
A Comparison of Classification Methods for Telediagnosis of Parkinson’s Disease


Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset
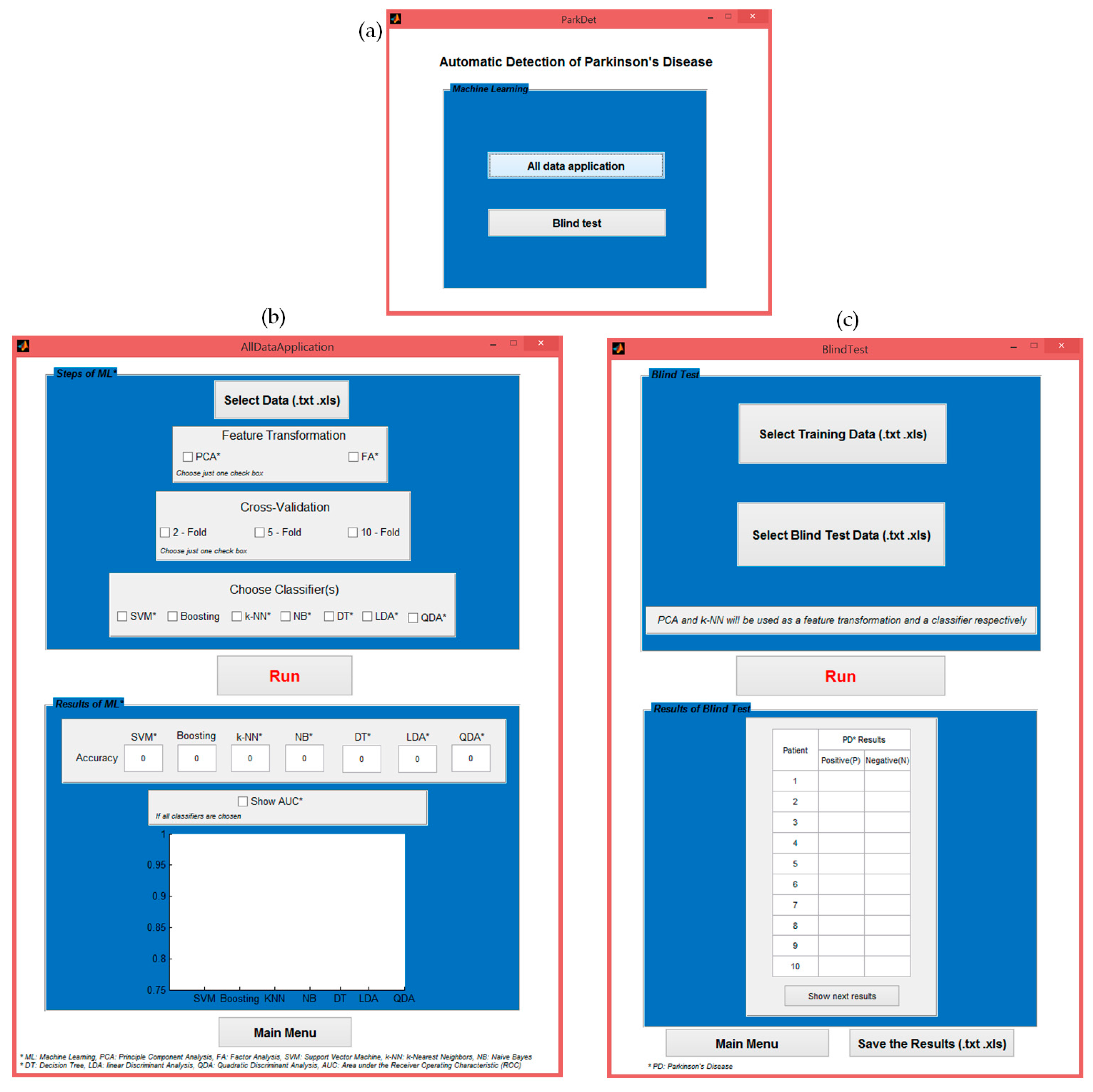
2.2. Telemedicine Application with the Created ParkDet 2.0
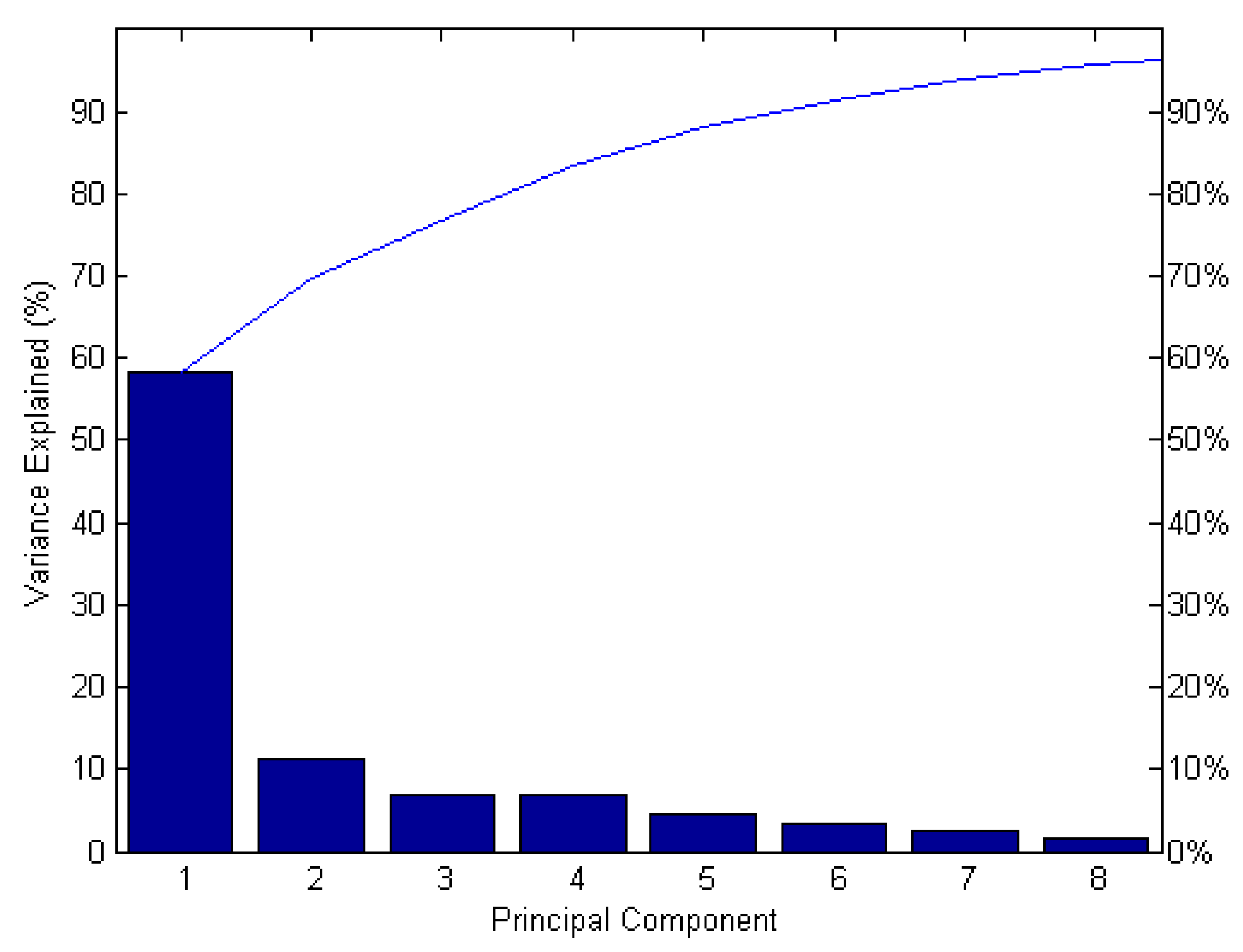
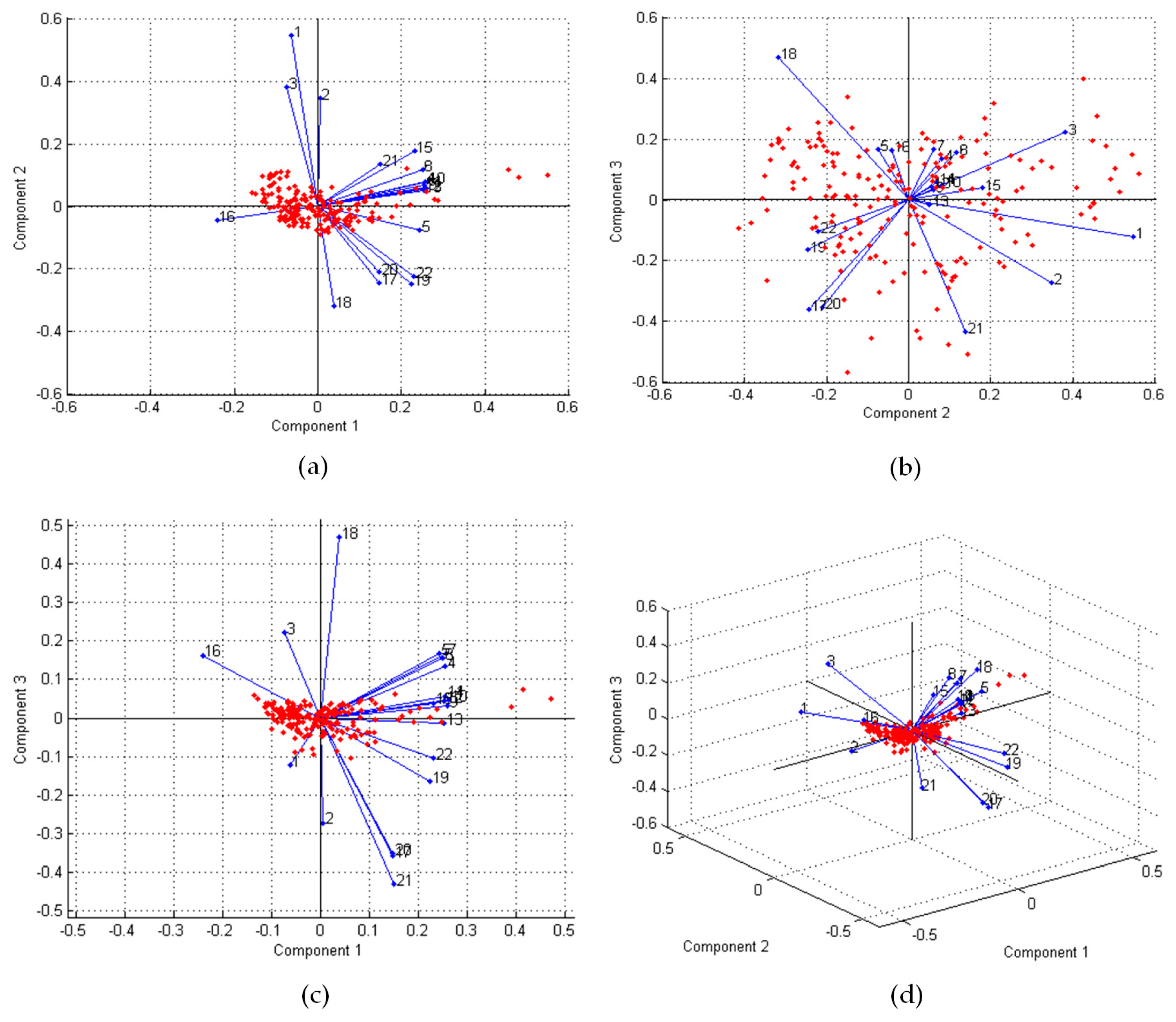
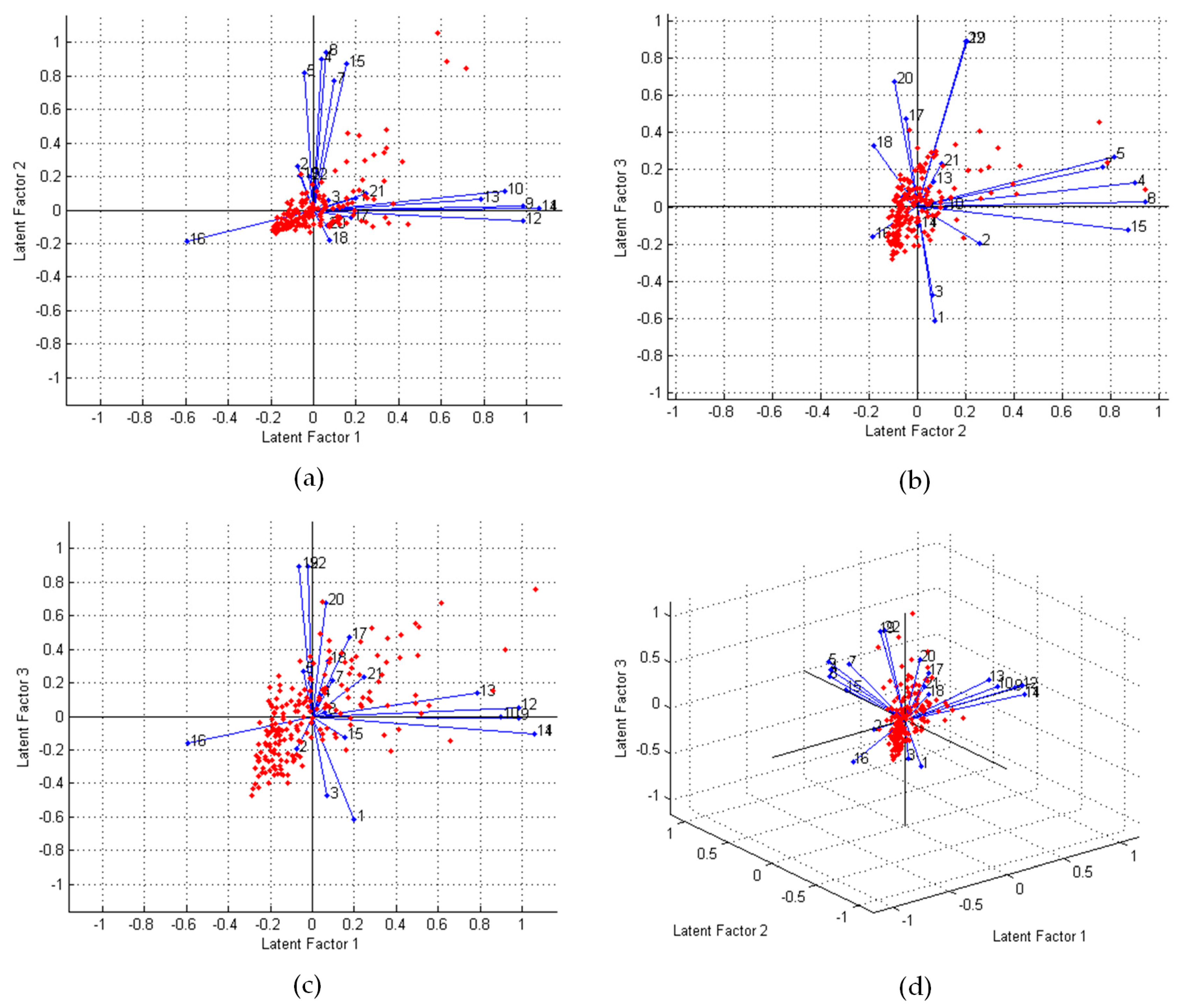
2.2.1. Feature Transformation
2.2.2. Cross-Validation
2.2.3. Classification Algorithms
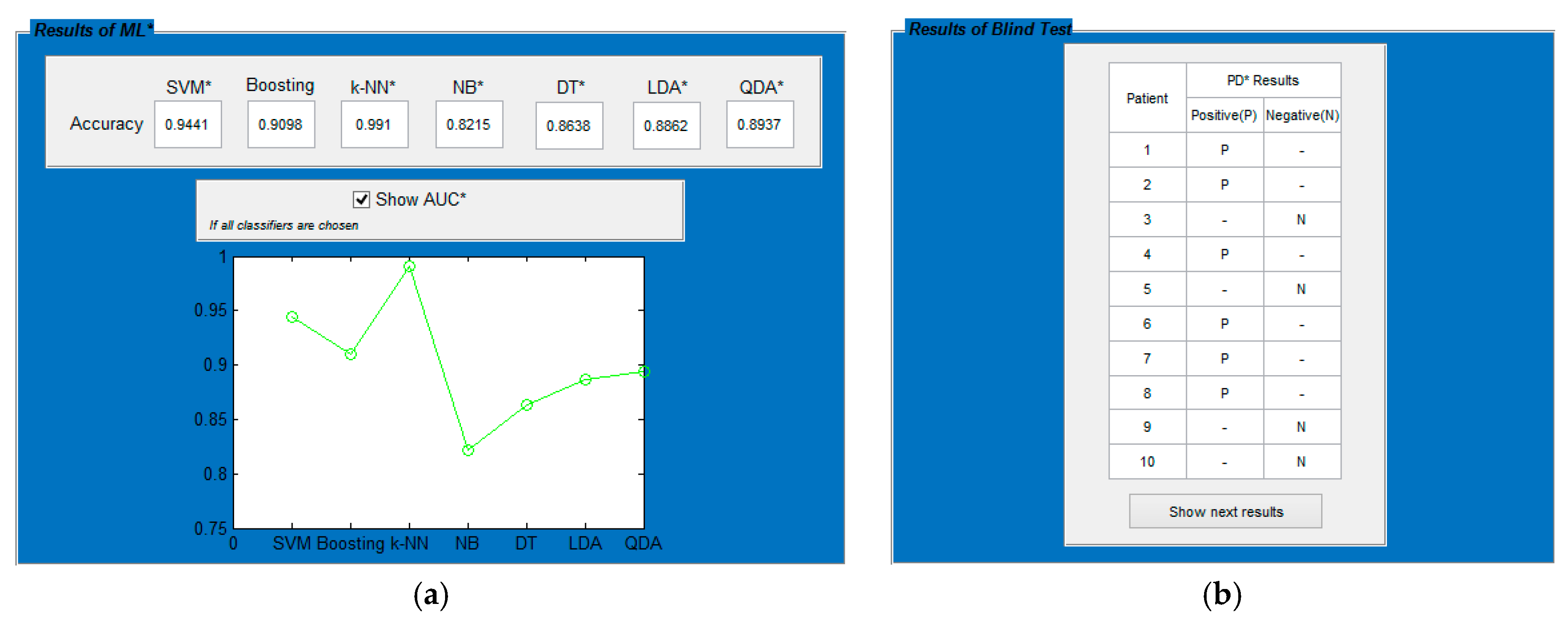
2.2.4. Experimental Implementations
2.2.5. Blind Test Implementation
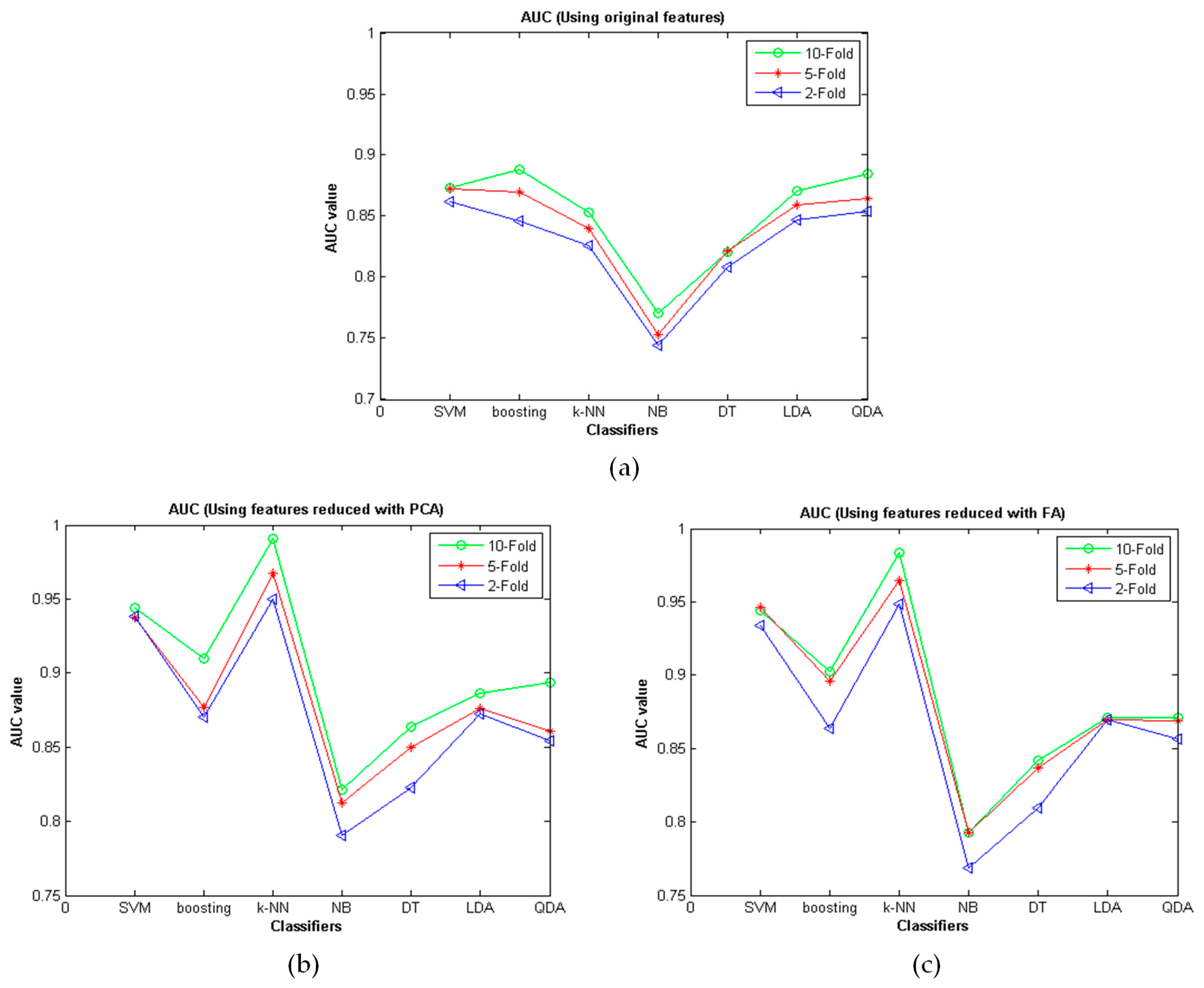
3. Results
4. Discussions
5. Conclusions
Acknowledgments
Conflicts of Interest
References
- Calle-Alonso, F.; Pérez, C.J.; Arias-Nicolás, J.P.; Martín, J. Computer-aided diagnosis system: A Bayesian hybrid classification method. Comput. Methods Programs Biomed. 2013, 112, 104–113. [Google Scholar] [CrossRef] [PubMed]
- Elizabeth, D.S.; Nehemiah, H.K.; Raj, C.S.R.; Kannan, A. Computer-aided diagnosis of lung cancer based on analysis of the significant slice of chest computed tomography image. IET Image Process. 2012, 6, 697–705. [Google Scholar] [CrossRef]
