The growth of data increased enormously during last two decades, which encouraged global researchers to explore new machine learning algorithms and artificial intelligence to cope with the big data. Various applications of big data are found in medicine, astrology, banking, and finance departments for managing their big databases [
10,
127]. In the healthcare industry, huge amounts of data are created for record keeping and patient care, which are used in improving healthcare facilities by providing population management and disease surveillance at reduced cost [
128]. Similarly, machine learning models for early disease diagnosis and prediction of disease outbreak and genomic medicine are now being used popularly [
129]. As an example, Chen et al. [
130] experimented on a hospital to study the outbreak of cerebral infarction using a CNN-based machine learning model which achieved a prediction accuracy of 94.8%. Now, big data also incorporates psychiatric research that gathers data for the person’s anxiety attacks and irregular sleep patterns to diagnose any psychological illness [
131]. Similarly, GPS-enabled trackers were developed for asthma patients by Asthmapolis that record inhaler usage by the patients. These recorded data are gathered in a central database used to analyze the needs of individual patients [
132]. In the field of agriculture, smart farming and precision agriculture are major technological advancements that incorporate cloud computing and machine learning algorithms [
133]. In this context, Singh et al. proposed a model for forecasting moisture in soil by using time series analysis [
134]. Data generated from various sources like wind direction predictors, GPS-enabled tractors, and crop sensors are used to elevate agricultural operations. Primarily Europe and North America use big data applications for agriculture, but most countries are still deprived of them [
135]. Similarly, other industries such as the aviation industry are growing rapidly and producing large amounts of data from weather sensors, aircraft sensors, and air. The application of big data analytics for aviation is necessary as latest aircrafts like the Boeing 787 obtains 1000 or more flight parameters, whereas older aircrafts like Legacy captured only 125+ parameters [
136]. Similarly, social media platforms like Facebook, Instagram, and Twitter generate data, its analysis is necessary to understand and gather public opinion or feedback about any product or service [
18,
137], which can be analyzed using machine learning applications of big data. Machine learning algorithms are used to analyze the behavior of the user via real-time analysis of the content browsed by them, and relevant online advertisements are recommended accordingly. Moreover, the detection of spam using data mining techniques also employs the use of machine learning [
138]. In addition, Hadoop and machine learning algorithms are used by banks for analysis of loan data to check the reliability of lending organizations, thereby increasing profitability and innovation [
139]. Recent studies in the field of construction, city, and property management specially reported that compatibility, interoperability, value, and reliability are critical factors of digital technology adoption and implementation [
140,
141,
142,
143,
144]. The network intrusion traffic challenge was resolved efficiently by Suthaharan et al. [
145] using machine learning and big data technologies. Distributed manufacturing industries use big data approaches to find new opportunities [
146]. Similarly, electrical power industries implement big data approaches for electricity demand forecasting [
147]. Processes of decision-making, value creation [
148], innovation, and supply chain [
149] were significantly enhanced using big data analytics techniques. Zhou et al. investigated a trajectory detection method to improve taxi services using big data from GPS [
150]. Applications of big data are also found in creating competitive advantages by troubleshooting, personalization, and detection of areas that require improvement [
151]. For predictive modeling, high-cardinality features are not used very often because of their randomness. To address this, Moeyersoms et al. [
152] introduced transformation functions in a churn predictive model that included high-cardinal features.
4.2. Big Data Applications for Disaster and Risk Management
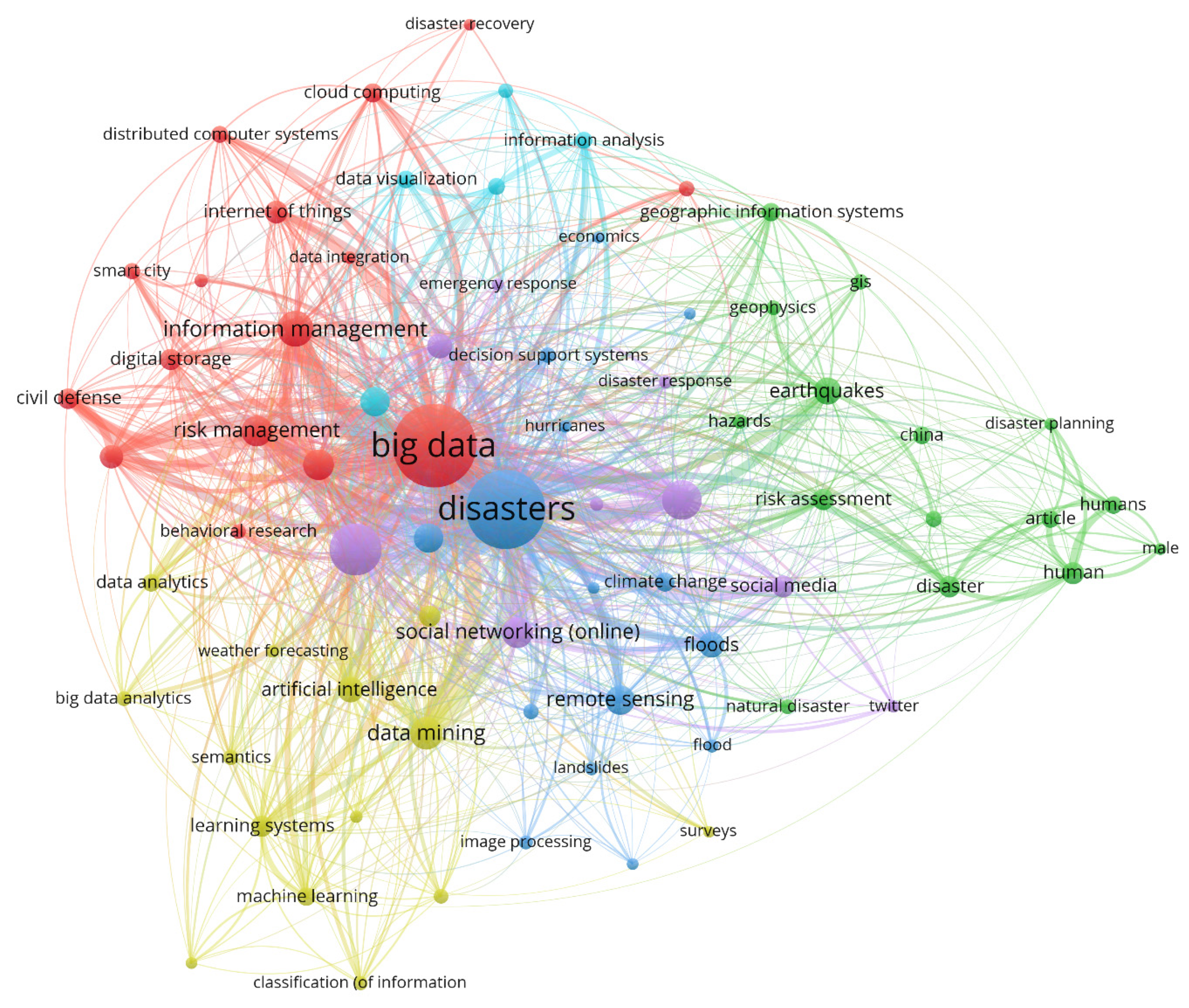
Big data systems proved to be valuable resources in disaster preparedness, management, and response. The disaster risk management authorities can use big data to monitor the population in case of an emergency. For example, areas having a high number of elderly people and children can be closely tracked so that they can be rescued as a priority. Additional post-disaster activities like logistics and resource planning and real-time communications are also facilitated by big data. Agencies associated with early disaster management also use big data technologies to predict the reaction of citizens in case of a crisis [
162]. In the current era, big data-based technologies are growing at an exponential rate, and research suggests that approximately 90% of data in the world were produced in the last two years [
163]. The emergency management authorities can use these data to make more informed and planned decisions in both pre- and post-disaster scenarios. The data were combined with geographical information and real-time imagery for disaster risk management in emergencies [
19]. During the Haiti earthquake incident, big data was used to rescue people in the post-disaster scenario. By conducting an analysis on the text data available regarding the earthquake, maps were created to identify the vulnerable and affected population from the area [
164]. At this time, the concept of digital humanitarian was first introduced, which involves the use of technology like crowdsourcing to generate maps of affected areas and people [
165]. Since then, it is a norm to use technology for disaster risk management and response. Various research studies were done on analyzing the sentiments of people at the time of disaster to identify their needs during the crisis [
19,
122,
162,
164,
165,
166]. Advanced methods of satellite imagery, machine learning, and predictive analysis are applied to gather information regarding any forthcoming disaster along with its consequences. Munawar et al. [
19] captured multispectral aerial images using an unmanned aerial vehicle (UAV) at the target site. Significant landmark objects like bridges, roads, and buildings were extracted from these images using edge detection [
167], Hough transform, and isotropic surround suppression techniques [
168,
169]. The resultant images were used to train an SVM classifier to identify the occurrence of flood in a new test image. Boakye et al. proposed a framework that uses big data analytics to predict the results of a natural disaster in the society [
162]. Machine learning and image processing also provide heat maps of the affected area, which are helpful in providing timely and quick aid to affected people [
166].
Table 16 shows the uses of big data for disaster risk management, as well as the phases and features of big data.
