1. Introduction
According to the World Health Organization (WHO), an estimated 264 million people around the world suffer from depression [
1]. Depression is one of the most troublesome and common mental disorders; it is the principal cause of disability worldwide and has a significant impact on the index of morbidity. This is because depression can lead to suicide and is the leading cause of suicide death. The number of suicides by depression reaches up to 800,000 per year worldwide [
2].
The number of people suffering from mental disorders, including depression, is continually growing, and this has an impact on human rights, the economy, and society [
3]. This is especially true in low-income countries. The exponential growth of the population and the fact that a large group of people is arriving to the age when depression is more likely to appear are factors that contribute to that growth [
2]. Other factors, such as political, social, cultural, and economic factors, play a significant role in the development of such disorders. That is why minority groups, such as people suffering from discrimination for their ethnicity, sexual orientation, gender identification, people suffering from domestic abuse, and people exposed to conflict or high stress, are at higher risk of developing major depressive disorder (MDD) [
4].
The disease’s characteristics are feelings of sadness, guilt, worthlessness, and self-loathing, loss of interest in usually interesting tasks, change in eating and sleeping habits leading to significant weight loss or gain, tiredness, lack of concentration, inability to take decisions, agitation or slowing of the psycho-motor activity, and recurrent thoughts of death. This symptoms can be a sign of MDD [
1,
5].
The consequences of depression are also a subject of concern. Individual consequences are present when a patient suffers from MDD; people with MDD are 40% to 61% more likely to die prematurely [
4]. However, there are also consequences that affect the patient’s environments, both social and economic, especially due to the growth of the number of people suffering from mental disorders. According to the World Economic Forum, the global economic impact of mental disorders climbed to USD 16.3 trillion in the period between 2011 and 2020 [
6]. Due to the lost in productivity in the work life of the patient, and according to the WHO, “depression and anxiety have a significant economic impact; the estimated cost to the global economy is US
$1 trillion per year in lost productivity” [
7].
Given the gravity of the symptoms and consequences of MDD, the implementation of preventive measures, as well as diagnosis and treatment aids, have become critical. However, due to the increasing number of people suffering from MDD and other mental disorders, the number of specialists in the subject has become insufficient to diagnose and treat all patients with mental health needs. In 2005, 0.6 psychiatrists graduated per 100,000 population [
8], meaning that every psychiatrist in the world would need to treat more than 100,000 patients in order to cover the world’s mental health needs. The estimate has not improved. According to the Mental health action plan 2013–2020 of the WHO [
4], in half the countries of the world, on average, there is one psychiatrist to serve 200,000 or more people. That is why the exploration of alternative solutions is key to solving this problem.
The computer science field has proposed the use of artificial intelligence (AI) to detect the risk of suffering MDD by using social media. The exponential growth of social media use [
9], coupled with research that links depression with the use of language [
10,
11] has made this proposal possible. Several workshops have proposed shared tasks [
12,
13] in which new solutions arise. Nevertheless, in the literature, the proposals are mainly based on representations that contain, in their majority, objective features, that is, features based on the structure of the text, or quantitative aspects of it, such as n-grams [
14], parts-of-speech, and number of words [
15,
16]. Even though in the literature there are proposals that use sentiment analysis, these proposals do not use only subjective information of the posts. These proposals combine them with other objective features and have limited information on sentiment, emotion, and other subjective features [
17,
18,
19,
20].
Moreover, several problems arise in the use of AI for decision making when such decisions are not interpretable. The psychological field requires an AI model that provides explanations so that experts understand the reason behind a decision made by it because they need to assess its validity [
21]. Since the psychological field is a medical field, the decisions taken by the specialist affect human lives. If they use a model to help with diagnosis, they need supplementary information to support and validate their diagnosis. Although some algorithms that can provide explanation have been used in the literature, the explainability of the algorithm has not been exploited or taken into consideration using only information linked with emotions and sentiment [
16,
22].
Hence, in this paper, we propose a contrast pattern-based classifier using only features based on emotion and sentiment analysis, which are easier to understand by human experts. The patterns extracted from this representation are used as an explanation of the final decision and are associated with human language, making them understandable to experts.
The contributions of this paper are as follows:
A feature representation based on sentiments and emotions, allowing an accurate classification for detecting depressive posts.
An explainable model based on contrast patterns achieving better area under the curve (AUC) and F1 regarding other state-of-the-art classifiers designed for detecting depression.
A set of extracted contrast patterns describing depressive posts in a language close to experts in the application area.
The paper is organized as follows.
Section 2 presents the previous works in the topic.
