
Spider Taylor-ChOA: Optimized Deep Learning Based Sentiment Classification for Review Rating Prediction



1
School of Computer Science and Technology, Dalian University of Technology, Dalian 116024, China
2
School of Computer Science and Engineering, Southeast University, Nanjing 210096, China
*
Author to whom correspondence should be addressed.
Appl. Sci. 2022, 12(7), 3211; https://0-doi-org.brum.beds.ac.uk/10.3390/app12073211
Submission received: 26 January 2022
/
Revised: 8 March 2022
/
Accepted: 11 March 2022
/
Published: 22 March 2022
(This article belongs to the Special Issue Advances in Artificial Intelligence Methods for Natural Language Processing)
Abstract
:The prediction of review rating is an imperative sentiment assessment task that aims to discover the intensity of users’ sentiment toward a target product from several reviews. This paper devises a technique based on sentiment classification for predicting the review rating. Here, the review data are taken from the database. The significant features, such as SentiWordNet-based statistical features, term frequency–inverse document frequency (TF-IDF), number of capitalized words, numerical words, punctuation marks, elongated words, hashtags, emoticons, and number of sentences are mined in feature extraction. The features are mined for sentiment classification, which is performed by random multimodal deep learning (RMDL). The training of RMDL is done using the proposed Spider Taylor-ChOA, which is devised by combining spider monkey optimization (SMO) and Taylor-based chimp optimization algorithm (Taylor-ChOA). Concurrently, the features are considered input for the review rating prediction, which determines positive and negative reviews using the hierarchical attention network (HAN), and training is done using proposed Spider Taylor-ChOA. The proposed Spider Taylor-ChOA-based RMDL performed best with the highest precision of 94.1%, recall of 96.5%, and highest F-measure of 95.3%. The proposed spider Taylor-ChOA-based HAN performed best with the highest precision of 93.1%, recall of 95.4% and highest F-measure of 94.3%.
1. Introduction
The processing of natural language represents the area of linguistics and artificial intelligence, which is dedicated to making computers comprehend words and statements printed in languages understandable by a human. The NLP comes to subsistence for easing the work of the user and for satisfying the wishes to exchange with a computer in natural language. As all users cannot model in a machine with a particular language, NLP aids those users who do not possess adequate time for learning new languages or acquiring excellence in it. NLP is categorized in two components, wherein the first understands natural language and the generation of natural language, which develops the task for comprehending and generating text. The aim of NLP is to collect more specialism in the system. The measure of NLP considers an algorithmic model, which permits the combination of generating and understanding language. It is even utilized in detecting a multilingual event [1]. Using the methods from sentiment assessment and NLP, we observed the expression of the user and link emotions. The civilizing norms added various twists. For instance, the subsequent statement is understood in various manners. The social media infrastructure offers both issues and prospects in this domain. Meanwhile, it grants anonymity among people writing on the web, and hence allows them to convey their feelings liberally. In addition, the data are accumulated for a provided interval, which is considered crucial in guaranteeing stability [2]. The assessment of sentiment has become a well-known domain, due to the requirements for tracking and managing population tendencies. Several institutions operate on this domain for meeting the expectations and desires of the customer. Due to emerging social media infrastructures, the assessment of sentiment has shifted from a document level assessment [3]. The analysis of sentiment helps to discover the orientation of opinion or text. The review has several facets with several opinions regarding each facet. The preliminary works in the sentiment assessment concentrated on discovering the complete sentiment of review as being negative or positive. This offered a way for a more fine-grained technique that aimed for predicting a rating for a provided review in a specific scale. These techniques tried to discover the complete rating in a direct manner from the provided text. The more modern work revealed the prediction of the overall rating and could be enhanced by first adapting the ratings at the facet level and then collecting them [4]. Over the last year, the review of the product medium has become a general place, and the emerging count of websites offers infrastructures for users to advertise individual computations and judgments of services and products. The data in product reviews have gained more attention by consumers and companies [5]. The prediction of the review rating is of great significance for business intelligence and sentiment assessment. The classical techniques worked well when the aspect–opinion pairs were precisely mined from aspect ratings and review texts. The issues of enhancing the prediction accuracy depend on capturing the semantics of the review content [6].
Despite the triumph of classical techniques in evaluating sentiment with biased text, the current focus is progressively changing to user authority and products on sentiments. In [7], a review rating prediction technique on the basis of NN was developed, but it adapted the impact of user on sentiment expression in terms of the word level. In [8], the user product neural network model (UPNN) was devised for sentiment assessment. In [9], deep memory network was adapted for capturing the product and user information for enhanced classification outcomes. In [10], a product–word tensor factorization model was developed for predicting the review rating. Although matrix factorization (MF) and deep neural network (DNN) have attained emerging outcomes in predicting the rating of a review, the examination of DNN has gained more attention. In [11], a neural collaborative filtering (NCF) was developed by employing a multi-layer representation for modeling the user–item communication. However, this technique is not fit for text information. In general, there exist three techniques for the assessment of sentiment, which include that which is lexicon based, including unsupervised methods [12], supervised practice [13], and a hybrid model that consists of both supervised and unsupervised techniques. The techniques with deep learning include CNN and recurrent neural networks (RNNs) and are utilized for classifying text sentiment. Machine learning with the deep model offers improved performance in the classification of sentiment. The classification of sentiment with deep learning utilizes end-to-end [14] patterns and executes text modeling and a classifier on the basis of the neural network [15].
The major contributions of this research are as follows:
- Spider Taylor-ChOA-based RMDL is employed for classifying the sentiment. The training of RMDL is done using the proposed spider Taylor-ChOA, which is obtained by combining the SMO and Taylor-ChOA.
- Spider Taylor-ChOA-based HAN is employed for predicting the review rating. The training of HAN is done using the proposed spider Taylor-ChOA, which is obtained by combining the SMO and Taylor-ChOA.
- We conduct extensive experiments on different datasets, and the experiment results show that the proposed method outperforms state-of-the-art methods for review rating prediction tasks.
The remainder of the paper is organized as follows: Section 2 describes the review of different course recommendation methods. In Section 3, we briefly introduce the architecture of the proposed framework. Systems implementation and evaluation are described in Section 4, and results and discussions are summarized in Section 5. Finally, Section 6 concludes the overall work and future research studies.
2. Related Work
Innumerable techniques are devised for sentiment classification and review rating prediction, but none of the techniques hybridize review rating and sentiment analysis. Thus, the motive is to devise a novel technique for sentiment analysis and review rating. Feng S. et al. [16] developed a technique, namely InterSentiment, for effective sentiment analysis and review rating. The technique bridged the gap between the sentiment model and user–product interaction model considering the deep model and jointly produced rating scores. However, the technique did not include the combination of semantics in deep models. To combine the semantics of the deep model, Zheng T. et al. [17] developed a technique based on biased user-given ratings based on texts for sentiment analysis. Here, the deep model was devised for examining the textual review. However, the technique did not undergo testing considering various classes and review infrastructures. To include testing with several classes and reviews, Ahmed B.H. and Ghabayen A.S. [18] developed the prediction of a review rating with a deep model. The method comprises two stages on the basis of the deep learning bi-directional gated recurrent unit (Bi-GRU) model. Here, the first phase utilized the prediction of polarities, and the second phase was utilized for predicting the review rating using the review text. However, the technique did not adopt the linguistic ruleswhile evaluating the review text. To include the linguistic rules, Sadiq S. et al. [19] devised Google App numeric reviews and a ratings contradiction prediction platform with a deep model. The model comprises two phases. Here, the first covers the prediction of polarity in each review considering the sentiment analysis tool and constructed ground truth. Then, in the second phase, the prediction of the star rating is done with a text format after the deep model. The technique faces high computational complexity. To reduce the computational complexity, Chambua J. and Niu Z. [20] devised a technique for predicting, learning and utilizing the review rating for sentiment analysis. The method considered the preference knowledge for predicting ratings. However, this technique produced poor accuracy. To enhance accuracy, Shrestha N. and Nasoz F. [21] devised a technique for analyzing sentiment by analyzing the compatibility of Amazon reviews. The analysis of sentiment was done for identifying the reviews using a deep model. Here, the semantic relation of the product data and review text was done to predict the rating score. However, the online review comprises huge noise, which is complicated to analyze. To discard noise, Bu J. et al. [22] devised a technique for rating reviews. Here, each review is manually annotated based on sentiment polarities. However, this technique cannot handle other databases. To manage other databases and make it flexible, Zhang K. et al. [23] devised a sentiment-aware interactive fusion network (SIFN) for recommending the item. Here, the user or item reviews were encoded with bidirectional encoder representations from transformers (BERT) for mining semantic features. At last, the rating prediction was done for analyzing the final score. The issues confronted by the classical sentiment analysis based on review rating prediction are listed as follows:
- The SC-based technique concentrates on extracting the content of the review and has the ability to combine user- and product-based features, but it fails to capture adequate interactions among them, expressed in a sparse matrix as collaborative filtering (CF) [16].
- To capture sufficient interactions, the review rating prediction platform with deep model is adapted. Here, the person that considers reviews assists in the rating prediction, with high star ratings being good reviews, but the user’s rating star-level information is complex to understand and analyze [18].
- To ease the understanding, the deep model is utilized, wherein the reviews are given in texts. The huge elevation in the count of review texts in various internet services, such as social media, adds huge confusion and leads to an information overload issue [17].
- To minimize the overload issue, the recent technique in recommender systems was controlled to attain enhanced efficiency by considering reviews to predict the rating. However, this technique faces difficulty when inferring the sentiment [19].
- To deal with sentiments, the most contemporary method adapted is deep neural networks [24] in matrix factorization. It shows good outcomes, but it mostly utilizes DNN for user–product interaction but is not suitable for review rating prediction.
The goal is to design an approach based on sentiment classification for review rating prediction. Here, the review data are considered for the feature extraction stage. The imperative features, such as SentiWordNet-based statistical features, TF-IDF-based features, number of capitalized words, numerical words, punctuation marks, elongated words, hashtags, emoticons, and number of sentences are mined in the feature extraction stage to enhance the classification. Then, the obtained features are utilized in the sentiment classification module, which is done with RMDL. The RMDL training is performed with the developed spider Taylor-ChOA, and is generated by integrating SMO and Taylor-ChOA. Concurrently, the features are adapted as input to the review rating prediction, wherein positive and negative reviews are obtained with HAN. The HAN training is done with the proposed spider Taylor-ChOA.
3. Proposed Method
The overall architecture of the spider Taylor-ChOA-based-HAN-method-based sentiment classification for review rating prediction is illustrated in Figure 1, which contains several components. The details of each component are presented next.
