An Approach to Chance Constrained Problems Based on Huge Data Sets Using Weighted Stratified Sampling and Adaptive Differential Evolution †


Department of Informatics, Kindai University, Osaka 577-8502, Japan
†
This paper is an extended version of our paper published in the 25th International Conference on Information and Software Technologies (ICIST 2019), held in Kaunas University of Technology (Lithuania) on 10–12 October 2019.
Computers 2020, 9(2), 32; https://0-doi-org.brum.beds.ac.uk/10.3390/computers9020032
Submission received: 19 March 2020
/
Revised: 13 April 2020
/
Accepted: 14 April 2020
/
Published: 16 April 2020
(This article belongs to the Special Issue Selected Papers from the 25th International Conference on Information and Software Technologies (ICIST 2019))
Abstract
:In this paper, a new approach to solve Chance Constrained Problems (CCPs) using huge data sets is proposed. Specifically, instead of the conventional mathematical model, a huge data set is used to formulate CCP. This is because such a large data set is available nowadays due to advanced information technologies. Since the data set is too large to evaluate the probabilistic constraint of CCP, a new data reduction method called Weighted Stratified Sampling (WSS) is proposed to describe a relaxation problem of CCP. An adaptive Differential Evolution combined with a pruning technique is also proposed to solve the relaxation problem of CCP efficiently. The performance of WSS is compared with a well known method, Simple Random Sampling. Then, the proposed approach is applied to a real-world application, namely the flood control planning formulated as CCP.
1. Introduction
In real-world applications, a wide range of uncertainties have to be taken into account. Therefore, optimization problems under uncertainties have been studied for many years. Generally speaking, there are two types of formulations for handling uncertainties in optimization problems. The first one is the deterministic optimization problem [1]. The second one is the stochastic optimization problem [2]. The robust optimization problem is a well-known deterministic formulation [1]. The robust optimization problem always considers the worst-case performance under uncertainties. Therefore, the overestimation of uncertainties may lead to a conservative decision in practice.
The Chance Constrained Problem (CCP), which is also referred to as the probabilistic constrained problem [3], is one of the possible formulations of the stochastic optimization problem. CCP is a risk-averse formulation of problem under uncertainties. Specifically, CCP ensures that the probability of meeting all constraints is above a certain level. Since the balance between optimality and reliability can be designated by CCP, many real-world applications have been formulated as CCPs [3,4,5].
CCP has been studied in the field of stochastic programming for many years [2]. In stochastic programming, the optimization methods of the nonlinear programming [6] have been used to solve CCP. Recently, Evolutionary Algorithms (EAs) have also been reported for solving CCPs [7,8,9]. However, in the conventional formulation of CCP, a well known probability distribution such as the normal distribution is used widely as a mathematical model of unknown uncertainties. Then, the pseudo data generated randomly by using the Monte Carlo method based on the mathematical model are used to represent uncertainties [10]. In some cases, the mathematical model is used to derive a deterministic formulation of CCP [2,11]. Otherwise, very few data, or scenarios, observed actually are used to represent uncertainties. As a drawback of the conventional formulation of CCP, the estimation error of uncertainties is unavoidable in the evaluation of solutions. In other words, if CCP is defined incompletely, the solution is also defective. Then, we cannot enjoy the benefit of CCP.
In recent years, due to advanced information technologies such as Wireless Sensor Networks (WSN) and Internet of Things (IoT) [12], huge data sets called “big data” have been easily obtained in various fields including culture, science, and industry [13]. In many real-world applications, the variance of observed data is caused by some uncertainties. These applications are probably formulated as CCP more accurately by using a large data set instead of the mathematical model.
In this paper, CCP was formulated by using a large data set called a full data set. However, we assumed that the full data set is too large to solve CCP practically. Therefore, in order to evaluate solutions of CCP, we had to reduce the size of the full data set. Clustering is a popular data reduction technique [14]. Clustering divides a data set into some subsets in order to meet two requirements: “Internal cohesion” and “External isolation”. As a drawback of clustering, the result of clustering depends on the structure of data. Moreover, it is not good at dealing with a huge data set [15].
Sampling is another technique of data reduction. In particular, Simple Random Sampling (SRS) is widely used due to its easy execution and simplicity [16]. SRS selects a few samples randomly from a huge data set and discards most of data. As a drawback of SRS, the key information in many data is likely to be lost. Therefore, a new data reduction method called Weighted Stratified Sampling (WSS) has been proposed by authors to use the full data set completely for solving CCP [17].
By using the new data reduction method called WSS, the above CCP based on the full data set is converted into a relaxation problem of CCP. In order to solve the relaxation problem of CCP efficiently, a new optimization method based on Differential Evolution (DE) [18] is also contrived in this paper. In the new optimization method, a pruning technique is introduced into an adaptive DE [19] for reducing the number of candidate solutions to be examined on the process of the optimization.
The proposed approach is applied to a real-world application, namely the flood control planning formulated as CCP [5]. In addition to the conventional reservoir, the water-retaining capacity of the forest is considered in the flood control planning. Incidentally, various reservoir systems have been studied for protecting a downstream area of river from flood damage [20,21,22]. Even though historical data are used in these studies, many of them have been limited to dealing with problems of deterministic formulation. A stochastic formulation such as CCP is generally a more realistic representation of the flood control planning because stream flows have randomness and are stochastic in nature.
