
An Interpretable Machine Learning Approach for Hepatitis B Diagnosis


 , , , , , and
, , , , , and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Collection
2.2. Data Preprocessing
- Fit the scaler using training data, i.e., using the fit() function to estimate the minimum and maximum values.
- Apply the scale to the training dataset, i.e., using the transform() function to normalize the data that would be used to train the model.
- Subsequently, apply only the scale on the test set.
2.3. Machine Learning Classifiers
2.3.1. Decision Tree
2.3.2. Logistic Regression
2.3.3. Support Vector Machine
2.3.4. Random Forest
2.3.5. XGBoost
2.3.6. AdaBoost
2.4. SHapley Additive exPlanations
2.5. Proposed HPV Detection Method
2.6. Performance Evaluation Metrics
3. Results
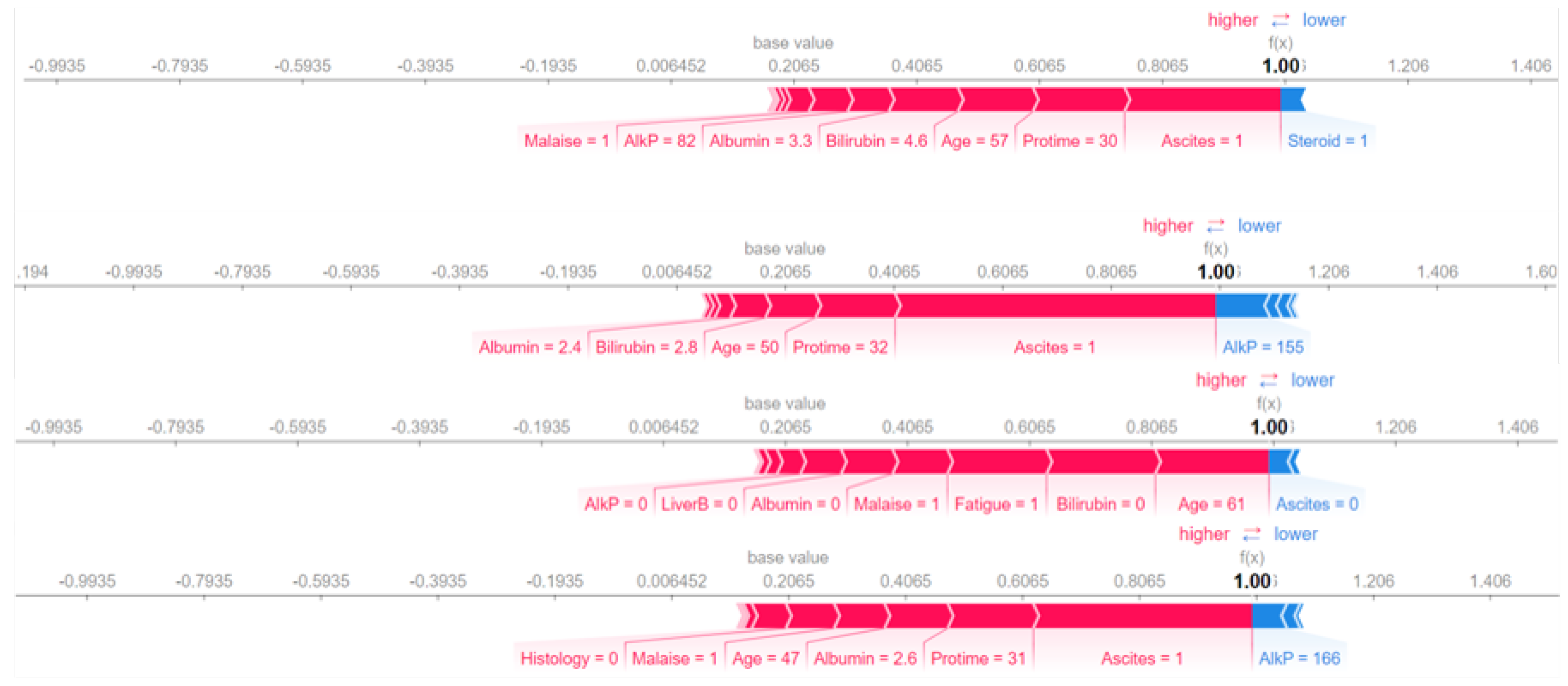
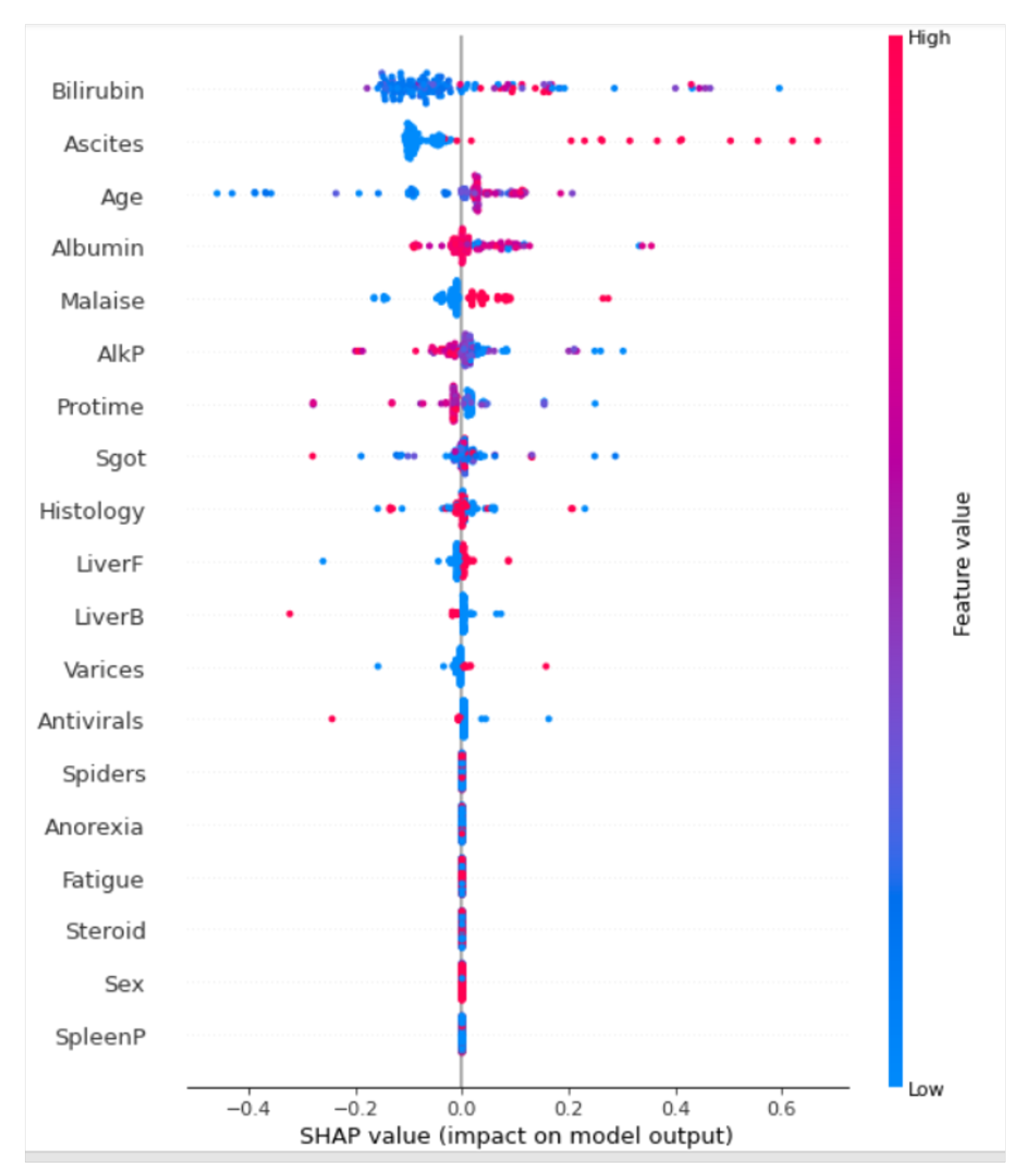
4. Interpretability
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hepatitis B Foundation: Hepatitis B Facts and Figures. 2019. Available online: https://deepai.org/machine-learning-glossary-and-terms/neural-network (accessed on 25 May 2022).
- Brouwer, W.; Chan, H.; Brunetto, M.; Martinot-Peignoux, M.; Arends, P.; Cornberg, M.; Cherubini, B.; Thompson, A.; Liaw, Y.; Marcellin, P.; et al. Good Practice in using HBsAg in Chronic Hepatitis B Study Group (GPs-CHB Study Group). Repeated Measurements of Hepatitis B Surface Antigen Identify Carriers of Inactive HBV During Long-term Follow-up. Clin. Gastroenterol. Hepatol. 2016, 10, 1481–1489. [Google Scholar] [CrossRef] [Green Version]
- WHO Fact Sheet: Hepatitis B—Symptoms. 2020. Available online: https://www.who.int/news-room/fact-sheets/detail/hepatitis-b (accessed on 30 April 2022).
- Mayo Clinic: Hepatitis B—Symptoms. 2020. Available online: https://shorturl.at/nuzV7 (accessed on 30 April 2022).
