
Predicting the Category and the Length of Punishment in Indonesian Courts Based on Previous Court Decision Documents


Abstract
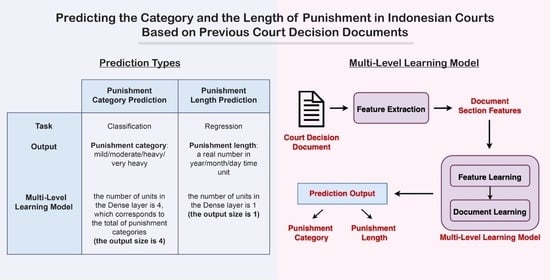
:
1. Introduction
- (1)
- What information from court decision documents are valuable/important for predicting the category and the length of punishment in Indonesian courts?
- (2)
- How effective is the multi-level learning CNN method with an attention mechanism for predicting the category and the length of punishment in Indonesian courts?
2. Related Work
3. Prediction Model
4. Research Methodology
4.1. Data Collection
- First-degree criminal decisions;
- Decisions that had permanent legal force (inkracht) [4] that were obtained from district courts in West Java, Central Java, East Java, Jakarta, or Yogyakarta;
- Decision documents that had pdf files.
4.2. Feature Extraction
4.2.1. Text Extraction
4.2.2. Token Normalization
- We identified the tokens that were typos or had the same meaning by examining the smallest edit distance compared to tokens in the dictionary, which contained 222,180 tokens. If the minimum edit distance obtained was less than three, it was considered as a typo. Approximately 96% of the tokens could be identified in this step; for example, ‘fundamentum’ (fundamental) was normalized as ‘fundamental’ (fundamental);
- If the minimum edit distance was more significant than three, we checked for invalid words that occurred because space was missing. Beginning from the left-hand side, we traced the word letter by letter and then checked whether the combination of letters existed in the dictionary. If the combination existed, we inserted a space and continued to trace the remaining letters in the word. We proceeded from the right-hand side if we could not search from the left-hand side. Approximately 26,676 tokens were identified and separated by spaces in this step; for example, ‘tidaknyapadasuatuwaktu’ was normalized as ‘tidaknya pada suatu waktu’ (not at a time);
- If the above step was unsuccessful, the next step was to identify the token as an unknown token by mapping it as a token ‘_unk_’. For example, ‘jpoooooooporoorjo’ was ‘_unk_’.
4.2.3. Document Section Annotation
