1. Introduction
The beyond 5th generation (B5G) mobile communication networks are envisioned to support Internet of Everything (IoE) applications (e.g., extended reality) with diverse requirements (e.g., latency, reliability, and data rate) [
1]; therefore, B5G will not only be a pipeline for data transmission, but also an innovation platform with great flexibility. Service-based architecture (SBA) is expected to become the infrastructure of B5G networks with its modular functions, simple interfaces, and automation mechanisms [
2]. After the 3rd Generation Partnership Project (3GPP) has defined a service-based 5G core network, the service-based radio access network has attracted great attention from academic scholars [
3,
4]. The SBA can leverage cloud computing resources to meet diverse and differentiated requirements through intelligent and automated scaling.
Consequently, the SBA greatly improves the management complexity because of the large number of network function instances deploying in cloud computing. Artificial intelligence (AI)-native management solutions by integrating AI techniques and closed-loop architecture will play a crucial role in the SBA to enable network intelligence and automation [
5,
6,
7,
8]. Beginning from Release 16 (R16), 3GPP introduced a new network function (NF), namely NetWork Data Analytics Function (NWDAF (3GPP TR 23.791, Study of Enablers for Network Automation for 5G (Release 16); 3GPP TR 23.700, Study on enablers for network automation for the 5G System (5GS) (Release 17); 3GPP TS 23.288, network data analytics services (Release 17))) in the 5G core network to make the AI-native solutions practically useful. On the one hand, NFs (e.g., Access and Mobility Management Function (AMF)) are carefully designed with an “EventExposure” service to expose the internal raw data to NWDAF. Further, NWDAF collects system-level information (e.g., the downlink data rate of a specific user equipment (UE)) from the Operations, Administration, and Maintenance (OAM) system. All network-level protocol parameters are available in NWDAF supported by the interaction architecture. On the other hand, NWDAF introduces some AI model operations procedures, including subscription, selection, training, and so on. NWDAF aims to provide AI models and algorithms as internal services, exposed to other NFs or OAM to make intelligent decisions for the self-optimization of protocol parameters. NWDAF facilitates an online monitor-analyze-plan-execute (MAPE) closed-loop process within the 5G core network, collecting network states from NFs, training data-driven AI models, making intelligent decisions, and executing actions for network control.
In this context, deep reinforcement learning (DRL), with its advantage of periodic interaction with the environment, has been widely noticed and applied to the automated management of networks. J. Yao, et al. [
9] propose a virtual network function (VNF) flexible deployment scheme based on reinforcement learning to maintain the quality-of-service (QoS) of 5G network slicing under limited physical network resources. W. Peng, et al. [
10] propose a DRL-based optimal placement for AMF considering user mobility and the arrival rate of user mobility management requests in a heterogeneous radio access network. H. T. Nguyen, et al. [
11] present the application of reinforcement learning technique for the horizontal scaling of VNFCs within ETSI-NFV architecture. Z. Yan, et al. [
12] combine DRL with graph convolutional networks (GCNs) for embedding virtual networks automatically to adapt them to the dynamic environment. P. Sun, et al. [
13] propose a VNF placement scheme, DeepOpt, which combines DRL and GNN for an efficient VNF placement and shows good performance on different network topologies. J. Kim, et al. [
14] propose a deep-Q-network-based cloud-native network function (CNF) placement algorithm (DQN-CNFPA) to minimize operation cost and traffic overload on edge clouds. J. Li, et al. [
15] formulate the VNF scheduling problem as a Markov decision process (MDP) problem with a variable action set, and DRL is developed to learn the best scheduling policy by continuously interacting with the network environment. Even though, almost all problems solved by DRLs are evaluated in a simulation manner, so the performance in real-world networks would be hard to know. Specifically, the state-of-the-art DRL algorithms ignore the random delays in the real-world networks that break the 0-delay assumptions of the standard MDPs, thereby degrading the performance.
This issue has recently received attention in the reinforcement learning field, where delays (including observation, reward, and action delays) are taken into consideration when modeling an MDP problem. S. Ramstedt, et al. [
16] pointed out that the standard DRLs are turn-based, because the environment pauses when the agent selects an action, and vice versa. It assumes that the state will not change until an action is executed, which is ill suited for real-time applications in which the environment’s state continues to evolve while the agent selects an action [
17]. Hence, the authors proposed a novel framework in which the agent is allowed exactly one timestep to select an action. B. Chen, et al. [
18] then proposed a multi-timestep framework to improve the performance of DRLs in a delayed system, which is enhanced from the one-timestep framework. They modeled it as a delay-aware MDP problem that can be converted to the standard MDP solved by a model-based DRL algorithm; however, the assumption that the delays are constant for several timesteps also mismatch the reality where delays are always random. To fill this gap, S. Ramstedt, et al. [
19] studied the anatomy of randomly delayed environment for off-policy multi-timestep value estimation. The authors analyzed the influence of actions on delayed observations in delayed environment and modeled it as a random delay MDP problem with an augmented state space and delayed dynamics (e.g., observation delays). A partial trajectory resampling method was proposed to collect samples to train the agent. Without difference, these frameworks adopt the same method that augments the state space using the latest-received observation and fixed-length action buffer. The main drawback of this method is the exponential growth of the state space with the delay value [
20].
