
Metaheuristic Algorithms to Optimal Parameters Estimation of a Model of Two-Stage Anaerobic Digestion of Corn Steep Liquor

1
Department of Bioinformatics and Mathematical Modelling, Institute of Biophysics and Biomedical Engineering, Bulgarian Academy of Sciences, Acad. G. Bonchev Str., Bl. 105, 1113 Sofia, Bulgaria
2
Department of Mechatronic Bio/Technological Systems, Institute of Robotics, Bulgarian Academy of Sciences, Acad. G. Bonchev Str., Bl. 2, 1113 Sofia, Bulgaria
3
Department Biotechnology—Bioremediation and Biofuels, The Stephan Angeloff Institute of Microbiology, Bulgarian Academy of Sciences, Acad. G. Bonchev Str., Bl. 26, 1113 Sofia, Bulgaria
*
Author to whom correspondence should be addressed.
Appl. Sci. 2023, 13(1), 199; https://0-doi-org.brum.beds.ac.uk/10.3390/app13010199
Submission received: 25 November 2022
/
Revised: 15 December 2022
/
Accepted: 21 December 2022
/
Published: 23 December 2022
(This article belongs to the Special Issue Advances in Artificial Intelligence: Machine Learning, Data Mining and Data Sciences)
Abstract
:Anaerobic Digestion (AD) of wastewater for hydrogen production is a promising technology resulting in the generation of value-added products and the reduction of the organic load of wastewater. The Two-Stage Anaerobic Digestion (TSAD) has several advantages over the conventional single-stage process due to the ability to control the acidification phase in the first bioreactor, preventing the overloading and/or the inhibition of the methanogenic population in the second bioreactor. To carry out any process research and process optimization, adequate mathematical models are required. To the best of our knowledge, no mathematical models of TSAD have been published in the literature so far. Therefore, the authors’ motivation is to present a high-quality model of the TSAD corn steeping process for the sequential production of H2 and CH4 considered in this paper. Four metaheuristics, namely Genetic Algorithm (GA), Firefly Algorithm (FA), Cuckoo Search Algorithm (CS), and Coyote Optimization Algorithm (COA), have been adapted and implemented for the first time for parameter identification of a new nonlinear mathematical model of TSAD of corn steep liquor proposed here. The superiority of some of the algorithms has been confirmed by a comparison of the observed numerical results, graphical results, and statistical analysis. The simulation results show that the four metaheuristics have achieved similar results in modelling the process dynamics in the first bioreactor. In the case of modelling the second bioreactor, a better description of the process dynamics trend has been obtained by FA, although GA has acquired the lowest value of the objective function.
1. Introduction
For many years, hydrogen has been considered an alternative to fossil fuels. Scientists have been aiming to develop an environmentally friendly method to produce hydrogen from biomass by optimizing Anaerobic Digestion (AD) systems [1]. In the AD process, microorganisms decompose biomass in the absence of oxygen. Through AD, food and animal wastes are recycled to produce hydrogen gas which can be subsequently converted into biogas (methane) [2,3].
The utilization of wastewater for hydrogen production through AD is promising as it results in the generation of value-added products and reduces the organic load of the wastewater. For example, Ref.[4] investigates the evaluation of hydrogen production with microbial consortia. The significant variables are optimized using a central composite design, resulting in two mathematical models. The resulting environmental benefits can be found in the removal of 50% of the COD, which could be further improved with the recovery of the other metabolites produced, mainly acetic and butyric acids.
The Two-Stage Anaerobic Digestion (TSAD), in which the hydrogen and methane production takes place in two separate bioreactors, has several advantages over the conventional single-stage process [5,6]. The TSAD permits the selection and the enrichment of different bacteria in each anaerobic digester and increases the stability of the whole process by controlling the acidification phase in the first digester and hence preventing the overloading and/or the inhibition of the methanogenic population in the second digester [5,6].
The production of corn starch and starch-derived products results in large amounts of aqueous by-products [7,8,9]. Corn Steep Liquor (CSL) is a concentrated liquid by-product derived from water and used in the initial stage of the corn wet milling process. Globally, large amounts of CSL are produced daily and discharged into waterways. Despite its high nutritional value and relatively low cost, currently, CSL is not widely used internationally as a feedstock in the fermentation industry. This is primarily because most corn producers sell off their products to dry milling operations, where the corn is processed for various corn-derived products such as corn flour.
CSL has been used recently as a substrate for AD [2]. An experimental study of two-stage anaerobic biodegradation of corn extract has been performed with mesophilic temperatures in both bioreactors. An automatic mode has been implemented using the developed computer system for monitoring and control. The so obtained experimental data are used here to develop a mathematical model.
For many industrially relevant processes, detailed models are not available due to an insufficient understanding of the underlying phenomena. Mathematical models, which naturally could be incomplete and inaccurate to a certain degree, can still be very useful and effective in describing the effects essential for control, optimization, or understanding of the process.
To the best of our knowledge, no mathematical models of TSAD of corn steep liquor have been published in the literature yet.
In this work, a mathematical model of TSAD of corn steep liquor is proposed. Metaheuristic algorithms are considered for model parameter estimation. The main advantage of metaheuristic techniques, which have been proven to be a good alternative to conventional optimization methods, is that they provide a satisfactory solution for a reasonable computational time [10]. Metaheuristics do not depend on the initial conditions of the model. This advantage allows efficient scanning of a large search space to reach a global extremum.
Two categories of metaheuristics are known: single-based and population-based solution methods [11]. In addition, some authors [12,13] proposed eight different groups—biology-based, physic-based, swarm-based, social-based, music-based, chemistry-based, sport-based, and math-based metaheuristic methods.
Evolutionary algorithms such as Genetic Algorithms (GA) [14,15] and Evolution Strategies [16]; Ant Colony Optimization (ACO) [17], Simulated Annealing (SA) [18], Firefly Algorithm (FA) [19], Artificial Bee Colony (ABC) optimization [20], Cuckoo Search Algorithm (CS) [21], etc., are, among many others, some of the examples of classical metaheuristics. Some of the population-based algorithms such as GA, FA and CS could be considered both as biology-based and swarm-based.
Some of the most powerful nature-inspired metaheuristics have been developed and tested for solving different optimization problems. A comprehensive review of metaheuristic algorithms is presented in [22]. Since optimization is a process of making things as efficient as possible, researchers continuously seek new and modified metaheuristic methods that outperform the existing ones. The application of metaheuristic techniques for solving numerical optimization problems is receiving increasing attention.
A new performance assessment method is discussed in [23]. It considers the influence of the control parameters on the metaheuristic algorithms. The method is demonstrated for GA. As a result, a better solution than the best reported so far in the literature is detected. Recently, new performance metrics of metaheuristic optimization methods have been proposed in [24]. The presented results show that the discussed metrics have a good distinctive performance for different algorithms. The best-found algorithm is Differential Evolution (DE). In [25], an NP-hard problem is solved based on multi-objective Tabu Search (TS), multi-objective variable neighborhood search, and multi-objective particle mass optimization. The presented results show that the performance of multi-objective TS is better than that of other proposed metaheuristic algorithms.
Real-life problems generally exhibit nonlinear constraints and dynamic components. GAs are well-known metaheuristics extremely applicable to problems with such characteristics. They have been well employed in many fields with still growing recognition [26]. GAs are often used instead of traditional optimization methods. Authors of [27] proposed a hybrid where the crossover and mutation operators of GA are integrated with the Teaching–Learning-Based Optimization and Particle Swarm Optimization (PSO) algorithms. The elitist strategy is utilized to boost evolutionary efficiency. A hybrid GA-PSO is proposed in [28] and compared with CS, PSO, GA, and Simulated Annealing. The results of this research indicate that PSO and GA-PSO produce optimal values for all considered objective functions.
So far, their effectiveness and robustness have been demonstrated in the mathematical modelling of fermentation processes. In [29], GA and the Artificial Bee Colony algorithm are applied to cultivation process modelling. A new approach for simultaneous parameter tuning of the metaheuristics is proposed. An optimization of wheat germ fermentation conditions using an artificial neural network combined with GA is discussed in [30]. Based on the optimized scheme, a 117% improvement is achieved compared to that of the control group. Authors in [31] propose GA for optimizing the productivity of the yeast fermentation process. The proposed GA obtains a higher yield production than the conventional open-loop system. A comparison of 8 modifications of GA (simple genetic algorithms and multi-population ones) is presented in [32] for parameter identification of fed-batch cultivation of S. cerevisiae. GA with the sequence of mutation, crossover, and selection operators is significantly faster than the other modifications.
