
LASSO Regression Modeling on Prediction of Medical Terms among Seafarers’ Health Documents Using Tidy Text Mining

 ,
,  , ,
, ,  , and
, and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Collection
2.2. Corpus Pre-Processing
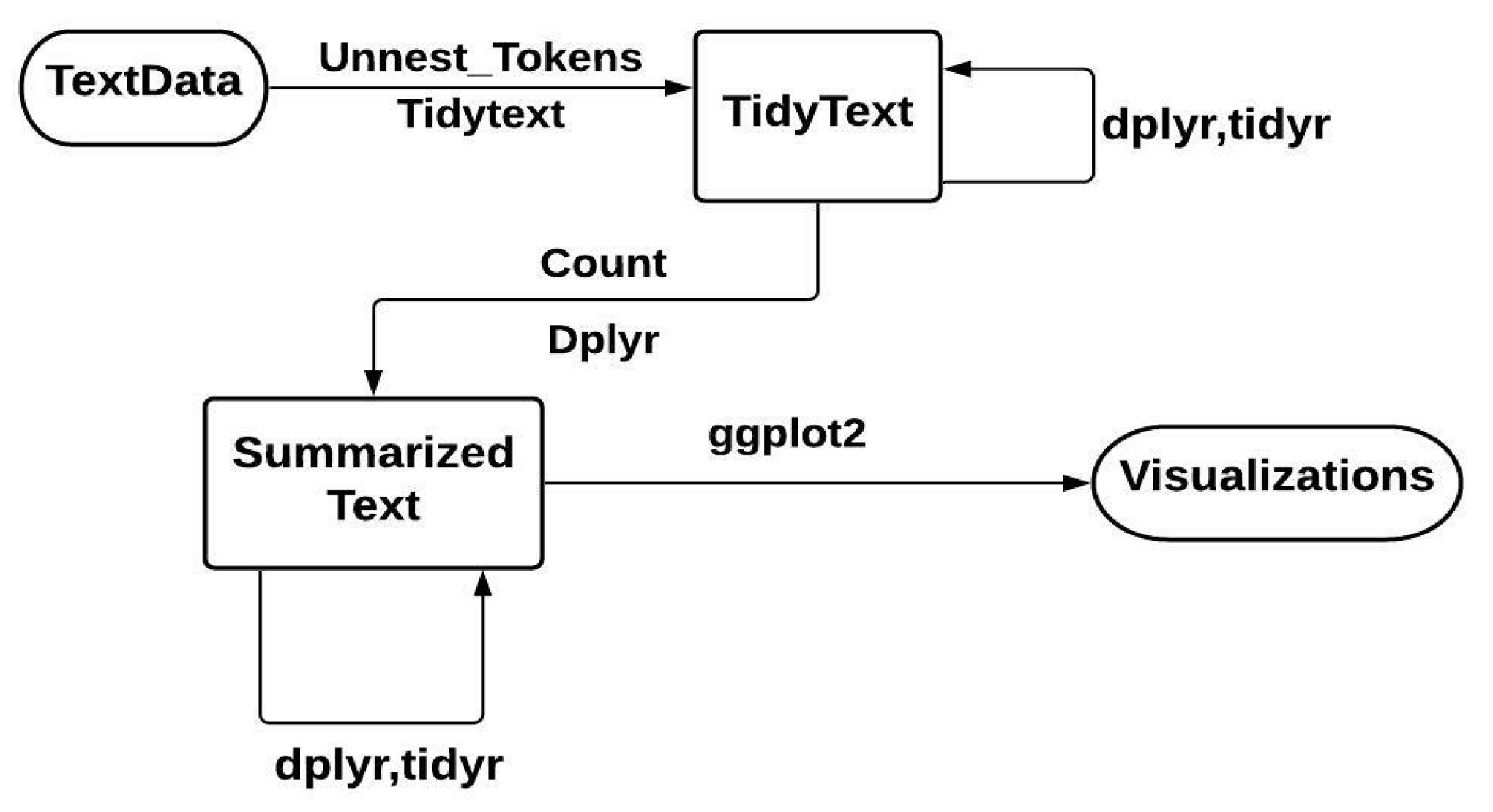
2.3. Tidy Text Mining and Packages
2.4. Sentimental Analysis
2.5. Calculation of Word and Document Frequency (TF-IDF)
2.6. Word Clouds
2.7. LASSO Regression Model
2.8. Model Training and Evaluation
3. Results
3.1. Sentimental Analysis
3.2. TF-IDF Calculation
3.3. Bigrams and Correlations
3.4. Text Classification with ML Modelling
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abila, S.S.; Acejo, I.L. Mental health of Filipino seafarers and its implications for seafarers’ education. Int. Marit. Health 2021, 72, 183–192. [Google Scholar] [CrossRef] [PubMed]
- Guillot-Wright, S. The changing economic structure of the maritime industry and its adverse effects on seafarers’ health care rights. Int. Marit. Health 2017, 68, 77–82. [Google Scholar] [CrossRef] [PubMed]
- Caruso, G. Do seafarers have sunshine. In Proceedings of the 8th International Symposium on Maritime Health (ISMH) Book of Abstracts, Rijeka, Croatia, 8–13 May 2005. [Google Scholar]
- Laraqui, O.; Manar, N.; Laraqui, S.; Ghailan, T.; Deschamps, F.; Hammouda, R.; Laraqui, C.E.H. Prevalence of skin diseases amongst Moroccan fishermen. Int. Marit. Health 2018, 69, 22–27. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mahdi, S.S.; Amenta, F. Eighty years of CIRM. A journey of commitment and dedication in providing maritime medical assistance. Int. Marit. Health 2016, 67, 187–195. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sagaro, G.; Battineni, G.; Di Canio, M.; Amenta, F. Self-Reported Modifiable Risk Factors of Cardiovascular Disease among Seafarers: A Cross-Sectional Study of Prevalence and Clustering. J. Pers. Med. 2021, 11, 512. [Google Scholar] [CrossRef]
- Antons, D.; Grünwald, E.; Cichy, P.; Salge, T.O. The application of text mining methods in innovation research: Current state, evolution patterns, and development priorities. R&D Manag. 2020, 50, 329–351. [Google Scholar] [CrossRef] [Green Version]