Learning from the state-of-the-art works, we can conclude that (1) few works take the delays between the agent and the environment into consideration to evaluate their impact on the performance of DRL-enabled network automation; (2) DRL algorithms considering the delays are evaluated in a controlled simulation environment (e.g., OpenAI Gym (Gym:
https://github.com/openai/gym (accessed on 2 October 2022) )) and are not really applied to real-world network automation; therefore, we are inspired to study the random-delay-corrected deep reinforcement learning framework for real-world online closed-loop network automation in this paper.
Firstly, we abstract the interaction patterns between the agent and the environment with a delay assumption to be three different scenarios including a turn-based scenario, a periodicity-based scenario with constant delays, and a periodicity-based scenario with random delays. The turn-based scenario means that the agent will generate an action for network control only if it receives an observation from the environment, which is designed to adopt the standard DRL algorithms. The periodicity-based scenarios with constant or random delays mean that the environment collects the state and the agent generates an action periodically at each time step, which is considered to capture the dynamics within the networks to improve the performance.
Secondly, we model the scenarios as a partial history-dependent Markov decision process (PH-MDP), which extends the standard MDP with a dynamic action buffer and the latest-received observations. The action buffer records the actions that will be executed before the agent generates a new action at each time step. The agent in the periodicity-based scenarios will receive none, one, or multiple observations at each time step, it will choose a fresh or latest-received observation to generate the action. Because of the dynamic action buffer, we propose a forward model to iteratively predict the next state using the latest-received observation and actions in the buffer. The predicted state will be input into the actor network of DRL algorithms to output an action. The PH-MDP is a general model that can be adopted into the three scenarios mentioned above. In order to obtain samples to train the agent, we propose a delay-corrected trajectory sampling method in the interactions between the agent and the environment. Based on the framework, we propose a delayed-DQN algorithm for further evaluation.
In order to validate our proposed methodologies, we develop a proof-of-concept (PoC) prototype of a cloud-native 5G core network based on some open-source projects. We build a Kubernetes-based cloud environment to deploy 5G core network function instances packaged in docker containers. The simulated 5G network consists of the stateless 5G core network provided by OpenAirInterface (OAI) projects and the radio access network provided by UERANSIM projects. For environment state collection, Prometheus is integrated in Kubernetes to collect multi-level resources (e.g., physical machine, pod, and docker resources). For network control, customized application programming interfaces (APIs) are implemented based on the Kubernetes APIs. The agent is built based on NVIDIA Cloud GPU that allows DRL algorithms to obtain network states from the environment, make decisions, and control the network in an online manner. To better load customized DRL algorithms from 3rd parties, we design and implement a customized algorithm uploading and running procedure.
On top of the prototype and the framework, we implement a delayed-deep-Q-network (delayed-DQN)-enabled AMF scaling use case for the specific evaluations. Several experiment scenarios are implemented including no-delay and turn-based scenarios, constant and random-delay scenarios with the standard DQN, and constant and random-delay scenarios with the delayed-DQN algorithms. The results show that (1) the periodicity-based pattern can be more beneficial to capture the network dynamics than the turn-based pattern; (2) the random-delay-corrected DRL framework can improve the performance when adopting the DQN algorithm in the periodicity-based scenarios; (3) smaller state collection time interval can further improve the performance of the delayed-DQN algorithm; (4) the proposed framework is well adopted in a real-world cloud-native 5G core network to enable AI-native network automation.
To the best of our knowledge, this is the first paper discussing DRL algorithms applications in a real-world online closed-loop network automation with random delays. Compared with the state-of-the-art works, our contributions are concluded as follows.
We abstract the interaction patterns between the agent and the environment and model them to be PH-MDP, a general model that supports turn-based and one-timestep/multi-timestep constant/random delays scenarios. With PH-MDP, it is not necessary to know the specific delays in advance; the agent can monitor whether an observation is received at regular intervals and obtain the delays from the time stamp carried within the observation; therefore, the PH-MDP is able to be well-adopted in a real-world system.
We prove that the PH-MDP can be transformed into the standard MDP in terms of the transmission probability. We propose a forward model instead of an augmented state space to learn the ground-truth transmission probability from a dynamic action buffer. Due to the uncertainty of delays, we propose a delay-corrected trajectory sampling method to obtain samples according to the time stamps of unordered actions and observations. The PH-MDP, forward model, and delay-corrected trajectory sampling method make up our proposed random-delay-corrected DRL framework.
We talk about the relationship between the time interval of state collection and ground-truth delays . We discuss ways to define how long one timestep should be, thereby supporting different scenarios (e.g., turn-based scenario) in the use case.
We develop a PoC prototype to evaluate our proposed framework in a real-world system. The environment is a stateless 5G core network deployed in a Kubernetes-based cloud computing with Prometheus for state collection and envAdapter for network control; the agent is an AI Engine (AIE) supported by NVIDIA Cloud CPU to enable customized DRL algorithms uploading and running. We design a specific DRL algorithm, delayed-DQN, based on the framework to enable automated scaling of AMF and several experiments are conducted to show the performance.
The rest of this paper is organized as follows.
Section 2 presents our proposed methodologies including scenario abstraction, modeling, and random-delay-corrected DRL framework.
Section 3 presents our developed PoC prototype including a Kubernetes-based cloud environment and NVIDIA Cloud GPU-based AIE.
Section 4 presents the implemented use case, delayed-DQN-enabled AMF scaling in detail, including architecture, reinforcement learning setting (state representation, action definition, and reward description), experiment setup/parameters, and evaluation results.