Algorithms such as GA can be very useful, but they still have some drawbacks when dealing with multimodal optimization problems [33]. Some results show that FA outperforms GA and is a powerful algorithm to solve even NP-hard problems [19,34,35]. In [36], an improved FA is utilized to solve the multi-depot vehicle routing problem with time windows. The work proves FA feasibility and shows that modified FA outperforms other competing algorithms (GA, ACO, TS, etc.) in terms of results and competence. Parameter estimation of a proposed hyperbolastic type-I diffusion process applying FA is presented in [37]. The low computational cost of FA makes it especially useful for addressing maximum likelihood estimation in diffusion processes. An interesting performance analysis of distance metrics on the exploitation properties and convergence behaviour of FA is presented in [38]. The optimal algorithm tuning based on unique distance metrics shows a new research area for solving large-scale optimization problems. In [39], the enhanced FA is hybridized with the CLT-based K-means algorithm to achieve optimal global convergence. The results show that the hybrid FA-K-means clustering method demonstrates statistically significant superiority compared to other advanced hybrid search variants—GA, DE, PSO, and Invasive Weed Optimization.
The CS algorithm attracts attention due to its simplicity and efficiency over GA because of using the Lévy flights instead of isotropic random walks [40]. Recently proposed CS algorithm [41] for an energy-efficient robotic mixed-model assembly line balancing problem outperforms GA in terms of obtained objective values. In [42], the CS algorithm employs theoretical anomaly generated by a single structure and different field data sets to estimate the model parameters. As a result, a rapid convergence of the objective function and the model parameters is observed. In [43], a technique combining a CS algorithm and a support vector machine is applied in the prognostic staging of oesophageal cancer based on the prognosis index. The proposed algorithm has the highest prediction accuracy compared to six swarm intelligence algorithms, including the ABC algorithm, FA, Gravitational search algorithm, etc., combined with support vector machine learning techniques.
A newly introduced metaheuristic algorithm, Coyote Optimization Algorithm (COA) [44], adopts an interesting technique to achieve a balance between exploration and exploitation [45], as well as the robustness and stability of the algorithm [46]. Binary COA with a hyperbolic transfer function in a wrapper model is applied to a feature selection problem [47]. The algorithm presents low standard deviations when compared to other metaheuristic algorithms and a great convergence curve. An accurate and stable ultrashort-term wind speed prediction method is achieved using chaotic COA [48]. The authors of [49] propose a novel fault diagnosis method in chemical processes based on the Bernoulli shift coyote optimization algorithm. The results demonstrate that the proposed method outperforms other methods in terms of classification accuracy. In [45], COA is proposed for optimal parameter estimation of a proton exchange membrane fuel cell model. The presented results show the superiority of COA over the other compared methods.
The known results indicate that metaheuristic techniques, such as GA, FA, CS, and COA, are particularly relevant nowadays, frequently preferred and efficiently used for many optimization problems, especially for model parameters optimization [29,31,37,42,45,50]. Moreover, they have not been employed in parameter estimation of TSAD of corn steep liquor model until now which is the motivation to adapt and apply them to the considered optimization problem.
The presented study focuses on the mathematical modelling of anaerobic biohydrogen production from corn steep liquor and the following anaerobic processing of the methane production under mesophilic conditions in a two-stage process. Model parameters identification is performed based on GA, FA, CS, and COA metaheuristic algorithms.
The specific contributions and innovations of this study are as follows:
- For the first time, a structure of nonlinear differential equations of two-stage anaerobic digestion of corn steep liquor is evaluated based on real experimental data.
- A new mathematical model of two-stage anaerobic digestion is developed. To our knowledge, no such models have been published so far.
- Four metaheuristic algorithms (GA, FA, CS, and COA) are adopted and successfully applied to identify the parameters of the model proposed here.
- The developed mathematical model could be used further for process investigation and optimization based on process monitoring and control.
The rest of the paper is organized in the following order. Section 2 presents the proposed mathematical model of a TSAD process and short descriptions of the applied metaheuristic algorithms, namely GA, FA, CS, and COA. Section 3 presents the numerical results obtained by the model parameters identification. The results of the comparison of the considered metaheuristics are discussed. Conclusions and further investigations are provided in Section 4.
2. Materials and Methods
2.1. Mathematical Model of the Two-Stage Anaerobic Digestion Process
The two-stage anaerobic digestion process of corn steep liquor for sequential production of H2 and CH4 is carried out in two separate bioreactors [2]. During the first stage, relatively fast-growing acidogenic microorganisms engaged in the production of volatile fatty acids and H2 are cultivated in the hydrogenic bioreactor BR1. Slow-growing acetogenic and methanogenic bacteria are developed during the second stage in the methanogenic bioreactor BR2. The volatile fatty acids are later transformed into CH4 and CO2 in BR2.
The process dynamics in the cascade BR1 and BR2 are presented, using mass balance, by a set of five Ordinary Differential Equations (ODEs) and two algebraic equations, as follows:
BR1:
BR2:
The system (1)–(5) describes the dynamics of the substrate concentration (), [g/L]; the microbial biomass concentration (), [g/L]; the product (acetate) formation () [g/L] in BR1. The algebraic equation describes the flow rate of the hydrogen () [dm3/L·h] in the gas phase of BR1. [g/L] is the concentration of the input substrate. For the specific growth rate [day−1] of hydrogen-producing microorganisms, a Monod-type function was adopted. [day−1] is the dilution rate for the first bioreactor BR1; [day−1] and [g/L] are Monod kinetic coefficients; and , and are yield coefficients, [g/g].
The system (6)–(8) describes a one-step transformation of the inlet acetate (coming from BR1) into methane by methanogenic microorganisms. A Monod type function was also adopted for the specific growth rate of the methanogenic biomass. In the model, is the microbial biomass concentration in BR2 [g/L], is the acetate concentration in BR2 [g/L], is the methane flow rate [dm3/L·day], [day−1] is the dilution rate for the second bioreactor BR2, is the specific growth rate (Monod type) of methanogens [day−1], and are yield coefficients, and [day−1] and [g/L] are kinetic coefficients.
The so presented model structure is used for the first time for modelling the corn steep liquor TSAD process considered here based on real experimental data.
2.2. Metaheuristic Optimization Algorithms
The model parameters identification problem of the TSAD process of corn steep liquor is solved using different metaheuristic algorithms. Four population-based metaheuristics, namely GA, FA, CS, and COA, are adopted and applied to the problem considered here. The chosen algorithms have proved their effectiveness and feasibility in their successful application to a wide range of problems [26,33,45,51,52]. A very brief description of each algorithm is presented below.
2.2.1. Genetic Algorithm
GA originated from the studies on cellular automata of John Holland [14]. Developed as an abstraction of the evolutionary process, GA typically operates on vectors whose elements belong to the binary alphabet {0, 1}. They use a recombination operator with background mutation. A population of a certain number of individuals is retained, where each individual is a promising solution to the problem under consideration. Each individual is measured and its “fitness” is estimated in proportion to the corresponding value of the objective function. The more suitable individuals are listed in a new population. In order to form a new solution [15], some of these individuals are altered using “genetic” operators. As a unary operation, mutation produces a small change in one individual, while higher order operations as crossover combine data from several individuals to create a new one. The algorithm converges in a certain number of iterations. The best individual from the last generation is regarded as a near-optimum (reasonable) solution to the problem.
The pseudocode which describes the functioning of GA is shown in Algorithm 1.
| Algorithm 1 Pseudocode of GA |
|
2.2.2. Firefly Algorithm
FA was introduced by Xin-She Yang [19] as a new metaheuristic algorithm mimicking the nature of fireflies. Different types of fireflies exhibit unique flashing patterns with two primary functions to interact with others: drawing the attention of potential mating partners and attracting potential victims. The flashing is no less significant as a defence mechanism. Idealizing some of the characteristics of the fireflies’ flashing lights allows them to be related to the objective functions of new metaheuristic algorithms which need to be optimized.
According to [53], the main steps of FA can be outlined in Algorithm 2.
| Algorithm 2 Pseudocode of FA |
|
2.2.3. Cuckoo Search Algorithm
Known for their aggressive reproduction strategy [21], cuckoos not only lay their eggs in other birds’ nests, but they may also remove others’ eggs with the purpose to secure their generation. This specific cuckoo’s brood parasitism reduces the possibility of their eggs being abandoned and thus increases the cuckoo’s reproductivity. The interesting breeding behaviour is implemented in the CS metaheuristic algorithm for resolving optimization problems [21]. The CS algorithm assumes the eggs in the host’s nest to be a set of potential solutions to an optimization problem, while the cuckoo egg itself is interpreted as a new one. At each iteration of the algorithm, these new and likely better solutions are used to achieve a very good final solution to the problem.