- Choi, W.J.; Choi, T.S. Automated pulmonary nodule detection based on three-dimensional shape-based feature descriptor. Comput. Methods Programs Biomed. 2014, 113, 37–54. [Google Scholar] [CrossRef] [PubMed]
- Tan, T.; Mordang, J.J.; van Zelst, J.; Grivegnée, A.; Mérida, A.G.; Melendez, J.M.; Mann, R.; Zhang, W.; Platel, B.; Karssemeijer, N. Computer-aided detection of breast cancers using Haar-like features in automated 3D breast ultrasound. Med. Phys. 2015, 42, 1498–1504. [Google Scholar] [CrossRef] [PubMed]
- Özkan, H.; Osman, O.; Şahin, S.; Boz, A.F. A Novel method for pulmonary embolism detection in CTA images. Comput. Methods Programs Biomed. 2014, 113, 757–766. [Google Scholar] [CrossRef] [PubMed]
- Goker, I.; Osman, O.; Ozekes, S.; Baslo, M.B.; Ertas, M.; Ulgen, Y. Classification of Juvenile Myoclonic Epilepsy Data Acquired Through Scanning Electromyography with Machine Learning Algorithms. J. Med. Syst. 2012, 36, 2705–2711. [Google Scholar] [CrossRef] [PubMed]
