
The Reliability Inference for Multicomponent Stress–Strength Model under the Burr X Distribution


1
Department of Mathematical Sciences, University of South Dakota, Vermillion, SD 57069, USA
2
College of Health Solutions, Arizona State University, Phoenix, AZ 85004, USA
3
Department of Statistics, University of Pretoria, Pretoria 0028, South Africa
4
Department of Statistics, Tamkang University, Tamsui District, New Taipei City 251301, Taiwan
5
School of Mathematics, Yunnan Normal University, Kunming 650500, China
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
AppliedMath 2024, 4(1), 394-426; https://0-doi-org.brum.beds.ac.uk/10.3390/appliedmath4010021
Submission received: 20 November 2023
/
Revised: 21 February 2024
/
Accepted: 27 February 2024
/
Published: 17 March 2024
Abstract
:The reliability of the multicomponent stress–strength system was investigated under the two-parameter Burr X distribution model. Based on the structure of the system, the type II censored sample of strength and random sample of stress were obtained for the study. The maximum likelihood estimators were established by utilizing the type II censored Burr X distributed strength and complete random stress data sets collected from the multicomponent system. Two related approximate confidence intervals were achieved by utilizing the delta method under the asymptotic normal distribution theory and parametric bootstrap procedure. Meanwhile, point and confidence interval estimators based on alternative generalized pivotal quantities were derived. Furthermore, a likelihood ratio test to infer the equality of both scalar parameters is provided. Finally, a practical example is provided for illustration.
1. Introduction
Systems or units that are subject to the competition between strength and stress have been studied under the commonly called stress–strength model. The system survives if the imposed stress is less than the system strength. Therefore, the stress–strength model plays a substantial role in many aspects, such as lifetime study, engineering, and supply and demand applications.
Let X be the system strength and Y be the stress applied. Then, the stress–strength reliability (SSR) is labeled as . Generally, X indicates the measurement of quality characteristics for the main subject and Y indicates the measurement of quality characteristics for the opposite subject in the system. Next, three cases are presented to illustrate the applications of a stress–strength system. In mechanical engineering, the strength measure X of a long horizontal part for a crane needs to exceed the stress of the loading weight Y from the lifted object of operation. The reliability is an essential quantity for assessing the quality of a crane. In the application of civil engineering, the tolerable bearing capacity of a suspension bridge is an important quality measure. The bearing capacity X from a pair of cables for the suspension bridge should exceed the total weight Y of the cars. In this application, a high reliability is essential for a suspension bridge design. In logistics applications, the supply capacity X can represent the strength and the demand Y can represent the stress. A high reliability indicates a reliable logistics system. In recent years, the stress–strength model has been broadly used in a variety of fields, such as economics, hydrology, reliability engineering, seismology, and survival analysis. The system reliability has also been studied by numerous researchers. Eryilmaz [1] developed formulae for R and the mean residual life at random time based on phase-type distributions, such as the Erlang distribution. Kundu and Raqad [2] investigated a modified maximum likelihood estimation for R based on Weibull distributions, each of which possess three parameters: shape, scale, and location. Krishnamoorthy and Lin [3] studied confidence limits for R by using the generalized variable approach through the maximum likelihood estimation method with two independent Weibull distributions. Mokhlis et al. [4] investigated the inferences of R under distributions that include general exponential and inverse-exponential forms. Surles and Padgett [5] studied the maximum likelihood estimate and Bayesian inference for R based on Burr X distributions with the equal scale parameter set to one. Wang et al. [6] acquired inference procedures for R with a generalized exponential distribution.
Very often, like in the aforementioned references, the studies of reliability inference are mainly concentrated on a system with a main component. Nevertheless, several practical systems, such as a system with series components, parallel components, or any combination of these two, are composed of multiple components to accomplish the required functions. Therefore, multicomponent system reliability investigations have attracted more attention lately. Commonly, multicomponent systems consist of main components, of which the strengths follow an independent and identical distribution (i.i.d.) subject to an opposite commonly distributed stress. The system survives if at least main components concurrently function. The multicomponent system is generally referred to as the s-out-of-k G system. There are numerous practical multicomponent systems in the world. For example, a communication system with three transmitters, where the expected message load requires at least two transmitters to be operational; otherwise, critical messages are lost. Hence, this transmission system is called a two-out-of-three G system. A second example, where the Airbus A-380 with four engines is capable of flying if and only if at least two of the four engines are functioning, is referred to as a two-out-of-four G system. Another example is a suspension bridge with k pairs of cables, which needs at least s pairs of unbroken cables to withstand the stress.
Let the k components’ strength variables in an s-out-of-k G system, where each component is subject to a stress measure Y, be . The multicomponent stress–strength reliability (MSR) , as presented by Bhattacharyya and Johnson [7], is given by
where is the common cumulative distribution (CDF) of and is the CDF of Y. The reliability inferences for s-out-of-k G systems based on different distribution models have been extensively investigated by several researchers. The work by Dey et al. [8] was based on random samples from Kumaraswamy distributions. The work by Kayal et al. [9] was based on random samples from Chen distributions. The works by Kizilaslan [10,11] were based on random samples from proportional reversed hazard rate distributions and a general class of inverse exponentiated distributions, respectively. The work by Kizilaslan and Nadar [12] was based on complete sample sets from bivariate Kumaraswamy distributions. The work by Nadar and Kizilaslan [13] was based on complete samples from Marshall–Olkin bivariate Weibull distributions. The works by Rao [14,15] were, respectively, based on complete random samples from Rayleigh and generalized Rayleigh distributions. The work by Rao et al. [16] was based on complete random samples from Burr XII distributions. The work by Shawky and Khan [17] was based on random samples from inverse Weibull distributions. The work by Lio et al. [18] was based on type II sample of strength and complete random sample of stress Burr XII distributions. The work by Sauer et al. [19] was based on progressively type II censored samples from generalized Pareto distributions. And the work by Wang et al. [20] was based on type II censored strength and complete stress samples from Rayleigh stress–strength models.
Burr [21] developed numerous distributions. Among them, both Burr X and Burr XII have been the most attractive in recent reliability studies. Meanwhile, Belili et al. [22] explored an elastic two-parameter family of distributions and provided numerous theoretical results that include vital parameters and behaviors of distribution functions, reliability measurements for the proposed two-parameter family, and applications to annual maximum floods and survival times for breast cancer patients. The proposed two-parameter family of distributions include the two-parameter Lindley distributions I and II, gamma Lindley distribution, quasi-Lindley distributions, pseudo-Lindley distribution, and XLindley distribution as special cases, but do not include the Burr types. Their proposed family of distributions could potentially be applied to the stress–strength reliability inference for the multicomponent system. Yousof et al. [23] and Jamal and Nasir [24] proposed two Burr X generators to create different families of distributions by using the CDF of a one-parameter Burr X distribution composite with and , where and are the CDF and survival function of a second distribution with parameter vector of one dimension or two dimensions, respectively. Therefore, both Burr X generalized distributions have two parameters or three parameters. Both papers developed numerous properties of these two generalized Burr X distributions that include stress–strength reliability for a one-component system. However, the practical application of stress–strength reliability was not provided. They also applied these two generalized Burr X distributions to model a random sample of 128 bladder cancer patients’ remission times (in months) and concurrently concluded that their respective extended Burr X distributions performed better than a one-parameter Burr X distribution. These two generalized Burr X distributions do not contain the current two-parameter Burr X distribution as a special case and could potentially be applied to the stress–strength reliability inference for a multicomponent system as well.
The Burr XII distribution has two shape parameters. For more information about Burr XII, readers may refer to Lio et al. [18]. The Burr X distribution considered in the current study has two parameters and the probability density function (PDF) and CDF, respectively, are defined as
where and are the scale and shape parameters, respectively. For easy reference, BurrX is used as the Burr X distribution with parameters and , hereafter. Because of the flexibility of use for any two-parameter distribution, BurrX has been investigated in the reliability studies of numerous scholars. Jaheen [25] explored the reliability and failure rate functions for the Burr X model by utilizing the empirical Bayesian estimation method based on complete random samples. Ahmad et al. [26] considered the empirical Bayes estimate of R based on random samples from a Burr X distribution. When both stress and strength Burr X distributions have scale parameters of one, Surles and Padgett [5] and Akgul and Senoglu [27] studied the inference of R using maximum likelihood and Bayes methods based on random samples and using a modified maximum likelihood estimate method based on ranked set samples, respectively. Surles and Padgett [5] applied a Burr X distribution to model the stress and strength reliability of a one-component system based on the strengths of two carbon fibers. However, according to a literature search, work that investigated based on a Burr X distribution has not appeared.