The pseudocode of the CS algorithm based on [21] is presented in Algorithm 3.
| Algorithm 3 Pseudocode of CS algorithm |
|
2.2.4. Coyote Optimization Algorithm
COA is a new population-based metaheuristic algorithm for optimization inspired by the Canis latrans species that dwells mainly in North America. The algorithm designed by Pierezan and Dos Santos Coelho [44] considers the social organization of the coyotes and their adaptation to the environment. The population of coyotes is divided into several packs Np with a predefined number Nc of coyotes each. The total population is formed by Np × Nc. Each coyote is a possible solution to the optimization problem and its social condition is the cost of the objective function. COA provides new mechanisms for balancing exploration and exploitation in the optimization process [44].
The pseudocode of the COA according to [44] is presented in Algorithm 4.
| Algorithm 4 Pseudocode of COA algorithm |
|
3. Results and Discussion
3.1. Simulation Setup
The proposed mathematical model consists of a set of five ODEs and two algebraic equations (Equations (1)–(9)) thus represented by seven dependent state variables x = [ ] and nine unknown parameters divided into two groups: p1 = [ ] and p2 = [ ].
Each individual of the population (chromosome in GA, firefly in FA, nest in CS, and coyote in COA) represents a potential solution to the problem—the corresponding unknown model parameter vector p1 or p2. Based on [54,55] and the authors’ expertise, each parameter of the model (1)–(9) has been coded in the specific range (lower bound (Lb) ≤ parameter ≤ upper bound (Ub)) as follows:
Each initial solution for all four metaheuristic algorithms has been generated based on
xj = rand ∗ (Ub − Lb) + Lb.
Further improvement of the solution has been made based on the specific algorithm inspired by the considered behaviour in nature in the case of GA, FA, CS, and COA. New solutions are generated taking into account the bounds (constraints) of the model parameters. In addition, each newly improved solution is tested to see if it is within the defined bounds.
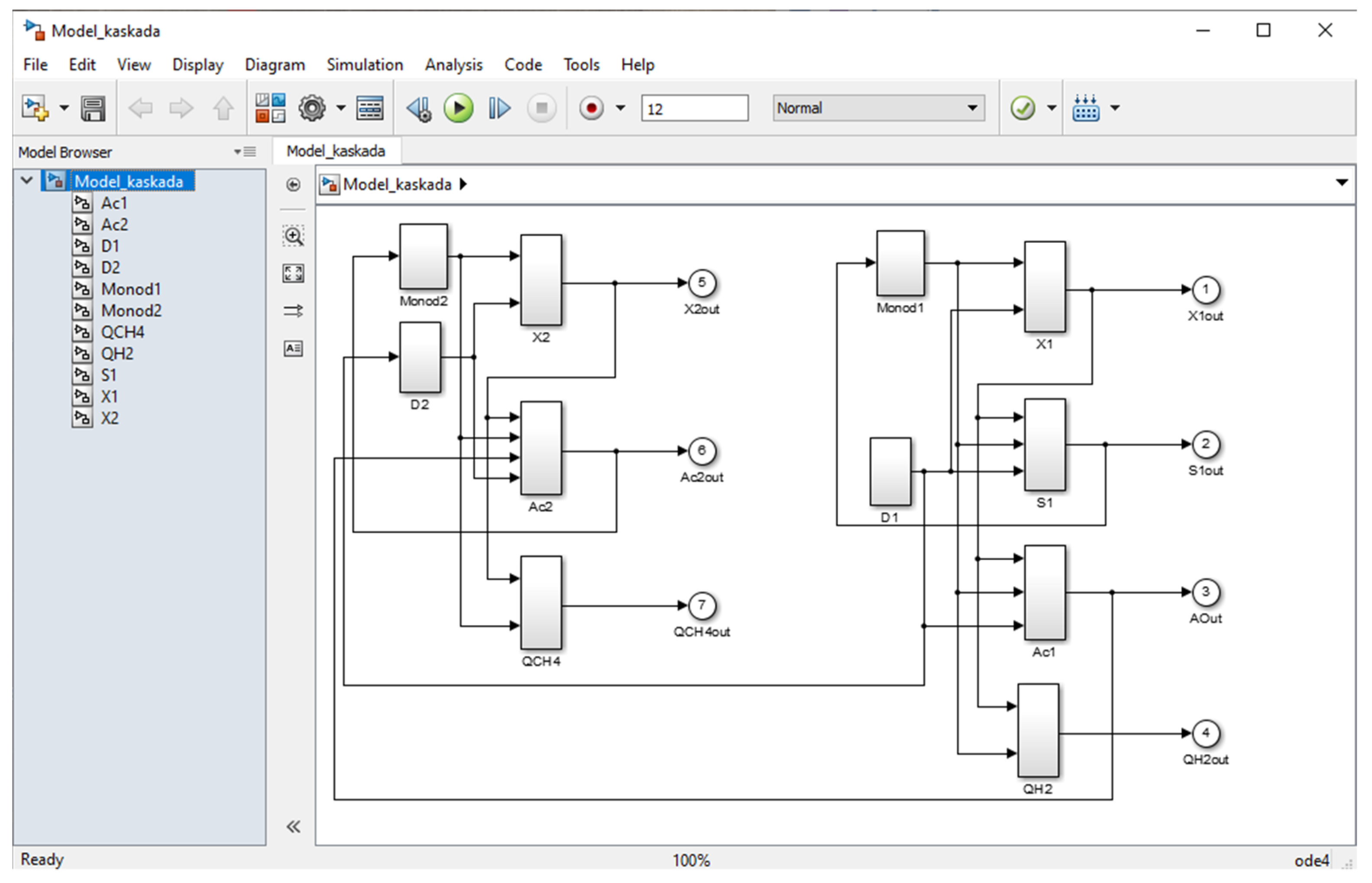
The metaheuristic algorithms have been executed on Intel® Core™i7-8700 CPU @ 3.20 GHz, 3192 MHz (ASBIS Bulgaria Ltd., Sofia, Bulgaria), 32 GB Memory (RAM), Windows 10 pro (64 bit) operating system. Matlab and Simulink R2019a environment are used. Based on the presented pseudocodes (Algorithms 1–4), the algorithms are implemented in Matlab code. Mathematical model of corn steep liquor TSAD process (Equations (1)–(9)) is presented as a Simulink file (see Figure 1). Solver options are fixed-step size of 0.01 and ode4 (Kunge-Kutta) with TIMESPAN = [0 12].
To achieve the best metaheuristic algorithm performance, necessary adjustments of the GA, FA, CS and COA parameters depending on the problem domain have been provided [23]. Starting from an already explored range of parameters variation in the case of GA [29,56,57], FA [19,34,35,36,38], CS [21,42,43,50], and COA [44,45,46] and taking into account the characteristics of the particular identification problem here, several pre-tests (based on trial-and-error method) have been performed to tune the parameters of GA, FA, CA, and COA. The four algorithms have been run for 100 iterations, which preliminary tests showed was sufficient for the algorithms to converge. The main GA functions are as follows: fitness function—linear ranking, selection function—roulette wheel selection, crossover function—double point crossover, and mutation function—bit inversion. A binary chromosome representation with a precision of binary representation 20 is used.
The set of optimal values used for the main parameters of the algorithms after a series of adjustments is listed in Table 1.
To ensure a fair comparison of the considered stochastic metaheuristics, each algorithm is run 30 times for 100 iterations; the initial solution is generated based on Equation (11) and the model parameter constraints (Lb and Ub) are as presented in (10).
A two-stage identification scheme is used. In the first step, the model parameters of the system (1)–(5), namely p1 = [ ] (search space dimension D = 5), have been estimated based on the objective function J1:
where n is the length of the data vector for the state variable ; is known experimental data; is a model prediction with a given set of the parameters.
On the second step, the model parameters p2 = [ ] (D = 4) have been estimated based on the objective function J2:
where m is the length of the data vector for the state variable ; is known experimental data; is a model prediction with a given set of the parameters.
3.2. Simulation Results
A series of parameter identification procedures of the proposed model (Equations (1)–(9)) using tuned GA, FA, CS, and COA has been performed. Due to the stochastic nature of the algorithms, a meaningful statistical analysis requires each metaheuristic to be run at least 30 times.
The best model parameter estimations obtained for models (1)–(9) with the corresponding values of the objective functions are summarized in Table 2.
