Multiple Regression Analysis and Frequent Itemset Mining of Electronic Medical Records: A Visual Analytics Approach Using VISA_M3R3



Abstract
:1. Introduction
2. Background
2.1. Spatial Structure of Visual Analytics
2.2. Modules of Visual Analytics Systems
2.1.1. Data Analytics Module
2.1.2. Interactive Visualization Module
2.3. Visual Analytics and Analytical Reasoning
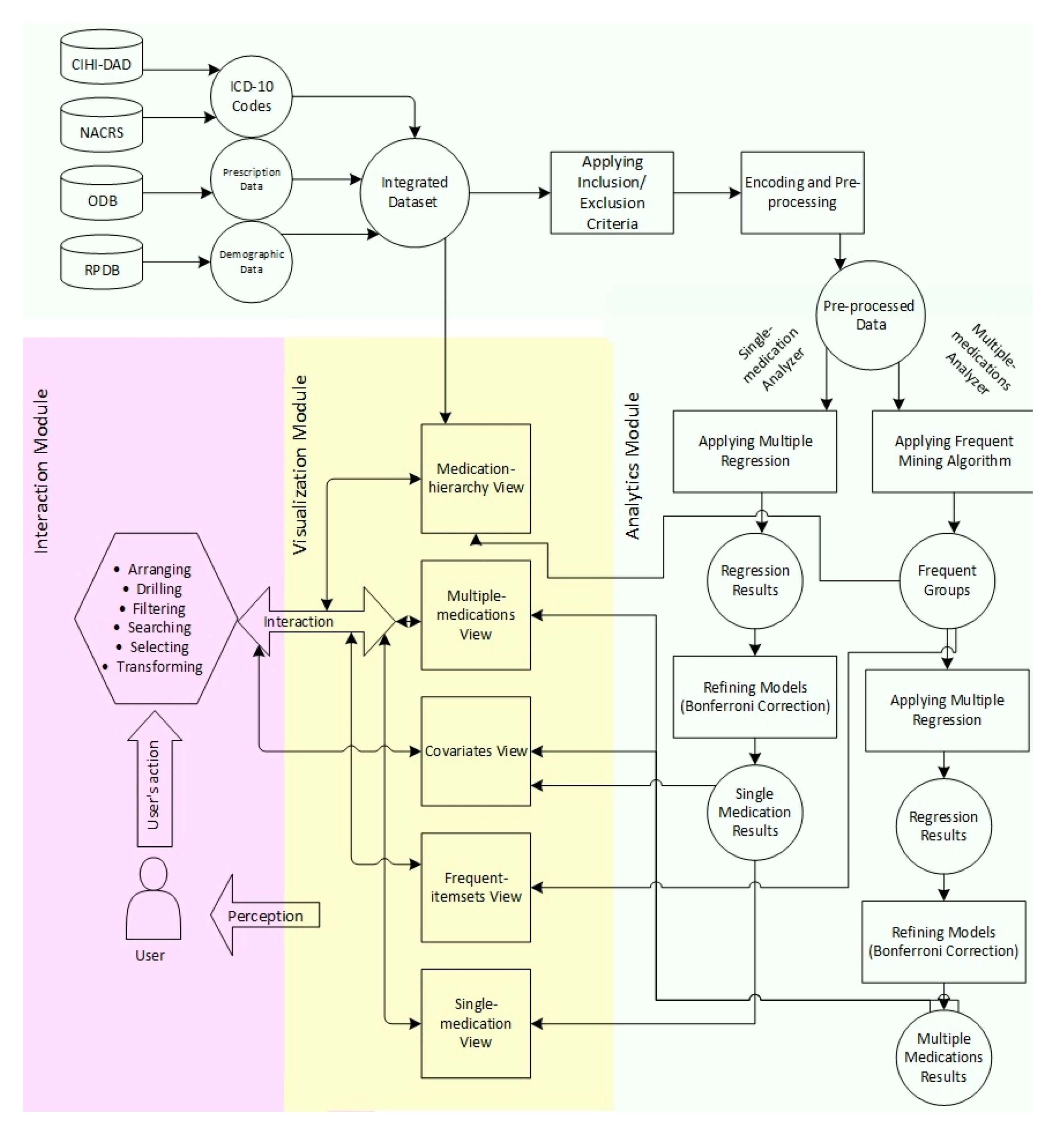
3. Materials and Methods
3.1. Design Process and Participants
3.2. Data Sources
3.3. Cohort Entry Criteria
3.4. Implementation Details
3.5. Workflow
4. Design of VISA_M3R3 and Results
4.1. Analytics Module
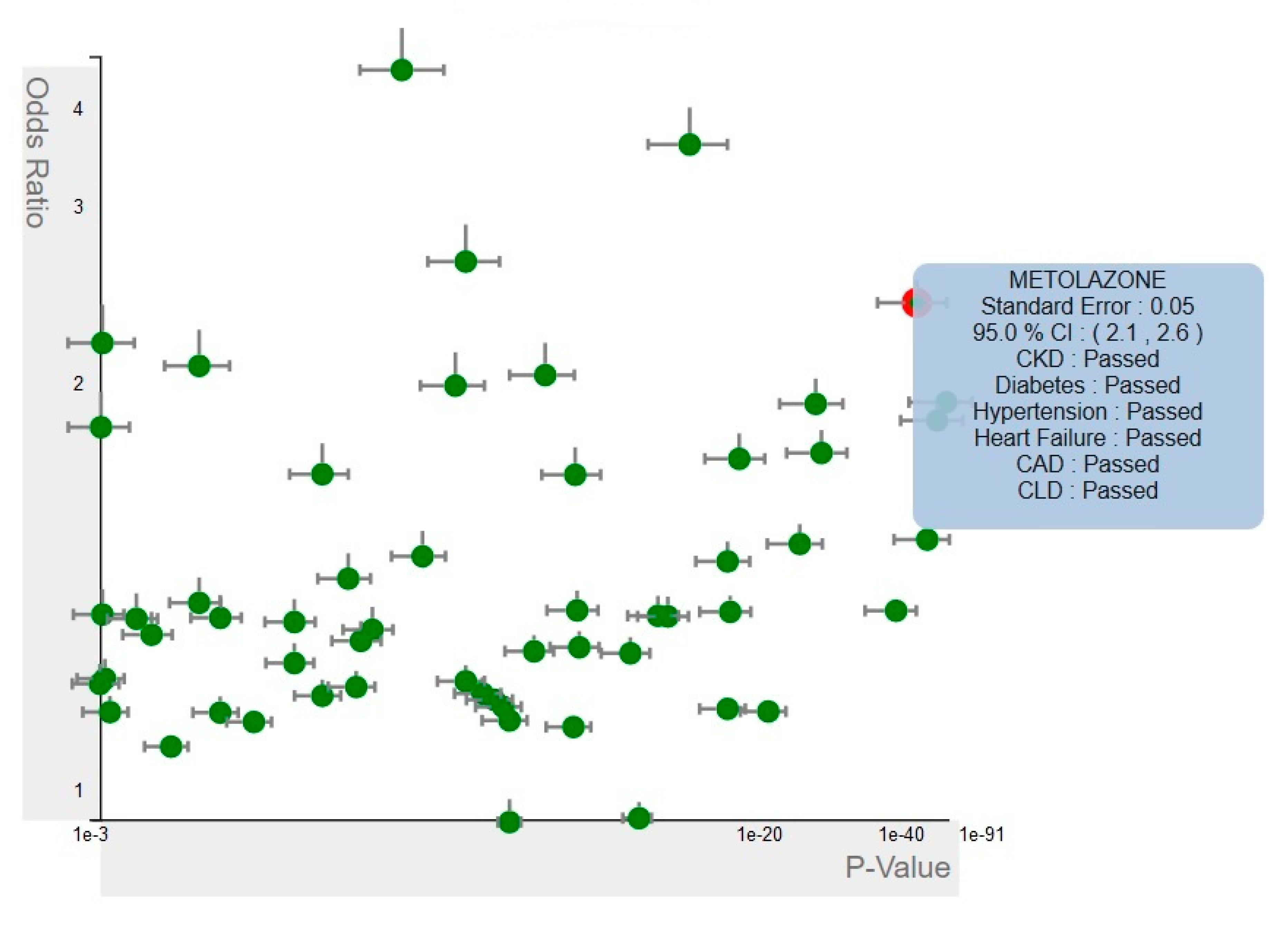
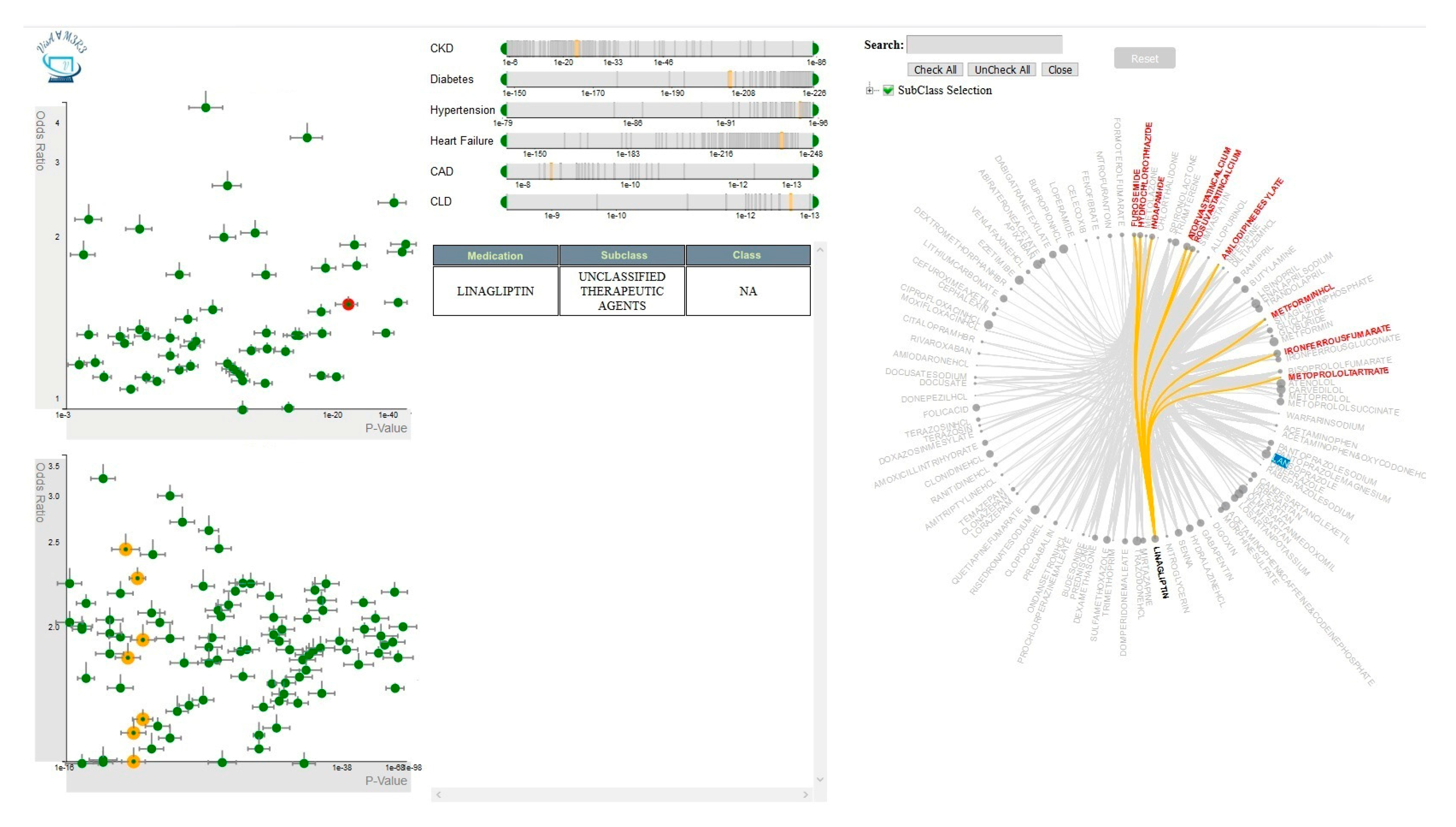
4.1.1. Single-Medication Analyzer
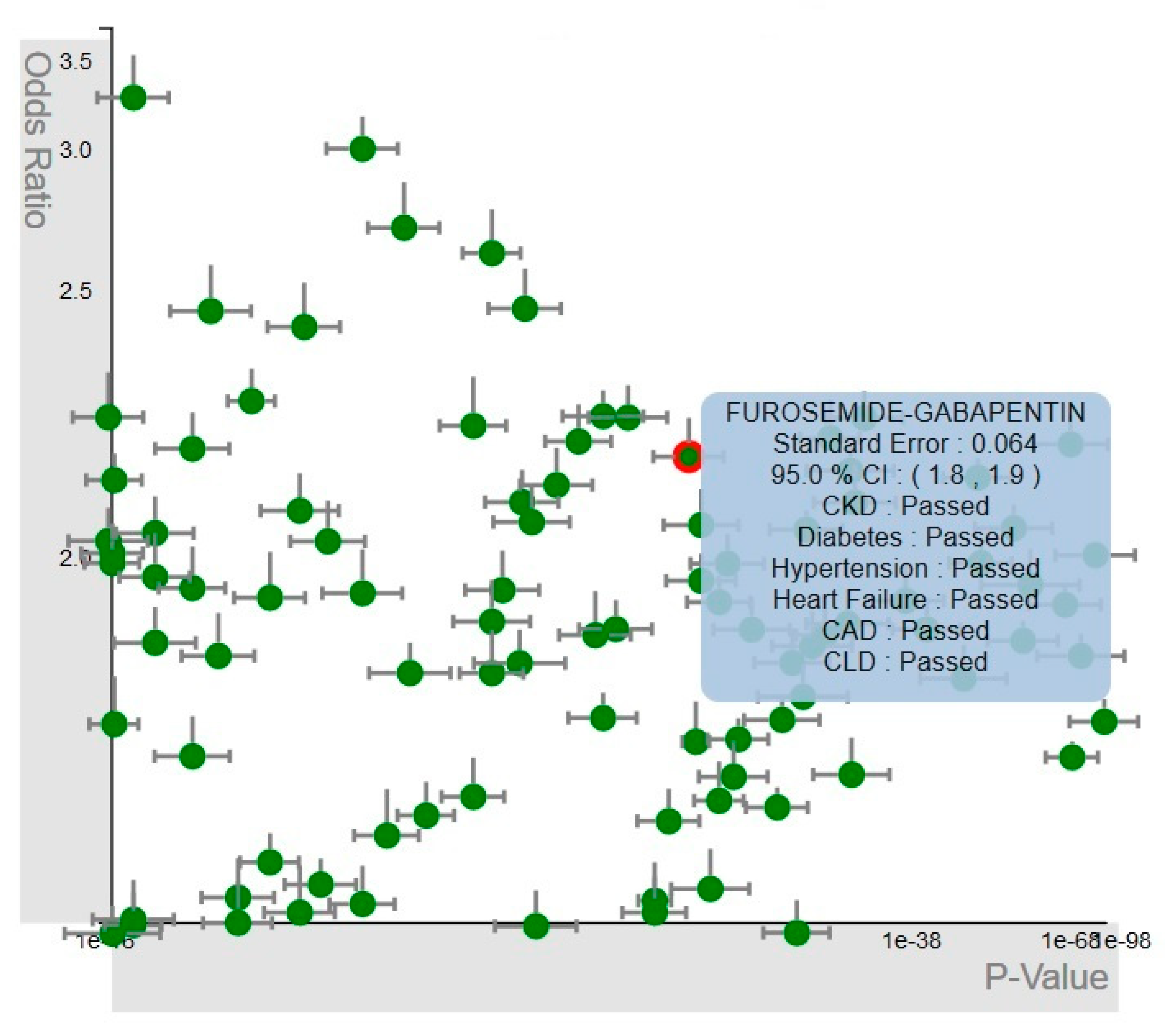
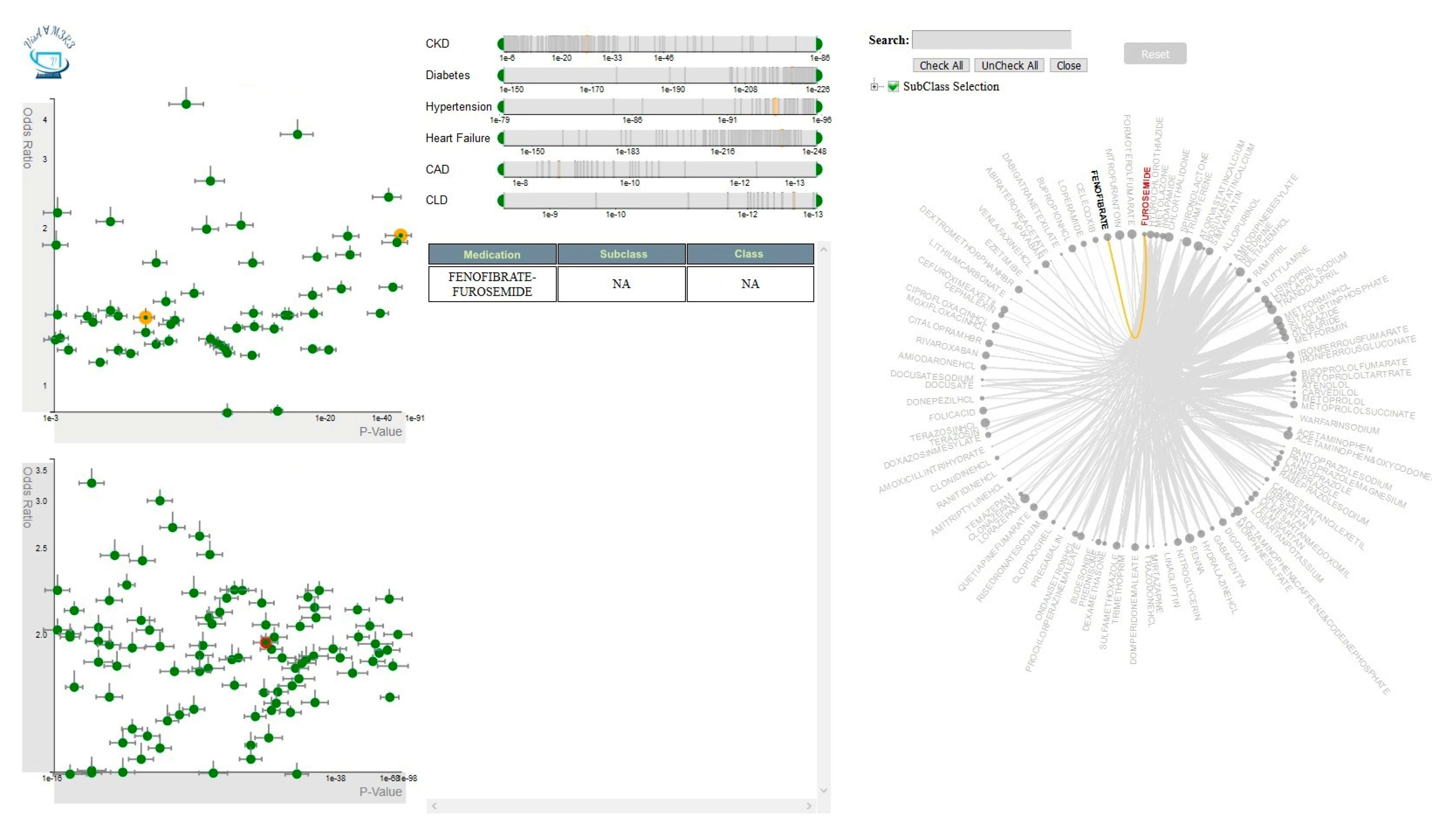
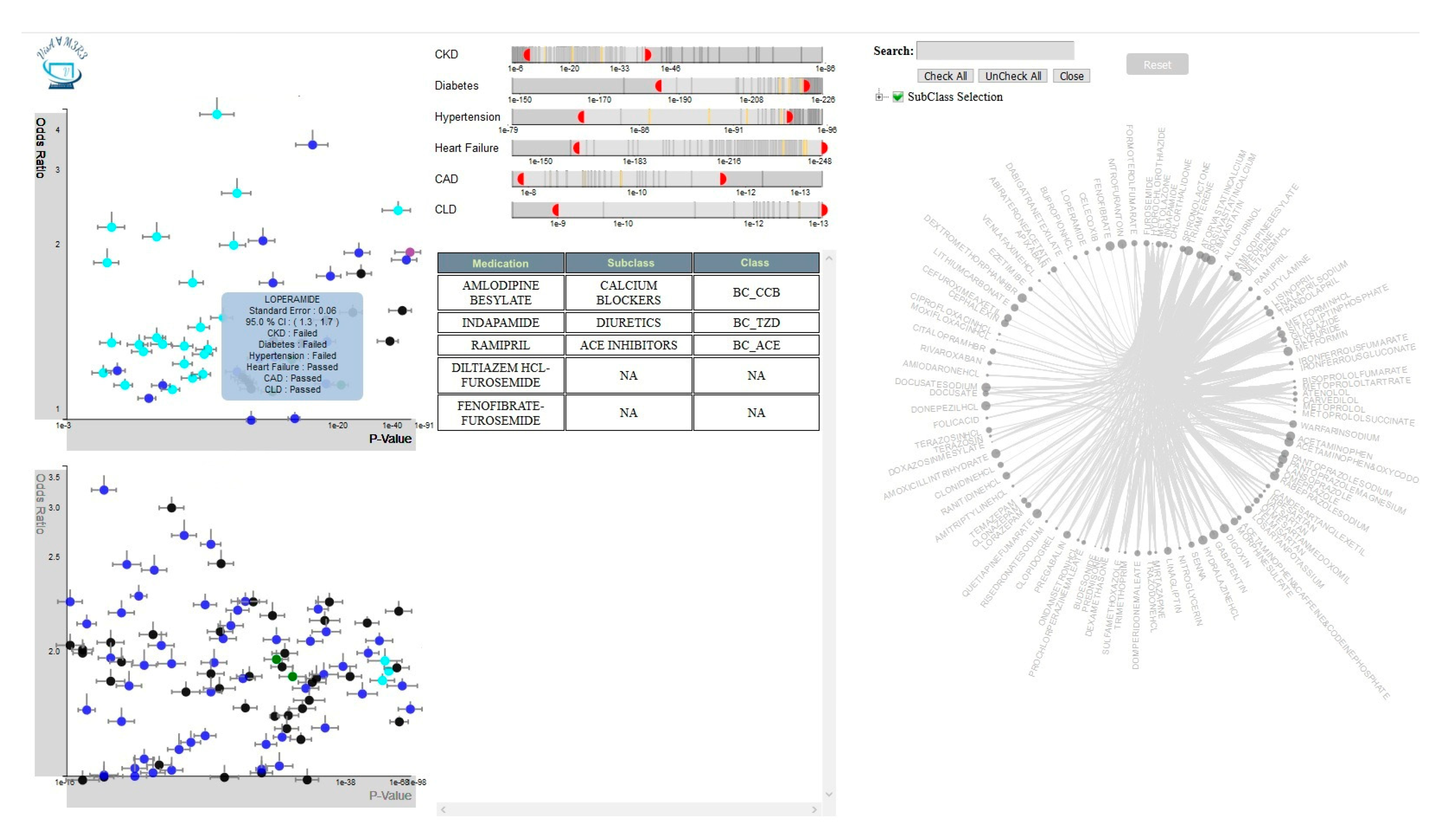
4.1.2. Multiple-Medications Analyzer
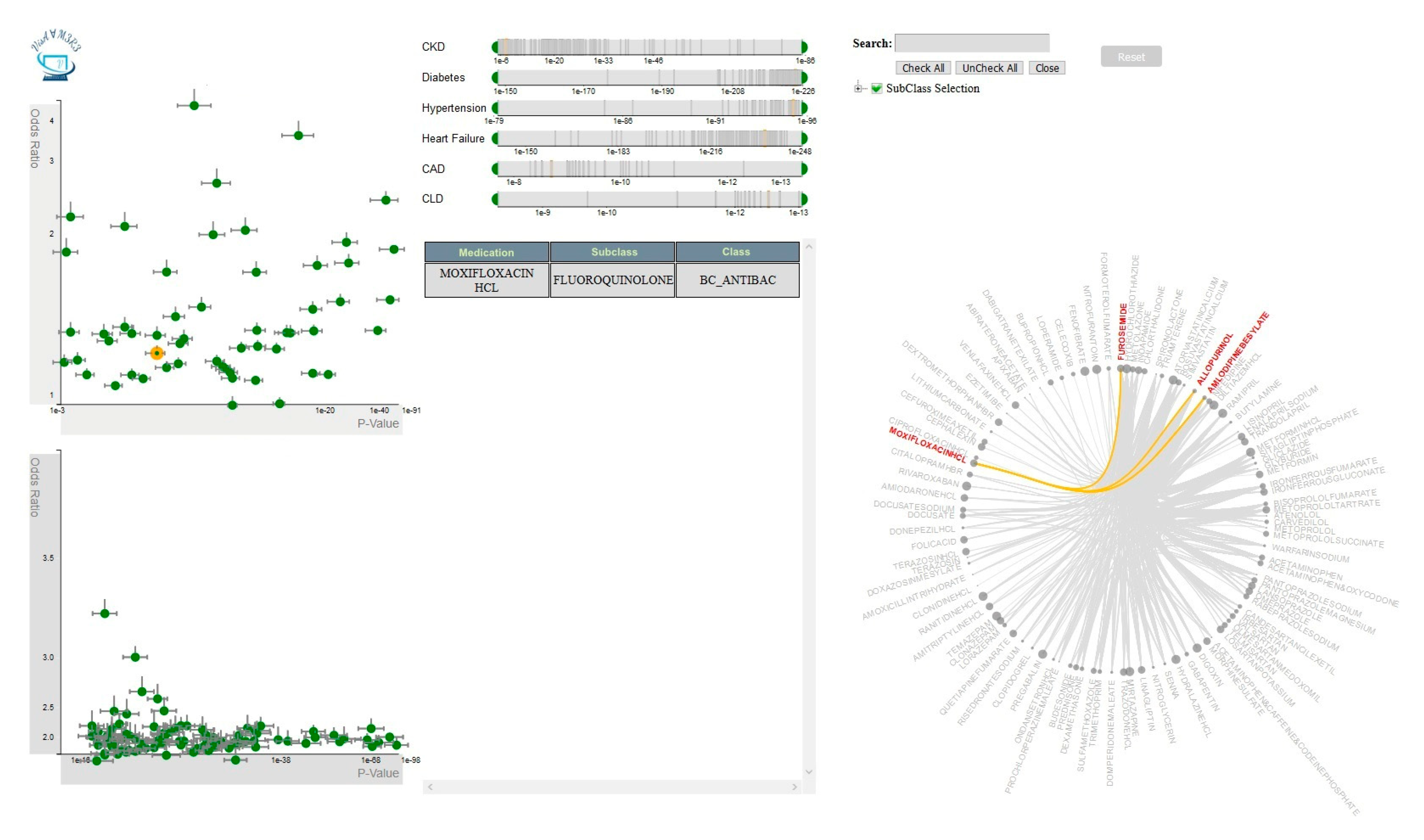
4.2. Visualization Module
4.2.1. Single-Medication View
4.2.2. Multiple-Medications View
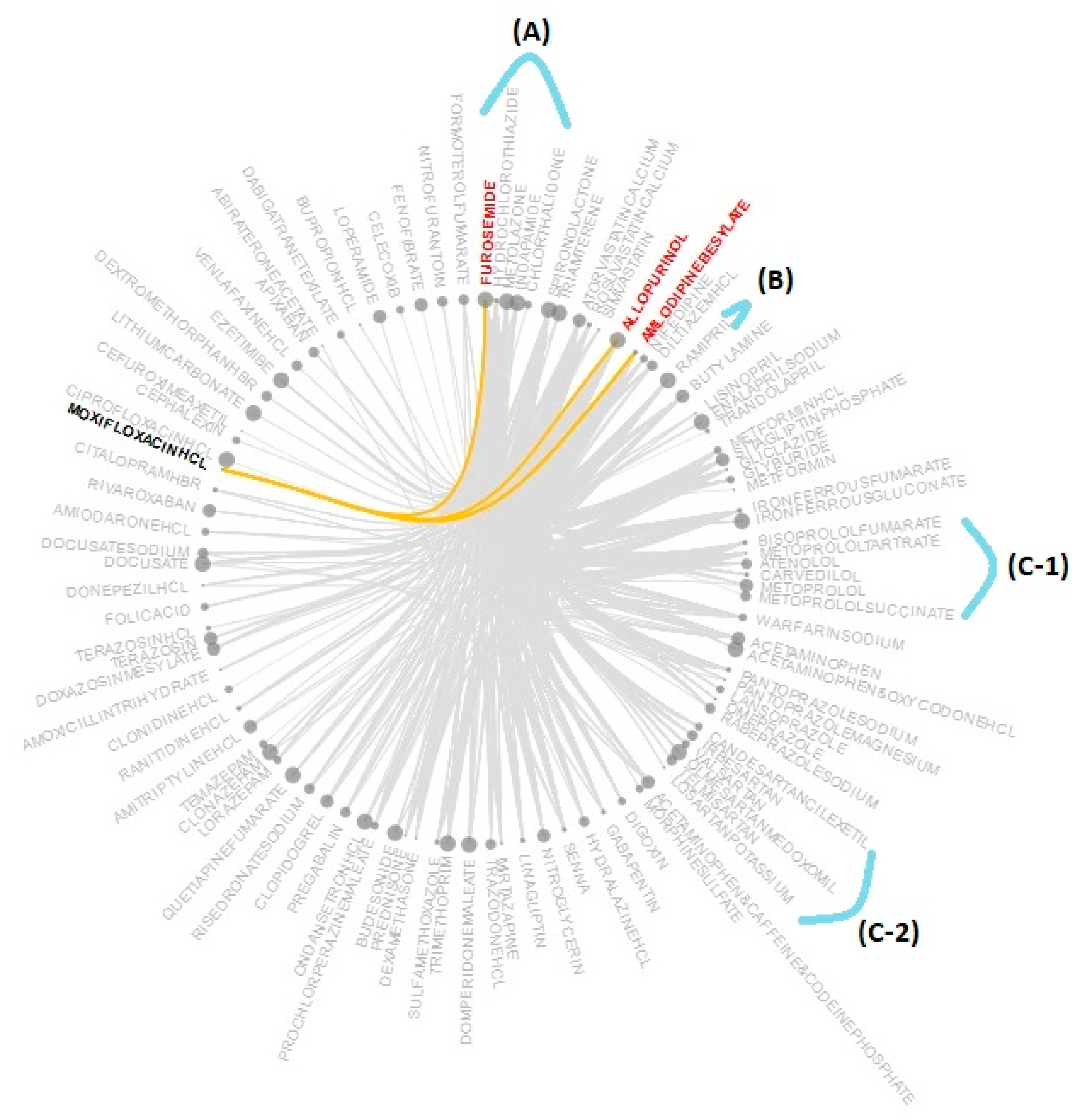
4.2.3. Frequent-Itemsets View
4.2.4. Covariates View
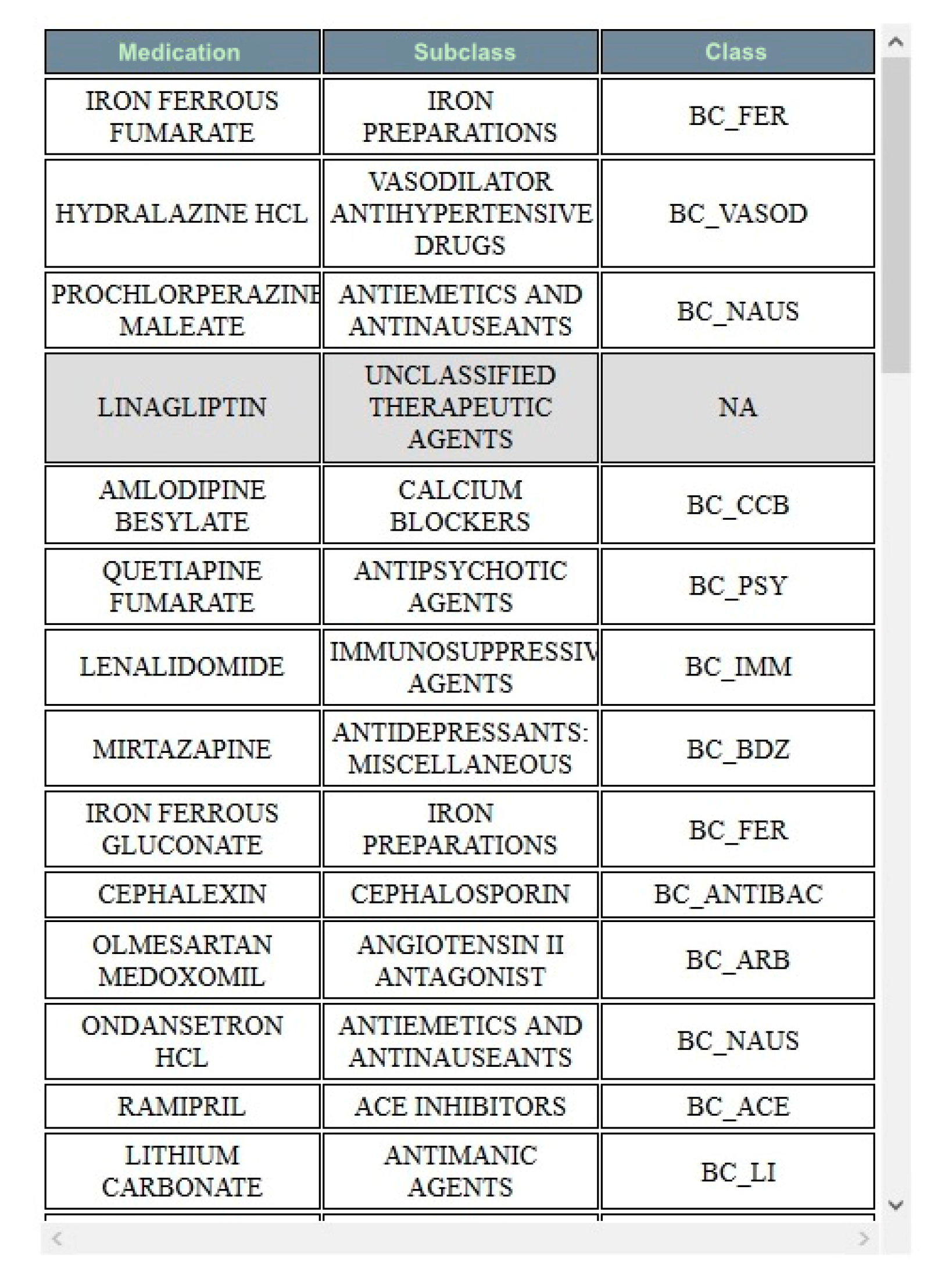
4.2.5. Medication-Hierarchy View
4.3. Interaction Module
4.3.1. Single-Medication View Interactions
4.3.2. Multiple-Medications View Interactions
4.3.3. Covariates View Interactions
4.3.4. Frequent-Itemsets View Interactions
4.3.5. Medication-Hierarchy View Interactions
4.3.6. Selection Controls
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Caban, J.J.; Gotz, D. Visual analytics in healthcare—Opportunities and research challenges. J. Am. Med. Inform. Assoc. 2015, 22, 260–262. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Delamarre, D.; Bouzille, G.; Dalleau, K.; Courtel, D.; Cuggia, M. Semantic integration of medication data into the EHOP Clinical Data Warehouse. Stud. Health Technol. Inform. 2015, 210, 702–706. [Google Scholar] [PubMed]
- Abramson, E.L.; Barrón, Y.; Quaresimo, J.; Kaushal, R. Electronic prescribing within an electronic health record reduces ambulatory prescribing errors. Jt. Comm. J. Qual. Patient Saf. 2011, 37, 470–478. [Google Scholar] [CrossRef]
- Kamal, N. Big Data and Visual Analytics in Health and Medicine: From Pipe Dream to Reality. J. Health Med. Inform. 2014, 5, e25. [Google Scholar] [CrossRef]
- Murdoch, T.B.; Detsky, A.S. The inevitable application of big data to health care. JAMA J. Am. Med. Assoc. 2013, 309, 1351–1352. [Google Scholar] [CrossRef]
- Honigman, B.; Light, P.; Pulling, R.M.; Bates, D.W. A computerized method for identifying incidents associated with adverse drug events in outpatients. Int. J. Med. Inform. 2001, 61, 21–32. [Google Scholar] [CrossRef]
- Hannan, T.J. Detecting adverse drug reactions to improve patient outcomes. Int. J. Med. Inform. 1999, 55, 61–64. [Google Scholar] [CrossRef]