- Shu, S.; William, C.W.; Zhuoru, Z.; Dan, D.C.; Jason, J.O.; Polin, C.; Fanpu, J.; Man-Fung, Y.; Guihua, Z.; Wai-Kay, S.; et al. Cost-effectiveness of universal screening for chronic hepatitis B virus infection in China: An economic evaluation. Lancet Glob. Health 2022, 10, e278–e287. [Google Scholar] [CrossRef]
- Tesfa, T.; Hawulte, B.; Tolera, A.; Abate, D. Hepatitis B virus infection and associated risk factors among medical students in Eastern Ethiopia. PLoS ONE 2021, 16, e0247267. [Google Scholar] [CrossRef]
- Nguyen, M.H.; Wong, G.; Gane, E.; Kao, J.H.; Dusheiko, G. Hepatitis B virus: Advances in prevention, diagnosis, and therapy. Clin. Microbiol. Rev. 2020, 33, e00046-19. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Protzer, U.; Siddiqui, A. Revisiting hepatitis B virus: Challenges of curative therapies. J. Virol. 2019, 93, e01032-19. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lazarus, J.V.; Block, T.; Bréchot, C.; Kramvis, A.; Miller, V.; Ninburg, M.; Pénicaud, C.; Protzer, U.; Razavi, H.; Thomas, L.A.; et al. The hepatitis B epidemic and the urgent need for cure preparedness. Nat. Rev. Gastroenterol. Hepatol. 2018, 15, 517–518. [Google Scholar] [CrossRef] [PubMed]
- Bartenschlager, R.; Urban, S.; Protzer, U. Towards curative therapy of chronic viral hepatitis. Z. Gastroenterol. 2019, 57, 61–73. [Google Scholar] [CrossRef]
- Chen, Y.; Luo, Y.; Huang, W.; Hu, D.; Zheng, R.Q.; Cong, S.Z.; Meng, F.K.; Yang, H.; Lin, H.J.; Sun, Y.; et al. Machine-learning-based classification of real-time tissue elastography for hepatic fibrosis in patients with chronic hepatitis B. Comput. Biol. Med. 2017, 89, 18–23. [Google Scholar] [CrossRef]
- Tai, W.; He, L.; Zhang, X.; Pu, J.; Voronin, D.; Jiang, S.; Zhou, Y.; Du, L. Characterization of the receptor-binding domain (RBD) of 2019 novel coronavirus: Implication for development of RBD protein as a viral attachment inhibitor and vaccine. Cell. Mol. Immunol. 2020, 17, 613–620. [Google Scholar] [CrossRef] [Green Version]
- Strother, H.W.; David, B.D. Estimation of the probability of an event as a function of several independent variables. Biometrika 1967, 54, 167–179. [Google Scholar]
- Uttreshwar, G.S.; Ghatol, A. Hepatitis B Diagnosis Using Logical Inference And Generalized Regression Neural Networks. In Proceedings of the 2009 IEEE International Advance Computing Conference, Patiala, India, 6–7 March 2009; pp. 1587–1595. [Google Scholar] [CrossRef]
- Wang, H.; Liu, Y.; Huang, W. Random forest and Bayesian prediction for Hepatitis B virus reactivation. In Proceedings of the 2017 13th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), Guilin, China, 29–31 July 2017; pp. 2060–2064. [Google Scholar] [CrossRef]
- Agbele, K.K.; Oriogun, P.K.; Seluwa, A.G.; Aruleba, K.D. Towards a model for enhancing ICT4 development and information security in healthcare system. In Proceedings of the 2015 IEEE International Symposium on Technology and Society (ISTAS), Dublin, Ireland, 11–12 November 2015; pp. 1–6. [Google Scholar]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar] [CrossRef]
- Aruleba, K.; Obaido, G.; Ogbuokiri, B.; Fadaka, A.O.; Klein, A.; Adekiya, T.A.; Aruleba, R.T. Applications of Computational Methods in Biomedical Breast Cancer Imaging Diagnostics: A Review. J. Imaging 2020, 6, 105. [Google Scholar] [CrossRef]
- Aruleba, R.T.; Adekiya, T.A.; Ayawei, N.; Obaido, G.; Aruleba, K.; Mienye, I.; Aruleba, I.; Ogbuokiri, B. COVID-19 Diagnosis: A Review of Rapid Antigen, RT-PCR and Artificial Intelligence Methods. Bioengineering 2022, 3, 153. [Google Scholar] [CrossRef]