The observed results are very interesting. Four distinct models are obtained based on the applied metaheuristic algorithms. The parameter estimations presented in Table 2 are generally satisfying and relevant to their physical meaning. The estimates of the maximum specific growth rate of the microbial biomass concentration in BR1 as well as the saturation constant are almost identical for the four algorithms. Yield coefficient is also estimated to the same order of magnitude by all algorithms. For BR2, the results are different. Both GA and FA provide similar results, while the estimates of CS and COA, especially for the parameter , differ by order of magnitude. In the case of dynamics in BR1, GA and FA result in similar models, while in the case of process dynamics in BR2, similar models are obtained by CS and COA, except the estimates of parameter .
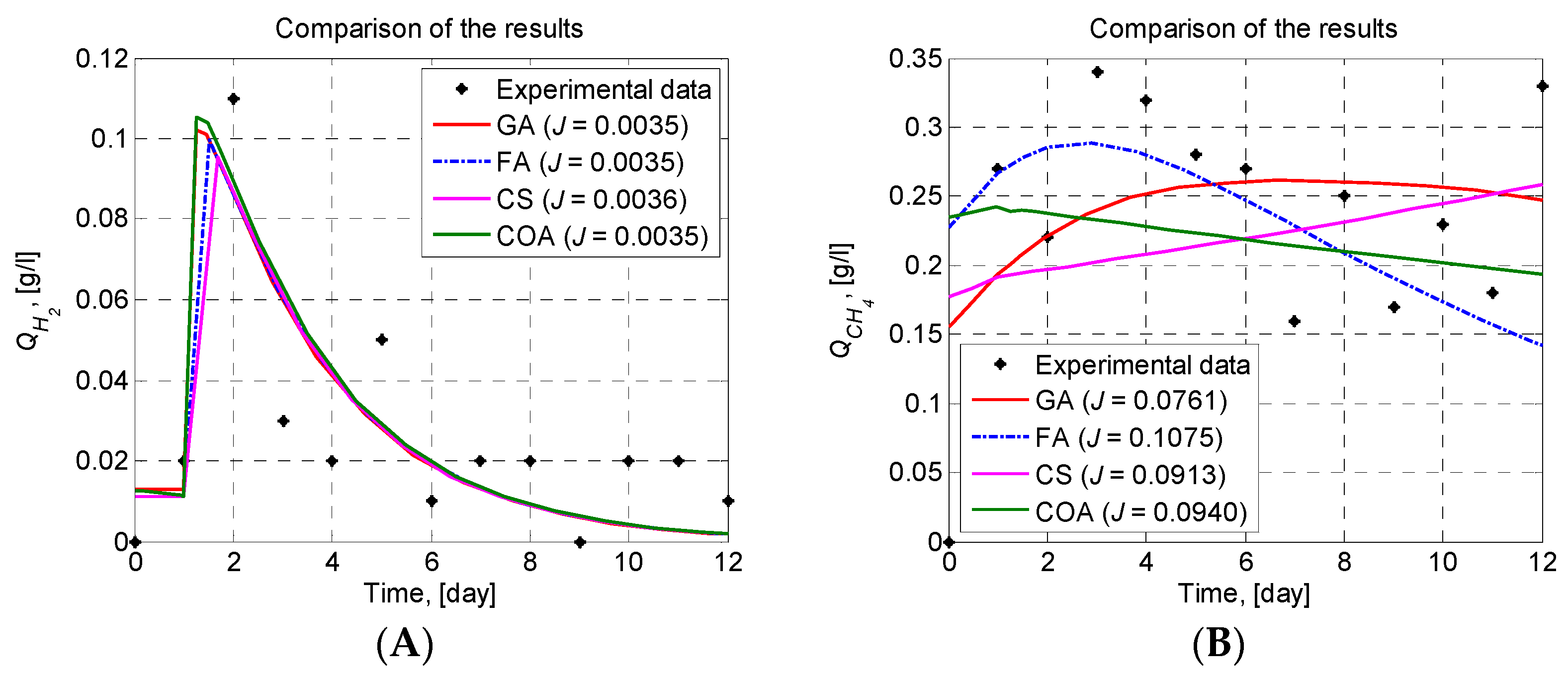
Since there are no reported parameter values for the proposed model or similar, it is not possible to determine which parameters, i.e., which model is the best. In such cases, a graphical comparison can clearly show if the model follows the experimental data, i.e., the presence or absence of systematic deviations between the model predictions and the experimental measurements. Such a quantitative measure is also an important criterion for the adequacy of the models proposed here. The model predictions of the state variables and , based on GA, FA, CS, and COA estimated set of model parameters, have been compared to the experimental data of the TSAD of corn steep liquor in Figure 2. J is the value of the mean least square error for each model (Equations (12) and (13)).
As can be seen in Figure 2, the models’ dynamics of the state variable in the BR1 are very similar. Therefore, the best model has to be determined based on the results for BR2. In BR2, the dynamics of the state variable predicted by GA, FA, CS, and COA are different. Although the resulting GA model has the lowest J value (J2 = 0.0761), the graphical comparison shows that the resulting FA model is better. The FA model describes the experimental data in the best way, following the trend of the dynamics. The CS and COA models have similar J values, but the resulting models’ dynamics do not follow the data trend very well. It should be mentioned that the experimental data are raw, unprocessed data. No filtering is applied in order to test the performance of the metaheuristics for a real nonlinear complex problem.
The performance of the considered metaheuristic algorithms has been statistically evaluated by comparing the observed average value, standard deviation (SD), and the median of the estimated model parameters and the obtained objective function value J2. A statistical analysis of the suggested algorithms in terms of average, SD, and median on the results for the second identification step is presented in Table 3. Only the second set of estimated model parameters, observed in the case of modelling the processes in BR2, is presented and discussed because of their crucial role and significance.
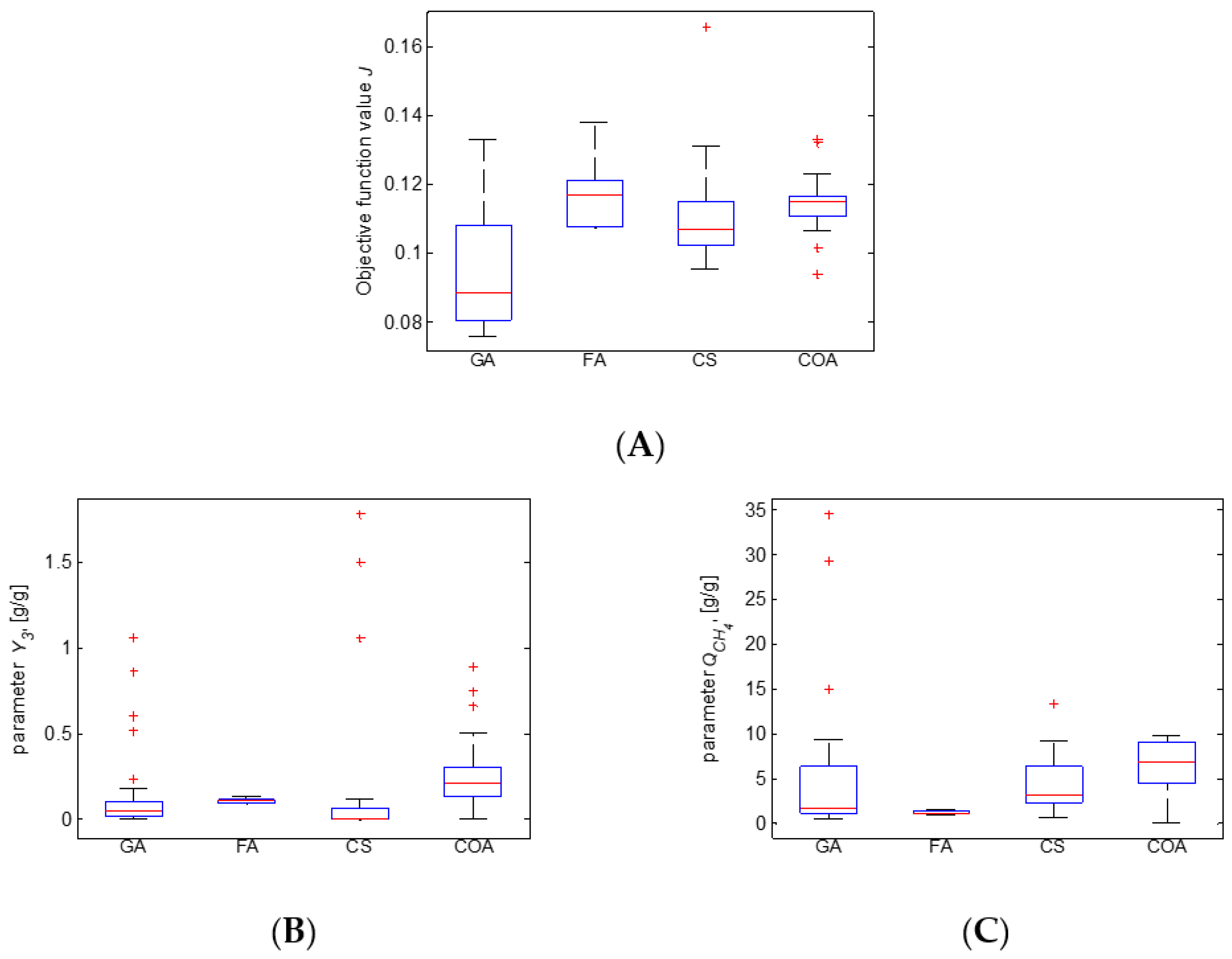
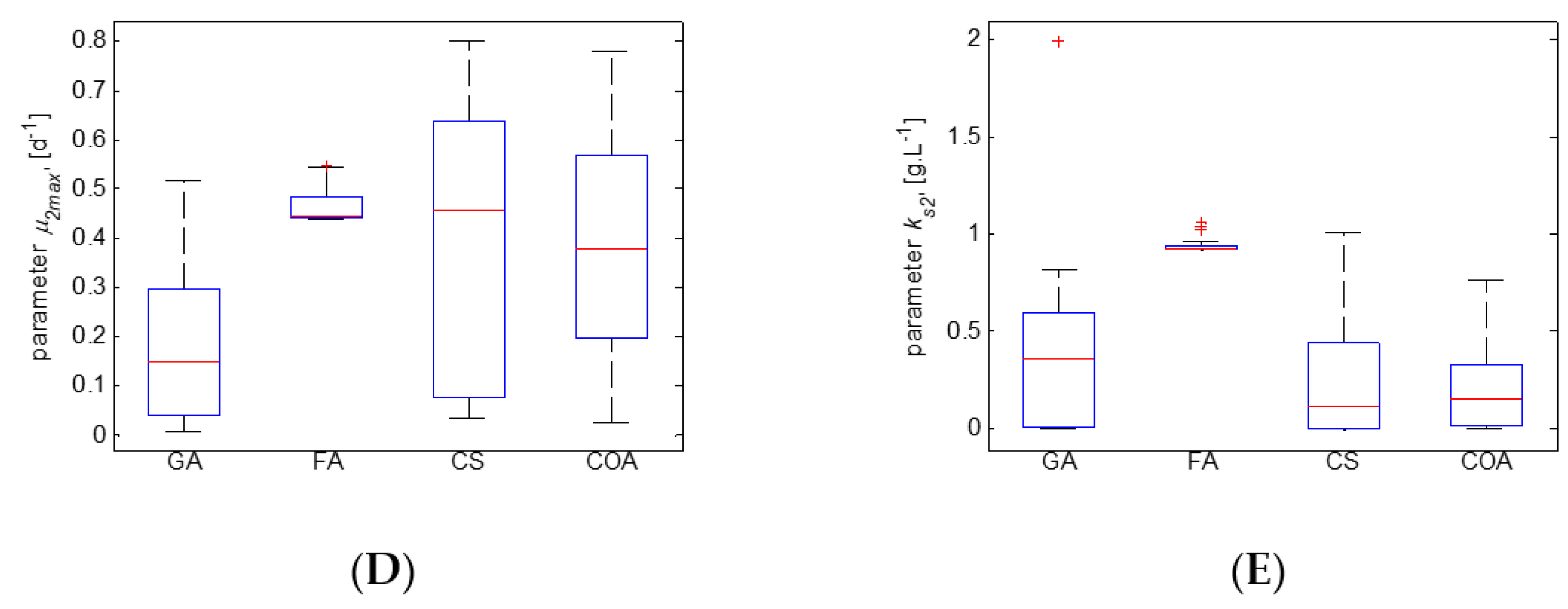
Box plot diagrams are commonly used to present summary statistics as a standard technique for analyzing the distribution of the model estimates [58,59]. Box plots of the obtained results are shown in Figure 3.