Section 3 presents the databases, representations, and classifiers used to construct the models used for evaluation.
Section 4 presents the results obtained in AUC and F1 measures and the statistical comparison between our model and other state-of-the-art models.
Section 5 presents a demonstration on how the contrast patterns extracted can be interpreted. Finally,
Section 6 presents our conclusions and future work
3. Materials and Methods
In this section, we present the databases we used for the comparison, the tools we used for extracting emotion and sentiment features, and the structure of the feature space created. We also describe the state-of-the-art models we reproduced for the comparison. Finally, we summarize the models used for the statistical analysis.
3.1. Databases
In this paper, we used five different publicly available databases;
Table 4 summarizes their characteristics.
The C-SSRS database was extracted by Gaur et al. [
36] to distinguish the severity risk of suicide in a user. They used four psychiatrists to classify Reddit posts into five categories:
Indicative of suicidal ideation.
Indicative of suicidal behavior.
Indicative of an actual attempt of suicide.
Suicide indicator (it contains reference to suicide but in an informative manner).
Supportive of suicidal people.
We relabeled every post labeled as supportive or a suicide indicator as non-depressive and every post labeled in any other category as depressive.
DDVHSM (depression detection via harvesting social media) is a database extracted by Guangyao Shen et al. [
37]. The research team labeled Twitter posts considering the appearance of specific text related to depression diagnosis, such as “I have been diagnosed with depression.”, “I am diagnosed with depression.”, and similar texts.
The Kaggle database is an open-source database of Twitter posts, annotated individually, as depressive or non-depressive. Since the posts were annotated individually, the number of users is unknown. The labeling was made considering the appearance of the stem “depress” on the text.
Both LOSADA databases are databases that were available in the eRisk lab of the CLEF in the years of 2017 and 2018 [
23,
40]. As described in [
39], to label a user as depressive or not depressive, they searched for mentions of diagnosis, such as “I have been diagnosed with depression.”, “I was diagnosed with depression.” and similar texts. Text such as “I am depressed.” or “I have depression.” were not considered, as they did not mention an explicit diagnosis. This labeling did not include individual post labels; we relabeled every post of a depressed user as depressive and every post of a not-depressed user as non-depressive.
3.2. Extraction of Sentiment Features
After having the databases with every post labeled individually as depressive or non-depressive, we processed the posts as shown in
Figure 1. We removed HTML tags, stopwords, and repeating punctuation. After that, some posts were left blank, so we removed them, as they would give no useful information for the comparison.
We then extracted emotion and sentiment features using the tools MeaningCloud [
41] and Paralleldots [
42]. The description of the features extracted with each tool is found in
Table 5 and
Table 6. We used five different APIs from Paralleldots: sentiment analysis, emotion analysis, sarcasm detection, intent analysis, and abuse analysis. The emotion analysis API uses a model based on Paul Ekman’s basic emotions theory [
43], replacing disgust and surprise by boredom and excitement [
42]. From MeaningCloud, we used the sentiment analysis API.
We built three different representations. The first representation contains only Paralleldots features with 23 different features, including the length of the post in words. The features in this representation are numerical and can take values from 0 to 1; the sum of features in the same category is equal to one.
The second representation contains only MeaningCloud features with 6 features, including the length of the post in words.
The third representation contains all features from both Paralleldots and Meanincloud with a total of 28 features, 22 of which are numerical and 5 which are nominal.
3.3. Classifier
For the three previously explained representations, we used PBC4cip, a contrast pattern-based classifier that addresses class imbalance problems [
44].
A contrast pattern is a pattern that describes a proportion of objects inside a class that differs significantly from other classes. Contrast patterns are a way of making a classifier explainable. This is because they can be interpreted in natural language and provide a model that is easy to understand for human experts in the field of the problem being solved [
45]. Contrast patterns are used for the resolution of tasks, such as bot detection [
45], masquerader detection [
46], image processing [
47], medical diagnosis [
48,
49], and fraud detection [
50]. Moreover, they are proven to be a more accurate model than other state-of-the-art models in certain problem resolutions [
44,
45,
51,
52].
PBC4cip (pattern-based classifier for class imbalance problems) is a classifier based on contrast patterns designed to deal with class imbalance problems. Its main goal is to avoid the model’s bias toward the most supported class by extracting a weight during the training phase. It then uses the weighting obtained in the training phase to balance the classes by rewarding the minority class by its low support and punishing the majority class by its higher support [
44].
