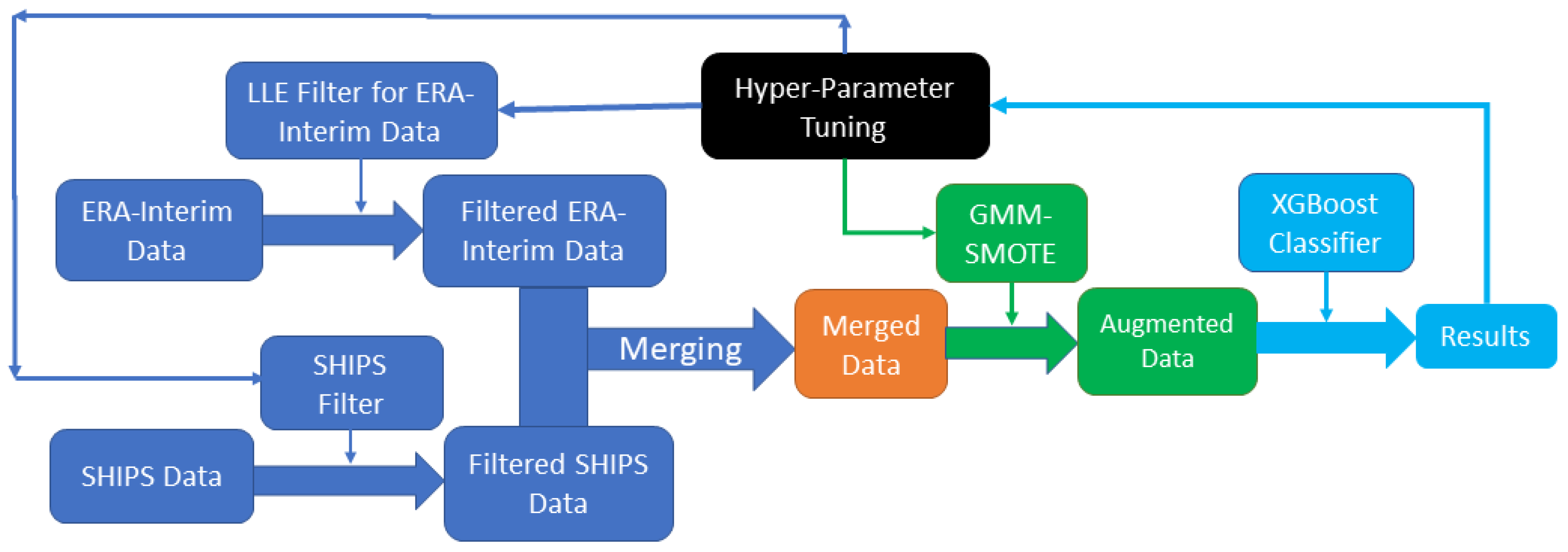
As in WY21 for the COR-SHIPS model, importance scores based on XGBoost are used to evaluate the contributions of a specific variable. However, in the LLE-SHIPS model, the inputs to the classifier are SHIPS variables and LLE-based derived variables, lle1, lle2, …, lle90, and the importance scores are for those input variables instead of the original ERA-Interim variables. At this moment, there are no available algorithms for directly calculating the importance score for the original ERA-Interim variables from XGBoost. So instead, we tried to relate the importance score (IS) of all the lle1, …, lle90 to individual ERA parameter groups (based on correlation) in two steps. First, the XGBoost was used to evaluate the importance score for SHIPS variables and lle1 to lle90 in the same way as in the COR-SHIPS model, and then a feature permutation approach was used to evaluate the importance score for the original ERA-Interim feature space separately, based on the importance score generated from the first step.
4.3.2. Group Importance in LLE
Molnar [
27] described a feature permutation approach to evaluate the importance of features on a training dataset for nonlinear models where the importance score cannot be derived easily. In that method, for the feature space in any given dataset
X,
f(
X) is the predicted value by the classifier
f, and
y is the ground truth. We denote that the loss of the classifier is
L(
y,
f(
X)). Then, for each feature in the feature space
X, permute its value to zero for all the observations while keeping other features unchanged (represented as
). Finally, the difference between the loss of the permuted feature space (
) and the original loss is calculated for each feature, and the difference is used as its importance.