4.3. Experiment
- One-level deep learning methods, which combine all the features used in a feature map. These baseline methods included CNN, LSTM, and BiLSTM;
- Multi-level deep learning methods, which consist of feature learning and document learning processes. These baseline methods included the LSTM+attention and BiLSTM+attention.
5. Results and Discussion
5.1. The Results for the Comparison of the Best Feature Representation
5.2. The Results for the Comparison of Using and Not Using Document Section Features
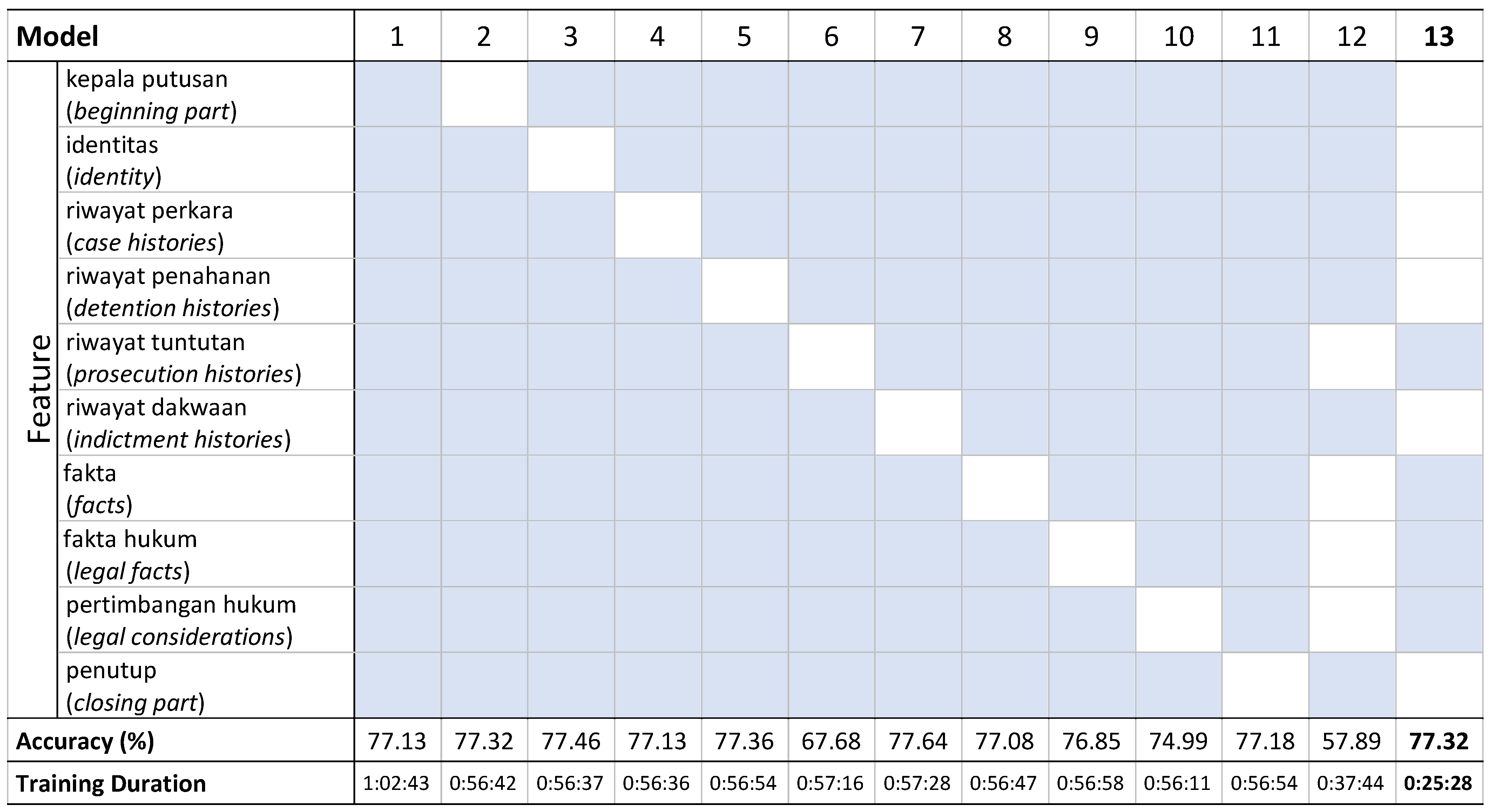
5.3. Ablation Analysis Results
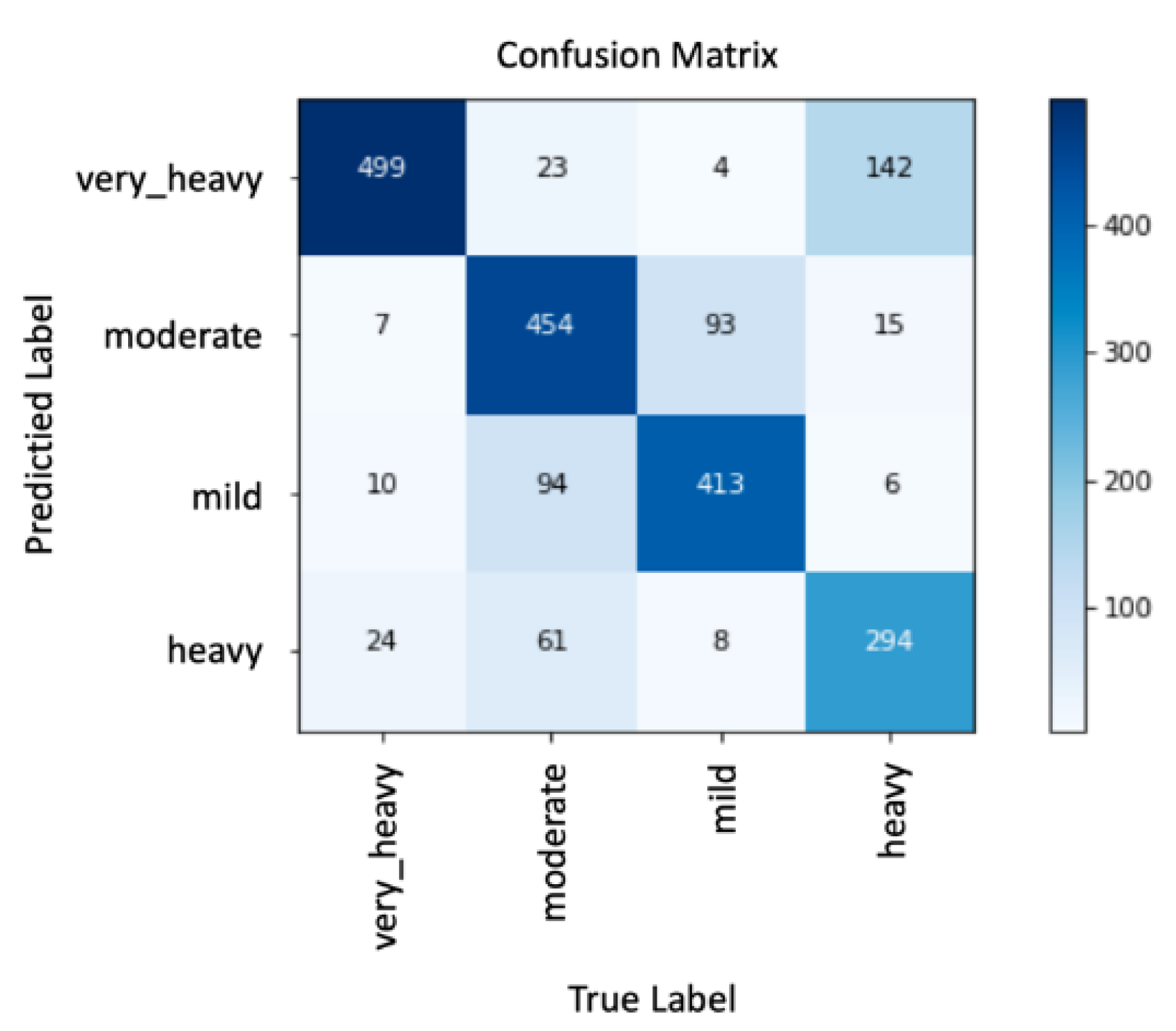
5.4. The Results for the Prediction of Punishment Category
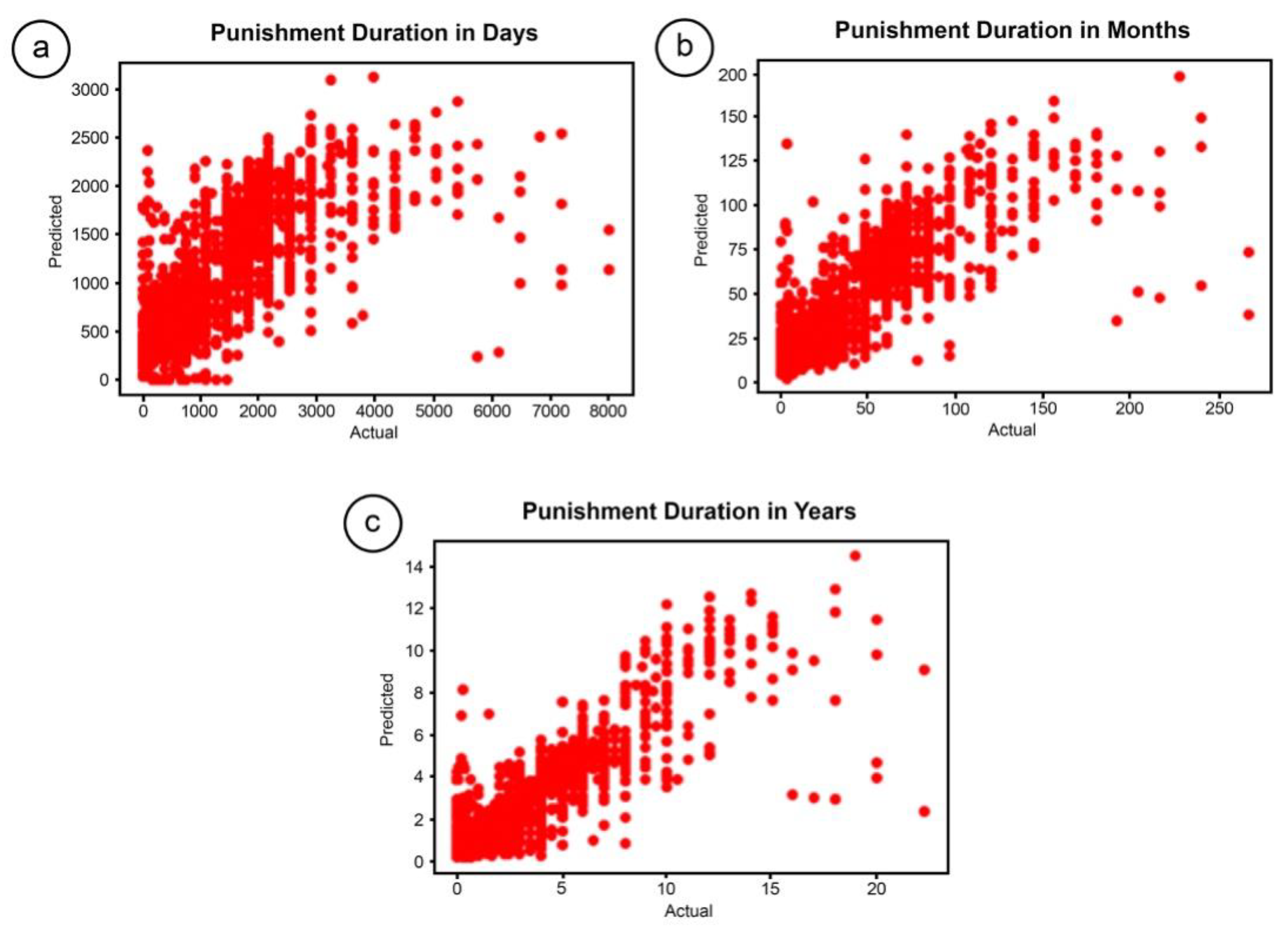
5.5. The Results for the Prediction of Length of Punishment
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Marzuki, P.M. Pengantar Ilmu Hukum; Kencana: Jakarta, Indonesia, 2008; ISBN 978-979-1486-53-8. [Google Scholar]
- Schmiegelow, H.; Schmiegelow, M. (Eds.) Institutional Competition between Common Law and Civil Law: Theory and Policy, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2014; ISBN 978-3-642-54660-0. [Google Scholar]
- Simanjuntak, E. Peran Yurisprudensi Dalam Sistem Hukum Di Indonesia The Roles of Case Law in Indonesian Legal System. J. Konstitusi 2019, 16, 83–104. [Google Scholar] [CrossRef]
- Lotulung, P.E. Peranan Yurisprudensi Sebagai Sumber Hukum; Badan Pembinaan Hukum Nasional Departemen Kehakiman: Jakarta, Indonesia, 1997. [Google Scholar]
- Butt, S. Judicial Reasoning and Review in the Indonesian Supreme Court. Asian J. Law Soc. 2019, 67–97. [Google Scholar] [CrossRef] [Green Version]
- Nuranti, E.Q.; Yulianti, E. Legal Entity Recognition in Indonesian Court Decision Documents Using Bi-LSTM and CRF Approaches. In Proceedings of the 2020 International Conference on Advanced Computer Science and Information Systems (ICACSIS), Depok, Indonesia, 17–18 October 2020; pp. 429–434. [Google Scholar] [CrossRef]
- Aletras, N.; Tsarapatsanis, D.; Preoţiuc-Pietro, D.; Lampos, V. Predicting Judicial Decisions of the European Court of Human Rights: A Natural Language Processing Perspective. PeerJ Comput. Sci. 2016, 2, e93. [Google Scholar] [CrossRef]