We used a Random Forest miner by using Twoing as a splitting measure for the decision trees. Due to the time-consuming nature of hyperparamenter optimization and the fact that we used multiple representations and databases, we based our decision on an extensive experimentation, where Twoing was shown to be the recommended measure to build C4.5 decision trees [
53].
3.4. State-of-the-Art Models
To compare the results with state-of-the art models fairly and precisely, we reproduced some of the models found in the literature. For every database, we extracted every representation, giving a total of 25 feature spaces. The representations extracted are described in detail in the following subsections.
3.4.1. Ensemble of Handcrafted Features and BOWs
The first representation we obtained is the one described in [
16], which is the best representation of the database LOSADA2016. For all databases and for each post, we extracted the features described in
Section 2.1.2. That is, the linguistic metadata and the three different BOWs with their correspondent weighting scheme. We then fed every representation individually to a different logistic regression classifier. Each classifier had its own class weighting defined. For the classifiers fed with the handcrafted features and the second BOW, the weights were
and
. For the classifier fed with the first BOW the weights were
and
. For the classifier fed with the third BOW, the weights were
and
. These weights were used, due to imbalanced class distribution to increase the cost of false negatives, as stated in the paper. The result of this classification was the unweighted mean of the four probabilities calculated by the models.
3.4.2. Ensemble of BOWs
The second representation uses the same operations defined in
Section 2.1.2 to extract three weighted BOWS. For the first BOW, we used the raw term frequency and information gain as local and global weights, respectively. For the second BOW, we used augmented term frequency and inverse document frequency. For the third BOW, we used logarithmic term frequency and relevance frequency [
22]. Each BOW was fed to a different logistic regression classifier with class weight as
and
for the three classifiers. The result was the unweighted mean of the three probabilities calculated by the models.
3.4.3. Parser Tree
The third representation [
36] consists of the following features:
First person pronoun ratio: the number of first pronouns (I, me, my, mine, or myself) per number of words in the post.
LabMT: whether or not there is a match with the words in the Language Assessment by Mechanical Turk, a database of words with happiness and internet usage scores [
54].
Height of dependency parse tree: a measure of readability, with the height being proportional to the readability of the text.
Maximum length of verb phrase: the length of the longest verb phrase in the post.
Number of pronouns: including personal (I, me, he, him, etc.), possessive (mine, yours, etc.), reflexive (myself, themselves, etc.), demonstrative (this, that, etc.), interrogative (what, who, which, etc.), and relative (whom, that, which, etc.).
Number of sentences.
Number of definite articles: the definite article “the”.
We extracted the features of dependency parse tree, number of pronouns, sentences and definite articles with the help of the Stanford CoreNLP Natural Language Processing Toolkit [
55]. For this representation, we used a Random Forest classifier with no weighting or any extra configuration since it was not specified in the original paper [
36].
3.4.4. VAD and Topics
The fourth representation [
37] includes the following features:
For this representation, we used a Naive Bayes model. We did not add any extra configuration to the model because it was not specified by the original paper [
37].
3.4.5. BOW
The fifth and last representation is described in [
58]; it consists of a classic tf-idf BOW, that is, a BOW that uses raw term frequency as the local weight and inverse document frequency as the global weight. For this representation, we used Ada boost since it was the one that performed the best in [
58]. We did not give the model extra configuration since it was not specified in the original paper.
3.5. Data Partitioning
For every representation discussed above, we performed a distribution optimally balanced stratified cross validation (DOB-SCV) partitioning [
59], using the tool KEEL. KEEL is an open-source tool for developing experiments. It contains a specific module for imbalanced databases. This module is important in these problems since most of the databases found are imbalanced, due to the relative prevalence of depression and lack of diagnosis of this disease.
4. Results and Evaluation
4.1. Metrics
The metrics we used to assess the results are F1 score and AUC. There are multiple reasons for choosing these metrics for our model evaluation. The F1 score is the harmonic mean of precision and recall, which means that it assesses both measures [
60], given the following formulas:
where
is the true positives,
is the false positives, and
is the false negatives. We have that
F1 is calculated by the following:
By doing so, the F1 score is an indicator of both quality and robustness.
On the other hand, “the AUC of a classifier is equivalent to the probability that the classifier will rank a randomly chosen positive instance higher than a randomly chosen negative instance” [
61]. This can be calculated using the following formula:
where
is the true negatives,
is the false negatives,
is the true positives, and
is the false positives. This is important in this specific problem because of the importance of classifying correctly positive instances of depression.