- Ozekes, S.; Osman, O. Computerized Lung Nodule Detection Using 3D Feature Extraction and Learning Based Algorithms. J. Med. Syst. 2010, 34, 185–194. [Google Scholar] [CrossRef] [PubMed]
- Backman, W.; Bendel, D.; Rakhit, R. The telecardiology revolution: Improving the management of cardiac disease in primary care. J. R. Soc. Med. 2010, 103, 442–446. [Google Scholar] [CrossRef] [PubMed]
- McLean, S.; Chandler, D.; Nurmatov, U.; Liu, J.; Pagliari, C.; Car, J.; Sheikh, A. Telehealthcare for asthma: A Cochrane review. Can. Med. Assoc. J. (CMAJ) 2011, 183, E733–E742. [Google Scholar] [CrossRef] [PubMed]
- Johnson, N.D. Teleradiology 2010: Technical and organizational issues. Pediatr. Radiol. 2010, 40, 1052–1055. [Google Scholar] [CrossRef] [PubMed]
- Evans, A.J.; Kiehl, T.R.; Croul, S. Frequently asked questions concerning the use of whole-slide imaging telepathology for neuropathology frozen sections. Semin. Diagn. Pathol. 2010, 27, 160–166. [Google Scholar] [CrossRef] [PubMed]
- Demaerschalk, B.M. Telestrokologists: Treating stroke patients here, there, and everywhere with telemedicine. Semin. Neurol. 2010, 30, 477–491. [Google Scholar] [CrossRef] [PubMed]
