
AID-U-Net: An Innovative Deep Convolutional Architecture for Semantic Segmentation of Biomedical Images

 ,
,  , ,
, ,  and
and
Abstract
:1. Introduction
- Low Computational Complexity: A lower number of learnable parameters with the same number of layers as those of a conventional U-Net, resulting in a faster learning convergence.
- Dimensional Flexibility: AID-U-Net’s architecture is designed to segment target objects in both 2D and 3D, by counting for both depth and width of the input data (unlike ResNet-based networks).
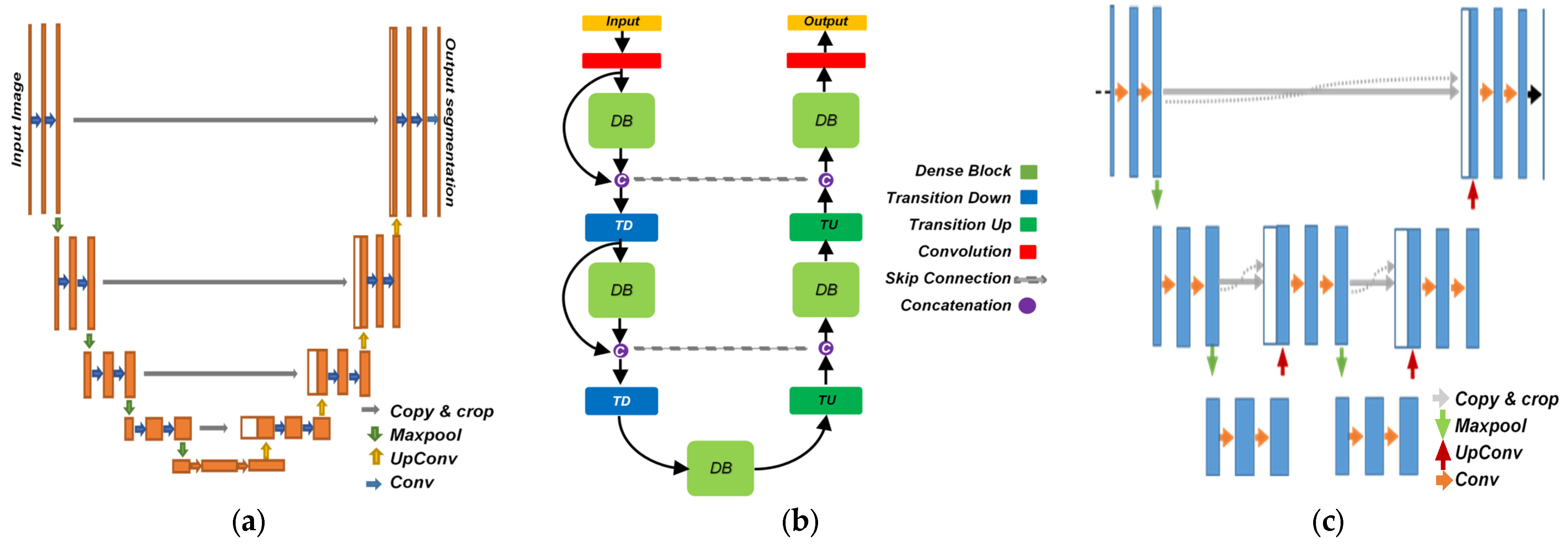
2. Literature Review
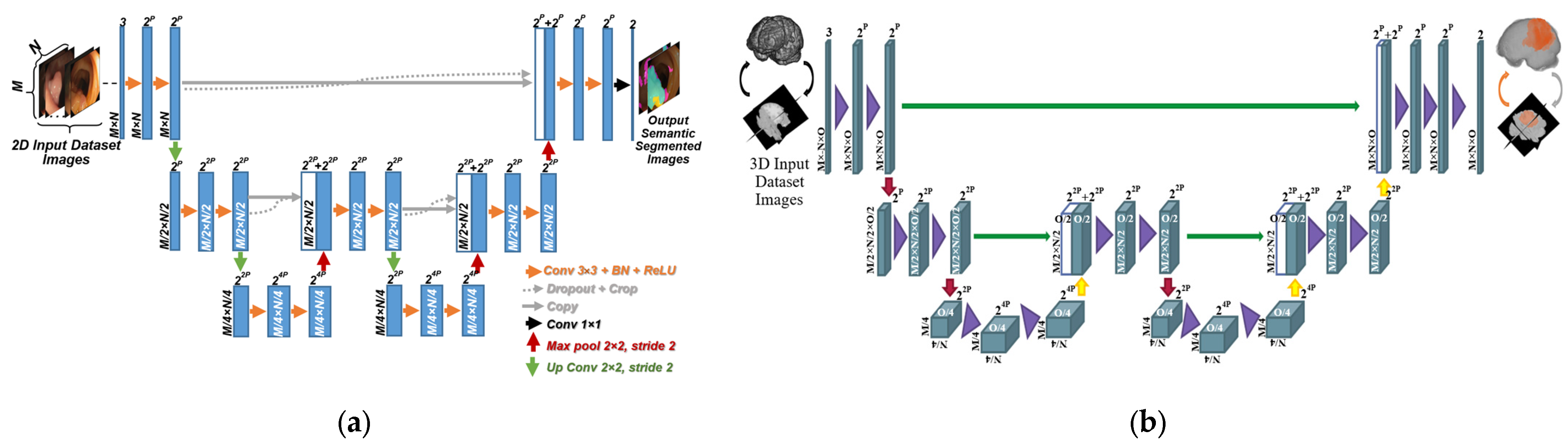
3. Methods
- Cropping procedure that makes the current CNN model applicable to different image sizes.
- Modified classification layer with generalized dice loss function to suit various types of input data and image qualities.
- Significant reduction in computational complexity in terms of the number of learnable parameters, compared to that of a U-Net with the same number of layers.
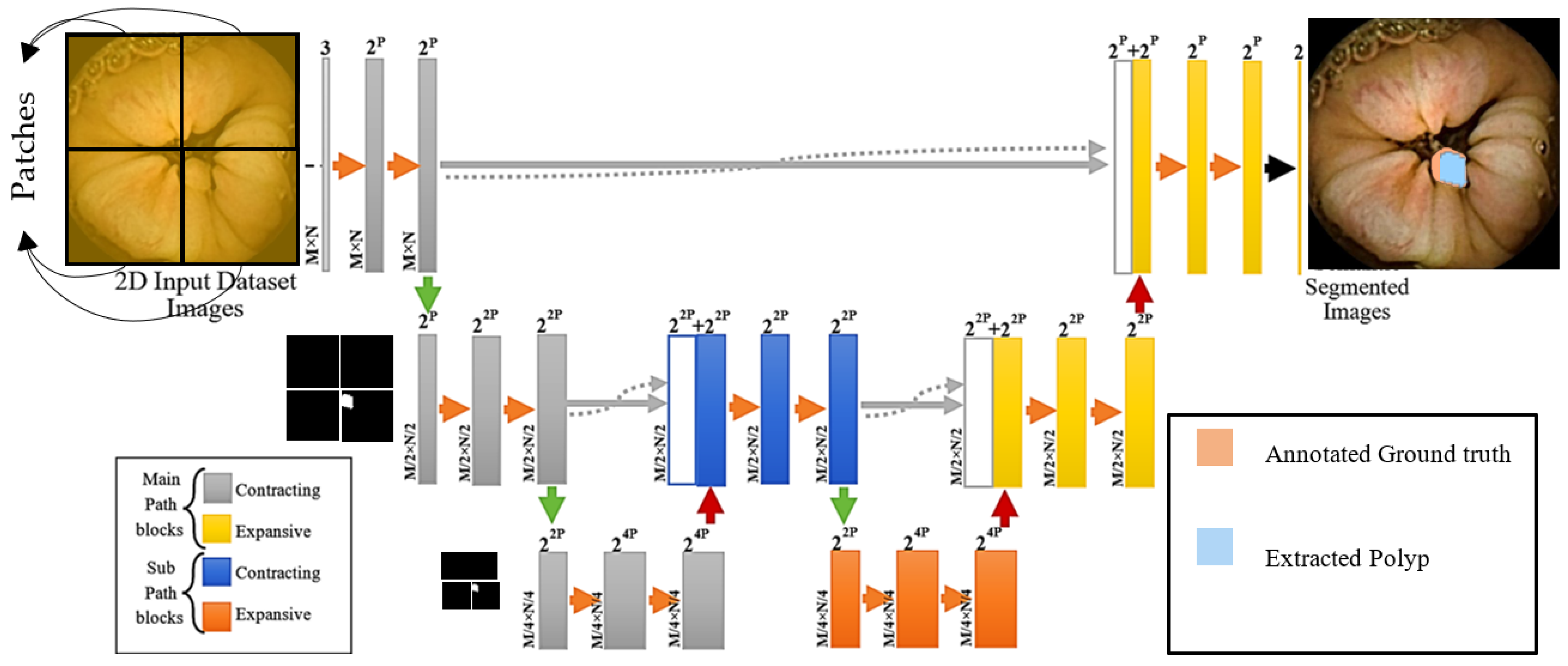
3.1. Deep Layers Combinations and Block Formation in AID-U-Net
- In Contracting path: A combination of cascaded convolution, Batch normalization, ReLU, convolution, Batch normalization, ReLU, dropout and cropping layer form a block called contracting block.