- Mienye, I.D.; Obaido, G.; Aruleba, K.; Dada, O.A. Enhanced Prediction of Chronic Kidney Disease Using Feature Selection and Boosted Classifiers. In International Conference on Intelligent Systems Design and Applications; Springer: Cham, Switzerland, 2022; pp. 527–537. [Google Scholar]
- Xiaolu, T.; Yutian, C.; Yutao, H.; Pi, G.; Mengjie, L.; Wangjian, Z.; Zhicheng, D.; Xiangyong, L.; Yuantao, H. Using Machine Learning Algorithms to Predict Hepatitis B Surface Antigen Seroclearance. Comput. Math. Methods Med. 1967, 2019, 2019. [Google Scholar]
- Akbar, K.W.; Peter, D.R.H. Machine learning in medicine: A primer for physicians. Am. J. Gastroenterol. 2010, 105, 1224–1226. [Google Scholar]
- Rohan, G.; Devesh, S.; Mehar, S.; Swati, T.; Rashmi, K.A.; Pravir, K. Artificial intelligence to deep learning: Machine intelligence approach for drug discovery. Mol. Divers 2021, 25, 1315–1360. [Google Scholar]
- Qing-Hai, Y.; Lun-Xiu, Q.; Marshonna, F.; Ping, H.; Jin, W.K.; Amy, C.P.; Richard, S.; Yan, L.; Ana, I.R.; Yidong, C.; et al. Predicting hepatitis B virus–positive metastatic hepatocellular carcinomas using gene expression profiling and supervised machine learning. Nat. Med. 2003, 9, 416–423. [Google Scholar]
- Tian, X.; Chong, Y.; Huang, Y.; Guo, P.; Li, M.; Zhang, W.; Du, Z.; Li, X.; Hao, Y. Using machine learning algorithms to predict hepatitis B surface antigen seroclearance. Comput. Math. Methods Med. 2019, 2019, 6915850. [Google Scholar] [CrossRef]
- Wübbolding, M.; Lopez Alfonso, J.C.; Lin, C.Y.; Binder, S.; Falk, C.; Debarry, J.; Gineste, P.; Kraft, A.R.; Chien, R.N.; Maasoumy, B.; et al. Pilot study using machine learning to identify immune profiles for the prediction of early virological relapse after stopping nucleos (t) ide analogues in HBeAg-negative CHB. Hepatol. Commun. 2021, 5, 97–111. [Google Scholar] [CrossRef] [PubMed]
- Putri, V.; Masjkur, M.; Suhaeni, C. Performance of SMOTE in a random forest and naive Bayes classifier for imbalanced Hepatitis-B vaccination status. J. Physics: Conf. Ser. 2021, 1863, 012073. [Google Scholar] [CrossRef]
- Kamimura, H.; Nonaka, H.; Mori, M.; Kobayashi, T.; Setsu, T.; Kamimura, K.; Tsuchiya, A.; Terai, S. Use of a Deep Learning Approach for the Sensitive Prediction of Hepatitis B Surface Antigen Levels in Inactive Carrier Patients. J. Clin. Med. 2022, 11, 387. [Google Scholar] [CrossRef]
- Xia, Z.; Qin, L.; Ning, Z.; Zhang, X. Deep learning time series prediction models in surveillance data of hepatitis incidence in China. PLoS ONE 2022, 17, e0265660. [Google Scholar] [CrossRef] [PubMed]
- Dua, D.; Graff, C.; UCI Machine Learning Repository. University of California, Irvine, School of Information and Computer Sciences. 2017. Available online: http://archive.ics.uci.edu/ml (accessed on 1 July 2022).
- Mgboh, U.; Ogbuokiri, B.; Obaido, G.; Aruleba, K. Visual Data Mining: A Comparative Analysis of Selected Datasets. In International Conference on Intelligent Systems Design and Applications; Springer: Cham, Switzerland, 2020; pp. 377–391. [Google Scholar]
- Scheda, R.; Diciotti, S. Explanations of Machine Learning Models in Repeated Nested Cross-Validation: An Application in Age Prediction Using Brain Complexity Features. Appl. Sci. 2022, 12, 6681. [Google Scholar] [CrossRef]
- Parvandeh, S.; Yeh, H.W.; Paulus, M.P.; McKinney, B.A. Consensus features nested cross-validation. Bioinformatics 2020, 36, 3093–3098. [Google Scholar] [CrossRef] [PubMed]
- Jones, I. Research Methods for Sports Studies; Routledge: London, UK, 2014. [Google Scholar]
- Patro, S.; Sahu, K.K. Normalization: A preprocessing stage. arXiv 2015, arXiv:1503.06462. [Google Scholar] [CrossRef]
- Sklearn Pipeline. 2022. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.pipeline.Pipeline.html (accessed on 15 October 2022).