- Rinner, C.; Grossmann, W.; Sauter, S.K.; Wolzt, M.; Gall, W. Effects of Shared Electronic Health Record Systems on Drug-Drug Interaction and Duplication Warning Detection. Biomed Res. Int. 2015, 2015, 380497. [Google Scholar] [CrossRef] [Green Version]
- Gruchalla, R.S. Clinical assessment of drug-induced disease. Lancet 2000, 356, 1505–1511. [Google Scholar] [CrossRef]
- Tandon, V.R.; Khajuria, V.; Mahajan, V.; Sharma, A.; Gillani, Z.; Mahajan, A. Drug-induced diseases (DIDs): An experience of a tertiary care teaching hospital from India. Indian J. Med. Res. 2015, 142, 33–39. [Google Scholar] [CrossRef]
- Gildon, B.; Condren, M.; Hughes, C. Impact of Electronic Health Record Systems on Prescribing Errors in Pediatric Clinics. Healthcare 2019, 7, 57. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Singer, A.; Duarte Fernandez, R. The effect of electronic medical record system use on communication between pharmacists and prescribers. BMC Fam. Pract. 2015, 16, 155. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Agrawal, A. Medication errors: Prevention using information technology systems. Br. J. Clin. Pharmacol. 2009, 67, 681–686. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Assadi, F.; Ghane Shahrbaf, F. Drug-induced renal disorders. J. Ren. Inj. Prev. 2015, 4, 57–60. [Google Scholar]
- Khan, S.; Loi, V.; Rosner, M.H. Drug-Induced Kidney Injury in the Elderly. Drugs Aging 2017, 34, 729–741. [Google Scholar] [CrossRef] [PubMed]
- Fusco, S.; Garasto, S.; Corsonello, A.; Vena, S.; Mari, V.; Gareri, P.; Ruotolo, G.; Luciani, F.; Roncone, A.; Maggio, M.; et al. Medication-Induced Nephrotoxicity in Older Patients. Curr. Drug Metab. 2016, 17, 608–625. [Google Scholar] [CrossRef]
- Selby, N.M.; Crowley, L.; Fluck, R.J.; McIntyre, C.W.; Monaghan, J.; Lawson, N.; Kolhe, N.V. Use of electronic results reporting to diagnose and monitor AKI in hospitalized patients. Clin. J. Am. Soc. Nephrol. 2012, 7, 533–540. [Google Scholar] [CrossRef] [Green Version]
- Porter, C.J.; Juurlink, I.; Bisset, L.H.; Bavakunji, R.; Mehta, R.L.; Devonald, M.A.J. A real-time electronic alert to improve detection of acute kidney injury in a large teaching hospital. Nephrol. Dial. Transplant. 2014, 29, 1888–1893. [Google Scholar] [CrossRef] [Green Version]
- Kaufman, J.; Dhakal, M.; Patel, B.; Hamburger, R. Community-Acquired Acute Renal Failure. Am. J. Kidney Dis. 1991, 17, 191–198. [Google Scholar] [CrossRef]
- Nash, K.; Hafeez, A.; Hou, S. Hospital-acquired renal insufficiency. Am. J. Kidney Dis. 2002, 39, 930–936. [Google Scholar] [CrossRef]
- Gandhi, T.K.; Burstin, H.R.; Cook, E.F.; Puopolo, A.L.; Haas, J.S.; Brennan, T.A.; Bates, D.W. Drug complications in outpatients. J. Gen. Intern. Med. 2000, 15, 149–154. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schetz, M.; Dasta, J.; Goldstein, S.; Golper, T. Drug-induced acute kidney injury. Curr. Opin. Crit. Care 2005, 11, 555–565. [Google Scholar] [CrossRef] [PubMed]