In reality, we do not always obtain a complete random sample, except for censored data. Moreover, under the current multicomponent model, usually only type II strength sample and complete random stress observations can be observed from the system. Therefore, the current research focused on some alternative inferential methodologies for when the strength data are a type II censored Burr X distributed sample and the stress data are a Burr X distributed random sample. The estimation methods for , , and include maximum likelihood and pivotal quantity estimation methods for type II censored strength and random stress samples. Based on our best knowledge, the approaches used in this work have not appeared in the literature regarding BurrX.
Section 2 briefly describes the structure information about typical type II censored strength and associated stress data sets from the aforementioned G system and the likelihood function based on those data sets from n G systems. In Section 3, the maximum-likelihood-based approaches are addressed for Burr X distributions. Additionally, asymptotic confidence intervals (ACIs) are derived via utilizing the delta method and bootstrap percentile procedure. Inferences based on pivotal quantities are given in Section 4, where numerous theorems to support the existence and uniqueness of each pivotal-quantity-based estimator are established. For the model test of the equivalence of Burr X scale parameters for strength and stress, Section 5 provides a ratio test. Section 6 provides a real data example for demonstration. Some concluding remarks are given in Section 7.
2. The Likelihood Function Based on Sample from G System
In a lifetime-testing experiment using n s-out-of-k G systems, where each system contains k strength components subject to a common stress, the strength and stress samples can be obtained, respectively, as
where represents the first s ordered strength statistics under type II censoring and represents the stress variable accordingly for . The strength quantities from all system components are independent and follow the common CDF with the PDF and the related stress measure follows the CDF with the PDF . Hence, the joint likelihood function based on the sample in Equation (3) is described as
When , the likelihood function of Equation (4) is for a series system; when , it is for a parallel system.
3. The Maximum Likelihood Estimators
The maximum likelihood estimation method is addressed based on the Burr X distributed strength and stress samples from n s-out-of-k G systems in this section. Let with and of (3) be the observed strength and associated stress samples for BurrX and BurrX, respectively. Via Equations (2) and the samples of (3), the likelihood function (4) of is given according to
Hence, the log-likelihood function with the constant term deleted is described as
3.1. Case 1: Equal Scale Parameters
Let . Equation (1) becomes
Moreover, the likelihood function of (5) is given as
and after dropping the constant term, the log-likelihood function is
where .
3.1.1. Point Estimators under Equal Scale Parameters
Taking partial derivatives of with respective to , , and , one obtains
The gradient of with respect to , and is given as
Then, the MLE of can be obtained by solving the normal equation . Moreover, the MLE of can be derived from Equation (7) and is given by
3.1.2. Approximated Confidence Interval for
The exact sampling distribution of is unknown and difficult to develop. Hence, the exact confidence interval of is not available. Here, two approximated confidence intervals (ACIs) of are established by utilizing the delta method and bootstrap sampling.
The observed Fisher information matrix, given , is presented as
and the second derivatives in the matrix can be derived directly. The details are omitted here for concision. An ACI is available via the delta method, as shown in Theorems 1 and 2.
Theorem 1.
Let be the MLE of . as , where ‘’ indicates ‘converges in distribution’.
Proof.
The theorem can be proved by following the asymptotic properties of MLEs along with the central limit theorem for the multivariate case. □
Theorem 2.
Let be the MLE of . If , then
where and .
Proof.
Appendix A provides the proof. □
Let be replaced by its MLE and . A ACI of is easily established through Theorem 2 and given by
where and
A negative lower bound may happen in the ACI established by the above procedure. To remove this downside, we can apply the delta methods with logarithmic transformation to develop the asymptotic normal distribution of . The procedure is given below:
Hence, a ACI of can instead be developed to be
where is obtained by utilizing the Taylor’s expansion for the delta method.
Furthermore, for comparison purposes, a second MLE-based ACI of , which is called the parametric bootstrap confidence interval (BCI), is constructed by utilizing the parametric bootstrap procedure that is detailed through Algorithm 1. For more information about the parametric bootstrap procedures, readers may refer to Efron [28] and Hall [29].
3.2. Case 2: Different Scale Parameters
Under this condition, , , and can be represented as
According to our best knowledge, no study has published the reliability inference for the multicomponent stress–strength model based on Burr X distributions under different parameters.
| Algorithm 1: Parametric bootstrap procedure under . |
|
3.2.1. Point Estimators under Different Parameters
Taking the partial derivatives of with respective to , , , and , one can have
In this case, the gradient of with respect to and is given as
The MLE of is the solution to the normal equation . The invariant property of maximum likelihood estimation allows the MLE of under different parameters to be established as
3.2.2. Approximated Confidence Interval for
In this case, the observed Fisher information matrix, given , is presented as
where the second derivatives in the matrix can be derived directly. Therefore, the detailed results are not given for brevity.
By using a similar process to that used to develop Theorem 2, replacing by , and having , a ACI of is given as
where
and
Moreover, an additional ACI of is derived to produce
where via Taylor’s expansion for the delta method [30].
The BCI of under this case can be obtained through a procedure presented above. Hence, the details are not given.
4. Inference Based on Pivotal Quantity
Pivotal quantities are developed through utilizing the stress and strength samples of (3). Moreover, some estimators for based on the pivotal quantities established in this section are uniquely derived by the associated theorems established below.
Theorem 3.
Let be a type II censored strength sample from BurrX. Then,
and
have independent chi-square distributions with degrees of freedom and , respectively. Therefore, and are pivotal quantities for and , respectively.
Proof.
Appendix B provides the proof. □
Theorem 4.
For a given stress random sample, of BurrX and are the associated ordered statistics. Then,
and
follow the independent chi-square distributions with degrees of freedom and , respectively. Therefore, and are the pivotal quantities for and , respectively.
Proof.
The proof is presented in Appendix C. □
In order to derive estimators for and by utilizing the pivotal quantities established above, additional theoretical results are required and stated below.
Lemma 1.
Given , is an increasing function of t.
Proof.
The proof is given in Appendix D. □
Corollary 1.
and are increasing functions.
Proof.
Appendix E shows the proof. □
4.1. Case 1:
In this case, let , , and . Theorems 3 and 4, combined with the probability independence between and , imply that the pivotal quantity
has a chi-square distribution with degrees of freedom . Meanwhile, Corollary 1 implies that is increasing with respect to .
Given , the equation of has a unique solution , which can be solved numerically by utilizing the bisection method or R function ‘uniroot’. is a generalized pivotal-based estimate of . Moreover, Theorem 3 implies where and
where
By the substitution method of Weerahandi [31], a generalized pivotal quantity can be uniquely obtained by substituting for in and the result is given as
where is the sample observation of . It is noted that the distribution of is free from unknown parameters and reduces to when . Hence, is a generalized pivotal-based estimate of . Let . Similarly, Theorem 4 implies that a generalized pivotal-based estimate of can be
Moreover, a generalized pivotal quantity of is derived as
The pivotal-based estimation method for a generalized confidence interval (GCI) of under the case of equal scale parameters can be implemented by Algorithm 2.
Remark 1.
Based on the pivotal quantity , given , a GCI confidence interval for λ is
where is the right-tail γth quantile of the chi-square distribution with k degrees of freedom.
Additionally, the GCI joint confidence regions for and can, respectively, be obtained by using and as
and
| Algorithm 2: Pivotal-quantity-based estimation method under . |
|
Remark 2.
Given the following listed null hypotheses vs. the alternative ones :
and , the decision of rejecting the null hypotheses and can be conducted by utilizing the following critical regions:
respectively.
4.2. Case 2:
Let , , , and Theorems 3 and 4 imply the follow theorem.
Theorem 5.
Let be a type II censored strength sample from BurrX and be a random stress sample from BurrX. Four pivotal quantities are listed below:
and
Then,
- and are probability independent;
- and are probability independent.
Following the process addressed in Section 4.1, let and , and use and to respresent the solutions to equations and , respectively. Adopting the substitution method from Weerahandi [31], the generalized pivotal quantity for is
with and
and the generalized pivotal quantity for is
Consequently, a generalized pivotal quantity for can be represented as
Additionally, the generalized estimates of under can be derived through Algorithm 3.
| Algorithm 3: Pivotal-quantity-based estimation method under . |
|
Remark 3.
For a given , two exact individual confidence intervals of and are, respectively, presented as
Additionally, two exact joint confidence regions for and are constructed by
and
respectively.
Remark 4.
Let . The list of null hypotheses vs. the alternative ones is displayed:
Under the significance level , the decision to reject in and for and can, respectively, be conducted using the following critical regions:
and
Remark 5.