- Medvedeva, M.; Vols, M.; Wieling, M. Using Machine Learning to Predict Decisions of the European Court of Human Rights. Artif. Intell. Law 2019, 28, 237–266. [Google Scholar] [CrossRef] [Green Version]
- Virtucio, M.B.L.; Aborot, J.A.; Abonita, J.K.C.; Avinante, R.S.; Copino, R.J.B.; Neverida, M.P.; Osiana, V.O.; Peramo, E.C.; Syjuco, J.G.; Tan, G.B.A. Predicting Decisions of the Philippine Supreme Court Using Natural Language Processing and Machine Learning. In Proceedings of the IEEE 42nd Annual Computer Software and Applications Conference (COMPSAC), Tokyo, Japan, 23–27 July 2018; Volume 2, pp. 130–135. [Google Scholar] [CrossRef]
- Kowsrihawat, K.; Vateekul, P.; Boonkwan, P. Predicting Judicial Decisions of Criminal Cases from Thai Supreme Court Using Bi-Directional Gru with Attention Mechanism. In Proceedings of the 5th Asian Conference on Defence Technology, ACDT 2018, Hanoi, Vietnam, 25–26 October 2018; pp. 50–55. [Google Scholar] [CrossRef]
- Kong, J.; Zhang, L.; Jiang, M.; Liu, T. Incorporating Multi-Level CNN and Attention Mechanism for Chinese Clinical Named Entity Recognition. J. Biomed. Inform. 2021, 116, 103737. [Google Scholar] [CrossRef]
- Li, J.; Jin, K.; Zhou, D.; Kubota, N.; Ju, Z. Attention Mechanism-Based CNN for Facial Expression Recognition. Neurocomputing 2020, 411, 340–350. [Google Scholar] [CrossRef]
- Wijayasingha, L.; Stankovic, J.A. Robustness to Noise for Speech Emotion Classification Using CNNs and Attention Mechanisms. Smart Health 2021, 19, 100165. [Google Scholar] [CrossRef]
- Wu, T.-H.; Kao, B.; Cheung, A.S.Y.; Cheung, M.M.K.; Wang, C.; Chen, Y.; Yuan, G.; Cheng, R. Integrating Domain Knowledge in AI-Assisted Criminal Sentencing of Drug Trafficking Cases. In Frontiers in Artificial Intelligence and Applications; Villata, S., Harašta, J., Křemen, P., Eds.; IOS Press: Amsterdam, The Netheralnds, 2020; ISBN 978-1-64368-150-4. [Google Scholar]
- Solihin, F.; Budi, I. Recording of Law Enforcement Based on Court Decision Document Using Rule-Based Information Extraction. In Proceedings of the 2018 International Conference on Advanced Computer Science and Information Systems, ICACSIS 2018, Yogyakarta, Indonesia, 27–28 October 2018; pp. 349–354. [Google Scholar] [CrossRef]