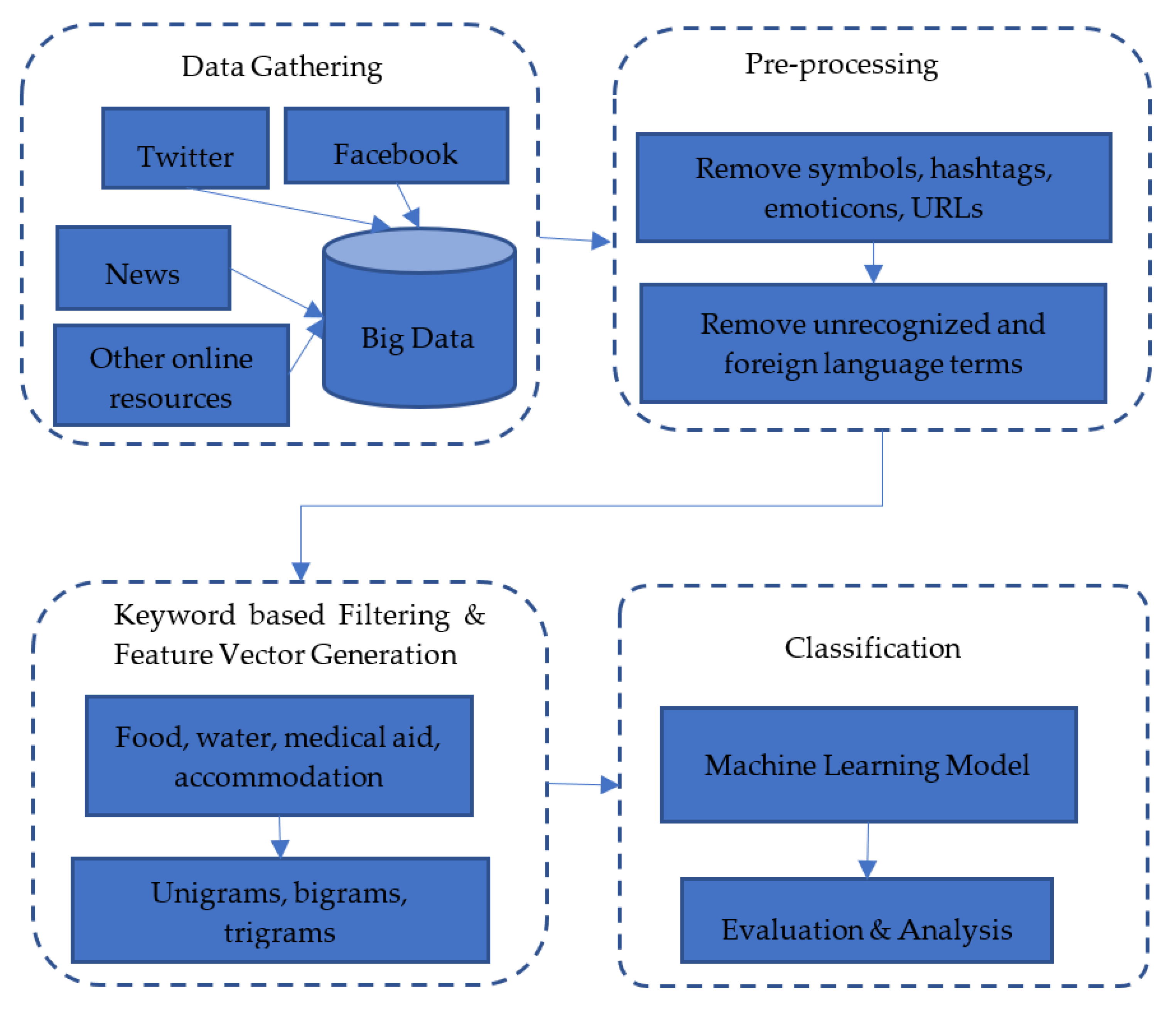
Social media is one of the best resources to gather real-time data at the time of crisis. It is being increasingly used for communication and coordination during emergencies [
184]. This calls for a system to be able to effectively manage these data and filter the data related to the needs and requests of the people during the post-disaster period. To be able to provide timely help, the big data generated from the social networks should be mined and analyzed to determine factors like which areas need the most relief services and should be prioritized by the relief workers, and what services are required by the people there [
137]. In this section, we propose a framework that extracts the data from various social media networks like Facebook, Twitter, news APIs, and other sources. The extracted data are mostly in the unstructured form and need to undergo cleaning and pre-processing to remove irrelevant and redundant information. This also involves removing URLs, emoticons, symbols, hashtags, and words from a foreign language. After applying these pre-processing steps, the data need to be filtered so that only relevant data are retained. During a post-disaster period, the basic needs of the people are related to food, water, medical aid, and accommodation. Hence, some keywords related to these four categories must be defined, so that only the data related to them are extracted. For example, the terms related to the keyword “food” may be “hunger, starved, eat”. A wide range of terms related to each keyword need to be defined so that maximum data related to them are extracted. It is also crucial to gather these data along with information related to the geographical location, so that location-wise aid could be provided. After gathering these data, the next step will be to train a machine learning model, to predict which area needs emergency services and which facilities are needed by the people over there. Before supplying data for classification, the data must be represented in the form of a feature vector so that they can be interpreted by the algorithm. A unigram-, bigram-, or trigram-based approach can be used for generation of a feature vector from the data. The basic workflow of the system is presented in
Figure 13.
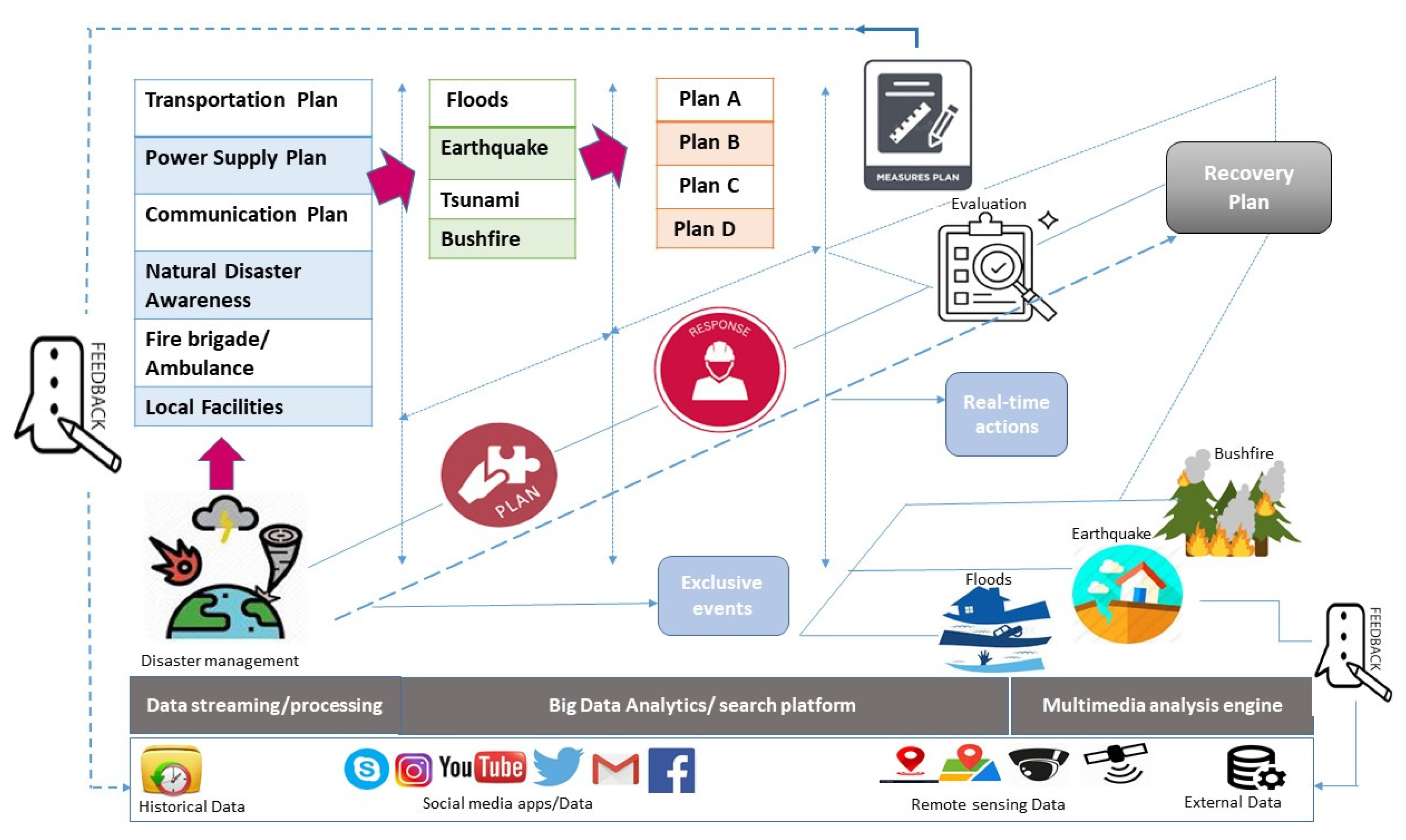
The integration of big data into disaster risk management planning can open many new avenues. At the time of disasters like floods, bush fires, storms, etc., there is a bulk of data generated as new reports, statistics, and social media posts, which all provide a tally of injuries, deaths, and other losses incurred [
77,
83,
137]. An overview of the suggested system is provided by
Figure 14. The collective historical data containing analytics of previous disasters are shared with the local authorities such as fire brigades, ambulances, transportation management, and disaster risk management officials. Acquisition of information leads to the formulation of plans to tackle the disaster and cope with the losses. This plan of action is generated based on the analysis of big data. Firstly, the data are processed to pick specifics of current disaster, while analyzing the issue helps in moving toward a response. This step involves more than one plan of action to have backup measures for coping with unforeseen issues. All these steps are fundamentally guided and backed with information gained through the rigorous processing of big data gathered as a bulk of raw information in the first step. The response stage is a merger of several simultaneous actions including management of disaster, evaluation of the plan, and real-time recovery measures for overcoming the disaster and minimizing losses. This method not only holds the potential for creating an iterative process which can be applied to various disasters but can also create an awareness and sense of responsibility among people regarding the importance of big data in disaster response and effective risk management.