The prediction of the review rating is considered an imperative sentiment analysis process, which aims to discover the user’s sentiment intensity toward target products from several types of reviews. The goal is to devise a technique based on sentiment classification for review rating prediction. Initially, the review data are taken from the database, and they are subjected to the feature extraction stage. The significant features, such as SentiWordNet-based statistical features, TF-IDF-based features, number of capitalized words, numerical words, punctuation marks, elongated words, hashtags, emoticons, and number of sentences are extracted in the feature extraction stage for further improvement of the classification process. After that, extracted features are passed to the sentiment classification module, which is carried out based on RMDL [25]. The training of RMDL is done using the proposed spider Taylor-ChOA, which is devised by combining SMO [26] and Taylor-ChOA. Concurrently, the features are considered as input for review rating prediction, which devises positive and negative reviews using HAN [27]. The training of HAN is done using the proposed spider Taylor-ChOA.
3.1. Data Acquisition
Consider an input review denoted as K, which comprises several parameters, which is given by
where symbolizes the review present in the dataset K with the mth attribute in the lth data, J is the total data, and L represents the total attributes. The subsequent step is to mine features from the review for simple processing.
3.2. Features Extraction
We present the significant features generated from the review, and the significance of the feature extraction is to generate highly relevant features that provide sentiment classification and review rating prediction. Hence, the input review is fed to the feature extraction phase, wherein the extraction of the SentiWordNet-based statistical features, numerical words, TF-IDF features, hashtags, emoticons, elongated words, punctuation marks, and number of sentences is performed.
SentiWordNet based statistical features: The SentiWordNet [28] assists in grouping the words into several sets of synonyms known as synsets. Each synset is linked with a polarity score of negative or positive. Here, the score adapts a value in 0 and 1, and its summation offers a value of 1 for each synset. By adapting the cores adapted, it is reliable for making a decision if the evaluation is negative or positive. The words contained in the SentiWordNet are devised based on the parts of speech acquired from WordNet, and thus it uses a program for adapting the scores to each word. Here, the weight tuning of negative and positive score values is given by
where symbolizes the positive score, signifies the negative score, and h refers to SentiWordNet. Considering the SentiWordNet score, the statistical features, such as mean and variance are evaluated as follows.
(i) Mean: It is evaluated by adopting the average of the SentiWordNet score for each word from the review and is expressed as
where n signifies overall words, refers to the SentiWordNet score of each review, and refers to overall scores generated from the word.
(ii) Variance: The variance is evaluated based on the mean value and is expressed as
where symbolizes the mean value. Hence, the SentiWordNet-based feature adapts the positive and negative scores of each word in the review; from that, the statistical features, such as the mean and variance, are evaluated. Thus, the SentiWordNet-based statistical features are expressed as .
Numerical words: The count of the text characters or numerical digits utilized for showing numerals is expressed as with dimension , respectively.
TF-IDF: TF-IDF [29] is utilized for building a composite weight for each term in each of the review data. TF measures how generally a term occurs in the review data, while IDF evaluates how significant a term is. The TF-IDF score is evaluated as
where R signifies the total count of the review data, the term frequency is expressed as , and symbolizes the inverse document frequency and refers to the TF-IDF feature with size .
Hashtags: The hashtag is commonly used to draw concentration, arrange, and promote. The use of hashtags started in Twitter as a means to make it simple for people to determine, follow, and contribute in a conversation. The number of hashtags is evaluated and expressed as .
Emoticons: The emoticons are a pictographic representation of facial appearance using specific characters, typically numbers, punctuation marks or letters. This emoticon assists in articulating the feelings of a person’s mood and is a time-saving method. The occurrence of positive and negative emoticons is evaluated and is expressed as .
Elongated words: The feature signifies elongated words, which are characters repeated more than two times in a review, and is expressed as
where signifies the overall hashtags contained in a mth review. The term is provided with a value of 0 for each elongated word in the review and 1 for the nonexistence of an elongated word. In addition, the elongated word feature considers the size of .
Punctuation marks: The punctuation marks featuring are considered an apostrophe, dot, or exclamation mark contained in a review.
where signifies the overall punctuation contained in a mth review. Here, is provided a value of 1 for the punctuation that occurs in the review and 0 for other cases. In addition, the feature has the size of .
Number of sentences: The count of sentences utilized for showing the process is expressed as .
3.3. Configuration of a Feature Vector
The feature vector is developed by combining the features, SentiWordNet, numerical words, TF-IDF, hashtags, emoticons, elongated words, punctuation marks, and number of sentences, and is expressed as,
where is the SentiWordNet features, signifies the numerical words, is the TF-IDF features, symbolizes the hashtags features, is the emoticons, is the elongated words, is the punctuation marks, and is the number of sentences.
The examples of feature extraction are described in Table 1.
3.4. Sentiment Classification
The proposed spider Taylor-ChOA-based RMDL is adapted to classify the sentiments from reviews considering the feature vector. Here, the spider Taylor-ChOA-based RMDL is obtained by combining spider Taylor-ChOA in the RMDL model for selecting optimal weights contained in RMDL [25]. The proposed spider Taylor-ChOA is adapted to optimize RMDL by selecting the optimal weights. The structure of RMDL and the training process are given below.
Architecture of RMDL: Here, the feature vector is adapted as an input of RMDL. RMDL [25] is a method that is used for any database to perform effective classification. The RMDL consists of various deep convolutional neural networks (CNN), deep neural networks (DNN), and deep recurrent neural networks (RNN). The count of nodes and layers of all deep learning multi-models are generated arbitrarily. Figure 2 displays the structure of the RMDL model.
The RMDL comprises three fundamental models of deep learning, namely CNN, RNN, and DNN, in a parallel manner. Here, each model is defined individually. The RMDL consists of n DNN, o RNN, and p CNN models.
(i) DNN: DNN is developed to learn various layer connections in which each layer receives a connection with a prior parameter and provides the connection to a consequent layer of the hidden part. The input indicates the association of features with the first hidden of all random models. The output layer determines various classes to perform multi-class classification and acquires one input for binary classification. In DNN, each learning unit is generated randomly, and it uses the standard backpropagation method with sigmoid, ReLU, and an activation function. Here, the activation function is expressed as
Here, the sigmoid function is expressed as
where represents a data point, and t signifies a random number such that .
where Y refers to an arbitrary number.
(ii) RNN: Another neural model that contributes in RMDL is RNN, which assigns more weights before a data point’s series. Hence, this technique is effective in classifying series data. In RNN, the neural network adapts the data of prior nodes for enhanced semantic analysis of the database and is expressed as
where signifies the state at time , represents the mapping string of feature space, and symbolizes the input at step v. In general, the weights are used for modeling the above formula given as
where symbolizes the recurrent matrix weight, expresses the input weight, is the bias, and expresses the element-wise function.
LSTM: LSTM is an exceptional type of RNN that preserves large dependencies in a more effective way in contrast to fundamental RNN. It is beneficial in overwhelming vanishing gradient problems. However, the LSTM represents a chain-like model that uses various gates to regulate the amount of data, which are permitted to each of the node state.
Here, the input gate is given by
where represents the bias vector, symbolizes the weight matrices, is the memory cell input at time v, H signifies the input, and R refers to the hidden layer.
Thereafter, the candidate memory cell value is given by
Then, the activation of forget gate is expressed as
where represents the sigmoid function, symbolizes the weight matrices, is the input to the memory cell at time v, represents the bias vector, and refers to the hidden layer at time .
Thereafter, the new memory cell value is expressed as
where signifies the input at time v, and the activation of the forget gate is given by .
The output gate value is expressed as
Gated recurrent unit (GRU): GRU represents a gating method of RNN and is adapted as a basic fundamental of the LSTM model, but there exist differences. The GRU consists of two gates, does not comprise internal memory, and non-linearity cannot be adapted. The explanation of the GRU cell is given by
where symbolizes the update gate vector of v, is the input vector, , I and signify the attribute matrices and vector, and refers to the activation function.
where symbolizes the output vector of , signifies the reset gate vector of v, refers to the update gate vector of v, signifies the hyperbolic tangent function, is the input vector, and , and signify the parameter matrices.
(iii) Convolutional neural networks (CNN): The CNN is adapted for categorizing the image. However, it is constructed to process images; the CNN is effectually adapted for classifying the texts. Here, the CNN is adapted for processing an image tensor, which is convoluted with different group of kernels with dimension . In addition, the final layers of CNN are fully connected. The output of RMDL is denoted as O.
3.5. Training of RMDL Using Proposed Spider Taylor-ChOA
The RMDL training is performed with the designed spider Taylor-ChOA. The proposed spider Taylor-ChOA is devised by combining the SMO and Taylor-ChOA. Here, the SMO [26] is inspired from spider monkeys. It is reliable in a group of swarm intelligence methods and offers self-organization that represents a global level response with interactions among low level units. It enhances integrated swarm intelligence. The SMO contains the potential to discover the global optimum and determine enhanced solutions. Thus, it offers the ability to find a balance between exploration and exploitation by controlling the convergence speed. Thus, the SMO is highly sensitive to hyperparameters. On the other hand, Taylor-ChOA is devised by combining the Taylor concept and ChOA by acquiring the benefits of both techniques. It helps to solve the issue of the convergence speed and addresses constrained and unconstrained problems. Thus, the incorporation of SMO and Taylor-ChOA helps to attain a global optimal solution. The steps of the designed spider Taylor-ChOA are given below.
Step 1: Initialization: At first, SMO [26] produces a randomly distributed population of spider monkeys, which is given by
where and represent the maximum and minimum bounds, and signifies the consistently distributed random number.
Step 2: Discovery of error: The optimal solution is found with an error function and is employed as minimization issue. It is expressed as
where is the expected output, O is the output generated from RMDL, and g is the number of data samples such that .
Step 3: Local Leader Phase (LLP): As per SMO [26], each spider monkey alters its current location on the basis of information of the local leader and the local group member’s experience, and is given by
where represents the current position of the spider monkey, is the uniformly distributed arbitrary number between 0 and 1, is the uniformly distributed arbitrary number between -1 and 1, is the position of the local leader, and is the arbitrarily selected spider monkey position.
Step 4: Global leader phase (GLP): In GLP, all update position of SM utilize the practice of global leader and local group members and is given by
where represents the global leader position.
From Taylor-ChOA, the update equation is given by
where r is the coefficient vector, the position of a chimp at iteration is specified as , the position of a chimp at iteration is specified as , expresses the vector of the prey position, and u implies the chaotic value. In addition, , and , where the value of v is reduced from 2.5 to 0 and denotes the random vector within the range .
Add on both sides,
The final update equation of the proposed spider Taylor-ChOA is given below,
Step 5: Global leader learning (GLL) phase: In the GLL phase, the global leader position is updated by adapting greedy selection in the population. Here, the SM position with minimal error in the population is chosen as the updated global leader position.
Step 6: Local leader learning (LLL) phase: In LLL, the position of the local leader is updated by adapting greedy selection in that set. Here, the SM position with minimal error in the group is selected as the local leader update position.
