
Fast Format-Aware Fuzzing for Structured Input Applications
1
College of Electronic Engineering, National University of Defense Technology, Hefei 230037, China
2
Anhui Province Key Laboratory of Cyberspace Security Situation Awareness and Evaluation, Hefei 230037, China
*
Author to whom correspondence should be addressed.
Appl. Sci. 2022, 12(18), 9350; https://0-doi-org.brum.beds.ac.uk/10.3390/app12189350
Submission received: 22 June 2022
/
Revised: 17 August 2022
/
Accepted: 14 September 2022
/
Published: 18 September 2022
(This article belongs to the Special Issue Resilience and Vulnerability in Cybersecurity)
Abstract
:Fuzzing is one of the most successful software testing techniques used to discover vulnerabilities in programs. Without seeds that fit the input format, existing runtime dependency recognition strategies are limited by incompleteness and high overhead. In this paper, for structured input applications, we propose a fast format-aware fuzzing approach to recognize dependencies from the specified input to the corresponding comparison instruction. We divided the dependencies into Input-to-State (I2S) and indirect dependencies. Our approach has the following advantages compared to existing works: (1) recognizing I2S dependencies more completely and swiftly using the input based on the de Bruijn sequence and its mapping structure; (2) obtaining indirect dependencies with a light dependency existence analysis on the input fragments. We implemented a fast format-aware fuzzing prototype, FFAFuzz, based on our method and evaluated FFAFuzz in real-world structured input applications. The evaluation results showed that FFAFuzz reduced the average time overhead by 76.49% while identifying more completely compared with Redqueen and by 89.10% compared with WEIZZ. FFAFuzz also achieved higher code coverage by 14.53% on average compared to WEIZZ.
1. Introduction
Fuzzing is one of the most successful software testing techniques for discovering vulnerabilities in programs [1]. Coverage-based Greybox Fuzzing (CGF) technology [2,3,4,5] creates a series of test cases with mutations guided by code coverage to continuously test the target, in the hope of discovering more vulnerabilities. Targeting applications with highly structured input, such as image players, which only accept valid image files as input, its blind mutations deprive the test case from passing the target’s embedded sanity check and prevent the fuzzer from exploring the deep code.
Thus, format-aware fuzzing has been proposed in recent decades. It parses the input format of the target software by expert-given prior knowledge or performing program analysis. The knowledge of the input format is then exploited to guide the generation of test cases. Those test cases maintaining the data consistency well will assist the fuzzer in testing the robustness of more and deeper code. The key issue we targeted in this paper is how to identify the input format comprehensively and efficiently.
At present, part of the existing research starts from artificially given a priori knowledge. LangFuzz [6] generates test cases that could pass the format check within the PHP interpreter based on the given-grammar. Based on the given data definition template written in XML, peach [7] is widely used to generate a large number of test cases meeting the file format, network protocol, or API and tests the robustness with targets including file parsers, network services, and web browsers. Fuzzers [8,9,10,11] are also similar to peach in that the user-supplied format template is required to parse and construct test cases following the format requirements. This type of method is fast and comprehensive, but labor-intensive and cannot identify unknown input format targets.
The current format-aware fuzzing methods deploying program analysis can parse input formats (from binary code, run state, etc.) without any a priori knowledge. In response to the key issue described above, the existing methods, and their limitations, I2S misses and indiscriminate dependency recognition are as follows.
Redqueen [12] and GRIMOIRE [13] recognize Input-to-State (I2S) dependencies by padding random values on test case fragments, selecting fragments causing execution path changes, and performing I2S dependency analysis on them. Such a selection of fragments for dependency recognition is called colorization. The main challenge is that colorization may fail to change the code coverage, because the constraint to trigger a new branch is not satisfied. We call this limitation I2S misses for such methods, meaning missing part of the I2S fields that are supposed to be recognized. Regarding the key issues above, I2S misses will result in the incomplete recognition of the input format.
SLF [14] and WEIZZ [15] recognize indirect dependencies by byte-flipping and observing, which compare instruction operand changes. In this paper, if a fragment cannot affect any comparison instruction operand, we consider it to be non-deps. “deps” is an abbreviation of “dependencies” here. Still, structured input contains long non-deps fields that have no impact on any target comparison instructions, and they lead to overhead for these approaches. We refer to this limitation as indiscriminate dependency recognition. With regard to the above-mentioned key issue, it is indicated that the time efficiency of input format recognition can be further improved.
I2S misses result in the absence of some I2S dependencies, which makes the input format recognition incomplete and prevents the fuzzer from discovering deeper bugs. Indiscriminate dependency recognition increases the wasteful overhead of input format recognition, dragging down the entire fuzzing test process and blocking the fuzzer from exploring more code and hunting for more software vulnerabilities. These are the motivations of this paper.
The objective of this paper is, based on existing work, to investigate the causes of and treatments for I2S misses and indiscriminate dependency recognition, design an optimized input format recognition approach, and apply it to format-aware fuzzing targeted at structured input applications.
Our approach. In this paper, focused on the key issue, to solve the two limitations discussed above, we propose a fast format-aware fuzzing approach. Targeting programs with structured input, it can perform lightweight program analysis and swiftly obtain the dependencies from the bytes of the input to the operands of the comparison instructions within the target. Utilizing these, it will construct test cases that fit the input format, improve the code coverage, and expose the hidden vulnerabilities of the target software.
To address I2S misses and enhance the effectiveness and efficiency of discovering I2S dependencies, I2S recognition based on de Bruijn matching is proposed and is applicable to scenarios without seeds that meet the input format. Assisted by the unique feature of the de Bruijn-based test case, the I2S dependencies are obtained directly by analyzing the runtime logs about the target’s comparison instructions. Unlike looking up the changes of key states, observing the I2S dependencies via matching the value of cmp operands to the fragments is its novelty. This approach can recognize more I2S dependencies than previous works [12,13].
Aimed at indiscriminate dependency recognition, we present an intelligent Selective Flip strategy to obtain indirect dependencies. We lightly identify and exclude those fragments that cannot affect any comparison instruction operands. Performing lightweight dependency existence analysis before recognizing to avoid ineffective identification is its novelty. In this way, we obtain indirect dependencies faster and more specifically from fragments containing dependencies.
We implemented a fast format-aware fuzzing prototype, FFAFuzz, and evaluated it compared with Redqueen and WEIZZ, using 11 real-world applications as benchmarks. The result showed that, in terms of effectiveness, FFAFuzz outperforms Redqueen significantly and is on par with WEIZZ. FFAFuzz reduces the time cost by up to 89.10% on average. Compared with WEIZZ, FFAFuzz can discover more than 14.53% of paths.
Contribution. In summary, we make the following contributions:
- To address I2S misses, we firstly present I2S recognition based on de Bruijn matching to obtain more I2S dependencies directly and promote more comprehensive identification of the input format. In addition, the de Bruijn-based test case generation algorithm is proposed for scenarios without seeds that meet the input format.
- Tackling indiscriminate dependency recognition, we firstly present the Selective Flip strategy to recognize indirect dependencies faster and more purposefully, while fragments without any dependencies will be omitted. This enables the input format recognition to be more efficient.
- We implemented a fast format-aware fuzzing prototype, FFAFuzz. Our evaluation results showed that FFAFuzz can recognize more dependencies faster than the state-of-the-art and can achieve higher code coverage regardless of whether the input satisfies the target format.
The remainder of this paper is organized as follows. Section 2 introduces the two common types of fields within the structured input, existing fuzzing approaches, and limitations. We describe the overview and the key stages of our method in Section 3. Section 4 present the evaluation. We discuss the limitations of FFAFuzz in Section 5 and conclude the paper in Section 6.
2. Background
In this section, we firstly divide the structured input into two common types of fields, header and trailer, depending on the impact on fuzzing, and we use the Tagged Image Files (TIF) file extension to briefly describe them. Then, we introduce existing fuzzing approaches and reveal the challenges.
2.1. Header and Trailer
We describe two common types of fields, header and trailer, within the structured input, using the TIF file format and the corresponding parsing code in the real-world software optipng.
Applications in the present computer systems generate and parse a large number of structured input all the time [16], and most of them store information as a long binary string in a chunk manner [8]. We refer to such software as structured input applications. Typically, some fragments hold the essential metadata such as the file signature, version [17], length, checksum [18], type [19], and so on. We refer to these short, but metadata-intensive fields as header fields, and those long, but lacking metadata fields as trailer fields. The control information stored in the header guides the parser on how to obtain the recorded information from the trailer and affects its execution path. Changing the contents of the bytes in the header will have more potential to affect the execution of the target program than those in the trailer during fuzzing.
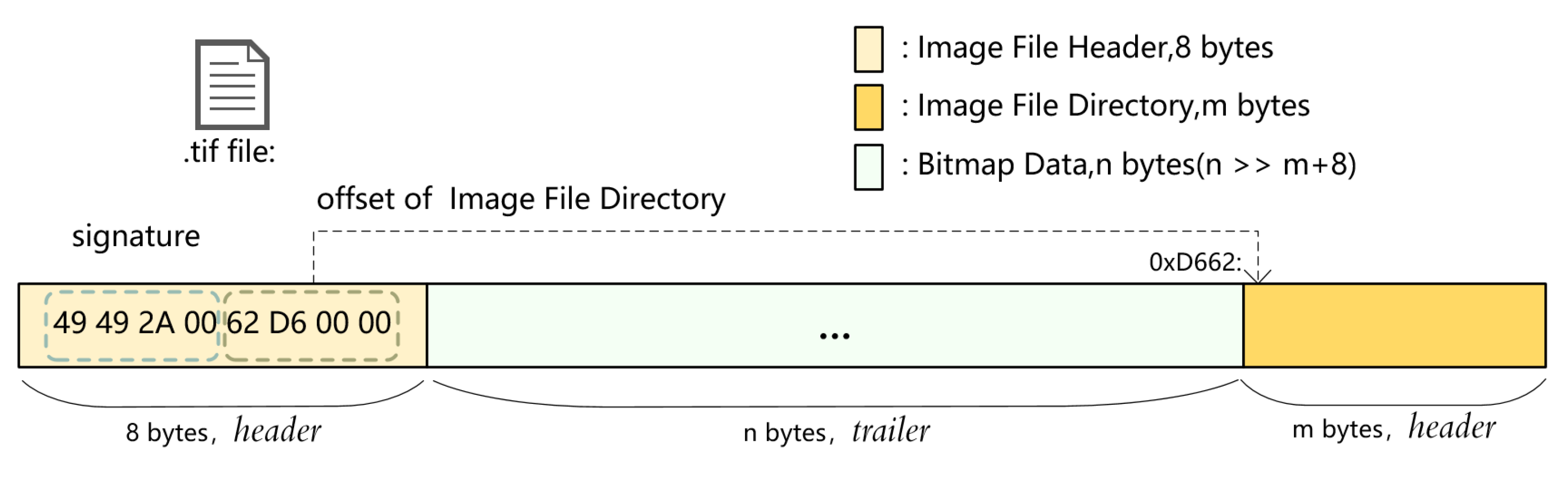
Tagged Image Files (TIF) contain graphic bitmap content and can be handled by image readers and writers easily. Figure 1 presents a TIF file internally consisting of three types of chunks, Image File Header (IFH), Bitmap Data, and Image File Directory (IFD) [20]:
- Image File Header (IFH): The first 4 bytes of the IFH are the signature of one TIF file, and the last four indicate the offset of the IFD chunk. For example, “62 D6 00 00” means that the IFD starts with 0xD662. The IFH belongs to header field.
- Bitmap Data: Image data in the .tif file are placed closely after the IFH, and each byte stores the RGB color or just the compressed data. Bitmap Data belong to the trailer field.
- Image File Directory (IFD): The location of the IFD is specified by the last 4 bytes within the IDH, with a length of n bytes, and n is far greater than . Most of the key control information such as the image height, width, compression method, bit rate, photometric interpretation, etc., is concentrated in the IFD. The IFD belongs to the header field.
Listing 1 shows how the signature within the IFH and the contents within the IFD are validated. The first 4 bytes of the IFD will be compared with the buffer containing “49 49 2a 00” in Line 6. Once this check fails, the function returns 0, and the application exits later to avoid further misreading of the data.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Listing 1.
.tif file parsing code fragments in optipng 0.7.7 pngxrtif.c.
 |
Like the example shown in Listing 1, although tiny in length compared with the trailer fields, the header fields contain more critical metadata and impact the execution of the target application more.
2.2. Current Fuzzing State-Of-the-Art
Existing fuzzing works have made great progress. For structured input programs, more improvements can still be made. We list the current state-of-the-art in the following.
2.2.1. Coverage-Based Greybox Fuzzing
A Coverage-based Greybox Fuzzer (CGF) would enter the initial seed into the queue. Each round, one seed is chosen from the queue and randomly performs mutations such as arithmetic increments and decrements, bit- or byte-flipping, substituting the fragment with values from a user-provided dictionary or constraint values collected at runtime, splicing, and so on. After mutating the seed into test cases, the fuzzer will launch the target with the input of the test case one by one and monitor the execution online using instrumentation. Then, the test case is scored based on whether the target crashes or hangs, its coverage, execution time, size, etc., and is seeded into the queue if the score is high; otherwise, it is discarded. Representative work includes AFL [2], AFLfast [3], AFLplusplus [4], and LibFuzzer [5].