This paper is an extended version of the paper presented in ICIST2019 [17] and differs from the conference paper in the following three points: (1) The necessary sample size for SRS is derived theoretically. Then, it is shown that the theoretical sample size is too large in practice; (2) By using larger data sets, the performance of WSS is examined more intensively by comparison with SRS. Then, it is proven that WSS outperforms SRS in the accuracy of the estimated probability; (3) The ability of the pruning technique to reduce the run time of the adaptive DE is evaluated. Then, it is shown that the effect of the pruning technique increases proportionally to the sample size of WSS.
The remainder of this paper is organized as follows. Section 2 formulates CCP from a full data set. Section 3 explains two data reduction methods, namely the conventional SRS and the proposed WSS. By using a data reduction method, a relaxation problem of CCP is also derived. Section 4 proposes an adaptive DE combined with a pruning technique for solving the relaxation problem of CCP efficiently. Section 5 examines the performance of WSS intensively by comparison with SRS. Section 6 applies the proposed approach to a real-world application, namely the flood control planning formulated as CCP. Section 7 evaluates the ability of the pruning technique to reduce the run time of the adaptive DE on a personal computer. Finally, Section 8 concludes this paper and provides future work.
2. Problem Formulation
In this paper, uncertainties are represented by a vector of random variables with a sample space . The collection of vectors is independent and identically distributed (i.i.d.). It is not necessarily that the collection of the elements of each vector is i.i.d. We suppose that both the sample space and the distribution of are unknown. However, a full data set including a huge number of data is available. Incidentally, the full data set can be regarded as a kind of “big data”. Symbols used in this paper are defined as follows:
- A vector of decision variables
- A vector of random variables
- A huge number of data, or a full data set
- Measurable function for constraints ,
- Objective function to be minimized
- Sufficiency level given by a probability .
2.1. Chance Constrained Problem (CCP)
Let be the probability that an event occurs. The joint probability meeting all probabilistic constraints , for a solution is described as
By using the probability in (1), CCP is formulated as
where a sufficiency level is given by an arbitrary probability.
In real-world applications, both the sample space and the distribution of are usually unknown. Therefore, it is impossible to solve CCP in (2) directly.
2.2. Equivalence Problem of CCP
As stated above, due to advanced information technology, we can suppose that a huge data set is available for estimating the unknown probability in (1) empirically.
First of all, the indicator function is defined as
By using the indicator function in (3), the unknown probability in (1) can be evaluated empirically from a huge number of data for a solution as
where denotes the size of the data set , or the total number of data .
From the law of large numbers [23], we can expect that holds. Therefore, by using the empirical probability in (4), CCP in (2) can be rewritten as
It is difficult to solve CCP in (5). In real-world applications, the function value in (4) has to be evaluated for each of the data through a time-consuming computer simulation. Thus, the full data set is too large to evaluate the empirical probability in (4). In order to solve CCP in (5) practically, we need to reduce the number of data included in the full data set.
3. Data Reduction Methods
In order to reduce the number of data included in the full data set , we explain two data reduction methods. Firstly, Simple Random Sampling (SRS) is the most popular method [24]. SRS is widely used due to its easy execution and simplicity [25]. Secondly, Weighted Stratified Sampling (WSS) is a new data reduction method proposed by authors in ICIST 2019 [17].
3.1. Simple Random Sampling (SRS)
3.1.1. Procedure of SRS
Some samples , are selected randomly from the full data set for making a sample set . The sample size N is far smaller than the data size . By using samples , selected by SRS, an empirical probability is calculated as
3.1.2. Theoretical Sample Size
Supposing that holds, we can estimate theoretically a necessary sample size for SRS. Let be a solution of CCP in (5). By using random samples , , the empirical probability in (6) is evaluated from defined as
The values of in (7), which depend on random samples , , are regarded as random variables obeying a binomial distribution. From the central limit theorem, the binomial distribution can be approximated by a normal distribution [23]. Therefore, for any and , the confidence interval of the unknown probability in (4) is described as
Let be the Cumulative Distribution Function (CDF) of the standard normal distribution. From (8), the risk of failure is derived as
From (9), the margin of error is also derived as
where is defined as .
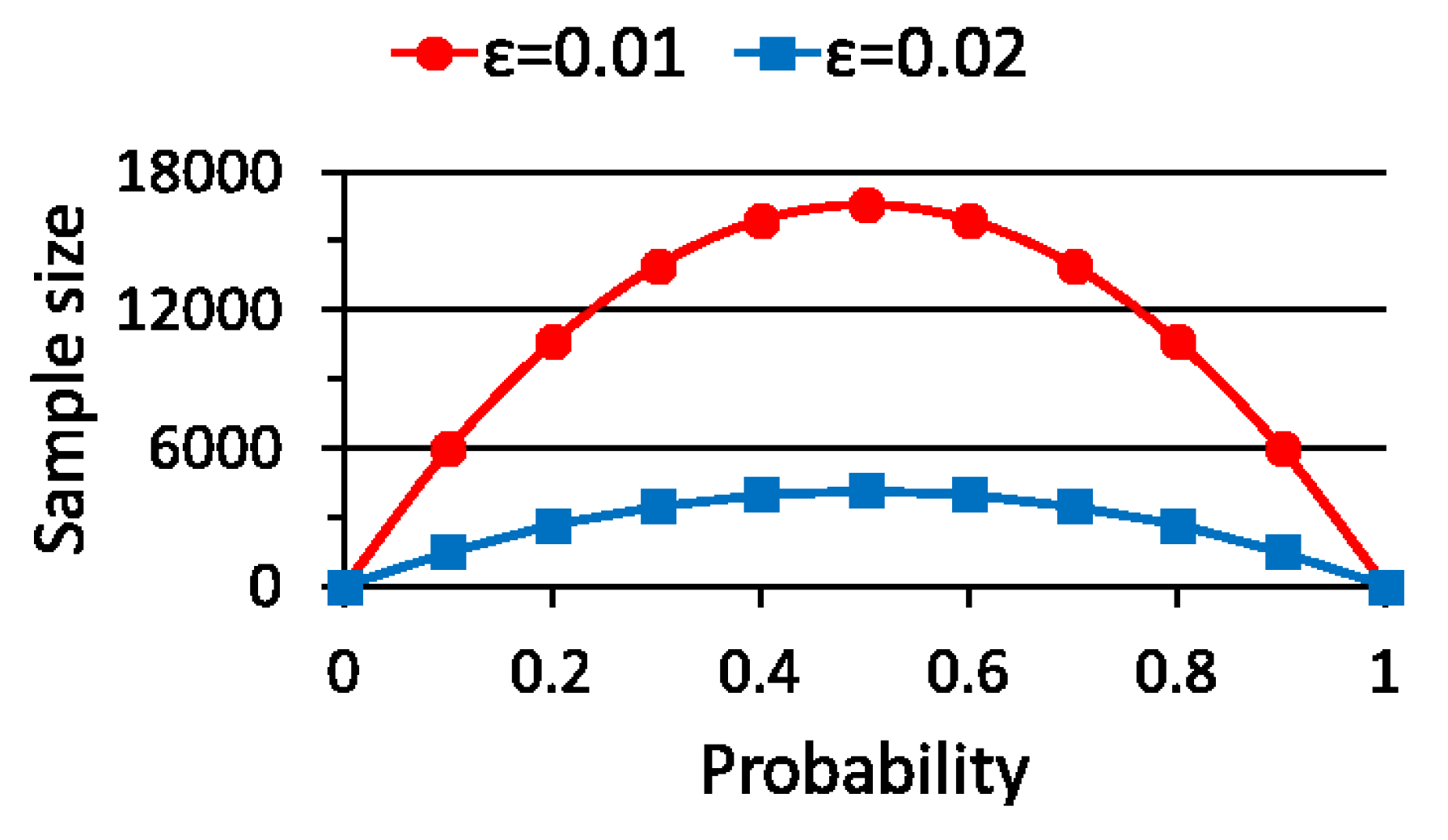
Figure 1 shows the margin of error given by (10) for the sample size N and the value of . Figure 2 shows the sample size given by (11) for the value of and .
3.2. Weighted Stratified Sampling (WSS)
Since every sample of SRS has the same probability of being chosen from the full data set , few samples are taken from the sparse part of . In addition to the defect of SRS, the majority of data are neglected by SRS even though the full data set is very large.
In order to use the full data set completely, we proposed a new data reduction method called WSS [17]. In the sampling technique called stratified sampling, which is often used in statistical survey [24], a data set is divided into some strata, or homogeneous subsets. This process is called stratification. Then, a few samples are selected from every stratum. Contrarily to clustering techniques used to divide a data set into some subsets [24], the stratification requires only “Internal cohesion” but not “External isolation”. Therefore, we can choose an arbitrary number of strata for WSS.
3.2.1. Procedure of WSS