- Herendeen, N.E.; Schaefer, G.B. Practical applications of telemedicine for pediatricians. Pediatr. Ann. 2009, 38, 567–569. [Google Scholar] [CrossRef] [PubMed]
- Tsang, M.W.; Kovarik, C.L. The role of dermatopathology in conjunction with teledermatology in resource-limited settings: Lessons from the African Teledermatology Project. Int. J. Dermatol. 2011, 50, 150–156. [Google Scholar] [CrossRef] [PubMed]
- Diamond, J.M.; Bloch, R.M. Telepsychiatry assessments of child or adolescent behavior disorders: A review of evidence and issues. Telemed. J. E Health 2010, 16, 712–716. [Google Scholar] [CrossRef] [PubMed]
- Berg, B.; Cortazar, B.; Derek, T.; Ozkan, H.; Feng, S.; Wei, Q.; Chan, R.Y.-L.; Burbano, J.; Farooqui, Q.; Lewinski, M.; et al. Cellphone-Based Hand-Held Microplate Reader for Point-of-Care Testing of Enzyme-Linked Immunosorbent Assays. ACS Nano 2015, 9, 7857–7866. [Google Scholar] [CrossRef] [PubMed]
- Feng, S.; Caire, R.; Cortazar, B.; Turan, M.; Wong, A.; Ozcan, A. Immunochromatographic Diagnostic Test Analysis Using Google Glass. ACS Nano 2014, 8, 3069–3079. [Google Scholar] [CrossRef] [PubMed]