- In expansive path: A combination of cascaded concatenation, Batch normalization, ReLU, convolution, Batch normalization, ReLU and dropout layers form another block called expansive block.
3.1.1. Pre-Processing
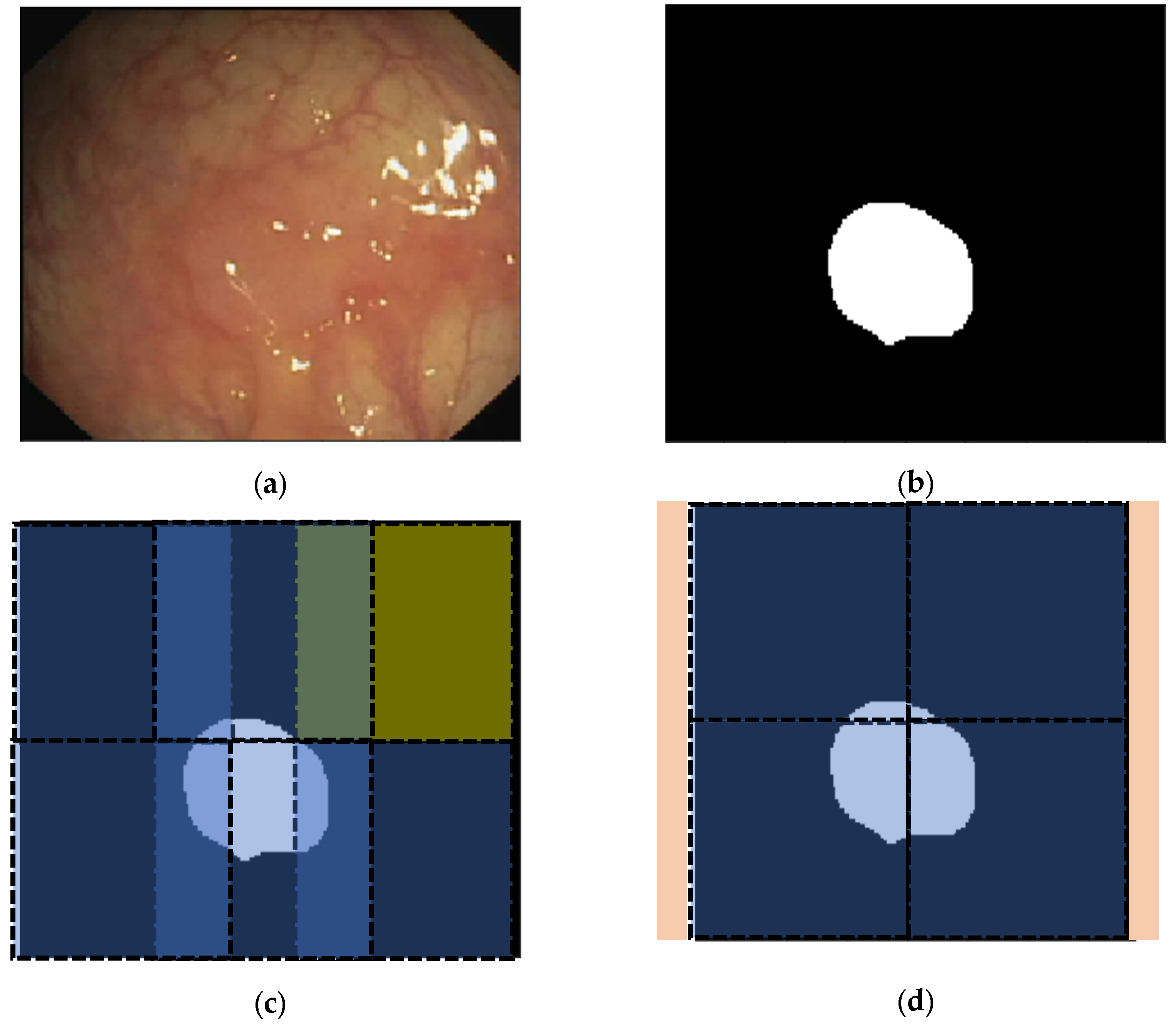
3.1.2. Cropping Procedure
3.2. Functionality of Downsampling (Contracting) and Upsampling (Expansive) Blocks
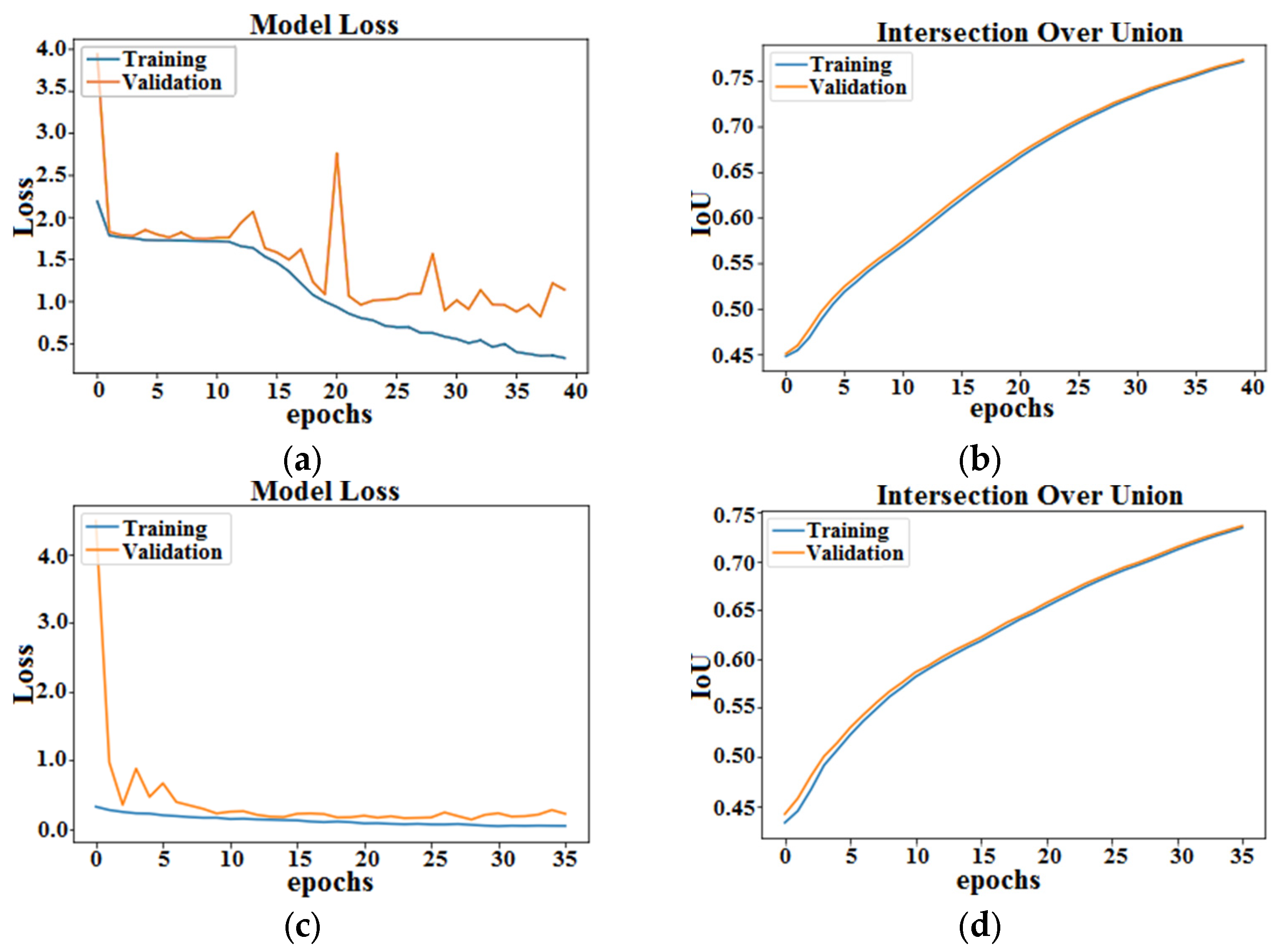
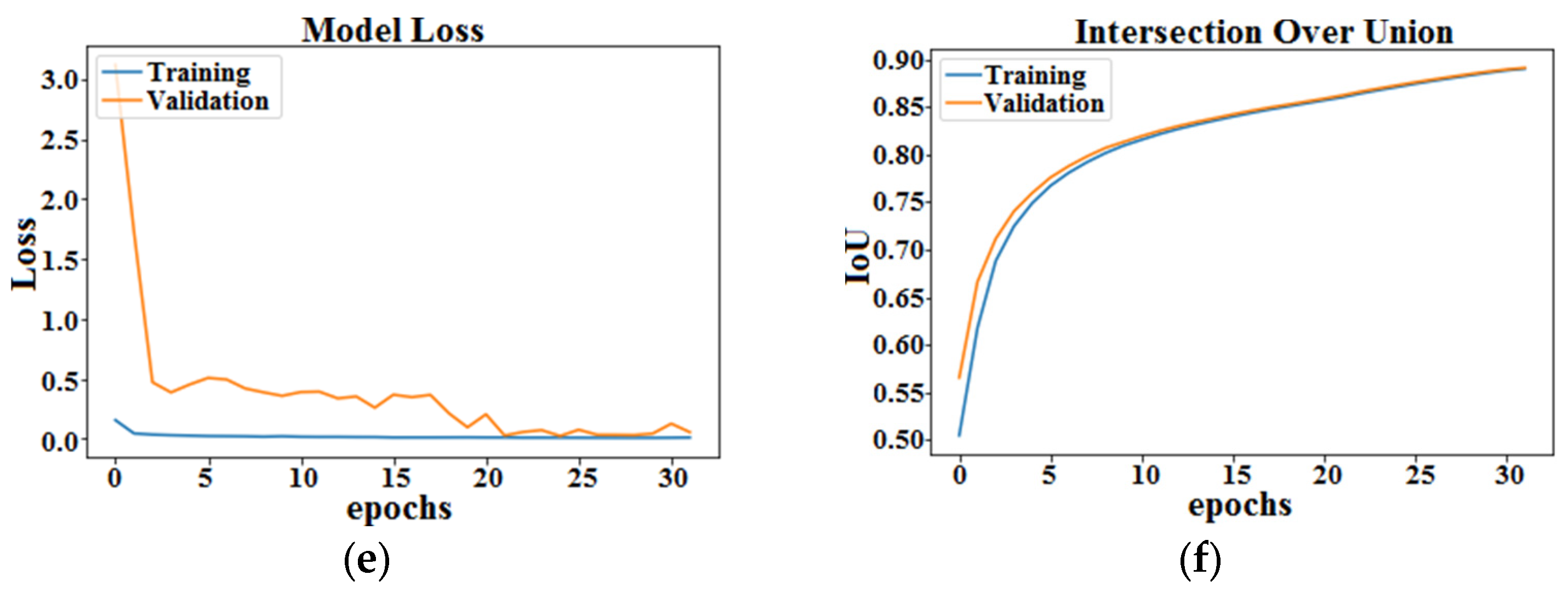
4. Implementation and Results
4.1. Datasets
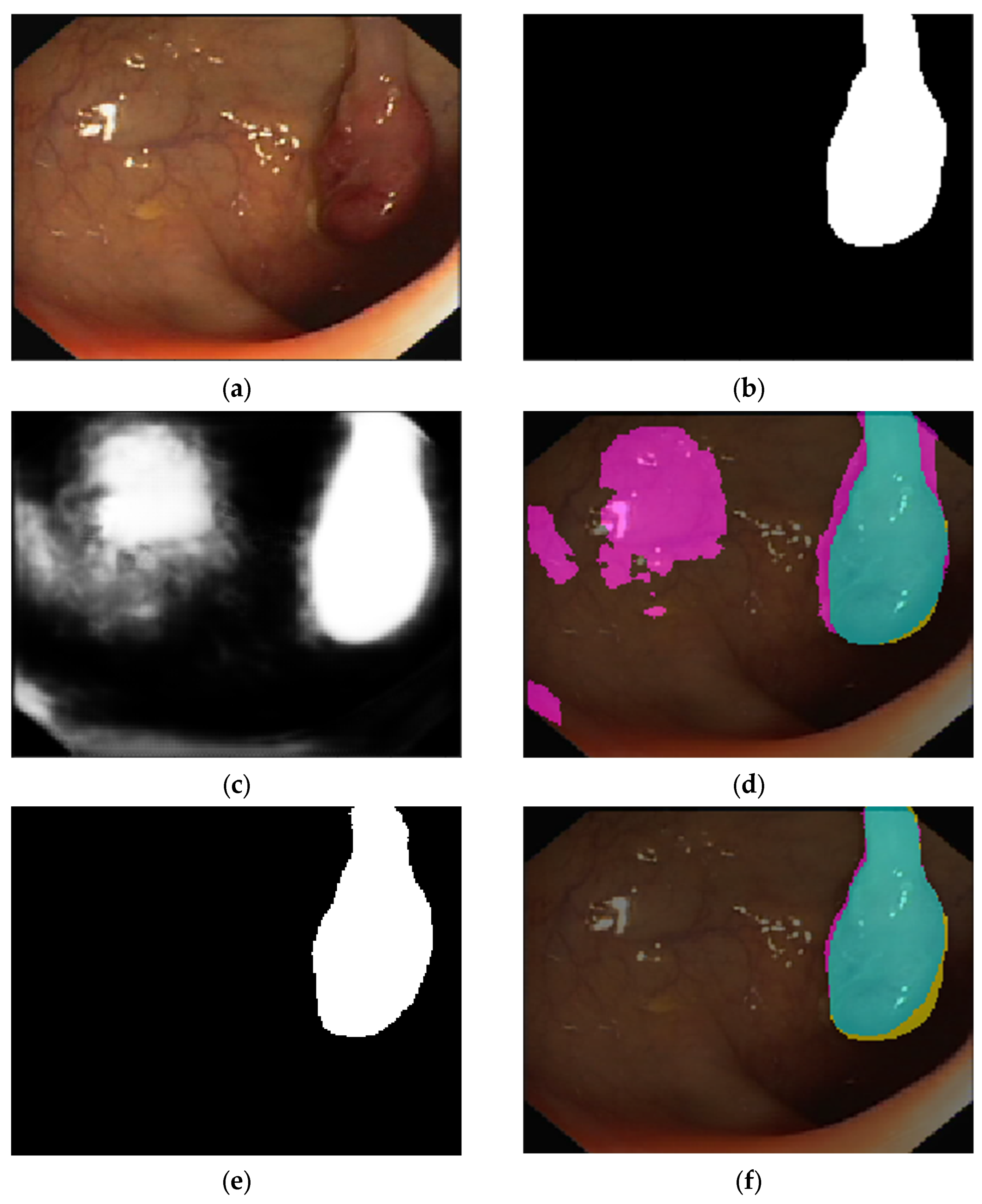