A sample set is generated from the full data set as follows:
- Step 1:
- By using a K-dimensional histogram, the full data set is divided exclusively into some strata , aswhere and , .Specifically, the K-dimensional histogram is a K-dimensional hypercube that contains the full data set . On each side of the K-dimensional hypercube, the entire range of data is divided into a series of intervals. In this paper, the number of intervals is the same on all sides. Moreover, all intervals on each side have equal widths. Therefore, the K-dimensional histogram is an equi-width histogram [26]. Each bin of the K-dimensional histogram is also a K-dimensional hypercube. Then, nonempty bins are used to define strata , .
- Step 2:
- A new sample point is generated for each stratum , . Then, the sample set is defined as .
- Step 3:
- The weight of each sample is given by the size of as .
By using a set of samples , and their weights obtained by WSS, an empirical probability is calculated to approximate in (4) as
where and , .
3.2.2. Sample Generation by WSS
Each of the samples of WSS is not necessary to be a sample from the stratum . For generating samples , in Step 2, we think about the optimality of the sample set . The best sample set minimizes the error metric of histogram [27] defined as
In order to minimize the error metric of histogram in (15), we will solve the following differential equation about because each term in (15) is convex.
By solving the differential equation in (16), we can obtain the optimal sample as
Consequently, in Step 2 of WSS, we have only to generate a new sample by using the average point of all data included in the stratum as shown in (17).
3.3. Relaxation Problems of CCP
As stated above, the equivalence problem of CCP in (5) is hard to solve. That is because the full data set is too large. Therefore, a data reduction method, namely SRS or WSS, is employed to formulate a relaxation problem of CCP. By using in (6) or in (14) to approximate in (4), the relaxation problem of CCP is formulated as
where the sample set denotes either or . The correction level is chosen as to compensate the margin of error caused by SRS or WSS.
4. Adaptive Differential Evolution with Pruning Technique
Differential Evolution (DE) has been proven to be one of the most powerful global optimization algorithms [28,29]. Unfortunately, cardinal DE [18] is only applicable to unconstrained problems. Moreover, the performance of DE is significantly influenced by its control parameter settings. Therefore, in order to solve the relaxation problem of CCP shown in (18) efficiently, a new optimization method called Adaptive DE with Pruning technique (ADEP) is proposed. In the proposed ADEP, three techniques are introduced into cardinal DE [18]: (1) Adaptive control of parameters [19]; (2) Constraint handling based on feasibility rule [30]; and (3) Pruning technique in selection [17].
4.1. Strategy of DE
As well as cardinal DE [18], ADEP has a set of candidate solutions , called population in each generation t. Each candidate solution is a vector of decision variables. The initial population is randomly generated according to a uniform distribution.
At each generation t, every is assigned to a target vector in turn. By using the basic strategy of DE called “DE/rand/1/bin” [18], a trial vector is generated from the target vector . Specifically, except for the current target vector , three other distinct vectors, say , , and , , are selected randomly from the population . By using the three vectors, the differential mutation generates a new real vector called mutated vector as
where is a control parameter called scale factor.
The binomial crossover between the mutated vector and the target vector generates another real vector called trial vector. Specifically, each component , of the trial vector is inherited from either or as
where is a control parameter called crossover rate. denotes a uniformly distributed random value. The subscript is selected randomly every time, which ensures that the newborn vector differs from the existing one at least one element.
4.2. Adaptive Control of Parameters
The performance of DE depends on control parameters, namely the scale factor in (19) and the crossover rate in (20). Therefore, various parameter adaptation mechanisms have been reported [28,29,31]. ADEP employs an adaptive parameter control mechanism in which feedback from the evolutionary search is used to dynamically change the control parameters [19].
According to the adaptive parameter control mechanism [19], all vectors , have their own control parameters, namely and , at each generation t. Then, these control parameters are initialized as and , .
For generating the mutated vector as shown in (19), the scale factor is decided by using the control parameter associated with the target vector as
where , are uniformly distributed values.
Similarly, for generating the trial vector as shown in (20), the crossover rate is decided by using the control parameter associated with the target vector as
where , are uniformly distributed values.
The trial vector generated by using in (21) and in (22) is compared with the target vector as described below. If is better than , is selected for a new vector of the next generation, and the control parameters of are decided as and . Otherwise, the target vector survives to the next generation, and the control parameters of are inherited from as and .
4.3. Constraint Handling and Pruning Technique in Selection
Evolutionary Algorithms (EAs) including DE are typically applied to problems in which bounds are the only constraints. Therefore, a number of Constraint Handling Techniques (CHTs) have been proposed in order to apply EAs to constrained optimization problems [32]. Among those CHTs, the feasibility rule [30] is one of the most widely used CHTs because of its simplicity and efficiency. Thus, ADEP uses a feasibility rule with the amount of constraint violation defined from (18) as
where the candidate solution of CCP in (18) is feasible if holds.
At each generation t, the trial vector , is compared with the corresponding target vector . Then, either the trial vector or the target vector is selected for a vector of the next generation. First of all, if the following condition is satisfied,
the trial vector is discarded immediately because is better than . Then, the trial vector survives to the next generation. Since the pruning technique based on the condition in (24) does not require the value of , it is very effective to reduce the run time of ADEP.