Although feature permutation is an efficient approach to evaluate the feature importance for different models, especially for a black-box model such as LLE, Molnar [
27] also indicates that the permutated feature importance could be biased by the highly correlated features. For example, if we evaluate the importance score for each of the 2072 variables, the result, i.e., the importance score, is not accurate due to the existence of the highly correlated variables because they could influence each other. Similar to the removal of highly correlated variables in the SHIPS data filter (WY21), pairwise correlations of all the 2072 features are calculated. For a given feature, all other features with a correlation higher than a predefined threshold, 0.8, are grouped together, and a filtering process removes any duplications and keeps a feature only once in the whole list. This process results in 135 groups, and then an importance score is calculated for each group by permuting all features in that group simultaneously.
The group-level importance score is calculated specifically as follows:
Given f: trained model; X: original feature space; y: ground truth; L(y, f(X)): loss between the ground truth and the predicted value by the classifier.
- 1.
Calculate as the sum of the importance score of lle1 to lle90 derived from XGBoost; here, it is 0.4288.
- 2.
Calculate the original model error L(y, f).
- 3.
For each group g:
- (a)
Generate feature matrix by setting features in that group to 0, which breaks the corresponding correlation between all the features.
- (b)
Calculate error L(y, f()).
- (c)
Estimate the importance for the group imp = L(y, f()) − L(y, f).
- (d)
Associate the score to the group g.
- (e)
Negative importance is set to 0.
- 4.