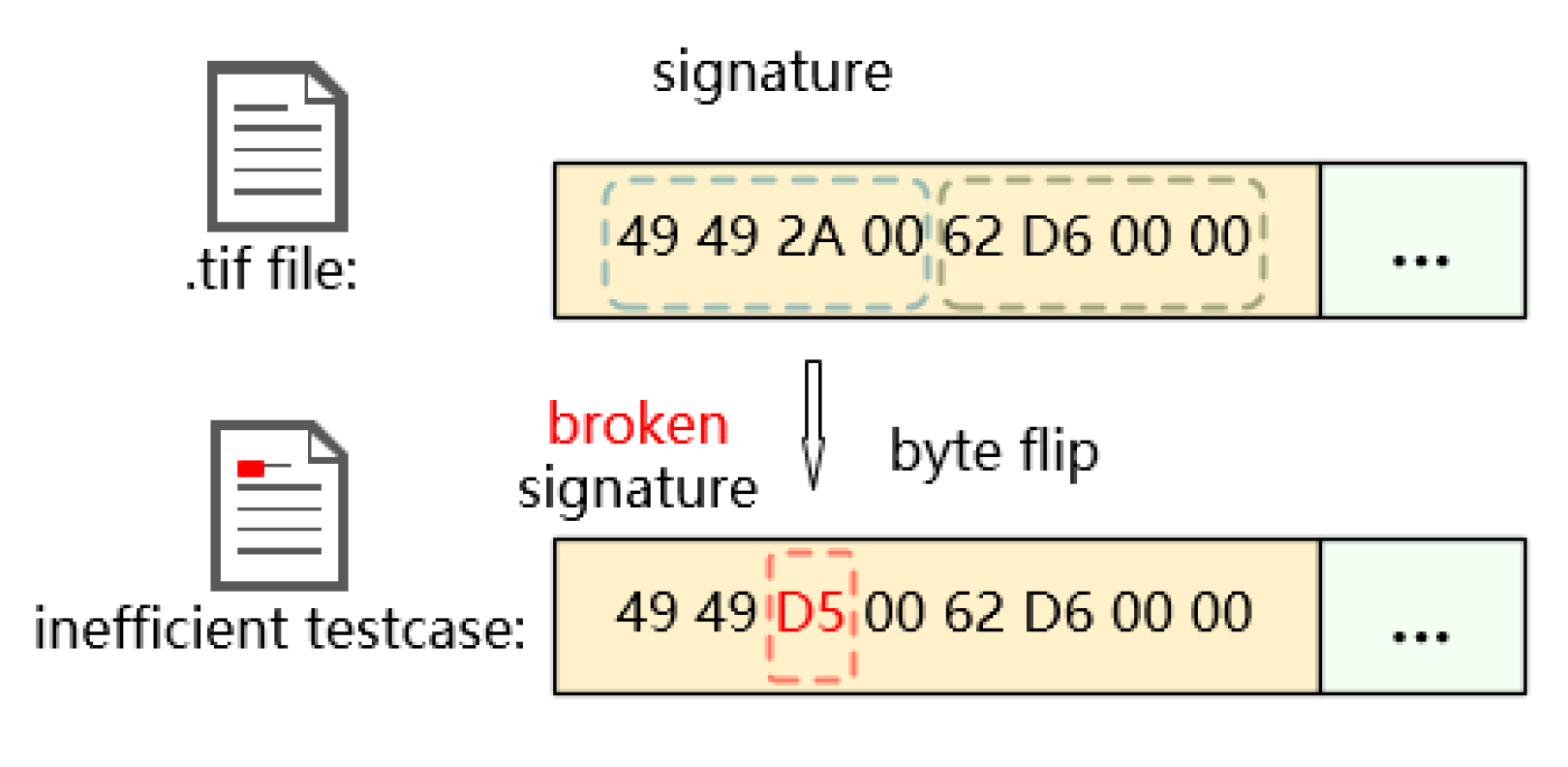
In the case of structured input applications, such methods can use an artificially given dictionary or automatically generated corpora to create test cases that may meet the format. This approach is lightweight and robust, but the blind mutation will break the consistency of the header and trailer, resulting in a multitude of inefficient test cases.
As Figure 2 shows, the yellow color box indicates the signature field of input, which contains hexadecimal data. Other fields are represented by green box. After blind byte-flipping, the signature of the test case changes from “49 49 2A 00” to “49 49 D5 00”, preventing it from passing the signature check in Listing 1, Line 6. The blind mutations of the traditional CGF deprive the test case from passing the target’s embedded sanity check and prevent the fuzzer from exploring the deeper level of code.
2.2.2. Format-Aware Fuzzing
Considering the inefficiency of the CGF test cases, various distinctive tools accept grammar guidance or expert-given format templates, which allow them to sense the target input format. Once the format information is sensed, the test cases that maintain the consistency of the header and trailer will be generated. We note such test cases as format-well. Representative work in this category includes: peach [7], LangFuzz [6], AFLSmart [8], QuickFuzz [9], FormatFuzzer [10], FaFuzzer [11].
Targeting structured input applications, these solutions work well for constructing format-well test cases for performing vulnerability tests on deep code. Nevertheless, the format awareness of such fuzzers relies on manually given format templates or grammar. This results not only in being labor intensive and manual errors, but also in an incapability to test targets in an unknown input format efficiently.
Thus, several research works have investigated capturing the dependency between the test case and target, without offering a priori knowledge or expensive techniques including symbolic execution and taint analysis. Via systematic bit-/byte-flipping or random value padding, the fuzzer monitors and analyzes changes in the state of the target. It then identifies the dependencies in the partial header and trailer fields. It grants the fuzzer some level of format-aware capability. Such research includes Redqueen [12], GRIMOIRE [13], SLF [14], and WEIZZ [15].
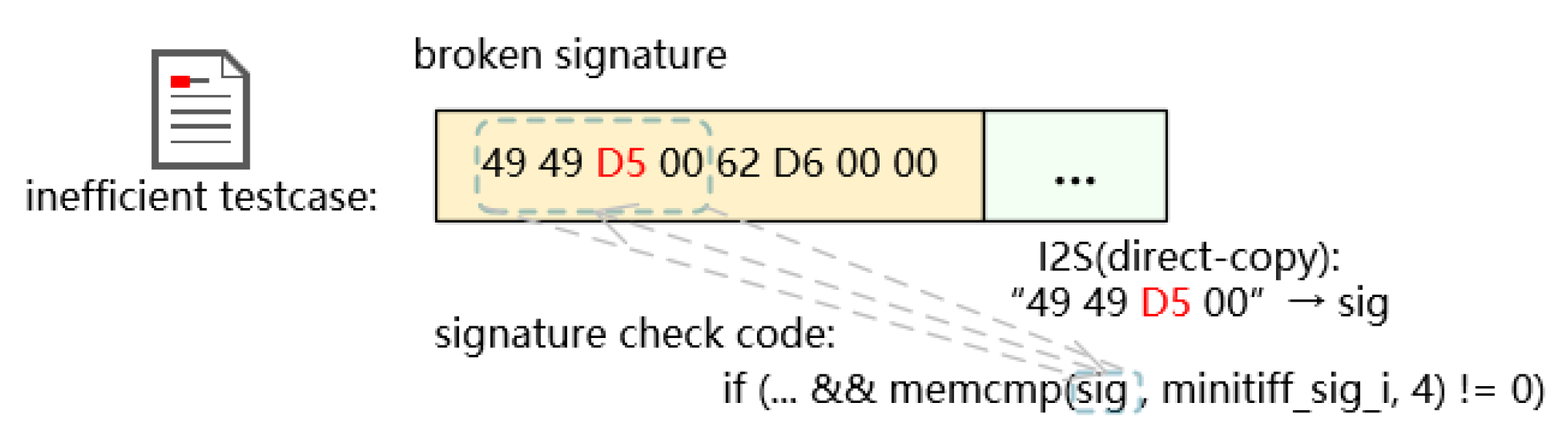
Redqueen [12] and GRIMOIRE [13] recognize dependencies based on whether the execution path has changed. Redqueen attempts to colorize the input with random bytes, identifies those fragments that caused the path coverage to change, and obtains the Input-to-State (I2S) dependencies for locating the header fields. Input-to-State (I2S) is a strong correspondence between the input and the current program state [12]. Figure 3 illustrates an example of this link between the input fragment and the target variable. The fragment signature, highlighted by a yellow block, has a direct relationship with the variable sig, while the value of sig is the direct copy of fragment signature. Based on Redqueen, GRIMOIRE recognizes the fragments that failed to trigger execution path changes as trailer fields, generalizes those fragments, and applies input mutations such as recursive replacement and string replacement.
SLF [14] and WEIZZ [15] focus on whether the operands of the cmp instruction have changed. Both of them flip the test case byte by byte, run the target, and monitor the changed operand of the cmp instruction to analyze indirect dependencies, for indexing the header fields and fixing the “magic byte” and “checksum” roadblocks. We call this scheme byte-by-byte analysis.
2.3. Challenges
The works described in Section 2.2 have yielded some success for real-world software or OS kernels. The following challenges still remain:
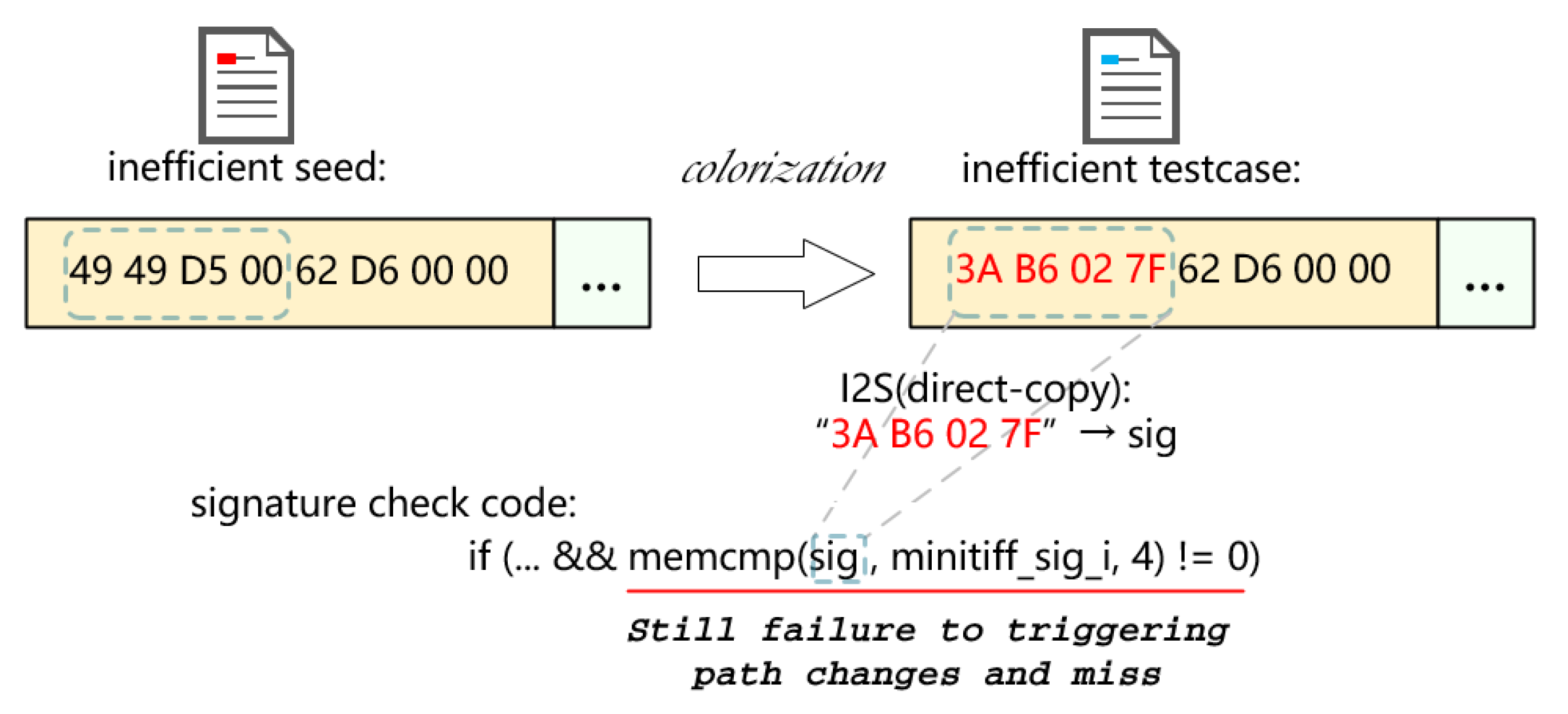
- I2S misses: Padding a header field with a random value does not necessarily trigger execution path changes, because the random one may not satisfy the constraint of its relevant cmp instructions. As Figure 4 shows, after colorization, the random value “3A B6 02 7F” overwritten on fragment signature denoted by the yellow box. It still fails to trigger path changes and leads fuzzers such as Redqueen and GRIMOIRE to mistakenly assume that no I2S dependency exists on fragment signature.
- Indiscriminate dependency recognition: Not all bytes deserve to be flipped. As stated in Section 2.1 and shown in Figure 5, the header fields containing the first eight and the last m bytes (indicated by yellow and orange box) are short in length, but efficient in dependence recognition, while little effect is gained on the middle long trailer fields. It is the short, but metadata-intensive header fields that ought to be worth performing byte-by-byte analysis, not the long, but sparse dependency trailer ones (represented by the green box); especially those cannot impact any operand of the cmp instructions. Thus, these methods suffer from inefficient dependency recognition from the trailer fields.
3. Methodology
To address I2S misses, we propose the I2S recognition based on de Bruijn matching method for recognizing I2S fields using de Bruijn-based as the initial inputs, in a scenario without seeds fitting the input format. With the help of the mapping structure created by the de Bruijn-based test case generation, the I2S recognition based on de Bruijn matching method will quickly match patterns between cmp operands and fragments within the input and then recognize the I2S fields to sense the I2S part of the input format, regardless of whether it the execution path changes.
Aimed at indiscriminate dependency recognition, we implemented the Selective Flip strategy, which is described below. We identified and excluded non-deps fields in Non-deps exclusion and recognized indirect dependencies from other fragments in Deps detection to perceive the format of the structured input further.