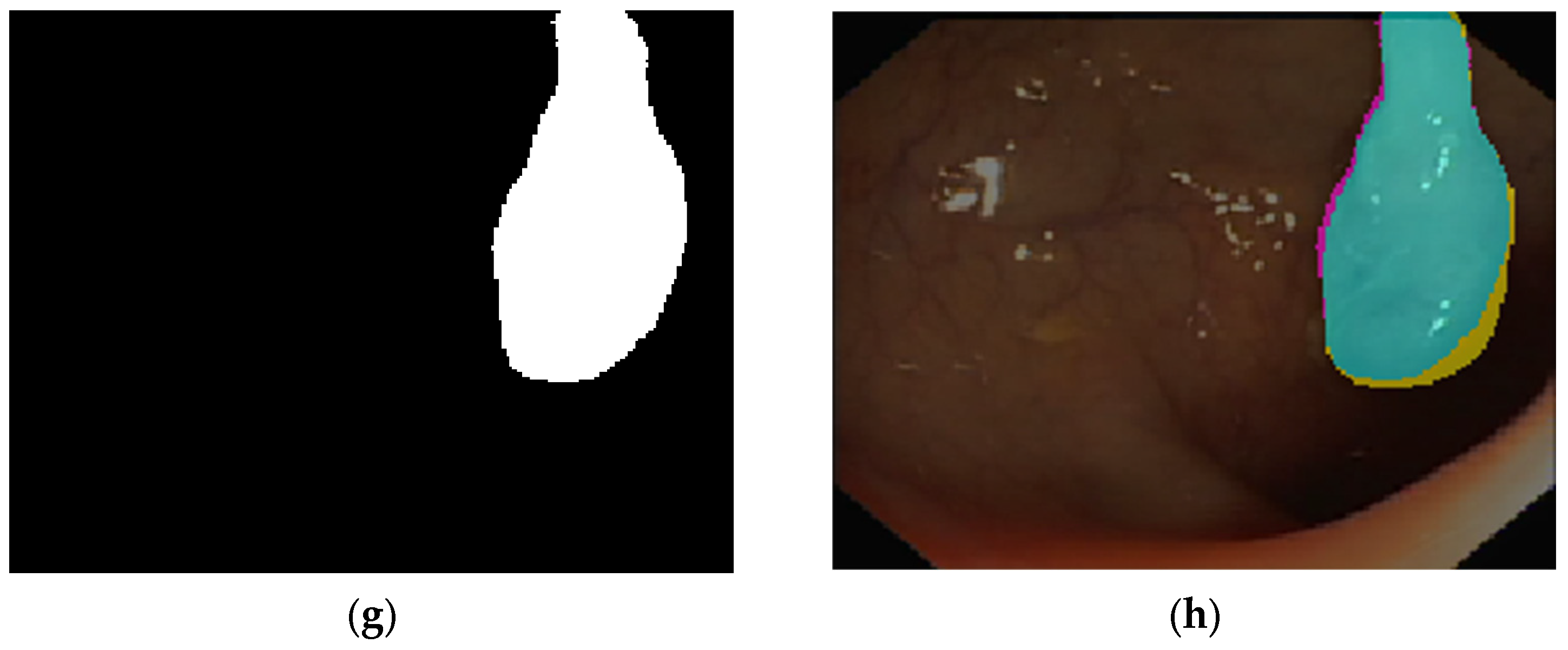
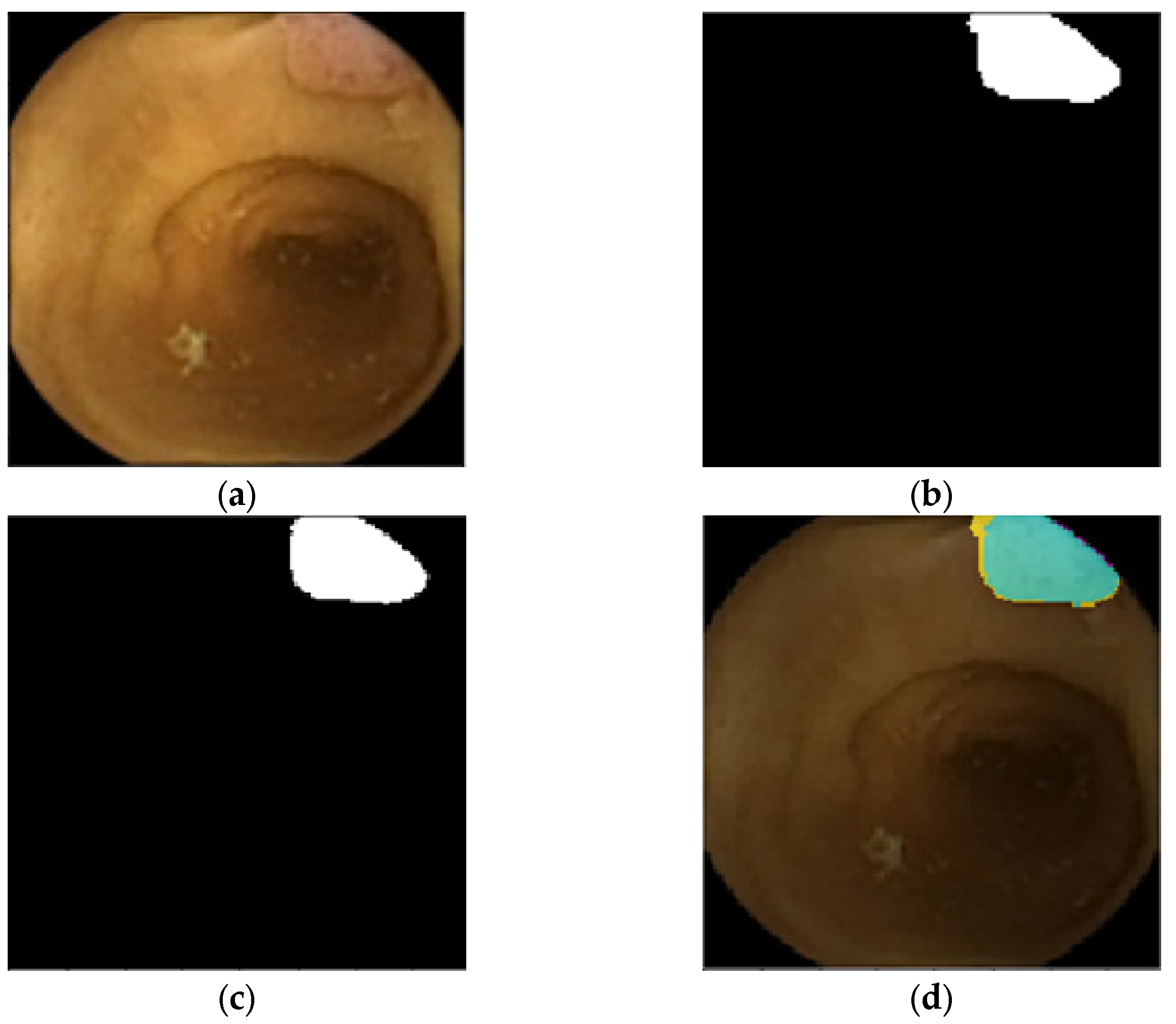
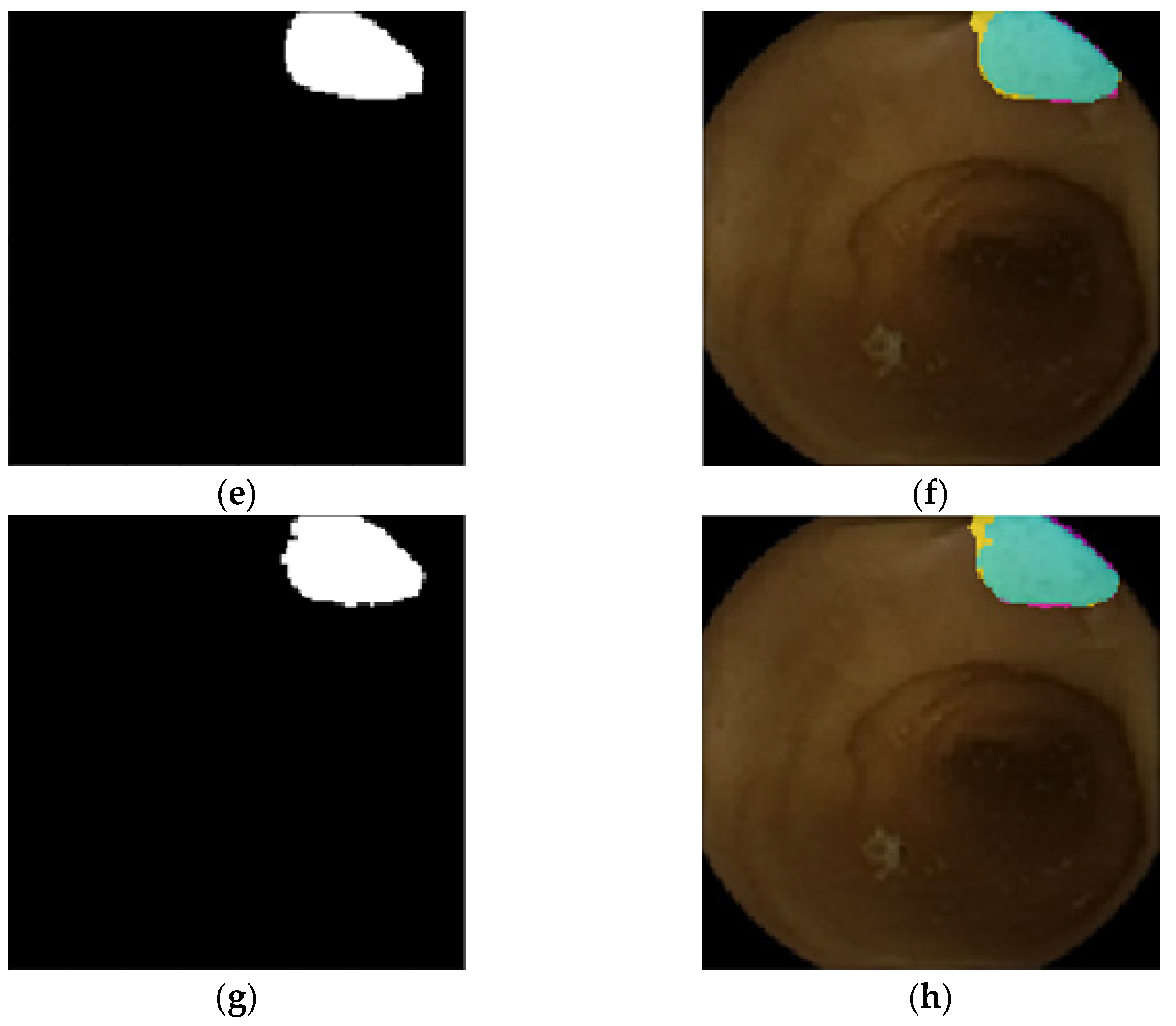
4.2. 2D Optical Colonoscopy Images
4.3. 2D Colon Capsule Endoscopy (CCE) Images
4.4. 2D Microscopic Images
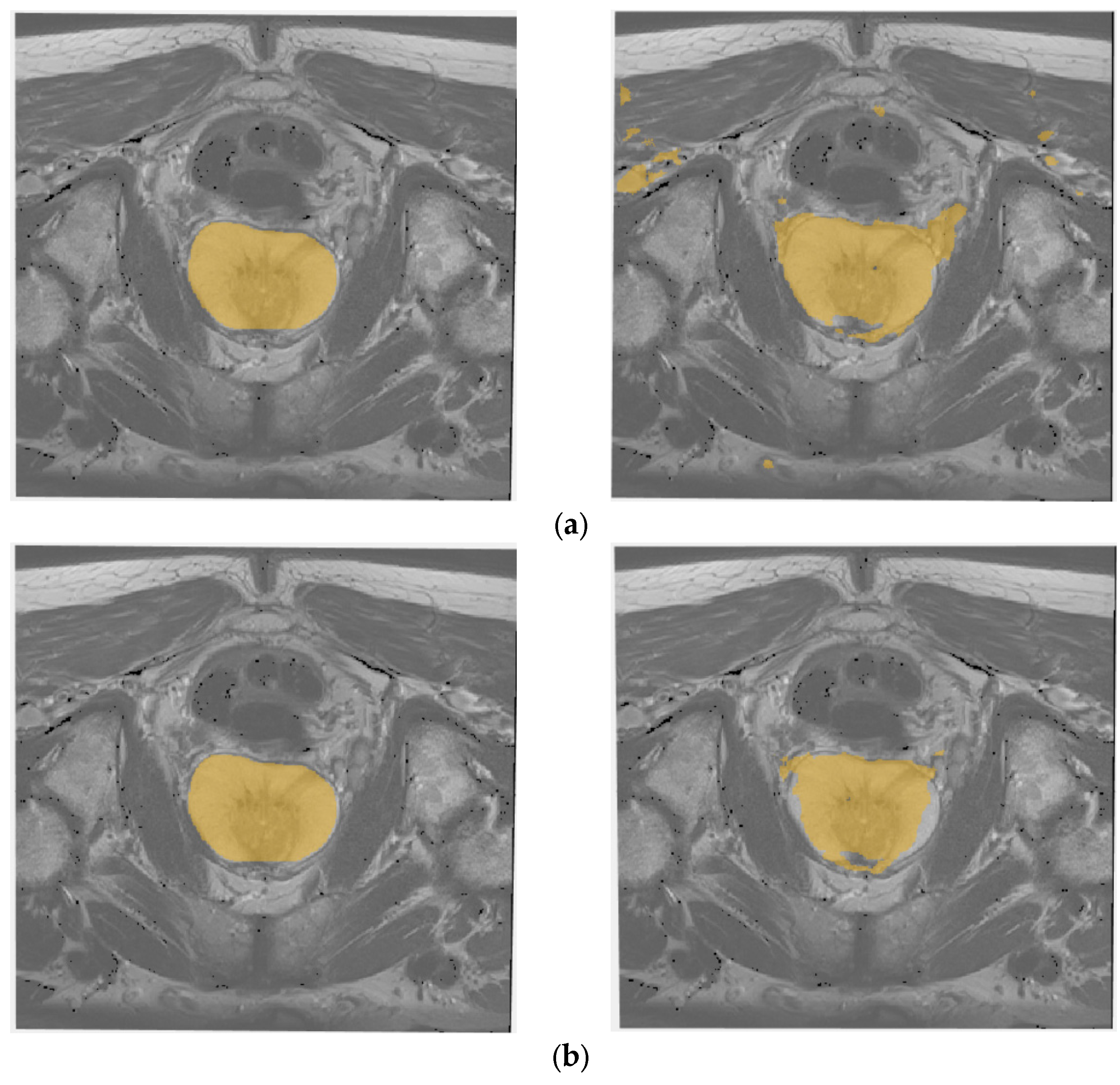
4.5. 3D Brain and Prostate Images
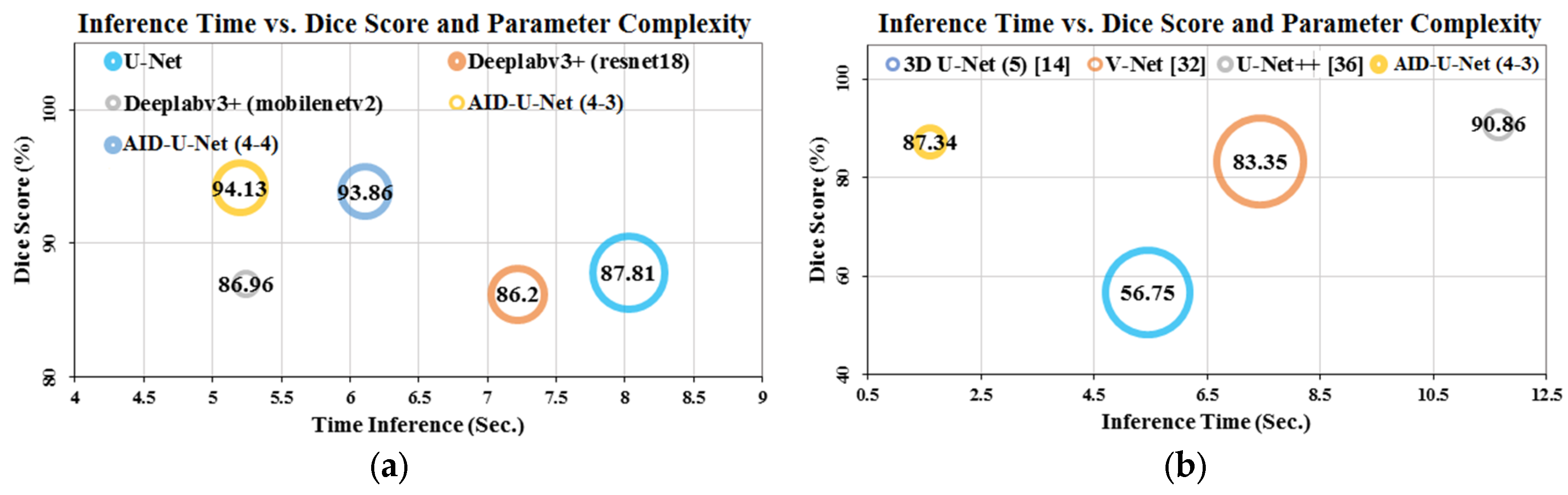
4.6. Time Inference vs. Performance and Computational Complexity
5. Discussion and Conclusions
5.1. Discussion