Only when the condition in (24) is not satisfied, the probability is evaluated by using the sample set to get the value of . If either of the following conditions is satisfied,
the trial vector is selected for a new vector of the next generation. Otherwise, the current target vector survives to the next generation and becomes a vector .
4.4. Proposed Algorithm of ADEP
The algorithm of ADEP is described as follows. The maximum number of generations is given as the termination condition. The population size is chosen as [18].
- Step 1:
- Randomly generate the initial population , . .
- Step 2:
- For to , evaluate and for each vector .
- Step 3:
- If holds, output the best solution and terminate ADEP.
- Step 4:
- For to , generate the trial vector from the target vector .
- Step 5:
- For to , evaluate for the trial vector .
- Step 6:
- For to , evaluate for only if the condition in (24) is not satisfied.
- Step 7:
- For to , select either or for . .
- Step 8:
- Go back to Step 3.
5. Performance Evaluation of WSS
We evaluate the performance of the proposed WSS by comparison with the conventional SRS. Specifically, by using WSS and SRS, we estimate the probability meeting as
where is a measurable function.
From (9) to (11), the performance of SRS depends on the value of the probability to be estimated. Therefore, by changing the value of in (26), we change the value of the probability to be estimated by SRS and WSS. From a full data set , the sample sets and are generated, respectively, by using SRS and WSS. Then, the estimation error is defined as
where the sample set denotes either or .
5.1. Case Study 1
Each value of practical data in (2) usually has a range. Therefore, a full data set is generated randomly by using a truncated normal distribution as
where the mean is and the variance is .
The truncated normal distribution in (28) is the probability distribution derived from that of a normally distributed random variable by bounding the random variable as . The correlation matrix of the random variables , is also given as
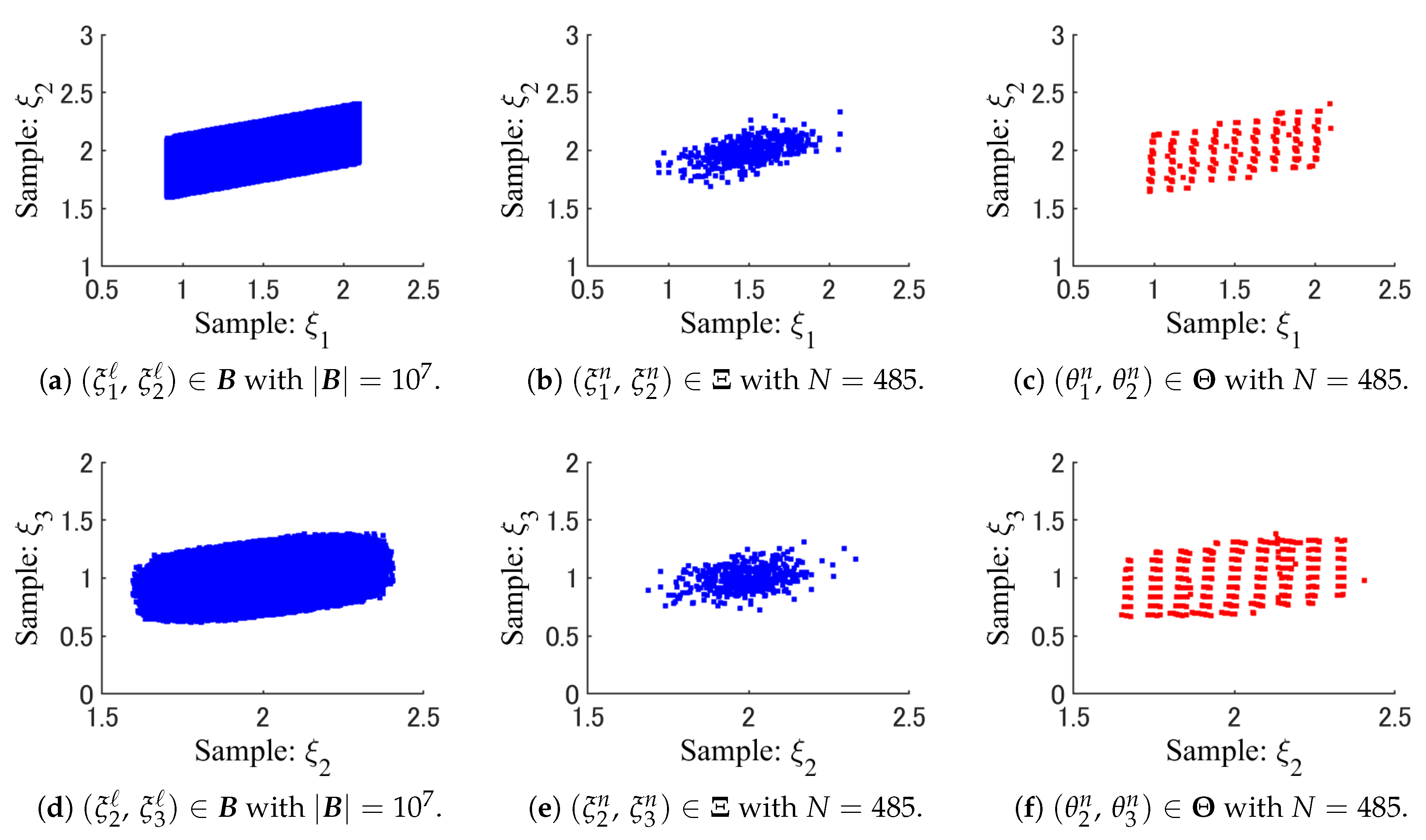
Please notice that the full data set is i.i.d. even if the elements of have a correlation. The size of the full data set generated randomly is . Figure 3 shows the spatial patterns of the full data and the random samples , selected by SRS. Figure 4 also shows the full data and the weighted samples generated by WSS.
From Figure 3 and Figure 4, we can see that the weighted samples , of WSS are scattered more widely as compared to the random samples of SRS. Especially, SRS has not taken any samples from the sparse part of the full data set in Figure 3.
For the probability in (26), a function is defined as
where the vector of decision variables is given as .
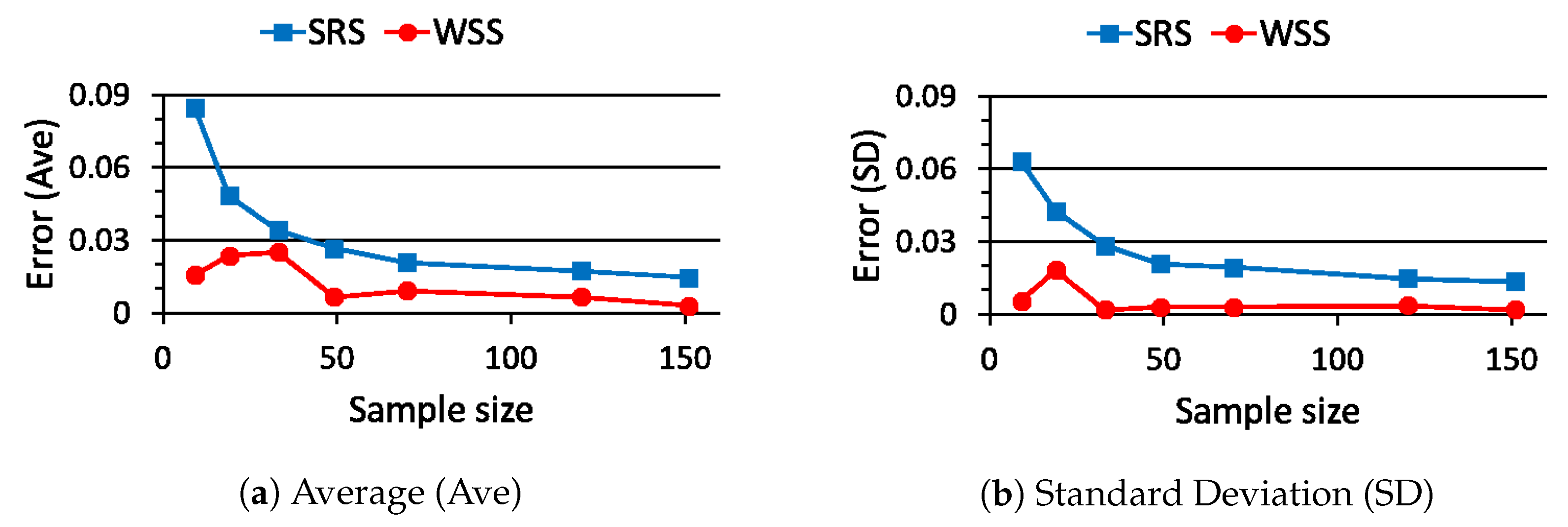
The probability in (26) becomes when is chosen. Then, the estimation errors in (27), namely and , are evaluated 100 times for each sample size by using different full data sets and summarized in Figure 5. From Figure 5, the average value and the standard deviation of are smaller than those of for any sample sizes. Furthermore, converges to almost zero faster than on average. Consequently, we can say that the proposed WSS outperforms the conventional SRS in the accuracy of the estimated probability.
The probability in (26) becomes when is chosen. The estimation errors in (27) are evaluated for WSS and SRS with the probability as stated above and summarized in Figure 6. The probability in (26) becomes when is chosen. The estimation errors in (27) are also evaluated for WSS and SRS with the probability and summarized in Figure 7. From Figure 6 and Figure 7, the standard deviation of is always smaller than that of . On the other hand, in the average value of the estimation errors, WSS seems to lose the advantage over SRS when the probability value gets closer to .
From Figure 5, Figure 6 and Figure 7, the performance of WSS depends not only on the sample size but also on the probability value to be estimated. Then, WSS outperforms SRS when the probability value is large. A large value is usually chosen for the probability meeting all constraints in CCP. Consequently, we can say that WSS is more suitable for formulating the relaxation problem of CCP in (18).
5.2. Case Study 2
A full data set is generated randomly as
where and .
The correlation matrix of the random variables , is also given as
The size of the full data set generated randomly is . Figure 8 shows the spatial patterns of the full data and the random samples , selected by SRS. Figure 9 also shows the full data and the weighted samples generated by WSS.
From Figure 8 and Figure 9, we can see that the weighted samples , of WSS are scattered more widely than the random samples of SRS. Some weighted samples shown in Figure 9 seem to be overlapped each other due to the high dimensionality of them. However, we can recognizable the uniformity in the pattern of the weighted samples .
For the probability in (26), a linear function is defined as
where the vector of decision variables is given as .
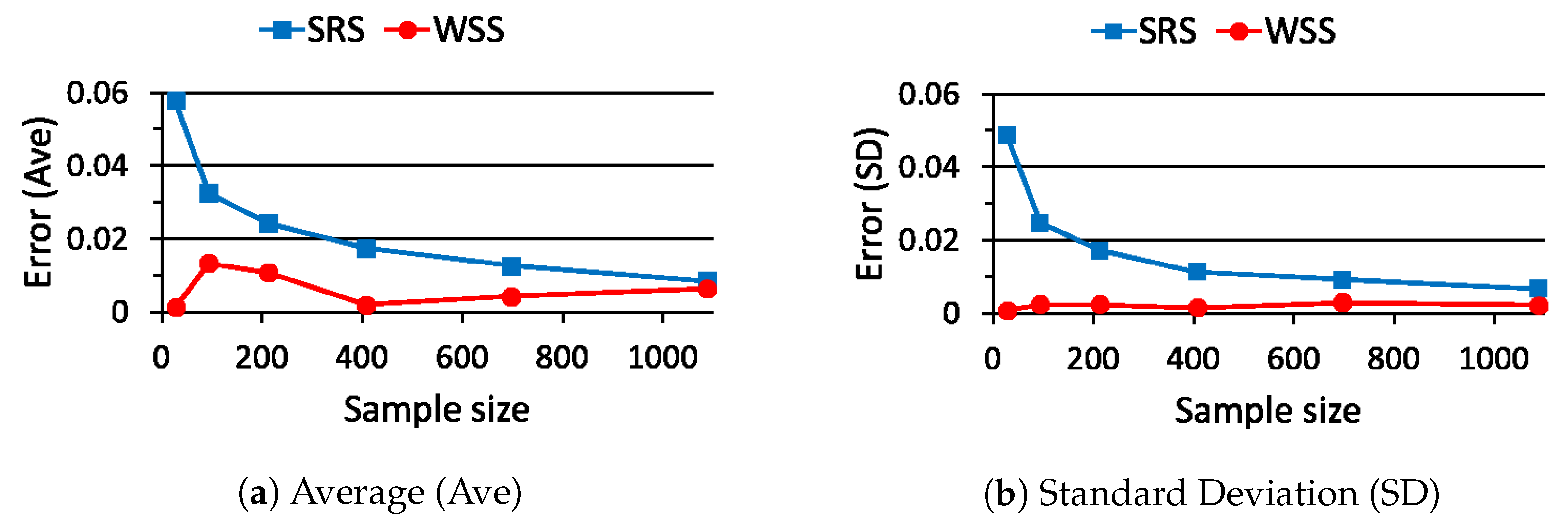
The probability in (26) becomes when is chosen. Then, the estimation errors in (27), namely and , are evaluated 100 times for each sample size by using different full data sets and summarized in Figure 10. From Figure 10, the average value and the standard deviation of are smaller than those of for any sample sizes. From these results, we confirm that the proposed WSS outperforms the conventional SRS in this case.
5.3. Case Study 3
A full data set , is generated randomly as shown in (31) and (32). For the probability in (26), a non-linear function is defined as
where the vector of decision variables is given as .
The probability in (26) becomes when is chosen. The estimation errors in (27) are evaluated for WSS and SRS with the probability as stated above and summarized in Figure 11. From Figure 11, WSS is also better than SRS because the average value and the standard deviation of are smaller than those of for any sample sizes.
6. Flood Control Planning
6.1. Formulation of CCP
Reservoirs are constructed to protect an urban area at the lower part of river from the flood damage caused by torrential rain. The flood control reservoir system design has been formulated as CCP [33]. In addition to the reservoir, the water-retaining capacity of forest is counted to prevent the flood caused by heavy rainfall. Thereby, the flood control planning is formulated as CCP [5].
