
Technique for Evaluating the Security of Relational Databases Based on the Enhanced Clements–Hoffman Model

 ,
,  ,
,
Abstract
:1. Introduction
- (a)
- To present a technique for evaluating the security of relational databases, the security system of which is based on the provisions of the enhanced theoretical Clements–Hoffman model, and the degree of security is calculated on the basis of a determined integral quantitative metric. This metric is the reciprocal of the total residual risk associated with the possibility of implementing threat in relation to a database object when using security measures;
- (b)
- To show the practical application of this technique for measuring the security of relational databases, including in order to identify a more secure one (in which solutions are used that provide a higher degree of database security).
2. Related Works
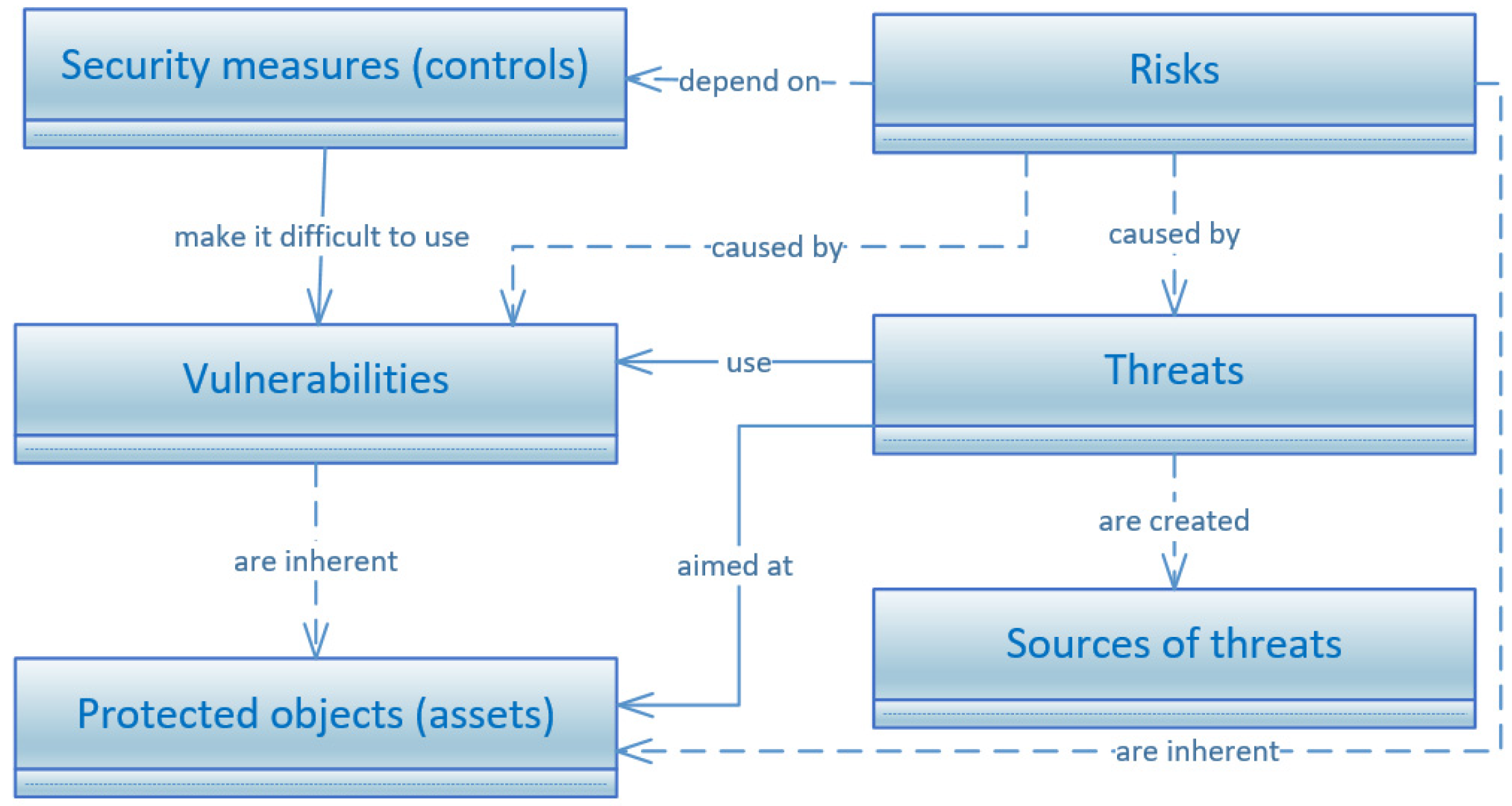
3. Enhanced Clements–Hoffman Model for Databases
- –
- , is the set of database security threats. According to studies [11,26,28,31,45,46,47], the main largest and most important threats (types of threats) to database security (to a greater extent they are associated with anthropogenic sources of threats—people or groups of persons, as a result of whose actions or inaction, the security of the considered system has been violated) are:
- ✓
- Excessive and unused privileges. For definiteness, let us designate this type of threat as ;
- ✓
- Privilege abuse—;
- ✓
- Input injection—;
- ✓
- Malware—;
- ✓
- Wweak audit trail—;
- ✓
- Storage media exposure—;
- ✓
- Exploitation of vulnerabilities and misconfigured databases—;
- ✓
- Unmanaged sensitive data—;
- ✓
- Inference—;
- ✓
- Denial of service—;
- ✓
- Limited security expertise and education—.
- –
- , is the set of protected database objects. Considering that database systems are information products with a dual nature (that is, consisting of two components (assets): DBMS software, independent of their scope, structure, semantic content of the accumulated and processed data, and the actual stored data), as well as the possible harmful effects on the corresponding assets, it is advisable to ensure the security of both components. For relational databases, as the most widespread (this thesis is confirmed by the results of DB-Engines and Popularity of Programming Language (PYPL) ratings [48,49], as well as reports of experts from the world-famous company Gartner, Inc. [50,51]), taking into account the possibility of various degrees of detail of these components, the following objects of protection can be distinguished [11,52]:
- ✓
- The entire database—;
- ✓
- Tables—;
- ✓
- Views—;
- ✓
- Tuples (rows) of tables—;
- ✓
- Separate fields (attribute values) of rows—;
- ✓
- Triggers—;
- ✓
- Persistent stored modules— and some others.