For computational purposes, it is important that for the s-out-of-k G; otherwise, the pivotal quantities and , cannot be obtained. Under this condition, the strength variables can be viewed as a random sample of size n. And an alternative approach utilizes the following pivotal quantities:
and
where if ; otherwise, , and are the order statistics of . It can be shown that and follow the chi-square distributions with degrees of freedom and , respectively. Consequently, the previous generalized point and confidence interval estimates can also be created.
5. Inference of
Practically, it is important to test whether the scale parameters are equal or not. For this purpose, the hypotheses and associated likelihood ratio test are displayed below:
The related likelihood ratio statistic has the property
where . Therefore, the likelihood ratio test can be conducted by utilizing the test statistic of with the reject region
where is selected to satisfy the size of the test.
6. Practical Data Application
Shasta Reservoir, which is the largest man-made lake, is located on the upper Sacramento River in northern California. The monthly water capacities in the months of August, September, and December from 1980 to 2015, which were accessed on 19 September 2021, were utilized for the demonstration of the processes presented. The data set was also studied under the Rayleigh distribution and Burr XII one, respectively, by Wang et al. [20] and Lio et al. [18].
Assume that the water level will not lead to excessive drought if the water capacity in December is less than the water capacities of at least two Augusts within the next five years, namely, the reliability states that in at least three years within the next five years, the water capacities in August are not less than the water capacity in the previous December. In this practical situation, , , and . Let be the capacity of December 1980; be the capacities of August from 1981 to 1985; be the capacity of December 1986; be the capacities of August from 1987 to 1991; and so on. For the purpose of easily fitting water capacities with BurrX, all the water capacities needed to be rescaled and divided by 3,014,878 (the maximal water capacity), and the transformed data are listed as follows:
For more detailed information about the above-transformed data, the reader may refer to Kizilaslan and Nadar [12], whereas all the monthly water capacities of the Shasta reservoir between 1981 to 1985 are presented in Appendix F.
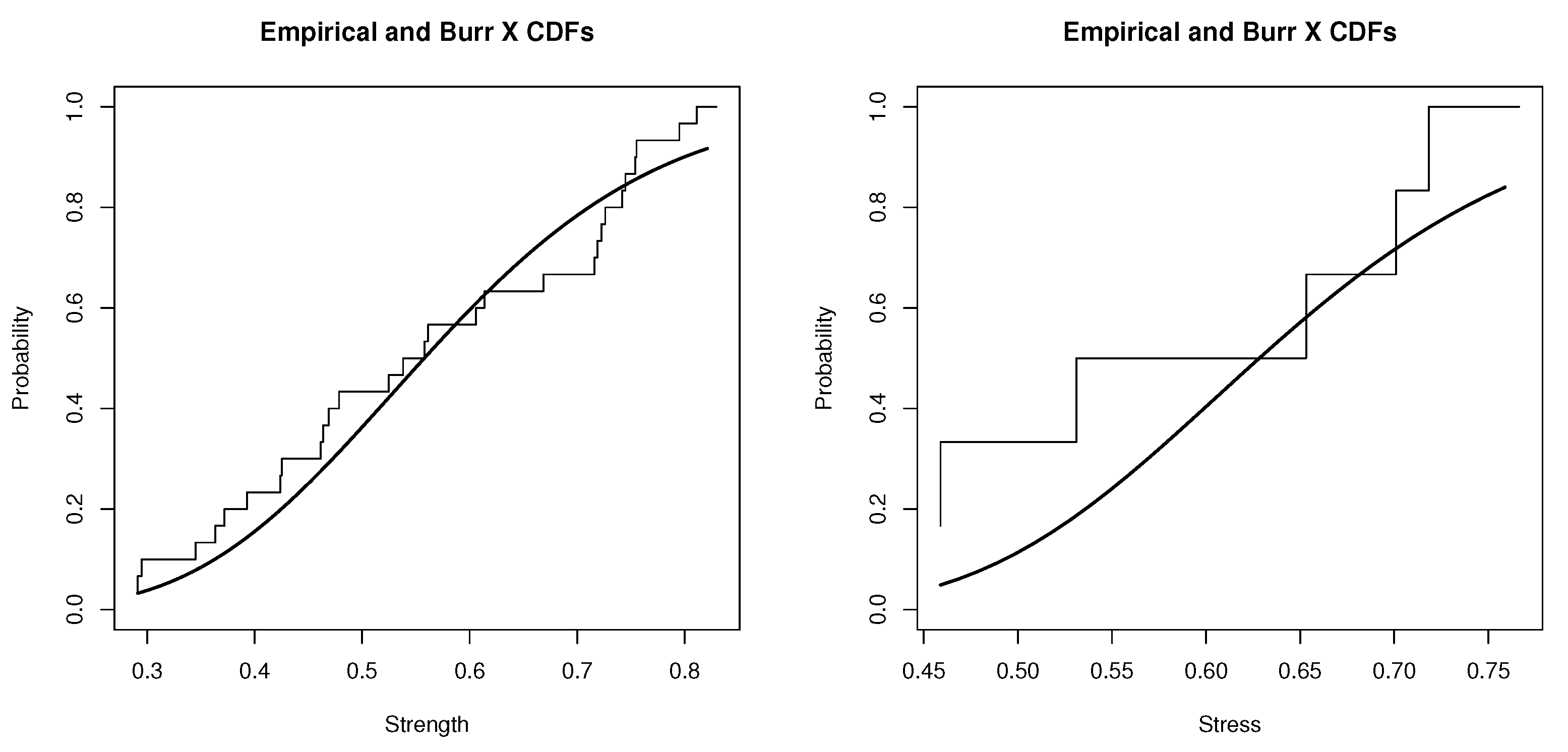
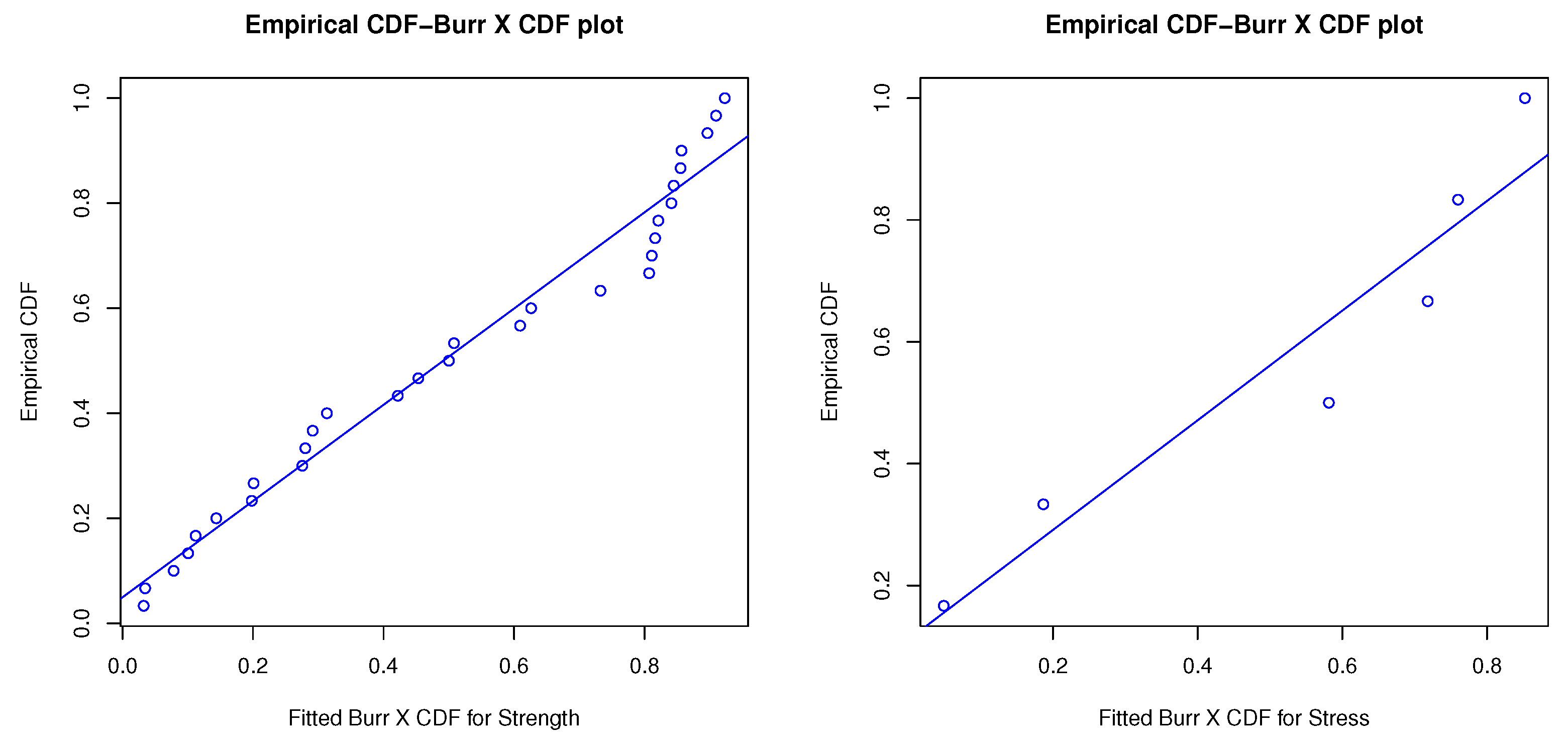
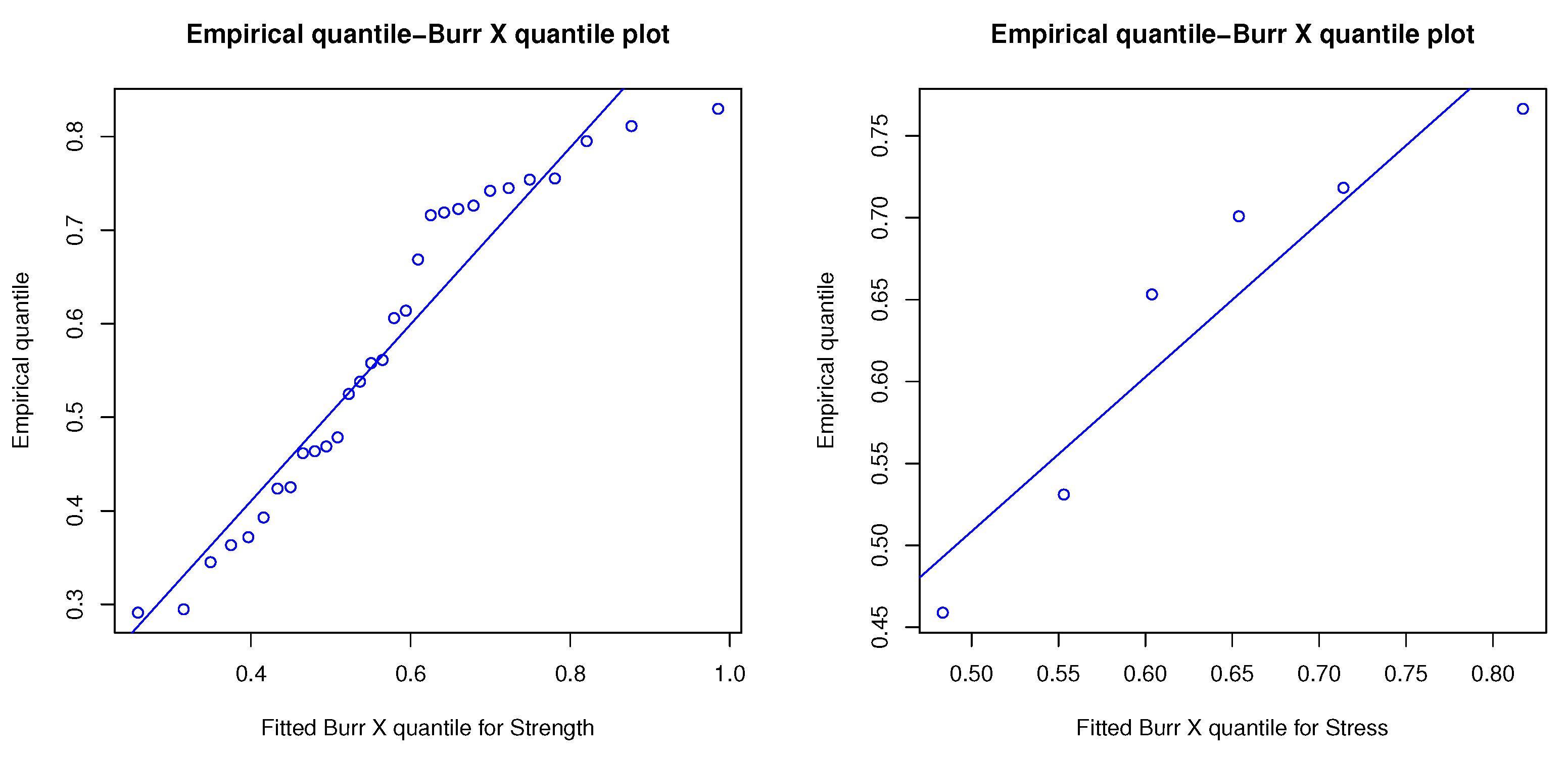
The Kolmogorov–Smirnov (K-S) test of a two-sided rejection region was used to evaluate the Burr X distribution fit of these data sets. The results from the K-S test for the strength and stress data included the following test statistic distances and the corresponding p-values (within brackets): and , respectively. In addition, the overlapped plots of sample empirical cumulative versus Burr X distributions, sample cumulative probability versus Burr X cumulative probability (P-P), and sample quantile versus Burr X quantile (Q-Q) are shown in Figure 1, Figure 2 and Figure 3, respectively. P-P plot is a probability plot for assessing how close a data set fits a specified model or how closely two data sets agree. A Q-Q plot is a graphic method for evaluating whether two data sets come from populations with a common distribution. Figure 2 shows two P-P plots to present the empirical CDFs of the strength sample (left side) and the stress sample (right side) versus the theoretical CDF of Burr X. The imposed linear regressions over P-P plots in Figure 2 were significant, with R-squared values of 0.97 and 0.91 for the complete strength and stress samples, respectively, and the imposed linear regressions over the Q-Q plots in Figure 3 were also significant, with R-squared values of 0.93 and 0.89 for the complete strength and stress samples, respectively. All information reveals that the Burr X distribution was a good fitting probability model for the transformed data sets as well.