4.2. Proposed Representations
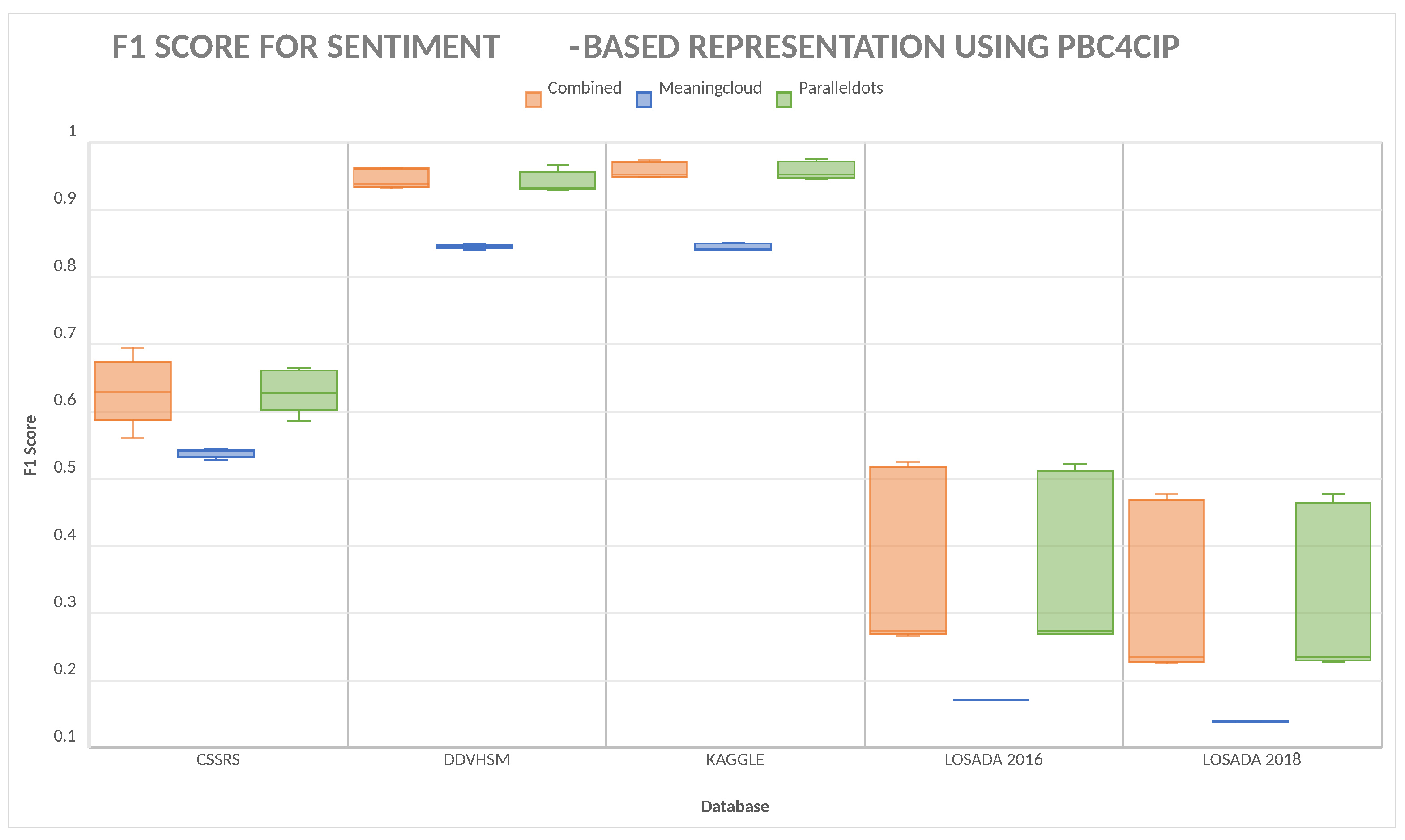
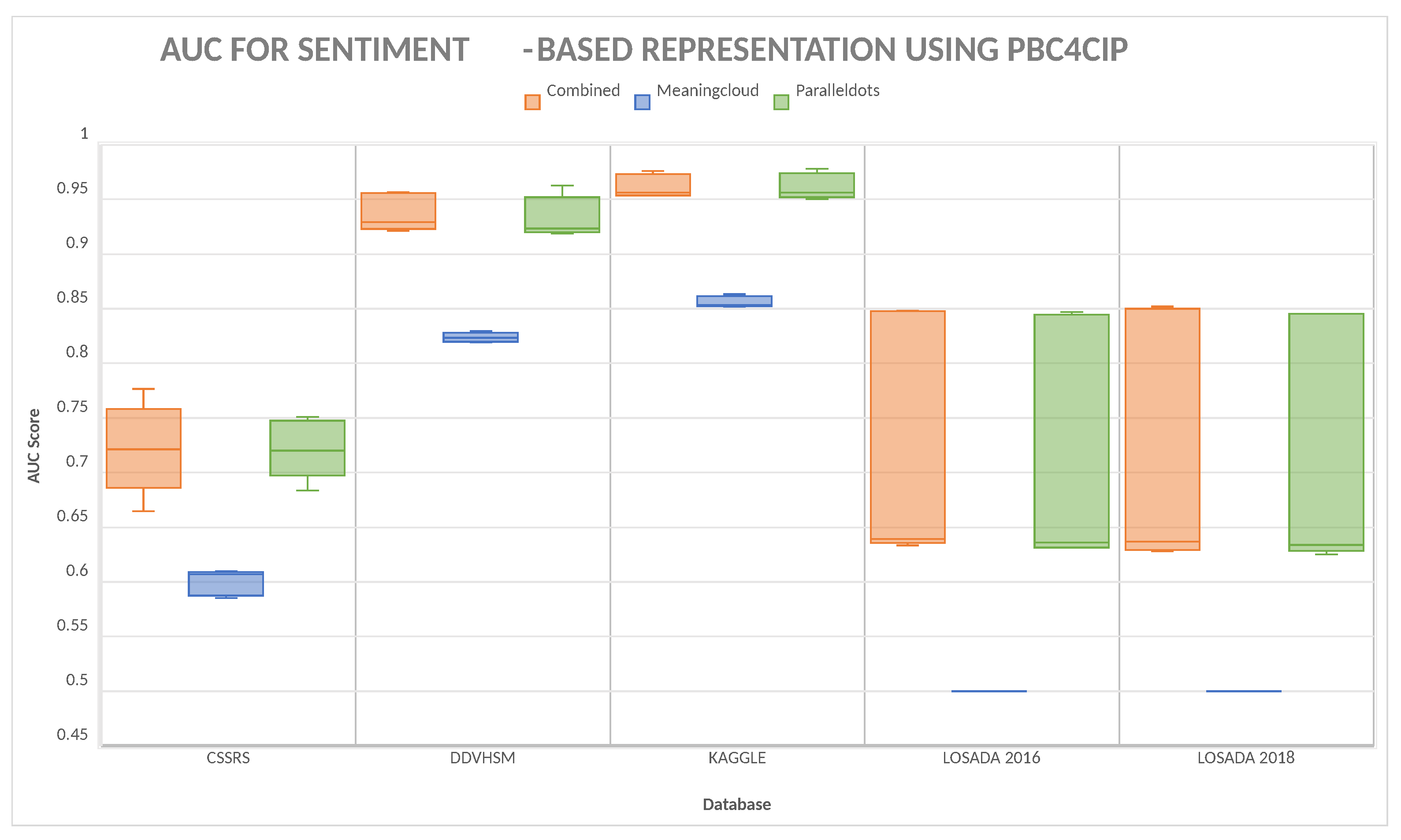
The first comparison we performed was between the three different representations proposed in this paper. As seen in
Figure 2 and
Figure 3, the worst performing representation is Meaningcloud in both metrics. This representation allows obtaining an average F1 score of 0.5076, having the best performance with the database of Kaggle with an average performance of 0.8459. The worst performance of this metric was with the LOSADA2018 database with an average performance of 0.1390. For the AUC, the worst performance is given by the Meaningcloud representation, having its best average performance of 0.8562 with Kaggle and its worst average performance of 0.5 with LOSADA2018; the predictions were not better than random predictions.
On the other hand, the best F1 performance was achieved by the combined representation with an average performance of 0.6457 taking into consideration all the databases. The best performance is with the database Kaggle with an average performance of 0.9586. The representation that gives the best AUC performance is again the combined representation, with its best average performance of 0.9621 with Kaggle and its worst average performance of 0.7170 with LOSADA2018.
It is important to denote that the difference between the results of the combined and Paralleldots representations has no significant difference in the F1 score, according to a Wilcoxon signed-ranks test [
62], which gives a p-value of 0.1416. Nevertheless, it does present a significant difference in the AUC metric with a p-value of 0.02444.
We chose combined as the best representation, given the results, and used it as the point of comparison with other representations and classifiers.