- –
- (1)
- Improper privilege management: incorrect assignment of privileges, elevation (escalation) of privileges, performing operations with excessive privileges;
- (2)
- Improper authorization: incorrect assignment of permissions for a critical resource, missing authorization, incorrect authorization, exposure of sensitive information through metadata, exposure of sensitive information through data queries. The authorization check is not performed or incorrectly performed when an actor attempts to access a resource or perform an action;
- (3)
- Improper authentication: weak password, outdated password, authentication bypass, incorrect implementation of the authentication algorithm, insufficient session expiration, use of a password hash instead of a password for authentication, etc.;
- (4)
- Uncontrolled resource consumption: the allocation of a limited resource is not properly controlled, thereby enabling an actor to influence the amount of resources consumed, which ultimately leads to their depletion;
- (5)
- Cleartext storage of sensitive information;
- (6)
- Inadequate encryption strength;
- (7)
- Improper scrubbing of sensitive data from decommissioned device: scrubbing may be missing, insufficient, or incorrect;
- (8)
- Use of a broken or risky cryptographic algorithm: use of a non-standard cryptographic primitive with no proven strength;
- (9)
- Use of insufficiently random values;
- (10)
- Insufficient verification of data authenticity: download of code without integrity check, improper validation of integrity check value, improper verification (no verification) of the cryptographic signature;
- (11)
- Improper input validation: improper validation of syntactic correctness of input data, improper validation of specified type of input data, improper validation of consistency within input, improper validation of unsafe equivalence in input. The input data are either not validated, or are incorrectly validated—without assurance that their use will not lead in the future to incorrect and unsafe data processing;
- (12)
- Use of prohibited code: functions, libraries, or third party components are used that has been explicitly prohibited, whether by the developer or the customer;
- (13)
- Embedded malicious code: Trojan horse, trapdoor, time bomb, logic bomb, spyware, etc.;
- (14)
- Violation of secure design principles: unnecessary complexity in the protection mechanism (a more complex mechanism is used than necessary); reliance on a single factor in a security decision; insufficient compartmentalization—functionality or processes that require different privilege levels, rights or permissions are not sufficiently separated; access check is not provided on a protected resource every time the resource is accessed by an entity; insufficient psychological acceptability (the difficulty and inconvenience of using the protection mechanism often encourages non-malicious users to disable or bypass it accidentally or deliberately); reliance on security through the obscurity (a defense mechanism is used, the strength of which heavily depends on its obscurity); imperfection of the mechanism for maintaining data integrity;
- (15)
- Incorrect provision of specified functionality: the code does not function according to its published specifications, potentially leading to incorrect usage;
- (16)
- Hidden functionality: there is functionality that is not documented, not part of the specification, and not accessible through an interface or command sequence. Hidden functionality can take many forms, including, for example, such as intentionally malicious code;
- (17)
- Incomplete documentation: there are no descriptions of all relevant elements of the product, such as its usage, structure, interfaces, design, implementation, configuration, operation, etc., which naturally complicates maintenance, indirectly affecting security due to lack of awareness, making it difficult to find and/or fixing vulnerabilities or taking a lot of time, which can also simplify the introduction of vulnerabilities;
- (18)
- Configuration error: non-compliance with safety requirements during the installation and configuration of the database. Administrative, auxiliary, educational accounts are installed, which are registered in the database by default without proper analysis and changing of default passwords, no limitations on the length and complexity of passwords are set, unused accounts are not blocked, critical updates are not installed, the event audit system is improperly configured, etc.
- –
- Thus, the Clements–Hoffman model was extended to a 6-tuple by including a set of vulnerabilities of objects, as a separate objectively existing category. This allows you to evaluate the probability of an unwanted incident and the security of the database as a whole more adequately. In addition, as a result of enhancing the Clements–Hoffman model, taking into account the dual nature of the relational database system and varying degrees of detail of its components, the following were determined: the main objects of protection;
- –
- The list of the main common weaknesses (as some types of vulnerabilities);
- –
- The main significant threats to the security of databases;
- –
- Integral metric of database security (as the reciprocal of the total residual risk).
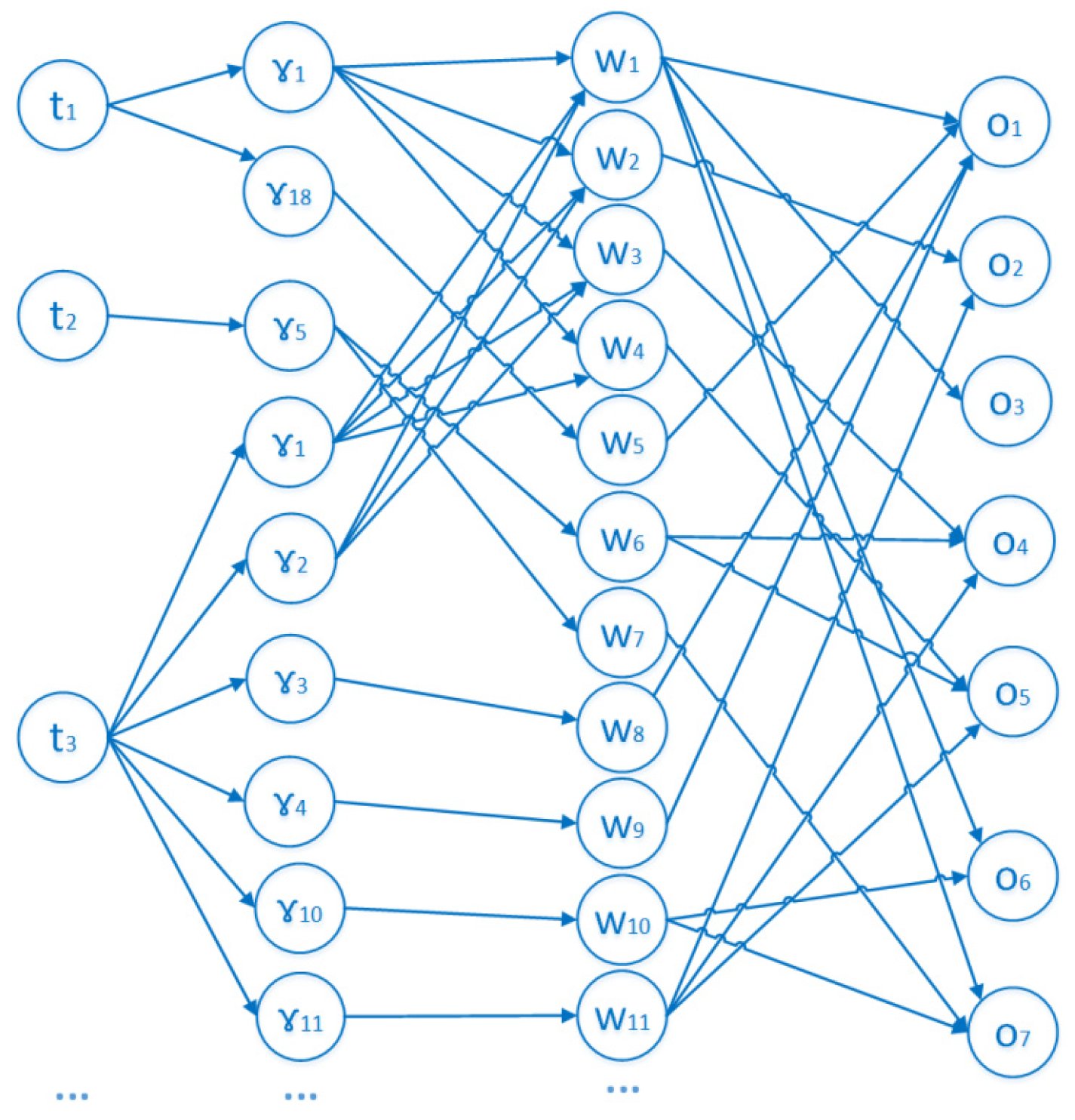
4. Evaluation Technique of Database Security
- –
- The probability of threat occurrence ();
- –
- The probability of exploiting the vulnerability ();
- –
- The amount of damage () in case of successful implementation of the threat in relation to the protected object;
- –
- The degree of security measure resistance (), characterized by the probability of overcoming it.