- Violina, S.; Budi, I. Pengembangan Sistem Ekstraksi Informasi Untuk Dokumen Legal Indonesia: Studi Kasus Dokumen Undang-Undang Republik Indonesia. In SRITI Proceeding: Seminar Nasional Riset Teknologi Informasi 2009; SRITI 2009: Yogyakarta, Indonesia, 2009; pp. 135–142. [Google Scholar]
- Chen, Y.; Wang, K.; Yang, W.; Qing, Y.; Huang, R.; Chen, P. A Multi-Channel Deep Neural Network for Relation Extraction. IEEE Access 2020, 8, 13195–13203. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; Adaptive Computation and Machine Learning; The MIT Press: Cambridge, MA, USA, 2016; ISBN 978-0-262-03561-3. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar] [CrossRef] [Green Version]
- Srinivasamurthy, R.S. Understanding 1D Convolutional Neural Networks Using Multiclass Time-Varying Signalss. Ph.D. Thesis, Clemson University, Clemson, SC, USA, 2018. [Google Scholar]
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D Convolutional Neural Networks and Applications: A Survey. Mech. Syst. Signal Process. 2019, 151, 107398. [Google Scholar] [CrossRef]
- Indolia, S.; Goswami, A.K.; Mishra, S.P.; Asopa, P. Conceptual Understanding of Convolutional Neural Network—A Deep Learning Approach. Procedia Comput. Sci. 2018, 132, 679–688. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. In Proceedings of the 1st International Conference on Learning Representations, ICLR 2013—Workshop Track Proceedings, Scottsdale, AZ, USA, 2–4 May 2013; pp. 1–12. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of Tricks for Efficient Text Classification. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2017—Proceedings of Conference, Valencia, Spain, 3–7 April 2017; Volume 2, pp. 427–431. [Google Scholar] [CrossRef]
- Ranzato, M.A.; Boureau, Y.; Cun, Y. Sparse Feature Learning for Deep Belief Networks. In Proceedings of the Advances in Neural Information Processing Systems; Platt, J., Koller, D., Singer, Y., Roweis, S., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2007; Volume 20. [Google Scholar]
- Gholamalinezhad, H.; Khosravi, H. Pooling Methods in Deep Neural Networks, a Review. arXiv 2020, arXiv:2009.07485. [Google Scholar]