- The architecture provides a flexible deep neural network with lower computational complexity compared to the-state-of-the-art U-Nets.
- AID-U-Net can increase the accuracy of semantic segmentation of small and scattered target objects by deploying different lengths for the direct and sub-paths of this model.
- First, the efficient combination of lengths for direct and sub-paths is not studied yet. As shown in [45], it is possible to embed pre-trained neural networks with specific lengths into the AID-U-Net. However, the lengths of direct and sub-paths for AID-U-Net architecture should be pre-defined, so that it could accept the pre-trained deep neural networks as its backbone.
- Acceptable range of the lengths for sub-paths has a maximum value K, limiting its functionality.
5.2. Conclusions and Future Work
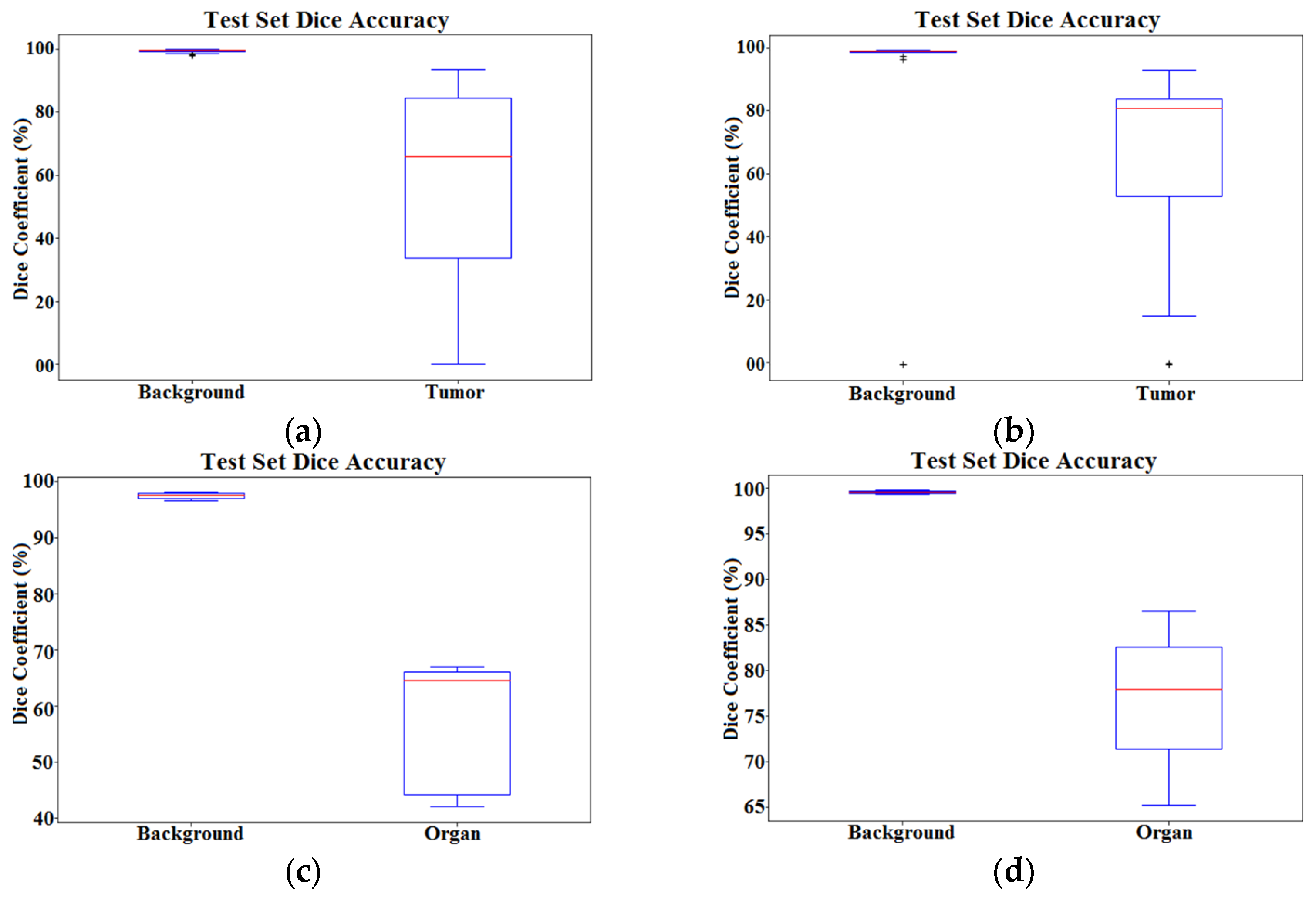
- Our proposed AID-U-Net model with two specific depth configurations for direct and sub-paths as (3, 1) and (2, 2), presented an average F1-Score increment of 3.82% for all 2D test data compared to that of a conventional U-Net and U-Net++.
- Similarly, regarding the mean BF-Score, we observed an improvement of 2.99% for all 3D test data compared to that of V-Net and 3D U-Net.
- The computational complexity of the proposed AID-U-Net model was significantly lower than the other competitive U-Nets, since the presence of sub-paths combined with the direct paths improves the low-scale object detection ability of the network and reduces the number of learnable parameters with the same number of layers in a conventional U-Net.