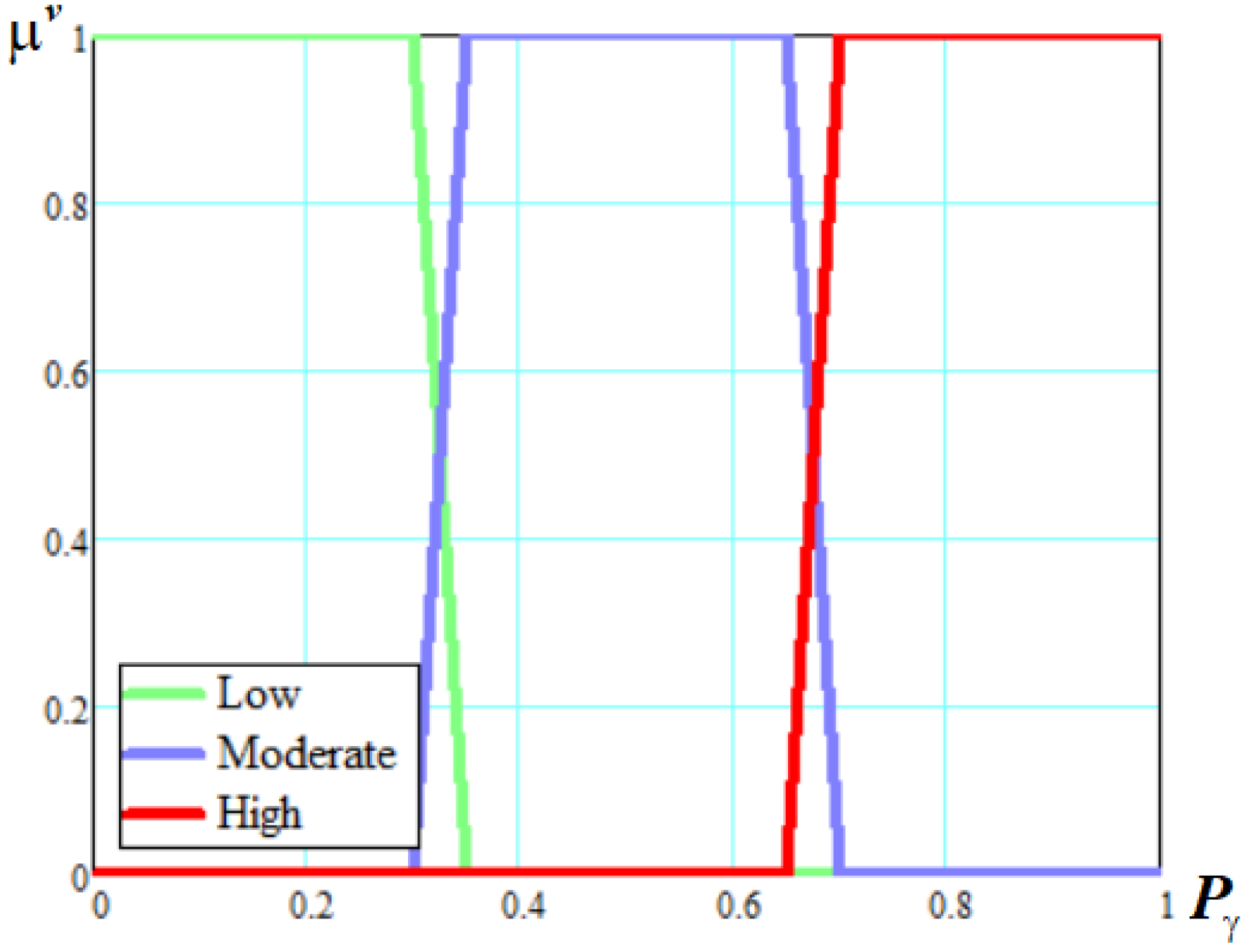
- –
- Low likelihood (L). This threat is unlikely to occur. There are no incidents, statistics, motives that would indicate that this can happen. The expected frequency of the threat does not exceed 1 time in 5 years;
- –
- Moderate likelihood (M). There are prerequisites for the emergence of a threat (there have been incidents in the past), there are statistics or other information indicating the possibility of a given threat, the attacker has the motivation to realize appropriate actions. The expected frequency of occurrence of this threat is approximately once a year;
- –
- High likelihood (H). There are objective prerequisites for the emergence of a threat. There are incidents, statistics, or other information indicating that the threat is most likely to realize, the attacker has motives to take appropriate action. The expected frequency of occurrence of a threat is on average once every four months or more often.
- –
- For level L—;
- –
- For level M—;
- –
- For level H—.
- –
- Linear Z-shaped membership function of a fuzzy set , corresponding to a fuzzy variable “L” for a linguistic variable :where are numeric parameters ();
- –
- Trapezoidal membership function of a fuzzy set corresponding to a fuzzy variable “M” for a linguistic variable :where are numeric parameters ();
- –
- Linear S-shaped membership function of a fuzzy set corresponding to a fuzzy variable “H” for a linguistic variable :where are numeric parameters ().
- –
- High (H). The vulnerability is easy to exploit and there is weak protection or no protection at all. The likelihood of exploiting a vulnerability (the likelihood of successful implementation of a threat due to a given vulnerability) is in the range [0.7, 1];
- –
- Moderate (M). The vulnerability can be exploited, but there is some protection. The likelihood of exploiting a vulnerability is in the range [0.3, 0.7];
- –
- Low (L). The vulnerability is difficult to exploit and there is good protection. The likelihood of exploiting a vulnerability is in the range [0, 0.3].
- –
- H is the high degree of security measure (mechanism) resistance (high level of control). It is unlikely that such a mechanism will be overcome. The likelihood of overcoming (bypassing) such a mechanism is in the range .
- –
- M is the moderate degree of security measure resistance. This measure provides some protection, but it is possible to overcome it, spending some effort. The likelihood of overcoming the corresponding security measure is in the range [0.4, 0.8].
- –
- L is the low degree of security measure resistance. This measure is quite easy to overcome. The likelihood of overcoming the corresponding security measure is in the range [0.8, 1].
5. Quantifying Database Security
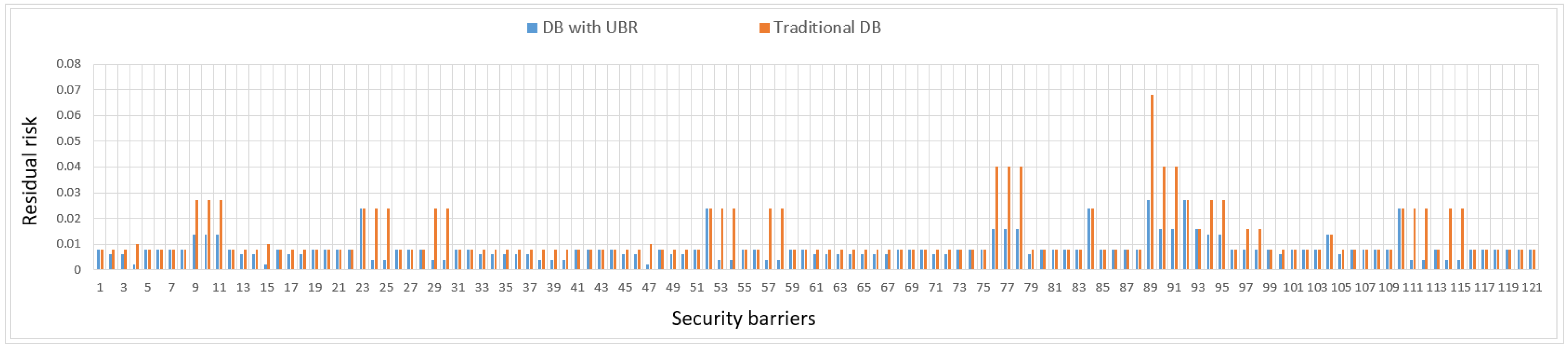
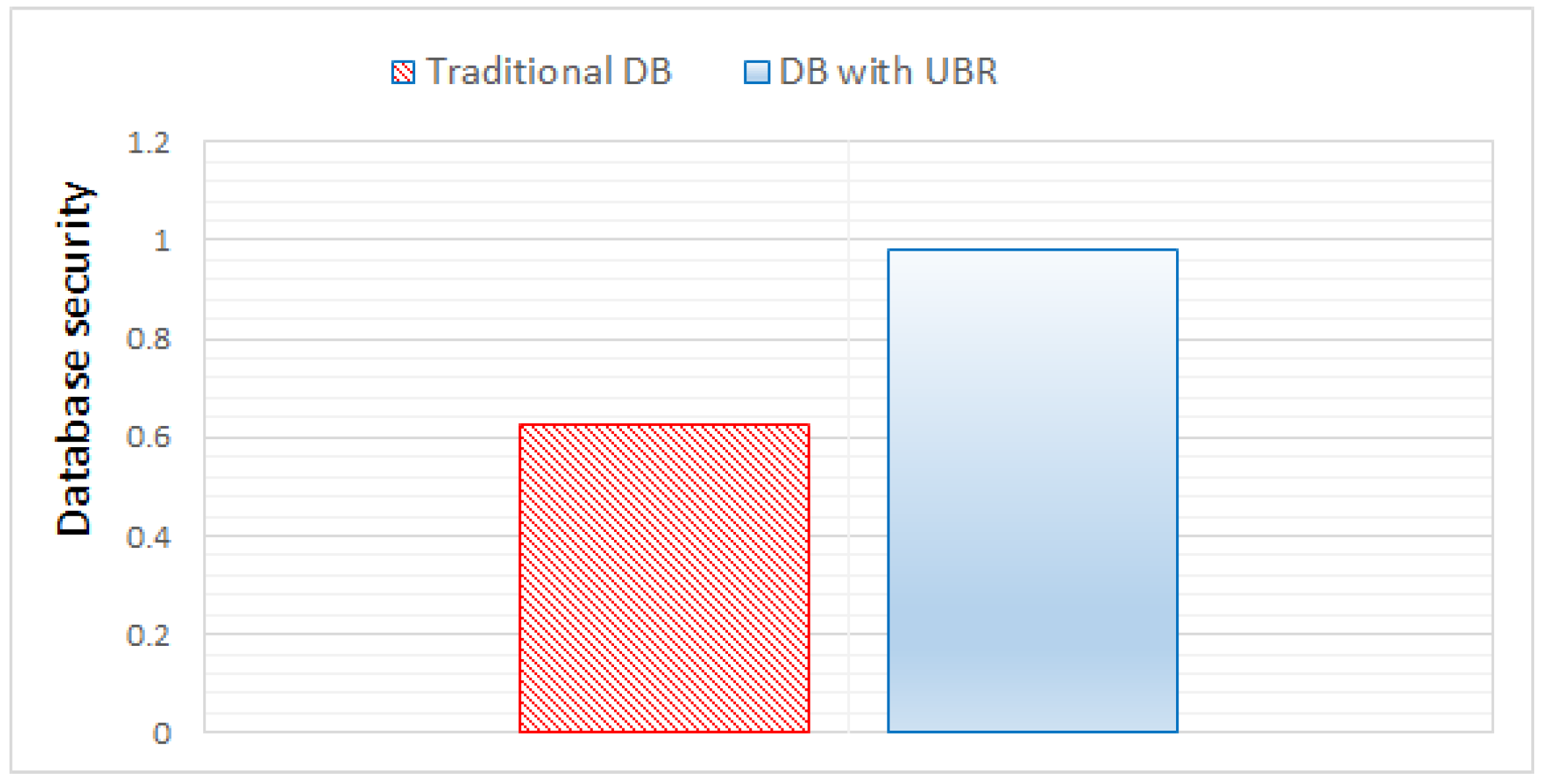
- As the studied databases, we consider databases designed based on the schema with the universal basis of relations and according to the traditional technology of relational databases.
- In the DB with UBR, which can be used as an ordinary DB, a data warehouse of various subject domains (SDs) or a configuration DB of the dataspace management environment [73,74,75], various security measures are implemented [76,77,78,79,80]. These measures are based on the provisions of the theory of relational databases [8,30,81], formal access control models [82,83] and ensuring data integrity [84], the potential of the modern blockchain model [85,86], row-level security (RLS) technology [87], SQL capabilities [45]. Separate elements of these solutions can be used to protect databases and data warehouses with various models (relational, NoSQL, NewSQL [12,39,82,88,89,90,91]). However, in this case, for traditional RDBs, which are investigated below, these measures were not implemented.
- It is believed that the likelihoods: is the likelihood of occurrence of the corresponding threats () and is the likelihood of exploitation the corresponding vulnerabilities () in relation to specific protected objects (,) are the same for the compared databases.
- Evaluation of the residual risk for the compared databases is carried out for the case of a “Low” amount of damage (damage level-2; Table 1 and Table 2) with a relative value of possible financial losses amounting to 0.2 (, where , are the numerical values (relative) values of damage for a database with UBR and traditional database, respectively).
- As security measures/controls (), some generalized solutions are used associated with a certain process, policy, device, established practice and other actions aimed at modifying the risk, namely:
- –
- —means that allow to identify and remove incorrectly assigned privileges. Such, for example, as: audit tools, utilities, scripts used by the database administrator (DBA) for aggregating user rights into a single repository, collecting information about users, their roles and behavior, as well as data privacy, identifying users who have too many privileges and users who do not use their rights, viewing and approving/rejecting the individual rights of users, tracking all actions to access the database, real-time alerts and blocking, detecting unusual access activity, etc.;