- Jeczmionek, E.; Kowalski, P.A. Flattening Layer Pruning in Convolutional Neural Networks. Symmetry 2021, 13, 1147. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015. [Google Scholar] [CrossRef]
- Galassi, A.; Lippi, M.; Torroni, P. Attention in Natural Language Processing. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4291–4308. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31th International Conference on Natural Information Processing System, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Bahdanau, D.; Cho, K.H.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Albon, C. Machine Learning with Python Cookbook: Practical Solutions from Preprocessing to Deep Learning, 1st ed.; O’Reilly Media: Sebastopol, CA, USA, 2018; ISBN 978-1-4919-8938-8. [Google Scholar]
- Carletta, J. Assessing Agreement on Classification Tasks: The Kappa Statistic. Comput. Linguist. 1996, 22, 249–254. [Google Scholar]
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Kang, H.; Yang, J. Performance Comparison of Word2vec and FastText Embedding Models. J. DCS 2020, 21, 1335–1343. [Google Scholar] [CrossRef]
- Thavareesan, S.; Mahesan, S. Sentiment Lexicon Expansion Using Word2vec and FastText for Sentiment Prediction in Tamil Texts. In Proceedings of the 2020 Moratuwa Engineering Research Conference (MERCon), Moratuwa, Sri Lanka, 28–30 July 2020; pp. 272–276. [Google Scholar]
- Tiun, S.; Mokhtar, U.A.; Bakar, S.H.; Saad, S. Classification of Functional and Non-Functional Requirement in Software Requirement Using Word2vec and Fast Text. J. Phys. Conf. Ser. 2020, 1529, 042077. [Google Scholar] [CrossRef]
- Xian, Y.; Choudhury, S.; He, Y.; Schiele, B.; Akata, Z. Semantic Projection Network for Zero- and Few-Label Semantic Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8248–8257. [Google Scholar]
- Santos, I.; Nedjah, N.; de Macedo Mourelle, L. Sentiment Analysis Using Convolutional Neural Network with FastText Embeddings. In Proceedings of the 2017 IEEE Latin American Conference on Computational Intelligence (LA-CCI), Arequipa, Peru, 8–10 November 2017; pp. 1–5. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. arXiv 2013, arXiv:1310. [Google Scholar]
