
Ensemble Transfer Learning for Fetal Head Analysis: From Segmentation to Gestational Age and Weight Prediction

 , , and
, , and
Abstract
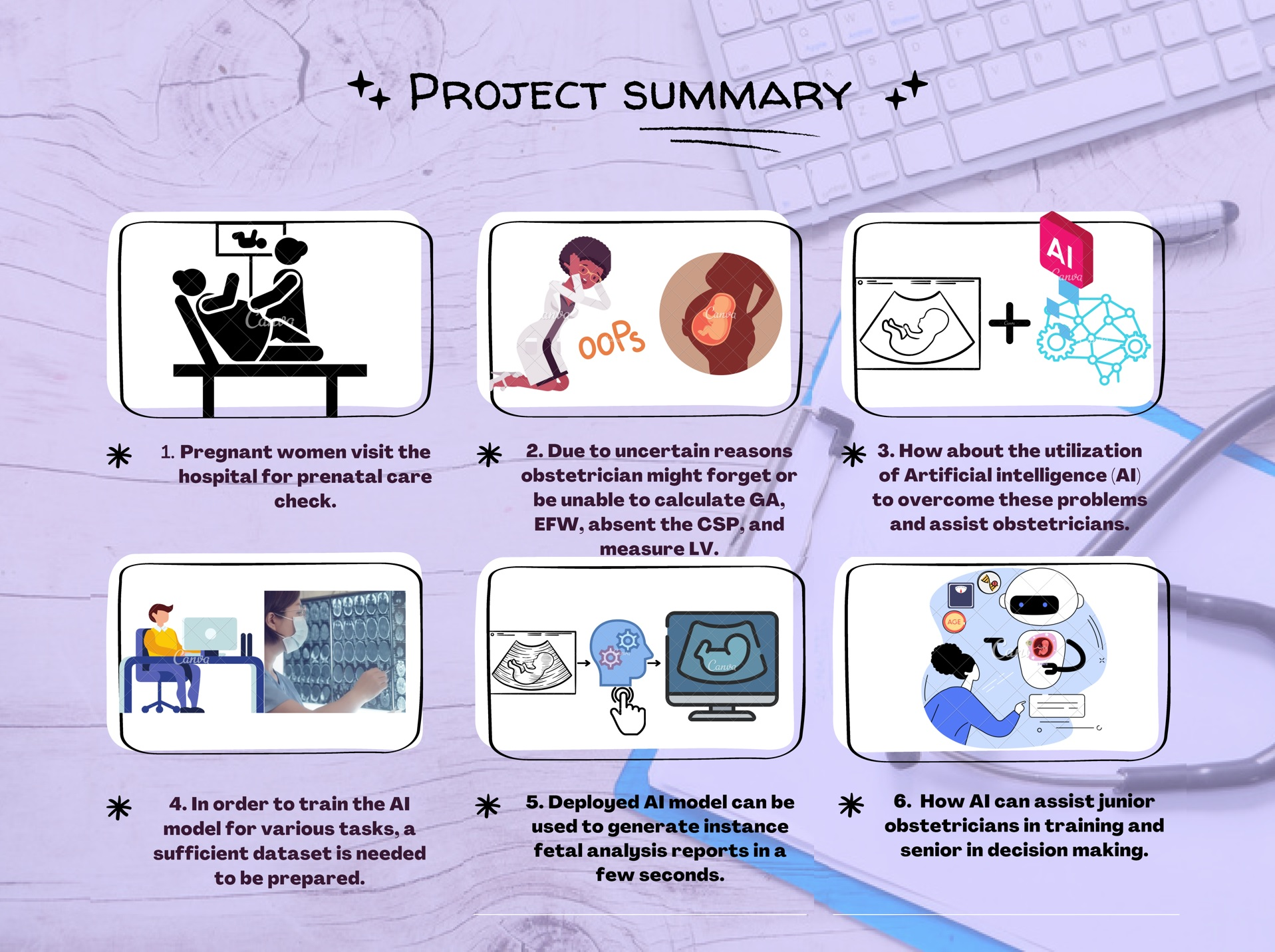
:
1. Introduction
1.1. Contributions
- We fine-tuned eight segmentation networks using a pre-trained lightweight network (EffientNetB0) and employed weighted voting ensemble learning on the trained segmentation networks to obtain the optimal segmentation result.
- We extensively evaluated the ensemble transfer learning model (ETLM) by performing three-level evaluations: fetal head segmentation evaluation, predicted mask and post-processing quality assessment, and head measurement evaluation.
- We generated a new fetal head measurement dataset and manually labeled it by adding fetal gestation age and weight.
- We evaluated the regression model result using an expert obstetrician, and a longitudinal reference using Pearson’s correlation coefficient (Pearson’s r).
1.2. Organization
2. Related Work
2.1. Fetal Head Segmentation
2.1.1. Traditional Approaches
2.1.2. Deep Learning
2.2. Fetal Head Measurement
2.3. GA and EFW Calculation
3. Materials and Methods
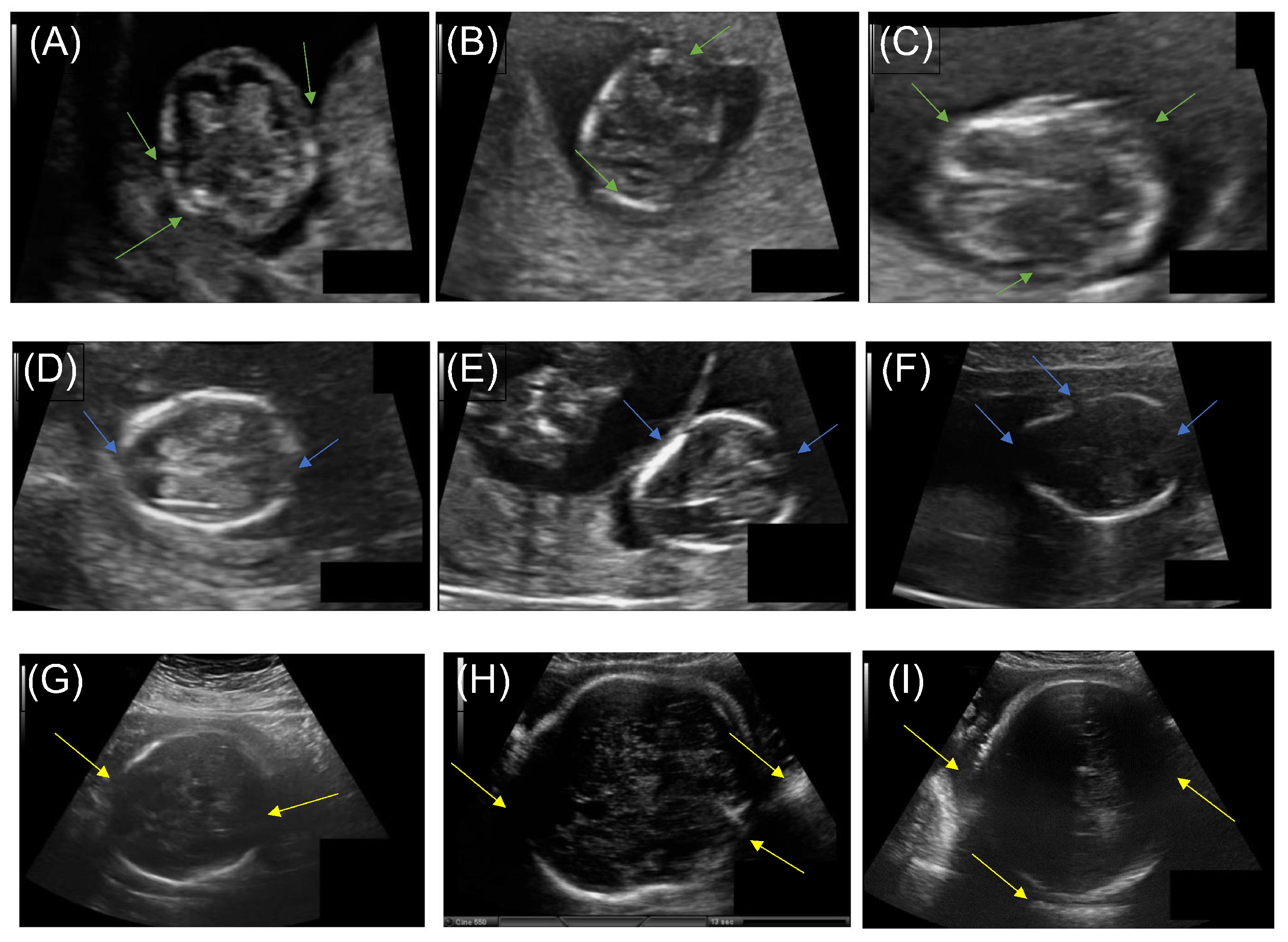
3.1. Methodology
- Automatic segmentation: takes as an input a ultrasound image, and gives an output binary mask representing the fetal head.