Step 7: Local leader decision (LLD) phase: In the LLD phase, if the position of any local leader is not updated to a specific threshold, then all members of that set update its position either by arbitrary initialization or by utilizing integrated information from the global leader and local leader and is given as,
Step 8: Global leader decision (GLD) phase: In GLD, the global leader position is noted, and if it is not updated to specific iterations, then the global leader splits the population into small groups.
Step 9: Error re-evaluation: The error value is calculated for each solution such that the least value of error is considered the best solution.
Step 10: Termination: All the aforementioned steps are iterated till the global optimal solution is attained. Algorithm 1 describes the proposed spider Taylor-ChOA algorithm.
| Algorithm 1: Pseudo code of proposed spider Taylor-ChOA |
|
Input: Spider monkey population F Output: Best solution Begin Initialize population in a random manner Evaluate error using Equation (25) Choose local and global leaders using greedy selection techniques. While (termination criterion is not satisfied) do Produce new position for all group members with local leader using Equation (26) Produce new position for all group members with global leader using Equation (43) Re-evaluate error using Equation (25) Apply greedy selection technique and choose the best one Evaluate the probability of each member Generate new position of all group member Update global position and local position of leader If the local group leader does not update the position, then redirect all members using Equation (44). If a global leader does not update his position, then divide the group into small groups. End while Return End |
3.6. Review Rating Prediction
The feature vector is given as an input. The proposed spider Taylor-ChOA-based HAN is adapted to categorize sentiments from reviews using the feature vector. Here, the spider Taylor-ChOA-based HAN is obtained by combining the spider Taylor-ChOA in the HAN model for choosing the optimal weights present in HAN. The developed spider Taylor-ChOA is employed to optimize HAN [27] by selecting the optimal weights. The structure of HAN and the training process are given below.
Architecture of HAN: The model of HAN [27] is displayed in Figure 3. It helps to concentrate on information for creating memories and focus on a particular task. It is flexible and easy to use.
The network has the ability to deal with various kinds of data. It selectively focuses on valuable parts. The HAN consists of several units, such as the word-level attention layer, word sequence encoder, sentence-level attention layer, and sentence encoder. Assume a review comprises L sentences and each sentence consists of words. expresses words in the ith sentence.
(i) Word encoder: Given a sentence with words , firstly the embedding of words to vectors is performed with an embedding matrix . The bidirectional GRU is used to obtain word annotations by summarizing the data with both directions of words and thus using contextual data in the annotation. The bidirectional GRU consists of a forward that reads sentence with to and backward GRU that reads using to :
This unit generates an annotation for a given word by combining the forward hidden state and the backward hidden state wherein that recapitulates data from the whole sentence centered among .
(ii) Word attention: Here, the attention method is used to mine the words that are essential to the meaning of the sentence and accumulate an illustration of informative words to form the sentence vector.
Here, the word annotation is subjected with one-layer MLP for obtaining as the hidden representation of , evaluating the importance of word with the word-level context vector , and acquiring normalized significance weight with the softmax function. Here, the word context vector is randomly initialized and learned jointly in the training process.
(iii) Sentence encoder: Provided the sentence vector, a review vector is obtained in which the bidirectional GRU is adapted to encode the sentences, which is expressed as,
The combination of and to produce sentence annotation i, that is, , and reveals the neighbor sentence around sentence i and concentrates on sentence i.
(iv) Sentence attention: For rewarding sentences that are clues for accurately classifying a review, the attention method is used, as well as for developing a sentence-level context vector and using the vector for evaluating sentence importance, and is expressed as,
where is the sentence annotation, is the sentence attention matrix, and refers to the bias.
where is the acquired normalized significance weight and is the transpose of the hidden representation.
where v refers to the review vector that summarizes all sentences from the review. Additionally, the sentence-level context vector is arbitrarily initialized and learned jointly throughout the training process. Here, the review vector indicates a high level representation of the review and is used as features for the sentiment categorization as
The negative log likelihood is used with right labels as the training loss, which is expressed as
where j signifies the label of review d. The output generated from the HAN is expressed as ℓ, which is the sentiment classification.
Training of the HAN using proposed spider Taylor-ChOA: The HAN training is carried out using the proposed spider Taylor-ChOA. The proposed spider Taylor-ChOA is devised by combining the SMO and Taylor-ChOA. The training steps of the proposed spider Taylor-ChOA are given below.
Step 1: Initialization: At first, the SMO [26] produces a randomly distributed population of spider monkeys, which is given by
where and represent the maximum and minimum bounds, and signifies the uniformly distributed random number.
Step 2: Discovery of error: The optimal solution is found with an error function, and is employed as a minimization problem, expressed as
where is the output to be expected, ℓ is the output generated with HAN, and g is the data samples count such that .
Step 3: Discovery of update equation: The final update equation of the designed spider Taylor-ChOA is provided as
Step 4: Error re-evaluation: The error value is calculated for each solution such that the least value of error is considered the best solution.
Step 5: Termination: All the aforementioned steps are iterated till the global optimal solution is attained.
4. Systems Implementation and Evaluation
In this section, we first present the datasets, then details about the experimental setup, baseline benchmarks, and finally, the evaluation metrics are shown.
4.1. Description of Datasets
In order to evaluate our system, three datasets are used, namely IMDB, Yelp 2013, and Yelp 2014 [30] (accessed on 15 November 2021, https://github.com/thunlp/NSC). The IMDB dataset helps to perform binary classification of sentiment. Here, a set of 25,000 highly polarized movie reviews for training and 25,000 for testing is considered and helps to predict positive or negative results. Yelp 2013 is a subset of Yelp’s reviews, businesses, and user data. Here, the information regarding eight metropolitan areas in Canada and USA are considered. Yelp 2014 is a subset of Yelp’s ratings, plain text reviews, and timestamps. This database contains reviews of 201 hotels and restaurants by 38,063 reviewers.
4.2. Experimental Setup
The method we proposed is implemented in the Python programming language. Our networks are trained on NVIDIA GTX 1080 in a 64-bit computer with Intel(R) Core(TM) i7-6700 CPU @3.4 GHz, 16 GB RAM and the Ubuntu 16.04 operating system.
4.3. Evaluation Metrics
The performance of the developed spider Taylor-ChOA-based HAN and RMDL is computed with precision, recall, F1-score, and RMSE.
Precision: It is termed as nearness of more than two dimensions among each other, and is given by
where symbolizes the true positive and represents the false positive.
Recall: It computes the complete actual positives which the system captures using the label of true positive, and it is formulated as
where symbolizes the false negative.
F1-score: It is weighted by the harmonic mean of recall and precision, and is modeled as
RMSE: It refers to the differences between values predicted by a technique and the observed values and is given by
where N refers to the number of non-missing data points, represents the actual observation time series, and signifies the estimated time series.
4.4. Baseline Methods
In order to evaluate the effectiveness of the proposed framework, our method is compared with several existing algorithms, as follows.
For sentiment classification, the techniques considered are hierarchical self-attentive convolution network (HSACN) [31], multichannel deep convolutional neural network (MCNN) [32], demand-aware collaborative Bayesian variational network (DCBVN) [33], and the proposed spider Taylor-ChOA-based RMDL. For the review rating, the techniques considered are DNN [16], CNN+LSTM [17], Bi-GRU [18], CNN [19] and the proposed spider Taylor-ChOA-based HAN.
5. Results and Discussion
The performance results of our proposed model are presented in this section. The results are compared with the previously introduced methods, which were tested on the same datasets.
5.1. Performance Evaluation Based on Sentiment Classification
The assessment of techniques with sentiment classification was done using precision, F1-score, recall, and RMSE, considering the IMDB, Yelp 2013, and Yelp 2014 databases.
(a) Assessment with IMDB dataset:Figure 4 presents the assessment based on sentiment classification using the IMDB database. The assessment with precision is revealed in Figure 4a. For training data = 60%, the precision measured by HSACN, MCNN, DCBVN, and the proposed spider Taylor-ChOA-based RMDL are 0.785, 0.825, 0.855, and 0.895. Additionally, for training data = 90%, the precision measured by HSACN, MCNN, DCBVN, and the proposed spider Taylor-ChOA-based RMDL are 0.852, 0.874, 0.905, and 0.941. The performance improvement in HSACN, MCNN, and DCBVN with respect to the proposed spider Taylor-ChOA-based RMDL using precision are 9.458%, 7.120%, and 3.825%.
The assessment with recall is revealed in Figure 4b. For training data = 60%, the recall values measured by HSACN, MCNN, DCBVN, and the proposed spider Taylor-ChOA-based RMDL are 0.795, 0.835, 0.865, and 0.905. Additionally, for training data = 90%, the recall values measured by HSACN, MCNN, DCBVN, and the proposed spider Taylor-ChOA-based RMDL are 0.865, 0.885, 0.914, and 0.965. The performance improvements in HSACN, MCNN, and DCBVN with respect to the proposed spider Taylor-ChOA-based RMDL using recall are 10.362%, 8.290%, and 5.284%. The assessment with the F-measure is revealed in Figure 4c. For training data = 60%, the F-measure values measured by HSACN, MCNN, DCBVN, and the proposed spider Taylor-ChOA-based RMDL are 0.790, 0.830, 0.860, and 0.900. Additionally, for training data = 90%, the F-measure values measured by HSACN, MCNN, DCBVN, and the proposed spider Taylor-ChOA-based RMDL are 0.859, 0.880, 0.910, and 0.953. The performance improvements in HSACN, MCNN, and DCBVN with respect to the proposed spider Taylor-ChOA-based RMDL using the F-measure are 9.863%, 7.660%, and 4.512%. The assessment with RMSE is revealed in Figure 4d. For training data = 60%, the RMSE values measured by HSACN, MCNN, DCBVN, and the proposed spider Taylor-ChOA-based RMDL are 0.485, 0.375, 0.239, and 0.199. Additionally, for training data = 100%, the RMSE values measured by HSACN, MCNN, DCBVN, and the proposed spider Taylor-ChOA-based RMDL are 0.395, 0.221, 0.141, and 0.097.