- Moffett, B.S.; Goldstei, S.L. Acute kidney injury and increasing nephrotoxic-medication exposure in noncritically-Ill children. Clin. J. Am. Soc. Nephrol. 2011, 6, 856–863. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rivosecchi, R.M.; Kellum, J.A.; Dasta, J.F.; Armahizer, M.J.; Bolesta, S.; Buckley, M.S.; Dzierba, A.L.; Frazee, E.N.; Johnson, H.J.; Kim, C.; et al. Drug Class Combination-Associated Acute Kidney Injury. Ann. Pharmacother. 2016, 50, 953–972. [Google Scholar] [CrossRef]
- Alexander, T.; McArthur, E.; Jandoc, R.; Welk, B.; Hayward, J.S.; Jain, A.K.; Braam, B.; Flockerzi, V.; Garg, A.X.; Quinn, R.R. Antihypertensive medications and the risk of kidney stones in older adults: A retrospective cohort study. Hypertens. Res. 2017, 40, 837–842. [Google Scholar] [CrossRef]
- Cartin-Ceba, R.; Kashiouris, M.; Plataki, M.; Kor, D.J.; Gajic, O.; Casey, E.T. Risk factors for development of acute kidney injury in critically ill patients: A systematic review and meta-analysis of observational studies. Crit. Care Res. Pract. 2012, 2012, 691013. [Google Scholar] [CrossRef]
- Zitnik, M.; Agrawal, M.; Leskovec, J. Modeling polypharmacy side effects with graph convolutional networks. Bioinformatics 2018, 34, i457–i466. [Google Scholar] [CrossRef] [Green Version]
- Collins, N. AI Predicts Drug Pair Side Effects/Stanford News. Available online: https://news.stanford.edu/2018/07/10/ai-predicts-drug-pair-side-effects/ (accessed on 5 January 2020).
- Han, J.; Kamber, M. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Koh, H.C.; Tan, G. Data mining applications in healthcare. J. Healthc. Inf. Manag. 2005, 19, 64–72. [Google Scholar]
- Basile, A.O.; Yahi, A.; Tatonetti, N.P. Artificial Intelligence for Drug Toxicity and Safety. Trends Pharmacol. Sci. 2019, 40, 624–635. [Google Scholar] [CrossRef]
- Lysenko, A.; Sharma, A.; Boroevich, K.A.; Tsunoda, T. An integrative machine learning approach for prediction of toxicity-related drug safety. Life Sci. Alliance 2018, 1, e201800098. [Google Scholar] [CrossRef] [Green Version]
- Schmider, J.; Kumar, K.; LaForest, C.; Swankoski, B.; Naim, K.; Caubel, P.M. Innovation in Pharmacovigilance: Use of Artificial Intelligence in Adverse Event Case Processing. Clin. Pharmacol. Ther. 2019, 105, 954–961. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dey, S.; Luo, H.; Fokoue, A.; Hu, J.; Zhang, P. Predicting adverse drug reactions through interpretable deep learning framework. BMC Bioinform. 2018, 19, 476. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Munsaka, M.S. Leveraging Machine Learning in the Analysis of Safety Data in Drug Research and Healthcare Informatics. In Proceedings of the Joint Statistical Meetings-Section for Statistical Programmers and Analysis, Baltimore, MD, USA, 29 July–3 August 2017. [Google Scholar]