Figure 12 shows a topological river model. Symbol ◯ denotes a forest considered in the flood control planning. There are three forests in watersheds. The gross area of each forest , is a constant. The amount of rainfall per unit area in each of the forests is a random variable. The water-retaining capacity of forest , per unit area is regarded as a decision variable because it can be controlled through the forest maintenance such as afforestation. According to the model of the forest mechanism [34], the inflow of water from each forest to the river is
where the effect of past rainfall is not considered in the model [34].
Symbol △ in Figure 12 denotes a reservoir. Three reservoirs are constructed in the river. The capacity of each reservoir , is also a decision variable. From in (35), the inflow of water from the river to the town located at the lower part of the river is calculated as
where , denotes defined by (35).
The probability of meeting has to be greater than . The maintenance cost of a forest is proportional to its capacity. The construction cost of a reservoir is proportional to the square of its capacity. Then, the flood control planning to minimize the total cost is formulated as
where , . From (36), functions , are derived as
6.2. Comparison of SRS and WSS
We suppose that the amount of rainfall in (37) is given as “big data”. For convenience, the full data set is generated randomly by using the truncated normal distribution shown in (31). Please notice that denotes the amount of rainfall in one period, but the river flow depending on an actual time. The inflow of water is derived from as shown in (35). Therefore, the full data set is i.i.d. On the other hand, a set of , is not i.i.d. The correlation matrix of the amounts of rainfalls , is given as
The size of the full data set generated randomly is . Figure 13 shows the spatial patterns of the full data , the random samples , selected by SRS, and the weighted samples , generated by WSS.
From Figure 13, we can see that the weighted samples , of WSS are scattered more widely than the random samples , of SRS. Some weighted samples of WSS seem to be overlapped each other in Figure 13 due to the high dimensionality of them. However, we can recognizable the uniformity in the pattern of the weighted samples .
The flood control planning formulated as CCP in (37) is transformed into an equivalence problem of CCP as shown in (5) by using the above full data set , . For a solution of the equivalence problem of CCP, the joint probability defined by (4) and (37) becomes . By using SRS and WSS respectively, we estimate the value of the joint probability .
The estimation errors in (27), namely and , are evaluated 100 times for each sample size by using different full data sets and summarized in Figure 14. From Figure 14, the average value and the standard deviation of are smaller than those of for any sample sizes. From these results, we confirm that WSS outperforms SRS in this case too.
6.3. Solution of CCP
By using the weighted samples , of WSS, the flood control planning formulated as CCP in (37) is transformed into a relaxation problem of CCP as shown in (18). That is because the result in Figure 14 shows that WSS estimates the value of using fewer samples than SRS. From the average value of in Figure 14, the sample size is chosen as .
The proposed ADEP is coded in MATLAB [35]. The parameters of ADEP and WSS are chosen as shown in Table 1. As stated above, the sample size is chosen as . For a sufficiency level in (37), the correction level in (18) is chosen as . The population size is decided as by recommendation of the literature [18]. The maximum number of generations is decided as through a preliminary experiment. Figure 15 shows the convergence graph of ADEP when the sufficiency level is chosen as or . The horizontal axis of Figure 15 is the number of generations. The vertical axis is the best objective function value achieved at each generation. From Figure 15, we can confirm that is a sufficiently large number of generations.
ADEP is applied to the relaxation problem of CCP 50 times. For the respective runs of ADEP, different full data sets and initial populations are generated randomly. Every solution obtained by ADEP for the relaxation problem of CCP is checked whether it also satisfies the constraint of the equivalence problem of CCP. From the ratio of the infeasible solutions that do not meet the constraint , the risk of failure in (8) is evaluated empirically.
Table 2 shows the results of the experiments conducted for several sufficiency levels in which denotes the objective function value of the best solution obtained by ADEP for a given ; and are empirical probabilities provided by ; is the estimation error defined by (27); is the risk of failure evaluated empirically as stated above. Except the risk of failure , the results in Table 2 are averaged over 50 runs.
From Table 2, we can confirm the usefulness of the proposed method. Even though the sample size N of WSS is small, the value of is very close to , and holds for every . Moreover, the majority of the solutions satisfy the constraint . Therefore, if we suppose that holds, the solution is regarded as a feasible solution of CCP in (37). We also see the trade-off between the optimality of the solution evaluated by and the reliability specified by . From the value of , it seems to be hard to obtain feasible solutions of CCP in (37) for a small sufficiency level: . That is because WSS is suitable for estimating a large value of as shown in Figure 5, Figure 6 and Figure 7.
7. Performance Evaluation of ADEP
For solving the relaxation problem of CCP efficiently, the pruning technique shown in (24) is introduced into an Adaptive DE (ADE) and ADEP is proposed. By comparing ADE with ADEP, the ability of the pruning technique to reduce the run time of ADE is evaluated. The flood control planning formulated as CCP in (37) is used to draw a comparison between ADE and ADEP. Therefore, the control parameters of them are given by Table 1 except the sampe size N. Thereby, ADE and ADEP are executed on a personal computer (CPU: Intel(R) Core(TM) [email protected], Memory: 16.0GB).