Based on the six three-out-of-five G systems provided in this example, the observed data collected from these multicomponent systems are given as follows:
The point and interval estimates for the multicomponent system reliability are shown in Table 1, where the significance level was set to . The estimated interval lengths for ACI, GCI, and BCI were 0.4641, 0.4519, and 0.4468, respectively, when , and 0.4935, 0.5138, and 0.5112, respectively, when . Under , three point estimates were larger than three point estimates under . It was observed that the point estimates were close to each other, except the MLE when . When comparing between all estimated interval lengths, the ACI of was found to perform equally well in terms of length.
Furthermore, to compare the equivalence between the scale parameters and from the strength and stress distributions, i.e., null hypothesis , the likelihood ratio test provided the statistic and p-value of and , respectively. Hence, the results indicate that under a 0.05 significance level, there is sufficient evidence to reject the null hypothesis. And the strength and stress distributions are suggested to have Burr X distributions with different scale parameters for the current monthly capacity applied. It is worth mentioning that the point estimates of under different parameters for both Burr X distributions were consistent with the point estimate results of under the Burr XII distribution modeling studied by Lio et al. [18], where both Burr XII distributions had one common parameter, while the Burr X modeling had different parameters for the same data sets considered.
7. Concluding Remarks
The inference for the multicomponent stress–strength model reliability was investigated using two-parameter Burr X distributions. The maximum likelihood and generalized pivotal quantity based estimators for the model parameters were constructed under equal scale parameters and different scale parameters, respectively. Moreover, confidence intervals were also provided by using the delta method with an asymptotic normal distribution, parametric bootstrap percentile, and generalized pivotal sampling.
Yousof et al. [23] and Jamal and Nasir [24] presented two different Burr X generators based on a one-parameter Burr X distribution. These two types of families have not been applied to estimate the reliability of the multicomponent stress–strength system and can be considered potential future research work. The other possible extension work is to extend the two-parameter Burr X distributions using the same approaches from Yousof et al. [23] and Jamal and Nasir [24]. When the research work is to establish the common goals based on a family of distributions, the model selection based on the Bayesian and likelihood approaches will be reasonably applied and a best model will be used to compare the based model. For more information, readers may also refer to [32,33,34].
Additionally, the present results were established under type II censoring for strength data sets. The approaches could possibly be extended to other censoring; for example, the progressively type-II or progressive first-failure type II censoring scheme with proper modification of pivotal quantities for the related samples. Viveros and Balakrishnan [35] provided more information about progressive censoring schemes. Additionally, the moment and maximum product of spacing estimations are interesting new directions. All of these are potential research opportunities.
Author Contributions
Y.L., D.-G.C., T.-R.T. and L.W. equally contributed to the work. All authors read and agreed to the published version of the manuscript.