Section 5 concludes this paper.
3. PoC Prototype: Real-World Cloud-Native 5G Core
In order to evaluate our proposed methodologies, we develop a PoC prototype based on some open-source projects, such as OAI. This prototype aims at managing a cloud-native 5G core network in an online manner automatically, which consists of a Kubernetes-based cloud environment and an AIE for deploying DRL algorithms. The AIE collects network state data from the environment to make an intelligent decision and then executes it in the environment via Kubernetes APIs.
3.1. The Kubernetes-Based Cloud Environment Deploying 5G Core Network Functions
The development target of the environment of the PoC prototype is to support online state collection and network controls, thereby providing samples for the agent to make intelligent decisions and APIs for executing these decisions. For this purpose, the environment is composed of the following components.
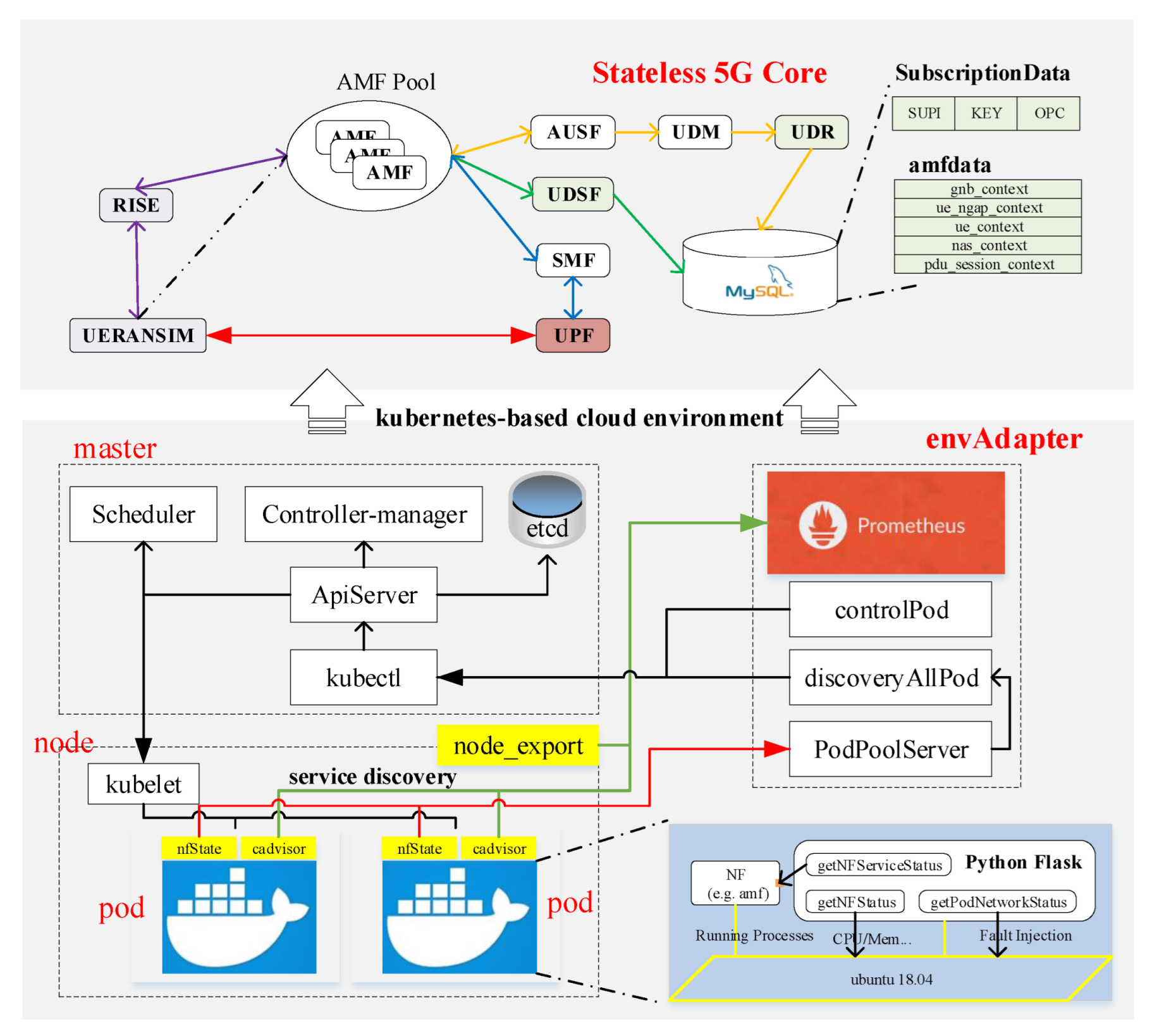
Stateless 5G Core. The stateless design of the 5G core network is envisioned to be an essential approach to better deploy 5G core network functions in a cloud environment without signaling message loss [
21]. This prototype aims to scale 5G core network resources automatically to process the time-varying signaling messages simulated by UERANSIM (UERANSIM: simulators for 5G gNBs and UEs without air–interface protocols) so that a message-level stateless 5G core network is set up with a set of OpenXG-5GCore projects (
http://git.opensource5g.org/dashboard/projects (accessed on 2 October 2022)). As is shown in
Figure 2, the stateless 5G core network consists of RAN Service Integrated Enabler (RISE), AMF, SMF, UDM, AUSF, UDR, UDSF, and UPF. RISE is a middleware between UERANSIM and AMF, responsible for the mutual conversion of HTTP1.1 and SCTP protocols to discover AMF instances. The SCTP protocol within AMF is replaced by HTTP1.1 to send/receive non-access-stratum (NAS) messages. Further, the communication contexts within AMF are removed to the unified data storage, UDSF, to make AMF stateless. When receiving one NAS message by AMF, it will try to obtain the corresponding contexts associated with someone’s identifier (e.g., SUPI) first. The processing results will also be updated in UDSF to ensure information consistency. UDSF maintains an MYSQL database storing contexts such as
gnb_context,
ue_ngap_context, and so on. With these network functions, the stateless 5G core network is able to inter-operate with open-source gNB/UE (e.g., UERANSIM) and also some commercial gNBs (e.g., Baicell, Amarisoft gNB) and UEs (e.g., Huawei Mate 30 5G Pro, Hongmi K30). Therefore, some high-level features such as UE-initiated registration and PDU session establishment procedures can be supported for real 3GPP-defined signaling messages. In order to collect the network-domain and service-domain data within the cloud-native 5G core network, some modifications are made to the state-of-the-art open-source projects. The “EventExposure” service within AMF and SMF is implemented to expose network-domain data, such as UEs’ SUPI, IP address UEs’ location, and so on. For UPF, we implement a non-3GPP-defined interface for UPF to expose the service-domain data such as uplink and downlink data rate of a certain UE because 3GPP has not designed the service-based interfaces for UPF.