Group importance scores are rescaled as attributing the total important scores by LLE variables based on the ratio of loss of a particular group to the total loss (sum of all group losses), and the specific calculation is:
With the final scaling procedure on the
, the group importance scores could be directly compared with those of the SHIPS features. Based on the above algorithm, the importance score for each group is calculated, and groups with the top five important scores are list in
Table 7. Intuitively, turning more variables to zero could reduce the model’s performance more than turning fewer variables to zero because changing more variables is likely to alternate the model’s performance more. However,
Table 7 shows that three of top five groups contain less than 15 variables while the largest group size is 309, and that indicates that the three groups with few variables play a more important role in RI prediction than the other groups, especially the groups with substantially more variables. The details of the top five groups are displayed in
Supplementary Material Table S1.
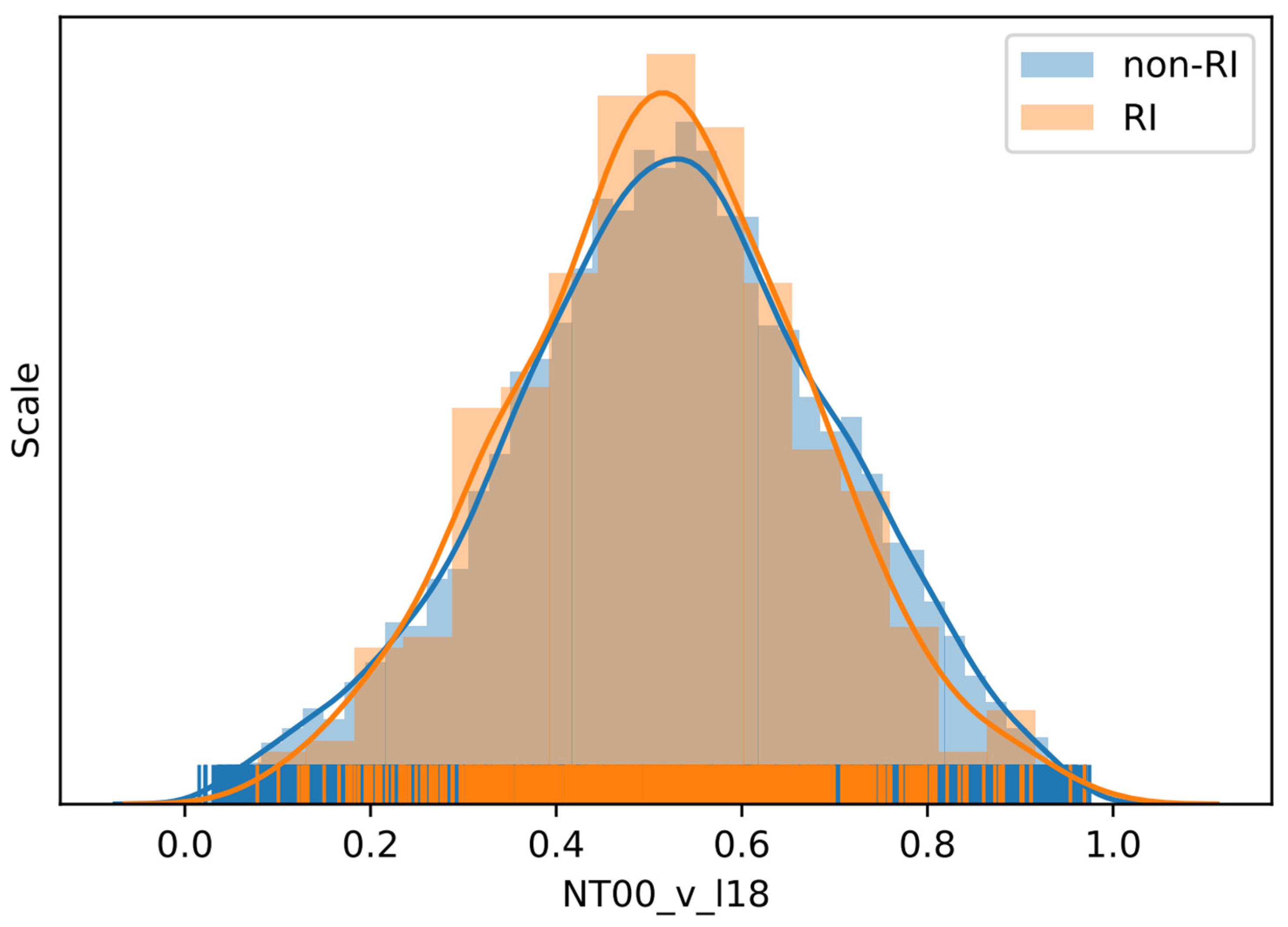
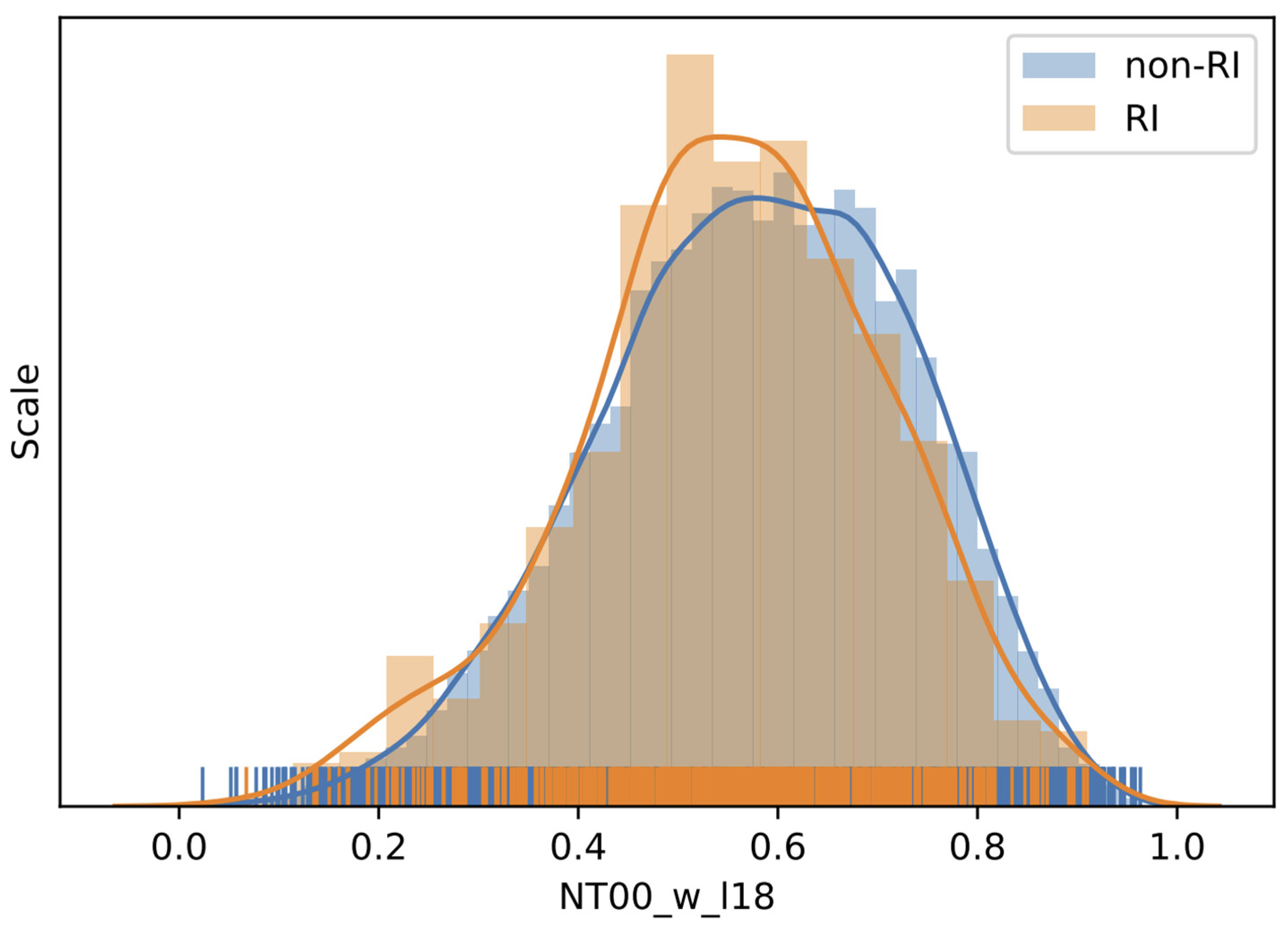
Group 49 (G49) has the highest IS, 0.023614, and it has five variables, NT06_v_l17, NT00_v_l17, NT12_v_l18, NT06_v_l18, and NT00_v_l18, which indicates that the northward wind speed on level 17 (450 hPa) at 6 h before and at present, together with level 18 (400 hPa) at 12 h before, 6 h before, and at present are important in RI prediction. The reason could be that the northward wind speed in 400 and 450 hPa changes faster than that of other levels when the RI starts to occur. We can also find that both 6 h before and the present northward wind speed are important at 400 and 450 hPa, while 12 h before only appears in 400 hPa. The result indicates that the northward wind speed in 400 and 450 hPa starts to change immediately 6–12 h before the occurrence of RI. To see the influence of this group of variables, the distributions of the meridional wind speed at 400 hPa at TC time (NT00_v_l18) for RI and non-RI instances are displayed in