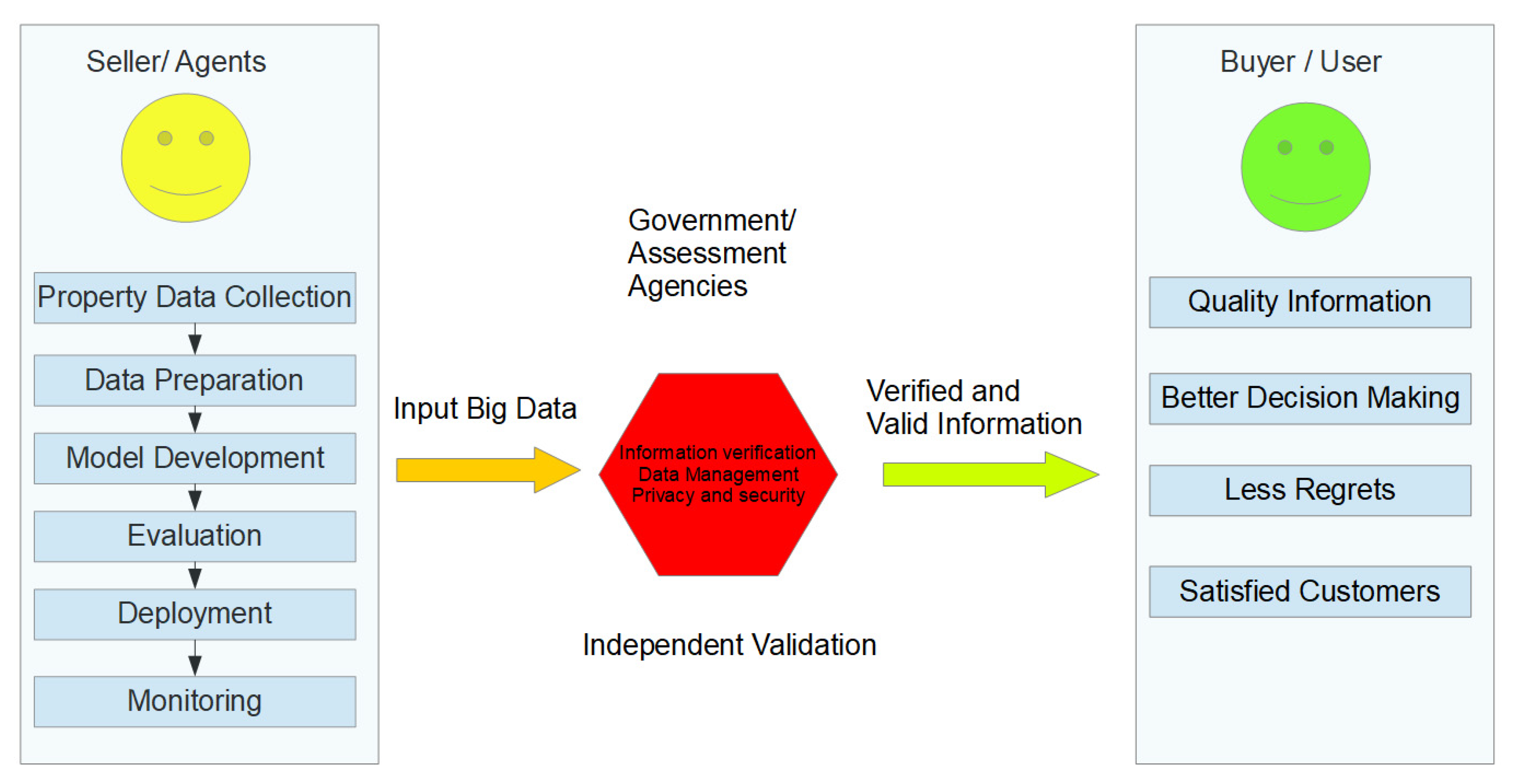
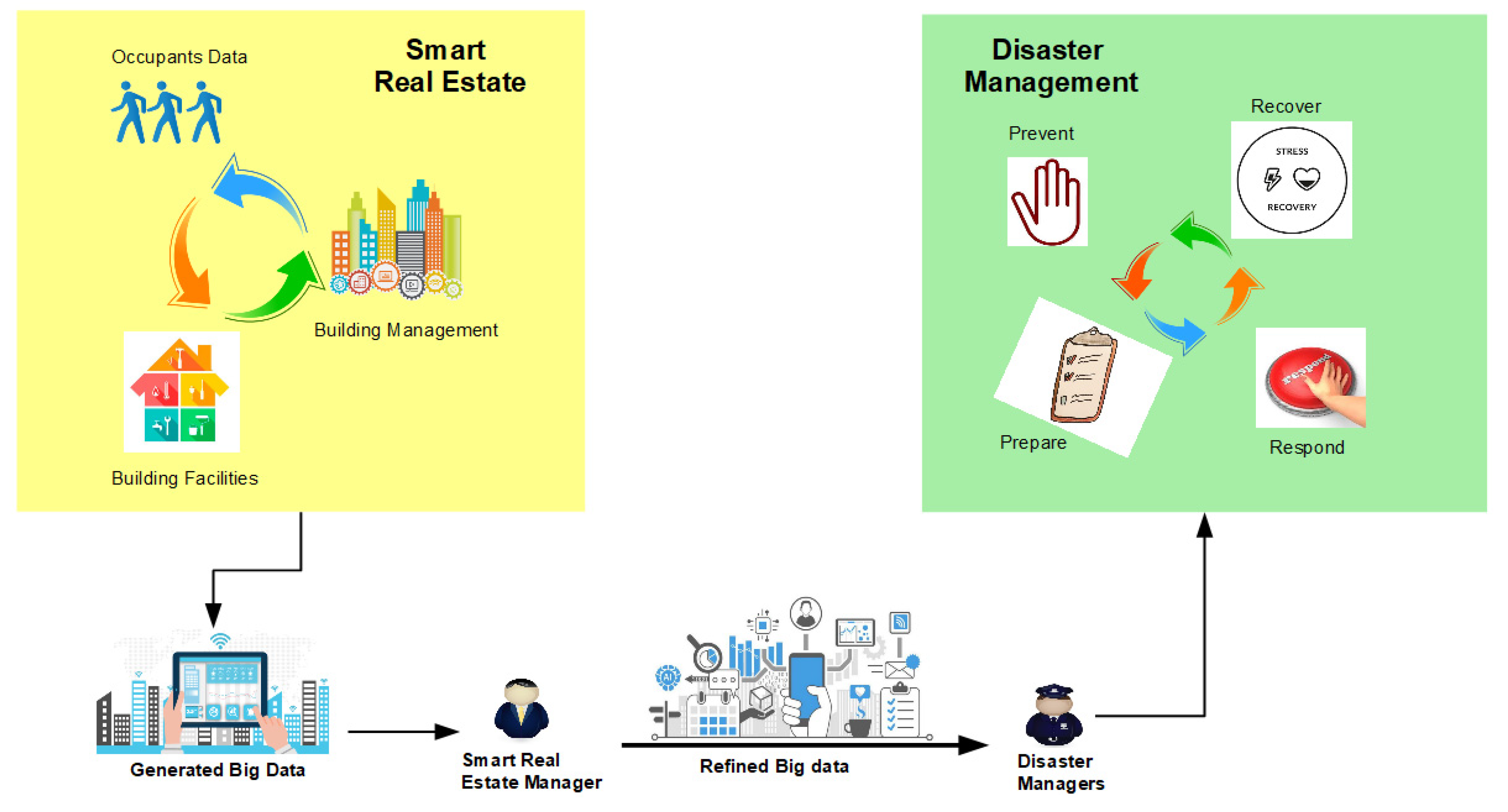
Based on the applications of big data in smart real estate and disaster management, a merging point can be highlighted where the input big data from smart real estate can help plan for disaster risks and manage them in case of occurrence, as shown in
Figure 15. The data of building occupants are usually maintained by the building managers and strata management. These data coupled with the data from building integration, maintenance, and facility management constitutes smart real estate big data controlled by the real estate managers. These data, if refined and shared with the disaster managers and response teams by the smart real estate management agencies and managers, can help in planning for disaster response. For example, the data related to available facilities at the building can help prepare the occupants for upcoming disasters through proper training and awareness, who can respond to these disasters in an efficient way. Similarly, knowledge of smart building components and the associated building management data can help address the four key areas of disaster risk management: prevent, prepare, respond, and recover. The proposed merging framework is inspired by the works of Grinberger et al. [
185], Lv et al. [
186], Hashem et al. [
187], and Shah et al. [
30]. Grinberger et al. [
185] used data obtained from smart real estate in terms of occupant data in terms of socioeconomic attributes such as income, age, car ownership, and building data based on value and floor space to investigate the disaster preparedness response for a hypothetical earthquake in downtown Jerusalem. Lv et al. [
186] proposed a model for using big data obtained from multimedia usage by real estate users to develop a disaster management plan for service providers such as traffic authorities, fire, and other emergency departments. Hashem et al. [
187] proposed an integrated model based on wireless sensing technologies that can integrate various components of smart cities for industrial process monitoring and control, machine health monitoring, natural disaster prevention, and water quality monitoring. Similarly, Shah et al. [
30] proposed a disaster-resilient smart city concept that integrates IoT and big data technologies and offers a generic solution for disaster risk management activities in smart city incentives. Their framework is based on a combination of the Hadoop Ecosystem and Apache Spark that supports both real-time and offline analysis, and the implementation model consists of data harvesting, data aggregation, data pre-processing, and a big data analytics and service platform. A variety of datasets from smart buildings, city pollution, traffic simulators, and social media such as Twitter are utilized for the validation and evaluation of the system to detect and generate alerts for a fire in a building, pollution level in the city, emergency evacuation path, and the collection of information about natural disasters such as earthquakes and tsunamis. Furthermore, Yang et al. [
25] proposed real-time feedback loops on nature disasters to help real estate and city decision-makers make real-time updates, along with a precision and dynamic rescue plan that helps in in all four phases of disaster risk management: prevention, mitigation, response, and recovery; this can help the city and real estate planners and managers to take prompt and accurate actions to improve the city’s resilience to disasters.
This is a two-way process where data from smart real estate can help prepare for disasters and vice vera. Big data used in preparedness and emergency planning may increase urban resilience as it will help to produce more accurate emergency and response plans. As such, Deal et al. [
188] argued that, for achieving the holistic results for developing urban resilience and promoting preparedness among the communities for disaster, there is a need to be able to translate big data at scales and in ways that are useful and approachable through sophisticated planning support systems. Such systems must possess a greater awareness of application context and user needs; furthermore, they must be capable of iterative learning, be capable of spatial and temporal reasoning, understand rules, and be accessible and interactive. Kontokosta and Malik [
189] introduced the concept of benchmarking neighborhood resilience by developing a resilience to emergencies and disasters index that integrates physical, natural, and social systems through big data collected from large-scale, heterogeneous, and high-resolution urban data to classify and rank the relative resilience capacity embedded in localized urban systems. Such systems can help improve urban resilience by preparing and producing accurate emergency responses in the case of disasters. Similarly, Klein et al. [
190] presented the concept of a responsive city, in which citizens, enabled by technology, take on an active role in urban planning processes. As such, big data can inform and support this process with evidence by taking advantage of behavioral data from infrastructure sensors and crowdsourcing initiatives to help inform, prepare, and evacuate citizens in case of disasters. Furthermore, the data can be overlaid with spatial information in order to respond to events in decreasing time spans by automating the response process partially, which is a necessity for any resilient city management. Owing to these systems and examples, it can be inferred that smart real estate and disaster risk management can act as lifelines to each other, where big data generated in one field can be used to help strengthen the other, which, if achieved, can help move toward integrated city and urban management.