- Vamathevan, J.; Clark, D.; Czodrowski, P.; Dunham, I.; Ferran, E.; Lee, G.; Li, B.; Madabhushi, A.; Shah, P.; Spitzer, M.; et al. Applications of machine learning in drug discovery and development. Nat. Rev. Drug Discov. 2019, 18, 463–477. [Google Scholar] [CrossRef]
- Rind, A.; Aigner, W.; Miksch, S.; Wiltner, S.; Pohl, M.; Turic, T.; Drexler, F. Visual Exploration of Time-Oriented Patient Data for Chronic Diseases: Design Study and Evaluation; Springer: Berlin/Heidelberg, Germany, 2011; pp. 301–320. [Google Scholar]
- Wilson, J.R. Fundamentals of systems ergonomics/human factors. Appl. Ergon. 2014, 45, 5–13. [Google Scholar] [CrossRef] [PubMed]
- Sedig, K.; Parsons, P. Design of Visualizations for Human-Information Interaction: A Pattern-Based Framework. Synth. Lect. Vis. 2016, 4, 1–185. [Google Scholar] [CrossRef]
- Ozturk, S.; Kayaalp, M.; McDonald, C.J. Visualization of patient prescription history data in emergency care. AMIA Annu. Symp. Proc. 2014, 2014, 963–968. [Google Scholar] [PubMed]
- Duke, J.D.; Li, X.; Grannis, S.J. Data visualization speeds review of potential adverse drug events in patients on multiple medications. J. Biomed. Inform. 2010, 43, 326–331. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Van der Corput, P.; Arends, J.; Van Wijk, J.J. Visualization of Medicine Prescription Behavior. Comput. Graph. Forum 2014, 33, 161–170. [Google Scholar] [CrossRef]
- Rind, A.; Wang, T.D.; Aigner, W.; Miksch, S.; Wongsuphasawat, K.; Plaisant, C.; Shneiderman, B.; Alexander Rind, B.; David Wang, T.; Aigner, W.; et al. Interactive Information Visualization to Explore and Query Electronic Health Records. Found. Trends Hum.-Comput. Interact. 2011, 5, 207–298. [Google Scholar] [CrossRef]
- Lavado, R.; Hayrapetyan, S.; Kharazyan, S. Expansion of the Benifits Package: The Experience of Armenia; World Bank: Yerevan, Armenia, 2018. [Google Scholar]
- Kosara, R.; Miksch, S. Visualization methods for data analysis and planning in medical applications. Int. J. Med. Inform. 2002, 68, 141–153. [Google Scholar] [CrossRef]
- Faisal, S.; Blandford, A.; Potts, H.W. Making sense of personal health information: Challenges for information visualization. Health Inform. J. 2013, 19, 198–217. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, C.H.; Yoon, H.J. Medical big data: Promise and challenges. Kidney Res. Clin. Pract. 2017, 36, 3–11. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Perer, A.; Wang, F.; Hu, J. Mining and exploring care pathways from electronic medical records with visual analytics. J. Biomed. Inform. 2015, 56, 369–378. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Simpao, A.F.; Ahumada, L.M.; Desai, B.R.; Bonafide, C.P.; Galvez, J.A.; Rehman, M.A.; Jawad, A.F.; Palma, K.L.; Shelov, E.D. Optimization of drug-drug interaction alert rules in a pediatric hospital’s electronic health record system using a visual analytics dashboard. J. Am. Med. Inform. Assoc. 2015, 22, 361–369. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Saffer, J.D.; Burnett, V.L.; Chen, G.; van der Spek, P. Visual analytics in the pharmaceutical industry. IEEE Comput. Graph. Appl. 2004, 24, 10–15. [Google Scholar] [CrossRef]