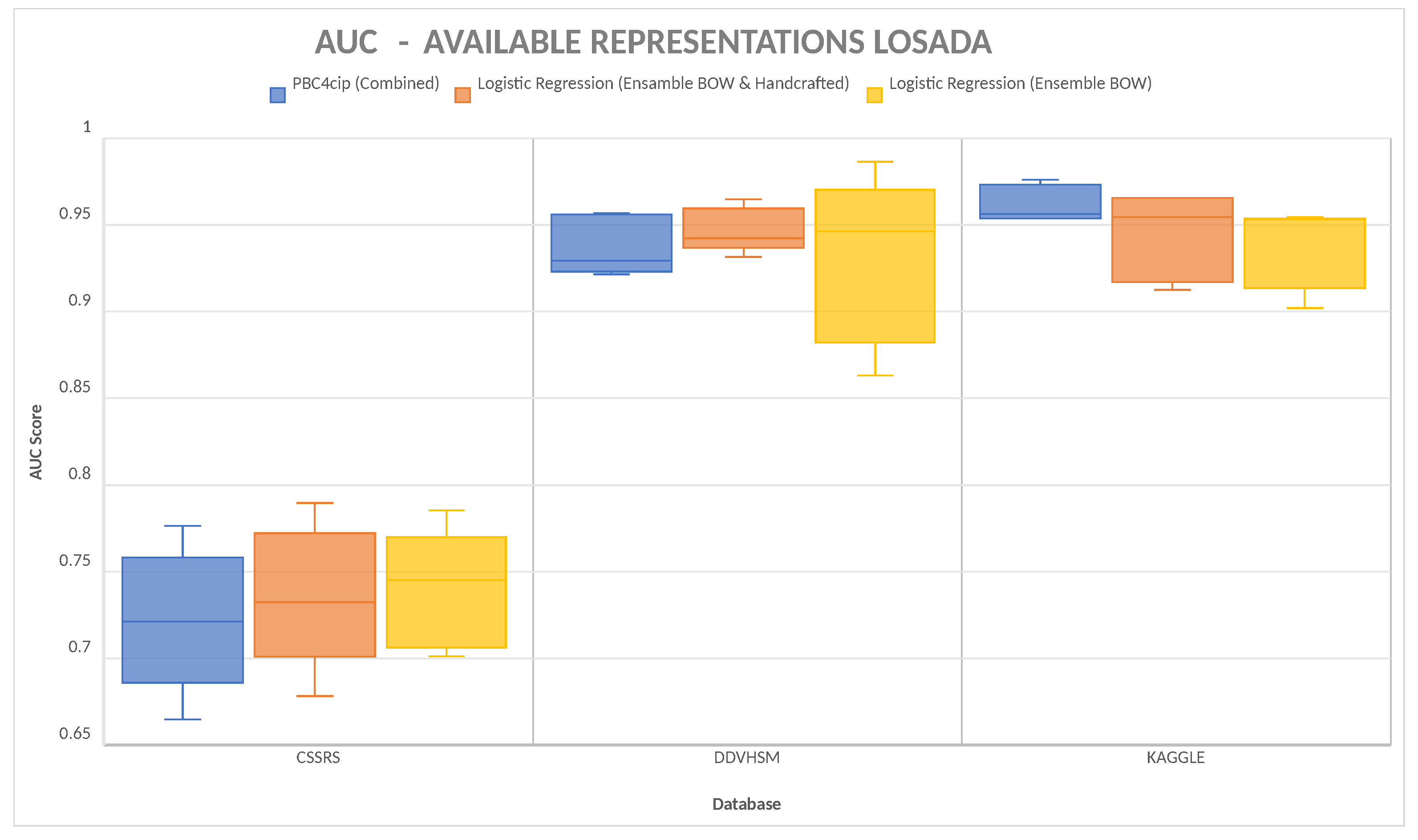
After determining the best representation using PBC4cip, we used that representation to compare it with the results of other proposals. Since we only have results for three of the five databases using the LOSADA2016 and LOSADA2018 representation and classification technique, the results are divided into two sets.
Figure 4 and
Figure 5 present the comparison between our representation and the representations of LOSADA2016 and LOSADA2018 for the available databases, which are CSSRS, DDVHSM, and Kaggle.