- Mudanyali, O.; Dimitrov, S.; Sikora, U.; Padmanabhan, S.; Navruz, I.; Ozcan, A. Integrated rapid-diagnostic-test reader platform on a cellphone. Lab Chip 2012, 12, 2678–2686. [Google Scholar] [CrossRef] [PubMed]
- Navruz, I.; Coskun, A.F.; Wong, J.; Mohammad, S.; Tseng, D.; Nagi, R.; Phillipsac, S.; Ozcan, A. Smart-phone based computational microscopy using multi-frame contact imaging on a fiber-optic array. Lab Chip 2013, 13, 4015–4023. [Google Scholar] [CrossRef] [PubMed]
- Arpali, S.A.; Arpali, C.; Coskun, A.F.; Chianga, H.H.; Ozcan, A. High-throughput screening of large volumes of whole blood using structured illumination and fluorescent on-chip imaging. Lab Chip 2012, 12, 4968–4971. [Google Scholar] [CrossRef] [PubMed]
- Wei, Q.; Luo, W.; Chiang, S.; Kappel, T.; Mejia, C.; Tseng, D.; Chan, R.Y.L.; Yan, E.; Qi, H.; Shabbir, F.; et al. Imaging and Sizing of Single DNA Molecules on a Mobile Phone. ACS Nano 2014, 8, 12725–12733. [Google Scholar] [CrossRef] [PubMed]
- Drotár, P.; Mekyska, J.; Rektorová, I.; Masarová, L.; Smékal, Z.; Fundez-Zanuy, M. Analysis of in-air movement in handwriting: A novel marker for Parkinson’s disease. Comput. Methods Programs Biomed. 2014, 117, 405–411. [Google Scholar] [CrossRef] [PubMed]
- Oung, Q.W.; Muthusamy, H.; Lee, H.L.; Basah, S.N.; Yaacob, S.; Sarillee, M.; Lee, C.H. Technologies for Assessment of Motor Disorders in Parkinson’s Disease: A review. Sensors 2015, 15, 21710–21745. [Google Scholar] [CrossRef] [PubMed]
- Hariharan, M.; Polat, K.; Sindhu, R. A new hybrid intelligent system for accurate detection of Parkinson’s disease. Comput. Methods Programs Biomed. 2014, 113, 904–913. [Google Scholar] [CrossRef] [PubMed]
- Westin, J.; Ghiamata, S.; Memedi, M.; Nyholm, D.; Johansson, A.; Dougherty, M.; Groth, T. A new computer method for assessing drawing impairment in Parkinson’s disease. J. Neurosci. Methods 2010, 190, 143–148. [Google Scholar] [CrossRef] [PubMed]
- Sarmiento, F.; Martínez, F.; Romero, E. Automatic characterization of the Parkinson disease by classifying the ipsilateral coordination and spatiotemporal gait patterns. In Proceedings of the 10th International Symposium on Medical Information Processing and Analysis, Cartagena de Indias, Colombia, 14–16 October 2014.