- (a)
- Eight segmentation models are fine-tuned independently using the pretrained CNN EfficientNetB0 as the feature extractor.
- (b)
- The segmentation predictions of these models are integrated through ETLM.
- Measurements extraction: from an automatically computed and smoothed binary mask, we fit an analytic explicit ellipse model that we use for computing the geometric measurements of interest, such as semi-axis and head orientation.
- (a)
- Image post-processing and smoothing.
- (b)
- Fetal head measurement.
- GA and EFW Prediction: from measurements and manual annotations, we fit a regression model that is able to predict GA and EFW, which we validate clinically.
- (a)
- Generate new GA and EFW dataset and labeling.
- (b)
- Trained multiple regression models on the new dataset.
- (c)
- Clinical and longitudinal study validation.
3.2. Dataset
3.3. Ensemble Transfer Learning Model (ETLM)
3.3.1. Transfer Learning
3.3.2. Ensemble Learning
3.3.3. Image Pre-Processing
- Normalization: the ultrasound image intensity range is 0 to 255. Therefore, we applied a normalization technique for shifting and rescaling values to fit in a range between 0 and 1. The Normalization Formula is as follows:where Z: the normalized value in the image, X: the original value in the image, : the minimum value in the image, and the maximum value in the image .
- Resizing: The original image and mask size is 800 × 540 pixels; the images and masks were resized into two different sizes, and the difference between the two inputs, 64 × 64 and 128 × 128, is compared to evaluate the lightweight models and to use low-cost resources. In addition, while the original mask intensity was only two values, 0 and 255, after mask resizing, the intensity of the masks randomly ranged between 0 and 255. Therefore, the threshold of the resized masks had to be set to the original intensity, where 0 represents black pixels, and 255 represents white pixels. Finally, Softmax [68] was used as the output function; therefore, we had to encode the mask values to 0 for black and 1 for white pixels.
- One-Hot encoding: One-hot encoding is not often used with numerical values (images). In this study, because the output function is Softmax and the loss function is categorical focal Jaccard loss, it is recommended that one-hot encoding be used. The class representing white pixels is (0, 1), and the class representing black pixels is (1, 0).
3.3.4. Hybrid Loss Function and Optimizer
3.4. Measurements Extraction
3.4.1. Post-Processing
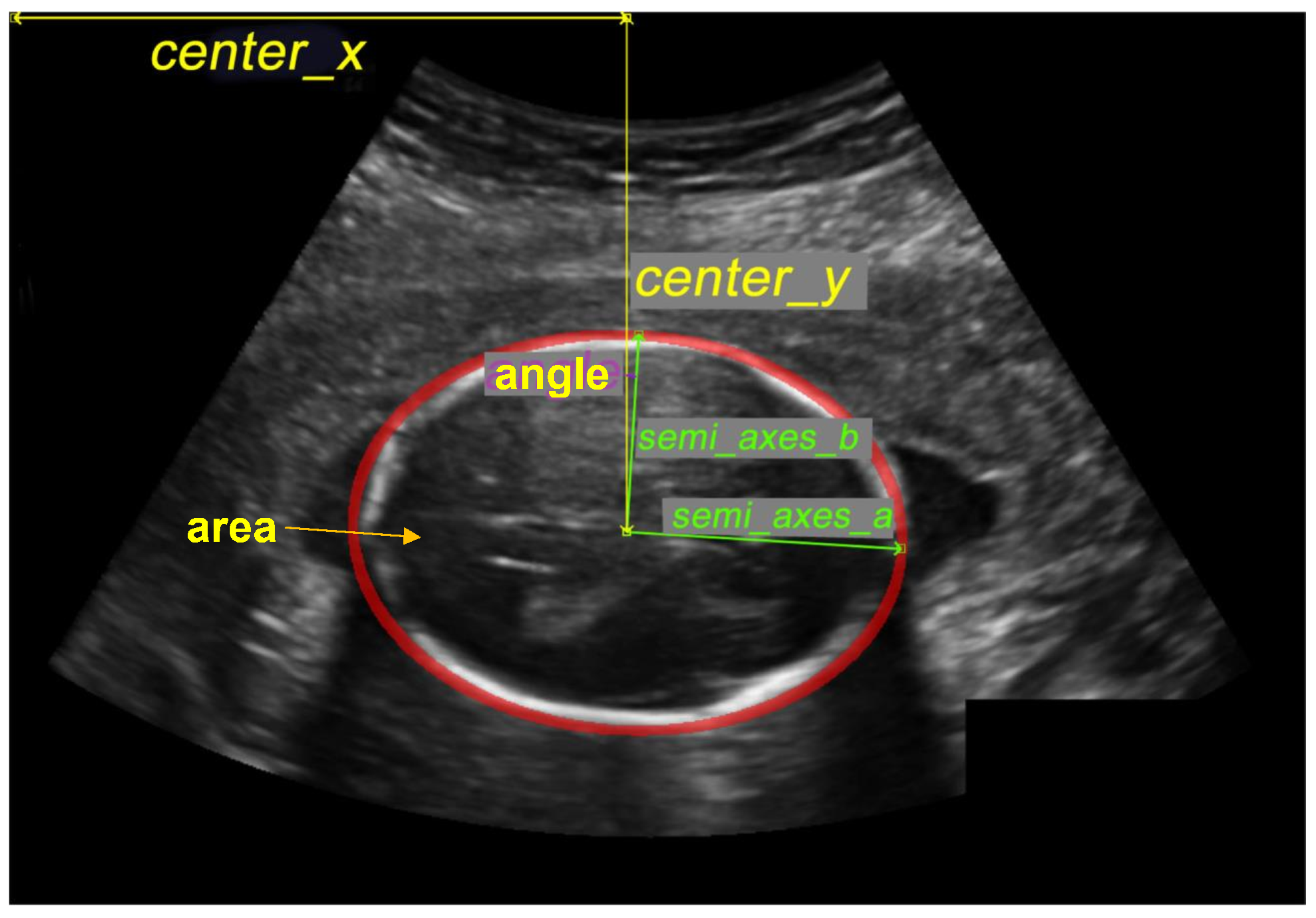
3.4.2. HC Measurements
- center x: represents the length in millimeters between the image’s beginning pixel on the x-axis and the ellipse’s middle pixel.
- center y: represents the length, in millimeters, between the image’s beginning pixel on the y-axis and the ellipse’s middle pixel.
- semi-axes a: Once the ellipse’s center is determined, the semi-axes determine the radius’s maximum value based on the distance between the ellipse’s middle and its farthest point.
- semi-axes b: Once the ellipse’s center is determined, the semi-axes determine the radius’s minimum value based on the distance between the ellipse’s middle and its nearest point.
- angle: contains the radian value of the angle formed by the center y and the semi-axis b.
- area: is the size of the area in millimeters that represent the fetal head.