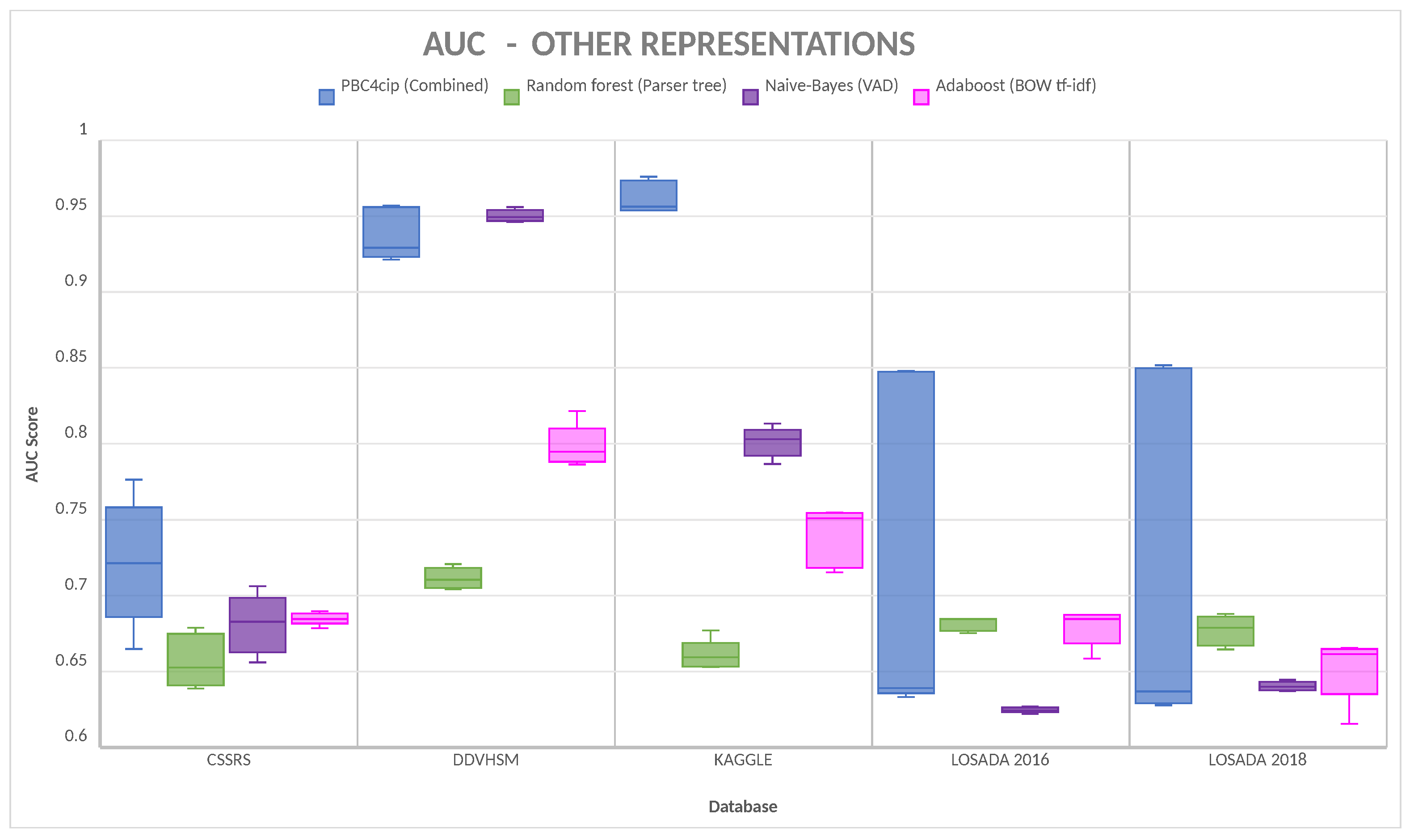
Figure 6 and
Figure 7 present the comparison between our representation and the representations of Parser tree, VAD, and BOW tf-idf for all databases.
4.3. LOSADA Representations
Figure 4 presents the available results of LOSADA2016 and LOSADA2018 representations. The three representation–classifier pairs perform better on the datasets DDVHSM and Kaggle and have a lower performance on CSSRS. The combined representation with PBC4cip performs better on DDVHSM and Kaggle with a mean performance of 0.9457 and 0.9586, respectively. On the other hand, the Ensemble of BOWs and Handcrafted features with logistic regression performs better on CSSRS with a mean performance of 0.6335.
As seen in
Figure 5, the same pattern is repeated when using AUC as the metric for performance. Nevertheless, using AUC, the Ensemble of BOWs and Handcrafted features with logistic regression performs better on both CSSRS and DDVHSM with a mean performance of 0.7357 and 0.9470, respectively. This contrasts with PBC4cip, which has a mean performance of 0.72191061 and 0.9375.