- Grave, E.; Bojanowski, P.; Gupta, P.; Joulin, A.; Mikolov, T. Learning Word Vectors for 157 Languages. arXiv 2018, arXiv:1802.06893. [Google Scholar]
- Sokolova, M.; Lapalme, G. A Systematic Analysis of Performance Measures for Classification Tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Holcomb, J.P.; Draper, N.R.; Smith, H.; Rawlings, J.O.; Pantula, S.G.; Dickey, D.A. Applied Regression Analysis Applied Regression Analysis: A Research Tool; Springer Texts in Statistics; Springer: New York, NY, USA, 1998; ISBN 978-1-4757-7155-8. [Google Scholar]
- Kleinberg, B.; van der Vegt, I.; Mozes, M. Measuring Emotions in the COVID-19 Real World Worry Dataset. arXiv 2020, arXiv:2004.04225. [Google Scholar]
- Israeli, O. A Shapley-Based Decomposition of the R-Square of a Linear Regression. J. Econ. Inequal. 2007, 5, 199–212. [Google Scholar] [CrossRef]
- Pishro-Nik, H. Introduction to Probability, Statistics, and Random Processes; Kappa Research, LLC: Blue Bell, PA, USA, 2014; ISBN 978-0-9906372-0-2. [Google Scholar]
- Yulianti, E.; Kurnia, A.; Adriani, M.; Duto, Y.S. Normalisation of Indonesian-English Code-Mixed Text and Its Effect on Emotion Classification. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 674–685. [Google Scholar] [CrossRef]
- Wan, L.; Papageorgiou, G.; Seddon, M.; Bernardoni, M. Long-Length Legal Document Classification. arXiv 2019, arXiv:1912.06905. [Google Scholar]
- Berglund, M.; Raiko, T.; Honkala, M.; Kärkkäinen, L.; Vetek, A.; Karhunen, J. Bidirectional Recurrent Neural Networks as Generative Models. In Proceedings of the 28th International Conference on Neural Information Processing Systems—Volume 1; MIT Press: Cambridge, MA, USA, 2015; pp. 856–864. [Google Scholar]
- Graves, A. Supervised Sequence Labelling with Recurrent Neural Networks; Studies in computational intelligence; Springer: Berlin/Heidelberg, Germany; New York, NY, USA, 2012; ISBN 978-3-642-24796-5. [Google Scholar]
- Van Houdt, G.; Mosquera, C.; Nápoles, G. A Review on the Long Short-Term Memory Model. Artif. Intell. Rev. 2020, 53, 5929–5955. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Punishment Category | Punishment Length (Days) | Number of Documents |
|---|---|---|