By changing the value of with a sample size , ADE and ADEP are applied to the relaxation problem of CCP, respectively, 50 times. Table 3 shows the results of the experiments average over 50 runs in which is the objective function value of the best solution ; is the empirical probability provided by . The run time of each algorithm except the generation of the full data set , is also shown in Table 3. Rate in Table 3 means the percentage of the trial vectors which are discarded by the pruning technique used in ADEP. Furthermore, the numbers in parenthesis indicate the standard deviations of the respective values in Table 3.
From Table 3, we confirm that the pruning technique works well for reducing the run time of ADEP. Besides, the high rate in Table 3 shows that more than half of the trial vectors are eliminated by the pruning technique without evaluating the value of in (23). From the values of and in Table 3, we can also see that ADE and ADEP find the same solution . Therefore, the pruning technique dose not harm the quality of the solution obtained by ADEP.
By using a larger sample size , ADE and ADEP are applied to the relaxation problem of CCP again 50 times. Table 4 shows the results of the experiments in the same way with Table 3. From Table 4, we can also confirm the effectiveness of the pruning technique used in ADEP.
Form Table 3 and Table 4, the run times of ADE and ADEP depend on the sample size N of WSS. The pruning technique of ADEP is more effective when a large sample size is required. We can also see that the sample size is large enough for solving the flood control planning because there is not much difference between the qualities of the solutions shown in Table 3 and Table 4.
The advantage of the pruning technique might not be demonstrated well enough due to the short run times of ADE shown in Table 3 and Table 4. The short run time of ADE is attributable to the simple forest mechanism model given by (35). If the inflow of water is estimated through a complex mathematical computation taking hours [36] or the amount of rainfall is predicted from a huge weather data set [37], we must realize the advantage of the pruning technique that surely reduces the run time of ADE without harming the quality of the obtained solution. In any case, we can confirm the expected performance of the pruning technique from the high rates shown in Table 3 and Table 4.
8. Conclusions
For solving CCP formulated from a huge data set, or a full data set, a new approach is proposed. By using the full data set instead of the mathematical model simulating uncertainties, the estimation error of uncertainties caused by the mathematical model can be eliminated. However, the full data set is usually too large to solve CCP practically. Therefore, a relaxation problem of CCP is derived by using a data reduction method. As a new data reduction method based on the stratified sampling, WSS is proposed and evaluated in this paper. Contrary to the well-known SRS, WSS can use the information of the full data set completely. Besides, it is shown that WSS outperforms SRS in the accuracy of the estimated probability. In order to solve the relaxation problem of CCP efficiently, an Adaptive DE combined with a Pruning technique (ADEP) is also proposed. The proposed approach is demonstrated through a real-world application, namely the flood control planning formulated as CCP.
Since huge data sets are available in various fields nowadays, many real-world applications can be formulated as CCPs without making mathematical models. Therefore, the combination of ADEP and WSS seems to be a promising approach to CCP formulated by using a huge data set. Especially, ADEP is applicable to any CCP in which the probabilistic constraint has to be evaluated empirically from a set of samples. On the other hand, there are the following open problems about WSS.
- How to properly make the strata from a full data set for WSS: The performance of WSS depends on the stratification method such as the number of strata and the shape of each stratum. By improving the stratification method, the optimal sample size of WSS will also be found.
- How to feedback the values of functions to generate samples : If we can use the function values effectively, we must be able to make the strata for WSS adaptively.
- How to cope with high-dimensional data sets: Since the similarity of data which are assigned in the same stratum is reduced in proportion to the dimensionality of the full data set, it may be hard to represent all data only by one sample .
In our future work, we will tackle the above open problems about WSS. Moreover, we would like to demonstrate the usefulness of the proposed approach through the various real-world applications which are formulated as CCPs by using huge data sets. In particular, it is necessary that the proposed approach to CCP be evaluated by using real data sets [36]. We also need to compare ADEP with state-of-the-art optimization methods such as Ant Colony Optimization (ACO) algorithm [38].
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ACO | Ant Colony Optimization |
| ADE | Adaptive Differential Evolution |
| ADEP | Adaptive Differential Evolution with Pruning technique |
| CCP | Chance Constrained Problem |
| CHT | Constraint Handling Technique |
| DE | Differential Evolution |
| EA | Evolutionary Algorithm |
| SRS | Simple Random Sampling |
| WSS | Weighted Stratified Sampling |
References
- Ben-Tal, A.; Ghaoui, L.E.; Nemirovski, A. Robust Optimization; Princeton University Press: Princeton, NJ, USA, 2009. [Google Scholar]
- Prékopa, A. Stochastic Programming; Kluwer Academic Publishers: Berlin, Germany, 1995. [Google Scholar]
- Uryasev, S.P. Probabilistic Constrained Optimization: Methodology and Applications; Kluwer Academic Publishers: Berlin, Germany, 2001. [Google Scholar]
- Lubin, M.; Dvorkin, Y.; Backhaus, S. A robust approach to chance constrained optimal power flow with renewable generation. IEEE Trans. Power Syst. 2016, 31, 3840–3849. [Google Scholar] [CrossRef] [Green Version]
- Tagawa, K.; Miyanaga, S. An approach to chance constrained problems using weighted empirical distribution and differential evolution with application to flood control planning. Electron. Commun. Jpn. 2019, 102, 45–55. [Google Scholar] [CrossRef]
- Bazaraa, M.S.; Sherali, H.D.; Shetty, C.M. Nonlinear Programming: Theory and Algorithm; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Poojari, C.A.; Varghese, B. Genetic algorithm based technique for solving chance constrained problems. Eur. J. Oper. Res. 2008, 185, 1128–1154. [Google Scholar] [CrossRef] [Green Version]