- –
- —tools provided by the DBMS and special developed means in the DB schema with UBR (means that ensure the maintenance of a special log-table of the modified data, the formation of data for a special table of users and some others [76]), allowing to identify and eliminate incorrectly assigned privileges;
- –
- —tools provided by the DBMS and special developed means in the DB schema with UBR (means providing the formation of data from a special table of the access privilege distribution to the data of other users and some others [76]), allowing to identify and eliminate incorrectly assigned privileges;
- –
- —tools provided by the DBMS and special developed means in the DB schema with UBR (means providing the data formation from a special table of restrictions on access rights to a specific data element and some others [76]), allowing to identify and eliminate incorrectly assigned privileges;
- –
- —means that allow to identify and eliminate excessive privileges; detect vulnerabilities, missing patches from vendors; inactive accounts, modify default passwords; properly configure the event auditing system, including tracking unusual user access activity, etc. Timely installation of patches or the use of virtual patches to protect the database;
- –
- —means that allow detecting unusual user access activity and complicating the leakage of confidential data from database tables (including the use of means for masking data provided by the DBMS and proposed in [79]; the usage of means of restricting access rights to a specific data element [76] implemented in the DB with UBR);
- –
- —means to detect unusual user access activity and complicate code disclosure of confidential persistent modules (including the use of means for masking data provided by the DBMS and proposed in [77]);
- –
- —means that allow to identify and eliminate incorrectly assigned privileges, detect vulnerabilities, inappropriate session duration, improper implementation of the algorithm, authentication protocol, settings. Timely installation of critical updates or the use of virtual patches to protect the database from attempts to exploit vulnerabilities until a full-fledged and permanent patch is deployed;
- –
- —means that allow controlling resource consumption (for example, through the profile mechanism—a named set of resource restrictions that can be used by the user);
- –
- —means that allow controlling the integrity of the trigger code and persistent stored modules, including those based on the potential of the modern blockchain model proposed in [78] and implemented in a DB with UBR;
- –
- —using parameterized queries, stored procedures, least privileges; escaping user input; converting data types to the type that was assumed by the logic of the program, checking the data entered by the user for compliance with the allowed character sequences;
- –
- —maintenance of the list of “prohibited” functions, procedures, the usage of which should be avoided;
- –
- − —anti-virus software;
- –
- –
- —means that implement security models based on: discretionary, mandatory, role-based, attribute policy, including those specific to a database with UBR [76];
- –
- —special documented diagnostic functions capable of identifying the causes of defects caused by the incorrect formation of primary keys, entering incorrect data, inadmissible entry, deletion, modification of data, unauthorized access to data, unauthorized changes to the database schema with UBR and its objects (including using the capabilities of blockchain technology [78]); special triggers that can be used to intercept and log operations performed in the database; DBMS audit tools;
- –
- —audit means built into the DBMS, including specially developed means in the DB schema with UBR (means that ensure the maintenance of a special log-table of the modified data);
- –
- —masking data of tables based on the approach described in [79];
- –
- —masking of stored objects using the means provided by the DBMS, as well as based on the approach described in [77];
- –
- —using transparent data encryption (TDE) and cryptographically strong primitives built into the DBMS as well as national encryption standards (for example, the symmetric block cipher “Kalyna” from the national standard of Ukraine DSTU 7624: 2014);
- –
- —timely installation of critical updates, monitoring of the cryptographic strength of the used implementations of encryption algorithms and randomness of numbers generated by pseudo-random number generators (PRNG) that meet the specified requirements;
- –
- —database administrator tools built into the DBMS, as well as specially developed scripts that simplify the work of the DBA;
- –
- —detailed documentation on the DBMS, DB with a description of all its corresponding elements, their use, including all the main components of the DB schema with UBR;
- –
- —audit, blocking a response if the number of requests is incorrect.