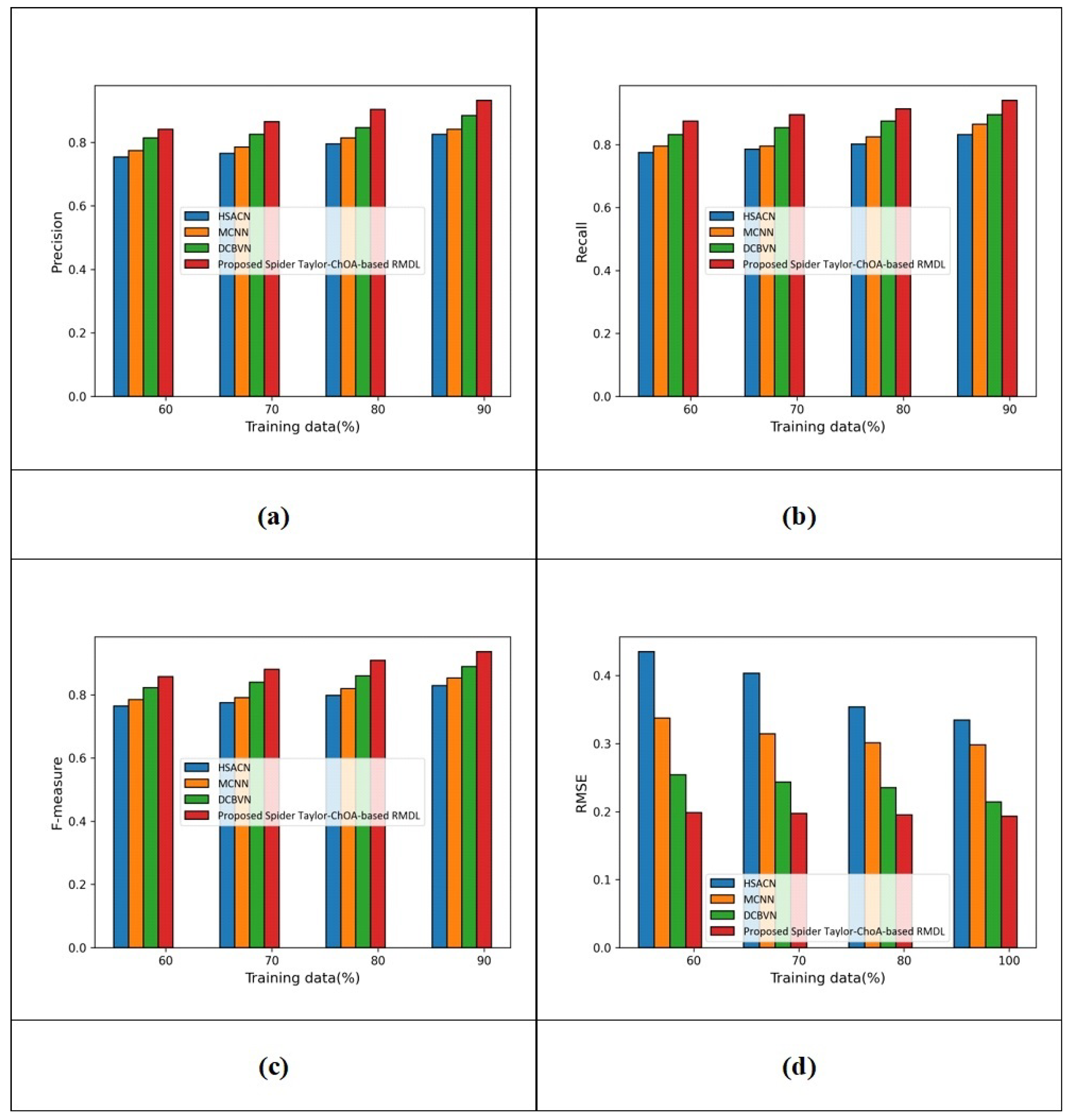
(b) Assessment with Yelp 2013 datasets: The assessment based on sentiment classification using the Yelp 2013 database is revealed in Figure 5. The assessment considering precision is displayed in Figure 5a.
When the data percentage considered for training is 60, the precision values measured by HSACN, MCNN, and DCBVN are 0.754, 0.775, and 0.814, while that of the proposed spider Taylor-ChOA-based RMDL is 0.842. Additionally, when the data percentage considered for training is 90, the precision values measured by HSACN, MCNN, and DCBVN are 0.825, 0.841, and 0.885, while that of the proposed spider Taylor-ChOA-based RMDL is 0.933. The performance improvements in HSACN, MCNN, DCBVN with respect to the proposed spider Taylor-ChOA-based RMDL using precision are 11.575%, 9.860%, and 5.144%. The assessment with recall is revealed in Figure 5b. When the data percentage considered for training is 60, the recall values measured by HSACN, MCNN, DCBVN, and the proposed spider Taylor-ChOA-based RMDL are 0.775, 0.795, 0.833, and 0.875. Additionally, when the data percentage considered for training is 90, the recall values measured by HSACN, MCNN, and DCBVN are 0.833, 0.865, and 0.895, while that of the proposed spider Taylor-ChOA-based RMDL is 0.941. The performance improvements in HSACN, MCNN, DCBVN with respect to the proposed spider Taylor-ChOA-based RMDL using recall are 11.477%, 8.076%, and 4.888%. The assessment with the F-measure is revealed in Figure 5c. When the data percentage considered for training is 60, the F-measure values measured by HSACN, MCNN, and DCBVN are 0.765, 0.785, and 0.823, while that of the proposed spider Taylor-ChOA-based RMDL is 0.858. Additionally, when the data percentage considered for training is 90, the F-measure values measured by HSACN, MCNN, and DCBVN are 0.829, 0.853, and 0.890, while that of the proposed spider Taylor-ChOA-based RMDL is 0.937. The performance improvements in HSACN, MCNN, and DCBVN with respect to the proposed spider Taylor-ChOA-based RMDL using F-measure are 11.526%, 8.964%, and 5.016%. The assessment with RMSE is revealed in Figure 5d. When the data percentage considered for training is 60, the RMSE values measured by HSACN, MCNN, DCBVN are 0.435, 0.337, and 0.254, while that of the proposed spider Taylor-ChOA-based RMDL is 0.199. Additionally, when the data percentage considered for training is 90, the RMSE values measured by HSACN, MCNN, and DCBVN are 0.335, 0.298, and 0.214, while that of the proposed spider Taylor-ChOA-based RMDL is 0.193.
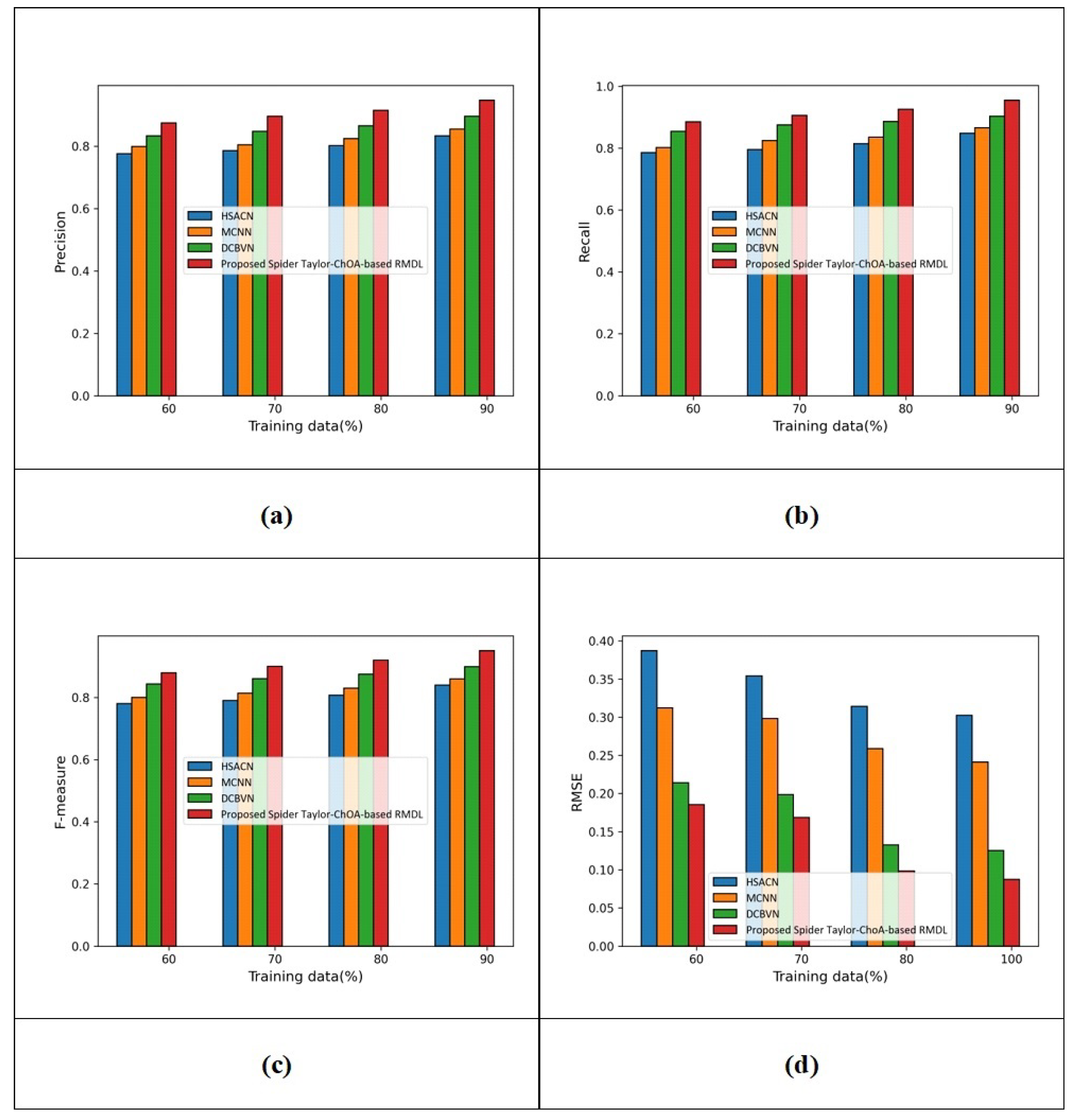
(c) Assessment with Yelp 2014 datasets:Figure 6 presents the assessment with a sentiment classification considering the Yelp 2014 database.