3.5. GA and EFW Prediction
3.5.1. Fetal Gestational Age Dataset
3.5.2. Fetal Weight Dataset
4. Experiments
4.1. Training
4.2. Segmentation Models Evaluation
4.2.1. Level 1: Segmentation Evaluation
4.2.2. Level 2: Post-Processing Evaluation
4.2.3. Level 3: Measurement Evaluation
4.3. Evaluation of GA and EFW Prediction
5. Results and Discussion
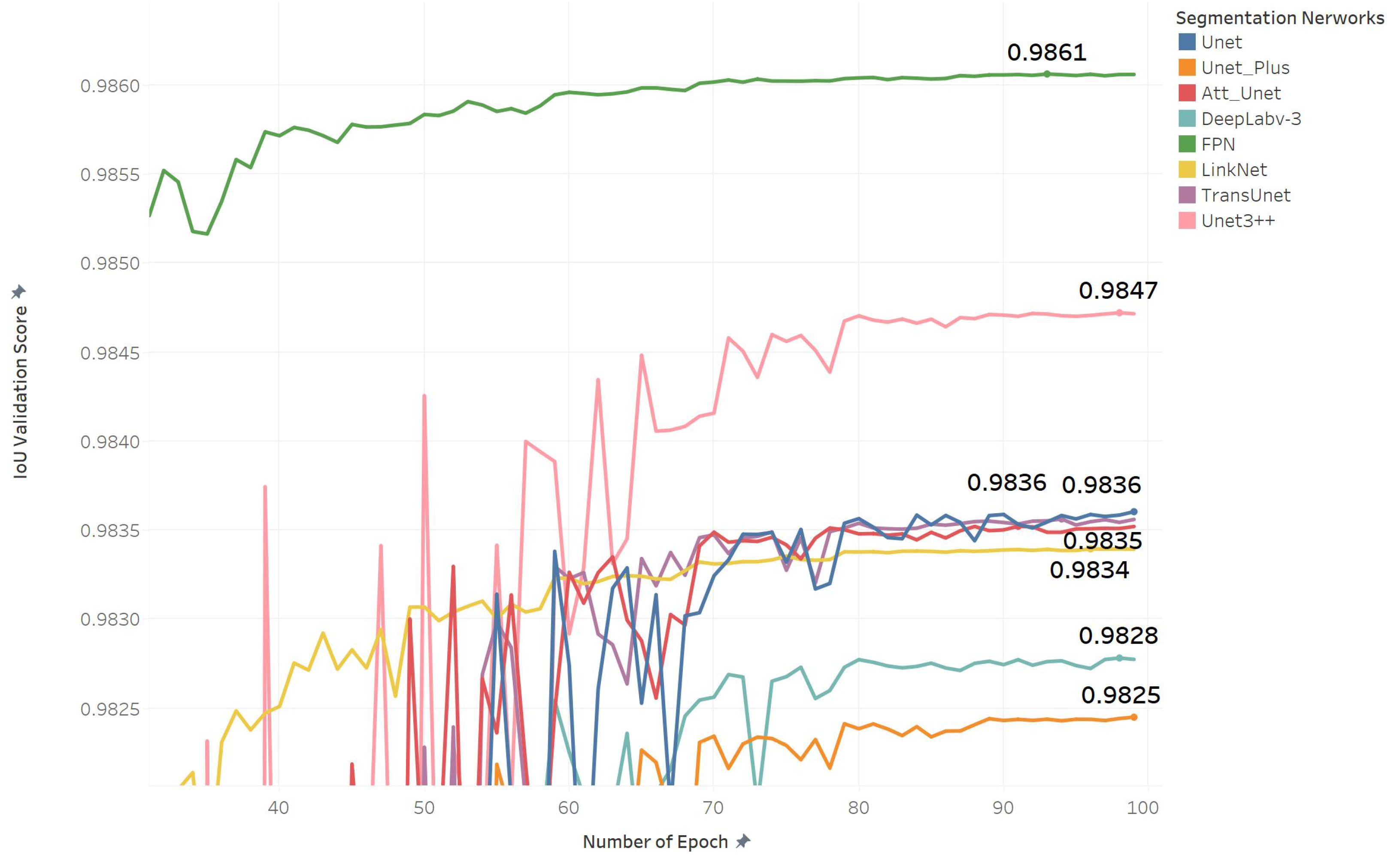
5.1. Segmentation Performance
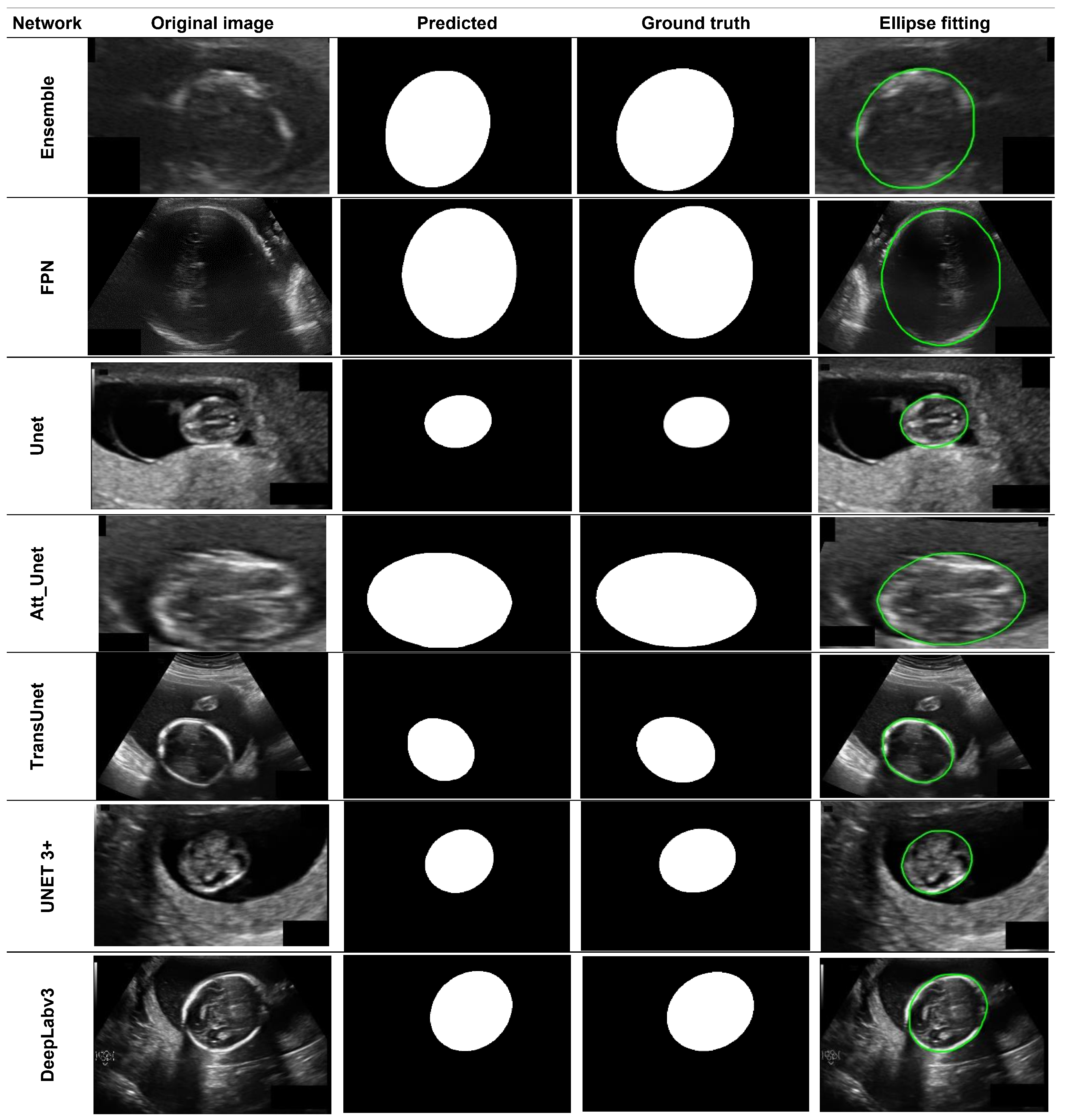
5.2. Measurements Performance
5.2.1. Post-Processing Evaluation
5.2.2. Fetal Head Measurement Evaluation
5.3. Comparative Analysis
5.4. GA and EFW Prediction Performance
- Validation of predicted GA: 50 random samples images taken from the testing set () were given to a senior attending physician with 21 years of experience in maternal-fetal medicine, to estimate GA. We used Pearson’s r to measure the strength of a linear association between the physician prediction and the model prediction for the same sample set. Because we do not have any pre-knowledge of the dataset in terms of ethnicity or location, the GA may vary based on these factors; therefore, in this work, we tried to predict the GA in the 50th percentile, and considered the median.