6. Conclusions
- –
- Identified the main significant threats to the security of databases;
- –
- The main protected objects are determined taking into account the dual nature of the relational database system and the various degrees of detail of its components.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Abadi, D.; Agrawal, R.; Ailamaki, A.; Balazinska, M.; Bernstein, P.A.; Carey, M.J.; Chaudhuri, S.; Dean, J.; Doan, A.; Franklin, M.J.; et al. The Beckman Report on Database Research. ACM SIGMOD Rec. 2014, 43, 61–70. [Google Scholar] [CrossRef] [Green Version]
- Abadi, D.; Ailamaki, A.; Andersen, D.; Bailis, P.; Balazinska, M.; Bernstein, P.; Boncz, P.; Chaudhuri, S.; Cheung, A.; Doan, A.; et al. The Seattle Report on Database Research. ACM SIGMOD Rec. 2020, 48, 44–53. [Google Scholar] [CrossRef] [Green Version]
- ISO/IEC 25010:2011 Systems and Software Engineering. Systems and Software Quality Requirements and Evaluation (SQuaRE). System and Software Quality Models. Available online: https://www.iso.org/standard/35733.html/ (accessed on 21 September 2021).
- Latham, D.C. Department of Defense Trusted Computer System Evaluation Criteria; Department of Defense: Arlington, VA, USA, 1986. Available online: http://csrc.nist.gov/publications/history/dod85.pdf (accessed on 21 September 2021).
- Commission of the European Communities. Information Technology Security Evaluation Criteria (ITSEC): Provisional Evaluation Criteria. Document COM(90) 314, Version 1.2. Available online: https://www.ssi.gouv.fr/uploads/2015/01/ITSEC-uk.pdf (accessed on 21 September 2021).
- ISO/IEC 21827:2008 Information Technology. Security Techniques. Systems Security Engineering. Capability Maturity Model® (SSE-CMM®). Available online: https://www.iso.org/obp/ui/#iso:std:iso-iec:21827:ed-2:v1:en (accessed on 21 September 2021).
- Common Criteria for Information Technology Security Evaluation Part 1: Introduction and General Model. Version 3.1 Revision 5 CCMB-2017-04-001. Available online: https://www.commoncriteriaportal.org/files/ccfiles/CCPART1V3.1R5.pdf (accessed on 21 September 2021).
- Jansen, W.; Gallagher, P.D. NISTIR 7564. Directions in Security Metrics Research. Available online: https://nvlpubs.nist.gov/nistpubs/legacy/ir/nistir7564.pdf (accessed on 21 September 2021).
- Juma, J.; Makupi, D. Understanding Database Security Metrics: A Review. Mara Int. J. Sci. Res. Publ. 2017, 1, 40–48. [Google Scholar]
- NIST Special Publication 800-55 Revision 1. 2008. Available online: https://csrc.nist.gov/publications/detail/sp/800-55/rev-1/final (accessed on 21 September 2021).
- Sandhu, R.S.; Jajodia, S. Data and Database Security and Controls. In Handbook of Information Security Management; Auerbach Publishers: Boca Raton, FL, USA, 1993; pp. 481–499. [Google Scholar]
- Date, C.J. An Introduction to Database Systems, 8th ed.; Pearson Education Inc.: New York, NY, USA, 2004. [Google Scholar]
- Neto, A.A.; Vieira, M.; Madeira, H. An appraisal to assess the security of database configurations. In Proceedings of the Second International Conference on Dependability, Athens, Greece, 18–23 June 2009; pp. 73–80. [Google Scholar] [CrossRef]
- Oracle. Database Security Assessment Tool User Guide. Available online: https://docs.oracle.com/en/database/oracle/security-assessment-tool/2.2.2/satug/index.html#UGSAT-GUID-C7E917BB-EDAC-4123-900A-D4F2E561BFE9 (accessed on 21 September 2021).
- Yesin, V.I.; Karpinski, M.P.; Yesina, M.V.; Vilihura, V.V. Formalized Representation for the Data Model with the Universal Basis of Relations. Int. J. Comput. 2019, 18, 453–460. [Google Scholar] [CrossRef]
- Savola, R.M. A Security Metrics Taxonomization Model for Software-Intensive Systems. J. Inf. Process. Syst. 2009, 5, 197–206. [Google Scholar] [CrossRef] [Green Version]
- Savola, R.M. Towards Measurement of Security Effectiveness Enabling Factors in Software Intensive Systems. Lect. Notes Softw. Eng. 2014, 2, 104–109. [Google Scholar] [CrossRef]
- Pendleton, M.; Garcia-Lebron, R.; Cho, J.-H.; Xu, S. A Survey on Systems Security Metrics. ACM Comput. Surv. 2017, 49, 1–35. [Google Scholar] [CrossRef] [Green Version]
- Bernik, I.; Prislan, K. Measuring Information Security Performance with 10 by 10 Model for Holistic State Evaluation. PLoS ONE 2016, 11, e0163050. [Google Scholar] [CrossRef] [Green Version]
- Kong, H.-K.; Kim, T.-S.; Kim, J. An analysis on effects of information security investments: A BSC perspective. J. Intell. Manuf. 2010, 23, 941–953. [Google Scholar] [CrossRef]
- Jacobs, M.A. Complexity: Toward an empirical measure. Technovation 2013, 33, 111–118. [Google Scholar] [CrossRef]
- Savola, R.M. Quality of security metrics and measurements. Comput. Secur. 2013, 37, 78–90. [Google Scholar] [CrossRef]
- Yasasin, E.; Schryen, G. Requirements for IT Security Metrics—An Argumentation Theory Based Approach. In European Conference on Information Systems—ECIS; Completed Research Paper; Paper 208; ECIS: Münster, Germany, 2015. [Google Scholar]
- Katt, B.; Prasher, N. Quantitative security assurance metrics: REST API case studies. In Proceedings of the 12th European Conference on Software Architecture: Companion Proceedings, Madrid, Spain, 24–28 September 2018; pp. 1–7. [Google Scholar]
- Sanders, W.H. Quantitative Security Metrics: Unattainable Holy Grail or a Vital Breakthrough within Our Reach? IEEE Secur. Priv. Mag. 2014, 12, 67–69. [Google Scholar] [CrossRef]
- Sarmah, S. Database Security—Threats & Prevention. Int. J. Comput. Trends Technol. (IJCTT) 2019, 67, 46–50. [Google Scholar]
- Awadallah, R.; Samsudin, A. Using Blockchain in Cloud Computing to Enhance Relational Database Security. IEEE Access 2021, 9, 137353–137366. [Google Scholar] [CrossRef]
- Pfleeger, C.P.; Pfleeger, S.L.; Margulies, J. Security in Computing, 5th ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2015. [Google Scholar]
- Mousa, A.; Karabatak, M.; Mustafa, T. Database security threats and challenges. In Proceedings of the 8th International Symposium on Digital Forensics and Security (ISDFS), Beirut, Lebanon, 1–2 June 2020; pp. 1–5. [Google Scholar]
- Connolly, T.M.; Begg, C.E. Database Systems: A Practical Approach to Design, Implementation, and Management; Pearson Education Limited: London, UK, 2015. [Google Scholar]
- Kulkarni, S.; Urolagin, S. Review of attacks on databases and database security techniques. Int. J. Emerg. Technol. Adv. Eng. 2012, 2, 2250–2459. [Google Scholar]
- Mishra, S.; Morris, R.; Chasalow, L. Information security effectiveness: A research framework. Issues Inf. Syst. 2011, 12, 246–255. [Google Scholar]
- Fabian, B.; Gürses, S.; Heisel, M.; Santen, T.; Schmidt, H. A comparison of security requirements engineering methods. Requir. Eng. 2009, 15, 7–40. [Google Scholar] [CrossRef]
- Hoffman, L.J. Modern Methods for Computer Security and Privacy; Prentice-Hall, Inc.: Englewood Cliffs, NJ, USA, 1977. [Google Scholar]
- Hoffman, L.J.; Clements, D. Fuzzy Computer Security Metrics: A Preliminary Report; Electronics Research Laboratory, College of Engineering University of California: Berkeley, CA, USA, 1977; Available online: https://www2.eecs.berkeley.edu/Pubs/TechRpts/1977/ERL-m-77-6.pdf (accessed on 21 September 2021).