- Ying, H.; Silex, C.; Schnitzer, A.; Leonhardt, S.; Schiek, M. Automatic Step Detection in the Accelerometer Signal. IFMBE Proc. 2007, 13, 80–85. [Google Scholar]
- Little, M.A.; McSharry, P.E.; Hunter, E.J.; Ramig, L.O. Suitability of dysphonia measurements for telemonitoring of Parkinson’s disease. IEEE Trans. Biomed. Eng. 2009, 56, 1015–1022. [Google Scholar] [CrossRef] [PubMed]
- Bhattacharya, I.; Bhatia, M.P.S. SVM Classification to Distinguish Parkinson Disease Patients. In Proceedings of the 1st Amrita ACM-W Celebration on Women in Computing, Coimbatore, India, 16–17 September 2010; pp. 1–6.
- Das, R. A Comparison of Multiple Classification Methods for Diagnosis of Parkinson Disease. Expert Syst. Appl. 2010, 37, 1568–1572. [Google Scholar] [CrossRef]
- Sakar, C.O.; Kursun, O. Telediagnosis of Parkinson’s Disease Using Measurements of Dysphonia. J. Med. Syst. 2010, 34, 591–599. [Google Scholar] [CrossRef] [PubMed]
- Ozcift, A. SVM Feature Selection Based Rotation Forest Ensemble Classifiers to Improve Computer-Aided Diagnosis of Parkinson Disease. J. Med. Syst. 2012, 36, 2141–2147. [Google Scholar] [CrossRef] [PubMed]
- Polat, K. Classification of Parkinson’s Disease Using Feature Weighting Method on the Basis of Fuzzy C-Means Clustering. Int. J. Syst. Sci. 2011, 43, 597–609. [Google Scholar] [CrossRef]
- Acevedo, E.; Acevedo, A.; Felipe, F. Associative Memory Approach for the Diagnosis of Parkinson’s Disease. Lect. Notes Comput. Sci. 2011, 6718, 103–117. [Google Scholar]
- Gök, M. An ensemble of k-nearest neighbours algorithm for detection of Parkinson’s disease. Int. J. Syst. Sci. 2015, 46, 1108–1112. [Google Scholar] [CrossRef]
- Boersma, P.; Weenink, D. Praat, a system for doing phonetics by computer. Glot Int. 2001, 5, 341–345. [Google Scholar]
- KayPENTAX. Kay Elemetrics Disordered Voice Database, Model 4337; Kay Elemetrics: Lincoln Park, NJ, USA, 2005. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Abdi, H.; Williams, L.J. Principal component analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Bartholomew, D.J.; Steele, F.; Galbraith, J.; Moustaki, I. Analysis of Multivariate Social Science Data, 2nd ed.; Statistics in the Social and Behavioral Sciences Series; Taylor Francis: Oxford, UK, 2008. [Google Scholar]
- McLachlan, G.; Do, K.-A.; Ambroise, C. Analyzing Microarray Gene Expression Data; Wiley: New York, NY, USA, 2004. [Google Scholar]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification, 2nd ed.; John Wiley & Sons: New York, NY, USA, 2000. [Google Scholar]
- Zhou, Z.-H. Ensemble Methods: Foundations and Algorithms; CRC Press: Boca Raton, FL, USA, 2012. [Google Scholar]
- Wu, X.; Kumar, V.; Ross, Q.J.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.; Ng, A.; Liu, B.; Yu, P.; et al. Top 10 Algorithms in Data Mining. Knowl. Inf. Syst. 2008, 14, 1–37. [Google Scholar] [CrossRef]
- Stuart, R.; Norvig, P. Artificial Intelligence: A Modern Approach, 2nd ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2003. [Google Scholar]
- Sakthivel, N.R.; Sugumaran, V.; Nair, B.B. Comparison of decision tree-fuzzy and rough set-fuzzy methods for fault categorization of mono-block centrifugal pump. Mech. Syst. Signal Process. 2010, 24, 1887–1906. [Google Scholar] [CrossRef]
- Davis, J.C. Statistics and Data Analysis in Geology, 3rd ed.; Wiley: New York, NY, USA, 2002. [Google Scholar]