- Validation of predicted EFW: In the case of EFW, the senior physician could not estimate the EFW based on fetal head images and required more factors such as FL, AC, and CRL. Therefore, a growth chart taken from a longitudinal reference was used for estimated fetal weight, regardless of fetal sex [82]. Then, Pearson’s r was used to measure the strength of the linear association between the longitudinal reference and the model prediction for the same sample set that fell in the range of . This study tried to predict the EFW in the 50th percentile and considered the median for the above mentioned reason.
6. Strength and Limitations
7. Conclusions and Future Work
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Longitudinal Reference

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gestational Age (Weeks) | Estimated Fetal Weight (g) by Percentile | |||||||||
| 2.5 | 5 | 10 | 25 | 50 | 75 | 90 | 95 | 97.5 | ||
| 14 | 70 | 73 | 78 | 83 | 90 | 98 | 104 | 109 | 113 | |
| 15 | 89 | 93 | 99 | 106 | 114 | 124 | 132 | 138 | 144 | |
| 16 | 113 | 117 | 124 | 133 | 144 | 155 | 166 | 174 | 181 | |
| 17 | 141 | 146 | 155 | 166 | 179 | 193 | 207 | 217 | 225 | |
| 18 | 174 | 181 | 192 | 206 | 222 | 239 | 255 | 268 | 278 | |
| 19 | 214 | 223 | 235 | 252 | 272 | 292 | 313 | 328 | 340 | |
| 20 | 260 | 271 | 286 | 307 | 330 | 355 | 380 | 399 | 413 | |
| 21 | 314 | 327 | 345 | 370 | 398 | 428 | 458 | 481 | 497 | |
| 22 | 375 | 392 | 412 | 443 | 476 | 512 | 548 | 575 | 595 | |
| 23 | 445 | 465 | 489 | 525 | 565 | 608 | 650 | 682 | 705 | |
| 24 | 523 | 548 | 576 | 618 | 665 | 715 | 765 | 803 | 830 | |
| 25 | 611 | 641 | 673 | 723 | 778 | 836 | 894 | 938 | 970 | |
| 26 | 707 | 743 | 780 | 838 | 902 | 971 | 1038 | 1087 | 1125 | |
| 27 | 813 | 855 | 898 | 964 | 1039 | 1118 | 1196 | 1251 | 1295 | |
| 28 | 929 | 977 | 1026 | 1102 | 1189 | 1279 | 1368 | 1429 | 1481 | |
| 29 | 1053 | 1108 | 1165 | 1251 | 1350 | 1453 | 1554 | 1622 | 1682 | |
| 30 | 1185 | 1247 | 1313 | 1410 | 1523 | 1640 | 1753 | 1828 | 1897 | |
| 31 | 1326 | 1394 | 1470 | 1579 | 1707 | 1838 | 1964 | 2046 | 2126 | |
| 32 | 1473 | 1548 | 1635 | 1757 | 1901 | 2047 | 2187 | 2276 | 2367 | |
| 33 | 1626 | 1708 | 1807 | 1942 | 2103 | 2266 | 2419 | 2516 | 2619 | |
| 34 | 1785 | 1872 | 1985 | 2134 | 2312 | 2492 | 2659 | 2764 | 2880 | |
| 35 | 1948 | 2038 | 2167 | 2330 | 2527 | 2723 | 2904 | 3018 | 3148 | |
| 36 | 2113 | 2205 | 2352 | 2531 | 2745 | 2959 | 3153 | 3277 | 3422 | |
| 37 | 2280 | 2372 | 2537 | 2733 | 2966 | 3195 | 3403 | 3538 | 3697 | |
| 38 | 2446 | 2536 | 2723 | 2935 | 3186 | 3432 | 3652 | 3799 | 3973 | |
| 39 | 2612 | 2696 | 2905 | 3135 | 3403 | 3664 | 3897 | 4058 | 4247 | |
| 40 | 2775 | 2849 | 3084 | 3333 | 3617 | 3892 | 4135 | 4312 | 4515 | |
References
- Mayer, D.P.; Shipilov, V. Ultrasonography and magnetic resonance imaging of uterine fibroids. Obstet. Gynecol. Clin. N. Am. 1995, 22, 667–725. [Google Scholar] [CrossRef]
- Griffin, R.M. Fetal Biometry. WebMD 2020. Available online: https://www.webmd.com/baby/fetal-biometry (accessed on 11 August 2022).
- Whitworth, M.B.L.; Mullan, C. Ultrasound for fetal assessment in early pregnancy. Cochrane Database Syst. Rev. 2015, 2015, CD007058. [Google Scholar] [CrossRef] [PubMed]
- Alzubaidi, M.; Agus, M.; Alyafei, K.; Althelaya, K.A.; Shah, U.; Abd-Alrazaq, A.; Anbar, M.; Makhlouf, M.; Househ, M. Toward deep observation: A systematic survey on artificial intelligence techniques to monitor fetus via ultrasound images. iScience 2022, 25, 104713. [Google Scholar] [CrossRef] [PubMed]
- Halle, K.F.; Fjose, M.; Kristjansdottir, H.; Bjornsdottir, A.; Getz, L.; Tomasdottir, M.O.; Sigurdsson, J.A. Use of pregnancy ultrasound before the 19th week scan: An analytical study based on the Icelandic Childbirth and Health Cohort. BMC Pregnancy Childbirth 2018, 18, 512. [Google Scholar] [CrossRef]
- Loughna, P.; Chitty, L.; Evans, T.; Chudleigh, T. Fetal Size and Dating: Charts Recommended for Clinical Obstetric Practice. Ultrasound 2009, 17, 160–166. [Google Scholar] [CrossRef]
- Jatmiko, W.; Habibie, I.; Ma’sum, M.A.; Rahmatullah, R.; Satwika, I.P. Automated Telehealth System for Fetal Growth Detection and Approximation of Ultrasound Images. Int. J. Smart Sens. Intell. Syst. 2015, 8, 697–719. [Google Scholar] [CrossRef]
- Schmidt, U.; Temerinac, D.; Bildstein, K.; Tuschy, B.; Mayer, J.; Sütterlin, M.; Siemer, J.; Kehl, S. Finding the most accurate method to measure head circumference for fetal weight estimation. Eur. J. Obstet. Gynecol. Reprod. Biol. 2014, 178, 153–156. [Google Scholar] [CrossRef]
- Noble, J.A. Ultrasound image segmentation and tissue characterization. Proc. Inst. Mech. Eng. Part H J. Eng. Med. 2010, 224, 307–316. [Google Scholar] [CrossRef]
- Van den Heuvel, T.L.A.; de Bruijn, D.; de Korte, C.L.; Ginneken, B. Automated measurement of fetal head circumference using 2D ultrasound images. PLoS ONE 2018, 13, e0200412. [Google Scholar] [CrossRef]
- Espinoza, J.; Good, S.; Russell, E.; Lee, W. Does the Use of Automated Fetal Biometry Improve Clinical Work Flow Efficiency? J. Ultrasound Med. 2013, 32, 847–850. [Google Scholar] [CrossRef]
- Ciurte, A.; Bresson, X.; Cuadra, M.B. A semi-supervised patch-based approach for segmentation of fetal ultrasound imaging. In Proceedings of the Challenge US: Biometric Measurements from Fetal Ultrasound Images, ISBI 2012, Barcelona, Spain, 2–5 May 2012; pp. 5–7. [Google Scholar]
- Ponomarev, G.V.; Gelfand, M.S.; Kazanov, M.D. A multilevel thresholding combined with edge detection and shape-based recognition for segmentation of fetal ultrasound images. In Proceedings of the Challenge US: Biometric Measurements from Fetal Ultrasound Images, ISBI 2012, Barcelona, Spain, 2–5 May 2012; pp. 17–19. [Google Scholar]
- Stebbing, R.V.; McManigle, J.E. A boundary fragment model for head segmentation in fetal ultrasound. In Proceedings of the Challenge US: Biometric Measurements from Fetal Ultrasound Images, ISBI, Barcelona, Spain, 2–5 May 2012; pp. 9–11. [Google Scholar]