- Sevinç, E. An empowered AdaBoost algorithm implementation: A COVID-19 dataset study. Comput. Ind. Eng. 2022, 165, 107912. [Google Scholar] [CrossRef]
- Ogbuokiri, B.; Ahmadi, A.; Bragazzi, N.L.; Movahedi Nia, Z.; Mellado, B.; Wu, J.; Orbinski, J.; Asgary, A.; Kong, J. Public sentiments toward COVID-19 vaccines in South African cities: An analysis of Twitter posts. Front. Public Health 2022, 10, 987376. [Google Scholar] [CrossRef]
- Mienye, I.D.; Sun, Y.; Wang, Z. Prediction performance of improved decision tree-based algorithms: A review. Procedia Manuf. 2019, 35, 698–703. [Google Scholar] [CrossRef]
- Lee, S.J.; Tseng, C.H.; Yang, H.Y.; Jin, X.; Jiang, Q.; Pu, B.; Hu, W.H.; Liu, D.R.; Huang, Y.; Zhao, N. Random RotBoost: An Ensemble Classification Method Based on Rotation Forest and AdaBoost in Random Subsets and Its Application to Clinical Decision Support. Entropy 2022, 24, 617. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, Q.; Hu, Y.; Sun-Woo, K.; Zhang, X.; Zhu, H.; Li, S. Novel binary logistic regression model based on feature transformation of XGBoost for type 2 Diabetes Mellitus prediction in healthcare systems. Future Gener. Comput. Syst. 2022, 129, 1–12. [Google Scholar] [CrossRef]
- Ogbuokiri, B.; Ahmadi, A.; Nia, Z.M.; Mellado, B.; Wu, J.; Orbinski, J.; Ali, A.; Jude, K. Vaccine Hesitancy Hotspots in Africa: An Insight from Geotagged Twitter Posts. TechRxiv 2022. [Google Scholar] [CrossRef]
- Bokaba, T.; Doorsamy, W.; Paul, B.S. Comparative study of machine learning classifiers for modelling road traffic accidents. Appl. Sci. 2022, 12, 828. [Google Scholar] [CrossRef]
- Ghosh, M.; Sanyal, G. An ensemble approach to stabilize the features for multi-domain sentiment analysis using supervised machine learning. J. Big Data 2018, 5, 1–25. [Google Scholar] [CrossRef]
- Huang, M.W.; Chen, C.W.; Lin, W.C.; Ke, S.W.; Tsai, C.F. SVM and SVM ensembles in breast cancer prediction. PLoS ONE 2017, 12, e0161501. [Google Scholar] [CrossRef]
- Mienye, I.D.; Sun, Y. A Survey of Ensemble Learning: Concepts, Algorithms, Applications, and Prospects. IEEE Access 2022, 10, 99129–99149. [Google Scholar] [CrossRef]
- Mienye, I.D.; Sun, Y.; Wang, Z. An improved ensemble learning approach for the prediction of heart disease risk. Inform. Med. Unlocked 2020, 20, 100402. [Google Scholar] [CrossRef]
- Schonlau, M.; Zou, R.Y. The random forest algorithm for statistical learning. Stata J. 2020, 20, 3–29. [Google Scholar] [CrossRef]
- Lin, W.; Wu, Z.; Lin, L.; Wen, A.; Li, J. An ensemble random forest algorithm for insurance big data analysis. IEEE Access 2017, 5, 16568–16575. [Google Scholar] [CrossRef]
- Zheng, H.; Yuan, J.; Chen, L. Short-term load forecasting using EMD-LSTM neural networks with a Xgboost algorithm for feature importance evaluation. Energies 2017, 10, 1168. [Google Scholar] [CrossRef] [Green Version]
- He, J.; Hao, Y.; Wang, X. An interpretable aid decision-making model for flag state control ship detention based on SMOTE and XGBoost. J. Mar. Sci. Eng. 2021, 9, 156. [Google Scholar] [CrossRef]
- Cheong, Q.; Au-Yeung, M.; Quon, S.; Concepcion, K.; Kong, J.D. Predictive Modeling of Vaccination Uptake in US Counties: A Machine Learning–Based Approach. J. Med. Internet Res. 2021, 23, e33231. [Google Scholar] [CrossRef]
- Dhaliwal, S. Effective intrusion detection system using XGBoost. Information 2018, 9, 149. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Chen, W. A comparative performance assessment of ensemble learning for credit scoring. Mathematics 2020, 8, 1756. [Google Scholar] [CrossRef]