The assessment with precision is displayed in Figure 6a. For training data = 60%, the precision measured by HSACN is 0.775, MCNN is 0.799, DCBVN is 0.833, and the proposed spider Taylor-ChOA-based RMDL is 0.875. Additionally, for training data = 90%, the precision measured by HSACN is 0.833, MCNN is 0.854, DCBVN is 0.895, and the proposed spider Taylor-ChOA-based RMDL is 0.947. The performance improvements of HSACN, MCNN, and DCBVN with respect to the proposed spider Taylor-ChOA-based RMDL using precision are 12.038%, 9.820%, and 5.491%. The assessment with recall is revealed in Figure 6b. For training data = 60%, the recall measured by HSACN is 0.785, that by MCNN is 0.801, that by DCBVN is 0.854, and that by the proposed spider Taylor-ChOA-based RMDL is 0.885. Additionally, for training data = 90%, the recall measured by HSACN is 0.848, that by MCNN is 0.865, that by DCBVN is 0.903, and that by the proposed spider Taylor-ChOA-based RMDL is 0.955. The performance improvements in HSACN, MCNN, and DCBVN with respect to the proposed spider Taylor-ChOA-based RMDL using recall are 11.204%, 9.424%, and 5.445%. The assessment with the F-measure is revealed in Figure 6c. For training data = 60%, the F-measure measured by HSACN is 0.780, that by MCNN is 0.800, that by DCBVN is 0.843, and that by the proposed spider Taylor-ChOA-based RMDL is 0.880. Additionally, for training data = 90%, the F-measure measured by HSACN is 0.840, that by MCNN is 0.860, that by DCBVN is 0.899, and that by the proposed spider Taylor-ChOA-based RMDL is 0.951. The performance improvements of HSACN, MCNN, and DCBVN with respect to the proposed spider Taylor-ChOA-based RMDL using the F-measure are 11.671%, 9.568%, and 5.467%.The assessment with RMSE is revealed in Figure 6d. For training data = 60%, the RMSE measured by HSACN is 0.387, that by MCNN is 0.313, that by DCBVN is 0.214, and that by the proposed spider Taylor-ChOA-based RMDL is 0.185. Additionally, for training data = 100%, the RMSE measured by HSACN is 0.303, that by MCNN is 0.241, that by DCBVN is 0.125, and that by the proposed spider Taylor-ChOA-based RMDL is 0.087.
5.2. Performance Evaluation Based on Review Rating Prediction
The assessment of techniques with the review rating is done using precision, F1-score, and recall considering the IMDB, Yelp 2013, and Yelp 2014 databases.
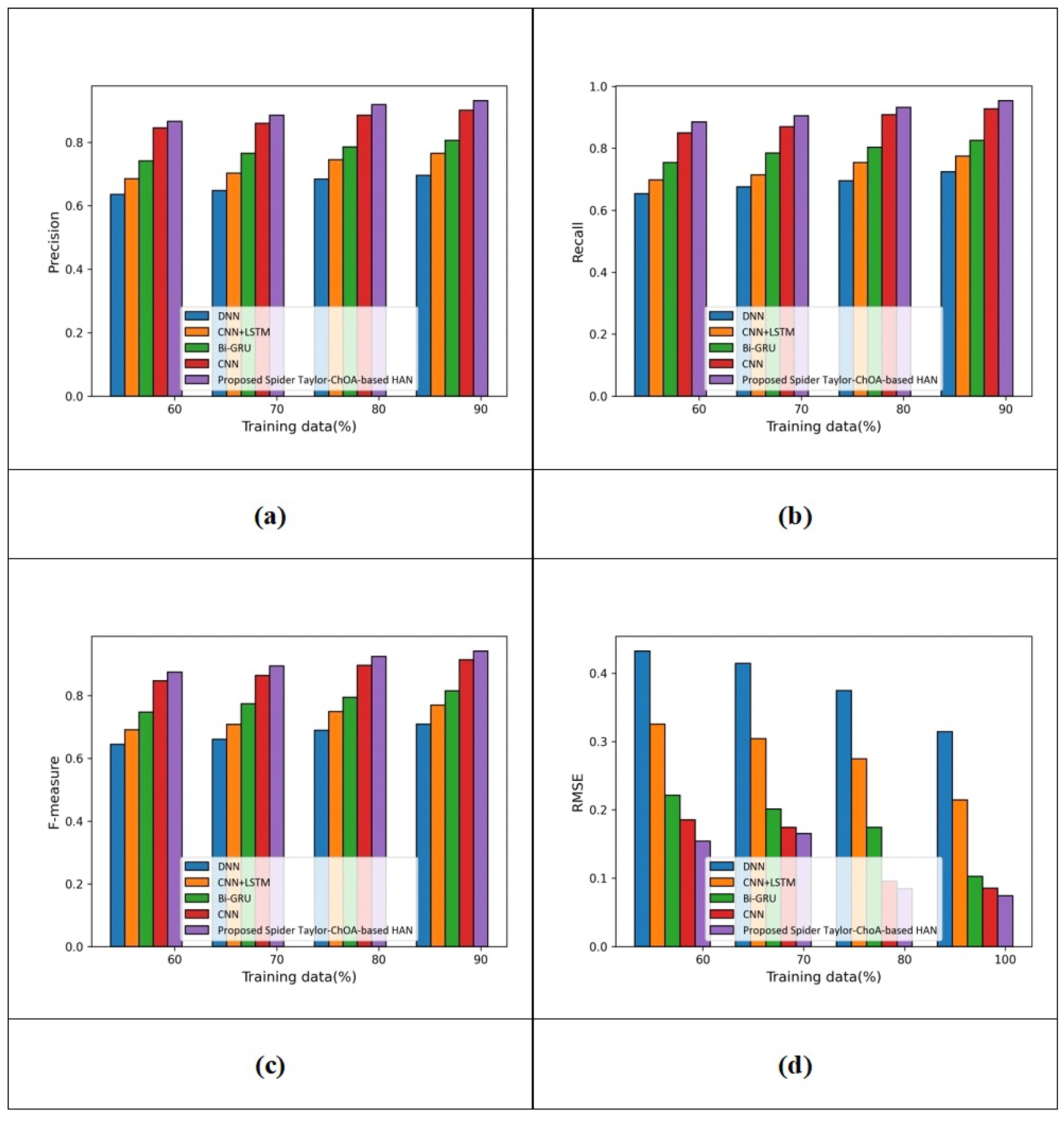
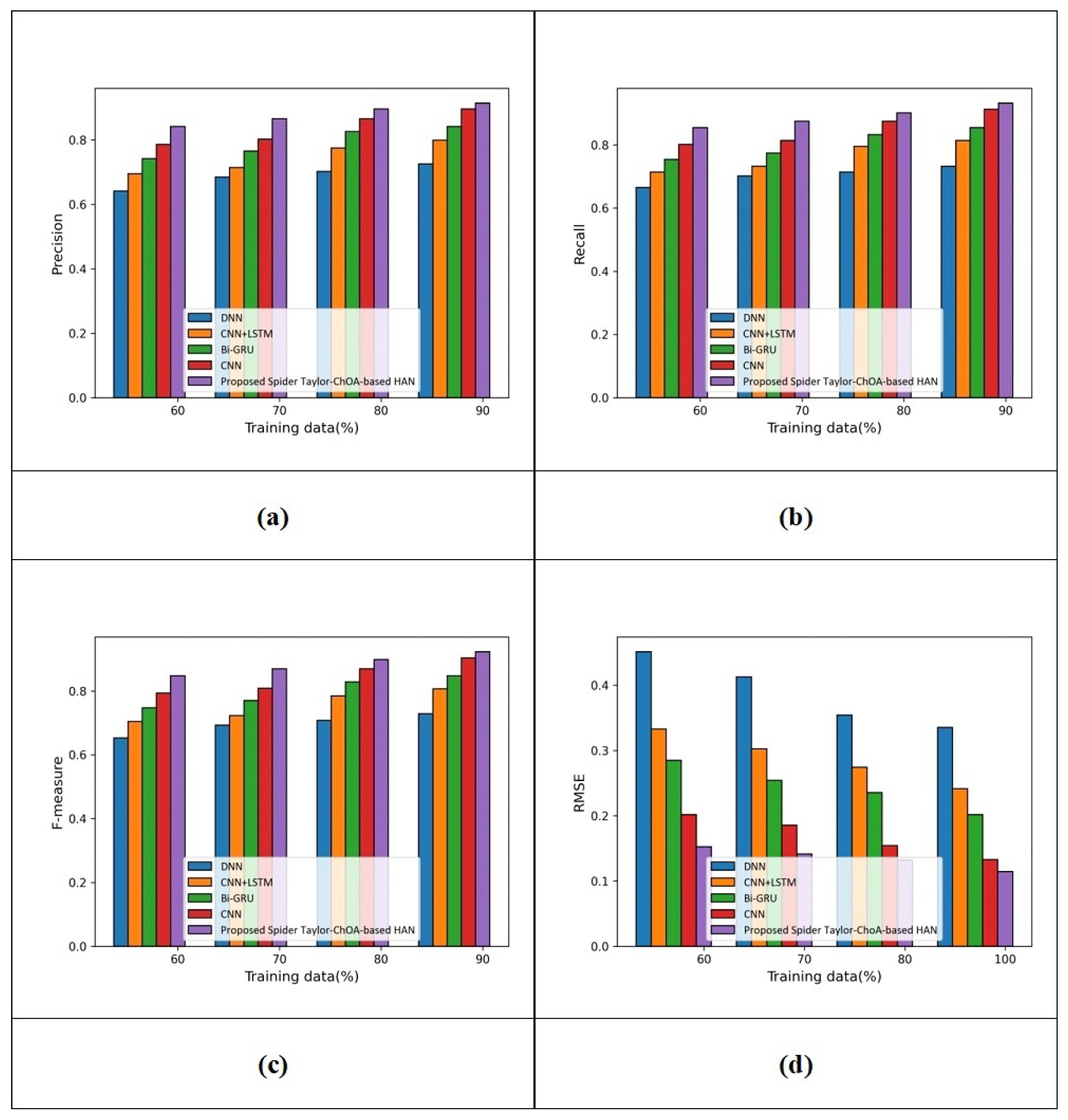
(a) Assessment with IMDB dataset:Figure 7 reveals the assessment considering the review rating with the IMDB database.
The assessment considering precision is displayed in Figure 7a. The precision values generated by DNN, CNN+LSTM, Bi-GRU, CNN and the proposed spider Taylor-ChOA-based HAN are 0.635, 0.685, 0.741, 0.845, and 0.865 when the training data are at 60%. Additionally, the precision values measured by DNN, CNN+LSTM, Bi-GRU, CNN and proposed Spider Taylor-ChOA-based HAN are 0.695, 0.765, 0.805, 0.901, and 0.931 for training data = 90%. The performance improvements in HSACN, MCNN, and DCBVN with respect to the proposed spider Taylor-ChOA-based RMDL using precision are 25.349%, 17.830%, 13.533%, and 3.222%. The assessment with recall is revealed in Figure 7b. The recall values measured by DNN, CNN+LSTM, Bi-GRU, CNN and the proposed spider Taylor-ChOA-based HAN are 0.654, 0.699, 0.754, 0.850, and 0.885 for training data = 60%. Additionally, the recall measured by DNN, CNN+LSTM, Bi-GRU, CNN and the proposed spider Taylor-ChOA-based HAN are 0.724, 0.775, 0.825, 0.928, and 0.954 for training data = 90%. The performance improvements in HSACN, MCNN, and DCBVN with respect to the proposed spider Taylor-ChOA-based RMDL using recall are 24.109%, 18.763%, 13.522%, and 2.725%. The assessment with the F-measure is revealed in Figure 7c. The F-measure values measured by DNN, CNN+LSTM, Bi-GRU, CNN and the proposed spider Taylor-ChOA-based HAN are 0.645, 0.692, 0.748, 0.847, and 0.875 for training data = 60%. Additionally, the F-measure measured by DNN, CNN+LSTM, Bi-GRU, CNN and the proposed spider Taylor-ChOA-based HAN are 0.709, 0.770, 0.815, 0.914, and 0.943 for training data = 90%. The performance improvements in HSACN, MCNN, and DCBVN with respect to the proposed spider Taylor-ChOA-based RMDL using F-measure are 24.814%, 18.345%, 13.573%, and 3.075%. The assessment with RMSE is revealed in Figure 7d. The RMSE values measured by HSACN, MCNN, DCBVN, and the proposed spider Taylor-ChOA-based RMDL are 0.433, 0.325, 0.221, 0.185, and 0.154 for training data = 60%. Additionally, the RMSE measured by HSACN, MCNN, DCBVN, and the proposed spider Taylor-ChOA-based RMDL are 0.314, 0.214, 0.102, 0.085, and 0.075 for training data = 100%.