- Parsons, P.; Sedig, K.; Mercer, R.E.; Khordad, M.; Knoll, J.; Rogan, P. Visual Analytics for supporting evidence-based interpretation of molecular cytogenomic findings. In Proceedings of the 2015 Workshop on Visual Analytics in Healthcare, New York, NY, USA, 25 October 2015; pp. 1–8. [Google Scholar]
- Amarasingham, R.; Patzer, R.E.; Huesch, M.; Nguyen, N.Q.; Xie, B. Implementing electronic health care predictive analytics: Considerations and challenges. Health Aff. 2014, 33, 1148–1154. [Google Scholar] [CrossRef]
- Feng, C.; Le, D.; Mccoy, A.B. Using Electronic Health Records to Identify Adverse Drug Events in Ambulatory Care: A Systematic Review Background and Significance. Appl. Clin. Inform. 2019, 10, 123–128. [Google Scholar] [CrossRef]
- Mittelstädt, S.; Hao, M.C.; Dayal, U.; Hsu, M.C.; Terdiman, J.; Keim, D.A. Advanced visual analytics interfaces for adverse drug event detection. In Proceedings of the 2014 International Working Conference on Advanced Visual Interfaces, Como, Italy, 27–30 May 2014; pp. 237–244. [Google Scholar]
- Ninkov, A.; Sedig, K. VINCENT: A visual analytics system for investigating the online vaccine debate. Online J. Public Health Inform. 2019, 11, e5. [Google Scholar] [CrossRef] [Green Version]
- Bernard, J.; Sessler, D.; Bannach, A.; May, T.; Kohlhammer, J. A visual active learning system for the assessment of patient well-being in prostate cancer research. In Proceedings of the 2015 Workshop on Visual Analytics in Healthcare, Chicago, IL, USA, 25 October 2015. [Google Scholar]
- Basole, R.C.; Braunstein, M.L.; Kumar, V.; Park, H.; Kahng, M.; Chau, D.H.; Tamersoy, A.; Hirsh, D.A.; Serban, N.; Bost, J.; et al. Understanding variations in pediatric asthma care processes in the emergency department using visual analytics. J. Am. Med. Inform. Assoc. 2015, 22, 318–323. [Google Scholar] [CrossRef] [Green Version]
- Huang, C.W.; Syed-Abdul, S.; Jian, W.S.; Iqbal, U.; Nguyen, P.A.; Lee, P.; Lin, S.H.; Hsu, W.D.; Wu, M.S.; Wang, C.F.; et al. A novel tool for visualizing chronic kidney disease associated polymorbidity: A 13-year cohort study in Taiwan. J. Am. Med. Inform. Assoc. 2015, 22, 290–298. [Google Scholar] [CrossRef]
- Klimov, D.; Shknevsky, A.; Shahar, Y. Exploration of patterns predicting renal damage in patients with diabetes type II using a visual temporal analysis laboratory. J. Am. Med. Inform. Assoc. 2015, 22, 275–289. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gotz, D.H.; Sun, J.; Cao, N. Multifaceted visual analytics for healthcare applications. IBM J. Res. Dev. 2012, 56, 12. [Google Scholar] [CrossRef]