- Anishchanka, U.V.; Krishtophic, A.M. Methods of evaluating the effectiveness of protecting the assets in information technology objects. Informatika 2004, 3, 95–105. [Google Scholar]
- Maslova, N.A. Methods for assessing the effectiveness of information systems protection systems. Artif. Intell. 2008, 4, 253–264. [Google Scholar]
- Domarev, V.V. Information Technology Security. Systems Approach; OOO «TID «DS»: Kyiv, Ukraine, 2004. [Google Scholar]
- Hoffmann, R.; Kiedrowicz, M.; Stanik, J. Evaluation of information safety as an element of improving the organization’s safety management. In Proceedings of the 20th International Conference on Circuits, Systems, Communications and Computers (CSCC 2016), MATEC Web of Conferences, Corfu Island, Greece, 14–17 July 2016; Volume 76, p. 04011. [Google Scholar] [CrossRef] [Green Version]
- Kiedrowicz, M.; Stanik, J. Method for assessing efficiency of the information security management system. In Proceedings of the 22nd International Conference on Circuits, Systems, Communications and Computers (CSCC 2018), MATEC Web of Conferences, Majorca, Spain, 14–17 July 2018; Volume 210, p. 04011. [Google Scholar] [CrossRef] [Green Version]
- Lee, M.-C. Information Security Risk Analysis Methods and Research Trends: AHP and Fuzzy Comprehensive Method. Int. J. Comput. Sci. Inf. Technol. 2014, 6, 29–45. [Google Scholar] [CrossRef]
- ISO/IEC 15408-1:2009. Information Technology. Security Techniques. Evaluation Criteria for IT Security. Part 1: Introduction and General Model. Available online: https://www.iso.org/standard/50341.html (accessed on 21 September 2021).
- ISO/IEC 27001:2013. Information Technology. Security Techniques. Information Security Management Systems. Requirements. Available online: https://www.iso.org/standard/54534.html (accessed on 21 September 2021).
- ISO/IEC 27004:2016. Information Technology. Security Techniques. Information Security Management. Monitoring, Measurement, Analysis and Evaluation. Available online: https://www.iso.org/standard/64120.html (accessed on 21 September 2021).
- Rohilla, S.; Mittal, P.K. Database Security: Threads and Challenges. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2013, 3, 810–813. [Google Scholar]
- Imperva Whitepaper. Top Ten Database Security Threats. 2015. Available online: https://informationsecurity.report/Resources/Whitepapers/e763d022-6ee4-4215-9efd-1896b0d9c381_wp_topten_database_threats%20imperva.pdf (accessed on 21 September 2021).
- Imperva Whitepaper. Top 5 Database Security Threats. 2016. Available online: https://www.imperva.com/docs/gated/WP_Top_5_Database_Security_Threats.pdf (accessed on 21 September 2021).
- DB-Engines Ranking. Available online: https://db-engines.com/en/ranking (accessed on 21 September 2021).
- TOPDB Top Database Index. Available online: https://pypl.github.io/DB.html (accessed on 21 September 2021).
- Adrian, M.; Feinberg, D.; Heudecker, N. Gartner Magic Quadrant for Operational Database Management Systems. ID G00376881. Available online: https://www.gartner.com/en/documents/3975492/magic-quadrant-for-operational-database-management-syste (accessed on 21 September 2021).
- Adrian, M.; Feinberg, D.; Greenwald, R.; Ronthal, A.; Cook, H. Critical Capabilities for Cloud Database Management Systems for Operational Use Cases. ID G00468197. Available online: https://www.oracle.com/explore/adw-ocom/gartner-cloud-database-management/?source=:ow:o:p:mt:::RC_WWMK200720P00100:Gartnerdatabase&intcmp=:ow:o:p:mt:::RC_WWMK200720P00100:Gartnerdatabase&lb-mode=overlay (accessed on 21 September 2021).
- Groff, J.; Weinberg, P.; Oppel, A. SQL: The Complete Reference, 3rd ed.; McGraw-Hill, Inc.: New York, NY, USA, 2010. [Google Scholar]
- Talabis, M.; Martin, J. Information Security Risk Assessment Toolkit Practical Assessments through Data Collection and Data Analysis; Syngress: Waltham, MA, USA, 2012. [Google Scholar]
- Whitman, M.E.; Mattord, H.J. Principles of Information Security, 6th ed.; Cengage Learning: Boston, MA, USA, 2017. [Google Scholar]
- NIST Special Publication 800-53 Revision 5. Security and Privacy Controls for Information Systems and Organizations; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2020. [CrossRef]
- ISO/IEC 27002:2013 Information Technology. Security Techniques. Code of Practice for Information Security Controls. Available online: https://www.iso.org/standard/54533.html (accessed on 21 September 2021).
- ISO/IEC 27000:2018 Information Technology. Security Techniques. Information Security Management Systems. Overview and Vocabulary. Available online: https://www.iso.org/standard/73906.html (accessed on 21 September 2021).
- Astakhov, A.M. The Art of Information Risk Management; DMK Press: Moscow, Russia, 2010. [Google Scholar]
- MITRE. CWE VIEW: Research Concepts. Available online: https://cwe.mitre.org/data/definitions/1000.html (accessed on 21 September 2021).
- Astakhov, A. Analysis of the Security of Corporate Systems; Open System DBMS: Moscow, Russia, 2002; pp. 7–8. Available online: https://www.osp.ru/os/2002/07-08/181720 (accessed on 21 September 2021).
- Averchenkov, V.I.; Rytov, M.Y.; Gainulin, T.R. Optimization of the choice of the composition of the means of engineering and technical information protection based on the Clements-Hoffman model. Bull. Bryansk State Tech. Univ. 2008, 1, 61–66. [Google Scholar]
- Karpychev, V.Y. Economic analysis of normative and technical support of information security. Econ. Anal. Theory Pract. 2011, 35, 2–18. [Google Scholar]
- Burtescu, E. Database security—Attacks and control methods. J. Appl. Quant. Methods 2009, 4, 449–454. [Google Scholar]
- Arkhipov, A.E. Expert-analytical assessment of information risks and the efficiency level of the information protection system. Radio Electron. Comput. Sci. Control 2009, 2, 111–115. [Google Scholar]
- Zadeh, L.A. The concept of a linguistic variable and its application to approximate reasoning—I. Inf. Sci. 1975, 8, 199–249. [Google Scholar] [CrossRef]
- Petrenko, S.A.; Simonov, S.V. Information Risk Management. Economically Justified Safety; DMK Press: Moscow, Russia, 2004. [Google Scholar]
- NIST Special Publication 800-30 Revision 1. Guide for Conducting Risk Assessments. Available online: https://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication800-30r1.pdf (accessed on 21 September 2021).