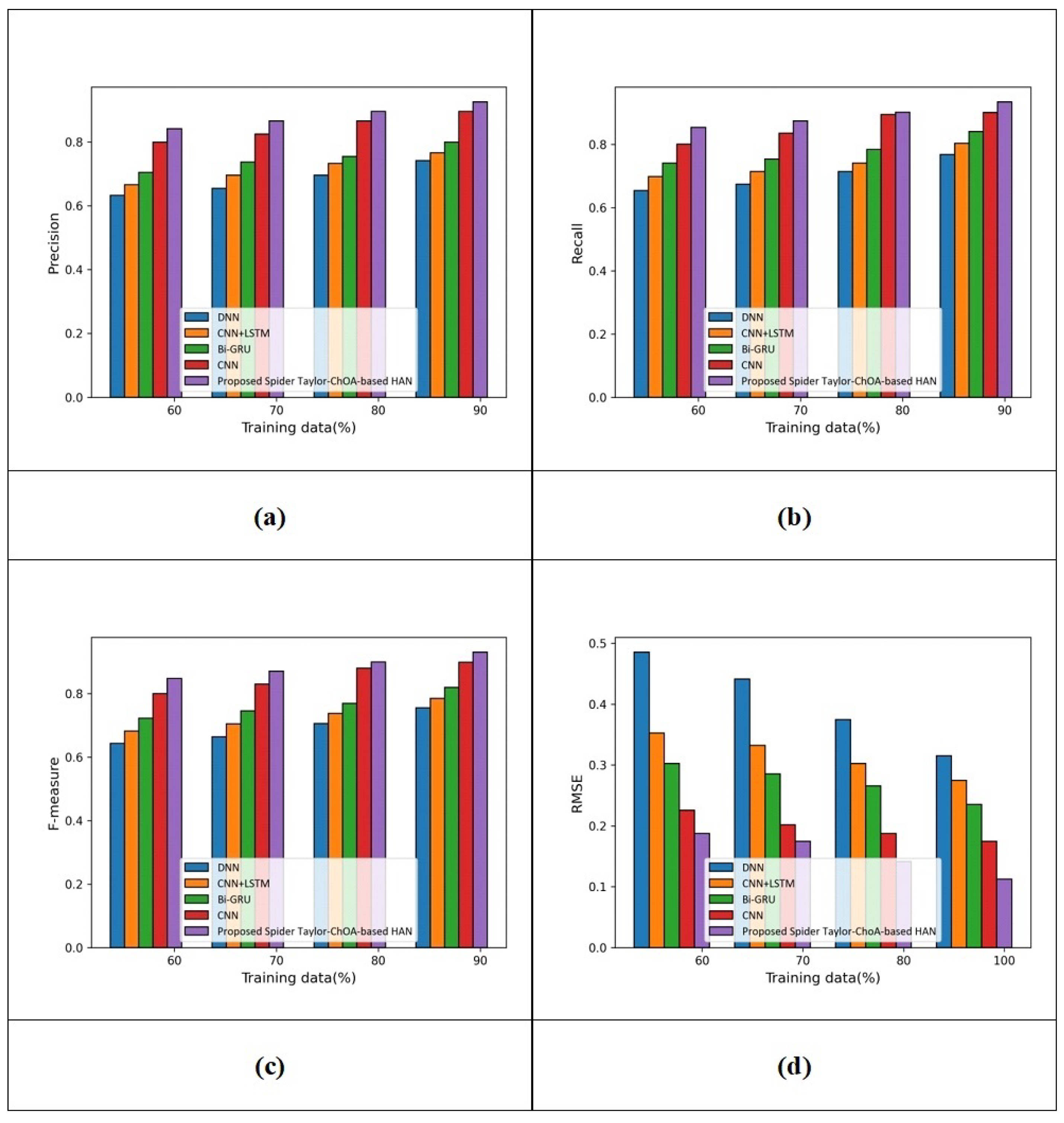
(b) Assessment with Yelp 2013 datasets: The assessment based on review rating using Yelp 2013 database is revealed in Figure 8.
The assessment with precision is displayed in Figure 8a. For training data = 60%, the precision of DNN is 0.633, that of CNN+LSTM is 0.665, that of Bi-GRU is 0.704, that of CNN is 0.799 and that of the proposed spider Taylor-ChOA-based HAN is 0.841. Additionally, for training data = 90%, the precision of DNN is 0.741, that of CNN+LSTM is 0.765, that of Bi-GRU is 0.799, that of CNN is 0.895, and that of the proposed Spider Taylor-ChOA-based HAN is 0.925. The performance improvements of DNN, CNN+LSTM, Bi-GRU, and CNN with respect to the proposed spider Taylor-ChOA-based HAN using precision are 19.891%, 17.297%, 13.621%, and 3.243%. The assessment with recall is revealed in Figure 8b. For training data = 60%, the recall of DNN is 0.654, that of CNN+LSTM is 0.699, that of Bi-GRU is 0.741, that of CNN is 0.801, and that of the proposed spider Taylor-ChOA-based HAN is 0.854. Additionally, for training data = 90%, the recall of DNN is 0.769, that of CNN+LSTM is 0.804, that of Bi-GRU is 0.841, that of CNN is 0.901, and that of the proposed spider Taylor-ChOA-based HAN is 0.935. The performance improvements of DNN, CNN+LSTM, Bi-GRU, and CNN with respect to the proposed spider Taylor-ChOA-based HAN using recall are 17.754%, 14.010%, 10.053%, and 3.636%. The assessment with the F-measure is revealed in Figure 8c. For training data = 60%, the F-measure of DNN is 0.643, that of CNN+LSTM is 0.682, that of Bi-GRU is 0.722, that of CNN is 0.800, and that of the proposed spider Taylor-ChOA-based HAN is 0.848. Additionally, for training data = 90%, the F-measure measured by DNN is 0.755, that of CNN+LSTM is 0.784, that of Bi-GRU is 0.819, that of CNN is 0.898, and that of the proposed spider Taylor-ChOA-based HAN is 0.930. The performance improvement of DNN, CNN+LSTM, Bi-GRU, CNN with respect to proposed Spider Taylor-ChOA-based HAN using F-measure are 18.817%, 15.698%, 11.935%, 3.440%.The assessment with RMSE is revealed in Figure 8d. For training data = 60%, the RMSE measured by DNN is 0.485, CNN+LSTM is 0.352, Bi-GRU is 0.303, CNN is 0.225, and proposed Spider Taylor-ChOA-based HAN is 0.187. Also, for training data = 100%, the RMSE measured by DNN is 0.315, CNN+LSTM is 0.275, Bi-GRU is 0.235, CNN is 0.175, and proposed Spider Taylor-ChOA-based HAN is 0.112.
(c) Assessment with Yelp 2014 Datasets:Figure 9 reveals the assessment considering review rating using Yelp 2014database.
The assessment using precision is displayed in Figure 9a. Considering training data = 60%, the highest precision of 0.841 is generated by the proposed spider Taylor-ChOA-based HAN, while the precision values of DNN, CNN+LSTM, Bi-GRU, and CNN are 0.641, 0.695, 0.741, 0.785. Additionally, for training data = 90%, the highest precision of 0.914 is generated by the proposed spider Taylor-ChOA-based HAN, while the precision values of DNN, CNN+LSTM, Bi-GRU, and CNN are 0.725, 0.799, 0.841, and 0.895. The performance improvements of DNN, CNN+LSTM, Bi-GRU, and CNN with respect to the proposed spider Taylor-ChOA-based HAN using precision are 20.678%, 12.582%, 7.986%, and 2.078%. The assessment with recall is revealed in Figure 9b. For training data = 60%, the highest recall of 0.854 is generated by proposed spider Taylor-ChOA-based HAN, while the recall values of DNN, CNN+LSTM, Bi-GRU, and CNN are 0.665, 0.714, 0.754, and 0.801. Additionally, for training data = 90%, the highest recall of 0.933 is measured by the proposed spider Taylor-ChOA-based HAN, while the recall values of DNN, CNN+LSTM, Bi-GRU, and CNN are 0.733, 0.814, 0.854, and 0.912. The performance improvements of DNN, CNN+LSTM, Bi-GRU, and CNN with respect to the proposed spider Taylor-ChOA-based HAN using recall are 21.436%, 12.754%, 8.467%, and 2.250%. The assessment with the F-measure is revealed in Figure 9c. For training data = 60%, the highest F-measure of 0.848 is generated by the proposed spider Taylor-ChOA-based HAN, while the F-measure values of DNN, CNN+LSTM, Bi-GRU, and CNN are 0.653, 0.704, 0.748, and 0.793. Additionally, for training data = 90%, the highest F-measure of 0.923 is generated by the proposed spider Taylor-ChOA-based HAN, while the F-measure values of DNN, CNN+LSTM, Bi-GRU, and CNN are 0.729, 0.806, 0.848, and 0.904. The performance improvements of DNN, CNN+LSTM, Bi-GRU, and CNN with respect to the proposed spider Taylor-ChOA-based HAN using the F-measure are 21.018%, 12.876%, 8.125%, and 2.058%. The assessment with RMSE is revealed in Figure 9d. For training data = 60%, the smallest RMSE of 0.153 is measured by the proposed spider Taylor-ChOA-based HAN while the RMSE values of DNN, CNN+LSTM, Bi-GRU, and CNN are 0.451, 0.333, 0.285, and 0.201. Additionally, for training data = 100%, the smallest RMSE of 0.114 is measured by the proposed spider Taylor-ChOA-based HAN, while the RMSE values of DNN, CNN+LSTM, Bi-GRU, and CNN are 0.335, 0.241, 0.201, and 0.133.
5.3. Comparative Discussion
Table 2 describes the assessment of techniques with sentiment classification. Using the IMDB database, the highest precision of 0.941 is measured by the proposed spider Taylor-ChOA-based RMDL while the precision values of HSACN, MCNN, and DCBVN are 0.852, 0.874, and 0.905.