In this section, we briefly describe the overview of our method, from one initial input being loaded, ending when all the recognized dependency information is output to other fuzzing parts. The overview is first presented, and then, the key steps are detailed.
3.1. Overview
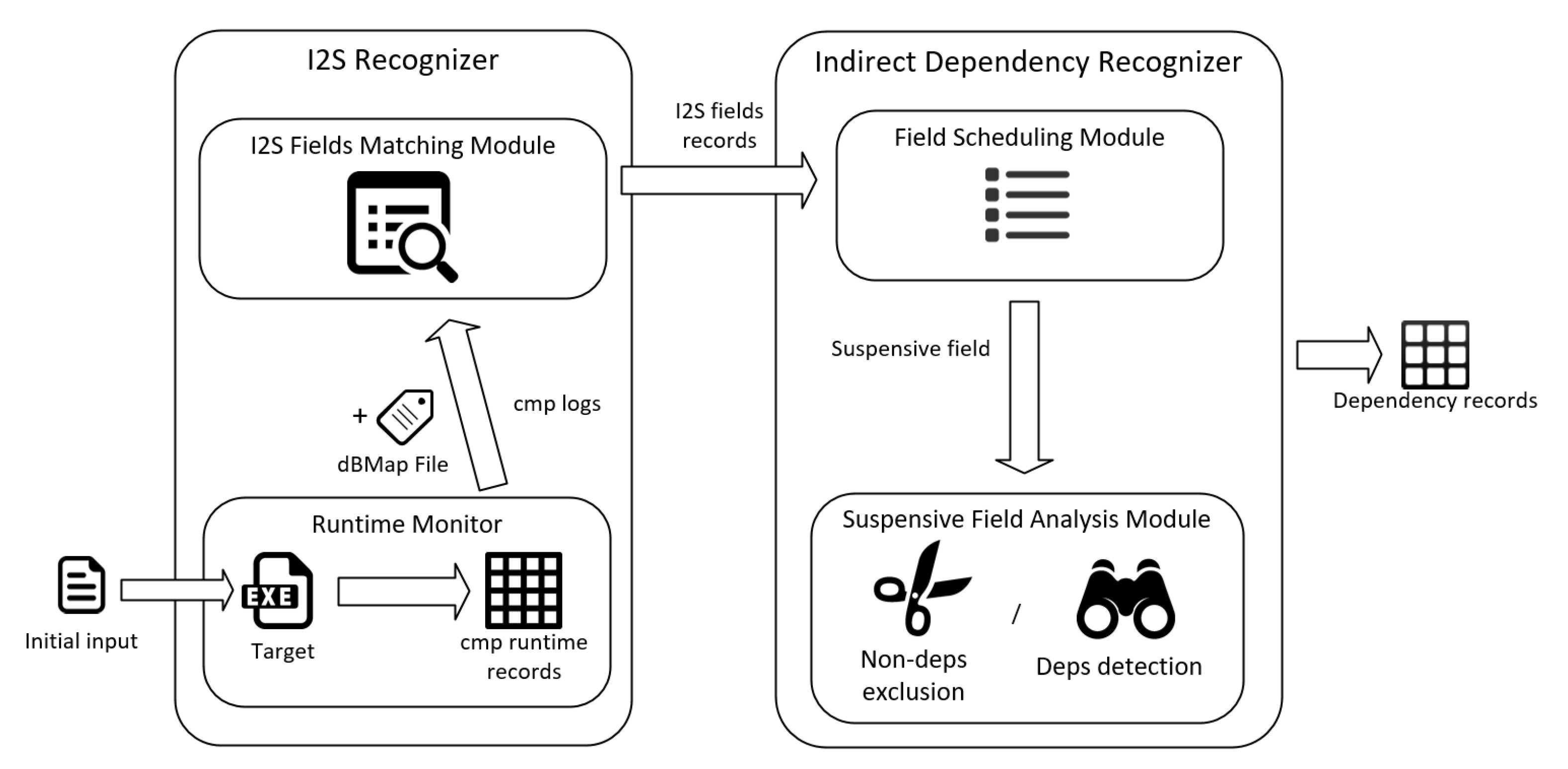
Our approach contains two main modules: I2S Recognizer and Indirect Dependency Recognizer, as Figure 6 shows.
In I2S Recognizer, Runtime Monitor runs the target, monitors all the triggered target comparison instructions, and records their runtime information as cmp logs. Then, the corresponding dBMap file assists in the I2S Fields Matching module. The I2S Fields Matching module loads the dBMap file and the runtime log from the target’s comparison instructions, recognizing I2S dependencies from the input fragment to the operand of the cmp instruction via the I2S recognition based on de Bruijn matching method. The I2S Fields Matching module will record all the I2S dependencies and arrange all the offsets of the I2S fields, as the input of Indirect Dependency Recognizer.
In Indirect Dependency Recognizer, after obtaining the output from I2S Recognizer, the Field Scheduling module collects all the fields that have not yet recognized dependencies and schedules these suspensive fields in a half-interval manner. The Suspensive Field Analysis module performs the Non-deps exclusion method on long fields to identify and exclude the non-deps fields and the Deps detection method on short fields to recognize indirect dependencies.
Finally, both I2S and other indirect dependencies recognized will be recorded and assist the other fuzzing parts.
In this case, I2S Recognizer identifies I2S fields, reducing the scale of the fields to be verified, achieving the effect of partial optimization. Compared to existing works, the I2S recognition based on de Bruijn matching method enables the mining of I2S fields that do not trigger execution path changes, alleviating the limit of I2S misses. Indirect Dependency Recognizer circumvents non-deps fields with the idea of half-pruning, reducing the cost of obtaining dependencies from trailer fields. Additional, if the initial input is format-well, we pass I2S Recognizer and start Indirect Dependency Recognizer directly.
The following subsections detail I2S Recognizer and Indirect Dependency Recognizer.
3.2. I2S Recognizer
We firstly describe de Bruijn sequences and the intuition of applying them to obtain I2S dependencies. Then, the finite-state automation for generating de Bruijn-based test cases is presented. Finally, how I2S Recognizer matches I2S fields via the I2S recognition based on de Bruijn matching method is detailed.
3.2.1. De Bruijn Sequence
We briefly present the concept of the de Bruijn sequence, its unique property, and the main idea of applying it to recognizing I2S dependencies.
The de Bruijn sequence [21] is a kind of pseudo-random sequence [22], which is in one-to-one correspondence with Euler cycles in the de Bruijn graph [23]. Given a t-sized alphabet , a k-ary, n-order de Bruijn sequence over A is a sequence for which all the n-tuples are contained in a -period of . It also means that every n-tuple occurs once and only once in a -cycle of the de Bruijn sequence, as a substring of consecutive symbols. Here, we denote all the k-ary, n-order de Bruijn sequences as . For example, 00010111, 01011100, 00111010 are three de Bruijn sequences of over alphabet . It is straightforward to observe that the offset of each three-length substring is unique in the entire sequence within period . Likewise, is a de Bruijn sequence of over , where the length of substrings such as , is no less than three and is unique in the entire string within period .
For an I2S field, the corresponding operand of the cmp instruction is direct-copy-related [24], meaning that it can be considered as a substring of the test case. In a de Bruijn sequence, each different subsequence has its unique offset. Therefore, a fast mapping table from “substring” to “offset” can be created, enabling matching the I2S field from its operand quickly, rather than costly traditional pattern matching across the whole test case.
3.2.2. de Bruijn-Based Test Case Generation
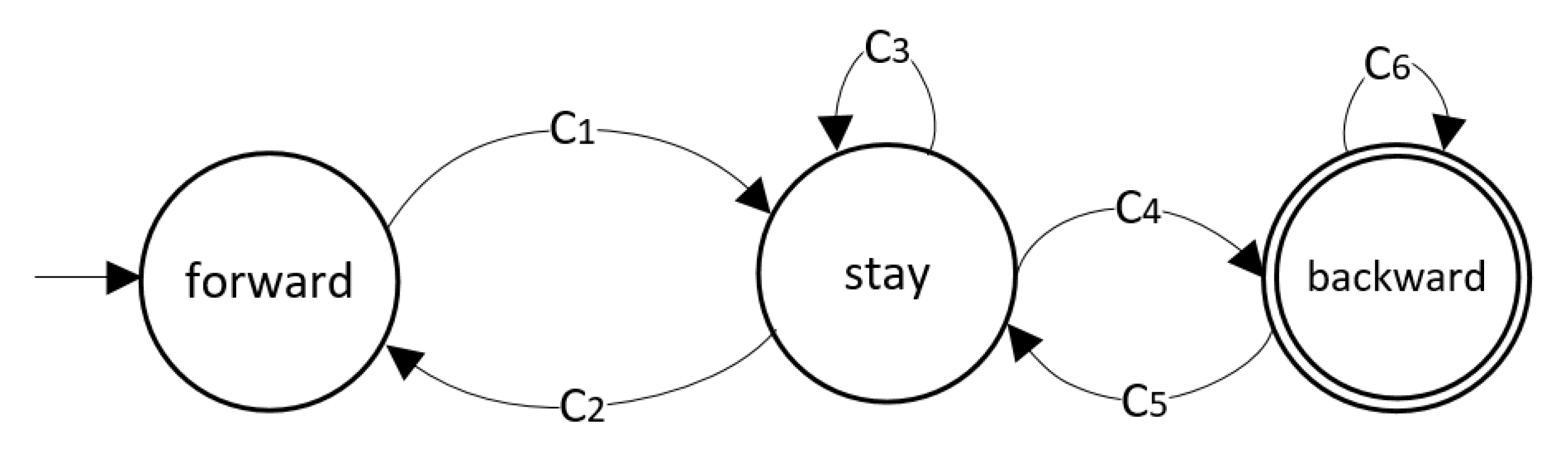
For one sequence of , any k-ary n-length tuple occurs once in a period of . According to this property, based on the idea of “prefer one” [25], our generation takes ary k, order n as the input and outputs all the sequences of and its mapping table dBMap. To avoid problems such as overflow due to recursion, our generation introduces a data stack dBStack, working as a Finite-state Automaton (FA) [26], shown in Figure 7. The FA is a five-tuple :
- is a finite set of states.
- is an alphabet of input characters. We take the constraints on which the current dBStack and dBMap are satisfied as the input. are the corresponding characters. If one of these is met, the correspond character is input into the FA. The second column of Table 1 lists all the input characters and their constraints.
- is the transition function. Table 1 describes all the shift rules about .
- is the start state.
- is the set of acceptable states.
The FA contains three states, , , and , as shown in Figure 7. According to the current state, dBStack and dBMap, we locate the satisfied constraint and perform the corresponding operation, then shift to the state specified in the “Next State” column of Table 1. From the perspective of sequence generation, we start by pressing the full n-length 0 into , recursively pushing up a character at the end of the string, and always check if the last substring is repeated. If so, then we try the next character or pop the dBStack to continue the last round; otherwise, we push up the new character and start a new round. This ensures that each substring whose length is no less than n is unique in dBStack, until a new character is stacked.
3.2.3. I2S Recognition Based on de Bruijn Matching
Considering the direct-copy-related association between the I2S field and its cmp operand, if the initial input is de Bruijn-based, then the operands of those I2S fields will be the subsequences of out de Bruijn-based input. By using the mapping table dBMap, we can directly index the value of the operands to positioning subsequences effectively within the de Bruijn-based initial input.
Algorithm 1 details how we obtain the I2S field through the operands of the cmp instructions. It takes the initial input T, mapping table , and alphabet A as the input and outputs the array that contains all the recorded dependencies we found and the set of all the I2S field offset ranges we found. stores all the operands of the cmp instructions in the last target execution.
For each operand recorded in cmp_map[], we calculate its and check if it is valid. If so, then we locate the suspensive fragment mapping from with the index of . Then, we try to flip the fragment, launch it, run the target, and monitor if the corresponding operand changes. I2S dependency exists if it changes. We mark the information of I2S dependency into and . After all the operands are analyzed, we output and in the end.
Using the direct-copy-related feature, we identify all I2S fields in the whole initial input, not limited in fragments that cause the execution path changes. While improving the amount of I2S fields, the scale of the fragments that need to be verified further is reduced for Indirect Dependency Recognizer.
| Algorithm 1: de Bruijn matching algorithm. |
Input: initial input: T, dBMap: , alphabet: A Output: Dependency array: , the offset ranges of I2S fields:  |
3.3. Indirect Dependency Recognizer
We briefly describe the overall design of Indirect Dependency Recognizer based on the Selective Flip strategy and its advantages over existing works first, then introduce the key parts Non-deps exclusion and Deps detection of the Selective Flip strategy in detail in the following.
For the byte that has indirect dependencies with the cmp operand, once we flip it, the value of the corresponding operand will change. On the contrary, if we flip the non-deps fragment, no cmp operand value is altered. Based on this intuition, we propose the Selective Flip strategy and apply it in Indirect Dependency Recognizer, to identify and pass the non-deps fragments in the trailer fields, only to flip those metadata-intensive fields.