- Liu, B.; Zhang, Q.; Fernández, F.V.; Gielen, G.G.E. An efficient evolutionary algorithm for chance-constrained bi-objective stochastic optimization. IEEE Trans. Evol. Comput. 2013, 17, 786–796. [Google Scholar] [CrossRef] [Green Version]
- Tagawa, K.; Miyanaga, S. Weighted empirical distribution based approach to chance constrained optimization problems using differential evolution. In Proceedings of the IEEE Congress on Evolutionary Computation (CEC2017), San Sebastian, Spain, 5–8 June 2017; pp. 97–104. [Google Scholar]
- Kroese, D.P.; Taimre, T.; Botev, Z.I. Handbook of Monte Carlo Methods; Wiley: Hoboken, NJ, USA, 2011. [Google Scholar]
- Tagawa, K. Group-based adaptive differential evolution for chance constrained portfolio optimization using bank deposit and bank loan. In Proceedings of the IEEE Congress on Evolutionary Computation (CEC2019), Wellington, New Zealand, 10–13 June 2019; pp. 1556–1563. [Google Scholar]
- Xu, L.D.; He, W.; Li, S. Internet of things in industries: A survey. IEEE Trans. Ind. Inform. 2014, 10, 2233–2243. [Google Scholar] [CrossRef]
- Rossi, E.; Rubattion, C.; Viscusi, G. Big data use and challenges: Insights from two internet-mediated surveys. Computers 2019, 8, 73. [Google Scholar] [CrossRef] [Green Version]
- Kile, H.; Uhlen, K. Data reduction via clustering and averaging for contingency and reliability analysis. Electr. Power Energy Syst. 2012, 43, 1435–1442. [Google Scholar] [CrossRef]
- Fahad, A.; Alshatri, N.; Tari, Z.; Alamri, A.; Khalil, I.; Zomaya, A.Y.; Foufou, S.; Bouras, A. A survey of clustering algorithms for big data: Taxonomy and empirical analysis. IEEE Trans. Emerg. Top. Comput. 2014, 2, 267–279. [Google Scholar] [CrossRef]
- Jayaram, N.; Baker, J.W. Efficient sampling and data reduction techniques for probabilistic seismic lifeline risk assessment. Earthq. Eng. Struct. Dyn. 2010, 39, 1109–1131. [Google Scholar] [CrossRef]
- Tagawa, K. Data reduction via stratified sampling for chance constrained optimization with application to flood control planning. In Proceedings of the ICIST 2019, CCIS 1078, Vilnius, Lithuania, 10–12 October 2019; Springer: Cham, Switzerland, 2019; pp. 485–497. [Google Scholar]
- Price, K.; Storn, R.M.; Lampinen, J.A. Differential Evolution: A Practical Approach to Global Optimization; Springer: Cham, Switzerland, 2005. [Google Scholar]
- Brest, J.; Greiner, S.; Boskovic, B.; Merink, M.; Zumer, V. Self-adapting control parameters in differential evolution: A comparative study on numerical benchmark problems. IEEE Trans. Evol. Comput. 2006, 10, 646–657. [Google Scholar] [CrossRef]
- Yazdi, J.; Neyshabouri, S.A.A.S. Optimal design of flood-control multi-reservoir system on a watershed scale. Nat. Hazards 2012, 63, 629–646. [Google Scholar] [CrossRef]
- Zhang, W.; Liu, P.; Chen, X.; Wang, L.; Ai, X.; Feng, M.; Liu, D.; Liu, Y. Optimal operation of multi-reservoir systems considering time-lags of flood routing. Water Resour. Manag. 2016, 30, 523–540. [Google Scholar] [CrossRef]
- Zhou, C.; Sun, N.; Chen, L.; Ding, Y.; Zhou, J.; Zha, G.; Luo, G.; Dai, L.; Yang, X. Optimal operation of cascade reservoirs for flood control of multiple areas downstream: A case study in the upper Yangtze river basin. Water 2018, 10, 1250. [Google Scholar] [CrossRef] [Green Version]
- Ash, R.B. Basic Probability Theory; Dover: Downers Grove, IL, USA, 2008. [Google Scholar]
- Han, J.; Kamber, M.; Pei, J. Data Mining—Concepts and Techniques; Morgan Kaufmann: Burlington, MA, USA, 2012. [Google Scholar]
- Tempo, R.; Calafiore, G.; Dabbene, F. Randomized Algorithms for Analysis and Control of Uncertain Systems: With Applications; Springer: Cham, Switzerland, 2012. [Google Scholar]
- Poosala, V.; Ioannidis, Y.E.; Haas, P.J.; Shekita, E.J. Improved histograms for selectivity estimation of range predicates. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Montreal, QC, Canada, 4–6 June 1996; pp. 294–305. [Google Scholar]
- Cormode, G.; Garofalakis, M. Histograms and wavelets on probabilistic data. IEEE Trans. Knowl. Data Eng. 2010, 22, 1142–1157. [Google Scholar] [CrossRef] [Green Version]
- Das, S.; Suganthan, P.N. Differential evolution: A survey of the state-of-the-art. IEEE Trans. Evol. Comput. 2011, 15, 4–31. [Google Scholar] [CrossRef]
- Eltaeib, T.; Mahmood, A. Differential evolution: A survey and analysis. Appl. Sci. 2018, 8, 1945. [Google Scholar] [CrossRef] [Green Version]
- Deb, K. An efficient constraint handling method for genetic algorithms. Comput. Methods Appl. Mech. Eng. 2000, 186, 311–338. [Google Scholar] [CrossRef]
- Tanabe, R.; Fukunaga, A. Reviewing and benchmarking parameter control methods in differential evolution. IEEE Trans. Evol. Comput. 2020, 50, 1170–1184. [Google Scholar] [CrossRef]
- Montes, E.E.; Coello, C.A.C. Constraint-handling in nature inspired numerical optimization: Past, present and future. Swarm Evol. Comput. 2011, 1, 173–194. [Google Scholar] [CrossRef]
- Prékopa, A.; Szántai, T. Flood control reservoir system design using stochastic programming. Math. Progr. Study 1978, 9, 138–151. [Google Scholar]
- Maita, E.; Suzuki, M. Quantitative analysis of direct runoff in a forested mountainous, small watershed. J. Jpn. Soc. Hydrol. Water Resour. 2009, 22, 342–355. [Google Scholar] [CrossRef] [Green Version]
- Martinez, A.R.; Martinez, W.L. Computational Statistics Handbook with MATLAB ®, 2nd ed.; Chapman & Hall/CRC: London, UK, 2008. [Google Scholar]
- Monrat, A.A.; Islam, R.U.; Hossain, M.S.; Andersson, K. Challenges and opportunities of using big data for assessing flood risks. In Applications of Big Data Analytics; Alani, M.M., Tawfik, H., Saeed, M., Anya, O., Eds.; Springer: Cham, Switzerland, 2018; Chapter 2; pp. 31–42. [Google Scholar]
- Reddy, P.C.; Babu, A.S. Survey on weather prediction using big data analytics. In Proceedings of the IEEE 2nd International Conference on Electrical, Computer and Communication Technologies, Coimbatore, India, 22–24 February 2017; pp. 1–6. [Google Scholar]
- Brociek, R.; Słota, D. Application of real ant colony optimization algorithm to solve space and time fractional heat conduction inverse problem. In Proceedings of the 22nd International Conference on Information and Software Technologies, ICIST2016, Communications in Computer and Information Science, Druskininkai, Lithuania, 13–15 October 2016; Springer: Cham, Switzerland, 2016; Volume 639, pp. 369–379. [Google Scholar]
Figure 1.
Error for sample size.