Funding
This study was partially based on research supported by the National Science and Technology Council, Taiwan, grant number NSC 112-2221-E-032-038-MY2. This work of Liang Wang was supported based on the National Natural Science Foundation of China (no. 12061091), the Yunnan Fundamental Research Projects (no. 202101AT070103) and the Yunnan Key Laboratory of Modern Analytical Mathematics and Applications (no. 202302AN360007). This work of Ding-Geng Chen was partially supported based on the South Africa National Research Foundation (NRF) and South Africa Medical Research Council (SAMRC) (South Africa DST-NRF-SAMRC SARChI Research Chair in Biostatistics to Professor Ding-Geng Chen, grant number 114613). The opinions expressed and conclusions arrived at are those of the author and are not necessarily to be attributed to the NRF and SAMRC.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Complete monthly water capacity data for the Shasta Reservoir from 1981 to 1985 are given in Appendix G. Section 6 includes the observed complete strength and stress data sets.
Acknowledgments
The authors would like to thank the editor and reviewers for their helpful comments and suggestions, which improved this paper significantly.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. The Verification of Theorem 2
Utilizing the mean value theorem for a derivative, the Taylor series expansion of is presented as
where and are the appropriate matrices of the first and second derivatives of with respect to , correspondingly, and is an appropriate value between and . Equation (A1) can also be represented as
Theorem 3 implies and when . Moreover, by the delta method [30] and Equation (A1), the variance of is approximated as
Therefore, through utilizing the delta method [30], Theorem 1 implies
The proof is done.
Appendix B. The Verification of Theorem 3
Given a positive integer , indicate the first s ordered statistics from a size k random sample of BurrX(). Therefore, , is viewed as a type II censored sample collected from an exponential distribution that has a mean of one. Because of the memory-less property of the exponential distribution, is a random sample from the exponential distribution that has a mean of one. Lawless [36] provided more information about the memory-less property of the exponential distribution.
For , let
Stephens [37] and Viveros and Balakrishnan [35] provided reasonable background to show that are the order statistics of a size random sample of the uniform distribution over the interval . Additionally, is independent of
It can be shown that the quantities and are independent and follow the chi-square distributions with degrees of freedom and , respectively. Furthermore, by the probability independence of , one can show that
and
are independent and follow chi-square distributions with degrees of freedom and , respectively.
The theorem is proven.
Appendix C. The Verification of Theorem 4
Let the ordered statistics of be denoted . Then, , , are ordered statistics from an exponential distribution that has a mean of one. The theorem can be proved by following the same proof procedure for the previous theorem.
Appendix D. The Verification of Lemma 1
Showing that for is equivalent to verifying
Let for and
for . Then,
It can be shown that
Hence, , is an increasing function and is an increasing function.
Lemma 1 is proven.
Appendix E. The Verification of Corollary 1
The definitions of and imply that
and
Appendix F. Complete Shasta Reservoir Water Capacity per Month

{kind=link}
{kind=link}
{kind=link}
Table A1.
The water capacity of Shasta reservoir from 1981 to 1985.
| Date | Storage AF | Date | Storage AF | Date | Storage AF |
|---|---|---|---|---|---|
| 01/1981 | 3,453,500 | 09/1982 | 3,486,400 | 05/1984 | 4,294,400 |
| 02/1981 | 3,865,200 | 10/1982 | 3,433,400 | 06/1984 | 4,070,000 |
| 03/1981 | 4,320,700 | 11/1982 | 3,297,100 | 07/1984 | 3,587,400 |
| 04/1981 | 4,295,900 | 12/1982 | 3,255,000 | 08/1984 | 3,305,500 |
| 05/1981 | 3,994,300 | 01/1983 | 3,740,300 | 09/1984 | 3,240,100 |
| 06/1981 | 3,608,600 | 02/1983 | 3,579,400 | 10/1984 | 3,155,400 |
| 07/1981 | 3,033,000 | 03/1983 | 3,725,100 | 11/1984 | 3,252,300 |
| 08/1981 | 2,547,600 | 04/1983 | 4,286,100 | 12/1984 | 3,105,500 |
| 09/1981 | 2,480,200 | 05/1983 | 4,526,800 | 01/1985 | 3,118,200 |
| 10/1981 | 2,560,200 | 06/1983 | 4,471,200 | 02/1985 | 3,240,400 |
| 11/1981 | 3,336,700 | 07/1983 | 4,169,900 | 03/1985 | 3,445,500 |
| 12/1981 | 3,492,000 | 08/1983 | 3,776,200 | 04/1985 | 3,546,900 |
| 01/1982 | 3,556,300 | 09/1983 | 3,616,800 | 05/1985 | 3,225,400 |
| 02/1982 | 3,633,500 | 10/1983 | 3,458,000 | 06/1985 | 2,856,300 |
| 03/1982 | 4,062,000 | 11/1983 | 3,395,400 | 07/1985 | 2,292,100 |
| 04/1982 | 4,472,700 | 12/1983 | 3,457,500 | 08/1985 | 1,929,200 |
| 05/1982 | 4,507,500 | 01/1984 | 3,405,200 | 09/1985 | 1,977,800 |
| 06/1982 | 4,375,400 | 02/1984 | 3,789,900 | 10/1985 | 2,083,100 |
| 07/1982 | 4,071,200 | 03/1984 | 4,133,600 | 11/1985 | 2,173,900 |
| 08/1982 | 3,692,400 | 04/1984 | 4,342,700 | 12/1985 | 2,422,100 |
Appendix G. R Codes for the Estimation Methods
library(nleqslv)
#
# Functions for Burr X distribution
# 1. Probability density function: dur
# 2. Cumulative distribution function: pbur
# 3. Quantile function: qbur
# 4. Random sample: rbur
dbur<-function(x,alpha,lambda)
{
return(2*x*alpha/lambda*exp(-x^2/lambda)*(1-exp(-x^2/lambda))^(alpha-1) )
}
pbur<-function(x,alpha,lambda)
{
return((1 - exp(-x^2/lambda))^alpha)
}
qbur<-function(p,alpha,lambda)
{
return(sqrt(-lambda*log(1-p^(1/alpha))))
}
rbur<-function(nn,alpha,lambda)
{
return( qbur(p=runif(nn, min=0,max=1),alpha=alpha,lambda=lambda) )
}
#######################################
# Maximum likelihood estimate (MLE)
# based on complete data
#######################################
mle.burX=function(x)
{
obj.MLE=function(parm){
alpha=parm[1]
lambda=parm[2]
logL = log(dburX(x,alpha,lambda))
return(-sum(logL))
} # End of the obj.MLE function
pa=rep(0,length=2)
pa[1]=runif(1,0,1)
pa[2]=runif(1,0,1)
nlminb(pa, obj.MLE, gradient = NULL, hessian = NULL,
lower =c(0.001,0.001), upper =c(Inf,Inf))
}
mle.bur2=function(x)
{
obj.MLE=function(parm)
{
alpha=parm[1]
lambda=parm[2]
logL = log(dburX(x,alpha,lambda))
return(-sum(logL))
} # End of the obj.MLE function
par=rep(0,length=2)
par[1]=runif(1,0,1)
par[2]=runif(1,0,1)
optim(par, obj.MLE, method="L-BFGS-B",
lower =c(0.001,0.001), upper =c(Inf,Inf))
}
mle.burf=function(x)
{
objLam=function(lambda)
{
return(-length(x)*lambda + sum(x^2) -
(- length(x)/sum(log(1 - exp(-x^2/lambda))))*
sum((x^2*exp(-x^2/lambda))/(1-exp(-x^2/lambda))))
}
unrt=nleqslv(x=lambda,objLam, jac=NULL,method =
c("Newton"),global = c("hook"),xscalm = c("auto"),control = list())
hlam=unrt$x
halp= - length(x)/sum(log(1 - exp(-x^2/hlam)))
return(list(halp=halp,hlam=hlam))
}
###############################################
# All strength observations x
# All stress observations y
##############################################
x=c(0.4238,0.5579,0.7262,0.8112,0.8296,0.2912,0.3634,0.3719,0.4637,
0.4785,0.5381,0.5612,0.7226,0.7449,0.7540,0.5249, 0.6060, 0.6686,
0.7159, 0.7552,0.3451, 0.4253, 0.4688, 0.7188, 0.7420,0.2948,
0.3929, 0.4616, 0.6139,0.7951 )
y=c(0.7009,0.6532,0.4589,0.7183,0.5310,0.7665)