4.3. Discussion
The current review provides a systematic view of the field of big data applications in smart real estate and disaster and risk management. This paper reviewed 139 articles on big data concepts and tools, as well as its applications in smart real estate and disaster management. Initially, the seven Vs of big data were explored with their applications in smart real estate and disaster management. This was followed by big data analytics tools including text, audio, video, and social media analytics with applications in smart real estate and disaster management. Next, big data analytics processes comprising data collection, storage, filtering, cleaning, analysis, and visualization were explored along with the technologies and tools used for each stage. Then, the two main frameworks for big data analytics, i.e., Hadoop and Apache Spark, were reviewed and compared based on their parameters and performance. Afterward, the applications of machine learning for big data were explored. This was followed by the challenges faced by big data, and potential solutions to its implementation in different fields were discussed. Lastly, a dedicated section explored the applications of big data in various fields with a specific focus on smart real estate and disaster management and how big data can be used to integrate the two fields. These findings and critical analyses distinguish this review from previous reviews. Another difference of this review compared with previous attempts is the focus of the present review on the applications of big data in smart real estate and disaster management that highlights the potential for integrating the two fields. The findings and major analyses are discussed below.
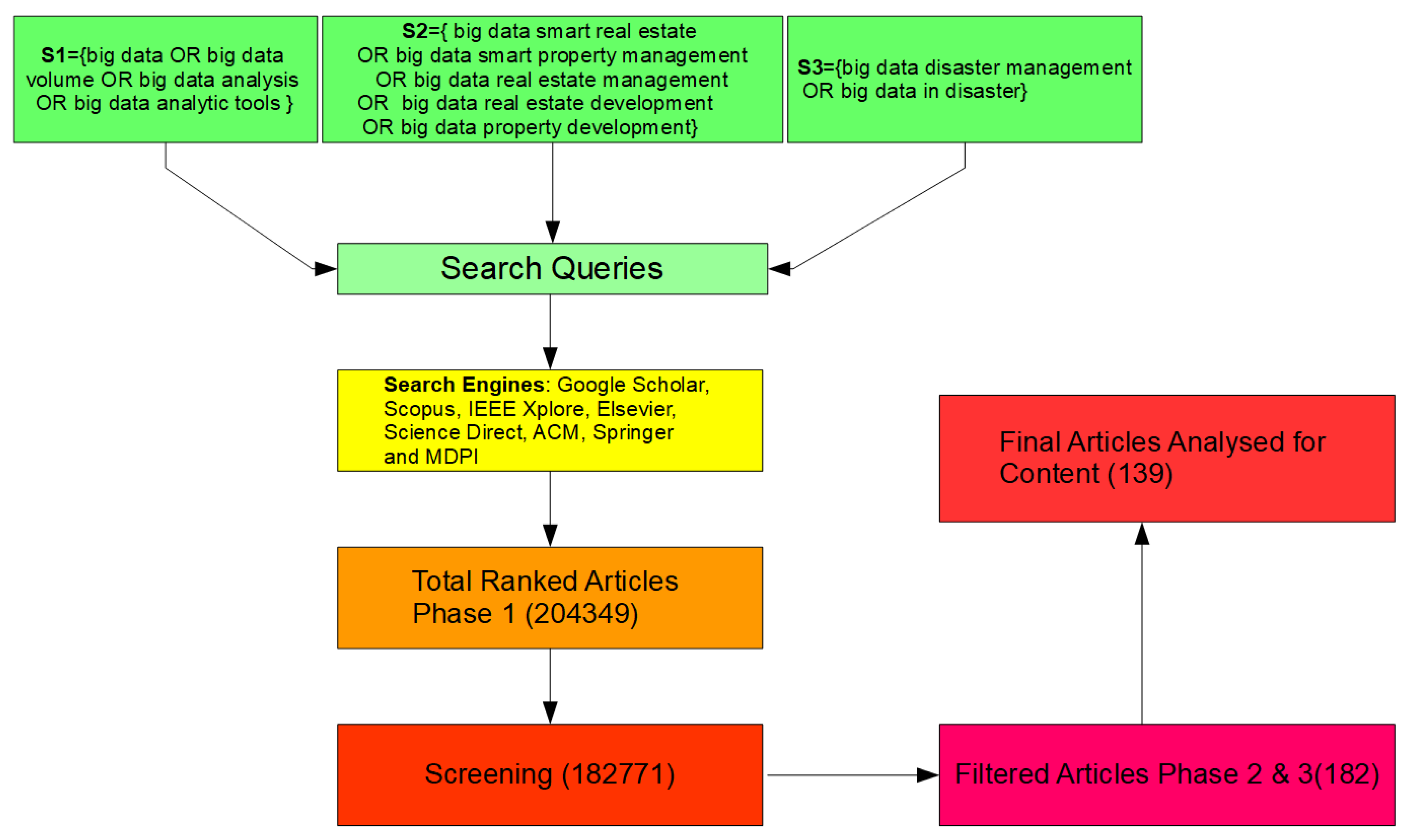
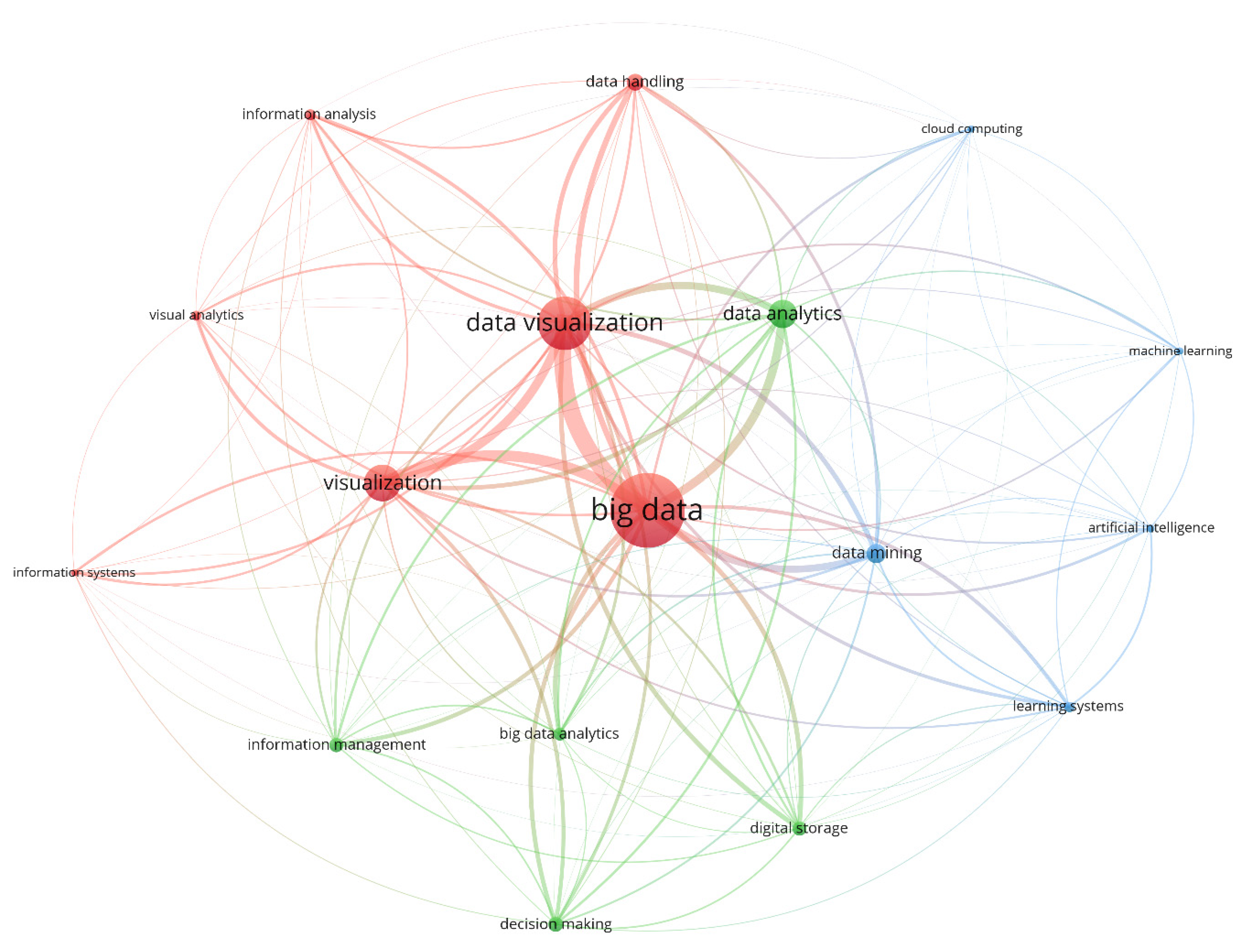
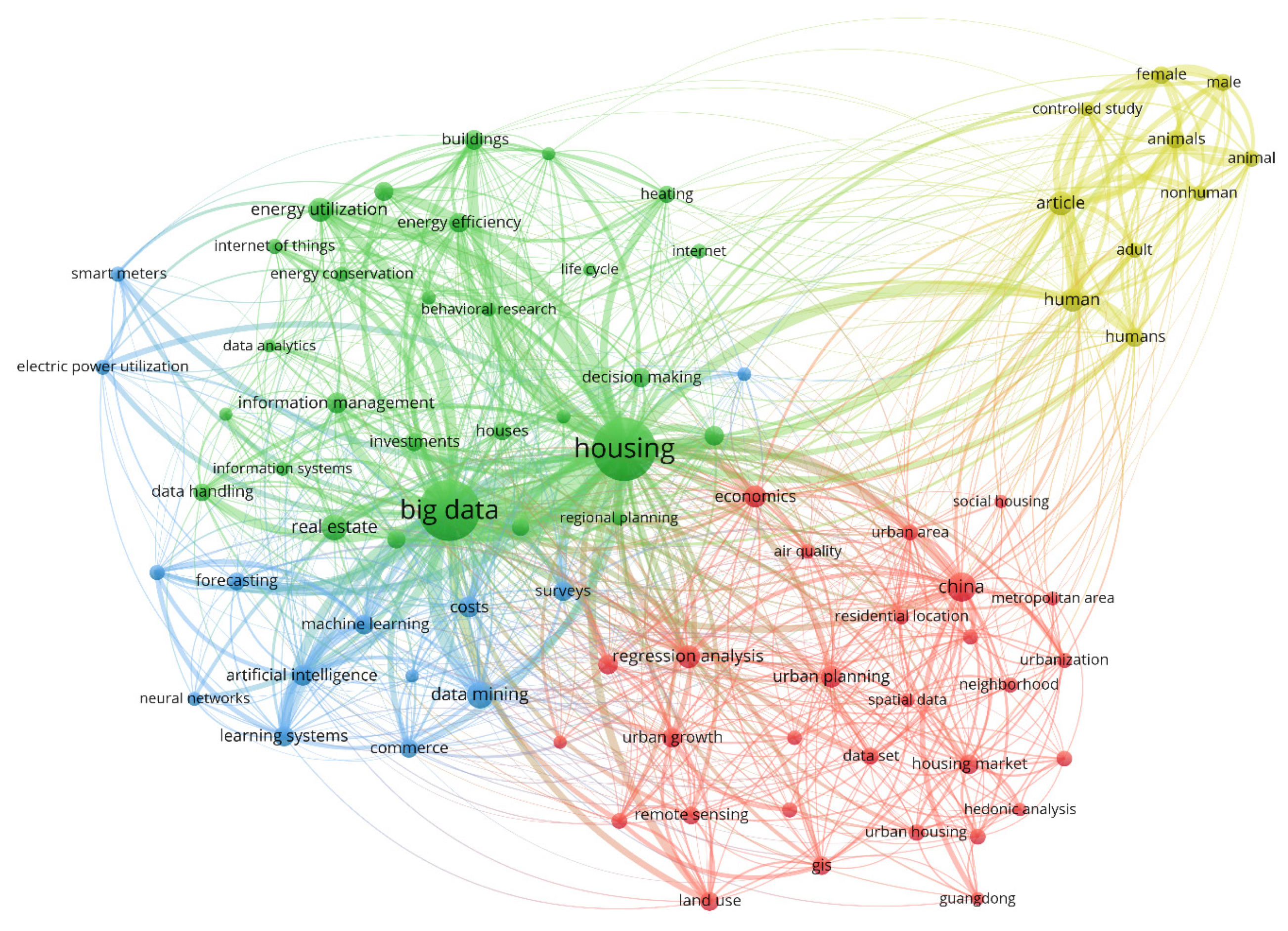
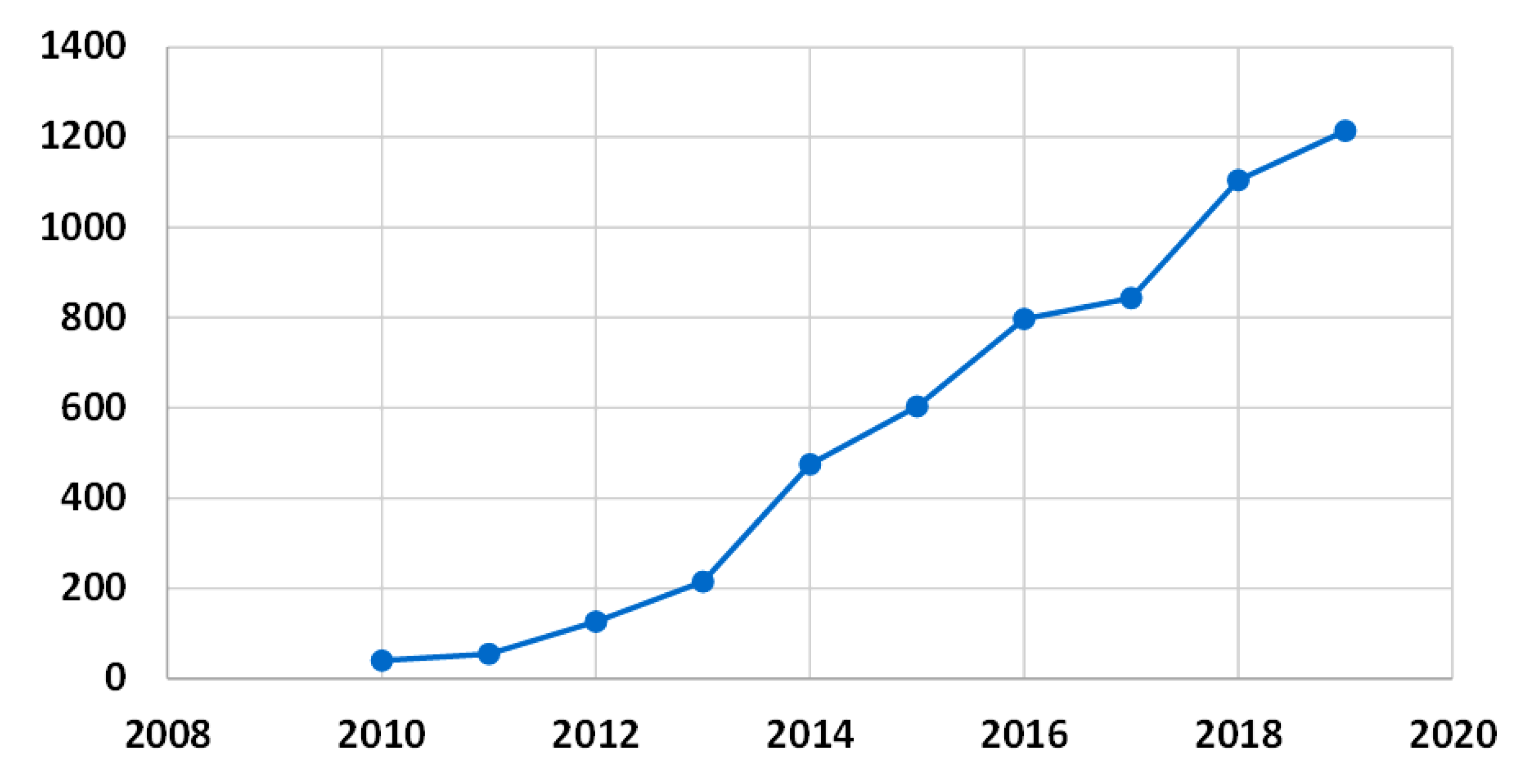
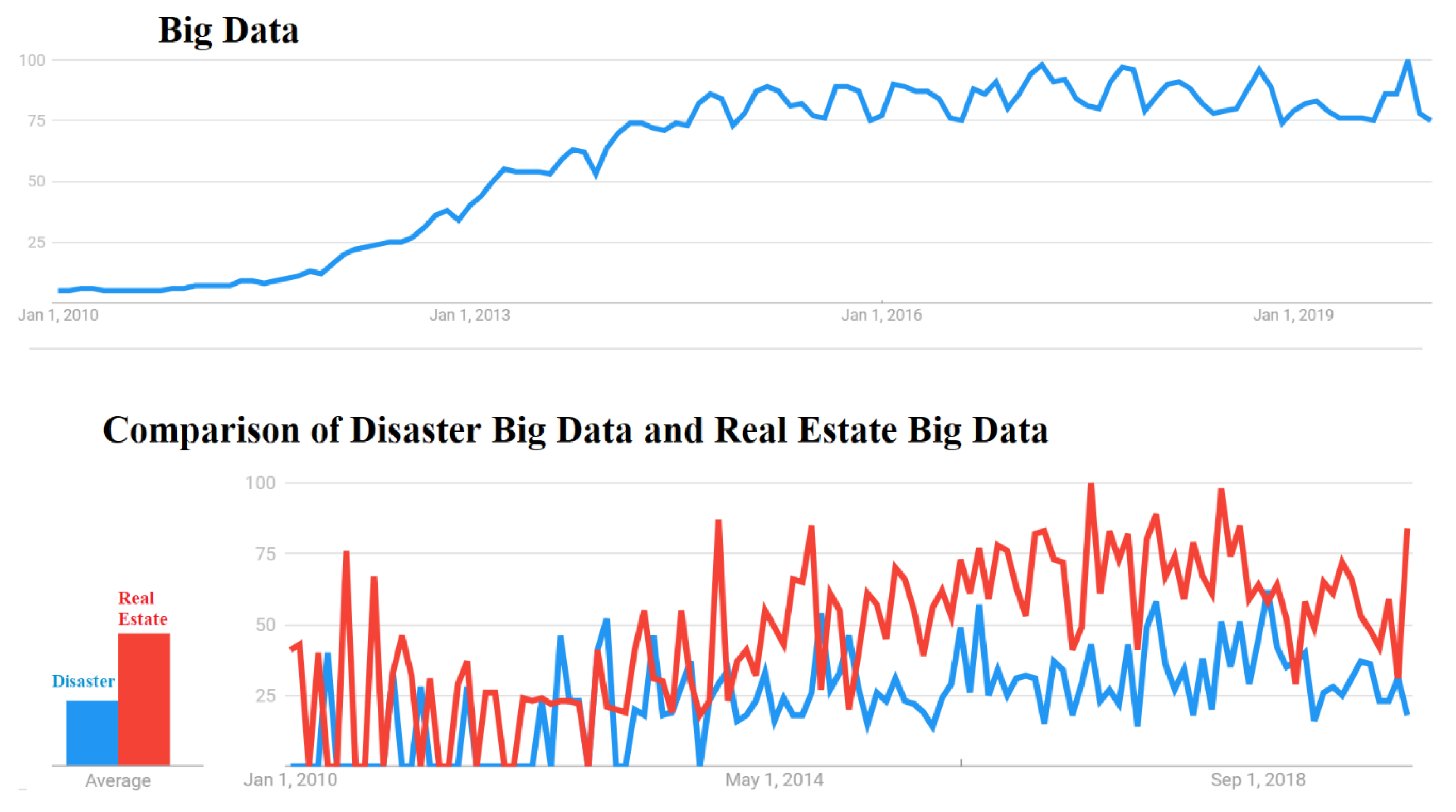
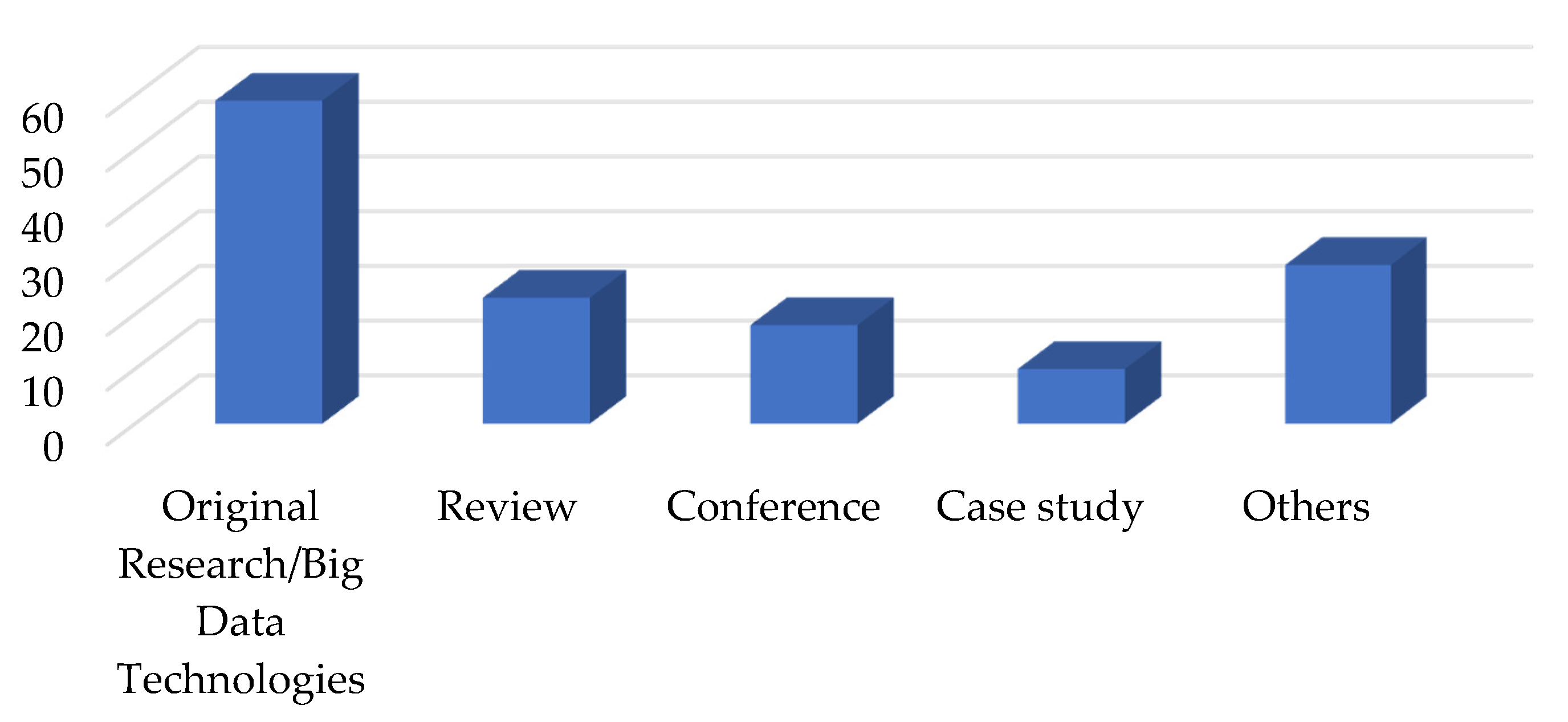
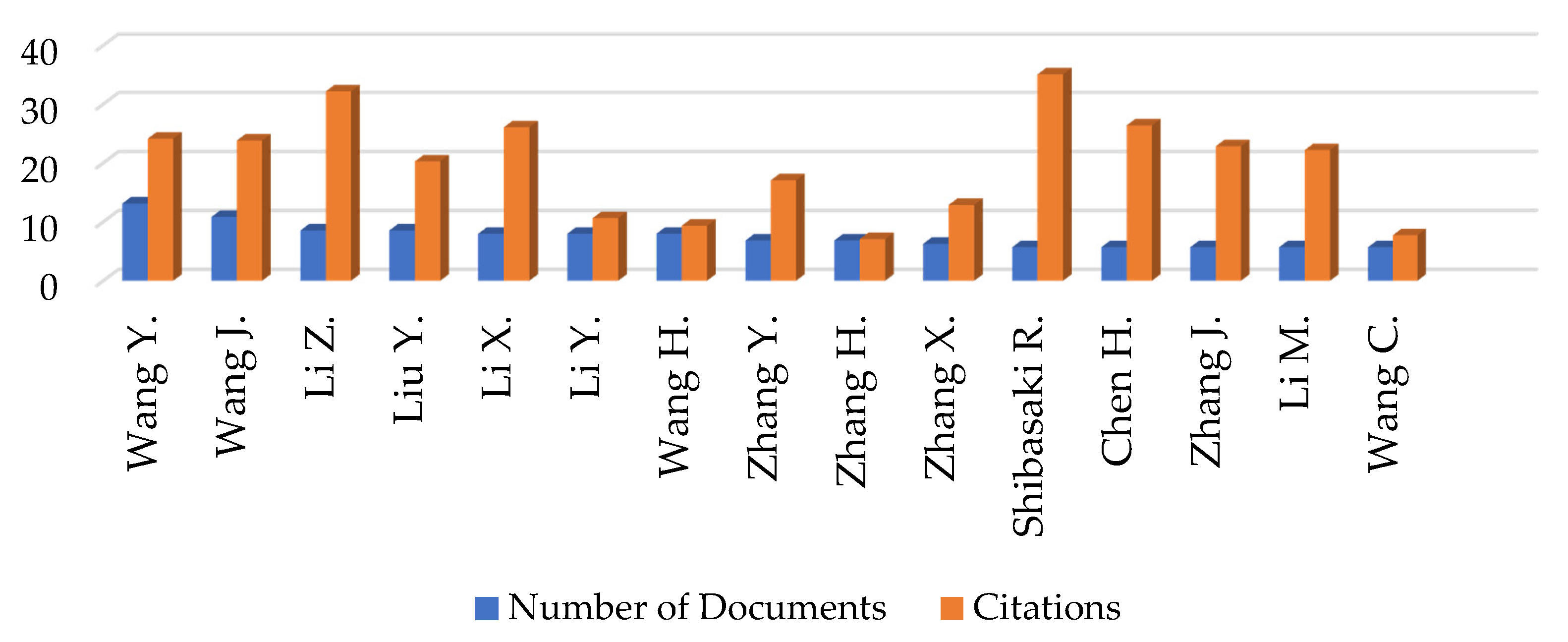
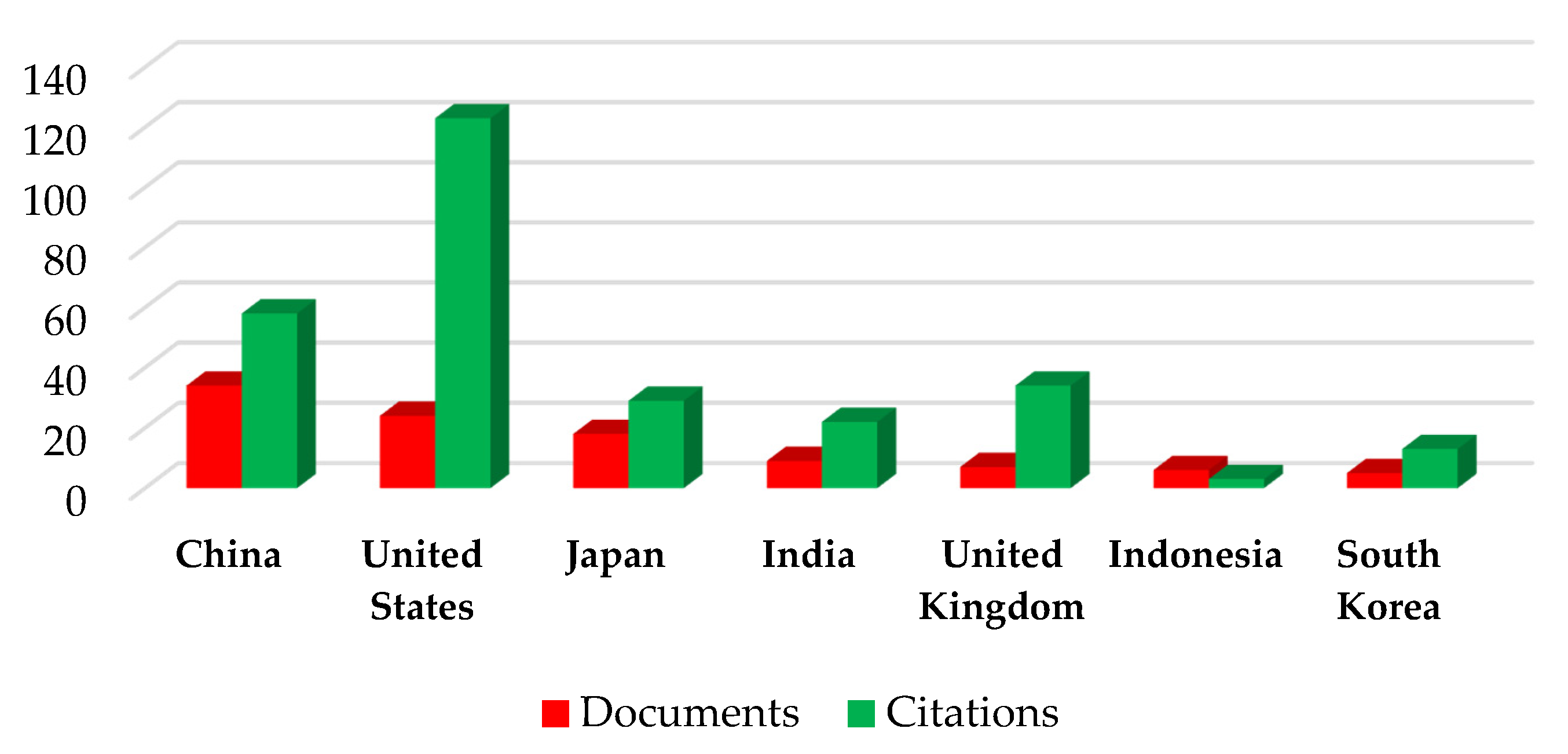
Firstly, it was found that the definition of big data continues to vary, and no exact size is defined to specify the volume of data that qualifies as big data. The concept of big data was found to be relative, and any data that cannot be handled by the traditional databases and data processing tools are classified as big data. In terms of the papers published in the area of big data, there as a significant growth in the number of articles in the last 10 years. A total of 139 relevant papers were investigated in detail, consisting of original research on big data technologies (59), reviews (23), conferences (18), and case studies (10). The analyses revealed that the keywords most frequently used in big data papers were dominated by analysis system, investigations, disaster risk management, real estate technologies, urban area, and implementation challenges. Furthermore, the publications were dominated by the journal lecture notes in computer science followed by the IOP conference series. In terms of the author-specific contributions Wang Y. and Wang J. lead the reviewed articles with 13 and 11 contributions and 24 citations each. Similarly, in country-specific analysis, China leads the reviewed articles with 34 publications followed by the United States with 24 articles; however, in terms of citations, the USA leads the table with 123 citations followed by China with 58 citations. Furthermore, in terms of the affiliated organizations of authors contributing the most to the articles reviewed, the Center for Spatial Information Science, University of Tokyo, Japan and the School of Computing and Information Sciences, Florida International University, Miami, Fl 33199, United States lead the race with six articles each, followed by the International Research Institute of Disaster Science (Irides), Tohoku University, Aoba 468-1, Aramaki, Aoba-Ku, Sendai, 980-0845, Japan with five articles.