- Sedig, K.; Parsons, P.; Babanski, A. Towards a Characterization of Interactivity in Visual Analytics. JMPT 2012, 3, 12–28. [Google Scholar]
- Keim, D.; Kohlhammer, J.; Ellis, G.; Mansmann, F. Mastering The Information Age—Solving Problems with Visual Analytics. Eurographics association: Geneva, Switzerland, 2010; ISBN 978-3-905673-77-7. [Google Scholar]
- Thomas, J.J.; Cook, K.A. A visual analytics agenda. IEEE Comput. Graph. Appl. 2006, 26, 10–13. [Google Scholar] [CrossRef]
- Ola, O.; Sedig, K. Discourse with Visual Health Data: Design of Human-Data Interaction. Multimodal Technol. Interact. 2018, 2, 10. [Google Scholar] [CrossRef] [Green Version]
- Cui, W. Visual Analytics: A Comprehensive Overview. IEEE Access 2019, 7, 81555–81573. [Google Scholar] [CrossRef]
- Keim, D.; Mansmann, F.; Thomas, J. Visual Analytics: How Much Visualization and How Much Analytics? ACM SIGKDD Explor. Newsl. 2010, 11, 5–8. [Google Scholar] [CrossRef]
- Jeong, D.H.; Ji, S.Y.; Suma, E.A.; Yu, B.; Chang, R. Designing a collaborative visual analytics system to support users’ continuous analytical processes. Hum.-Centric Comput. Inf. Sci. 2015, 5, 5. [Google Scholar] [CrossRef] [Green Version]
- Ola, O.; Sedig, K. The Challenge of Big Data in Public Helth: An Opportunity for Visual Analytics. Online J. Public Health Inform. 2014, 5, 223. [Google Scholar]
- Parsons, P.; Sedig, K. Distribution of information processing while performing complex cognitive activities with visualization tools. In Handbook of Human Centric Visualization; Springer: New York, NY, USA, 2014; pp. 693–715. ISBN 9781461474852. [Google Scholar]
- Sedig, K.; Parsons, P. Interaction Design for Complex Cognitive Activities with Visual Representations: A Pattern-Based Approach. AIS Trans. Hum.-Comput. Interact. 2013, 5, 84–133. [Google Scholar] [CrossRef] [Green Version]
- Green, T.M.; Maciejewski, R. A role for reasoning in visual analytics. In Proceedings of the 2013 46th Hawaii International Conference on System Sciences, Wailea, HI, USA, 7–10 January 2013; pp. 1495–1504. [Google Scholar]
- Han, J.; Kamber, M.; Pei, J. Data Mining. Concepts and Techniques, 3rd ed.; The Morgan Kaufmann Series in Data Management Systems; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Kusiak, A. Feature transformation methods in data mining. IEEE Trans. Electron. Packag. Manuf. 2001, 24, 214–221. [Google Scholar] [CrossRef]
- Agrawal, R.; Swami, A.; Imielinski, T. Database Mining: A Performance Perspective. IEEE Trans. Knowl. Data Eng. 1993, 5, 914–925. [Google Scholar] [CrossRef] [Green Version]
- Sahu, H.; Shrma, S.; Gondhalakar, S. A Brief Overview on Data Mining Survey. IJCTEE 2008, 1, 114–121. [Google Scholar]
- Heer, J.; Kandel, S. Interactive analysis of big data. XRDS Crossroads ACM Mag. Stud. 2012, 19, 50–54. [Google Scholar] [CrossRef]