- Kornienko, A.A.; Nikitin, A.B.; Diasamidze, S.V.; Kuz’menkova, E.Y. Simulation of computer attacks on distributed software. Bull. St. Petersburg State Transp. Univ. 2018, 15, 613–628. [Google Scholar]
- FSTEC Russia. Methodology for Determining Current Threats to the Security of Personal Data during Their Processing in Personal Data Information Systems. Available online: https://fstec.ru/tekhnicheskaya-zashchita-informatsii/dokumenty/114-spetsialnye-normativnye-dokumenty/380-metodika-opredeleniya-aktualnykh-ugroz-bezopasnosti-personalnykh-dannykh-pri-ikh-obrabotke-v-informatsionnykh-sistemakh-personalnykh-dannykh-fstek-rossii-2008-god (accessed on 21 September 2021).
- Leonenkov, A.V. Fuzzy Modeling in MATLAB and Fuzzytech; BHV Petersburg: Sankt-Petersburg, Russia, 2005. [Google Scholar]
- Kruglov, V.V.; Dli, M.I.; Golunov, R.Y. Fuzzy Logic and Artificial Neural Networks; Fizmatlit: Moscow, Russia, 2001. [Google Scholar]
- Piegat, A. Fuzzy Modeling and Control; Physica-Verlag: Heidelberg, Germany, 2001. [Google Scholar]
- Yesin, V.I.; Vilihura, V.V. Method for Development of Databases Easily Adaptable to Variations in The Subject Domain. Telecommun. Radio Eng. 2019, 78, 595–605. [Google Scholar] [CrossRef]
- Yesin, V.I.; Karpinski, M.; Yesina, M.V.; Vilihura, V.V.; Veselska, O.; Wieclaw, L. Approach to Managing Data From Diverse Sources. In Proceedings of the 10th IEEE International Conference on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications (IDAACS), Metz, France, 18–21 September 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Franklin, M.; Halevy, A.; Maier, D. From databases to dataspaces: A new abstraction for information management. ACM SIGMOD Rec. 2005, 34, 27–33. [Google Scholar] [CrossRef]
- Yesin, V.I.; Yesina, M.V.; Rassomakhin, S.G.; Karpinski, M. Ensuring Database Security with the Universal Basis of Relations. In CISIM 2018: Computer Information Systems and Industrial Management; Lecture Notes in Computer Science, 11127; Saeed, K., Homenda, W., Eds.; Springer: Cham, Switzerland, 2018; Chapter 42; pp. 510–522. [Google Scholar] [CrossRef]
- Yesin, V.; Karpinski, M.; Yesina, M.; Vilihura, V.; Warwas, K. Hiding the Source Code of Stored Database Programs. Information 2020, 11, 576. [Google Scholar] [CrossRef]
- Yesin, V.I.; Yesina, M.V.; Vilihura, V.V.; Yesin, V. Monitoring the integrity and authenticity of stored database objects. Telecommun. Radio Eng. 2020, 79, 1029–1054. [Google Scholar] [CrossRef]
- Yesin, V.; Vilihura, V.; Yesin, V. Some approach to data masking as means to counteract the inference threat. Radiotekhnika 2019, 3, 113–130. [Google Scholar] [CrossRef] [Green Version]
- Yesin, V.; Karpinski, M.; Yesina, M.; Vilihura, V.; Warwas, K. Ensuring Data Integrity in Databases with the Universal Basis of Relations. Appl. Sci. 2021, 11, 8781. [Google Scholar] [CrossRef]
- Sadalage, P.J.; Fowler, M. NoSQL Distilled: A Brief Guide to the Emerging World of Polyglot Persistence; Pearson Education: London, UK, 2013. [Google Scholar]
- Harrison, M.A.; Ruzzo, W.L.; Ullman, J.D. Protection in operating systems. Commun. ACM 1976, 19, 461–471. [Google Scholar] [CrossRef]
- Lipton, R.J.; Snyder, L. A Linear Time Algorithm for Deciding Subject Security. J. ACM 1977, 24, 455–464. [Google Scholar] [CrossRef]
- Clark, D.D.; Wilson, D.R. A Comparison of Commercial and Military Computer Security Policies. In Proceedings of the IEEE Symposium on Research in Security and Privacy (SP’87), Oakland, CA, USA, 27–29 April 1987; IEEE Press: Oakland, CA, USA, 1987; pp. 184–193. [Google Scholar]
- Bashir, I. Mastering Blockchain: Distributed Ledger Technology, Decentralization, and Smart Contracts Explained, 2nd ed.; Packt Publishing: Birmingham, UK, 2018. [Google Scholar]
- Antonopoulos, A.M. Mastering Bitcoin: Programming the Open Blockchain, 2nd ed.; O’Reilly Media: Sebastopol, CA, USA, 2017. [Google Scholar]
- Cotner, C.; Miller, R.L. International Business Machines Corporation. Row-Level Security in a Relational Database Management System. US Patent 8,478,713 B2, 16 January 2018. N 15/343,568. [Google Scholar]