- Croux, C.; Joossens, K. Influence of observations on the misclassification probability in quadratic discriminant analysis. J. Multivar. Anal. 2005, 96, 384–403. [Google Scholar] [CrossRef]
- Huang, J.; Ling, C. Using AUC and accuracy in evaluating learning algorithms. IEEE Trans. Knowl. Data Eng. 2005, 17, 299–310. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Definitions |
|---|---|
| MDVP: Fo (Hz) | Average vocal fundamental frequency |
| MDVP: Fhi (Hz) | Max. vocal fundamental frequency |
| MDVP: Flo (Hz) | Min. vocal fundamental frequency |
| MDVP: Jitter (%) | Jitter as a percentage |
| MDVP: Jitter (Abs) | Absolute jitter in microseconds |
| MDVP: RAP | Relative amplitude perturbation |
| MDVP: PPQ | Five-point period perturbation quotient |
| MDVP: Shimmer | local shimmer |
| MDVP: Shimmer (dB) | local shimmer in decibels |
| MDVP: APQ | 11-point amplitude perturbation quotient |
| Shimmer: APQ3 | Three point amplitude perturbation quotient |
| Shimmer: DDA | Average absolute difference between consecutive differences between the amplitudes of consecutive periods |
| Shimmer: APQ5 | Five point amplitude perturbation quotient |
| Jitter:DDP | Average absolute difference of differences between cycles, divided by the average period |
| NHR | Noise-to-harmonics ratio |
| HNR | Harmonics-to-noise ratio |
| RPDE | Recurrence period density entropy |
| DFA | Signal fractal scaling exponent |
| D2 | Correlation dimension |
| PPE | Pitch period entropy |
| Spread1 | Two nonlinear measures of fundamental frequency variation |
| Spread2 |
| Dataset | SVM | Boosting | k-NN | NB | DT | LDA | QDA |
|---|---|---|---|---|---|---|---|
| Original | 0.8615 | 0.8462 | 0.8258 | 0.7446 | 0.8087 | 0.8465 | 0.8539 |
| with FA | 0.9338 | 0.8636 | 0.9487 | 0.7690 | 0.8097 | 0.8696 | 0.8563 |
| with PCA | 0.9385 | 0.8705 | 0.9502 | 0.7903 | 0.8227 | 0.8723 | 0.8539 |
| Dataset | SVM | Boosting | k-NN | NB | DT | LDA | QDA |
|---|---|---|---|---|---|---|---|
| Original | 0.8728 | 0.8697 | 0.8395 | 0.7534 | 0.8215 | 0.8592 | 0.8642 |
| with FA | 0.9461 | 0.8961 | 0.9649 | 0.7930 | 0.8365 | 0.8698 | 0.8686 |
| with PCA | 0.9376 | 0.8765 | 0.9672 | 0.8125 | 0.8497 | 0.8764 | 0.8608 |
| Dataset | SVM | Boosting | k-NN | NB | DT | LDA | QDA |
|---|---|---|---|---|---|---|---|
| Original | 0.8735 | 0.8882 | 0.8532 | 0.7702 | 0.8210 | 0.8710 | 0.8847 |
| with FA | 0.9439 | 0.9026 | 0.9832 | 0.7928 | 0.8417 | 0.8713 | 0.8712 |
| with PCA | 0.9441 | 0.9098 | 0.9910 | 0.8215 | 0.8638 | 0.8862 | 0.8937 |
| Reference | Classifier | Accuracy (%) | |
|---|---|---|---|
| Developed method | k-NN using the created ParkDet 2.0 | 99.1 | |
| Little [28] | Kernel SVM | 91.4 | |
| Battacharya [29] | SVM | 65.22 | |
| Das [30] | Neural Network | 92.9 | |
| Sakar [31] | SVM | 92.75 | |
| Polat [33] | FCMFW | 97.93 | |
| Acevedo [34] | ABBAM | 97.17 | |
| Ozcift [32] | IBk | 96.93 | |
| Gök [35] | k-NN | 98.46 | |
© 2016 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ozkan, H. A Comparison of Classification Methods for Telediagnosis of Parkinson’s Disease. Entropy 2016, 18, 115. https://0-doi-org.brum.beds.ac.uk/10.3390/e18040115
Ozkan H. A Comparison of Classification Methods for Telediagnosis of Parkinson’s Disease. Entropy. 2016; 18(4):115. https://0-doi-org.brum.beds.ac.uk/10.3390/e18040115
Chicago/Turabian StyleOzkan, Haydar. 2016. "A Comparison of Classification Methods for Telediagnosis of Parkinson’s Disease" Entropy 18, no. 4: 115. https://0-doi-org.brum.beds.ac.uk/10.3390/e18040115