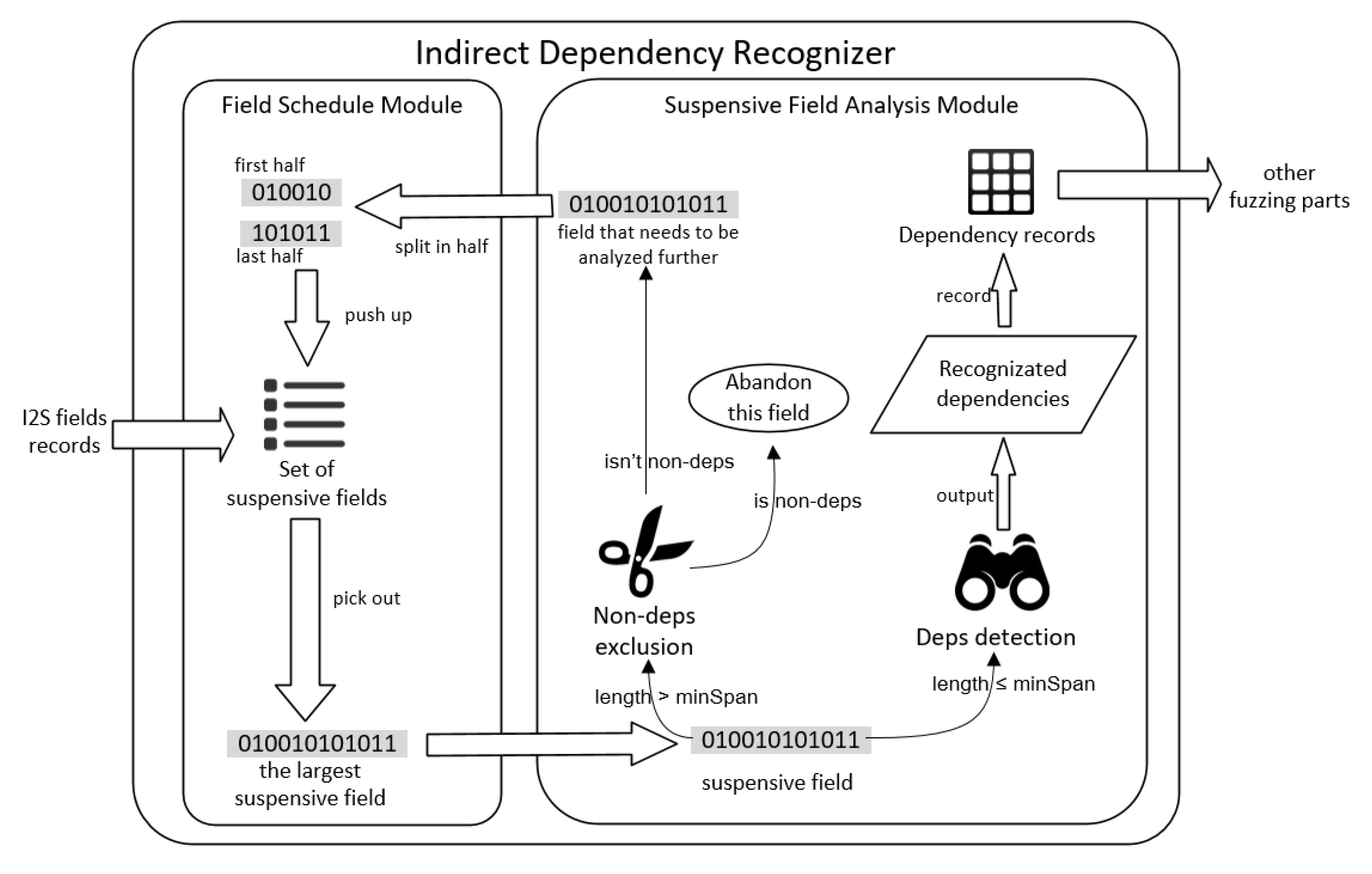
Indirect Dependency Recognizer contains two main modules: Field Schedule and Suspensive Field Analysis. Figure 8 shows how Indirect Dependency Recognizer processes dependency recognition intelligently.
Indirect Dependency Recognizer takes the I2S field records as the input and recognizes and records all the indirect dependencies. The major parts are as follows:
- Field Schedule module: Load I2S field records, and collect all the fields that have not yet recognized dependencies initially. Pick out the largest one, and output it to the Suspensive Field Analysis module. Load the field that needs to be analyzed further, split it in half, and push them into the set of suspensive fields.
- Suspensive Field Analysis module: Load the suspensive field from the Field Schedule module. Perform Non-deps exclusion if its length is greater than minSpan; otherwise, perform Deps detection. Once the target field is non-deps, Suspensive Field Analysis will just abandon it to reduce the cost. Otherwise, output it to Field Schedule. After Deps detection, all the recognized dependencies will be recorded. Finally, if no suspensive field exists, Suspensive Field Analysis outputs the dependencies records to assist other fuzzing parts. Additionally, is configured as Equation (A1).
Additionally, we regard a comparison instruction as “uncontrollable” when the values of its operands change frequently and are not controlled by the input. To collect those uncontrollable ones, the target binary will be run twice with the same input. All the changed cmp operands are regarded as uncontrollable and collected in the set .
Like WEIZZ and SLF, we identify indirect dependencies through byte-by-byte analysis. Module Suspensive Field Analysis will catch and pass non-deps fragment in the Non-deps exclusion step, and the costly analysis will be performed centrally in those metadata-intensive fields.
As a result, all the fields associated with the target cmp operands have been recorded, guiding the fuzzer to mutate the initial input and test the deeper code with a higher probability.
3.3.1. Non-Deps Exclusion
As indicated above, flipping a non-deps field has no effect on changing the value of all the cmp instruction operands. By utilizing skip_cmp, if we flip one fragment and none of the cmp operands change their values, we consider this fragment to be a non-deps one.
Algorithm 2 demonstrates how it recognize a non-deps fragment in only one target execution. Taking initial input T, the offset range of the unvalidated field , and the set of uncontrollable cmp instructions , we flip the fragment specified by , then launch it and run the target to capture all the runtime log for the instruction operands in . After that, it iterates over the values of the cmp operands, and once a changed value is found, we restore T and output because it still contains fields that have dependencies on the target. Otherwise, we restore T and output .
| Algorithm 2: Non-deps field recognition algorithm. |
Input: initial input: T, offset range of suspensive field: , uncontrollable cmp: Output: If the fragment specified by is -  |
As described above, we recognize whether the fragment specified is non-deps with low overhead and reduce the scale of workload in Deps detection.
3.3.2. Deps Detection
“Deps” means dependencies here. Deps detection performs byte-by-byte analysis on the specified suspensive field to recognize indirect dependencies in each byte of it.
As Algorithm 3 shows, in the stage of Deps detection, all the bytes within the specified fragment will be examined for what dependencies exist. The dependencies we obtained are recorded into with the information such as the index of the byte, the affected cmp instruction, and the type of affected operand. Finally, we output the dependency array and finish.
| Algorithm 3: Deps detection algorithm. |
Input: initial input: T, offset range of suspensive field: , dependency array: Output: Dependency array:  |
The time complexity analysis of the Selective Flip strategy and the comparative analysis with WEIZZ we place in Appendix C.
3.4. Time Complexity Analysis
In the following, the time complexities of Algorithms 1–3, the strategy Selective Flip, and the whole method are discussed. Moreover, the comparison of our methods with related methods in existing work is made.
3.4.1. De Bruijn Matching Algorithm
In Algorithm 1, is the basic operation of Algorithm 1. We denote by the number of all cmp executed within the target program, with T as the input; is the number of cmp operands with I2S dependencies. The execution count is denoted as C, with . . When all valid matches to fields are real I2S fields, then . only if all valid matches to fields are not I2S fields. Overall, the time complexity of Algorithm 1 is .
Redqueen [12] determines the possible I2S fields by “colorization”. It matches their value against the operands of each cmp within the target program. If the matching is successful, the I2S field is patched with the value of another operand. After the modification, the target program is launched once to check if a new path is generated. If it is, an I2S dependency exists in that field. The basic operation is target execution. We denote by the number of possible I2S fields, with ; is the count of target program execution for possible I2S fields, . When all the possible I2S fields are real I2S fields without any misclassifications or omissions, then . only if all the possible I2S fields are not I2S fields, but matched successfully. By the above, its time complexity is .
In most cases, as , Algorithm 1 is able to outperform Redqueen’s approach.
3.4.2. Non-Deps Exclusion
The basic operation of Algorithm 2 is to check Line 5. We denote by the number of executed cmp instructions in the target program using T as the input, and their operands are not affected by other external factors (environment variables, time, etc.), ; C is the count of the basic operation, . if no cmp exists in the target program. if all the operands of cmp are checked for changes. From the above, is its time complexity.
3.4.3. Deps Detection
The basic operation of Algorithm 3 is the check statement within the for loop statement in Line 6. We denote by l the byte-length of the suspensive field, ; is the number of executed cmp instructions in the target program using T as the input, and their operands are not affected by other external factors (environment variables, time, etc.), ; C is the count of the basic operation. . As above, the time complexity is .
3.4.4. Selective Flip Strategy
The Selective Flip strategy schedules the suspensive fields and performs Non-deps exclusion for long suspensive fields and Deps detection for ones shorter than . Denote n as the length of the input. According to Appendix C, our theoretical analysis demonstrates that its time complexity depends on the distribution of fragments with dependencies. , , and correspond to the time complexity in the worst, majority of, and ideal scenarios.
GETDEPS is the dependency recognition procedure of WEIZZ [15]. It is similar to Deps detection. Every time one byte is flipped, it launches the target and marks the cmp instructions whose operands have changed, and the dependencies between the flipped byte and the cmp operand are recognized accordingly. We denote by n the length of the input. is its time complexity.
As mentioned in Appendix C, the Selective Flip strategy outperforms GETDEPS with an time complexity in the ideal case, when each byte within the input is not associated with the cmp instruction of the target program. Mostly, the fields with dependencies are concentrated in the front of the input, and the quantity of their bytes is far less than the total length of the input. is its complexity. When the length of fields with dependencies is large and evenly distributed, Selective Flip has overhead in halving to identify and exclude non-deps fragments. In the worst case, all the bytes within the input have dependencies with the cmp instructions within the target program. Non-deps exclusion is unable to exclude any non-deps fragments. is its time complexity.
Comparing with GETDEPS, Selective Flip outperforms in most cases and is on a par in the worst case.
3.4.5. The Whole Method
Combining I2S recognition based on de Bruijn matching and the strategy Selective Flip, we discuss the overall time complexity of the proposed method in this paper. Based on the above analysis, the time complexity of our method is , and in the ideal, majority of, and worst cases, respectively. depends on the specific target program. The number of cmp instructions depends on the specific target program, and n represents the length of the initial input.
The time overhead of Redqueen reaches , where represents the number of possible I2S fields discovered by colorization. The number of cmp instructions within the software is proportional to its size. This also means that, for most real-world software with complex functionalities, is much larger than . As a result, is larger than in the majority of cases. This results in Redqueen’s approach being less time efficient than our method.
Procedure GETDEPS performs the basic operation in , and ours performs in the worst case. This means that compared with WEIZZ, the performance of our approach still needs to be further improved in the rare cases where all fields have dependencies. In the majority of them, the time complexity reaches , which is less than GETDEPS’s. From the above, our method outperforms WEIZZ in most cases and is comparable in the worst case.
4. Implementation and Evaluation
In this section, we implemented a fast format-aware fuzzing prototype, FFAFuzz. To evaluate FFAFuzz, we used 11 real-world software with structured input as the benchmarks to compare with Redqueen [12] and WEIZZ [15] as the baselines, then we indicate the results and discuss them.
4.1. Implementation
We implemented our fast format-aware fuzzing approach on top of WEIZZ 1.00c and QEMU 3.1.0 for x86-64 Linux targets and built up the prototype FFAFuzz, recognizing I2S dependencies via I2S recognition based on de Bruijn matching and other indirect dependencies by Selective Flip.
4.2. Research Questions
- RQ 1. How does the dependency obtained by FFAFuzz compare in quantity with existing methods?
- RQ 2. Does FFAFuzz help to speed up the dependency recognition compared with existing solutions?
- RQ 3. Does FFAFuzz help practical vulnerability mining?
The first two research question focus on evaluating the effectiveness and time efficiency of FFAFuzz. The third evaluates the practicality of FFAFuzz in a real-world vulnerability hunting work.
4.3. Evaluation Setup
Experiment environment: We conducted all our experiments on a server running 64-bit Ubuntu 20.04, with two Intel(R) Xeon(R) [email protected] CPUs and 128 GB of RAM. Each fuzzer on each target application was run in identical configurations, and the experiments were repeated five times in all cases.
Baseline: In the evaluation, FFAFuzz was compared with Redqueen [12] and WEIZZ [15]. Table 2 lists some information about these fuzzers.
Through padding the fragments with random values, Redqueen observes those fragments that triggered execution path changes and recognizes I2S fields within these fragments via matching the fragment value only based on colorization. WEIZZ recognizes both I2S and indirect dependencies by byte-by-byte analysis instead of value matching like Redqueen does. It observes the changing cmp operand and marks the dependency between the flipped byte and the cmp operand if the operand changed in value consequently after flipping this byte.
Considering that Redqueen was developed on KAFL [27] and spotlights kernel fuzzing, we adopted the Redqueen mode of AFL++ [4] version 3.14c [28] to be fair.
Benchmarks: Eleven target programs were selected as the benchmarks, representing different types of structured input binaries, including audio, image, and video processing, executable program parsing, etc. Table 3 details those targets.
4.4. RQ1: The Effectiveness Evaluation
In this experiment, we evaluated the effectiveness of FFAFuzz input dependency recognition, by comparing the number of recognized dependencies with Redqueen and WEIZZ.
Both the format-well and de Bruijn-based the initial inputs were adopted for the scenarios with and without prior knowledge of the input format, respectively. To evaluate the quantity of dependencies, Redqueen, WEIZZ, and FFAFuzz perform dependency recognition on the 11 targets as the benchmarks. For statistical purposes, we regarded a dependency as a three-tuple . If the o-offset byte in the initial input could affect the operand of the comparison instruction in the target, we deemed that one dependency exists between the o-offset byte and the of . In other words, when the o-offset byte is flipped, the operand of the comparison instruction will have its value changed.