Kubernetes-based Cloud Environment. The stateless 5G core network is implemented to be adaptable in the cloud environment with instances packaged in Docker containers. Kubernetes, an open-source cloud environment, is chosen to orchestrate all NF instances in this PoC prototype. As is shown in
Figure 2, we integrate Prometheus into Kubernetes to collect the resource-domain data automatically. Prometheus is an open-source monitor for resource utilization of physical machines, virtual machines, Kubernetes nodes, and Kubernetes Pods deploying NF instances. To make this happen, each Kubernetes worker node is equipped with
node_export, each Pod is equipped with
cadvisor, and Prometheus should be configured to support the service discovery procedure within Kubernetes.
There exists one situation that one Pod may be alive while the NF instance deployed in this Pod may crash because of some bugs. In this context, we customize a Python service named nfState.py that will work after one Pod is instantiated. It implements three interfaces to collect network-domain and service-domain data of NFs and control the resource utilization (e.g., CPU, memory); therefore, we can check if the Python service is alive to judge if the NF instance is available. getNFStatus is used to obtain the running-time process identity (PID), CPU, memory, traffic load information, and/or static capacity of NF instances. getNFServiceStatus is used to obtain the signaling status of UE and/or running-time downlink/uplink traffic data. getPodNetworkStatus is used to obtain the delay and packet loss rate information of the NF instances.
On top of the basic environment, we implement the envAdapter to provide unified APIs for data collection and network control. Three Python services are implemented to reach this target, including controlPod, discoveryAllPod, and PodPoolServer. The controlPod service exposes the capabilities of horizontal or vertical scaling of NF instances (e.g., adding a new Pod instance). The discoveryAllPod service is used to obtain the IP addresses of all available network function instances to support network-domain service discovery procedures. The PodPoolServer service integrates network data from different domains (e.g., network-domain, resource-domain, and service-domain) together, facilitating graph-based association and then exposing them to the AIE.
3.2. The Artificial Intelligence Engine Deploying DRL Algorithms
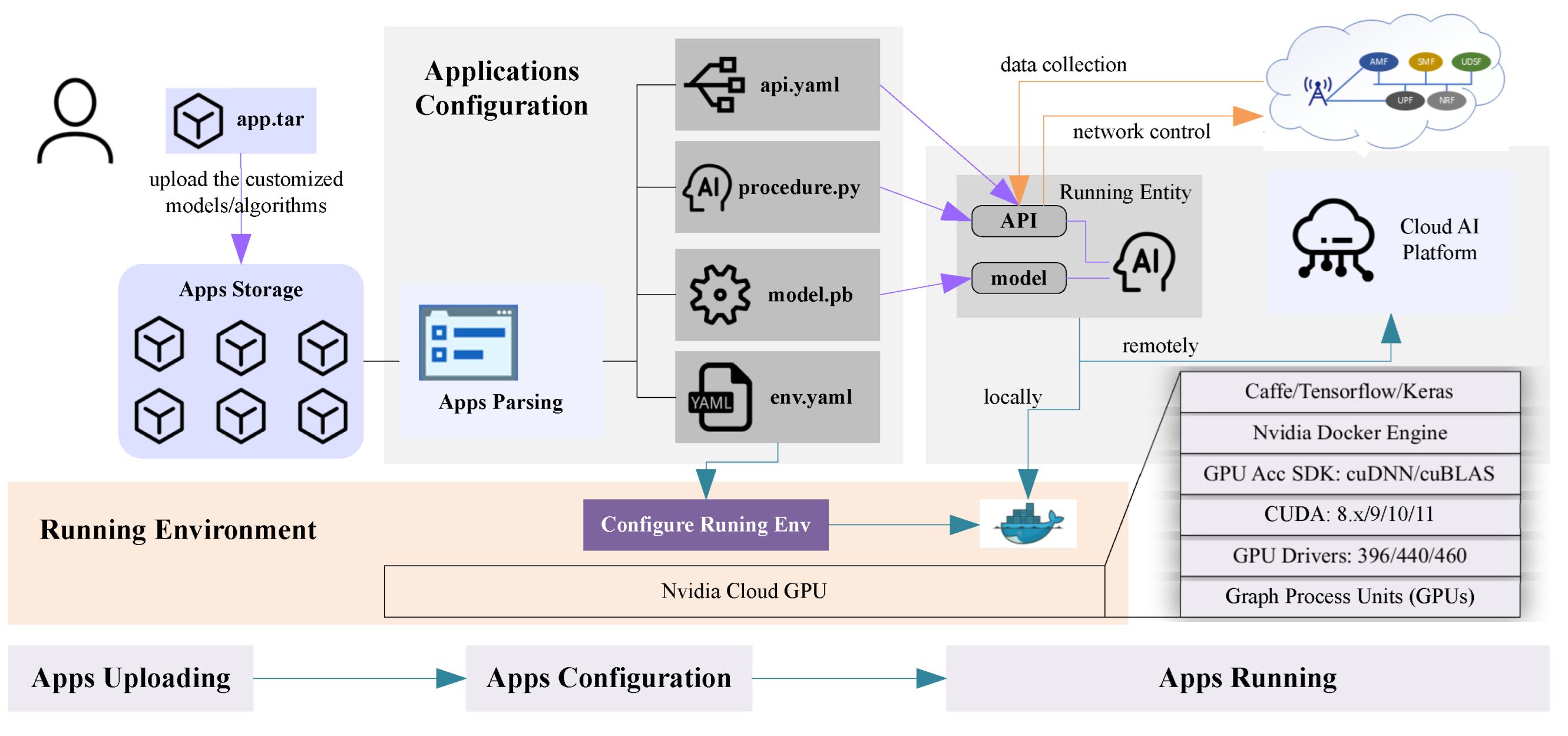