- Keim, D.; Mansmann, F.; Schneidewind, J.; Thomas, J.; Ziegler, H. Visual analytics: Scope and challenges. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2008; pp. 76–90. [Google Scholar]
- Kehrer, J.; Hauser, H. Visualization and visual analysis of multifaceted scientific data: A survey. IEEE Trans. Vis. Comput. Graph. 2013, 19, 495–513. [Google Scholar] [CrossRef] [PubMed]
- Heuer, R.J. Psychology of Intelligence Analysis; Center for the Study of Intelligence, Central Intelligence Agency: McLean, VA, USA, 1999; ISBN 9781929667000. [Google Scholar]
- Gilhooly, K.J. Working Memory and Reasoning. In The Nature of Reasoning; Cambridge University Press: Cambridge, UK, 2004; pp. 49–77, ISBN 0-521-81090-6 (Hardcover), 0-521-00928-6 (Paperback). [Google Scholar]
- Leighton, J.P. Defining and Describing Reason. In The Nature of Reasoning; Cambridge University Press: Cambridge, UK, 2004; pp. 3–11, ISBN 0-521-81090-6 (Hardcover); 0-521-00928-6 (Paperback). [Google Scholar]
- Varga, M.; Varga, C. Visual Analytics: Data, Analytical and Reasoning Provenance. In Building Trust in Information; Springer: Cham, Switzerland, 2016; pp. 141–150. [Google Scholar]
- Arifin, S.; Zulkardi, Z.; Indra Putri, R.; Hartono, Y.; Susanti, E. Developing Ill-defined problem-solving for the context of “South Sumatera”. J. Phys. Conf. Ser. 2017, 943, 12038. [Google Scholar] [CrossRef]
- Muller, M. Participatory Design: The third space in HCI. In The Human-Computer Interaction Handbook; CRC Press: Boca Raton, FL, USA, 2007; pp. 1087–1108. [Google Scholar]
- Williams, D.A.; McCullagh, P.; Nelder, J.A. Generalized Linear Models. Biometrics 1984, 40, 566. [Google Scholar] [CrossRef]
- Spence, R. Sensitivity encoding to support information space navigation: A design guideline. Inf. Vis. 2002, 1, 120–129. [Google Scholar] [CrossRef]
- Wu, X.; Zhang, W.; Ren, H.; Chen, X.; Xie, J.; Chen, N. Diuretics associated acute kidney injury: Clinical and pathological analysis. Ren. Fail. 2014, 36, 1051–1055. [Google Scholar] [CrossRef]
- Chao, C.-T.; Tsai, H.-B.; Wu, C.-Y.; Lin, Y.-F.; Hsu, N.-C.; Chen, J.-S.; Hung, K.-Y. Cumulative Cardiovascular Polypharmacy Is Associated With the Risk of Acute Kidney Injury in Elderly Patients. Medicine 2015, 94, e1251. [Google Scholar] [CrossRef]
- Ho, K.M.; Power, B.M. Benefits and risks of furosemide in acute kidney injury. Anaesthesia 2010, 65, 283–293. [Google Scholar] [CrossRef] [PubMed]
- Verdoodt, A.; Honore, P.M.; Jacobs, R.; De Waele, E.; Gorp, V.V.; De Regt, J.; Spapen, H.D. Do statins induce or protect from acute kidney injury and chronic kidney disease: An update review in 2018. J. Transl. Intern. Med. 2018, 6, 21–25. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pierson-Marchandise, M.; Gras, V.; Moragny, J.; Micallef, J.; Gaboriau, L.; Picard, S.; Choukroun, G.; Masmoudi, K.; Liabeuf, S. The drugs that mostly frequently induce acute kidney injury: A case—Noncase study of a pharmacovigilance database. Br. J. Clin. Pharmacol. 