- Perez-Gonzalez, J.L.; Muńoz, J.C.B.; Porras, M.C.R.; Arámbula-Cosío, F.; Medina-Bańuelos, V. Automatic Fetal Head Measurements from Ultrasound Images Using Optimal Ellipse Detection and Texture Maps. In Proceedings of the VI Latin American Congress on Biomedical Engineering CLAIB 2014, Paraná, Argentina, 29–31 October 2014; Braidot, A., Hadad, A., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 329–332. [Google Scholar] [CrossRef]
- Shrimali, V.; Anand, R.S.; Kumar, V. Improved segmentation of ultrasound images for fetal biometry, using morphological operators. In Proceedings of the 2009 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Minneapolis, MI, USA, 3–6 September 2009; pp. 459–462. [Google Scholar] [CrossRef]
- Rueda, S.; Fathima, S.; Knight, C.L.; Yaqub, M.; Papageorghiou, A.T.; Rahmatullah, B.; Foi, A.; Maggioni, M.; Pepe, A.; Tohka, J.; et al. Evaluation and Comparison of Current Fetal Ultrasound Image Segmentation Methods for Biometric Measurements: A Grand Challenge. IEEE Trans. Med. Imaging 2014, 33, 797–813. [Google Scholar] [CrossRef]
- Jardim, S.M.; Figueiredo, M.A. Segmentation of fetal ultrasound images. Ultrasound Med. Biol. 2005, 31, 243–250. [Google Scholar] [CrossRef]
- Ahmad, M.; Qadri, S.F.; Ashraf, M.U.; Subhi, K.; Khan, S.; Zareen, S.S.; Qadri, S. Efficient Liver Segmentation from Computed Tomography Images Using Deep Learning. Comput. Intell. Neurosci. 2022, 2022, 2665283. [Google Scholar] [CrossRef]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.; van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Strasbourg, France, 27 September–1 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar] [CrossRef]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef] [Green Version]
- Torres, H.R.; Morais, P.; Oliveira, B.; Birdir, C.; Rüdiger, M.; Fonseca, J.C.; Vilaça, J.L. A review of image processing methods for fetal head and brain analysis in ultrasound images. Comput. Methods Programs Biomed. 2022, 215, 106629. [Google Scholar] [CrossRef]
- Mayer, C.; Joseph, K.S. Fetal growth: A review of terms, concepts and issues relevant to obstetrics. Ultrasound Obstet. Gynecol. 2013, 41, 136–145. [Google Scholar] [CrossRef]
- Dudley, N.J. A systematic review of the ultrasound estimation of fetal weight. Ultrasound Obstet. Gynecol. 2005, 25, 80–89. [Google Scholar] [CrossRef]
- Carneiro, G.; Georgescu, B.; Good, S.; Comaniciu, D. Detection and Measurement of Fetal Anatomies from Ultrasound Images using a Constrained Probabilistic Boosting Tree. IEEE Trans. Med. Imaging 2008, 27, 1342–1355. [Google Scholar] [CrossRef]
- Lu, W.; Tan, J.; Floyd, R. Automated fetal head detection and measurement in ultrasound images by iterative randomized hough transform. Ultrasound Med. Biol. 2005, 31, 929–936. [Google Scholar] [CrossRef]
- Zhang, L.; Ye, X.; Lambrou, T.; Duan, W.; Allinson, N.; Dudley, N.J. A supervised texton based approach for automatic segmentation and measurement of the fetal head and femur in 2D ultrasound images. Phys. Med. Biol. 2016, 61, 1095–1115. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Wang, Y.; Lei, B.; Cheng, J.Z.; Qin, J.; Wang, T.; Li, S.; Ni, D. Automatic Fetal Head Circumference Measurement in Ultrasound Using Random Forest and Fast Ellipse Fitting. IEEE J. Biomed. Health Inform. 2018, 22, 215–223. [Google Scholar] [CrossRef] [PubMed]
- Sobhaninia, Z.; Rafiei, S.; Emami, A.; Karimi, N.; Najarian, K.; Samavi, S.; Reza Soroushmehr, S.M. Fetal Ultrasound Image Segmentation for Measuring Biometric Parameters Using Multi-Task Deep Learning. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 6545–6548. [Google Scholar] [CrossRef]
- Cerrolaza, J.J.; Sinclair, M.; Li, Y.; Gomez, A.; Ferrante, E.; Matthew, J.; Gupta, C.; Knight, C.L.; Rueckert, D. Deep learning with ultrasound physics for fetal skull segmentation. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 564–567. [Google Scholar] [CrossRef]
- Budd, S.; Sinclair, M.; Khanal, B.; Matthew, J.; Lloyd, D.; Gomez, A.; Toussaint, N.; Robinson, E.C.; Kainz, B. Confident Head Circumference Measurement from Ultrasound with Real-Time Feedback for Sonographers. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2019, Shenzhen, China, 13–17 October 2019; Shen, D., Liu, T., Peters, T.M., Staib, L.H., Essert, C., Zhou, S., Yap, P.T., Khan, A., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 683–691. [Google Scholar] [CrossRef] [Green Version]
- Chaurasia, A.; Culurciello, E. LinkNet: Exploiting encoder representations for efficient semantic segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Qiao, D.; Zulkernine, F. Dilated Squeeze-and-Excitation U-Net for Fetal Ultrasound Image Segmentation. In Proceedings of the 2020 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Virtual, 27–29 October 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Desai, A.; Chauhan, R.; Sivaswamy, J. Image Segmentation Using Hybrid Representations. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Aji, C.P.; Fatoni, M.H.; Sardjono, T.A. Automatic Measurement of Fetal Head Circumference from 2-Dimensional Ultrasound. In Proceedings of the 2019 International Conference on Computer Engineering, Network, and Intelligent Multimedia (CENIM), Surabaya, Indonesia, 19–20 November 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Sobhaninia, Z.; Emami, A.; Karimi, N.; Samavi, S. Localization of Fetal Head in Ultrasound Images by Multiscale View and Deep Neural Networks. In Proceedings of the 2020 25th International Computer Conference, Computer Society of Iran (CSICC), Tehran, Iran, 1–2 January 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Brahma, K.; Kumar, V.; Samir, A.E.; Chandrakasan, A.P.; Eldar, Y.C. Efficient Binary Cnn For Medical Image Segmentation. In Proceedings of the 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), Nice, France, 13–16 April 2021; pp. 817–821. [Google Scholar] [CrossRef]
- Zeng, Y.; Tsui, P.H.; Wu, W.; Zhou, Z.; Wu, S. Fetal Ultrasound Image Segmentation for Automatic Head Circumference Biometry Using Deeply Supervised Attention-Gated V-Net. J. Digit. Imaging 2021, 34, 134–148. [Google Scholar] [CrossRef] [PubMed]