In order to provide AI-native functionalities for the agent to learn from the collected state of the underlying networks, we consider that there will be a scalable and effective engine running multiple and customized DRL algorithms in real-world systems.
For this purpose, we develop an AIE referring to NVIDIA Cloud GPU solutions and implement a procedure for customized AI algorithms uploading, parsing, and running, which is illustrated in
Figure 3. As is shown, the procedure includes “Apps Uploading”, “Apps Configuration”, and “Apps Running” in order. The model designer first uploads the application package (app.tar) that consists of the AI models/algorithms and requirements for running environment/network data. The application package will be stored in the “apps” database, waiting to be parsed and allocated with one or more NVIDIA Docker instances.
During “Apps Configuration”, the application package is decompressed with four files that are “api.yaml”, “env.yaml”, “model.pb”, and “procedure.py”, respectively. The “api.yaml” indicates the required network data for training the uploaded AI model and the network control interfaces for executing generated actions (or decisions). The AIE maintains all APIs for network data retrieval and network control and opens them all to ensure their availability for model designers. Moreover, different AI models/algorithms may be written with a different version of Python and neural networks so that the running environment requirements should be indicated specifically in “env.yaml”. For example, one AI model/algorithm may run with Python 3.6 and Tensorflow 2.0 supporting GPU, while another one may run with Python 3.5 and Pytorch. The model designer may upload a pre-trained model optionally that is in the format of “model.pb”. The main logic of the AI model/algorithm, including data retrieval, model training, model inference, and decision-making, is written in “procedure.py”. With the four files, NWDAF then assigns the AI model/algorithm with one or more compliant NVIDIA Docker instances for running.
Afterward, the AI model/algorithm running in NVIDIA Docker obtains the network data from the “data” database following the configured data APIs. The generated results can be used for network control following the configured network control APIs; therefore, the MAPE closed-loop architecture is implemented in the AIE, which facilitates the online network automation for a cloud-native 5G core network.