- Zheng, H.; Xiao, F.; Sun, S.; Qin, Y. Brillouin Frequency Shift Extraction Based on AdaBoost Algorithm. Sensors 2022, 22, 3354. [Google Scholar] [CrossRef]
- Huang, X.; Li, Z.; Jin, Y.; Zhang, W. Fair-AdaBoost: Extending AdaBoost method to achieve fair classification. Expert Syst. Appl. 2022, 202, 117240. [Google Scholar] [CrossRef]
- Ding, Y.; Zhu, H.; Chen, R.; Li, R. An Efficient AdaBoost Algorithm with the Multiple Thresholds Classification. Appl. Sci. 2022, 12, 5872. [Google Scholar] [CrossRef]
- Nohara, Y.; Matsumoto, K.; Soejima, H.; Nakashima, N. Explanation of machine learning models using improved Shapley Additive Explanation. In Proceedings of the 10th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics, Niagara Falls, NY, USA, 7–10 September 2019; pp. 546–546. [Google Scholar]
- Mangalathu, S.; Hwang, S.H.; Jeon, J.S. Failure mode and effects analysis of RC members based on machine-learning-based SHapley Additive exPlanations (SHAP) approach. Eng. Struct. 2020, 219, 110927. [Google Scholar] [CrossRef]
- García, M.V.; Aznarte, J.L. Shapley additive explanations for NO2 forecasting. Ecol. Inform. 2020, 56, 101039. [Google Scholar] [CrossRef]
- Strumbelj, E.; Kononenko, I. An efficient explanation of individual classifications using game theory. J. Mach. Learn. Res. 2010, 11, 1–18. [Google Scholar]
- Nohara, Y.; Matsumoto, K.; Soejima, H.; Nakashima, N. Explanation of machine learning models using shapley additive explanation and application for real data in hospital. Comput. Methods Programs Biomed. 2022, 214, 106584. [Google Scholar] [CrossRef]
- Pokharel, S.; Sah, P.; Ganta, D. Improved prediction of total energy consumption and feature analysis in electric vehicles using machine learning and shapley additive explanations method. World Electr. Veh. J. 2021, 12, 94. [Google Scholar] [CrossRef]
- Santos, R.N.; Yamouni, S.; Albiero, B.; Vicente, R.; A Silva, J.; FB Souza, T.; CM Freitas Souza, M.; Lei, Z. Gradient boosting and Shapley additive explanations for fraud detection in electricity distribution grids. Int. Trans. Electr. Energy Syst. 2021, 31, e13046. [Google Scholar] [CrossRef]
- Meddage, P.; Ekanayake, I.; Perera, U.S.; Azamathulla, H.M.; Md Said, M.A.; Rathnayake, U. Interpretation of Machine-Learning-Based (Black-box) Wind Pressure Predictions for Low-Rise Gable-Roofed Buildings Using Shapley Additive Explanations (SHAP). Buildings 2022, 12, 734. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Elgeldawi, E.; Sayed, A.; Galal, A.R.; Zaki, A.M. Hyperparameter tuning for machine learning algorithms used for arabic sentiment analysis. Informatics 2021, 8, 79. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation 609 coefficient (MCC) over F1 score and accuracy in binary classification 610 evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef] [Green Version]
- Mienye, I.D.; Sun, Y. Performance analysis of cost-sensitive learning methods with application to imbalanced medical data. Inform. Med. Unlocked 2021, 25, 100690. [Google Scholar] [CrossRef]
- Trevethan, R. Sensitivity, specificity, and predictive values: Foundations, pliabilities, and pitfalls in research and practice. Front. Public Health 2017, 5, 307. [Google Scholar] [CrossRef]
- Mienye, I.D.; Sun, Y. Improved heart disease prediction using particle swarm optimization based stacked sparse autoencoder. Electronics 2021, 10, 2347. [Google Scholar] [CrossRef]