| Mild | 0–479 | 5561 |
| Moderate | 480–1079 | 5991 |
| Heavy | 1080–1799 | 4112 |
| Very Heavy | 1800–8000 | 5811 |
| No. | Document Sections | Strings That Often Identified the Sections |
|---|---|---|
| 1. | Kepala putusan (document opener) | ‘PUTUSAN’ (‘DECISION’) Always in the first line |
| 2. | Identitas terdakwa (defendant’s identity) | ‘Nama…’, ‘Terdakwa I: Nama…’ (‘Name…’, “Defendant I: Name…”) |
| 3. | Riwayat perkara (case history) | ‘Para terdakwa didampingi oleh penasihat…’, ‘Pengadilan Negeri tersebut’ (‘The defendants were accompanied by an adviser…’) |
| 4. | Riwayat penahanan (detention history) | ‘Terdakwa ditahan dengan penahanan Rumah/Rutan/Kota/Negara oleh…’, ‘Terdakwa dalam perkara ini tidak ditahan’ (‘The defendant was detained at Home/Detention Center/City/State detention by…’, ‘The defendant in this case was not detained’) |
| 5. | Riwayat tuntutan (prosecution history) | ‘Telah/Setelah mendengar tuntutan…’ (‘After hearing the demands…’) |
| 6. | Riwayat dakwaan (indictment history) | ‘Menimbang, bahwa terdakwa… dakwaan Jaksa…’ (‘Considering, that the defendant… the prosecutor’s indictment…’) |
| 7. | Fakta (facts) | ‘Menimbang, bahwa dipersidangan telah mengajukan/mendengar/membaca/memeriksa…’ (‘Considering, that at the court submitted/heard/read/examined…’) |
| 8. | Fakta hukum (legal facts) | “Menimbang,… fakta-fakta/fakta hukum…” (“Considering,… facts/legal facts…”) |
| 9. | Pertimbangan hukum (legal considerations) | ‘Menimbang,… majelis hakim… berdasarkan fakta hukum/fakta-fakta…’ (‘Considering,… the panel of judges… based on facts/legal facts…’) |
| 10. | Amar putusan (verdict) | ‘MENGADILI’ (‘JUDGE’) |
| 11. | Penutup (closing) | ‘Demikianlah…’ (‘Declares…’) |
| Annotator | Cohen’s Kappa |
|---|---|
| 1 and 2 | 0.93 |
| 1 and Rule-based | 0.71 |
| 2 and Rule-based | 0.70 |
| No. | Experiment Scenario | Method | Evaluation Metric |
|---|---|---|---|
| 1. | The comparison of the best feature representation | Fast TextWord2vec | accuracy |
| 2. | The comparison of using and not using document section features | CNN+attention (full text) CNN+attention (document section features) | accuracy |
| 3. | The investigation of important features | Ablation analysis | accuracy |