3.3. Implementation
The prototype runs on four virtual machines (VMs) deployed on one SANGFOR (
https://www.sangfor.com.cn/ (accessed on 2 October 2022)) server, including three VMs for deploying a Kubernetes (One master and two work nodes: 8-cores CPU, 8G memory, Ubuntu 18.04; Kubernetes version: 1.17.4)-based cloud environment and one VM (AIE: 32-cores CPU; 32G memory; Ubuntu 18.04; GPU version: NVIDIA A100-PCI; NVIDIA-SMI 470.141.03; CUDA version 11.4; cuDNN version: v8.2.4; installation tutorials for NVIDIA Cloud GPU:
https://zhuanlan.zhihu.com/p/406815658 (accessed on 2 October 2022)) for deploying an AIE. The communication between Kubernetes nodes is via a Flannel plugin with which a Calico (
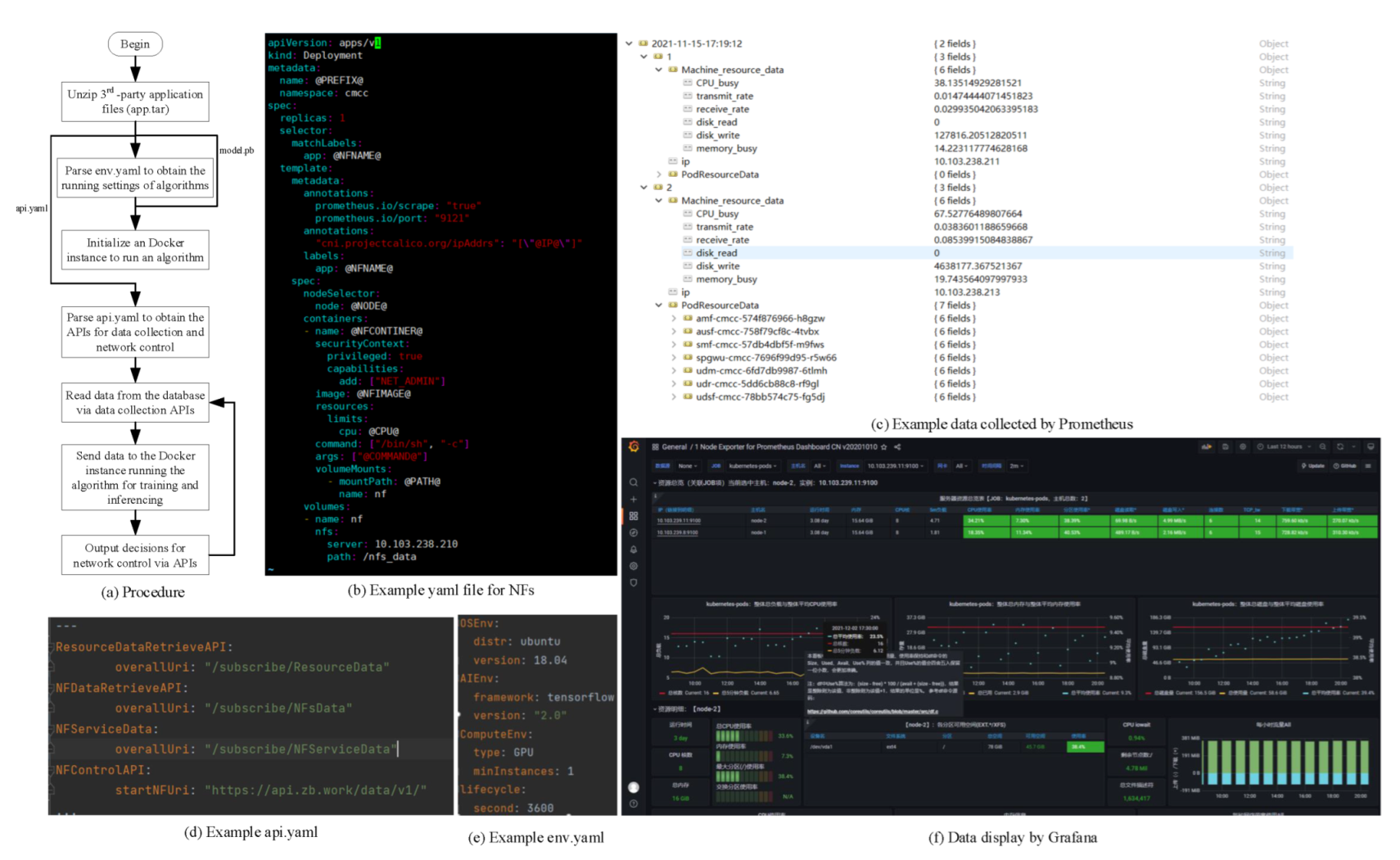
https://www.cnblogs.com/xin1006/p/14989365.html (accessed on 2 October 2022)) plugin is integrated to maintain the IP addresses of Pods. Each NF is packaged in one Docker instance via one specific Dockerfile shown in
Figure 4b to be deployed in a Pod on one work node.
@PREFIX@: The unique name of deployment of the Docker instance, e.g., amf.
@NFNAME@: The unique name of Pod when deploying different instances, e.g., amf.
@IP@: The unique IP address of Pod is set supported by the Calico plugin, e.g., 10.244.1.19.
@NODE@: The selected node to deploy a new Pod instance, e.g., node2.
@NFCONTAINER@: The name of newly created container, e.g., amf-1.
@NFIMAGE@: The selected image file to create a new Pod instance (the image file shall be available on the selected node), e.g., amf:cmcc.
@CPU@: The required CPU resource, e.g., 50 m. If the available CPU resource of the selected node is lower than the required one, the Pod instance cannot be created successfully.
@COMMAND@: The commands to run the scripts (nfState.py for opening the states of the Pod instance) and the executable file of NF (e.g., /amf/build/amf/build/amf –c /home/amf.conf -o).
@PATH@: The file sharing path between the container and the host, e.g., /home/.
The whole procedure is illustrated in
Figure 4a. Firstly, users upload their 3rd-party applications packaged in compressed files (e.g., app.tar). The AIE unzips these files to obtain four elements including “env.yaml”, “api.yaml”, “procedure.py”, and “model.pb”. An example “env.yaml” is shown in
Figure 4e, which indicates the requirements of the running environment; an example “api.yaml” is shown in
Figure 4d, which indicates the APIs for data collection and network control. With the “env.yaml” file, the AIE creates a new NVIDIA Docker instance to the application with “procedure.py” (logic of the algorithms) and “model.pb” (non-trained or trained neural network). The data manager within the AIE periodically collects state data from the underlying environment and provides many fine-grained APIs for data openness. The example data collected by Prometheus are shown in
Figure 4c, which can also be displayed graphically via Grafana.