- Battineni, G.; Sagaro, G.G.; Chintalapudi, N.; Amenta, F. Conceptual Framework and Designing for a Seafarers’ Health Observatory (SHO) Based on the Centro Internazionale Radio Medico (C.I.R.M.) Data Repository. Sci. World J. 2020, 2020, 8816517. [Google Scholar] [CrossRef] [PubMed]
- Chintalapudi, N.; Battineni, G.; Di Canio, M.; Sagaro, G.G.; Amenta, F. Text mining with sentiment analysis on seafarers’ medical documents. Int. J. Inf. Manag. Data Insights 2020, 1, 100005. [Google Scholar] [CrossRef]
- Ribeiro, J.; Duarte, J.; Portela, F.; Santos, M. Automatically detect diagnostic patterns based on clinical notes through Text Mining. Procedia Comput. Sci. 2019, 160, 684–689. [Google Scholar] [CrossRef]
- Grover, P.; Kar, A.K. Big Data Analytics: A Review on Theoretical Contributions and Tools Used in Literature. Glob. J. Flex. Syst. Manag. 2017, 18, 203–229. [Google Scholar] [CrossRef]
- Wu, C.-S.; Kuo, C.-J.; Su, C.-H.; Wang, S.; Dai, H.-J. Using text mining to extract depressive symptoms and to validate the diagnosis of major depressive disorder from electronic health records. J. Affect. Disord. 2019, 260, 617–623. [Google Scholar] [CrossRef]
- Karami, A.; Ghasemi, M.; Sen, S.; Moraes, M.F.; Shah, V. Exploring diseases and syndromes in neurology case reports from 1955 to 2017 with text mining. Comput. Biol. Med. 2019, 109, 322–332. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guerreiro, J.; Rita, P. How to predict explicit recommendations in online reviews using text mining and sentiment analysis. J. Hosp. Tour. Manag. 2019, 43, 269–272. [Google Scholar] [CrossRef]
- Denecke, K.; Deng, Y. Sentiment analysis in medical settings: New opportunities and challenges. Artif. Intell. Med. 2015, 64, 17–27. [Google Scholar] [CrossRef]
- Nandwani, P.; Verma, R. A review on sentiment analysis and emotion detection from text. Soc. Netw. Anal. Min. 2021, 11, 81. [Google Scholar] [CrossRef] [PubMed]
- Vij, A.; Pruthi, J. An automated Psychometric Analyzer based on Sentiment Analysis and Emotion Recognition for healthcare. Procedia Comput. Sci. 2018, 132, 1184–1191. [Google Scholar] [CrossRef]