- Xu, L.; Gao, S.; Shi, L.; Wei, B.; Liu, X.; Zhang, J.; He, Y. Exploiting Vector Attention and Context Prior for Ultrasound Image Segmentation. Neurocomputing 2021, 454, 461–473. [Google Scholar] [CrossRef]
- Skeika, E.L.; Luz, M.R.D.; Fernandes, B.J.T.; Siqueira, H.V.; De Andrade, M.L.S.C. Convolutional Neural Network to Detect and Measure Fetal Skull Circumference in Ultrasound Imaging. IEEE Access 2020, 8, 191519–191529. [Google Scholar] [CrossRef]
- Wu, L.; Xin, Y.; Li, S.; Wang, T.; Heng, P.A.; Ni, D. Cascaded Fully Convolutional Networks for automatic prenatal ultrasound image segmentation. In Proceedings of the 2017 IEEE 14th International Symposium on Biomedical Imaging (ISBI 2017), Melbourne, Australia, 18–21 April 2017; pp. 663–666. [Google Scholar] [CrossRef]
- Sinclair, M.; Baumgartner, C.F.; Matthew, J.; Bai, W.; Martinez, J.C.; Li, Y.; Smith, S.; Knight, C.L.; Kainz, B.; Hajnal, J.; et al. Human-level Performance On Automatic Head Biometrics in Fetal Ultrasound Using Fully Convolutional Neural Networks. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 17–21 July 2018; pp. 714–717. [Google Scholar] [CrossRef]
- Al-Bander, B.; Alzahrani, T.; Alzahrani, S.; Williams, B.M.; Zheng, Y. Improving fetal head contour detection by object localisation with deep learning. In Medical Image Understanding and Analysis; Zheng, Y., Williams, B.M., Chen, K., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 142–150. [Google Scholar] [CrossRef]
- Zhang, J.; Petitjean, C.; Lopez, P.; Ainouz, S. Direct estimation of fetal head circumference from ultrasound images based on regression CNN. In Proceedings of the Third Conference on Medical Imaging with Deep Learning, Montreal, QC, Canada, 6–8 July 2020; Arbel, T., Ben Ayed, I., de Bruijne, M., Descoteaux, M., Lombaert, H., Pal, C., Eds.; PMLR: Baltimore, MA, USA, 2020; Volume 121, pp. 914–922. [Google Scholar]
- Fiorentino, M.C.; Moccia, S.; Capparuccini, M.; Giamberini, S.; Frontoni, E. A regression framework to head-circumference delineation from US fetal images. Comput. Methods Programs Biomed. 2021, 198, 105771. [Google Scholar] [CrossRef]
- Li, P.; Zhao, H.; Liu, P.; Cao, F. Automated measurement network for accurate segmentation and parameter modification in fetal head ultrasound images. Med. Biol. Eng. Comput. 2020, 58, 2879–2892. [Google Scholar] [CrossRef]
- Verburg, B.O.; Steegers, E.A.P.; De Ridder, M.; Snijders, R.J.M.; Smith, E.; Hofman, A.; Moll, H.A.; Jaddoe, V.W.V.; Witteman, J.C.M. New charts for ultrasound dating of pregnancy and assessment of fetal growth: Longitudinal data from a population-based cohort study. Ultrasound Obstet. Gynecol. 2008, 31, 388–396. [Google Scholar] [CrossRef]
- Mu, J.; Slevin, J.C.; Qu, D.; McCormick, S.; Adamson, S.L. In vivo quantification of embryonic and placental growth during gestation in mice using micro-ultrasound. Reprod. Biol. Endocrinol. 2008, 6, 34. [Google Scholar] [CrossRef]
- Butt, K.; Lim, K. Determination of Gestational Age by Ultrasound: In Response. J. Obstet. Gynaecol. Can. 2016, 38, 432. [Google Scholar] [CrossRef]
- Salomon, L.J.; Bernard, J.P.; Ville, Y. Estimation of fetal weight: Reference range at 20–36 weeks’ gestation and comparison with actual birth-weight reference range. Ultrasound Obstet. Gynecol. 2007, 29, 550–555. [Google Scholar] [CrossRef]
- Hadlock, F.P.; Harrist, R.; Sharman, R.S.; Deter, R.L.; Park, S.K. Estimation of fetal weight with the use of head, body, and femur measurements—A prospective study. Am. J. Obstet. Gynecol. 1985, 151, 333–337. [Google Scholar] [CrossRef]
- Hammami, A.; Mazer Zumaeta, A.; Syngelaki, A.; Akolekar, R.; Nicolaides, K.H. Ultrasonographic estimation of fetal weight: Development of new model and assessment of performance of previous models. Ultrasound Obstet. Gynecol. 2018, 52, 35–43. [Google Scholar] [CrossRef] [Green Version]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and Flexible Image Augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]
- Hesamian, M.H.; Jia, W.; He, X.; Kennedy, P. Deep Learning Techniques for Medical Image Segmentation: Achievements and Challenges. J. Digit. Imaging 2019, 32, 582–596. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Chaudhuri, K., Salakhutdinov, R., Eds.; PMLR: Baltimore, MA, USA, 2019; Volume 97, pp. 6105–6114. [Google Scholar]
- Yang, Y.; Lv, H. Discussion of Ensemble Learning under the Era of Deep Learning. arXiv 2021, arXiv:2101.08387. [Google Scholar]
- Polikar, R. Ensemble learning. In Ensemble Machine Learning: Methods and Applications; Zhang, C., Ma, Y., Eds.; Springer US: Boston, MA, USA, 2012; pp. 1–34. [Google Scholar] [CrossRef]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Stoyanov, D., Taylor, Z., Carneiro, G., Syeda-Mahmood, T., Martel, A., Maier-Hein, L., Tavares, J.M.R., Bradley, A., Papa, J.P., Belagiannis, V., et al., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Le Folgoc, L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Y Hammerla, N.; Kainz, B.; et al. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.W.; Wu, J. UNet 3+: A Full-Scale Connected UNet for Medical Image Segmentation. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 1055–1059. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar] [CrossRef]
- O’Malley, Tom and Bursztein, Elie and Long, James and Chollet, François and Jin, Haifeng and Invernizzi, Luca and others. et al. KerasTuner. 2019. Available online: https://github.com/keras-team/keras-tuner (accessed on 1 April 2022).
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Asgari Taghanaki, S.; Abhishek, K.; Cohen, J.P.; Cohen-Adad, J.; Hamarneh, G. Deep semantic segmentation of natural and medical images: A review. Artif. Intell. Rev. 2021, 54, 137–178. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bertels, J.; Eelbode, T.; Berman, M.; Vandermeulen, D.; Maes, F.; Bisschops, R.; Blaschko, M.B. Optimizing the Dice Score and Jaccard Index for Medical Image Segmentation: Theory and Practice. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2019, Shenzhen, China, 13–17 October 2019; Shen, D., Liu, T., Peters, T.M., Staib, L.H., Essert, C., Zhou, S., Yap, P.T., Khan, A., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 92–100. [Google Scholar] [CrossRef]