As shown in Figure 3A, the median of the objective function values obtained from 30 runs of GA is better than that of the rest of the results, including the minimum achieved by the other algorithms. On the other hand, the SD in the case of GA is larger. The best SD is observed for the results of COA, followed by those of FA. The median of 30 runs of CS is better than the median of COA and FA. These observations are a reason to conclude that the advantages and disadvantages of the considered algorithms should be analyzed in depth. Subsequently, a hybrid metaheuristic can be designed to combine the advantages.
It is shown that the distribution of FA estimates of the model parameters is smaller than that of the rest of the algorithms. The FA SD is times smaller than the SD of GA, CS, and COA. The model parameters and are more difficult to evaluate than the model parameters and . This is an interesting result, taking into account that the parameters and are usually the most sensitive ones [60]. It is worth investigating the sensitivity of the parameters of the new mathematical model proposed here. Moreover, outliers have been observed among parameter estimates, especially for the model parameter . Such outliers may appear in a sample of a normally distributed population, but this kind of result would be of interest to future research.
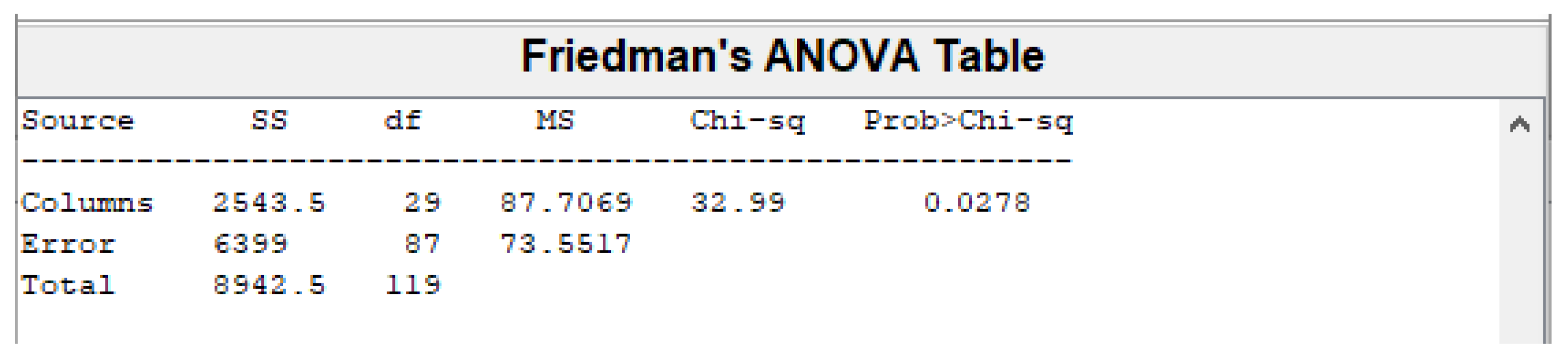
Friedman’s non-parametric test [61] was used to determine whether or not there was a statistically significant difference between the GA, FA, CS, and COA-derived objective function values for the 30 runs. The test is performed in Matlab R2013a using the function friedman. The obtained results are shown in Figure 4.
Since the p-value is less than 0.05, the null hypothesis that the mean of the objective function is the same for all four algorithms can be rejected. This is sufficient evidence to conclude that the results obtained by GA, FA, CS, and COA are statistically significant.
For practical applications, it is important to use a method that is theoretically guaranteed to converge, robust method, a method that has such a guarantee starting from any initial solution [62]. The estimates presented from 30 runs of each metaheuristic and the statistical results discussed confirm the robustness of the GA, FA, CS, and COA considered here. The observed SD, especially for FA and COA, was 0.0094 and 0.0074, respectively. It is shown that the studied algorithms, starting from 30 different initial solutions, converge to very close (statistically equal) values of the objective function.
In summary, based on the results obtained and the analysis carried out, the model estimated by applying FA is assumed to be a better mathematical model of the TSAD process considered here. The obtained model parameters’ estimates p1 = [ = 0.017 day−1 = 1.1 g/L = 0.22 = 10.28 = 8.12] and p2 = [ = 0.44 day−1 = 0.92 g/L = 0.1 = 0.99] are physically correct and adequate based on the published mathematical models of AD processes close to the one proposed here [54,55].
The proposed mathematical model of the TSAD process obtained by FA has satisfactory accuracy. It could be further used for process investigation as well as for process control and optimization.