#-------------------------------------------------
# Test of Kolmogorov--Smirnov for the Burr X distribution
# data set for the strength obervations x and~
# data set for the stress observations y.
# Plot empirical and Burr X CDFs
#----------------------------------------------------------
ksBurX=function(x,alternative = "two.sided", plot = FALSE)
{
est=mle.burf(x)
lambda=est$hlam
alpha=est$halp
x=sort(x)
mini <- min(x)
maxi <- max(x)
res <- ks.test(x, pburX, alpha,lambda, alternative = alternative)
ye=numeric(length(x))
ye[1] = 1/length(x)
for(i in 2:length(x)) ye[i] = ye[i-1] + ye[1]
if (plot == TRUE)
{
plot(x,ye,ylim =c(0,1),xlim=c(mini,maxi),
type="S",main = "Empirical DF and Burr X CDF", xlab = "Strength",
ylab = "Probability")
t <- seq(mini, maxi, by~= 0.01)
y <- pburX(t, alpha, lambda)
lines(t,y, lwd = 2)
}
return(res)
}
###############################################
# For P-P plots
#
###############################################
CDFX<-function(x,alternative="two.sided",plot=TRUE)
{
est=mle.burf(x)
lambda=est$hlam
alpha=est$halp
x=sort(x)
mini <- min(x)
maxi <- max(x)
res <- ks.test(x, pburX, alpha,lambda, alternative = alternative)
ye=numeric(length(x))
ye[1] = 1/length(x)
xe=numeric(length(x))
xe[1]=pburX(x[1],alpha,lambda)
for(i in 2:length(x))
{ ye[i] = ye[i-1] + ye[1]
xe[i] =pburX(x[i],alpha,lambda)
}
fit=lm(ye~xe)
summary(fit)
if (plot == TRUE)
{
plot(xe,ye,ylim =c(min(ye),max(ye)),xlim=c(min(xe),max(xe)),
type="p",col="blue",main = "Empirical CDF-Burr X CDF plot",
xlab = "Fitted Burr X CDF for Strength",ylab = "Empirical CDF")
abline(fit,col="blue")
}
return(fit)
}
#####################################################
# For Q-Q plots
#
#####################################################
quantX<-function(x,alternative="two.sided",plot=TRUE)
{
est=mle.burf(x)
lambda=est$hlam
alpha=est$halp
x=sort(x)
mini <- min(x)
maxi <- max(x)
res <- ks.test(x, pburX, alpha,lambda, alternative = alternative)
ye=x
n=length(x)
xe=numeric(n)
xe[1]=qburX((1-0.5)/n,alpha,lambda)
for(i in 2:length(x)) xe[i] =qburX((i-0.5)/n,alpha,lambda)
fit=lm(ye~xe)
summary(fit)
if (plot == TRUE)
{
plot(xe,ye,ylim =c(min(ye),max(ye)),xlim=c(min(xe),max(xe)), type="p",
col="blue",main = "Empirical quantile-Burr X quantile plot",
xlab = "Fitted Burr X quantile for Strength", ylab = "Empirical quantile")
abline(fit,col="blue")
}
return(fit)
}
# Data set
k=5
s=3
# The 3 out of 5 G system data set
# xL=matrix(nrow=6,ncol=s)
# y is the corresponding stress data set
x=matrix(nrow=6,ncol=s)
x[1,]=c(0.4238,0.5579,0.7262)
x[2,]=c(0.2912,0.3634,0.3719)
x[3,]=c(0.5381,0.5612,0.7226)
x[4,]=c(0.5249,0.6060,0.6686)
x[5,]=c(0.3451,0.4253,0.4688)
x[6,]=c(0.2948,0.3929,0.4616)
y=c(0.7009,0.6532,0.4589,0.7183,0.5310,0.7665)
n=dim(x)[1]
# The partition set over [0, 1] for evaluating integral
u =numeric(1000)
du = 1/1000
u[1] = du/2
for(i in 2:1000) u[i] = u[i-1] + du
##################################################
# Find maximum likelihood estimator of
# reliability for multicomponent system
# assuming equal scale parameter
######################################
# Log-likelihood function for equal rate parameter
# Based on type II strength data set and the
# corresponding stress data set
#
obj<-function(par)
{
lambda=par[1]; alpha1=par[2]; alpha2=par[3]
temp1=sum(log(dbur(x,alpha1,lambda)))
temp2=(k-s)*sum(log(1-pbur(x[,s],alpha1,lambda)))
temp3=sum(log(dbur(y,alpha2,lambda)))
tTemp = temp1+temp2+temp3
return(-tTemp)
}
# Reliability of system
#
Relibyks3=function(alpha1,alpha2)
{
tempa = 0
# cat("s =", s, "k =",k,"\n")
for(i in s:k)
{
ch1=choose(k,i)
temp= 0
for(j in 0:(k-i))
{
ch2 =choose(k-i,j)
temp=temp + ch2 *((-1)^j)* (alpha2/(alpha1*(j+i) + alpha2))
}
temp=temp*ch1
tempa = tempa + temp
}
return(tempa)
}
# Calculating gradient of reliability function
#
gradient3 = function(lambda,alpha1,alpha2)
{
tempaL1 = 0; tempaL2=0
for(i in s:k)
{
ch1=choose(k,i)
temp1= 0; temp2=0
for(j in 0:(k-i))
{
ch2 =choose(k-i,j)
temp1=temp1 + ch2 *((-1)^j)* (alpha2*(j+i)/(alpha1*(j+i) + alpha2)^2)
temp2=temp2 +ch2*((-1)^j)*(alpha1*(j+i)/(alpha1*(j+i) + alpha2)^2 )
}
temp1=temp1*ch1
temp2 = temp2*ch1
tempaL1 = tempaL1 + temp1
tempaL2 =tempaL2 + temp2
}
dRdL = 0
return(list(dRdL=dRdL, dRda1=(-1)*tempaL1, dRda2 = tempaL2))
}
#
# Main program is given as follows
#
# Maximum likelihood estimates for three parameters
par=c(0.06,0.1,0.5)
out= optim(par,obj,method="L-BFGS-B",lower=c(0.05,0.05,0.05),
hessian="TRUE")
hlambda =out$par[1]
ha1 = out$par[2]
ha2 = out$par[3]
hRsk=Relibyks3(alpha1=ha1,alpha2=ha2)
# 2. Bootstrap procedure
Bha1 = numeric(BOOT)
Bha2 = numeric(BOOT)
Bhlambda = numeric(BOOT)
BhRsk = numeric(BOOT)
# 2. generating bootstrap sample and get bootstrap MLE
for(iB in 1:BOOT)
{
y = rbur(nn=n,alpha=ha2,lambda=hlambda)
for(ii in 1:n)
{
x[ii,]= sort(rbur(nn=k,alpha =ha1,lambda=hlambda))[1:s]
}
Bpar=c(0.5,1.2,2.5)
BBpar= optim(par,obj,method="SANN")$par
Bhlambda[iB]=BBpar[1]
Bha1[iB] = BBpar[2]
Bha2[iB] = BBpar[3]
BhRsk[iB]=Relibyks(alpha1=Bha1[iB],alpha2=Bha2[iB])
cat(iB, "th run","\n")
}
conf=quantile(BhRsk, probs=c(0.025,0.975), type = 1)
# find ACI
zq = abs(qnorm(0.025))
Fm=out$hessian
Covar=solve(Fm)
## Find confidence interval of reliability
gRadlist=gradient3(lambda=hlambda,alpha1=ha1,alpha2=ha2)
gRad=numeric(3)
gRad[1]=gRadlist$dRdL; gRad[2]=gRadlist$dRda1;gRad[3]=gRadlist$dRda2
varRsk = t(gRad)%*%Covar%*%t(t(gRad))
varlnRsk = varRsk/hRsk
CL =hRsk/exp(zq*sqrt(varlnRsk))
CU =hRsk*exp(zq *sqrt(varlnRsk))
#Output results
cat("Simulation results: LBRsk = ",conf[1]," UBRsk = ",conf[2]," hRsk = ",
hRsk,"\n")
cat("ACI is", CL, " ", CU,"\n")
# end of the case for equal rate~parameter
##################################################
# Find maximum likelihood estimator of
# reliability for multicomponent system
# assuming different scale parameters (four parameters)
#
######################################
# log-likelihood function
obj<-function(par)
{
lambda1=par[1];alpha1=par[2];lambda2=par[3]; alpha2=par[4]
temp1=sum(log(dbur(x,alpha1,lambda1)))
temp2=(k-s)*sum(log(1-pbur(x[,s],alpha1,lambda1)))
temp3=sum(log(dbur(y,alpha2,lambda2)))
tTemp = temp1+temp2+temp3
return(-tTemp)
}
#
#
Relibyks4=function(lambda1,alpha1,lambda2,alpha2)
{
tempa = 0
# cat("s =", s, "k =",k,"\n")
for(i in s:k)
{
ch1=choose(k,i)
temp= 0
for(j in 0:(k-i))
{
ch2 =choose(k-i,j)
v=du*sum( (1 - u^(lambda2/lambda1))^(alpha1*(i+j))*(1-u)^(alpha2-1))
temp=temp + alpha2*ch2 *((-1)^j)*v
}
temp=temp*ch1
tempa = tempa + temp