Figure 2. The results do not show any substantial differences between the RI and non-RI distributions. One may notice that the RI instances are more concentrated around the mean than that of the non-RI instances. Correspondingly, non-RI instances demonstrate the heavy tails, but it may simply be due to the large number of non-RI instances. Some simple quantitative statistics of the RI instances and non-RI instances over variable NT00_v_l18 are displayed in
Table 8. The higher standard deviation and interquartile range confirm that the distribution of non-RI instances is flatter than that of RI instances. Since the mid-layer velocity is closely related to the movement of TCs, this importance of NT00_v_l18 says that the meridional motion of TC affects RI. This is not unexpected because storm speed was used in the seminal RI study by KD03. Intuitively, a smaller meridional speed means TCs move northward slower and have more time to obtain more energy than those moving fast in that direction. The numbers confirmed the argument because the mean and median meridional speeds for RI cases are smaller than those for non-RI cases, but the median difference is not statistically significant with the Mann–Whitney test (
Table 8).
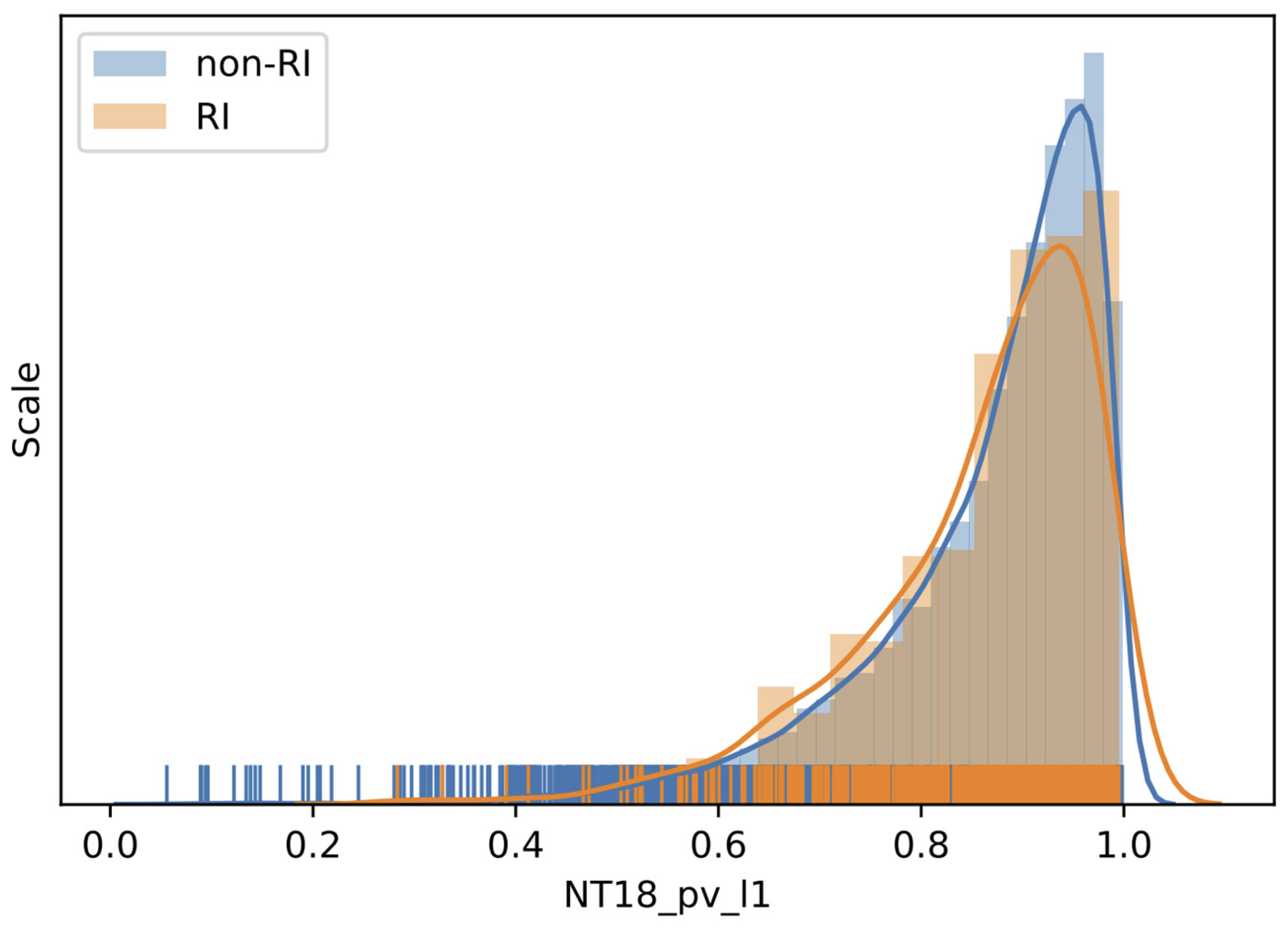
The second most important group, the G88 with an IS of 0.021988, only has one variable, NT18_pv_l1, and the potential vorticity is at 18 h before on the first level (1000 hPa). The importance score for NT18_pv_l1 is even 17% higher than that for the most important variable in