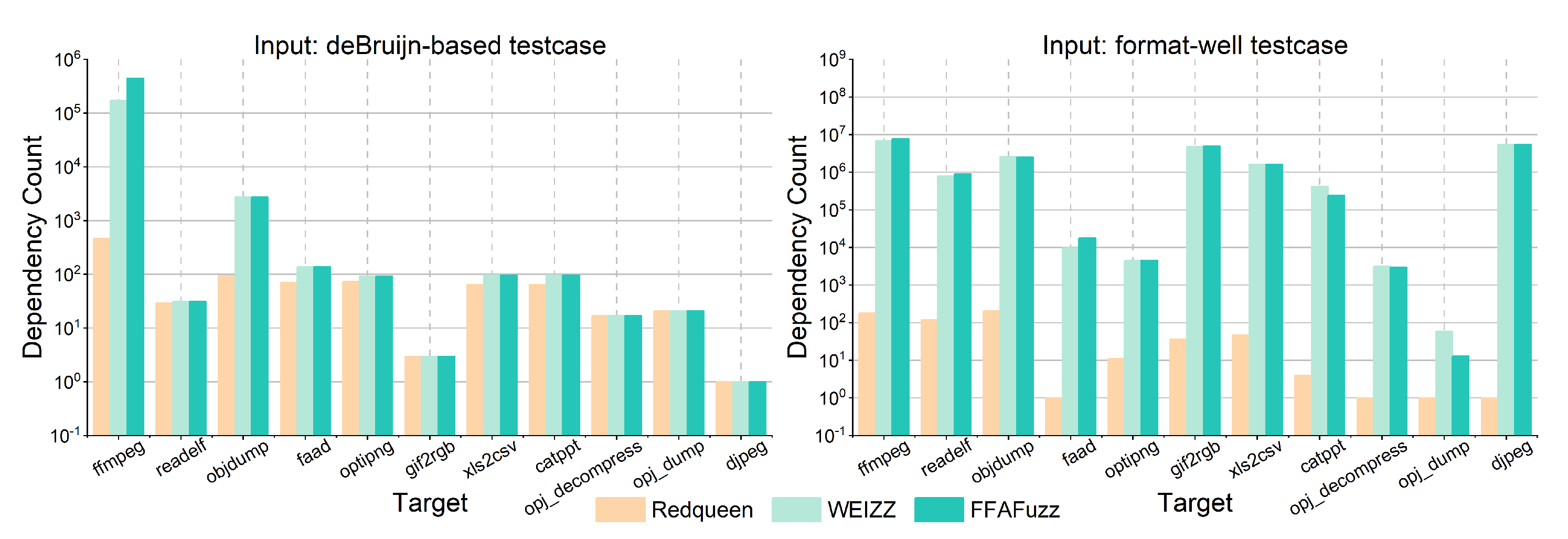
Figure 9 below presents the result of dependency recognition performed by FFAFuzz, WEIZZ, and Redqueen.
From the result of RQ1, we can observe that:
- The recognized dependency amount of both FFAFuzz and WEIZZ is greater than that of Redqueen, especially the average boost of 29k-times when adopting format-well as the initial input.
- All three perform equally well on the targets readelf, faad, optipng, gif2rgb, etc., in the case of an unknown input format.
- Given de Bruijn-based input and not, the mean deviation between FFAFuzz and WEIZZ was 26.67% and 23.19%, respectively. This indicates that the captured dependency quantities of FFAFuzz and WEIZZ are roughly equal in orders of 10.
FFAFuzz and WEIZZ recognized more dependencies than Redqueen. That is because not only FFAFuzz and WEIZZ could mine dependencies from header fields such as the file signature and version, but also indirect dependencies from the complex data processing comparisons.
Given the de Bruijn-based test case as the input, FFAFuzz, Redqueen, and WEIZZ performed equally well on most target programs. Since the de Bruijn-based as the initial input is a kind of pseudo-random sequence and inherently unformatted for the targets, it fails checks such as magic-byte checks. The target applications treat it as an illegal one and terminate their execution to avoid misreading the data further. Thus, no deeper data processing comparison code is covered, and the quantity of dependencies obtained by those three fuzzers is approximately equal.
The performance of FFAFuzz is similar to WEIZZ, whether the de Bruijn-based test case is given or not, as the FFAFuzz method of recognizing dependencies is basically the same as the WEIZZ byte-by-byte analysis scheme GETDEPS. Non-deps exclusion only identifies and excludes non-deps fragments and does not raise the quantity of dependencies.
Responding to RQ1, for most targets as the benchmarks and regardless of the prior knowledge of the input format, FFAFuzz largely outperformed Redqueen and was on a par with WEIZZ, in terms of the effectiveness.
4.5. RQ2: The Efficiency Evaluation
In this experiment, we evaluated the time efficiency of FFAFuzz input dependency recognition, comparing the time cost with Redqueen and WEIZZ.
For evaluating the time efficiency, the multi-sized gradient initial input set (including 4 kb, 16 kb, 64 kb, 256 kb, 512 kb de Bruijn-based, and format-well test cases) were used as the input, and Redqueen, WEIZZ, and FFAFuzz all performed dependency recognition on the 11 targets as the benchmarks. Finally, we evaluated the time cost of the respectively compared fuzzing methods.
For the target catppt, we used the initial input set including 8 kb, 64 kb, 128 kb, 256 kb, 512 kb de Bruijn-based, and format-well as the initial inputs. As the MSDN document [29] demonstrates, an empty .ppt file still consists of several .xml files to store data such as theme, layout, etc., leading the minimum length of the .ppt file to exceed our expectation of 16kb. The 8kb format-well .ppt file comes from Windows updates [30].
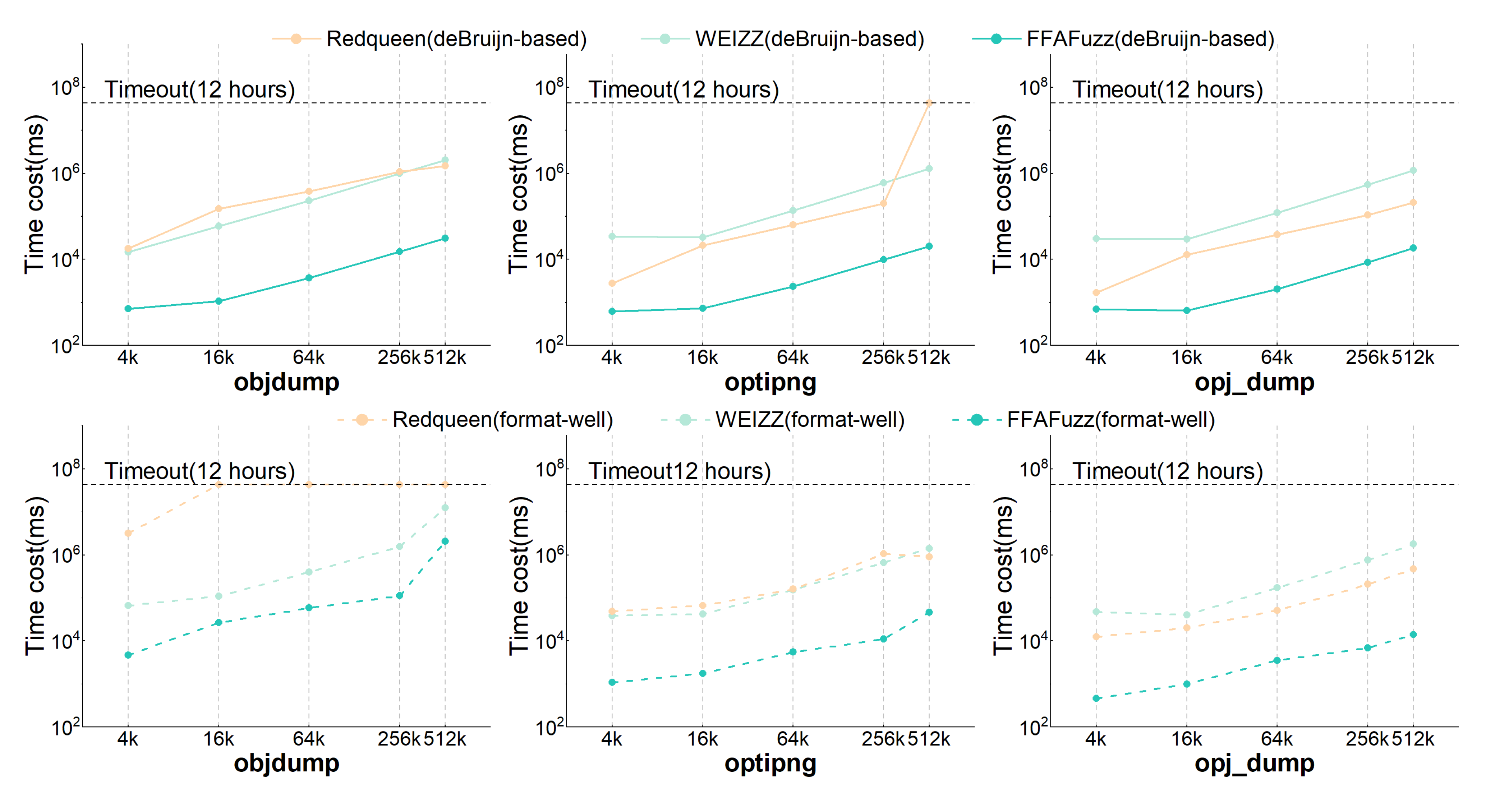
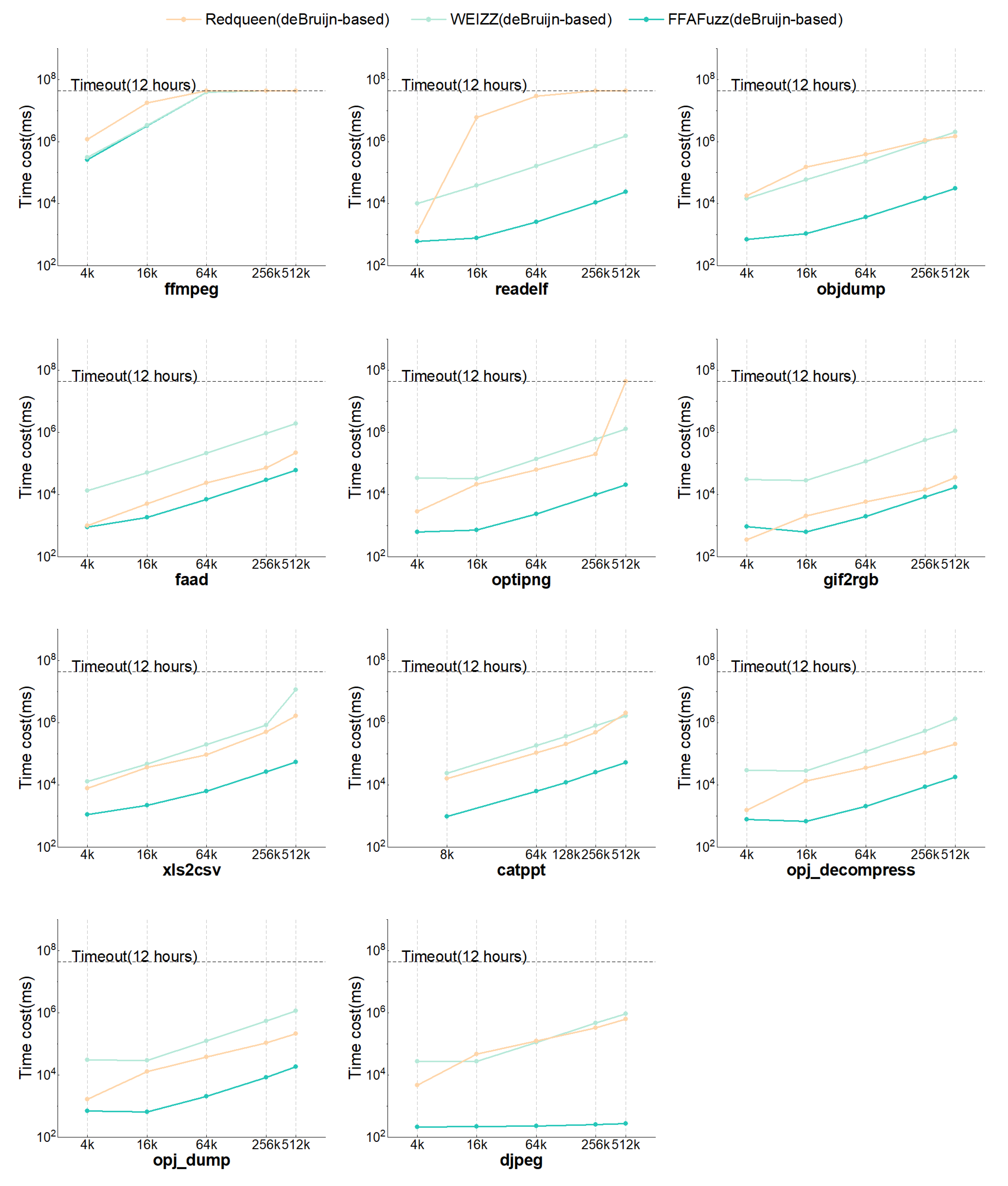
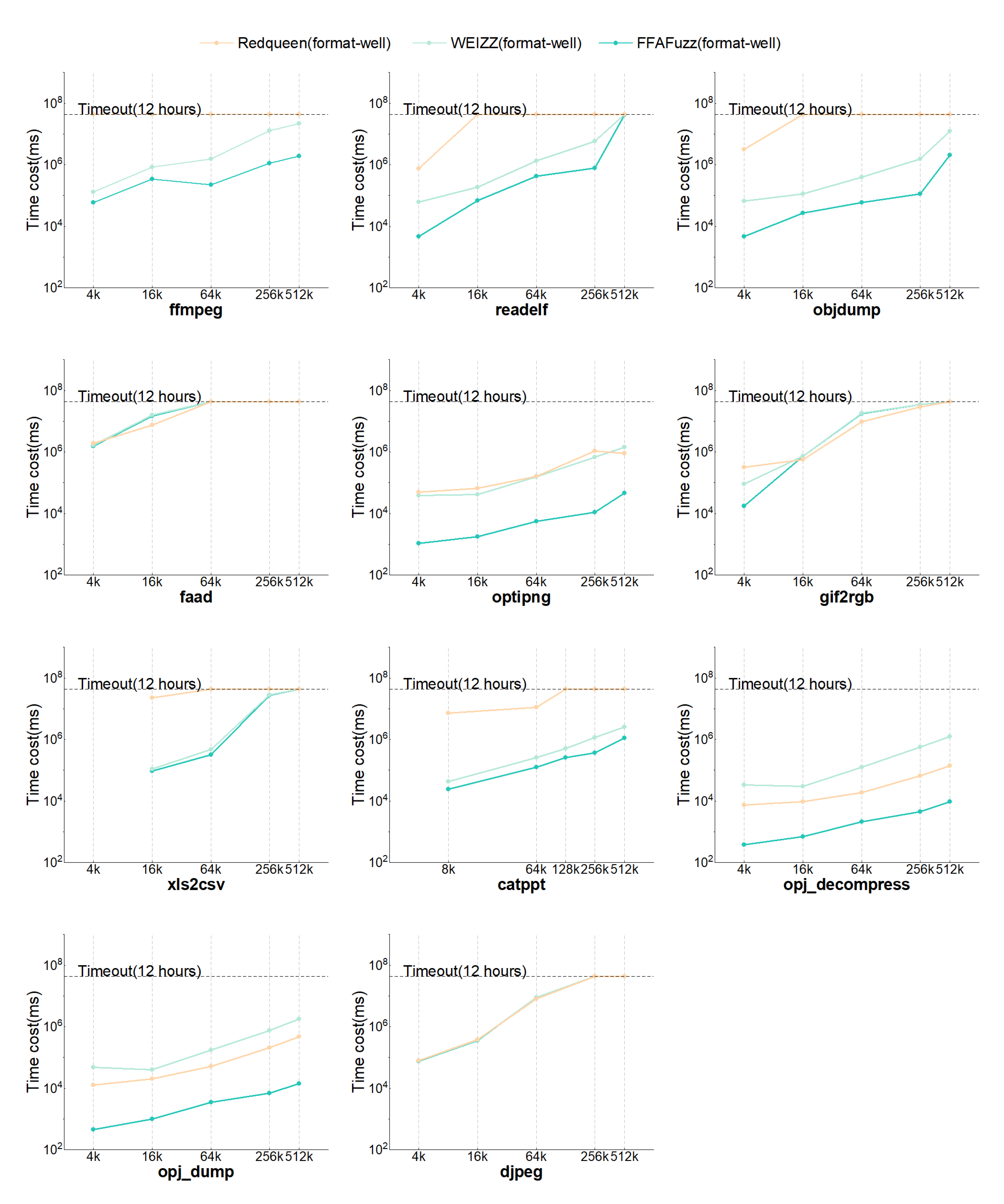
Figure 10 shows the time overhead of dependency recognition by various compared fuzzers, over the targets objdump, optipng, and opj_dump. All the results are shown in Figure A1 and Figure A2.