}
return(tempa)
}
#
# gradient of reliability function under four parameters
gradient4 = function(lambda1,alpha1,lambda2,alpha2)
{
tempaL1 = 0; tempaL2=0;tempaL3=0;tempaL4=0
for(i in s:k)
{
ch1=choose(k,i)
temp1= 0; temp2=0;temp3=0;temp4=0
for(j in 0:(k-i))
{
ch2 =choose(k-i,j)*(-1)^j
temp1=temp1 + ch2*alpha2*alpha1*(j+i)*lambda2/lambda1^2*sum((1-u^(lambda2/
lambda1))^(alpha1*(i+j)-1)*
(1-u)^(alpha2-1)*u^(lambda2/lambda1)*log(u))*du
temp2=temp2 +ch2*(j+i)*alpha2*sum((1-u^(lambda2/lambda1))^(alpha1*(i+j))*
log(1-u^(lambda2/lambda1))*
(1-u)^(alpha2-1))*du
temp3=temp3 +ch2*alpha2*alpha1*(j+i)/lambda1*sum((1-u^(lambda2/lambda1))^
(alpha1*(i+j)-1)*
(1-u)^(alpha2-1)*(-u^(lambda2/lambda1))*log(u))*du
temp4=temp4 +ch2*du*(sum((1-u^(lambda2/lambda1))^(alpha1*(j+i))*(1-u)^
(alpha2-1))+
alpha2*sum((1-u^(lambda2/lambda1))^(alpha1*(j+i))*(1 -u)^(alpha2-1)*
log(1-u)))
}
temp1=temp1*ch1
temp2 = temp2*ch1
temp3 =temp3*ch1
temp4 =temp4*ch1
tempaL1 = tempaL1 + temp1
tempaL2 =tempaL2 +temp2
tempaL3 =tempaL3 + temp3
tempaL4 =tempaL4 + temp4
}
return(list(dRdL1=tempaL1, dRda1=tempaL2, dRdL2 = tempaL3, dRda2 =
tempaL4))
}
#
# Pivotal quantity method for three parameters
#
#
xL=matrix(nrow=n,ncol=s)
p1X= numeric(n)
p1Y = numeric(n)
whRsk=numeric(BOOT)
library(HDInterval)
obj<-function(par)
{
lambda=par[1]; alpha1=par[2]; alpha2=par[3]
temp1=sum(log(dbur(x,alpha1,lambda)))
temp2=(k-s)*sum(log(1-pbur(x[,s],alpha1,lambda)))
temp3=sum(log(dbur(y,alpha2,lambda)))
tTemp = temp1+temp2+temp3
return(-tTemp)
}
gRad = numeric(3)
zq = abs(qnorm(0.025))
par=c(2.5,2.5,2.5)
out= optim(par,obj,method="L-BFGS-B",lower=c(0.5,0.5,0.5),hessian="TRUE")
hlambda =out$par[1]
ha1 = out$par[2]
ha2 = out$par[3]
hRsk=Relibyks3(ha1,ha2)
for(jq in 1:BOOT)
{
# 1. generating data sets for x and y
y = rbur(nn=n,alpha=ha2,lambda=hlambda)
for(i in 1:n)
{
x[i,]= sort(rbur(nn=k,alpha = ha1,lambda=hlambda))[1:s]
}
par=c(2.5,2.5,2.05)
out= optim(par,obj,method="L-BFGS-B",lower=c(0.5,0.5,0.5))
whla = out$par[1]
log(1 - exp(-y^2/whla))
wha1 = - rchisq(1,df=2*n*s)/(2*((k-s)*sum(log(1 - exp(-x[,s]^2/whla))) +
sum(log(1 - exp(-x^2/whla)))))
wha2 = - rchisq(1, df=2*n)/(2*sum(log(1 - exp(-y^2/whla))))
whRsk[jq]=Relibyks(wha1,wha2)
}
conf=hdi(whRsk, credMass = 0.95)
Lbconf = conf[1]
Ubconf = conf[2]
BhRsk = mean(whRsk)
lnw1 = mean(log((1+whRsk)/(1-whRsk)))
hRskF = (exp(lnw1) - 1)/(exp(lnw1) +1)
#
# Pivotal quantity method with four parameters
#
xL=matrix(nrow=n,ncol=s)
p1X= numeric(n)
p1Y = numeric(n)
whRsk=numeric(BOOT)
library(HDInterval)
obj<-function(par)
{
lambda1=par[1]; alpha1=par[2];lambda2=par[3]; alpha2=par[4]
temp1=sum(log(dbur(x,alpha1,lambda1)))
temp2=(k-s)*sum(log(1-pbur(x[,s],alpha1,lambda1)))
temp3=sum(log(dbur(y,alpha2,lambda2)))
tTemp = temp1+temp2+temp3
return(-tTemp)
}
zq = abs(qnorm(0.025))
par=c(2.5,2.5,2.5,2.5)
out= optim(par,obj,method="L-BFGS-B",lower=c(0.5,0.5,0.5,0.5),
hessian="TRUE")
hlambda1 =out$par[1]
ha1 = out$par[2]
hlambda2 =out$par[3]
ha2 = out$par[4]
for(jq in 1:BOOT)
{
par=c(1.5,1.5,1.05,1.05)
out= optim(par,obj,method="L-BFGS-B",lower=c(0.5,0.5,0.5,0.5))
whla1 = out$par[1]
wha1=out$par[2]
whla2=out$par[3]
wha2 =out$par[4]
wha1 = rchisq(1,df=2*n*s)/(-2*((k-s)*sum(log(1 - exp(-x[,s]^2/whla1)))) )
wha2 =rchisq(1, df=2*n)/(-2*sum(log(1 - exp(-y^2/whla2))))
whRsk[jq]=Relibyks4(whla1,wha1,whla2,wha2)
cat(" Boot Run at ",jq,"\n")
}
conf=hdi(whRsk, credMass = 0.95)
Lbconf = conf[1]
Ubconf = conf[2]
BhRsk = mean(whRsk)
lnw1 = mean(log((1+whRsk)/(1-whRsk)))
hRskF = (exp(lnw1) - 1)/(exp(lnw1) +1)
cat(BhRsk," ",hRskF,"\n")
cat("GCI = ",Lbconf," GCU = ",Ubconf,"\n")
References
- Eryilmaz, S. Phase type stress-strength models with reliability applications. Commun. Stat.—Simul. Comput. 2018, 47, 954–963. [Google Scholar] [CrossRef]
- Kundu, D.; Raqad, M.D. Estimation of R = P(Y < X) for three-parameter Weibull distribution. Stat. Probab. Lett. 2009, 79, 1839–1846. [Google Scholar]
- Krishnamoorthy, K.; Lin, Y. Confidence limits for stress-strength reliability involving Weibull models. J. Stat. Plan. Inference 2010, 140, 1754–1764. [Google Scholar] [CrossRef]
- Mokhlis, N.A.; Ibrahim, E.J.; Ibrahim, E.J. Stress-strength reliability with general form distributions. Commun. Stat.—Theory Methods 2017, 46, 1230–1246. [Google Scholar] [CrossRef]
- Surles, J.G.; Padgett, W.J. Inference for P(Y < X) in the Burr Type X Model. J. Appl. Stat. Sci. 1998, 7, 225–238. [Google Scholar]
- Wang, B.; Geng, Y.; Zhou, J. Inference for the generalized exponential stress-strength model. Appl. Math. Model. 2018, 53, 267–275. [Google Scholar] [CrossRef]
- Bhattacharyya, G.K.; Johnson, R.A. Estimation of reliability in multicomponent stress-strength model. Am. Stat. Assoc. 1947, 69, 966–970. [Google Scholar] [CrossRef]
- Dey, S.; Mazucheli, J.; Anis, M.Z. Estimation of reliability of multicomponent stress-strength for a Kumaraswamy distribution. Commun. Stat.—Theory Methods 2017, 46, 1560–1572. [Google Scholar] [CrossRef]
- Kayal, T.; Tripathi, Y.M.; Dey, S.; Wu, S.J. On estimating the reliability in a multicomponent stress-strength model based on Chen distribution. Commun. Stat.—Theory Methods 2020, 49, 2429–2447. [Google Scholar] [CrossRef]
- Kizilaslan, F. Classical and Bayesian estimation of reliability in a multicomponent stress-strength model based on the proportional reversed hazard rate model. Math. Comput. Simul. 2017, 136, 36–62. [Google Scholar] [CrossRef]
- Kizilaslan, F. Classical and Bayesian estimation of reliability in a multicomponent stress-strength model based on a general class of inverse exponentiated distributions. Stat. Pap. 2018, 59, 1161–1192. [Google Scholar] [CrossRef]
- Kizilaslan, F.; Nadar, M. Estimation of reliability in a multicomponent stress-strength model based on a bivariate Kumaraswamy distribution. Stat. Pap. 2018, 59, 307–340. [Google Scholar] [CrossRef]
- Nadar, M.; Kizilaslan, F. Estimation of reliability in a multicomponent stress-strength model based on a Marshall-Olkin bivariate Weibull distribution. IEEE Trans. Reliab. 2016, 65, 370–380. [Google Scholar] [CrossRef]
- Rao, G.S. Estimation of reliability in multicomponent stress-strength model based on Rayleigh distribution. ProbStat Forum 2012, 5, 150–161. [Google Scholar]
- Rao, G.S. Estimation reliability in multicomponent stress-strength based on generalized Rayleigh distribution. J. Mod. Appl. Stat. Methods 2014, 13, 367–379. [Google Scholar] [CrossRef]