- Moreira, L.B.; Namen, A.A. A hybrid data mining model for diagnosis of patients with clinical suspicion of dementia. Comput. Methods Programs Biomed. 2018, 165, 139–149. [Google Scholar] [CrossRef]
- Marir, F.; Said, H.; Al-Obeidat, F. Mining the Web and Literature to Discover New Knowledge about Diabetes. Procedia Comput. Sci. 2016, 83, 1256–1261. [Google Scholar] [CrossRef] [Green Version]
- Abirami, A.M.; Gayathri, V. A survey on sentiment analysis methods and approach. In Proceedings of the 2016 Eighth International Conference on Advanced Computing (ICoAC), Chennai, India, 19–21 January 2017; pp. 72–76. [Google Scholar] [CrossRef]
- Barlas, P.; Adam, S.; Chatelain, C.; Paquet, T. A Typed and Handwritten Text Block Segmentation System for Heterogeneous and Complex Documents. In Proceedings of the 2014 11th IAPR International Workshop on Document Analysis Systems, Tours, France, 7–10 April 2014; pp. 46–50. [Google Scholar] [CrossRef] [Green Version]
- Zeng, D.; Peng, J.; Fong, S.; Qiu, Y.; Wong, R. Medical data mining in sentiment analysis based on optimized swarm search feature selection. Australas. Phys. Eng. Sci. Med. 2018, 41, 1087–1100. [Google Scholar] [CrossRef]
- CRAN—Package Tidytext. Available online: https://cran.r-project.org/web/packages/tidytext/index.html (accessed on 23 February 2022).
- Wickham, H. Tidy Data. J. Stat. Softw. 2014, 59, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Data Visualization with R and ggplot2|the R Graph Gallery. Available online: https://www.r-graph-gallery.com/ggplot2-package.html (accessed on 1 March 2022).
- Rathore, A.K.; Kar, A.K.; Ilavarasan, P.V. Social Media Analytics: Literature Review and Directions for Future Research. Decis. Anal. 2017, 14, 229–249. [Google Scholar] [CrossRef]
- Emmert-Streib, F.; Dehmer, M. High-Dimensional LASSO-Based Computational Regression Models: Regularization, Shrinkage, and Selection. Mach. Learn. Knowl. Extr. 2019, 1, 359–383. [Google Scholar] [CrossRef] [Green Version]
- Text Mining and Word Cloud Fundamentals in R: 5 Simple Steps You Should Know—Easy Guides—Wiki—STHDA. Available online: http://www.sthda.com/english/wiki/text-mining-and-word-cloud-fundamentals-in-r-5-simple-steps-you-should-know (accessed on 1 March 2022).