4. Conclusions and Future Works
In this paper, a new mathematical model of two-stage anaerobic digestion of corn steep liquor has been proposed. The model has been presented as a set of five ordinary differential equations and two algebraic equations, representing seven dependent state variables (substrate concentration () in BR1; microbial biomass concentration in BR1 () and BR2 (); acetate formation in BR1 () and BR2 (); flow rate of the hydrogen () in the gas phase of BR1 and methane flow rate in BR2). The mathematical model consists of nine unknown model parameters divided into two groups, p1 = [ ] and p2 = [ ]. Different metaheuristic algorithms, some of the popular algorithms of the swarm intelligence domain, have been applied to estimate the unknown parameters based on experimental data.
The feasibility of the Genetic algorithm, Firefly algorithm, Cuckoo search algorithm, and Coyote Optimization Algorithm applied to a parameter identification problem has been highlighted. The chosen metaheuristic algorithms have been adapted and implemented here for the first time for parameter estimation of a newly proposed nonlinear mathematical model of TSAD of corn steep liquor. To confirm the superiority of some of the algorithms, a comparison between the techniques has been made—using the observed numerical results, graphical results, and statistical analysis.
The simulation results of the parameters’ identification of the proposed mathematical models show that GA, FA, CS, and COA techniques can predict the experimental results. The four metaheuristics have achieved similar results in modelling the process dynamics in BR1. In the case of modelling the process dynamics in BR2, the lowest value of the objective function has been achieved by GA (J = 0.0761). A better description of the process dynamics trend, however, has been obtained by FA (J = 0.1075). The observed objective function values of CS and COA are J = 0.0913 and J = 0.0940, respectively. It has been demonstrated that the considered metaheuristics are efficient and are also powerful algorithms for parameter identification of complex nonlinear models. As a result, a mathematical model of TSAD of corn steep liquor with a high degree of accuracy is proposed. The model can be used for a simulation of the process behaviour to gather enough information for planning subsequent laboratory experiments. The mathematical model can also be used to optimize the process based on a designed control system. A good model in control loop synthesis is required to obtain optimal control.
In addition, the numerical results have been compared based on box plots—a standard technique for analysis of the distribution of the obtained model estimates. The statistical results show that the parameter estimates are more easily obtained compared to the parameter estimates and . Such results are interesting, and it is worth conducting further research on the sensitivity of the model parameters to optimize the identification process.
Although some good results have been achieved with the application of the considered metaheuristics, there are still some limitations that need to be improved in future. First, the presence of several sets of raw experimental data is important for model validation. This is crucial, especially in the case of modelling non-linear, time-varying processes with interdependent variables, such as the one considered in this paper. Additional laboratory experiments are planned to be carried out. Second, it is well known that to achieve better performance, the input parameters of metaheuristic algorithms should be adjusted according to the problem domain. A joint set-up procedure [29] will be applied to the algorithms’ parameters to significantly improve their performance. Finally, the results of the statistical analysis will be used for improving the efficiency of the algorithms. More numerical experiments will be conducted to identify the strengths and weaknesses of the studied metaheuristic algorithms. More powerful hybrid algorithms will be developed with a rapid convergence speed and robustness, as presented in [63,64].
Author Contributions
Conceptualization, O.R. and E.C.; methodology, O.R. and E.C.; software, O.R.; validation, O.R. and E.C.; formal analysis, O.R. and E.C.; investigation, O.R. and E.C.; data curation, O.R. and E.C.; writing—original draft preparation, O.R. and E.C.; writing—O.R. and E.C.; visualization, O.R. and E.C.; supervision, O.R.; project administration, E.C.; funding acquisition, E.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
This research has been supported by the Bulgarian National Science Fund, Grant No KП-06-H46/4 “Experimental studies, modelling and optimal technologies for biodegradation of agricultural waste with hydrogen and methane production”.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Kyazze, G.; Dinsdale, R.; Guwy, A.J.; Hawkes, F.R.; Premier, G.C.; Hawkes, D.L. Performance Characteristics of a Two-Stage Dark Fermentative System Producing Hydrogen and Methane Continuously. Biotechnol. Bioeng. 2007, 97, 759–770. [Google Scholar] [CrossRef] [PubMed]
- Chorukova, E.; Hubenov, V.; Gocheva, Y.; Simeonov, I. Two-Phase Anaerobic Digestion of Corn Steep Liquor in Pilot Scale Biogas Plant with Automatic Control System with Simultaneous Hydrogen and Methane Production. Appl. Sci. 2022, 12, 6274. [Google Scholar] [CrossRef]
- Ma, Y.; Chen, X.; Khan, M.Z.; Xiao, J.; Alugongo, G.M.; Liu, S.; Wang, J.; Cao, Z. Effect of the Combining Corn Steep Liquor and Urea Pre-treatment on Biodegradation and Hydrolysis of Rice Straw. Front. Microbiol. 2022, 13, 916195. [Google Scholar] [CrossRef] [PubMed]
- Martinez-Burgos, W.J.; Sydney, E.B.; de Paula, D.R.; Medeiros, A.B.P.; de Carvalho, J.C.; Molina, D.; Soccol, C.R. Hydrogen Production by Dark Fermentation Using a New Low-Cost Culture Medium Composed of Corn Steep Liquor and Cassava Processing Water: Process Optimization and Scale-Up. Bioresour. Technol. 2021, 320 Pt B, 124370. [Google Scholar] [CrossRef] [PubMed]
- Simeonov, I.; Chorukova, E. Mathematical Modeling of the Anaerobic Digestion with Production of Hydrogen and Methane. In Proceedings of the 4th International Conference on Water, Energy and Environment (ICWEE), Burgas, Bulgaria, 1–2 June 2016; pp. 32–38. [Google Scholar]
- Koutrouli, E.C.; Kalfas, H.; Gavala, H.N.; Skiadas, I.V.; Stamatelatou, K.; Lyberatos, G. Hydrogen and Methane Production Through Two-stage Mesophilic Anaerobic Digestion of Olive Pulp. Bioresour. Technol. 2009, 100, 3718–3723. [Google Scholar] [CrossRef]
- Govender, D. The Purification of Corn Steep Liquor as a Fermentation Feedstock by Ultrafiltration. Ph.D. Thesis, Durban University of Technology, Durban, South Africa, 2008. [Google Scholar]
- Manju, R.; Srikantaswamy, S.; Shivakumar, D.; Jagadish, K.; Abhilash, M.R. Corn Steep Liquor Additive Aided Composting for Municipal Solid Waste and Evolution of its Characteristics. Int. J. Res. Appl. Sci. Eng. Technol. 2017, 5, 511–517. [Google Scholar] [CrossRef]
- Xiao, X.; Hou, Y.; Liu, Y.; Liu, Y.; Zhao, H.; Dong, L.; Du, J.; Wang, Y.; Bai, G.; Luo, G. Classification and Analysis of Corn Steep Liquor by UPLC/Q-TOF MS and HPLC. Talanta 2013, 107, 344–348. [Google Scholar] [CrossRef]
- Chopard, B.; Tomassini, M. Performance and limitations of metaheuristics. In An Introduction to Metaheuristics for Optimization; Springer: Berlin/Heidelberg, Germany, 2018; pp. 191–203. [Google Scholar]