- Meier, A.; Kaufmann, M. SQL & NoSQL Databases. Databases Models, Languages, Consistency Options and Architectures for Big Data Management; Springer Fachmedien: Wiesbaden, Germany, 2019. [Google Scholar] [CrossRef]
- Harrison, G. Next Generation Databases: NoSQL, NewSQL, and Big Data; Apress: Berkeley, CA, USA, 2015. [Google Scholar]
- Pavlo, A.; Aslett, M. What’s Really New with NewSQL? ACM SIGMOD Rec. 2016, 45, 45–55. [Google Scholar] [CrossRef]
- Garcia-Molina, H.; Ullman, J.D.; Widom, J. Database Systems: The Complete Book, 2nd ed.; Pearson Prentice Hall: Upper Saddle River, NJ, USA, 2009. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
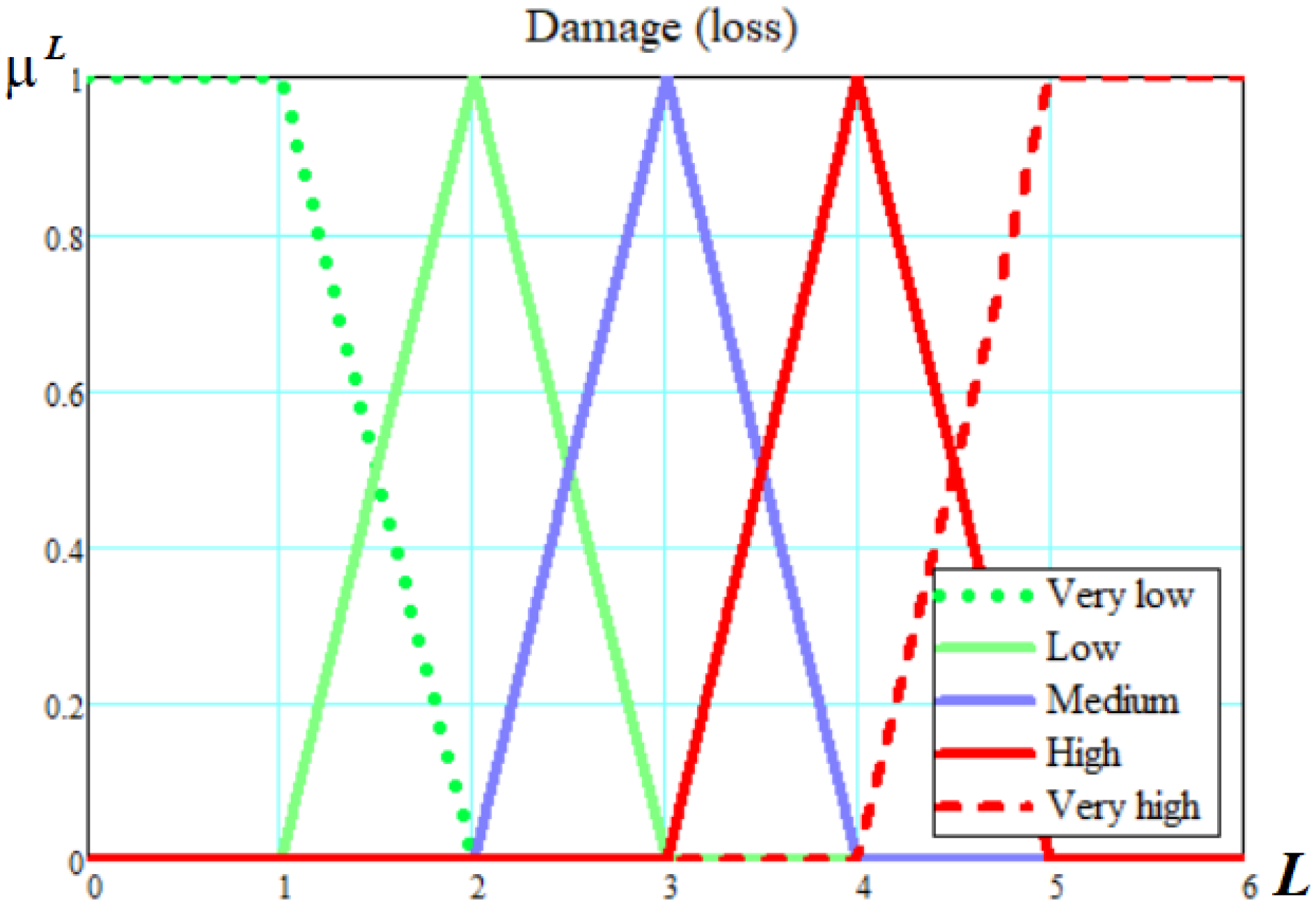
| Level | Semantic Characteristic | |
|---|---|---|
| 1 | Very low | Loss can be ignored. |
| 2 | Low | The damage can be easily eliminated; the costs of eliminating the consequences of the threat implementation are low. |
| 3 | Medium | Eliminating consequences of the threat implementation is not associated with large costs. |
| 4 | High | Eliminating consequences of the threat implementation is associated with significant financial losses. |
| 5 | Very high | The organization ceases to exist. |
| Level | Range | Range | |
|---|---|---|---|
| 1 | Very low | <100 $ | 0.1 |
| 2 | Low | (100–1000) $ | (0.1, 0.3] |
| 3 | Medium | (1000–10,000) $ | (0.3, 0.6] |
| 4 | High | (10,000–100,000) $ | (0.6, 0.9] |
| 5 | Very high | >100,000 $ | >0.9 |
| Barrier No. | Security Measure | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | “M”/0.4 | “M”/0.5 | “H”/0.8 | “H”/0.8 | 0.008 | 0.008 | ||||
| 2 | “M”/0.4 | “M”/0.5 | “H”/0.85 | “H”/0.8 | 0.006 | 0.008 | ||||
| 3 | “M”/0.4 | “M”/0.5 | “H”/0.85 | “H”/0.8 | 0.006 | 0.008 | ||||
| 4 | “L”/0.1 | “M”/0.5 | “H”/0.8 | “L”/0 | 0.002 | 0.01 | ||||
| 5 | “M”/0.4 | “M”/0.5 | “H”/0.8 | “H”/0.8 | 0.008 | 0.008 | ||||
| 6 | “M”/0.4 | “M”/0.5 | “H”/0.8 | “H”/0.8 | 0.008 | 0.008 | ||||
| 7 | “M”/0.4 | “M”/0.5 | “H”/0.8 | “H”/0.8 | 0.008 | 0.008 | ||||
| 8 | “M”/0.4 | “M”/0.5 | “H”/0.8 | “H”/0.8 | 0.008 | 0.008 | ||||
| 9 | “M”/0.4 | “H”/0.85 | “H”/0.8 | “M”/0.6 | 0.0136 | 0.0272 | ||||
| 10 | “M”/0.4 | “H”/0.85 | “H”/0.8 | “M”/0.6 | 0.0136 | 0.0272 | ||||
| 11 | “M”/0.4 | “H”/0.85 | “H”/0.8 | “M”/0.6 | 0.0136 | 0.0272 | ||||
| 12 | “M”/0.4 | “M”/0.5 | “H”/0.8 | “H”/0.8 | 0.008 | 0.008 | ||||
| 13 | “M”/0.4 | “M”/0.5 | “H”/0.85 | “H”/0.8 | 0.006 | 0.008 | ||||
| 14 | “M”/0.4 | “M”/0.5 | “H”/0.85 | “H”/0.8 | 0.006 | 0.008 | ||||
| 15 | “L”/0.1 | “M”/0.5 | “H”/0.8 | “L”/0 | 0.002 | 0.01 | ||||
| 16 | “M”/0.4 | “M”/0.5 | “H”/0.8 | “H”/0.8 | 0.008 | 0.008 | ||||
| 17 | “M”/0.4 | “M”/0.5 | “H”/0.85 | “H”/0.8 | 0.006 | 0.008 | ||||
| 18 | “M”/0.4 | “M”/0.5 | “H”/0.85 | “H”/0.8 | 0.006 | 0.008 | ||||
| 19 | “M”/0.4 | “M”/0.5 | “H”/0.8 | “H”/0.8 | 0.008 | 0.008 | ||||
| 20 | “M”/0.4 | “M”/0.5 | “H”/0.8 | “H”/0.8 | 0.008 | 0.008 | ||||
| 21 | “M”/0.4 | “M”/0.5 | “H”/0.8 | “H”/0.8 | 0.008 | 0.008 | ||||
| 22 | “M”/0.4 | “M”/0.5 | “H”/0.8 | “H”/0.8 | 0.008 | 0.008 | ||||
| 23 | “M”/0.4 | “M”/0.5 | “M”/0.4 | “M”/0.4 | 0.024 | 0.024 | ||||
| 24 | “M”/0.4 | “M”/0.5 | “H”/0.9 | “M”/0.4 | 0.004 | 0.024 | ||||
| 25 | “M”/0.4 | “M”/0.5 | “H”/0.9 | “M”/0.4 | 0.004 | 0.024 | ||||
| 26 | “M”/0.4 | “M”/0.5 | “H”/0.8 | “H”/0.8 | 0.008 | 0.008 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yesin, V.; Karpinski, M.; Yesina, M.; Vilihura, V.; Rajba, S.A. Technique for Evaluating the Security of Relational Databases Based on the Enhanced Clements–Hoffman Model. Appl. Sci. 2021, 11, 11175. https://0-doi-org.brum.beds.ac.uk/10.3390/app112311175
Yesin V, Karpinski M, Yesina M, Vilihura V, Rajba SA. Technique for Evaluating the Security of Relational Databases Based on the Enhanced Clements–Hoffman Model. Applied Sciences. 2021; 11(23):11175. https://0-doi-org.brum.beds.ac.uk/10.3390/app112311175
Chicago/Turabian StyleYesin, Vitalii, Mikolaj Karpinski, Maryna Yesina, Vladyslav Vilihura, and Stanislaw A. Rajba. 2021. "Technique for Evaluating the Security of Relational Databases Based on the Enhanced Clements–Hoffman Model" Applied Sciences 11, no. 23: 11175. https://0-doi-org.brum.beds.ac.uk/10.3390/app112311175