Table A1, BD12 with a 0.0188 score, which is also the highest importance for a single variable. This result proved that our AI system could identify important features, which may not be in the commonly used dataset, such as the SHIPS database. However, the role of pv in RI was identified by others already (e.g., [
28,
29]). Tsujino and Kuo [
28] detailed the changes of pv during the RI of Super Typhoon Haiyan (2013) with numerical simulation. They emphasized the pv increasing at around 3–5 km height at the beginning stage of the RI. Carefully checking their results (
Figure 2b,c), one can find the pv actually increases simultaneously around the sea level in the 20–40 km range from the center, which is the same as what we identified here by the NT18_pv_l1.
Figure 2 and
Figure 3 display the distribution of potential vorticity at 1000 hPa for RI and non-RI instances, respectively, and the corresponding quantitative statistics are also listed in
Table 8. The means and medians of RI and non-RI cases follow the same pattern. That is, the non-RI medians are higher than the RI medians, and the pv median difference is statistically significant at the 0.05 significance level. The result is consistent with Rogers et al. [
30], who composited airborne Doppler radar data for intensifying and stable TCs and found the mean pv with intensifying TCs is significantly lower than that for TCs in a steady state.
All level one pv (three of them) are grouped in G63 with importance scores (IS) (0.010746). All level two pv are in G55 with four members and 0.004744 IS. All other pv are in G4 with 140 members but IS being only 0.006264. Those numbers illustrated that only lower layer pv affects the RI process.
The third most important group is G1, which has 309 features in the group, and with an IS of 0.019687. Since all types of ERA-Interim variables are included in the group, it is difficult to trace back which variable is more important.