The highest precision is measured by the proposed spider Taylor-ChOA-based RMDL, as the RMDL contains the amalgamation of deep models, which helps to increase the precision. The highest recall of 0.965 is measured by the proposed spider Taylor-ChOA-based RMDL, while the recall values of HSACN, MCNN, and DCBVN are 0.865, 0.885, and 0.914. The highest recall reveals that the technique returns the most pertinent results. The highest F-measure of 0.953 is measured by the proposed spider Taylor-ChOA-based RMDL, while the recall values of HSACN, MCNN, and DCBVN are 0.859, 0.880, and 0.910. The highest F-measure reveals that the technique is effective in handling the uneven class. The smallest RMSE of 0.097 is measured by the proposed spider Taylor-ChOA-based RMDL, while the RMSE values of HSACN, MCNN, and DCBVN are 0.395, 0.221, and 0.141. Using the Yelp 2013 database, the highest precision of 0.933, highest recall of 0.941, highest F-measure of 0.937, and smallest RMSE of 0.193 are measured by the proposed spider Taylor-ChOA-based RMDL. Using the Yelp 2014 database, the highest precision of 0.947, highest recall of 0.955, highest F-measure of 0.951, and smallest RMSE of 0.087 are measured by the proposed spider Taylor-ChOA-based RMDL.
Table 3 displays the assessment with the review rating prediction by altering the training data. Using the IMDB database, the highest precision of 0.931 is measured by the proposed spider Taylor-ChOA-based HAN, while the precision values evaluated by DNN, CNN+LSTM, Bi-GRU, and CNN are 0.695, 0.765, 0.805, and 0.901.
The highest precision is due to the HAN, which helps to make an effective review rating. The highest recall of 0.954 is measured by the proposed spider Taylor-ChOA-based HAN, while the recall values evaluated by DNN, CNN+LSTM, Bi-GRU, and CNN are 0.724, 0.775, 0.825, and 0.928. The highest recall reveals that the proposed spider Taylor-ChOA-based HAN is effective in making a relevant prediction. The highest F-measure of 0.943 is measured by the proposed spider Taylor-ChOA-based HAN, while the F-measure values evaluated by DNN, CNN+LSTM, Bi-GRU, and CNN are 0.709, 0.770, 0.815, and 0.914. The F-measure tends to be high when the precision and recall are high. The smallest RMSE of 0.075 is measured by the proposed spider Taylor-ChOA-based HAN, while the RMSE values evaluated by DNN, CNN+LSTM, Bi-GRU, and CNN are 0.314, 0.214, 0.102, and 0.085. Using the Yelp 2013 database, the highest precision of 0.925, highest recall of 0.935, highest F-measure of 0.930 and smallest RMSE of 0.112 are measured by the proposed spider Taylor-ChOA-based HAN. Using the Yelp 2014 database, the highest precision of 0.914, highest recall of 0.933, highest F-measure of 0.923 and smallest RMSE of 0.114 are measured by the proposed spider Taylor-ChOA-based HAN.
6. Conclusions and Future Work
This research aims to develop a method on the basis of sentiment classification for review rating prediction. The review data undergo feature extraction, wherein imperative features, such as SentiWordNet-based statistical features, TF-IDF-based features, the number of capitalized words, numerical words, punctuation marks, elongated words, hashtags, emoticons, and number of sentences, are extracted. Then, the spider Taylor-ChOA-based RMDL is employed for classifying the sentiment. The training of RMDL is done using the proposed spider Taylor-ChOA, which is obtained by combining the SMO and Taylor-ChOA. The spider Taylor-ChOA-based HAN is employed for predicting the review rating. The training of HAN is done using the proposed spider Taylor-ChOA, which is obtained by combining the SMO and Taylor-ChOA. We conduct extensive experiments on different datasets, and the experiment results show that the proposed method outperforms state-of-the-art methods of review rating prediction tasks. The features mined are employed in the review rating prediction, which helps to devise the review as being positive and negative using HAN. The proposed spider Taylor-ChOA-based RMDL provides enhanced performance with the highest precision of 94.1%, recall of 96.5%, and highest F-measure of 95.3%. The proposed spider Taylor-ChOA-based HAN offers improved performance with the highest precision of 93.1%, highest recall of 95.4% and the highest F-measure of 94.3%. The proposed method is limited in extracting capitalized words, numerical words, punctuation marks, hash tags, number of sentences, emoticons and elongated words with their proper sentiments. In the future, we plan to enhance the pre-processing with word embeddings by exploiting deep recurrent neural networks. We can also extend this research via convolution neural networks. Additionally, other datasets can be adapted to check the feasibility of the proposed model.
Author Contributions
S.K.B. designed and wrote the paper; H.L. supervised the work; S.K.B. performed the experiments with advice from B.X.; and D.K.S. organized and proofread the paper. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data used in the experiments are publicly available. Details are given in Section 4.1.
Acknowledgments
The authors appreciate and acknowledge anonymous reviewers for their reviews and guidance.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ChOA | Chimp Optimization Algorithm. |
| CNN | Convolutional Neural Network. |
| DCBVN | Demand-aware Collaborative Bayesian Variational Network. |
| DNN | Deep Neural Networks. |
| GRU | Gated Recurrent Unit. |
| HAN | Hierarchical Attention Network. |
| LSTM | Long Short-Term Memory. |
| NLP | Natural Language Processing. |
| RMDL | Random Multimodal Deep Learning. |
| SMO | Spider Monkey Optimization. |
References
- Khurana, D.; Koli, A.; Khatter, K.; Singh, S. Natural language processing: State of the art, current trends and challenges. arXiv 2017, arXiv:1708.05148. [Google Scholar]
- Rajput, A. Natural language processing, sentiment analysis, and clinical analytics. In Innovation in Health Informatics; Elsevier: Amsterdam, The Netherlands, 2020; pp. 79–97. [Google Scholar]
- Yıldırım, E.; Çetin, F.S.; Eryiğit, G.; Temel, T. The impact of NLP on Turkish sentiment analysis. Türkiye Bilişim Vakfı Bilgi. Bilim. Ve Mühendisliği Derg. 2015, 7, 43–51. [Google Scholar]
- Mukherjee, S.; Basu, G.; Joshi, S. Incorporating author preference in sentiment rating prediction of reviews. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 47–48. [Google Scholar]
- De Albornoz, J.C.; Plaza, L.; Gervás, P.; Díaz, A. A joint model of feature mining and sentiment analysis for product review rating. In European Conference on Information Retrieval; Springer: Berlin/Heidelberg, Germany, 2011; pp. 55–66. [Google Scholar]
- Jin, Z.; Li, Q.; Zeng, D.D.; Zhan, Y.; Liu, R.; Wang, L.; Ma, H. Jointly modeling review content and aspect ratings for review rating prediction. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016; pp. 893–896. [Google Scholar]
- Tang, D.; Qin, B.; Liu, T.; Yang, Y. User modeling with neural network for review rating prediction. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Tang, D.; Qin, B.; Liu, T. Learning semantic representations of users and products for document level sentiment classification. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015; pp. 1014–1023. [Google Scholar]
- Dou, Z.Y. Capturing user and product information for document level sentiment analysis with deep memory network. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; pp. 521–526. [Google Scholar]
- Li, F.; Liu, N.N.; Jin, H.; Zhao, K.; Yang, Q.; Zhu, X. Incorporating reviewer and product information for review rating prediction. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Zainuddin, N.; Selamat, A.; Ibrahim, R. Hybrid sentiment classification on twitter aspect-based sentiment analysis. Appl. Intell. 2018, 48, 1218–1232. [Google Scholar] [CrossRef]
- Kalaivani, P.; Shunmuganathan, K. Feature reduction based on genetic algorithm and hybrid model for opinion mining. Sci. Program. 2015, 2015, 961454. [Google Scholar] [CrossRef]
- Hernández-Hernández, J.L.; Hernández-Hernández, M.; Sabzi, S.; Paredes-Valverde, M.A.; Penna, A.F. A Byte Pattern Based Method for File Compression. In International Conference on Technologies and Innovation; Springer: Berlin/Heidelberg, Germany, 2019; pp. 122–134. [Google Scholar]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent convolutional neural networks for text classification. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Feng, S.; Song, K.; Wang, D.; Gao, W.; Zhang, Y. InterSentiment: Combining deep neural models on interaction and sentiment for review rating prediction. Int. J. Mach. Learn. Cybern. 2021, 12, 477–488. [Google Scholar] [CrossRef]
- Zheng, T.; Wu, F.; Law, R.; Qiu, Q.; Wu, R. Identifying unreliable online hospitality reviews with biased user-given ratings: A deep learning forecasting approach. Int. J. Hosp. Manag. 2021, 92, 102658. [Google Scholar] [CrossRef]
- Ahmed, B.H.; Ghabayen, A.S. Review rating prediction framework using deep learning. J. Ambient. Intell. Humaniz. Comput. 2020, 1–10. [Google Scholar] [CrossRef]
- Sadiq, S.; Umer, M.; Ullah, S.; Mirjalili, S.; Rupapara, V.; Nappi, M. Discrepancy detection between actual user reviews and numeric ratings of Google App store using deep learning. Expert Syst. Appl. 2021, 181, 115111. [Google Scholar] [CrossRef]
- Chambua, J.; Niu, Z. Review text based rating prediction approaches: Preference knowledge learning, representation and utilization. Artif. Intell. Rev. 2021, 54, 1171–1200. [Google Scholar] [CrossRef]
- Shrestha, N.; Nasoz, F. Deep learning sentiment analysis of amazon.com reviews and ratings. arXiv 2019, arXiv:1904.04096. [Google Scholar] [CrossRef]
- Bu, J.; Ren, L.; Zheng, S.; Yang, Y.; Wang, J.; Zhang, F.; Wu, W. ASAP: A Chinese Review Dataset Towards Aspect Category Sentiment Analysis and Rating Prediction. arXiv 2021, arXiv:2103.06605. [Google Scholar]
- Zhang, K.; Qian, H.; Liu, Q.; Zhang, Z.; Zhou, J.; Ma, J.; Chen, E. SIFN: A Sentiment-aware Interactive Fusion Network for Review-based Item Recommendation. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Online, Australia, 1–5 November 2021; pp. 3627–3631. [Google Scholar]
- Pan, D.; Yuan, J.; Li, L.; Sheng, D. Deep neural network-based classification model for Sentiment Analysis. In Proceedings of the 2019 6th International Conference on Behavioral, Economic and Socio-Cultural Computing (BESC), Beijing, China, 28–30 October 2019; pp. 1–4. [Google Scholar]
- Kowsari, K.; Heidarysafa, M.; Brown, D.E.; Meimandi, K.J.; Barnes, L.E. Rmdl: Random multimodel deep learning for classification. In Proceedings of the 2nd International Conference on Information System and Data Mining, Lakeland, FL, USA, 9–11 April 2018; pp. 19–28. [Google Scholar]
- Bansal, J.C.; Sharma, H.; Jadon, S.S.; Clerc, M. Spider monkey optimization algorithm for numerical optimization. Memetic Comput. 2014, 6, 31–47. [Google Scholar] [CrossRef]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Ohana, B.; Tierney, B. Sentiment classification of reviews using SentiWordNet. ComTech 2016, 7, 285–294. [Google Scholar]
- Christian, H.; Agus, M.P.; Suhartono, D. Single document automatic text summarization using term frequency-inverse document frequency (TF-IDF). ComTech Comput. Math. Eng. Appl. 2016, 7, 285–294. [Google Scholar] [CrossRef]
- Chen, H.; Sun, M.; Tu, C.; Lin, Y.; Liu, Z. Neural sentiment classification with user and product attention. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 1650–1659. [Google Scholar]
- Zeng, H.; Ai, Q. A Hierarchical Self-attentive Convolution Network for Review Modeling in Recommendation Systems. arXiv 2020, arXiv:2011.13436. [Google Scholar]
- Da’u, A.; Salim, N.; Rabiu, I.; Osman, A. Recommendation system exploiting aspect-based opinion mining with deep learning method. Inf. Sci. 2020, 512, 1279–1292. [Google Scholar]
- Wang, C.; Zhu, H.; Zhu, C.; Zhang, X.; Chen, E.; Xiong, H. Personalized Employee Training Course Recommendation with Career Development Awareness. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 1648–1659. [Google Scholar]
Figure 1.