- Rao, G.S.; Aslam, M.; Kundu, D. Burr type XII distribution parametric estimation and estimation of reliability of multicomponent stress-strength. Commun. Stat.—Theory Methods 2015, 44, 4953–4961. [Google Scholar] [CrossRef]
- Shawky, A.I.; Khan, K. Reliability estimation in multicomponent stress-strength based on inverse Weibull distribution. Processes 2022, 10, 226. [Google Scholar] [CrossRef]
- Lio, Y.L.; Tsai, T.-R.; Wand, L.; Cecilio Tejada, I.P. Inferences of the Multicomponent Stress-Strength Reliability for Burr XII Distributions. Mathematics 2022, 10, 2478. [Google Scholar] [CrossRef]
- Sauer, L.; Lio, Y.; Tsai, T.-R. Reliability inference for the multicomponent system based on progressively type II censoring samples from generalized Pareto distributions. Mathematics 2020, 8, 1176. [Google Scholar] [CrossRef]
- Wang, L.; Lin, H.; Ahmadi, K.; Lio, Y. Estimation of stress-strength reliability for multicomponent system with Rayleigh data. Energies 2021, 14, 7917. [Google Scholar] [CrossRef]
- Burr, I.W. Cumulative frequency functions. Ann. Math. Stat. 1942, 13, 215–232. [Google Scholar] [CrossRef]
- Belili, M.C.; Alshangiti, A.M.; Gemeay, A.M.; Zeghdoudi, H.; Karakaya, K.; Bakr, M.E.; Balogun, O.S.; Atchade, M.N.; Hussam, E. Two-paramter family of distributions: Properties, estimation, and applications. AIP Adv. 2023, 13, 105008. [Google Scholar] [CrossRef]
- Yousof, H.M.; Afify, A.Z.; Hamedani, G.G.; Aryal, G. The Burr X generator of distributions for lifetime data. J. Stat. Theory Appl. 2017, 16, 288–305. [Google Scholar] [CrossRef]
- Jamal, F.; Nasir, M.A. Generalized Burr X family of distributions. Int. J. Math. Stat. 2018, 19, 55–73. [Google Scholar]
- Jaheen, Z.F. Empirical Bayes estimation of the reliability and failure rate functions of the Burr type X failure model. J. Appl. Stat. Sci. 1996, 3, 281–288. [Google Scholar]
- Ahmad, K.E.; Fakhry, M.E.; Jaheen, Z.F. Empirical Bayes estimation of P(Y < X) and characterization of Burr-type X model. J. Stat. Plan. Inference 1997, 64, 297–308. [Google Scholar]
- Akgul, F.G.; Senoglu, B. Inferences for stress-strength reliability of Burr type X distributions based on ranked set sampling. Commun. Stat.—Simul. Comput. 2022, 51, 3324–3340. [Google Scholar] [CrossRef]
- Efron, B. Jackknife, Bootstrap, Other Resampling Plans. In CBMS-NSF Regional Conference Series in Applied Mathematics; SIAM: Philadelphia, PA, USA, 1982; Volume 38. [Google Scholar]
- Hall, P. Theoretical comparison of bootstrap confidence intervals. Annu. Stat. 1988, 16, 927–953. [Google Scholar] [CrossRef]
- Xu, J.; Long, J.S. Using the Delta Method Tonconstruct Confidence Intervals for Predicted Probabilities, Rates, and Discrete Changes; Lecture Notes; Indiana University: Bloomington, IN, USA, 2005. [Google Scholar]
- Weerahandi, S. Generalized Inference in Repeated Measures: Exact Methods in MANOVA and Mixed Models; Wiley: New York, NY, USA, 2004. [Google Scholar]
- Cherstvy, A.G.; Thapa, S.; Wagner, C.E.; Metzler, R. Non-Gaussian, non-ergodic, and non-Fickian diffusion of tracers in mucin hydrogels. Soft Matter 2019, 15, 2526–2551. [Google Scholar] [CrossRef]
- Thapa, S.; Park, S.; Kim, Y.; Jeon, J.-H.; Metzler, R.; Lomholt, M.A. Bayesian inference of scaled versus fractional Brownian motion. J. Phys. A Math. Theor. 2022, 55, 194003. [Google Scholar] [CrossRef]
- Krog, J.; Lomholt, M.A. Bayesian inference with information content model check for Langevin equations. Phys. Rev. E 2017, 96, 062106. [Google Scholar] [CrossRef] [PubMed]
- Viveros, R.; Balakrishnan, N. Interval estimation of parameters of life from progressively censored data. Technometrics 1994, 36, 84–91. [Google Scholar] [CrossRef]
- Lawless, J.F. Statistical Models and Methods for Lifetime Data, 2nd ed.; Wiley: New York, NY, USA, 2003. [Google Scholar]
- Stephens, M.A. Tests for the exponential distribution. In Goodness-of-Fit Techniques; D’Agostino, R.B., Stephens, M.A., Eds.; Marcel Dekker: New York, NY, USA, 1986; pp. 421–459. [Google Scholar]
Figure 1.
Step figure is the sample empirical distribution and curve is the fitted Burr X distribution. Left side is for strength data modeling with BurrX. Right side is for stress data modeling with BurrX.
Figure 1.
Step figure is the sample empirical distribution and curve is the fitted Burr X distribution. Left side is for strength data modeling with BurrX. Right side is for stress data modeling with BurrX.

Figure 2.
Sample cumulative probability vs. Burr X cumulative probability plot overlapped with the regression line. Left side is for strength data modeling with BurrX and fitting regression line with R2 = 0.97. Right side is for stress data modeling with BurrX and fitting regression line with R2 = 0.91.
Figure 2.
Sample cumulative probability vs. Burr X cumulative probability plot overlapped with the regression line. Left side is for strength data modeling with BurrX and fitting regression line with R2 = 0.97. Right side is for stress data modeling with BurrX and fitting regression line with R2 = 0.91.

Figure 3.
Sample quantile vs. Burr X quantile plot overlapped with the regression line. Left side is for strength data modeling with BurrX and fitting regression line with R2 = 0.93. Right side is for stress data modeling with BurrX and fitting regression line with R2 = 0.89.
Figure 3.
Sample quantile vs. Burr X quantile plot overlapped with the regression line. Left side is for strength data modeling with BurrX and fitting regression line with R2 = 0.93. Right side is for stress data modeling with BurrX and fitting regression line with R2 = 0.89.

Table 1.
The estimation results for using the collected data from 3-out-of-5 G system.
| ACI | GCI | BCI |
| ACI | GCI | BCI |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Lio, Y.; Chen, D.-G.; Tsai, T.-R.; Wang, L. The Reliability Inference for Multicomponent Stress–Strength Model under the Burr X Distribution. AppliedMath 2024, 4, 394-426. https://0-doi-org.brum.beds.ac.uk/10.3390/appliedmath4010021
AMA Style
Lio Y, Chen D-G, Tsai T-R, Wang L. The Reliability Inference for Multicomponent Stress–Strength Model under the Burr X Distribution. AppliedMath. 2024; 4(1):394-426. https://0-doi-org.brum.beds.ac.uk/10.3390/appliedmath4010021
Chicago/Turabian StyleLio, Yuhlong, Ding-Geng Chen, Tzong-Ru Tsai, and Liang Wang. 2024. "The Reliability Inference for Multicomponent Stress–Strength Model under the Burr X Distribution" AppliedMath 4, no. 1: 394-426. https://0-doi-org.brum.beds.ac.uk/10.3390/appliedmath4010021