- Zou, F.; Shen, L.; Jie, Z.; Zhang, W.; Liu, W. A Sufficient Condition for Convergences of Adam and RMSProp. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 11119–11127. [Google Scholar] [CrossRef]
- Ning, C.; Liu, S.; Qu, M. Research on removing noise in medical image based on median filter method. In Proceedings of the 2009 IEEE International Symposium on IT in Medicine & Education, Albuquerque, NM, USA, 2–5 August 2009; Volume 1, pp. 384–388. [Google Scholar] [CrossRef]
- Van der Walt, S.; Schönberger, J.L.; Nunez-Iglesias, J.; Boulogne, F.; Warner, J.D.; Yager, N.; Gouillart, E.; Yu, T. Scikit-image: Image processing in Python. PeerJ 2014, 2, e453. [Google Scholar] [CrossRef] [PubMed]
- Song, Y.; Liu, J. An improved adaptive weighted median filter algorithm. J. Phys. Conf. Ser. 2019, 1187, 042107. [Google Scholar] [CrossRef]
- Hu, C.; Wang, G.; Ho, K.C.; Liang, J. Robust Ellipse Fitting with Laplacian Kernel Based Maximum Correntropy Criterion. IEEE Trans. Image Process. 2021, 30, 3127–3141. [Google Scholar] [CrossRef]
- Al-Thelaya, K.; Agus, M.; Gilal, N.; Yang, Y.; Pintore, G.; Gobbetti, E.; Calí, C.; Magistretti, P.; Mifsud, W.; Schneider, J. InShaDe: Invariant Shape Descriptors for visual 2D and 3D cellular and nuclear shape analysis and classification. Comput. Graph. 2021, 98, 105–125. [Google Scholar] [CrossRef]
- Gavin, H.P. The Levenberg-Marquardt Algorithm for Nonlinear Least Squares Curve-Fitting Problems; Duke University: Durham, NC, USA, 2019; pp. 1–19. [Google Scholar]
- Voglis, C.; Lagaris, I. A rectangular trust region dogleg approach for unconstrained and bound constrained nonlinear optimization. In Proceedings of the WSEAS International Conference on Applied Mathematics, Corfu Island, Greece, 17–19 August 2004; Volume 7. [Google Scholar]
- Altman, D.G.; Chitty, L.S. New charts for ultrasound dating of pregnancy. Ultrasound Obstet. Gynecol. 1997, 10, 174–191. [Google Scholar] [CrossRef]
- Sedgwick, P. Pearson’s correlation coefficient. BMJ 2012, 345, e4483. [Google Scholar] [CrossRef]
- Kiserud, T.; Piaggio, G.; Carroli, G.; Widmer, M.; Carvalho, J.; Neerup Jensen, L.; Giordano, D.; Cecatti, J.G.; Abdel Aleem, H.; Talegawkar, S.A.; et al. The World Health Organization Fetal Growth Charts: A Multinational Longitudinal Study of Ultrasound Biometric Measurements and Estimated Fetal Weight. PLoS Med. 2017, 14, e1002220. [Google Scholar] [CrossRef] [Green Version]
- Samajdar, T.; Quraishi, M.I. Analysis and Evaluation of Image Quality Metrics. In Information Systems Design and Intelligent Applications; Mandal, J.K., Satapathy, S.C., Kumar Sanyal, M., Sarkar, P.P., Mukhopadhyay, A., Eds.; Springer: New Delhi, India, 2015; pp. 369–378. [Google Scholar] [CrossRef]
- Qadri, S.F.; Shen, L.; Ahmad, M.; Qadri, S.; Zareen, S.S.; Khan, S. OP-convNet: A Patch Classification-Based Framework for CT Vertebrae Segmentation. IEEE Access 2021, 9, 158227–158240. [Google Scholar] [CrossRef]
- Lundin, A. Clarius Mobile Health Makes Leadership Changes to Accelerate Growth. AXIS Imaging News 2022. [Google Scholar]
- Strumia, A.; Costa, F.; Pascarella, G.; Del Buono, R.; Agrò, F.E. U smart: Ultrasound in your pocket. J. Clin. Monit. Comput. 2021, 35, 427–429. [Google Scholar] [CrossRef]






| Trimesters of Pregnancy | Training Sets | Testing Sets |
|---|---|---|
| First trimester | 165 | 55 |
| Second trimester | 693 | 233 |
| Third trimester | 141 | 47 |
| Total | 999 | 335 |
| Model Name | Backbone | Output Function | Normalization | One-Hot Encoding | Optimizer | Loss Function | Batch Size | Epoch | Input Size | Trainable Params |
|---|---|---|---|---|---|---|---|---|---|---|
| UNet | EfficientNetB0 | Softmax | 0 to 1 | 0 = black pixel 1 = weight pixel | RMSprop + Scheduler Learning Rate Step Decay | Categorical Focal Jaccard loss | 32 | 100 | 64 × 64 128 × 128 | 2,776,114 |
| UNet_plus | 2,389,042 | |||||||||
| Att_UNet | 2,614,725 | |||||||||
| UNet 3+ | 3,183,330 | |||||||||
| TransUNet | 2,218,322 | |||||||||
| FPN | 4,911,614 | |||||||||
| LinkNet | 6,049,342 | |||||||||
| DeepLabv3 | 4,027,810 |
| Formula | Mean HC of the GT | Mean HC by Each Formula | Mean Difference |
|---|---|---|---|
| Our formula | 174.3831 mm | 174.2411 mm | −0.14203 |
| Other Formula | 178.3705 mm | 3.9874 |
| GA Validation | GA Training | GA Testing | |
|---|---|---|---|
| Dataset | (10–40) weeks | (13–25) weeks | GA < 13 GA > 25 |
| Training | 999 | 692 | 307 |
| Testing | 335 | 232 | 103 |
| Total | 1334 | 924 | 410 |
| EFW Validation | EFW Training | EFW Testing | |
|---|---|---|---|
| Dataset | (10–40) weeks | (20–36) weeks | GA < 20 GA > 36 |
| Training | 999 | 551 | 448 |
| Testing | 335 | 175 | 160 |
| Total | 1334 | 726 | 608 |
| Level 1 Segmentation Evaluation | Level 2 Post-Processing Evaluation | Level 3 Measurement Evaluation | |
|---|---|---|---|
| Total | Training 80% Validation 20% | Validation 100% | Validation 100% |
| Augmented | 7992 1998 | ||
| Training Set | 999 | ||
| Testing Set | 335 |
| Model Trained with Input Size | Network | Augmentation | ACC | mIoU | Pre | Recall | DSC | AUC | MSE | mPA | Time (min) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 128 × 128 | UNet | No | 0.9855 | 0.9667 | 0.9780 | 0.9740 | 0.9854 | 0.9820 | 0.014 | 0.9711 | 0:11:02 |
| UNet_plus | 0.9852 | 0.9662 | 0.9710 | 0.9815 | 0.9851 | 0.9842 | 0.014 | 0.9665 | 0:10:43 | ||
| Att_UNet | 0.9862 | 0.9680 | 0.9769 | 0.9787 | 0.9862 | 0.9841 | 0.013 | 0.9721 | 0:11:35 | ||
| UNet 3+ | 0.9856 | 0.9671 | 0.9770 | 0.9766 | 0.9856 | 0.9830 | 0.014 | 0.9693 | 0:25:20 | ||
| TransUNet | 0.9852 | 0.9662 | 0.9783 | 0.974 | 0.9852 | 0.9821 | 0.014 | 0.9756 | 0:12:08 | ||
| FPN | 0.9866 | 0.9693 | 0.9790 | 0.9778 | 0.9860 | 0.9840 | 0.013 | 0.9730 | 0:13:29 | ||
| LinkNet | 0.9857 | 0.9673 | 0.9770 | 0.9760 | 0.9856 | 0.9830 | 0.014 | 0.9692 | 0:12:14 | ||
| Deeplabv3 | 0.9852 | 0.9660 | 0.9791 | 0.9727 | 0.9845 | 0.9817 | 0.014 | 0.9763 | 0:11:04 | ||
| 64 × 64 | UNet | Yes | 0.9917 | 0.9810 | 0.9870 | 0.9859 | 0.9916 | 0.9900 | 0.008 | 0.9870 | 0:39:00 |