From the result of RQ2, we can observe that:
- Regardless of the prior knowledge of the target input format, in most cases, FFAFuzz outperformed Redqueen and WEIZZ in terms of the time overhead of dependency recognition. Figure A1 indicates that, when the inputs were de Bruijn-based test cases, FFAFuzz reduced the time cost by an average of 89.10% compared to WEIZZ and 76.49% compared to Redqueen. When the inputs were format-well as the initial inputs, it reduced the time overhead by an average of 55.25% compared to WEIZZ and 63.33% compared to Redqueen.
- The time cost of FFAFuzz dependency recognition was roughly equal to that of WEIZZ when facing targets such as djpeg, faad, etc., and using format-well as the initial inputs.
The reason why FFAFuzz reduces the time overhead is that Non-deps exclusion identifies and excludes non-deps fragments in a lightweight manner. The theoretical analysis in Appendix C indicates that FFAFuzz is in the majority of the cases. The result of RQ2 corroborates this.
Using format-well as the initial inputs, the performance was comparable to WEIZZ. The reasons for this are that few non-deps fields exist in the format-well inputs, and Selective Flip is hard to optimize for such scenarios via Non-deps exclusion. For example, the data fields in .jpg and .jpeg hold the data compressed by the algorithms such as the Discrete Cosine Transform (DCT) and Huffman coding [31]. Each time djpeg parses one .jpg file, the contests of the data fields will be decoded and compared, resulting in few non-deps fields. Non-deps exclusion is unable to scale down the range of unvalidated fragments, leaving FFAFuzz on par with WEIZZ in terms of time cost. It can be confirmed as the opposite when using the de Bruijn-based test case as the input. The theoretical analysis in Appendix C indicates FFAFuzz is in this case as well.
Responding to RQ2, in terms of time efficiency, FFAFuzz recognizes dependencies faster than WEIZZ and Redqueen in most cases, and even if no non-deps fragments exist, FFAFuzz performs on par with WEIZZ.
4.6. RQ3: The Practicality Evaluation
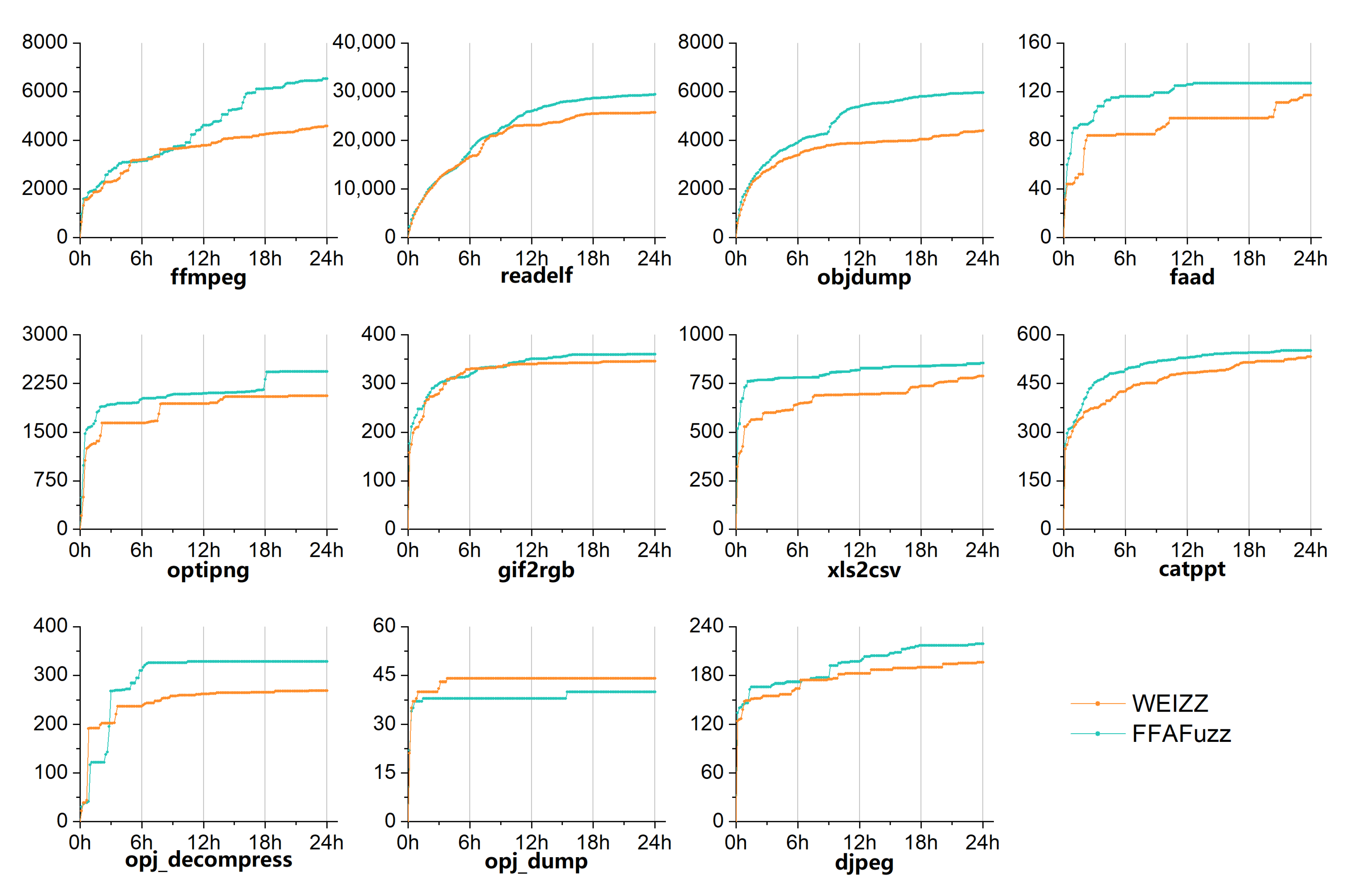
In this experiment, we evaluated the practicality of FFAFuzz in a real-world vulnerability hunting work.
Considering that we adopted the Redqueen mode of AFL++ and its fuzzing part is distinguishable from WEIZZ and FFAFuzz, to be fair, we evaluated the number of paths discovered in 24 h for the 11 targets via WEIZZ and FFAFuzz, not including Redqueen.
Figure 11 shows the results of FFAFuzz and WEIZZ.
Compared with WEIZZ, FFAFuzz can enhance the capability of path discovering of most targets as the benchmarks. Especially, FFAFuzz explored 42.36% and 35.62% more paths than WEIZZ for targets ffmpeg and objdump, respectively, and 14.53% for all the targets on average. In addition, FFAFuzz constructed 79 inputs triggering target program exception, which helps developers fix the possible vulnerabilities.
The main reason FFAFuzz outperformed WEIZZ and REDQUEEN is that our approach recognizes dependencies faster than others in the baseline. With the help of Non-deps exclusion in the Selective Flip stage, FFAFuzz could find those non-deps fields at a low cost and bypass them directly; this overcomes the obstacle of indiscriminate dependency recognition. Especially for the input with broken fields corrupted by mutations, FFAFuzz could quickly observe them and concentrated its resources on discovering the dependencies from the header fields. This will facilitate the fuzzer to test more code within the target program faster, in turn generating crash inputs that trigger program exceptions and helping developers increase the security and robustness of the target program.
Responding to RQ3, FFAFuzz can boost the code coverage to increase the efficiency of vulnerability discovery.
5. Limitations
According to the three experiments above, FFAFuzz can quickly recognize dependencies between input and comparison instructions, but limitations still remain as follows:
- While evaluating the effectiveness of FFAFuzz, comparing the result of the scenes of having prior format knowledge than not, the capability of dependency recognition relies on the execution path triggered by the test case closely. In other words, the effectiveness of dependency recognition is tied to how the test case fits the format requirements of the target. This suggests that FFAFuzz could be further enhanced with information such as key state changes [32]. In the next step, we plan to investigate and summarize the key states worthy of attention in the fuzzing test and design a purposeful instrument scheme to obtain and utilize more information about the key states, to enhance the efficiency in discovering software vulnerabilities.
- While evaluating the time efficiency of FFAFuzz, FFAFuzz is significantly faster than WEIZZ and Redqueen in most cases. Using inputs without any non-deps field, such as the situation where one data field is calculated for validating its checksum or decoded by a complex encoding algorithm such as the DCT and Huffman coding, FFAFuzz does not show much of an improvement. This suggests that FFAFuzz could be further enhanced by recognizing specific types of fields [14]. In the future, we plan to research current public file formats, protocols, and other structured input, select representative fields types, and design the corresponding recognition rules to recognize and classify dependencies more closely.
- The configuration rules of are static and inflexible. It would probably be better if could be adaptively adjusted according to the actual execution of the target. As the next step, we start from the theoretical analysis in Appendix C, capture the information about the code coverage, executed cmp instructions, the execution time, etc., utilizing instruments or simulators (QEMU [33], unicorn [34], FRIDA [35], etc.), to automatically adjust during the fuzzing test process.
6. Conclusions
While current format-aware fuzzing techniques have had achievements, they are still facing limits such as I2S misses or indiscriminate dependency recognition.
In this work, facing structured input applications, we presented a fast format-aware fuzzing approach for recognizing byte dependencies fully automatically and quickly without any format template, grammar, or dictionary. We enhanced the efficiency of byte dependency computing with I2S recognition based on de Bruijn matching and Selective Flip. It works by matching the I2S dependencies from the operand of the target comparison instructions and detecting indirect dependencies while identifying and avoiding non-deps fragments, solving the challenges of I2S misses and indiscriminate dependency recognition.
According to this method, we implemented a fast format-aware fuzzing prototype, FFAFuzz. The result showed that, in terms of effectiveness, FFAFuzz outperformed Redqueen significantly and was on par with WEIZZ, while FFAFuzz reduced the time cost by up to 89.10% on average. Compared with WEIZZ, FFAFuzz discovered more than 14.53% of the paths. In addition, 79 crashes were generated by FFAFuzz. This demonstrates that FFAFuzz reduced the time overhead of dependency recognition while identifying dependencies more completely and achieved higher code coverage than the state-of-the-art.
Author Contributions
Conceptualization, Y.L. and Z.C.; methodology, Z.C. and K.Z.; software, Z.C.; validation, Z.C. and K.Z.; investigation, Z.C.; resources, Y.L.; data curation, Z.C., K.Z. and L.Y.; writing—original draft preparation, Z.C.; writing—review and editing, Y.L., K.Z., L.Y., J.Z. and Z.C.; supervision, Y.L.; project administration, Y.L. All authors read and agreed to the published version of the manuscript.