- Namdar, K.; Haider, M.A.; Khalvati, F. A Modified AUC for Training Convolutional Neural Networks: Taking Confidence into Account. Front. Artif. Intell. 2021, 4, 582928. [Google Scholar] [CrossRef]
- Luo, J.; Liang, X.; Xin, J.; Li, J.; Li, P.; Zhou, Q.; Hao, S.; Zhang, H.; Lu, Y.; Wu, T.; et al. Predicting the Onset of Hepatitis B Virus–Related Acute-on-Chronic Liver Failure. Clin. Gastroenterol. Hepatol. 2022; in press. [Google Scholar] [CrossRef]
- Yarasuri, V.K.; Indukuri, G.K.; Nair, A.K. Prediction of Hepatitis Disease Using Machine Learning Technique. In Proceedings of the 2019 Third International conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), Palladam, India, 12–14 December 2019; pp. 265–269. [Google Scholar] [CrossRef]
- Fatima, M.; Pasha, M. Survey of Machine Learning Algorithms for Disease Diagnostic. J. Intell. Learn. Syst. Appl. 2017, 9, 16. [Google Scholar] [CrossRef] [Green Version]
- Ali, N.; Srivastava, D.; Tiwari, A.; Pandey, A.; Pandey, A.K.; Sahu, A. Predicting Life Expectancy of Hepatitis B Patients using Machine Learning. In Proceedings of the 2022 IEEE International Conference on Distributed Computing and Electrical Circuits and Electronics (ICDCECE), Ballari, India, 23–24 April 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Kolyshkina, I.; Simoff, S. Interpretability of Machine Learning Solutions in Public Healthcare: The CRISP-ML Approach. Front. Big Data 2021, 4, 660206. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.Y.; Lampertico, P.; Nam, J.Y.; Lee, H.C.; Kim, S.U.; Sinn, D.H.; Seo, Y.S.; Lee, H.A.; Park, S.Y.; Lim, Y.S.; et al. An artificial intelligence model to predict hepatocellular carcinoma risk in Korean and Caucasian patients with chronic hepatitis B. J. Hepatol. 2022, 76, 311–318. [Google Scholar] [CrossRef] [PubMed]
- Khan, S.; Ullah, R.; Khan, A.; Ashraf, R.; Ali, H.; Bilal, M.; Saleem, M. Analysis of hepatitis B virus infection in blood sera using Raman spectroscopy and machine learning. Photodiagn. Photodyn. Ther. 2018, 23, 89–93. [Google Scholar] [CrossRef] [PubMed]
- Vijayalakshmi, C.; Mohideen, S.P. Predicting Hepatitis B to be acute or chronic in an infected person using machine learning algorithm. Adv. Eng. Softw. 2022, 172, 103179. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, Z.; Wang, Y.; Fang, M.; Zhou, J.; Li, Y.; Dai, E.; Feng, Z.; Wang, H.; Yang, Z.; et al. Using quasispecies patterns of hepatitis B virus to predict hepatocellular carcinoma with deep sequencing and machine learning. J. Infect. Dis. 2021, 223, 1887–1896. [Google Scholar] [CrossRef] [PubMed]
- Bar-Lev, S.; Reichman, S.; Barnett-Itzhaki, Z. Prediction of vaccine hesitancy based on social media traffic among Israeli parents using machine learning strategies. Isr. J. Health Policy Res. 2021, 10, 1–8. [Google Scholar] [CrossRef]
- Albogamy, F.R.; Asghar, J.; Subhan, F.; Asghar, M.Z.; Al-Rakhami, M.S.; Khan, A.; Nasir, H.M.; Rahmat, M.K.; Alam, M.M.; Lajis, A.; et al. Decision Support System for Predicting Survivability of Hepatitis Patients. Front. Public Health 2022, 10, 862497. [Google Scholar] [CrossRef]
- Wei, R.; Wang, J.; Wang, X.; Xie, G.; Wang, Y.; Zhang, H.; Peng, C.Y.; Rajani, C.; Kwee, S.; Liu, P.; et al. Clinical prediction of HBV and HCV related hepatic fibrosis using machine learning. EBioMedicine 2018, 35, 124–132. [Google Scholar] [CrossRef] [Green Version]