4. Use Case: Delayed-DQN-Enabled AMF Scaling
On top of the PoC prototype, we implement a use case to evaluate our proposed random-delay-corrected DRL framework. In the 5G core network, AMF is of vital importance for connecting the radio access networks and core networks, which may result in performance bottlenecks. Our previous work [
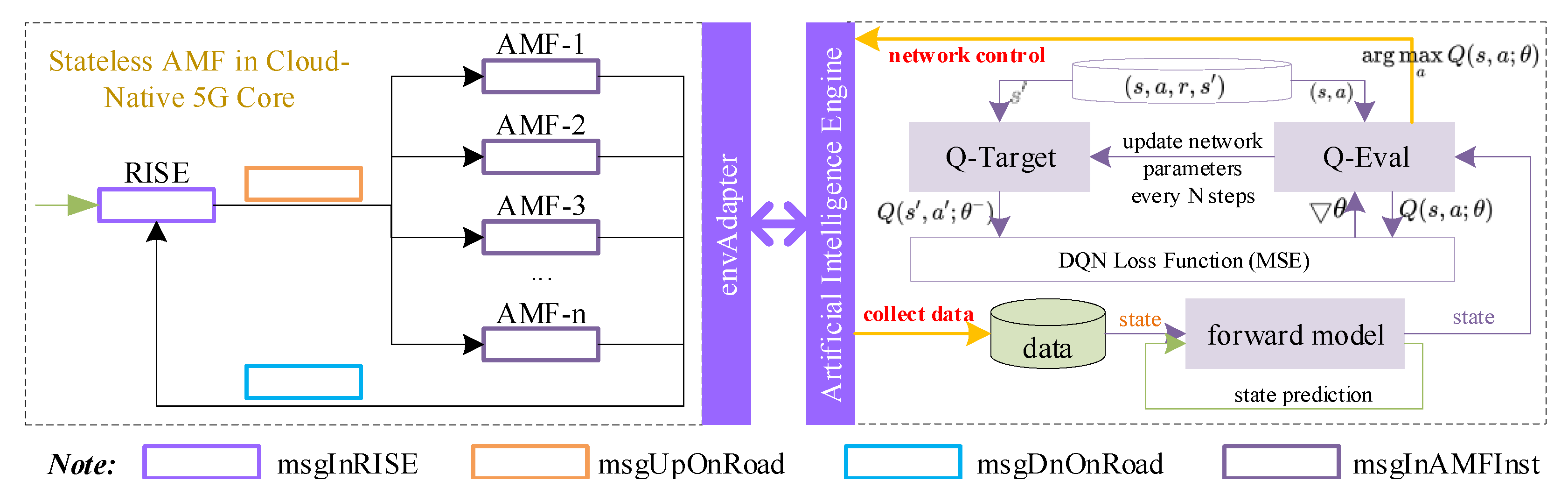
21] has designed and implemented a message-level stateless AMF that helps to realize signaling-no-loss and UE-unaware scaling; therefore, we choose to implement a delayed-DQN-enabled AMF scaling use case for the validation. The architecture is illustrated in
Figure 5.
Within the environment, multiple AMF instances collaborate together to process signaling messages. RISE performs as a middle box between the radio access networks and the 5G core networks, which inherit the SCTP server from AMF. RISE receives all signaling messages and mixes them without considering the procedures or UEs that individual message belongs to. Moreover, stateless AMF is implemented by decoupling the communication contexts from the functional procedures. In this context, RISE can distribute all signaling messages into multiple AMF instances to be processed, thus supporting UE-unaware message-level load balancing.
We abstract the working model as the left figure of
Figure 5. Each component (e.g., RISE, AMF) is with a message queue for caching unprocessed signaling messages. For example, the purple rectangle named “msgInRISE” is the message queue within RISE to cache the upcoming signaling request messages with the Poisson distribution. Additionally, “msgUpOnRoad” and “msgDnOnRoad” represent the uplink/downlink signaling messages that are still on the road to the peer entities for simplification. The service rate of “msgInRISE” and “msgInAMFInst” is related to the processing capabilities of RISE and AMF instances, while that of “msgUpOnRoad” and “msgDnOnRoad” is related to the uplink and downlink delays between RISE and AMF instances. Moreover, the signaling messages from RISE are distributed to the AMF instance that has a minimum number of unprocessed messages one by one to be balanced among multiple AMF instances. The target is to allocate an adaptive number of stateless AMF instances to process the upcoming request messages at a low cost.
4.1. Reinforcement Learning
For this purpose, the problem is modeled as a MDP, including state representation, action definition, and reward description that are illustrated as follows:
State Representation: The state is represented as . is defined as the vector of a number of messages in “msgInRISE” (), “msgUpOnRoad” (), and “msgDnOnRoad” () message queues, that is . donates the vector of uplink () and downlink () delays between RISE and AMF instances, that is . represents the vector of the number of CPU cores of AMF instances, that is and represents the vector of number of the unprocessed messages within AMF instances, that is , where is the maximum number of AMF instances supported in the system. For AMF instances that are not instantiated, the corresponding number of CPU cores and unprocessed messages is 0.
Action Definition: An action is a valid decision on the number of AMF instances, which may be “”, “0”, or “1”. “” means that envAdapter deletes one AMF instance if the number of AMF instances is more than 1. The unprocessed messages in the to-be-deleted AMF instance are equally distributed among other live AMF instances. The AMF instance can accept these messages unless the number of unprocessed messages itself does not exceed its 90% of maximum capacity () so some messages may be discarded. “0” means that the environment keeps running without any change in the number of AMF instances. “1” means that a new AMF instance will be instantiated if the number of AMF instances is less than .