| UNet_plus | 0.9898 | 0.9767 | 0.9843 | 0.9833 | 0.9896 | 0.9880 | 0.010 | 0.9815 | 0:38:18 | ||
| Att_UNet | 0.9919 | 0.9815 | 0.9881 | 0.9863 | 0.9919 | 0.9900 | 0.008 | 0.9875 | 0:40:38 | ||
| UNet 3+ | 0.9920 | 0.9816 | 0.9883 | 0.9862 | 0.9919 | 0.9904 | 0.007 | 0.9892 | 1:16:44 | ||
| TransUNet | 0.9913 | 0.9802 | 0.9873 | 0.9851 | 0.9912 | 0.9896 | 0.008 | 0.9873 | 0:44:44 | ||
| FPN | 0.9926 | 0.9831 | 0.9887 | 0.9878 | 0.9925 | 0.9913 | 0.007 | 0.9886 | 0:48:51 | ||
| LinkNet | 0.9912 | 0.9800 | 0.9868 | 0.9854 | 0.9911 | 0.9896 | 0.008 | 0.9860 | 0:46:13 | ||
| Deeplabv3 | 0.9908 | 0.9790 | 0.9869 | 0.9838 | 0.9903 | 0.9889 | 0.009 | 0.9842 | 1:07:17 | ||
| ETLM | 0.9928 | 0.9841 | 0.9892 | 0.9881 | 0.9934 | 0.9918 | 0.008 | 0.9904 | NA | ||
| 128 × 128 | UNet | Yes | 0.9928 | 0.9820 | 0.9888 | 0.9886 | 0.9928 | 0.9917 | 0.007 | 0.9898 | 0:37:15 |
| UNet_plus | 0.9923 | 0.9807 | 0.9879 | 0.9879 | 0.9922 | 0.9911 | 0.007 | 0.9877 | 0:35:10 | ||
| Att_UNet | 0.9928 | 0.9819 | 0.9887 | 0.9885 | 0.9927 | 0.9916 | 0.007 | 0.9891 | 0:38:59 | ||
| UNet 3+ | 0.9933 | 0.9832 | 0.9900 | 0.9890 | 0.9933 | 0.9921 | 0.006 | 0.9908 | 1:40:12 | ||
| TransUNet | 0.9928 | 0.9819 | 0.9890 | 0.9884 | 0.9927 | 0.9916 | 0.007 | 0.9892 | 0:38:29 | ||
| FPN | 0.9939 | 0.9846 | 0.9908 | 0.9899 | 0.9938 | 0.9928 | 0.006 | 0.9905 | 0:42:47 | ||
| LinkNet | 0.9927 | 0.9817 | 0.9892 | 0.9879 | 0.9926 | 0.9914 | 0.007 | 0.9886 | 0:36:30 | ||
| Deeplabv3 | 0.9926 | 0.9828 | 0.9886 | 0.9878 | 0.9923 | 0.9913 | 0.007 | 0.9884 | 0:43:11 | ||
| ETLM | 0.9942 | 0.9853 | 0.9913 | 0.9903 | 0.9908 | 0.99316 | 0.005 | 0.9914 | NA |
| Model Trained with Input Size | Network | Original Training Images | mHD (mm) | MSD (mm) | RVD | MSSIM | PSNR |
|---|---|---|---|---|---|---|---|
| 64 × 64 | ETLM | Yes | 0.927634 | 0.0034989 | −0.00387 | 0.98108–0.98255 | 25.142206 |
| FPN | 1.186636 | 0.0049680 | −0.01237 | 0.97322–0.97544 | 23.47897 | ||
| UNet | 1.118771 | 0.0048532 | −0.01213 | 0.97352–0.9757270 | 23.5358 | ||
| Att_UNet | 1.512662 | 0.0049149 | −0.01222 | 0.973301–0.9755263 | 23.505971 | ||
| Trans_UNet | 1.118771 | 0.0049047 | −0.01208 | 0.97344304–0.97563850 | 23.50993 | ||
| 128 × 128 | ETLM | Yes | 0.753095 | 0.0018117 | 0.001639 | 0.989922–0.990706 | 28.247806 |
| FPN | 0.625412 | 0.0020034 | −0.00264 | 0.9888480–0.9896689 | 27.536022 | ||
| UNet | 1.250824 | 0.0020566 | −0.00196 | 0.98856–0.989421 | 27.484995 | ||
| Att_UNet | 0.988862 | 0.0020950 | −0.00177 | 0.988375–0.989247 | 27.41142 | ||
| Trans_UNet | 0.753095 | 0.0020579 | −0.00243 | 0.988523–0.98937365 | 27.43699 |
| Model Trained with Input Size | Network | Original Testing Images | mHD (mm) | MAD (mm) | DCS |
|---|---|---|---|---|---|
| 128 × 128 | ETLM | Yes | 1.6715 | 1.8735 | 0.9716 |
| Type of Comparison | Segmentation | Measurement | Model Weight | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Network | ACC | mIoU | Pre | mPA | DSC | MAD | mHD | Model Trained with Input Size | Bach Size | GPU RAM | Epochs | Training Time |
| ETLM [UNet: Att_UNet: FPN] [0.3: 0.3: 0.4] | 0.9942 | 0.9853 | 0.9913 | 0.9914 | 0.9716 | 1.87 | 1.67 | 128 × 128 | 32 | 11 GB | 300 | 2:01 h |
| VNet-c [43] | 0.9888 | 0.9594 | 0.9767 | NA | 0.9791 | 1.89 | NA | 512 × 512 | 4 | 6 GB | 300 | 53:35 h |
| VSAL [42] | NA | NA | N/A | 0.990 | 0.9710 | NA | 3.234 | 256 × 256 | 4 | 24 GB | 100 | 17:30 h |
| SAPNet [49] | NA | 0.9646 | NA | 0.9802 | 0.9790 | 1.81 | 1.22 | 480 × 320 | 10 | 11 GB | 700 | NA |
| Regression CNN [47] | NA | NA | NA | NA | 0.9776 | 1.90 | 1.32 | 800 × 800 | 16 | NA | 1500 | NA |
| DAG V-Net [41] | NA | NA | NA | NA | 0.9793 | 1.77 | 1.27 | 768 × 512 | 2 | 11 GB | 20 | 30 h |
| MTLN [32] | NA | NA | NA | NA | 0.9684 | 2.12 | 1.72 | 800 × 540 | NA | 11 GB | 200 | 15 h |
| UNet [36] | NA | NA | NA | NA | 0.9731 | 2.69 | NA | 216 × 320 | 4 | 32 GB | 100 | NA |
| DSCNN [40] | NA | NA | NA | NA | 0.9689 | NA | NA | NA | NA | NA | NA | NA |
| MS-LinkNet [39] | NA | NA | NA | NA | 0.9375 | 2.27 | 3.70 | NA | 10 | 11 GB | 150 | 18 h |
| Fetal GA Prediction in the 50th Percentile (13 > GA > 25) Week | EFW Prediction in the 50th Percentile (20 > GA > 36) Week | |||
|---|---|---|---|---|
| Regression model | MSE | Pearson’s r | MSE | Pearson’s r |
| Polynomial Regression | 0.00033 | 0.9958 | 9.08723 | 0.9422 |
| Linear Regression | 0.00205 | 0.9899 | 0.00035 | 0.9988 |
| Random Forest Regressor | 0.00842 | 0.9511 | 6.54380 | 0.9844 |
| XGBRFRegressor | 0.02268 | 0.9505 | 0.00018 | 0.9847 |
| Neural network | 0.01392 | 0.9805 | 0.00256 | 0.9946 |
| KNeighbors Regressor | 0.00921 | 0.9582 | 0.00214 | 0.9841 |
| SGDRegressor | 0.00219 | 0.9901 | 0.00146 | 0.9968 |
| AdaBoostRegressor | 0.01086 | 0.9505 | 0.00100 | 0.9843 |
| BaggingRegressor | 0.01081 | 0.9832 | 0.00281 | 0.9964 |
| StackingRegressor | 0.00824 | 0.9506 | 6.93890 | 0.9843 |
| LinearSVR | 0.00199 | 0.9901 | 0.00054 | 0.9989 |
| LGBMRegressor | 0.01011 | 0.9514 | 7.72867 | 0.9843 |
| Lasso | 0.08300 | NA | 0.17339 | 0.8507 |
| VotingRegressor | 0.00248 | 0.9909 | 0.00031 | 0.8507 |
| BayesianRidge | 0.00206 | 0.9899 | 0.00035 | 0.9988 |
| Deep NN | 0.00072 | 0.9978 | 0.00068 | NA |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alzubaidi, M.; Agus, M.; Shah, U.; Makhlouf, M.; Alyafei, K.; Househ, M. Ensemble Transfer Learning for Fetal Head Analysis: From Segmentation to Gestational Age and Weight Prediction. Diagnostics 2022, 12, 2229. https://0-doi-org.brum.beds.ac.uk/10.3390/diagnostics12092229
Alzubaidi M, Agus M, Shah U, Makhlouf M, Alyafei K, Househ M. Ensemble Transfer Learning for Fetal Head Analysis: From Segmentation to Gestational Age and Weight Prediction. Diagnostics. 2022; 12(9):2229. https://0-doi-org.brum.beds.ac.uk/10.3390/diagnostics12092229
Chicago/Turabian StyleAlzubaidi, Mahmood, Marco Agus, Uzair Shah, Michel Makhlouf, Khalid Alyafei, and Mowafa Househ. 2022. "Ensemble Transfer Learning for Fetal Head Analysis: From Segmentation to Gestational Age and Weight Prediction" Diagnostics 12, no. 9: 2229. https://0-doi-org.brum.beds.ac.uk/10.3390/diagnostics12092229