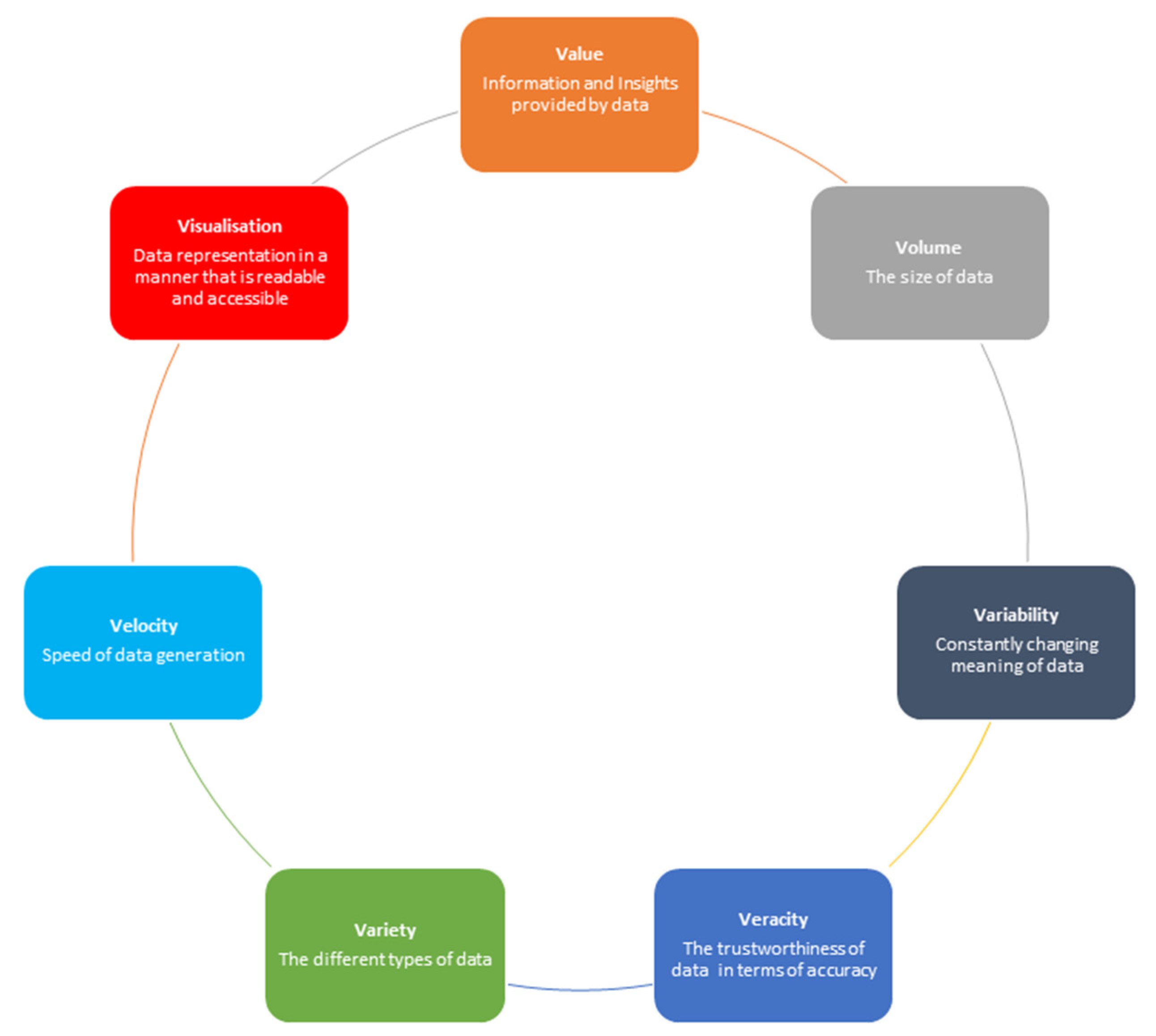
In the next step, a seven Vs model was discussed from the literature to review the distinctive features of big data, including variety, volume, velocity, value, veracity, variability, and visualization. Various tools and technologies used in each stage of the big data lifecycle were critically examined to assess their effectiveness, along with implementation examples in smart real estate and disaster management. Variety can help in disaster risk management through major machine–human interactions by extracting data from data lakes. It can help in smart real estate management through urban big data that can be converged, analyzed, and mined with depth via the Internet of things, cloud computing, and artificial intelligence technology to achieve the goal of intelligent administration of the smart real estate. The volume of big data can be used in smart real estate through e-commerce platforms and digital marketing for improving the financial sector, hotel services, culture, and tourism. For the velocity aspect, new information is shared on sites such as Facebook, Twitter, and YouTube every second that can help disaster risk managers plan for upcoming disasters, as well as know the current impacts of the occurring disasters, using efficient data extraction tools. In smart real estate, big data-assisted customer analysis and advertising architecture can be used to speed up the advertising process, approaching millions of users in single clicks, which helps in user segmentation, customer mining, and modified and personalized precise advertising delivery to achieve high advertising arrival rate, as well as superior advertising exposure/click conversion rate. In case of the value aspect of big data, disaster risk management decision-making systems can be used by disaster managers to make precise and insightful decisions. Similarly, in smart real estate, neighborhood value can be enhanced through creation of job opportunities and digital travel information to promote smart mobility. In the context of the veracity of big data, sophisticated software tools can be developed that extract meaningful information from vague, poor-quality information or misspelled words on social media to promote local real estate business and address or plan for upcoming disasters. Variability of the big data can be used to develop recommender systems for finding places with the highest wellness state or assessing the repayment capabilities of large real estate organizations. Similarly, variability related to rainfall patterns or temperature can be used to plan effectively for hydro-meteorological disasters. In the case of the visualization aspect of big data, 360 cameras, mobile and terrestrial laser scanners [
74,
144,
191,
192,
193,
194], and 4D advertisements can help boost the smart real estate business. Similarly, weather sensors can be used to detect ambiguities in weather that can be visualized to deal with local or global disasters.
After the seven Vs were investigated, big data analytics and the pertinent techniques including text, audio, video, and social media mining were explored. Text mining can be used to extract useful data from news, email, blogs, and survey forms through NER and RE. Cassandra NoSQL, WordNet, ConceptNet, and SenticNet can be used for text mining. In the case of smart real estate, text mining can be used to explore hotel guest experience and satisfaction and real estate investor psychology, whereas, in disaster risk management, it can be used to develop tools such as DisasterMapper that can synthesize multi-source data, as well as contribute spatial data mining, text mining, geological visualization, big data management, and distributed computing technologies in an integrated environment. Audio analytics can aid smart real estate through property auctioning, visual feeds using digital cameras, and associated audio analytics based on the conversation between the real estate agent and the prospective buyer to boost the real estate sales. In case of disaster risk management, audio analytics can help in event detection, collaborative answering, surveillance, threat detection, and telemonitoring. Video analytics can be used in disaster management for accident cases and investigations, as well as disaster area identification and damage estimation, whereas, in smart real estate, it can be used for threat detection, security enhancements, and surveillance. Similarly, social media analytics can help smart real estate through novel recommender systems for shortlisting places that interests users related to cultural heritage sites, museums, and general tourism using machine learning and artificial intelligence. Similarly, multimedia big data extracted from social media can enhance real-time detection, alert diffusion, and spreading alerts over social media for tackling disasters and their risks.
In the data analytics processes, steps including data collection, storage, filtering, cleaning, analysis, and visualization were explored along with the pertinent tools present for each step. The tools for data collection include Semantria, which is deployed through web, with the limitation of crashing on large datasets, web-deployable Opinion crawl, which cannot be used for advanced SEO audits, Open text deployed through Captiva, having rigorous requirements of configurations, and Trackur, which is costly. These tools can be used for sentiment and content analyses of the real estate stakeholders. Among the tools for data storage, NoSQL tools were explored considering four categories: column-oriented, document-oriented, graph, and key value. Apache Cassandra, HBase, MongoDB, CouchDB, Terrastore, Hive, Neo4j, AeroSpike, and Voldemort have applications in the areas of Facebook inbox search, online trading, asset tracking system, textbook management system, International Business Machines, and event processing that can be applied to both smart real estate and disaster management. Among the data filtering tools, Import.io, Parsehub, Mozenda, Content Grabber, and Octoparse were explored, which are web- and cloud-based software and are helpful for scheduling of data and visualizations using point-and-click approaches. The output data from these tools in the shape of data reports, google sheets, and CSV files can be used by both smart real estate managers and disaster risk management teams. Among the data cleaning tools, Data Cleaner, Map Reduce, Open Refine, Reifier, and Trifecta Wrangler use Hadoop frameworks and web services for duplicate value detection, missing value searches among the sheets at higher pace, and accuracy levels that can help smart real estate and disaster management detect ambiguities in the reports and address the issues accordingly. Lastly, for data visualization tools, Tableau, Microsoft Power BI, Plotly, Gephi, and Excel were explored that can help the real estate managers promote immersive visualizations and generation of user-specific charts. Other tools such as 360 cameras, VR and AR gadgets, and the associated 4D advertisements can help boost property sales, as well as prepare the users for disaster response.