- Dimitri, G.M.; Beqiri, E.; Placek, M.M.; Czosnyka, M.; Stocchetti, N.; Ercole, A.; Smielewski, P.; Lió, P.; Anke, A.; Beer, R.; et al. Modeling Brain–Heart Crosstalk Information in Patients with Traumatic Brain Injury. Neurocrit. Care 2021, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Ternès, N.; Rotolo, F.; Michiels, S. Empirical extensions of the lasso penalty to reduce the false discovery rate in high-dimensional Cox regression models. Stat. Med. 2016, 35, 2561–2573. [Google Scholar] [CrossRef]
- Kan, H.J.; Kharrazi, H.; Chang, H.-Y.; Bodycombe, D.; Lemke, K.; Weiner, J.P. Exploring the use of machine learning for risk adjustment: A comparison of standard and penalized linear regression models in predicting health care costs in older adults. PLoS ONE 2019, 14, e0213258. [Google Scholar] [CrossRef] [PubMed]
- Khanji, C.; Lalonde, L.; Bareil, C.; Lussier, M.-T.; Perreault, S.; Schnitzer, M.E. Lasso Regression for the Prediction of Intermediate Outcomes Related to Cardiovascular Disease Prevention Using the TRANSIT Quality Indicators. Med. Care 2019, 57, 63–72. [Google Scholar] [CrossRef] [PubMed]
- Shan, C. Research of Support Vector Machine in Text Classification. In Future Computer, Communication, Control and Automation; Zhang, T., Ed.; Advances in Intelligent and Soft Computing; Springer: Berlin/Heidelberg, Germany, 2012; Volume 119, pp. 567–573. [Google Scholar] [CrossRef]
- Hassani, H.; Beneki, C.; Unger, S.; Mazinani, M.T.; Yeganegi, M.R. Text Mining in Big Data Analytics. Big Data Cogn. Comput. 2020, 4, 1. [Google Scholar] [CrossRef] [Green Version]
- Tabe-Bordbar, S.; Emad, A.; Zhao, S.D.; Sinha, S. A closer look at cross-validation for assessing the accuracy of gene regulatory networks and models. Sci. Rep. 2018, 8, 6620. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Iversen, R.T.B. The mental health of seafarers. Int. Marit. Health 2012, 63, 78–89. [Google Scholar] [PubMed]
- Pencina, M.J.; D’Agostino, R.B.; D’Agostino, R.B.; Vasan, R.S. Evaluating the added predictive ability of a new marker: From area under the ROC curve to reclassification and beyond. Stat. Med. 2008, 27, 157–172. [Google Scholar] [CrossRef]
- Woldaregay, A.Z.; Walderhaug, S.; Hartvigsen, G.; Guitton, M.; Seale, D. Telemedicine Services for the Arctic: A Systematic Review. JMIR Med. Inform. 2017, 5, e16. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mair, F.; Fraser, S.; Ferguson, J.; Webster, K. Telemedicine via satellite to support offshore oil platforms. J. Telemed. Telecare 2008, 14, 129–131. [Google Scholar] [CrossRef] [PubMed]
- Dehours, E.; Vallé, B.; Bounes, V.; Girardi, C.; Tabarly, J.; Concina, F.; Pujos, M.; Ducassé, J.L. User satisfaction with maritime telemedicine. J. Telemed. Telecare 2012, 18, 189–192. [Google Scholar] [CrossRef] [PubMed]
- Wang, D.; Hu, B.; Hu, C.; Zhu, F.; Liu, X.; Zhang, J.; Wang, B.; Xiang, H.; Cheng, Z.; Xiong, Y.; et al. Clinical Characteristics of 138 Hospitalized Patients With 2019 Novel Coronavirus—Infected Pneumonia in Wuhan, China. JAMA 2020, 323, 1061–1069. [Google Scholar] [CrossRef] [PubMed]
- The Novel Coronavirus Pneumonia Emergency Response Epidemiology Team. The Epidemiological Characteristics of an Outbreak of 2019 Novel Coronavirus Diseases (COVID-19)—China, 2020. China CDC Wkly. 2020, 2, 113–122. [Google Scholar] [CrossRef]
- Paraskevis, D.; Kostaki, E.; Magiorkinis, G.; Panayiotakopoulos, G.; Sourvinos, G.; Tsiodras, S. Full-genome evolutionary analysis of the novel corona virus (2019-nCoV) rejects the hypothesis of emergence as a result of a recent recombination event. Infect. Genet. Evol. 2020, 79, 104212. [Google Scholar] [CrossRef] [PubMed]