- Gogna, A.; Tayal, A. Metaheuristics: Review and application. J. Exp. Theor. Artif. Intell. 2013, 25, 503–526. [Google Scholar] [CrossRef]
- Alatas, B.; Bingol, H. Comparative Assessment of Light-Based Intelligent Search and Optimization Algorithms. Light Eng. 2020, 28, 51–59. [Google Scholar] [CrossRef]
- Akyol, S.; Alatas, B. Plant intelligence based metaheuristic optimization algorithms. Artif. Intell. Rev. 2017, 47, 417–462. [Google Scholar] [CrossRef]
- Holland, J.H. Adaptation in Natural and Artificial Systems, 2nd ed.; MIT Press: Cambridge, MA, USA, 1992. [Google Scholar]
- Goldberg, D. Genetic Algorithms in Search, Optimization and Machine Learning; Addison-Wesley Publishing Company: Boston, MA, USA, 1989. [Google Scholar]
- Beyer, H.G.; Schwefel, H.P. Evolution Strategies—A Comprehensive Introduction. Nat. Comput. 2002, 1, 3–52. [Google Scholar] [CrossRef]
- Dorigo, M.; Birattari, M.; Stutzle, T. Ant Colony Optimization. IEEE Comput. Intell. Mag. 2006, 1, 28–39. [Google Scholar] [CrossRef]
- Kirkpatrick, S.; Gelatt, C.D.; Vecchi, M.P. Optimization by Simulated Annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.-S. Firefly Algorithm for Multimodal Optimization. Lect. Notes Comput. Sci. 2009, 5792, 169–178. [Google Scholar]
- Karaboga, D. Artificial Bee Colony Algorithm. Scholarpedia 2010, 5, 6915. [Google Scholar] [CrossRef]
- Yang, X.-S.; Deb, S. Cuckoo Search via Levy flights. In Proceedings of the World Congress on Nature & Biologically Inspired Computing (NaBIC), Coimbatore, India, 9–11 December 2009; pp. 210–214. [Google Scholar]
- Abdel-Basset, M.; Abdel-Fatah, L.; Kumar Sangaiah, A. Chapter 10—Metaheuristic Algorithms: A Comprehensive Review. In Intelligent Data-Centric Systems, Computational Intelligence for Multimedia Big Data on the Cloud with Engineering Applications; Sangaiah, A.K., Sheng, M., Zhang, Z., Eds.; Academic Press: Cambridge, MA, USA, 2018; pp. 185–231. [Google Scholar] [CrossRef]
- Dillen, W.; Lombaert, G.; Schevenels, M. Performance Assessment of Metaheuristic Algorithms for Structural Optimization Taking into Account the Influence of Algorithmic Control Parameters. Front. Built Environ. 2021, 15, 618851. [Google Scholar] [CrossRef]
- Djebedjian, B.; Abdel-Gawad, H.A.A.; Ezzeldin, R.M. Global Performance of Metaheuristic Optimization Tools for Water Distribution Networks. Ain Shams Eng. J. 2021, 12, 223–239. [Google Scholar] [CrossRef]
- Chouhan, V.K.; Goodarzian, F.; Esfandiari, M.; Abraham, A. Designing a New Supply Chain Network Considering Transportation Delays Using Meta-Heuristics. In Intelligent and Fuzzy Techniques for Emerging Conditions and Digital Transformation; Kahraman, C., Cebi, S., Cevik Onar, S., Oztaysi, B., Tolga, A.C., Sari, I.U., Eds.; INFUS 2021 Lecture Notes in Networks and Systems; Springer: Cham, Switzerland, 2022; Volume 307. [Google Scholar] [CrossRef]
- Katoch, S.; Chauhan, S.S.; Kumar, V. A Review on Genetic Algorithm: Past, Present, and Future. Multimed. Tools Appl. 2021, 80, 8091–8126. [Google Scholar] [CrossRef]
- Goodarzian, F.; Ghasemi, P.; Gunasekaren, A.; Taleizadeh, A.A.; Abraham, A. A sustainable-resilience healthcare network for handling COVID-19 pandemic. Ann. Oper. Res. 2022, 312, 761–825. [Google Scholar] [CrossRef]
- Khan, S.S.; Qamar, I.; Sohail, M.U.; Swati, R.F.; Ahmad, M.A.; Qureshi, S.R. Comparison of Optimization Techniques and Objective Functions Using Gas Generator and Staged Combustion LPRE Cycles. Appl. Sci. 2022, 12, 10462. [Google Scholar] [CrossRef]
- Roeva, O.; Zoteva, D.; Castillo, O. Joint Set-up of Parameters in Genetic Algorithms and the Artificial Bee Colony Algorithm: An Approach for Cultivation Process Modelling. Soft Comput. 2020, 25, 2015–2038. [Google Scholar] [CrossRef]
- Zheng, Z.Y.; Guo, X.N.; Zhu, K.X.; Peng, W.; Zhou, H.M. Artificial Neural Network—Genetic Algorithm to Optimize Wheat Germ Fermentation Condition: Application to the Production of Two Anti-Tumor Benzoquinones. Food Chem. 2017, 227, 264–270. [Google Scholar] [CrossRef] [PubMed]
- Chuo, H.S.E.; Lo, C.Y.K.; Tan, M.K.; Tham, H.J.; Kumaresan, S.; Teo, K.T.K. Optimization of Yeast Fermentation Process using Genetic Algorithm. In Proceedings of the 2021 IEEE International Conference on Artificial Intelligence in Engineering and Technology (IICAIET), Kota Kinabalu, Malaysia, 13–15 September 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Angelova, M.; Tzonkov, S.; Pencheva, T. Genetic Algorithms Based Parameter Identification of Yeast Fed-Batch Cultivation. In Numerical Methods and Applications; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2011; Volume 6046. [Google Scholar] [CrossRef]
- Li, J.; Wei, X.; Li, B.; Zeng, Z. A Survey on Firefly Algorithms. Neurocomputing 2022, 500, 662–678. [Google Scholar] [CrossRef]
- Yang, X.-S. Firefly Algorithm, Levy Flights and Global Optimization. In Research and Development in Intelligent Systems XXVI; Bramer, M., Ellis, R., Petridis, M., Eds.; Springer: London, UK, 2010; pp. 209–218. [Google Scholar]
- Yang, X.-S. Firefly Algorithm, Stochastic Test Functions and Design Optimisation. Int. J. Bio-Inspired Comput. 2010, 2, 78–84. [Google Scholar] [CrossRef]
- Yesodha, R.; Amudha, T. A Bio-inspired Approach: Firefly Algorithm for Multi-Depot Vehicle Routing Problem with Time Windows. Comput. Commun. 2022, 190, 48–56. [Google Scholar] [CrossRef]
- Barrera, A.; Román-Román, P.; Torres-Ruiz, F. A Hyperbolastic Type-I Diffusion Process: Parameter Estimation by Means of the Firefly Algorithm. BioSystems 2018, 163, 11–22. [Google Scholar] [CrossRef]
- Liaquat, S.; Zia, M.F.; Saleem, O.; Asif, Z.; Benbouzid, M. Performance Analysis of Distance Metrics on the Exploitation Properties and Convergence Behaviour of the Conventional Firefly Algorithm. Appl. Soft Comput. 2022, 126, 109255. [Google Scholar] [CrossRef]
- Ikotun, A.M.; Ezugwu, A.E. Enhanced Firefly-K-Means Clustering with Adaptive Mutation and Central Limit Theorem for Automatic Clustering of High-Dimensional Datasets. Appl. Sci. 2022, 12, 12275. [Google Scholar] [CrossRef]
- Yang, X.-S. Nature-Inspired Optimization Algorithms, 1st ed.Elsevier: Boston, MA, USA, 2014. [Google Scholar]
- Belkharroubi, L.; Yahyaoui, K. Solving the Energy-Efficient Robotic Mixed-Model Assembly Line Balancing Problem Using a Memory-Based Cuckoo Search Algorithm. Eng. Appl. Artif. Intell. 2022, 114, 105112. [Google Scholar] [CrossRef]
- Turan-Karaoğlan, S.; Göktürkler, G. Cuckoo Search Algorithm for Model Parameter Estimation from Self-Potential Data. J. Appl. Geophys. 2021, 194, 104461. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, Q.; Yang, Y.; Wang, L.; Song, X.; Zhao, X. Prognostic Staging of Esophageal Cancer Based on Prognosis Index and Cuckoo Search Algorithm-Support Vector Machine. Biomed. Signal Process. Control 2023, 79, 104207. [Google Scholar] [CrossRef]
- Pierezan, J.; Dos Santos Coelho, L. Coyote Optimization Algorithm: A New Metaheuristic for Global Optimization Problems. In Proceedings of the 2018 IEEE Congress on Evolutionary Computation (CEC), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Yuan, Z.; Wang, W.; Wang, H.; Yildizbasi, A. Developed Coyote Optimization Algorithm and Its Application to Optimal Parameters Estimation of PEMFC Model. Energy Rep. 2020, 6, 1106–1117. [Google Scholar] [CrossRef]