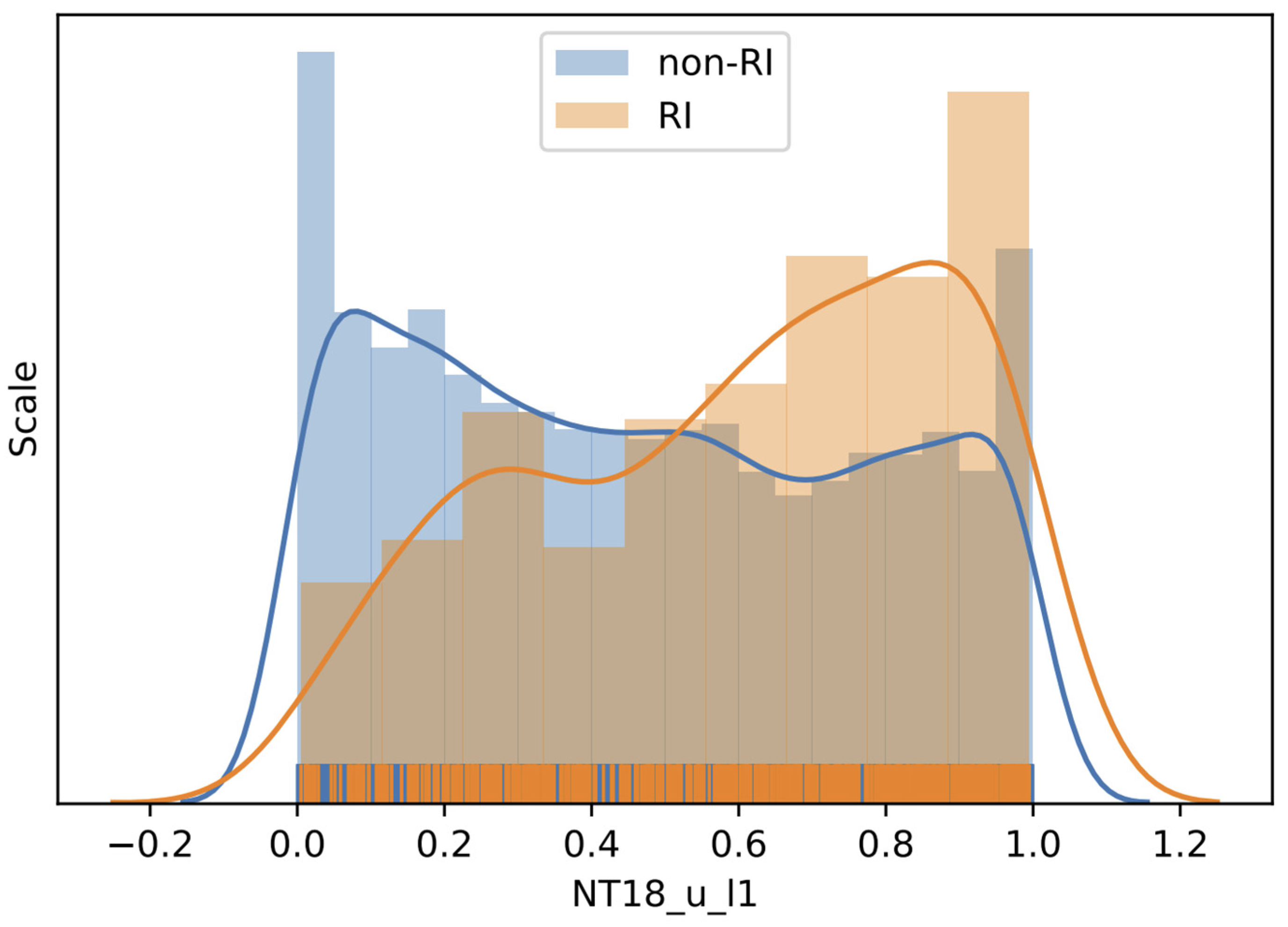
The fourth most important group is G29, which has an IS of 0.019662, very close to the third highest value, and consists of 11 variables, i.e., NT18_u_l1, NT12_u_l1, NT06_u_l1, NT00_t_l10, NT00_u_l16, NT00_u_l17, NT06_u_l17, NT12_u_l17, NT18_u_l18, NT12_u_l18, and NT18_u_l17. We can find that most of the variables in the group are u, the zonal wind speed. It is interesting to note that the zonal speeds at 1000 hPa (level 1) 6–18 h before the current time are highly correlated with the corresponding speeds at 450 hPa (level 17) and 400 hPa (level 18). As we carried out before, we chose NT18_u_l1, the zonal speed at 1000 hPa 18 h before the current time, as the group representative and displayed the value distributions for RI and non-RI cases (
Figure 4) and quantitative statistics (
Table 8). The distributions for RI and non-RI instances are substantially different, unlike the cases for NT00_v_l18 and NT18_pv_l1. Both of the distributions are non-Gaussian and with minor second modes. However, more RI instance values are close to one while more non-RI instance values approach zero. From
Table 8, we can find lower 25 percentile, median, and 75 percentile of non-RI instances than those of RI instances. Similarly, the
p value of NT18_u_l1 indicates that the median difference between RI and non-RI instances is statistically significant.