- Tsumoto, S.; Kimura, T.; Iwata, H.; Hirano, S. Mining Text for Disease Diagnosis. Procedia Comput. Sci. 2017, 122, 1133–1140. [Google Scholar] [CrossRef]
- Metsker, O.; Bolgova, E.; Yakovlev, A.; Funkner, A.; Kovalchuk, S. Pattern-based Mining in Electronic Health Records for Complex Clinical Process Analysis. Procedia Comput. Sci. 2017, 119, 197–206. [Google Scholar] [CrossRef]
- Pletscher-Frankild, S.; Pallejà, A.; Tsafou, K.; Binder, J.X.; Jensen, L.J. DISEASES: Text mining and data integration of disease–gene associations. Methods 2015, 74, 83–89. [Google Scholar] [CrossRef]
- He, K.; Hong, N.; Lapalme-Remis, S.; Lan, Y.; Huang, M.; Li, C.; Yao, L. Understanding the patient perspective of epilepsy treatment through text mining of online patient support groups. Epilepsy Behav. 2019, 94, 65–71. [Google Scholar] [CrossRef] [Green Version]
- Groenhof, T.K.J.; Koers, L.R.; Blasse, E.; de Groot, M.; Grobbee, D.E.; Bots, M.L.; Asselbergs, F.W.; Lely, A.T.; Haitjema, S.; van Solinge, W.; et al. Data mining information from electronic health records produced high yield and accuracy for current smoking status. J. Clin. Epidemiol. 2020, 118, 100–106. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lucini, F.R.; Fogliatto, F.S.; da Silveira, G.J.; Neyeloff, J.; Anzanello, M.J.; Kuchenbecker, R.S.; Schaan, B.D. Text mining approach to predict hospital admissions using early medical records from the emergency department. Int. J. Med. Inform. 2017, 100, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Kocbek, S.; Cavedon, L.; Martinez, D.; Bain, C.; Mac Manus, C.; Haffari, G.; Zukerman, I.; Verspoor, K. Text mining electronic hospital records to automatically classify admissions against disease: Measuring the impact of linking data sources. J. Biomed. Inform. 2016, 64, 158–167. [Google Scholar] [CrossRef] [PubMed]
- Meaney, C.; Moineddin, R.; Voruganti, T.; O’Brien, M.A.; Krueger, P.; Sullivan, F. Text mining describes the use of statistical and epidemiological methods in published medical research. J. Clin. Epidemiol. 2016, 74, 124–132. [Google Scholar] [CrossRef] [PubMed]
- Grantz, K.H.; Meredith, H.R.; Cummings, D.A.T.; Metcalf, C.J.E.; Grenfell, B.T.; Giles, J.R.; Mehta, S.; Solomon, S.; Labrique, A.; Kishore, N.; et al. The use of mobile phone data to inform analysis of COVID-19 pandemic epidemiology. Nat. Commun. 2020, 11, 4961. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Case Number | Diagnosis | Medical Abstract | Suggested Treatment |
|---|---|---|---|---|
| 2006 | 88 | Abdominalgia | Mild pain in the lower part of the stomach and temperature. | Discontinue aspirin. Keep patient bed rest in the most comfortable position. Apply an ice bag wrapped in a cotton cloth on the painful area if it relieves pain. |
| 2008 | 17 | Acute Gastritis | The patient said he has stomach pain; he has a history of hyperacidity. | Keep patient rest in a sitting position. Give buscopan one tablet every six hrs. give antacid every six hrs. Give omeprazole one tablet every twelve hrs. Light boiled food diet with a large intake of mineral water. Give news in twelve hrs. |
| 2009 | 151 | Allergic Reaction | The rash on a body appears in various places namely round an eye, bridge of the nouse, behind an ear, on a breast and a back, on a neck and hands. | Keep resting cotton loose-fitting clothes. continue ciprofloxacin milligram. Cetrizine or chlophenaramine. Boiled food diet with abundant water. Avoid all contact with cargo. |