- Alamsyah, A.; Fadila, T. Increased accuracy of prediction hepatitis disease using the application of principal component analysis on a support vector machine. J. Phys. Conf. Ser. 2021, 1968, 012016. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| S/N | Attribute | Type | Description |
|---|---|---|---|
| 1 | Class = “Died”, “Lived” | Nominal | Patients that died or survived |
| 2 | Age | Numeric | Patient’s age |
| 3 | Gender | Nominal | Male or Female |
| 4 | Steroid | Nominal | Increases HBV replication |
| 5 | Antivirals | Nominal | Drugs to stop or slow replication of HBV |
| 6 | Fatigued | Nominal | Impairment of functional capabilities due to HBV |
| 7 | Malaise | Nominal | State of discomfort and unwell |
| 8 | Anorexia | Nominal | Loss of appetite |
| 9 | Liver_big | Nominal | Enlarged liver |
| 10 | Liver_firm | Nominal | Enlarged liver |
| 11 | Spleen_palable | Nominal | Enlarged spleen |
| 12 | Spiders | Nominal | Abnormal collection of blood vessels clustered near the skin surface |
| 13 | Ascites | Nominal | Abnormal accumulation of fluids in the abdomen |
| 14 | Varices | Nominal | Enlarged veins |
| 15 | Bilirubin | Numeric | Yellowship pigment formed after the breakdown of red blood cells. |
| 16 | Alk_Phosphate | Numeric | Used for screening fibrosis levels |
| 17 | Sgot | Numeric | Liver enzyme |
| 18 | Albumin | Numeric | Protein made by the liver |
| 19 | Protime | Numeric | Protein made by the liver |
| 20 | Histology | Nominal | Microscopy study of the liver |
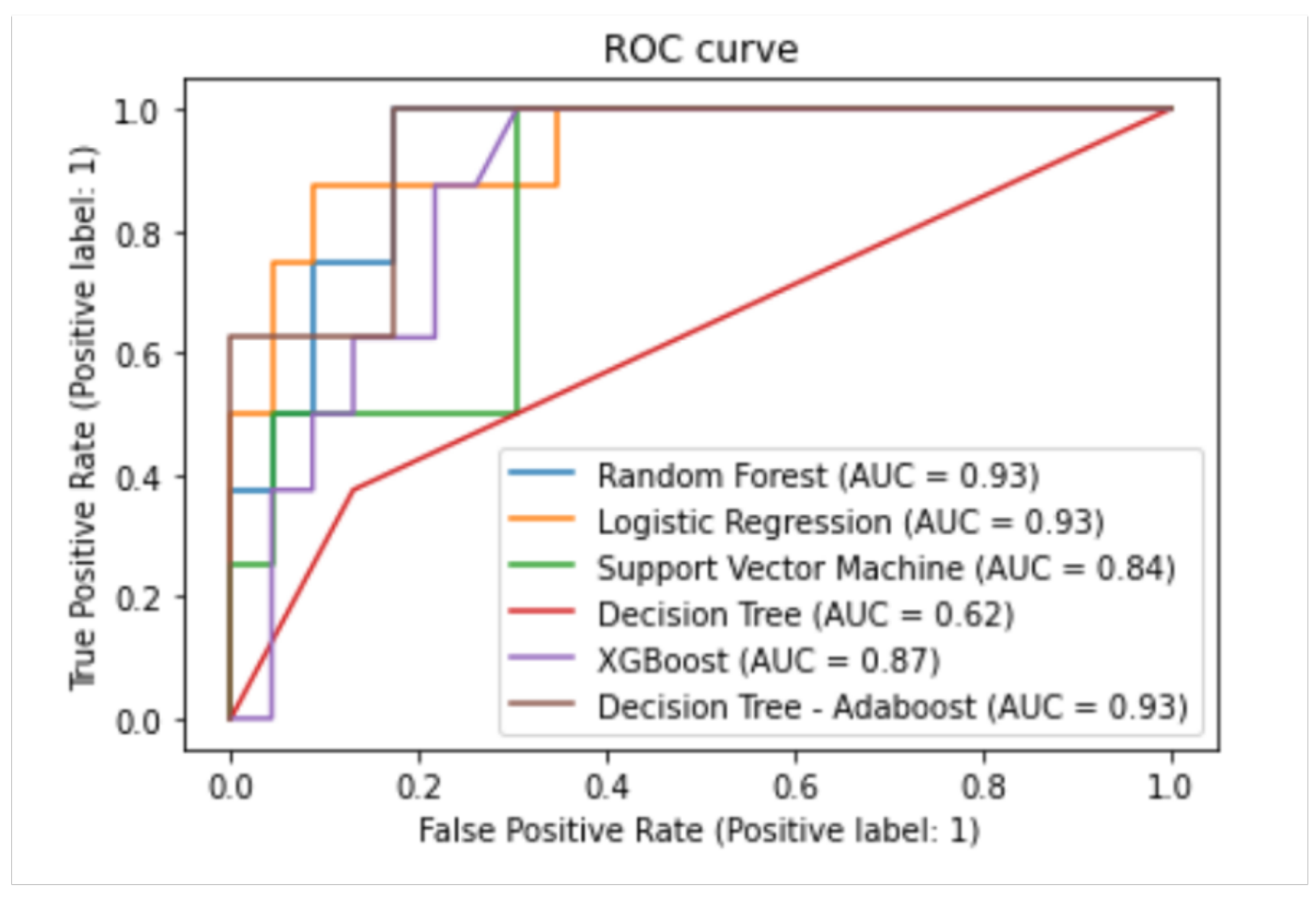
| Algorithm | Balanced Accuracy (%) | Specificity (%) | Sensitivity (%) | AUC (%) |
|---|---|---|---|---|
| Decision Tree | 73 | 80 | 66 | 62 |
| Logistic Regression | 82 | 89 | 74 | 93 |
| Support Vector Machine | 73 | 67 | 80 | 84 |
| Random Forest | 86 | 90 | 82 | 93 |
| Adaboost | 92 | 91 | 93 | 93 |
| XGBoost | 90 | 92 | 88 | 87 |
| Reference | Method | Model Explainability |
|---|---|---|
| Tian et al. [25] | XGBoost, LR, RF and DCT | ✗ |
| Khan et al. [79] | SVM | ✗ |
| Vijayalakshmi et al. [80] | SGD | ✗ |
| Kamimura et al. [28] | DNN | ✗ |
| Putri et al. [27] | RF, NB | ✗ |
| Chen et al. [81] | RF | ✗ |
| Bar-lev et al. [82] | LR, RF and NN | ✗ |
| Wu et al. [83] | CNN | ✗ |
| Wübbolding et al. [26] | LR, SVM and SGD | ✗ |
| Kim et al. [78] | GBM | ✓ |
| Xia et al. [29] | LSTM, RNN and BPNN | ✗ |
| Wei et al. [84] | DCT, RF and GB | ✗ |
| Alamsyah and Fadila [85] | SVM | ✗ |
| Our work | RF, LR, SVM, DCT, AdaBoost, and XGBoost | ✓ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Obaido, G.; Ogbuokiri, B.; Swart, T.G.; Ayawei, N.; Kasongo, S.M.; Aruleba, K.; Mienye, I.D.; Aruleba, I.; Chukwu, W.; Osaye, F.; et al. An Interpretable Machine Learning Approach for Hepatitis B Diagnosis. Appl. Sci. 2022, 12, 11127. https://0-doi-org.brum.beds.ac.uk/10.3390/app122111127
Obaido G, Ogbuokiri B, Swart TG, Ayawei N, Kasongo SM, Aruleba K, Mienye ID, Aruleba I, Chukwu W, Osaye F, et al. An Interpretable Machine Learning Approach for Hepatitis B Diagnosis. Applied Sciences. 2022; 12(21):11127. https://0-doi-org.brum.beds.ac.uk/10.3390/app122111127
Chicago/Turabian StyleObaido, George, Blessing Ogbuokiri, Theo G. Swart, Nimibofa Ayawei, Sydney Mambwe Kasongo, Kehinde Aruleba, Ibomoiye Domor Mienye, Idowu Aruleba, Williams Chukwu, Fadekemi Osaye, and et al. 2022. "An Interpretable Machine Learning Approach for Hepatitis B Diagnosis" Applied Sciences 12, no. 21: 11127. https://0-doi-org.brum.beds.ac.uk/10.3390/app122111127