- Ali, E.S.; Abd Elazim, S.M.; Balobaid, A.S. Implementation of Coyote Optimization Algorithm for Solving Unit Commitment Problem in Power Systems. Energy 2022, 263, 125697. [Google Scholar] [CrossRef]
- De Souza, R.C.T.; de Macedo, C.A.; dos Santos Coelho, L.; Pierezan, J.; Mariani, V.C. Binary Coyote Optimization Algorithm for Feature Selection. Pattern Recognit. 2020, 107, 107470. [Google Scholar] [CrossRef]
- Ding, L.; Bai, Y.L.; Fan, M.H.; Yu, Q.H.; Zhu, Y.J.; Chen, X.Y. Serial-Parallel Dynamic Echo State Network: A Hybrid Dynamic Model Based on a Chaotic Coyote Optimization Algorithm for Wind Speed Prediction. Expert Syst. Appl. 2023, 212, 118789. [Google Scholar] [CrossRef]
- Hu, X.; Hu, M.; Yang, X. A Novel Fault Diagnosis Method for TE Process Based on Optimal Extreme Learning Machine. Appl. Sci. 2022, 12, 3388. [Google Scholar] [CrossRef]
- Roeva, O.; Atanassova, V. Cuckoo search algorithm for model parameter identification. Int. J. Bioautom. 2016, 20, 483–492. [Google Scholar]
- Nguyen, T.T.; Pham, T.D.; Kien, L.C.; Dai, L.V. Improved Coyote Optimization Algorithm for Optimally Installing Solar Photovoltaic Distribution Generation Units in Radial Distribution Power Systems. Complexity 2020, 2020, 1603802. [Google Scholar] [CrossRef]
- Shehab, M.; Khader, A.T.; Al-Betar, M.A. A survey on applications and variants of the cuckoo search algorithm. Appl. Soft Comput. 2017, 61, 1041–1059. [Google Scholar] [CrossRef]
- Yang, X.-S. Nature-Inspired Meta-Heuristic Algorithms; Luniver Press: Beckington, UK, 2008. [Google Scholar]
- Diop, S.; Simeonov, I. On the Biomass Specific Growth Rates Estimation for Anaerobic Digestion using Differential Algebraic Techniques. Int. J. Bioautom. 2009, 13, 47–56. [Google Scholar]
- Noykova, N.; Muller, T.G.; Gyllenberg, M.; Timmer, J. Quantitative Analyses of Anaerobic Wastewater Treatment Processes: Identifiability and Parameter Estimation. Biotechnol. Bioeng. 2002, 78, 89–103. [Google Scholar] [CrossRef] [PubMed]
- de Menezes, L.H.S.; Carneiro, L.L.; de Carvalho Tavares, I.M.; Santos, P.H.; das Chagas, T.P.; Mendes, A.A.; da Silva, E.G.P.; Franco, M.; de Oliveira, J.R. Artificial Neural Network Hybridized with a Genetic Algorithm for Optimization of Lipase Production from Penicillium roqueforti ATCC 10110 in Solid-State Fermentation. Biocatal. Agric. Biotechnol. 2021, 31, 101885. [Google Scholar] [CrossRef]
- Jiao, Y.; Zhou, J.; Ma, X.; He, C.; Pan, X.; Liu, X.; Zhang, Q.; Awasth, M.K. Exergy analysis and optimization of bio-hydrogen and bio-methane cogeneration from corn stover based on genetic algorithm. Bioresour. Technol. Rep. 2022, 18, 101113. [Google Scholar] [CrossRef]
- Firouzi, B.; Abbasi, A.; Sendur, P.; Zamanian, M.; Chen, H. Enhancing the performance of Piezoelectric Energy Harvester under electrostatic actuation using a robust metaheuristic algorithm. Eng. Appl. Artif. Intell. 2023, 118, 105619. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Mohamed, R.; Saber, S.; Askar, S.S.; Abouhawwash, M. Modified flower pollination algorithm for global optimization. Mathematics 2021, 9, 1661. [Google Scholar] [CrossRef]
- Roeva, O. Sensitivity Analysis of E. coli Fed-batch Cultivation Local Models. Math. Balk. New Ser. 2011, 25, 395–411. [Google Scholar]
- Friedman, M.A. Comparison of Alternative Tests of Significance for the Problem of M Rankings. Ann. Math. Stat. 1940, 11, 86–92. [Google Scholar] [CrossRef]
- Arora, J.S. Chapter 14—Practical applications of optimization. In Introduction to Optimum Design, 3rd ed.; Academic Press: Cambridge, MA, USA, 2012; pp. 575–617. [Google Scholar] [CrossRef]
- Alghamdi, A.S. A Hybrid Firefly–JAYA Algorithm for the Optimal Power Flow Problem Considering Wind and Solar Power Generations. Appl. Sci. 2022, 12, 7193. [Google Scholar] [CrossRef]
- Zhao, X.; Tang, Z.; Cao, F.; Zhu, C.; Periaux, J. An Efficient Hybrid Evolutionary Optimization Method Coupling Cultural Algorithm with Genetic Algorithms and Its Application to Aerodynamic Shape Design. Appl. Sci. 2022, 12, 3482. [Google Scholar] [CrossRef]
Figure 1.
Mathematical model of corn steep liquor TSAD process ((1)–(9)) described in Simulink.

Figure 2.
Graphical comparison of the results. (A) dynamics; (B) dynamics.

Figure 3.
Box plot for the results of the second identification step. (A) objective function J2; (B) parameter ; (C) parameter ; (D) parameter ; (E) parameter .
Figure 3.
Box plot for the results of the second identification step. (A) objective function J2; (B) parameter ; (C) parameter ; (D) parameter ; (E) parameter .


Figure 4.
Friedman’s test results.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
The optimal values of the main parameters of the metaheuristic algorithms.
| GA | Value |
| population size n | 100 |
| generation gap | 0.97 |
| crossover rate | 0.80 |
| mutation rate | 0.05 |
| FA | Value |
| number of fireflies n | 20 |
| initial attractiveness β0 | 1 |
| light absorption coefficient γ | 1 |
| randomization parameter α | 0.2 |
| CS | Value |
| number of nests n | 20 |
| switching parameter pa | 0.25 |
| Lévy exponent λ | 1.5 |
| COA | Value |
| number of packs Np | 30 |
| number of coyotes Nc | 100 |
| probability of eviction of a coyote p_leave | 0.0005 × Nc2 |
| scatter probability Ps | 1/D |
| association probability Pa | (1−Ps)/2 |
Table 2.
Model parameter estimations.
| J1 | J2 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| GA | 0.012 | 0.944 | 0.067 | 14.671 | 11.289 | 0.0035 | 0.517 | 0.812 | 0.029 | 0.543 | 0.0761 |
| FA | 0.017 | 1.100 | 0.222 | 10.276 | 8.117 | 0.0035 | 0.443 | 0.919 | 0.100 | 0.989 | 0.1075 |
| CS | 0.010 | 1.139 | 0.010 | 0.122 | 13.727 | 0.0036 | 0.077 | 0.001 | 19.781 | 2.298 | 0.0913 |
| COA | 0.012 | 1.004 | 12.137 | 5.702 | 11.598 | 0.0035 | 0.029 | 0.0001 | 24.272 | 7.933 | 0.0940 |
Table 3.
Statistical analysis of the results.
| Algorithm | J2 | |||||
|---|---|---|---|---|---|---|
| GA | average | 0.09552 | 0.14501 | 5.32245 | 0.18386 | 0.36572 |
| SD | 0.01732 | 0.26303 | 8.04380 | 0.14778 | 0.41212 | |
| median | 0.08833 | 0.05033 | 1.74911 | 0.14962 | 0.35478 | |
| FA | average | 0.11683 | 0.11048 | 1.10871 | 0.46463 | 0.94210 |
| SD | 0.00936 | 0.01077 | 0.18236 | 0.03767 | 0.03814 | |
| median | 0.11686 | 0.10858 | 0.99504 | 0.44297 | 0.92456 | |
| CS | average | 0.10984 | 0.21904 | 4.26557 | 0.40936 | 0.26250 |
| SD | 0.01361 | 0.53544 | 2.99461 | 0.28370 | 0.32967 | |
| median | 0.10693 | 0.00138 | 3.07739 | 0.45413 | 0.11308 | |
| COA | average | 0.11454 | 0.28767 | 6.18897 | 0.37877 | 0.21275 |
| SD | 0.00741 | 0.23002 | 3.01675 | 0.22794 | 0.21626 | |
| median | 0.11521 | 0.21474 | 6.85870 | 0.37701 | 0.14627 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Roeva, O.; Chorukova, E. Metaheuristic Algorithms to Optimal Parameters Estimation of a Model of Two-Stage Anaerobic Digestion of Corn Steep Liquor. Appl. Sci. 2023, 13, 199. https://0-doi-org.brum.beds.ac.uk/10.3390/app13010199
AMA Style
Roeva O, Chorukova E. Metaheuristic Algorithms to Optimal Parameters Estimation of a Model of Two-Stage Anaerobic Digestion of Corn Steep Liquor. Applied Sciences. 2023; 13(1):199. https://0-doi-org.brum.beds.ac.uk/10.3390/app13010199
Chicago/Turabian StyleRoeva, Olympia, and Elena Chorukova. 2023. "Metaheuristic Algorithms to Optimal Parameters Estimation of a Model of Two-Stage Anaerobic Digestion of Corn Steep Liquor" Applied Sciences 13, no. 1: 199. https://0-doi-org.brum.beds.ac.uk/10.3390/app13010199
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.