| 2013 | 597 | Fever | Stomach pain with loose motions, mainly at night. Burning sensation during urination especially during evenings when the fever sets in. | Keep bed rest far from air draughts and extremes of temp. Apply ice bag wrapped in a cotton cloth on the head when temperature rises above 39 °C Continue Paracetamol, Ciprofloxacin, continue also Buscopan. |
| 2014 | 1042 | Haemorrhage | Patient with profuse blooding from yesterday at the gingival level (maybe the presence of abscess) and of the urinary tract. He has lost knowledge several times yesterday and today, already underway in fluid therapy. | Continue fluid therapy with Ranitidine fl inside the flexo, Tranexamic acid is not available onboard. Give as antibiotic Amoxicillin 1 g CPR if not allergic. Urgent disembarkation should be organized with a faster vehicle. |
| 2016 | 197 | Anxious-Depressive Syndrome | Please note that for the last two days the patient had been complaining of improper sleep. He reported that he was feeling a little depressed. He also reported that he does not feel capable of keeping navigational watches during hours of darkness as it gives him a feeling of loneliness. | Keep at rest in the bed or armchair as he prefers but, in any case, under continuous control by a friendly person. Remove from his cabin dangerous objects (knives, forks, glasses, razor blades, belts, shoelaces, dangerous drugs, gas lighters, anything through which he can injure himself or other people). |
| 2020 | 746 | Foreign Body | One of the people in the crew has swollen right eye. He got some foreign dust particles inside his eye, he rubbed his eye with his dirty hands, the eye started swelling and itching. We gave him an eyewash and suggested washing the eye regularly. Looks like due to rubbing the eye, he developed an eye infection. Kindly advise treatment we can give. | Keep rest not necessary in bed in a semi-dark room. Wash accurately’s the eye with sterile saline solution or e Optrex or other eye leashes. Then when dry apply eye antibiotic ointment and cover with a sterile or light bandage. |
| 2021 | 54 | Odontalgia | Complain regarding the patient’s tooth on the lower left molar. It was found out that the filling was been detached which causes pain. | Keep at rest. Apply inside the tooth cavity a small ball of cotton wool soaked in clove oil. Administer Paracetamol one 500 mg tablet every 6 h and Co-amoxiclav one gram tablet every 12 h. A light diet with easily chewable foods and a large intake of liquids. |
| Model | Accuracy (%) | Sensitivity (%) | Specificity (%) | ROC |
|---|---|---|---|---|
| SVM | 64.2 | 68.3 | 45.3 | 0.597 |
| RF | 59.0 | 59.8 | 55.4 | 0.613 |
| LASSO | 93.8 | 97.9 | 80.6 | 0.976 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chintalapudi, N.; Angeloni, U.; Battineni, G.; di Canio, M.; Marotta, C.; Rezza, G.; Sagaro, G.G.; Silenzi, A.; Amenta, F. LASSO Regression Modeling on Prediction of Medical Terms among Seafarers’ Health Documents Using Tidy Text Mining. Bioengineering 2022, 9, 124. https://0-doi-org.brum.beds.ac.uk/10.3390/bioengineering9030124
Chintalapudi N, Angeloni U, Battineni G, di Canio M, Marotta C, Rezza G, Sagaro GG, Silenzi A, Amenta F. LASSO Regression Modeling on Prediction of Medical Terms among Seafarers’ Health Documents Using Tidy Text Mining. Bioengineering. 2022; 9(3):124. https://0-doi-org.brum.beds.ac.uk/10.3390/bioengineering9030124
Chicago/Turabian StyleChintalapudi, Nalini, Ulrico Angeloni, Gopi Battineni, Marzio di Canio, Claudia Marotta, Giovanni Rezza, Getu Gamo Sagaro, Andrea Silenzi, and Francesco Amenta. 2022. "LASSO Regression Modeling on Prediction of Medical Terms among Seafarers’ Health Documents Using Tidy Text Mining" Bioengineering 9, no. 3: 124. https://0-doi-org.brum.beds.ac.uk/10.3390/bioengineering9030124