Author Contributions
Funding

Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhao, Z.; Zheng, P.; Xu, S.; Wu, X. Object Detection with Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Blanes-Vidal, V.; Baatrup, G.; Nadimi, E.S. Addressing priority challenges in the Detection and Assessment of Colorectal Polyps from Capsule endoscopy and Colonoscopy in Colorectal Cancer Screening using Machine Learning. Acta Oncol. 2019, 58, 29–36. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 27th IEEE Conference on Computer Vision and Pattern Recognition (CVPR2014), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Nadimi, E.S.; Buijs, M.; Herp, J.; Krøijer, R.; Kobaek-Larsen, M.; Nielsen, E.; Pedersen, C.D.; Blanes-Vidal, V.; Baatrup, G. Application of Deep Learning for Autonomous Detection and Localization of Colorectal Polyps in Wireless Colon Capsule Endoscopy. J. Comput. Electr. Eng. 2020, 81, 106531. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In Computer Vision and Pattern Recognition (ECCV2016); Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; Volume 9908. [Google Scholar]
- Iandola, F.; Moskewicz, M.; Karayev, S.; Girshick, R.; Darrell, T.; Keutzer, K. DenseNet: Implementing Efficient ConvNet Descriptor Pyramids. arXiv 2014, arXiv:1404.1869. [Google Scholar]
- Song, Y.; Rana, M.N.; Qu, J.; Liu, C. A Survey of Deep Learning Based Methods in Medical Image Processing. Curr. Signal Transduct. Ther. 2021, 16, 101–114. [Google Scholar] [CrossRef]
- Papandreou, G.; Chen, L.C.; Murphy, K.P.; Yuille, A.L. Weakly-and Semi-Supervised Learning of a Deep Convolutional Network for Semantic Image Segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 15), Washington, DC, USA, 7–13 December 2015; pp. 1742–1750. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 2015), Washington, DC, USA, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the 28 th International Conference on Neural Information Processing Systems, Cambridge, MA, USA, 7–12 December 2015. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the 14th European Conference on Computer Vision (ECCV2016), Amsterdam, The Netherlands, 21–37 October 2016. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition (CVPR2016), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef] [Green Version]
- Li, Q.; Yang, G.; Chen, Z.; Huang, B.; Chen, L.; Xu, D.; Zhou, X.; Zhong, S.; Zhang, H.; Wang, T. Colorectal Polyp Segmentation Using A Fully Convolutional Neural Network. In Proceedings of the 10th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI2017), Shanghai, China, 14–16 October 2017. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. Neural Inf. Process. Syst. 2016, 29, 379–387. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV2015), Washington, DC, USA, 7–13 December 2015. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation; Springer: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Sun, F.; Yang, G.; Zhang, A.; Zhang, Y. Circle-U-Net: An Efficient Architecture for Semantic Segmentation. Algorithms 2021, 14, 159. [Google Scholar] [CrossRef]
- Sahafi, A.; Wang, Y.; Rasmussen, C.L.M.; Bollen, P.; Baatrup, G.; Blanes-Vidal, V.; Herp, J.; Nadimi, E.S. Edge artificial intelligence wireless video capsule endoscopy. Sci. Rep. 2022, 12, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Jégou, S.; Drozdzal, M.; Vazquez, D.; Romero, A.; Bengio, Y. The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1175–1183. [Google Scholar]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, H.; Zhang, J.; Huang, K.; Liang, K.; Yu, Y. FastFCN: Rethinking Dilated Convolution in the Backbone for Semantic Segmentation. arXiv 2019, arXiv:1903.11816. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 4th International Conference on 3D Vision (3DV2016), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Xia, X.; Kulis, B. W-Net: A Deep Model for Fully Unsupervised Image Segmentation. arXiv 2017, arXiv:1711.08506. [Google Scholar]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef] [Green Version]
- Isensee, F.; Jaeger, P.F.; Kohl, S.A.; Petersen, J.; Maier-Hein, K.H. nnU-Net: A self-configuring method for deep learning-based biomedical image segmentation. Nat Methods 2021, 18, 203–211. [Google Scholar] [CrossRef] [PubMed]
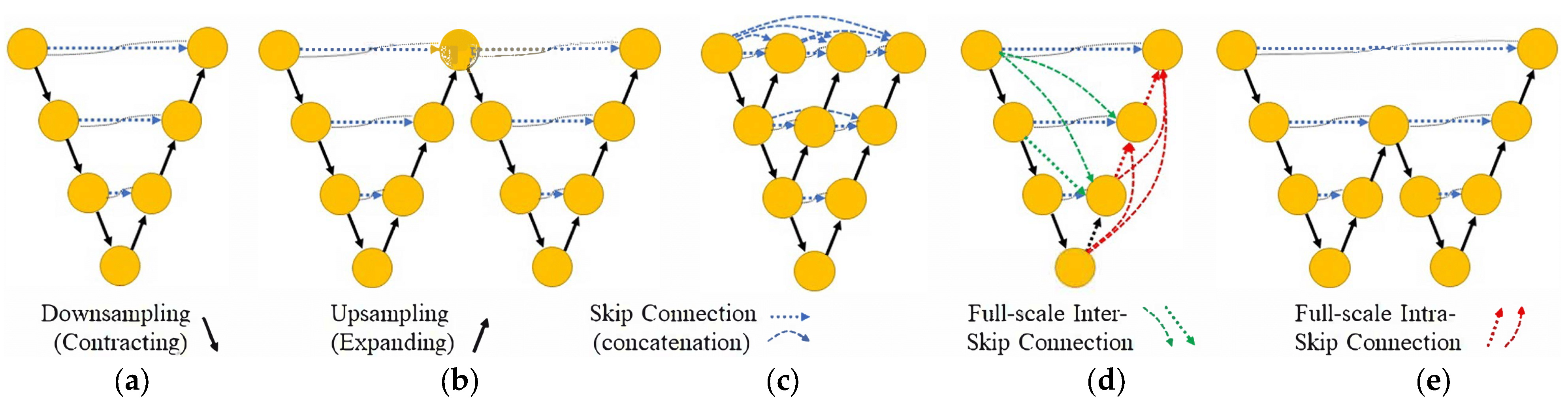
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2018; Volume 11045. [Google Scholar]
- Jiang, Y.; Wang, M.; Xu, H. A Survey for Region-Based Level Set Image Segmentation. In Proceedings of the 2012 11th International Symposium on Distributed Computing and Applications to Business, Engineering & Science, Guilin, China, 19–22 October 2012; pp. 413–416. [Google Scholar]
- Benboudjema, D.; Pieczynski, W. Unsupervised Statistical Segmentation of Nonstationary Images Using Triplet Markov Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1367–1378. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kornilov, A.S.; Safonov, I.V. An Overview of Watershed Algorithm Implementations in Open Source Libraries. J. Imaging 2018, 4, 123. [Google Scholar] [CrossRef] [Green Version]
- Wang, G.; Li, W.; Zuluaga, M.A.; Pratt, R.; Patel, P.A.; Aertsen, M.; Doel, T.; David, A.L.; Deprest, J.; Ourselin, S.; et al. Interactive Medical Image Segmentation Using Deep Learning with Image-Specific Fine Tuning. IEEE Trans. Med. Imaging 2018, 37, 1562–1573. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation. IEEE Trans. Med. Imaging 2020, 39, 1856–1867. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.W.; Wu, J. UNet 3+: A Full-Scale Connected UNet for Medical Image Segmentation. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 1055–1059. [Google Scholar] [CrossRef]
- Gadosey, P.K.; Li, Y.; Agyekum, E.A.; Zhang, T.; Liu, Z.; Yamak, P.T.; Essaf, F. SD-UNet: Stripping down U-Net for Segmentation of Biomedical Images on Platforms with Low Computational Budgets. Diagnostics 2020, 10, 110. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Liu, Y.; Georgiou, T. A review of semantic segmentation using deep neural networks. Int. J. Multimed. Inf. Retr. 2018, 7, 87–93. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV2018), Munich, Germany, 8–14 September 2018. [Google Scholar] [CrossRef]
- CVC-ClinicDB. Available online: https://polyp.grand-challenge.org/CVCClinicDB/ (accessed on 22 September 2022).
