite, H.G.; de Castro, N.L.M.; Soares, C.P.B.; Castro, R.V.O.; Farias, A.A. Machine learning: Modeling increment in diameter of individual trees on Atlantic Forest fragments. Ecol. Indic. 2020, 117, 106685. [Google Scholar] [CrossRef]
- Abegg, M.; Kükenbrink, D.; Zell, J.; Schaepman, M.E.; Morsdorf, F. Terrestrial laser scanning for forest inventories-tree diameter distribution and scanner location impact on occlusion. Forests 2017, 8, 184. [Google Scholar] [CrossRef] [Green Version]
- Suraj Reddy, R.; Rakesh, A.; Jha, C.S.; Rajan, K.S. Automatic Estimation of Tree Stem Attributes Using Terrestrial Laser Scanning in Central Indian Dry Deciduous Forests. Curr. Sci. 2018, 114, 201–206. [Google Scholar] [CrossRef]
- Peñalver, A.; Aguilar, F.J.; Nemmaoui, A.; Rivas, J.R.; Triana, Á.A.; Aguilar, M.A.; Llanderal, A. Precisión y eficiencia del inventario de plantaciones de teca en Ecuador mediante escáner láser terrestre. Madera Bosques 2021, 27, e2712097. [Google Scholar] [CrossRef]
- Guerra-Hernández, J.; Cosenza, D.N.; Rodriguez, L.C.E.; Silva, M.; Tomé, M.; Díaz-Varela, R.A.; González-Ferreiro, E. Comparison of ALS- and UAV(SfM)-derived high-density point clouds for individual tree detection in Eucalyptus plantations. Int. J. Remote Sens. 2018, 39, 5211–5235. [Google Scholar] [CrossRef]
- Lin, Y.-C.; Liu, J.; Fei, S.; Habib, A. Leaf-Off and Leaf-On UAV LiDAR Surveys for Single-Tree Inventory in Forest Plantations. Drones 2021, 5, 115. [Google Scholar] [CrossRef]
- Newnham, G.J.; Armston, J.D.; Calders, K.; Disney, M.I.; Lovell, J.L.; Schaaf, C.B.; Strahler, A.H.; Mark Danson, F. Terrestrial laser scanning for plot-scale forest measurement. Curr. For. Rep. 2015, 1, 239–251. [Google Scholar] [CrossRef] [Green Version]
- Liang, X.; Kankare, V.; Yu, X.; Hyyppä, J.; Holopainen, M. Automated Stem Curve Measurement Using Terrestrial Laser Scanning. IEEE Trans. Geosci. Remote Sens. 2014, 52, 1739–1748. [Google Scholar] [CrossRef]
- Saarinen, N.; Kankare, V.; Vastaranta, M.; Luoma, V.; Pyörälä, J.; Tanhuanpää, T.; Liang, X.; Kaartinen, H.; Kukko, A.; Jaakkola, A.; et al. Feasibility of Terrestrial laser scanning for collecting stem volume information from single trees. ISPRS J. Photogramm. Remote Sens. 2017, 123, 140–158. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Regression Method | R2 Mean Value (%) | R2 Standard Deviation (%) | R2 Range (Min/Max %) |
|---|---|---|---|
| GBoost | 87.21 a | 1.02 | 84.92–89.65 |
| CatBoost | 87.08 a | 1.06 | 84.80–89.43 |
| LR | 86.87 a | 1.08 | 83.17–89.32 |
| AdaBoost | 86.59 a | 1.26 | 83.16–89.80 |
| RFR | 82.50 b | 1.44 | 79.04–86.42 |
| DTR | 78.35 c | 2.23 | 72.93–83.76 |
| Regression Method | R2 Mean Value (%) | R2 Standard Deviation (%) | R2 Range (Min/Max %) |
|---|---|---|---|
| GBoost | 90.16 a | 0.91 | 87.52–92.32 |
| CatBoost | 90.15 a | 0.93 | 88.00–91.98 |
| AdaBoost | 88.73 ab | 1.02 | 85.75–91.46 |
| RFR | 88.67 ab | 1.04 | 85.23–91.13 |
| LR | 87.81 b | 1.13 | 84.33–90.70 |
| DTR | 81.22 c | 1.67 | 76.31–86.01 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aguilar, F.J.; Nemmaoui, A.; Aguilar, M.A.; Peñalver, A. Building Tree Allometry Relationships Based on TLS Point Clouds and Machine Learning Regression. Appl. Sci. 2021, 11, 10139. https://0-doi-org.brum.beds.ac.uk/10.3390/app112110139
Aguilar FJ, Nemmaoui A, Aguilar MA, Peñalver A. Building Tree Allometry Relationships Based on TLS Point Clouds and Machine Learning Regression. Applied Sciences. 2021; 11(21):10139. https://0-doi-org.brum.beds.ac.uk/10.3390/app112110139
Chicago/Turabian StyleAguilar, Fernando J., Abderrahim Nemmaoui, Manuel A. Aguilar, and Alberto Peñalver. 2021. "Building Tree Allometry Relationships Based on TLS Point Clouds and Machine Learning Regression" Applied Sciences 11, no. 21: 10139. https://0-doi-org.brum.beds.ac.uk/10.3390/app112110139