| 4. | The prediction of punishment category | LSTM BiLSTM CNN LSTM+attention BiLSTM+attention CNN+attention | precision, recall, F-1 score, and accuracy |
| 5. | The prediction of punishment length | LSTM+attention BiLSTM+attention CNN+attention | R2 score |
| Model | Accuracy |
|---|---|
| FastText | 72.94% |
| Word2vec | 77.13% |
| Input | Accuracy |
|---|---|
| Not using the document section features (that is, using all the content in the document) | 50.12% |
| Using the document section features (10 features) | 77.13% |
| Model | Precision | Recall | F1Score | Accuracy |
|---|---|---|---|---|
| LSTM | 44.81% | 44.23% | 41.85% | 49.14% |
| BiLSTM | 50.53% | 47.95% | 43.77% | 52.03% |
| CNN | 74.58% | 75.10% | 74.55% | 75.17% |
| LSTM+attention | 65.01% | 64.87% | 64.80% | 65.44% |
| BiLSTM+attention | 65.30% | 65.73% | 65.43% | 65.81% |
| CNN+attention | 77.08% | 77.36% | 76.81% | 77.32% |
| Class | Precision | Recall | F1score |
|---|---|---|---|
| Mild | 79% | 80% | 79% |
| Moderate | 80% | 72% | 75% |
| Heavy | 76% | 64% | 69% |
| Very Heavy | 75% | 92% | 82% |
| Time Unit | Value Distribution | R2 Score |
|---|---|---|
| Days | 0–8000 | 44.37% |
| Months | 0–270 | 60.79% |
| Years | 0–23 | 67.16% |
| Model | R2 Score |
|---|---|
| LSTM+attention | 38.65% |
| BiLSTM+attention | 41.54% |
| CNN+attention | 67.16% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nuranti, E.Q.; Yulianti, E.; Husin, H.S. Predicting the Category and the Length of Punishment in Indonesian Courts Based on Previous Court Decision Documents. Computers 2022, 11, 88. https://0-doi-org.brum.beds.ac.uk/10.3390/computers11060088
Nuranti EQ, Yulianti E, Husin HS. Predicting the Category and the Length of Punishment in Indonesian Courts Based on Previous Court Decision Documents. Computers. 2022; 11(6):88. https://0-doi-org.brum.beds.ac.uk/10.3390/computers11060088
Chicago/Turabian StyleNuranti, Eka Qadri, Evi Yulianti, and Husna Sarirah Husin. 2022. "Predicting the Category and the Length of Punishment in Indonesian Courts Based on Previous Court Decision Documents" Computers 11, no. 6: 88. https://0-doi-org.brum.beds.ac.uk/10.3390/computers11060088