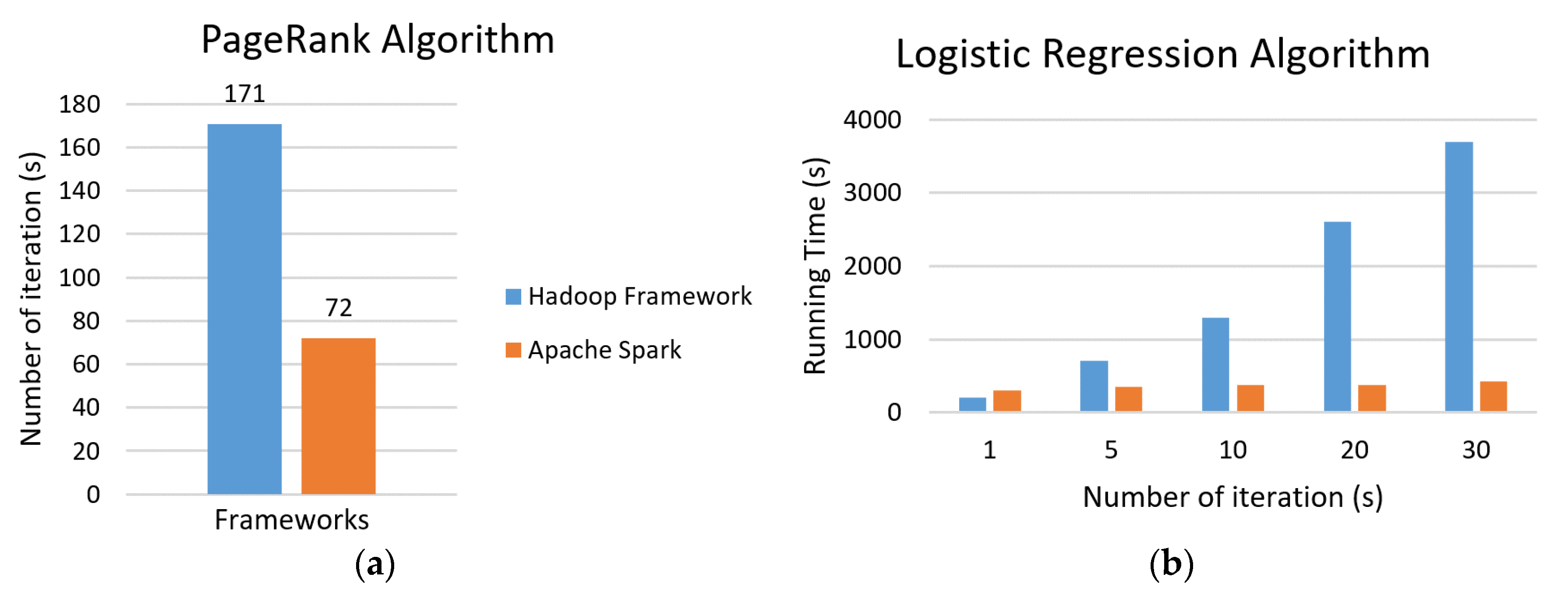
Two major frameworks for data analysis were identified which are Hadoop and Apache Spark. By conducting a critical analysis and comparison of these two frameworks, it was inferred that Apache Spark has several advantages over Hadoop which includes increased networking memory, the ability to perform real-time processing, faster speed, and increased storage capacity, which can help the real estate consumer make better and informed decisions. Similarly, disaster managers can prepare and respond in a better way to the upcoming or occurred disasters based on well-sorted and high-quality information. However, best results can be achieved by using a combination of these frameworks as discussed in Mavridis and Karatza [
110] to incorporate the prominent features from both frameworks. In addition, applications of machine learning such as speech recognition, predictive algorithms, and stock market price fluctuation analyses can help real estate users and investors in making smart decisions. Furthermore, clustering, prediction and decision-making can help disaster managers cluster the events, predict upcoming disasters, and make better decisions for dealing with them.
Following the framework exploration, the four most dominant challenges encountered while dealing with big data were highlighted, including data security and privacy, heterogeneity and incompleteness, fault tolerance, and storage. To deal with the first challenges, solutions such as using authentication methods, like Kerberos, and encrypted files are suggested. Furthermore, logging of attacks or unusual behavior and secure communication through SSL and TLS can handle the privacy and security concerns. Such privacy concerns, if addressed properly, can motivate real estate users to use the smart features and technologies and incline them toward adopting more technologies, thus disrupting the traditional real estate market and moving toward a smart real estate. Similarly, privacy concerns, if addressed, can motivate people to help disaster risk management teams on a volunteer basis rather than sneakily analyzing social media stuff without approval. To deal with heterogeneity and incompleteness, data imputation for missing values, building learning models, and filling data with the most frequent values are some solutions. Similarly, to tackle fault tolerance, dividing computations into sub-tasks and checkpoint applications for recursive tasks are potential solutions. Lastly, to tackle the challenge of storage, SDD and PCM can be used.
Finally, in terms of the applications of big data, it is evident that, in almost all fields, ranging from technology to healthcare, education, agriculture, business, and even social life, big data plays an important role. Since data are generated every second, it is important to know how to use them well. In healthcare settings, patient information and medical outcomes are recorded on a regular basis, which add to the generation of data in the healthcare sector. Arranging and understanding these data can help in identifying key medical procedures, their outcomes, and possibly ways in which patient outcomes could be enhanced through certain medicines. Similarly, education, business, technology, and agriculture can all benefit from data gathered by these fields. Using existing data in a positive manner can pave a way forward for each field. Something that is already known and exists in databases in an organized manner can help people around the world and ensure that big data could be put to good use. For example, recently, big data analytics was successfully integrated for disaster prediction and response activities. Big data consisting of weather reports, past flood events, historic data, and social media posts can be gathered to analyze various trends and identify the conditioning factors leading to a disaster. These data can also be examined to determine the most disaster-prone regions by generating susceptibility maps. Furthermore, these data can be used to train a machine learning model, which could make predictions about the occurrence of disasters and detect the effected regions from a given test image. The use of social media is a huge source of generating data. These data are already being used for various marketing researches and the analysis of human psychology and behaviors. If these data are used with safety and put to sensible use, there is a chance that every field could benefit from the inexhaustible data sources that exist on the worldwide web. Similarly, for smart real estate management, big data has huge potential in the areas of technology integration, technology adoption, smart homes and smart building integration, customer management, facilities management, and others. As such, the customers or users can enjoy the personalization, cross-matching, property information, and buyer demand analysis with the help of big data resources such as customer data surveys, feedback analyses, data warehouses, buyer click patterns, predictive analytics tools, access to government information, and social media analytics. The owners, agents, or sellers can benefit from building performance databases, property value analysis, resident, strata, and enterprise management, online transactions, and potential clients/business identification using big data resources of building maintenance data, occupant data, government reports, local contracts, property insights, analytics tools, customer surveys, and demand analysis. Similarly, the government and regulatory authorities can provide more public services, detect frauds, and address user and citizen privacy and security issues through linkages of the central databases to ensure provision of services in the smart real estate set-up.
For disaster risk management, the four stages of prevention, preparedness, response, and recovery can be aided through big data utilizations. As such, big data can help in risk assessment and mitigation, disaster prediction, tracking and detection, establishing warning systems, damage assessment, damage estimation, landmark (roads, bridges, buildings) detection, post-disaster communications establishment, digital humanitarian relief missions, and sentiment analysis in the disaster recovery process to help mitigate or respond to natural disasters such as earthquakes, hurricanes, bushfires, volcanic eruptions, tsunamis, floods, and others. Tools and technologies such as GPS, LiDAR, IoT, stepped frequency microwave radiometer (SFMR), satellite imagery, and drone-based data collection can aid the disaster risk management processes. In addition, the fields of smart real estate and disaster management can be integrated where smart big data from real estate can help the disaster risk management team prepare and respond to the disasters. As such, the data received from building occupants, building integration, maintenance, and facility management can be shared with the disaster management teams who can integrate with the central systems to better respond to disasters or emergencies.
This paper provides a detailed analysis of big data concepts, its tools, and techniques, data analytics processes, and tools, along with their applications in smart real estate and disaster management, which can help in defining the research agenda in the two main domains of smart real estate and disaster management and move toward an integrated management system. It has implications for creating a win–win situation in the smart real estate. Specifically, it can help smart real estate managers, agents, and sellers attract more customers toward the properties through immersive visualizations, thus boosting the business and sales. The customers, on the other hand, can make better and regret-free decisions based on high-quality, transparent, and immersive information, thus raising their satisfaction levels. Similarly, the government and regulatory authorities can provide better citizen services, ensure safety and privacy of citizens, and detect frauds. Similarly, the proposed framework for disaster risk management can help the disaster risk managers plan for, prepare for, and respond to upcoming disasters through refined, integrated, and well-presented big data. In addition, the current study has implications for research where the integration of the two fields, i.e., smart real estate and disaster management, can be explored from a new integrated perspective, while conceptual and field-specific frameworks can be developed for realizing an integrated, holistic, and all-inclusive smart city dream.
The limitation of the paper is its focus on two domains; however, future studies can also focus on the application of big data in construction management and other disciplines. This paper reviewed 139 articles published between 2010 and 2020, but further articles from before 2010, as well as articles focusing on smart cities, can be reviewed in the future to develop a holistic city management plan. Among the other limitations, a focus on only two types of frameworks (Hadoop and Apache Spark) and non-focus on other digital disruptive technologies such as the Big9 technologies discussed by Ullah et al. [
18] are worth mentioning. Furthermore, the current study based its review on the articles retrieved through a specific sampling method, which may not be all-inclusive and exhaustive; thus, future studies repeated with the same keywords at different times may yield different results.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}