- CVC-ColonDB. Available online: http://mv.cvc.uab.es/projects/colon-qa/cvccolondb/ (accessed on 22 September 2022).
- EtisLarib. Available online: https://polyp.grand-challenge.org/EtisLarib/ (accessed on 22 September 2022).
- Cell Tracking Challenge 2D Datasets. Available online: http://celltrackingchallenge.net/datasets/ (accessed on 22 September 2022).
- Isensee, F.; Kickingereder, P.; Wick, W.; Bendszus, M.; Maier-Hein, K.H. Brain Tumor Segmentation and Radiomics Survival Prediction: Contribution to the BRATS 2017 Challenge. In Proceedings of the BrainLes: International MICCAI Brainlesion Workshop, Quebec City, QC, Canada, 14 September 2017; pp. 287–297. [Google Scholar]
- Tang, Y.; Yang, D.; Li, W.; Roth, H.R.; Landman, B.; Xu, D.; Hatamizadeh, A. Self-Supervised Pre-Training of Swin Transformers for 3D Medical Image Analysis. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–20 June 2022; pp. 20698–20708. [Google Scholar]
- Tashk, A.; Şahin, K.E.; Herp, J.; Nadimi, E.S. A CNN Architecture for Detection and Segmentation of Colorectal Polyps from CCE Images. In Proceedings of the 5th International Image Processing Applications and Systems 2022 (IPAS’22), Geneva, Italy, 5–7 December 2022. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Semantic Segmentation Methods | Method’s Descriptions | Strengths | Limitations |
|---|---|---|---|
| U-Net [19] | FC layer modification |
|
|
| Circle-U-Net [20] | Circle-connectlayers, as the backbone of ResUNet-a architecture |
|
|
| Fully Convolutional DenseNet [22] | Feed-forward FCN with 2 Transitions Down (TD) and 2 Transitions Up (TU) |
|
|
| DeepLabv3+ [23] | Convolutions with upsampling filters, Atrous Convolution, and CRFs |
|
|
| FastFCN [24] | Joint Pyramid Upsampling (JPU). |
|
|
| W-Net [26] | A Deep Model for Fully Unsupervised Image Segmentation. |
|
|
| U-Net++ [34] | An efficient ensemble of U-Nets of varying depths with redesigning with Nested and dense skip connection. |
|
|
| U-Net3+ [35] | A full-scale connected U-Net with full-scale skip connections |
|
|
| SD-UNet [36] | Stripping down U-Net for segmentation of Biomedical Images. |
|
|
| Dataset | No. of Images | Input Size | Modality | Provider |
|---|---|---|---|---|
| CCE | 4144 | 512 × 512 | RGB Images | [4] |
| CVC-ClinicDB | 612 | 288 × 384 | RGB Images | [39] |
| CVC-ColonDB | 379 | 574 × 500 | RGB Images | [40] |
| CVC-ETIS-Larib | 196 | 966 × 1225 | RGB Images | [41] |
| G-A cells | 230 | 696 × 520 | Gray-level images | [42] |
| Brain Tumor | 484 | M × N × P | CT-Scan Voxels | [43] |
| Prostate Cancer | 484 | M × N × P | CT-Scan Voxels | [44] |
| Evaluation Metrics | U-Net++ | U-Net (4) | AID-U-Net (3, 1) | AID-U-Net (2, 2) |
|---|---|---|---|---|
| F1-Score (%) (↑) | 90.32 | 73.68 | 91.00 | 74.08 |
| IoU (%) (↑) | 82.34 | 58.33 | 83.49 | 58.83 |
| Learnable Param.s 1(↓) | 9.0 M | 4.0 M | 3.4 M | 924 K |
| Evaluation Metrics | U-Net++ | U-Net (4) | AID-U-Net (3, 1) | AID-U-Net (2, 2) |
|---|---|---|---|---|
| F1-Score (%) (↑) | 87.64 | 81.19 | 86.82 | 88.12 |
| IoU (%) (↑) | 78.00 | 68.34 | 76.71 | 78.76 |
| Learnable Param.s 1(↓) | 9.0 M | 4.0 M | 3.4 M | 924 K |
| Evaluation Metrics | U-Net++ | U-Net (4) | AID-U-Net (3, 1) | AID-U-Net (2, 2) |
|---|---|---|---|---|
| F1-Score (%) (↑) | 94.36 | 93.22 | 95.66 | 98.18 |
| IoU (%) (↑) | 89.32 | 87.30 | 91.68 | 96.43 |
| Learnable Param.s 1(↓) | 9.0 M | 4.0 M | 3.4 M | 924 K |
| Network-Related Parameters | U-Net | AID-U-Net(3, 1) | AID-U-Net(2, 2) |
|---|---|---|---|
| Direct contract Depth | 4 | 3 | 2 |
| Downsampling Coeff. | 5 | 5 | 5 |
| Sub-contract Depth | N/A | 1 | 1 |
| Total No. Layers | 69 | 69 | 69 |
| Learnable parameters 1 | 22.4 M | 9.7 M | 3.1 M |
| 3D Network | Global Accuracy (%) | Mean Accuracy (%) | Mean IoU (%) | Weighted IoU (%) | Mean BF Score (%) |
|---|---|---|---|---|---|
| U-Net (3) | 99.4 | 84.34 | 83.92 | 98.81 | 77.51 |
| AID-U-Net (2, 1) | 99.67 | 92.83 | 91.35 | 99.35 | 89.19 |
| 3D Network | Global Accuracy (%) | Mean Accuracy (%) | Mean IoU (%) | Weighted IoU (%) | Mean BF Score (%) |
|---|---|---|---|---|---|
| U-Net (3) | 98.1 | 61.08 | 59.98 | 96.26 | 80.24 |
| AID-U-Net (2, 1) | 98.99 | 93.54 | 83.23 | 98.21 | 93.27 |
| 3D Network | No. Layers | No. Learnable Parameters (↓) | Global Acc. (%) (↑) | Mean Acc. (%) (↑) | Mean IoU (%) (↑) | Weighted IoU (%) (↑) | Mean BF Score (%) (↑) |
|---|---|---|---|---|---|---|---|
| U-Net (5) | 85 | 77.2 M | 98.1 | 98.24 | 68.74 | 40.19 | 56.57 |
| V-Net (5) | 116 | 80.8 M | 99.62 | 87.04 | 85.54 | 71.81 | 83.35 |
| AID-U-Net (3, 2) | 85 | 10.9 M | 98.84 | 96.37 | 88.15 | 78.43 | 87.34 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tashk, A.; Herp, J.; Bjørsum-Meyer, T.; Koulaouzidis, A.; Nadimi, E.S. AID-U-Net: An Innovative Deep Convolutional Architecture for Semantic Segmentation of Biomedical Images. Diagnostics 2022, 12, 2952. https://0-doi-org.brum.beds.ac.uk/10.3390/diagnostics12122952
Tashk A, Herp J, Bjørsum-Meyer T, Koulaouzidis A, Nadimi ES. AID-U-Net: An Innovative Deep Convolutional Architecture for Semantic Segmentation of Biomedical Images. Diagnostics. 2022; 12(12):2952. https://0-doi-org.brum.beds.ac.uk/10.3390/diagnostics12122952
Chicago/Turabian StyleTashk, Ashkan, Jürgen Herp, Thomas Bjørsum-Meyer, Anastasios Koulaouzidis, and Esmaeil S. Nadimi. 2022. "AID-U-Net: An Innovative Deep Convolutional Architecture for Semantic Segmentation of Biomedical Images" Diagnostics 12, no. 12: 2952. https://0-doi-org.brum.beds.ac.uk/10.3390/diagnostics12122952