2017, 83, 1341–1349. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Perez-Ruiz, F. Treatment with Allopurinol is Associated with Lower Risk of Acute Kidney Injury in Patients with Gout: A Retrospective Analysis of a Nested Cohort. Rheumatol. Ther. 2017, 4, 419–425. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Malbrain, M.L.N.G.; Lambrecht, G.L.Y.; Daelemans, R.; Lins, R.L.; Hermans, P.; Zachee, P. Acute renal failure due to bilateral lymphomatous infiltrates—Primary extranodal non-Hodgkin’s lymphoma (p-EN-NHL) of the kidneys: Does it really exist? Clin. Nephrol. 1994, 42, 163–169. [Google Scholar]
- Anderson, F.A.; Wyman, A.; Varon, J.; McCullough, P.A.; Devlin, J.W.; Weir, M.R.; Katz, J.N.; Szczech, L.A.; Granger, C.B.; Dasta, J.F.; et al. Acute Kidney Injury and Cardiovascular Outcomes in Acute Severe Hypertension Acute Kidney Injury and Cardiovascular Outcomes in Acute Severe Hypertension. Circulation 2010, 121, 2183–2191. [Google Scholar]
- Kandler, K.; Jensen, M.E.; Nilsson, J.C.; Møller, C.H.; Steinbrüchel, D.A. Acute kidney injury is independently associated with higher mortality after cardiac surgery. J. Cardiothorac. Vasc. Anesth. 2014, 28, 1448–1452. [Google Scholar] [CrossRef]
- Martines, A.M.F.; Masereeuw, R.; Tjalsma, H.; Hoenderop, J.G.; Wetzels, J.F.M.; Swinkels, D.W. Iron metabolism in the pathogenesis of iron-induced kidney injury. Nat. Rev. Nephrol. 2013, 9, 385–398. [Google Scholar] [CrossRef]
- Da’as, N.; Polliack, A.; Cohen, Y.; Amir, G.; Darmon, D.; Kleinman, Y.; Goldfarb, A.W.; Ben-Yehuda, D. Kidney involvement and renal manifestations in non-Hodgkin’s lymphoma and lymphocytic leukemia: A retrospective study in 700 patients. Eur. J. Haematol. 2001, 67, 158–164. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Satisfied Filters | Color of the Glyphs |
|---|---|
| 6 | Green |
| 5 | Black |
| 4 | Blue |
| 3 | Cyan |
| 2 | Purple |
| 1 | Grey |
| 0 | Yellow |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdullah, S.S.; Rostamzadeh, N.; Sedig, K.; Garg, A.X.; McArthur, E. Multiple Regression Analysis and Frequent Itemset Mining of Electronic Medical Records: A Visual Analytics Approach Using VISA_M3R3. Data 2020, 5, 33. https://0-doi-org.brum.beds.ac.uk/10.3390/data5020033
Abdullah SS, Rostamzadeh N, Sedig K, Garg AX, McArthur E. Multiple Regression Analysis and Frequent Itemset Mining of Electronic Medical Records: A Visual Analytics Approach Using VISA_M3R3. Data. 2020; 5(2):33. https://0-doi-org.brum.beds.ac.uk/10.3390/data5020033
Chicago/Turabian StyleAbdullah, Sheikh S., Neda Rostamzadeh, Kamran Sedig, Amit X. Garg, and Eric McArthur. 2020. "Multiple Regression Analysis and Frequent Itemset Mining of Electronic Medical Records: A Visual Analytics Approach Using VISA_M3R3" Data 5, no. 2: 33. https://0-doi-org.brum.beds.ac.uk/10.3390/data5020033