Funding
This research was supported by the National Key Research and Development Project of China (No. 2017YFB0802900).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are available on request to the authors.
Acknowledgments
We sincerely thank the Reviewers for their perspectives and comments, which helped us improve this work.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Figure A1.
The time costs over the 11 targets of each compared fuzzer input with de Bruijn-based as the initial inputs.
Figure A1.
The time costs over the 11 targets of each compared fuzzer input with de Bruijn-based as the initial inputs.

Figure A2.
The time costs over the 11 targets of each compared fuzzer input with format-well as the initial inputs.
Figure A2.
The time costs over the 11 targets of each compared fuzzer input with format-well as the initial inputs.

To better visualize the enhancement effect, we evaluated the results using the following statistical methods.
We denote several variables as follows:
- B is the benchmarks.
- F is the set of fuzzers.
- I is the set of initial inputs.
- is the number of initial inputs in I.
- is the time cost of fuzzer in performing dependency recognition on the target with initial input .
- is the growth factor, indicating how much the time efficiency can be improved by fuzzer compared to fuzzer , when using initial input and performing dependency recognition on the target . Here, .
- is the average growth factor, indicating how much the average time efficiency can be improved by fuzzer compared to fuzzer , when using initial input and performing dependency recognition on the target . Here, .
- is the global average growth factor, indicating how much the average time efficiency can be improved by fuzzer compared to fuzzer , when using the initial input in I and performing dependency recognition on the targets in B. Here, .
In our evaluation, we notate the benchmarks as , the set of fuzzers as , the set of de Bruijn-based initial inputs as and the set of format-well initial inputs as . From the results in the evaluation of RQ2, we concluded the average growth factors of the 11 targets as the benchmarks as follows.
Table A1.
The average growth factors in RQ2.
| Target | ||||
|---|---|---|---|---|
| ffmpeg | 4.30% | 34.03% | 76.61% | 98.33% |
| readelf | 97.48% | 89.99% | 63.09% | 80.20% |
| objdump | 97.74% | 98.18% | 86.02% | 98.91% |
| faad | 96.00% | 55.12% | 2.92% | −15.73% |
| optipng | 98.21% | 93.12% | 96.89% | 97.11% |
| gif2rgb | 98.00% | 13.47% | 16.65% | −8.35% |
| xls2csv | 95.97% | 92.82% | 12.22% | 59.14% |
| catppt | 96.60% | 94.93% | 53.84% | 98.89% |
| opj_decompress | 98.09% | 84.51% | 98.63% | 92.47% |
| opj_dump | 98.13% | 86.22% | 98.56% | 95.64% |
| djpeg | 99.63% | 98.96% | 2.32% | 0.01% |
| Global average growth factor | 89.10% | 76.49% | 55.25% | 63.33% |
Appendix B
Considering that the generation of the de Bruijn-based test cases could be performed before fuzzing the target, we implemented this method as a separate tool and supplied APIs to FFAFuzz to call the matching function.
In Equation (A1), we denote as the byte length of the initial input. As described above, Non-deps exclusion enables our method to identify those non-deps fragments and pass them. It allows our dependency recognition to have fewer times of flipping the initial input and launching the target, compared with byte-by-byte analysis. When , the distance of overhead between our method and byte-by-byte analysis is tiny, so we configured as to perform Deps detection on the initial input directly. If , is configured as 32 after balancing between the lengths of the header fields in those popular existing file formats and the actual performance. To avoid a large ineffective execution of Non-deps exclusion when using initial inputs without non-deps fields, we configured as to limit the count of performing Non-deps exclusion to be acceptable.
Appendix C
In this section, the time complexity of the Selective Flip strategy is computed and compared with GETDEPS, the dependency recognition procedure of WEIZZ [15]. Denote n as the length of the input. Our theoretical analysis demonstrates that the time overhead of the Selective Flip strategy is related to n. , , and correspond to the time complexity of the Selective Flip strategy in the worst, majority of, and ideal scenarios, respectively.
The upper bound of its time overhead is approximately equal to GETDEPS, and better time efficiency can be achieved when the distribution of the header fields is concentrated.
Appendix C.1. The Time Complexity of Selective Flip
The Selective Flip strategy divides the dependency recognition of the entire initial input into several small-scale equivalent tasks. For fields larger than , Non-deps exclusion is used to lightly analyze the existence of dependencies in the field, and if not, it will be excluded directly; otherwise, the field will continue to be split in half and wait for the next round of analysis. The fields less than or equal to are then processed in Deps detection.
Based on Algorithms 2 and 3, we can conclude that and the following for loop statements are heavy in time overhead. They will thus be considered as basic operations. We denote by the count of the basic operations when using n-byte-long input and performing Selective Flip once.
The time overhead of Selective Flip in the ideal, majority of, and worst-case scenarios will be discussed in the following.
Appendix C.1.1. The Ideal Scenario
Ideally, no dependencies exist in the initial input. Selective Flip treats the entire input as a suspensive field and performs Non-deps exclusion. The basic operation is executed only once. The entire input will be flipped and used as the input. After the execution, no cmp operands were affected because the whole input is the non-deps one. We conclude:
is the time complexity of Selective Flip in this case.
Appendix C.1.2. The Majority of Scenarios
As Section 2.1 described, header fields are tiny, but metadata-intensive and adjacent. They can be commonly found in various types of structured inputs. In this case, Selective Flip will exclude the non-deps fragment of length , , , …, and finally perform Deps detection on the header fields.
Each time a non-deps fragment is excluded by Selective Flip, Non-deps exclusion is performed two times, the first time on the large fragment including header fields and the second time on the non-deps half of the large fragment. Finally, the non-deps fragment is excluded.
Selective Flip performs Deps detection on the header fields. Deps detection will execute the basic operation as many times as they are long.
We denote as the length of these fields, t as the count of performing Non-deps Exclusion. From the above, we have , and this leads to . Taking t as an integer, thus . We conclude:
From Equation (A3), is the time complexity of Selective Flip in the majority of scenarios.
Appendix C.1.3. The Worst Scenario
In the worst scenario, the header fields are distributed evenly and spaced less than , making it impossible for Selective Flip to recognize and exclude non-deps fragment by Non-deps exclusion. Eventually, the whole initial input is divided into several fragments with lengths no greater than , and Deps detection is performed one by one. Based on Algorithms 2 and 3, we can infer:
None of fragments longer than are excluded by Non-deps exclusion. This leads to the count of basic operations performed on this fragment being equal to the sum of those performed on the left and right halves, then plus this basic operation. Thus, . Fragments with lengths no longer than will be handled by Deps detection. The count of basic operations is equal to the fragment length, .
To analyze the time complexity, computing the basic operation count of Non-deps exclusion is needed. We used BVT, a type of binary tree for the discussion.
Definition A1.
For any positive integer n, is a binary tree, and each node in the tree has the following properties:
- The value of the root node is n.
- The value of the leaf node is 1.
- If a node with the value p is not a leaf node, then its left child node has the value , and the right one has the value
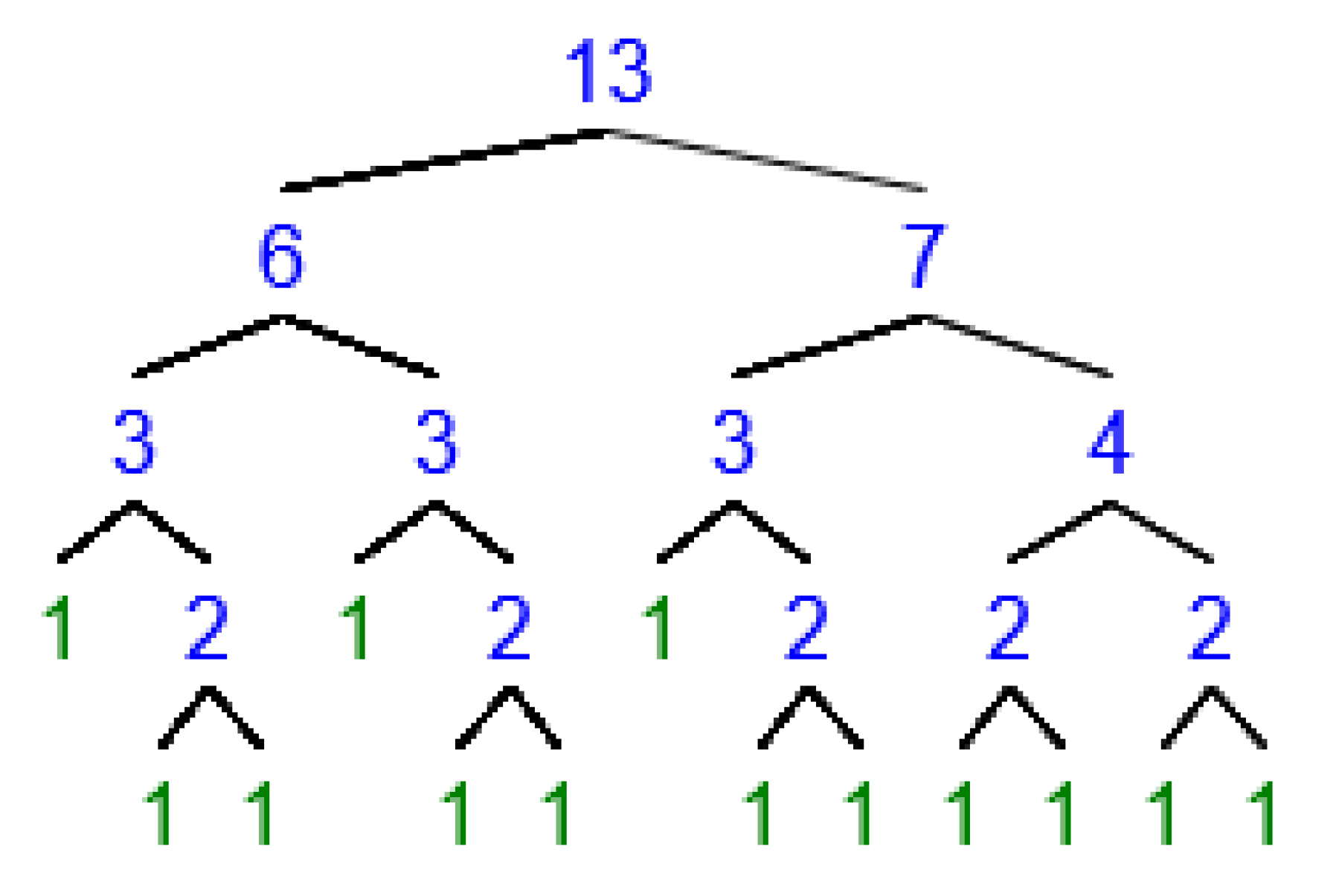
BVT(13) is shown in Figure A3. All the green nodes are leaves and the blue ones can be divided into their own left and right childs.
Figure A3.
An illustration of BVT(13).

The basic operation count of Non-deps exclusion is equal to the number of nodes whose values in are greater than by this.
Definition A2.
is a special depth of , all nodes under D whose values are no greater than m.
Definition A3.
For any real number x, , .
Definition A4.
For any real number x, , .
Theorem A1.
For any positive integer a and any real number x, .
Proof.
Theorem A2.
For any positive integer a and any real number x, .
Proof.
Theorem A3.
For any positive integer a and any real number x, .
Proof.
Theorem A4.
For any positive integer a and any real number x, .
Proof.
Next, we discuss the value of the nodes of with the same depth.
Theorem A5.
For all integers d, n such that and , the nodes in with depth d have the value or .
Proof.
When the depth is 0, the value of the node with depth 1 is or . □
Assume that a positive integer d, the nodes in with depth d has the value or .
In the depth , then four possible values exist, , , , and .
From Theorems A1–A4, we can infer that
In the depth , the values in with depth still match the value or .
The value of the leaf node is 1. From this, the upper bound of d can be calculated as follows:
Considering that d is an integer, the upper bound of d is . □
By the former theorem and the definition of , the calculation of will be concluded as follows.
Corollary A1.
For all positive integers n, m such that , .
Proof.
From the definition about , we learn that all the nodes with depth have values no greater than m. Thus,
Considering that is an integer, then . □
After can be calculated, an important issue is how to compute the number of nodes at depths of or higher. We start with the property of . As defined in Definition A1, we found:
Theorem A6.
For all integers n, is a balanced binary tree.
Proof.
Assume that there exists an integer for which is not a balanced binary tree. The difference in height between the two subtrees of the root node will be greater than 1. This leads to the difference of the root children to be greater than 1 also, which conflicts with Definition A1 and Theorem A5. As a result, for all integers n, is a balanced binary tree. □
Given that is a balanced binary tree, we can directly use the properties of a balanced binary tree to calculate the number of nodes.
Lemma A1.
If the depth of a balanced binary tree is , then for any integer d, such that:
- , the number of the nodes with depth d,;
- , the number of the nodes with a depth no greater than d,.
Proof.
From Definition A1, for any integer d, , the node with depth d has two children. We can conclude:
Lemma A1 demonstrates the relationship between the number of nodes and the depth.
Theorem A7.
If the depth of a balanced binary tree is , then for any integer d, such that:
- The number of nodes with depth d and value is .
- The number of nodes with depth d and value is .
Proof.
From Lemma A1, nodes of depth d exist. Theorem A5 demonstrates that the nodes in with depth d have the value or .
If , then fragments will be equally divided into the initial input of length n. The lengths of all the fragments are equal to , and the values of each node with depth d are equal to .