Reward Description: A reward is a signal telling the agent how good the current action is doing. The reinforcement learning agent aims to maximize the estimation of discounted accumulative rewards to obtain better long-term performance. In this use case, the agent is envisioned to learn an optimal policy for deploying an adaptive number of AMF instances under UE signaling requests lasting for certain time steps with a Poisson distribution. The reward function is defined as (
20). Firstly, the current number of AMF instances
is calculated as (
17), where
denotes the number of AMF instance before executing an action. Then, the average capacity (
) of unprocessed signaling messages among all AMF instances is calculated as (
18), where
denotes the total number of unprocessed signaling messages in the system,
denotes the processing capability of AMF instances (messages per second), and
T denotes the running time before arriving at next time step. When
exceeds the
times maximum capacity
, we set
to calculate a negative reward value to punish such actions. Then, the basic reward value
is calculated as (
19), considering the QoS for processing signaling messages and the costs for deploying AMF instances at the same time. In order to limit the reward value in each step to
, the reward value is normalized as defined in (
20); therefore, we obtain the final reward value
.
4.2. Experiment Setup and Parameters
In this experiment, three types of signaling requests including
RegistrationRequest,
ServiceRequest, and
PDUSessionEstablishmentRequest were simulated by UERANSIM following the
-like flow pattern (that is
). There are flows varying from
in 10 time steps. Each type of signaling request is processed via a service function chain (e.g.,
RegistrationRequest is processed via a 〈AMF-AUSF-UDM-UDR〉 chain). Further, each type of signaling request has different resource (e.g., CPU) requirements in different network functions and has different
ttl. The detailed parameters for signaling requests are shown in
Table 1.
In addition, we deploy four instances for each network function except AMF and maximum
AMF instances in this use case to process these signaling requests. In the beginning, there is only one AMF instance available and the agent will decide to add/delete/maintain the number of AMF instances according to the received state time by time. For each instance, the maximum capacity and CPU are set to be
and
. Neural networks’ parameters are shown in
Table 2.
The experiment will run for episodes and 20,000 time steps for each one. In order to explore the possible states in the environment, we set the maximum epsilon and epsilon decay to be and , respectively. At each time step, the agent will randomly choose an action with a probability and then will be changed to be until it reaches .
4.3. Benchmark Scenarios
To evaluate the performance and feasibility of our proposed random-delay-corrected DRL framework (delayed-DQN in this use case), we design the following scenarios:
No-delay scenario. This is an idle scenario with the assumption that the collected state will arrive at the agent immediately without delays; therefore, delayed-DQN works the same as the standard DQN.
Turn-based scenario. There are constant or random delays between the agent and the environment, but the agent will only generate an action when it receives the collected state, whose interaction pattern is shown in
Figure 1a.
Constant-delay scenario with the standard DQN. In this scenario, the delays are transformed to be constant delays by carefully choosing the time interval
as presented in
Section 2.3. Then, the interaction pattern works as shown in
Figure 1b. The standard DQN (DQN algorithm with the standard MDP) is used to try to learn an optimal policy for better AMF scaling.
Random-delay scenario with the standard DQN. We design a scenario where the standard DQN tries to learn an optimal policy in a random-delay environment.
Constant-delay scenario with delayed-DQN. Different from the above scenario, this scenario adopts our proposed delayed-DQN to learn an optimal policy.
Random-delay scenario with delayed-DQN. This agent is equipped with the delayed-DQN algorithm to learn from delay-corrected trajectories sampling in a random-delay scenario.
4.4. Evaluation Results
The evaluation results are shown in
Figure 6. As we can see from
Figure 6a, the no-delay scenario shows the optimal training results compared to others while the turn-based scenario shows the worst performance, which proves that the turn-based pattern cannot adapt to the dynamics in the real-world networks. However, we can still figure out that the periodicity-based pattern shown in
Figure 1b,c cannot train an optimal agent when the standard DQN algorithms are used, especially for the random-delay scenario. Although the constant-delay scenario with the standard DQN trains a near-optimal agent, the reward has high fluctuation that can affect the final decisions. Moreover, the random-delay scenario with the standard DQN even has little improvement compared to the turn-based scenario. The results tell us we can not adopt the standard DQN algorithm to the periodicity-based scenarios directly, which cannot guarantee performance. After that, our proposed delayed-DQN based on the random-delay-corrected DRL framework is integrated with the periodicity-based pattern for the validation. The results show that the performance of the delayed-DQN algorithm is very close to the optimal value of the no-delay scenario for both constant-delay and random-delay scenarios.
Figure 6b–f evaluate the impact of the state collection time interval
on the performance of DQN algorithms. For the evaluation, we set three different
values, which are 20, 10, and 5 time steps, respectively. Generally, we can see that it performs better when for
than the other two scenarios no matter what interaction pattern is chosen. The results prove that frequent state collection with smaller time intervals
can better adapt to network dynamics.
In summary,
Figure 6 proves that (1) the periodicity-based pattern can be more beneficial to capture the network dynamics than the turn-based pattern; (2) the random-delay-corrected DRL framework can improve the performance when adopting the DQN algorithm in the periodicity-based scenarios; (3) smaller state collection time interval
can further improve the performance of the delayed-DQN algorithm.



 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}