An illustration of sentiment classification for review rating prediction model using the proposed spider Taylor-ChOA-based HAN and RMDL.
Figure 1.
An illustration of sentiment classification for review rating prediction model using the proposed spider Taylor-ChOA-based HAN and RMDL.

Figure 2.
An illustration of the RMDL model.

Figure 3.
An illustration of hierarchical attention network (HAN) Model.

Figure 4.
Results based on sentiment classification using IMDB datasets with (a) precision (b) recall (c) F-measure and (d) RMSE.
Figure 4.
Results based on sentiment classification using IMDB datasets with (a) precision (b) recall (c) F-measure and (d) RMSE.

Figure 5.
Results based on sentiment classification using Yelp 2013 datasets with (a) precision (b) recall (c) F-measure and (d) RMSE.
Figure 5.
Results based on sentiment classification using Yelp 2013 datasets with (a) precision (b) recall (c) F-measure and (d) RMSE.

Figure 6.
Results based on sentiment classification using Yelp 2014 datasets with (a) precision (b) recall (c) F-measure and (d) RMSE.
Figure 6.
Results based on sentiment classification using Yelp 2014 datasets with (a) precision (b) recall (c) F-measure and (d) RMSE.

Figure 7.
Results based on review rating prediction using IMDB datasets with (a) precision (b) recall (c) F-measure and (d) RMSE.
Figure 7.
Results based on review rating prediction using IMDB datasets with (a) precision (b) recall (c) F-measure and (d) RMSE.

Figure 8.
Results based on review rating prediction using Yelp 2013 datasets with (a) precision (b) recall (c) F-measure and (d) RMSE.
Figure 8.
Results based on review rating prediction using Yelp 2013 datasets with (a) precision (b) recall (c) F-measure and (d) RMSE.

Figure 9.
Results based on review rating prediction using Yelp 2014 datasets with (a) precision (b) recall (c) F-measure and (d) RMSE.
Figure 9.
Results based on review rating prediction using Yelp 2014 datasets with (a) precision (b) recall (c) F-measure and (d) RMSE.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Example of feature extraction.
| Cap | Emo | Hash | Elong | Positive | Negative | Punj | Numerical | No. of Sent. |
|---|---|---|---|---|---|---|---|---|
| 116 | 10 | 36 | 0 | 13 | 116 | 10 | 36 | 0 |
| 137 | 8 | 42 | 0 | 3 | 137 | 8 | 42 | 0 |
| 160 | 10 | 42 | 2 | 12 | 160 | 10 | 42 | 2 |
| 172 | 11 | 33 | 5 | 7 | 172 | 11 | 33 | 5 |
| 109 | 10 | 19 | 0 | 8 | 109 | 10 | 19 | 0 |
| 17 | 3 | 4 | 0 | 6 | 17 | 3 | 4 | 0 |
| 115 | 9 | 25 | 0 | 1 | 115 | 9 | 25 | 0 |
| 145 | 6 | 67 | 5 | 7 | 145 | 6 | 67 | 5 |
| 365 | 18 | 103 | 6 | 8 | 365 | 18 | 103 | 6 |
| 120 | 11 | 41 | 0 | 13 | 120 | 11 | 41 | 0 |
| Features | TF-IDF | |||||||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.090 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0.037 | 0 | 0.074 | 0 | 0.044 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0.037 | 0 | 0.074 | 0 | 0.044 | 0 |
| 0 | 0 | 0 | 0 | 0.073 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0.111 | 0 | 0 | 0 | 0 | 0 |
Table 2.
Comparison of proposed spider Taylor-ChOA-based RMDL with existing methods based on sentiment classification, in terms of precision, recall, F-measure and RMSE. The best results are displayed in boldface.
Table 2.
Comparison of proposed spider Taylor-ChOA-based RMDL with existing methods based on sentiment classification, in terms of precision, recall, F-measure and RMSE. The best results are displayed in boldface.
| Datasets | Metrics | HSACN | MCNN | DCBVN | Proposed Method |
|---|---|---|---|---|---|
| IMDB | Precision | 0.852 | 0.874 | 0.905 | 0.941 |
| Recall | 0.865 | 0.885 | 0.914 | 0.965 | |
| F-measure | 0.859 | 0.880 | 0.910 | 0.953 | |
| RMSE | 0.39559 | 0.221 | 0.141 | 0.097 | |
| Yelp 2013 | Precision | 0.825 | 0.841 | 0.885 | 0.933 |
| Recall | 0.833 | 0.865 | 0.895 | 0.941 | |
| F-measure | 0.829 | 0.853 | 0.890 | 0.937 | |
| RMSE | 0.335 | 0.298 | 0.214 | 0.193 | |
| Yelp 2014 | Precision | 0.833 | 0.854 | 0.895 | 0.947 |
| Recall | 0.848 | 0.865 | 0.903 | 0.955 | |
| F-measure | 0.840 | 0.860 | 0.899 | 0.951 | |
| RMSE | 0.859 | 0.880 | 0.910 | 0.953 |
Table 3.
Comparison of proposed spider Taylor-ChOA-based HAN with existing methods using based on review rating prediction, in terms of precision, recall, F-measure and RMSE. The best results are displayed in boldface.
Table 3.
Comparison of proposed spider Taylor-ChOA-based HAN with existing methods using based on review rating prediction, in terms of precision, recall, F-measure and RMSE. The best results are displayed in boldface.
| Datasets | Metrics | DNN | CNN+LSTM | Bi-GRU | CNN | Proposed Method |
|---|---|---|---|---|---|---|
| IMDB | Precision | 0.695 | 0.765 | 0.805 | 0.901 | 0.931 |
| Recall | 0.724 | 0.775 | 0.825 | 0.928 | 0.954 | |
| F-measure | 0.709 | 0.770 | 0.815 | 0.914 | 0.943 | |
| RMSE | 0.314 | 0.214 | 0.102 | 0.085 | 0.075 | |
| Yelp 2013 | Precision | 0.741 | 0.765 | 0.799 | 0.895 | 0.925 |
| Recall | 0.769 | 0.804 | 0.841 | 0.901 | 0.935 | |
| F-measure | 0.755 | 0.784 | 0.819 | 0.898 | 0.930 | |
| RMSE | 0.315 | 0.275 | 0.235 | 0.175 | 0.112 | |
| Yelp 2014 | Precision | 0.725 | 0.799 | 0.841 | 0.895 | 0.914 |
| Recall | 0.733 | 0.814 | 0.854 | 0.912 | 0.933 | |
| F-measure | 0.729 | 0.806 | 0.848 | 0.904 | 0.923 | |
| RMSE | 0.335 | 0.241 | 0.201 | 0.133 | 0.114 |
Table 4.
Comparison of proposed spider Taylor-ChOA-based HAN with existing methods, in terms of accuracy (ACC) and RMSE. The best results are displayed in boldface.
Table 4.
Comparison of proposed spider Taylor-ChOA-based HAN with existing methods, in terms of accuracy (ACC) and RMSE. The best results are displayed in boldface.
| Methods | IMDB | Yelp 2013 | Yelp 2014 | |||
|---|---|---|---|---|---|---|
| ACC | RMSE | ACC | RMSE | ACC | RMSE | |
| Trigram+UPF | 0.404 | 1.764 | 0.570 | 0.803 | 0.576 | 0.789 |
| TextFeature UPF | 0.402 | 1.774 | 0.561 | 1.822 | 0.579 | 0.791 |
| JMARS | N/A | 1.773 | N/A | 0.985 | N/A | 0.999 |
| UPNN (CNN) | 0.435 | 1.602 | 0.596 | 0.784 | 0.608 | 0.764 |
| UPNN (NSC) | 0.471 | 1.443 | 0.631 | 0.702 | N/A | N/A |
| NSC+UPA | 0.533 | 1.281 | 0.650 | 0.692 | 0.667 | 0.654 |
| HSACN | 0.852 | – | 0.825 | – | 0.833 | – |
| MCNN | 0.874 | – | 0.841 | – | 0.854 | – |
| DCBVN | 0.905 | – | 0.885 | – | 0.895 | – |
| Proposed Method | 0.941 | – | 0.933 | – | 0.947 | – |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Banbhrani, S.K.; Xu, B.; Lin, H.; Sajnani, D.K. Spider Taylor-ChOA: Optimized Deep Learning Based Sentiment Classification for Review Rating Prediction. Appl. Sci. 2022, 12, 3211. https://0-doi-org.brum.beds.ac.uk/10.3390/app12073211
AMA Style
Banbhrani SK, Xu B, Lin H, Sajnani DK. Spider Taylor-ChOA: Optimized Deep Learning Based Sentiment Classification for Review Rating Prediction. Applied Sciences. 2022; 12(7):3211. https://0-doi-org.brum.beds.ac.uk/10.3390/app12073211
Chicago/Turabian StyleBanbhrani, Santosh Kumar, Bo Xu, Hongfei Lin, and Dileep Kumar Sajnani. 2022. "Spider Taylor-ChOA: Optimized Deep Learning Based Sentiment Classification for Review Rating Prediction" Applied Sciences 12, no. 7: 3211. https://0-doi-org.brum.beds.ac.uk/10.3390/app12073211
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.