Figure 2.
Sample size for probability.

Figure 3.
Patterns of the full data and the random samples selected by SRS.

Figure 4.
Patterns of the full data and the weighted samples generated by WSS.

Figure 5.
Estimation error for sample size when ().

Figure 6.
Estimation error for sample size when ().

Figure 7.
Estimation error for sample size when ().

Figure 8.
Patterns of the full data and the random samples selected by SRS.

Figure 9.
Patterns of the full data and the weighted samples generated by WSS.

Figure 10.
Estimation error for sample size with the linear function in (33).
Figure 10.
Estimation error for sample size with the linear function in (33).

Figure 11.
Estimation error for sample size with the non-linear function in (34).
Figure 11.
Estimation error for sample size with the non-linear function in (34).

Figure 12.
Topological river model.

Figure 13.
Patterns of the full data set, the random samples of SRS, and the weighted samples of WSS.
Figure 13.
Patterns of the full data set, the random samples of SRS, and the weighted samples of WSS.

Figure 14.
Estimation error for sample size in the flood control planning.

Figure 15.
Convergence graph of ADEP.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Parameters of ADEP and WSS for the relaxation problem of CCP.
| Generation: | Population Size: | Sample Size: N | Correction Level: |
|---|---|---|---|
| 80 | 30 | 482 |
Table 2.
Solutions obtained by ADEP for CCP in (37).
Table 2.
Solutions obtained by ADEP for CCP in (37).
Table 3.
Comparison between ADE and ADEP with sample size .
| ADE | ADEP | ||||||
|---|---|---|---|---|---|---|---|
| Time [s] | Time [s] | Rate | |||||
| () | () | () | () | () | () | () | |
| () | () | () | () | () | () | () | |
| () | () | () | () | () | () | () | |
| () | () | () | () | () | () | () | |
Table 4.
Comparison between ADE and ADEP with sample size .
| ADE | ADEP | ||||||
|---|---|---|---|---|---|---|---|
| Time [s] | Time [s] | Rate | |||||
| () | () | () | () | () | () | () | |
| () | () | () | () | () | () | () | |
| () | () | () | () | () | () | () | |
| () | () | () | () | () | () | () | |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Tagawa, K. An Approach to Chance Constrained Problems Based on Huge Data Sets Using Weighted Stratified Sampling and Adaptive Differential Evolution. Computers 2020, 9, 32. https://0-doi-org.brum.beds.ac.uk/10.3390/computers9020032
AMA Style
Tagawa K. An Approach to Chance Constrained Problems Based on Huge Data Sets Using Weighted Stratified Sampling and Adaptive Differential Evolution. Computers. 2020; 9(2):32. https://0-doi-org.brum.beds.ac.uk/10.3390/computers9020032
Chicago/Turabian StyleTagawa, Kiyoharu. 2020. "An Approach to Chance Constrained Problems Based on Huge Data Sets Using Weighted Stratified Sampling and Adaptive Differential Evolution" Computers 9, no. 2: 32. https://0-doi-org.brum.beds.ac.uk/10.3390/computers9020032
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.