4.4. Other Models
As seen in
Figure 6, for both LOSADA2016 and LOSADA2018 databases, the VAD representation with Naive Bayes classification presents the worst performance in F1 score. On the other hand, for the DDVHSM database, it presents the best performance. For the CSSRS and Kaggle database, the tf-idf BOW using Ada Boost classification presents the worst performance but has a better performance in the LOSADA2016 and LOSADA2018 databases. For all databases except DDVHS, the best performance is given by the sentiment-based representation with PBC4cip.
Figure 7 shows that for AUC, VAD features using Naive Bayes classification present the worst performance for LOSADA2016 and LOSADA2018. It also shows that it has a higher performance in CSSRS, DDVHSM, and Kaggle databases, having the best performance in DDVHSM. The parser tree representation with Random Forest classification presents a similar performance in all databases in comparison with its counterparts.
As we have stated before, for all databases except DDVHSM, the best performance is given by sentiment-based representation with PBC4cip.
4.5. Wilcoxon Test
After obtaining and visually comparing the results, we performed a Wilcoxon signed-ranks test [
62] to assess whether there is a significant difference between the results of the different classifiers or not. We used this test because it is recommended in cases where the same models or subjects are assessed under more than one different condition. It is also recommended when what is being assessed is the definite numeric scores instead of nominal values [
63].
The Wilcoxon signed rank test has a null hypothesis and an alternative hypothesis , where and are the datasets that are being compared. We first have to subtract the values of one dataset from the other dataset, that is, . After that, we have to rank the absolute values of D in ascending order, that is, the smallest value of is number 1, and the highest value of is number n, where n is the number of values in the datasets.
We then add all the positive values of
D obtaining
and all the negative values of
D obtaining
. We obtain the Wilcoxon statistic using the following formula:
We obtain the Wilcoxon critical value using the Wilcoxon signed-ranked test quantiles table. After that, we compare and . If , then we reject the null hypothesis, meaning that there is a statistical difference between the datasets. On the other hand, if , we accept the null hypothesis, meaning that there is no statistical difference between the datasets.
Table 7 shows the mean of the scores obtained by each model per database. The values used for the Wilcoxon test were the results obtained per partition, for each database.
Table 8 shows the results obtained from the test. When comparing the models, we could see that the logistic regression classifier together with the Ensemble of BOWs and Handcrafted features performed better on some databases. Nevertheless, according to the Wilcoxon test performed, there is no significant difference between the F1 score and AUC of the sentiment-based representation together with PBC4cip. The results also show that there are classifiers and representations with which there is a significant difference. However, the difference proves an advantage of using sentiment-features with PBC4cip over the other classifiers. Moreover, PBC4cip provided patterns that explain the decisions taken by the classifiers. The features that are taken more into consideration by the model to classify a social media post as depressive or not depressive are as follows:
The emotions of sadness, excitement, anger, and boredom in the text.
The polarity of the text, especially whether the text is neutral or not.
The subjectivity of the text.
6. Conclusions and Future Work
Depression detection has become an essential task, as it has multiple risks to individuals, society, and economics. Due to the lack of specialists per patients, this task has become difficult and has escalated, becoming a global problem. Since there is a link between language and signs of depression, social media is used to detect depression, using users’ posts. The literature shows that most of these solutions provide a representation of text using objective features, such as the number of pronouns, the count of a certain word, or the use of certain phrases inside the text.
However, as far as we know, state-of-the-art proposals do not provide their result in a language close to the human expert, which is essential for helping decision makers in the application area. Hence, in this paper, we proposed a new representation of the text based on sentiment analysis and emotions to provide an understandable representation, allowing to discriminate depressive and non-depressive posts in a language close to that of human experts. The aim was to provide experts the information of social media to aid in the diagnosis of users, who may not know they have depression. We also proposed an understandable model based on our representation and pattern-based classification, obtaining both an understandable and accurate model for human experts.
Our proposed model outperforms most of the other five state-of-the-art models for depression detection. Additionally, it provides insights on the sentiment-features that define a depressive or a non-depressive post, providing more information to an expert or even the posts’ author. Moreover, based on the statistical tests and F1 and AUC metrics, our model statistically outperforms the Random Forest, Naive Bayes, and AdaBoost models using the parser-tree, VAD and Topics, and BOW representations. However, it obtains similar statistical results to the logistic regression models, using the ensemble of BOWs and handcrafted features representations. Consequently, we can conclude that our proposed model, as well as the representation based on sentiments and emotions, allows for providing the best classification results for predicting depressive posts.
In future work, we plan on exploring new representations, including features directly related to the medical symptoms of depression and fuzzy pattern classification. The assessment of psychology experts on the patterns and the subsequent interpretation is also part of our future work on this topic.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}