If , then . fragments of length will have their lengths added by 1. Thus, the number of nodes with value is . The number of the nodes with depth d and value is . □
In conclusion, the number of nodes in with a depth no greater than and a value not equal to m is the basic operation count of Selective Flip. We conclude:
Corollary A1 illustrates that , computing in time. Based on Theorem A1, is the complexity of and . Thus, is the scale of and . and .
Above all, is the time complexity of Selective Flip in the worst case.
References
- Zhu, X.; Wen, S.; Camtepe, S.; Xiang, Y. Fuzzing: A Survey for Roadmap. ACM Comput. Surv. 2022, 54. [Google Scholar] [CrossRef]
- American Fuzzy Lop. Available online: https://lcamtuf.coredump.cx/afl/ (accessed on 13 August 2022).
- Böhme, M.; Pham, V.T.; Roychoudhury, A. Coverage-based Greybox Fuzzing as Markov Chain. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; ACM: Vienna, Austria, 2016; pp. 1032–1043. [Google Scholar] [CrossRef]
- Fioraldi, A.; Maier, D.; Eißfeldt, H.; Heuse, M. AFL++: Combining Incremental Steps of Fuzzing Research. In Proceedings of the 14th USENIX Workshop on Offensive Technologies (WOOT 20), San Francisco, CA, USA, 11 August 2020; p. 12. [Google Scholar]
- libFuzzer—A Library for Coverage-Guided Fuzz Testing—LLVM 15.0.0git Documentation. Available online: https://www.llvm.org/docs/LibFuzzer.html (accessed on 13 August 2022).
- Holler, C.; Herzig, K.; Zeller, A. Fuzzing with Code Fragments (-2). In Proceedings of the 21st USENIX Security Symposium (USENIX Security 12), Bellevue, WA, USA, 8–10 August 2012; p. 14. [Google Scholar]
- Peach Fuzzer. Available online: https://peachtech.gitlab.io/peach-fuzzer-community/ (accessed on 13 August 2022).
- Pham, V.T.; Boehme, M.; Santosa, A.E.; Caciulescu, A.R.; Roychoudhury, A. Smart Greybox Fuzzing. IEEE Trans. Softw. Eng. 2019, 47, 1980–1997. [Google Scholar] [CrossRef]
- Grieco, G.; Ceresa, M.; Buiras, P. QuickFuzz: An Automatic Random Fuzzer for Common File Formats. ACM Sigplan Not. 2016, 51, 13–20. [Google Scholar] [CrossRef]
- Dutra, R.; Gopinath, R.; Zeller, A. FormatFuzzer: Effective Fuzzing of Binary File Formats. arXiv 2021, arXiv:2109.11277. [Google Scholar]
- Wang, Y.; Wu, Z.; Wei, Q.; Wang, Q. Field-aware Evolutionary Fuzzing Based on Input Specifications and Vulnerability Metrics. In Proceedings of the 2019 IEEE 10th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 18–20 October 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Aschermann, C.; Schumilo, S.; Blazytko, T.; Gawlik, R.; Holz, T. REDQUEEN: Fuzzing with Input-to-State Correspondence. In Proceedings of the 2019 Network and Distributed System Security Symposium, San Diego, CA, USA, 24–27 February 2019; Internet Society: San Diego, CA, USA, 2019. [Google Scholar] [CrossRef]
- Blazytko, T.; Aschermann, C.; Schlögel, M.; Abbasi, A.; Schumilo, S.; Wörner, S.; Holz, T. GRIMOIRE: Synthesizing Structure while Fuzzing. In Proceedings of the 28th USENIX Security Symposium (USENIX Security 19), Santa Clara, CA, USA, 14–16 August 2019; p. 18. [Google Scholar]
- You, W.; Liu, X.; Ma, S.; Perry, D.; Zhang, X.; Liang, B. SLF: Fuzzing without Valid Seed Inputs. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), Montreal, QC, Canada, 25–31 May 2019; p. 12. [Google Scholar]
- Fioraldi, A.; D’Elia, D.C.; Coppa, E. WEIZZ: Automatic grey-box fuzzing for structured binary formats. In Proceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis, Virtual, 18–22 July 2020; pp. 1–13. [Google Scholar] [CrossRef]
- McDaniel, M.; Heydari, M. Content based file type detection algorithms. In Proceedings of the 36th Annual Hawaii International Conference on System Sciences, Big Island, HI, USA, 6–9 January 2003; p. 10. [Google Scholar] [CrossRef]
- Ali, H.A.; Ne’ma, B.M. Effective Variations on Opened GIF Format Images. IJCSNS 2008, 8, 70. [Google Scholar]
- Cui, W.; Peinado, M.; Chen, K.; Wang, H.J.; Irun-Briz, L. Tupni: Automatic reverse engineering of input formats. In Proceedings of the 15th ACM Conference on Computer and Communications Security—CCS ’08, Alexandria, VA, USA, 27–31 October 2008; ACM Press: Alexandria, VA, USA, 2008; p. 391. [Google Scholar] [CrossRef]
- Iuliani, M.; Shullani, D.; Fontani, M.; Meucci, S.; Piva, A. A Video Forensic Framework for the Unsupervised Analysis of MP4-Like File Container. IEEE Trans. Inf. Forensics Secur. 2019, 14, 635–645. [Google Scholar] [CrossRef]
- TIFF: Summary from the Encyclopedia of Graphics File Formats. Available online: https://www.fileformat.info/format/tiff/egff.htm (accessed on 13 August 2022).
- Bruijn, N.G.d. A combinatorial problem. Proc. Sect. Sci. K. Ned. Akad. Wet. Amst. 1946, 49, 758–764. [Google Scholar]
- Shubin, D.N.; Lobov, E.M. Using CUDA technology to form ensembles of pseudo-random sequences and calculating their correlation functions. In Proceedings of the 2017 Systems of Signal Synchronization, Generating and Processing in Telecommunications (SINKHROINFO), Kazan, Russia, 3–4 July 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Gabric, D.; Sawada, J.; Williams, A.; Wong, D. A Successor Rule Framework for Constructing $k$ -Ary de Bruijn Sequences and Universal Cycles. IEEE Trans. Inf. Theory 2020, 66, 679–687. [Google Scholar] [CrossRef]
- Liang, J.; Wang, M.; Zhou, C.; Wu, Z.; Jiang, Y.; Liu, J.; Liu, Z.; Sun, J. PATA: Fuzzing with Path Aware Taint Analysis. In Proceedings of the 2022 IEEE Symposium on Security and Privacy (SP), Los Angeles, CA, USA, 7–11 November 2022; p. 17. [Google Scholar]
- Fredricksen, H. A Survey of Full Length Nonlinear Shift Register Cycle Algorithms. SIAM Rev. 1982, 24, 195–221. [Google Scholar] [CrossRef]
- Sipser, M. Introduction to the Theory of Computation, 3rd ed.; Cengage Learning: Andover, MA, USA, 2013. [Google Scholar]
- Schumilo, S.; Aschermann, C.; Gawlik, R.; Schinzel, S.; Holz, T. kAFL: Hardware-Assisted Feedback Fuzzing for OS Kernels. In Proceedings of the 26th USENIX Security Symposium (USENIX Security 17), Vancouver, BC, Canada, 16–18 August 2017; p. 17. [Google Scholar]
- Release 3.14c · AFLplusplus/AFLplusplus. Available online: https://github.com/AFLplusplus/AFLplusplus/releases/tag/3.14c (accessed on 13 August 2022).
- [MS-PPT]: PowerPoint (.ppt) Binary File Format|Microsoft Docs. Available online: https://docs.microsoft.com/en-us/openspecs/office_file_formats/ms-ppt/6be79dde-33c1-4c1b-8ccc-4b2301c08662 (accessed on 13 August 2022).
- Update Helps Unmanaged Office 2010 Users Work with Microsoft RMS in Windows. Available online: https://support.microsoft.com/en-gb/topic/update-helps-unmanaged-office-2010-users-work-with-microsoft-rms-in-windows-e4bc163d-e54d-6e39-d2b6-2ef93566f4ff (accessed on 13 August 2022).
- Yuan, S.; Hu, J. Research on image compression technology based on Huffman coding. J. Vis. Commun. Image Represent. 2019, 59, 33–38. [Google Scholar] [CrossRef]
- Aschermann, C.; Schumilo, S.; Abbasi, A.; Holz, T. Ijon: Exploring Deep State Spaces via Fuzzing. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 21 May 2020; pp. 1597–1612. [Google Scholar] [CrossRef]
- QEMU. Available online: https://www.qemu.org/ (accessed on 13 August 2022).
- Unicorn. Unicorn—The Ultimate CPU Emulator. Available online: https://www.unicorn-engine.org/ (accessed on 13 August 2022).
- Frida • A World-Class Dynamic Instrumentation Framework. Available online: https://frida.re/ (accessed on 13 August 2022).
Figure 1.
Layout of chunks within the .tif file.

Figure 2.
Example of an inefficient .tif test case due to blind mutations.

Figure 3.
Example of an I2S dependency.

Figure 4.
Example of I2S misses caused by colorization on invalid fields.

Figure 5.
Example of inefficient byte-by-byte analysis on the trailer field.

Figure 6.
The overview of FFAFuzz with de Bruijn-based input.

Figure 7.
The FA of de Bruijn-based test case generation.

Figure 8.
The overall design of Indirect Dependency Recognizer.

Figure 9.
The dependency amounts obtained by dependency recognition for RQ1.

Figure 10.
The time overhead of dependency recognition by various compared fuzzers.

Figure 11.
The number of paths discovered over the 11 targets of FFAFuzz and WEIZZ with format-well as the initial inputs.
Figure 11.
The number of paths discovered over the 11 targets of FFAFuzz and WEIZZ with format-well as the initial inputs.

Table 1.
Shift rule table.
| Current State | Input (Constraint) | Operations | Next State |
|---|---|---|---|
| forward | : dBStack exists |
if dBStack is full, then Output(string in dBStack, dBMap) else dBStack.push(0) | stay |
| stay | : dBMap[dBStack’s top n-tuple] == NULL_INDEX or the bottom n-tuple in dBStack not yet traversed |
if dBMap[dBStack’s top n-tuple] == NULL_INDEX then dBMap[dBStack’s top n-tuple] = the offset of dBStack’s top n-tuple else dBStack.buffer[dBStack.top]++ | forward |
| stay | : dBMap[dBStack’s top n-tuple] != NULL_INDEX and dBStack.buffer[dBStack.top] < |
if dBStack’s top n-tuple is unique, then dBMap[dBStack’s top n-tuple] == NULL_INDEX dBStack.buffer[dBStack.top]++ | stay |
| stay | : dBStack.buffer[dBStack.top] == | No operation | backward |
| backward | : dBStack’s top n-tuple is unique or the bottom n-tuple in dBStack not yet traversed |
if dBStack’s top n-tuple is unique, then dBMap[dBStack’s top n-tuple] == NULL_INDEX dBStack.pop() | stay |
| backward | : the bottom n-tuple in dBStack has been traversed | finish | backward |
Table 2.
Baseline.
| Fuzzer | Dependency Recognition via Value Matching | Dependency Recognition via Value Alteration Inference |
|---|---|---|
| Redqueen | Value matching based on colorization | ✕ |
| WEIZZ | ✕ | Byte-by-byte analysis |
| FFAFuzz | de Bruijn matching | Selective Flip |
Table 3.
Targets and configurations.
| Target | Version | Description | Binary | Execution Arguments |
|---|---|---|---|---|
| ffmpeg | 5.0.1 “Lorentz” | Audio parsing and processing | ffmpeg | -y -i @@ -c:v mpeg4 -c:a out.mp4 |
| readelf | 2.38 | Executable and Linkable Format (.elf) file parsing | readelf | -a @@ |
| objdump | 2.38 | Executable and Linkable Format (.elf) file parsing | objdump | -x @@ |
| faad | 2.9.2 | Advanced Audio Coding (.aac) file parsing and processing | faad | @@ -o out.wav |
| OptiPNG | 0.7.7 | Portable Network Graphics (.png) file parsing and processing | optipng | @@ -clobber -out out.png |
| gif2rgb | giflib-5.2.1 | Graphics Interchange Format (.gif) file parsing and processing | gif2rgb | @@ |
| xls2csv | Catdoc 0.95 | Microsoft Excel 97-2003 Worksheet (.xls) file parsing | xls2csv | @@ |
| catppt | Catdoc 0.95 | Microsoft PowerPoint Presentation (.ppt) file parsing | catppt | @@ |
| opj_decompress | openjpeg-2.4.0 | JPEG 2000 Core Coding format (.jp2) file parsing and processing | opj_decompress | -i @@ -o out.png |
| opj_dump | openjpeg-2.4.0 | JPEG 2000 Core Coding format (.jp2) file parsing | opj_dump | -i @@ |
| djpeg | libjpeg-turbo-2.1.3 | Joint Photographic Experts Group (.jpeg) file parsing and processing | djpeg | -gif -outfile out.git @@ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Chen, Z.; Lu, Y.; Zhu, K.; Yu, L.; Zhao, J. Fast Format-Aware Fuzzing for Structured Input Applications. Appl. Sci. 2022, 12, 9350. https://0-doi-org.brum.beds.ac.uk/10.3390/app12189350
AMA Style
Chen Z, Lu Y, Zhu K, Yu L, Zhao J. Fast Format-Aware Fuzzing for Structured Input Applications. Applied Sciences. 2022; 12(18):9350. https://0-doi-org.brum.beds.ac.uk/10.3390/app12189350
Chicago/Turabian StyleChen, Zehan, Yuliang Lu, Kailong Zhu, Lu Yu, and Jiazhen Zhao. 2022. "Fast Format-Aware Fuzzing for Structured Input Applications" Applied Sciences 12, no. 18: 9350. https://0-doi-org.brum.beds.ac.uk/10.3390/app12189350
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.