Similar to the meridional speeds (G49) but slightly different, the eastward wind speeds at level 17 (450 hPa) and 18 (400 hPa) in G29 also play an important role in RI prediction. In addition to the 400 and 450 hPa eastward wind speed, the eastward wind at 1000 hPa at 6, 12, and 18 h is also in G29. Wang et al. [
10] found that “low-level shear between 850 (or 700) and 1000 hPa is more negatively correlated with TC intensity change than any deep-layer shear during the active typhoon season”, which matches our findings that eastward wind speed, related to the VWS, at 1000 hPa is significant in RI prediction. Additionally, we also recognize that the mid-level (400 and 450 hPa) eastward wind speed (possibly via VWS) is important to TC intensity change. One exception variable in this group is the temperature at 775 hPa, NT00_t_l10; although it is highly correlated with
u in terms of value, it is possibly misplaced in the group because there is only one
t variable in the group.
The fifth most important score is 0.01728 with G3, consisting of 148 w (the pressure vertical velocity) variables. In other words, all w components for four times and 37 levels are all grouped here. In the warm core of a TC, the upward motions near the center as part of the secondary circulation (also with low-level inflow and upper-level outflow) show strong correlations among the motion at different times (from 18 h before to current time) for all vertical layers. This strong linear relationship is partially due to the relative uniform distribution of the vertical velocity across most of atmosphere [
31] and partially due to the averaging process in the 240 km × 240 km boxes, which smoothed out all the differences between the eyes and eyewalls [
32]. Rogers et al. [
30] found that the eyewall vertical velocity is significantly higher in intensifying (IN) cases than that in steady state cases. While downward motion was identified by Rogers et al. [
30] very close to TC centers in IN cases, on average the results there show that stronger upward eyewall vertical velocity is in favor to RI, possibly due to the stronger secondary circulation. Similar to previous figures,
Figure 5 displays the distribution of pressure vertical velocity at 400 hPa (level 18) for RI and non-RI instances, respectively, and we can find the distribution of RI more right skewed than that of non-RI instances. This is because the pressure vertical velocity is of negative values for upward moving air, and the finding is confirmed by the corresponding quantitative statistics listed in
Table 8, with the RI mean and median being smaller than the non-RI mean and median.
This result seems to be not consistent with what was found with the SHIPS data. In the SHIPS database, variables O500 and O700 for the pressure vertical velocity (w) at 500 and 700 hPa are highly correlated (Table A1 in WY21) and are ranked only 72 with a 0.0058 importance score (see
Table A1). The contributions from all the w components together are almost three times more important than the single w representative, O500, as measured by IS here. One plausible interpretation is that differences among the 148 variables are smoothed out, and the higher IS contribution is simply due to the much higher number of actual variables than a single representative variable. More research is needed to figure out the details for the contribution of the pressure vertical velocity to the RI process.
In sum, two out of the top five important groups, G45 and G29, contain eastward and northward wind speed variables, especially at 400, 450, and 1000 hPa. Those speeds are related to the VWS-involved wind velocity at 400, 450, and 1000 hPa pressure levels, which are known to play a significant role in RI prediction, as revealed by Wang et al. [
10]. Another group, G3, only contains the pressure vertical velocity, which indicates that vertical pressure speed is critical in RI prediction. Other than the O500 and O700 included in the SHIPS database, it is necessary to dig out details of the pressure vertical velocity contribution to RI at different pressure levels without heavy grouping.
Here, we derive the group level importance score for ERA-Interim variables. Although the AI system consists of too many components so that the score is not 100% accurate, the system is still able to identify useful features in addition to the SHIPS database.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




